Linux内核启动(理论,0.11版本)分段与分页
为什么要虚拟内存
我们知道,在之前上微机原理时,我们的程序是可以直接访问内存的,而且访问的是直接的物理内存,在实模式下,寄存器是16位的,数组总线(data bus)是16位的,但地址总线是20位的,这带来了一个问题,需要两个寄存器去访问一个数据,为什么地址中心不是16位呢,那样不就好了,不是不想,是不够用啊,16位的地址总线才能访问64KB内存。所以用CS:IP两个寄存器去访问内存。
这样做有什么问题呢,碎片。碎片分为内部碎片和外部碎片,内部碎片是指已经被分配但是没有被使用的地址空间,比如你申请了7bit但是内存为了对齐不得不给你分配8bit的空间,这就产生了1bit的碎片,外部碎片是指未分配且未使用的地址空间,申请4字节的Int类型,再申请8字节的long类型,为了内存对齐,其中4字节无法装入8字节类型,这就产生了4字节的外部碎片。
内部碎片是已经被分配的内存,是操作系统不可以利用的空间,但是外部碎片是未被分配的,但是该空间过小,无法装载资源,无法被利用,外部碎片是可以解决的。
为了解决内存的碎片化问题,计算机专家们提出了分段式管理的思想,但是再说分段之前需要说一下早期的虚拟内存模型
早期虚拟内存模型
在经历了纯物理地址后,科学家们期望解决这种内存模型难以统一的问题,于是虚拟内存技术孕育而生,但困扰科学家们的是,如何将虚拟地址转换成物理地址。早期的科学家想到的是将整个程序作为一个整体,并为每个进程分配一个基址寄存器和界限寄存器,基址寄存器存放该虚拟地址在实际物理地址的起点,界限寄存器用来判定程序是否访问非法地址,通过这种方式,实际的地址是很好计算的(实际地址=虚拟地址+基址),这种方式虽然解决了地址翻译问题,但是产生了大量的内部碎片。

从图中可以看出,如果我们将整个地址空间放入物理内存,那么栈和堆之间的空间并没有被进程使用,却依然占用了实际的物理内存。因此,简单的通过基址寄存器和界限寄存器实现的虚拟内存很浪费。
另外,我们必须要确保内存足够放得下进程的虚拟地址空间,但通常主存成本是比较昂贵的,不如磁盘廉价,这种方式通常不支持大的虚拟地址,如果剩余物理内存无法提供连续区域来放置完整的地址空间,进程便无法运行。例如现在32位的进程空间通常是4GB,主存根本就装不下几个进程。
所以我们需要物尽其用,早起的科学家们想到了分段这种思想
分段式管理的思想
分段思想其实就是将基址加界限的概念泛化,在上述例子中,我们为代码、堆、栈分别设置一个段基址加段界限寄存器,这样我们不必要每次都强制装入整个进程空间,每个基址寄存器存放在该段在物理地址的实际空间,界限寄存器用来保护地址空间,对程序未使用的空间我们没必要为其分配,我们仍需要为堆分配较多的内存,除了堆段,其余空间都是在编译期间就确定了的,这样便大大提高了内存的利用率,而且我们发现可以离散的分配内存空间,即物理内存中的地址不必要时连续的,能大大提高对物理地址的利用率。

分段地址的转换
分段式的思想讲完了,但是还有一些问题,地址怎么转换,其实分段地址转换与基址加界限的思想差不多,操作系统通过维护一个段表来维护各段的信息
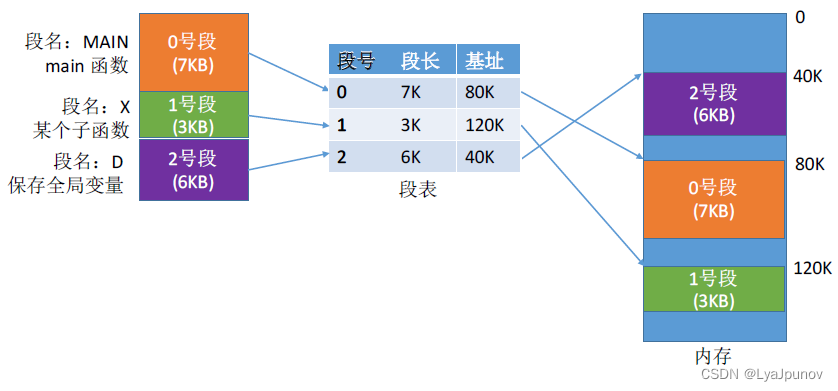
段表的地址是操作系统维护的,段表项主要维护段长和段基址,段基址指该段在物理内存中的起始地址,那么该段中的虚拟地址对于实际地址为 段基址+段内偏移
分段系统的逻辑地址结构是段号(段名) 和 段内地址(段内偏移量)组成的,下图很好的说明了分段是怎么找到实际内存地址的。
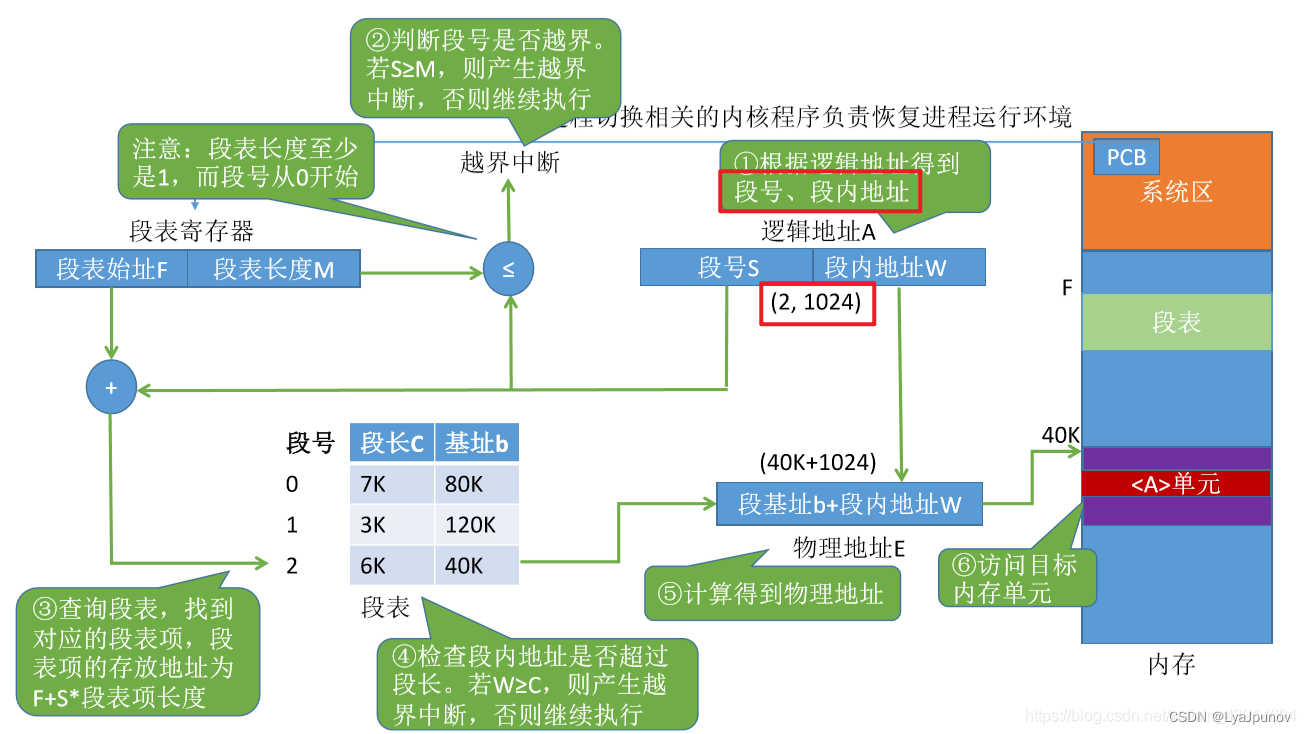
你可能发现了,虚拟地址中每个段的起始地址都是固定的,每个段的总大小也是固定的,其大小为 2p2^p2p 字节 其中 ppp 为段内地址的位数。此外,栈是反向增长的,因此段表中必须维护一个比特位,描述是否为栈段。
分段的优点
**1、**生成了虚拟内存,避免了程序直接访问物理内存
**2、**很大程度上避免了内存浪费
**3、**可以很好的支持共享
随着分段机制的不断改进,系统设计人员很快意识到,通过再多一点的硬件支持,就能实现新的效率提升。具体来说,要节省内存,有时候在地址空间之间共享(share)某些内存段是有用的。尤其是,代码共享很常见,今天的系统仍然在使用。
为了支持共享,需要一些额外的硬件支持,这就是保护位(protection bit)。基本为每个段增加了几个位,标识程序是否能够读写该段,或执行其中的代码。通过将代码段标记为只读,同样的代码可以被多个进程共享,而不用担心破坏隔离。
**4、**虚拟地址翻译太慢
我们每次翻译一个虚拟地址都需要去找寻段表中的段表项,相当于多一次地址访问,这太慢了!解决方案是为计算机设置一个小型的硬件设备,将虚拟地址直接映射到物理地址,而不必再访问段表。这种设备称为转换检测缓冲区 (Translation Lookaside Buffer,TLB),有时又称为快表。快表是一个小的高速缓存,现代操作系统无论是分段还是分页中都利用了这种软件技术。
分段的缺点
**1、**太多的外部碎片
例如4kb的空间装入3kb的段,产生的1kb的空间无法在装入任何段,产生碎片的主要原因是因为分段使用的大小是不确定的。外部碎片可通过紧凑的方式以合成较大的空闲空间,但这需要大量成本,操作系统难以维护。由于这个原因分页思想诞生
分页式管理的思想
分段式管理一段时间后主存上会遍布着大大小小的外部碎片,操作系统难以维护,分页的思想就是将空间划分成较小的,固定长度的分片,这就是分页式管理,分页式管理将程序资源划分为固定大小的页,将每一个虚拟页映射到物理页之中,由于每个页是固定大小的,操作系统可以整齐的分配物理内存空间,避免产生了外部碎片,例如一个页大小是4kb,而主存是40kb,操作系统稍加管理便能确保无论何时都能整齐的装入10个页面。
页在物理内存中也不是连续存在的,进程未使用的页也没有必要为其分配内存,通过这种方式我们就解决了由分段产生的大量外部碎片问题,同时由于页比较小,只有在已使用的页才会产生较少的内部碎片,这是可以接受的,目前来看,分页是一种很好的办法。

分页地址的转换
分页地址的转换与分段地址转换一致,为页基址+页内偏移,页表是操作系统维护的,操作系统知道页表的起始位置,页表项大小是固定的,在32位地址空间中通常是8字节,这64bit中不仅存储了页基址,还存放着一些其他重要的数据。
假设我们有一个线性地址,已经经过了分段机制的转换,其地址为二进制表示0000000011_0100000000_000000000000,那他的转换过程就如下图所示

高 10 位负责在页目录表中找到一个页目录项,这个页目录项的值加上中间 10 位拼接后的地址去页表中去寻找一个页表项,这个页表项的值,再加上后 12 位偏移地址,就是最终的物理地址。
现在我们是不是出现了很多关于地址的名词,逻辑地址,线性地址,物理地址,虚拟地址,这我们就不得不讲讲Intel管理内存的两板斧了,分段与分页,对就是上面说的,进入保护模式后,分段就必须打开了,分页不是必须的,
分段机制的目的是为每个程序或者任务提供单独的代码段数据段和栈段,使其不会相互干扰。
分页机制的目的使程序可以按需取用内存,也可以在多任务的时候起到隔离内存空间的作用
逻辑地址:我们程序员写代码时给出的地址叫逻辑地址,其中包含段选择子和偏移地址两部分。
线性地址:通过分段机制,将逻辑地址转换后的地址,叫做线性地址。而这个线性地址是有个范围的,这个范围就叫做线性地址空间,32 位模式下,线性地址空间就是 4G。
物理地址:就是真正在内存中的地址,它也是有范围的,叫做物理地址空间。那这个范围的大小,就取决于你的内存有多大了。
虚拟地址:如果没有开启分页机制,那么线性地址就和物理地址是一一对应的,可以理解为相等。如果开启了分页机制,那么线性地址将被视为虚拟地址,这个虚拟地址将会通过分页机制的转换,最终转换成物理地址。
相关文章:
Linux内核启动(理论,0.11版本)分段与分页
为什么要虚拟内存 我们知道,在之前上微机原理时,我们的程序是可以直接访问内存的,而且访问的是直接的物理内存,在实模式下,寄存器是16位的,数组总线(data bus)是16位的,…...

数据与C(字符串)
目录 一.概念引入 二.字符串(数组存储,必须以\0结尾) 三.错误示范 四.strlen()和sizeof()相对于字符串的不同 一.概念引入 “a”,a哪个是字符哪个又是字符串,嘿嘿不用猜了 我们在上一章中说过&#x…...

Python+Go实践(电商架构三)
文章目录服务发现集成consul负载均衡负载均衡算法实现配置中心nacos服务发现 我们之前的架构是通过ipport来调用的python的API,这样做的弊端是 如果新加一个服务,就要到某个服务改web(go)层的调用代码,配置IP/Port并发…...
基于 MySQL 排它锁实现分布式可重入锁解决方案
一、MySQL 排它锁和共享锁 在进行实验前,先来了解下MySQL 的排它锁和共享锁,在 MySQL 中的锁分为表锁和行锁,在行锁中锁又分成了排它锁和共享锁两种类型。 1. 排它锁 排他锁又称为写锁,简称X锁,是一种悲观锁&#x…...

【大数据】Hadoop-HA-Federation-3.3.1集群高可用联邦安装部署文档(建议收藏哦)
背景概述 单 NameNode 的架构使得 HDFS 在集群扩展性和性能上都有潜在的问题,当集群大到一定程度后,NameNode 进程使用的内存可能会达到上百 G,NameNode 成为了性能的瓶颈。因而提出了 namenode 水平扩展方案-- Federation。 Federation 中…...

【设计模式之美 设计原则与思想:面向对象】14 | 实战二(下):如何利用面向对象设计和编程开发接口鉴权功能?
在上一节课中,针对接口鉴权功能的开发,我们讲了如何进行面向对象分析(OOA),也就是需求分析。实际上,需求定义清楚之后,这个问题就已经解决了一大半,这也是为什么我花了那么多篇幅来讲…...

工作技术小结
2023/1/31 关于后端接口编写小结 1,了解小程序原型图流程和细节性的东西 2,数据库关联结构仔细分析,找到最容易查询的关键字段,标语表之间靠什么关联 2023/2/10 在web抓包过程中,如果要实现批量抓取,必须解…...
无重复字符的最长子串-力扣3-java
一、题目描述给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。示例 1:输入: s "abcabcbb"输出: 3 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。示例 2:输入: s "bbbbb"输出: 1解释: 因为…...
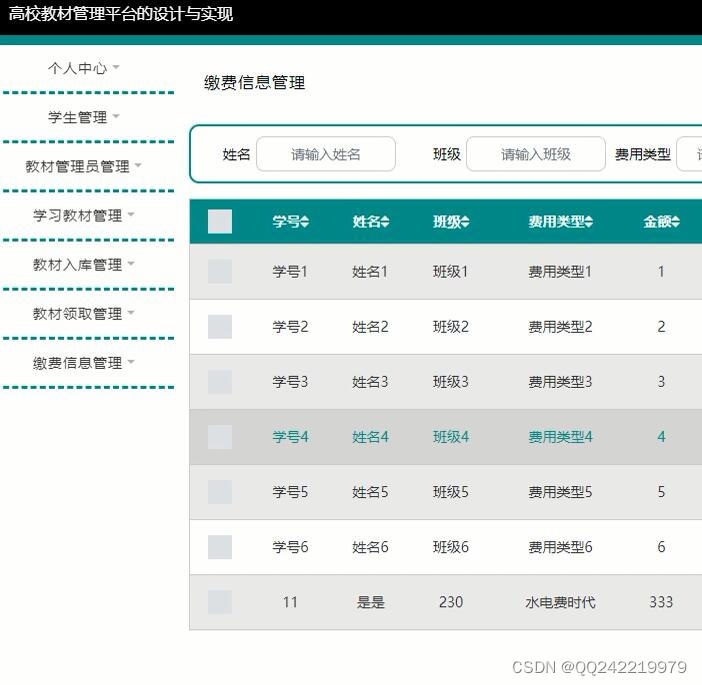
java ssm高校教材管理平台 idea maven
设计并且实现一个基于JSP技术的高校教材管理平台的设计与实现。采用MYSQL为数据库开发平台,SSM框架,Tomcat网络信息服务作为应用服务器。高校教材管理平台的设计与实现的功能已基本实现,主要学生、教材管理、学习教材、教材入库、教材领取、缴…...
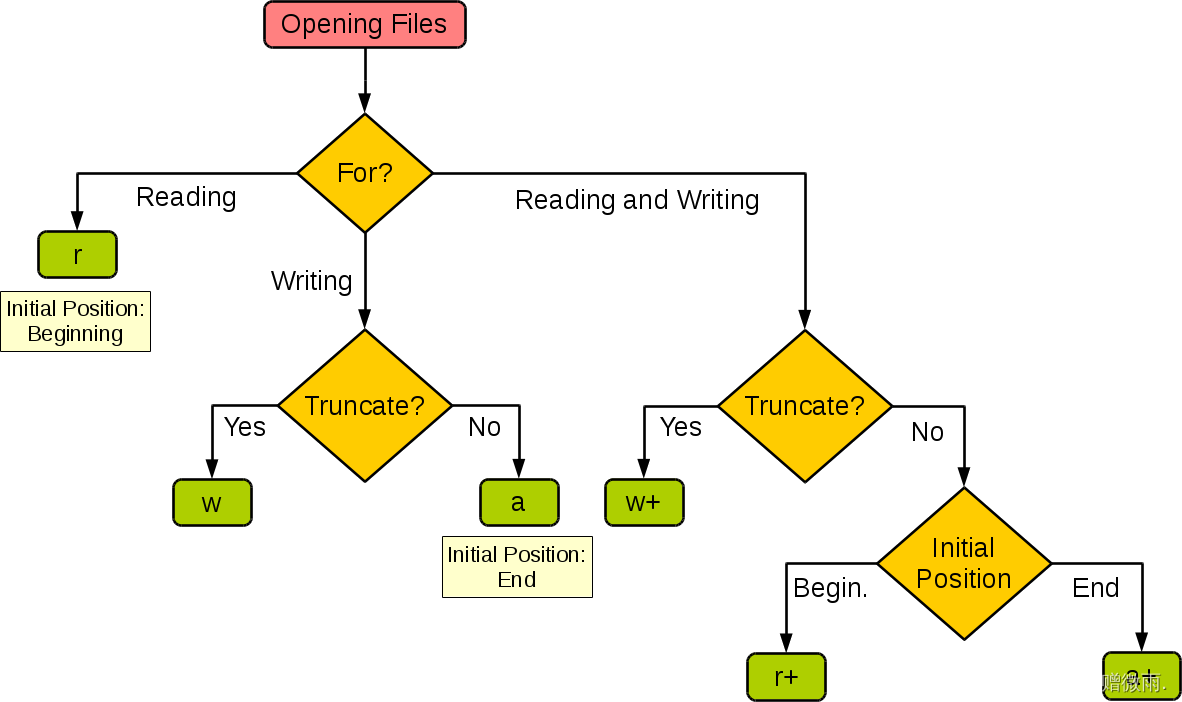
【Python学习笔记】25.Python3 输入和输出(1)
前言 在前面几个章节中,我们其实已经接触了 Python 的输入输出的功能。本章节我们将具体介绍 Python 的输入输出。 输出格式美化 Python两种输出值的方式: 表达式语句和 print() 函数。 第三种方式是使用文件对象的 write() 方法,标准输出文件可以用…...
C++复习笔记8
泛型编程:编写的是与类型无关的通用代码,是代码复用的一种手段,模板是泛型编程的基础。 1.函数模板:类型参数化,增加代码复用性。例如对于swap函数,不同类型之间进行交换都需要进行重载,但是函数…...

RabbitMQ入门
目录1. 搭建示例工程1.1. 创建工程1.2. 添加依赖2. 编写生产者3. 编写消费者4. 小结需求 官网: https://www.rabbitmq.com/ 需求:使用简单模式完成消息传递 步骤: ① 创建工程(生成者、消费者) ② 分别添加依赖 ③ 编…...
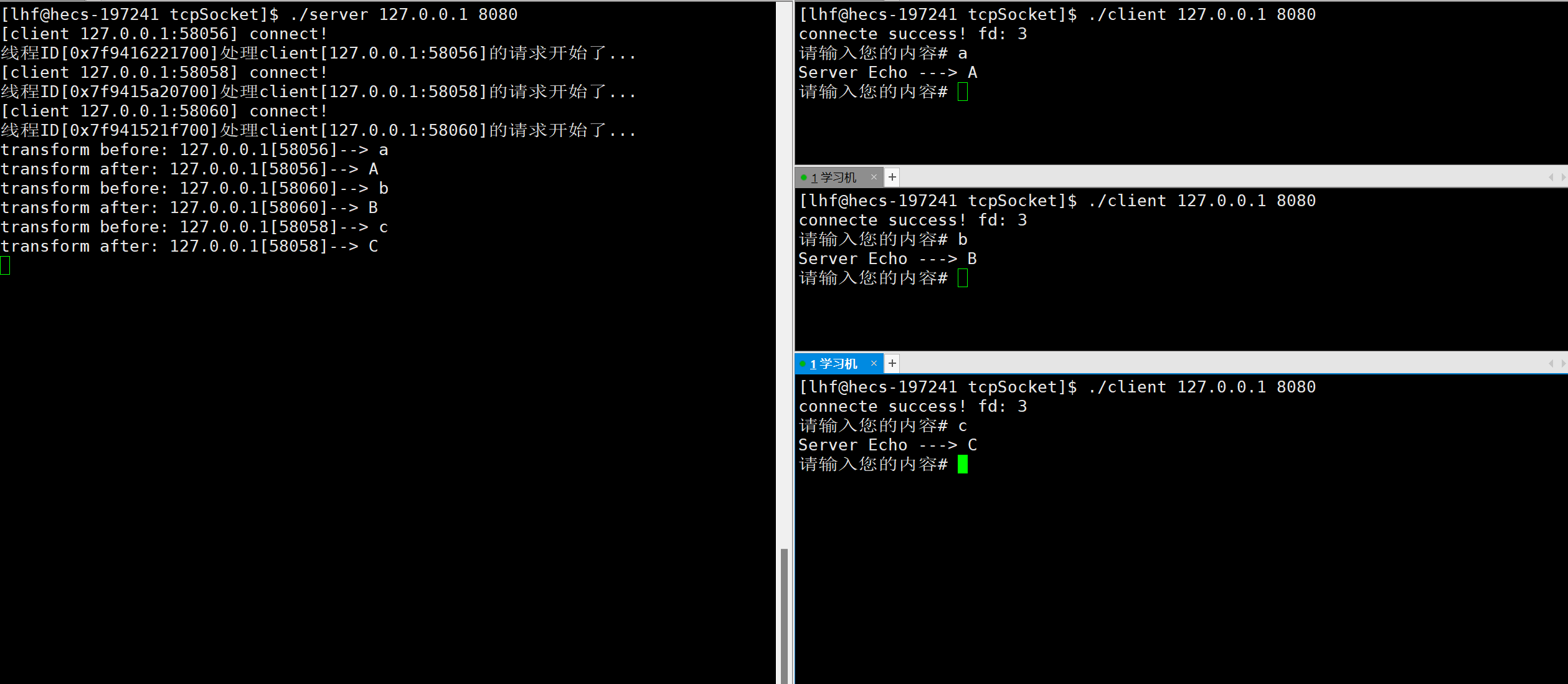
【计算机网络】Linux环境中的TCP网络编程
文章目录前言一、TCP Socket API1. socket2. bind3. listen4. accept5. connect二、封装TCPSocket三、服务端的实现1. 封装TCP通用服务器2. 封装任务对象3. 实现转换功能的服务器四、客户端的实现1. 封装TCP通用客户端2. 实现转换功能的客户端五、结果演示六、多进程版服务器七…...
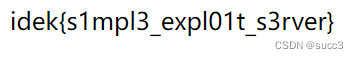
idekCTF 2022 比赛复现
Readme 首先 []byte 是 go 语言里面的一个索引,比如: package mainimport "fmt"func main() {var str string "hello"var randomData []byte []byte(str)fmt.Println(randomData[0:]) //[104 101 108 108 111] }上面这串代码会从…...

jvm的类加载过程
加载 通过一个类的全限定名获取定义此类的二进制字节流将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口链接 验证 验证内容的合法性准备 把方法区的静态变量初…...
VOC数据增强与调整大小
数据增强是针对数据集图像数量太少所采取的一种方法。 博主在实验过程中,使用自己的数据集时发现其数据量过少,只有280张,因此便想到使用数据增强的方式来获取更多的图像信息。对于图像数据,我们可以采用旋转等操作来获取更多的图…...

Linux 安装jenkins和jdk11
Linux 安装jenkins和jdk111. Install Jdk112. Jenkins Install2.1 Install Jenkins2.2 Start2.3 Error3.Awakening1.1 Big Data -- Postgres4. Awakening1. Install Jdk11 安装jdk11 sudo yum install fontconfig java-11-openjdk 2. Jenkins Install 2.1 Install Jenkins 下…...
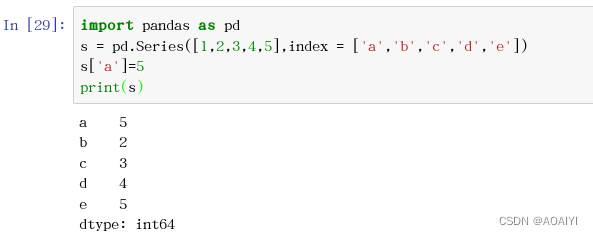
Pandas——Series操作【建议收藏】
pandas——Series操作 作者:AOAIYI 创作不易,觉得文章不错或能帮助到你学习,可以点赞收藏评论哦 文章目录pandas——Series操作一、实验目的二、实验原理三、实验环境四、实验内容五、实验步骤1.创建Series2.从具体位置的Series中访问数据3.使…...
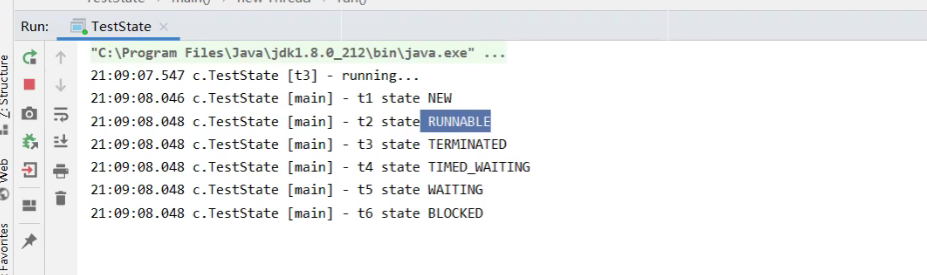
JUC并发编程Ⅰ -- Java中的线程
文章目录线程与进程并行与并发进程与线程应用应用之异步调用应用之提高效率线程的创建方法一:通过继承Thread类创建方法二:使用Runnable配合Thread方法三:使用FutureTask与Thread结合创建查看进程和线程的方法线程运行的原理栈与栈帧线程上下…...
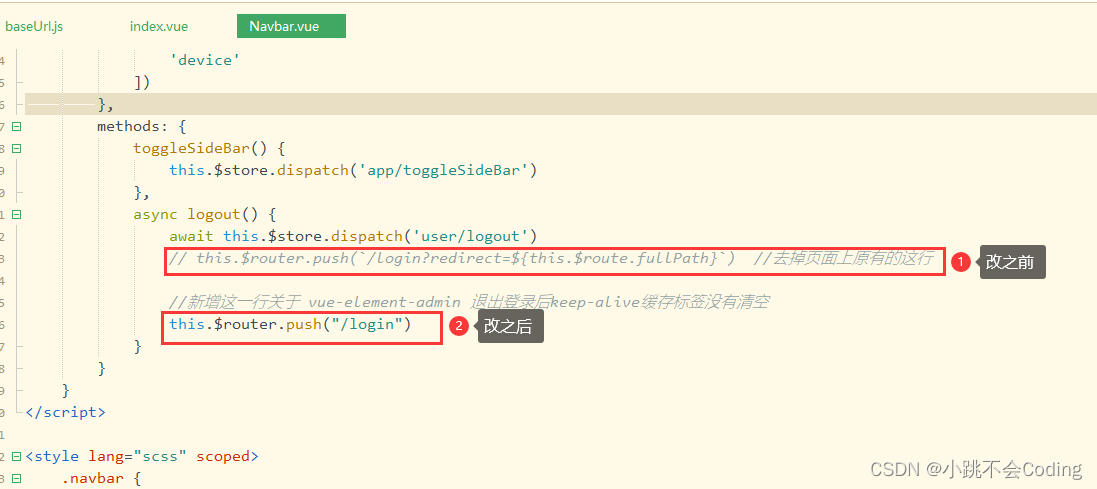
基于vue-admin-element开发后台管理系统【技术点整理】
一、Vue点击跳转外部链接 点击重新打开一个页面窗口,不覆盖当前的页面 window.open(https://www.baidu.com,"_blank")"_blank" 新打开一个窗口"_self" 覆盖当前的窗口例如:导入用户模板下载 templateDownload() {wi…...
)
别再纠结了!手把手教你根据项目需求选对Intel Realsense型号(D455/D435i/D415/T265实战对比)
深度视觉硬件选型指南:Intel RealSense全系型号实战解析 在计算机视觉和机器人领域,选择合适的3D感知硬件往往决定了项目成败。面对Intel RealSense系列中D455、D435i、D415和T265等不同型号,许多开发者常陷入"参数对比陷阱"——过…...
)
手把手教你:在无外网环境下搞定VSCode插件离线安装(附下载地址拼接技巧)
企业内网开发环境高效配置指南:VSCode插件离线部署实战 在高度安全管控的企业研发环境中,外网隔离是常见的安全策略。当新入职的工程师第一次打开内网电脑上的VSCode时,面对空空如也的插件市场,那种无从下手的焦虑感我深有体会。三…...
)
从劝退到离不开:Vim新手入门实战博客(附高效技巧)
文章目录前言💙一、vim是什么?💜二、为什么要学习vim?💚三、vim总览💔四、vim的基本操作4.1vim正常模式命令集(命令模式)4.2vim底行模式命令集4.3vim视图模式💗五、一些小技巧💖六、…...

openOii:开源工业信息集成框架架构解析与实战指南
1. 项目概述与核心价值最近在开源社区里,一个名为openOii的项目引起了我的注意。这个由开发者 Xeron2000 发起的项目,从名字上就透着一股“开放”和“工业”的气息。作为一个在工业自动化和数据集成领域摸爬滚打了十多年的老兵,我深知在制造业…...

大疆智图+B3DM切片+Cesium:5分钟搞定倾斜摄影三维模型在线发布
大疆智图B3DM切片Cesium:零代码实现倾斜摄影三维模型Web发布全指南 当无人机航拍的倾斜摄影数据需要快速在Web端展示时,技术栈的衔接往往成为最大障碍。本文将手把手带您实现从大疆智图生成B3DM切片到Cesium可视化呈现的完整流程,全程无需编写…...

2026最权威的AI辅助写作方案推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在当下的学术环境里头,知网的AI内容识别机制已然全面实现落地,针对由…...
Windows 11任务栏透明化完整教程:TranslucentTB让你的桌面焕然一新
Windows 11任务栏透明化完整教程:TranslucentTB让你的桌面焕然一新 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 想让Windo…...

Axure RP中文语言包技术深度解析:从键值对到国际化架构的工程实践
Axure RP中文语言包技术深度解析:从键值对到国际化架构的工程实践 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn 在…...

Firefly:一站式大模型训练工具,从零到一掌握LLM微调
1. 项目概述:一站式大模型训练工具Firefly 如果你正在寻找一个能够让你快速上手,从零开始训练或微调主流大语言模型(LLM)的开源项目,那么Firefly(流萤)绝对值得你花时间深入了解。作为一名在AI…...

adloop:可编程规则引擎驱动的浏览器网络请求深度拦截与定制
1. 项目概述:一个被低估的广告拦截与隐私增强工具如果你和我一样,是个对网页上无处不在的弹窗广告、自动播放视频和恼人的跟踪脚本感到深恶痛绝的互联网用户,那你一定尝试过各种广告拦截器。从大名鼎鼎的AdBlock Plus、uBlock Origin…...