遗传算法原理详细讲解(算法+Python源码)
博主介绍:✌专研于前后端领域优质创作者、本质互联网精神开源贡献答疑解惑、坚持优质作品共享、掘金/腾讯云/阿里云等平台优质作者、擅长前后端项目开发和毕业项目实战,深受全网粉丝喜爱与支持✌有需要可以联系作者我哦!
🍅文末获取源码联系🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
目录
一、遗传算法
二、常见的遗传算法变体
三、遗传算法操作步骤
1. 基因编码(Representation):
2. 初始化种群(Initialization):
3. 适应度评估(Evaluation):
4. 选择(Selection):
5. 交叉(Crossover):
6. 变异(Mutation):
7. 替换(Replacement):
8. 重复迭代(Iteration):
9. 收敛检测:
10. 最优解提取:
四、算法演示(Python)
五、总结
大家点赞、收藏、关注、评论啦 !
谢谢哦!如果不懂,欢迎大家下方讨论学习哦。
一、遗传算法
遗传算法的概念最早由约翰·霍兰德(John Holland)在20世纪60年代提出。霍兰德是一位美国的电气工程师和计算机科学家,他对生物学中的自然选择和遗传机制产生了浓厚兴趣,并试图将这些生物学原理应用于解决优化和搜索问题。霍兰德的观点: 约翰·霍兰德在20世纪60年代初期,通过研究自然选择和遗传机制,提出了一种新颖的优化算法的思想。他认为,自然选择的过程中,通过基因的遗传和变异,使得物种逐渐适应环境,并找到更好的生存策略。他意识到这一思想可以应用于解决工程和计算问题。 霍兰德于1975年出版了一本名为《自然和人工系统中的适应性》(Adaptation in Natural and Artificial Systems)的书,其中详细介绍了他的遗传算法理论。这本书被认为是遗传算法的奠基之作。
基本原理: 遗传算法的基本原理是通过模拟自然选择和遗传机制进行优化。个体(解决方案)被编码为基因型,通过遗传操作(交叉和变异)来生成新的个体。适应度函数用于评估个体的优劣,更适应环境的个体有更高的概率被选中进入下一代。
演化过程: 遗传算法的演化过程模拟了生物进化的过程,包括选择、交叉和变异。适应度高的个体更有可能被选中,同时,基因交叉和变异引入了新的基因组合,增加了搜索空间的多样性。
应用: 随着计算机科学和人工智能的发展,遗传算法被应用于解决各种优化问题,如组合优化、函数优化、机器学习等。它在搜索空间庞大、复杂问题中的全局搜索能力使其受到了广泛关注。
二、常见的遗传算法变体
-
标准遗传算法(Standard Genetic Algorithm, SGA):
主要特点是通用,适用于各种优化问题。 -
进化策略(Evolutionary Strategies, ES):
优点: 强调个体的变异,通过适应性进化来探索搜索空间。在高维、大规模问题中表现较好。 -
遗传规划算法(Genetic Programming, GP):
优点: 用于自动发现计算机程序或表达式,适用于符号回归、符号分类等问题。能够发现复杂的解决方案。 -
遗传局部搜索算法(Genetic Local Search, GLS):
优点: 结合了遗传算法和局部搜索的优点,通过遗传算法进行全局搜索,然后通过局部搜索进行精细调整。在解空间的不同区域都能有效搜索。 -
多目标遗传算法(Multi-Objective Genetic Algorithm, MOGA):
优点: 用于处理多目标优化问题,同时优化多个目标函数。通过 Pareto 最优前沿来表示和保留多个解决方案。 -
协同演化(Co-Evolution):
- 优点: 多种群体之间进行协同演化,每个群体演化出一部分解决方案。适用于解决复杂问题,能够处理多个相互影响的子问题。
-
遗传局部优化算法(Genetic Local Optimization, GLO):
优点: 结合了全局搜索和局部优化的特点,利用全局搜索来探索解空间,再通过局部优化进行细致调整。 -
差分进化算法(Differential Evolution, DE):
优点: 强调差分操作,通过对个体之间的差异进行搜索。在全局优化问题中表现良好,对参数敏感性较小。 -
自适应遗传算法(Adaptive Genetic Algorithm):
优点: 能够动态调整算法参数,适应问题的特性。在问题变化较大或参数选择困难时具有较好的适应性。 -
混合遗传算法(Hybrid Genetic Algorithm):
优点: 结合遗传算法与其他优化方法,如局部搜索、模拟退火等。在不同问题场景中综合利用不同算法的优势。
三、遗传算法操作步骤
1. 开始
2. 初始化种群
3. 评估种群中每个个体的适应度
4. 是否满足停止条件?
- 是:结束,输出最优解
- 否:
5. 选择操作:根据适应度选择父代个体
6. 交叉操作:对选定的父代进行基因交叉,生成新个体
7. 变异操作:对新生成的个体进行基因变异
8. 评估新生成的个体的适应度
9. 替换操作:将新生成的个体替换掉原种群中适应度较差的个体
10. 回到步骤4
11. 结束
1. 基因编码(Representation):
- 个体表示: 解决方案被编码成一个个体,通常称为染色体。染色体由基因组成,而基因则是问题的解决方案的一部分。
- 编码方式: 基因可以用二进制、实数、整数等方式进行编码,具体取决于问题的性质。
2. 初始化种群(Initialization):
- 种群生成: 随机生成初始的个体群体,即种群。每个个体代表问题的一个可能解。
3. 适应度评估(Evaluation):
- 适应度函数: 为每个个体计算适应度值,该值表示个体解决问题的优劣程度。适应度函数是根据问题的特性而定义的。
4. 选择(Selection):
- 轮盘赌选择: 个体被选择的概率与其适应度成正比。适应度较高的个体更有可能被选中,以模拟自然选择的过程。
5. 交叉(Crossover):
- 基因交叉: 选定一对父代个体,通过某种方式将它们的基因组合生成新的个体。常见的交叉方式包括单点交叉、多点交叉、均匀交叉等。
6. 变异(Mutation):
- 基因变异: 对个体的某些基因进行随机变动。变异操作引入了新的基因信息,有助于保持种群的多样性。
7. 替换(Replacement):
- 新一代形成: 通过选择、交叉和变异生成的新个体替代原来种群中的一部分个体。替换操作保持种群规模不变。
8. 重复迭代(Iteration):
- 演化过程: 通过反复进行选择、交叉、变异和替代,逐渐进化种群。迭代次数可以根据问题的复杂性和算法性能进行调整。
9. 收敛检测:
- 停止条件: 当达到预定的停止条件(如迭代次数达到设定值或找到满意的解)时,遗传算法终止。
10. 最优解提取:
- 解的提取: 在遗传算法运行结束后,从最终的种群中提取具有最佳适应度的个体,即优秀的解决方案。
其核心思想就是通过模拟自然选择、遗传机制,遗传算法能够在搜索空间中自适应地寻找问题的优秀解。主要是通过交叉和变异引入新的组合解。
四、算法演示(Python)
问题描述: 该问题涉及通过遗传算法优化四个参数(p1、p2、q1、q2),使得目标函数的值最小化。目标函数用于拟合一些实际数据,其中包括肝、肺、胃内的浓度数据。
编码和解码:
- 编码: 每个个体(种群中的一个成员)通过二进制编码表示四个参数。
- 解码: 通过解码操作将二进制编码转换为实际参数值。
目标函数设计:
- 提供了两种不同的目标函数(F和F2)供选择。
- 目标函数的计算基于实际数据和模型预测值之间的误差。
适应度函数:
- 适应度函数根据目标函数的值计算个体的适应度。适应度越高,个体越有可能被选择为父代。
遗传算法操作:
- 选择: 根据适应度选择个体,采用轮盘赌选择。
- 交叉和变异: 采用单点交叉操作,以一定的概率发生交叉,并对基因进行变异。
- 替换: 将新生成的个体替换掉原种群中适应度较差的个体。
迭代: 通过多次迭代,不断演化种群,寻找最优解。
结果输出: 打印最终种群中适应度最好的个体及其对应的参数值。
import numpy as np
import warningswarnings.filterwarnings('ignore')DNA_SIZE = 20 # DNA长度(二进制编码长度)
POP_SIZE = 150 # 初始种群数量
CROSSOVER_RATE = 0.95 # 交叉率
MUTATION_RATE = 0.005 # 变异率 将0.005改为0.01
N_GENERATIONS = 1000 # 进化代数 进化代数在 800—1200 之间比较适合,本文选取进化1000代
p1_BOUND = [0, 1] # 确定参数的范围
p2_BOUND = [0, 1]
q1_BOUND = [0, 1]
q2_BOUND = [0, 1]dic_liver = {0.167: 0.681, 0.5: 0.436, 1: 0.709, 2: 0.263, 6: 0.12} # 键表示时间(h),值表示肝内的浓度
dic_lung = {0.167: 1.069, 0.5: 0.689, 1: 0.666, 2: 0.342, 6: 0.162} # 表示肺内的浓度
dic_stomach = {0.167: 4.827, 0.5: 3.866, 1: 1.67, 2: 1.638, 6: 0.798} # 表示胃内的浓度的def F(p1, p2, q1, q2): # 设计目标函数 法一fun = 0for key, value in dic_liver.items():fun = ((p1 * np.exp(-q1 * key) + p2 * np.exp(-q2 * key)) - value) ** 2 + funreturn fundef F2(p1, p2, q1, q2): # 设计目标函数 法二l1 = list(dic_liver.keys())l2 = list(dic_liver.values())result = [((p1 * np.exp(-q1 * i) + p2 * np.exp(-q2 * i)) - j) ** 2 for i, j in zip(l1, l2)]# result = sum(result)total = 0for i in range(len(result)):total = total + result[i]return total# 求最小值对应的适应度函数
def get_fitness(pop):p1, p2, q1, q2 = translateDNA(pop)pred = F(p1, p2, q1, q2)return -(pred - np.max(pred)) + 1e-3 # 要加上一个很小的正数def translateDNA(pop): # 解码 pop表示种群矩阵,一行表示一个二进制编码表示的DNA,矩阵的行数为种群数目 即行数为150行,列数为每个DNA长度*DNA个数,即20*4=80列(150*80)p1_pop = pop[:, :20]p2_pop = pop[:, 20:40]q1_pop = pop[:, 40:60]q2_pop = pop[:, 60:]p1 = p1_pop.dot(2 ** np.arange(DNA_SIZE)[::-1]) / float(2 ** DNA_SIZE - 1) * (p1_BOUND[1] - p1_BOUND[0]) + p1_BOUND[0]p2 = p2_pop.dot(2 ** np.arange(DNA_SIZE)[::-1]) / float(2 ** DNA_SIZE - 1) * (p2_BOUND[1] - p2_BOUND[0]) + p2_BOUND[0]q1 = q1_pop.dot(2 ** np.arange(DNA_SIZE)[::-1]) / float(2 ** DNA_SIZE - 1) * (q1_BOUND[1] - q1_BOUND[0]) + q1_BOUND[0]q2 = q2_pop.dot(2 ** np.arange(DNA_SIZE)[::-1]) / float(2 ** DNA_SIZE - 1) * (q2_BOUND[1] - q2_BOUND[0]) + q2_BOUND[0]return p1, p2, q1, q2# 以下函数包含两个功能,交叉和变异
def crossover_and_mutation(pop, CROSSOVER_RATE=0.95): # 单点交叉new_pop = []for father in pop: # 遍历种群中的每一个个体,将该个体作为父亲child = father # 孩子先得到父亲的全部基因(这里我把一串二进制串的那些0,1称为基因)if np.random.rand() < CROSSOVER_RATE: # 产生子代时不是必然发生交叉,而是以一定的概率发生交叉mother = pop[np.random.randint(POP_SIZE)] # 再种群中选择另一个个体,并将该个体作为母亲cross_points = np.random.randint(low=0, high=DNA_SIZE * 4) # 随机产生交叉的点child[cross_points:] = mother[cross_points:] # 孩子得到位于交叉点后的母亲的基因mutation(child) # 每个后代有一定的机率发生变异new_pop.append(child)return new_pop# 基本位变异算子
def mutation(child, MUTATION_RATE=0.005):if np.random.rand() < MUTATION_RATE: # 以MUTATION_RATE的概率进行变异mutate_point = np.random.randint(0, DNA_SIZE * 4) # 随机产生一个实数,代表要变异基因的位置child[mutate_point] = child[mutate_point] ^ 1 # 将变异点的二进制为反转(异或运算符 1与1为0、1与0为1、0与0为0)def select(pop, fitness): # 描述了从np.arange(POP_SIZE)里选择每一个元素的概率,概率越高约有可能被选中,最后返回被选中的个体即可idx = np.random.choice(np.arange(POP_SIZE), size=POP_SIZE, replace=True,p=(fitness) / (fitness.sum()))return pop[idx]# # np.random.choice()函数的用法
# arr = ['pooh', 'rabbit', 'piglet', 'Christopher']
# np.random.choice(aa_milne_arr, size=11, p=[0.5, 0.1, 0.1, 0.3])def print_info(pop):fitness = get_fitness(pop)min_fitness_index = np.argmin(fitness) # 表示为array的最大值/最小值对应的索引print("min_fitness:", fitness[min_fitness_index])p1, p2, q1, q2 = translateDNA(pop)print("最优的基因型:", pop[min_fitness_index])print("(p1, p2, q1, q2):",(p1[min_fitness_index], p2[min_fitness_index], q1[min_fitness_index], q2[min_fitness_index]))if __name__ == "__main__":pop = np.random.randint(2, size=(POP_SIZE, DNA_SIZE * 4)) # matrix (POP_SIZE, DNA_SIZE) POP_SIZE为150,DNA_SIZE为20for _ in range(N_GENERATIONS): # 迭代N代pop = np.array(crossover_and_mutation(pop, CROSSOVER_RATE)) # 进行交叉和变异fitness = get_fitness(pop)pop = select(pop, fitness)print_info(pop)

五、总结
遗传算法通过模拟自然选择和遗传机制,能够在搜索空间中找到较好的解决方案,尤其在复杂问题和大规模搜索空间中表现出色。但是存在最大缺点是需要巨大计算资源,对于及时响应存在不足问题。目前对于遗传算法还有待深入研究,尤其是对于不同实际问题需求,数据特点等,通过引入随机操作等降低算法时间和空间复杂度是一项值得深入的研究方向。
大家点赞、收藏、关注、评论啦 !
谢谢哦!如果不懂,欢迎大家下方讨论学习哦。
相关文章:
遗传算法原理详细讲解(算法+Python源码)
博主介绍:✌专研于前后端领域优质创作者、本质互联网精神开源贡献答疑解惑、坚持优质作品共享、掘金/腾讯云/阿里云等平台优质作者、擅长前后端项目开发和毕业项目实战,深受全网粉丝喜爱与支持✌有需要可以联系作者我哦! 🍅文末获…...

Linux文本处理指令汇总
Linux文本处理命令主要包括以下几种: grep:用于在文件中搜索包含指定字符串的行。 [roothanyw-bash-python ~]# grep root /etc/passwd root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologinawk:用于在文件中进行…...

Prompt Engineering
目录 什么是提示工程 什么是提示工程 在当今人工智能领域,提问大型语言模型(Large Language Models,LLM)已经成为一种常见的实践,但如何向这些模型提出问题,或者更准确地说,如何引导它们产生期…...

Ansible剧本playbooks
playbooks概述 Ansible剧本(playbook)是用于配置、部署和管理被控节点的一种描述文件。通过编写详细的剧本描述和执行其中的任务(tasks),可以使远程主机达到预期的状态。剧本由一个或多个"play"组成的列表构…...

Excel·VBA时间范围筛选及批量删除整行
看到一个帖子《excel吧-筛选开始时间,结束时间范围内的所有记录》,根据条件表中的开始时间和结束时间构成的时间范围,对数据表中的开始时间和结束时间范围内的数据进行筛选 目录 批量删除整行,整体删除批量删除整行,分…...

Map转成String,String 转换成Map
一、使用场景 把一个map转换成json字符串后存放在Redis中,然后在redis中取出json字符串,再把字符串转变成原来的Map 二、具体实现 1.1 Map转成String 这里使用是阿里巴巴fastjson Map<String, Object> reportData dssDashboardService.getRep…...
分享一个剧本(改编自我)
不知道是不是错过了一个喜欢我的女孩,一个很不错的女孩,当初没勇气表白。去年表白过但女孩表示仅想是永远的朋友,今天翻他的朋友圈发现2021年我生日时,她分享了这首歌曲,还评论Best wishes!!!,高中有一次我…...

结合Tensuns管理prometheus的blackbox与告警设置
场景说明: 因为业务服务器已经完成了三级等保,禁止在业务服务器上部署任何应用,遂选择一台新的服务器部署prometheus,采用blackbox_exporter监控业务服务器的端口与域名状态。 Tensuns项目介绍 https://github.com/starsliao/T…...

printf实现
这是我看之前公司的旧代码摘录下来的, 感觉写的还算可以吧, void printfsend(UART_TypeDef UARTx, uint8_t *buf, int len) {uint8_t printbuf[256];for (int i 0; i < len; i){printbuf[i] buf[i];}#ifdef ENABLE_PERIAL_TESTif (uart_printf_switch_gloab){UART_Send…...

Elasticsearch 中的 term、terms 和 match 查询
目录 term 查询 terms 查询 match 查询 注意事项 结论 Elasticsearch 提供了多种查询类型,用于不同的搜索需求。term、terms 和 match 是其中最常用的一些查询类型。下面分别介绍每种查询类型的用法和特点。 term 查询 term 查询用于精确值匹配。它通常用于关…...

美易官方:开盘:美股高开科技股领涨 标普指数创盘中新高
**开盘:美股高开科技股领涨 标普指数创盘中新高** 在周三的交易中,美国股市高开,科技股领涨市场,标普500指数创下盘中新高。投资者对经济复苏的乐观情绪以及对科技公司业绩的看好,共同推动了市场的上涨。 盘初…...

STM32F407移植OpenHarmony笔记2
接上篇,搭建完开发环境后,我们还要继续工作。 官方合作的开发板刚好有STM32F407,我准备试一下开发板的demo,虽然我用的不是他们的开发板。 先下载以下3份代码: https://gitee.com/openharmony/device_board_talkweb…...

数据仓库-相关概念
简介 数据仓库是一个用于集成、存储和管理大量数据的系统。它用于支持企业决策制定过程中的数据分析和报告需求。数据仓库从多个来源收集和整合数据,并将其组织成易于查询和分析的结构。 数据仓库的主要目标是提供高性能的数据访问和分析能力,以便…...
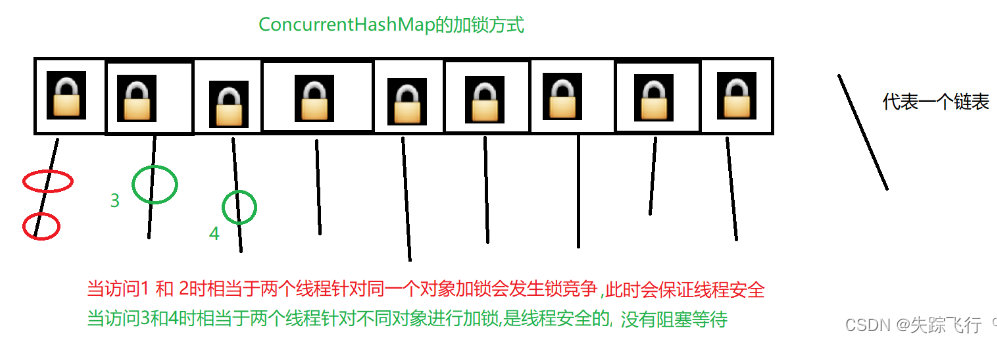
线程的面试八股
Callable接口 Callable是一个interface,相当于给线程封装了一个返回值,方便程序猿借助多线程的方式计算结果. 创建一个匿名内部类, 实现 Callable 接口. Callable 带有泛型参数. 泛型参数表示返回值的类型. 重写 Callable 的 call 方法, 完成累加的过程. 直接通过返回值返…...
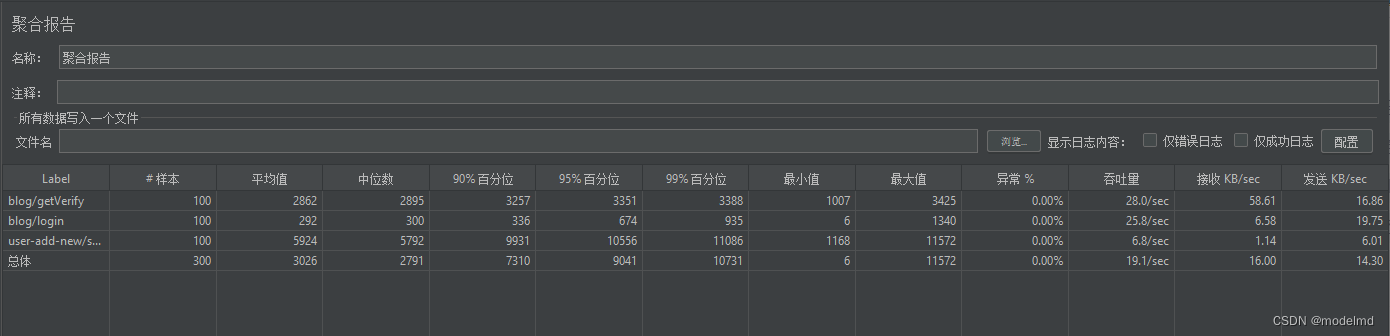
Jmeter 配置元件
Jmeter 配置元件 CSV 数据集配置HTTP Cookie 管理器HTTP Header 信息头管理器增加多个用户案列 使用Jmeter发送请求的时候,需要配置元件,配置请求Header、Cookie、数据集合等。可以模拟多个在线用户登录,修改请求头数据。 CSV 数据集配置 C…...

Java- @FunctionalInterface声明一个接口为函数式接口
基本介绍 FunctionalInterface 是 Java 8 中引入的注解,用于声明一个接口是函数式接口。函数式接口是指仅包含一个抽象方法的接口,可以用于支持 Lambda 表达式和方法引用。FunctionalInterface 注解确保该接口只包含一个抽象方法,从而确保其…...

Java使用Netty实现端口转发Http代理Sock5代理服务器
Java使用Netty实现端口转发&Http代理&Sock5代理服务器.md 一、简介1.功能2.参数配置3.程序下载4.程序启动5.源码 一、简介 这里总结整理了之前使用Java写的端口转发、Http代理、Sock5代理程序,放在同一个工程中,方便使用。 开发语言:…...
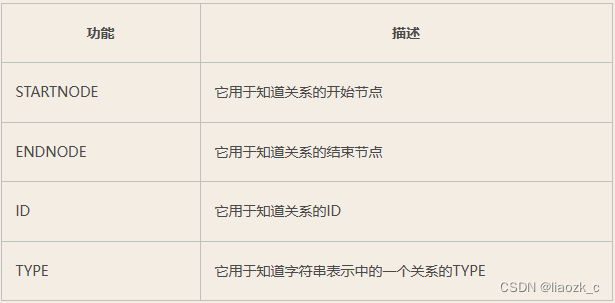
Linux环境docker安装Neo4j,以及Neo4j新手入门教学(超详细版本)
目录 1、 图数据库Neo4j简介1.1 什么是图数据库1.2 能解决什么痛点1.3 对比关系型数据库1.4 什么是Neo4j1.5 Neo4j的构建元素 2. 环境搭建2.1 安装Neo4j Community Server2.2 docker 安装Neo4j Community Server2.3 Neo4j Desktop安装 3. Neo4j - CQL使用3.1 Neo4j - CQL简介3.…...

C++ inline 关键字有什么做用?
C/C 之中 inline 是一个很有意思的关键字,奇奇怪怪的用法见过不少,今天抽点时间出来聊聊这个东西。 inline 可以用在那些方面?修饰 inline 内链关键字到底有什么作用? OK:started 1、inline 可以用在类成员函数的声明…...
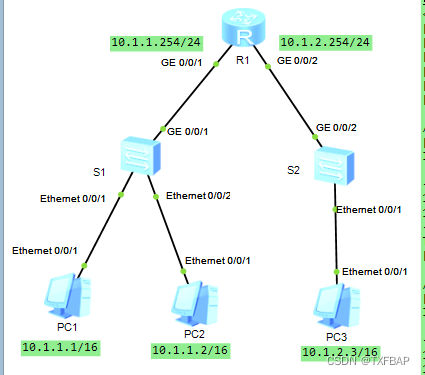
eNSP学习——理解ARP及Proxy ARP
目录 名词解释 实验内容 实验目的 实验步骤 实验拓扑 配置过程 基础配置 配置静态ARP 名词解释 ARP (Address Resolution Protocol)是用来将IP地址解析为MAC地址的协议。ARP表项可以分为动态和静态两种类型。 动态ARP是利用ARP广播报文,动态执行并自动进…...

从AwesomeCursorPrompt看提示工程:如何设计高效AI编程指令
1. 项目概述:从“AwesomeCursorPrompt”看提示工程的工程化实践最近在折腾AI编程助手,特别是Cursor这个工具,发现一个挺有意思的现象:很多人觉得它“不够聪明”,或者用起来效果时好时坏。其实,这背后往往不…...

RT-Thread aarch64虚拟平台文件系统移植实战:从QEMU virt到LittleFS
1. 项目概述与核心价值最近在折腾RT-Thread的aarch64虚拟平台,特别是qemu-virt64-aarch64这个BSP(Board Support Package,板级支持包)上的文件系统支持。这看起来像是一个很具体的移植工作,但实际上,它触及…...

如何用AEUX免费实现设计到动画的无缝转换:完整指南
如何用AEUX免费实现设计到动画的无缝转换:完整指南 【免费下载链接】AEUX Editable After Effects layers from Sketch artboards 项目地址: https://gitcode.com/gh_mirrors/ae/AEUX AEUX是一款免费开源的动效设计工具,它能让你从Figma或Sketch直…...

Motorola LS2208条码扫描器USB接口模式解析与Python数据采集实战
1. 项目概述:从“扫码枪”到数据采集终端在仓库、快递站或者超市收银台,我们每天都能看到工作人员拿着一个像手枪一样的东西,“嘀”一声,商品信息就录入了系统。这个设备就是条码扫描器,很多人习惯叫它“扫码枪”。你可…...

HART协议实战:从帧结构解析到MCU数据处理的完整代码指南
1. HART协议基础与帧结构解析 第一次接触HART协议时,我被它独特的"模拟信号数字信号"叠加方式惊艳到了。想象一下,在工业现场常见的4-20mA模拟信号线上,还能叠加数字通信信号,就像在一条老式电话线上同时传输语音和宽带…...

终极指南:3分钟掌握Deepin Boot Maker,轻松制作Linux启动盘
终极指南:3分钟掌握Deepin Boot Maker,轻松制作Linux启动盘 【免费下载链接】deepin-boot-maker 项目地址: https://gitcode.com/gh_mirrors/de/deepin-boot-maker 你是否曾经因为复杂的命令行操作而对Linux系统安装望而却步?或者面对…...

3分钟快速激活方案:KMS_VL_ALL_AIO智能脚本全解析
3分钟快速激活方案:KMS_VL_ALL_AIO智能脚本全解析 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否曾经为Windows系统或Office办公软件的激活问题而烦恼?频繁的激活…...

基于计算机视觉的屏幕内容智能识别与自动化实践
1. 项目概述:当屏幕成为你的“眼睛”最近在折腾一个挺有意思的项目,我把它叫做“Screen Vision”,直译过来就是“屏幕视觉”。这名字听起来有点玄乎,但核心想法其实很直接:让计算机程序能像人一样,“看懂”…...

Armv8-A内存模型特性寄存器详解与应用
1. Armv8-A内存模型特性寄存器概述在Armv8-A架构中,内存模型特性寄存器(Memory Model Feature Registers,简称MMFR)是一组关键的系统寄存器,用于描述处理器实现的内存管理功能特性。这些寄存器采用只读访问模式&#x…...

苏峻:一个“产品偏执狂”的20年跨界史,从讲台到造车,他到底在疯什么?icar
苏峻:一个“产品偏执狂”的20年跨界史,从讲台到造车,他到底在疯什么?一个50岁的清华大学设计学博士,当过15年大学老师,做过空气净化器,卖过200万台,现在又跑去造车。有人说他是疯子&…...