flume案例
在构建数仓时,经常会用到flume接收日志数据,通常涉及到的组件为kafka,hdfs等。下面以一个flume接收指定topic数据,并存入hdfs的案例,大致了解下flume相关使用规则。
版本:1.9
Source
Kafka Source就是一个Apache Kafka消费者,它从Kafka的topic中读取消息。 如果运行了多个Kafka Source,则可以把它们配置到同一个消费者组,以便每个source都读取一组唯一的topic分区。
目前支持Kafka 0.10.1.0以上版本,最高已经在Kafka 2.0.1版本上完成了测试,这已经是Flume 1.9发行时候的最高的Kafka版本了。
| 属性名 | 默认值 | 解释 |
|---|---|---|
| channels | – | 与Source绑定的channel,多个用空格分开 |
| type | – | 组件类型,这个是: |
| kafka.bootstrap.servers | – | Source使用的Kafka集群实例列表 |
| kafka.consumer.group.id | flume | 消费组的唯一标识符。如果有多个source或者Agent设定了相同的ID,表示它们是同一个消费者组 |
| kafka.topics | – | 将要读取消息的目标 Kafka topic 列表,多个用逗号分隔 |
| kafka.topics.regex | – | 会被Kafka Source订阅的 topic 集合的正则表达式。这个参数比 kafka.topics 拥有更高的优先级,如果这两个参数同时存在,则会覆盖kafka.topics的配置。 |
| batchSize | 1000 | 一批写入 channel 的最大消息数 |
| batchDurationMillis | 1000 | 一个批次写入 channel 之前的最大等待时间(毫秒)。达到等待时间或者数量达到 batchSize 都会触发写操作。 |
| backoffSleepIncrement | 1000 | 当Kafka topic 显示为空时触发的初始和增量等待时间(毫秒)。等待时间可以避免对Kafka topic的频繁ping操作。默认的1秒钟对于获取数据比较合适, 但是对于使用拦截器时想达到更低的延迟可能就需要配置更低一些。 |
| maxBackoffSleep | 5000 | Kafka topic 显示为空时触发的最长等待时间(毫秒)。默认的5秒钟对于获取数据比较合适,但是对于使用拦截器时想达到更低的延迟可能就需要配置更低一些。 |
| useFlumeEventFormat | false | 默认情况下,从 Kafka topic 里面读取到的内容直接以字节数组的形式赋值给Event。如果设置为true,会以Flume Avro二进制格式进行读取。与Kafka Sink上的同名参数或者 Kafka channel 的parseAsFlumeEvent参数相关联,这样以对象的形式处理能使生成端发送过来的Event header信息得以保留。 |
| setTopicHeader | true | 当设置为 |
| topicHeader | topic | 如果 setTopicHeader 设置为 |
| kafka.consumer.security.protocol | PLAINTEXT | 设置使用哪种安全协议写入Kafka。可选值: |
| more consumer security props | 如果使用了SASL_PLAINTEXT、SASL_SSL 或 SSL 等安全协议,参考 Kafka security 来为消费者增加安全相关的参数配置 | |
| Other Kafka Consumer Properties | – | 其他一些 Kafka 消费者配置参数。任何 Kafka 支持的消费者参数都可以使用。唯一的要求是使用“kafka.consumer.”这个前缀来配置参数,比如: |
必需的参数已用 粗体 标明。
已经弃用的一些属性:
| 属性名 | 默认值 | 解释 |
|---|---|---|
| topic | – | 改用 kafka.topics |
| groupId | flume | 改用 kafka.consumer.group.id |
| zookeeperConnect | – | 自0.9.x起不再受kafka消费者客户端的支持。以后使用kafka.bootstrap.servers与kafka集群建立连接 |
| migrateZookeeperOffsets | true | 如果找不到Kafka存储的偏移量,去Zookeeper中查找偏移量并将它们提交给 Kafka 。 它应该设置为true以支持从旧版本的FlumeKafka客户端无缝迁移。 迁移后,可以将其设置为false,但通常不需要这样做。 如果在Zookeeper未找到偏移量,则可通过kafka.consumer.auto.offset.reset配置如何处理偏移量。可以从 Kafka documentation 查看更多详细信息。 |
Channel
此处选择memory channel,内存 channel 是把 Event 队列存储到内存上,队列的最大数量就是 capacity 的设定值。它非常适合对吞吐量有较高要求的场景,但也是有代价的,当发生故障的时候会丢失当时内存中的所有 Event。 必需的参数已用 粗体 标明。
| 属性 | 默认值 | 解释 |
|---|---|---|
| type | – | 组件类型,这个是: |
| capacity | 100 | 内存中存储 Event 的最大数 |
| transactionCapacity | 100 | source 或者 sink 每个事务中存取 Event 的操作数量(不能比 capacity 大) |
| keep-alive | 3 | 添加或删除一个 Event 的超时时间(秒) |
| byteCapacityBufferPercentage | 20 | 指定 Event header 所占空间大小与 channel 中所有 Event 的总大小之间的百分比 |
| byteCapacity | Channel 中最大允许存储所有 Event 的总字节数(bytes)。默认情况下会使用JVM可用内存的80%作为最大可用内存(就是JVM启动参数里面配置的-Xmx的值)。 计算总字节时只计算 Event 的主体,这也是提供 byteCapacityBufferPercentage 配置参数的原因。注意,当你在一个 Agent 里面有多个内存 channel 的时候, 而且碰巧这些 channel 存储相同的物理 Event(例如:这些 channel 通过复制机制( 复制选择器 )接收同一个 source 中的 Event), 这时候这些 Event 占用的空间是累加的,并不会只计算一次。如果这个值设置为0(不限制),就会达到200G左右的内部硬件限制。 |
Sink
HDFS Sink ,这个Sink将Event写入Hadoop分布式文件系统(也就是HDFS)。 目前支持创建文本和序列文件。 它支持两种文件类型的压缩。 可以根据写入的时间、文件大小或Event数量定期滚动文件(关闭当前文件并创建新文件)。 它还可以根据Event自带的时间戳或系统时间等属性对数据进行分区。 存储文件的HDFS目录路径可以使用格式转义符,会由HDFS Sink进行动态地替换,以生成用于存储Event的目录或文件名。 使用此Sink需要安装hadoop, 以便Flume可以使用Hadoop的客户端与HDFS集群进行通信。 注意, 需要使用支持sync() 调用的Hadoop版本 。
| 属性名 | 默认值 | 解释 |
|---|---|---|
| channel | – | 与 Sink 连接的 channel |
| type | – | 组件类型,这个是: |
| hdfs.path | – | HDFS目录路径(例如:hdfs://namenode/flume/webdata/) |
| hdfs.filePrefix | FlumeData | Flume在HDFS文件夹下创建新文件的固定前缀 |
| hdfs.fileSuffix | – | Flume在HDFS文件夹下创建新文件的后缀(比如:.avro,注意这个“.”不会自动添加,需要显式配置) |
| hdfs.inUsePrefix | – | Flume正在写入的临时文件前缀,默认没有 |
| hdfs.inUseSuffix | .tmp | Flume正在写入的临时文件后缀 |
| hdfs.emptyInUseSuffix | false | 如果设置为 |
| hdfs.rollInterval | 30 | 当前文件写入达到该值时间后触发滚动创建新文件(0表示不按照时间来分割文件),单位:秒 |
| hdfs.rollSize | 1024 | 当前文件写入达到该大小后触发滚动创建新文件(0表示不根据文件大小来分割文件),单位:字节 |
| hdfs.rollCount | 10 | 当前文件写入Event达到该数量后触发滚动创建新文件(0表示不根据 Event 数量来分割文件) |
| hdfs.idleTimeout | 0 | 关闭非活动文件的超时时间(0表示禁用自动关闭文件),单位:秒 |
| hdfs.batchSize | 100 | 向 HDFS 写入内容时每次批量操作的 Event 数量 |
| hdfs.codeC | – | 压缩算法。可选值: |
| hdfs.fileType | SequenceFile | 文件格式,目前支持: |
| hdfs.maxOpenFiles | 5000 | 允许打开的最大文件数,如果超过这个数量,最先打开的文件会被关闭 |
| hdfs.minBlockReplicas | – | 指定每个HDFS块的最小副本数。 如果未指定,则使用 classpath 中 Hadoop 的默认配置。 |
| hdfs.writeFormat | Writable | 文件写入格式。可选值: |
| hdfs.threadsPoolSize | 10 | 每个HDFS Sink实例操作HDFS IO时开启的线程数(open、write 等) |
| hdfs.rollTimerPoolSize | 1 | 每个HDFS Sink实例调度定时文件滚动的线程数 |
| hdfs.kerberosPrincipal | – | 用于安全访问 HDFS 的 Kerberos 用户主体 |
| hdfs.kerberosKeytab | – | 用于安全访问 HDFS 的 Kerberos keytab 文件 |
| hdfs.proxyUser | 代理名 | |
| hdfs.round | false | 是否应将时间戳向下舍入(如果为true,则影响除 |
| hdfs.roundValue | 1 | 向下舍入(小于当前时间)的这个值的最高倍(单位取决于下面的 hdfs.roundUnit ) 例子:假设当前时间戳是18:32:01,hdfs.roundUnit = |
| hdfs.roundUnit | second | 向下舍入的单位,可选值: |
| hdfs.timeZone | Local Time | 解析存储目录路径时候所使用的时区名,例如:America/Los_Angeles、Asia/Shanghai |
| hdfs.useLocalTimeStamp | false | 使用日期时间转义符时是否使用本地时间戳(而不是使用 Event header 中自带的时间戳) |
| hdfs.closeTries | 0 | 开始尝试关闭文件时最大的重命名文件的尝试次数(因为打开的文件通常都有个.tmp的后缀,写入结束关闭文件时要重命名把后缀去掉)。 如果设置为1,Sink在重命名失败(可能是因为 NameNode 或 DataNode 发生错误)后不会重试,这样就导致了这个文件会一直保持为打开状态,并且带着.tmp的后缀; 如果设置为0,Sink会一直尝试重命名文件直到成功为止; 关闭文件操作失败时这个文件可能仍然是打开状态,这种情况数据还是完整的不会丢失,只有在Flume重启后文件才会关闭。 |
| hdfs.retryInterval | 180 | 连续尝试关闭文件的时间间隔(秒)。 每次关闭操作都会调用多次 RPC 往返于 Namenode ,因此将此设置得太低会导致 Namenode 上产生大量负载。 如果设置为0或更小,则如果第一次尝试失败,将不会再尝试关闭文件,并且可能导致文件保持打开状态或扩展名为“.tmp”。 |
| serializer | TEXT | Event 转为文件使用的序列化器。其他可选值有: |
| serializer.* | 根据上面 serializer 配置的类型来根据需要添加序列化器的参数 |
完整案例如下:
a1.sources=r1
a1.channels=c1
a1.sinks=k1a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hmcs030:9092,hmcs031:9092,hmcs032:9092
a1.sources.r1.kafka.topics= hmcs_network_enterprise_climb
a1.sources.r1.kafka.consumer.group.id = hmcs_network_enterprise_climb_group
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.hmcs.interceptor.DecodeInterceptor$Buildera1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 10000
a1.channels.c1.parseAsFlumeEvent = falsea1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://ns1/flume/enterprise/networkEnterData/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = climbNetworkEnter-
a1.sinks.k1.hdfs.round = false
a1.sinks.k1.hdfs.rollInterval = 300
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.fileType=DataStreama1.sources.r1.channels = c1
a1.sinks.k1.channel= c1
启动命令如下:
nohup /usr/local/flume/bin/flume-ng agent -c /usr/local/flume/conf/ -f /usr/local/flume/job/kafka_memory_hdfs.conf -n a1 -Dflume.root.logger=info,console >/usr/local/flume/logs/kafka_memory_hdfs.log 2>&1 &相关文章:

flume案例
在构建数仓时,经常会用到flume接收日志数据,通常涉及到的组件为kafka,hdfs等。下面以一个flume接收指定topic数据,并存入hdfs的案例,大致了解下flume相关使用规则。 版本:1.9 Source Kafka Source就是一…...
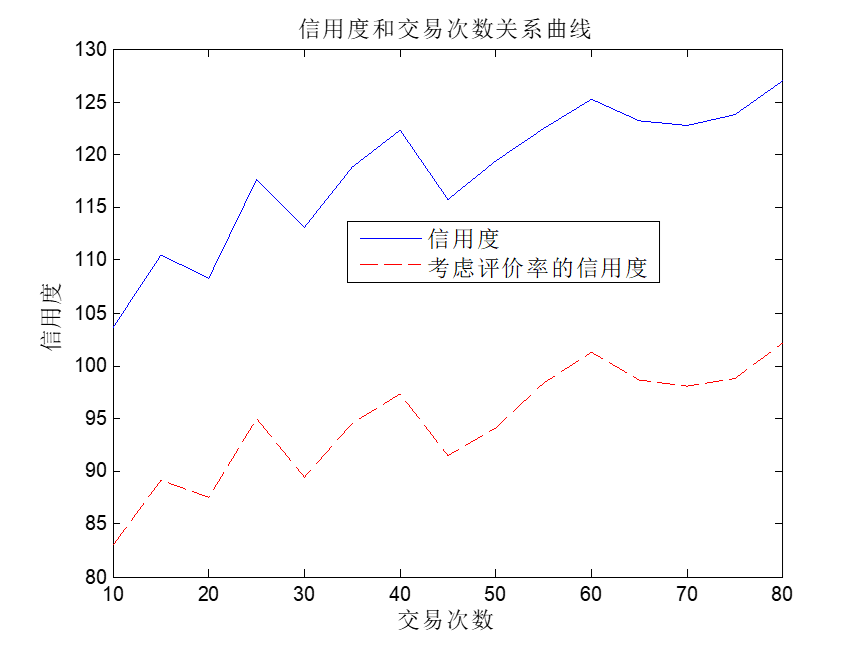
信用评价研究MATLAB仿真代码
信用评价是各种店铺卖家分析买家信用行为的重要内容, 本文给出随机仿真代码模拟实际交易过程的信用评价. 主要研究内容有: (1)研究最大交易额和信用度的关系 (2)研究买家不评价率对信用度影响 (3)研究交易次数对信用度影响 MATLAB程序如下: 主程序main.m %% clc;close a…...

网络安全产品之认识防毒墙
在互联网发展的初期,网络结构相对简单,病毒通常利用操作系统和软件程序的漏洞发起攻击,厂商们针对这些漏洞发布补丁程序。然而,并不是所有终端都能及时更新这些补丁,随着网络安全威胁的不断升级和互联网的普及…...

android 防抖工具类,经纬度检查工具类
一:点击事件防抖工具类: public abstract class ThrottleClickListener implements View.OnClickListener {private long clickLastTimeKey 0;private final long thresholdMillis 500;//millisecondsOverridepublic void onClick(View v) {long curr…...
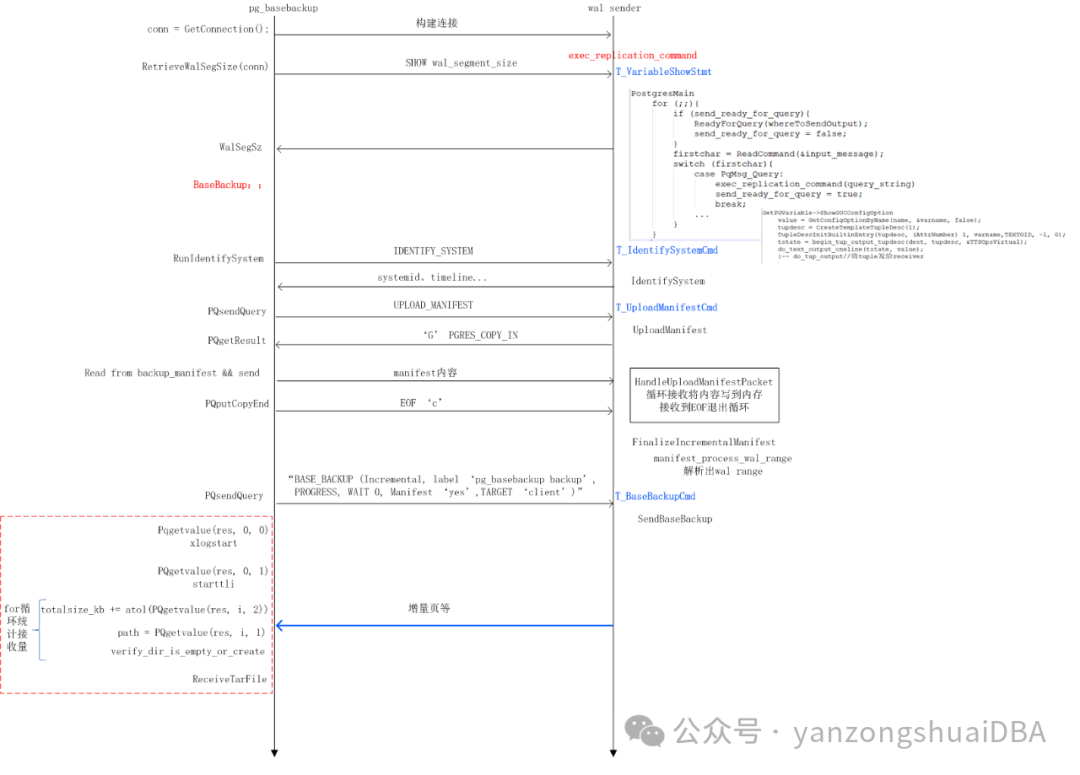
PgSQL - 17新特性 - 块级别增量备份
PgSQL - 17新特性 - 块级别增量备份 PgSQL可通过pg_basebackup进行全量备份。在构建复制关系时,创建备机时需要通过pg_basebackup全量拉取一个备份,形成一个mirror。但很多场景下,我们往往不需要进行全量备份/恢复,数据量特别大的…...
的非语法糖和语法糖的用法)
Vue3setup()的非语法糖和语法糖的用法
1、setup()的语法糖的用法 script标签上写setup属性,不需要export default {} setup() 都可以省 创建每个属性或方法时也不需要return 导入某个组件时也不需要注册 <script setup > // script标签上写setup属性,不需要export default {} set…...

HTTP状态信息
1xx: 信息 消息:描述:100 Continue服务器仅接收到部分请求,但是一旦服务器并没有拒绝该请求,客户端应该继续发送其余的请求。101 Switching Protocols服务器转换协议:服务器将遵从客户的请求转换到另外一种协议。 2xx: 成功 消息:描述:200…...

CSS之边框样式
让我为大家介绍一下边框样式吧!如果大家想更进一步了解边框的使用,可以阅读这一篇文章:CSS边框border 属性描述none没有边框,即忽略所有边框的宽度(默认值)solid边框为单实线dashed边框为虚线dotted边框为点线double边框为双实线 代码演示&…...
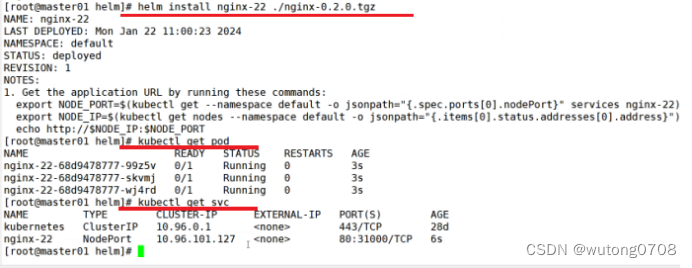
k8s-helm
Helm: 什么是helm,在没有这个heml之前,deployment service ingress的作用就是通过打包的方式,把deployment service ingress这些打包在一块,一键式的部署服务,类似于yum 官方提供的一个类似于安全仓库的功能,可以实现…...
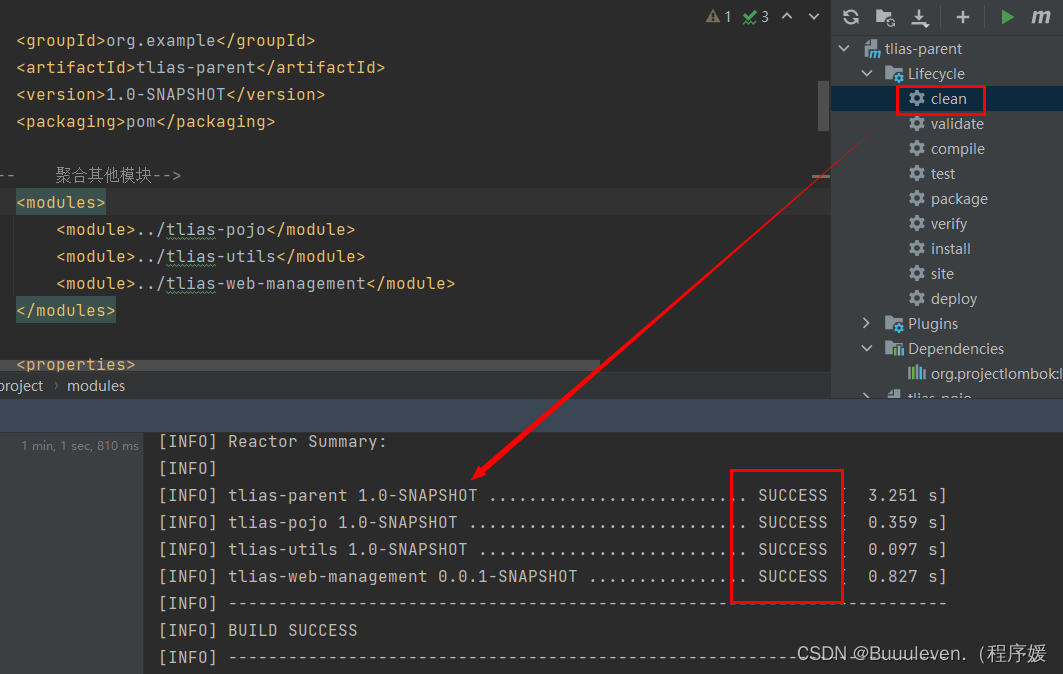
黑马程序员JavaWeb开发|Maven高级
一、分模块设计与开发 分模块设计: 将项目按照功能拆分成若干个子模块,方便项目的管理维护、扩展,也方便模块间的相互调用,资源共享。 注意:分模块开发需要先对模块功能进行设计,再进行编码。不会先将工…...
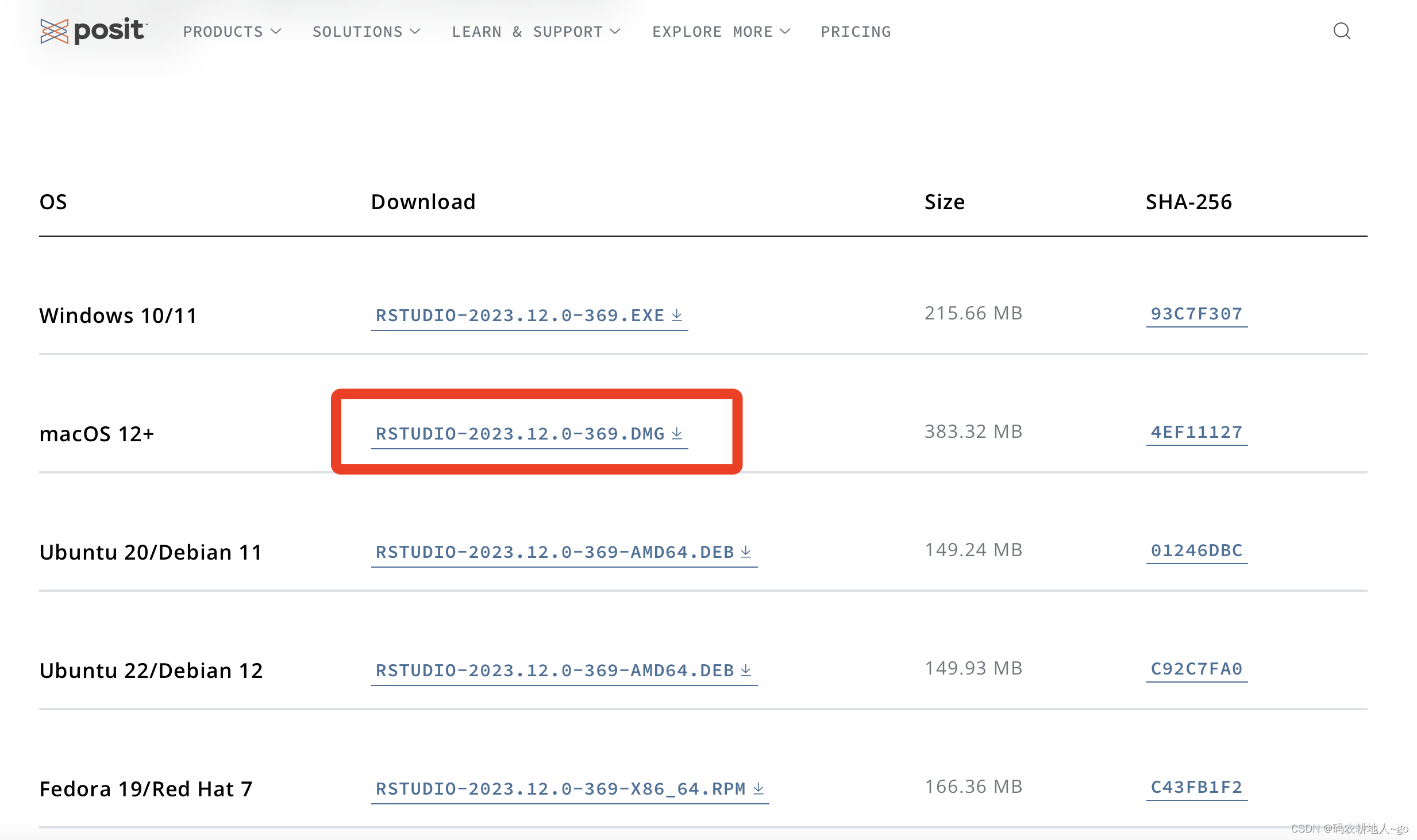
【经验分享】MAC系统安装R和Rstudio(保姆级教程)安装下载只需5min
最近换了Macbook的Air电脑,自然要换很多新软件啦,首先需要安装的就是R和Rstudio啦,网上的教程很多很繁琐,为此我特意总结了最简单实用的安装方式: 一、先R后Rstudio 二、R下载 下载网址:https://cran.r-project.org …...
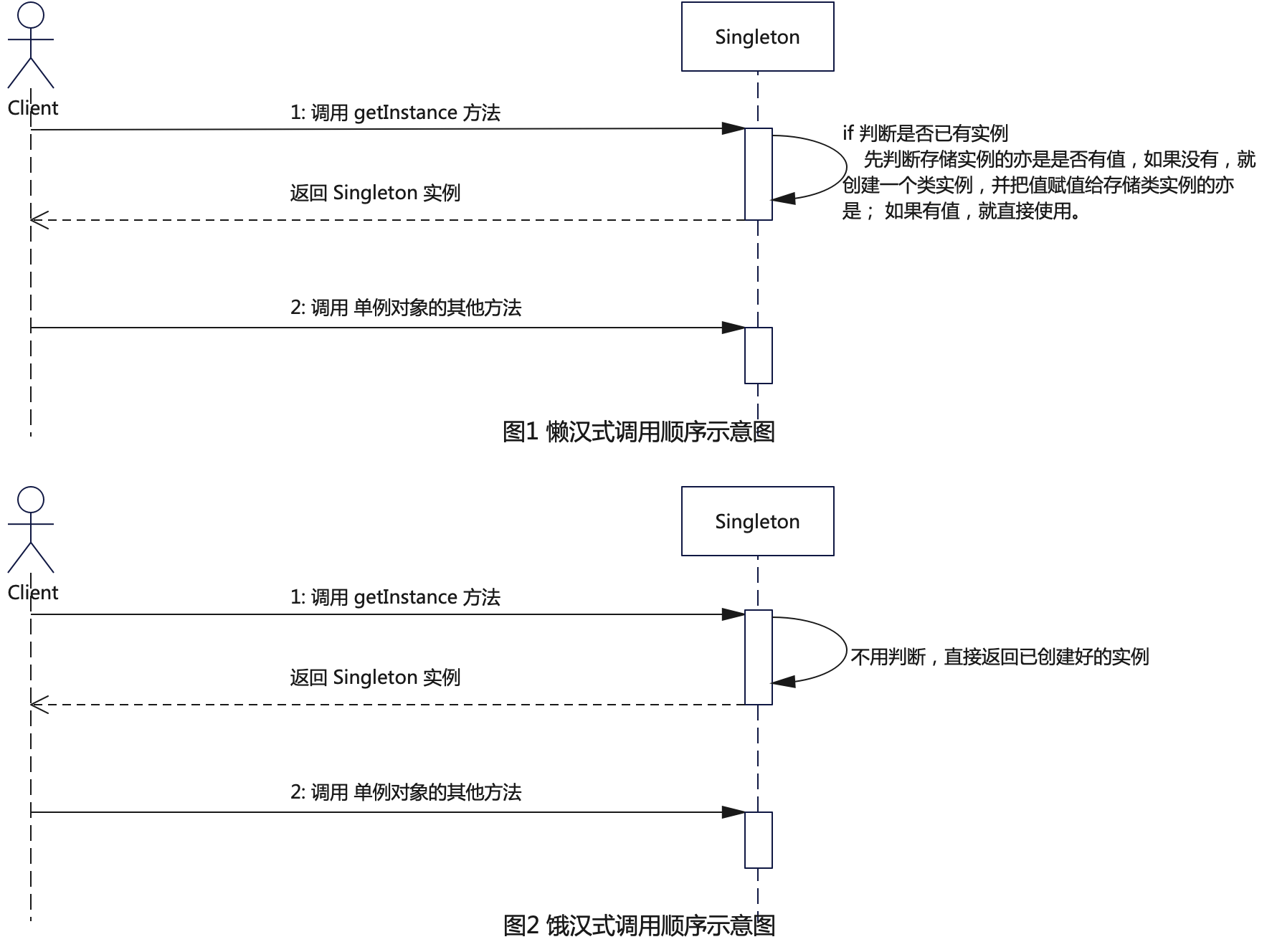
探索设计模式的魅力:“感受单例模式的力量与神秘” - 掌握编程的王牌技巧
在软件开发的赛场上,单例模式以其独特的魅力长期占据着重要的地位。作为设计模式中的一员,它在整个软件工程的棋盘上扮演着关键性角色。本文将带你深入探索单例模式的神秘面纱,从历史渊源到现代应用,从基础实现到高级技巧…...

SpringCloud Aliba-Seata【上】-从入门到学废【7】
目录 🧂.Seata是什么 🌭2.Seata术语表 🥓3.处理过程 🧈4.下载 🍿5.修改相关配置 🥞6.启动seata 1.Seata是什么 Seata是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能…...
C# Cad2016二次开发选择csv导入信息(七)
//选择csv导入信息 [CommandMethod("setdata")] //本程序在AutoCAD的快捷命令是"DLLLOAD" public void setdata() {Microsoft.Win32.OpenFileDialog dlg new Microsoft.Win32.OpenFileDialog();dlg.DefaultExt ".csv";// Display OpenFileDial…...
[陇剑杯 2021]日志分析
[陇剑杯 2021]日志分析 题目做法及思路解析(个人分享) 问一:单位某应用程序被攻击,请分析日志,进行作答: 网络存在源码泄漏,源码文件名是_____________。(请提交带有文件后缀的文件名&…...
Java面试汇总——jvm篇
目录 JVM的组成: 1、JVM 概述(⭐⭐⭐⭐) 1.1 JVM是什么? 1.2 JVM由哪些部分组成,运行流程是什么? 2、什么是程序计数器?(⭐⭐⭐⭐) 3、介绍一下Java的堆(⭐⭐⭐⭐) 4、虚拟机栈(⭐⭐⭐⭐) 4.1 什么是虚拟机栈&…...
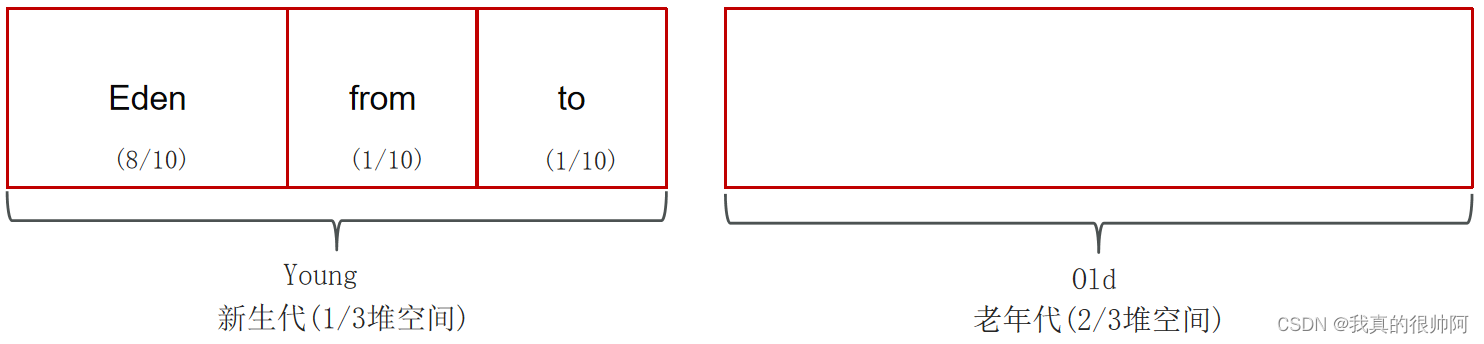
数据结构:完全二叉树(递归实现)
如果完全二叉树的深度为h,那么除了第h层外,其他层的节点个数都是满的,第h层的节点都靠左排列。 完全二叉树的编号方法是从上到下,从左到右,根节点为1号节点,设完全二叉树的节点数为sum,某节点编…...
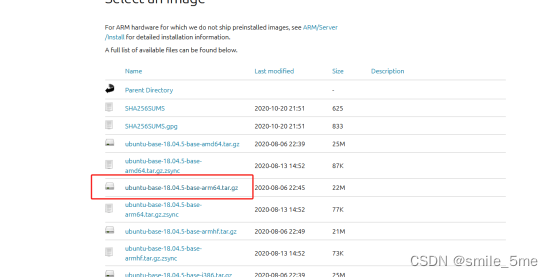
RK3568 移植Ubuntu
使用ubuntu-base构建根文件系统 1、到ubuntu官网获取 ubuntu-base-18.04.5-base-arm64.tar.gz Ubuntu Base 18.04.5 LTS (Bionic Beaver) 2、将获取的文件拷贝到ubuntu虚拟机,新建目录,并解压 mkdir ubuntu_rootfs sudo tar -xpf u...
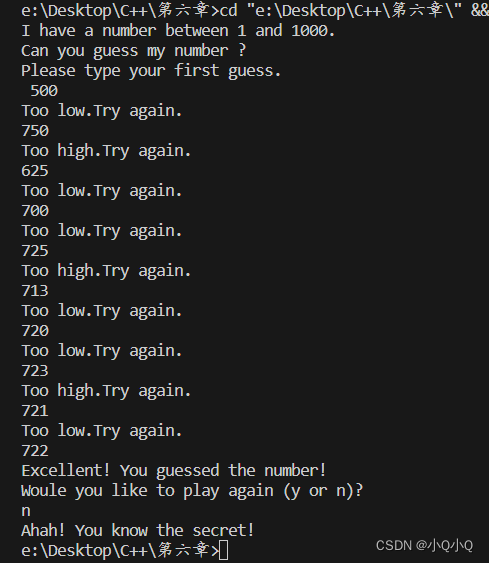
C++大学教程(第九版)6.34猜数字游戏 6.35 修改的猜数字游戏
文章目录 6.34题目代码运行截图6.35题目代码运行截图 6.34题目 猜数字游戏)编写一个程序,可以玩“猜数字”的游戏。具体描述如下:程序在1~1000之间的整数中随机选择需要被猜的数,然后显示: 代码 #include <iostream> #include <cstdlib>…...

【立创EDA-PCB设计基础】5.布线设计规则设置
前言:本文详解布线前的设计规则设置。经过本专栏中的【立创EDA-PCB设计基础】前几节已经完成了布局,接下来开始进行布线,在布线之前,要设置设计规则。 目录 1.间距设置 1.1 安全间距设置 1.2 其它间距设置 2.物理设置 2.1 导…...

OAuth 2.0 and OIDC 三大安全机制对比:State vs Nonce vs PKCE
一、问题背景 OAuth 2.0 和 OpenID Connect 的授权流程依赖浏览器重定向,这天然暴露了多种攻击面: 攻击类型描述CSRF攻击者诱导用户的浏览器携带恶意授权码完成绑定Token 重放窃取的 id_token 被重复提交给客户端授权码劫持恶意应用在同一设备上拦截授…...

打破平台壁垒:Windows上安装APK文件的完整解决方案
打破平台壁垒:Windows上安装APK文件的完整解决方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾想过在Windows电脑上直接运行安卓应用ÿ…...

如何免费下载百度文库文档:三步搞定PDF保存的终极指南
如何免费下载百度文库文档:三步搞定PDF保存的终极指南 【免费下载链接】baidu-wenku fetch the document for free 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wenku 你是否经常在百度文库找到完美的学习资料或工作报告,却因为需要下载券…...

单元体幕墙计算方法研究
单元体幕墙计算方法研究 一、单元板块计算 选择隔离的单个单元进行计算,不需要考虑周边单元的影响。 单元之间的相互影响,来自于左右立柱的变形不一致,在截面选择上反应的就是左右立柱的截面参数的不同。 所以,单元间的相互影响,可以通过控制左右立柱截面参数的相近而进…...
)
保姆级教程:用Python+NumPy复现经典Laplacian曲面编辑算法(附源码)
从理论到代码:Python实现Laplacian曲面编辑的完整指南 在三维图形处理领域,Laplacian曲面编辑技术因其出色的细节保持能力而备受推崇。这项技术允许开发者对三维模型进行直观的变形操作,同时保持模型表面的几何细节不被破坏。本文将带您从零开…...

为AI编程助手构建安全防线:Cursor自定义规则实战指南
1. 项目概述:为AI编程助手装上“安全护栏” 如果你和我一样,深度使用Cursor这类AI编程助手,那你一定体验过它带来的效率革命。它能帮你生成代码、重构函数、甚至解释复杂的逻辑,就像一个不知疲倦的编程伙伴。但硬币总有另一面——…...

树莓派扩展板EYESPI Pi Beret:简化硬件连接,加速原型开发
1. 项目概述:为什么我们需要EYESPI Pi Beret?玩树莓派的朋友,尤其是喜欢捣鼓屏幕和传感器的,肯定都经历过那个阶段:面对一堆杜邦线,对照着屏幕驱动板的引脚定义,一个个数着树莓派的GPIO针脚&…...

ARM Cortex-X4/X925处理器仿真模型与指令集详解
1. ARM Cortex-X4/X925处理器仿真模型概述处理器仿真模型在现代芯片设计中扮演着至关重要的角色,特别是在Arm架构的生态系统中。作为Arm最新一代高性能核心,Cortex-X4和X925的Iris仿真组件提供了完整的指令集和微架构行为建模,使开发者能够在…...

基于Kubernetes Lease构建分布式部署锁:解决CI/CD环境下的资源竞争
1. 项目概述:从“clawfight”看一场被遗忘的社区技术博弈看到“2019-02-18/clawfight”这个标题,很多人的第一反应可能是困惑。它不像一个标准的软件项目名,没有清晰的版本号,也没有指明具体的技术栈。但恰恰是这种看似随意的命名…...
基于GEMMA与NeoPixel制作智能可穿戴首饰:从硬件选型到代码实现
1. 项目概述:当微型控制器遇见珠宝设计几年前,当我第一次把一块微控制器塞进一个首饰盒里,看着它驱动一圈LED发出柔和的光晕时,我就知道,电子制作和个性化穿戴的结合,远不止于智能手表或健身手环。我们今天…...