无/自监督去噪(1)——一个变迁:N2N→N2V→HQ-SSL
目录
- 1. 前沿
- 2. N2N
- 3. N2V——盲点网络(BSNs,Blind Spot Networks)开创者
- 3.1. N2V实际是如何训练的?
- 4. HQ-SSL——认为N2V效率不够高
- 4.1. HQ-SSL的理论架构
- 4.1.1. 对卷积的改进
- 4.1.2. 对下采样的改进
- 4.1.3. 比N2V好在哪?
- 4.2. HQ-SSL的实际实现
- 补:HQ-SSL的训练和测试须知
知乎同名账号同步发表
1. 前沿
N2N,即Noise2Noise: Learning Image Restoration without Clean Data,2018 ICML的文章。
N2V,即Noise2Void - Learning Denoising from Single Noisy Images,2019 CVPR的文章。
这两个工作都是无监督去噪的重要开山之作,本文先对其进行简单总结,然后引出一个变体:HQ-SSL(2019 NIPS)。
本系列会对近一两年的顶会顶刊无监督图像恢复(主要是去噪)工作、时间有点久远但是非常经典的无监督图像恢复工作进行学习总结。欢迎大家评论交流、关注、批评。
2. N2N
相信大家对这句话不算陌生:同一场景下的两次含噪声的观测(noisy observation)。
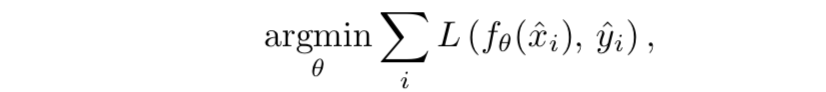
上图就是该方法的训练策略, x i x_i xi和 y i y_i yi分别表示同一个场景下的两次相互独立的含噪声的观测。 f θ ( ⋅ ) f_\theta(·) fθ(⋅)表示网络。
为什么这样训练就能让 f θ ( ⋅ ) f_\theta(·) fθ(⋅)学会去噪呢?这是因为有如下假设:
- 第一,噪声零均值假设;
- 第二, x i x_i xi和 y i y_i yi是同一场景下的两次观测;
- 第三,不同次的含噪声的观测之间,噪声相互独立。
为了简便起见,我们将一张noisy image表示为如下形式:
i m a g e = s i g n a l + n o i s e image=signal+noise image=signal+noise
即含噪声的图片是由信号和噪声想加而成(这样不严谨,因为噪声未必是加性噪声,但是此处为了方便,我们可以这样阐述)。我们可以将 x i x_i xi和 y i y_i yi分别用上述形式表示如下:
x i = s i + x n i , y i = s i + y n i x_i=s_i+xn_i,y_i=s_i+yn_i xi=si+xni,yi=si+yni
我们将 x i x_i xi和 y i y_i yi两张图片都表示为信号+噪声的形式,再用前文的损失函数,即网络尝试学会将 x i x_i xi映射为 y i y_i yi。由于噪声相互独立这一假设, x n i xn_i xni和 y n i yn_i yni毫无关联,但由于这是同一场景下的两次观测,所以两者中信号的部分都用 s i s_i si表示。
网络尝试学会将 x i x_i xi映射为 y i y_i yi,就是将 s i + x n i s_i+xn_i si+xni映射为 s i + y n i s_i+yn_i si+yni:
f θ ( x i ) = f θ ( s i + x n i ) → s i + y n i f_\theta(x_i)=f_\theta(s_i+xn_i)→s_i+yn_i fθ(xi)=fθ(si+xni)→si+yni
由于 x n i xn_i xni和 y n i yn_i yni毫无关联,将 x n i xn_i xni映射为 y n i yn_i yni是不可能的。此时用数学语言表述,网络的输出可以表示为如下形式:
f θ ( x i ) = f θ ( s i + x n i ) → s i + 随机噪声 f_\theta(x_i)=f_\theta(s_i+xn_i)→s_i+随机噪声 fθ(xi)=fθ(si+xni)→si+随机噪声
网络并没有办法建立xn_i和yn_i的联系,这种 随机 → 随机 随机→随机 随机→随机的映射,最终会演变为 随机 → E ( 随机 ) 随机→E(随机) 随机→E(随机)的映射。由于噪声零均值这一假设,上式可以进一步写为:
f θ ( x i ) = f θ ( s i + x n i ) → E ( s i + 随机噪声 ) = s i + E ( 随机噪声 ) = s i f_\theta(x_i)=f_\theta(s_i+xn_i)→E(s_i+随机噪声)=s_i+E(随机噪声)=s_i fθ(xi)=fθ(si+xni)→E(si+随机噪声)=si+E(随机噪声)=si
所以,只要满足噪声零均值假设、两次观测x和y在同一场景下、两次观测的噪声相互独立,那么就可以通过让网络学习从x映射到y的方式学会去噪。作者亦通过实验证明了有效性。
3. N2V——盲点网络(BSNs,Blind Spot Networks)开创者
N2V可以视为对N2N的批判,理由如下:
N2N的训练数据是相同场景的两次不同noisy observation组成的pair,实际使用的时候,两次不同的观测很难是相同场景的。比如医学图像,两次拍摄的时间不一样,也许器官在位置上发生了细微的变化,这就不能叫做严格的相同场景。
以上的问题,核心在于训练需要两张noisy image。那么能否只用一张noisy image就完成训练呢?当然可以,其实N2N之后涌现了Neighbor2Neighbor、N2V这样优秀的工作,这些都可以不必依赖于noisy image pair,而是依赖于single noisy image就能够完成训练。Neighbor2Neighbor是对一张noisy image进行采样得到pair,然后采用N2N的方式进行训练,并通过loss消除location gap;N2V则完全采用了和N2N不一样的思路,接下来我们主要介绍一下N2V,因为它是BSNs的开创者(to my best knowledge,所以此说法如有不对请评论区指出)。
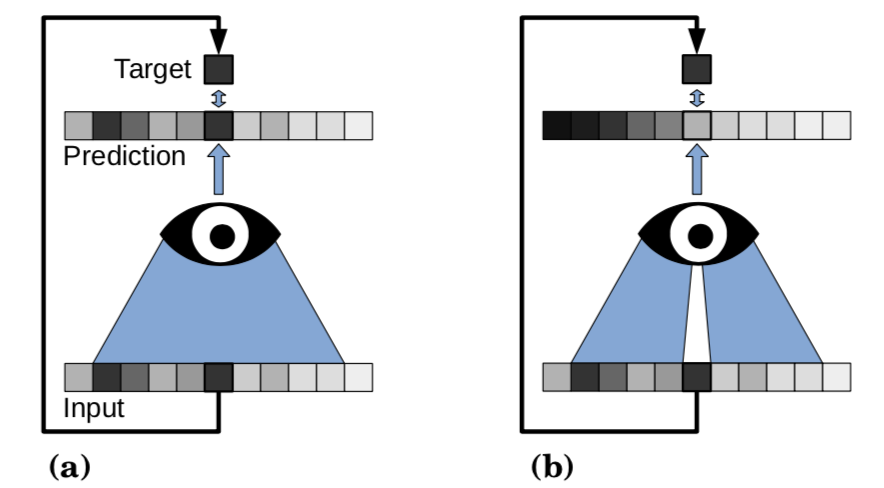
这是N2V论文中的图,在有监督学习中,给网络输入Input,获得Prediction,通过让Prediction接近GT,就能够让网络学会去噪。如果是无监督,那么这个Label是不存在的。如上图左侧(a),由于Prediction最终要接近Input,所以网络会学习恒等映射。但是我们的目标就是中single noisy image完成训练,既没有GT,也没有相同场景下的另一个噪声观测,实验要怎么做呢?
我们可以选择如上图(b)的做法,对比图(a)的感受野,我们将(b)中的感受野的中心部分挖掉一个像素,然后将剩余的部分作为Input,我们记为 I n p u t b l i n d Input_{blind} Inputblind。由于网络看不到Input的中心像素点,我们称这个像素点为Blind Spot,也就是盲点。所有存在盲点的方法,我们都可以归类为Blind Spot Networks,也就是BSNs。我们将没有挖掉中心像素的Input记为 I n p u t t o t a l Input_{total} Inputtotal,网络的输出Prediction和 I n p u t t o t a l Input_{total} Inputtotal做loss,就可以促进网络学会去噪。
所以,N2V就讲完了(bushi…
简单说一下,我们只需要对Input做一件事——挖掉它的中心像素,然后扔给网络。网络的输出和Input之间的差距作为loss,就能让网络学会去噪。但是,这一切是有前提的,N2V有如下假设:
(我们依旧将像素视为信号+噪声)
- 不同像素位置,信号是相互有关联的;
- 不同像素位置,噪声是相互没有关联的(在一些文章中称为噪声独立假设);
- 噪声的均值为0。
网络可以看到除了中心像素以外的全部像素,包括它们的信号和噪声。网络实际学习的事情就是:如何根据周围的像素点,推测出中心像素点。由于不同像素位置的信号互有关联,比如你鼻孔边缘像素的附近可能是鼻屎,鼻子像素的附近可能有黑头,所以通过周围像素的信号,可能可以推测出中心像素的信号;但是依据噪声独立假设,无法通过周围像素的噪声推测出中心像素的噪声。所以将网络输出的中心像素 x p r e x_{pre} xpre和Input中被屏蔽的中心像素 x i n x_{in} xin做loss:
x p r e − x i n = s p r e + n p r e − ( s i n + n i n ) = s p r e − s i n + ( n p r e − n i n ) x_{pre}-x_{in}=s_{pre}+n_{pre}-(s_{in}+n_{in})=s_{pre}-s_{in}+(n_{pre}-n_{in}) xpre−xin=spre+npre−(sin+nin)=spre−sin+(npre−nin)
s和n分别表示信号和噪声。为了表述方便,上式直接用了减法。根据在N2N部分的讲解,相信你已经猜到了网络的输出会是如下形式:
x p r e = s p r e + n p r e → E ( s i n + 随机噪声 ) = s i n + E ( 随机噪声 ) x_{pre}=s_{pre}+n_{pre}→E(s_{in}+随机噪声)=s_{in}+E(随机噪声) xpre=spre+npre→E(sin+随机噪声)=sin+E(随机噪声)
根据噪声零均值假设,我们有:
x p r e → s i n + E ( 随机噪声 ) = s i n x_{pre}→s_{in}+E(随机噪声)=s_{in} xpre→sin+E(随机噪声)=sin
3.1. N2V实际是如何训练的?
上文所述,我们将Input中心像素点挖掉,并让网络的输出和完整的Input做loss。可是这样会导致每次只有一个像素影响训练过程。此部分我们简单讲下N2V原文是如何训练模型的。

N2V实际的训练方式:随机选取 64 × 64 64 \times 64 64×64大小的patch,记为x。在x中随机选取N个点,对每个点p,都随机用一个点的像素替换它(具体地,在以p为中心、以网络感受野为大小的区域,如上图(b),用该区域内的一个随机像素(蓝色)替换中心像素(红色))。这样,x中就被创造了N个盲点,将这样的x记为 x b l i n d x_{blind} xblind。将 x b l i n d x_{blind} xblind输入到网络,获得输出记为y。我们将x中N个点和y中对应位置的N个点做loss。这样,输入一个 64 × 64 64 \times 64 64×64的patch做训练,一次就能够计算N个点对应的梯度。(注意采样N个点的过程中采用了stratified sampling以避免clustering,这个stratified sampling是分层采样,本文不进行讲解)
4. HQ-SSL——认为N2V效率不够高
本文是2019 NeurIPS的论文:High-Quality Self-Supervised Deep Image Denoising,作者认为N2V存在的问题是:N2V将输入的一部分pixel进行屏蔽,也只有这一部分pixel才能对loss进行贡献,作者认为这样会相对降低训练效率。本文本质上还是盲点网络派系BSNs的思想。
在4.1中,我们先阐述HQ-SSL的架构,以及作者认为他们比N2V更优的原因,并在4.2中阐述此架构的实际实现。在4.3中简单回顾本工作中盲点思想的体现。最后在4.4讲述一些公式,阐明本工作如何利用所设计的架构进行训练和去噪。
4.1. HQ-SSL的理论架构
主要是对卷积和下采样的改进,下面详细阐述。
4.1.1. 对卷积的改进
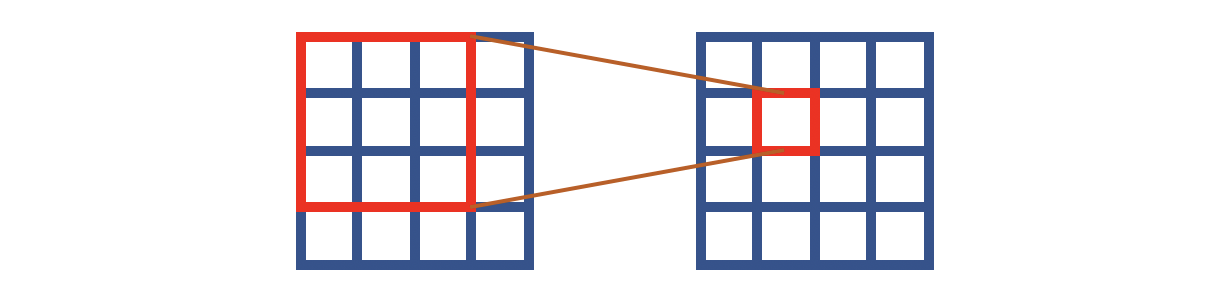
传统的卷积如上图所示,这里假设是 3 × 3 3 \times 3 3×3大小的卷积。注意输入和输出的对应关系:输出像素是输入对应感受野的中心位置。这就意味着网络推测一个像素,实际上用的是所有相邻位置+自身位置的像素。在N2V中,我们已经见识了盲点的思想,即像素的推测靠的是所有相邻位置的像素,但不包含自身位置的像素。如果将这种思想转换为卷积操作,姑且可以认为等价于下图的形式:
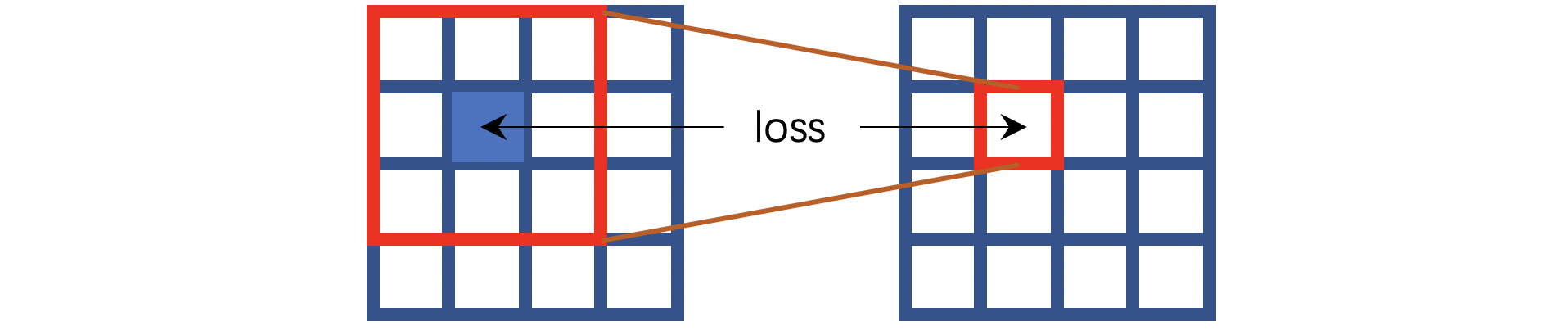
我用蓝色表示这个像素点是不可见的,也就是说卷积操作是无法看见中心像素点的。但是要求这样的计算能够推测中心位置的像素。这就是HQ-SSL的中心思想,不过这个工作并没有按照上图那样操作,它将卷积操作改造成了如下的方式:
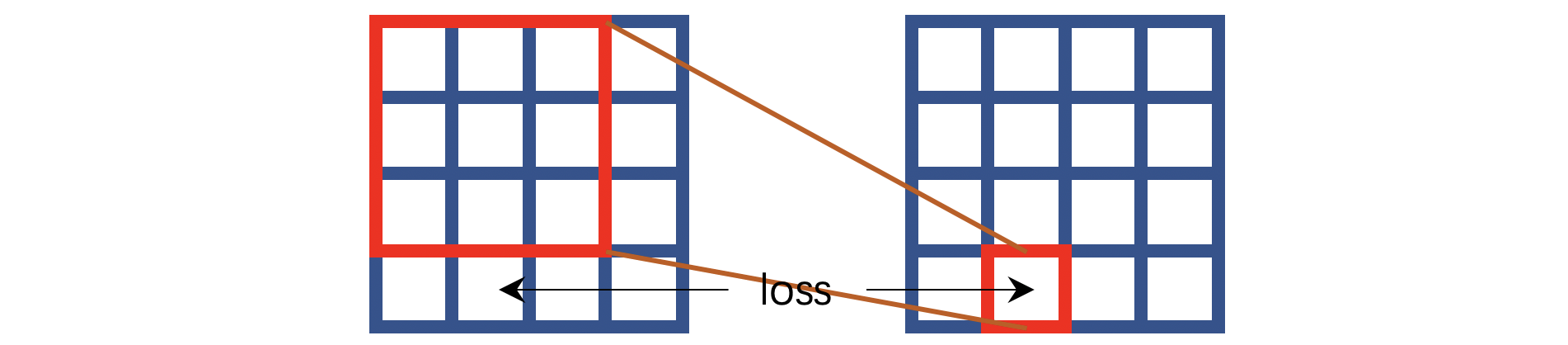
HQ-SSL将卷积操作分为了四个方向,上图对应的是其中一种方向——输出像素取决于对应输入像素的上方相邻像素。如果算上所有四个方向,那么输出像素就取决于对应输入像素的上方、左方、下方、右方的若干相邻像素。
⚠️注意作者的思路是:N2V工作中的盲点本质上是让模型根据周围的像素点推测中心像素点,那么我们可以改造卷积操作,让每一次卷积运算都只能看见中心位置像素的若干相邻像素。
⭐️在实现上,作者采用的是 平移 + 补 0 + 裁剪 平移+补0+裁剪 平移+补0+裁剪的操作,用下图简单阐述:
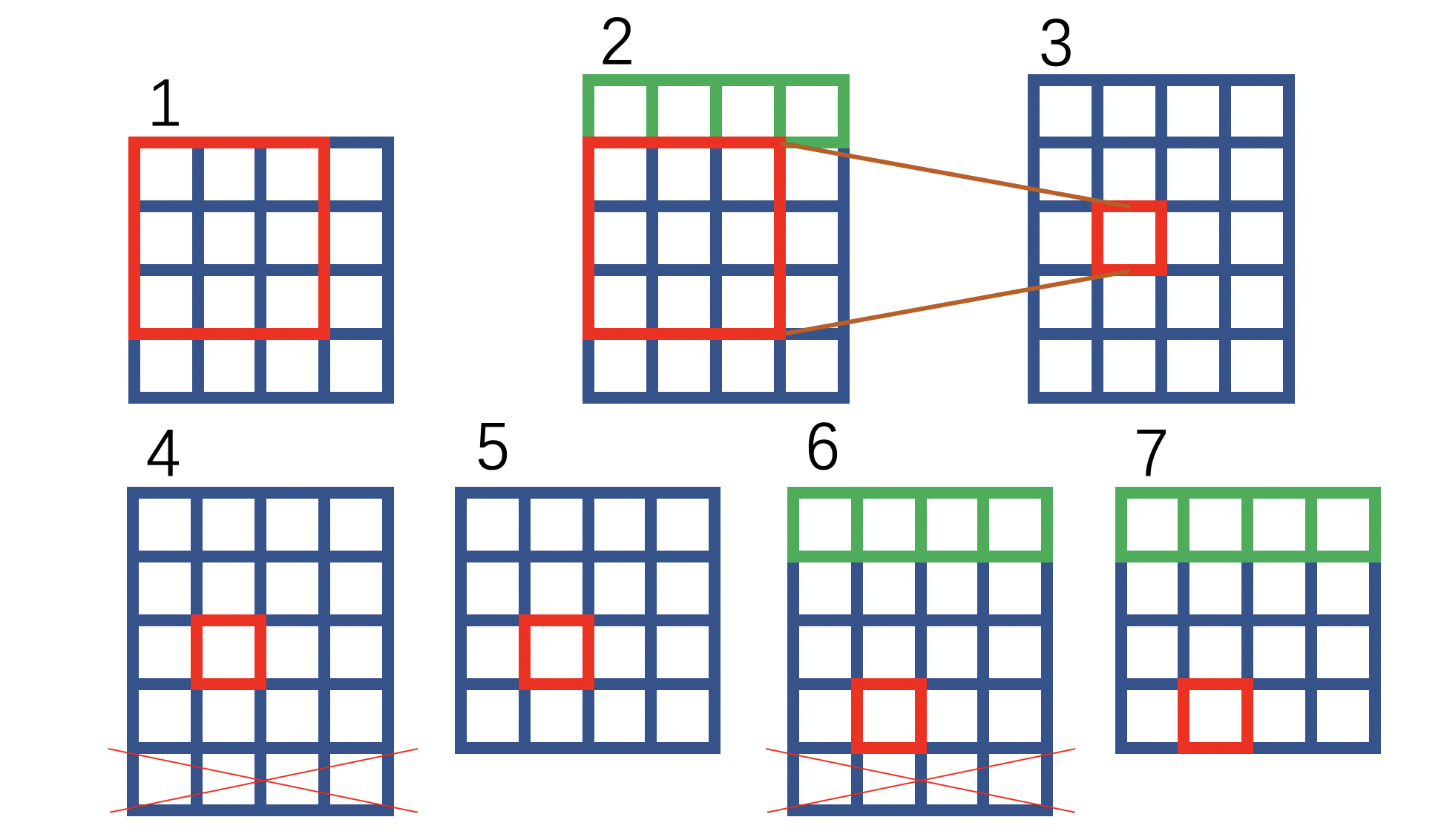
绿色表示补零操作,红色叉叉表示裁剪。可以看到,如上图操作之后,1和7的对应位置关系等价于上文所述HQ-SSL对卷积操作的改进方式:
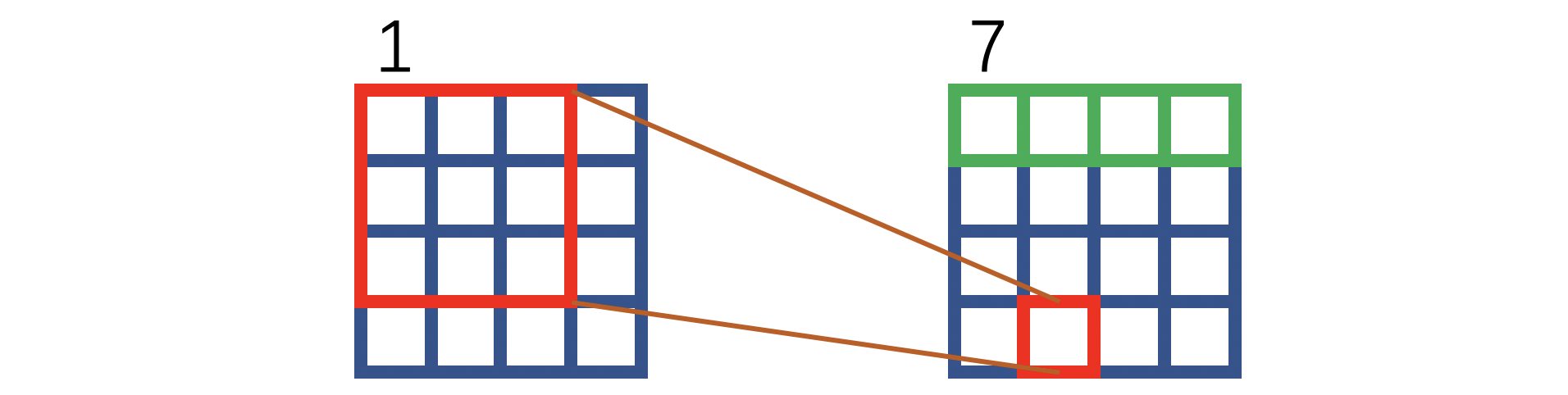
注意:上述内容是根据作者提供的源代码获知,如果读者需要使用HQ-SSL,可以直接使用官方提供的代码。2023 CVPR有一篇工作引用了HQ-SSL,其官方代码和HQ-SSL的代码在卷积操作上是一致的。之所以写这段话,是因为HQ-SSL个人认为文章的关键段落较为晦涩,看不懂的读者朋友可以考虑直接看官方的代码,写的还是很易懂的。
⚠️注意:上述内容的补零和裁剪可以视为平移,上图仅平移了1个像素,是因为卷积核大小是 3 × 3 3 \times 3 3×3。如果是更大的卷积核,那么可以考虑不同的平移像素数量。
4.1.2. 对下采样的改进
如果采用传统的 2 × 2 2 \times 2 2×2下采样,那么在上采样后, 2 × 2 2 \times 2 2×2区域内的四个像素,分别将和对应输入的同位置区域的四个像素相关联。作者针对下采样才用了和对卷积一样的改进方案—— 平移 + 裁剪 平移+裁剪 平移+裁剪:
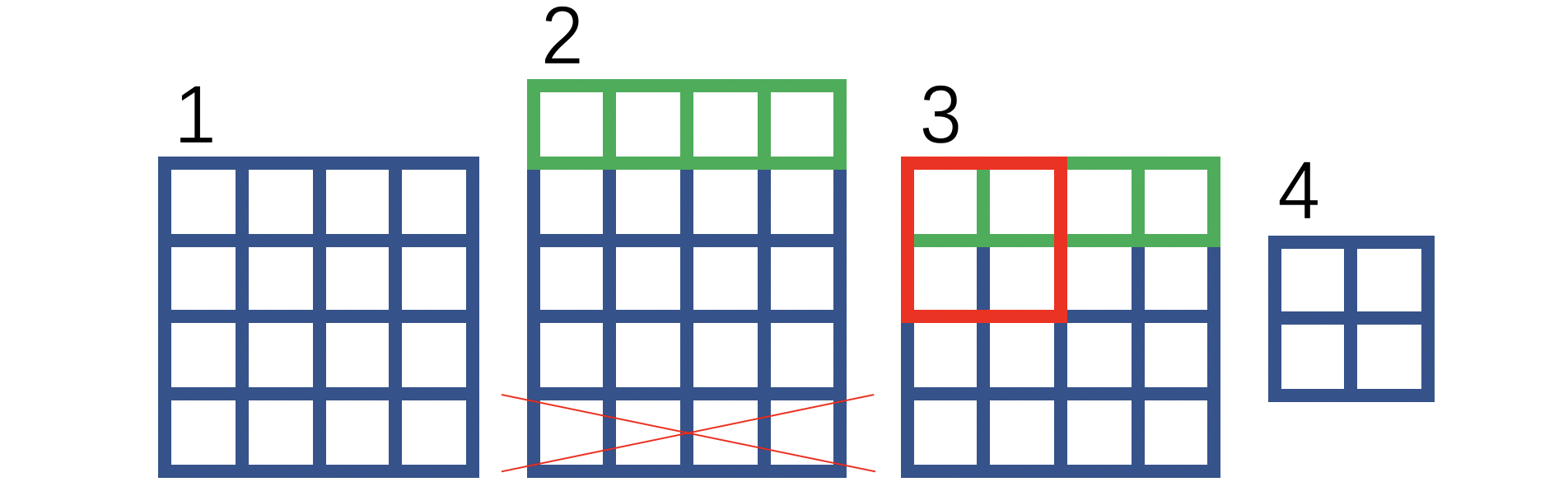
绿色方框表示补0,红色叉叉表示裁剪。我们将1和4放到下图,并用不同的颜色,这样可以直观理解:
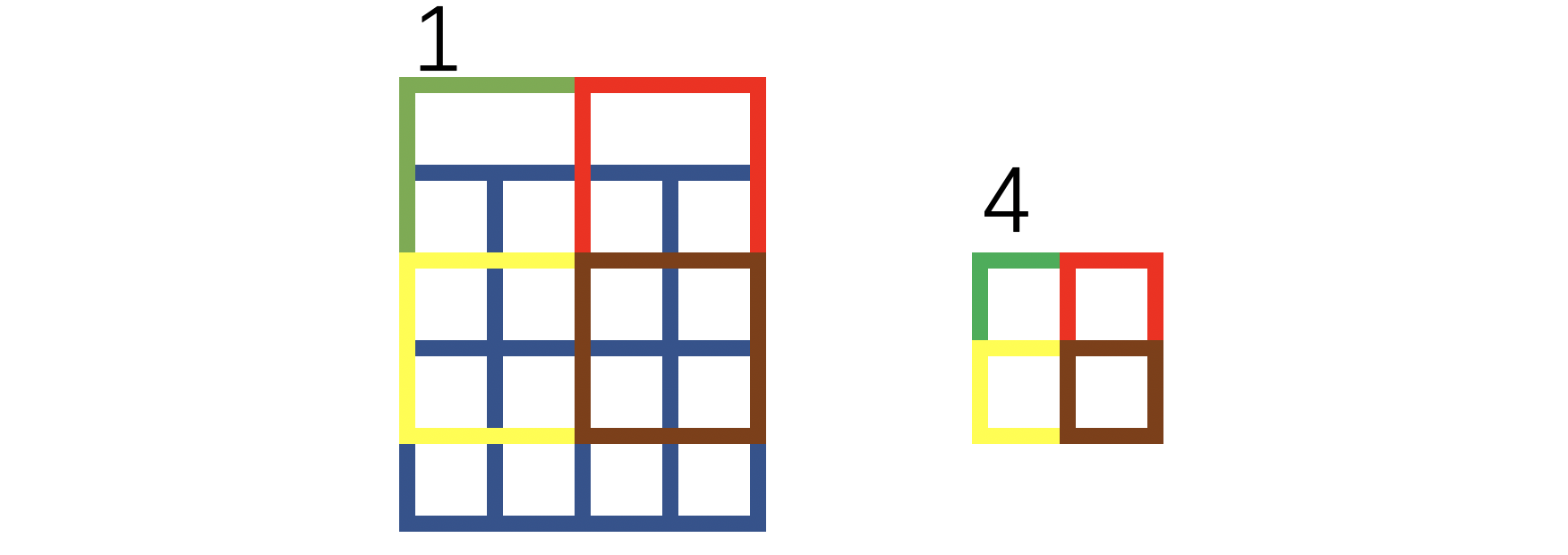
通过上图你可以认为下采样也有一个感受野,每个像素的感受野对应于该像素的位置以及该像素位置的上方位置。
和卷积一样,下采样也会对应四个方向。下采样的方向和卷积的方向是一致的。
注意上采样没有被改造。
4.1.3. 比N2V好在哪?
这里我就直接摘录原文的内容了:
N2V是将输入的一部分pixel进行屏蔽,只有这部分pixel才能对loss做贡献,或者只有这部分pixel才是loss的组成部分。作者认为这样会降低训练效率,所以采用HQ-SSL的设计思想,通过对卷积和下采样进行改造,可以等价出盲点网络BSN的效果。而且,由于仅仅改变了卷积和下采样,所有pixel都是loss的组成部分,或者说所有pixel都能对loss做贡献、对训练做贡献。
4.2. HQ-SSL的实际实现
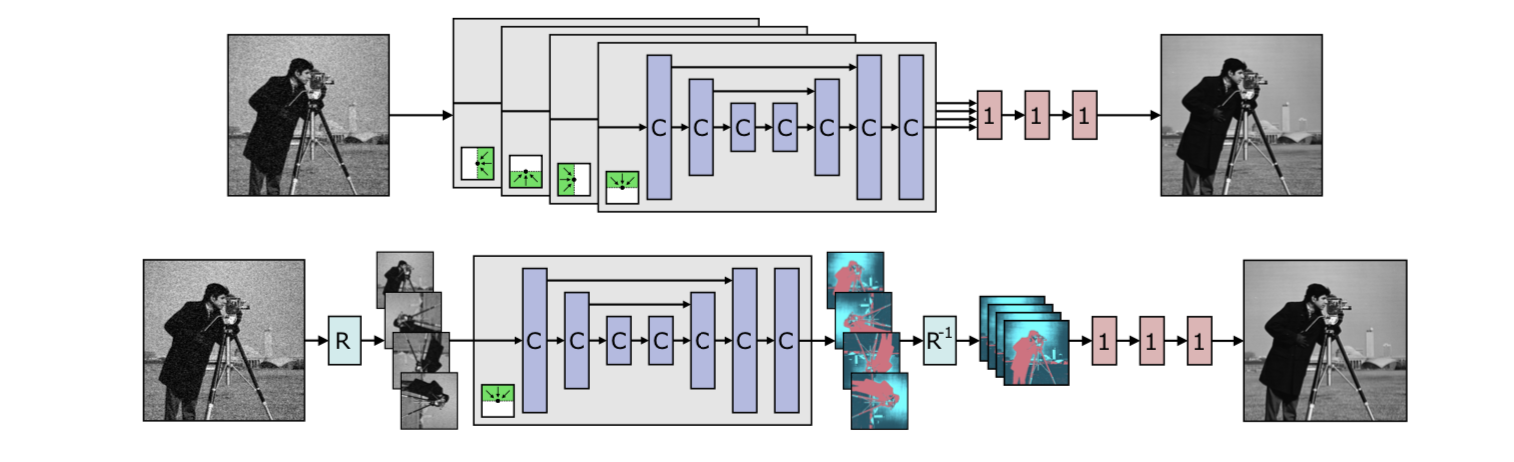
先看上图的上半部分,拥有4个branch。C表示4.1中所讲述的改造后的卷积,1表示 1 × 1 1 \times 1 1×1的卷积。绿色的部分表示四个方向的感受野,对应四个方向的卷积和下采样。再看上图的下半部分,表示作者实际的实现方式,虽然只有一个branch,但是通过旋转操作(图中的R)等价出了四个方向的卷积和下采样。由于只有一个branch,显然网络的参数量被大幅减少。
补:HQ-SSL的训练和测试须知
⭐️如果没有此部分内容,我们会根据对N2V的印象认为HQ-SSL的训练方式是:将上图右端的预测结果和左边的输入做loss,并以此训练。在测试阶段则是直接将noisy image输入网络,就能够获得对应的去噪结果。
实际上不是,在论文的第三节(3 Self-supervised Bayesian denoising with blind-spot networks),作者对训练和测试过程进行了阐述。摘录网上博客对此部分的分析(我没有深究这地方):
网络输出噪声的一些分布参数,利用预测的参数可以进行去噪。
具体内容我不太感兴趣,所以不深究了。我阅读这篇论文主要目的是学习它的盲点思想。后续也有2023 CVPR的文章Spatially Adaptive Self-Supervised Learning for Real-World Image Denoising采用了HQ-SSL的盲点网络的设计(下一篇博客我将讲述它,届时我会将链接放在这里)。
相关文章:
无/自监督去噪(1)——一个变迁:N2N→N2V→HQ-SSL
目录 1. 前沿2. N2N3. N2V——盲点网络(BSNs,Blind Spot Networks)开创者3.1. N2V实际是如何训练的? 4. HQ-SSL——认为N2V效率不够高4.1. HQ-SSL的理论架构4.1.1. 对卷积的改进4.1.2. 对下采样的改进4.1.3. 比N2V好在哪ÿ…...

【24.1.19】
24.1.19 本周工作内容下周工作计划 本周工作内容 本周的话主要的一个工作还是第三部分页面部分的完成工作,那就先来汇报一下第三部分的工作进度,第三部分的页面工作呢已经完成啦,就在刚刚提交啦全部的代码,那么这一部分的工作呢也…...

使用mamba替换conda和anaconda配置环境安装软件
使用mamba替换miniconda和anaconda,原因是速度更快,无论是创建新环境还是激活环境 conda、mamba、anaconda都是蟒蛇的意思… 下载mambaforge wget https://github.com/conda-forge/miniforge/releases/latest/download/Mambaforge-Linux-x86_64.sh ba…...
鸿蒙开发系列教程(四)--ArkTS语言:基础知识
1、ArkTS语言介绍 ArkTS是HarmonyOS应用开发语言。它在保持TypeScript(简称TS)基本语法风格的基础上,对TS的动态类型特性施加更严格的约束,引入静态类型。同时,提供了声明式UI、状态管理等相应的能力,让开…...
Pix2Pix理论与实战
本文为🔗365天深度学习训练营 中的学习记录博客 原作者:K同学啊|接辅导、项目定制 我的环境: 1.语言:python3.7 2.编译器:pycharm 3.深度学习框架Pytorch 1.8.0cu111 一、引入 在之前的学习中,我们知道…...
)
[GN] 后端接口已经写好 初次布局前端需要的操作(例)
提示:前端项目一定要先引入组件 配置。再编码!!!! 文章目录 使用 vue-cli 脚手架初始化前端工程化配置引入Vue前端组件库 -- arco前后端联调引入Md 编辑器组件 使用 vue-cli 脚手架初始化 使用安装脚手架工具…...

AIGC:人工智能驱动的数据分析新时代
AIGC:人工智能驱动的数据分析新时代 随着人工智能技术的迅猛发展,我们正迎来数据分析的新时代,其中AIGC(Artificial Intelligence with Generative Capabilities)的应用成为引领潮流的重要方向。本文将深入探讨几个关…...

Windows Qt C++ VTK 借助msys环境搭建
本示例仅仅是搭建环境,后续使用还得大佬指导。 Qt 6.6.0 MinGW 64bit 借助msys2 来安装VTK 包,把*.dll 链接进来,就可以用了。 先安装VTK 包。 Package: mingw-w64-x86_64-vtk - MSYS2 Packages 执行 pacman 命令:pacman -…...

尚硅谷Nginx高级配置笔记
写在前面:本笔记是学习尚硅谷nginx可成的时候的笔记,不是原创,如有需要,可以去官网看视频,以下是pdf文件 Nginx高级 第一部分:扩容 通过扩容提升整体吞吐量 1.单机垂直扩容:硬件资源增加 云…...
论rtp协议的重要性
rtp ps流工具 rtp 协议,实时传输协议,为什么这么重要,可以这么说,几乎所有的标准协议都是国外创造的,感叹一下,例如rtsp协议,sip协议,webrtc,都是以rtp协议为基础&#…...
【Github搭建网站】零基础零成本搭建个人Web网站~
Github网站:https://github.com/ 这是我个人搭建的网站:https://xf2001.github.io/xf/ 大家可以搭建完后发评论区看看!!! 搭建教程:https://www.bilibili.com/video/BV1xc41147Vb/?spm_id_from333.999.0.0…...
unocss+iconify技术在vue项目中使用20000+的图标
安装依赖 npm i unocss iconify/json配置依赖 vue.config.js文件 uno.config.js文件 main.js文件 使用 <i class"i-fa:user"></i> <i class"i-fa:key"></i>class名是 i- 开头,跟库名:图标名,那都有什么库…...
python 自动化模块 - pyautogui初探
python 自动化模块 - pyautogui 引言一、安装测试二、简单使用三、常用函数总结 引言 在画图软件中使用pyautogui拖动鼠标,画一个螺旋式的正方形 - (源码在下面) PyAutoGUI允许Python脚本控制鼠标和键盘,以自动化与其他应用程序的交互。API的设计非常简…...
UE5 蓝图编辑美化学习
虚幻引擎中干净整洁蓝图的15个提示_哔哩哔哩_bilibili 1.双击线段成节点。 好用,爱用 2.用序列节点 好用,爱用 3.用枚举。 好用,能避免一些的拼写错误 4.对齐节点 两点一水平线 5.节点上下贴节点 (以前不懂,现在经常…...
基于动态顺序表实现通讯录项目
本文中,我们将使用顺序表的结构来完成通讯录的实现。 我们都知道,顺序表实际上就是一个数组。而使用顺序表来实现通讯录,其内核是将顺序表中存放的数据类型改为结构体,将联系人的信息存放到结构体中,通过对顺序表的操…...
python使用jupyter记笔记
目录 一、安装 二、运行jupyter 三、使用 四、记笔记 Jupyter Notebook(此前被称为 IPython notebook)是一个交互式笔记本,支持运行 40 多种编程语言。 Jupyter Notebook 的本质是一个 Web 应用程序,便于创建和共享程序文档&a…...

C#封装服务
C#封装服务 新建服务项目;重构 OnStart 和 OnStop using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Diagnostics; using System.Linq; using System.ServiceProcess; using System.Text; using S…...

手写Vue3源码
Vue3核心源码 B站视频地址:https://www.bilibili.com/video/BV1nW4y147Pd?p2&vd_source36bacfbaa95ea7a433650dab3f7fa0ae Monorepo介绍 Monorepo 是管理项目代码的一种方式,只在一个仓库中管理多个模块/包 一个仓库可以维护多个模块,…...

如何无需重复输入FTP信息来安装WordPress主题和插件
WordPress作为一个广受欢迎的内容管理系统,提供了丰富的主题和插件来扩展网站的功能和外观。然而,许多用户在安装这些主题和插件时,经常遇到需要重复输入FTP信息的麻烦。幸运的是,有几种方法可以解决这个问题,让安装过…...

开发安全之:JSON Injection
Overview 在 XXX.php 的第 X 行中,responsemsg() 方法将未经验证的输入写入 JSON。攻击者可以利用此调用将任意元素或属性注入 JSON 实体。 Details JSON injection 会在以下情况中出现: 1. 数据从一个不可信赖的数据源进入程序。 2. 将数据写入到 …...

终极指南:如何用OpenHTMLtoPDF轻松生成专业级PDF文档
终极指南:如何用OpenHTMLtoPDF轻松生成专业级PDF文档 【免费下载链接】openhtmltopdf An HTML to PDF library for the JVM. Based on Flying Saucer and Apache PDF-BOX 2. With SVG image support. Now also with accessible PDF support (WCAG, Section 508, PDF…...
深度使用指南)
告别混乱搜索:Visual Paradigm 17.0 企业模型查找器(Enterprise Model Finder)深度使用指南
Visual Paradigm 17.0企业级模型检索革命:从精准定位到团队协作的全链路优化 在大型软件工程或复杂系统设计项目中,建模师们常常陷入"模型迷宫"的困境——当项目积累到数百个UML图、上千个业务流程图时,找到一个特定类定义或流程节…...

基于 RPA 自动化技术的私域机器人助手构建指南
利用自动化工作流实现私域运营中的消息智能响应与多任务协同 能力介绍 在私域流量运营中,如何高效响应用户需求、精细化管理社群是提升转化率的关键。传统的人工客服模式往往面临响应不及时、重复性劳动繁重等问题。 本方案基于 RPA(机器人流程自动化…...

告别客户端安装!浏览器远程控制的终极方案:noVNC实战指南
告别客户端安装!浏览器远程控制的终极方案:noVNC实战指南 【免费下载链接】noVNC VNC client web application 项目地址: https://gitcode.com/gh_mirrors/no/noVNC 还在为跨平台远程控制而烦恼吗?还在为每个设备都要安装专用客户端而…...

CFO必看|OpenAI官方写给财务团队的Codex教程:5大场景+可直接复制的Prompt
OpenAI发布Codex财务团队教程,5大场景一键生成MBR报告、财务模型审计、CFO汇报材料、差异分析及预测刷新,让财务人专注数字核查与决策准备。内容由AI智能生成有用高效赋能CFO团队,释放财务决策核心价值。近日,OpenAI出了一份财务团…...

杰理之RX修改为连接一个TX后需要再次按键或者其他操作才能连接第二个TX的功能需求【篇】
void user_wireless_dev_pair_code_pri() { y_printf(“user_wireless_dev_pair_code_pri”); u32 pair_code 0; wireless_dev_get_pair_code(“big_rx”, (u8 *)&pair_code, 1); wireless_dev_set_pair_code(“big_rx”, (u8 *)&pair_code); } //连接一个无线麦后&am…...

抖音直播数据采集:如何用Golang构建实时弹幕监控系统
抖音直播数据采集:如何用Golang构建实时弹幕监控系统 【免费下载链接】douyin-live-go 抖音(web) 弹幕爬虫 golang 实现 项目地址: https://gitcode.com/gh_mirrors/do/douyin-live-go 在直播电商和内容创作日益火爆的今天,数据驱动的运营决策变得…...

OpenShift高可用集群搭建后,这10个运维“救命”命令和5个常见故障排查场景你必须知道
OpenShift高可用集群运维实战:10个关键命令与5大故障场景深度解析 当你的OpenShift集群从测试环境迈向生产环境时,那些在搭建阶段被忽略的运维细节往往会突然成为拦路虎。不同于标准Kubernetes,OpenShift在提供企业级功能的同时也带来了更复杂…...

智慧养殖与猪行为实例分割数据集 动物行为分析数据集 生猪进食数据集 生猪睡觉站立姿态识别数据集 yolo格式数据集
猪行为实例分割数据集核心信息 类别 Tags 标签 Instance Segmentation 实例分割 Model 模型Classes (4) 类别(4) Eating 进食 Lying 躺着 Sitting 坐着 Standing 站立数据集关键信息表信息类别具体内容数据集类别猪行为实例分割数据集,聚焦猪…...

Box64终极指南:如何在ARM设备上轻松运行x86程序?三个简单步骤解锁无限可能
Box64终极指南:如何在ARM设备上轻松运行x86程序?三个简单步骤解锁无限可能 【免费下载链接】box64 Box64 - Linux Userspace x86_64 Emulator with a twist, targeted at ARM64, RV64 and LoongArch Linux devices 项目地址: https://gitcode.com/gh_m…...