【机器学习】DBSCAN算法
参考链接:
https://blog.csdn.net/haveanybody/article/details/113092851
https://www.jianshu.com/p/dd6ce77bfb8a
1 介绍
DBSCAN(Density-Based Spatial Clustering of Applica tion with Noise)算法是于1996年提出的一种简单的、有效的基于密度的聚类算法,该算法利用类的密度连通性快速发现任意形状的类。该算法的中心思想是:对于一个类中的每一个点P(不包括边界点),在给定的某个Eps邻域内数据点的个数不少于Minpts。
DBSCAN算法不属于图聚类算法。图聚类算法是一种基于图结构的聚类算法,它利用图中的顶点和边的信息来划分聚类。DBSCAN算法不需要构建图结构,它只需要计算数据点之间的距离,然后根据密度阈值和邻域半径来判断数据点是否属于某个聚类。
DBSCAN算法的主要优点是:
- 它可以发现任意形状的聚类,而不是像K-means算法那样只能发现球形的聚类。
- 它可以识别噪声点,并将它们从聚类中排除,而不是像层次聚类算法那样将所有的数据点都分配到某个聚类中。
- 它不需要事先指定聚类的个数,而是根据数据的密度自动确定聚类的个数。
DBSCAN算法的主要缺点是:
- 它对密度阈值和邻域半径的选择非常敏感,不同的参数设置可能导致不同的聚类结果。
- 它对高维数据的处理效果不佳,因为高维空间中的距离计算很难反映数据的真实相似度。
- 它对不同密度的聚类的划分效果不佳,因为它使用的是全局的密度阈值,而不是针对每个聚类的局部密度阈值。
2 代码
2.1 直接调用sklearn的接口
本小节最后会给出完整代码,在这之前,先对代码中出现的一些关键点做一个简单的笔记:
2.1.1 数据标准化方法
# 生成包含750个样本的聚类数据集,其中每个样本属于上述三个中心之一,cluster_std 控制聚类的标准差
X, labels_true = make_blobs(n_samples=750, centers=centers, cluster_std=0.4, random_state=0)
X = StandardScaler().fit_transform(X) # 对样本数据进行标准化处理,确保每个特征的均值为0,标准差为1
# X = MinMaxScaler().fit_transform(X) # 对数据进行归一化处理
数据预处理方法有很多,像常用的标准化、归一化、特征工程之类,这里主要介绍一下标准化和归一化。
标准化处理通常是为了确保不同特征的尺度一致,使得模型更容易收敛并提高算法的性能。虽然标准化处理在大多数情况下是有益的,但对于不规则数据(如存在极端离群值或不符合正态分布的数据),有时候可能需要谨慎处理。
对于不规则数据,可以考虑使用其他数据预处理方法,例如:
- 归一化(Normalization): 将数据缩放到一个固定的范围,例如 [0, 1]。这对于受极端值影响较大的情况可能更合适。
- RobustScaler: 该方法对数据中的离群值具有鲁棒性,因此在存在离群值的情况下可能更适用。
- 特征工程: 根据数据的特点进行定制的特征变换,以满足特定的数据分布。
最终选择哪种预处理方法取决于数据的性质和模型的需求。在处理不规则数据时,建议进行实验比较不同的方法,以找到最适合特定数据集的预处理策略。
归一化(Normalization)和标准化(Standardization)是两种不同的数据缩放方法,尽管它们的目标都是使得特征在数值上更一致,但采用的处理方式略有不同。
-
归一化: 归一化的目标是将数据缩放到一个固定的范围,通常是 [0, 1]。最常见的归一化方法是使用最小-最大缩放,公式为:
X normalized = X − X min X max − X min X_{\text{normalized}} = \frac{X - X_{\text{min}}}{X_{\text{max}} - X_{\text{min}}} Xnormalized=Xmax−XminX−Xmin
这确保了所有特征的值都在 0 到 1 之间。
-
标准化: 标准化的目标是使得数据的分布具有标准正态分布的特性,即均值为 0,标准差为 1。最常见的标准化方法是使用 Z 分数标准化,公式为:
X standardized = X − μ σ X_{\text{standardized}} = \frac{X - \mu}{\sigma} Xstandardized=σX−μ
其中 (\mu) 是均值,(\sigma) 是标准差。标准化处理后的数据集具有均值为 0,标准差为 1 的性质。
虽然这两种方法有不同的数学表达式,但它们的目的都是为了处理不同尺度的特征,使得模型更容易学习和收敛。选择使用归一化还是标准化通常取决于具体的任务和数据集的特点。
需要注意的是,在本文的示例代码中,直接将X = StandardScaler().fit_transform(X)换成X = MinMaxScaler().fit_transform(X)最后计算轮廓系数的时候会报错:ValueError: Number of labels is 1. Valid values are 2 to n_samples - 1 (inclusive),为啥我目前也还不知道,有知道的好兄弟记得评论区踢我。
2.1.2 算法评估指标
当对聚类结果进行评估时,这些指标提供了关于聚类性能的不同方面的信息:
- 同质性(Homogeneity): 衡量每个聚类中的成员是否都属于同一类别。同质性得分越高,表示聚类结果越好。
- 完整性(Completeness): 度量是否找到了每个真实类别的所有成员。完整性得分越高,表示聚类结果越完整。
- V-measure: 同质性和完整性的调和平均,提供了对聚类结果的整体评估。
- 调整兰德指数(Adjusted Rand Index): 用于度量聚类结果与真实标签之间的相似性,接近 1 表示较高的相似性。
- 调整互信息(Adjusted Mutual Information): 度量聚类结果与真实标签之间的信息一致性。
- 轮廓系数(Silhouette Coefficient): 用于度量聚类结果的紧密性和分离性,值越接近 1 表示聚类结果越好。
DBSCAN是一种无监督聚类算法,它不要求输入数据包含真实标签。在正常的使用情况下,DBSCAN 是无需真实标签的。然而,在示例代码中,labels_true 是提供的真实标签,主要是用于验证聚类算法的性能,以评估聚类结果与真实标签之间的相似性。
通常情况下,对于无监督聚类算法,我们在实际应用中不知道数据的真实标签,因此评估聚类算法的性能时使用的是无监督的内部评估指标,如轮廓系数、Calinski-Harabasz指数、DB指数等,它们不依赖于真实标签。这些指标可以在没有真实标签的情况下,通过对聚类结果自身进行评估,提供一些关于聚类质量的信息。
- Calinski-Harabasz指数
Calinski-Harabasz指数(也称为方差比标准)是一种用于评估聚类结果的有效性的指标。它通过计算簇内的离散度与簇间的分离度之间的比率来度量聚类的紧密度和分离度。指数值越高,表示聚类效果越好。
具体计算方式为:
Calinski-Harabasz指数 = 簇间离散度 簇内离散度 × 样本数量 − 簇数量 簇数量 − 1 \text{Calinski-Harabasz指数} = \frac{\text{簇间离散度}}{\text{簇内离散度}} \times \frac{\text{样本数量} - \text{簇数量}}{\text{簇数量} - 1} Calinski-Harabasz指数=簇内离散度簇间离散度×簇数量−1样本数量−簇数量
其中,簇内离散度是各个簇内样本与其簇内均值的距离的总和,簇间离散度是所有簇中心与数据整体均值的距离的总和。
Calinski-Harabasz指数越高,表示簇间的分离度较高,簇内的离散度较低,聚类效果越好。
在 scikit-learn 中,可以使用 metrics.calinski_harabasz_score 函数来计算Calinski-Harabasz指数。例如:
from sklearn import metrics
calinski_harabasz_score = metrics.calinski_harabasz_score(X, labels)
print("Calinski-Harabasz指数:%0.3f" % calinski_harabasz_score)
- DB指数
对于密度聚类算法(如DBSCAN),DB指数(Davies-Bouldin指数)是一种用于评估聚类结果的指标。DB指数考虑了簇的紧密度和分离度,越小的值表示聚类结果越好。
DB指数的计算方式是对每个簇,计算该簇内每个点与簇内其他点的平均距离(紧密度),然后找到与该簇最近的其他簇,计算两个簇中心的距离(分离度)。DB指数是紧密度与分离度的加权平均值,公式如下:
D B = 1 k ∑ i = 1 k max j ≠ i ( S i + S j d ( C i , C j ) ) DB = \frac{1}{k} \sum_{i=1}^{k} \max_{j \neq i} \left( \frac{S_i + S_j}{d(C_i, C_j)} \right) DB=k1i=1∑kj=imax(d(Ci,Cj)Si+Sj)
其中:
- (k) 是簇的数量。
- (S_i) 是簇内点到簇中心的平均距离。
- (d(C_i, C_j)) 是簇中心之间的距离。
DB指数的优点是越小越好,表示簇内紧密度越高,簇间分离度越好。但请注意,DB指数的计算也涉及到对距离的定义,这在密度聚类中可能涉及到一些具体的选择。
在 scikit-learn 中,可以使用 metrics.davies_bouldin_score 函数来计算DB指数。例如:
from sklearn import metricsdb_score = metrics.davies_bouldin_score(X, labels)
print("DB指数:%0.3f" % db_score)
DB指数是一种适用于密度聚类算法的评估指标,对于不同形状和大小的簇都比较稳健。
在计算DB指数时,涉及到对距离的定义,特别是在密度聚类中,选择距离的度量方式可能会影响DB指数的计算结果。通常来说,DB指数的计算可以使用不同的距离度量方法,其中 Euclidean 距离是最常见的选择。
在 scikit-learn 中,默认的距离度量方式通常是 Euclidean 距离,因为 Euclidean 距离在许多情况下都是一种合理的选择。然而,对于一些特定的密度聚类场景,也可以考虑使用其他距离度量方法,例如 Mahalanobis 距离,特别是当数据具有不同的方差和协方差结构时。
在使用 metrics.davies_bouldin_score 函数计算DB指数时,你可以通过传递 metric 参数来指定距离度量方式。例如,使用 Mahalanobis 距离:
from sklearn import metrics
from scipy.spatial.distance import mahalanobis# 自定义 Mahalanobis 距离的度量方式
def mahalanobis_distance(X, Y):# 在这里实现 Mahalanobis 距离的计算方式# ...# 计算DB指数,使用 Mahalanobis 距离
db_score = metrics.davies_bouldin_score(X, labels, metric=mahalanobis_distance)
print("DB指数:%0.3f" % db_score)
需要注意的是,Mahalanobis 距离的计算需要对每个簇内的协方差矩阵进行估计,这可能会增加计算的复杂性。选择合适的距离度量方式应该根据具体的数据特点和任务需求来进行。
- 轮廓系数
轮廓系数(Silhouette Coefficient)是一种用于评估聚类结果好坏的指标,它结合了簇内的紧密度和簇间的分离度。轮廓系数的取值范围在 [-1, 1] 之间,具体定义如下:
对于每个样本:
- 计算该样本与同簇内其他样本的平均距离,记为 (a)(簇内紧密度)。
- 计算该样本与最近的其他簇中所有样本的平均距离,记为 (b)(簇间分离度)。
- 轮廓系数 (s) 的计算方式为 ( b − a ) / max ( a , b ) (b - a) / \max(a, b) (b−a)/max(a,b)。
对于整个数据集,轮廓系数是所有样本轮廓系数的平均值。
轮廓系数的解释:
- 轮廓系数接近1表示簇内样本距离紧密,簇间样本距离相对较远,聚类效果较好。
- 轮廓系数接近0表示簇内样本距离和簇间样本距离相近,表明聚类结果不清晰。
- 轮廓系数接近-1表示簇内样本距离松散,簇间样本距离较近,聚类效果差。
轮廓系数可以用于选择合适的聚类数目,因为它在聚类数目选择上的峰值通常对应于较好的聚类结果。在使用轮廓系数时,需要注意对于某些不适合聚类的数据集,轮廓系数可能并不是一个有效的指标。
2.1.3 绘图颜色
colors = [plt.cm.Spectral(each) for each in np.linspace(0, 1, len(unique_labels))]
这行代码用于生成一组颜色,以便在可视化中为不同的聚类标签选择不同的颜色。
np.linspace(0, 1, len(unique_labels)): 生成一个从 0 到 1 的等差数列,数列的长度与聚类标签的数量相同。这个数列将用于确定颜色映射的位置,确保每个聚类标签都有一个对应的颜色。plt.cm.Spectral(each): 使用Spectral颜色映射,根据上面生成的等差数列中的每个值,获取相应位置的颜色。这样就得到了一组不同的颜色,每个颜色对应一个聚类标签。
这种方式确保了在可视化中使用了一组视觉上区分度较高的颜色,以区分不同的聚类。每个聚类标签都被分配一种颜色,使得在可视化中可以清晰地区分不同的簇。
2.1.4 完整代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
from sklearn import metrics
from sklearn.datasets import make_blobs
from sklearn.preprocessing import StandardScaler, MinMaxScaler# 生成三个聚类中心的样本数据
centers = [[1, 1], [-1, -1], [1, -1], [-1,1]]# 生成包含750个样本的聚类数据集,其中每个样本属于上述三个中心之一,cluster_std 控制聚类的标准差
X, labels_true = make_blobs(n_samples=750, centers=centers, cluster_std=0.4, random_state=0)
X = StandardScaler().fit_transform(X) # 对样本数据进行标准化处理,确保每个特征的均值为0,标准差为1
# X = MinMaxScaler().fit_transform(X) # 对数据进行归一化处理# 使用 DBSCAN 算法进行聚类
# eps 控制邻域的半径,min_samples 指定一个核心点所需的最小样本数
db = DBSCAN(eps=0.3, min_samples=20).fit(X)# 创建一个布尔掩码,标记核心样本点
core_samples_mask = np.zeros_like(db.labels_, dtype=bool) # 创建一个与 db.labels_ 具有相同形状的全零数组,数据类型为布尔型
core_samples_mask[db.core_sample_indices_] = True # 将核心样本的位置标记为True# 获取每个样本点的聚类标签
labels = db.labels_ # labels_ 属性可以返回聚类结果,-1表示是离群点。
# print(labels)# 统计聚类结果的一些信息
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0) # 计算聚类的数量,忽略噪声点(标签为-1的点)
n_noise_ = list(labels).count(-1) # 统计噪声点的数量print('估计的聚类数量:%d' % n_clusters_)
print('估计的噪声点数量:%d' % n_noise_)
# 同质性和完整性的得分越高越好
print("同质性:%0.3f" % metrics.homogeneity_score(labels_true, labels)) # 同质性,衡量每个群集中的成员是否都属于同一类别
print("完整性:%0.3f" % metrics.completeness_score(labels_true, labels)) # 完整性,度量是否找到了每个真实类别的所有成员
print("V-measure:%0.3f" % metrics.v_measure_score(labels_true, labels)) # V-measure,同质性和完整性的调和平均
# 调整兰德指数越接近1,说明聚类结果与真实标签之间具有越高的相似度
print("调整兰德指数:%0.3f" % metrics.adjusted_rand_score(labels_true, labels)) # 调整兰德指数,用于度量聚类结果与真实标签之间的相似性
print("调整互信息:%0.3f" % metrics.adjusted_mutual_info_score(labels_true, labels)) # 调整互信息,度量聚类结果与真实标签之间的信息一致性
print("轮廓系数:%0.3f" % metrics.silhouette_score(X, labels)) # 轮廓系数,度量聚类结果的紧密性和分离性,接近1表示聚类结果越好
print("DB指数:%0.3f" % metrics.davies_bouldin_score(X, labels)) # DB指数,衡量簇内紧密度和簇间分离度的指标,越小越好# 画图
# 移除黑色(表示噪声),用于标识噪声点
unique_labels = set(labels) # 聚类得到的标签,即聚类得到的簇,标记为{0,1,2,-1},其中-1为噪声点
colors = [plt.cm.Spectral(each) for each innp.linspace(0, 1, len(unique_labels))] # 生成一组颜色,以便在可视化中为不同的聚类标签选择不同的颜色,color.shape=(4,4)
# 遍历每个聚类标签,为每个簇选择颜色进行可视化
for k, col in zip(unique_labels, colors):if k == -1:# 对于标签为-1的噪声点,使用黑色col = (0, 0, 0, 1)# 获取属于当前聚类的样本点class_member_mask = (labels == k)# 绘制核心样本点(大圆点)xy1 = X[class_member_mask & core_samples_mask]plt.plot(xy1[:, 0], xy1[:, 1], 'o', markerfacecolor=tuple(col),markeredgecolor='k', markersize=8)# 绘制非核心样本点(小圆点)xy2 = X[class_member_mask & ~core_samples_mask]plt.plot(xy2[:, 0], xy2[:, 1], 'o', markerfacecolor=tuple(col),markeredgecolor='k', markersize=6)plt.title('Estimated number of clusters: %d' % n_clusters_)
plt.show()
2.2 不使用sklearn接口
(待补充)
相关文章:

【机器学习】DBSCAN算法
参考链接: https://blog.csdn.net/haveanybody/article/details/113092851 https://www.jianshu.com/p/dd6ce77bfb8a 1 介绍 DBSCAN(Density-Based Spatial Clustering of Applica tion with Noise)算法是于1996年提出的一种简单的、有效的基于密度的聚类算法&…...
Uniapp软件库源码-全新带勋章等
测试环境:php7.1。ng1.2,MySQL 5.6 常见问题: 配置好登录后转圈圈,检查环境及伪静态以及后台创建好应用 上传图片不了,检查php拓展fileinfo 以及public文件权限 App个人主页随机背景图,在前端uitl文件夹里面…...

Microsoft Excel 直方图
Microsoft Excel 直方图 1. 数据示例2. 打开 EXCEL3. settings4. 单击直方图柱,右键“添加数据标签”References 1. 数据示例 2. 打开 EXCEL 数据 -> 数据分析 -> 直方图 3. settings 输入区域样本值、接受区域分类间距,输出选项选择“新工作表组…...
如何录制屏幕视频?让视频制作更简单!
随着数字化时代的来临,录制屏幕视频成为一种常见的传播和教学方式。无论是制作演示文稿、教学视频,还是记录游戏操作,屏幕录制为用户提供了强大而灵活的工具。可是您知道如何录制屏幕视频吗?本文将深入介绍两种常见的屏幕录制方法…...

【JavaEE进阶】 关于应用分层
文章目录 🎋序言🍃什么是应⽤分层🎍为什么需要应⽤分层🍀如何分层(三层架构)🎄MVC和三层架构的区别和联系🌳什么是高内聚低耦合⭕总结 🎋序言 在我们进行项目开发时我们如果一股脑将所有代码都…...
【已解决】c语言const/指针学习笔记
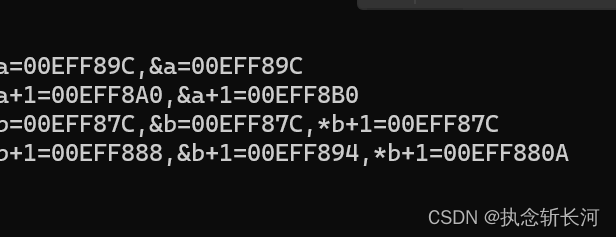
本博文源于笔者正在复习const在左与在右,指针优先级、a,&a,*a的区别。 1、const在左与在右 int const *p const int *p int * const p int const * const p const int * const p* 在const右边,指向的数据不可以改变,可以改变地址 * 在c…...
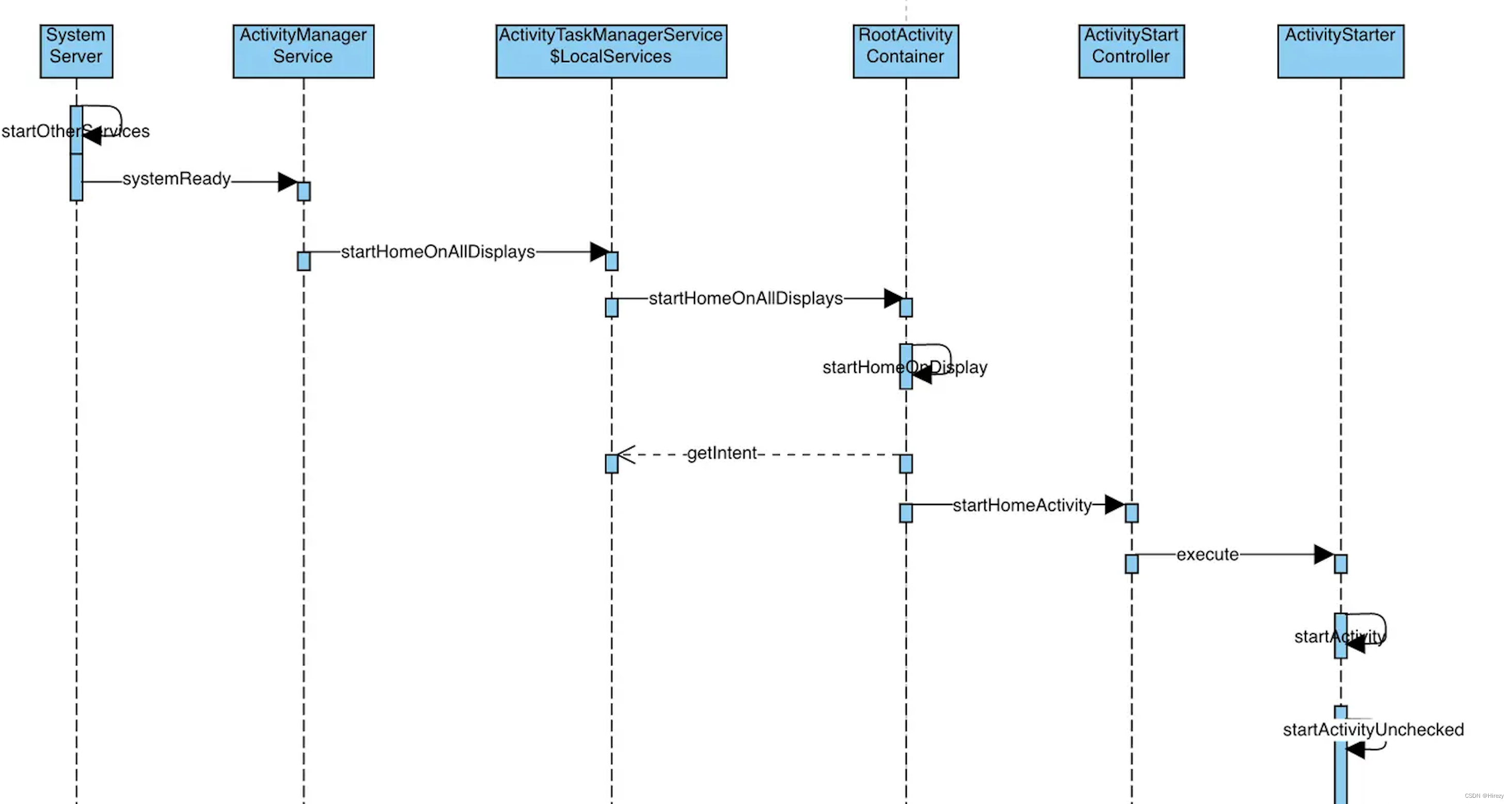
Android 系统启动过程纪要(基于Android 10)
前言 看过源码的都知道,Launcher系统启动都会经过这三个进程 init ->zygote -> system_server。今天我们就来讲解一下这三个进程以及Launcher系统启动。 init进程 准备Android虚拟机环境:创建和挂载系统文件目录;初始化属性服务&…...
【Docker实用篇】一文入门Docker(4)Docker-Compose
目录 1.Docker-Compose 1.1.初识DockerCompose 1.2.安装DockerCompose 1.2.1 修改文件权限 1.2.2 Base自动补全命令: 1.3部署微服务集群 1.3.1.compose文件 1.3.2.修改微服务配置 1.3.3.打包 1.3.4.拷贝jar包到部署目录 1.3.5.部署 1.Docker-Compose Doc…...
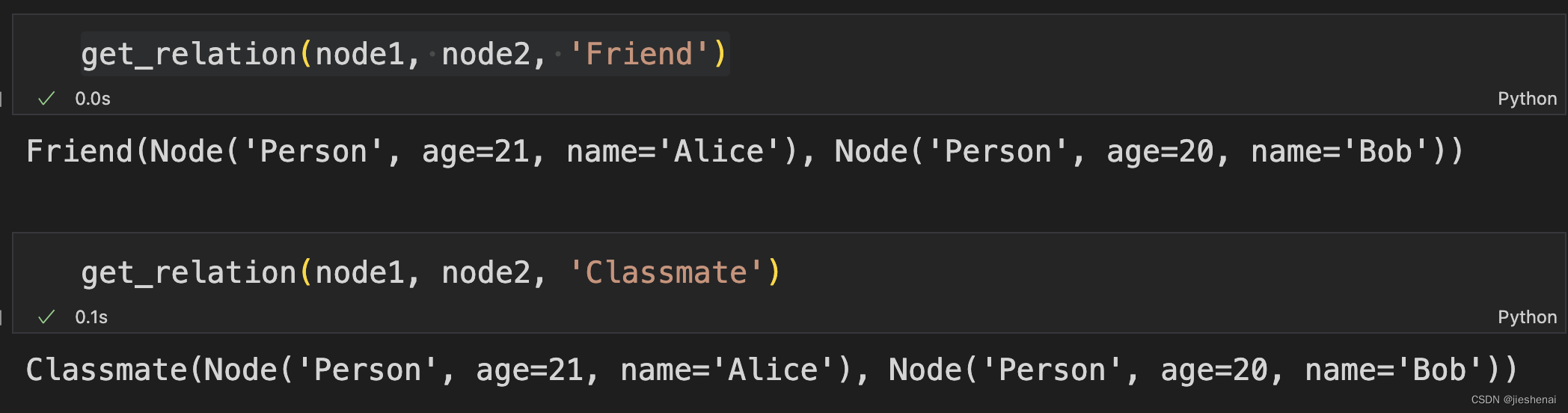
neo4j 图数据库 py2neo 操作 示例代码
文章目录 摘要前置NodeMatcher & RelationshipMatcher创建节点查询获取节点节点有则查询,无则创建创建关系查询关系关系有则查询,无则创建 Cypher语句创建节点 摘要 利用py2neo包,实现把excel表里面的数据,插入到neo4j 图数据…...

从uptime看linux平均负载
从前遇到系统卡顿只会top。。top看不出来怎么搞呢? Linux系统提供了丰富的命令行工具,以帮助用户和系统管理员监控和分析系统性能。在这些工具中,uptime、mpstat和pidstat是非常有用的命令,它们可以帮助你理解系统的平均负载以及资…...
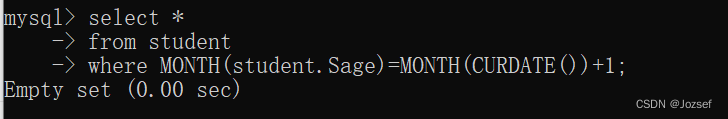
经典数据库练习题及答案
数据表介绍 --1.学生表 Student(SId,Sname,Sage,Ssex) --SId 学生编号,Sname 学生姓名,Sage 出生年月,Ssex 学生性别 --2.课程表 Course(CId,Cname,TId) --CId 课程编号,Cname 课程名称,TId 教师编号 --3.教师表 Teacher(TId,Tname) --TId 教师编号,Tname 教师姓名 --4.成绩…...
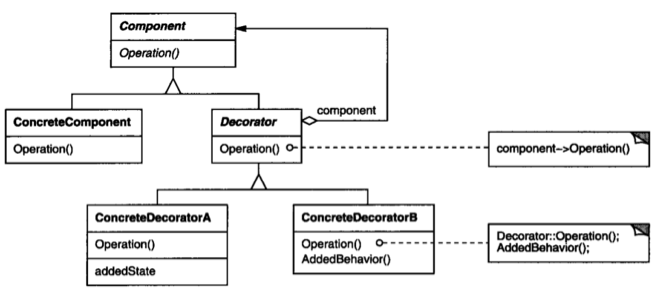
架构篇06-复杂度来源:可扩展性
文章目录 预测变化应对变化小结 复杂度来源前面已经讲了高性能和高可用,今天来聊聊可扩展性。 可扩展性指系统为了应对将来需求变化而提供的一种扩展能力,当有新的需求出现时,系统不需要或者仅需要少量修改就可以支持,无须整个系…...

flowable流程结束触发监听器 flowable获取结束节点 flowable流程结束事件响应监听器
flowable流程结束触发监听器 | flowable流程结束获取结束节点 | flowable流程结束事件响应监听器 下面代码是该监听器是对每个到达结束事件后执行的。 原本的流程定义是如果其中任意某个节点进行了驳回,则直接结束流程。 所以在每个节点的驳回对应的排他网关都设…...

【Python3】【力扣题】389. 找不同
【力扣题】题目描述: 【Python3】代码: 1、解题思路:使用计数器分别统计字符串中的元素和出现次数,两个计数器相减,结果就是新添加的元素。 知识点:collections.Counter(...):字典子类&#x…...
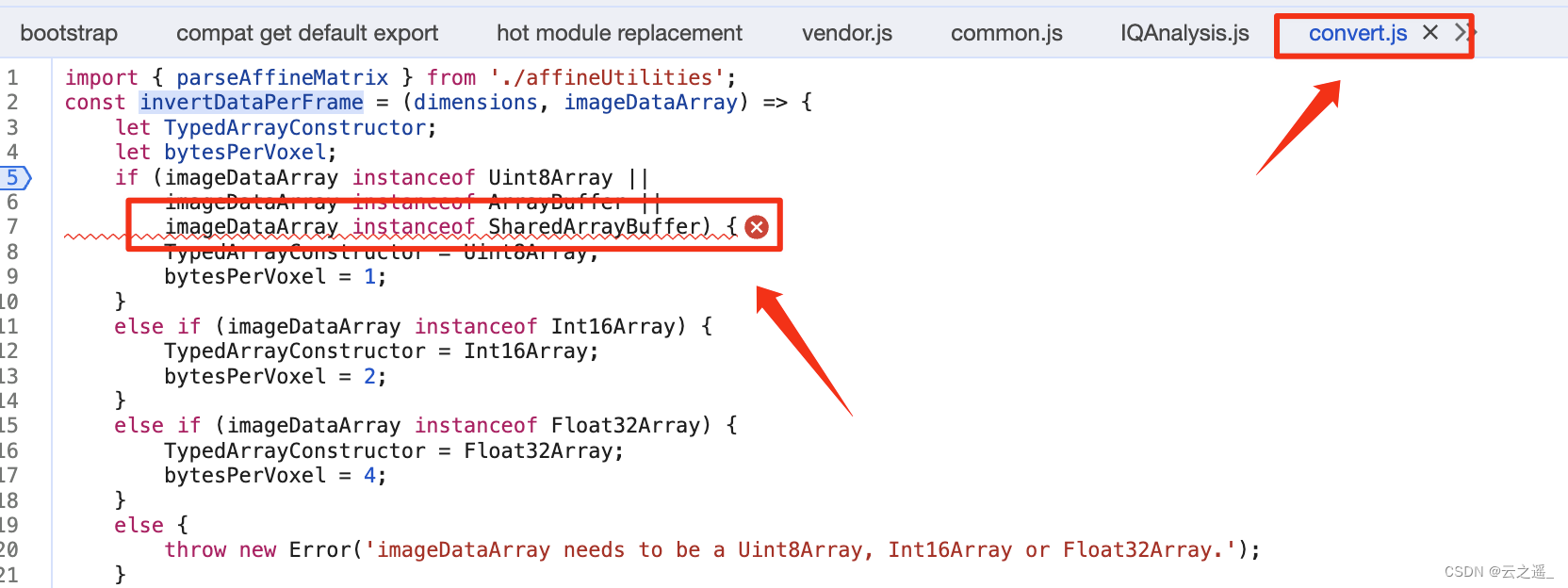
【从0上手cornerstone3D】如何加载nifti格式的文件
在线演示 支持加载的文件格式 .nii .nii.gz 代码实现 npm install cornerstonejs/nifti-volume-loader// ------------- 核心代码 Start------------------- // 注册一个nifti格式的加载器 volumeLoader.registerVolumeLoader("nifti",cornerstoneNiftiImageVolu…...

c# 学习笔记 - 异步编程
文章目录 1. 异步编程介绍1.1 简单介绍1.2 async/await 使用1.3 Task/Task<TResult> 对象 2. 样例2.1 迅速启动所有任务,仅当需要结果才等待任务执行2.2 使用 await 调用异步方法,即使这个异步方法内有 await 也不会同时执行回调和向下执行操作(必…...
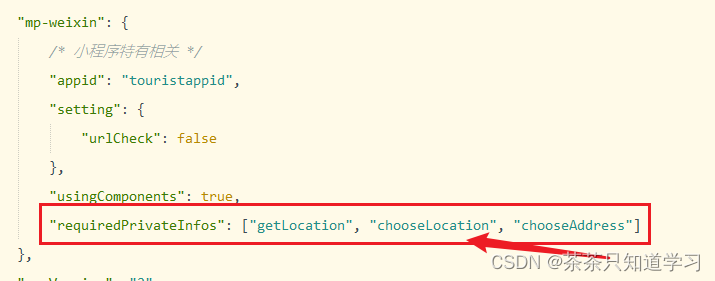
设置了uni.chooseLocation,小程序中打不开
设置了uni.chooseLocation,在小程序打不开,点击没反应,地图显现不出来; 解决方案: 1.Hbuilder——微信开发者工具路径没有配置 打开工具——>设置 2.微信小程序服务端口没有开 解决方法:打开微信开发…...

spring retry 配置及使用
spring retry 配置及使用 接口或功能因外界异常导致失败后进行重推机制 依赖 <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.3.1.RELEASE</version></p…...

uni-app的组件(二)
多项选择器checkbox-group 多项选择器,内部由多个 checkbox 组成。 <checkbox-group><checkbox checked color"red" value"1"></checkbox> 篮球<!-- disabled:是否禁用 --><checkbox disabled color"rgba(0,0…...

项目开发中安全问题以及解决办法——客户传进来的数据不可信
用户传进来的数据是不可信的,比如下面这种情况下: PostMapping("/order") public void wrong(RequestBody Order order) { this.createOrder(order); } Data public class Order { private long itemId; //商品ID private BigDecimal ite…...

AR 巡检:6 大黄金行业与厂商推荐
AR 巡检是将增强现实技术与工业巡检流程深度融合的智能运维方案,核心作用是通过虚实叠加实现设备状态可视化、巡检流程标准化与故障诊断智能化。传统巡检依赖纸质记录、人工记忆和经验判断,存在漏检误检率高、数据无法实时同步、故障排查周期长等问题&am…...

基于哪吒D1与Node-RED的机械臂视觉控制边缘计算方案
1. 项目概述与核心价值最近在折腾一个挺有意思的项目,核心是把一块搭载了全志D1芯片的哪吒开发板,变成一个能同时控制机械臂和拍照的智能边缘节点。这个想法的源头,其实挺实际的:在很多自动化测试、小型分拣或者教育演示的场景里&…...
)
从CAN报文到转速值:手把手拆解SAE J1939-71的F004参数组(附Python解析代码)
从CAN报文到转速值:SAE J1939-71的F004参数组实战解析与Python实现 在汽车电子和商用车诊断领域,SAE J1939协议栈堪称工程师的"第二语言"。而其中J1939-71文档定义的参数组(PGN)解析,则是将原始CAN报文转化为工程价值的核心技能。本…...
)
告别Rufus!在Ubuntu 22.04上用Ventoy打造你的万能Windows安装盘(附PE系统集成)
在Ubuntu 22.04上使用Ventoy打造全能Windows安装与维护工具盘 作为一名长期以Linux为主力系统的开发者,难免会遇到需要为朋友或备用机安装Windows的场景。传统方案往往要求我们临时切换到Windows环境使用Rufus等工具,既低效又违背Linux用户的习惯。本文将…...

如何在Windows上轻松安装安卓应用:APK-Installer完整指南
如何在Windows上轻松安装安卓应用:APK-Installer完整指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想在Windows电脑上直接运行安卓应用&am…...

Python爬虫遇到InsecureRequestWarning?别慌,这3种方法帮你搞定urllib3的SSL证书警告
Python爬虫遇到InsecureRequestWarning?3种专业级解决方案与安全实践 当你兴致勃勃地运行新写的Python爬虫脚本时,控制台突然跳出一堆黄字警告:"InsecureRequestWarning: Unverified HTTPS request is being made..."。这场景就像…...

Vidupe智能视频去重工具:3步高效清理重复视频的实用指南
Vidupe智能视频去重工具:3步高效清理重复视频的实用指南 【免费下载链接】vidupe Vidupe is a program that can find duplicate and similar video files. V1.211 released on 2019-09-18, Windows exe here: 项目地址: https://gitcode.com/gh_mirrors/vi/vidup…...
)
解放双手!用STAR-CCM+的3D-CAD模块快速清理与简化仿真几何(保姆级教程)
解放双手!用STAR-CCM的3D-CAD模块快速清理与简化仿真几何(保姆级教程) 在CAE仿真领域,几何模型的质量往往直接决定仿真效率与结果可靠性。许多工程师都有过这样的经历:从设计部门拿到一个细节完美的CAD模型,…...

如何快速掌握AI音频处理:免费开源语音转换与分离终极指南
如何快速掌握AI音频处理:免费开源语音转换与分离终极指南 【免费下载链接】Retrieval-based-Voice-Conversion-WebUI Easily train a good VC model with voice data < 10 mins! 项目地址: https://gitcode.com/GitHub_Trending/re/Retrieval-based-Voice-Conv…...

测试TVS:SP0503BAHTG
简 介: 本文测试了SP0503BAHTG三通道TVS二极管阵列的特性。通过设计测试电路板,测量了该器件对1kHz正弦波的限幅效果,测得反向导通电压约-0.8V,顶部饱和电压6.3V。在1MHz高频测试中观察到快速响应特性,通过矩形波上升沿…...