基于 MySQL 排它锁实现分布式可重入锁解决方案
一、MySQL 排它锁和共享锁
在进行实验前,先来了解下MySQL 的排它锁和共享锁,在 MySQL 中的锁分为表锁和行锁,在行锁中锁又分成了排它锁和共享锁两种类型。
1. 排它锁
排他锁又称为写锁,简称X锁,是一种悲观锁,具有悲观锁的特征,如一个事务获取了一个数据行的X锁,其他事务尝试获取锁时就会等待另一个事务的释放。其中在 InnoDB 引擎下做写操作时 (UPDATE、DELETE、INSERT)都会自动给涉及到的数据加上 X 锁,因此当多线程情况下对同一条数据进行更新,在MySQL中不会出现线程安全问题。
其中 SELECT 语句默认不会加锁,如果查询的数据已经存在 X 锁,则会返回其最近提交的数据,如果希望每次获取的数据都是更新后最新的数据,当存在有更新时,则等待更新完成后获取新的值,这种情况下就需要对 SELECT 语句也要存在 X 锁,其中 SELECT 语句加 X 锁的话需要使用 FOR UPDATE 语句。
比如:当前有一张表结构如下:
CREATE TABLE `lock` (`id` int NOT NULL AUTO_INCREMENT,`name` varchar(255) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
写入一条测试数据:
INSERT INTO `testdb`.`lock`(`id`, `name`) VALUES (1, 'lock1');
下面,我使用 Navicat 开启了两个对话框,我在第一个对话框中,使用手动提交事务的方式执行更新语句,并且既不提交也不回滚事务:
BEGIN;
UPDATE `lock` SET `name` = 'lock2' WHERE id = 1;
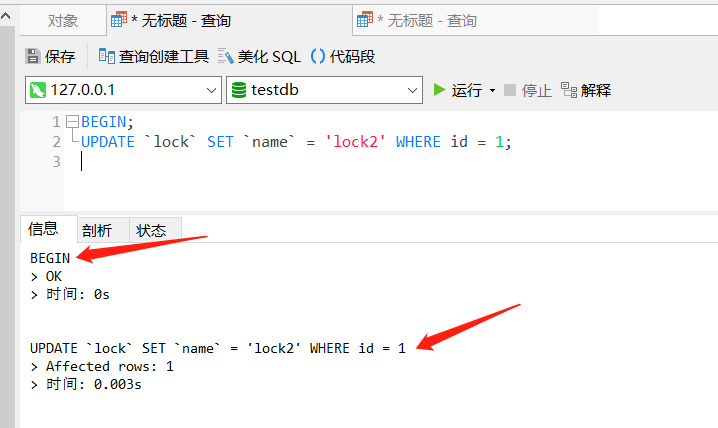
下面在另一个对话框中,查询 id = 1 的数据:
SELECT * FROM `lock` where id = 1
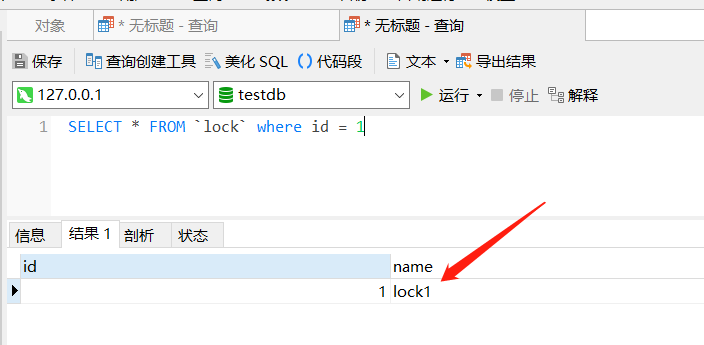
可以看到,并没有拿到最新的内容,因为此时 X 锁还没有释放,那此时对查询语句进行调整下,加上 FOR UPDATE 语句:
SELECT * FROM `lock` where id = 1 FOR UPDATE
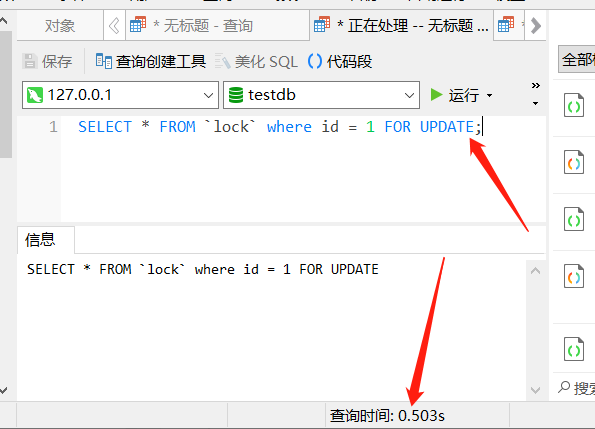
此时会发现,查询语句一直在等待,因为这个查询语句在等待 X 锁的释放,下面对第一个对话框中,执行提交事务:
COMMIT;
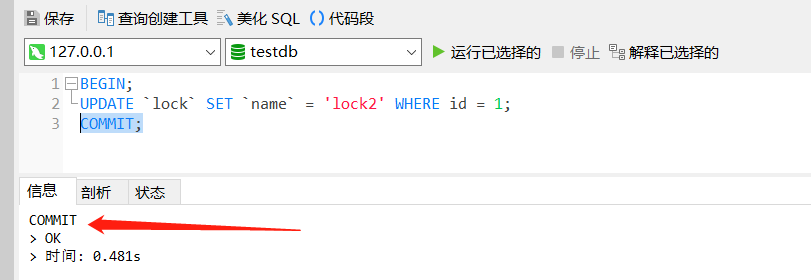
在回到第二个对话框中查看:
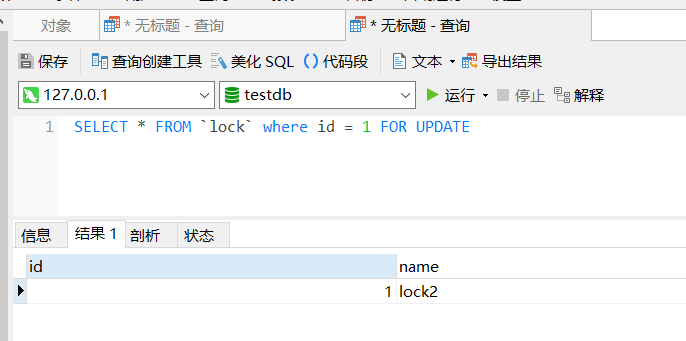
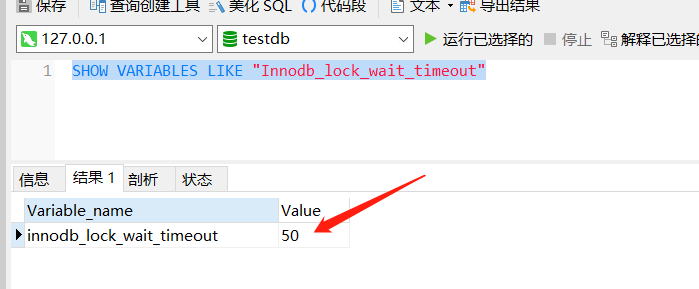
已经拿到最新的值。这里需要注意下,你的是不是出现了超时报错,这是因为 Innodb 引擎对等待锁有个等待超时时间,默认情况下是 50s ,可以通过下面指令查看:
SHOW VARIABLES LIKE "Innodb_lock_wait_timeout"
如果感觉太小,可以通过下面指令调整:
SET innodb_lock_wait_timeout = 100
上面的操作已经感觉出来 X 锁的效果,那当两个 SELECT 语句都加上 FOR UPDATE 呢,比如在第一个回话框中,使用手动事务执行 SELECT 语句,同样不提交事务:
BEGIN;
SELECT * FROM `lock` where id = 1 FOR UPDATE;
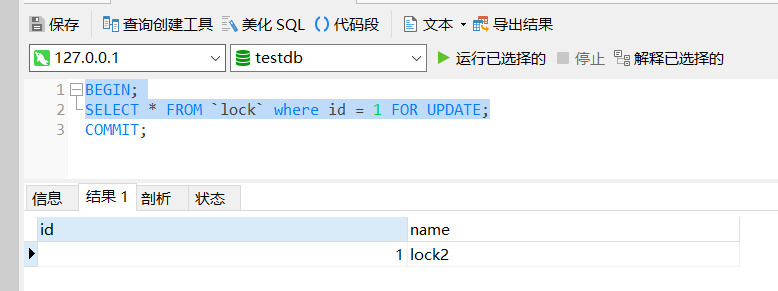
在第二个对话框同样执行相同的代码,可以发现被阻塞掉了。
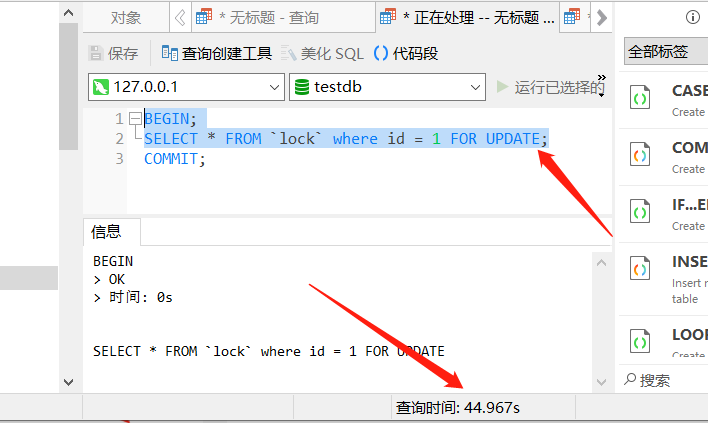
当第一个提交事务后,第二个紧接着也查出了信息,这也正符合排他锁的特征。
2. 共享锁
共享锁可以理解为读锁,简称S锁,可以对多个事务SELECT情况下读取同一数据时不会阻塞,但是如果存在写操作时 (UPDATE、DELETE、INSERT),SELECT语句也会被阻塞,在MySQL中使用 S 锁需要使用 LOCK IN SHARE MODE。
例如还是开启两个对话框,在第两个对话框中,都查询 id = 1 的数据,并加上 S 锁,最后同样不提交事务:
BEGIN;
SELECT * FROM `lock` where id = 1 LOCK IN SHARE MODE;
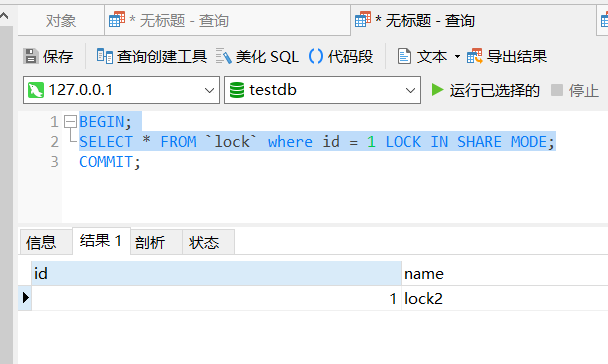
可以发现两个都拿到了数据,对两个都提交事务后,假如第一个对话框中是更新操作,最后同样不提交事务:
BEGIN;
UPDATE `lock` SET `name` = 'lock3' WHERE id = 1 ;
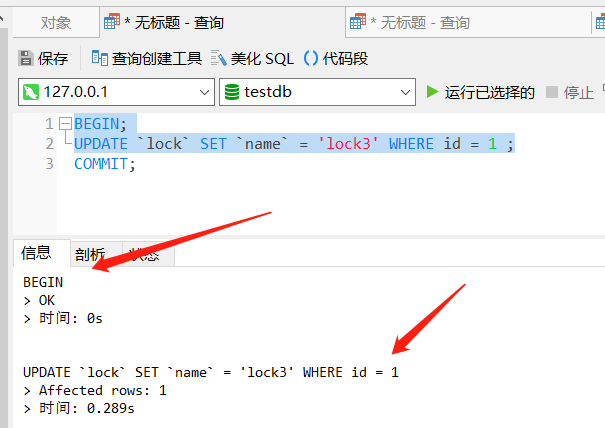
在第二个对话框中还是加上 S 锁的查询操作:
BEGIN;
SELECT * FROM `lock` where id = 1 LOCK IN SHARE MODE;
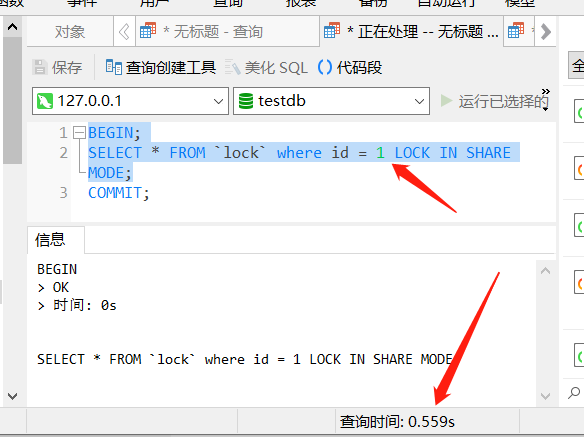
可以看到查询被阻塞了,当第一个对话框中提交了事务,这里才会返回结果:
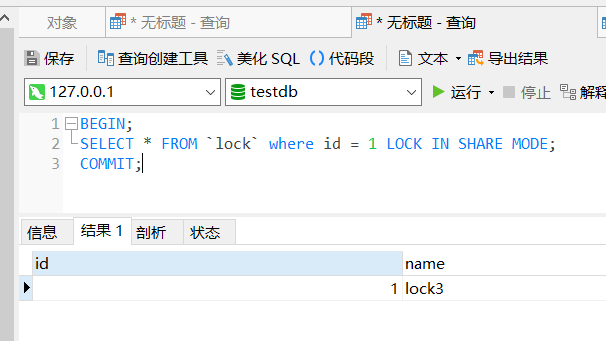
读到这里相信大家已经对 MySQL 的排它锁和共享锁有了一定的了解,下面我们基于 排它锁 实现分布式锁的场景。
二、基于 MySQL 排它锁实现分布式可重入锁
根据上面的实例可以看到排它锁具有阻塞等待的效果,和我们 JVM 中普通的锁的效果是一致的,但普通的锁通常只能在单个 JVM 中,但现在的服务,动则都要多台集群部署,对于不同的 JVM 普通的锁实在心有余而力不足,此时就要考虑使用分布式锁,目前分布式锁的解决方案也比较多,例如基于 Redis 的 setNx 实现的分布式锁,相关框架有 Redissson ,还有基于 Zookeeper 的临时节点实现的分布式锁,相关框架有 Curator 等等,而且这些都有方案实现锁的可重入性。
本文我们再介绍一种基于 MySQL 的方案,毕竟现在再小的项目基本都会引入数据库,我们在此基础上延伸也少了其他框架的学习。
实现的思路:
- 数据库中创建一个
lock表 ,里面根据场景添加数据,一行就代表一个分布式锁的句柄。 - 在项目中在需要锁的方法中首先开启事务,保证下面的操作在事务中,事务可借助
Spring的@Transactional注解。 - 在获取锁时,使用
SELECT * FROM lock WHERE id = #{id} FOR UPDATE排它锁语句执行。 - 如果正常查询到则获取锁成功,此时如果其他事务也在获取锁,则因为排他锁的原因会阻塞等待。
- 此时如果还要获取锁,也就是对于锁的可重入性设计,可以利用同一个事务中对于同一条数据
FOR UPDATE不会阻塞的特征,只需在同一个事务中再次获取锁的操作即可实现 。 - 方法执行完,如果是手动事务一定要提交或回滚事务,即表示释放锁,如果是
Spring的@Transactional注解,则会自动提交或回滚。
开始实施:
首先新建一个 SpringBoot 项目,在 pom 中引入 mybatis-plus 依赖:
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.3.2</version>
</dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId>
</dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.1.6</version>
</dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId>
</dependency>下面在配置文件中增加 MySQL 的配置:
server:port: 8081spring:datasource:url: jdbc:mysql://127.0.0.1:3306/testdb?useUnicode=true&characterEncoding=utf8&serverTimezone=UTCusername: rootpassword: roottype: com.alibaba.druid.pool.DruidDataSource
下面获取锁的逻辑其实就是一个 Mapper 中的 Select 操作:
@Mapper
public interface LockMapper {/*** 尝试获取锁*/@Select("SELECT id FROM `lock` where id = #{id} FOR UPDATE;")Long tryLock(@Param("id") Long id);
}
下面编写一个线程安全的例子,使用 10 个线程,去对一个全局 int 变量做 +1 操作,这里为了方便测试,直接声明成 Controller
@RestController
public class LockService {private volatile int count = 0;@GetMapping("/test")public void test() {for (int i = 0; i < 10; i++) {new Thread(() -> {testLock();}).start();}}public void testLock() {count++;System.out.print(count+" , ");}
}
运行后,访问测试接口,查看控制台打印的效果:
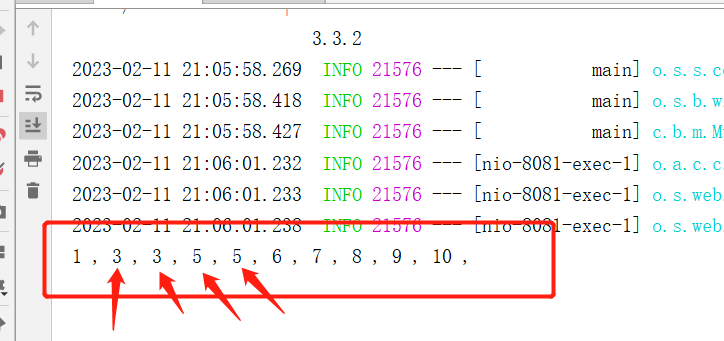
可以看到已经出现线程安全问题了,下面我们改造成使用 MySQL 的排他锁进行协调,这里需要注意下,这里事务使用的是 Spring 的 @Transactional 注解,是基于 AOP 实现的,因此 LockService 需要从 Spring 容器中获取 ,另外对于锁的超时可以捕获 CannotAcquireLockException 异常。
@RestController
public class LockService {@ResourceLockService lockService;@ResourceLockMapper lockMapper;private final Long LOCK_ID = 1L;private volatile int count = 0;@GetMapping("/test")public void test() {for (int i = 0; i < 10; i++) {new Thread(() -> {lockService.testLock();}).start();}}@Transactional(rollbackFor = Exception.class)public void testLock() {try {//获取锁,如果获取不到则阻塞if (Objects.nonNull(lockMapper.tryLock(LOCK_ID))){count++;System.out.print(count + " , ");}} catch (CannotAcquireLockException e) {System.out.println("获取锁超时!");}}
}
执行后,查看日志:
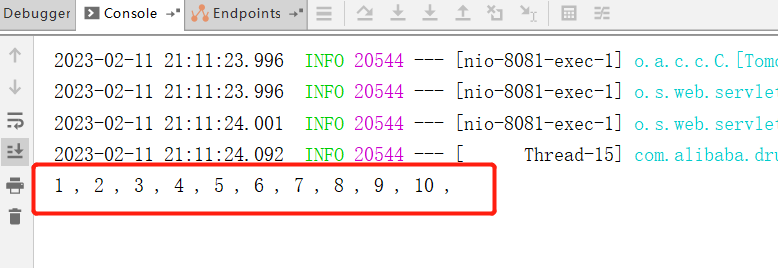
细心地话可以明显感觉执行速度比之前慢了,因为出现了阻塞情况,通过数据可以看到已经解决了线程安全问题,但是锁的可重入性呢,我们在获取到锁后,再次获取锁看看是否正常,注意可重入锁表示锁中锁,锁的对象一定要是一致的,也就是这里的锁的 ID 要是一致的:
@RestController
public class LockService {@ResourceLockService lockService;@ResourceLockMapper lockMapper;private final Long LOCK_ID = 1L;private volatile int count = 0;@GetMapping("/test")public void test() {for (int i = 0; i < 10; i++) {new Thread(() -> {lockService.testLock();}).start();}}@Transactional(rollbackFor = Exception.class)public void testLock() {try {//获取锁,如果获取不到则阻塞if (Objects.nonNull(lockMapper.tryLock(LOCK_ID))){// 重入锁if (Objects.nonNull(lockMapper.tryLock(LOCK_ID))){count++;System.out.print(count + " , ");}}} catch (CannotAcquireLockException e) {System.out.println("获取锁超时!");}}
}
运行后,查看日志:
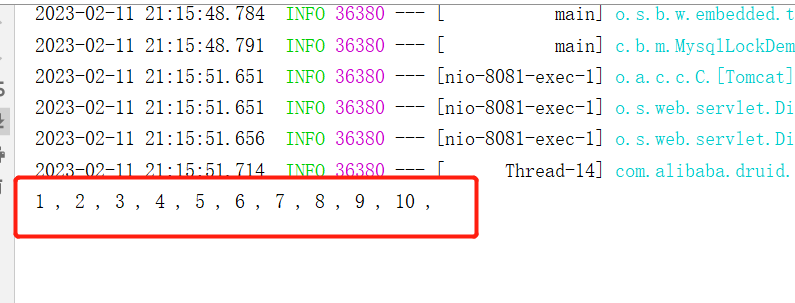
可以看到可重入锁场景下也是可以正常获取到锁。
三、总结
本文基于 MySQL 实现的一种分布式可重入锁的效果,由于锁是使用的 MySQL 的排他锁,因此在多个 JVM 中也是可以实现锁的效果。这里主要讲解了实现思路,对于模块的封装没有做过多的设计,如果有想法的小伙伴也可以发动想法封装一下。另外由于是使用了 MySQL 如果是大量并发的情况下,可能会对 MySQL 造成一些压力。另外可能由于某些原因造成一端持有锁的时间过长,其余等待锁发生超时现象,超时情况这里未做处理,后续可以根据实际情况进行重试或错误处理。
相关文章:
基于 MySQL 排它锁实现分布式可重入锁解决方案
一、MySQL 排它锁和共享锁 在进行实验前,先来了解下MySQL 的排它锁和共享锁,在 MySQL 中的锁分为表锁和行锁,在行锁中锁又分成了排它锁和共享锁两种类型。 1. 排它锁 排他锁又称为写锁,简称X锁,是一种悲观锁&#x…...

【大数据】Hadoop-HA-Federation-3.3.1集群高可用联邦安装部署文档(建议收藏哦)
背景概述 单 NameNode 的架构使得 HDFS 在集群扩展性和性能上都有潜在的问题,当集群大到一定程度后,NameNode 进程使用的内存可能会达到上百 G,NameNode 成为了性能的瓶颈。因而提出了 namenode 水平扩展方案-- Federation。 Federation 中…...

【设计模式之美 设计原则与思想:面向对象】14 | 实战二(下):如何利用面向对象设计和编程开发接口鉴权功能?
在上一节课中,针对接口鉴权功能的开发,我们讲了如何进行面向对象分析(OOA),也就是需求分析。实际上,需求定义清楚之后,这个问题就已经解决了一大半,这也是为什么我花了那么多篇幅来讲…...

工作技术小结
2023/1/31 关于后端接口编写小结 1,了解小程序原型图流程和细节性的东西 2,数据库关联结构仔细分析,找到最容易查询的关键字段,标语表之间靠什么关联 2023/2/10 在web抓包过程中,如果要实现批量抓取,必须解…...
无重复字符的最长子串-力扣3-java
一、题目描述给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。示例 1:输入: s "abcabcbb"输出: 3 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。示例 2:输入: s "bbbbb"输出: 1解释: 因为…...
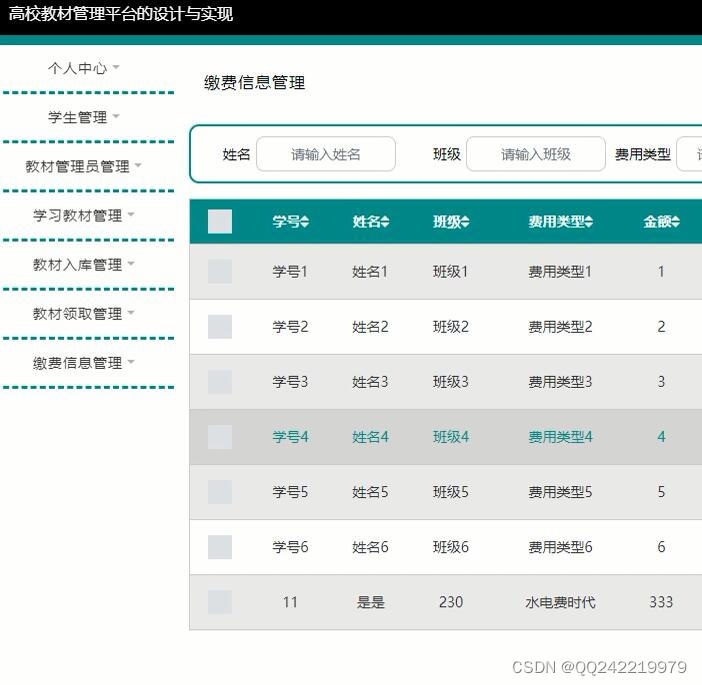
java ssm高校教材管理平台 idea maven
设计并且实现一个基于JSP技术的高校教材管理平台的设计与实现。采用MYSQL为数据库开发平台,SSM框架,Tomcat网络信息服务作为应用服务器。高校教材管理平台的设计与实现的功能已基本实现,主要学生、教材管理、学习教材、教材入库、教材领取、缴…...
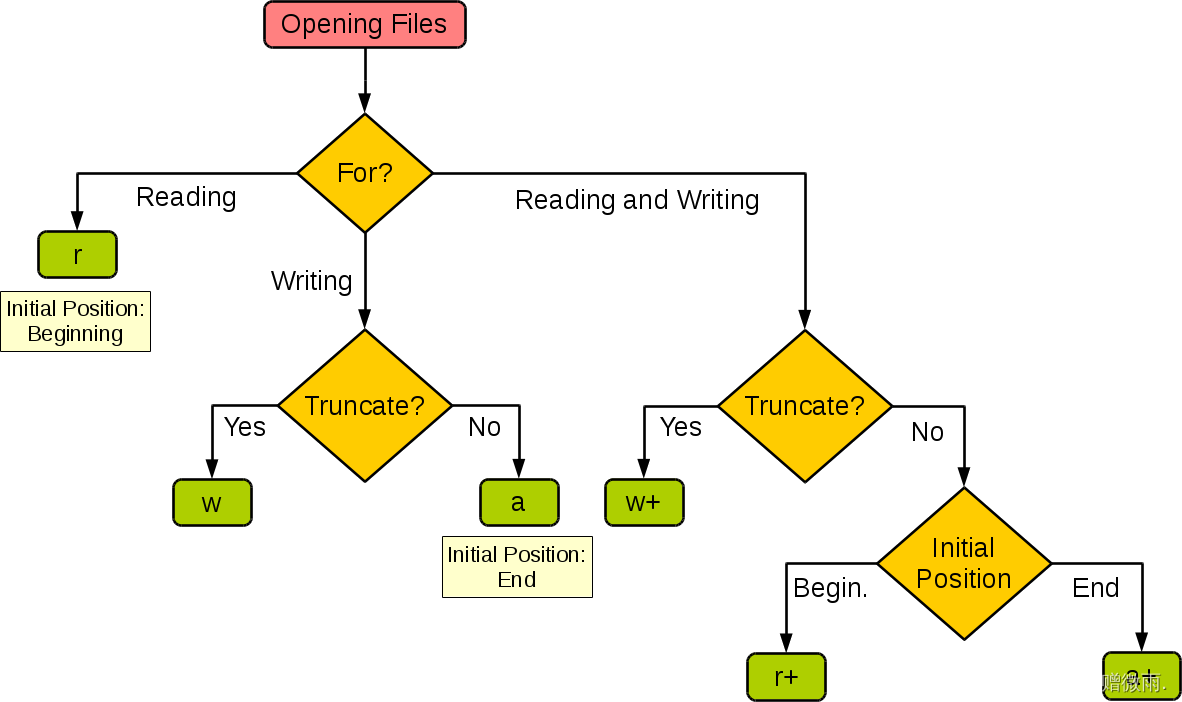
【Python学习笔记】25.Python3 输入和输出(1)
前言 在前面几个章节中,我们其实已经接触了 Python 的输入输出的功能。本章节我们将具体介绍 Python 的输入输出。 输出格式美化 Python两种输出值的方式: 表达式语句和 print() 函数。 第三种方式是使用文件对象的 write() 方法,标准输出文件可以用…...
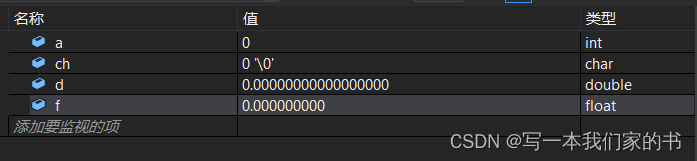
C++复习笔记8
泛型编程:编写的是与类型无关的通用代码,是代码复用的一种手段,模板是泛型编程的基础。 1.函数模板:类型参数化,增加代码复用性。例如对于swap函数,不同类型之间进行交换都需要进行重载,但是函数…...

RabbitMQ入门
目录1. 搭建示例工程1.1. 创建工程1.2. 添加依赖2. 编写生产者3. 编写消费者4. 小结需求 官网: https://www.rabbitmq.com/ 需求:使用简单模式完成消息传递 步骤: ① 创建工程(生成者、消费者) ② 分别添加依赖 ③ 编…...
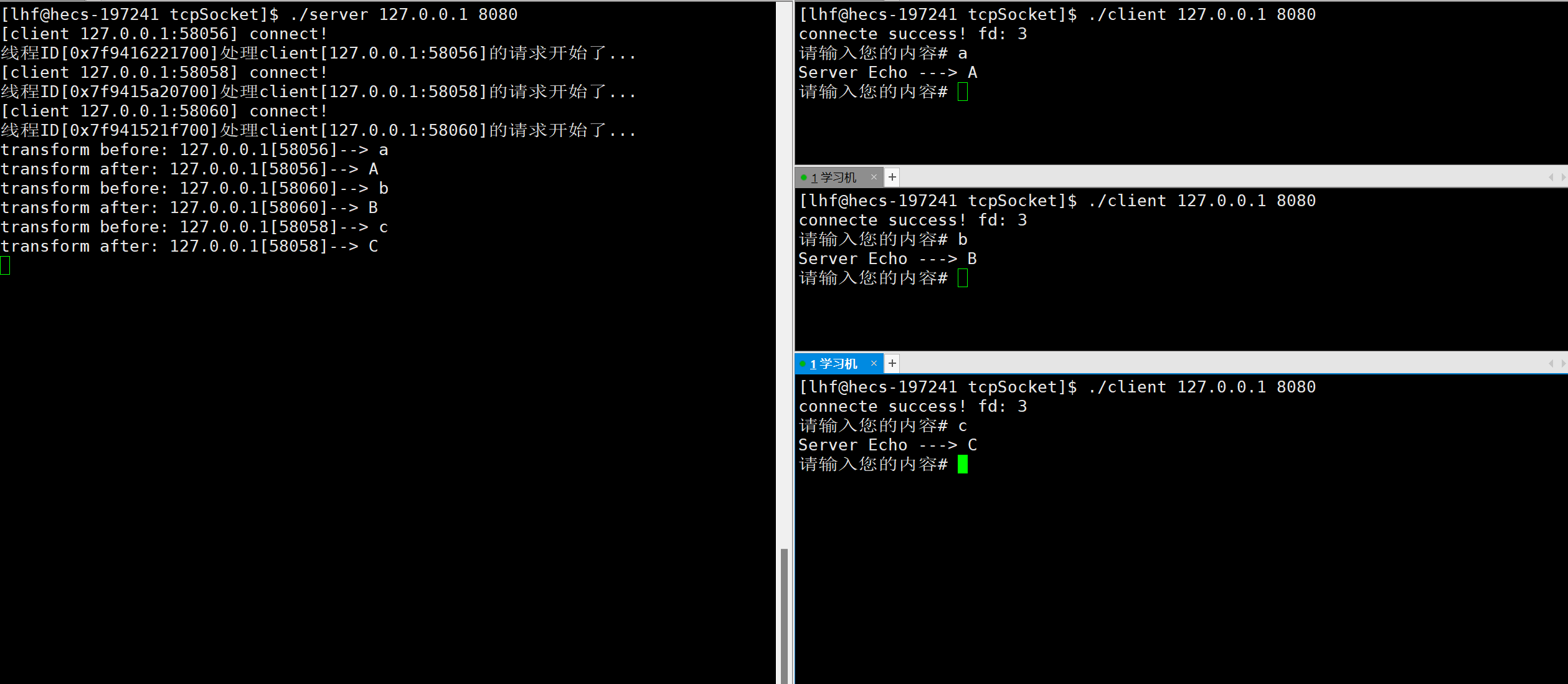
【计算机网络】Linux环境中的TCP网络编程
文章目录前言一、TCP Socket API1. socket2. bind3. listen4. accept5. connect二、封装TCPSocket三、服务端的实现1. 封装TCP通用服务器2. 封装任务对象3. 实现转换功能的服务器四、客户端的实现1. 封装TCP通用客户端2. 实现转换功能的客户端五、结果演示六、多进程版服务器七…...
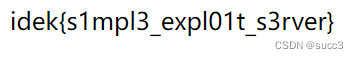
idekCTF 2022 比赛复现
Readme 首先 []byte 是 go 语言里面的一个索引,比如: package mainimport "fmt"func main() {var str string "hello"var randomData []byte []byte(str)fmt.Println(randomData[0:]) //[104 101 108 108 111] }上面这串代码会从…...

jvm的类加载过程
加载 通过一个类的全限定名获取定义此类的二进制字节流将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口链接 验证 验证内容的合法性准备 把方法区的静态变量初…...
VOC数据增强与调整大小
数据增强是针对数据集图像数量太少所采取的一种方法。 博主在实验过程中,使用自己的数据集时发现其数据量过少,只有280张,因此便想到使用数据增强的方式来获取更多的图像信息。对于图像数据,我们可以采用旋转等操作来获取更多的图…...

Linux 安装jenkins和jdk11
Linux 安装jenkins和jdk111. Install Jdk112. Jenkins Install2.1 Install Jenkins2.2 Start2.3 Error3.Awakening1.1 Big Data -- Postgres4. Awakening1. Install Jdk11 安装jdk11 sudo yum install fontconfig java-11-openjdk 2. Jenkins Install 2.1 Install Jenkins 下…...
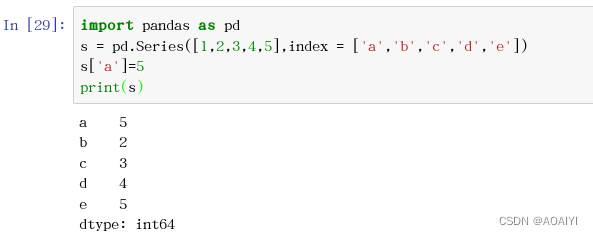
Pandas——Series操作【建议收藏】
pandas——Series操作 作者:AOAIYI 创作不易,觉得文章不错或能帮助到你学习,可以点赞收藏评论哦 文章目录pandas——Series操作一、实验目的二、实验原理三、实验环境四、实验内容五、实验步骤1.创建Series2.从具体位置的Series中访问数据3.使…...
JUC并发编程Ⅰ -- Java中的线程
文章目录线程与进程并行与并发进程与线程应用应用之异步调用应用之提高效率线程的创建方法一:通过继承Thread类创建方法二:使用Runnable配合Thread方法三:使用FutureTask与Thread结合创建查看进程和线程的方法线程运行的原理栈与栈帧线程上下…...
基于vue-admin-element开发后台管理系统【技术点整理】
一、Vue点击跳转外部链接 点击重新打开一个页面窗口,不覆盖当前的页面 window.open(https://www.baidu.com,"_blank")"_blank" 新打开一个窗口"_self" 覆盖当前的窗口例如:导入用户模板下载 templateDownload() {wi…...
【C语言学习笔记】:通讯录管理系统
系统中需要实现的功能如下: ✿ 添加联系人:向通讯录中添加新人,信息包括(姓名、性别、年龄、联系电话、家庭住址)最多记录1000人 ✿ 显示联系人:显示通讯录中所有的联系人信息 ✿ 删除联系人:按…...
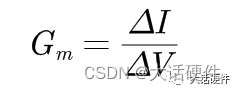
开关电源环路稳定性分析(10)——OPA和OTA型补偿器传递函数
大家好,这里是大话硬件。 在前面9讲的内容中将开关电源环路分析进行了梳理,我相信很多人即使都看完了,应该还是不会设计,而且还存在几个疑问。比如我随便举几个: 开关电源的带宽怎么设定?开关电源精度和什…...
)
2.11知识点整理(关于pycharm,python,pytorch,conda)
pycharm 设置anaconda环境: File -> Settings->选择左侧的project xxx再选择打开Project Interpreter页->选择add添加解释器->添加Anaconda中Python解释器(Anaconda安装目录下的python.exe) (选择existing environment ÿ…...

3个步骤让AMD显卡也能运行CUDA程序:ZLUDA终极指南
3个步骤让AMD显卡也能运行CUDA程序:ZLUDA终极指南 【免费下载链接】ZLUDA CUDA on non-NVIDIA GPUs 项目地址: https://gitcode.com/GitHub_Trending/zl/ZLUDA 你是否曾经因为手头只有AMD显卡,却想运行那些需要CUDA加速的深度学习框架而感到无奈&…...
Windows 11任务栏透明化神器:TranslucentTB让你的桌面焕然一新!
Windows 11任务栏透明化神器:TranslucentTB让你的桌面焕然一新! 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 你…...

2026届学术党必备的AI写作网站实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 作为学术研究启动时核心的前置材料的开题报告,要完成文献梳理,要搭建…...

Axure RP 多版本中文语言包技术解析:从键值对到专业本地化的架构演进
Axure RP 多版本中文语言包技术解析:从键值对到专业本地化的架构演进 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn …...

在Serv00共享主机上部署SOCKS5代理:原理、部署与优化指南
1. 项目概述与核心价值最近在折腾一些需要稳定网络连接的自托管服务时,遇到了一个经典难题:如何在资源受限的共享主机环境里,搭建一个轻量、稳定且可控的网络代理通道。这让我想起了之前在社区里看到的一个项目——cmliu/socks5-for-serv00。…...

观察Taotoken在多模型并发调用时的延迟表现与稳定性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型并发调用时的延迟表现与稳定性 在构建复杂的AI应用时,开发者常常需要同时或交替调用多个不同的大…...

从零构建趣味AI应用:技术架构、核心实现与部署实战
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫miaoquai,作者是jingchang0623。光看这个名字,可能有点摸不着头脑,但点进去一看,发现这是一个关于“喵趣AI”的开源项目。作为一个在AI应用和开源社区混…...
:企业级生产环境已验证)
DeepSeek R1模型API接入全流程(含鉴权失效应急手册):企业级生产环境已验证
更多请点击: https://intelliparadigm.com 第一章:DeepSeek R1模型API接入全流程(含鉴权失效应急手册):企业级生产环境已验证 DeepSeek R1 是当前高性能开源大语言模型之一,其官方 API 提供稳定、低延迟的…...

终极指南:如何通过AKShare金融数据接口库快速获取全球交易所数据
终极指南:如何通过AKShare金融数据接口库快速获取全球交易所数据 【免费下载链接】akshare AKShare is an elegant and simple financial data interface library for Python, built for human beings! 开源财经数据接口库 项目地址: https://gitcode.com/gh_mirr…...

芯片行业变革:开源硬件、可重构芯片与商业模式创新
1. 行业拐点:传统芯片商业模式为何难以为继?干了十几年芯片设计,从流片工程师到项目负责人,我亲眼见证了行业从“黄金时代”到如今“卷成本、卷工艺”的艰难转型。最近和几个老同事聊天,大家不约而同地提到一个词&…...