【Python】01快速上手爬虫案例一:搞定豆瓣读书
文章目录
- 前言
- 一、VSCode+Python环境搭建
- 二、爬虫案例一
- 1、爬取第一页数据
- 2、爬取所有页数据
- 3、格式化html数据
- 4、导出excel文件
前言
实战是最好的老师,直接案例操作,快速上手。
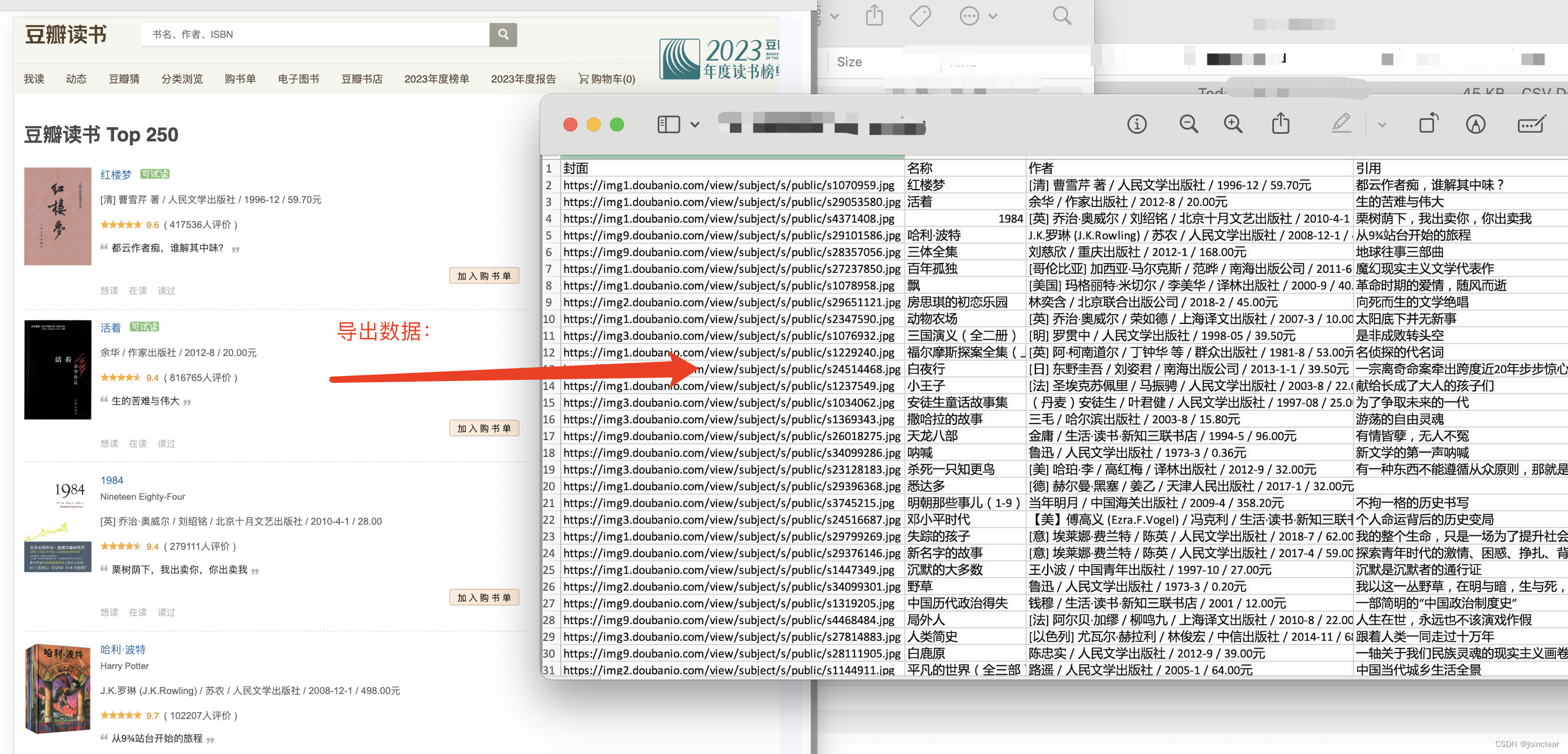
案例一,爬取数据,最终效果图:
一、VSCode+Python环境搭建
开发环境:MacBook Pro + VSCode + Python。
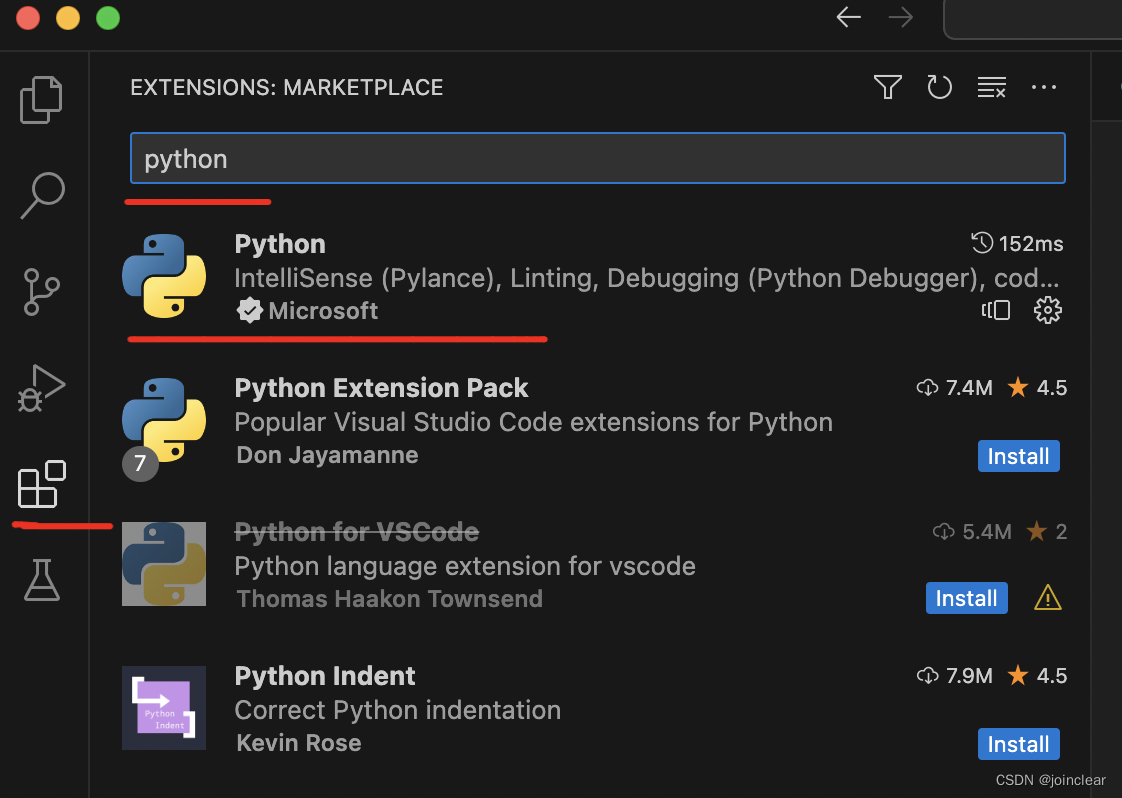
打开最新版VSCode,安装Python开发环境,快捷键:cmd+shift+x。
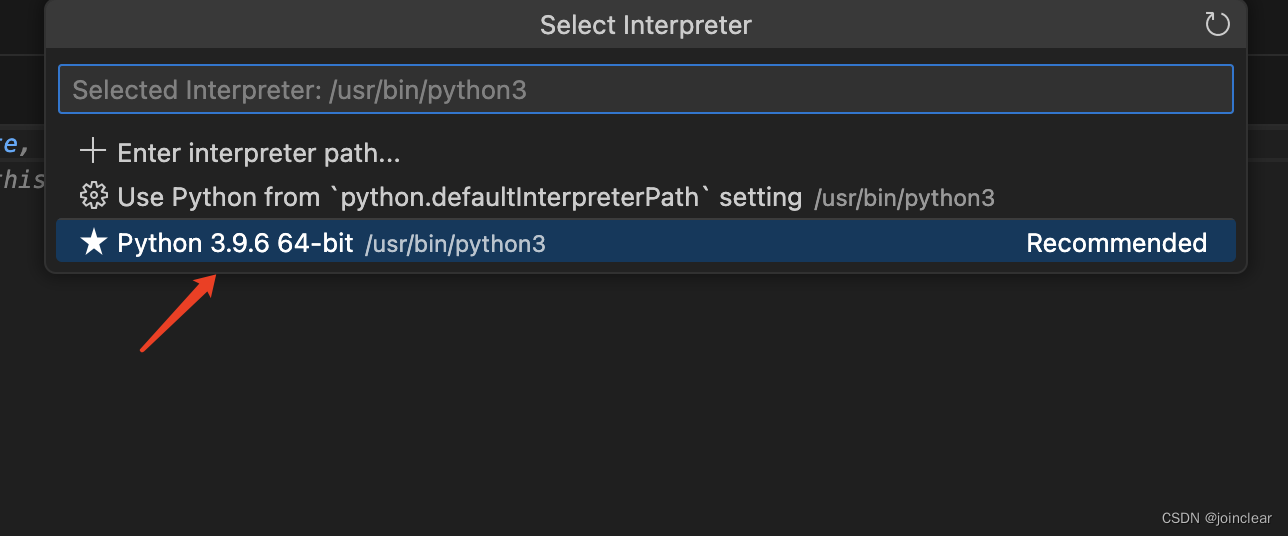
选择Python解释器,快捷键:cmd+shift+p。输入:Python: Select Interpreter,选择解释器。
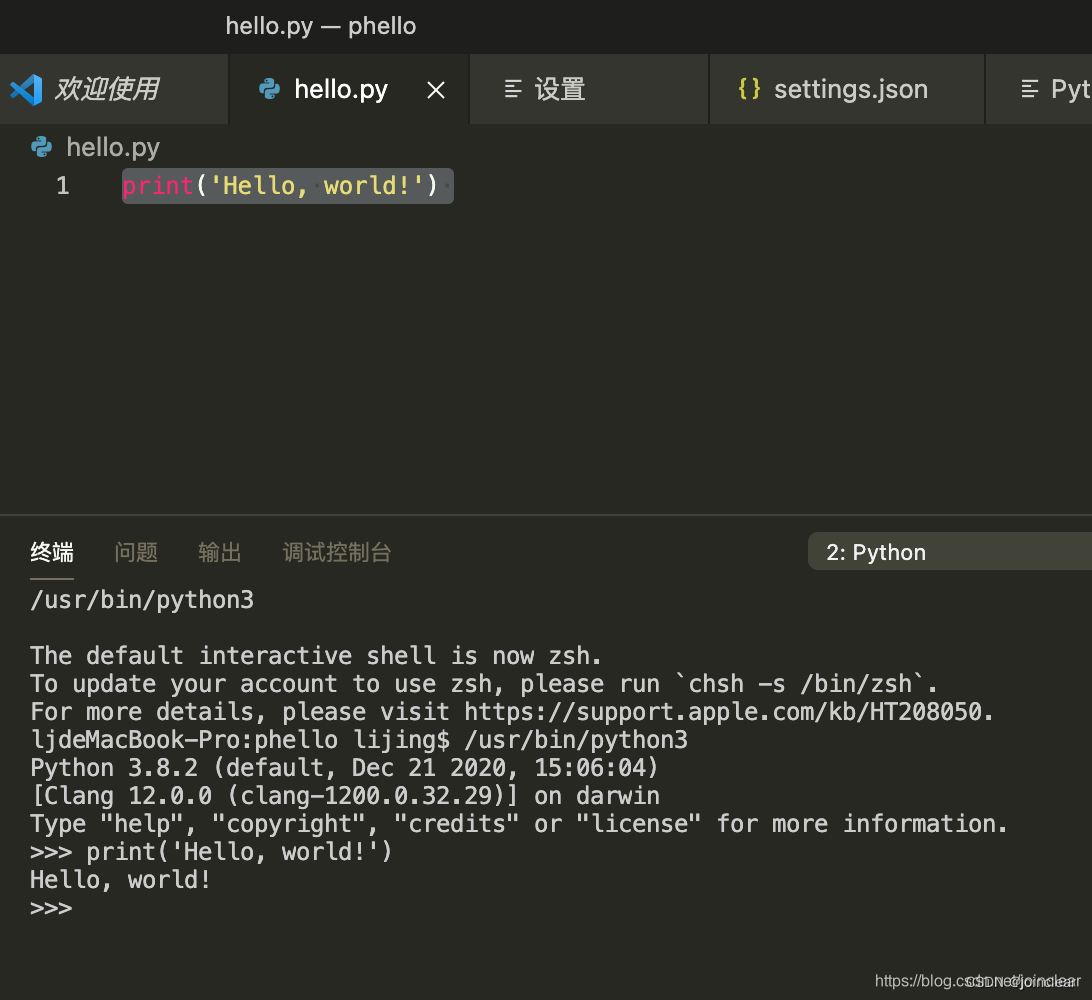
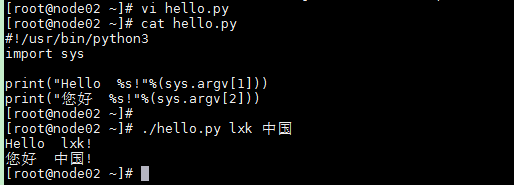
写“hello world”。
新建文件,输入print(‘hello world~’),另存为hello.py文件。
shift+enter 运行:
二、爬虫案例一
以爬取“豆瓣读书TOP250”的书籍为案例。
网址链接:https://book.douban.com/top250?start=0
1、爬取第一页数据
代码如下:
import requests
def askUrl(url):head = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.1 Safari/605.1.15"}html="" r = requests.get(url, headers = head) html = r.text print(html) return htmlif __name__ == "__main__": askUrl("https://book.douban.com/top250?start=0")
head->User-Agent的值可以从这个地方获取:
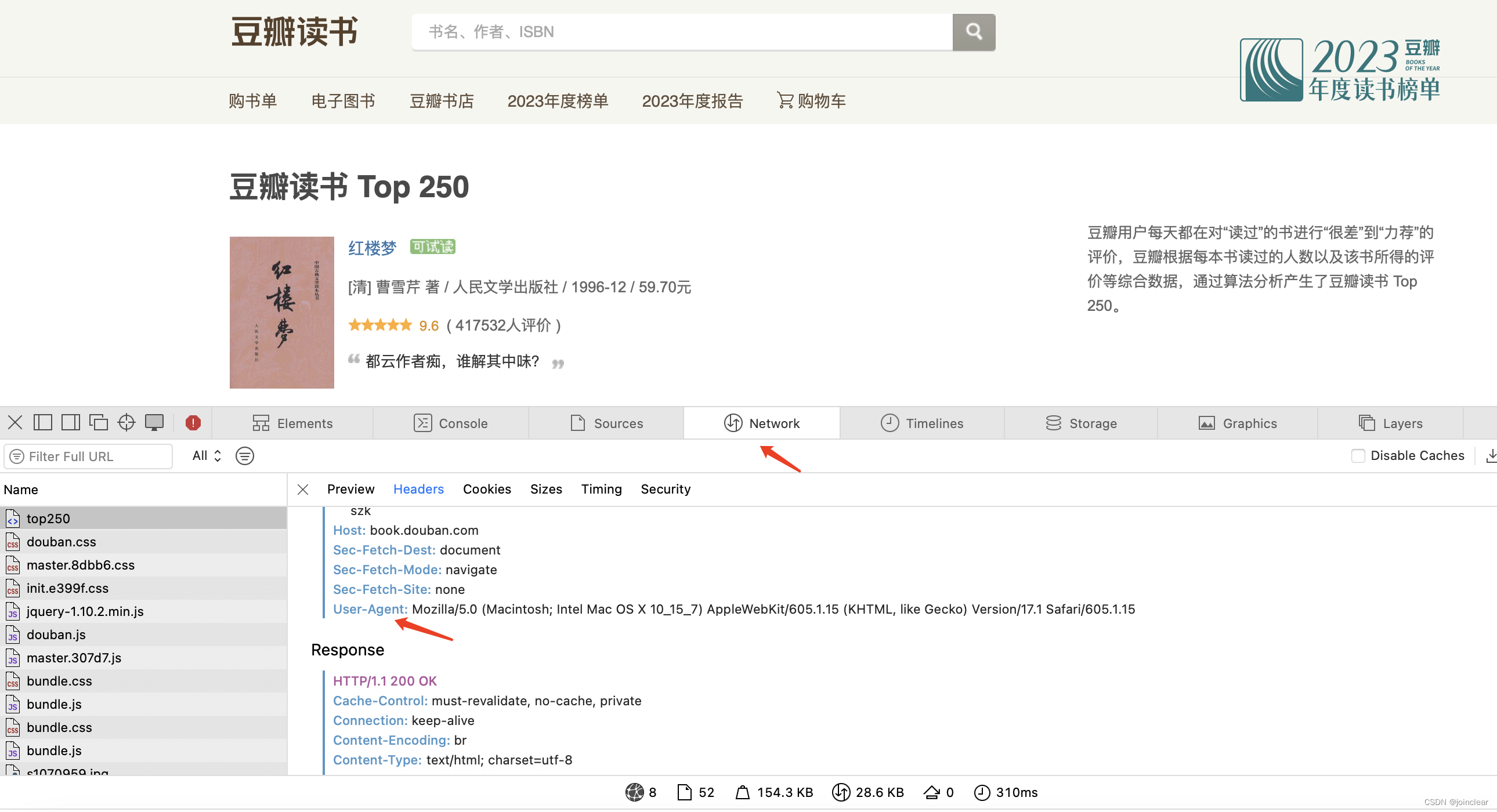
如果import requests报错,使用pip3 install requests安装。
运行之后,结果如下:
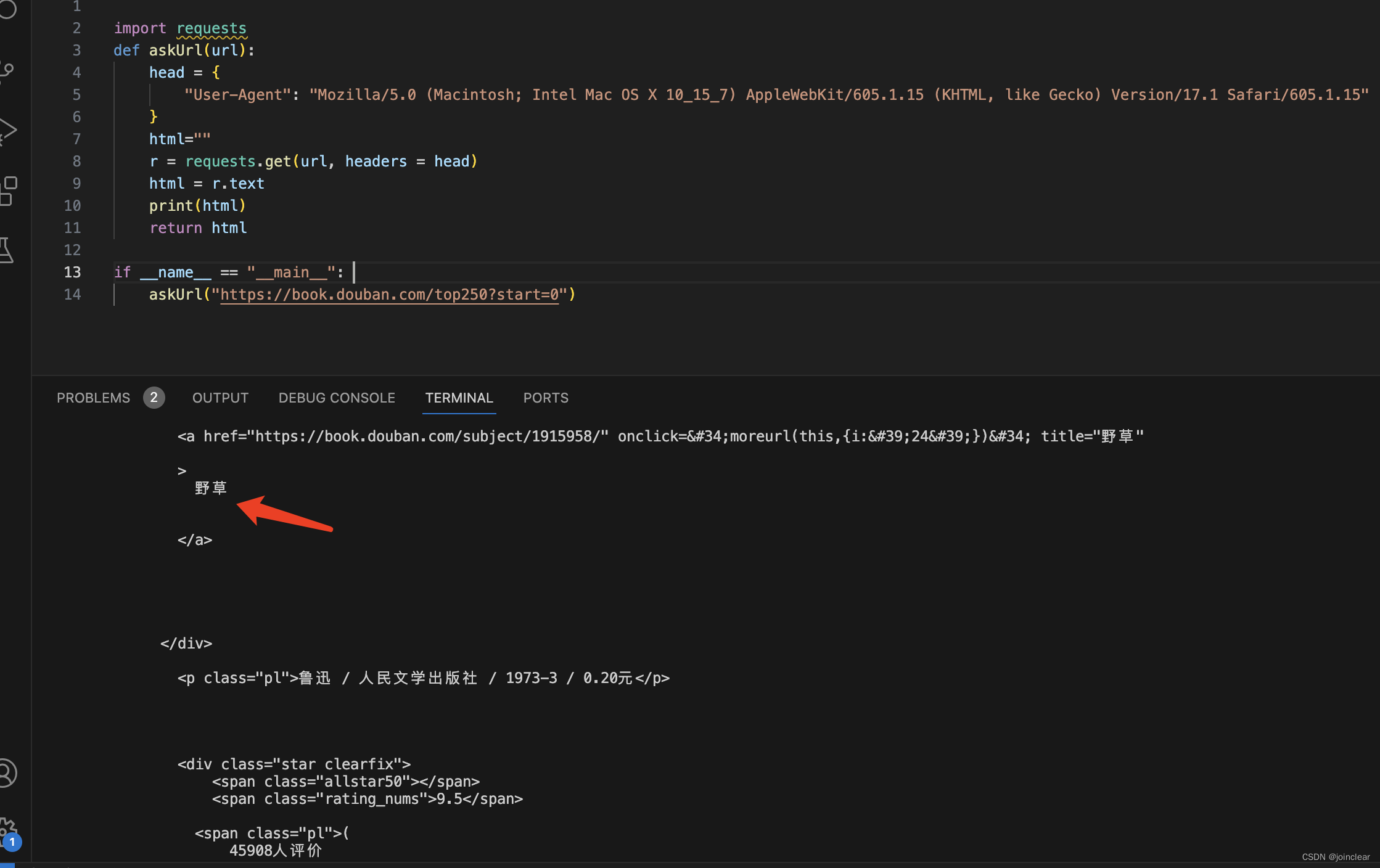
第一页25个,都以html的形式显示了出来,第25个为书籍《野草》。
2、爬取所有页数据
代码如下:
import requests
def askUrl(url):head = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.1 Safari/605.1.15"}r = requests.get(url, headers = head)html = r.textprint(html)def getData(baseurl):for i in range(0, 10):url = baseurl + str(i * 25)html = askUrl(url)if __name__ == "__main__": baseurl = "https://book.douban.com/top250?start="getData(baseurl)运行之后,结果如下:
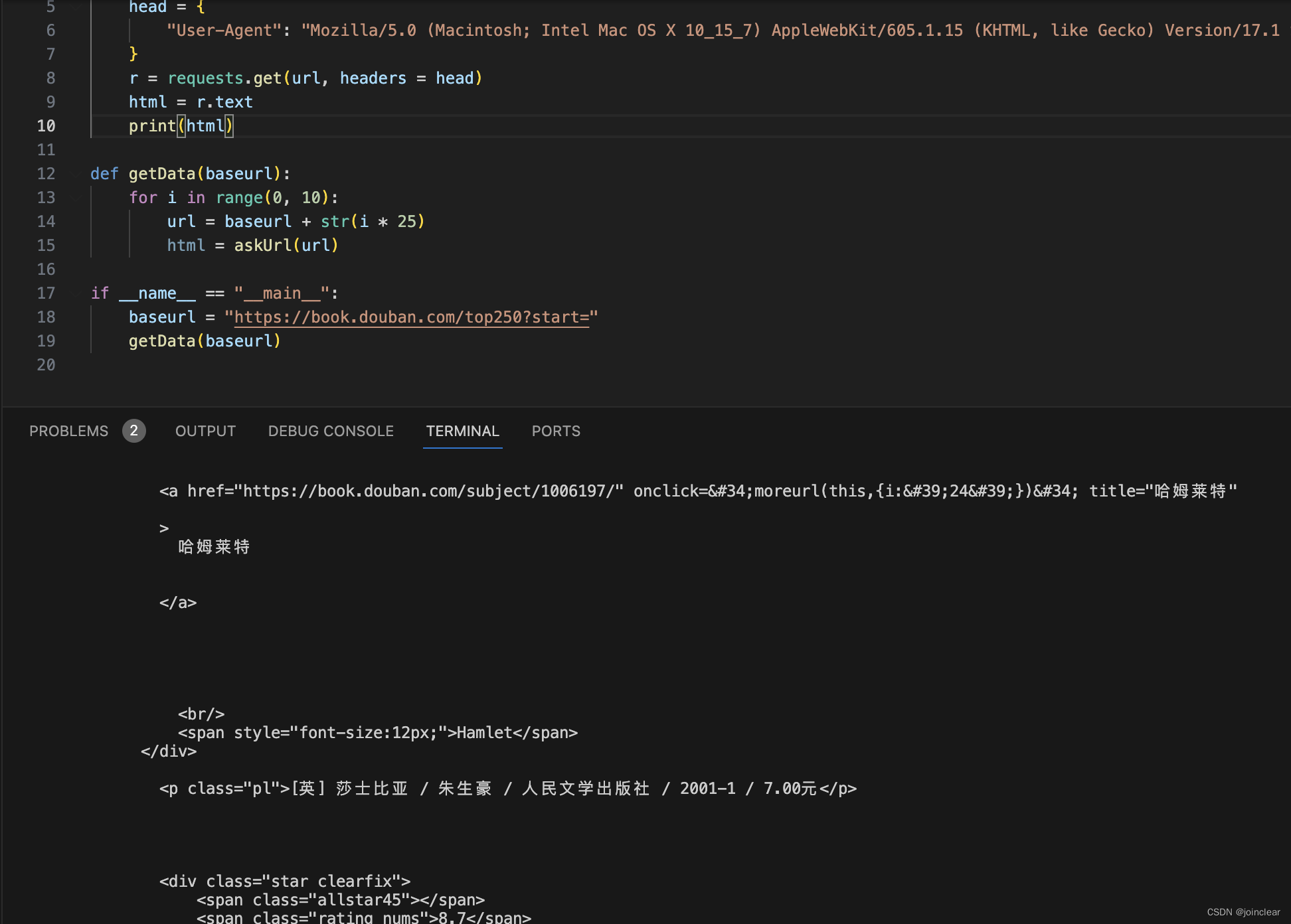
最后一页,最后一个,为书籍《哈姆莱特》。
3、格式化html数据
上面1和2,只是输出了html源码,现在按自己需要的几个字段进行格式化。
分别取这4个字段:封面图、书籍名称、作者(出版社、价格等)、引用。
这里使用lxml库,解析html。
# 导入lxml库子模块etree
from lxml import etree
格式化代码如下:
import requests
from lxml import etree def askUrl(url):head = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.1 Safari/605.1.15"}html="" r = requests.get(url, headers = head) html = r.text parse = etree.HTML(html) # 数据# all_tr = parse.xpath('/html[@class="ua-mac ua-webkit book-new-nav"]/body/div[@id="wrapper"]/div[@id="content"]/div[@class="grid-16-8 clearfix"]/div[@class="article"]/div[@class="indent"]/table')all_tr = parse.xpath('//*[@id="content"]/div/div[1]/div/table')for tr in all_tr:tr_data = {'vover': ''.join(tr.xpath('./tr/td[1]/a/img/@src')).strip(), # 封面图'name': ''.join(tr.xpath('./tr/td[2]/div[@class="pl2"]/a/text()')).strip(), # 书名'author': ''.join(tr.xpath('./tr/td[2]/p[1]/text()')).strip(), # 作者'quote': ''.join(tr.xpath('./tr/td[2]/p[2]/span/text()')).strip() # 引用}print(tr_data)if __name__ == "__main__": askUrl("https://book.douban.com/top250?start=0") 如果报错:
urllib3 v2 only supports OpenSSL 1.1.1+, currently the 'ssl' module is compiled with 'LibreSSL 2.8.3'.
解决方法:
pip3 install urllib3==1.26.15
结果如下:
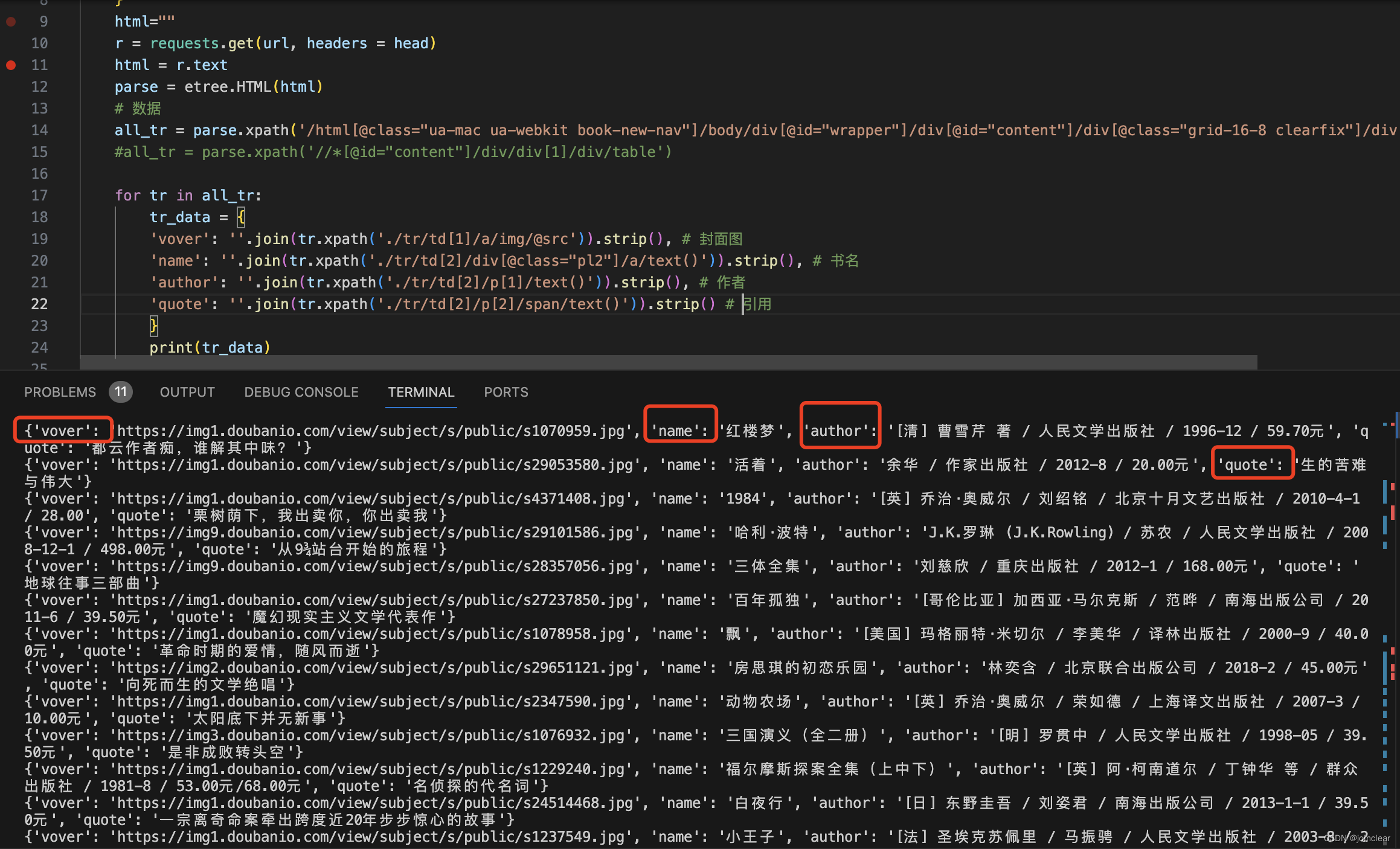
数据,已经非常清晰了。
PS:使用parse.xpath,最重要的是获取到准确的xpath值。
两个方法:
方法一:Google Chrome浏览器插件:xpath helper。
效果如下:
弹出插件面板:cmd+shift+x。
选中:shift。
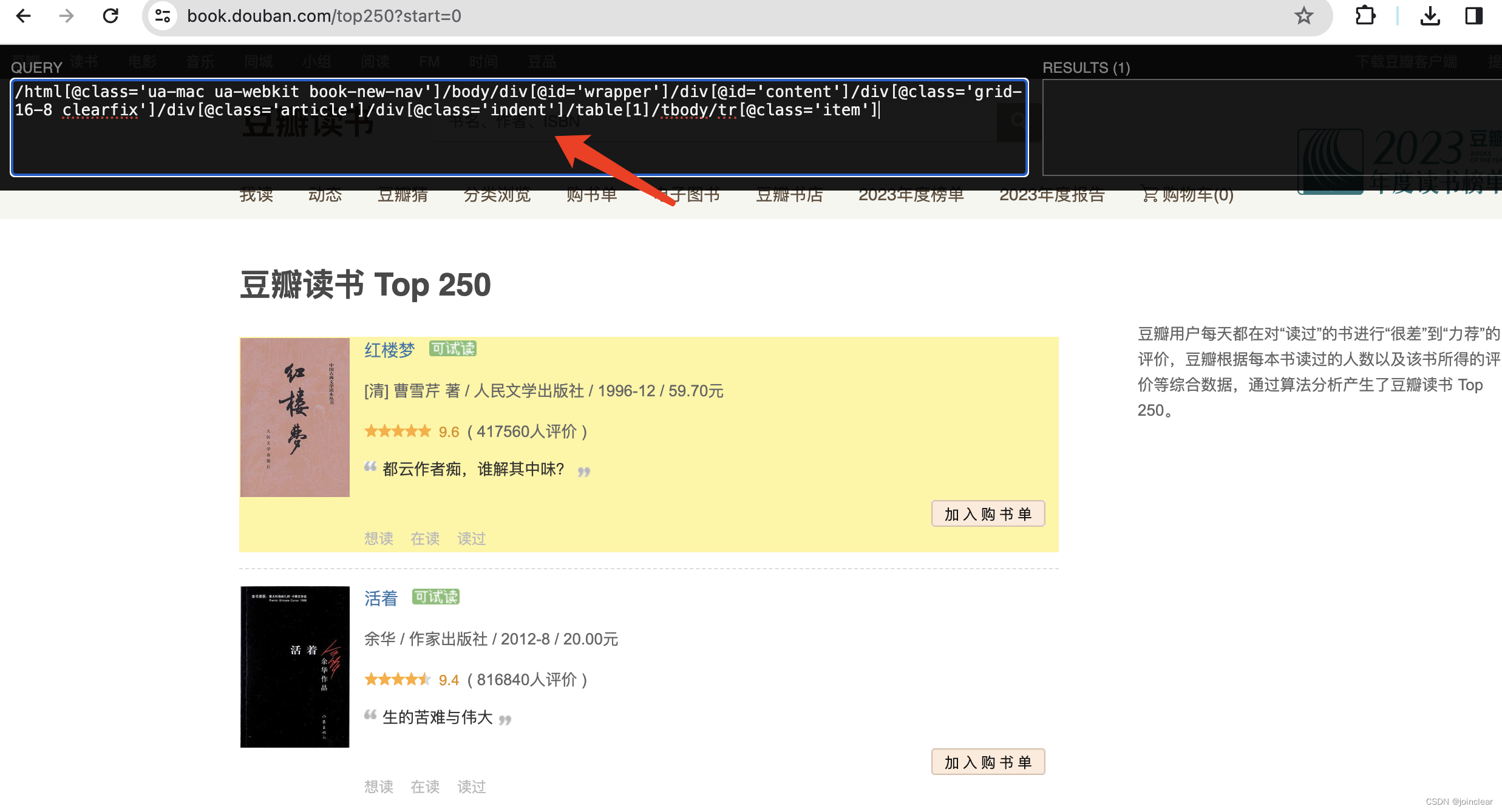
取到的值为:
# 原始值
/html[@class='ua-mac ua-webkit book-new-nav']/body/div[@id='wrapper']/div[@id='content']/div[@class='grid-16-8 clearfix']/div[@class='article']/div[@class='indent']/table[1]/tbody/tr[@class='item']# 优化后的值(使用此值,去掉了tbody和[1])
/html[@class='ua-mac ua-webkit book-new-nav']/body/div[@id='wrapper']/div[@id='content']/div[@class='grid-16-8 clearfix']/div[@class='article']/div[@class='indent']/table方法二:Google Chrome浏览器,查看源代码。
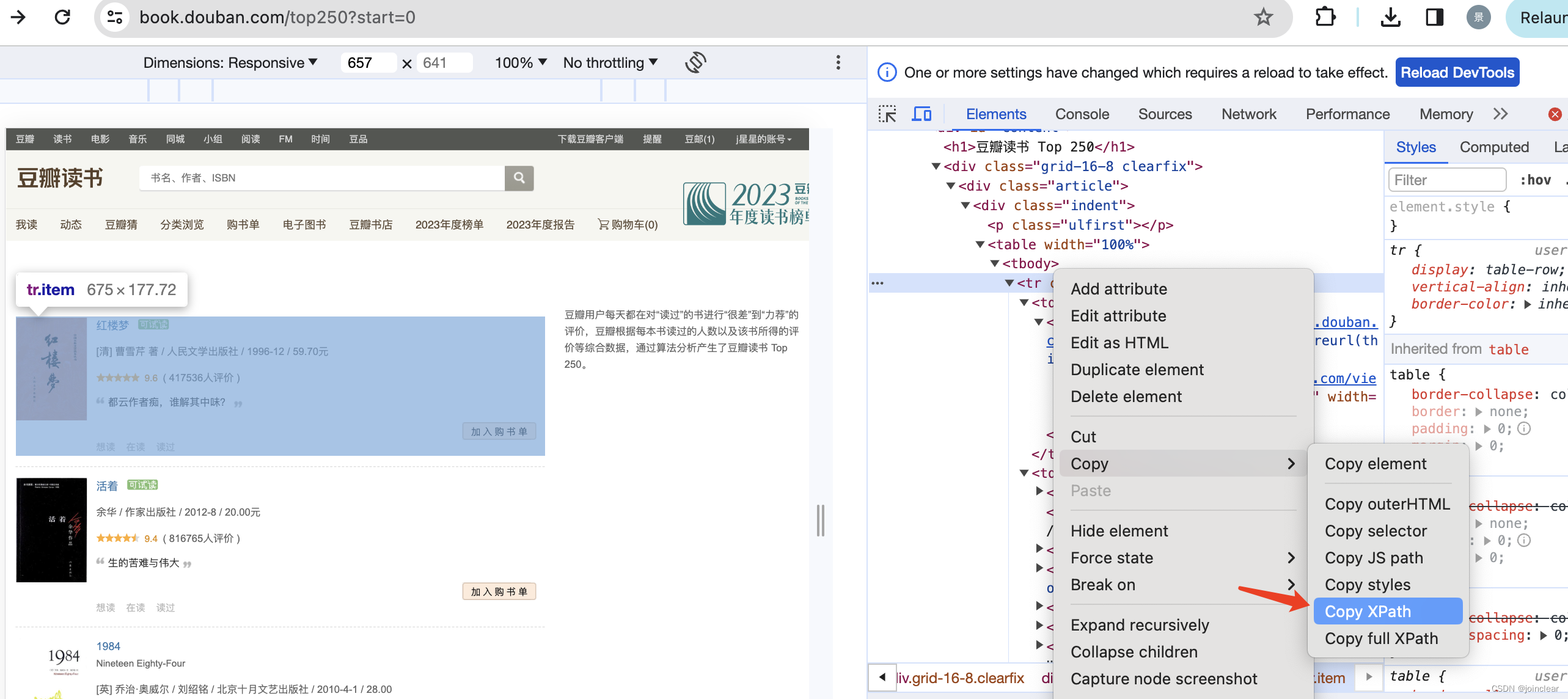
取到的值为:
# 原始值
//*[@id="content"]/div/div[1]/div/table[1]/tbody/tr# 优化后的值(使用此值,去掉了tbody和[1])
//*[@id="content"]/div/div[1]/div/table每一个字段对应的xpath值,也是这么获取。
4、导出excel文件
生成csv格式文件。
导入csv库:
import csv
导出cvs文件(第一页25条),代码如下:
import requests
from lxml import etree
import csvdef askUrl(url):head = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.1 Safari/605.1.15"}html="" r = requests.get(url, headers = head) html = r.text parse = etree.HTML(html) # 数据all_tr = parse.xpath('//*[@id="content"]/div/div[1]/div/table')# 创建book.csv文件with open('book.csv', 'a', encoding='utf_8_sig', newline='') as fp: header = ['封面','名称', '作者', '引用'] writer = csv.writer(fp) writer.writerow(header)for tr in all_tr:tr_data = {'vover': ''.join(tr.xpath('./tr/td[1]/a/img/@src')).strip(), # 封面图'name': ''.join(tr.xpath('./tr/td[2]/div[@class="pl2"]/a/text()')).strip(), # 书名'author': ''.join(tr.xpath('./tr/td[2]/p[1]/text()')).strip(), # 作者'quote': ''.join(tr.xpath('./tr/td[2]/p[2]/span/text()')).strip() # 引用}# print(tr_data)# 写入数据行with open('book.csv', 'a', encoding='utf_8_sig', newline='') as fp: fieldnames = ['vover','name', 'author', 'quote'] writer = csv.DictWriter(fp, fieldnames) writer.writerow(tr_data)if __name__ == "__main__": askUrl("https://book.douban.com/top250?start=0")
导出的book.csv文件(第一页),如下:

导出cvs文件(所有的250条),代码如下:
import requests
from lxml import etree
import csvdef askUrl(url):head = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.1 Safari/605.1.15"}r = requests.get(url, headers = head)html = r.text# print(html)parse = etree.HTML(html)all_tr = parse.xpath('//*[@id="content"]/div/div[1]/div/table')for tr in all_tr:tr_data = {'vover': ''.join(tr.xpath('./tr/td[1]/a/img/@src')).strip(), # 封面图'name': ''.join(tr.xpath('./tr/td[2]/div[@class="pl2"]/a/text()')).strip(), # 书名'author': ''.join(tr.xpath('./tr/td[2]/p[1]/text()')).strip(), # 作者'quote': ''.join(tr.xpath('./tr/td[2]/p[2]/span/text()')).strip() # 引用}# print(tr_data)# 写入数据行with open('bookall.csv', 'a', encoding='utf_8_sig', newline='') as fp: fieldnames = ['vover','name', 'author', 'quote'] writer = csv.DictWriter(fp, fieldnames) writer.writerow(tr_data)def getData(baseurl):# 创建book.csv文件with open('bookall.csv', 'a', encoding='utf_8_sig', newline='') as fp: header = ['封面','名称', '作者', '引用'] writer = csv.writer(fp) writer.writerow(header)# 插入25页的数据for i in range(0, 10):url = baseurl + str(i * 25)html = askUrl(url)if __name__ == "__main__": baseurl = "https://book.douban.com/top250?start="getData(baseurl)导出的book.csv文件(所有页250条数据),如下:
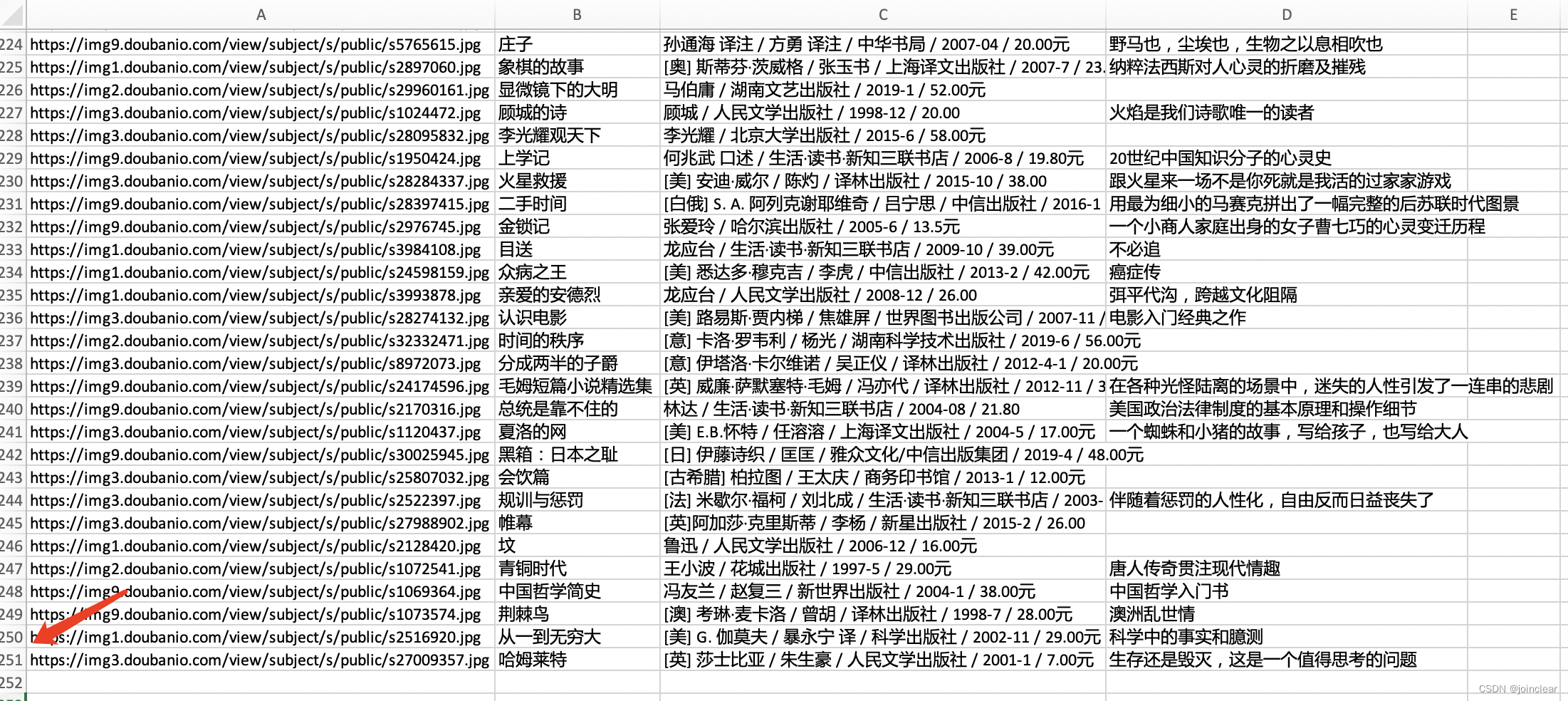
相关文章:
【Python】01快速上手爬虫案例一:搞定豆瓣读书
文章目录 前言一、VSCodePython环境搭建二、爬虫案例一1、爬取第一页数据2、爬取所有页数据3、格式化html数据4、导出excel文件 前言 实战是最好的老师,直接案例操作,快速上手。 案例一,爬取数据,最终效果图: 一、VS…...

JavaEE 网络编程
JavaEE 网络编程 文章目录 JavaEE 网络编程引子1. 网络编程-相关概念1.1 基本概念1.2 发送端和接收端1.3 请求和响应1.4 客户端和服务端 2. Socket 套接字2.1 数据包套接字通信模型2.2 流套接字通信模型2.3 Socket编程注意事项 3. UDP数据报套接字编程3.1 DatagramSocket3.2 Da…...
)
5.rk3588用cv读取图片(C++)
rk3588自带了cv,不需要重新安装,执行以下操作即可: 一、读取图片 1.读取某张图片 #define HAVE_OPENCV_VIDEO #define HAVE_OPENCV_VIDEOIO#include <opencv2/opencv.hpp> #include <iostream> #include <opencv2/opencv.h…...
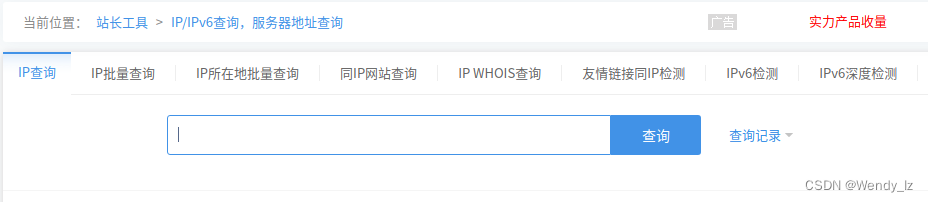
Github 无法正常访问?一招解决
查询IP网址: https://ip.chinaz.com/ 主页如下: 分别查询以下三个网址的IP: github.com github.global.ssl.fastly.net assets-cdn.github.com 修改 hosts 文件: 将 /etc/hosts 复制到 home 下 sudo cp /etc/hosts ./ gedit hosts 在底下…...
架构师的36项修炼-08系统的安全架构设计
本课时讲解系统的安全架构。 本节课主要讲 Web 的攻击与防护、信息的加解密与反垃圾。其中 Web 攻击方式包括 XSS 跨站点脚本攻击、SQL 注入攻击和 CSRF 跨站点请求伪造攻击;防护手段主要有消毒过滤、SQL 参数绑定、验证码和防火墙;加密手段,…...
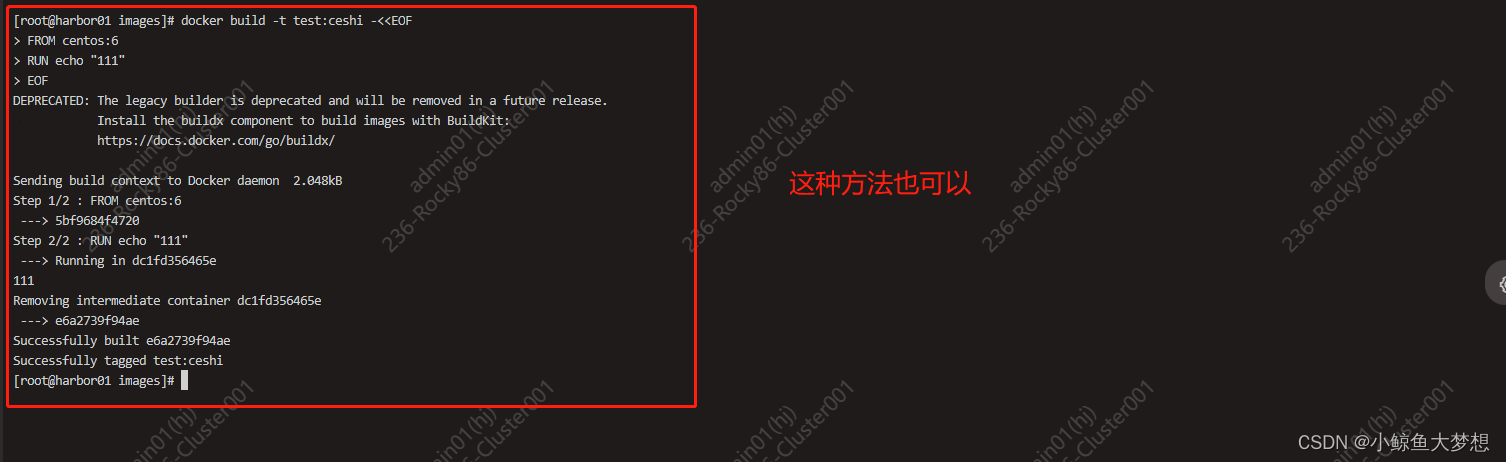
docker 构建应用
docker 应用程序开发手册 开发 docker 镜像 Dockerfile 非常容易定义镜像内容由一系列指令和参数构成的脚本文件每一条指令构建一层一个 Dockerfile 文件包含了构建镜像的一套完整指令指令不区分大小写,但是一般建议都是大写从头到尾按顺序执行指令必须以 FROM 指…...

Go语言grpc服务开发——Protocol Buffer
文章目录 一、Protocol Buffer简介二、Protocol Buffer编译器安装三、proto3语言指南四、序列化与反序列化五、引入grpc-gateway1、插件安装2、定义proto文件3、生成go文件4、实现Service服务5、gRPC服务启动方法6、gateway服务启动方法7、main函数启动8、验证 相关参考链接&am…...

【开源】基于JAVA语言的实验室耗材管理系统
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 耗材档案模块2.2 耗材入库模块2.3 耗材出库模块2.4 耗材申请模块2.5 耗材审核模块 三、系统展示四、核心代码4.1 查询耗材品类4.2 查询资产出库清单4.3 资产出库4.4 查询入库单4.5 资产入库 五、免责说明 一、摘要 1.1…...
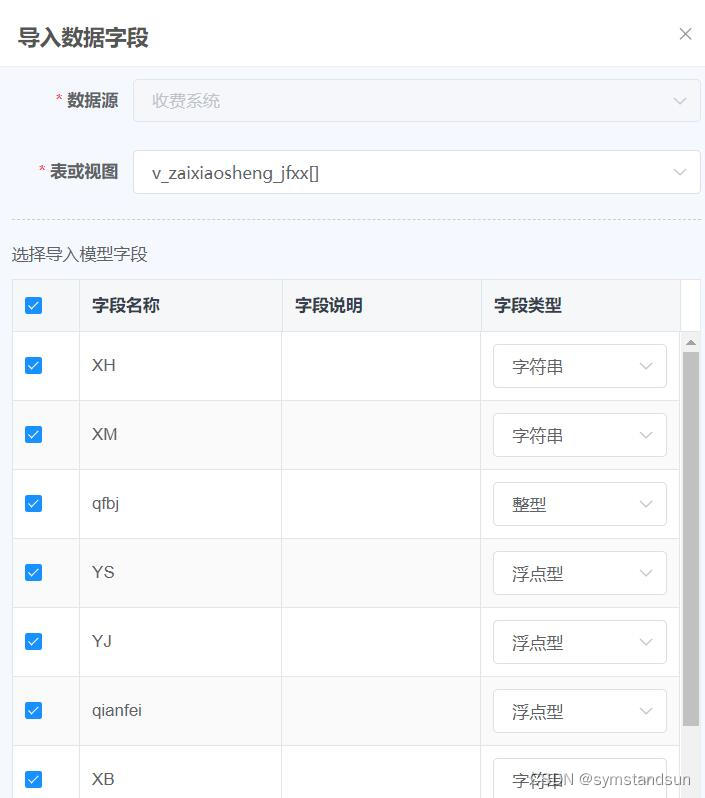
金智易表通构建学生缴费数据查询+帆软构建缴费大数据报表并整合到微服务
使用金智易表通挂接外部数据,快速建设查询类服务,本次构建学生欠费数据查询,共有3块设计,规划如下: 1、欠费明细查询:学校领导和财务处等部门可查询全校欠费学生明细数据;各二级学院教职工可查询本二级学院欠费学生明细数据。 2、大数据统计报表:从应收总额、欠费总额…...

MySQL复合索引
复合索引是指在数据库表上同时包含两个或更多列的索引。它们对于优化涉及这些列的查询非常有效,特别是当这些列常常在查询条件(如WHERE子句)、排序(ORDER BY子句)和连接(JOIN条件)中使用时。 复…...

Web3 游戏开发者的数据分析指南
作者:lesleyfootprint.network 在竞争激烈的 Web3 游戏行业中,成功不仅仅取决于游戏的发布,还需要在游戏运营过程中有高度的敏锐性,以应对下一次牛市的来临。 人们对 2024 年的游戏行业充满信心。A16Z GAMES 和 GAMES FUND ONE …...
temu跨境电商怎么样?做temu蓝海项目有哪些优势?
在全球电商市场激烈的竞争中,Temu跨境电商平台以其独特的优势和策略,逐渐崭露头角。对于许多想要拓展海外市场的商家来说,Temu的蓝海项目提供了一个充满机遇的新平台。本文将深入探讨Temu跨境电商的优势以及在蓝海市场中的发展前景。 全球化市…...
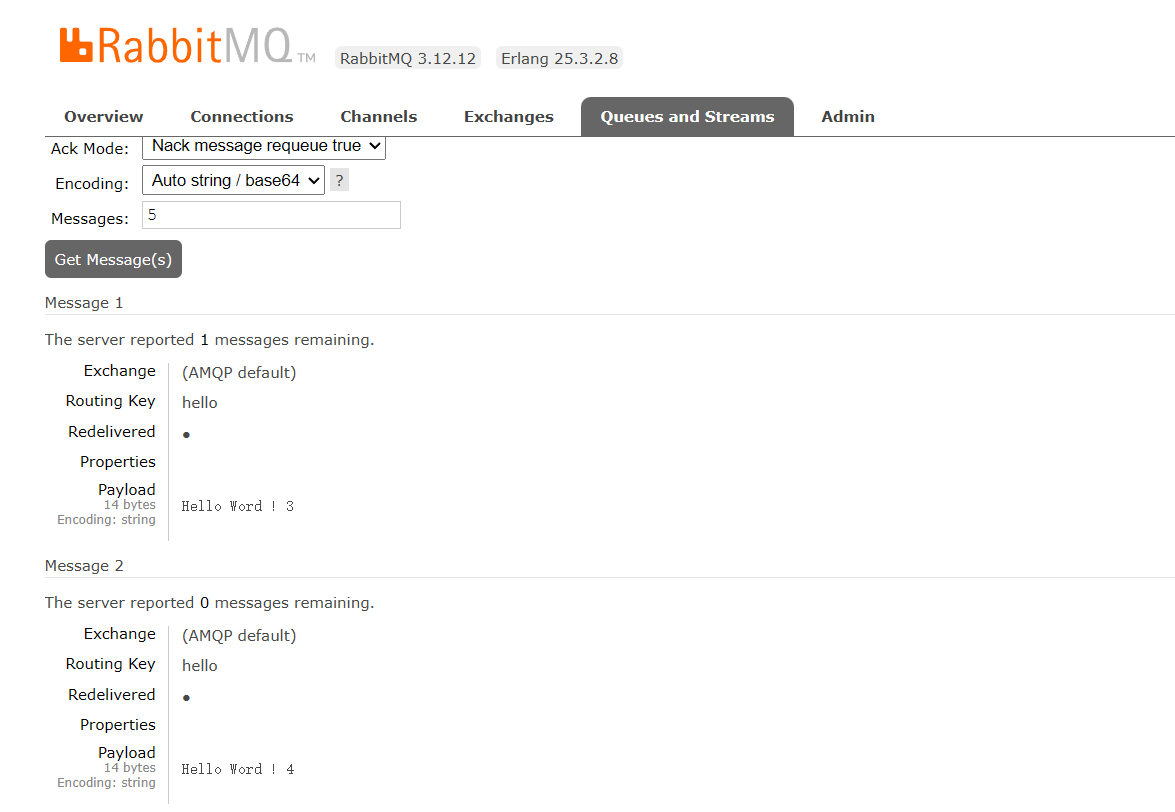
C#使用RabbitMQ-1_Docker部署并在c#中实现简单模式消息代理
介绍 RabbitMQ是一个开源的消息队列系统,实现了高级消息队列协议(AMQP)。 🍀RabbitMQ起源于金融系统,现在广泛应用于各种分布式系统中。它的主要功能是在应用程序之间提供异步消息传递,实现系统间的解耦和…...

EasyExcel中自定义拦截器的运用
在EasyExcel中自定义拦截器不仅可以帮助我们不止步于数据的填充,而且可以对样式、单元格合并等带来便捷的功能。下面直接开始 我们定义一个MergeWriteHandler的类继承AbstractMergeStrategy实现CellWriteHandler public class MergeLastWriteHandler extends Abst…...
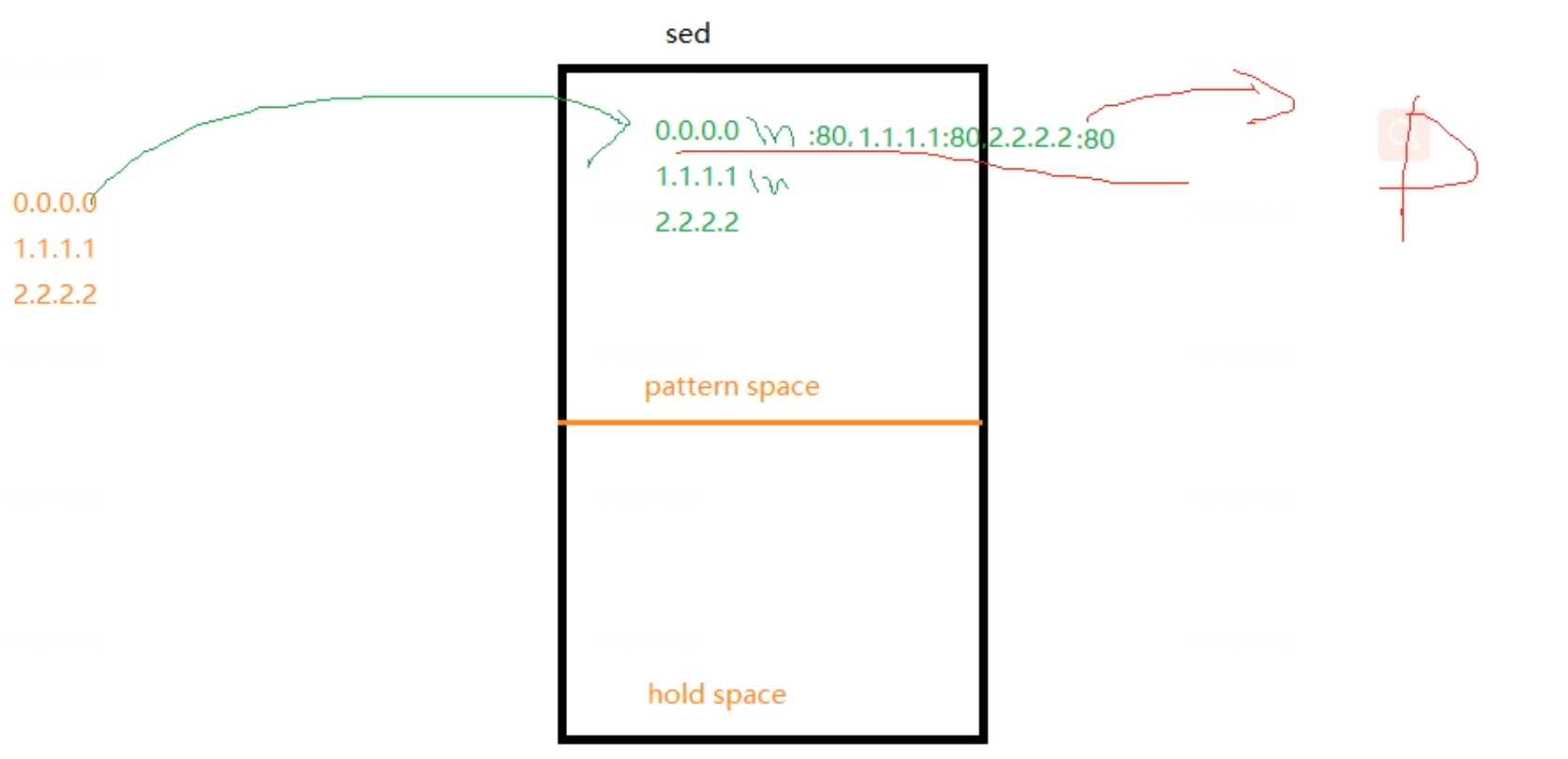
shell编程-7
shell学习第7天 sed的学习1.sed是什么2.sed有两个空间pattern hold3.sed的语法4. sed里单引号和双引号的区别:5.sed的查找方式6.sed的命令sed的标签用法sed的a命令:追加sed的i命令:根据行号插入sed的c命令:整行替换sed的r命令sed的s命令:替换sed的d命令:删除sed中的&符号 7…...

工业智能网关储能物联网应用实现能源的高效利用及远程管理
储能电力物联网是指利用物联网技术和储能技术相结合,实现对电力系统中各种储能设备的智能管理和优化控制。随着可再生能源的不断发展和应用,电力系统面临着越来越大的电力调度和储能需求而储能电力物联网的出现可以有效解决这一问题,提高电力…...

虹科数字化与AR部门升级为安宝特AR子公司
致关心虹科AR的朋友们: 感谢您一直以来对虹科数字化与AR的支持和信任,为了更好地满足市场需求和公司发展的需要,虹科数字化与AR部门现已升级为虹科旗下独立子公司,并正式更名为“安宝特AR”。 ”虹科数字化与AR“自成立以来&…...

服务器是什么?(四种服务器类型)
服务器 服务器定义广义: 专门给其他机器提供服务的计算机。狭义:一台高性能的计算机,通过网络提供外部计算机一些业务服务 个人PC内存大概8G,服务器内存128G起步 服务器是什么 服务器指的是 网络中能对其他机器提供某些服务的计算机系统 ,相对…...
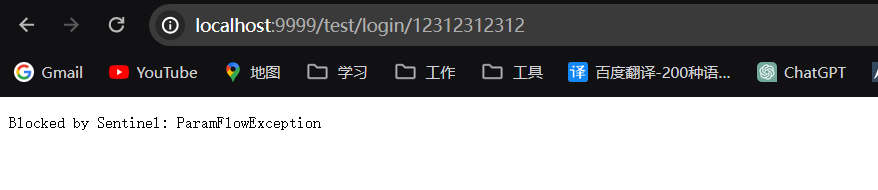
09-微服务Sentinel整合GateWay
一、概述 在微服务系统中,网关提供了微服务系统的统一入口,所以我们在做限流的时候,肯定是要在网关层面做一个流量的控制,Sentinel 支持对 Spring Cloud Gateway、Zuul 等主流的 API Gateway 进行限流。 1.1 总览 Sentinel 1.6.…...
python基础学习-03 安装
python3 可应用于多平台包括 Windows、Linux 和 Mac OS X。 Unix (Solaris, Linux, FreeBSD, AIX, HP/UX, SunOS, IRIX, 等等。)Win 9x/NT/2000Macintosh (Intel, PPC, 68K)OS/2DOS (多个DOS版本)PalmOSNokia 移动手机Windows CEAcorn/RISC OSBeOSAmigaVMS/OpenVMSQNXVxWorksP…...

基于Arduino与GPS的物联网数据采集器:从硬件搭建到地图可视化
1. 项目概述:一个硬件极客的万圣节“寻宝图” 又到万圣节了,除了琢磨穿什么奇装异服,你是不是也在头疼怎么规划“不给糖就捣蛋”的路线?每年都像开盲盒,有的门口堆满南瓜灯的人家只给了一根棒棒糖,而某个其…...

终极指南:如何永久冻结IDM试用期实现终身免费使用
终极指南:如何永久冻结IDM试用期实现终身免费使用 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script 你是否曾经为IDM(Internet Download Ma…...

从Scratch图形化到Python代码:用树莓派给LeArm机械臂做二次开发实战
从Scratch图形化到Python代码:用树莓派给LeArm机械臂做二次开发实战 当Scratch积木块拼接的机械臂动作开始显得单调时,便是时候揭开底层控制的神秘面纱了。本文将带您跨越图形化编程的舒适区,用树莓派的Python环境重新定义LeArm机械臂的智能—…...
)
保姆级教程:在Ubuntu 20.04上从源码编译aarch64-linux-gnu交叉工具链(GCC 9.2.0 + Glibc 2.30)
深度实践:从源码构建aarch64-linux-gnu交叉工具链全指南 在嵌入式开发领域,交叉编译工具链的构建能力是区分普通开发者与资深工程师的重要标志。当现成的预编译工具链无法满足特定需求时,从源码手动构建工具链不仅能解决兼容性问题࿰…...

移动端大语言模型本地部署:从模型轻量化到推理引擎实战
1. 项目概述:当GPT遇见移动端,一个开源项目的诞生最近在GitHub上闲逛,发现了一个挺有意思的项目,叫Taewan-P/gpt_mobile。光看名字,你大概就能猜到它的核心:把类似GPT这样的大语言模型(LLM&…...

避坑指南:Unity游戏在Linux上运行报错?OpenCV依赖和文件权限问题排查实录
Unity游戏Linux部署避坑指南:从权限修复到OpenCV依赖全解析 当你在Ubuntu上双击那个刚导出的Unity游戏.x86_64文件时,屏幕却弹出一行冰冷的错误信息——这种从云端跌入谷底的体验,每个跨平台开发者都经历过。不同于Windows的一键运行…...

JetBrains IDE试用期重置终极指南:简单三步实现30天无限续杯
JetBrains IDE试用期重置终极指南:简单三步实现30天无限续杯 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否曾经在项目开发的关键时刻,突然看到JetBrains IDE弹出"评估期已结束…...

DeepSeek LeetCode 2421. 好路径的数目 Python3实现
给你 Python3 版本的代码,思路和之前的 Java 实现一致: 完整代码 python class Solution: def numberOfGoodPaths(self, vals: List[int], edges: List[List[int]]) -> int: n len(vals) # 1. 构建邻接表 gr…...

基于双线性插值的AMG8833热成像分辨率提升方案与嵌入式实现
1. 项目概述:从8x8到15x15,一次软件驱动的热成像分辨率革命如果你玩过基于AMG8833这类低成本红外热成像传感器的项目,大概率会对它那8x8的“马赛克”图像印象深刻——64个像素点,勉强能看出个温度轮廓,但细节ÿ…...

跨平台鼠标控制库ez-cursor-free:原理、实现与自动化实战
1. 项目概述与核心价值如果你是一名开发者,尤其是经常需要处理跨平台UI自动化、游戏脚本或者桌面应用交互的开发者,那么你一定对“鼠标控制”这个基础但又充满细节的环节感到过头疼。不同的操作系统(Windows, macOS, Linux)提供了…...