序列到序列模型
一.序列到序列模型的简介
序列到序列(Sequence-to-Sequence,Seq2Seq)模型是一类用于处理序列数据的深度学习模型。该模型最初被设计用于机器翻译,但后来在各种自然语言处理和其他领域的任务中得到了广泛应用。
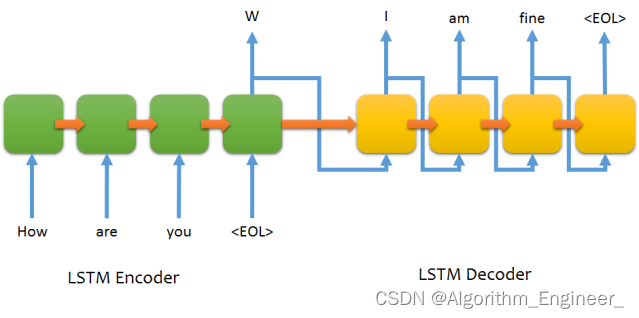
Seq2Seq模型的核心思想是接受一个输入序列,通过编码(Encoder)将其映射到一个固定长度的表示,然后通过解码(Decoder)将这个表示映射回输出序列。这使得Seq2Seq模型适用于处理不定长输入和输出的任务。
以下是Seq2Seq模型的基本架构:
编码器(Encoder):接受输入序列,并将其转换成一个固定长度的表示。这个表示通常是一个向量,包含输入序列的语义信息。常见的编码器包括循环神经网络(RNN)、门控循环单元(GRU)、长短时记忆网络(LSTM)等。解码器(Decoder):接受编码器生成的表示,并将其解码为输出序列。解码器通过逐步生成输出序列的元素,直到遇到终止标记或达到最大长度。注意力机制(Attention)(可选):用于处理长序列和对输入序列的不同部分赋予不同的重要性。注意力机制允许解码器在生成每个输出元素时关注输入序列的不同部分,从而更好地处理长距离依赖关系。
Seq2Seq模型在许多任务中都表现出色,包括:
机器翻译
文本摘要
语音识别
图片描述生成
问答系统等
在训练过程中,通常使用教师强制(Teacher Forcing)方法,即将实际目标序列中的每个元素作为解码器的输入,而不是使用解码器自身生成的元素。在推断过程中,可以使用贪婪搜索或束搜索等策略来生成输出序列。
总体而言,Seq2Seq模型为处理序列数据提供了一种强大的框架,但也面临一些挑战,如处理长序列、处理稀疏数据等。近年来,一些改进和变体的模型被提出来应对这些挑战,例如Transformer模型。
二.基本原理
Seq2Seq模型的基本原理涉及到编码器-解码器结构,其中输入序列通过编码器被映射到一个固定长度的表示,然后解码器将这个表示映射回输出序列。下面是Seq2Seq模型的基本原理:
编码器(Encoder):接受输入序列 X=(x1,x2,...,xT),其中 T 是序列的长度。每个输入元素 xt通过嵌入层转换为向量表示(embedding)。这些嵌入向量通过编码器网络,例如循环神经网络(RNN)、门控循环单元(GRU)、长短时记忆网络(LSTM)等,产生一个上下文表示(Context Vector)。h=Encoder(X)上下文表示 hh 包含了输入序列的语义信息,可以看作是输入序列的固定长度表示。解码器(Decoder):接受编码器生成的上下文表示 hh。解码器以一个特殊的起始标记作为输入,开始生成输出序列 Y=(y1,y2,...,yT),其中 T′T′ 是输出序列的长度。在每个时间步,解码器产生一个输出元素 ytyt,并更新其内部状态。yt,st=Decoder(yt−1,st−1,h)这里,st 是解码器的隐藏状态,yt−1 是上一个时间步的输出元素。在初始步骤,y0 为起始标记。生成输出序列:重复解码器的步骤,直到生成终止标记或达到最大输出序列长度。Y=Decoder(yT′−1,sT′−1,h)最终的输出序列 YY 包含了模型对输入序列的翻译或转换。
在训练时,通常使用教师强制(Teacher Forcing)方法,即将实际目标序列中的每个元素作为解码器的输入。在推断过程中,可以使用贪婪搜索或束搜索等策略来生成输出序列。
总体而言,Seq2Seq模型通过编码器-解码器结构实现了将不定长的输入序列映射到不定长的输出序列的任务,使其适用于多种序列到序列的问题。
三.序列到序列的注意力机制
注意力机制(Attention Mechanism)是一种允许神经网络关注输入序列中不同部分的机制。它最初被引入到序列到序列(Seq2Seq)模型中,以解决模型处理长序列时的问题。注意力机制使得模型能够在生成输出序列的每个元素时,对输入序列的不同部分分配不同的注意力权重。
基本的注意力机制包括三个主要组件:
查询(Query):用于计算注意力权重的向量,通常是解码器中的隐藏状态。
键(Key)和值(Value):用于表示输入序列的向量。键和值可以看作是编码器中的隐藏状态,它们将用于计算注意力分布。
注意力分数(Attention Scores):通过计算查询和键之间的相似性,得到表示注意力权重的分数。通常使用点积、加性(concatenative)、缩放点积等方法计算。
这样,模型在生成每个输出元素时,可以根据输入序列的不同部分分配不同的注意力,从而更好地捕捉长距离依赖关系。
注意力机制的引入不仅提高了模型的性能,而且也为处理更长序列和全局信息提供了一种有效的方式。在Seq2Seq模型中,Transformer模型的成功应用注意力机制,成为了自然语言处理领域的一个重要发展方向。
以下是使用PyTorch实现的基本的序列到序列模型(Seq2Seq)和注意力机制的代码。这个代码使用了一个简单的循环神经网络(RNN)作为编码器和解码器,并添加了注意力机制。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as Fclass Encoder(nn.Module):def __init__(self, input_size, hidden_size):super(Encoder, self).__init__()self.embedding = nn.Embedding(input_size, hidden_size)self.rnn = nn.GRU(hidden_size, hidden_size)def forward(self, input):embedded = self.embedding(input)output, hidden = self.rnn(embedded)return output, hiddenclass Attention(nn.Module):def __init__(self, hidden_size):super(Attention, self).__init__()self.hidden_size = hidden_sizeself.attn = nn.Linear(hidden_size * 2, hidden_size)self.v = nn.Parameter(torch.rand(hidden_size))def forward(self, hidden, encoder_outputs):seq_len = encoder_outputs.size(0)hidden = hidden.repeat(seq_len, 1, 1)energy = F.relu(self.attn(torch.cat((hidden, encoder_outputs), dim=2)))energy = energy.permute(1, 2, 0)v = self.v.repeat(encoder_outputs.size(0), 1).unsqueeze(1)attention_scores = torch.bmm(v, energy).squeeze(1)attention_weights = F.softmax(attention_scores, dim=1)context_vector = torch.bmm(encoder_outputs.permute(1, 0, 2), attention_weights.unsqueeze(2)).squeeze(2)return context_vectorclass Decoder(nn.Module):def __init__(self, output_size, hidden_size):super(Decoder, self).__init__()self.embedding = nn.Embedding(output_size, hidden_size)self.rnn = nn.GRU(hidden_size * 2, hidden_size)self.fc = nn.Linear(hidden_size, output_size)self.attention = Attention(hidden_size)def forward(self, input, hidden, encoder_outputs):embedded = self.embedding(input).view(1, 1, -1)context = self.attention(hidden, encoder_outputs)rnn_input = torch.cat((embedded, context.unsqueeze(0)), dim=2)output, hidden = self.rnn(rnn_input, hidden)output = output.squeeze(0)output = self.fc(output)return output, hiddenclass Seq2Seq(nn.Module):def __init__(self, encoder, decoder, device):super(Seq2Seq, self).__init__()self.encoder = encoderself.decoder = decoderself.device = devicedef forward(self, src, trg, teacher_forcing_ratio=0.5):batch_size = trg.shape[1]trg_len = trg.shape[0]trg_vocab_size = self.decoder.fc.out_featuresoutputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)encoder_outputs, hidden = self.encoder(src)input = trg[0, :]for t in range(1, trg_len):output, hidden = self.decoder(input, hidden, encoder_outputs)outputs[t] = outputteacher_force = random.random() < teacher_forcing_ratiotop1 = output.argmax(1)input = trg[t] if teacher_force else top1return outputs四.序列到序列模型存在的问题和挑战
尽管序列到序列(Seq2Seq)模型在处理序列数据上取得了很多成功,但也面临一些问题和挑战,其中一些包括:
处理长序列:Seq2Seq模型在处理长序列时可能面临梯度消失和梯度爆炸的问题,导致模型难以捕捉长距离依赖关系。注意力机制是一种缓解这个问题的方法,但仍然存在一定的挑战。稀疏性和OOV问题:对于自然语言处理等任务,词汇表往往很大,而训练数据中的词汇可能很稀疏。这导致模型难以处理未在训练数据中见过的词汇,即Out-Of-Vocabulary(OOV)问题。Subword分词和字符级别的建模等方法可以缓解这个问题。过度翻译和生成问题:Seq2Seq模型在训练时使用了教师强制,即将实际目标序列中的每个元素作为解码器的输入。这可能导致模型在生成时出现过度翻译的问题,即生成与目标不完全一致的序列。在推断时采用不同的生成策略,如束搜索,可以部分缓解这个问题。缺乏全局一致性:Seq2Seq模型通常是基于局部信息的,每个时间步只关注当前输入和先前的隐藏状态。这可能导致生成的序列缺乏全局一致性。Transformer模型引入的自注意力机制可以更好地处理全局信息,但仍然存在一些挑战。对训练数据质量和多样性的敏感性:Seq2Seq模型对训练数据的质量和多样性敏感。缺乏多样性的数据集可能导致模型泛化能力差。数据增强和更复杂的模型架构可以帮助处理这个问题。推断速度较慢:一些Seq2Seq模型在推断时可能较慢,尤其是在处理长序列时。Transformer等模型在这方面有一些改进,但仍需要考虑推断效率。
对这些问题的研究和改进使得Seq2Seq模型不断演进,并推动了更先进的模型的发展,例如Transformer和其变体。
相关文章:
序列到序列模型
一.序列到序列模型的简介 序列到序列(Sequence-to-Sequence,Seq2Seq)模型是一类用于处理序列数据的深度学习模型。该模型最初被设计用于机器翻译,但后来在各种自然语言处理和其他领域的任务中得到了广泛应用。 Seq2Seq模型的核…...
复习提纲4)
计算机网络(第六版)复习提纲4
计算机网络的体系结构: 三类体系结构: OSI七层:物理层比特位传输,链路层相邻链路传输检验,网络层进行路由选择,运输层实现端到端进程通信,会话层连接管理,表示层数据格式,…...

天拓分享:汽车零部件制造企业如何利用边缘计算网关和数网星平台实现数控机床数据采集分析
一、项目背景 某汽车零部件制造企业为了提高生产效率、降低能耗和提高产品质量,决定引入TDE边缘计算网关和数网星工业互联网平台,对数控机床进行数据采集与分析。 二、解决方案 1、设备选型与配置:考虑到企业生产需求和数控机床的特性&…...
爬虫逆向开发教程1-介绍,入门案例
爬虫前景 在互联网的世界里,数据就是新时代的“黄金”。而爬虫,就是帮助我们淘金的“工具”。随着互联网的不断发展,数据量呈现指数级的增长,在数据为王的时代,有效的挖掘数据和利用,你会得到更多东西。 学…...
时序分解 | Matlab实现CEEMDAN+PE自适应噪声完备集合经验模态分解+排列熵计算
时序分解 | Matlab实现CEEMDANPE自适应噪声完备集合经验模态分解排列熵计算 目录 时序分解 | Matlab实现CEEMDANPE自适应噪声完备集合经验模态分解排列熵计算效果一览基本介绍程序设计参考资料 效果一览 基本介绍 CEEMDANPE自适应噪声完备集合经验模态分解排列熵计算 运行环境m…...

Oracle命令大全
文章目录 1. SQL*Plus命令(用于连接与管理Oracle数据库)2. SQL数据定义语言(DDL)命令3. SQL数据操作语言(DML)命令4. PL/SQL程序块5. 系统用户管理6. 数据备份与恢复相关命令1. SQL*Plus命令(用…...
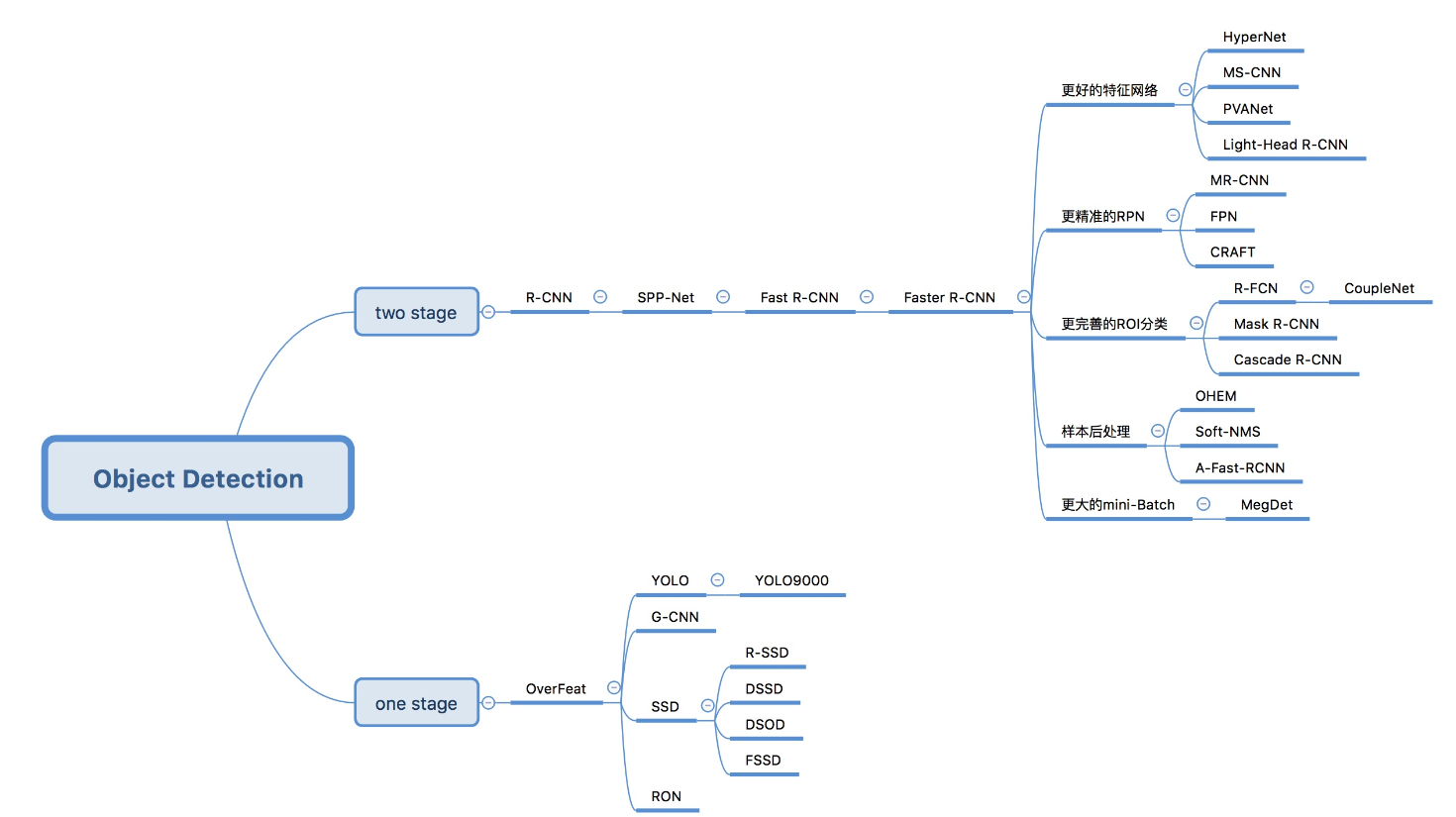
目标检测--01
基本概念 什么是目标检测? 目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的类别和位置,是计算机视觉领域的核心问题之一。由于各类物体有不同的外观、形状…...

MyBatisPlus学习笔记三-核心功能
接上篇: MyBatisPlus学习笔记二-CSDN博客 1、核心功能-IService开发基础业务接口 1.1、介绍 1.2、引用依赖 1.3、配置文件 1.4、用例-新增 1.5、用例-删除 1.6、用例-根据id查询 1.7、用例-根据ids查询 2、核心功能-IService开发复杂业务接口 2.1、实例-更新 3、…...

【并发编程系列】putIfAbsent和getOrDefault用法
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...
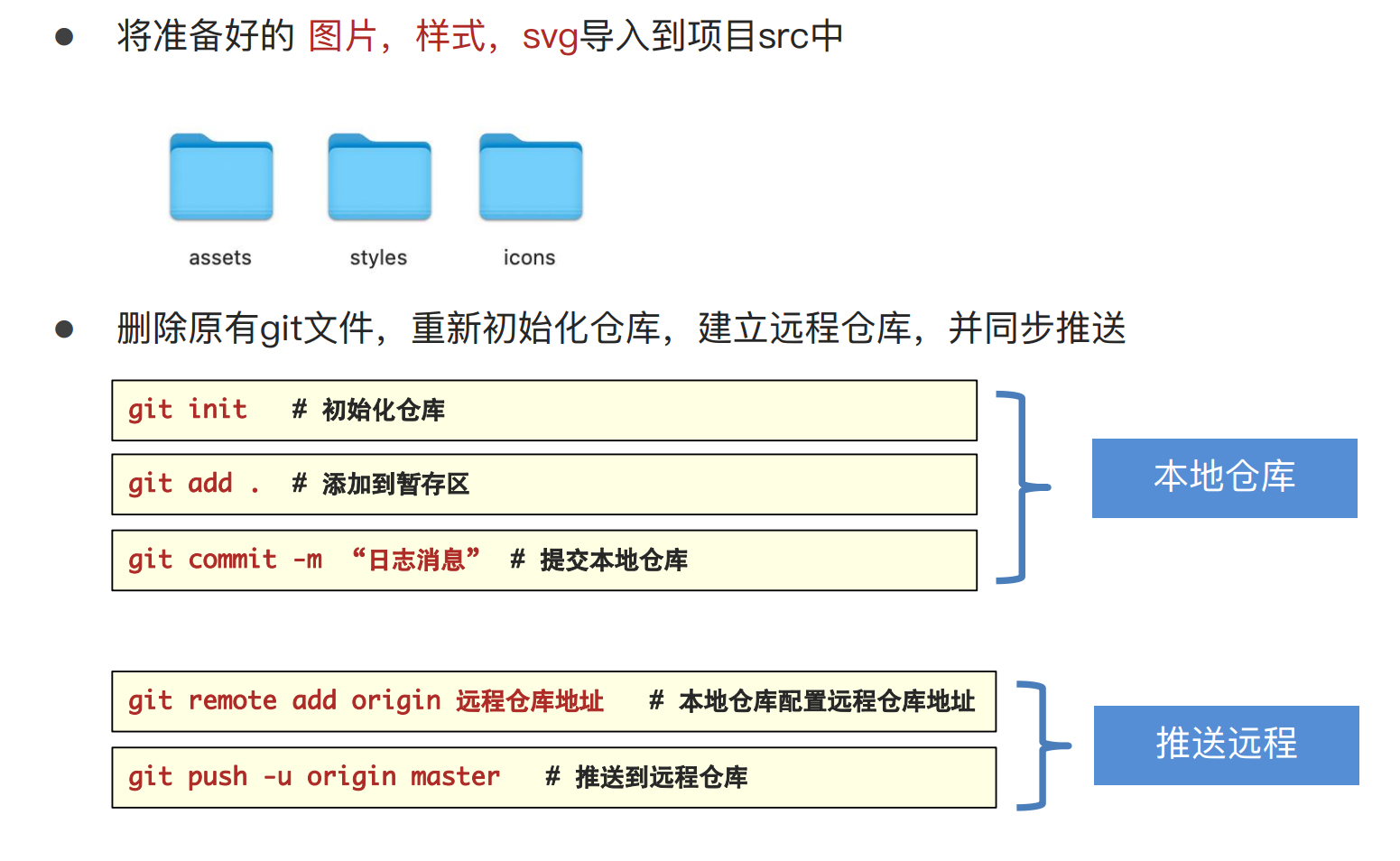
人力资源智能化管理项目(day01:基础架构拆解)
学习源码可以看我的个人前端学习笔记 (github.com):qdxzw/frontlearningNotes 觉得有帮助的同学,可以点心心支持一下哈 一、基础架构拆解 1.拉取模板代码 git clone GitHub - PanJiaChen/vue-admin-template: a vue2.0 minimal admin template 项目名 2.core-js…...

JAVA ORM Bee的设计模式分析
创建型 工厂模式(Factory Pattern) 日志工厂 LoggerFactory 静态工厂模式 *(Static Factory) BeeFactoryHelper 单例模式(Singleton Pattern) 使用单例模式管理系统的配置信息 HoneyConfig 建…...
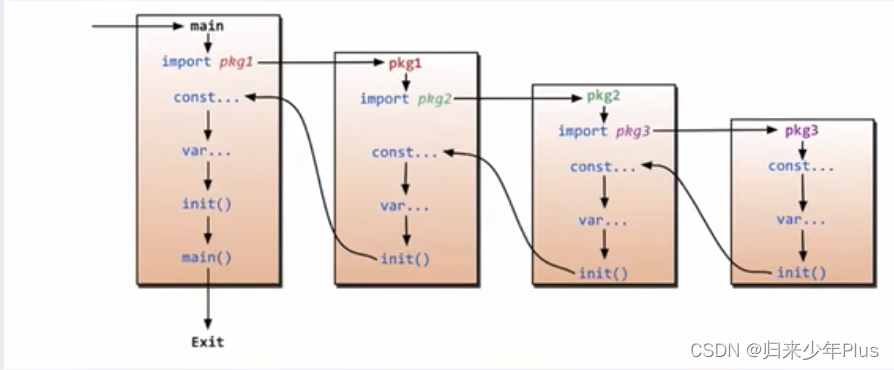
go语言(三)----函数
1、函数单变量返回 package mainimport "fmt"func fool(a string,b int) int {fmt.Println("a ",a)fmt.Println("b ",b)c : 100return c}func main() {c : fool("abc",555)fmt.Println("c ",c)}2、函数多变量返回 pack…...

鸿蒙原生应用/元服务开发-延迟任务说明(一)
一、功能介绍 应用退至后台后,需要执行实时性要求不高的任务,例如有网络时不定期主动获取邮件等,可以使用延迟任务。当应用满足设定条件(包括网络类型、充电类型、存储状态、电池状态、定时状态等)时,将任务…...

正信晟锦:借钱一直都不还可以起诉吗
在日常生活中,我们可能会遇到一些经济困难,需要向亲朋好友或者金融机构借款。然而,有些人在借款后并没有按照约定的时间还款,甚至一直拖欠不还。这种情况下,债权人是否可以起诉债务人呢?答案是肯定的。 我们需要明确的…...

npm run dev 启动vue的时候指定端口
使用的是 Vue CLI 来创建和管理 Vue 项目, 可以通过设置 --port 参数来指定启动的端口号。以下是具体的步骤: 打开命令行终端 进入您的 Vue 项目目录 运行以下命令,通过 --port 参数指定端口号(例如,这里设置端口号…...
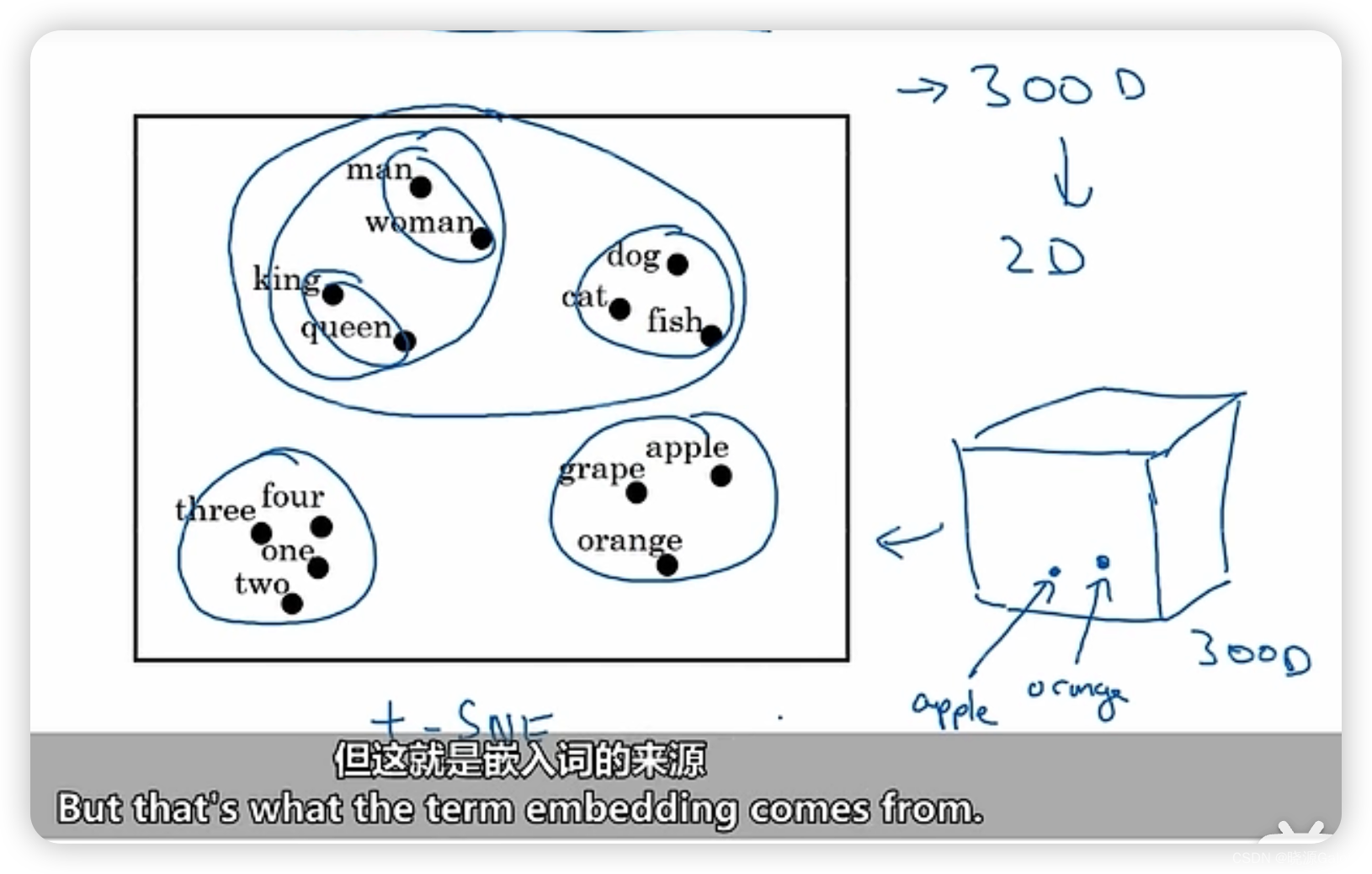
深度学习|16.1 词表示、embedding
文章目录 词表示one-hot编码 embedding编码工具t-SNE——将多维空间投射到二维平面 词表示 one-hot编码 若有n类词,则用n维向量对单个类进行区分。在这个n维向量里面第i维为1,则说明这是第i个词,并且要求其他位置都是为0. embedding编码 每…...
)
.NetRSA签名(调的JAVA的接口)
公共类: using Org.BouncyCastle.Crypto.Parameters; using Org.BouncyCastle.Security; using System; using System.IO; using System.Security.Cryptography; using System.Security.Cryptography.X509Certificates;namespace CommonUtils {/// <summary>/// 将私钥&…...

CSS||选择器
目录 作用 分类 基础选择器 标签选择器 编辑类选择器 id选择器 通配符选择器 作用 选择器(选择符)就是根据不同需求把不同的标签选出来这就是选择器的作用。 简单来说,就是选择标签用的。 选择器的使用一共分为两步: 1.…...

几种常见的算法
一、冒泡排序法 冒泡排序法 原始数据:3 2 7 6 8 第1次循环:(最大的跑到最右边) 2 3 7 6 8(3和2比较,2<3 所以2和3交换位置) 2 3 7 6 8(3和7比较,3<7 所以不需要交…...
、curl_setopt()和curl_exec()等cURL函数)
原生的cURL函数而不是 tp6框架的Http类,curl_init()、curl_setopt()和curl_exec()等cURL函数
GET请求示例: // 初始化 cURL $ch curl_init(); // 设置 cURL 选项 curl_setopt($ch, CURLOPT_URL, https://example.com/api/resource); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // 执行 cURL 并获取返回结果 $response curl_exec($ch); // 关闭 cURL…...

Rust内存安全:所有权、借用与生命周期深度解析
Rust内存安全:所有权、借用与生命周期深度解析 引言 在Rust开发中,内存安全是其最核心的特性。作为一名从Python转向Rust的后端开发者,我深刻体会到Rust在内存安全方面的革命性设计。Rust通过所有权系统、借用机制和生命周期注解࿰…...

LeetCode 找到最终的安全状态题解
LeetCode 找到最终的安全状态题解 题目描述 给定一个有向图,找到所有安全节点。安全节点是永远不会走向环的节点。 示例: 输入:graph [[1,2],[2,3],[5],[0],[5],[],[]]输出:[2,4,5,6] 解题思路 方法:拓扑排序 思路&am…...

【图像增强】基于Grünwald–Letnikov和Riesz分数阶算子的四种分数阶PDE图像增强算法的MATLAB实现
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室👇 关注我领取海量matlab电子书和…...

【开源首发】双脑 AI 工作流:强制模型隔离 + 省 60% Token,完美替代 CrewAI,支持本地 Ollama 免费跑
前言 大家好,我是一名大一的生物医药数据科学专业学生。最近半年一直在用 AI 做各种自动化工具,前前后后踩了 LangChain 和 CrewAI 的无数坑。 我发现所有主流 AI Agent 框架都有一个致命的设计盲区:它们默认相信 AI 能自己监督自己。但实际…...

Hermes Agent框架对接Taotoken自定义供应商的配置指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent框架对接Taotoken自定义供应商的配置指南 对于使用Hermes Agent框架的开发者而言,能够灵活接入不同的模型…...

[Android] 文案设计助手_24.06.25
[Android] 文案设计助手_24.06.25 链接:https://pan.xunlei.com/s/VOszMVvm4BmG5za6Ib11nfGrA1?pwdsg9f# 文案设计助手,助您文案生成、自动写作,模拟手写生成器。免登陆,下载即用,无需会员。...

压接 vs 焊接:高速连接器组装工艺的选型指南与实战对比
摘要/前言在通信设备、工业控制及数据中心硬件设计中,连接器的组装工艺选择直接影响产品的可靠性、可维护性与生产良率。压接(Press-Fit)与焊接(Soldering)是当前通孔连接器最主要的两种电气互连方式。压接依靠过盈配合…...

前端工程化18:前端单元测试Jest实战,保障项目代码稳定性
前端工程化18:前端单元测试Jest实战,保障项目代码稳定性 文章目录 前端工程化18:前端单元测试Jest实战,保障项目代码稳定性 前言 一、单元测试核心概念 1. 什么是单元测试 2. 单元测试优势 3. 适用测试场景 二、Jest环境快速搭建 1. 安装依赖 2. 新增测试运行脚本 3. 目录规…...

从设计到验证:如何用ADS的HB2TonePAE_FPswp模板快速评估你的PA线性度?
射频功放线性度评估实战:ADS高级仿真模板深度解析 在射频功率放大器(PA)的设计流程中,线性度评估往往是最耗时的环节之一。传统方法需要工程师手动搭建测试平台,不仅效率低下,还容易引入人为误差。Keysight ADS软件内置的HB2ToneP…...

工业 DC-DC 标准封装设计探讨 钡特电源 DB2-12D15D 与金升阳 A1215D-2WR3 工业模块电源盘点
在工业控制与嵌入式系统设计中,12V 输入转 15V 输出的 2W 隔离供电方案,是模拟电路、信号调理模块的核心供电选择。伴随国内电子制造技术持续突破,国产直流电源模块在标准化封装、电气性能稳定性上不断贴合行业通用规范,成为推动国…...