elasticsearch[二]-DSL查询语法:全文检索、精准查询(term/range)、地理坐标查询(矩阵、范围)、复合查询(相关性算法)、布尔查询
ES-DSL查询语法(全文检索、精准查询、地理坐标查询)
1.DSL查询文档
elasticsearch 的查询依然是基于 JSON 风格的 DSL 来实现的。
1.1.DSL 查询分类
Elasticsearch 提供了基于 JSON 的 DSL(Domain Specific Language)来定义查询。常见的查询类型包括:
-
查询所有:查询出所有数据,一般测试用。例如:match_all
-
全文检索(full text)查询:利用分词器对用户输入内容分词,然后去倒排索引库中匹配。例如:
- match_query
- multi_match_query
-
精确查询:根据精确词条值查找数据,一般是查找 keyword、数值、日期、boolean 等类型字段。例如:
- ids
- range
- term
-
地理(geo)查询:根据经纬度查询。例如:
- geo_distance
- geo_bounding_box
-
复合(compound)查询:复合查询可以将上述各种查询条件组合起来,合并查询条件。例如:
- bool
- function_score
查询的语法基本一致:
GET /indexName(索引库名称)/_search
{"query": {"查询类型": {"查询条件": "条件值"}}
}我们以查询所有为例,其中:
- 查询类型为 match_all
- 没有查询条件
// 查询所有
GET /heima/_search
{"query": {"match_all": {}}
}其它查询无非就是查询类型、查询条件的变化。
1.2. 全文检索查询
1.2.1. 使用场景
全文检索查询的基本流程如下:
- 对用户搜索的内容做分词,得到词条
- 根据词条去倒排索引库中匹配,得到文档 id
- 根据文档 id 找到文档,返回给用户
比较常用的场景包括:
- 商城的输入框搜索
- 百度输入框搜索
例如京东:

因为是拿着词条去匹配,因此参与搜索的字段也必须是可分词的 text 类型的字段。
1.2.2. 基本语法
常见的全文检索查询包括:
- match 查询:单字段查询
- multi_match 查询:多字段查询,任意一个字段符合条件就算符合查询条件
match 查询语法如下:
GET /indexName/_search
{"query": {"match": {"FIELD": "TEXT"}}
}mulit_match 语法如下:
GET /indexName/_search
{"query": {"multi_match": {"query": "TEXT","fields": ["FIELD1", " FIELD12"]}}
}1.2.3. 示例
match 查询示例:

multi_match 查询示例:
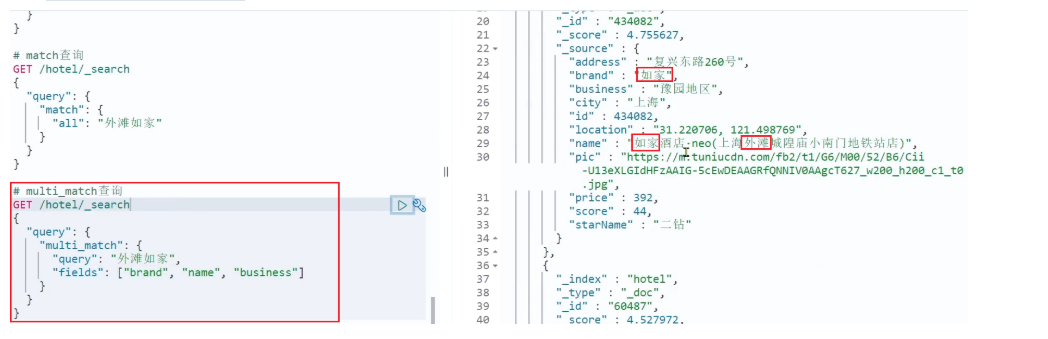
可以看到,两种查询结果是一样的,为什么?
因为我们将 brand、name、business 值都利用 copy_to 复制到了 all 字段中。因此你根据三个字段搜索,和根据 all 字段搜索效果当然一样了。
但是,搜索字段越多,对查询性能影响越大,因此建议采用 copy_to,然后单字段查询的方式。
1.2.4. 总结
match 和 multi_match 的区别是什么?
- match:根据一个字段查询
- multi_match:根据多个字段查询,参与查询字段越多,查询性能越差
1.3. 精准查询
精确查询一般是查找 keyword、数值、日期、boolean 等类型字段。所以不会对搜索条件分词。常见的有:
- term:根据词条精确值查询
- range:根据值的范围查询
1.3.1.term 查询
因为精确查询的字段搜是不分词的字段,因此查询的条件也必须是不分词的词条。查询时,用户输入的内容跟自动值完全匹配时才认为符合条件。如果用户输入的内容过多,反而搜索不到数据。
语法说明:
// term查询
GET /indexName/_search
{"query": {"term": {"FIELD": {"value": "VALUE"}}}
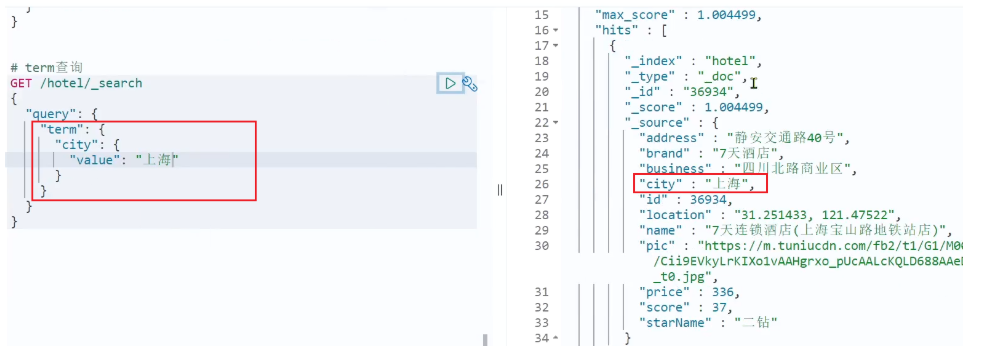
}示例:
当我搜索的是精确词条时,能正确查询出结果:
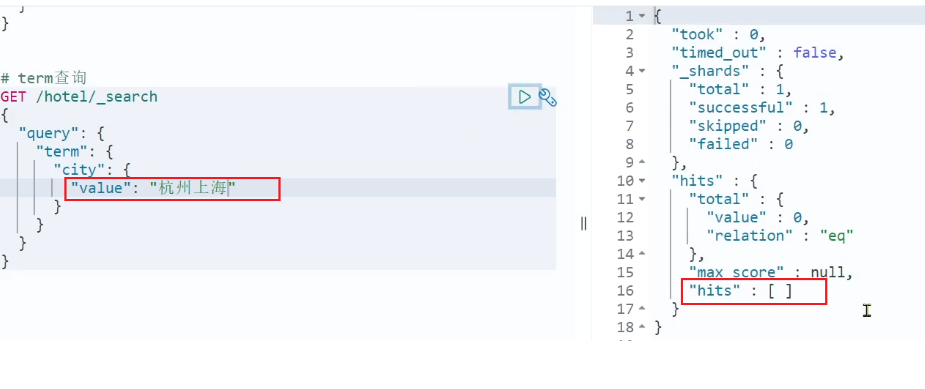
但是,当我搜索的内容不是词条,而是多个词语形成的短语时,反而搜索不到:
1.3.2.range 查询
范围查询,一般应用在对数值类型做范围过滤的时候。比如做价格范围过滤。
基本语法:
// range查询
GET /indexName/_search
{"query": {"range": {"FIELD": {"gte": 10, // 这里的gte代表大于等于,gt则代表大于"lte": 20 // lte代表小于等于,lt则代表小于}}}
}示例:

1.3.3. 总结
精确查询常见的有哪些?
- term 查询:根据词条精确匹配,一般搜索 keyword 类型、数值类型、布尔类型、日期类型字段
- range 查询:根据数值范围查询,可以是数值、日期的范围
1.4. 地理坐标查询
所谓的地理坐标查询,其实就是根据经纬度查询,官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/geo-queries.html
常见的使用场景包括:
- 携程:搜索我附近的酒店
- 滴滴:搜索我附近的出租车
- 微信:搜索我附近的人
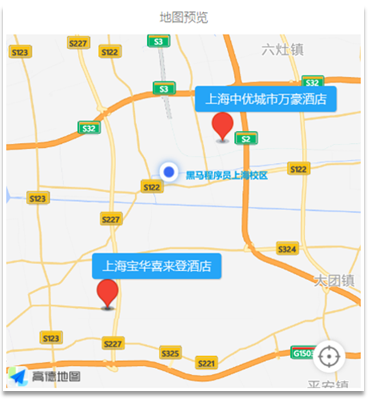
附近的酒店:
附近的车:
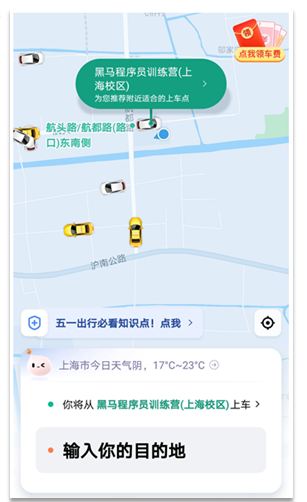
1.4.1. 矩形范围查询
矩形范围查询,也就是 geo_bounding_box 查询,查询坐标落在某个矩形范围的所有文档:
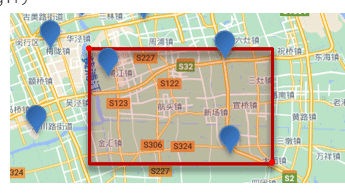
查询时,需要指定矩形的左上、右下两个点的坐标,然后画出一个矩形,落在该矩形内的都是符合条件的点。
语法如下:
// geo_bounding_box查询
GET /indexName/_search
{"query": {"geo_bounding_box": {"FIELD": {"top_left": { // 左上点"lat": 31.1,"lon": 121.5},"bottom_right": { // 右下点"lat": 30.9,"lon": 121.7}}}}
}这种并不符合 “附近的人” 这样的需求,所以我们就不做了。
1.4.2. 附近查询
附近查询,也叫做距离查询(geo_distance):查询到指定中心点小于某个距离值的所有文档。
换句话来说,在地图上找一个点作为圆心,以指定距离为半径,画一个圆,落在圆内的坐标都算符合条件:

语法说明:
// geo_distance 查询
GET /indexName/_search
{"query": {"geo_distance": {"distance": "15km", // 半径"FIELD": "31.21,121.5" // 圆心}}
}示例:
我们先搜索陆家嘴附近 15km 的酒店:
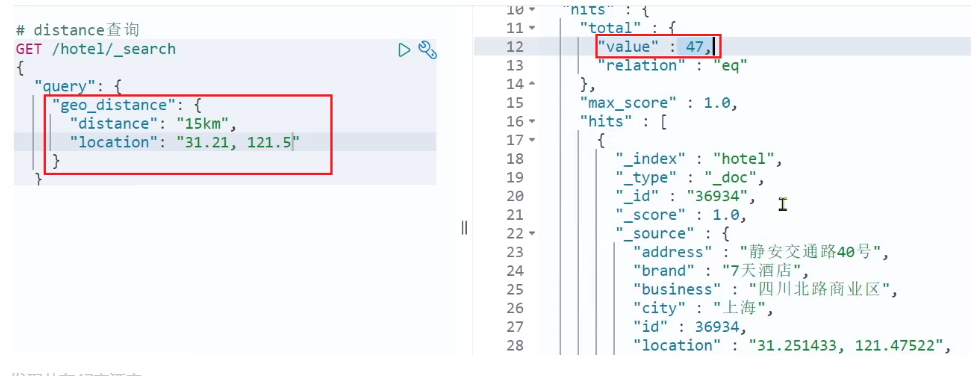
发现共有 47 家酒店。
然后把半径缩短到 3 公里:
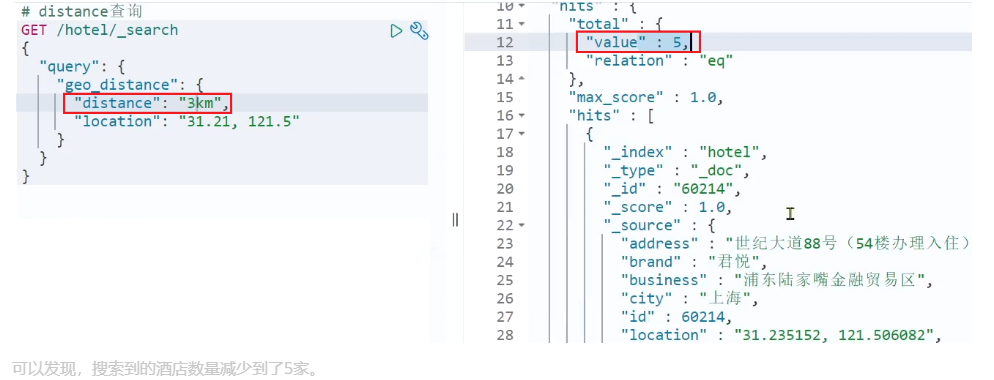
1.5. 复合查询
复合(compound)查询:复合查询可以将其它简单查询组合起来,实现更复杂的搜索逻辑。常见的有两种:
- fuction score:算分函数查询,可以控制文档相关性算分,控制文档排名
- bool query:布尔查询,利用逻辑关系组合多个其它的查询,实现复杂搜索
1.5.1. 相关性算分
当我们利用 match 查询时,文档结果会根据与搜索词条的关联度打分(_score),返回结果时按照分值降序排列。
例如,我们搜索 “虹桥如家”,结果如下:
[{"_score" : 17.850193,"_source" : {"name" : "虹桥如家酒店真不错",}},{"_score" : 12.259849,"_source" : {"name" : "外滩如家酒店真不错",}},{"_score" : 11.91091,"_source" : {"name" : "迪士尼如家酒店真不错",}}
]在 elasticsearch 中,早期使用的打分算法是 TF-IDF 算法,公式如下:

在后来的 5.1 版本升级中,elasticsearch 将算法改进为 BM25 算法,公式如下:

TF-IDF 算法有一各缺陷,就是词条频率越高,文档得分也会越高,单个词条对文档影响较大。而 BM25 则会让单个词条的算分有一个上限,曲线更加平滑:
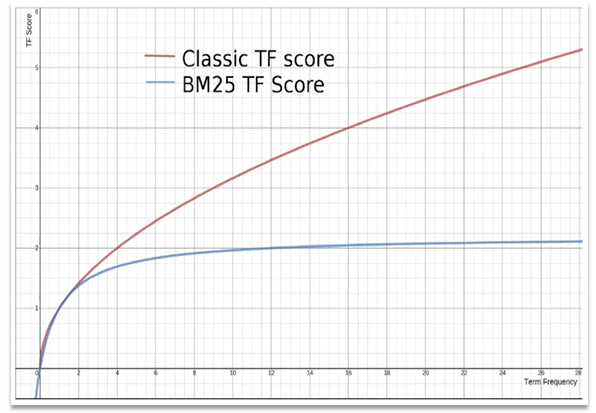
小结:elasticsearch 会根据词条和文档的相关度做打分,算法由两种:
- TF-IDF 算法
- BM25 算法,elasticsearch5.1 版本后采用的算法
1.5.2. 算分函数查询
根据相关度打分是比较合理的需求,但合理的不一定是产品经理需要的。
以百度为例,你搜索的结果中,并不是相关度越高排名越靠前,而是谁掏的钱多排名就越靠前。如图:

要想认为控制相关性算分,就需要利用 elasticsearch 中的 function score 查询了。
1)语法说明

function score 查询中包含四部分内容:
- 原始查询条件:query 部分,基于这个条件搜索文档,并且基于 BM25 算法给文档打分,原始算分(query score)
- 过滤条件:filter 部分,符合该条件的文档才会重新算分
- 算分函数:符合 filter 条件的文档要根据这个函数做运算,得到的函数算分(function score),有四种函数
- weight:函数结果是常量
- field_value_factor:以文档中的某个字段值作为函数结果
- random_score:以随机数作为函数结果
- script_score:自定义算分函数算法
- 运算模式:算分函数的结果、原始查询的相关性算分,两者之间的运算方式,包括:
- multiply:相乘
- replace:用 function score 替换 query score
- 其它,例如:sum、avg、max、min
function score 的运行流程如下:
- 1)根据原始条件查询搜索文档,并且计算相关性算分,称为原始算分(query score)
- 2)根据过滤条件,过滤文档
- 3)符合过滤条件的文档,基于算分函数运算,得到函数算分(function score)
- 4)将原始算分(query score)和函数算分(function score)基于运算模式做运算,得到最终结果,作为相关性算分。
因此,其中的关键点是:
- 过滤条件:决定哪些文档的算分被修改
- 算分函数:决定函数算分的算法
- 运算模式:决定最终算分结果
2)示例
需求:给 “如家” 这个品牌的酒店排名靠前一些
翻译一下这个需求,转换为之前说的四个要点:
- 原始条件:不确定,可以任意变化
- 过滤条件:brand = “如家”
- 算分函数:可以简单粗暴,直接给固定的算分结果,weight
- 运算模式:比如求和
因此最终的 DSL 语句如下:
GET /hotel/_search
{"query": {"function_score": {"query": { .... }, // 原始查询,可以是任意条件"functions": [ // 算分函数{"filter": { // 满足的条件,品牌必须是如家"term": {"brand": "如家"}},"weight": 2 // 算分权重为2}],"boost_mode": "sum" // 加权模式,求和}}
}测试,在未添加算分函数时,如家得分如下:
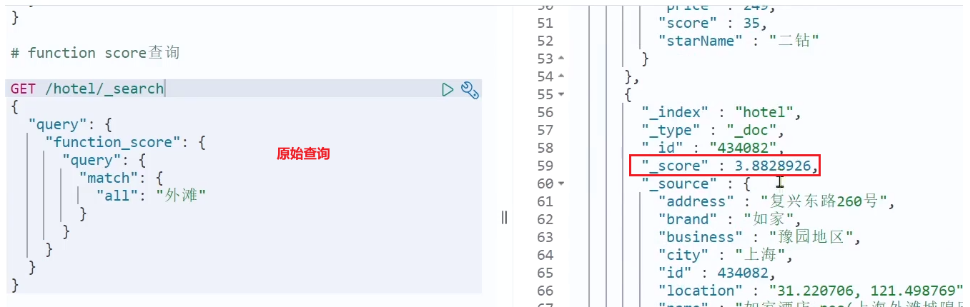
添加了算分函数后,如家得分就提升了:

3)小结
function score query 定义的三要素是什么?
- 过滤条件:哪些文档要加分
- 算分函数:如何计算 function score
- 加权方式:function score 与 query score 如何运算
1.5.3. 布尔查询
布尔查询是一个或多个查询子句的组合,每一个子句就是一个子查询。子查询的组合方式有:
- must:必须匹配每个子查询,类似 “与”
- should:选择性匹配子查询,类似 “或”
- must_not:必须不匹配,不参与算分,类似 “非”
- filter:必须匹配,不参与算分
比如在搜索酒店时,除了关键字搜索外,我们还可能根据品牌、价格、城市等字段做过滤:

每一个不同的字段,其查询的条件、方式都不一样,必须是多个不同的查询,而要组合这些查询,就必须用 bool 查询了。
需要注意的是,搜索时,参与打分的字段越多,查询的性能也越差。因此这种多条件查询时,建议这样做:
- 搜索框的关键字搜索,是全文检索查询,使用 must 查询,参与算分
- 其它过滤条件,采用 filter 查询。不参与算分
1)语法示例:
GET /hotel/_search
{"query": {"bool": {"must": [{"term": {"city": "上海" }}],"should": [{"term": {"brand": "皇冠假日" }},{"term": {"brand": "华美达" }}],"must_not": [{ "range": { "price": { "lte": 500 } }}],"filter": [{ "range": {"score": { "gte": 45 } }}]}}
}2)示例
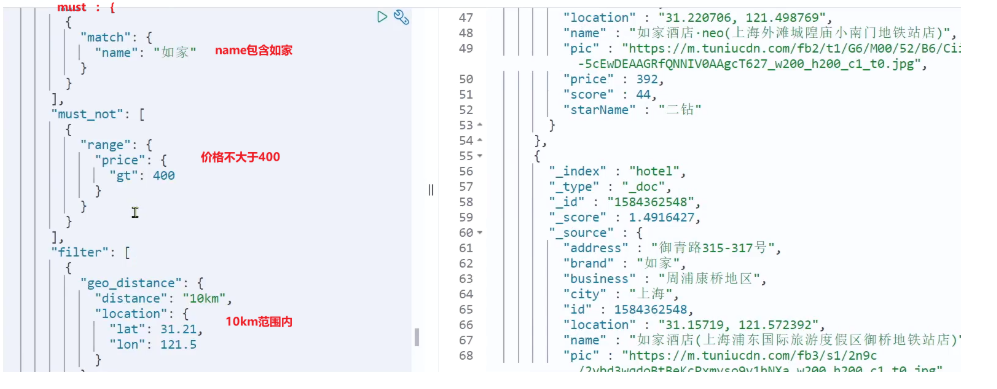
需求:搜索名字包含 “如家”,价格不高于 400,在坐标 31.21,121.5 周围 10km 范围内的酒店。
分析:
- 名称搜索,属于全文检索查询,应该参与算分。放到 must 中
- 价格不高于 400,用 range 查询,属于过滤条件,不参与算分。放到 must_not 中
- 周围 10km 范围内,用 geo_distance 查询,属于过滤条件,不参与算分。放到 filter 中
3)小结
bool 查询有几种逻辑关系?
- must:必须匹配的条件,可以理解为 “与”
- should:选择性匹配的条件,可以理解为 “或”
- must_not:必须不匹配的条件,不参与打分
- filter:必须匹配的条件,不参与打分
参考链接:https://www.cnblogs.com/DeryKong/p/17002533.html
相关文章:
elasticsearch[二]-DSL查询语法:全文检索、精准查询(term/range)、地理坐标查询(矩阵、范围)、复合查询(相关性算法)、布尔查询
ES-DSL查询语法(全文检索、精准查询、地理坐标查询) 1.DSL查询文档 elasticsearch 的查询依然是基于 JSON 风格的 DSL 来实现的。 1.1.DSL 查询分类 Elasticsearch 提供了基于 JSON 的 DSL(Domain Specific Language)来定义查…...

Microsoft Word 设置底纹
Microsoft Word 设置底纹 References 打开文档页面,选中特定段落或全部文档 在“段落”中单击“边框”下三角按钮 在列表中选择“边框和底纹”选项 在“边框和底纹”对话框中单击“底纹”选项卡 在图案样式和图案颜色列表中设置合适颜色的底纹,单击“确…...

【大数据】Flink 详解(九):SQL 篇 Ⅱ
《Flink 详解》系列(已完结),共包含以下 10 10 10 篇文章: 【大数据】Flink 详解(一):基础篇【大数据】Flink 详解(二):核心篇 Ⅰ【大数据】Flink 详解&…...
workflow源码解析:GoTask
关于go task 提供了另一种更简单的使用计算任务的方法,模仿go语言实现的go task。 使用go task来实计算任务无需定义输入与输出,所有数据通过函数参数传递。 与ThreadTask 区别 ThreadTask 是有模板,IN 和 OUT, ThreadTask 依赖…...
SpringMVC入门案例
引言 Spring MVC是一个基于MVC架构的Web框架,它的主要作用是帮助开发者构建Web应用程序。它提供了一个强大的模型驱动的开发方式,可以帮助开发者实现Web应用程序的各种功能,如请求处理、数据绑定、视图渲染、异常处理等。 开发步骤 1.创建we…...

Docker本地私有仓库搭建配置指导
一、说明 因内网主机需要拉取镜像进行Docker应用,因此需要一台带外主机作为内网私有仓库来提供内外其他docker业务主机使用。参考架构如下: 相关资源:加密、Distribution registry、Create and Configure Docker Registry、Registry部署、D…...
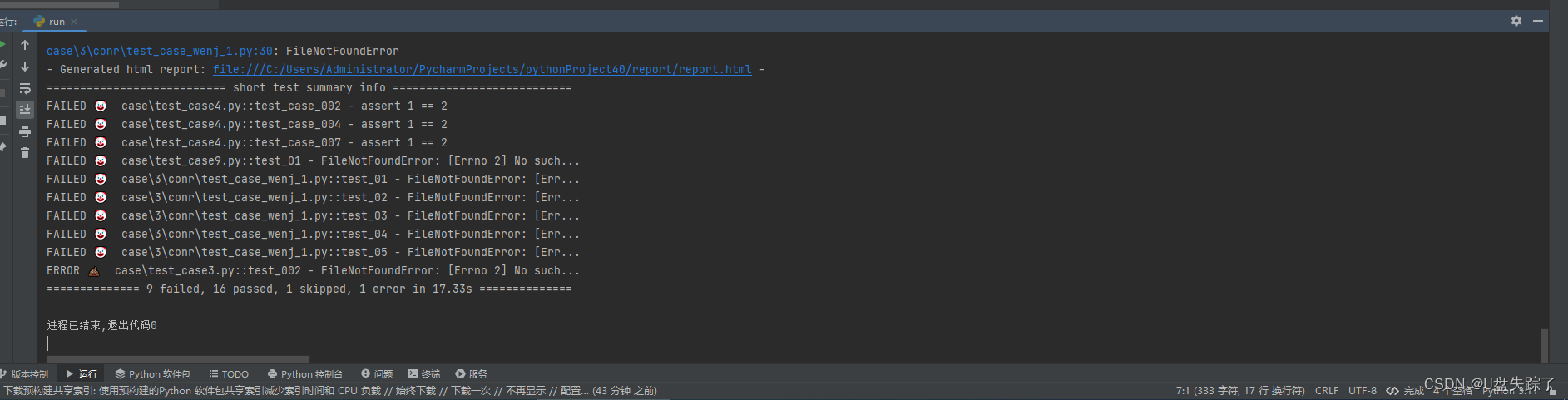
python 通过定时任务执行pytest case
这段Python代码使用了schedule库来安排一个任务,在每天的22:50时运行。这个任务执行一个命令来运行pytest,并生成一个报告。 代码开始时将job_done变量设为False,然后运行预定的任务。一旦任务完成,将job_done设置为True并跳出循…...

算法面试题:合并两个有序链表
描述:给定两个按非递减顺序排列的链表,合并两个链表,并将结果按非递减顺序排列。 例如: # 链表 1: 1 -> 2 -> 4 # 链表 2: 1 -> 3 -> 4合并后的链表应该是:1 -> 1 -> 2 -> 3 -> 4 -> 4 …...

LaWGPT安装和使用教程的复现版本【细节满满】
文章目录 前言一、下载和部署1.1 下载1.2 环境安装1.3 模型推理 总结 前言 LaWGPT 是一系列基于中文法律知识的开源大语言模型。该系列模型在通用中文基座模型(如 Chinese-LLaMA、ChatGLM等)的基础上扩充法律领域专有词表、大规模中文法律语料预训练&am…...

西门子博途用SCL语言写的入栈出栈
1.用户登录 #pragma code ("useadmin.dll") #include "PWRT_api.h" #pragma code() PWRTLogin(1) 2.用户退出 #pragma code ("useadmin.dll") #include "PWRT_api.h" #pragma code() PWRTLogout(); 3.画面跳转 SetPictureName("P…...

密码产品推介 | 沃通安全电子签章系统(ES-1)
产品介绍 沃通安全电子签章系统(ES-1)是一款基于密码技术、完全自主研发的商用密码产品,严格遵循国家密码管理局制定的相关标准,可为企业和个人提供安全、合规的电子签章功能服务。产品的主要用途是为各类文书、合同、表单等电子…...

蓝桥杯真题(Python)每日练Day1
说明:在CSP认证的基础上(可以看看本人CSP打卡系列的博客)备赛2024蓝桥杯(Python),本人专业:大数据与数据科学 因此对python要求熟练掌握,通过练习蓝桥杯既能熟悉语法又能锻炼算法和思…...
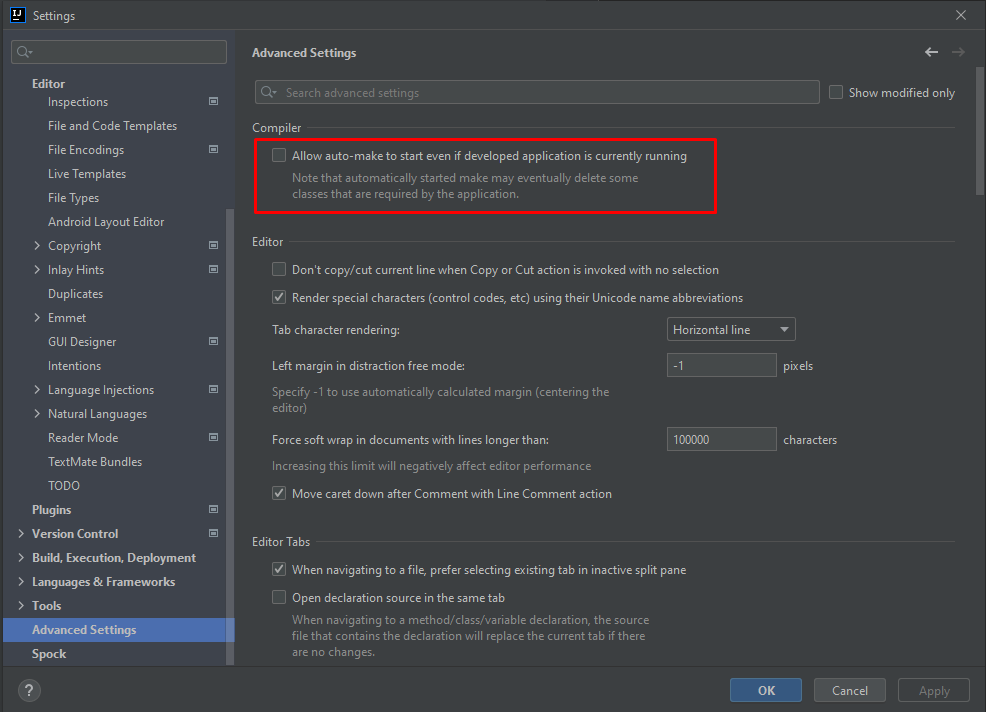
IDEA怎么用Devtools热部署
IDEA怎么用Devtools热部署 大家知道在项目开发过程中,有时候会改动代码逻辑或者修改数据结构,为了能使改动的代码生效,往往需要重启应用查看改变效果,这样会相当耗费时间。 重启应用其实就是重新编译生成新的Class文件࿰…...

boost.circular_buffer的使用和介绍
C 文章目录 C 很多时候,我们需要在内存中记录最近一段时间的数据,如操作记录等。由于这部分数据记录在内存中,因此并不能无限递增,一般有容量限制,超过后就将最开始的数据移除掉。在stl中并没有这样的数据结构…...
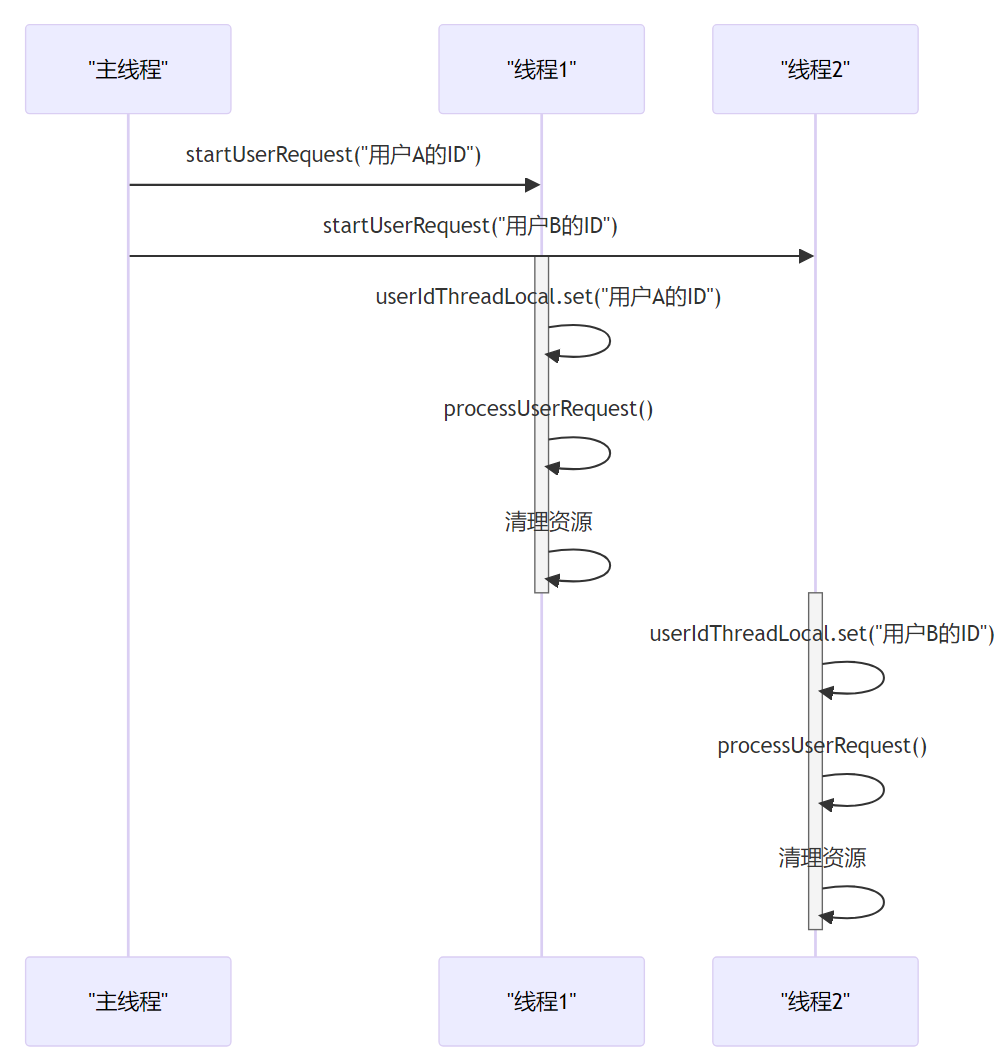
深入理解Java中的ThreadLocal
第1章:引言 大家好,我是小黑。今天咱们来聊聊ThreadLocal。首先,让咱们先搞清楚,ThreadLocal是个什么玩意儿。简单说,ThreadLocal可以让咱们在每个线程中创建一个变量的“私有副本”。这就意味着,每个线程…...

【重点】【DP】300. 最长递增子序列
题目 更好的方法是耐心排序,参见《算法小抄》的内容!!! 法1:DP 基础解法必须掌握!!! class Solution {public int lengthOfLIS(int[] nums) {if (nums null || nums.length 0) …...
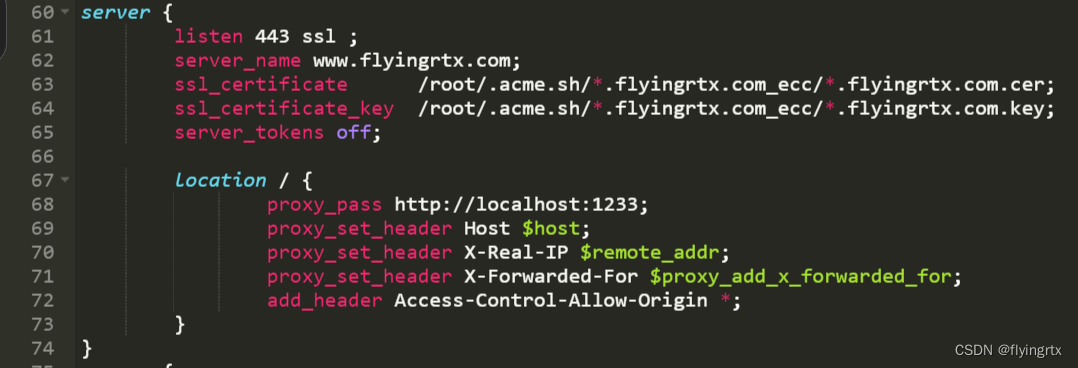
使用freessl为网站获取https证书及配置详细步骤
文章目录 一、进入freessl网站二、修改域名解析记录三、创建证书四、配置证书五、服务启动 一、进入freessl网站 首先进入freessl网站,需要注册一个账号 freessl网站 进入网站后填写自己的域名 接下来要求进行DCV配置 二、修改域名解析记录 到域名管理处编辑域名…...
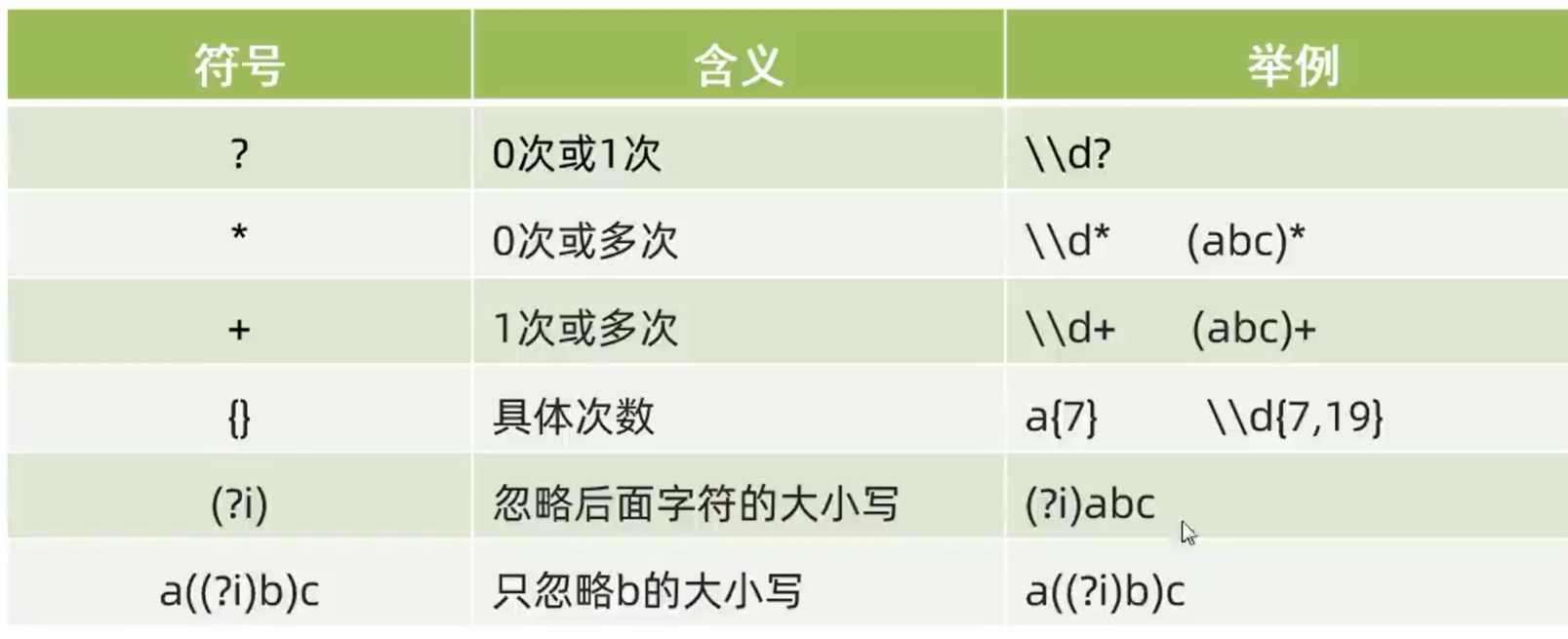
Java-初识正则表达式 以及 练习
目录 什么是正则表达式? 1. 正则表达式---字符类(一个大括号匹配一个字符): 2. 正则表达式---预字符类(也是匹配一个字符): 正则表达式---数量词 (可以匹配多个字符)…...
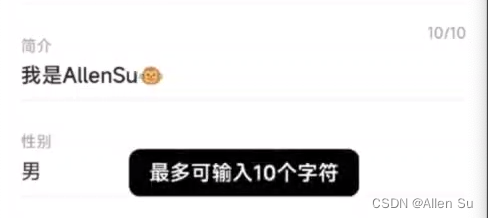
【Flutter 问题系列第 80 篇】TextField 输入框组件限制可输入的最大长度后,输入的内容中包含表情符号时,获取输入的内容数还是会超出限制的问题
这是【Flutter 问题系列第 80 篇】,如果觉得有用的话,欢迎关注专栏。 博文当前所用 Flutter SDK:3.10.5、Dart SDK:3.0.5 一:问题描述 在输入用户名称、简介等内容时,一般我们都会限制输入框内最大可输入…...

漏洞检测和评估【网站子域扫描工具02】
上一篇:爬取目标网站的域名和子域名【网站子域扫描工具01】 在Python中,有一些流行的漏洞扫描库可以对子域进行漏洞扫描和评估,比如Nmap、Sublist3r等。 1.端口扫描 以下是一个简单的示例代码,展示了如何使用Nmap进行基本的端口扫…...

企业级RAG系统数据可信生死线:Perplexity验证功能内测权限仅剩最后17个——附白名单申请通道
更多请点击: https://kaifayun.com 第一章:企业级RAG系统数据可信生死线:Perplexity验证功能内测权限仅剩最后17个——附白名单申请通道 在企业级RAG(Retrieval-Augmented Generation)系统中,检索结果与生…...

人工智能,应用层和算法层到底该怎么选?
想做AI,但是应用层和算法层到底有啥区别?”“我非科班,能学算法吗?”“哪个方向薪资更高、更有前景?”其实不止新手,就连一些转行做AI的从业者,初期也会被这两个方向搞懵。毕竟都属于人工智能领…...
)
别再搜组策略了!Windows 11家庭版设置密码永不过期的3个命令行方法(实测有效)
Windows 11家庭版密码永不过期终极指南:抛弃组策略的3种命令行方案 每次开机都要重新设置密码?Windows 11家庭版用户常常陷入这种困扰。与专业版不同,家庭版系统阉割了组策略编辑器这个关键工具,让普通用户面对密码过期问题时束手…...

创业团队如何通过taotoken的token plan有效控制ai应用开发成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业团队如何通过taotoken的token plan有效控制ai应用开发成本 对于资源有限的创业团队和独立开发者而言,在开发AI应用…...

10分钟打造专属AI歌手:Retrieval-based-Voice-Conversion-WebUI语音克隆终极指南
10分钟打造专属AI歌手:Retrieval-based-Voice-Conversion-WebUI语音克隆终极指南 【免费下载链接】Retrieval-based-Voice-Conversion-WebUI Easily train a good VC model with voice data < 10 mins! 项目地址: https://gitcode.com/GitHub_Trending/re/Retr…...

为什么你的 Multi-Agent 系统越加 Agent 越慢:并发与调度的反直觉陷阱
为什么你的 Multi-Agent 系统越加 Agent 越慢:并发与调度的反直觉陷阱 一、引言 钩子:90% 大模型开发者都踩过的性能悖论 你是否有过这样的经历:花了两周时间把单 Agent 的文档分析系统改造成多 Agent 协作架构,原本预期 5 个 Agent 能把处理速度提升 4 倍,结果上线后发…...

2025届学术党必备的AI辅助写作方案实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 跟着学术钻研持续深入,开题报告身为钻研项目要紧起点,它的质量径直作…...

独立开发者如何通过 Taotoken Token Plan 套餐优化项目预算
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何通过 Taotoken Token Plan 套餐优化项目预算 对于独立开发者或小型团队而言,在项目开发中引入大模型能力…...

米尔RK3562开发板深度评测:工业边缘AI网关的性价比之选
1. 项目概述:为什么关注米尔RK3562开发板?最近在给一个工业边缘计算项目选型,核心需求是在一个环境相对严苛的车间里,部署一个集成了视觉识别、多路传感器数据采集和本地轻量级推理的网关设备。性能不能太弱,否则处理不…...

Google I/O 2026 推出 Antigravity SDK:本地构建 AI Agent,灵活定制功能
Antigravity SDK 登场当开发者需要将 AI 能力嵌入自有应用时,常见做法是通过 API 调用远程 Agent 服务,但这种方式存在延迟高、定制性差、依赖网络等问题。据悉,Google 在 I/O 2026 大会上给出了另一种解法 ---- Antigravity SDK,…...