【Flink-1.17-教程】-【四】Flink DataStream API(1)源算子(Source)
【Flink-1.17-教程】-【四】Flink DataStream API(1)源算子(Source)
- 1)执行环境(Execution Environment)
- 1.1.创建执行环境
- 1.2.执行模式(Execution Mode)
- 1.3.触发程序执行
- 2)源算子(Source)
- 2.1.准备工作
- 2.2.从集合中读取数据
- 2.3.从文件读取数据
- 2.4.从 Socket 读取数据
- 2.5.从 Kafka 读取数据
- 2.6.从数据生成器读取数据
- 2.7.Flink 支持的数据类型
DataStream API 是 Flink 的核心层 API。一个 Flink 程序,其实就是对 DataStream 的各种转换。具体来说,代码基本上都由以下几部分构成:
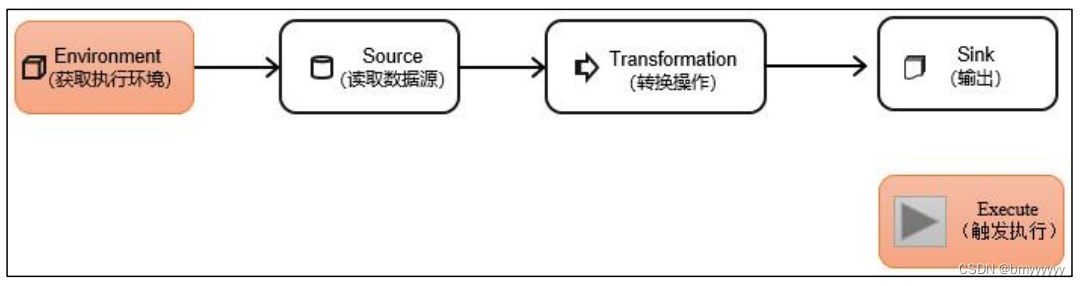
1)执行环境(Execution Environment)
Flink 程序可以在各种上下文环境中运行:我们可以在本地 JVM 中执行程序,也可以提交到远程集群上运行。
不同的环境,代码的提交运行的过程会有所不同。这就要求我们在提交作业执行计算时,首先必须获取当前 Flink 的运行环境,从而建立起与 Flink 框架之间的联系。
1.1.创建执行环境
我们要获取的执行环境,是 StreamExecutionEnvironment 类的对象,这是所有 Flink 程序的基础。在代码中创建执行环境的方式,就是调用这个类的静态方法,具体有以下三种。
1、getExecutionEnvironment
最简单的方式,就是直接调用 getExecutionEnvironment 方法。它会根据当前运行的上下文直接得到正确的结果:如果程序是独立运行的,就返回一个本地执行环境;如果是创建了jar 包,然后从命令行调用它并提交到集群执行,那么就返回集群的执行环境。也就是说,这个方法会根据当前运行的方式,自行决定该返回什么样的运行环境。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
这种方式,用起来简单高效,是最常用的一种创建执行环境的方式。
2、createLocalEnvironment
这个方法返回一个本地执行环境。可以在调用时传入一个参数,指定默认的并行度;如果不传入,则默认并行度就是本地的 CPU 核心数。
StreamExecutionEnvironment localEnv = StreamExecutionEnvironment.createLocalEnvironment();
3)createRemoteEnvironment
这个方法返回集群执行环境。需要在调用时指定 JobManager 的主机名和端口号,并指定要在集群中运行的 Jar 包。
StreamExecutionEnvironment remoteEnv = StreamExecutionEnvironment
.createRemoteEnvironment(
"host", // JobManager 主机名
1234, // JobManager 进程端口号
"path/to/jarFile.jar" // 提交给 JobManager 的 JAR 包
);
在获取到程序执行环境后,我们还可以对执行环境进行灵活的设置。比如可以全局设置程序的并行度、禁用算子链,还可以定义程序的时间语义、配置容错机制。
1.2.执行模式(Execution Mode)
从 Flink 1.12 开始,官方推荐的做法是直接使用 DataStream API,在提交任务时通过将执行模式设为 BATCH 来进行批处理。不建议使用 DataSet API。
// 流处理环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream API 执行模式包括:流执行模式、批执行模式和自动模式。
-
流执行模式(Streaming)
这是 DataStream API 最经典的模式,一般用于需要持续实时处理的无界数据流。默认情况下,程序使用的就是 Streaming 执行模式。
-
批执行模式(Batch)
专门用于批处理的执行模式。
-
自动模式(AutoMatic)
在这种模式下,将由程序根据输入数据源是否有界,来自动选择执行模式。批执行模式的使用。主要有两种方式:
(1)通过命令行配置
bin/flink run -Dexecution.runtime-mode=BATCH ...
在提交作业时,增加 execution.runtime-mode 参数,指定值为 BATCH。
(2)通过代码配置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
在代码中,直接基于执行环境调用 setRuntimeMode 方法,传入 BATCH 模式。
实际应用中一般不会在代码中配置,而是使用命令行,这样更加灵活。
1.3.触发程序执行
需要注意的是,写完输出(sink)操作并不代表程序已经结束。因为当 main() 方法被调用时,其实只是定义了作业的每个执行操作,然后添加到数据流图中;这时并没有真正处理数据——因为数据可能还没来。Flink 是由事件驱动的,只有等到数据到来,才会触发真正的计算,这也被称为“延迟执行”或“懒执行”。
所以我们需要显式地调用执行环境的 execute() 方法,来触发程序执行。execute() 方法将一直等待作业完成,然后返回一个执行结果(JobExecutionResult)。
env.execute();
2)源算子(Source)
Flink 可以从各种来源获取数据,然后构建 DataStream 进行转换处理。一般将数据的输入来源称为数据源(data source),而读取数据的算子就是源算子(source operator)。所以,source 就是我们整个处理程序的输入端。

在 Flink1.12 以前,旧的添加 source 的方式,是调用执行环境的 addSource()方法:
DataStream<String> stream = env.addSource(...);
方法传入的参数是一个“源函数”(source function),需要实现 SourceFunction 接口。
从 Flink1.12 开始,主要使用流批统一的新 Source 架构:
DataStreamSource<String> stream = env.fromSource(…)
Flink 直接提供了很多预实现的接口,此外还有很多外部连接工具也帮我们实现了对应的 Source,通常情况下足以应对我们的实际需求。
2.1.准备工作
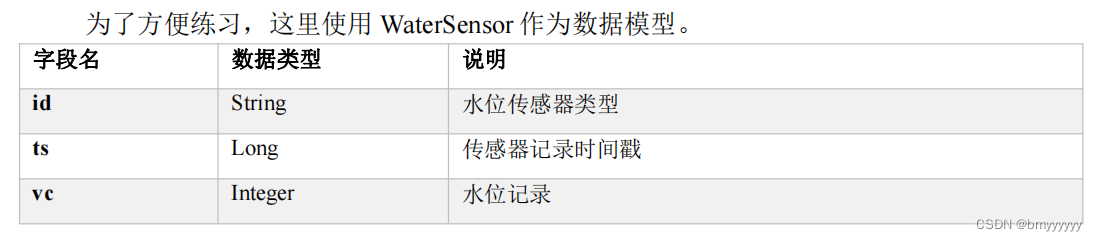
具体代码如下:
public class WaterSensor {public String id;public Long ts;public Integer vc;// 一定要提供一个 空参 的构造器public WaterSensor() {}public WaterSensor(String id, Long ts, Integer vc) {this.id = id;this.ts = ts;this.vc = vc;}public String getId() {return id;}public void setId(String id) {this.id = id;}public Long getTs() {return ts;}public void setTs(Long ts) {this.ts = ts;}public Integer getVc() {return vc;}public void setVc(Integer vc) {this.vc = vc;}@Overridepublic String toString() {return "WaterSensor{" +"id='" + id + '\'' +", ts=" + ts +", vc=" + vc +'}';}@Overridepublic boolean equals(Object o) {if (this == o) {return true;}if (o == null || getClass() != o.getClass()) {return false;}WaterSensor that = (WaterSensor) o;return Objects.equals(id, that.id) &&Objects.equals(ts, that.ts) &&Objects.equals(vc, that.vc);}@Overridepublic int hashCode() {return Objects.hash(id, ts, vc);}
}这里需要注意,我们定义的 WaterSensor,有这样几个特点:
- 类是公有(public)的
- 有一个
无参的构造方法 - 所有属性都是公有(public)的
- 所有属性的类型都是可以序列化的
Flink 会把这样的类作为一种特殊的 POJO(Plain Ordinary Java Object 简单的 Java 对象,实际就是普通 JavaBeans)数据类型来对待,方便数据的解析和序列化。另外我们在类中还重写了 toString 方法,主要是为了测试输出显示更清晰。
我们这里自定义的 POJO 类会在后面的代码中频繁使用,所以在后面的代码中碰到,把这里的 POJO 类导入就好了。
2.2.从集合中读取数据
最简单的读取数据的方式,就是在代码中直接创建一个 Java 集合,然后调用执行环境的 fromCollection 方法进行读取。这相当于将数据临时存储到内存中,形成特殊的数据结构后,作为数据源使用,一般用于测试。
public class CollectionDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// TODO 从集合读取数据DataStreamSource<Integer> source = env.fromElements(1,2,33); // 从元素读
// .fromCollection(Arrays.asList(1, 22, 3)); // 从集合读source.print();env.execute();}
}
2.3.从文件读取数据
真正的实际应用中,自然不会直接将数据写在代码中。通常情况下,我们会从存储介质中获取数据,一个比较常见的方式就是读取日志文件。这也是批处理中最常见的读取方式。
读取文件,需要添加文件连接器依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>
示例如下:
public class FileSourceDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// TODO 从文件读: 新Source架构FileSource<String> fileSource = FileSource.forRecordStreamFormat(new TextLineInputFormat(),new Path("input/word.txt")).build();env.fromSource(fileSource, WatermarkStrategy.noWatermarks(), "filesource").print();env.execute();}
}
/**** 新的Source写法:* env.fromSource(Source的实现类,Watermark,名字)**/
说明:
- 参数可以是目录,也可以是文件;还可以从 HDFS 目录下读取,使用路径 hdfs://…;
- 路径可以是相对路径,也可以是绝对路径;
- 相对路径是从系统属性 user.dir 获取路径:idea 下是 project 的根目录,standalone 模式下是集群节点根目录;
2.4.从 Socket 读取数据
不论从集合还是文件,我们读取的其实都是有界数据。在流处理的场景中,数据往往是无界的。
我们之前用到的读取 socket 文本流,就是流处理场景。但是这种方式由于吞吐量小、稳定性较差,一般也是用于测试。
DataStream<String> stream = env.socketTextStream("localhost", 7777);
2.5.从 Kafka 读取数据
Flink 官方提供了连接工具 flink-connector-kafka ,直接帮我们实现了一个消费者 FlinkKafkaConsumer,它就是用来读取 Kafka 数据的 SourceFunction。
所以想要以 Kafka 作为数据源获取数据,我们只需要引入 Kafka 连接器的依赖。Flink 官方提供的是一个通用的 Kafka 连接器,它会自动跟踪最新版本的 Kafka 客户端。目前最新版本只支持 0.10.0 版本以上的 Kafka。这里我们需要导入的依赖如下。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
代码如下:
public class KafkaSourceDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// TODO 从Kafka读: 新Source架构KafkaSource<String> kafkaSource = KafkaSource.<String>builder().setBootstrapServers("hadoop102:9092,hadoop103:9092,hadoop104:9092") // 指定kafka节点的地址和端口.setGroupId("atguigu") // 指定消费者组的id.setTopics("topic_1") // 指定消费的 Topic.setValueOnlyDeserializer(new SimpleStringSchema()) // 指定 反序列化器,这个是反序列化value.setStartingOffsets(OffsetsInitializer.latest()) // flink消费kafka的策略.build();env
// .fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafkasource").fromSource(kafkaSource, WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(3)), "kafkasource").print();env.execute();}
}
/*** kafka消费者的参数:* auto.reset.offsets* earliest: 如果有offset,从offset继续消费; 如果没有offset,从 最早 消费* latest : 如果有offset,从offset继续消费; 如果没有offset,从 最新 消费** flink的kafkasource,offset消费策略:OffsetsInitializer,默认是 earliest* earliest: 一定从 最早 消费* latest : 一定从 最新 消费****/
2.6.从数据生成器读取数据
Flink 从 1.11 开始提供了一个内置的 DataGen 连接器,主要是用于生成一些随机数,用于在没有数据源的时候,进行流任务的测试以及性能测试等。1.17 提供了新的 Source 写法,需要导入依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-datagen</artifactId>
<version>${flink.version}</version>
</dependency>
代码如下:
public class DataGeneratorDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 如果有n个并行度, 最大值设为a// 将数值 均分成 n份, a/n ,比如,最大100,并行度2,每个并行度生成50个// 其中一个是 0-49,另一个50-99env.setParallelism(2);/*** 数据生成器Source,四个参数:* 第一个: GeneratorFunction接口,需要实现, 重写map方法, 输入类型固定是Long* 第二个: long类型, 自动生成的数字序列(从0自增)的最大值(小于),达到这个值就停止了* 第三个: 限速策略, 比如 每秒生成几条数据* 第四个: 返回的类型*/DataGeneratorSource<String> dataGeneratorSource = new DataGeneratorSource<>(new GeneratorFunction<Long, String>() {@Overridepublic String map(Long value) throws Exception {return "Number:" + value;}},100,RateLimiterStrategy.perSecond(1),Types.STRING);env.fromSource(dataGeneratorSource, WatermarkStrategy.noWatermarks(), "data-generator").print();env.execute();}
}
2.7.Flink 支持的数据类型
1、Flink 的类型系统
Flink 使用“类型信息”(TypeInformation)来统一表示数据类型。TypeInformation 类是 Flink 中所有类型描述符的基类。它涵盖了类型的一些基本属性,并为每个数据类型生成特定的序列化器、反序列化器和比较器。
2、Flink 支持的数据类型
对于常见的 Java 和 Scala 数据类型,Flink 都是支持的。Flink 在内部,Flink 对支持不同的类型进行了划分,这些类型可以在 Types 工具类中找到:
(1)基本类型
所有 Java 基本类型及其包装类,再加上 Void、String、Date、BigDecimal 和 BigInteger。
(2)数组类型
包括基本类型数组(PRIMITIVE_ARRAY)和对象数组(OBJECT_ARRAY)。
(3)复合数据类型
- Java 元组类型(TUPLE):这是 Flink 内置的元组类型,是 Java API 的一部分。最多 25 个字段,也就是从 Tuple0~Tuple25,不支持空字段。
- Scala 样例类及 Scala 元组:不支持空字段。
- 行类型(ROW):可以认为是具有任意个字段的元组,并支持空字段。
- POJO:Flink 自定义的类似于 Java bean 模式的类。
(4)辅助类型
Option、Either、List、Map 等。
(5)泛型类型(GENERIC)
Flink 支持所有的 Java 类和 Scala 类。不过如果没有按照上面 POJO 类型的要求来定义,就会被 Flink 当作泛型类来处理。Flink 会把泛型类型当作黑盒,无法获取它们内部的属性;它们也不是由 Flink 本身序列化的,而是由 Kryo 序列化的。
在这些类型中,元组类型和 POJO 类型最为灵活,因为它们支持创建复杂类型。而相比之下,POJO 还支持在键(key)的定义中直接使用字段名,这会让我们的代码可读性大大增加。所以,在项目实践中,往往会将流处理程序中的元素类型定为 Flink 的 POJO 类型。
Flink 对 POJO 类型的要求如下:
- 类是公有(public)的
- 有一个无参的构造方法
- 所有属性都是公有(public)的
- 所有属性的类型都是可以序列化的
3、类型提示(Type Hints)
Flink 还具有一个类型提取系统,可以分析函数的输入和返回类型,自动获取类型信息,从而获得对应的序列化器和反序列化器。但是,由于 Java 中泛型擦除的存在,在某些特殊情况下(比如 Lambda 表达式中),自动提取的信息是不够精细的——只告诉 Flink 当前的元素由“船头、船身、船尾”构成,根本无法重建出“大船”的模样;这时就需要显式地提供类型信息,才能使应用程序正常工作或提高其性能。
为了解决这类问题,Java API 提供了专门的“类型提示”(type hints)。
回忆一下之前的 word count 流处理程序,我们在将 String 类型的每个词转换成(word,count)二元组后,就明确地用 returns 指定了返回的类型。因为对于 map 里传入的 Lambda 表达式,系统只能推断出返回的是 Tuple2 类型,而无法得到 Tuple2<String, Long>。只有显式地告诉系统当前的返回类型,才能正确地解析出完整数据。
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG));
Flink 还专门提供了 TypeHint 类,它可以捕获泛型的类型信息,并且一直记录下来,为运行时提供足够的信息。我们同样可以通过.returns()方法,明确地指定转换之后的 DataStream 里元素的类型。
returns(new TypeHint<Tuple2<Integer, SomeType>>(){})
相关文章:
【Flink-1.17-教程】-【四】Flink DataStream API(1)源算子(Source)
【Flink-1.17-教程】-【四】Flink DataStream API(1)源算子(Source) 1)执行环境(Execution Environment)1.1.创建执行环境1.2.执行模式(Execution Mode)1.3.触发程序执行…...

【蓝桥杯EDA设计与开发】资料汇总以及立创EDA及PCB相关技术资料汇总(持续更新)
[18/01/2024]:目前为了准备蓝桥杯做一些资料贴,于是写下这一篇博客。 各种资料均来源于网络以及部分书籍、手册等文档,参考不保证其准确性。 如果在准备蓝桥杯,可与我私信共同学习!!!…...

JavaEE学习笔记 2024-1-18 --模块化Controller层、AJAX与JSON
上一篇 个人整理非商业用途,欢迎探讨与指正!! 文章目录 11.模块化Controller层12.AJAX12.1使用场景 13.JSON13.1如何使用后端发送JSON数据 11.模块化Controller层 将对应模块的Servlet写入到一个指定的模块中,模块化编程 使用switch方式 p…...

rpc跨平台通信的简单案例,java和go
当我们使用Go和Java进行RPC(Remote Procedure Call,远程过程调用)跨平台通信时,你可以使用gRPC作为通信框架。gRPC是一个高性能、开源的RPC框架,它支持多种编程语言,包括Go和Java。下面我将为你提供一个简单…...

Java设计模式之观察者模式详解
Java设计模式之观察者模式详解 大家好,我是免费搭建查券返利机器人赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天,我们将一同深入探讨Java设计模式之观察者模式,这是一种代…...
分布式锁实现(mysql,以及redis)以及分布式的概念
道生一,一生二,二生三,三生万物 我旁边的一位老哥跟我说,你知道分布式是是用来干什么的嘛?一句话给我干懵了,我能隐含知道,大概是用来做分压处理的,并增加系统稳定性的。但是具体如…...

实现分布式锁:Zookeeper vs Redis
目录 引言 1. Zookeeper分布式锁 1.1特点和优势: 强一致性 顺序节点 Watch机制 1.2 Zookeeper分布式锁代码示例 2. Redis分布式锁 2.1特点和优势: 简单高效 可续租性 灵活性 2.2Redis分布式锁代码示例 3.对比和选择 3.1 一致性要求 3.2…...
电脑录屏必备技能,让分享变得更加简单!
随着网络技术的飞速发展,电脑录屏已经成为日常工作和学习中不可或缺的一部分。无论是录制在线课程、游戏解说、软件教程,还是远程会议、演示文稿等,电脑录屏都有着广泛的应用。接下来,本文将介绍三种常见的电脑录屏方法࿰…...
重构改善既有代码的设计-学习(一):封装
1、封装记录(Encapsulate Record) 一些记录性结构(例如hash、map、hashmap、dictionary等),一条记录上持有什么字段往往不够直观。如果其使用范围比较宽,这个问题往往会造成许多困扰。所以,记录…...

Python图像处理【19】基于霍夫变换的目标检测
基于霍夫变换的目标检测 0. 前言1. 使用圆形霍夫变换统计图像中圆形对象2. 使用渐进概率霍夫变换检测直线2.1 渐进霍夫变换原理2.2 直线检测 3. 使用广义霍夫变换检测任意形状的对象3.1 广义霍夫变换原理3.2 检测自定义形状 小结系列链接 0. 前言 霍夫变换 (Hough Transform,…...
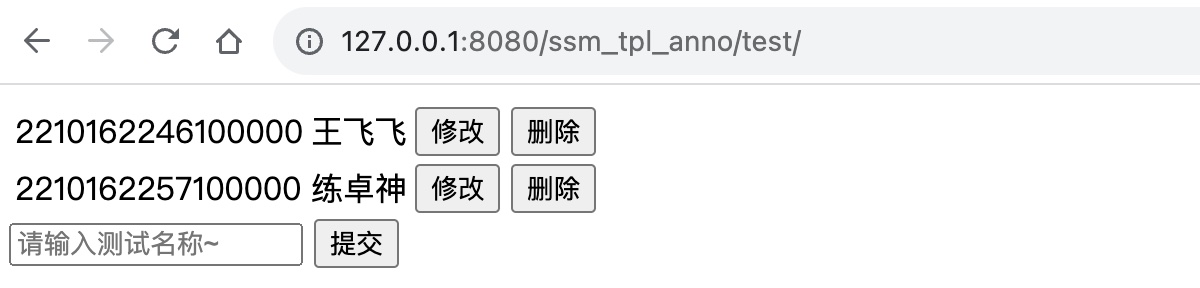
Spring+SprinMVC+MyBatis注解方式简易模板
SpringSprinMVCMyBatis注解方式简易模板代码Demo GitHub访问 ssm-tpl-anno 一、数据准备 创建数据库test,执行下方SQL创建表ssm-tpl-cfg /*Navicat Premium Data TransferSource Server : 127.0.0.1Source Server Type : MySQLSource Server Version :…...

Python基础第五篇(Python数据容器)
文章目录 一、数据容器入门二、数据容器 list 列表(1),list 列表定义(2),list列表的索引(3),list列表的常见操作(4),list列表的遍历 三、数据容器:tuple(元组)(1),tuple元组定义(2),tuple元组的索引(3),tuple元组的常见操作(4),tuple元组的遍…...
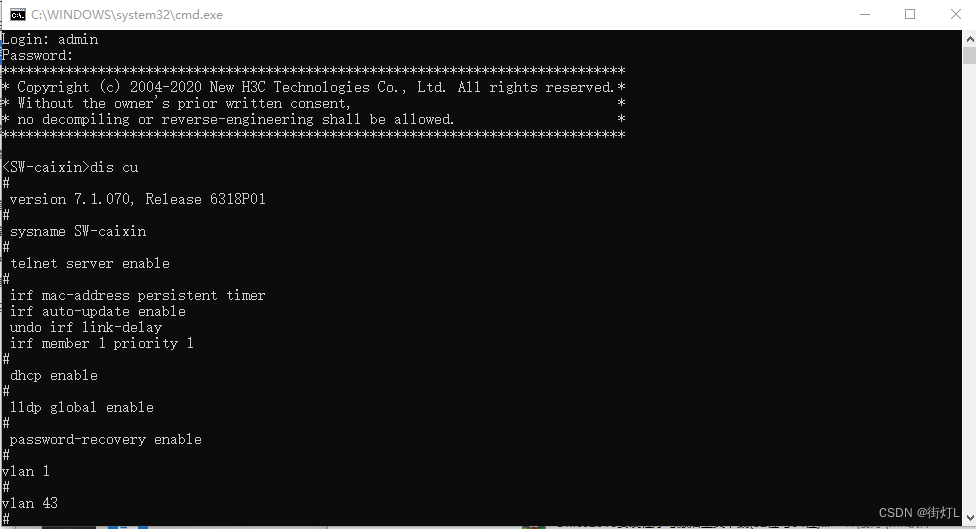
【H3C】配置AAA认证和Telnet远程登陆,S5130 Series交换机
AAA配置步骤为: 1.开启telent远程登陆服务 2.创建用户,设置用户名、密码、用户的服务类型 3.配置终端登录的数量 4.配置vlan-if的ip地址,用来远程登陆 5.允许对应的vlan通过 1.开启telent远程登陆服务 sys …...
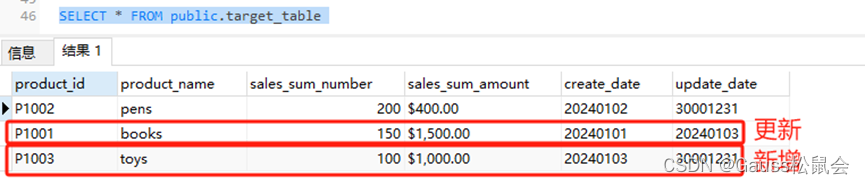
GaussDB数据库中的MERGE INTO介绍
一、前言 二、GaussDB MERGE INTO 语句的原理概述 1、MERGE INTO 语句原理 2、MERGE INTO 的语法 3、语法解释 三、GaussDB MERGE INTO 语句的应用场景 四、GaussDB MERGE INTO 语句的示例 1、示例场景举例 2、示例实现过程 1)创建两个实验表,并…...
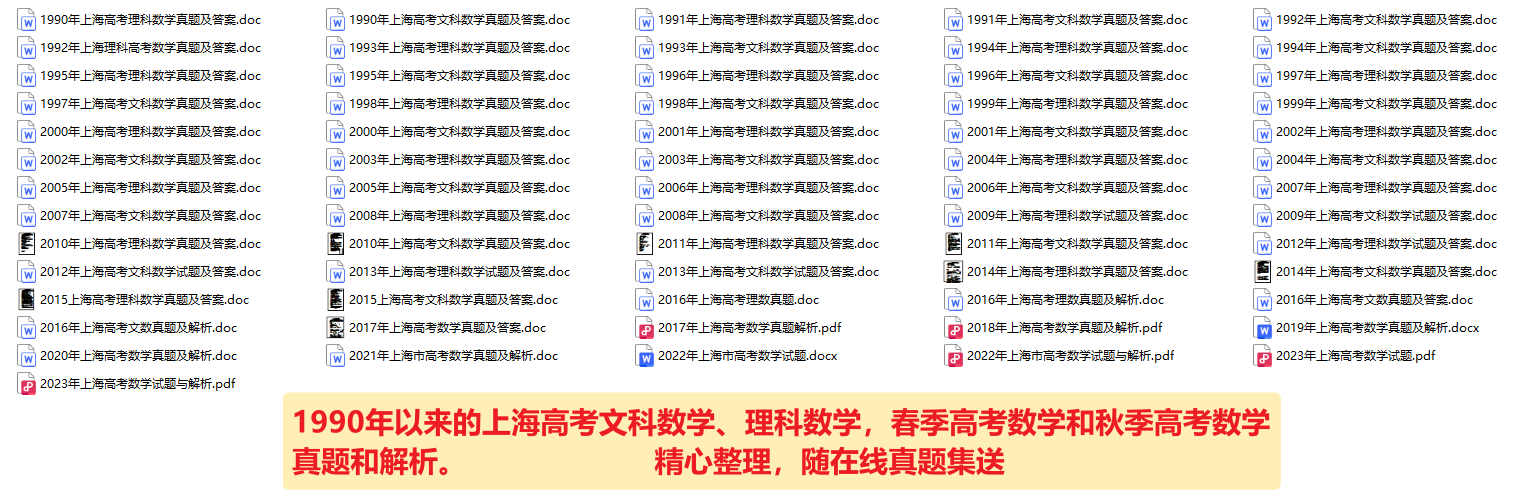
2024年上海高考数学最后四个多月的备考攻略,目标140+
亲爱的同学们,寒假已经来临,春节即将到来,距离2024年上海高考已经余额不足5个月了。作为让许多学子头疼,也是拉分大户的数学科目,你准备好了吗?今天,六分成长为您分享上海高考数学最后四个多月的…...

SSL证书自动化管理有什么好处?如何实现SSL证书自动化?
SSL证书是用于加密网站与用户之间传输数据的关键元素,在维护网络安全方面,管理SSL证书与部署SSL证书一样重要。定期更新、监测和更换SSL证书,可以确保网站的安全性和合规性。而自动化管理可以为此节省时间,并避免人为错误和不必要…...
路由器初始化配置、功能配置
实验环境 拓扑图 Ip规划表(各组使用自己的IP规划表) 部门 主机数量 网络地址 子网掩码 网关 可用ip Vlan 市场部 38 192.168.131.0 255.255.255.0 192.168.131.1 2-254 11 研发部 53 192.168.132.0 255.255.255.0 192.168.132.1 2-2…...
node介绍
1.node是什么 Node是一个基于Chrome V8引擎的JS运行环境。 Node不是一个独立的语言、node不是JS框架。 Node是一个除了浏览器之外的、可以让JS运行的环境 Node.js是一个让JS运行在服务端的开发平台,是使用事件驱动,异步非阻塞I/O,单线程&…...

海外抖音TikTok、正在内测 AI 生成歌曲功能,依靠大语言模型 Bloom 进行文本生成歌曲
近日,据外媒The Verge报道,TikTok正在测试一项新功能,利用大语言模型Bloom的AI能力,允许用户上传歌词文本,并使用AI为其添加声音。这一创新旨在为用户提供更多创作音乐的工具和选项。 Bloom 是由AI初创公司Hugging Fac…...

【ARM 嵌入式 编译系列 3.6 -- 删除lib中的某个文件】
请阅读【嵌入式开发学习必备专栏 之 ARM GCC 编译专栏】 文章目录 删除lib中的某个文件 删除lib中的某个文件 比如,如果要删除 libc.a 静态库中的特定对象文件并重新使用这个静态库,在终端中可以使用 ar 命令。ar 是一个归档工具,它可以创建…...

告别GDB依赖:在NEMU里打造专属调试器,我是如何搞定单步执行与内存扫描的
从零构建教学级调试器:NEMU Monitor模块深度解析与实践指南 在计算机系统与体系结构的学习过程中,调试器如同探索程序执行奥秘的显微镜。传统调试工具如GDB虽然功能强大,但其内部工作机制对初学者而言却如同黑箱。本文将带您深入NEMU模拟器的…...

RAG知识库全流程实操:从分块→检索→生成,逐步拆解
搭了个 RAG,文档灌进去,问题丢过来,回答出来了——看起来能用了。 但问它"RAG 四代架构是什么",它编了个"第一代 RTG"——这个术语根本不存在。问它"嵌入模型中文怎么选",它说"建…...

2026年盲审前论文降AI攻略:盲审提交前AIGC超标免费4.8元知网达标完整处理方案
2026年盲审前论文降AI攻略:盲审提交前AIGC超标免费4.8元知网达标完整处理方案 答辩前三天,AI率还有74%。 翻遍论坛找方法,最终用嘎嘎降AI(www.aigcleaner.com)把74%降到6.8%,4.8元,当天搞定。…...

tinySPL 与 U-Boot 核心区别
tinySPL 与 U-Boot 核心区别 一、定位本质项目tinySPLU-Boot定位轻量极简二级引导,专为RTOS/裸机设计通用全能大型Bootloader,主打Linux系统体积极小,几十KB级别大,几百KB~数MB设计目标极速启动、轻量化、适配嵌入式轻系统功能最全…...
)
Perplexity引用格式设置全链路解析(含BibTeX/CSL/DOI自动映射底层逻辑)
更多请点击: https://kaifayun.com 第一章:Perplexity引用格式设置全链路解析(含BibTeX/CSL/DOI自动映射底层逻辑) Perplexity 在学术写作支持中并非原生集成引文管理,但其底层可对接外部文献元数据服务,实…...

2026 酒店无人直播服务商推荐:警惕一次性收费陷阱,用心服务才是核心
"一次购买,无任何后续费用!"—— 这样的宣传语让不少酒店经营者心动不已,以为找到了低成本获客的捷径。然而,现实往往事与愿违:软件使用不到1个月,算力耗尽无法开播;直播间频繁卡顿、…...

Codex + SSH 远程运维实战:让 AI 管你的云服务器
Codex SSH 远程运维实战:让 AI 管你的云服务器从 Docker 部署到数据库调优,从日志排查到安全加固——用 Codex CLI 通过 SSH 管理云服务器的完整实战指南。一、为什么用 Codex 做运维? 传统运维的痛点: 半夜报警,睡眼…...

3步实现B站缓存视频智能转换:高效保存珍贵学习资源
3步实现B站缓存视频智能转换:高效保存珍贵学习资源 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾为B站缓存视频无法在其他…...

如何快速配置PlotSquared:Minecraft领地管理完整教程
如何快速配置PlotSquared:Minecraft领地管理完整教程 【免费下载链接】PlotSquared PlotSquared - Reinventing the plotworld 项目地址: https://gitcode.com/gh_mirrors/pl/PlotSquared 你是否厌倦了Minecraft服务器中混乱的建筑和领地冲突?想要…...

在Nodejs后端服务中集成Taotoken实现统一的大模型调用网关
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Nodejs后端服务中集成Taotoken实现统一的大模型调用网关 当你的后端服务需要接入多种大模型能力时,直接对接不同厂商…...