string 模拟实现
string的数据结构
char* _str;
size_t _size;
size_t _capacity;_str 是用来存储字符串的数组,采用new在堆上开辟空间;
_size 是用来表示字符串的长度,数组大小strlen(_str);
_capacity 是用来表示_str的空间大小, _capacity 不包括字符串中 '\0' 所占的空间。。
string的构造、析构函数和operator=
在STL中这个构造函数有很多的版本,但是这里只实现常用的几个版本

string s1;
string s2("hello world");
string s3(s2);1)缺省构造函数
string(const char* str = ""): _size(strlen(str)){_capacity = _size;_str = new char[_capacity + 1];strcpy(_str, str);}下面有几个错误版本:
a) 构造函数的类型转换错误
string(const char* str):_str(str), _size(strlen(str)), _capacity(strlen(str))
{}
string s2("hello world");如果这样设计就会出现下面的报错信息:
![]()
str 是一个const char* 类型的数据,_str 是一个char* 数据类型,在初始化列表中将str 初始化_str,会导致权限放大的问题,同时还有浅拷贝的问题。
如果我们将string数据结构中的 _str 类型改为const char* 可以解决这个问题,但是又带来了新的问题 :string的内容是不能被修改的;
所以我们不能将数据结构中的_str类型改变为const char*.我们只能修改构造函数。
改进:
在初始化_str时,我们可以申请一块大小为 strlen(str)+1 的空间(要为\0也开辟一个字节的空间),将str中的值拷贝到这块空间中,再让_str指向这块空间(这也是深拷贝的过程)。在初始化列表中,我们可以只初始化 _size(strlen(str)) ,因为对于这种用一个常量字符串进行初始化的情况,我们通常会开辟大小为_size的空间,所以_capacity = _size,如果将_capacity的初始化也写在初始化列表中,就要保证_size初始化的顺序在_capcity初始化之前,而这个初始化顺序取决于两者变量声明的顺序,与初始化列表中的顺序无关。
b)对str空指针解引用问题
string(const char* str): _size(strlen(str))
{_capacity = _size;_str = new char[_capacity + 1];strcpy(_str, str);
}
string s1;
我们在使用cout打印 s1._str 时,流插入自动识别类型,识别到const char* ,但是不打印这个指针,它是通过解引用打印这个字符串,这样就会产生对空指针的解引用 (因为s1._str 被初始化为NULL)。
改进:
1. 单独处理
而STL库中对于这种情况,就直接打印空。为了解决这个问题,我们就需要设计一个无参的构造函数,当创建对象时,如果没有传递值,我们就将这个对象的内容设置成\0。
string():_str(new char), _size(0), _capacity(0)
{_str[0] = '\0';
}string():_str(new char[1]), _size(0), _capacity(0)
{_str[0] = '\0';
}想一下这两中方式哪一个比较好呢?答案是第二种。
虽然这两种写法都是申请一个字节的空间用来存储\0,但是我们要考虑一下析构函数,如果写成第一种情况,它的析构函数就要写成以下形式:
~string()
{delete _str; // 释放动态分配的内存_str = nullptr;_size = 0;_capacity = 0;
}但是对于其他有初始值创建对象来说,它们申请的往往是一个数组,这样析构函数就要写成这种形式:
~string()
{delete[] _str; // 释放动态分配的内存_str = nullptr;_size = 0;_capacity = 0;
}所以为了统一析构函数的写法,我们通常采用第一种方法进行申请空间。
2. 利用缺省值
设置缺省值有以下四种方法:
string(const char* str): _size(strlen(str))
{_capacity = _size;_str = new char[_capacity + 1];strcpy(_str, str);
}
string(const char* str = nullptr)
string(const char* str = '\0')
string(const char* str = "\0")
string(const char* str = "")第一种会导致strlen求size时,对空指针进行解引用。
第二种会导致强制类型转换,左边是const char* 类型,右边是char类型;
第三种:strlen在求长度时遇到\0就会停止,所以_size = 0-->_capacity = 1,_str中拷贝进入一个\0;
第四种:当然第三种方法中的'\0'也可以不写,因为一个常量字符串默认会以\0作为结尾;
这几种方法中,第四种方法是比较合适的。
c)最终版本
string(const char* str = ""): _size(strlen(str))
{_capacity = _size;_str = new char[_capacity + 1];strcpy(_str, str);
}2)拷贝构造函数
这个函数同样要注意的是,拷贝的时候要进行深拷贝。
string(const string& s):_capacity(s._capacity), _size(s._size)
{_str = new char[s._capacity + 1];strcpy(_str, s._str);
}3)析构函数
~string()
{delete[] _str; // 释放动态分配的内存_str = nullptr;_size = 0;_capacity = 0;
}4)operator=
operate= 的使用对象是两个已经存在的对象:用一个对象赋值给另一个对象。
而拷贝构造是用一个已经存在的对象去初始化另一个对象。
实现这个操作符需要考虑三种情况:主要是空间大小关系
为了避免讨论过多的情况(目的地空间不足还需要进行扩容;如果扩容的空间过大会导致空间浪费),较好的实现方法就是将目的地空间原始空间先释放掉,然后再开辟一个块与起始空间相等的空间,最后在进行值拷贝,所以这种拷贝也叫做深拷贝。
// 这里设置返回值,主要是为了支持连续赋值的使用场景
string& operator=(const string& s)
{delete[] _str;_str = new char[s._capacity + 1];strcpy(_str, s._str);_capacity = s._capacity;_size = s._size;return *this;
}但是这种实现方式还存在几个问题:
a)自己给自己赋值时,会出现问题,当执行 delete[] _str 后,_str 不再指向有效的内存。若之后仍然进行 strcpy(_str, s._str) 操作 (s._str) ,就会导致非法访问已释放的内存,可能会引发程序崩溃或未定义行为;
b)当先给原始空间释放过后,开辟空间失败后会回到main函数中抛异常,此时目的地空间已将被释放了。
解决方法:
a)遇到自己给自己拷贝时,不进行操作直接返回。
b)我们可以先用一个临时变量将起始内容拷贝到这块临时空间后,再释放起始空间,最后将目的地指针指向这块临时空间即可。
// 这里设置返回值,主要是为了支持连续赋值的使用场景
string& operator=(const string& s)
{/*delete[] _str;_str = new char[s._capacity + 1];strcpy(_str, s._str);_capacity = s._capacity;_size = s._size;return *this;*/if (this != &s){char* temp = new char[s._capacity + 1];strcpy(temp, s._str);delete[] _str;_str = temp;_capacity = s._capacity;_size = s._size;return *this;}return *this;
}Iterators:
1)begin、end
Return iterator to beginning / end
Returns an iterator pointing to the first / past-the-end character of the string.
上面的 iterator 是一个宏定义:
typedef char* iterator;iterator begin()
{return _str;
}iterator end()
{return _str + _size;
}其实迭代器可以理解成指针,但是迭代器的实现不一定是使用指针实现的。
迭代器是一种用于访问容器中元素的对象,它通常是指向容器中某个元素的指针或对象。迭代器的底层实现可以使用指针、类或模板等多种方式。
对于C++ STL中的标准容器,其迭代器一般采用指针来实现。例如,对于
vector容器,其迭代器类型为指向元素类型的指针。对于list容器,其迭代器类型为双向链表节点指针。而对于map或set容器,其迭代器类型为指向关键字和值类型的指针。除了使用指针实现迭代器外,还可以使用类或模板等方式实现。例如,迭代器可以作为容器的内部类来实现,或者可以使用模板来实现通用迭代器。
迭代器还有const类型的。
const_iterator begin() const
{return _str;
}const_iterator end() const
{return _str + _size;
}迭代器的用法我会在下面遍历string时讲到,这里先简单说一下:const类型的迭代器,只能查看数据,不能修改数据;而没有const修饰的迭代器既可以查看也可以修改。
2)rbegin、rend
Return reverse iterator to reverse beginning
Returns a reverse iterator pointing to the last character of the string。
这个迭代器和上面一个是相反的,rend返回指向第一个字符的迭代器,rbegin返回指向最后一个字符的迭代器。
需要注意的是,rbegin在从后向前移动时,用的是rbegin++,而不是rbegin--。
总结一下,在STL中迭代器的区间都是左闭右开的。
Element access:
1)operator[ ]
这种操作符的作用就相当于我们访问数组时的 [ ],所以两者的用法是一样的。
char& operator[](size_t pos)
{assert(pos >= 0 && pos < _size);return _str[pos];
}但是对于下面这种情况会出现错误:
char& operator[](size_t pos)
{assert(pos >= 0 && pos < _size);return _str[pos];
}void func(const string& s1)
{cout << s1[1] << endl;
}int main()
{string s("Hello world");func(s);return 0;
}通常我们在函数不改变实参时,会将接收参数的类型设置成 const string& (因为函数形参是实参的一个临时拷贝,这个过程需要调用拷贝构造函数,如果函数参数用引用接收,就不会调用拷贝构造函数,减少了一定的消耗),但是,这样之后我们会发现这样就使用不了 [ ] 操作符了,这是因为 const对象s1不能调用非const成员函数 char& operator[](size_t pos) ,所以我们需要将 char& operator[](size_t pos) 函数设置成为const类型的。
但是如果只将该操作符重载为const成员函数,这样做就会导致我们不能通过 [ ] 操作符进行更改string对象的内容了,所以我们需要有这两种函数构成重载,在需要时调用合适的函数。
// const对象不能调用非const成员函数,
// 但是对于[]操作符在有些情况下是需要进行更改的:s[pos]++
// 所以这里就需要有两个[]操作符构成重载
const char& operator[](size_t pos) const
{assert(pos >= 0 && pos < _size);return _str[pos];
}char& operator[](size_t pos)
{assert(pos >= 0 && pos < _size);return _str[pos];
}遍历
1)[ ]+下标
// 保证const对象能够调用这个函数
size_t size() const
{return _size;
}// 这里需要有两个[]操作符构成重载
const char& operator[](size_t pos) const
{assert(pos >= 0 && pos < _size);return _str[pos];
}char& operator[](size_t pos)
{assert(pos >= 0 && pos < _size);return _str[pos];
}
2)迭代器:iterator (用指针模拟实现)
typedef char* iterator;
iterator begin()
{return _str;
}iterator end()
{return _str + _size;
}string::iterator it = s1.begin();
while (it != s1.end())
{cout << *it << " ";it++;
}3)范围for
底层使用迭代器实现的,所以只要有迭代器,范围for语法就能使用。
for (auto ch : s1)
{cout << ch << " ";
}这种写法的底层会被替换成上面迭代器的写法。
所以对于下面这种情况就会出错:
typedef char* iterator;
iterator begin()
{return _str;
}iterator end()
{return _str + _size;
}void print(const string& s)
{for (auto ch : s){cout << ch << " ";}
}s对象为const类型的,所以需要调用const类型的迭代器。所以迭代器也需要实现两种类型的:一个const修饰的、一种没有const修饰的。
字符串比较
利用运算符重载和ASCII码进行比较字符串的大小,功能类似于strcmp函数。
bool operator==(const string& s)
{return (strcmp(_str, s._str) == 0);
}bool operator!=(const string& s)
{return !(*this == s);
}错误点:
需要注意的是,这里不是写成
bool operator!=(const string& s)
{return !(_str == s._str);
}这是因为:如果你直接写成 _str == s._str,将无法调用 operator== 的重载函数。因为 _str 和 s._str 都是指向字符串的指针,这时的==就是判断值是否相等的==,所以这个表达式比较的是两个指针的地址是否相等。
*this == s 这种写法,使用*this表示当前对象自身,表示==左边是一个对象,右边也是一个对象,这时就会调用operator==进行比较两对象的字符串是否相等了。
改进:
但是这样写还是有一点缺陷的:如果我将*this放在操作符==的右边时,会出现问题
bool operator!=(const string& s)
{return !(s == *this);
}因为在这一步中 s == *this ==左边对象类型为const类型,当它调用operator==函数时,会造成权限的放大(this没有被const关键字修饰,const对象不能调用非const成员函数),所以我们需要在operator==函数中用const修饰this,这样无论是const对象调用==,还是普通对象调用==都是没有问题的,因为权限是可以缩小的,而不能被放大。
同时在实现其他操作符时尽量进行操作符的复用前面我们实现过的操作符,这样有以下好处:
代码重用:通过复用已经实现过的操作符,可以减少代码的冗余和重复。这样可以提高代码的可维护性和可读性,同时也减少了错误的可能性。
一致性:通过复用已经实现过的操作符,可以保持代码的一致性。如果已经实现的操作符被正确测试和验证过,那么在其他操作符中复用它们可以确保整个代码逻辑的一致性。
减少错误:通过复用已经实现过的操作符,可以减少错误和漏洞的引入。如果一个操作符已经被正确实现和测试,并且在其他地方进行了广泛使用和验证,那么在其他操作符中复用它可以避免重新实现相同的逻辑并减少出错的可能性。
提高效率:复用已经实现过的操作符可以提高代码的执行效率。已经实现的操作符通常会经过优化和性能测试,因此复用它们可以避免重复的计算和处理,从而提高整体的执行效率。
最后实现的代码为:
bool operator==(const string& s) const
{return (strcmp(_str, s._str) == 0);
}bool operator!=(const string& s) const
{return !(*this == s);
}bool operator>(const string& s) const
{return (strcmp(_str, s._str) > 0);
}bool operator>=(const string& s) const
{return (*this > s || *this == s);
}bool operator<(const string& s) const
{return !(*this >= s);
}bool operator<=(const string& s) const
{return (*this == s || *this < s);
}总结一下:
1)对于不修改对象的成员的函数时,尽量使用const修饰该函数;
2)如果这个函数需要同时满足这两种情况时,就需要使用函数重载:
a)在读取数据时我们不希望进行更改成员,要使用const进行修饰该函数;
b)如果我们在读的过程中也想要修改时,就不能使用const进行修饰。
操作符优先级问题
同时在使用的过程中,还有一点细节需要注意:
cout << s1 > s2 << endl;因为流插入<< 的运算优先级比较高,会先运算 cout << s1,它的返回值为ostream的一个流,左边s2 << endl 返回值也是一个流,最后在进行运算 ostream > ostream ,此时类型就不匹配了。
报错内容为:
二元“<<”: 没有找到接受“string”类型的右操作数的运算符(或没有可接受的转换)所以在进行这个运算时,要加一个括号,以免出现错误。
Modifiers:
1)reserve
Request a change in capacity
Requests that the string capacity be adapted to a planned change in size to a length of up to n characters.
它不会改变string的length,只是进行扩容(分配更大的空间并修改capacity)。
void reserve(size_t n)
{char* temp = new char[n + 1]; //注意为\0开辟一个空间strcpy(temp, _str);delete[] _str;_str = temp;_capacity = n;
} 当然这个reserve还有一点瑕疵,当n小于_capacity时,会进行缩容
(缩容可能会带来一定的风险:如果进行插入操作还要再进行扩容,形成抖动--反复的释放和申请空间。因为C++不支持释放空间的一部分,要想达到缩容效果,只能开辟一块较小的空间,然后将内容拷贝到这块空间,并将_str指向这块空间)
并且当缩容的空间小于_str的字符长度时,通过strcpy拷贝还会产生越界的问题。
缩容指的是将动态数组或容器的内部数组大小减小,以释放多余的内存。虽然缩容可以减少内存的使用,但同时也可能带来以下问题:
内存分配和释放开销:缩容需要重新分配内存,并将原有数据复制到新的内存中。这一过程会产生一定的时间和空间开销,而且频繁进行缩容操作会加剧这一问题。
导致内存碎片:由于缩容会释放一部分内存,这些内存空间可能不能连续使用,从而导致内存碎片的产生。内存碎片会影响内存分配和释放的效率,甚至可能导致程序出现内存溢出等问题。
降低性能:缩容可能会导致性能下降。如果缩容频繁进行,那么每次重新分配内存和复制数据都会耗费时间和计算资源,从而降低程序的整体性能。
可能引发bug:在进行缩容操作时,如果没有正确处理好指针和迭代器等相关问题,就可能会引发程序崩溃、数据丢失等错误,甚至可能会破坏程序的正确性和稳定性。
所以库里的reserve是不支持缩容的。
void reserve(size_t n)
{if (n > _capacity){char* temp = new char[n + 1]; //为\0开辟一个空间if (_str){strcpy(temp, _str);delete[] _str;}_str = temp;_capacity = n;}
}
同时这里使用new开辟空间时,不用再向malloc一样进行检查temp是否为空,因为new如果空间开辟失败也不会返回NULL,而是抛异常。
我们还需要判断一下,_str是否为空,如果为空就不需要再将_str内容拷贝给temp中了,只进行扩容操作(会出现空指针解引用的问题),不为空时才进行拷贝。
2)resize
Resize string
Resizes the string to a length of n characters.
If n is smaller than the current string length, the current value is shortened to its first n character, removing the characters beyond the nth.
resize的功能与reserve的功能类似,resize不仅能够扩容还能够进行初始化。
注意库里面resize的细节:
同时resize在扩容时还存在一定的内存对齐,这导致有时候开辟的空间会大于我们的需求。(注意不同的编译器实现不同,在VS上会存在这种情况,但是在g++编译器上,它只会申请我们给定的空间大小)
示例一:
std::string s3;
s3.resize(10, 'x');
cout << s3.c_str() << endl;
s3.resize(20, 'y');
cout << s3.c_str() << endl;
我们发现对于已经初始化的部分,resize是不会再进行初始化了,它只会在新开辟的空间进行初始化。
示例二:
std::string s3;
s3.resize(10, 'x');
cout << s3.c_str() << endl;
s3.resize(20, 'y');
cout << s3.c_str() << endl;
s3.resize(5, 'y');
cout << s3.c_str() << endl;
- resize的实现
主要进行空间三种空间大小的比较
void resize(size_t n, char ch = '\0') // 扩容+初始化
{// 三种情况进行讨论if (n <= _size){// 容量不变,只改变内容_size = n;_str[_size] = '\0';}else{if (n > _capacity) // 需要的空间大于原本的空间时,进行扩容{reserve(n);}// 当需要的空间大于_size但小于_capacity时,不需要进行扩容直接进行初始化// 将新开辟的空间进行初始化size_t i = _size;while (i < n){_str[i] = ch;i++;}_size = n;_str[_size] = '\0';}
}3)insert
void insert(size_t pos, char ch)
{assert(pos >= 0 && pos <= _size);// 如果空间不足,需要进行扩容if (_size + 1 > _capacity){reserve(_size + 1);}// 移动数据for (size_t i = _size; i > pos; i--){_str[i] = _str[i - 1];}_str[pos] = ch;_size++;_str[_size] = '\0';
}因为在插入一个字符之前需要将在指定位置后面的字符向后移动,将这个空间给空出来。
移动数据有两种方法:
一种是将当前数据移动到后面;
另一种是将当前数据的前一个数据移动到当前位置。
第一种方法的最后一步是 end 移动到0时,进行最后一次移动数据,end--,结束条件是-1 <= 0,条件为假,退出循环。
第二种方法的最后一步是end移动到下标为1的位置上时,进行最后一次移动数据,end--,结束条件是0 < 0,条件为假,退出循环。
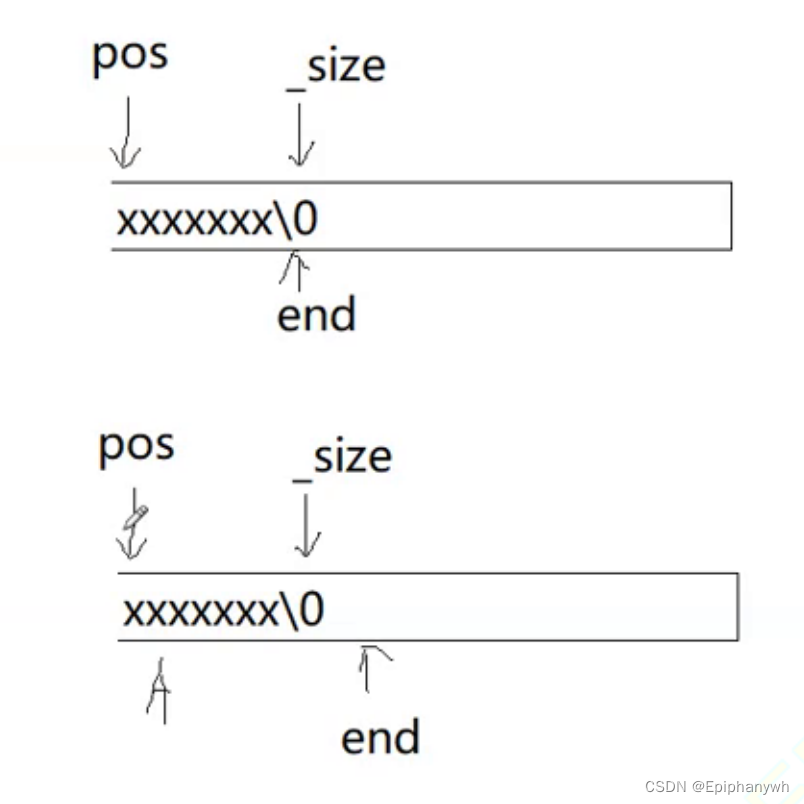
但是如果移动数据部分,是以下样式的写法在进行头插时会出现错误:
size_t end = _size;
while(end <= pos)
{_str[end+1] = _str[end];end--;
}当pos为0,最后一次循环时end为0,0--,又因为end为size_t数据类型的,0--后是一个很大的数,而不是-1.
如果我们将end的数据类型改为int类型也不能解决这个问题。这是因为_size是一个size_t类型的,在定义int end = _size时,会进行类型提升,end最终还是size_t的类型。
所以不能使用这个方法挪动数据。
4)operator+=、append、push_back
void reserve(size_t n)
{char* temp = new char[n + 1]; //为\0开辟一个空间strcpy(temp, _str);delete[] _str;_str = temp;_capacity = n;
}void push_back(char ch)
{// 判断容量if (_size + 1 > _capacity){// 扩容(添加单个字符时,一次扩容二倍)if (_capacity == 0)reserve(2);else{reserve(_capacity * 2); // capacity不包括\0的空间}}// 添加_str[_size] = ch;_size++;_str[_size] = '\0';
}void append(const char* str)
{// 判断容量size_t len = strlen(str);if (_size + len > _capacity){// 扩容(添加单个字符时,一次扩容需要的空间大小)reserve(_capacity + len);}strcpy(_str + _size, str);_size += len;
}string& operator+=(char ch)
{push_back(ch);return *this;
}string& operator+=(const char* str)
{append(str);return *this;
}5)erase
void erase(size_t pos, size_t len = npos)
{assert(pos < _size && pos >= 0); // 条件为假进行断言size_t end = pos + len;size_t begin = pos;if (len == npos || pos + len > _size) // pos + len = 0{_str[pos] = '\0';_size = pos;}else{/*for (size_t i = end; i <= _size; i++){_str[begin++] = _str[i];}*/strcpy(_str + pos, _str + pos + len);_size -= len;}
}细节:
1、npos

静态变量在声明时是不能给缺省值的,因为在声明时给的缺省值是被用来在构造函数初始化列表中初始化成员变量时使用的。
而静态变量是属于整个类的,不能在某一个对象中进行初始化。所以静态变量的初始化应该在类外进行,而不应该在构造函数中。
但是C++在这块语法上有一个槽点:
上面已经提到static修饰的变量是不能在类中进行初始化的,但是如果在之前的基础上加上一个const就可以在声明时进行初始化:
static const size_t npos = -1;但是这种写法只针对于整形静态变量,对于其他数据类型的变量都不能这样使用。
否则会有以下报错信息:
![]()
static const double temp = 1.1;2、

这里的第二种情况要考虑len==npos,因为npos是一个size_t最大的数,这个最大的数尽管加上一也会进行溢出,所以需要单独进行判断一下:

6)swap
交换有两种情况:
一种是直接内容不变,直接交换指向两个内容的指针
另一种是指向内容的指针不变,将两部分的内容进行交换。
显然第一种方式更为高效。(string类中使用的是第一种交换方法,而在算法模板中的交换函数用的是第二种方法)
void swap(string& s)
{// 交换容量size_t t = _size;_size = s._size;// 交换指针char* temp = _str;s._size = t;_str = s._str;s._str = temp;// 如果_size>_capacity则需要进行扩容s.reserve(s._size);reserve(_size);
}Non-member function overloads
1)流插入
Ⅰ. 流插入的使用细节
int main()
{std::string s("0123456");s1 += '\0';s1 += "XXXXXX";cout << s << endl;cout << s.c_str() << endl;
}这两种打印方式不同主要在于:在打印 s 时是通过 s 的 size 决定打印的内容的;
在打印 s.c_str() 时,是通过 ‘\0’ 决定打印的内容的。
所以上面的打印结果为:
0123456\0XXXXXX 和 0123456
主要原因是,虽然两个都是使用 << 进行打印,但是两者调用的函数是不一样的:
第一个,<< 操作符的右面数据类型为string,所以在打印的时候会调用:
ostream& operator<<(ostream& out, const string& s)
{for (auto ch : s){out << ch;}return out;
}这个循环是从string的开头打印到结尾,将所有的内容都打印出来。
iterator begin()
{return _str;
}iterator end()
{return _str + _size;
}第二个,<< 操作符右面的数据类型为const char* (因为s.c_str() 函数的返回值就是const char* ),所以它调用的函数就是C++自己实现的基本类型操作符,就相当于打印一个字符串,功能类似于puts、printf("%s")。所以遇到\0就会停止打印。
const char* c_str()
{return _str;
}Ⅱ. 流插入的模拟实现
使用迭代器,流插入的一般实现方法,我已经在另一篇博客中详细介绍了,这里不做赘述:
链接:http://t.csdnimg.cn/eenhr
但是对于有迭代器的类来说,我们除了使用一般方法,还可以用迭代器帮助我们访问类的私有成员对象。
ostream& operator<<(ostream& out, const string& s)
{for (auto ch : s){out << ch;}return out;
}这个函数将放在全局中,函数内部使用迭代器和公有成员 <<,注意内部的 << 是C++基本类型的流提取操作符。
2)流提取
Ⅰ.流提取的使用细节
-
将换行符和空格为两个字符的分隔符
cin 和 scanf 一样,会将换行符和空格为两个字符的分隔符。看一个实例:
istream& operator>>(istream& in, string& s)
{char ch;in >> ch;while (ch != ' ' && ch != '\n'){s += ch;in >> ch;}return in;
}
程序还没有结束,在这段代码中,我们认为当输入一个回车时这个“hello world”字符串就会结束。但是,默认情况下,会将 空格和回车 这两个字符作为两个字符之间的分隔符,不会作为一个有效字符从缓冲区中读取出来,所以ch永远读不到空格和换行符,也就不会跳出循环。
-
缓冲区细节
cin和C语言中的scanf使用不是同一个缓冲区。所以我们在使用时要配套使用:使用cin从标准输入读取,使用cout从缓冲区读出;使用 scanf 从标准输入读取,使用 printf 从缓冲区读出。
在 C++ 中,
cin对象是 C++ 标准库中的输入流对象,它使用了独立于 C 语言的缓冲区。当你使用cin对象进行输入操作时,输入的数据首先会被存储在cin对象的缓冲区中,然后再根据需要从缓冲区中读取数据。而在 C 语言中,
scanf函数使用的是标准输入流stdin,它也有自己的缓冲区。当你使用scanf函数进行输入操作时,输入的数据会直接存储在stdin的缓冲区中。尽管
cin和scanf使用了不同的缓冲区,但它们最终都会从标准输入中读取数据。因此,在 C++ 和 C 混合编程时,如果你先使用了cin进行输入操作,然后又使用了scanf,你需要注意输入缓冲区的状态。由于cin和scanf使用不同的缓冲区,可能会导致输入的数据不符合预期。为了避免这种混乱,可以在使用
scanf前先使用cin.ignore()清空cin缓冲区中的未读取字符,或者使用fflush(stdin)清空stdin缓冲区中的内容。这样可以确保下一个输入操作从一个干净的缓冲区开始。需要注意的是,
fflush(stdin)并不是标准 C 的规定,它是一种常见的编译器扩展。在某些编译器中,fflush(stdin)可能会导致未定义行为。因此,在使用fflush(stdin)时要谨慎,并根据具体的编译器和平台进行判断。
Ⅱ. 流提取的模拟实现
如果你希望将空格和换行符都作为字符串的一部分进行读取,可以使用 getline 函数来代替 >> 操作符。getline 函数可以读取一行完整的输入,包括其中的空格和换行符。此时我们再使用空格和换行符作为循环结束条件才可行。
#include <iostream>
using namespace std;
istream& operator>>(istream& in, string& s)
{char ch;ch = in.get();while (ch != ' ' && ch != '\n'){s += ch;ch = in.get();}return in;
}int main()
{string s2;cin >> s2;cout << s2 << endl;return 0;
}
在这段程序中,当读到空格时,认为这个字符串是一个有效字符并读取到ch中,然后进行循环条件的判断。读取到空格直接就跳出循环,剩余的内容没有被读取出来,world会被留到缓冲区中。
当然,库里面为了减少扩容的次数,会先设置一个预填空间,当这个空间满了之后,就将这个空间的内容添加到string中,然后string一次就会开辟预填空间的大小的空间,预填空间容量归零;同时再次输入进去的字符还是先添加到预填空间中,等预填空间满了之后再次添加到string中……
istream& operator>>(istream& in, string& s)
{s.clear();char ch = in.get();char buff[128];size_t i = 0;while (ch != ' ' && ch != '\n'){buff[i++] = ch;if (i == 127){buff[127] = '\0';s += buff;i = 0;}ch = in.get();}if (i != 0){buff[i] = '\0';s += buff;}return in;
}其实就是以空间换时间的策略。
今天的分享就到这里了,如果,你感觉这篇博客对你有帮助的话,就点个赞吧!感谢感谢……
相关文章:
string 模拟实现
string的数据结构 char* _str; size_t _size; size_t _capacity; _str 是用来存储字符串的数组,采用new在堆上开辟空间; _size 是用来表示字符串的长度,数组大小strlen(_str); _capacity 是用来表示_str的空间大小, _capacity…...
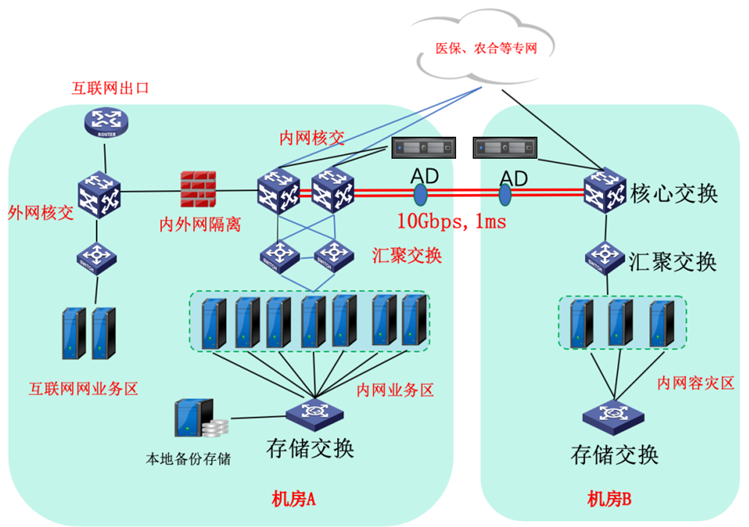
医院网络安全建设:三网整体设计和云数据中心架构设计
医院网络安全问题涉及到医院日常管理多个方面,一旦医院信息管理系统在正常运行过程中受到外部恶意攻击,或者出现意外中断等情况,都会造成海量医疗数据信息的丢失。由于医院信息管理系统中存储了大量患者个人信息和治疗方案信息等,…...
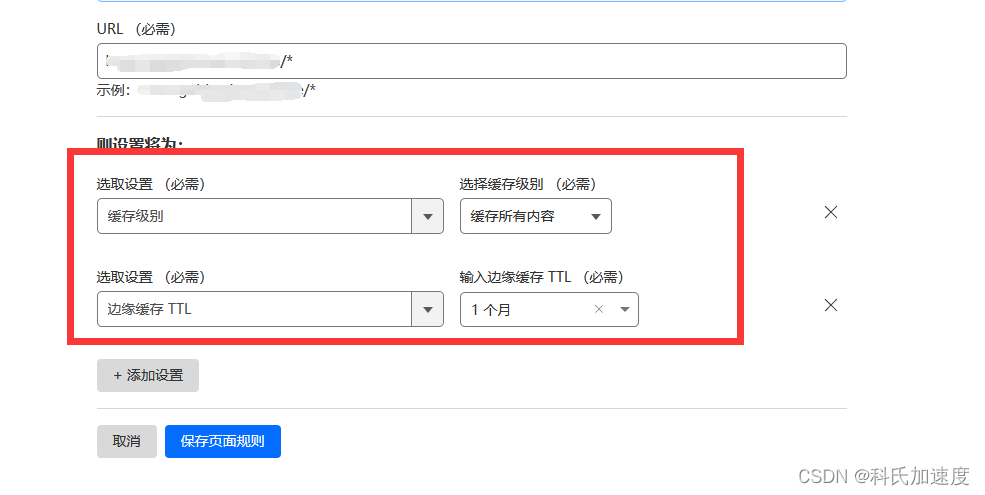
Cloudflare cdn 基本使用
个人版免费试用,一个邮箱账号只能缓存一个网站cdn。 地址:cloudflare.com 创建站点 在网站创建站点,填上你的域名 点击进入网站 缓存全局配置 可清除缓存,设置浏览器缓存时间 我设置了always online,防止服务器经常不稳定 缓…...

Oracle21C + PLSQL Developer 15 + Oracle客户端21安装配置完整图文版
一、Oracle21C PLSQL Developer 15 Oracle客户端文件下载 1、Oracl21C下载地址:Database Software Downloads | Oracle 中国 2、 PLSQL Developer 15下载地址:Registered download PL/SQL Developer - Allround Automations 3、 Oracle 客户端下载地址…...

编程笔记 html5cssjs 038 CSS背景
编程笔记 html5&css&js 038 CSS背景 一、CSS 背景属性二、CSS background-color三、不透明度 / 透明度四、使用 RGBA 的透明度五、CSS 背景图像六、CSS 背景重复CSS background-repeatCSS background-repeat: no-repeatCSS background-position 七、练习小结࿱…...
springmvc上传与下载
文件上传 结构图 导入依赖 <dependency><groupId>jstl</groupId><artifactId>jstl</artifactId><version>1.2</version></dependency><dependency><groupId>org.springframework</groupId><artifactId…...
论文阅读笔记AI篇 —— Transformer模型理论+实战 (一)
资源地址Attention is all you need.pdf(0积分) - CSDN 第一遍阅读(Abstract Introduction Conclusion) Abstract中强调Transformer摒弃了循环和卷积网络结构,在English-to-German翻译任务中,BLEU得分为28.4, 在En…...
)
Linux之shell编程(BASH)
Shell编程概述(THE bourne-again shell) Shell名词解释(外壳,贝壳) Kernel Linux内核主要是为了和硬件打交道 Shell 命令解释器(command interperter) Shell是一个用C语言编写的程序,他是用户使用Lin…...
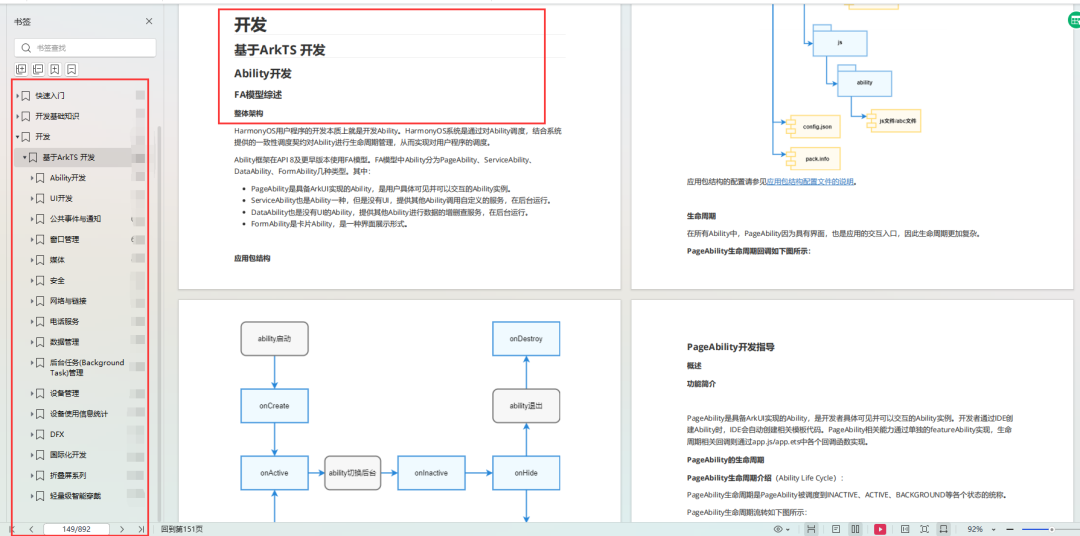
HarmonyOS—声明式UI描述
ArkTS以声明方式组合和扩展组件来描述应用程序的UI,同时还提供了基本的属性、事件和子组件配置方法,帮助开发者实现应用交互逻辑。 创建组件 根据组件构造方法的不同,创建组件包含有参数和无参数两种方式。 说明 创建组件时不需要new运算…...
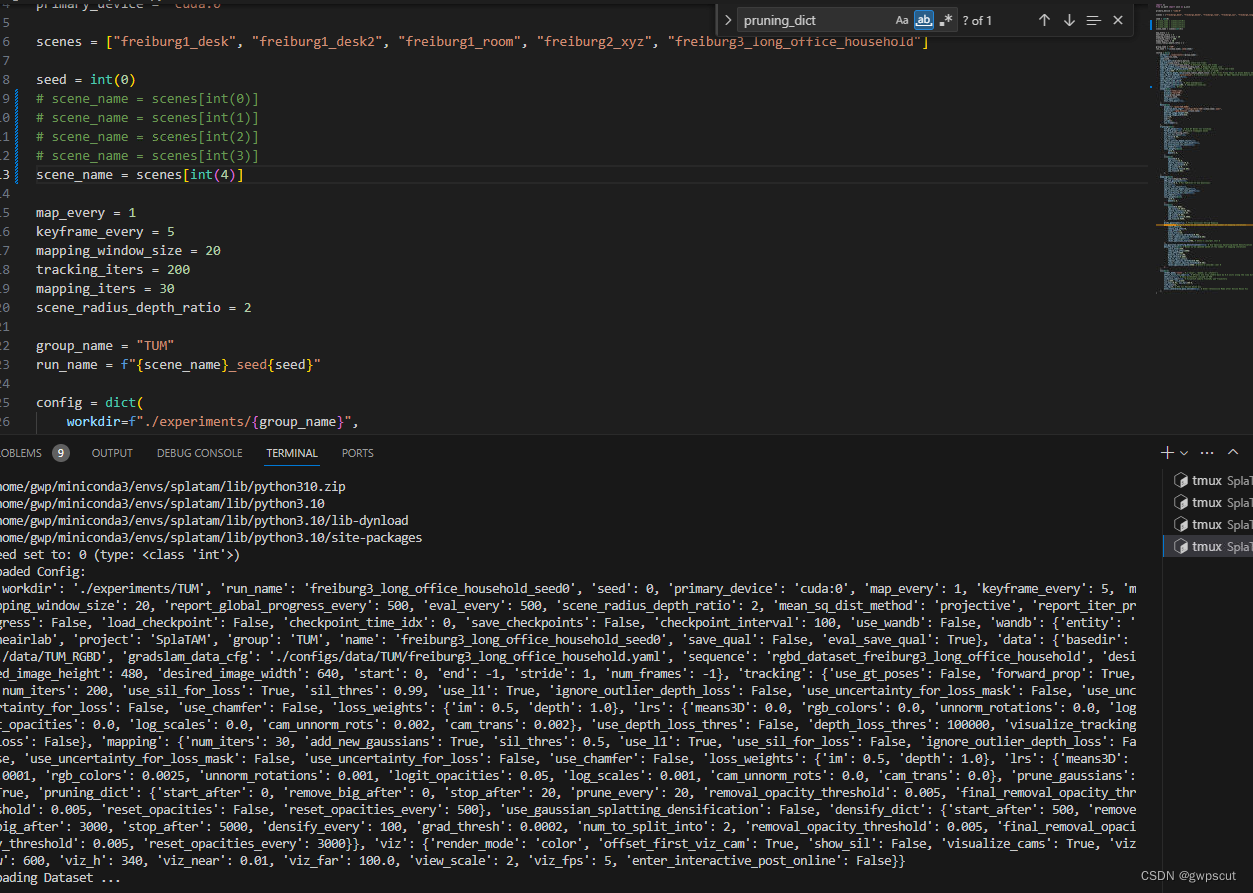
实验笔记之——基于TUM-RGBD数据集的SplaTAM测试
之前博客对SplaTAM进行了配置,并对其源码进行解读。 学习笔记之——3D Gaussian SLAM,SplaTAM配置(Linux)与源码解读-CSDN博客SplaTAM全称是《SplaTAM: Splat, Track & Map 3D Gaussians for Dense RGB-D SLAM》,…...
SpringBoot SaToken Filter如用使用ControllerAdvice统一异常拦截
其实所有的Filter都是一样的原理 大致流程: 创建一个自定义Filter, 用于拦截所有异常此Filter正常进行后续Filter调用当调用后续Filter时, 如果发生异常, 则委托给HandlerExceptionResolver进行后续处理即可 以sa-token的SaServletFilter为例 首先注册SaToken的过滤器 pac…...

基于HarmonyOS的华为智能手表APP开发实战——Fitness_华为手表app开发
、 基于HarmonyOS的华为智能手表APP开发实战——Fitness_华为手表app开发 Excerpt 文章浏览阅读8.7k次,点赞6次,收藏43次。本文针对华为HarmonyOS智能穿戴产品(即HUAWEI WATCH 3)开发了一款运动健康类的游戏化APP——Fitness,旨在通过游戏化的方式,提升用户运动动机。_华…...

1.6用命令得到ip和域名解析<网络>
专栏导航 第五章 如何用命令得到自己的ip<本地> 第六章 用命令得到ip和域名解析<网络> ⇐ 第七章 用REST API实现dynv6脚本(上) 用折腾路由的兴趣,顺便入门shell编程。 第六章 用命令得到ip和域名解析<网络> 文章目录 专栏导航第六章 用命令得到ip和域名解…...

leetcode 399除法求值 超水带权并查集
题目 class Solution { public:int f[45];double multi[45];map<string,int>hash;int tot0;int seek(int x){if(xf[x]) return x;int faf[x];f[x]seek(fa);multi[x]*multi[fa];return f[x];}vector<double> calcEquation(vector<vector<string>>&…...

【Linux】Linux 系统编程——touch 命令
文章目录 1.命令概述2.命令格式3.常用选项4.相关描述5.参考示例 1.命令概述 在**Linux 中,每个文件都与时间戳相关联,每个文件都存储了上次访问时间、**上次修改时间和上次更改时间的信息。因此,每当我们创建新文件并访问或修改现有文件时&a…...
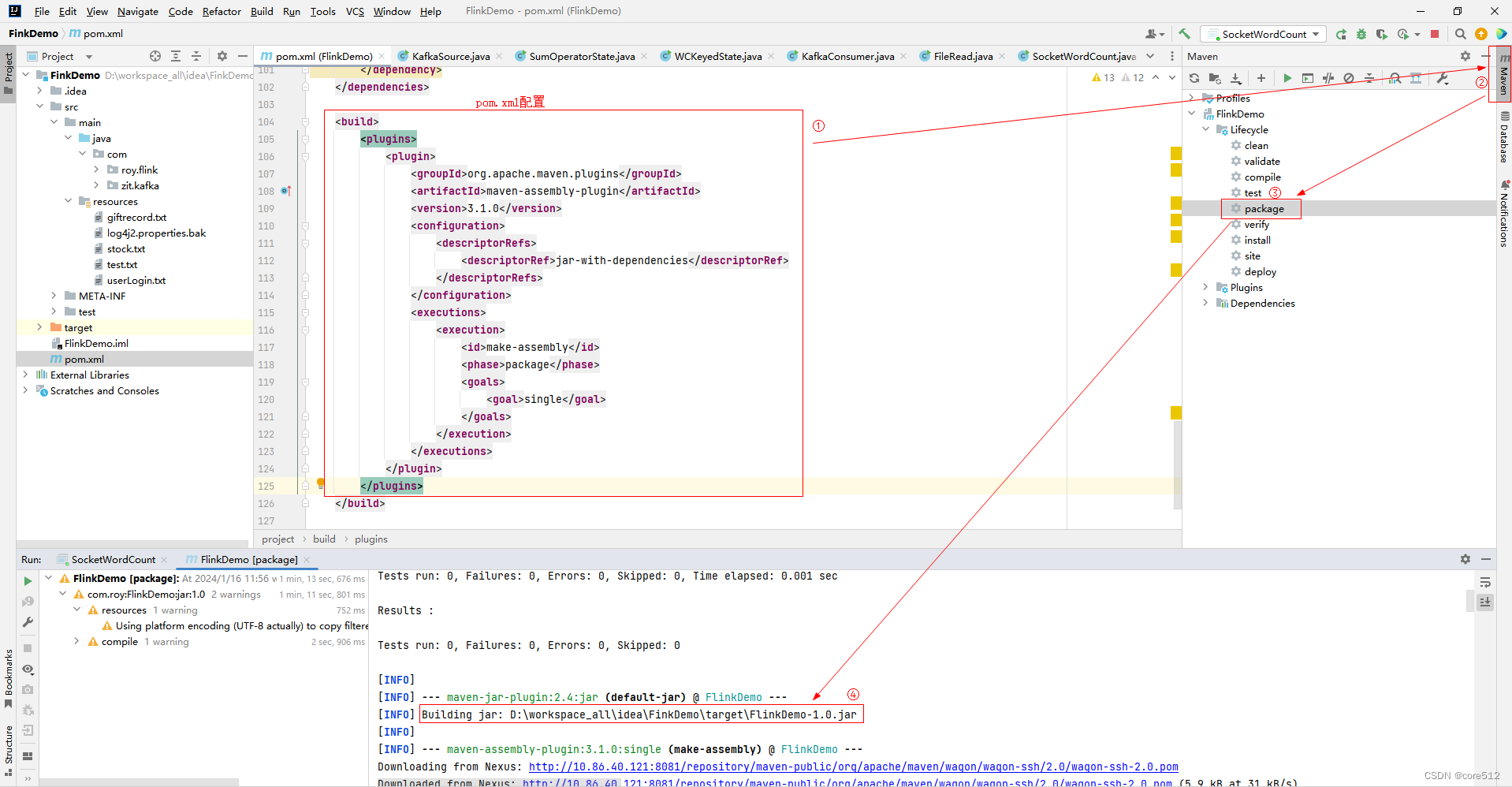
SpringBoot项目打包
1.在pom.xml中加入如下配置 <build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.1.0</version><configuration><descriptorRef…...

Android Google 开机向导定制 setup wizard
Android 开机向导定制 采用 rro_overlays 机制来定制开机向导,定制文件如下: GmsSampleIntegrationOverlay$ tree . ├── Android.bp ├── AndroidManifest.xml └── res └── raw ├── wizard_script_common_flow.xml ├── wizard_script…...

OpenEL GS之深入解析视频图像处理中怎么实现错帧同步
一、什么是错帧同步? 现在移动设备的系统相机的最高帧率在 120 FPS 左右,当帧率低于 20 FPS 时,用户可以明显感觉到相机画面卡顿和延迟。我们在做相机预览和视频流处理时,对每帧图像处理时间过长(超过 30 ms)就很容易造成画面卡顿,这个场景就需要用到错帧同步方法去提升…...

MyBatis处理LIKE查询时,如何将传值中包含下划线_和百分号%等特殊字符处理成普通字符而不是SQL的单字符通配符
MySQL中,_和%在LIKE模糊匹配中有特殊的含义: 下划线 _ 在LIKE模糊匹配中表示匹配任意单个字符。百分号 % 在LIKE模糊匹配中表示匹配任意多个字符(包括零个字符) 如果这种字符不经过处理,并且你的模糊查询sql语句书写…...
 国际化)
Spring MVC(三) 国际化
SpringMVC 国际化 1、添加相关依赖2、配置MessageSourceBean方式一:ReloadableResourceBundleMessageSource方式二:ResourceBundleMessageSource 3、添加消息资源文件英文 messages_en.properties中文 messages_zh_CN.properties默认 messages.propertie…...

AnimateDiff:3分钟让静态图像动起来的AI动画生成神器
AnimateDiff:3分钟让静态图像动起来的AI动画生成神器 【免费下载链接】animatediff 项目地址: https://ai.gitcode.com/hf_mirrors/ai-gitcode/animatediff 你是否想过,只需几句话就能让静态图片活起来?是否在寻找将创意想法快速转化…...
)
ElevenLabs湖北话语音合成:从零部署到商用级TTS的7大避坑步骤(附武汉/宜昌/襄阳三方言测试数据)
更多请点击: https://kaifayun.com 第一章:ElevenLabs湖北话语音合成的技术定位与方言价值 ElevenLabs 作为全球领先的AI语音生成平台,其核心能力聚焦于高保真、情感化、多语言的文本到语音(TTS)合成。尽管官方尚未正…...

JMeter gRPC性能测试解决方案:微服务协议性能验证技术实现
JMeter gRPC性能测试解决方案:微服务协议性能验证技术实现 【免费下载链接】jmeter-grpc-request JMeter gRPC Request load test plugin for gRPC 项目地址: https://gitcode.com/gh_mirrors/jm/jmeter-grpc-request 随着微服务架构的普及,gRPC已…...

5分钟搞定:用WinDiskWriter在Mac上制作Windows启动盘,轻松绕过TPM限制
5分钟搞定:用WinDiskWriter在Mac上制作Windows启动盘,轻松绕过TPM限制 【免费下载链接】windiskwriter 🖥 Windows Bootable USB creator for macOS. 🛠 Patches Windows 11 to bypass TPM and Secure Boot requirements. &#x…...

7.1 DRAM Basics: Internals, Operation
这两段截图是《Memory Systems》一书中关于 DRAM 最基础定义的阐述。我为您提供翻译和深度解读: 1. 中文翻译 图1: 随机存取存储器(RAM)如果每一位使用一个单一的晶体管-电容器对,则被称为动态随机存取存储器(DRAM)。图 7.3 在右下角展示了 DRAM 存储单元的电路。这个电…...

Windows 环境 OpenClaw 2.7.5 一键安装避坑指南
OpenClaw 一键安装包|可视化部署,简化环境配置流程✨适配系统:Windows10/11 64 位当前版本:v2.7.5(虾壳云版)✨核心优势:全程可视化操作,不用命令行、不用手动配置 Python/Node.js&a…...

硬件选型干货|钡特电源DQ1-15D1709S与金升阳QA01-17属工业标准模块电源,避坑指南
在工业电子硬件研发中,工业DC-DC模块是板级隔离供电的核心器件,其标准化封装、性能稳定性及国产化水平,直接影响研发效率、系统可靠性与供应链安全。钡特电源DQ1-15D1709S与金升阳QA01-17作为国产直流电源模块领域的代表性型号,均…...

Fere AI 新手快速上手指南
在快速迭代的开发节奏中,我们常常面临这样的困境:想要为应用集成智能对话能力,却被复杂的模型部署、高昂的算力成本或是晦涩的 API 文档劝退。很多时候,开发者需要的不是一个庞大的底层框架,而是一个能够即插即用、稳定可靠且易于集成的智能服务接口。无论是构建客服机器人…...
)
Linux驱动开发实战:为I.MX6ULL编写一个DS18B20的字符设备驱动(从设备树到应用测试)
Linux驱动开发实战:I.MX6ULL平台DS18B20字符设备驱动全流程解析 在嵌入式Linux开发领域,能够完整实现一个符合内核规范的设备驱动是工程师的核心能力之一。本文将带您深入探索如何为I.MX6ULL处理器开发DS18B20温度传感器的标准字符设备驱动,…...

图片转Word怎么转?2026年图片转文档完整方法与工具对比
日常工作中,我们经常需要将拍摄的照片、截图或扫描的纸质文件转换成可编辑的Word文档。无论是转录会议笔记、整理手写资料,还是数字化办公文件,高效的转换工具能显著提升工作效率。本文将详细介绍多种图片转word文档的方法,帮你找…...