HugggingFace 推理 API、推理端点和推理空间相关模型部署和使用以及介绍
HugggingFace 推理 API、推理端点和推理空间相关模型部署和使用以及介绍。
Hugging Face是一家开源模型库公司。
2023年5月10日,Hugging Face宣布C轮1亿美元融资,由Lux Capital领投,红杉资本、Coatue、Betaworks、NBA球星Kevin Durant等跟投,其估值增长到了20亿美元。
2023年5月16日,Hugging Face首次登上了福布斯北美人工智能50强榜单。
2023年7月2号,参数总量达1760亿的BLOOM大模型经过为期117天的训练宣告完成,其参数总量恰好比OpenAI已经发布了近三年的GPT-3多10亿。
接触 AI 的同学肯定对HuggingFace[1]有所耳闻,它凭借一个开源的 Transformers 库迅速在机器学习社区大火,为研究者和开发者提供了大量的预训练模型,成为机器学习界的 GitHub。在 HuggingFace 上我们不仅可以托管模型,还可以方便地使用各种模型的 API 进行测试和验证,部署属于自己的模型 API 服务,创建自己的模型空间,分享自己的模型。本文将介绍 HuggingFace 的推理 API、推理端点和推理空间的使用方法。
HuggingFace 推理 API
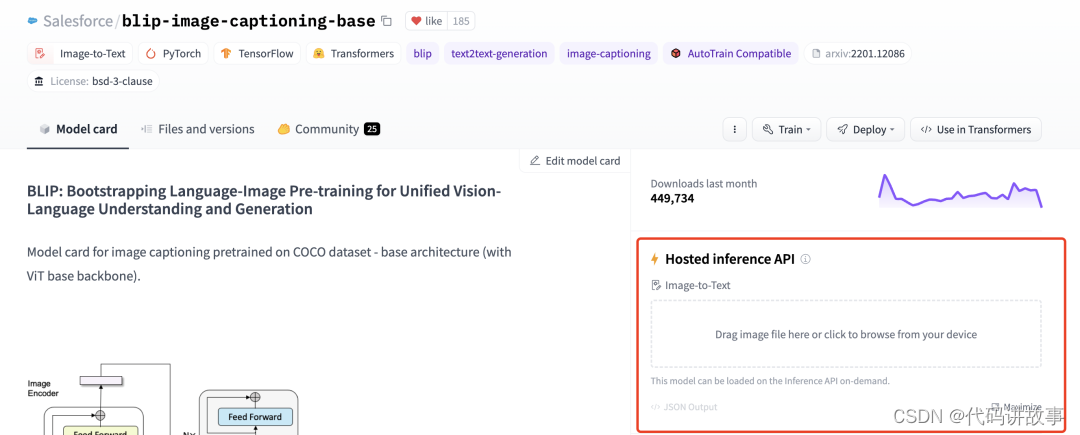
在 HuggingFace 托管的模型中,有些模型托管之后会提供推理 API,如果我们想快速验证模型是否可以满足我们的需求,可以使用这些 API 进行测试,下面以这个模型为例Salesforce/blip-image-captioning-base进行介绍,该模型可以通过图片生成英文描述。
1.HuggingFace是什么
可以理解为对于AI开发者的GitHub,提供了模型、数据集(文本|图像|音频|视频)、类库(比如transformers|peft|accelerate)、教程等。
2.为什么需要HuggingFace
主要是HuggingFace把AI项目的研发流程标准化,即准备数据集、定义模型、训练和测试。
HuggingFace是一个高速发展的社区,包括Meta、Google、Microsoft、Amazon在内的超过5000家组织机构在为HuggingFace开源社区贡献代码、数据集和模型。目前包括模型236,291个,数据集44,810个。刚开始大多数的模型和数据集是NLP方向的,但图像和语音的功能模型正在快速更新中。
HuggingFace GitHub可以看到包括常用的transformers、datasets、diffusers、accelerate、pef和optimum类库。
Hugging Face最初是一家总部位于纽约的初创企业,专注于聊天机器人服务。然而,他们在创业过程中开源了一个名为Transformers的库,并在GitHub上发布。虽然聊天机器人业务并没有取得成功,但这个库却在机器学习社区迅速走红。目前,Hugging Face已经分享了超过100,000个预训练模型和10,000个数据集,成为机器学习界的重要开源资源。
hugging face官网: https://huggingface.co/
更多好用又免费ai工具推荐
0. >>>免费cha/t/g/p/t中文版(免f墙版) : https://ymiai.top/
1.>>>免费ai绘画网站: : https://tusiart.com/
2.>>>免费ai写作网站: : https://chat.moyanaigc.com
3.>>>免费ai绘画网站 : https://www.acgnai.com/
Hugging Face之所以取得巨大的成功,原因有二。首先,它使得非专业人士,尤其是初学者,能够快速使用科研专家们训练出的强大模型。这为我们提供了便利,使我们能够在短时间内应用高质量的模型。其次,Hugging Face的开放文化、合作态度以及利他利己的精神吸引了大量人才。许多业界知名人士在Hugging Face上使用和提交新的模型,这让我们能够站在他们的肩膀上,不必从零开始。尽管我们没有像他们那样丰富的计算资源和数据集,但Hugging Face为我们提供了平台和工具,使我们能够与专家们共同合作。
在国内,Hugging Face也广泛应用于各个领域。许多开源框架本质上都是利用Hugging Face的Transformers库进行模型微调(当然也有许多专家默默地贡献模型和数据集)。许多自然语言处理工程师的招聘要求明确要求熟悉Hugging Face的Transformers库的使用。在我们简要介绍了Hugging Face的强大功能之后,让我们看看如何开始使用Hugging Face。因为它不仅提供了丰富的数据集,还提供了各种模型供我们自由下载和调用,所以入门非常简单。即使对于GPT和BERT等模型的细节了解不多,也可以使用它们的模型(当然,还是有必要了解一下我为你写的关于BERT的简介)。
2016年,一家名为Hugging Face的公司应运而生。
在成立初期的2016年,就像许多类似的初创公司一样,Hugging Face专注于聊天机器人领域。他们开发了一个基于LSTM的聊天机器人应用程序,主要面向青少年的情感和娱乐服务。然而,由于技术尚未成熟以及商业模式难以变现,尽管Hugging Face拥有一定的核心用户群体,但公司的发展速度相对缓慢。
直到2018年,面对发展瓶颈,创始人决定开放聊天机器人的AI模型,让用户自行开发服务,初衷是通过用户共创来获得灵感。这一出人意料的举动却成为Hugging Face进入高速发展的快车道,开启了取得成功的新篇章。
由于开源的AI模型数量有限,Hugging Face迅速成为人工智能开发者的聚集地。创始团队随后根据用户需求转变自身的聊天平台为开发者社区,并逐渐形成了全球最大的自然语言处理开源模型数据库。
同年,Hugging Face发布了Transformers框架,该框架基于注意力机制,在机器翻译、语音识别、文本生成等自然语言处理任务中得到广泛应用。Transformers框架以其高性能和开源属性成为机器学习工具库中最为重要的资源之一,使Hugging Face迅速提升了知名度和影响力。
如今,Hugging Face已经成为机器学习模型研究的中心,成为GitHub上增长最快的人工智能项目之一。
hugging face
打造机器学习领域的“GitHub”
Hugging Face致力于构建机器学习领域的”GitHub”,专注于自然语言处理(NLP)技术,并通过技术创新不断丰富产品与服务,成为广大研究人员和技术开发者的合作伙伴。
在Hugging Face的技术DNA中,核心项目是于2018年开源的Transformers,一种面向自然语言处理的预训练语言模型。Transformers基于注意力机制,在翻译、语音识别、图像分类、文本生成等NLP任务中得到广泛应用。Hugging Face开发的模型和数据集可以直接使用,实现推理和迁移学习,使Transformers框架在性能和易用性上处于业界领先地位。
BERT模型利用两个Transformers网络进行预训练,使模型能够同时学习当前和历史位置的信息。而GPT-3模型也利用Transformers进行训练,在语言生成方面展示了大型语言模型的巨大潜力。
Transformers彻底改变了深度学习在NLP领域的发展范式,降低了相关研究和应用的门槛。因此,Hugging Face迅速崛起成为行业翘楚,成为人工智能社区中最有影响力的技术供应商。通过提供高性能且易用的技术解决方案,Hugging Face为研究人员和开发者们带来了巨大的价值。
页面小组件
推理 API 有两种使用方式,一种是在模型页面的右侧找到推理 API 的小组件页面,初始界面如下图所示:
可以在这个页面中上传图片,然后就可以看到模型进行推理运行,等一会后推理结果就出来了,如下图所示:
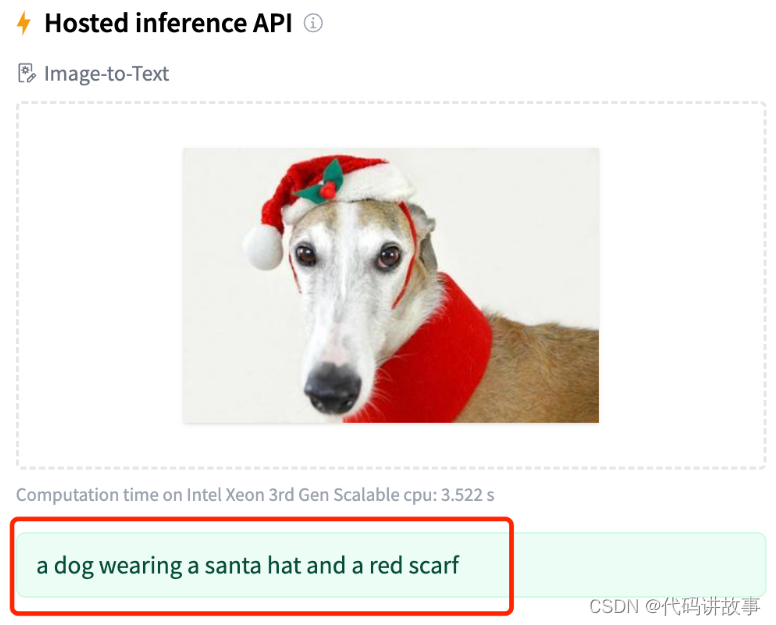
推理结果为:“a dog wearing a santa hat and a red scarf”(一只狗戴着圣诞老人的帽子和红色的围巾)
页面小组件的方式是 HuggingFace 自动帮助模型创建的,具体的信息可以参考这里[2]。
代码调用
另外一种方式是通过代码对推理 API 进行调用,在右侧的Deploy菜单中选择Inference API,如下图所示:
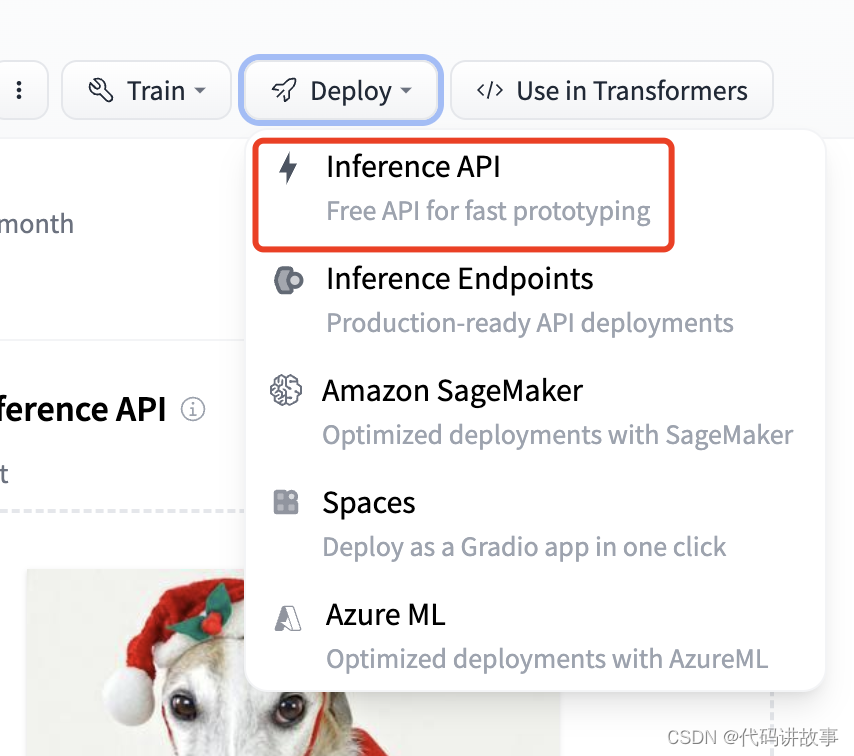
打开菜单后可以看到几种代码调用方式,分别有 Python, JavaScript 和 Curl:

这里我们选择 Curl 方式来进行调用,我们可以直接复制界面上的 Curl 命令,注意其中包含了我们的 API token,所以不要随意分享出去,然后在终端上执行命令,就可以看到预测结果了:
$ curl https://api-inference.huggingface.co/models/Salesforce/blip-image-captioning-base \-X POST \--data-binary '@dogs.jpg' \-H "Authorization: Bearer hf_xxxxxxxxxxxxxxxxxxxxxx"# 输出结果
[{"generated_text":"a dog wearing a santa hat and a red scarf"}]%
HuggingFace 推理端点(Endpoint)
推理 API 虽然方便,但推理 API 一般用于测试和验证,由于速率限制,官方不推荐在生产环境中使用,而且也不是所有模型都有提供推理 API。如果想要在生产环境部署一个专属的推理 API 服务,我们可以使用 HuggingFace 的推理端点(Endpoint)。
推理端点的部署也比较简单,首先在Deploy菜单中选择Inference Endpoints,如下图所示:
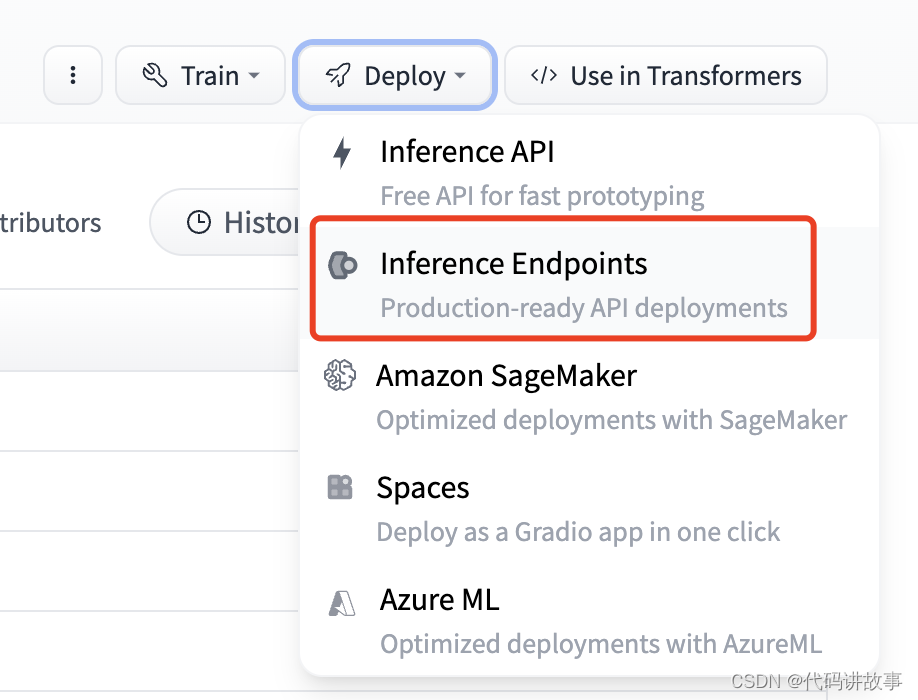
打开菜单后可以看到新建推理端点的界面,如下图所示:
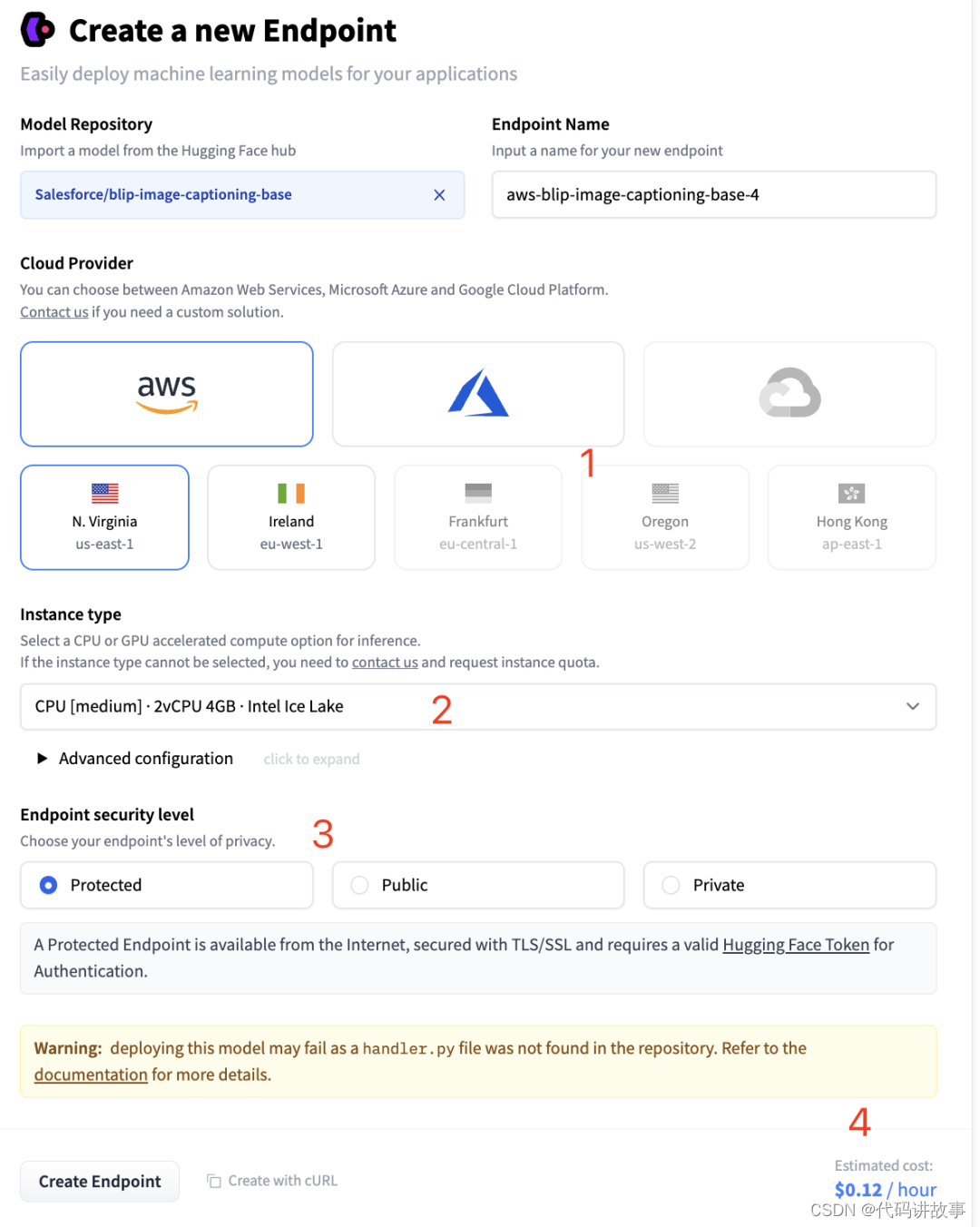
首先是服务器的选择,先选择云服务厂商,目前只有 AWS 和 Azure 两种,再选择机器区域节点。
然后是服务器的配置,HuggingFace 默认会给出模型的最低推理配置,如果我们想要更高的配置,可以点击2中的下拉框进行选择。
接着是推理端点的安全等级,有 3 种选择,分别是Protected、Public和Privaate
Pubulic:推理端点运行在公共的 HuggingFace 子网中,互联网上的任何人都可以访问,无需任何认证。
Protected:推理端点运行在公共的 HuggingFace 子网,互联网上任何拥有合适 HuggingFace Token 的人都可以访问它。
Privacy:推理端点运行在私有的 HuggingFace 子网,不能通过互联网访问,只能通过你的 AWS 或 Azure 账户中的一个私有连接来使用,可以满足最严格的合规要求。
最后显示的是服务器的价格,按小时算,根据配置的不同,价格也会有所不同。HuggingFace API 是免费的,但 HuggingFace 的推理端点是要收费的,毕竟是自己专属的 API 服务。因为推理端点部署是收费的,所以在部署之前需要在 HuggginFace 中添加付款方法,一般使用国内的 Visa 或 Master 卡就可以了。
信息确认无误后点击Create Endpoint按钮创建推理端点,创建成功后可以进入推理端点的详情页面看到如下信息:
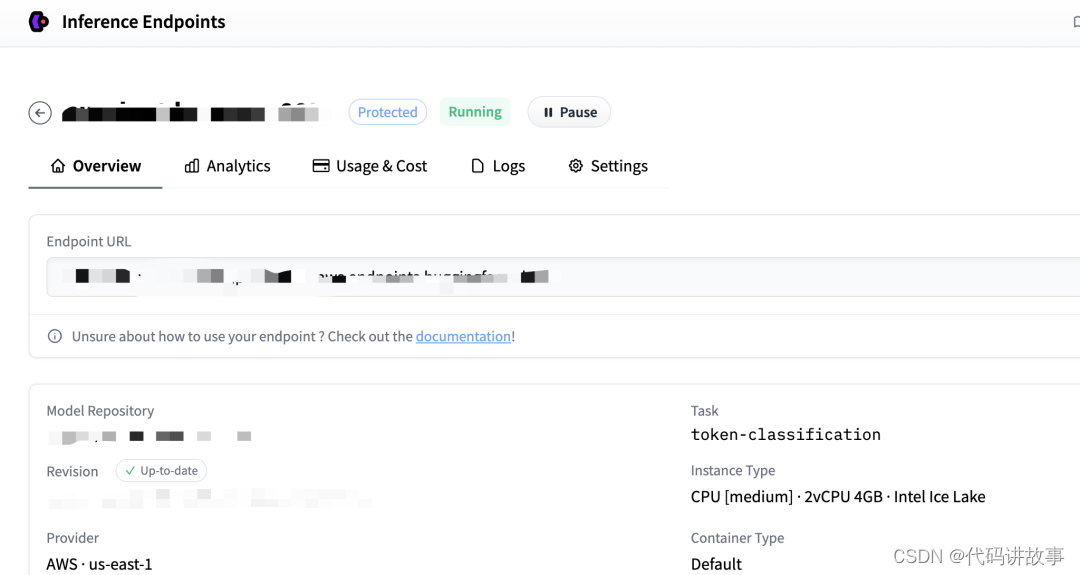
其中Endpoint URL就是部署好的推理端点地址,我们可以跟调用推理 API 一样的方式来使用它,示例代码如下:
$ curl https://your-endpoint-url \-X POST \--data-binary '@dogs.jpg' \-H "Authorization: Bearer hf_xxxxxxxxxxxxxxxxxxxxxx"
HuggingFace 模型空间(Space)
HuggingFace 推理端点是部署 API 服务,但是如果我们想要分享自己的模型,让别人可以直接在浏览器中使用模型的功能,这时候就需要使用 HuggingFace 的模型空间(Space)了。
要部署一个模型空间,首先在模型的Deploy菜单中选择Spaces,如下图所示:
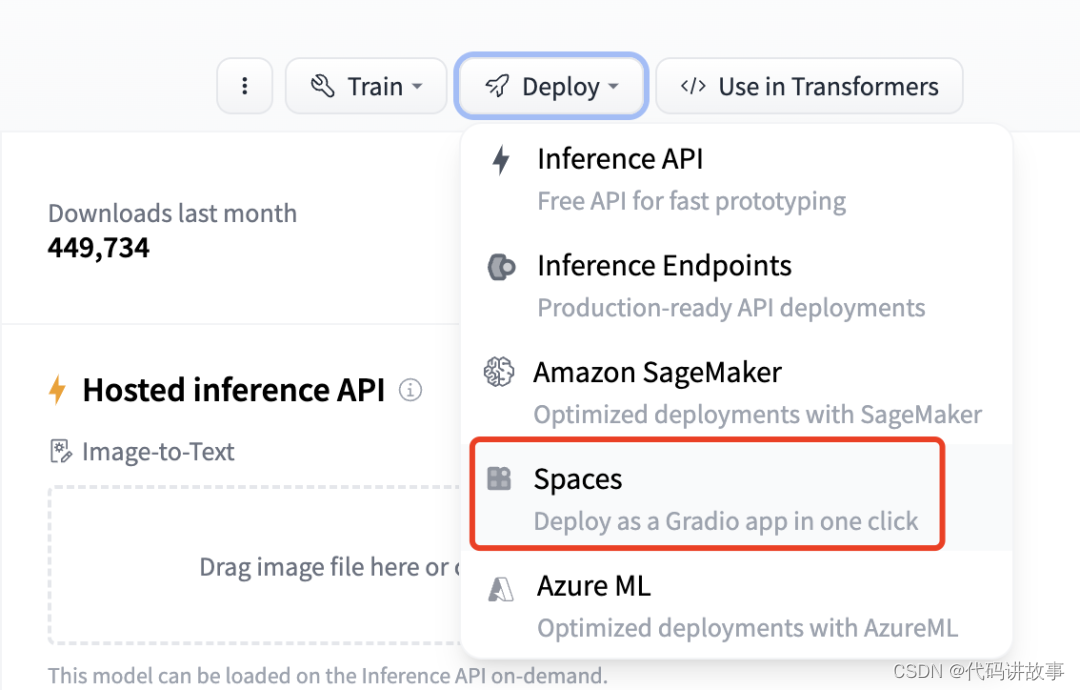
选择菜单后可以看到空间创建的引导界面,如下图所示:
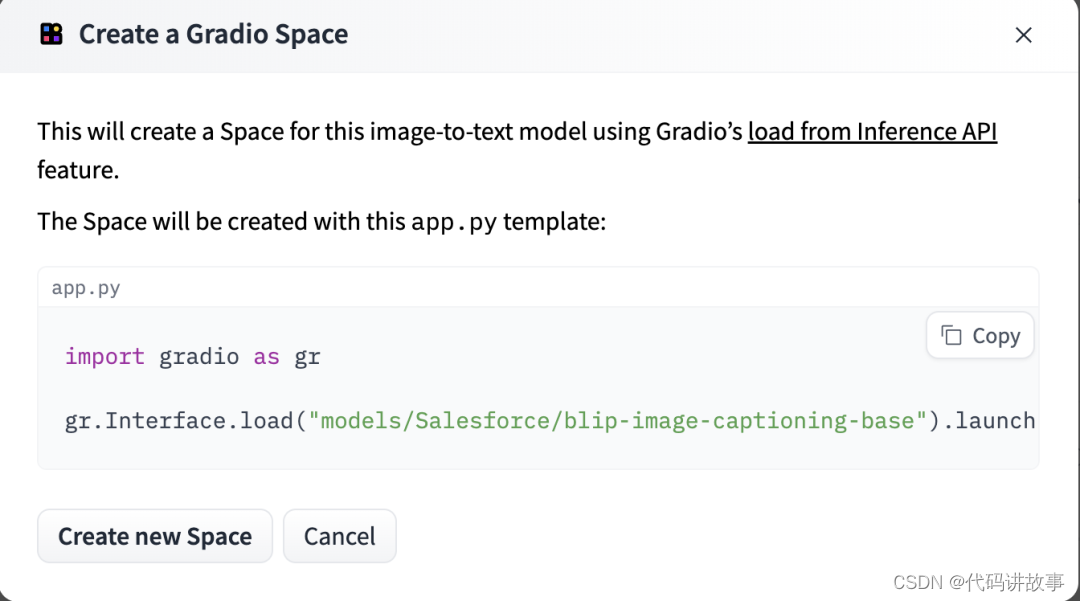
界面中显示了启动模型的 Python 脚本,然后我们点击Create new Space按钮进入空间的创建页面,如下图所示:
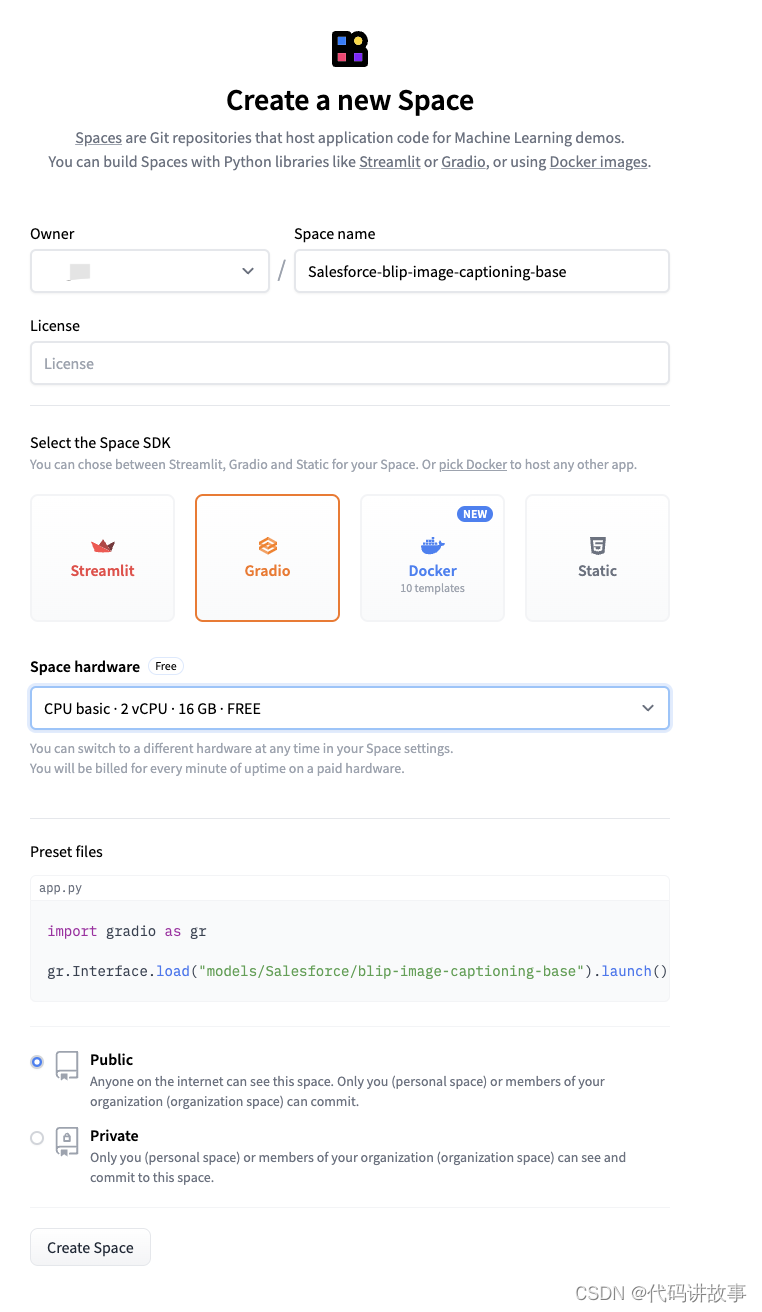
在模型创建页面中,我们需要设置以下信息:
首先要指定空间的名称,一般以模型的名称命名。
然后选择空间的 SDK,目前有Streamlit、Gradio、Docker和Static 四种。
Streamlit:Streamlit 是一个可以帮助我们快速创建数据应用的 Python 库,可以在浏览器中直接使用模型,它相比Gradio可以支持更加丰富的页面组件,界面也更加美观。
Gradio:Gradio 也是一个编写 GUI 界面的 Python 库,相对Streamlit来说,它的 GUI 功能虽然比较少,但它的优势在于简单易用,一般演示的 Demo 用它就足够了。
Docker:推理空间也可以使用 Docker 容器进行部署,它内部支持了 10 种模版。
Static:静态页面,我理解是包括 Html、Js、Css 等前端资源来作为页面展示。
然后选择空间硬件,HuggingFace 为每个空间提供了一个免费的配置:
2 核 CPU 16G 内存,用这个配置部署推理空间是免费的,如果你想要更高的配置,也可以选择付费的配置。

最后是安全等级,有Public和Private两种,Public 是公开的,任何人都可以访问,但只有你的组织成员可以修改,Private 是私有的,只有你的组织成员可以访问。
设置完后点击Create Space按钮就开始创建推理空间了,创建完成后会自动跳转到空间的页面,如下图所示:
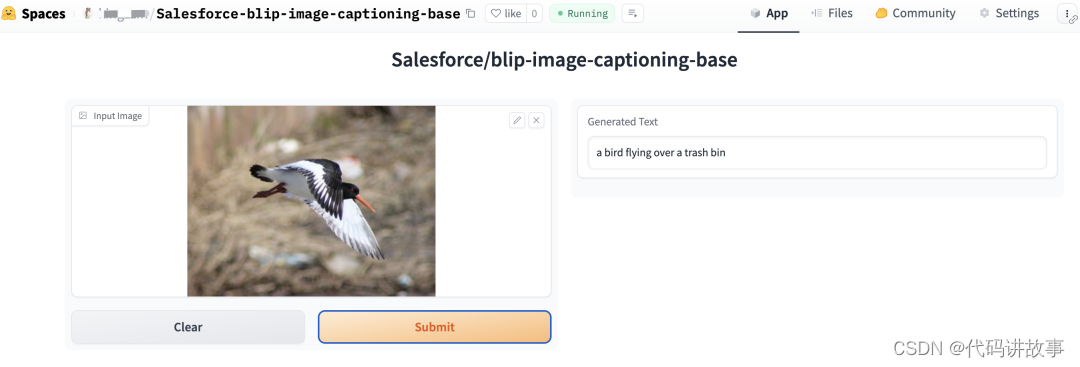
如果推理空间的安全等级设置为 Public,你就可以将空间的 URL 分享给其他人使用了。想查看 HuggingFace 推理空间更多的信息,可以参考这里[3]。
总结
本文介绍了 HuggingFace 的推理 API、推理端点和推理空间的使用方法,推理 API 是免费的,使用 HuggingFace 自建的 API 服务,推理端点是部署自己专属的 API 服务,但需要收取一定的费用。推理空间是部署模型的 Web 页面,可以直接在浏览器中使用模型的功能,可以用于演示和分享模型,有一定的免费额度。
参考:
[1] HuggingFace: https://huggingface.co/
[2] https://huggingface.co/docs/hub/models-widgets
[3] https://huggingface.co/docs/hub/spaces
相关文章:
HugggingFace 推理 API、推理端点和推理空间相关模型部署和使用以及介绍
HugggingFace 推理 API、推理端点和推理空间相关模型部署和使用以及介绍。 Hugging Face是一家开源模型库公司。 2023年5月10日,Hugging Face宣布C轮1亿美元融资,由Lux Capital领投,红杉资本、Coatue、Betaworks、NBA球星Kevin Durant等跟投…...

python的tabulate包在命令行下输出表格不对齐
用tabulate可以在命令行下输出表格。 from tabulate import tabulate# 定义表头 headers [列1, 列2, 列3]# 每行的内容 rows [] rows.append((张三,数学,英语)) rows.append((李四,信息科技,数学))# 使用 tabulate 函数生成表格 output tabulate(rows, headersheaders, tab…...
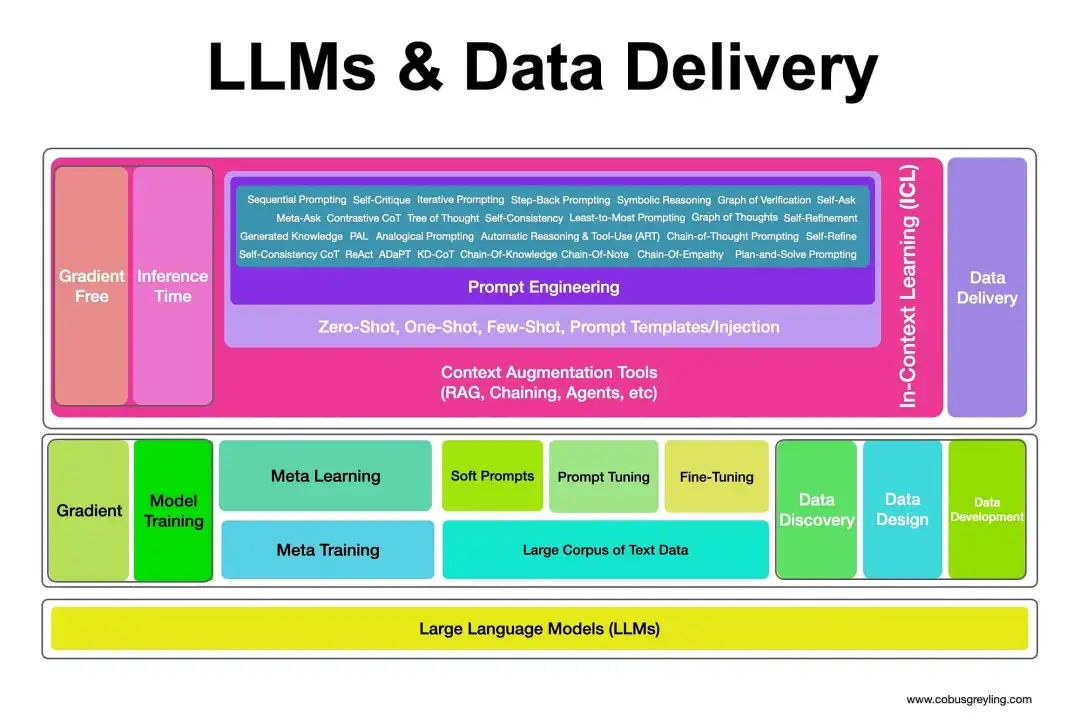
LLM之幻觉(二):大语言模型LLM幻觉缓减技术综述
LLM幻觉缓减技术分为两大主流,梯度方法和非梯度方法。梯度方法是指对基本LLM进行微调;而非梯度方法主要是在推理时使用Prompt工程技术。LLM幻觉缓减技术,如下图所示: LLM幻觉缓减技术值得注意的是: 检索增强生成&…...

C# 使用多线程,关闭窗体时,退出所有线程
this.Close(); 只是关闭当前窗口,若不是主窗体的话,是无法退出程序的,另外若有托管线程(非主线程),也无法干净地退出;Application.Exit(); 强制所有消息中止,退出所有的窗体&…...

数据结构实验6:图的应用
目录 一、实验目的 1. 邻接矩阵 2. 邻接矩阵表示图的结构定义 3. 图的初始化 4. 边的添加 5. 边的删除 6. Dijkstra算法 三、实验内容 实验内容 代码 截图 分析 一、实验目的 1.掌握图的邻接矩阵的存储定义; 2.掌握图的最短路径…...

Spring Boot整合JUnit
引言 测试是软件开发过程中不可或缺的一环,而JUnit作为Java生态中最流行的测试框架之一,与Spring Boot的整合为开发者提供了一套强大的测试工具。本文将讨论Spring Boot整合JUnit的技术细节、最佳实践以及测试驱动开发(TDD)的优雅…...
)
uniapp写小程序实现清除缓存(存储/获取/移除/清空)
在uni-app中,可以使用uni.setStorageSync和uni.getStorageSync来进行数据的存储和获取。而移除缓存数据可以使用uni.removeStorageSync,清空缓存数据可以使用uni.clearStorageSync。 以下是使用示例: 存储数据: uni.setStorage…...

js菜单隐藏显示
1、树状结构对应的表: 2、生成menulist的SQL语句 select {"id":"MenuID","parent":"ParentID","FirstLvMenu":"FirstLvMenu", "text":"MenuName","url":"MenuUrl",&quo…...
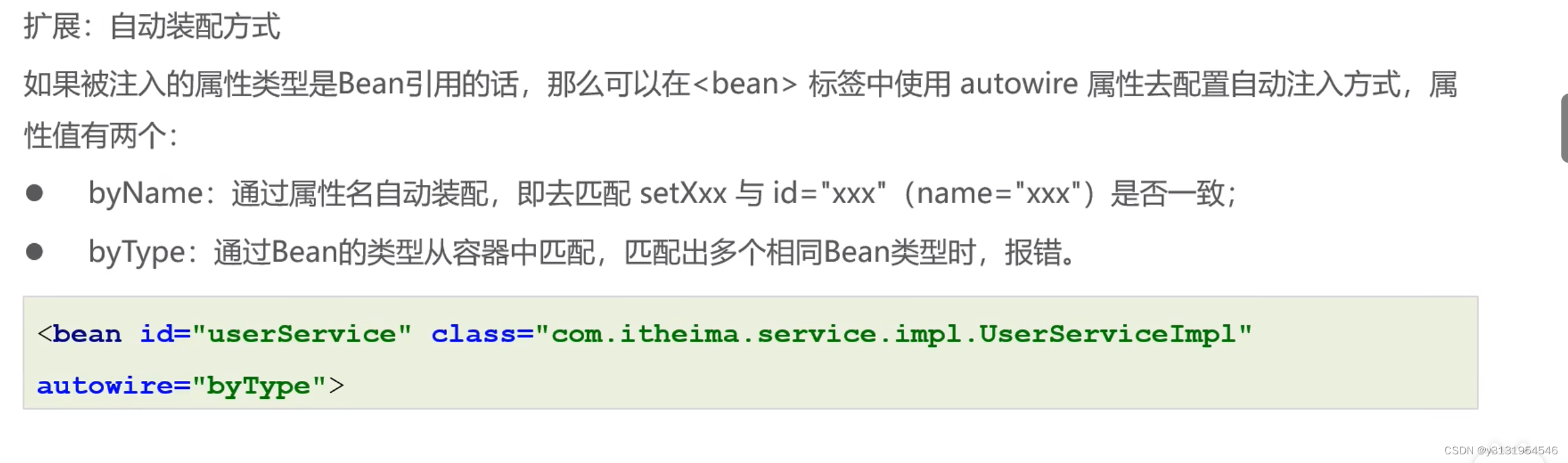
学习Spring的第五天(Bean的依赖注入)
Bean的依赖注入有两种方式: 一 . 常规Bean的依赖注入 很简单,不过多赘述了,注意ref: 是构造函数或set方法的参数,一般为对象, value: 是构造函数或set方法的参数,一般为值. 看下图 1.1 下面来演示一下集合数据类型的关于Bean的依赖注入 1.1.1这是List的注入(演示泛型为Strin…...

GAN在图像数据增强中的应用
在图像数据增强领域,生成对抗网络(GAN)的应用主要集中在通过生成新的图像数据来扩展现有数据集的规模和多样性。这种方法特别适用于训练数据有限的情况,可以通过增加数据的多样性来提高机器学习模型的性能和泛化能力。 以下是GAN在…...

Git推送本地文件到仓库
1. 在 Gitee 上创建一个新的仓库: 登录到 Gitee(https://gitee.com)账号。在 Gitee 主页上选择 "新建仓库" 或类似选项。输入仓库名称和描述,并选择其他相关选项(如公开/私有)。确认创建仓库 …...

Django笔记(一):环境部署
目录 Python虚拟环境 安装virtualenv 创建环境 激活环境 关闭: 安装Django VSCode配置 Python插件 Django插件 解释器选择 Django部署 创建项目 创建app 创建模板 编写视图 编写路由 启动服务器 访问 Python虚拟环境 安装virtualenv pip i…...
用Pytorch实现线性回归模型
目录 回顾Pytorch实现步骤1. 准备数据2. 设计模型class LinearModel代码 3. 构造损失函数和优化器4. 训练过程5. 输出和测试完整代码 练习 回顾 前面已经学习过线性模型相关的内容,实现线性模型的过程并没有使用到Pytorch。 这节课主要是利用Pytorch实现线性模型。…...

WordPress模板层次与常用模板函数
首页: home.php index.php 文章页: single-{post_type}.php – 如果文章类型是videos(即视频),WordPress就会去查找single-videos.php(WordPress 3.0及以上版本支持) single.php index.php 页面: 自定义模板 – 在WordPre…...
HarmonyOS应用开发者高级认证试题库(鸿蒙)
目录 考试链接: 流程: 选择: 判断 单选 多选 考试链接: 华为开发者学堂华为开发者学堂https://developer.huawei.com/consumer/cn/training/dev-certification/a617e0d3bc144624864a04edb951f6c4 流程: 先进行…...
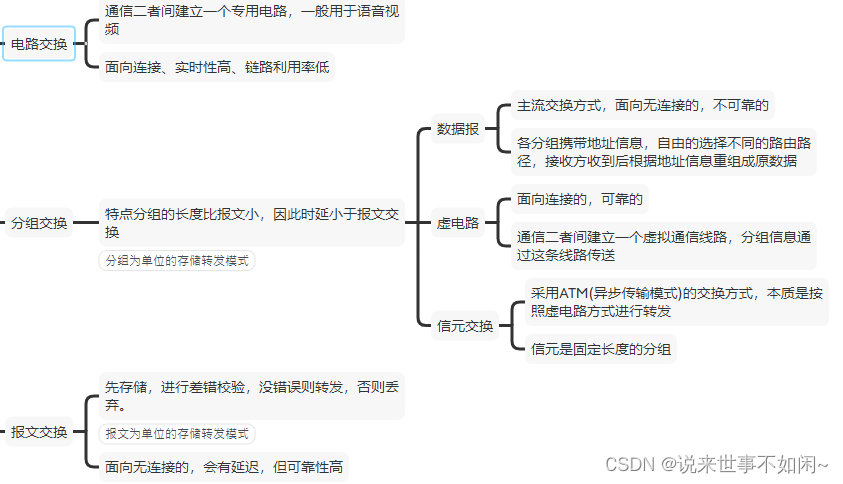
系分备考计算机网络传输介质、通信方式和交换方式
文章目录 1、概述2、传输介质3、网络通信4、网络交换5、总结 1、概述 计算机网路是系统分析师考试的常考知识点,本篇主要记录了知识点:网络传输介质、网络通信和数据交换方式等。 2、传输介质 网络的传输最常见的就是网线,也就是双绞线&…...

js原生面试总结
冒泡循环 var arr[2,1,3,4,9,7,6,8] // 外层循环代表循环次数 内层循环时每次的两两对比 少一次循环 for (let i 0; i < arr.length-1; i) {// 如果进入判断代表当前值大于下一个是需要进行冒泡排序的let booltruefor (let j 0; j < arr.length-1-i; j) {// 虽然…...
接口自动化测试框架设计
文章目录 接口测试的定义接口测试的意义接口测试的测试用例设计接口测试的测试用例设计方法postman主要功能请求体分类JSON数据类型postman内置参数postman变量全局变量环境变量 postman断言JSON提取器正则表达式提取器Cookie提取器postman加密接口签名 接口自动化测试基础getp…...
详解ISIS动态路由协议
华子目录 前言应用场景历史起源ISIS路由计算过程ISIS的地址结构ISIS路由器分类ISIS邻居关系的建立P2PMA ISIS中的DIS与OSPF中DR的对比链路状态信息的交互ISIS的最短路径优先算法(SPF)ISIS区域划分ISIS区域间路由访问原理ISIS与OSPF的不同ISIS与OSPF的术语…...
Linux操作系统----gdb调试工具(配实操图)
绪论 “不用滞留采花保存,只管往前走去,一路上百花自会盛开。 ——泰戈尔”。本章是Linux工具篇的最后一章。gdb调试工具是我们日常工作中需要掌握的一项重要技能我们需要基本的掌握release和debug的区别以及gdb的调试方法的指令。下一章我们将进入真正…...

Qt QSettings管理Windows环境变量:原理、实现与实战优化
1. 项目概述最近在做一个Qt开发的桌面工具,里面有个功能点需要动态修改用户的系统环境变量,比如把一些我们自己打包的工具路径加到用户的PATH里,这样用户在其他地方打开命令行也能直接调用。一开始想着用系统API或者直接写注册表,…...

终极虚拟定位指南:FakeLocation让你的Android设备位置自由
终极虚拟定位指南:FakeLocation让你的Android设备位置自由 【免费下载链接】FakeLocation Xposed module to mock locations per app. 项目地址: https://gitcode.com/gh_mirrors/fak/FakeLocation 你是否厌倦了应用的位置限制?想要在社交软件中保…...

极域电子教室破解指南:3分钟重获电脑自主权,学习效率翻倍
极域电子教室破解指南:3分钟重获电脑自主权,学习效率翻倍 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 你是否曾在机房上课时,面对老师全屏广…...
)
ArcMap新手必看:手把手教你给‘无家可归’的图层安个‘家’(Define Projection保姆级教程)
ArcMap坐标系急救指南:从“Unknown”到精确定位的完整解决方案 引言:当图层变成“流浪者”时 第一次在ArcMap中看到图层属性显示“Unknown”或“Undefined”时,很多新手会陷入困惑——这些数据明明有坐标数值,为什么软件却无法识别…...

Phyphox实验避坑指南:测声速时管长、温度、管口校正那些事儿
Phyphox声速测量实验的进阶精度优化手册 在物理实验教学中,声速测量一直是验证波动理论的基础实践。但当智能手机传感器遇上共振管法,看似简单的实验背后藏着诸多魔鬼细节——管口切割的平整度会引入0.5%的误差,手掌温度能在3分钟内使铝管共振…...
)
文献综述怎么写?研一萌新用Scholaread三天搞定开题文献综述(附100+篇文献整合方法)
开题在即,你面对电脑屏幕上50个PDF发呆,复制粘贴了20页摘要却被导师批"毫无逻辑"。问题不在于你不努力,而在于缺少系统化的文献综述工具链。本文拆解用Scholaread完成高质量文献综述的完整流程,让你从"不知道怎么开…...

手把手教你用Python3运行seeyon_exp工具,一键检测致远OA常见漏洞
手把手教你用Python3运行seeyon_exp工具进行致远OA漏洞检测 在当今企业数字化办公环境中,协同办公系统承载着大量核心业务数据,其安全性至关重要。致远OA作为国内广泛使用的办公自动化平台,近年来曝光的多个高危漏洞引起了安全从业者的高度关…...

帆软FineReport 10升级实战:从路径映射到安全配置的完整指南
1. 从FineReport 9到10的升级背景与准备工作 最近接手了一个企业级报表系统的升级项目,需要将现有的FineReport 9环境迁移到最新的10版本。在实际操作过程中发现,这不仅仅是简单的版本替换,而是涉及到路径映射、参数调整、安全配置等多个关键…...

STM32固件防抄攻略:手把手教你用Programmer CLI读取芯片ID并实现简易加密
STM32固件防抄实战:基于芯片ID的低成本加密方案设计与实现 在硬件产品开发中,固件安全往往是被忽视的一环。许多中小团队在产品量产前夕才意识到,精心设计的电路和算法可能因为固件被轻易复制而失去竞争优势。STM32系列MCU凭借其丰富的产品线…...
的预配置策略与实战价值)
当台风来袭时,电网如何“未雨绸缪”?聊聊应急移动电源(MPS)的预配置策略与实战价值
当台风来袭时,电网如何“未雨绸缪”?应急移动电源(MPS)的预配置策略与实战价值 台风过境时,医院ICU的呼吸机突然断电、通信基站的备用电池耗尽、交通信号灯集体瘫痪——这些场景并非虚构,而是真实发生在201…...