MySQL表的基本插入查询操作详解

博学而笃志,切问而近思
文章目录
- 插入
- 插入更新
- 替换
- 查询
- 全列查询
- 指定列查询
- 查询字段为表达式
- 查询结果指定别名
- 查询结果去重
- WHERE 条件
- 基本比较
- 逻辑运算符
- 使用LIKE进行模糊匹配
- 使用IN进行多个值匹配
- 排序
- 筛选分页结果
- 更新数据
- 删除数据
- 截断表
- 聚合函数
- COUNT
- SUM
- AVG
- MAX
- MIN
- group by
- having
- 面试题:SQL查询中各个关键字的执行先后顺序?
- 总结
插入
在MySQL中,INSERT语句用于将新行插入数据库表中。
基本语法:
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);
table_name: 要插入数据的表名。column1, column2, column3, ...: 要插入数据的列名。value1, value2, value3, ...: 要插入的实际数据值。
例如,如果有一个名为 t1 的表,包含 name 和 sex 列,可以使用以下INSERT语句插入新的记录:
create table t1(-> name varchar(5),-> sex char(1));
Query OK, 0 rows affected (0.02 sec)mysql> insert into t1(name, sex) values('张三','男');
Query OK, 1 row affected (0.00 sec)

这将在t1表中插入一条新记录。另一种插入方式是省略列名,但在这种情况下,必须确保提供的值的顺序与表中列的顺序相匹配:
insert into t1 values('李四','男');

其中into是可以省略不写的,但是一般不建议省略
insert t1 values('王五','男');

还可以一次插入多条记录,只需在VALUES子句中提供多个值集:
insert into t1 values('赵六','女'),('托尼','男');

这将在t1表中插入两条记录。需要注意的是,如果插入的数据违反表中的任何约束(如主键约束或唯一性约束),则插入操作将失败。
插入更新
在MySQL中,要实现插入数据,如果数据已经存在,则进行更新操作,可以使用INSERT INTO ... ON DUPLICATE KEY UPDATE语句。这通常用于处理唯一性约束,例如主键或唯一索引。
基本语法:
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...)
ON DUPLICATE KEY UPDATE
column1 = VALUES(column1), column2 = VALUES(column2), ...;
这里的关键是ON DUPLICATE KEY UPDATE子句,它指定了在出现主键冲突时应执行的更新操作。
例如,如果有一个名为 t2 的表,其中 id 是主键。

表中已经有如下数据

而此时如果再插入(1, '曹操', 68)这样一组数据,则会发生冲突。如果就是想插入这么一组数据的话,可以将造成冲突的那一组数据删除后在插入这一组数据,但是这样就有些麻烦了,还可以使用更新插入语句来操作。

insert into t2 values(1, '曹操', 68)-> on duplicate key update name='曹操', age=68;

注意:这种方法仅在表中存在唯一性约束(主键或唯一索引)时有效。如果没有唯一性约束,将不会执行更新操作。
替换
在MySQL中,可以使用REPLACE INTO语句来插入数据,如果唯一键(主键或唯一索引)已经存在,则替换(删除现有记录并插入新记录)。这可以用于插入或更新的场景。
基本语法:
REPLACE INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);
与INSERT INTO语句不同的是,REPLACE INTO不需要ON DUPLICATE KEY UPDATE子句,因为它总是执行替换操作。
例如在如上的 t2 表中:

执行如下的替换操作。
replace into t2 values(2, '刘备', 100);

如果表中已经存在id为2的记录,它将被删除,并用新的数据(id=2,name=‘刘备’,age=100)替换。
需要注意的是,
REPLACE INTO会删除已存在的记录,因此谨慎使用,特别是在需要保留历史数据的情况下。
查询
从MySQL数据库中查询数据的操作,可以使用SELECT语句。
基本语法:
SELECT column1, column2, ...
FROM table_name
WHERE condition;
column1, column2, ...: 要检索的列名。table_name: 要检索数据的表名。WHERE condition: 可选的条件,用于过滤检索的数据。
例如,要从名为 t2 的表中检索所有人的姓名和年龄:
select name, age from t2;

全列查询
要执行全列查询,即检索表中的所有列,你可以使用通配符 *。
基本语法:
SELECT *
FROM table_name;
这将检索指定表中的所有列的数据。例如查询t2表中的所有数据。
select * from t2;

这将返回表中所有行的所有列数据。尽管使用 * 通配符可以方便地检索所有列,但在实际应用中不建议使用*进行全列查询,因为查询的列越多,意味着需要传输的数据量越大。有时最好明确指定要检索的列,以避免不必要的数据传输和提高查询性能。
指定列查询
指定列查询是通过明确列出你想要检索的列来执行的,指定列的顺序不需要按定义表的顺序来。
基本语法:
SELECT column1, column2, ...
FROM table_name;
column1, column2, ...: 要检索的列名。table_name: 要检索数据的表名。
例如,查询 t2 表的 id、name 列,可以执行以下查询:
select id, name from t2;

这将返回 t2 表中所有行的 id 和 name 列的数据。
查询字段为表达式
- 表达式不包含任何字段
select name, 100 from t2;
查询一个没有任何意义的列(100)。

- 表达式包含一个字段
select name, age + 100 from t2;
对查询的age列的结果都加上100。

- 表达式包含多个字段
select name, id + age from t2;
将查询的id和age加起来。

查询结果指定别名
在MySQL中可以为查询结果中的列或表达式指定别名,以提高结果的可读性或用于后续引用。
基本语法:
SELECT column_name [AS] alias_name
FROM table_name;
例如查询 t2 表中人物百年后的年龄:
select name, age + 100 as '百年后年龄' from t2;

as也可以省略,别名提高了查询结果的可读性,并且在复杂查询中尤其有用。
查询结果去重
在MySQL中,要从查询结果中去重,可以使用DISTINCT关键字。DISTINCT关键字用于删除结果集中重复的行。
基本语法:
SELECT DISTINCT column1, column2, ...
FROM table_name;
例如t2表中有如下数据,表中有重复数据:

如果想要检索数据,并确保name和age都是唯一的,可以使用DISTINCT,这将返回去重后的所有行数据。
select distinct name, age from t2;

需要注意的是,使用
DISTINCT可能会影响查询的性能,因为它需要进行额外的处理以找到并删除重复的行。在使用时要注意查询的效率。
WHERE 条件
WHERE子句用于在MySQL查询中指定条件,以过滤满足特定条件的行。
基本语法:
SELECT column1, column2, ...
FROM table_name
WHERE condition;
column1, column2, ...: 要检索的列名。table_name: 要检索数据的表名。condition: 用于过滤行的条件。
条件可以是任何能返回布尔值(True或False)的表达式。例如,你可以使用比较运算符(例如=, <, >, <=, >=)和逻辑运算符(例如AND, OR, NOT)来构建条件。
WHERE 条件中可以使用表达式,但是别名不能用在 WHERE 条件中使用。
| 比较运算符 | 说明 |
|---|---|
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 等于,例如 NULL = NULL 的结果是 NULL |
| <=> | <=> 是一种特殊的比较运算符,用于比较两个表达式是否相等,包括处理 NULL 值。它返回一个布尔值,表示两个表达式是否相等。 |
| !=, <> | 不等于 |
| BETWEEN a0 AND a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) |
| IN (option, …) | 如果是 option 中的任意一个,返回 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
| 逻辑运算符 | 说明 |
|---|---|
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为 FALSE(0) |
基本比较
select name, salary
from employees
where salary > 5000;
此查询将检索工资大于5000的员工的姓名和工资。

逻辑运算符
select name, department
from employees
where salary > 5000 and department = '蜀国';
此查询将检索工资大于5000且部门为’蜀国’的员工的姓名和部门。

使用LIKE进行模糊匹配
select name, salary, department
from employees
where name like '许%';
此查询将检索名字以’许’开头的员工的信息。

使用IN进行多个值匹配
select name, department
from employees
where department in ('蜀国');
此查询将检索部门为’蜀国’的员工的姓名和部门。

排序
在MySQL中,可以使用ORDER BY子句对查询结果进行排序。ORDER BY子句允许你指定一个或多个列作为排序的基准,并指定升序(ASC)或降序(DESC)排序。ORDER BY中也可以使用表达式和使用列别名。
基本语法:
SELECT column1, column2, ...
FROM table_name
ORDER BY column1 [ASC | DESC], column2 [ASC | DESC], ...;
column1, column2, ...: 要检索的列名。table_name: 要检索数据的表名。ORDER BY: 指定排序的列和排序顺序(可选)。
没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序。
例如有一个名为 employees 的表,包含 name 和 salary 列,你可以按工资降序排序:
select name, salary
from employees
order by salary desc;
这将返回按工资降序排序的员工姓名和工资。

如果要按多个列进行排序,可以指定多个列名,并为每个列指定排序顺序。例如,按部门升序排序,然后按工资降序排序:
select name, salary, department
from employees
order by department asc, salary desc;
这将返回按部门升序排序,对于相同部门的员工,按工资降序排序的结果。

需要注意的是,如果不指定排序顺序,默认为升序(ASC)。如果要降序排序,必须显式指定为
DESC。NULL 视为比任何值都小,降序出现在最下面。
筛选分页结果
在MySQL中要筛选分页结果,可以使用LIMIT和OFFSET子句。LIMIT用于限制返回的行数,而OFFSET用于指定结果集的起始位置。
基本语法:
SELECT column1, column2, ...
FROM table_name
ORDER BY column1 [ASC | DESC], column2 [ASC | DESC], ...
LIMIT number_of_rows OFFSET offset_value;
column1, column2, ...: 要检索的列名。table_name: 要检索数据的表名。ORDER BY: 指定排序的列和排序顺序(可选)。LIMIT: 指定返回的行数。OFFSET: 指定结果集的起始位置。
例如查询 employees 表按工资降序排序的前5名员工:
select name, salary
from employees
order by salary desc
limit 5;

如果想获取下一个页的结果,可以使用OFFSET。例如,要获取第6到10名员工:
select name, salary
from employees
order by salary desc
limit 5 offset 5;

需要注意的是,
OFFSET的值表示跳过的行数,而不是页数。如果要实现分页功能,你需要根据每页的行数和当前页数计算LIMIT和OFFSET的值。对未知表进行查询时,最好加一条 LIMIT 1,避免因为表中数据过大,查询全表数据导致数据库卡死。
更新数据
在MySQL中,UPDATE语句用于修改表中现有记录的数据。
基本语法:
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
table_name: 要更新数据的表名。column1, column2, ...: 要更新的列名。value1, value2, ...: 要更新的新值。WHERE condition: 可选,用于指定要更新的记录的条件。
例如,将 employees 表工资提高10%,可以执行如下的UPDATE语句:
update employees
set salary = salary + salary * 0.1;
这将更新employees表中所有员工的工资,使其增加10%。

如果你只想更新满足特定条件的记录,可以使用WHERE子句。例如,只更新部门为’蜀国’的员工的工资:
update employees
set salary = salary * 1.1
where department='蜀国';

需要谨慎使用
UPDATE语句,特别是在没有WHERE子句的情况下,因为它将影响表中的所有记录。务必确保在执行更新之前理解并检查条件,以防止意外的数据更改。
删除数据
在MySQL中,DELETE语句用于从表中删除记录。
基本语法:
DELETE FROM table_name
WHERE condition;
table_name: 要删除数据的表名。WHERE condition: 用于指定要删除的记录的条件。
例如在 employees 表中,你想删除所有工资低于5000的员工记录,可以执行如下的DELETE语句:
DELETE FROM employees
WHERE salary < 50000;

这将删除employees表中所有工资低于50000的员工记录。如果你希望删除表中的所有记录,可以不使用WHERE子句:
DELETE FROM employees;
这将删除employees表中的所有记录,但保留表的结构。
需要特别注意的是,
DELETE语句删除的记录是永久性的,谨慎使用以防止意外的数据损失。务必在执行DELETE语句之前仔细检查WHERE条件,确保只删除你想要删除的记录。
截断表
在MySQL中,可以使用TRUNCATE TABLE语句截断(清空)表,该操作会删除表中的所有行,但保留表的结构。
基本语法:
TRUNCATE TABLE table_name;
table_name: 要截断的表名。
例如你执行如下的TRUNCATE TABLE语句,这将删除employees表中的所有行,但保留表的结构(列定义、索引等)。
TRUNCATE TABLE employees;
需要注意的是,与
DELETE FROM语句不同,TRUNCATE TABLE是一个DDL(数据定义语言)语句,而不是DML(数据操作语言)语句。因此,TRUNCATE TABLE操作通常比DELETE FROM操作更快,因为它不会以逐行的方式删除记录,而是直接删除整个表的数据。
然而,TRUNCATE TABLE有一些限制,例如不能用于有外键引用的表,以及在事务中的表。在这些情况下,可能需要使用DELETE FROM语句,并且会重置 AUTO_INCREMENT 项 。
聚合函数
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的最小值,不是数字没有意义 |
COUNT
COUNT 函数是用于计算表中行的数量的聚合函数。
基本语法:
SELECT COUNT(column_name) FROM table_name WHERE condition;
column_name: 要计数的列名,或使用*表示计数所有行。table_name: 要计数数据的表名。WHERE condition: 可选,用于指定条件以过滤计数的行。
COUNT 函数返回一个整数,表示满足条件的行的数量。
- 计算表中所有行的数量:
select count(*) from employees;
这将返回 “employees” 表中的总行数。

- 计算特定条件下的行数:
select count(*) from employees where department='吴国';
这将返回 “employees” 表中部门为 ‘吴国’ 的员工的数量。

需要注意的是,
COUNT函数可以用于不同的情境,包括计算所有行、计算满足特定条件的行数,或者在与其他聚合函数和GROUP BY子句一起使用时,用于分组计数。
SUM
SUM 函数是 MySQL 中的一个聚合函数,用于计算指定列的数值总和。
基本语法:
SELECT SUM(column_name) FROM table_name WHERE condition;
column_name: 要计算总和的列名。table_name: 包含要计算总和的数据的表名。WHERE condition: 可选,用于指定条件以过滤计算总和的行。
例如计算 employees 表中的工资总和:
select sum(salary) from employees;

如果你只想计算特定条件下的工资总和,可以使用 WHERE 子句:
select sum(salary) from employees where department='蜀国';

SUM函数对于计算数值型列的总和非常有用,例如货币金额或数量。你还可以将SUM与其他聚合函数和GROUP BY子句一起使用,以便对数据进行更详细的汇总和分组。
AVG
AVG 函数是 MySQL 中的一个聚合函数,用于计算指定列的数值平均值。
基本语法:
SELECT AVG(column_name) FROM table_name WHERE condition;
column_name: 要计算平均值的列名。table_name: 包含要计算平均值的数据的表名。WHERE condition: 可选,用于指定条件以过滤计算平均值的行。
例如计算employees表的工资的平均值:
select avg(salary) from employees;

如果你只想计算特定条件下的平均值,可以使用 WHERE 子句:
select avg(salary) from employees where department='魏国';

AVG函数对于计算数值型列的平均值非常有用。与SUM类似,你还可以将AVG与其他聚合函数和GROUP BY子句一起使用,以便对数据进行更详细的汇总和分组。
MAX
MAX 函数是 MySQL 中的一个聚合函数,用于计算指定列的最大值。
基本语法:
SELECT MAX(column_name) FROM table_name WHERE condition;
column_name: 要计算最大值的列名。table_name: 包含要计算最大值的数据的表名。WHERE condition: 可选,用于指定条件以过滤计算最大值的行。
例如查询employees表中工资的最大值:
select max(salary) from employees;

如果你只想计算特定条件下的最大值,可以使用 WHERE 子句:
select max(salary) from employees where department='魏国';

MAX函数对于找出数值型列的最大值非常有用。可以将MAX与其他聚合函数和GROUP BY子句一起使用,以便对数据进行更详细的汇总和分组。
MIN
MIN 函数和MAX函数相对应,也是 MySQL 中的一个聚合函数,用于计算指定列的最小值。
基本语法:
SELECT MIN(column_name) FROM table_name WHERE condition;
column_name: 要计算最小值的列名。table_name: 包含要计算最小值的数据的表名。WHERE condition: 可选,用于指定条件以过滤计算最小值的行。
例如查询employees表中的最小工资:
select min(salary) from employees;

如果只想计算特定条件下的最小值,可以使用 WHERE 子句:
select min(salary) from employees where department='魏国';

MIN函数对于找出数值型列的最小值非常有用。可以将MIN与其他聚合函数和GROUP BY子句一起使用,以便对数据进行更详细的汇总和分组。
group by
GROUP BY 子句用于对查询结果按照一个或多个列进行分组。它通常与聚合函数(如 COUNT、SUM、AVG、MAX、MIN)一起使用,以便对每个分组应用这些聚合函数。
基本语法:
SELECT column1, column2, ..., aggregate_function(column)
FROM table_name
WHERE condition
GROUP BY column1, column2, ...;
column1, column2, ...: 要选择的列。aggregate_function(column): 对每个分组应用的聚合函数。table_name: 要查询的表名。WHERE condition: 可选,用于指定条件以过滤行。GROUP BY column1, column2, ...: 指定要分组的列。
例如想统计每个国家的员工总工资,可以使用 GROUP BY 子句:
select department,sum(salary)
from employees
group by department;

having
HAVING 子句用于在使用 GROUP BY 子句进行分组后,对分组结果进行筛选。它允许你使用条件过滤分组后的结果,类似于 WHERE 子句对未分组的数据进行过滤。
基本语法:
SELECT column1, column2, ..., aggregate_function(column)
FROM table_name
WHERE condition
GROUP BY column1, column2, ...
HAVING condition;
column1, column2, ...: 要选择的列。aggregate_function(column): 对每个分组应用的聚合函数。table_name: 要查询的表名。WHERE condition: 可选,用于指定条件以过滤行。GROUP BY column1, column2, ...: 指定要分组的列。HAVING condition: 对分组结果进行筛选的条件。
HAVING 子句在分组后对分组结果进行条件过滤,与 WHERE 子句不同,它可以使用聚合函数的结果进行比较。例如,查询国家的总工资大于20000的国家:
select department '国家', sum(salary) '工资'
from employees
group by department
having sum(salary) > 20000;

HAVING子句通常用于在进行分组后,对聚合结果进行进一步的过滤。
面试题:SQL查询中各个关键字的执行先后顺序?
在一个 SQL 查询中,关键字的执行顺序通常按照以下顺序进行:
-
FROM: 定义要查询的表。
-
JOIN: 如果在查询中使用了多个表,
JOIN用于将它们连接起来。 -
WHERE: 用于过滤满足特定条件的行。
-
GROUP BY: 将结果按照指定的列进行分组。
-
HAVING: 在分组后对分组结果进行筛选。
-
SELECT: 选择要显示的列或进行计算。
-
DISTINCT: 用于返回唯一不重复的行。
-
ORDER BY: 对结果进行排序。
-
LIMIT: 用于限制返回的行数。
这个顺序并不是固定的,具体的查询可能会根据需求有所变化。例如,GROUP BY 和 HAVING 只在进行分组操作时才会使用,而 DISTINCT、ORDER BY 和 LIMIT 只在需要时才会使用。
需要注意的是,这里只是一个通用的执行顺序,实际查询可能会因为具体的需求而有所调整。在编写复杂的查询时,建议根据实际情况合理使用这些关键字。
总结
我们对于数据库的操作,大多都是对表的操作,也可以说在数据库中,一切皆为表。可见在数据库中对表的操作占有的比重是非常大的。因此这篇文章就介绍了一些常用的对于表的操作,希望对你有所帮助!

相关文章:
MySQL表的基本插入查询操作详解
博学而笃志,切问而近思 文章目录 插入插入更新 替换查询全列查询指定列查询查询字段为表达式查询结果指定别名查询结果去重 WHERE 条件基本比较逻辑运算符使用LIKE进行模糊匹配使用IN进行多个值匹配 排序筛选分页结果更新数据删除数据截断表聚合函数COUNTSUMAVGMAXM…...

『 C++ 』红黑树RBTree详解 ( 万字 )
文章目录 🦖 红黑树概念🦖 红黑树节点的定义🦖 红黑树的插入🦖 数据插入后的调整🦕 情况一:ucnle存在且为红🦕 情况二:uncle不存在或uncle存在且为黑🦕 插入函数代码段(参考)🦕 旋转…...

c# 人脸识别的思路
在C#中实现人脸识别,您可以使用诸如虹软ArcFace等第三方人脸识别SDK。以下是一个基于虹软ArcFace SDK的C#人脸识别示例的大致步骤: 安装与引用SDK: 首先,您需要从虹软官网下载适用于C#的ArcFace人脸识别SDK,并将其安装…...

如何用AI提高论文阅读效率?
已经2024年了,该出现一个写论文解读AI Agent了。 大家肯定也在经常刷论文吧。 但真正尝试过用GPT去刷论文、写论文解读的小伙伴,一定深有体验——费劲。其他agents也没有能搞定的,今天我发现了一个超级厉害的写论文解读的agent ,…...
文件重命名方法:不同路径的文件名大小写如何批量转换技巧
在文件管理中,经常要处理文件重命名的问题,尤其是涉及到不同路径下的文件名大小写转换时。下面来看云炫文件管理器如何批量转换文件名的大小写的技巧,轻松完成这项任务。 准备多个不同路径文件夹,在里面各放几个文件。接下来开始…...

深度学习中的最优化算法是什么?
在深度学习中,最优化算法主要用于调整神经网络的参数(如权重和偏差),以最小化或最大化某个目标函数(通常是损失函数)。这些算法对于训练高效、准确的深度学习模型至关重要。以下是几种在深度学习中常用的最…...

SQL执行时间过长如何优化
这个问题,其实跟慢 SQl 排查解决有点像。可以从以下这几个方面入手: 确定瓶颈 首先查看 MySQL 日志、慢查询日志、explain 分析 SQL 的执行计划、profile 分析执行耗时、Optimizer Trace分析详情等操作,确定查询执行的瓶颈在哪里。只有确定…...
局部阈值 local_threshold
Currently the operator offers only the Method adapted_std_deviation. This algorithm is a text binarization technique and provides good results for document images. 目前这个算子只提供adapted_std_deviation方法,这个算子是一个文本二值化技术…...
)
【C/C++】C语言的高级编程(内存分区,指针)
C语言的高级编程【内存,指针】 基本知识变量gcc size工具 内存分区指针相关定义和赋值指针加法函数指针多级指针数组指针传参 基本知识 变量 变量解释全局变量出现在代码块{}之外的变量就是全局变量局部变量一般情况下,代码块{}内部定义的变量就是自动…...
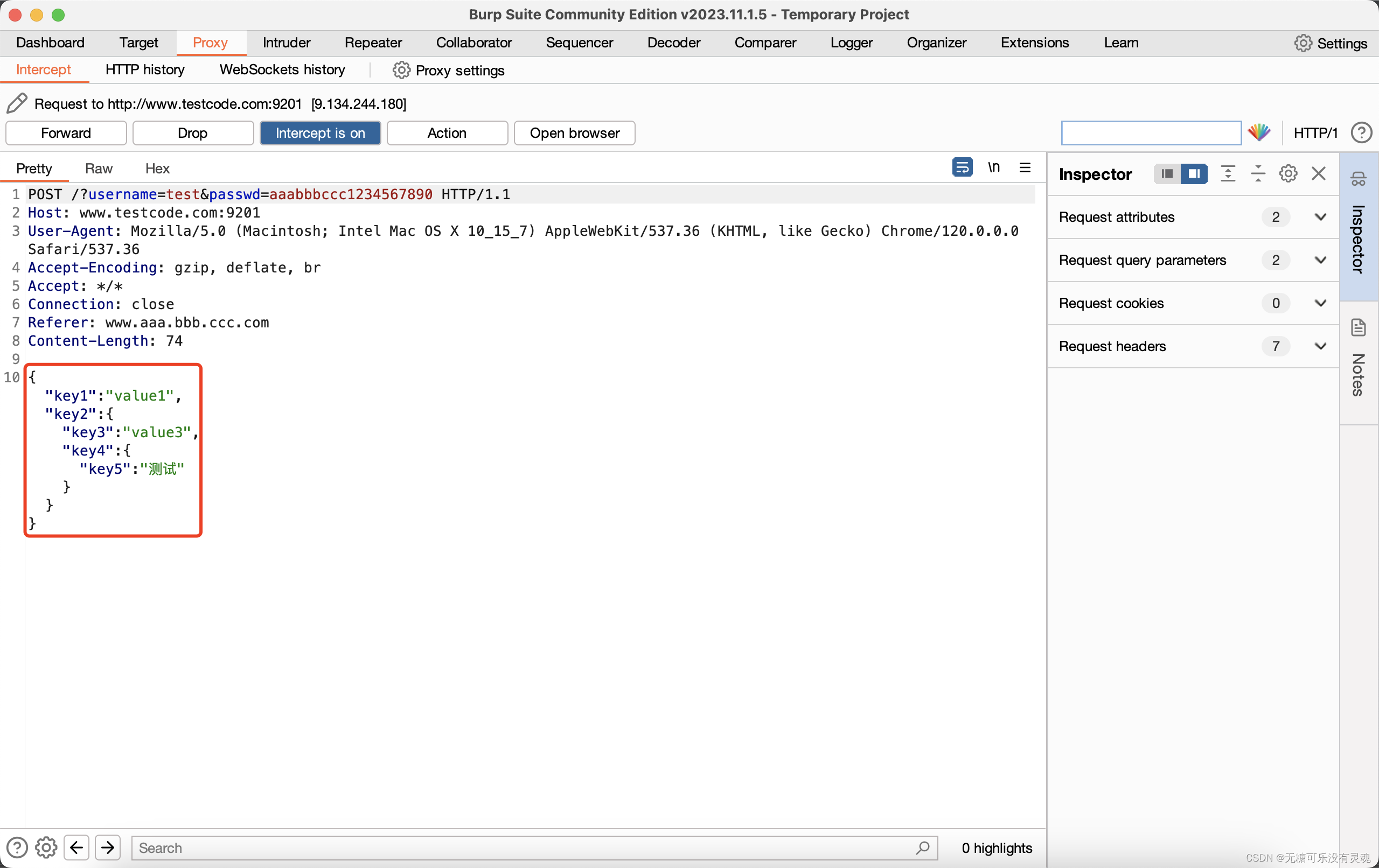
Python ❀ 使用代码实现API接口调用详解
文章目录 1. 工具准备1.1. requests代码包1.2. BurpSuite抓包工具 2. 操作过程2.1. 一个简单的请求2.1.1. Burp获取响应2.1.2. 转发获取响应 2.2. 构造GET类型URL参数2.3. 构造请求头部2.4. 构造POST类型payload数据2.4.1. urlencoded格式2.4.2. json格式 本文主要讲解常用API接…...
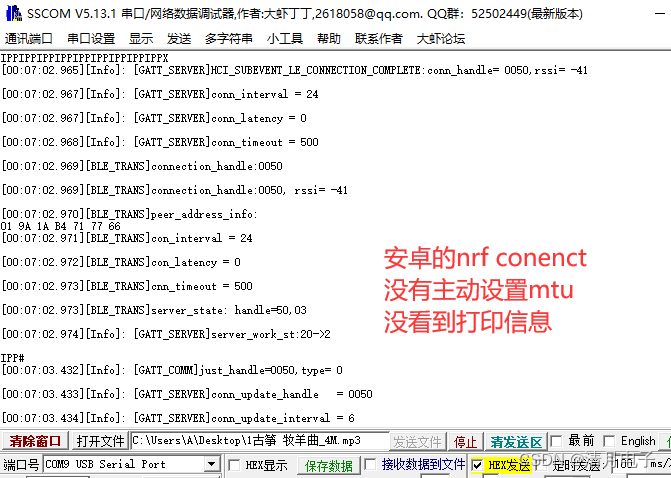
关于KT6368A双模蓝牙芯片的BLE在ios的lightblue大数量数据测试
测试简介 关于KT6368A双模蓝牙芯片的BLE在ios的lightblue app大数量数据测试 测试环境:iphone7 。KT6368A双模程序96B6 App:lightblue ios端 可以打开log日志查看通讯流程 测试数据:长度是1224个字节,单次直接发给KT6368A&a…...
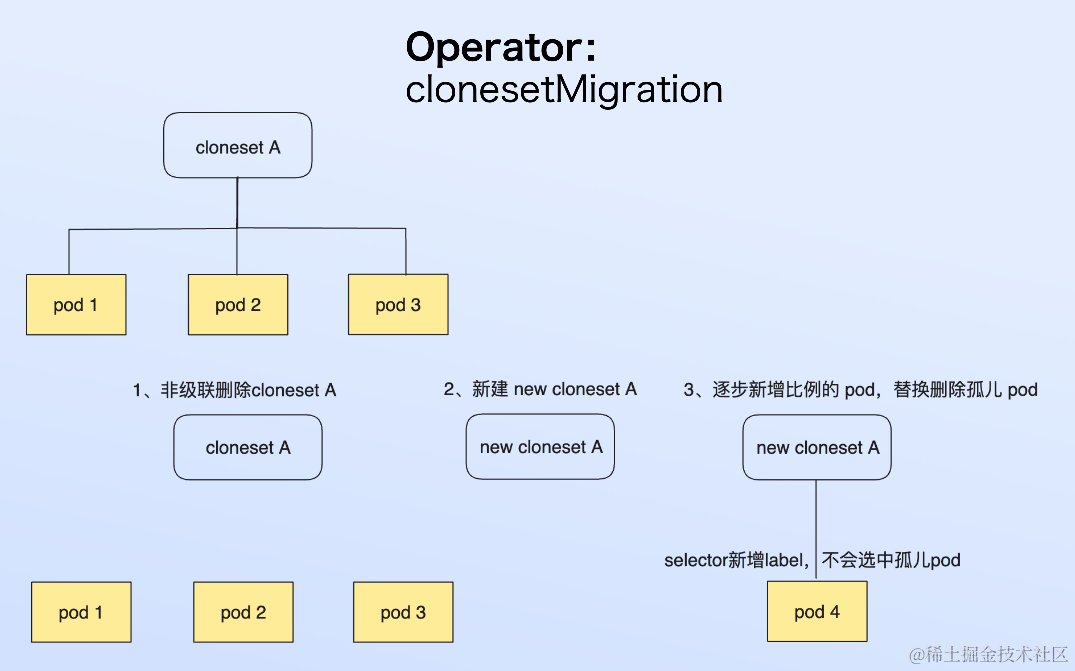
云边协同的 RTC 如何助力即构全球实时互动业务实践
作者:即构科技 由 51 CTO 主办的“WOT 全球技术创新大会 2023深圳站”于 11 月 24 日 - 25 日召开,即构科技后台技术总监肖潇以“边缘容器在全球音视频场景的探索与实践”为主题进行分享。 边缘计算作为中心云计算的补充,通过边缘容器架构和…...

使用python连接elasticsearch
有一个困惑了好久的问题,那就是从python里面连接elasticsearch总是报错。大致长这样 一开始我是看网上把es的安全功能关闭,也就是下面的内容,这个要进入到es的docker中去改config/elasticsearch.yml配置文件,但是这样改了以后kib…...

使用elasticsearchdump迁移elasticsearch数据实战
目录 1.安装nodejs 2.安装elasticsearchdump 3.迁移 4.核对数据 5.注意事项 1.安装nodejs https://ascendking.blog.csdn.net/article/details/135509838 2.安装elasticsearchdump npm install elasticdump -g 3.迁移 elasticdump --inputhttp://用户:密码源ES地址/源…...
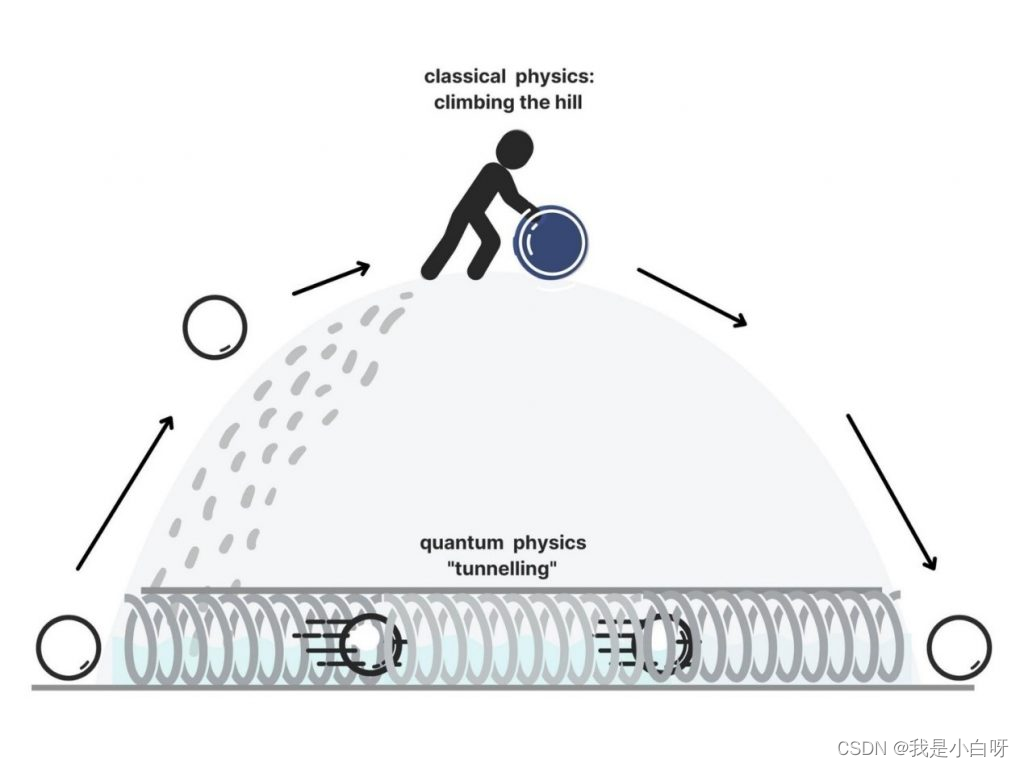
指向未来: 量子纠缠的本质是一个指针
指向未来: 量子纠缠的本质是一个指针 概述基本概念理解量子纠缠PythonJavaC 理解波粒二象性PythonJavaC 理解量子隧穿理解宇宙常量PythonJavaC 概述 量子纠缠 (Quantum Entanglement) 是量子系统重两个或多个粒子间的一种特殊连接, 这种连接使得即使相隔很远, 这些粒子的状态也…...

Zookeeper启动报错常见问题以及常用zk命令
Zk常规启动的命令如下 sh bin/zkServer.sh start 启动过程如果存在失败,是没办法直接看出什么问题,只会报出来 Starting zookeeper … FAILED TO START 可以用如下命令启动,便于查看zk启动过程中的详细错误 sh bin/zkServer.sh start-for…...

【数据结构 】哈夫曼编译码器
数据结构-----哈夫曼编译码器 题目题目描述基本要求算法分析 代码实现初始化编码解码打印代码打印哈夫曼树 总结 题目 题目描述 利用哈夫曼编码进行信息通信可大大提高信道利用率,缩短信息传输时间,降低传输成本。 要求:在发送端通过一个编…...

大屏项目:react中实现3d效果的环形图包括指引线
参考链接3d环形图 3d效果的环形图 项目需求实现方式指引线(线的样式字体颜色) 项目需求 需要在大屏上实现一个3d的环形图,并且自带指引线,指引线的颜色和每段数据的颜色一样,文本内容变成白色,数字内容变…...

【STM32】STM32学习笔记-FlyMCU串口下载和STLINK Utility(30)
00. 目录 文章目录 00. 目录01. 串口简介02. 串口连接电路图03. FlyMCU软件下载程序04. 串口下载原理05. FlyMCU软件其它操作06. STLINK Utility软件07. 软件下载08. 附录 01. 串口简介 串口通讯(Serial Communication)是一种设备间非常常用的串行通讯方式,因为它简…...

oracle rac 12.2.0.1CPU使用率100%
oracle rac 12.2.0.1 CPU使用率100% 查看是集群的java进程"oracle.ops.opsctl.OPSCTLDriver config database"占用cpu 根据进程号查找父进程,发现是/oracle/GRID/122/perl/bin/perl /oracle/GRID/122/tfa/gcmproddb01/tfa_home/bin/tfactl.pl rediscover -mode full …...

RuoYi-Vue-Plus项目实战:用WebSocket实现‘服务端通知’功能,我踩了这些坑
RuoYi-Vue-Plus实战:WebSocket服务端通知功能深度解析与避坑指南 在当今企业级应用开发中,实时通信已成为提升用户体验的关键要素。当产品经理提出"后台操作成功时前端实时弹窗提示"的需求时,作为技术负责人的你该如何选择技术方案…...

多语种语音合成新突破,ElevenLabs维吾尔语TTS上线即受限?3类企业正在紧急迁移替代方案
更多请点击: https://kaifayun.com 第一章:ElevenLabs维吾尔语TTS上线即受限的技术真相 ElevenLabs在2024年3月宣布支持维吾尔语(ug)文本转语音,但实际调用API时立即触发服务端策略拦截——即便请求头携带合法API密钥…...

华硕笔记本终极性能优化方案:G-Helper轻量级控制工具完全指南
华硕笔记本终极性能优化方案:G-Helper轻量级控制工具完全指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenb…...

如何用嘎嘎降AI处理心理学论文:心理学研究生毕业论文降AI4.8元完整操作教程
如何用嘎嘎降AI处理心理学论文:心理学研究生毕业论文降AI4.8元完整操作教程 关于心理学论文降AI教程,有几个细节提前知道能少走很多弯路。 核心用嘎嘎降AI(www.aigcleaner.com),4.8元,达标率99.26%。这篇…...

OpenSpec+Qoder 规范AI编程助手
OpenSpec 是 Fission AI 团队开源、面向 AI 编程助手的「规范驱动开发」轻量级框架与 CLI 工具,核心是 Spec First, Code Later(先定规范、再写代码),解决 AI 编程需求跑偏、上下文丢失、结果不可控的问题。 现根据下面的官网安装…...

每天节省20分钟:淘宝淘金币自动化脚本的终极效率革命
每天节省20分钟:淘宝淘金币自动化脚本的终极效率革命 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinbi 你是否…...

Cortex-Debug架构深度解析:从GDB MI协议到VSCode调试体验的完整实现
Cortex-Debug架构深度解析:从GDB MI协议到VSCode调试体验的完整实现 【免费下载链接】cortex-debug Visual Studio Code extension for enhancing debug capabilities for Cortex-M Microcontrollers 项目地址: https://gitcode.com/gh_mirrors/co/cortex-debug …...

AssetRipper:3步解锁Unity游戏资源逆向提取的终极免费方案
AssetRipper:3步解锁Unity游戏资源逆向提取的终极免费方案 【免费下载链接】AssetRipper GUI Application to work with engine assets, asset bundles, and serialized files 项目地址: https://gitcode.com/GitHub_Trending/as/AssetRipper 在Unity游戏开发…...

ZVM嵌入式实时虚拟机:在ARMv8-A上实现Linux与Zephyr的混合关键性系统
1. 项目概述与核心价值如果你正在从事嵌入式系统开发,尤其是涉及汽车电子、工业控制或5G通信设备这类对实时性和可靠性要求极高的领域,那么你肯定对“既要、又要、还要”的困境深有体会。我们常常需要在同一块硬件上,既要运行一个功能丰富、生…...

DownKyi终极指南:B站视频下载与管理的完整专业解决方案
DownKyi终极指南:B站视频下载与管理的完整专业解决方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&…...