Kafka-服务端-副本机制
Kafka从0.8版本开始引入副本(Replica)的机制,其目的是为了增加Kafka集群的高可用性。
Kafka实现副本机制之后,每个分区可以有多个副本,并且会从其副本集合(Assigned Replica,AR)中选出一个副本作为Leader副本,所有的读写请求都由选举出的Leader副本处理。
剩余的其他副本都作为Follower副本,Follower副本会从Leader副本处获取消息并更新到自己的Log中。
我们可以认为Follower副本是Leader副本的热备份。
一般情况下,同一分区的多个副本会被均匀地分配到集群中的不同Broker上,当Leader副本的所在的Broker出现故障后,可以重新选举新的Leader副本继续对外提供服务。
通过这种方式提高了Kafka集群的可用性。
副本
在一个分区的Leader副本中会维护自身以及所有Follower副本的相关状态,而Follower副本只维护自己的状态。
此外,还有“本地副本”和“远程副本”两个概念需要读者注意,“本地副本”是指副本对应的Log分配在当前的Broker上,“远程副本”则是指副本对应的Log分配在其他的Broker上,在当前Broker上仅仅维护了副本的LEO等信息。
一个副本是“本地副本”还是“远程副本”与它是Leader副本还是Follower副本没有直接联系,如图所示。
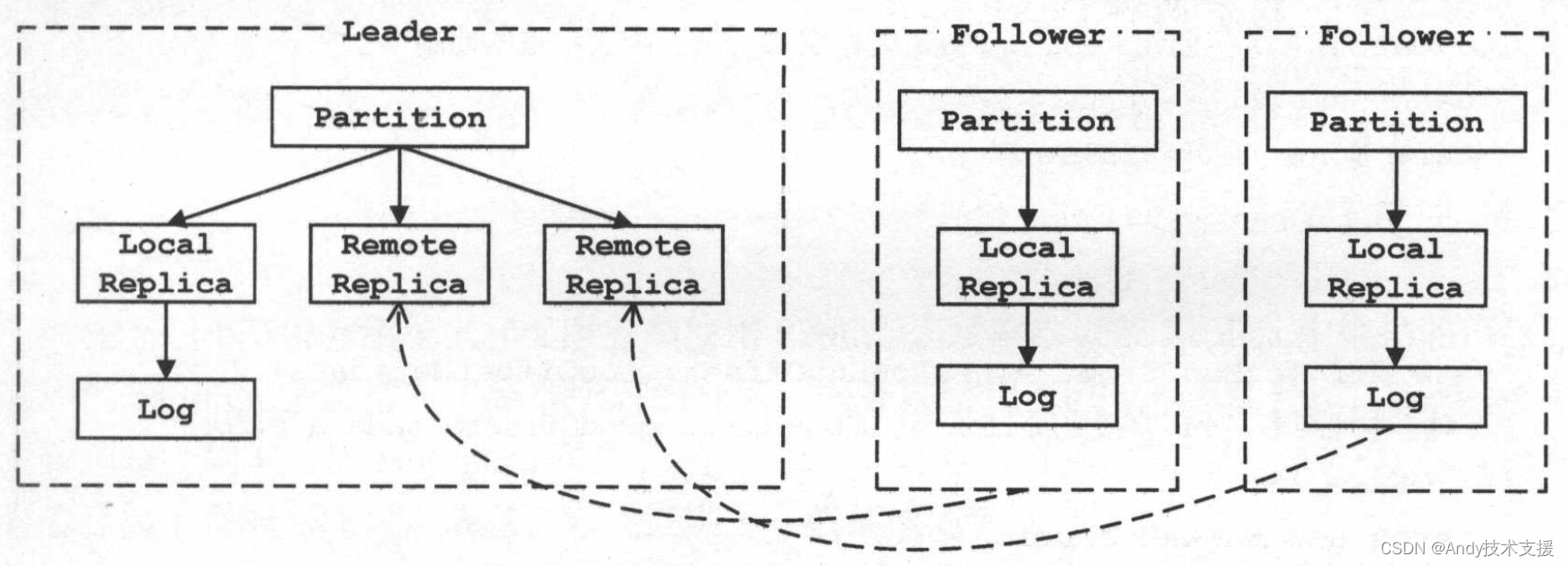
分区
Kafka服务端使用Replica表示副本以及Replica中维护的信息,其中的partition字段指向了副本所属的分区。
服务端使用Partition表示分区,Partition负责管理每个副本对应的Replica对象,进行Leader副本的切换,ISR集合的管理以及调用日志存储子系统完成写入消息,它还提供了一些其他的辅助方法。
Partition中的核心字段的含义如下所述。
- topic和partitionld:此Partition对象代表的Topic名称和分区编号。
- localBrokerld:当前Broker的id,可以与replicald比较,从而判断指定的Replica对是否表示本地副本。
- logManager:当前Broker上的LogManager对象。
- zkUtils:操作ZooKeeper的辅助类。
- leaderEpoch:Leader副本的年代信息。
- leaderReplicaldOpt:该分区的Leader副本的id。
- inSyncReplicas:Set[Replica]类型,该集合维护了该分区的ISR集合,ISR集合是AR集合的子集。
- assignedReplicaMap:Pool[Int,Replica]类型,维护了该分区的全部副本的集合(AR集合)的信息。
Partition中的方法按照功能可以划分为下列五类。
- 获取(或创建)Replica:getOrCreateReplica方法。
- 副本的Leader/Follower角色切换:makeLeader方法和makeFollower方法。
- ISR集合管理:maybeExpandIsr方法和maybeShrinkIsr()方法。
- 调用日志存储子系统完成消息写入:appendMessagesToLeader()方法。
- 检测HW的位置:checkEnoughReplicasReachOffset方法
创建副本
getOrCreateReplica()方法主要负责在AR集合(assignedReplicaMap)中查找指定副本的Replica对象,如果查找不到则创建Replica对象并添加到AR集合中管理。
如果创建的是Local Replica,还会创建(或恢复)对应的Log并初始化(或恢复)HW。
HW与Log.recoveryPoint类似,也会需要记录到文件中保存,在每个lig目录下都有一个replication-offset-checkpoint文件记录了此目录下每个分区的HW。
在ReplicaManager启动时会读取此文件到highWatermarkCheckpoints这个Map中,之后会定时更新replication-offset-checkpoint文件。
ISR集合管理
Partition除了对副本的Leader/Follower角色进行管理,还需要管理ISR集合。
随着Follower副本不断与Leader副本进行消息同步,Follower副本的LEO会逐渐后移,并最终追赶上Leader副本的LEO,此时该Follower副本就有资格进入ISR集合。
Partition.maybeExpandIsr()方法实现了扩张ISR集合的功能,其调用栈如图所示,它是在updateFollowerLogReadResults()方法中被调用的,在前面介绍DelayedFetch的处理流程时提到过此方法的功能,该方法用于处理来自Follower的FetchRequest。
追加消息
在分区中,只有Leader副本能够处理读写请求。
Partition.appendMessagesToLeader方法提供了向Leader副本对应的Log中追加消息的功能。
在前面介绍的DelayedProduce处理流程中,ReplicaManager.appendToLocalLog()方法就是基于此方法实现的。
ReplicaManager
在一个Broker上可能分布着多个Partition的副本信息,ReplicaManager的主要功能是管理一个Broker范围内的Partition信息。
ReplicaManager的实现依赖于前面介绍的日志存储子系统、DelayedOperationPurgatory、KafkaScheduler等组件,底层依赖于Partition和Replica。
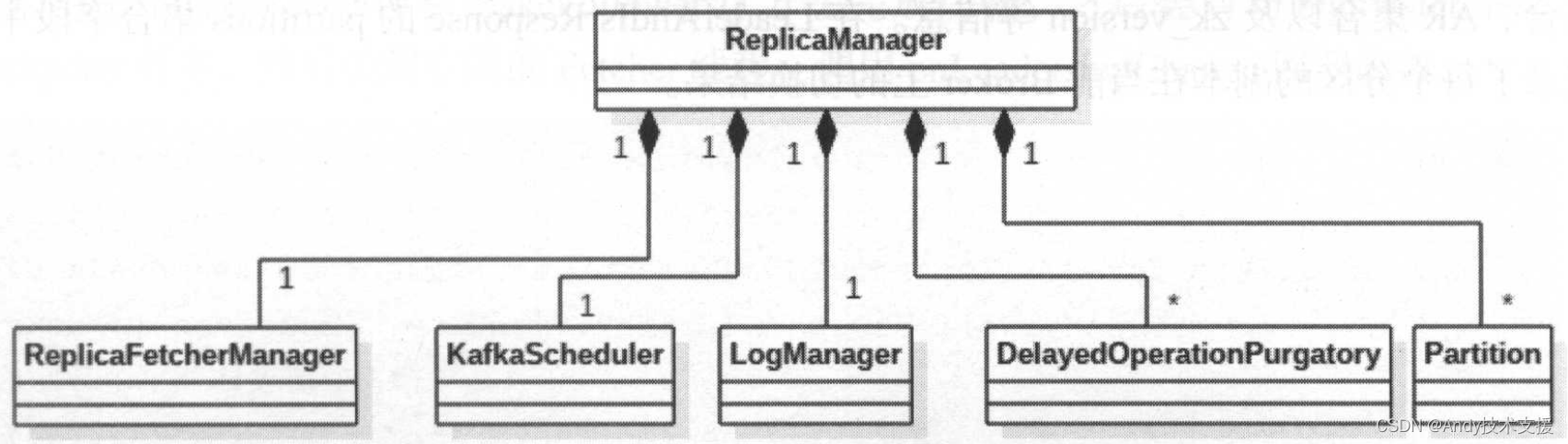
ReplicaManager中各个字段的含义和功能如下所述。
- logManager:LogManager对象,对分区的读写操作都委托给底层的日志存储子系统。
- scheduler:KafkaSchedule对象,用于执行ReplicaManager中的周期性定时任务。在ReplicaManager中总共有三个周期性任务,它们分别是highwatermark-checkpoint任务、isr-expiration任务、isr-change-propagation任务。
- controllerEpoch:记录KafkaController的年代信息,当重新选举Controller Leader时该字段值会递增。之后,在ReplicaManager处理来自KafkaController的请求时,会先检测请求中携带的年代信息是否等于controllerEpoch字段的值,这就避免接收旧Controller Leader发送的请求。这种设计方式在分布式系统中比较常见。
- localBrokerld:当前Broker的id,主要用于查找Local Replica。
- allPartitions:Pool[(String,Int),Partition]类型,其中保存了当前Broker上分配的所有Partition信息。这里需要注意Pool的valueFactory,当从Pool查找不到指定key时,则使用valueFactory创建一个默认value值放入Pool并返回。
- replicaFetcherManager:在ReplicaFetcherManager中管理了多个ReplicaFetcherThread线程,ReplicaFetcherThread线程会向Leader副本发送FetchRequest请求来获取消息,实现Follower副本与Leader副本同步。ReplicaFetcherManager对象在ReplicaManager初始化时被创建,后面会详细介绍ReplicaFetcherManager与ReplicaFetcherThread的功能。
- highWatermarkCheckpoints:Map[String,OffsetCheckpoint]类型,用于缓存每个log目录与OffsetCheckpoint之间的对应关系,OffsetCheckpoint记录了对应log目录下的replication-offset-checkpoint文件,该文件中记录了data目录下每个Partition的HW。ReplicaManager中的highwatermark-checkpoint任务会定时更新replication-offset-checkpoint文件的内容。
- isrChangeSet:Set[TopicAndPartition]类型,用于记录ISR集合发生变化的分区信息。
- delayedProducePurgatory、delayedFetchPurgatory:用于管理DelayedProduce和DelayedFetch的DelayedOperationPurgatory对象。
- zkUtils:操作ZooKeeper的辅助类。
副本角色切换
在Kafka集群中会选举一个Broker成为KafkaController的Leader,它负责管理整个Kafka集群。
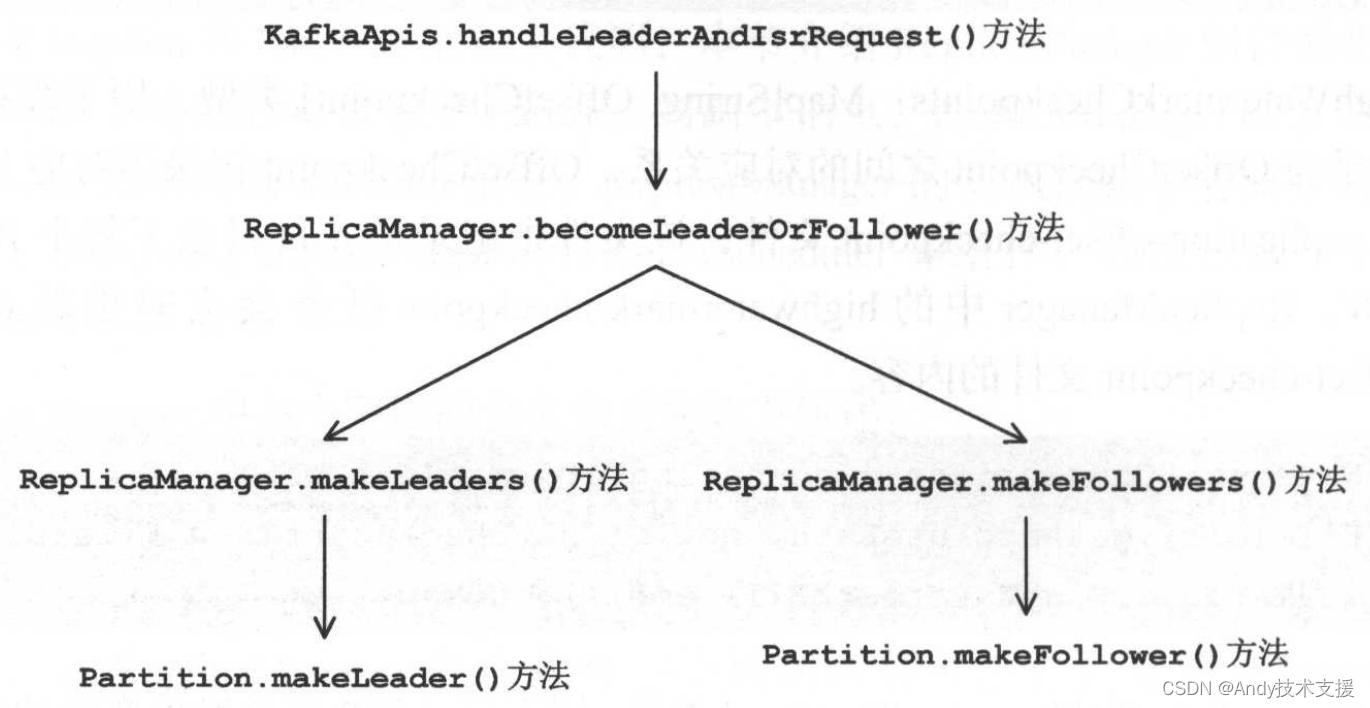
Controller Leader根据Partition的Leader副本和Follower副本的状态向对应的Broker节点发送LeaderAndIsrRequest,这个请求主要用于副本的角色切换,即指导Broker将其上的哪些分区的副本切换成Leader角色,哪些分区的副本切换成Follower介绍。
LeaderAndIsrRequest首先由KafkaAPis.handleLeaderAndIsrRequest()方法进行处理,其核心逻辑是通过ReplicaManager提供的becomeLeaderOrFollower方法实现的,而becomeLeaderOrFollower又依赖于上一小节介绍的Partition.makeLeader方法和makeFollower方法,上述调用关系如图所示。
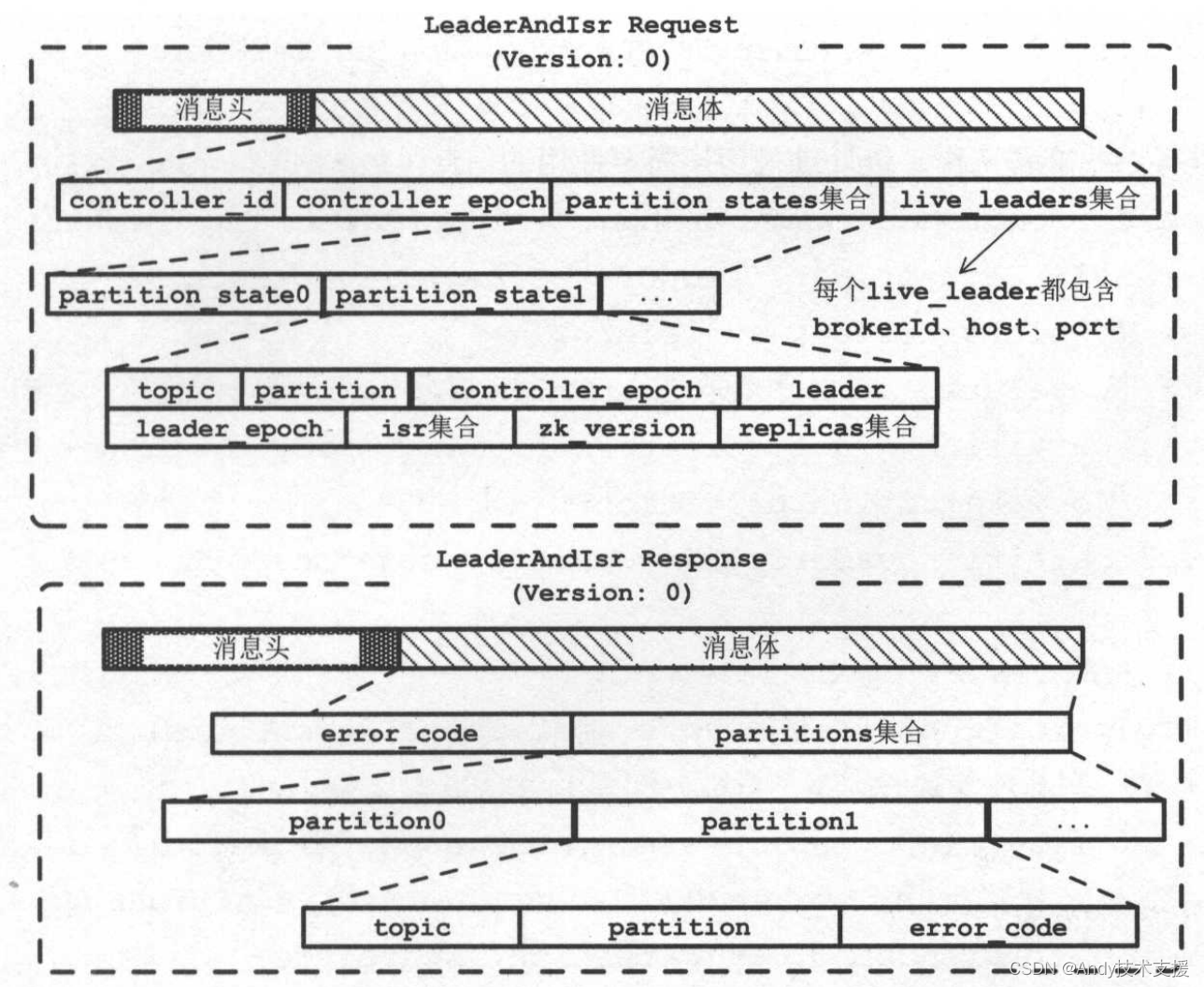
在开始分析becomeLeaderOrFollower方法前,先来介绍一下LeaderAndIsrRequest和LeaderAndIsrResponse的格式,如图所示。在LeaderAndIsrRequest中比较重要的是partition_states集合这个字段,其中包含了每个分区的Leader副本所在的Brokerld、ISR集合、AR集合以及zk_version等信息。在LeaderAndIsrResponse的partitions集合字段中记录了每个分区的副本在当前Broker上的切换结果。
ReplicaManager.becomeLeaderOrFollower方法的主要逻辑是:获取(或创建)指定的Partition对象,根据partitionStates的信息对其切换成Leader/Follower的副本进行分类,并分别调用makeLeader和makeFollowers方法完成切换。
之后会启动highwatermark-checkpoint任务,然后关闭空闲的Fetcher线程,调用onLeadershipChange回调函数。
追加/读取消息
当Local Replica切换为Leader副本之后,就可以处理生产者发送的ProducerRequest,将消息写入到Log中。
在前面分析DelayedProduce的处理流程时,简单介绍了ReplicaManager.appendMessages方法,当时着重关注了与DelayedProduce相关的处理以及sendResponseCallback回调方法的实现。
这里详细分析appendToLocalLog方法的实现,它首先会检测消息要写入的Topic是否为Kafka的内部Topic(目前Kafka只有OffsetsTopic一个内部Topic),如果是内部Topic则需要检测是否允许对内部Topic进行追加,最终调用Partition.appendMessagesToLeader()方法完成消息追加。
appendToLocalLog方法的第二个参数记录了每个分区需要追加的消息集合。
消息同步
Follower副本与Leader副本同步的功能由ReplicaFetcherManager组件实现。
ReplicaFetcherManager继承了AbstractFetcherManager。
AbstractFetcherManager的继承和依赖关系如图所示。
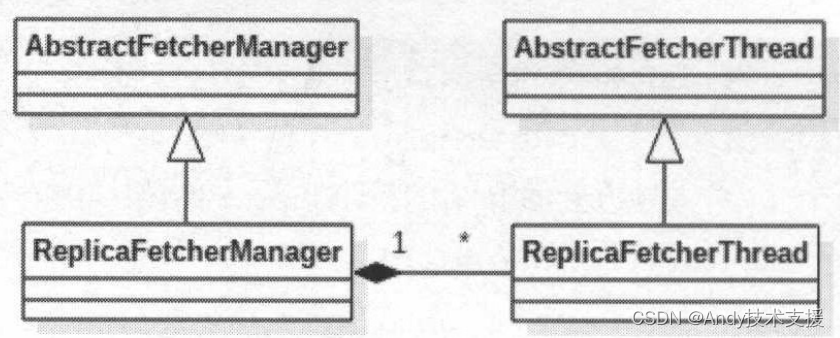
在AbstractFetchManager中使用fetcherThreadMap字段(HashMap[BrokerAndFetcherld,AbstractFetcherThread]类型)管理AbstractFetcherThread,该Map的key值是BrokerAndFetcherld类型对象,其中封装了Broker的网络位置信息(brokerld、host、port等)以及对应的Fetcher线程的id。
AbstractFetcherManager中还提供了addFetcherForPartitions方法、removeFetcherForPartitions方法和shutdownldleFetcherThreads方法对fetcherThreadMap集合进行管理。
AbstractFetcherManager.addFetcherForPartitions()方法会让Follower副本从指定的offset开始与Leader副本进行同步。
该方法的参数涉及BrokerAndInitialOffset类,它其中封装了Broker的网络位置信息以及同步的起始offset。
具体的同步逻辑交由ReplicaFetcherThread线程处理。
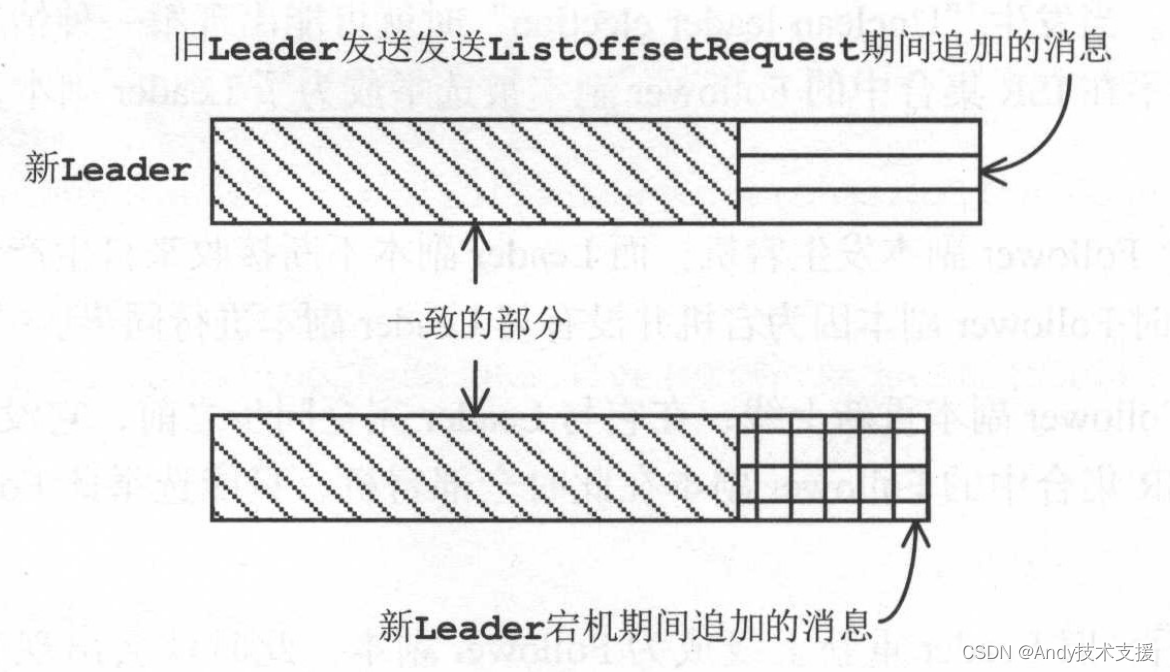
在Follower发送ListOffsetRequest期间,新Leader可能不断追加消息,新Leader的LEO落后于Follower的LEO的场景得到改变,此时就不再需要进行截断操作了,Follower可以继续从其LEO与Leader进行同步。
这样新Leader与Follower的消息可能存在不一致的情况,如图所示。
关闭副本
当Broker接收到来自KafkaController的StopReplicaRequest请求时,会关闭其指定的副本,并根据StopReplicaRequest中的字段决定是否删除副本对应的Log。
在分区的副本进行重新分配、关闭Broker等过程中都会使用到此请求,但是需要注意的是,StopReplicaRequest并不代表一定会删除副本对应的Log,例如shutdown的场景下就没有必要删除Log。
而在重新分配Partition副本的场景下,就需要将旧副本及其Log删除。
先来介绍StopReplicaRequest、StopReplicaResponse的格式,如图所示。
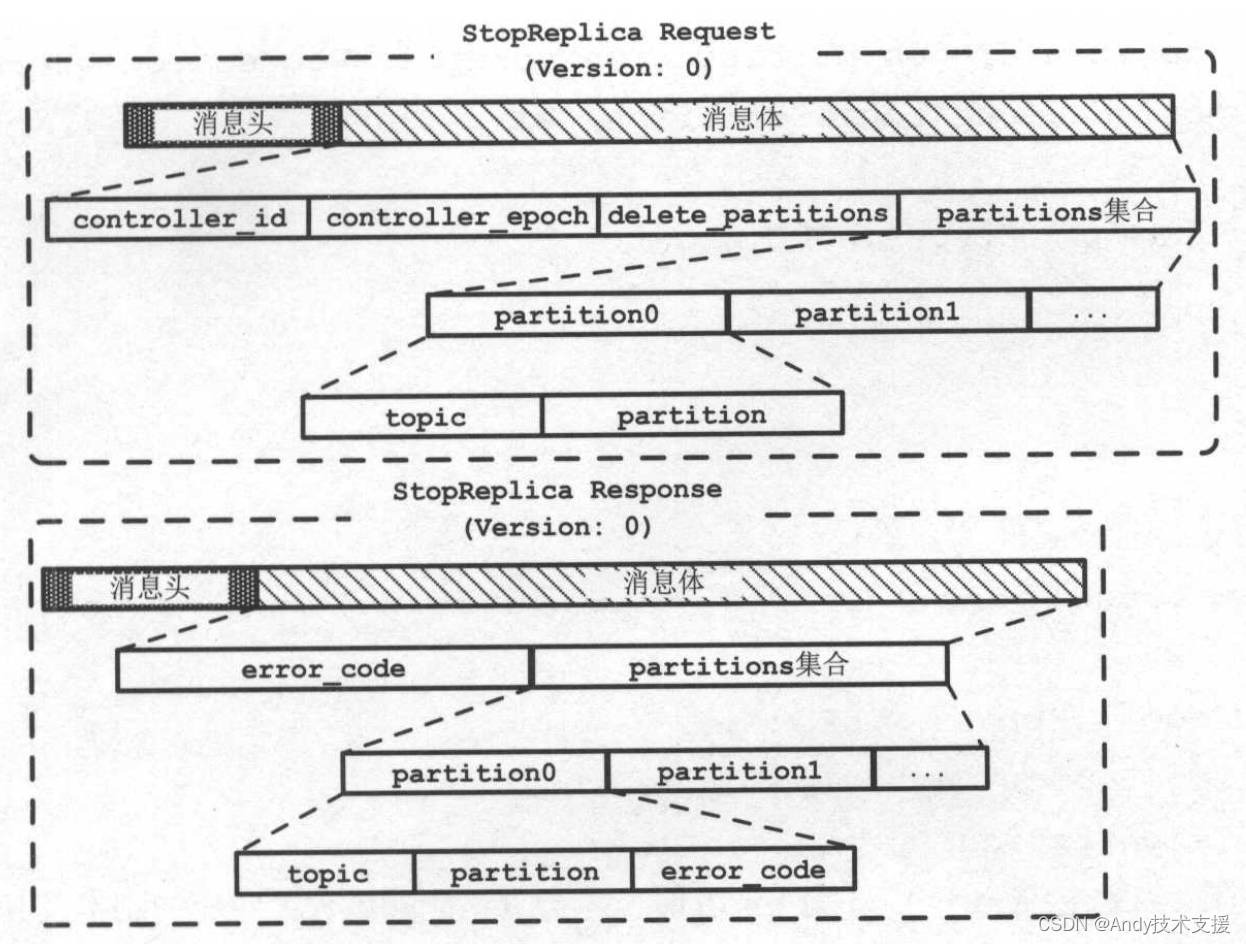
StopReplicaRequest中的delete_partitions字段是一个boolean类型的值,表示是否要删除副本及其Log,partitions集合字段中记录待关闭的分区信息。
StopReplicaResponse的partitions集合记录了每个分区对应的处理结果。
API层接收到StopReplicaRequest后直接调用了ReplicaManager.stopReplicas()方法进行处理。
stopReplicas方法首先检查请求中的controllerEpoch值,之后停止指定分区的同步操作,最后遍历partitions集合根据delete_partitions的值决定是否对Log进行删除。
ReplicaManager中的定时任务
在ReplicaManager中总 共 有highwatermark-checkpoint、isr-expiration、isr-change-propagation三个定时任务。
highwatermark-checkpoint任务会周期性地记录每个Replica的HW并保存到其log目录中的replication-offset-checkpoint文件中。
isr-expiration任务会周期性地调用maybeShrinkIsr()方法检测每个分区是否需要缩减其ISR集合。
isr-change-propagation任务会周期性地将ISR集合发生变化的分区记录到ZooKeeper中。
如果检测到highwatermarkcheckpoint任务未启动,会调用startHighWaterMarksCheckPointThread方法启动highwatermark-checkpoint任务。
MetadataCache
MetadataCache是Broker用来缓存整个集群中全部分区状态的组件。
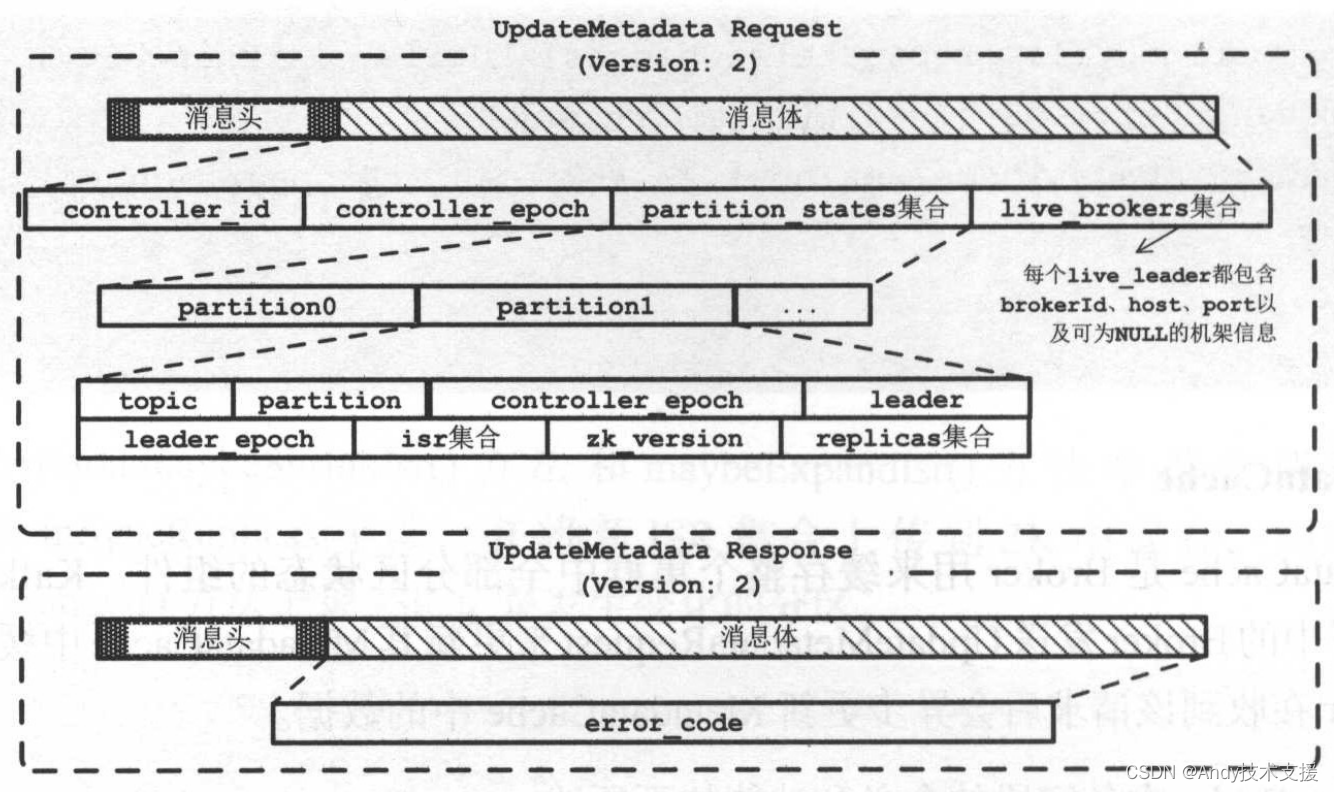
KafkaController通过向集群中的Broker发送UpdateMetadataRequest来更新其MetadataCache中缓存的数据,每个Broker在收到该请求后会异步更新MetadataCache中的数据。
MetadataCache中各字段的含义和功能如下所述。
- cache:Map[String,Map[Int,PartitionStateInfo]]类型,记录了每个分区的状态,其中使用PartitionStatelnfo记录Partition的状态。
- aliveBrokers:Map[Int,Broker]类型,记录了当前可用的Broker信息,其中使用Broker类记录每个存活Broker的网络位置信息(host、ip、port等)。
- aliveNodes:Map[Int,Map[SecurityProtocol,Node]]类型,记录了可用节点的信息。
在开始分析Kafka处理UpdateMetadataRequest请求更新MetadataCache的流程之前,先来看一下UpdateMetadataRequest和UpdateMetadataResponse的格式,如图所示。
相关文章:
Kafka-服务端-副本机制
Kafka从0.8版本开始引入副本(Replica)的机制,其目的是为了增加Kafka集群的高可用性。 Kafka实现副本机制之后,每个分区可以有多个副本,并且会从其副本集合(Assigned Replica,AR)中选出一个副本作为Leader副本,所有的读写请求都由…...
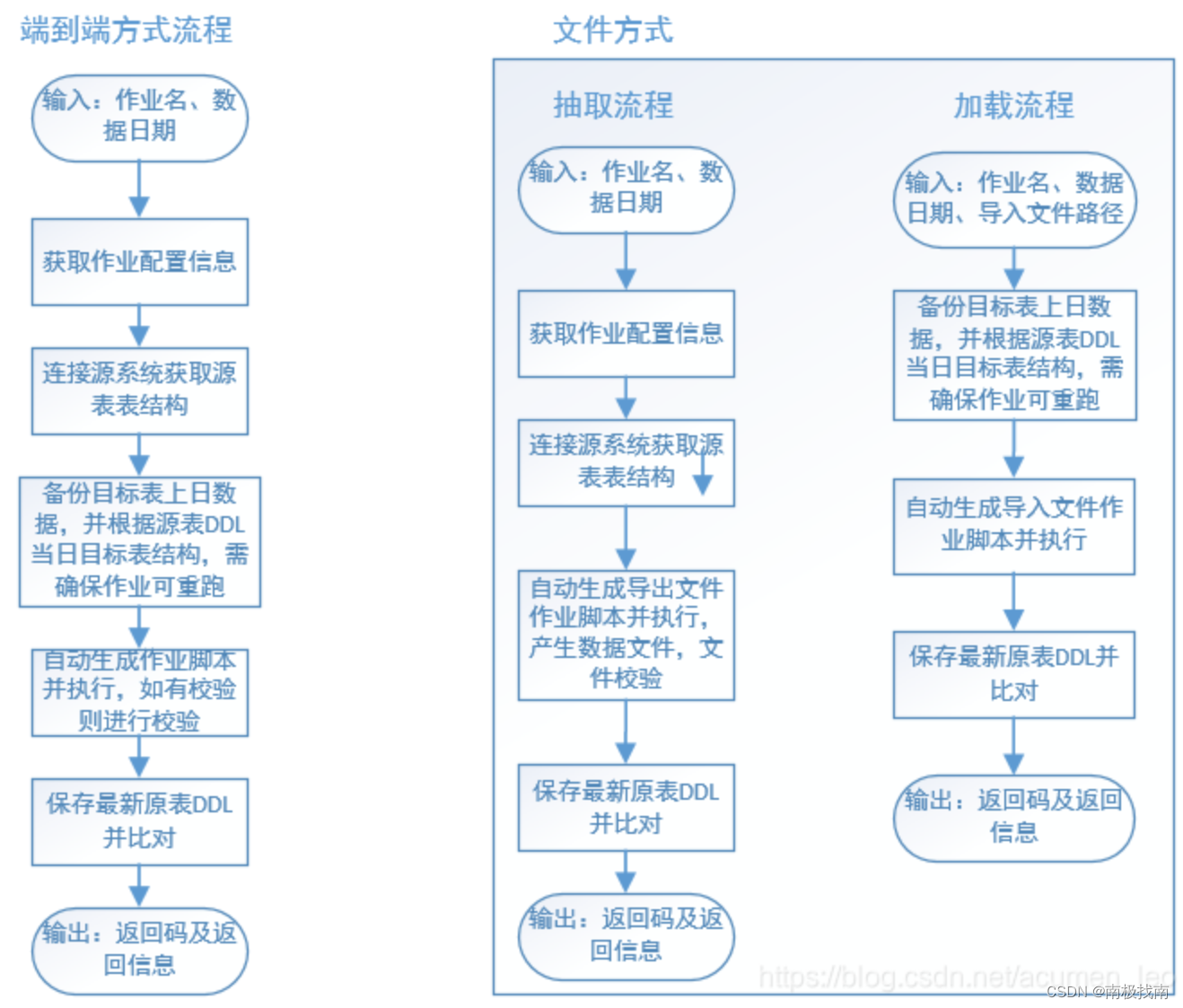
银行数据仓库体系实践(4)--数据抽取和加载
1、ETL和ELT ETL是Extract、Transfrom、Load即抽取、转换、加载三个英文单词首字母的集合: E:抽取,从源系统(Souce)获取数据; T:转换,将源系统获取的数据进行处理加工,比如数据格式转化、数据精…...
云计算入门——Linux 命令行入门
云计算入门——Linux 命令行入门 前些天发现了一个人工智能学习网站,通俗易懂,风趣幽默,最重要的屌图甚多,忍不住分享一下给大家。点击跳转到网站。 介绍 如今,我们许多人都熟悉计算机(台式机和笔记本电…...
的发展)
自然语言处理(NLP)的发展
自然语言处理的发展 随着深度学习和大数据技术的进步,自然语言处理取得了显著的进步。人们正在研究如何使计算机更好地理解和生成人类语言,以及如何应用NLP技术改善搜索引擎、语音助手、机器翻译等领域。 方向一:技术进步 自然语言处理&…...
让uniapp小程序支持多色图标icon:iconfont-tools-cli
前景: uniapp开发小程序项目时,对于iconfont多色图标无法直接支持;若将多色icon下载引入项目则必须关注包体,若将图标放在oss或者哪里管理,加载又是一个问题,因此大多采用iconfont-tools工具,但…...

丹麦公司注册优势 丹麦公司注册条件 丹麦公司注册注意事项
丹麦公司注册优势 1、开-放的商业环境,拥有公平透明的商业法律和制度。 2、简化的注册流程,无需繁琐的审批程序和复杂的材料准备。 3、全球认可的声誉,有助于提升贵公司的国际形象。 4、该国的政-府在坚持适度紧缩的财政政策,…...
C++PythonC# 三语言OpenCV从零开发(4):视频流读取
文章目录 相关链接视频流读取CCSharpPython 总结 相关链接 C&Python&Csharp in OpenCV 专栏 【2022B站最好的OpenCV课程推荐】OpenCV从入门到实战 全套课程(附带课程课件资料课件笔记) OpenCV 教程中文文档|OpenCV中文 OpenCV教程中文文档|W3Csc…...
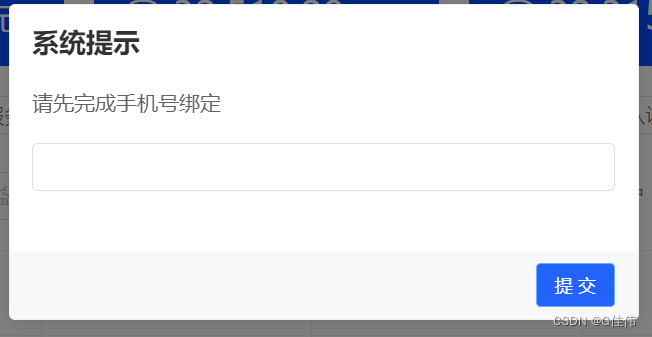
vue element MessageBox.prompt this.$prompt组件禁止显示右上角关闭按钮,取消按钮,及点击遮罩层关闭
vue element MessageBox.prompt this.$prompt组件禁止或取消显示右上角关闭按钮,取消按钮,及点击遮罩层关闭 实现效果: 实现代码 MessageBox.prompt(请先完成手机号绑定, 系统提示, {confirmButtonText: 提 交,showClose: false,closeOnClic…...

Oracle 日常健康脚本
文章目录 摘要常用脚本 摘要 保持 Oracle 数据库的良好健康状况对于系统的可靠性和性能至关重要。本文将介绍一些常用的 Oracle 日常健康脚本,帮助您监控数据库并及时识别潜在的问题,以保证数据库的稳定运行。 常用脚本 1.查询数据库实例和实例级别的…...

leetcode670最大交换
给定一个非负整数,你至多可以交换一次数字中的任意两位。返回你能得到的最大值。 示例 1 : 输入: 2736 输出: 7236 解释: 交换数字2和数字7。 示例 2 : 输入: 9973 输出: 9973 解释: 不需要交换。 注意: 给定数字的范围是 [0, 108] int maximumSwap(int num) {…...

XML 注入漏洞原理以及修复方法
漏洞名称:XML注入 漏洞描述:可扩展标记语言 (Extensible Markup Language, XML) ,用于标记电子文件使其具 有结构性的标记语言,可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。 XM…...

x-cmd pkg | dasel - JSON、YAML、TOML、XML、CSV 数据的查询和修改工具
目录 简介首次用户快速实验指南基本功能性能特点竞品进一步探索 简介 dasel,是数据(data)和 选择器(selector)的简写,该工具使用选择器查询和修改数据结构。 支持 JSON,YAML,TOML&…...

Oracle 19c RAC集群管理 ---------关键参数以及常用命令
Oracle 19c RAC集群管理 ---------关键参数 Oracle 19C RAC 参数最佳实践 --开启强制归档 ALTER DATABASE FORCE LOGGING; --设置 30分钟 强制归档 ALTER SYSTEM SET ARCHIVE_LAG_TARGET1800 SCOPEBOTH SID*; --设置期望undo保持时间3h ALTER SYSTEM SET UNDO_RETENTION21600…...

时限挑战——深度解析Pytest插件 pytest-timeout
在软件开发中,测试用例的执行时间通常是一个关键考虑因素。Pytest插件 pytest-timeout 提供了一个强大的插件,允许你设置测试用例的超时时间。本文将深入介绍 pytest-timeout 插件的基本用法和实际案例,助你精确掌控测试用例的执行时限。 什么…...

Java入门篇:打造你的Java开发环境——从零开始配置IDEA与Eclipse
引言 “工欲善其事,必先利其器” 作为每一位Java初学者的必经之路,搭建合适的开发环境是至关重要的第一步。本篇将详细指导你如何安装并配置两大主流Java开发工具——IntelliJ IDEA和Eclipse,助你在编程之旅上迈出坚实的第一步。 一、Java开发环境准备 1. 下载并安装Java D…...
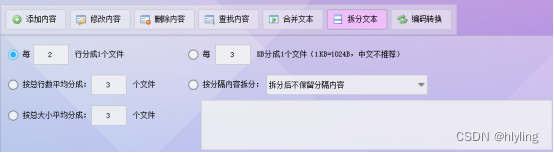
文本批量处理大师:简化文本处理,释放无限生产力!
在数字化时代,我们每天都要处理大量的文本数据,无论是办公文档、网页内容还是社交媒体帖子。然而,面对海量的信息,传统的一键式操作已经无法满足我们的需求。我们需要一个更高效、更智能的工具来提升我们的工作效率。今天…...

Go 方法
第 1 章 方法 Go 语言也支持面向对象的思想;所谓面向对象编程:1对象就是简单的一个值或者变量,并且拥有其方法2方法是某种特定类型的函数3 面向对象编程就是使用方法来描述每个数据结构的属性和操作; 使用者不需要了解对象本身的…...

深度学习与大数据在自然语言处理中的应用与进展
引言 在当今社会,深度学习和大数据技术的快速发展为自然语言处理(NLP)领域带来了显著的进步。这种技术能够使计算机更好地理解和生成人类语言,从而推动了搜索引擎、语音助手、机器翻译等领域的创新和改进。 NLP的发展与技术进步…...
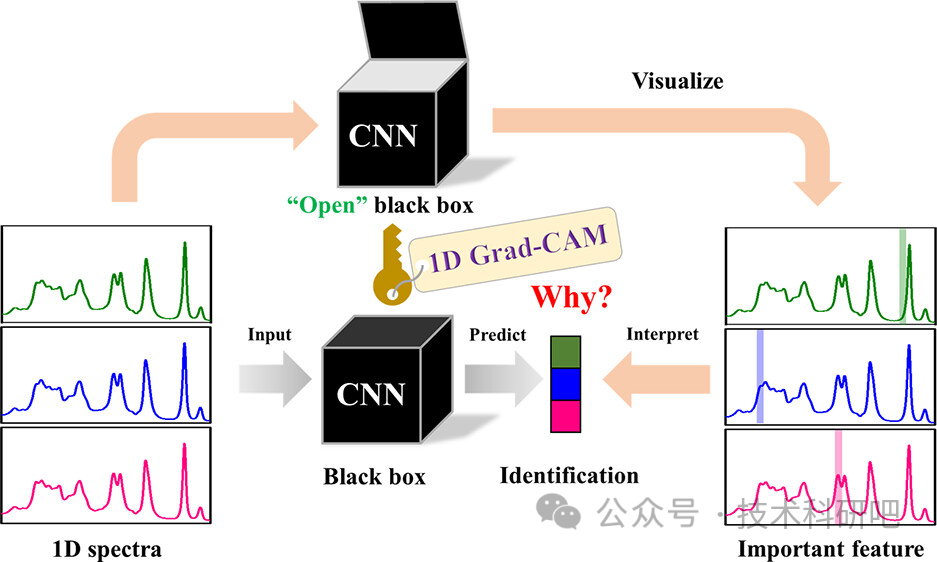
GPT4+Python近红外光谱数据分析及机器学习与深度学习建模
详情点击链接:GPT4Python近红外光谱数据分析及机器学习与深度学习建模 第一:GPT4 1、ChatGPT(GPT-1、GPT-2、GPT-3、GPT-3.5、GPT-4模型的演变) 2、ChatGPT对话初体验 3、GPT-4与GPT-3.5的区别,以及与国内大语言模…...
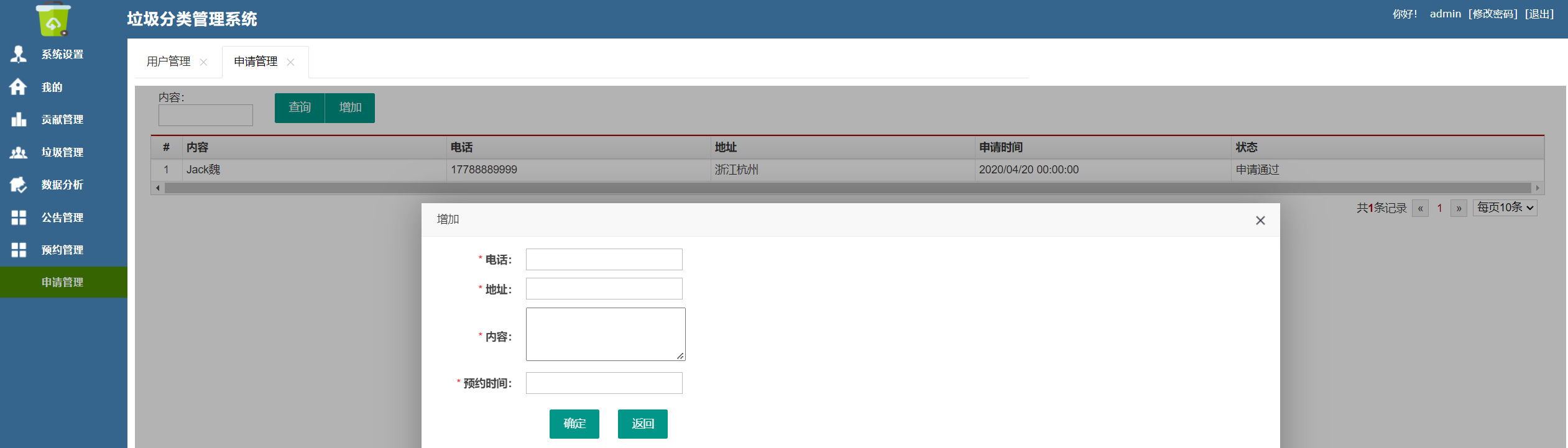
Java项目:12 Springboot的垃圾回收管理系统
作者主页:源码空间codegym 简介:Java领域优质创作者、Java项目、学习资料、技术互助 文中获取源码 1.介绍 垃圾分类查询管理系统,对不懂的垃圾进行查询进行分类并可以预约上门回收垃圾。 让用户自己分类垃圾, 按国家标准自己分类…...

Gitee领跑本土化开发体验:深度解析国内代码托管平台的选择之道
在数字化转型浪潮中,代码托管平台已成为开发者团队不可或缺的基础设施。国内市场经过多年发展,已经从单一的海外平台依赖,逐步形成了多元化的平台选择生态。其中,Gitee凭借其本土化优势脱颖而出,成为众多国内开发团队的…...
)
手把手教你用STC89C52单片机驱动DS1302时钟模块(附完整代码)
STC89C52与DS1302时钟模块实战指南:从硬件搭建到代码实现 1. 项目概述与硬件准备 在嵌入式系统开发中,实时时钟(RTC)功能是许多项目的核心需求。STC89C52作为经典的51系列单片机,与DS1302时钟模块的组合,为开发者提供了经济实惠且…...

好用的昆明线上经营推广哪家好选
在数字化浪潮席卷的当下,昆明的企业和商家们越来越意识到线上经营推广的重要性。选择一家靠谱的线上经营推广公司,能够让企业在激烈的市场竞争中脱颖而出。那么,在昆明众多的推广公司中,哪家才是比较好的选择呢?今天&a…...

AI商品计划:中国鞋服零售如何用机器学习解决库存与周转难题
过去十年,中国鞋服零售经历了从线下到线上、从粗放铺货到精准运营的剧烈转变。但一个老问题始终没变:该备多少货,备在哪,备什么颜色尺码。备多了,资金压在仓库,季末折扣吞噬利润;备少了…...

钉钉数字化转型避坑指南:这10个“雷区”90%企业都踩过
钉钉数字化转型避坑指南:这10个“雷区”90%企业都踩过在数字经济浪潮下,企业数字化转型已从“可选项”变为“生存必修课”。而钉钉作为国内领先的企业数字化平台,凭借其开放生态、低代码能力和丰富应用,成为众多企业转型的首选基座…...
的开发详解五:SigmaStudio实战技巧与模块高效应用)
ADAU1701(含A2B)的开发详解五:SigmaStudio实战技巧与模块高效应用
1. SigmaStudio模块查找的终极技巧 第一次打开SigmaStudio时,面对左侧密密麻麻的模块列表,我完全懵了。就像走进一个巨大的图书馆却找不到分类标签,ADI把200多个算法模块分散在30多个分类里,光Volume Controls下面就有12种音量调节…...

基于Cadence Virtuoso的gm/ID曲线仿真与参数扫描实战指南
1. 从零理解gm/ID设计方法学 在模拟电路设计领域,随着工艺节点不断缩小,我们这些工程师遇到了一个尴尬的现实:教科书里的那些经典公式越来越不灵了。记得我第一次用28nm工艺设计运放时,按照传统方法计算的增益和实测结果差了近40%…...

开源机械爪资源宝库:从入门到进阶的完整实践指南
1. 项目概述:一个为开源“机械爪”而生的资源宝库如果你对机器人、自动化或者开源硬件感兴趣,最近又在琢磨着给自己的项目加个能抓取、能操作的“手”,那么你很可能已经听说过或者正在寻找“OpenClaw”相关的资料。vincentkoc/awesome-opencl…...

终极实战指南:用MifareOneTool解决Windows平台MIFARE Classic卡操作难题
终极实战指南:用MifareOneTool解决Windows平台MIFARE Classic卡操作难题 【免费下载链接】MifareOneTool A GUI Mifare Classic tool on Windows(停工/最新版v1.7.0) 项目地址: https://gitcode.com/gh_mirrors/mi/MifareOneTool 想象…...
)
YOLOv8花生种子霉变识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 本文基于YOLOv8目标检测算法,构建了一套火焰烟雾检测系统,并对两类目标(有火/烟、无火/烟)进行了训练与评估。实验使用自建数据集,共包含训练集248张、验证集77张、测试集42张。实验结果表明,模型在测…...