Gold-YOLO(NeurIPS 2023)论文与代码解析
paper:Gold-YOLO: Efficient Object Detector via Gather-and-Distribute Mechanism
official implementation:https://github.com/huawei-noah/Efficient-Computing/tree/master/Detection/Gold-YOLO
存在的问题
在过去几年里,YOLO系列已经成为了实时目标检测领域最先进以及最常用的方法。许多研究通过修改模型架构、数据增强、设计新的损失函数将baseline提升到了一个更高的水平。但现有的模型仍然存在信息融合的问题,尽管FPN和PANet在一定程度上缓解了该问题。
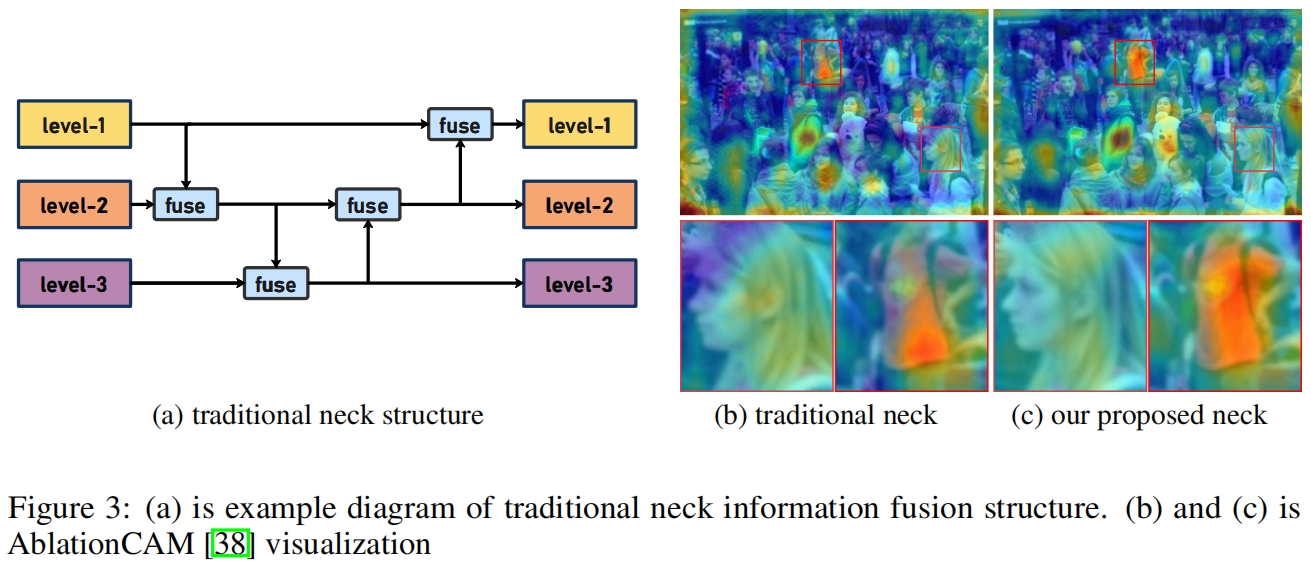
传统的neck如FPN以及相关变体的结构如图3(a)所示,但是这种信息融合的方法存在一个明显的缺陷:当需要跨层融合信息时(如level-1和level-3),FPN式的结构无法无损的传输信息,这阻碍了YOLO系列更好的进行信息融合。
本文的创新点
针对FPN式结构存在的问题,本文在TopFormer理论的基础上,提出了一种新的聚合-分发(GD)机制,它通过融合多层特征并将全局信息注入到更高层,在YOLO中实现高效的信息交换。这显著增加了neck的信息融合能力,同时没有显著增加延迟。
基于此提出了一个新的模型Gold-YOLO,它提高了多尺度特征融合的能力,并在所有尺度上实现了延迟和精度之间的理想平衡。
此外,本文首次在YOLO系列中实现了MAE-style的预训练,使得YOLO系列可以从无监督预训练中受益。
方法介绍
如图3所示,在FPN的结构中,只能完全融合相邻层的信息,对于其它层的信息,只能间接的“递归”获得。这种传输模式可能导致计算过程中信息的丢失。为了避免这种情况,本文放弃了递归方法,构建了一种新的聚合-分发机制。通过使用一个统一的模块从各层收集和融合信息,然后将其分发到不同的层。
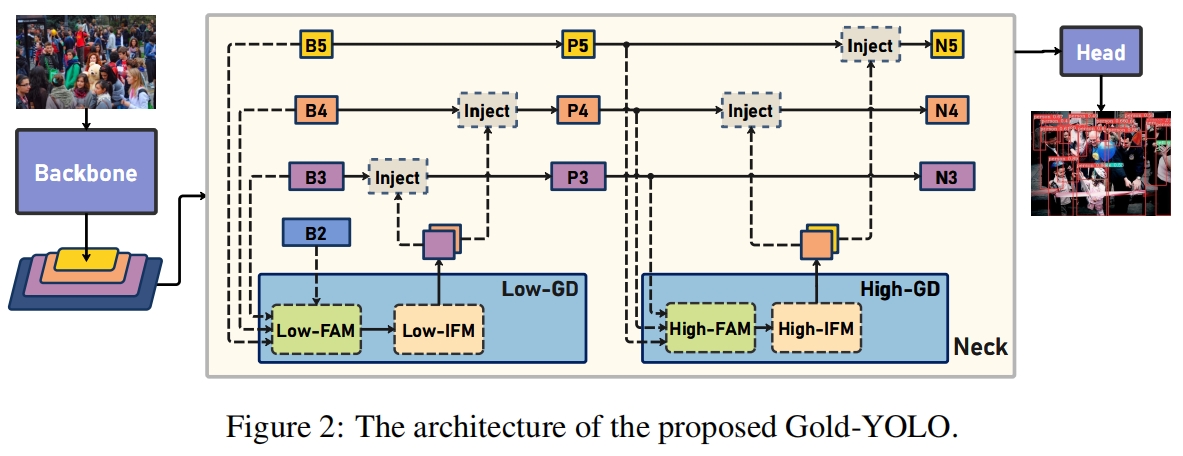
具体实现中,聚合与分发的过程对应三个模块:特征对齐模块(Feature Alignment Module, FAM)、信息融合模块(Information Fusion Module, IFM)、信息注入模块(Information Injection Module, Inject)。完整结构如图2所示
- gather过程包括两步。首先,FAM从不同层收集和对齐特征。然后,IFM通过融合对齐的特征得到全局信息。
- 在获得全局信息后,inject模块将这些信息distribute到每个level中,并使用简单的注意力操作进行注入,从而提高分支的检测能力。
为了增加模型检测不同大小对象的能力,提出了两个分支,low-stage GD和high-stage GD。如图2所示,neck的输入包括backbone提取的特征图B2,B3,B4,B5,其中 \(B_{i}\in \mathbb{R}^{N\times C_{Bi}\times R_{Bi}}\),N是batch size,C是通道数,R=HxW。
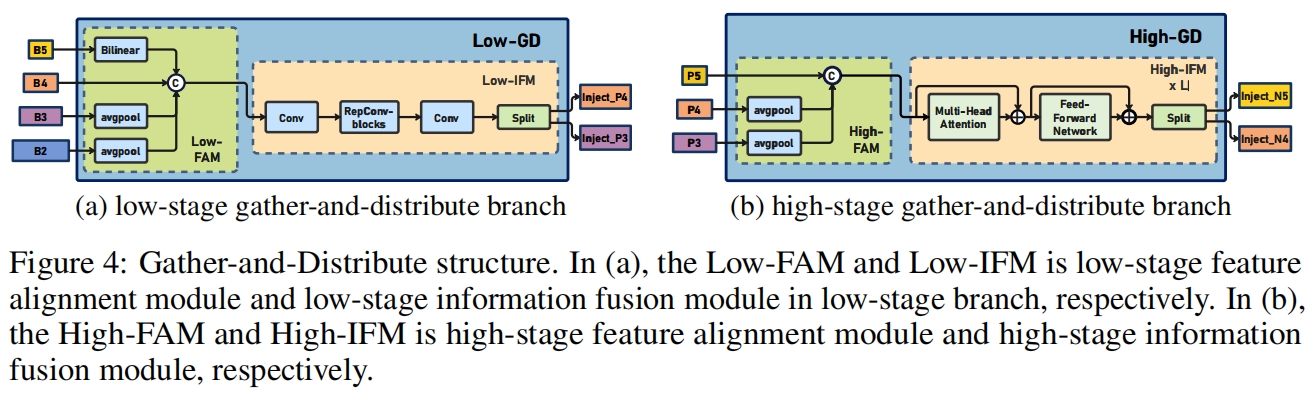
Low GD
结构如图4(a)所示
Low-FAM
在Low-FAM中,用average pooling下采样得到一个统一大小的 \(F_{align}\)。这里选择 \(R_{B4}=\frac{1}{4}R\) 作为目标大小。
Low-IFM
Low-IFM包括多层重参数化卷积Block (RepBlock) 和一个split操作。具体来说,RepBlock取 \(F_{align}\)(\(channel=sum(C_{B2},C_{B3},C_{B4},C_{B5})\))作为输入得到 \(F_{fuse}\)(\(channel=C_{B4}+C_{B5}\)),然后沿通道维度split成 \(F_{inj\_P3}\) 和 \(F_{inj\_P4}\)。如下
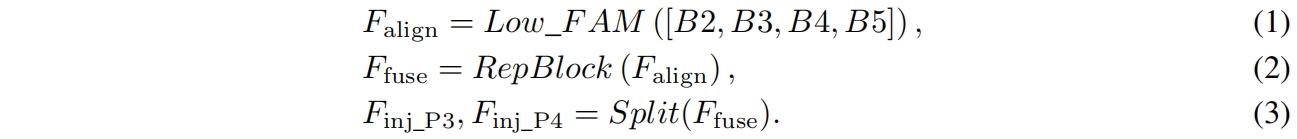
Information injection module
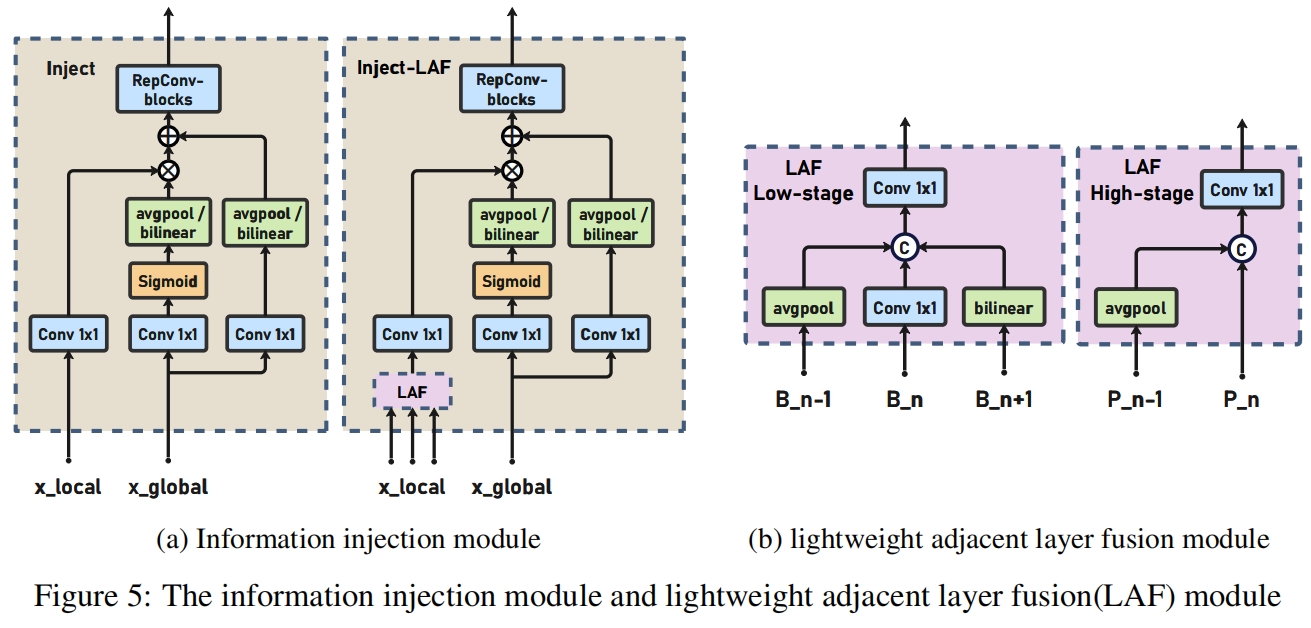
为了更有效的将全局信息注入到不同的层,作者采用注意力机制来融合信息,如图5所示。具体来说,同时输入局部信息(当前层)和全局信息(IFM生成的)并分别记为 \(F_{local}\) 和 \(F_{inj}\),\(F_{inj}\) 通过两个不同的卷积层分别得到 \(F_{global\_embed}\) 和 \(F_{act}\)。\(F_{local}\) 通过卷积得到 \(F_{local\_embed}\)。然后通过注意力计算得到融合特征 \(F_{out}\)。其中 \(F_{local}\) 等于 \(Bi\),具体如下

High GD
High-GD融合Low-GD得到的特征 {P3, P4, P5},如图4(b)所示
High-FAM
High-FAM和Low-FAM的操作一样,通过全局平均池化下采样来对齐大小,目标大小为 \(R_{P5}=\frac{1}{8}R\)。
Hign-IFM
High-IFM包括多个transformer block和一个split操作。具体包括三步
- High-FAM的输出 \(F_{align}\) 通过transformer block融合得到 \(F_{fuse}\)
- \(F_{fuse}\) 通过1x1卷积通道降维到 \(sum(C_{P4},C_{P5})\)
-
沿通道进行split操作得到 \(F_{inj\_N4}\) 和 \(F_{inj\_N5}\)
具体如下

式(8)中的transformer融合模块包括多个堆叠的transformer block,每个block包含一个multi-head attention block、一个ffn、一个residual connection。具体配置和LeViT一样,K,Q的维度设为D(例如16),V的维度为2D(例如32)。考虑到推理速度,替换掉了一些速度不友好的操作,每个卷积的LN换成了BN,所有的GELU激活换成了ReLU。为了增强transformer block中的局部连接,两个1x1卷积中间增加了一层深度卷积。FFN的expansion factor设为2。
Information injection module
这里和Low-GD中的结构一样,其中 \(F_{local}\) 等于 \(Pi\),具体如下

Enhanced cross-layer information flow
为了进一步提升性能,作者借鉴YOLOv6里的PAFPN提出了一个Inject-LAF模块。这个模块是注入模块的增加,其中在注入模块的输入位置新加了一个轻量的相邻层融合模块(lightweight adjacent layer fusion, LAF)。为了实现速度和精度的平衡,设计了两种LAF:low-level LAF和high-level LAF,分别用于低层注入(合并相邻两层的特征)和高层注入(合并相邻一层的特征),具体结构如图5(b)所示。
代码解析
官方的实现是基于YOLOv6的实现,其中n,s的neck是"RepGDNeck",m的neck是"GDNeck",l的neck是"GDNeck2",因为从实验结果看,提升比较明显的事nano和small版本,因此这里只解析一下RepGDNeck的实现。具体实现代码在Efficient-Computing/Detection/Gold-YOLO/gold_yolo/reppan.py中,forward实现如下
def forward(self, input):(c2, c3, c4, c5) = input # [(16,32,160,160),(16,64,80,80),(16,128,40,40),(16,256,20,20)]# Low-GD## use conv fusion global infolow_align_feat = self.low_FAM(input) # (16,480,40,40)low_fuse_feat = self.low_IFM(low_align_feat) # (16,96,40,40)low_global_info = low_fuse_feat.split(self.trans_channels[0:2], dim=1) # [(16,64,40,40),(16,32,40,40)]## inject low-level global info to p4c5_half = self.reduce_layer_c5(c5) # (16,64,20,20)p4_adjacent_info = self.LAF_p4([c3, c4, c5_half]) # (16,64,40,40)p4 = self.Inject_p4(p4_adjacent_info, low_global_info[0]) # (16,64,40,40)p4 = self.Rep_p4(p4) # (16,64,40,40), 式(7)## inject low-level global info to p3p4_half = self.reduce_layer_p4(p4) # (16,32,40,40)p3_adjacent_info = self.LAF_p3([c2, c3, p4_half]) # (16,32,80,80)p3 = self.Inject_p3(p3_adjacent_info, low_global_info[1]) # (16,32,80,80)p3 = self.Rep_p3(p3) # (16,32,80,80)# High-GD## use transformer fusion global infohigh_align_feat = self.high_FAM([p3, p4, c5]) # (16,352,10,10)high_fuse_feat = self.high_IFM(high_align_feat) # (16,352,10,10)high_fuse_feat = self.conv_1x1_n(high_fuse_feat) # (16,192,10,10)high_global_info = high_fuse_feat.split(self.trans_channels[2:4], dim=1) # [(16,64,10,10),(16,128,10,10)]## inject low-level global info to n4n4_adjacent_info = self.LAF_n4(p3, p4_half) # (16,64,40,40)n4 = self.Inject_n4(n4_adjacent_info, high_global_info[0]) # (16,64,40,40)n4 = self.Rep_n4(n4) # (16,64,40,40)## inject low-level global info to n5n5_adjacent_info = self.LAF_n5(n4, c5_half) # (16,128,20,20)n5 = self.Inject_n5(n5_adjacent_info, high_global_info[1]) # (16,128,20,20)n5 = self.Rep_n5(n5) # (16,128,20,20)outputs = [p3, n4, n5] # [(16,32,80,80),(16,64,40,40),(16,128,20,20)]return outputs首先是Low-GD,self.low_FAM的实现如下
def forward(self, x):x_l, x_m, x_s, x_n = x# [(16,32,160,160),(16,64,80,80),(16,128,40,40),(16,256,20,20)]B, C, H, W = x_s.shapeoutput_size = np.array([H, W])if torch.onnx.is_in_onnx_export():self.avg_pool = onnx_AdaptiveAvgPool2dx_l = self.avg_pool(x_l, output_size)x_m = self.avg_pool(x_m, output_size)x_n = F.interpolate(x_n, size=(H, W), mode='bilinear', align_corners=False)out = torch.cat([x_l, x_m, x_s, x_n], 1) # (16,480,40,40)return outself.low_IFM的实现如下,其中的block是RepVGGBlock
self.low_IFM = nn.Sequential(Conv(extra_cfg.fusion_in, extra_cfg.embed_dim_p, kernel_size=1, stride=1, padding=0), # 480,96*[block(extra_cfg.embed_dim_p, extra_cfg.embed_dim_p) for _ in range(extra_cfg.fuse_block_num)], # 3Conv(extra_cfg.embed_dim_p, sum(extra_cfg.trans_channels[0:2]), kernel_size=1, stride=1, padding=0),
)接着通过split操作得到low_global_info,即inject模块的输入 \(F_{inj\_P3}\) 和 \(F_{inj\_P4}\)。
以上分别对应式(1)~式(3)
接下来是inject模块,self.LAF_p4的实现如下
def forward(self, x):N, C, H, W = x[1].shapeoutput_size = (H, W)if torch.onnx.is_in_onnx_export():self.downsample = onnx_AdaptiveAvgPool2doutput_size = np.array([H, W])x0 = self.downsample(x[0], output_size)x1 = self.cv1(x[1])x2 = F.interpolate(x[2], size=(H, W), mode='bilinear', align_corners=False)return self.cv_fuse(torch.cat((x0, x1, x2), dim=1))self.Inject_p4的实现如下
def forward(self, x_l, x_g):'''x_g: global featuresx_l: local features'''B, C, H, W = x_l.shapeg_B, g_C, g_H, g_W = x_g.shapeuse_pool = H < g_Hlocal_feat = self.local_embedding(x_l)global_act = self.global_act(x_g) # 式(4)global_feat = self.global_embedding(x_g) # 式(5)if use_pool:avg_pool = get_avg_pool()output_size = np.array([H, W])sig_act = avg_pool(global_act, output_size)global_feat = avg_pool(global_feat, output_size)else:sig_act = F.interpolate(self.act(global_act), size=(H, W), mode='bilinear', align_corners=False)global_feat = F.interpolate(global_feat, size=(H, W), mode='bilinear', align_corners=False)out = local_feat * sig_act + global_feat # 式(6)return out然后self.Rep_p4对应式(7)。接下来inject to p3和p4的操作是一致的。
接下来是Hign-GD,输入是C5以及Low-GD的输出P3、P4。
self.high_FAM的实现如下
def forward(self, inputs):B, C, H, W = get_shape(inputs[-1])H = (H - 1) // self.stride + 1W = (W - 1) // self.stride + 1output_size = np.array([H, W])if not hasattr(self, 'pool'):self.pool = nn.functional.adaptive_avg_pool2dif torch.onnx.is_in_onnx_export():self.pool = onnx_AdaptiveAvgPool2dout = [self.pool(inp, output_size) for inp in inputs]return torch.cat(out, dim=1)self.high_IFM采用transformer block,这里具体实现就不贴了。然后是1x1卷积接split操作。上面对应式(8)~式(10)
然后是inject模块,首先self.LAF_n4只融合相邻一层的特征
def forward(self, x1, x2):if torch.onnx.is_in_onnx_export():self.pool = onnx_AdaptiveAvgPool2delse:self.pool = nn.functional.adaptive_avg_pool2dN, C, H, W = x2.shapeoutput_size = np.array([H, W])x1 = self.pool(x1, output_size)return torch.cat([x1, x2], 1)接下来的self.Inject_n4和self.Rep_n4与low-GD中的self.Inject_p4和self.Rep_p4是一样的。
实验结果
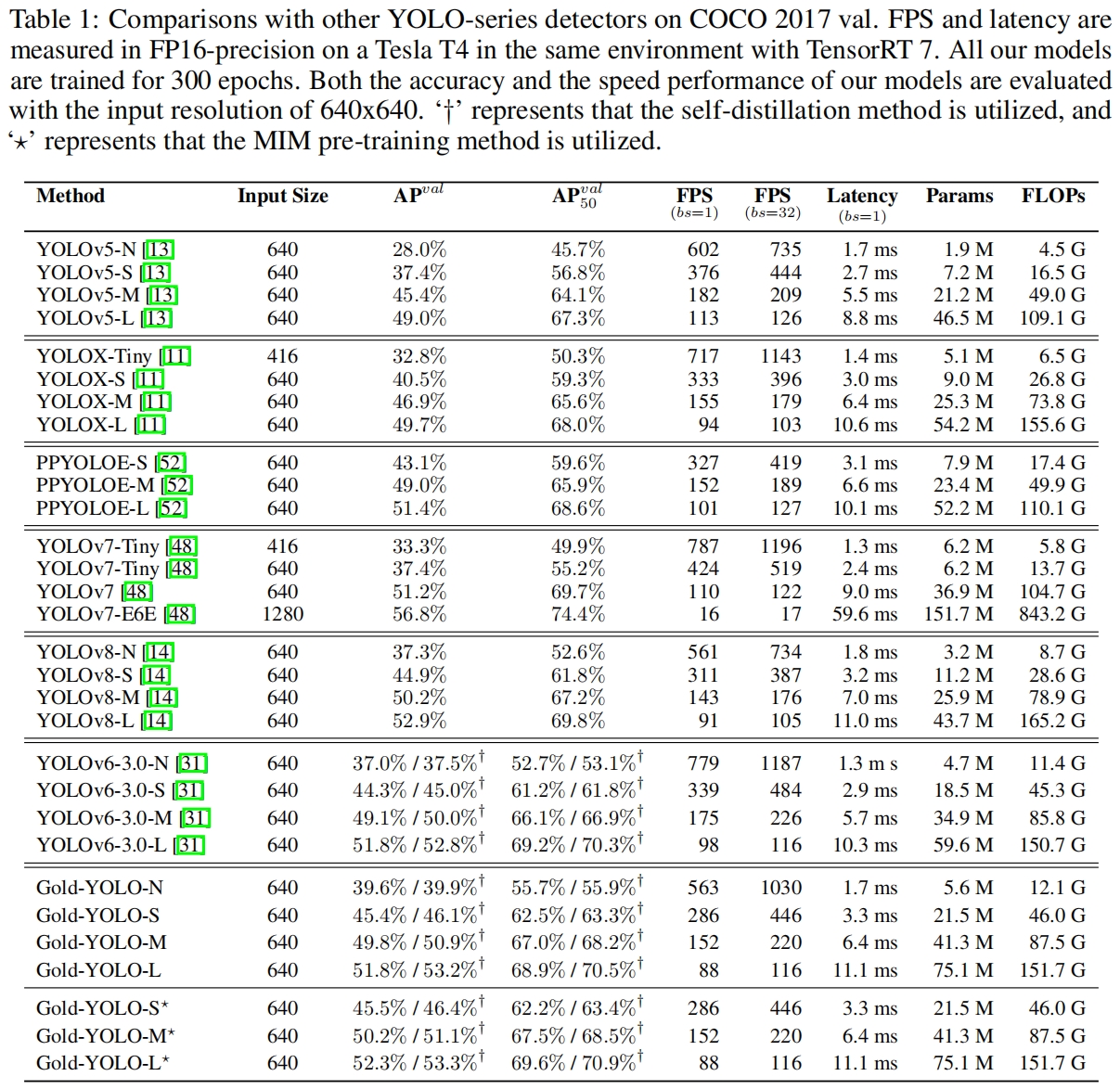
GOLD-YOLO和其他YOLO的效果对比如下,可以看出主要提升在nano和small版本上。
相关文章:
Gold-YOLO(NeurIPS 2023)论文与代码解析
paper:Gold-YOLO: Efficient Object Detector via Gather-and-Distribute Mechanism official implementation:https://github.com/huawei-noah/Efficient-Computing/tree/master/Detection/Gold-YOLO 存在的问题 在过去几年里,YOLO系列已经…...

多个coco数据标注文件合并
一、coco数据集是什么? COCO(Common Objects in Context)是一个用于目标检测和图像分割任务的标注格式。如果你有多个COCO格式的JSON文件,你可能需要将它们合并成一个文件,以便更方便地处理和管理数据。在这篇博客中&…...

Kubernetes(K8S)拉取本地镜像部署Pod 实现类似函数/微服务功能(可设置参数并实时调用)
以两数相加求和为例,在kubernetes集群拉取本地的镜像,实现如下效果: 1.实现两数相加求和 2.可以通过curl实时调用,参数以GET方式提供,并得到结果。(类似调用函数) 一、实现思路 需要准备如下的…...
k8s使用ingress实现应用的灰度发布升级
v1是1.14.0版本nginx ,实操时候升级到v2是1.20.0版本nginx,来测试灰度发布实现过程 一、方案:使用ingress实现应用的灰度发布 1、服务端:正常版本v1,灰度升级版本v2 2、客户端:带有请求头versionv2标识的请求访问版…...
最新热门商用GPT4.0带MJ绘画去授权版本自定义三方接口(开心版)
一台VPS 搭建宝塔 解析域名 上传程序至根目录 访问首页在线安装配置数据库 PHP版本选择:7.3 安装完成后访问网站首页即可! 配置APIKEY,登录网站后台自定义配置,不然网站无法使用! 网站后台地址/admin 默认账号:admin 密码…...

Halcon基于形状的模板匹配inspect_shape_model
Halcon基于形状的模板匹配 基于形状的匹配,就是使用目标对象的轮廓形状来描述模板。Halcon中有操作助手,可以直观 地进行形状模板匹配的参数选择以及效果测试。如果使用算子编写,步骤如下。 (1)从参考图像上选择检测的…...

html中根元素以及根元素字体的含义
在 HTML 中,根元素是指 <html> 标签,可以使用 CSS 来设置根元素的字体大小。根元素的字体大小会影响整个页面的文本内容,默认情况下,根元素的字体大小是浏览器默认的大小。 要设置根元素的字体大小,你可以使用 …...
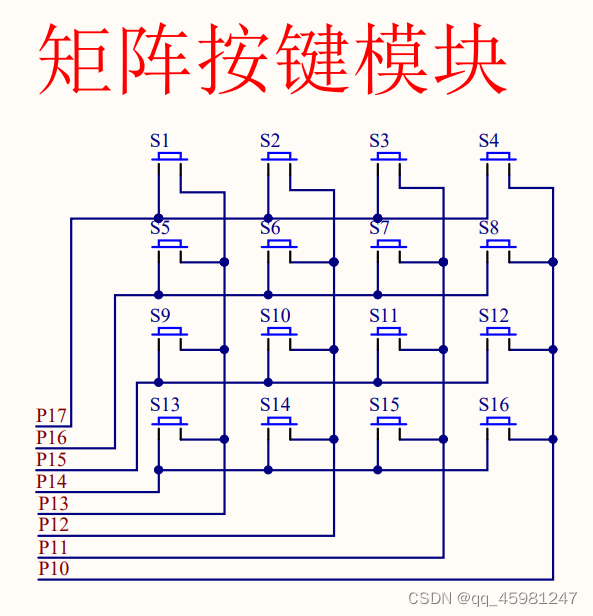
51单片机1-6
目录 单片机介绍 点亮一个LED 流水灯参考代码 点亮流水LEDplus版本 独立按键 独立按键控制LED亮灭 静态数码管 静态数码管显示 动态数码管显示 模块化编程 调试工具 矩阵键盘 矩阵键盘显示数据 矩阵键盘密码锁 学习B站江协科技课程笔记。 安装keil,下…...
vue2(Vuex)、vue3(Pinia)、react(Redux)状态管理
vue2状态管理Vuex Vuex 是一个专为 Vue.js应用程序开发的状态管理模式。它使用集中式存储管理应用的所有组件的状态,以及规则保证状态只能按照规定的方式进行修改。 State(状态):Vuex 使用单一状态树,即一个对象包含全部的应用层…...

用户画像项目背景
1,用户画像项目介绍 大数据平台简介 数据仓库+用户画像+推荐系统 (1)数据仓库:加快数据的分析和查询 数据仓库分层:ODS层(映射HDFS的数据)—DW(数据仓库层)–APP(层)—BI(层) DW:DWD明细数据层(数据的清洗和转换),DWM(轻度聚合层),DWS(高度聚合),APP(层),DIM(层) …...

Go使用记忆化搜索的套路【以20240121力扣每日一题为例】
题目 分析 这道题很明显记忆化搜索,用py很容易写出来 Python class Solution:def splitArray(self, nums: List[int], k: int) -> int:n len(nums)# 寻找分割子数组中和的最小的最大值s [0]for num in nums:s.append(s[-1] num)#print(s)cachedef dfs(cur,…...

【LeetCode】每日一题 2024_1_21 分割数组的最大值(二分)
文章目录 LeetCode?启动!!!题目:分割数组的最大值题目描述代码与解题思路 LeetCode?启动!!! 今天是 hard,难受,还好有题解大哥的清晰讲解 题目&a…...
)
bevy the book 20140118翻译(全)
源自:Bevy Book: Introduction 主要用 有道 翻译。 Introduction 介绍 Getting Started 开始 Setup 设置 Apps 应用程序 ECS Plugins 插件 Resources 资源 Next Steps 下一个步骤 Contributing 贡献 Code 代码 Docs 文档 Building Bevys Ecosystem 构建 b…...

MySQL数据库面试知识点
1、数据库基础: MySQL是一个开源的关系型数据库管理系统,用于存储、管理和检索数据。它支持多种存储引擎,包括InnoDB、MyISAM等。MySQL是由瑞典公司MySQL AB开发,后来被Sun Microsystems收购,最终被甲骨文公司(Oracle…...
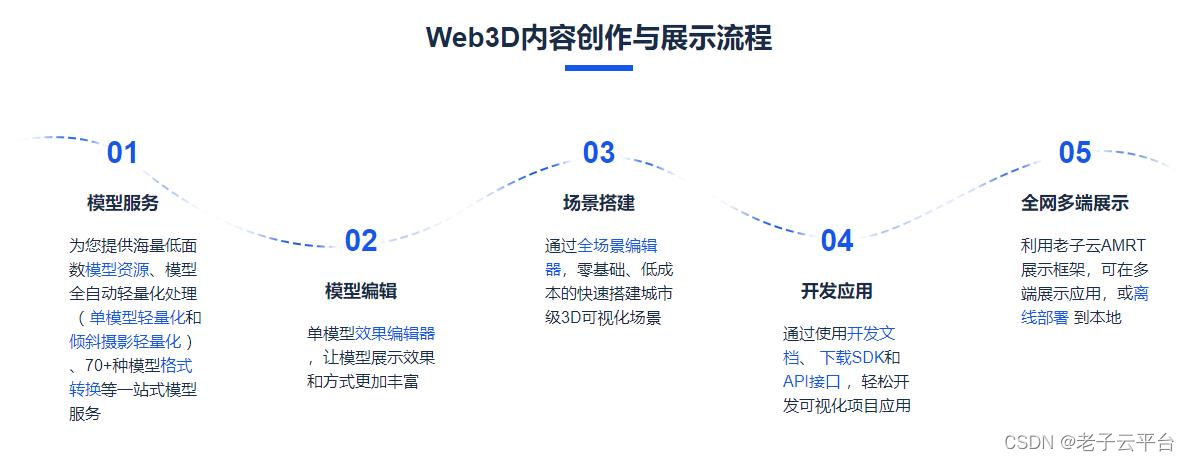
超优秀的三维模型轻量化、格式转换、可视化部署平台!
1、基于 HTML5 和 WebGL 技术,可在主流浏览器上进行快速浏览和调试,支持PC端和移动端 2、自主研发 AMRT 展示框架和9大核心技术,支持3D模型全网多端流畅展示与交互 3、提供格式转换、减面展UV、烘焙等多项单模型和倾斜摄影模型轻量化服务 4、…...
云原生全栈监控解决方案(全面详解)
【作者】JasonXu 前言 当前全球企业云化、数字化进程持续加速,容器、微服务等云原生技术在软件架构中快速渗透,IT 架构云化、复杂化持续驱动性能监控市场。企业云化、数字化持续转型,以及为了考虑系统的弹性、效率,企业软件开发中…...

代码随想录二刷 | 回溯 |复原IP地址
代码随想录二刷 | 回溯 |复原IP地址 题目描述解题思路代码实现 题目描述 93.复原IP地址 给定一个只包含数字的字符串,复原它并返回所有可能的 IP 地址格式。 有效的 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成&am…...
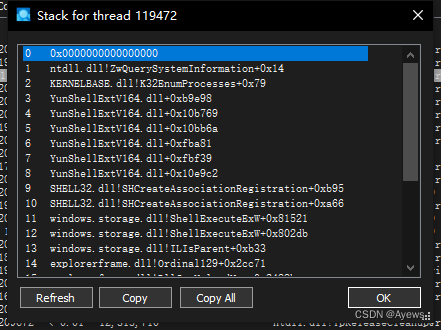
windows资源管理器占用过高CPU的问题
最近,笔者的电脑在进行文件操作时变得异常的卡顿,打开任务管理器发现windows资源管理器占用了50%-80%的CPU。这里指的文件操作包括但不限于解压,复制,粘贴,甚至重命名一个文件夹都会引起50%的CPU占用。起初笔者认为可能…...
------大总结(学了要会用-------教你如何使用))
redis的常见数据类型和应用场景(非八股)------大总结(学了要会用-------教你如何使用)
Redis的数据类型 Redis 提供了丰富的数据类型,常见的有五种: String(字符串),Hash(哈希),List(列表),Set(集合)、Zset&am…...
UE 可靠UDP实现原理
发送 我们的消息发送都是通过 UChannel 来处理的,通过调用 UChannel::SendBunch 统一处理。 发送的 Bunch 是以 FOutBunch 的形式存在的。当 bReliable 为 True 的时候,表示 Bunch 是可靠的。 发送逻辑直接从UChannel::SendBunch处开始分析 1、大小限…...

ChatGPT资源宝库:从提示工程到项目实践的完整指南
1. 项目概述:一份关于ChatGPT的“Awesome”清单意味着什么?如果你最近在GitHub上搜索过任何与ChatGPT、AI或提示工程相关的内容,那么你大概率见过一个以“awesome-”开头的仓库。而sindresorhus/awesome-chatgpt无疑是这个领域里最知名、最常…...
)
保姆级教程:在CentOS 7/8服务器上部署DrissionPage爬虫(含Chrome无头模式配置)
CentOS服务器上DrissionPage爬虫的工业级部署指南 1. 环境准备与Chrome浏览器安装 在CentOS服务器上部署基于DrissionPage的爬虫系统,首要任务是构建稳定可靠的浏览器运行环境。与个人开发环境不同,生产服务器通常需要面对无图形界面、资源受限等特殊场景…...

免费额度即将失效?ElevenLabs 2024.6.1新规生效前,必须完成的5项额度迁移准备
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs免费额度机制的本质解析 ElevenLabs 的免费额度并非按“每月重置”的静态配额,而是一种基于账户生命周期的动态信用池(Credit Pool),其底层由实…...

地下态势智能研判,拔高硐室深部安全透明管控等级技术白皮书
地下态势智能研判,拔高硐室深部安全透明管控等级技术白皮书 副标题:全要素三维动态重建井下场景,融合井下无感坐标解算、跨断面跨镜轨迹串联、身体指纹人员轨迹存档,井下风险前置感知、动态全程透明追溯 前言 矿山井下深部硐室与纵…...

Wand-Enhancer终极指南:免费解锁WeMod专业功能的完整解决方案
Wand-Enhancer终极指南:免费解锁WeMod专业功能的完整解决方案 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的高昂订阅费…...

零基础实操:小龙虾 AI OpenClaw 接入 Kimi 详细步骤
前置准备 获取小龙虾open claw一键安装包(www.totom.top)并安装电脑端已成功安装并正常运行OpenClaw客户端,顶部 Gateway 状态保持在线设备网络通畅,可正常访问 Kimi 开放平台拥有可正常登录的 Kimi 月之暗面 Moonshot 账号账号提…...

DIY便携FPV地面站:从电路设计到3D打印的完整制作指南
1. 项目概述:为什么需要一个便携式FPV地面站?玩FPV(第一人称视角)飞行,无论是竞速穿越还是航拍探索,最核心的体验就是那块屏幕。大多数飞手依赖FPV眼镜带来的沉浸感,但在很多场景下,…...

CN2628 可用太阳能供电 5 伏特低压差电压调制集成电路
概述: CN2628是一款可用太阳能供电的低噪声线性电压调制集成电路,采用固定5.0V输出电压,最大 输出电流可达1安培,在5.5V到7V的输入电压范围内输出电压精度可达1%。CN2628工作电流只有520微安,而且同输入和输出的压差没有关系。 CN…...

Claw框架数据库迁移工具claw-migrate:原理、实践与团队协作指南
1. 项目概述:一个专为Claw设计的迁移工具最近在折腾一个叫Claw的开源项目,它本身是一个轻量级的Web框架,用起来挺顺手。但项目迭代过程中,难免会遇到数据库结构变更、数据迁移这类“脏活累活”。手动写SQL脚本?太原始&…...

智能体开发实战:从框架选型到部署优化的完整指南
1. 项目概述:一个为智能体开发者准备的“军火库”如果你正在或打算踏入智能体(Agent)开发这个领域,那么你很可能已经体会过那种“万事开头难”的迷茫。从选择哪个框架开始,到如何设计一个有效的智能体工作流࿰…...