【AI量化分析】小明在量化中使用交叉验证原理深度分析解读
进行交叉验证好处
提高模型的泛化能力:通过将数据集分成多个部分并使用其中的一部分数据进行模型训练,然后使用另一部分数据对模型进行测试,可以确保模型在未见过的数据上表现良好。这样可以降低模型过拟合或欠拟合的风险,提高模型的泛化能力。
最大化数据利用:在传统的机器学习流程中,通常将数据集分为训练集和测试集,训练集用于训练模型,而测试集用于评估模型的性能。这种方式可能会导致数据的浪费,因为测试集可能没有充分利用。通过交叉验证,每个样本都可以被用作训练集和验证集,从而更好地利用所有可用的数据。
稳定性和可重复性:由于交叉验证可以产生一致的结果,因此可以提高实验的稳定性和可重复性。在进行机器学习实验时,不同的数据划分可能导致不同的结果。通过交叉验证,可以消除这种随机性,得到更加稳定和可靠的结果。
参数选择:交叉验证还可以用于选择最佳的模型参数。例如,可以通过比较不同参数设置下的交叉验证结果,选择最优的参数。这种方法可以帮助我们找到在各种不同场景下都能表现良好的参数。
降低偏差:将数据集随机分成多个部分可以减少由单一数据划分带来的偏差。例如,如果数据集中的某些样本具有特殊的特征或分布,那么这些样本可能会对模型的训练产生影响。通过交叉验证,可以确保每个子集都有相似的分布,从而降低偏差。
总的来说,交叉验证是一种非常有效的机器学习方法,可以帮助我们提高模型的泛化能力、稳定性和可重复性,同时还可以用于选择最佳的模型参数。在进行机器学习实验时,建议使用交叉验证来获得更加准确和可靠的结果。
为什么说交叉验证是最好的分割数据的方法
根据目的和意图,对数据分割的方法有简单拆分,分层拆分,留出拆分,但是以上方法都不完美,最好的拆分方法是交叉验证拆分:将数据集分成k份,每次使用其中的k-1份数据进行训练,剩余的一份数据进行测试。这种方法的优点是能够充分利用数据,并且在每次迭代中都保留了一部分数据作为验证集,有助于调整模型参数和选择最佳模型。但需要注意的是,k的选择会影响模型的泛化能力,通常k值越大,模型的泛化能力越强。
以下是交叉验证的源码
from sklearn.model_selection import KFold
import pandas as pd# 读取数据
data = pd.read_csv('stock_data.csv')
X = data.drop('date', axis=1) # 假设日期作为目标变量
y = data['date']# 定义交叉验证
kf = KFold(n_splits=5, shuffle=True, random_state=42)for train_index, test_index in kf.split(X):# 提取训练和测试数据X_train, X_test = X.iloc[train_index], X.iloc[test_index]y_train, y_test = y.iloc[train_index], y.iloc[test_index]# 在此处进行模型训练和评估等操作# ...
n_estimators 是个啥?
在机器学习和数据科学中,n_estimators 是一个常用于集成学习算法的参数,特别是在随机森林(Random Forest)和梯度提升机(Gradient Boosting)等算法中。这个参数表示在构建集成模型时所使用的基学习器的数量。
具体来说:
在随机森林中,n_estimators 指的是森林中决策树的数量。
在梯度提升机中,n_estimators 指的是模型中的弱学习器或基模型的数量。
为了获得更好的预测性能,通常建议使用足够多的基学习器来形成集成模型。然而,增加基学习器的数量并不总是带来性能提升,因为过拟合也可能发生。因此,选择一个合适的 n_estimators 值通常需要进行一些实验和交叉验证。
在随机森林中,除了 n_estimators 外,还有一个与之相关的参数叫做 max_depth,它限制了每棵树的最大深度。这些参数可以用来控制模型的复杂度和过拟合的风险。
交叉验证如何
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score# 读取数据
data = pd.read_csv('stock_data.csv')
X = data[['open', 'high', 'low', 'close']]
y = data['date']# 定义参数网格
param_grid = {'n_estimators': [100, 200, 300, 400, 500]}# 定义交叉验证和模型评估
kf = KFold(n_splits=5, shuffle=True, random_state=42)
score_func = lambda model, X, y: accuracy_score(y, model.predict(X))# 执行网格搜索
grid = GridSearchCV(RandomForestClassifier(), param_grid, cv=kf, scoring=score_func)
grid.fit(X, y)# 输出最佳参数和最高得分
print("Best parameters:", grid.best_params_)
print("Best score:", grid.best_score_)
在上述代码中,我们首先从数据集中读取特征和目标变量。然后,我们定义了一个参数网格param_grid,其中包含不同的n_estimators值。接下来,我们使用5折交叉验证KFold来划分数据集,并定义一个评估函数score_func,用于计算模型的准确率。然后,我们使用GridSearchCV执行网格搜索,传入我们的模型(RandomForestClassifier)、参数网格、交叉验证和评估函数。最后,我们打印出最佳参数和最高得分。
通过执行上述代码,我们可以找到最佳的n_estimators值,使得模型在交叉验证中获得最高的准确率。你可以根据实际情况调整参数网格中的其他超参数,以找到最佳的模型配置。
接近股市
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_score, cross_validatedef regress_process(estimator, train_x, train_y_regress, test_x, test_y_regress):# 训练训练集数据estimator.fit(train_x, train_y_regress)# 使用训练好的模型预测测试集对应的ytest_y_prdict_regress = estimator.predict(test_x)# 绘制实际股价涨跌幅度plt.plot(test_y_regress.cumsum())# 绘制通过模型预测的股价涨跌幅度plt.plot(test_y_prdict_regress.cumsum())# 针对训练集数据做交叉验证scores = cross_val_score(estimator, train_x, train_y_regress, cv=10)# 打印交叉验证得分print('Cross-validation scores: ', scores)print('Mean cross-validation score: ', np.mean(scores))# 实例化随机森林回归对象estimator
estimator = RandomForestRegressor()
# 将回归模型对象、训练集x、训练集连续y值、测试集x、测试集连续y值传入
regress_process(estimator, train_x, train_y_regress, test_x, test_y_regress)
探索随机森林的神奇力量,掌握参数调整的魔法,让我们在金融领域中驾驭数据的海洋。使用交叉验证作为指南,让我们找到最佳的模型配置,为我们的预测之旅保驾护航。

现在,请闭上眼睛,想象一下你是一名勇敢的探险家,手持一把神奇的指南针,在数据的大陆上探索未知的领域。这个指南针就是交叉验证,它会指引你找到最佳的模型配置,帮助你战胜数据挑战。
当你遇到一个神秘的山洞时,不要害怕,打开你的指南针,让它指引你前行。你会发现,这个山洞里面隐藏着许多宝藏,这些宝藏就是不同的参数配置。有些宝藏会让你的模型熠熠生辉,有些则会让你的模型黯然失色。
通过交叉验证,你可以安全地探索这个山洞,找到属于你的最佳宝藏。你会发现,这个宝藏不仅仅是一组超参数,更是一种智慧和勇气的象征。
所以,现在拿起你的指南针,踏上你的数据探险之旅吧!让交叉验证成为你的得力助手,共同开启一段令人难忘的旅程。相信我,当你找到那颗最佳的超参数组合时,你会发现整个世界都在为你喝彩!
相关文章:
【AI量化分析】小明在量化中使用交叉验证原理深度分析解读
进行交叉验证好处 提高模型的泛化能力:通过将数据集分成多个部分并使用其中的一部分数据进行模型训练,然后使用另一部分数据对模型进行测试,可以确保模型在未见过的数据上表现良好。这样可以降低模型过拟合或欠拟合的风险,提高模…...
2024最新版Visual Studio Code安装使用指南
2024最新版Visual Studio Code安装使用指南 Installation and Usage Guide for the Latest Visual Studio Code in 2024 By JacksonML Visual Studio Code最新版1.85已经于2023年11月由其官网 https://code.visualstudio.com正式发布,这是微软公司2024年发行的的最…...

接口请求重试八种方法
请求三方接口需要加入重试机制 一、循环重试 在请求接口的代码块中加入循环,如果请求失败则继续请求,直到请求成功或达到最大重试次数。 int retryTimes 3; for(int i 0;i < retryTimes;i){try{//请求接口的代码break;}catch(Exception e){//处理…...
【Linux 基础】常用基础指令(上)
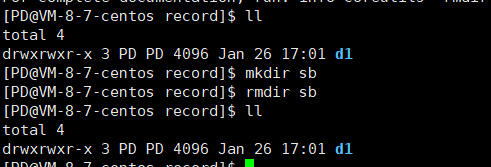
文章目录 一、 创建新用户并设置密码二、ls指令ls指令基本概念ls指令的简写操作 三、pwd指令四、cd指令五、touch指令六、rm指令七、mkdir指令八、rmdir 指令 一、 创建新用户并设置密码 ls /home —— 查看存在多少用户 whoami —— 查看当前用户名 adduser 用户名 —— 创建新…...

【RT-DETR有效改进】EfficientFormerV2移动设备优化的视觉网络(附对比试验效果图)
前言 大家好,我是Snu77,这里是RT-DETR有效涨点专栏。 本专栏的内容为根据ultralytics版本的RT-DETR进行改进,内容持续更新,每周更新文章数量3-10篇。 专栏以ResNet18、ResNet50为基础修改版本,同时修改内容也支持Re…...

《动手学深度学习(PyTorch版)》笔记4.4
注:书中对代码的讲解并不详细,本文对很多细节做了详细注释。另外,书上的源代码是在Jupyter Notebook上运行的,较为分散,本文将代码集中起来,并加以完善,全部用vscode在python 3.9.18下测试通过。…...

Linux/Academy
Enumeration nmap 首先扫描目标端口对外开放情况 nmap -p- 10.10.10.215 -T4 发现对外开放了22,80,33060三个端口,端口详细信息如下 结果显示80端口运行着http,且给出了域名academy.htb,现将ip与域名写到/et/hosts中,然后从ht…...
windows .vscode的json文件配置 CMake 构建项目 调试窗口中文设置等
一、CMake 和 mingw64的安装和环境配置 二、tasks.json和launch.json文件配置 tasks.json {"version": "2.0.0","options": {"cwd": "${workspaceFolder}/build"},"tasks": [{"type": "shell&q…...

uniapp canvas做的刮刮乐解决蒙层能自定义图片
最近给湖南中烟做元春活动,一个月要开发4个小活动,这个是其中一个难度一般,最难的是一个类似鲤鱼跃龙门的小游戏,哎,真实为难我这个“拍黄片”的。下面是主要代码。 <canvas :style"{width:widthpx,height:hei…...

利用SPI,结合数据库连接池durid进行数据服务架构灵活设计
接着上一篇文章业务开始围绕原始凭证展开,而展开的基础无疑是围绕着科目展开的。首先我们业务层面以财政部的小企业会计准则的一级科目引入软件中。下面我们来考虑如何将科目切入软件更加灵活,方便业务扩展、维护与升级。 SPI是首先想到的数据服务方式 为什么会想到它呢?首…...

自动驾驶的决策层逻辑
作者 / 阿宝 编辑 / 阿宝 出品 / 阿宝1990 自动驾驶意味着决策责任方的转移 我国2020至2025年将会是向高级自动驾驶跨越的关键5年。自动驾驶等级提高意味着对驾驶员参与度的需求降低,以L3级别为界,低级别自动驾驶环境监测主体和决策责任方仍保留于驾驶…...

排序算法——希尔排序算法详解
希尔排序算法详解 一. 引言1. 背景介绍1.1 数据排序的重要性1.2 希尔排序的由来 2. 排序算法的分类2.1 比较排序和非比较排序2.2 希尔排序的类型 二. 希尔排序基本概念1. 希尔排序的定义1.1 缩小增量排序1.2 插入排序的变种 2. 希尔排序的工作原理2.1 分组2.2 插入排序2.3 逐步…...

Docker 容器内运行 mysqldump 命令来导出 MySQL 数据库,自动化备份
备份容器数据库命令: docker exec 容器名称或ID mysqldump -u用户名 -p密码 数据库名称 > 导出文件.sql请替换以下占位符: 容器名称或ID:您的 MySQL 容器的名称或ID。用户名:您的 MySQL 用户名。密码:您的 MySQL …...

【Java万花筒】数字信号魔法:Java库的魅力解析
从傅立叶到矩阵:数字信号Java库全景剖析 前言 随着数字信号处理在科学、工程和数据分析领域的广泛应用,开发者对高效、灵活的工具的需求日益增长。本文旨在探讨几个与数字信号处理相关的Java库,通过介绍其特点、用途以及与已有库的关系&…...

面试高频知识点:2线程 2.1 线程池 2.1.2 JDK中常见的线程池实现有哪些?
1. Executors类 Executors类是线程池的工厂类,提供了一些静态方法用于创建不同类型的线程池。然而,它的使用并不推荐在生产环境中,因为它存在一些缺点,比如默认使用无界的任务队列,可能导致内存溢出。 2. ThreadPool…...
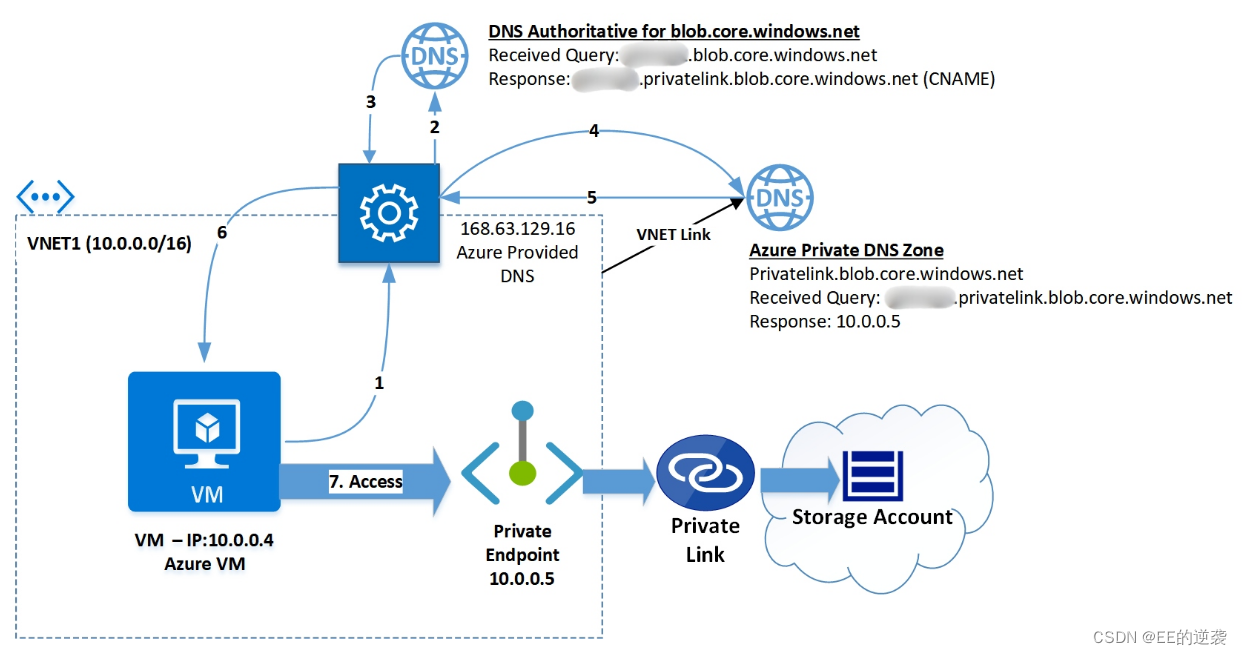
Azure Private endpoint DNS 记录是如何解析的
Private endpoint 从本质上来说是Azure 服务在Azure 虚拟网络中安插的一张带私有地址的网卡。 举例来说如果Storage account在没有绑定private endpoint之前,查询Storage account的DNS记录会是如下情况: Seq Name …...

windows 安装sql server 华为云文档
先安装net3.5,剩下安装sqlserver步骤看下面文档 安装SQL Server_弹性云服务器 ECS_最佳实践_搭建Microsoft SharePoint Server 2016_华为云 (huaweicloud.com)...

相同主题文章竟同时发表在同一个2区期刊 | 孟德尔随机化周报(1.10-1.16)
欢迎报名2024年郑老师团队课程课程! 郑老师科研统计培训,包括临床数据、公共数据分析课程,欢迎报名 孟德尔随机化,Mendilian Randomization,简写为MR,是一种在流行病学领域应用广泛的一种实验设计方法,利用…...

网络安全的使命:守护数字世界的稳定和信任
在数字化时代,网络安全的角色不仅仅是技术系统的守护者,更是数字社会的信任保卫者。网络安全的使命是保护、维护和巩固数字世界的稳定性、可靠性以及人们对互联网的信任。本文将深入探讨网络安全是如何履行这一使命的。 第一部分:信息资产的…...

【七、centos要停止维护了,我选择Almalinux】
搜索镜像 https://developer.aliyun.com/mirror/?serviceTypemirror&tag%E7%B3%BB%E7%BB%9F&keywordalmalinux dvd是有界面操作的,minimal是最小化只有命里行 镜像下载地址 安装和centos基本一样的,操作命令也是一样的,有需要我…...

ColorBrewer终极指南:快速掌握专业地图配色方案
ColorBrewer终极指南:快速掌握专业地图配色方案 【免费下载链接】colorbrewer 项目地址: https://gitcode.com/gh_mirrors/co/colorbrewer ColorBrewer是一个基于Cynthia Brewer博士研究成果的专业颜色方案工具,专门为地图制图和数据可视化提供科…...

2025最权威的降AI率方案实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 随着人工智能技术迅猛地发展,它在学术研究领域的应用越发深入,对高等…...

终极指南:如何用免费软件完全掌控Windows电脑风扇噪音与散热平衡
终极指南:如何用免费软件完全掌控Windows电脑风扇噪音与散热平衡 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_T…...

在 Vue 2 与 Vue 3 中使用 markdown-it-vue 渲染 Markdown 和数学公式
markdown-it-vue 是一个功能强大的 Markdown 渲染 Vue 组件,它基于 markdown-it 解析引擎,集成了多种插件,开箱即用地支持GitHub风格的Markdown、代码高亮、图表(Mermaid, ECharts)、表情符号(emoji&#x…...

[A2A协议与实现-01]借助A2A协议打破智能体孤岛
A2A协议是一个开放标准,它实现了Agent之间的无缝通信和协作。它为使用不同框架和由不同供应商构建的Agent提供了一种通用语言,从而促进了互操作性并打破了信息孤岛。A2A协议使得来自不同开发者、基于不同框架构建、并由不同组织拥有的Agent能够联合起来协…...
)
Vue2项目里,用lodash的debounce给搜索框‘降降温’(附完整代码和常见坑点)
Vue2实战:用lodash的debounce优化搜索框性能与避坑指南 搜索框是Web应用中最高频的交互组件之一,但处理不当可能成为性能黑洞。当用户快速输入"vue"、"react"等关键词时,传统实现会为每个字符触发搜索请求,导…...

终极指南:如何快速解决iPhone在Windows上的USB网络共享问题
终极指南:如何快速解决iPhone在Windows上的USB网络共享问题 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.com/g…...

Attention Is All You Need:一篇论文,改变了整个世界
先讲一个场景。 2017年,谷歌大脑的一间办公室。 八个研究员,围坐在一起。 他们在讨论一个问题: 现有的翻译模型,为什么总是翻译得不够好? 长句子,翻译到后面,前面的意思就丢了。 复杂的语法结构…...

AD21编译报错“contains floating input pins”?别慌,可能是你的元件库电气类型没设对
AD21编译报错“contains floating input pins”深度解析与实战解决方案 当你满怀信心地在AD21中完成PCB设计,点击编译按钮时,突然跳出的"contains floating input pins"报错就像一盆冷水浇下来。这个看似简单的错误提示背后,隐藏着…...

信息量模型避坑指南:用ArcGIS做地灾评价,这3个细节错了全盘皆输
信息量模型避坑指南:用ArcGIS做地灾评价,这3个细节错了全盘皆输 地质灾害易发性评价是地质工程领域的核心课题之一。在山区开发、城市规划等场景中,准确预测地质灾害风险区域,能够为防灾减灾提供科学依据。信息量模型因其计算简单…...