《动手学深度学习(PyTorch版)》笔记1
Chapter1 Introduction
1.1 机器学习的关键组件
- data
每个数据集由一个个样本(example, sample)组成,大多时候,它们遵循独立同分布(independently and identically distributed, i.i.d.)。 样本有时也叫做数据点(data point)或数据实例(data instance),通常每个样本由一组称为特征(features,或协变量(covariates))的属性组成。 机器学习模型会根据这些属性进行预测。 在监督学习问题中,要预测的是一个特殊的属性,它被称为标签(label,或目标(target))。 - model
深度学习与经典方法的区别主要在于:前者关注的功能强大的模型,这些模型由神经网络错综复杂的交织在一起,包含层层数据转换,因此被称为深度学习(deep learning)。 - loss function
机器学习中,我们需要定义模型的优劣程度的度量,这个度量在大多数情况是“可优化”的,这被称之为目标函数(objective function)。 我们通常定义一个目标函数,并希望优化它到最低点。 因为越低越好,所以这些函数有时被称为损失函数(loss function,或cost function)。
通常,损失函数是根据模型参数定义的,并取决于数据集。 在一个数据集上,我们可以通过最小化总损失来学习模型参数的最佳值。 该数据集由一些为训练而收集的样本组成,称为训练数据集(training dataset,或称为训练集(training set))。 然而,在训练数据上表现良好的模型,并不一定在“新数据集”上有同样的性能,这里的“新数据集”通常称为测试数据集(test dataset,或称为测试集(test set))。 当一个模型在训练集上表现良好,但不能推广到测试集时,这个模型被称为过拟合(overfitting)的。 - optimization algorithm
深度学习中,大多流行的优化算法通常基于一种基本方法–梯度下降(gradient descent)。 简而言之,在每个步骤中,梯度下降法都会检查每个参数,看看如果仅对该参数进行少量变动,训练集损失会朝哪个方向移动。 然后,它在可以减少损失的方向上优化参数。
1.2 各种机器学习问题
- 监督学习
监督学习(supervised learning)擅长在“给定输入特征”的情况下预测标签。 每个“特征-标签”对都称为一个样本(example)。 有时,即使标签是未知的,样本也可以指代输入特征。 我们的目标是生成一个模型,能够将任何输入特征映射到标签(即预测)。
监督学习的学习过程一般可以分为三大步骤:- 从已知大量数据样本中随机选取一个子集,为每个样本获取真实标签。有时,这些样本已有标签(例如,患者是否在下一年内康复?);有时,这些样本可能需要被人工标记(例如,图像分类)。这些输入和相应的标签一起构成了训练数据集;
- 选择有监督的学习算法,它将训练数据集作为输入,并输出一个“已完成学习的模型”;
- 将之前没有见过的样本特征放到这个“已完成学习的模型”中,使用模型的输出作为相应标签的预测。
- 回归
回归(regression)是最简单的监督学习任务之一。当标签取任意数值时,我们称之为回归问题,此时的目标是生成一个模型,使它的预测非常接近实际标签值。 - 分类
区分 “哪一个”的问题叫做分类(classification)问题。 分类问题希望模型能够预测样本属于哪个类别(category,正式称为类(class))。 例如,手写数字可能有10类,标签被设置为数字0~9。 最简单的分类问题是只有两类,这被称之为二项分类(binomial classification)。 回归是训练一个回归函数来输出一个数值; 分类是训练一个分类器来输出预测的类别,预测类别的概率的大小传达了一种模型的不确定性。
当有两个以上的类别时,我们把这个问题称为多项分类(multiclass classification)问题。 常见的例子包括手写字符识别 {0,1,2,…9,a,b,c,…}。 与解决回归问题不同,分类问题的常见损失函数被称为交叉熵(cross-entropy)。 - 标注
学习预测不相互排斥的类别的问题称为多标签分类(multi-label classification)。 - 搜索
有时我们不仅仅希望输出一个类别或一个实值,例如在信息检索领域,我们希望对一组项目进行排序。 - 推荐
另一类与搜索和排名相关的问题是推荐系统(recommender system),它的目标是向特定用户进行“个性化”推荐。尽管推荐系统具有巨大的应用价值,但单纯用它作为预测模型仍存在一些缺陷。 首先,我们的数据只包含“审查后的反馈”:用户更倾向于给他们感觉强烈的事物打分。 例如,在五分制电影评分中,会有许多五星级和一星级评分,但三星级却明显很少。 此外,推荐系统有可能形成反馈循环:推荐系统首先会优先推送一个购买量较大(可能被认为更好)的商品,然而目前用户的购买习惯往往是遵循推荐算法,但学习算法并不总是考虑到这一细节,进而更频繁地被推荐。 - 序列学习
序列学习需要摄取输入序列或预测输出序列,或两者兼而有之。 具体来说,输入和输出都是可变长度的序列,例如机器翻译和从语音中转录文本。 - 无监督学习
数据中不含有“目标”的机器学习问题通常被为无监督学习(unsupervised learning)。- 聚类(clustering)问题:没有标签的情况下,我们是否能给数据分类呢?
- 主成分分析(principal component analysis)问题:我们能否找到少量的参数来准确地捕捉数据的线性相关属性?
- 因果关系(causality)和概率图模型(probabilistic graphical models)问题:我们能否描述观察到的许多数据的根本原因?
- 生成对抗性网络(generative adversarial networks):为我们提供一种合成数据的方法,甚至像图像和音频这样复杂的非结构化数据,潜在的统计机制是检查真实和虚假数据是否相同的测试。
- 与环境交互(强化学习)
在强化学习问题中,智能体(agent)在一系列的时间步骤上与环境交互。 在每个特定时间点,智能体从环境接收一些观察(observation),并且必须选择一个动作(action),然后通过某种机制(有时称为执行器)将其传输回环境,最后智能体从环境中获得奖励(reward)。 此后新一轮循环开始,智能体接收后续观察,并选择后续操作,依此类推。 请注意,强化学习的目标是产生一个好的策略(policy)。 强化学习智能体选择的“动作”受策略控制,即一个从环境观察映射到行动的功能。
当环境可被完全观察到时,强化学习问题被称为马尔可夫决策过程(markov decision process)。 当状态不依赖于之前的操作时,我们称该问题为上下文赌博机(contextual bandit problem)。 当没有状态,只有一组最初未知回报的可用动作时,这个问题就是经典的多臂赌博机(multi-armed bandit problem)。
1.3 参考文献
- PyTorch documentation
- PyTorch中文文档
相关文章:
》笔记1)
《动手学深度学习(PyTorch版)》笔记1
Chapter1 Introduction 1.1 机器学习的关键组件 data 每个数据集由一个个样本(example, sample)组成,大多时候,它们遵循独立同分布(independently and identically distributed, i.i.d.)。 样本有时也叫做数据点(dat…...
)
前端工程化之:webpack1-5(配置文件)
一、配置文件 webpack 提供的 cli 支持很多的参数,例如 --mode ,但更多的时候,我们会使用更加灵活的配置文件来控制 webpack 的行为。 默认情况下, webpack 会读取 webpack.config.js 文件作为配置文件,但也可以通过 C…...

代码随想录栈和队列专题二刷复盘day17
栈和队列理论基础 队列是先进先出,栈是先进后出 栈和队列是STL里面的两个数据结构 三个最为普遍的STL版本 1.HP STL其他版本的C STL,一般是以HP STL为蓝本实现出来的,HP STL是C STL的第一个实现版本,且开放源代码 2.P.J.Plauger…...
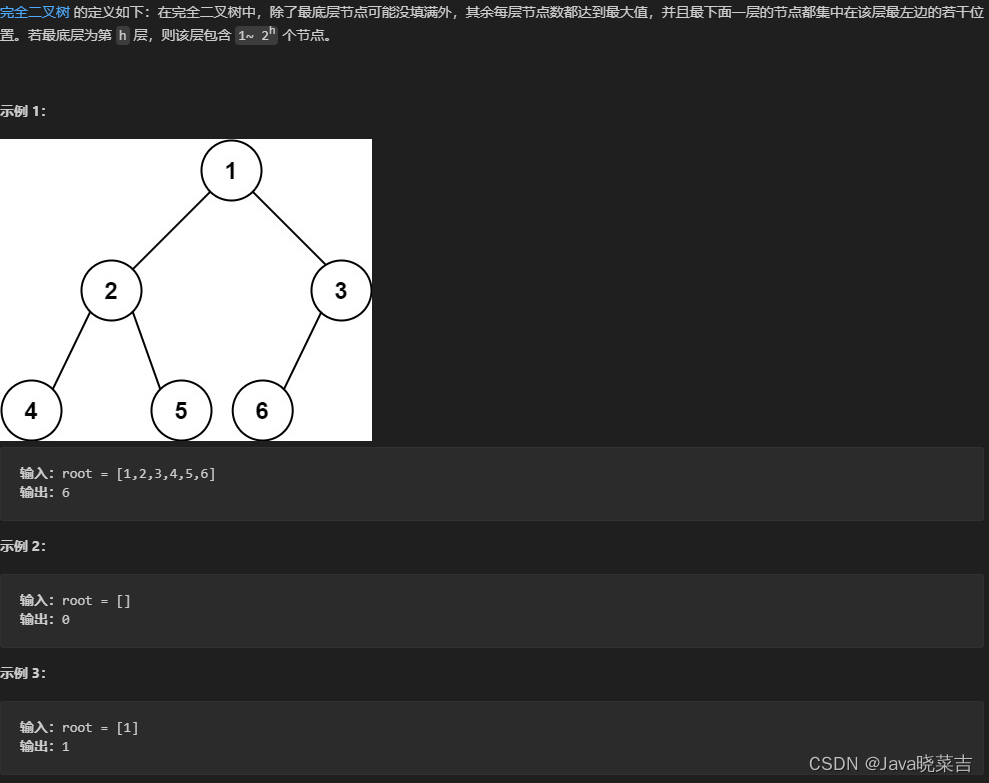
代码随想录算法刷题训练营day16
代码随想录算法刷题训练营day16:LeetCode(104)二叉树的最大深度 、LeetCode(559)n叉树的最大深度、LeetCode(111)二叉树的最小深度、LeetCode(222)完全二叉树的节点个数 LeetCode(104)二叉树的最大深度 题目 代码 /*** Definition for a binary tree node.* publ…...

【C语言/数据结构】排序(直接插入排序|希尔排序)
🌈个人主页:秦jh__https://blog.csdn.net/qinjh_?spm1010.2135.3001.5343🔥 系列专栏:《数据结构》https://blog.csdn.net/qinjh_/category_12536791.html?spm1001.2014.3001.5482 目录 插入排序 直接插入排序&…...
Jupyter Notebook安装使用教程
Jupyter Notebook 是一个基于网页的交互式计算环境,允许你创建和共享包含代码、文本说明、图表和可视化结果的文档。它支持多种编程语言,包括 Python、R、Julia 等。其应用场景非常广泛,特别适用于数据科学、机器学习和教育领域。它可以用于数…...

Unity 中的接口和继承
在Unity的游戏开发中,理解面向对象编程的概念,如类、接口、继承和多态性,是非常重要的。本文旨在帮助理解和掌握Unity中接口和继承的概念,以及如何在实际项目中应用这些知识。 类和继承 在C#和Unity中,类是构建应用程序…...
)
C++区间覆盖(贪心算法)
假设有n个区间,分别是:[l1,r1], [l2,r2], [l3,r3].....[ln,rn] 从这n个区间中选出某些区间,要求这些区间满足两两不相交,最多能选出多少个区间呢? 基本思路: 按照右端点从小到大排序,再比较左端…...
Python with Office 054 - Work with Word - 7-9 插入图像 (3)
近日详细学习了寒冰老师的很好的书《让Python遇上Office》,总结了系列视频。 这个是其中的一集:如何在Word中插入图像,我会陆续分享其他的视频并加上相应说明 https://www.ixigua.com/7319498175104942643?logTage9d15418663166a05d10...

Nodejs前端学习Day4_fs文件系统模块基础应用之成绩转换
君子应有龙蛇之变,处于木雁之间 文章目录 前言一、fs文件系统模块1.1 判断文件是否读取成功1.2 向指定的文件中写入内容1.2.1 fs.writeFile的语法格式1.2.2 fs.readFile和fs.writeFile的运用——成绩转换 总结 前言 Day3fs开了点头 一、fs文件系统模块 1.1 判断文…...
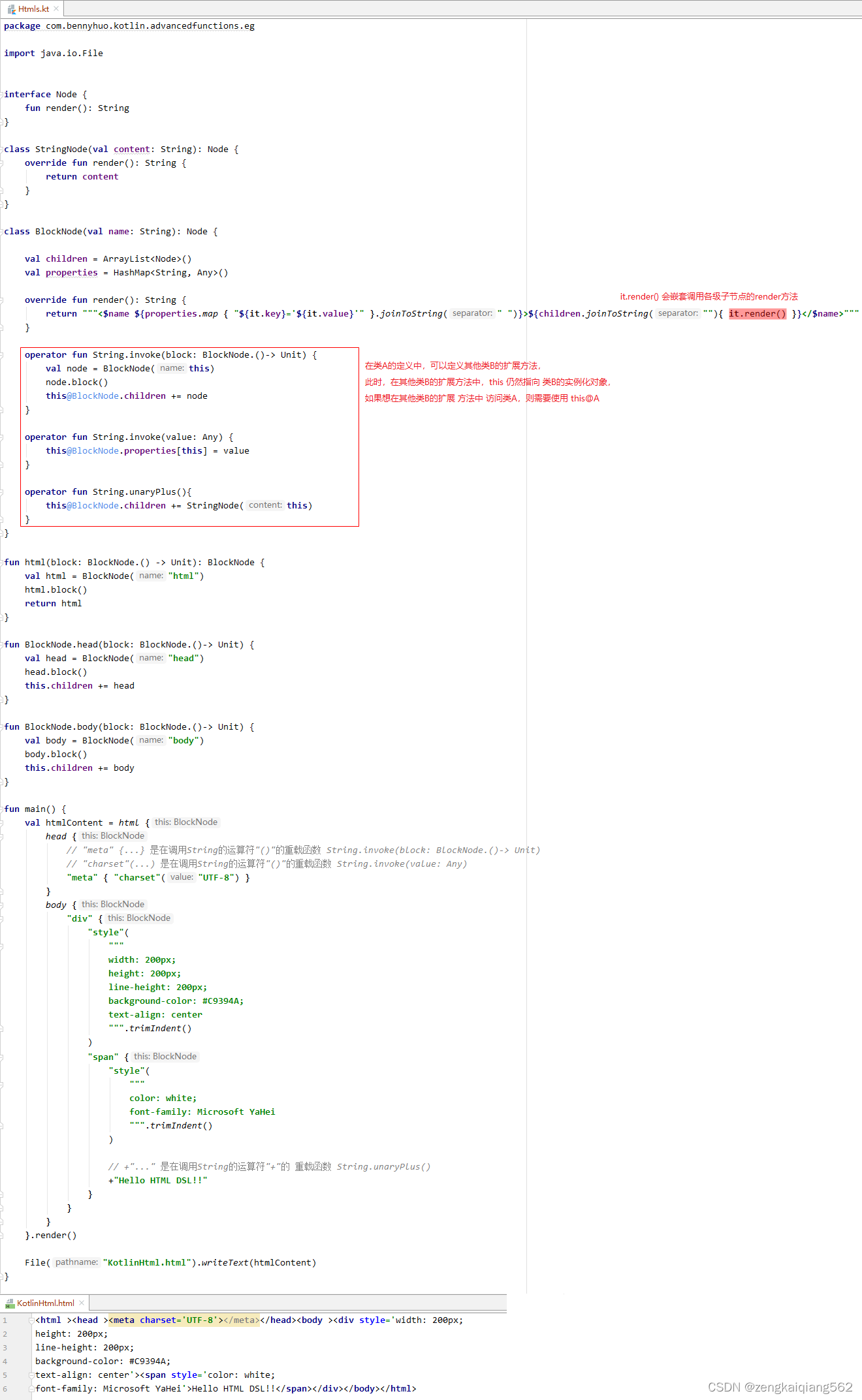
五、Kotlin 函数进阶
1. 高阶函数 1.1 什么是高阶函数 以下 2 点至少满足其一的函数称为高阶函数: 形参列表中包含函数类型的参数 //参数 paramN 可以是:函数引用、函数类型变量、或 Lambda 表达式。 fun funName(param1: Type1, param2: Type2, ... , paramN: (p1: T1, p2…...
》 –– 学习笔记(一))
重温《深入理解Java虚拟机:JVM高级特性与最佳实践(第二版)》 –– 学习笔记(一)
第一部分:走近Java 第1章:走近Java 1.1 Java的技术体系 SUN 官方所定义的 Java 技术体系包括:Java程序设计语言、Java虚拟机、Class文件格式、Java API类库、第三方(商业机构和开源社区)Java类库。 其中࿰…...

定向减免!函数计算让轻量 ETL 数据加工更简单,更省钱
作者:澈尔、墨飏 业内较为常见的高频短时 ETL 数据加工场景,即频率高时延短,一般均可归类为调用密集型场景。此场景有着高并发、海量调用的特性,往往会产生高额的计算费用,而业内推荐方案一般为攒批处理,业…...

git checkout和git switch的区别
git checkout 和 git switch 是 Git 中用于切换分支的命令,但它们在某些方面有一些区别。需要注意的是,git switch 是在 Git 2.23 版本引入的,它提供了一种更直观的分支切换方式。 git checkout: 分支切换: 在 Git 2.…...
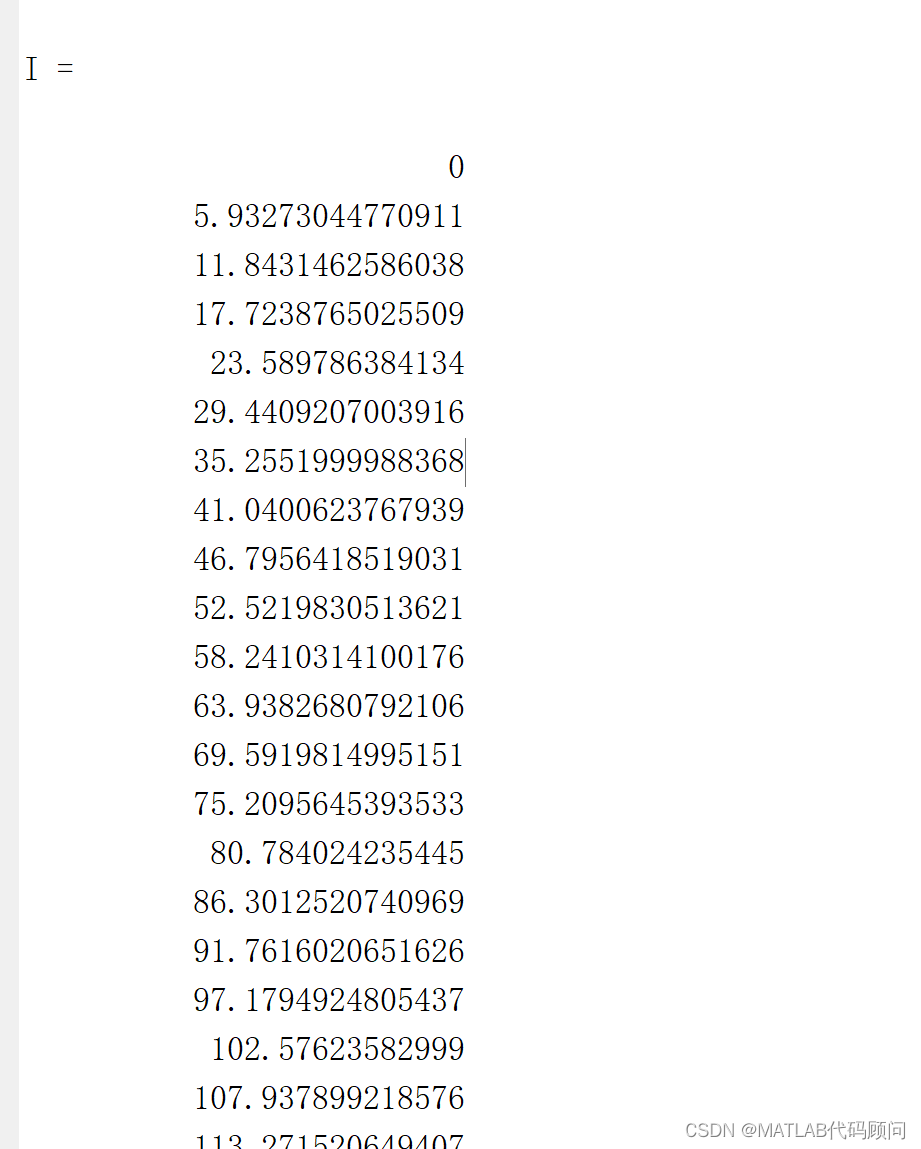
故障树分析蒙特卡洛仿真程序(附MATLAB完整代码)
故障树是一种特殊的倒立树状逻辑因果关系图,它用事件符号、逻辑门符号和转移符号描述系统中各种事件之间的因果关系,通过对引起系统故障的各种因素进行逻辑因果分析,确定导致故障发生的各种可能的原因,并通过定性和定量分析找出系…...
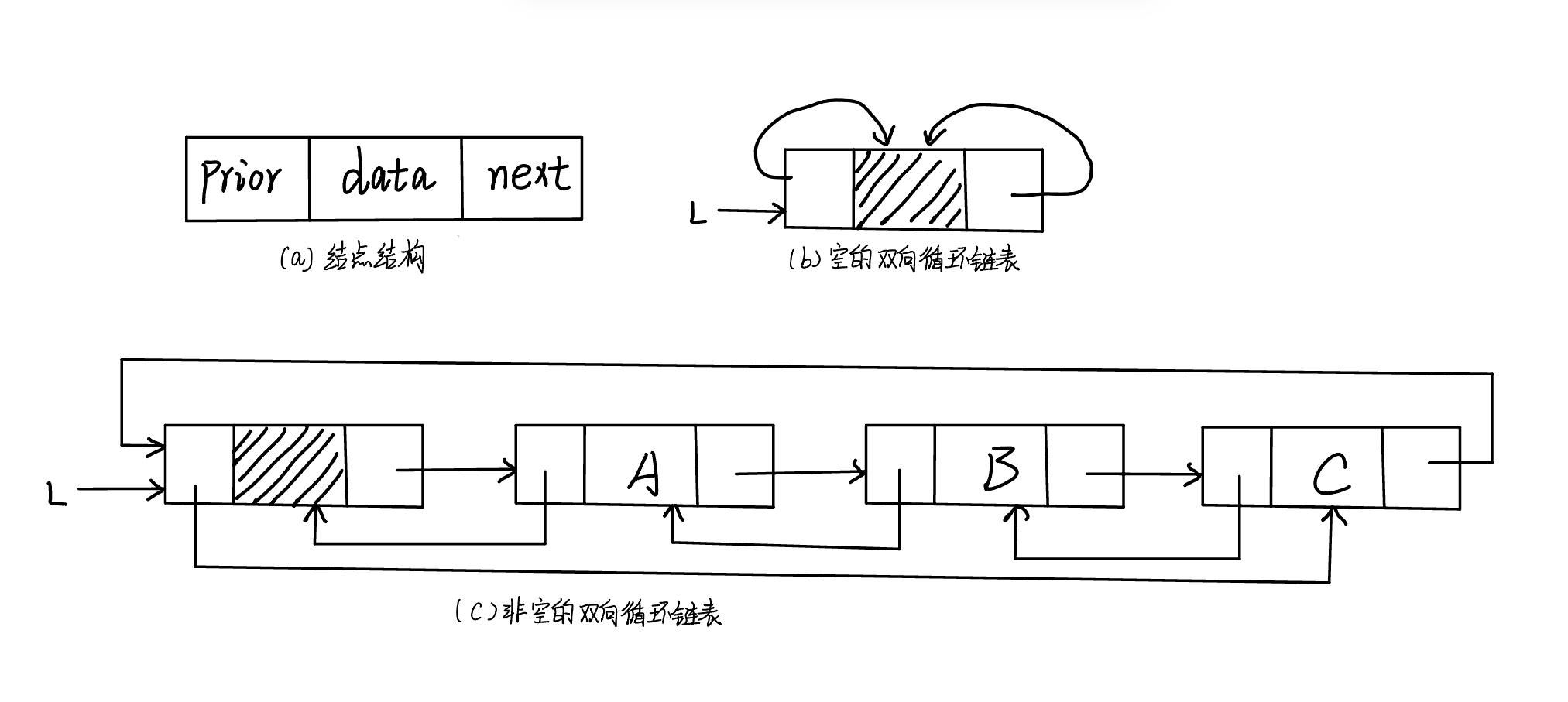
数据结构-线性表
文章目录 数据结构—线性表1.线性表的定义和基本操作线性表的定义线性表的特点线性表的基本操作 2.线性表的顺序存储和链式存储表示顺序存储链式存储单链表循环链表双向链表 数据结构—线性表 1.线性表的定义和基本操作 线性表的定义 定义:线性表是具有相同数据类…...
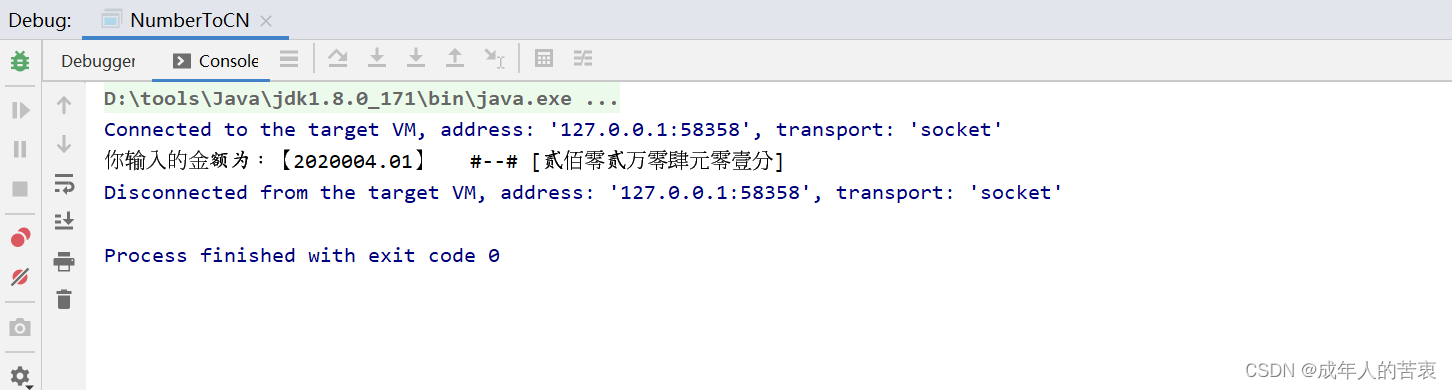
java金额数字转中文
java金额数字转中文 运行结果: 会进行金额的四舍五入。 工具类源代码: /*** 金额数字转为中文*/ public class NumberToCN {/*** 汉语中数字大写*/private static final String[] CN_UPPER_NUMBER {"零", "壹", "贰",…...
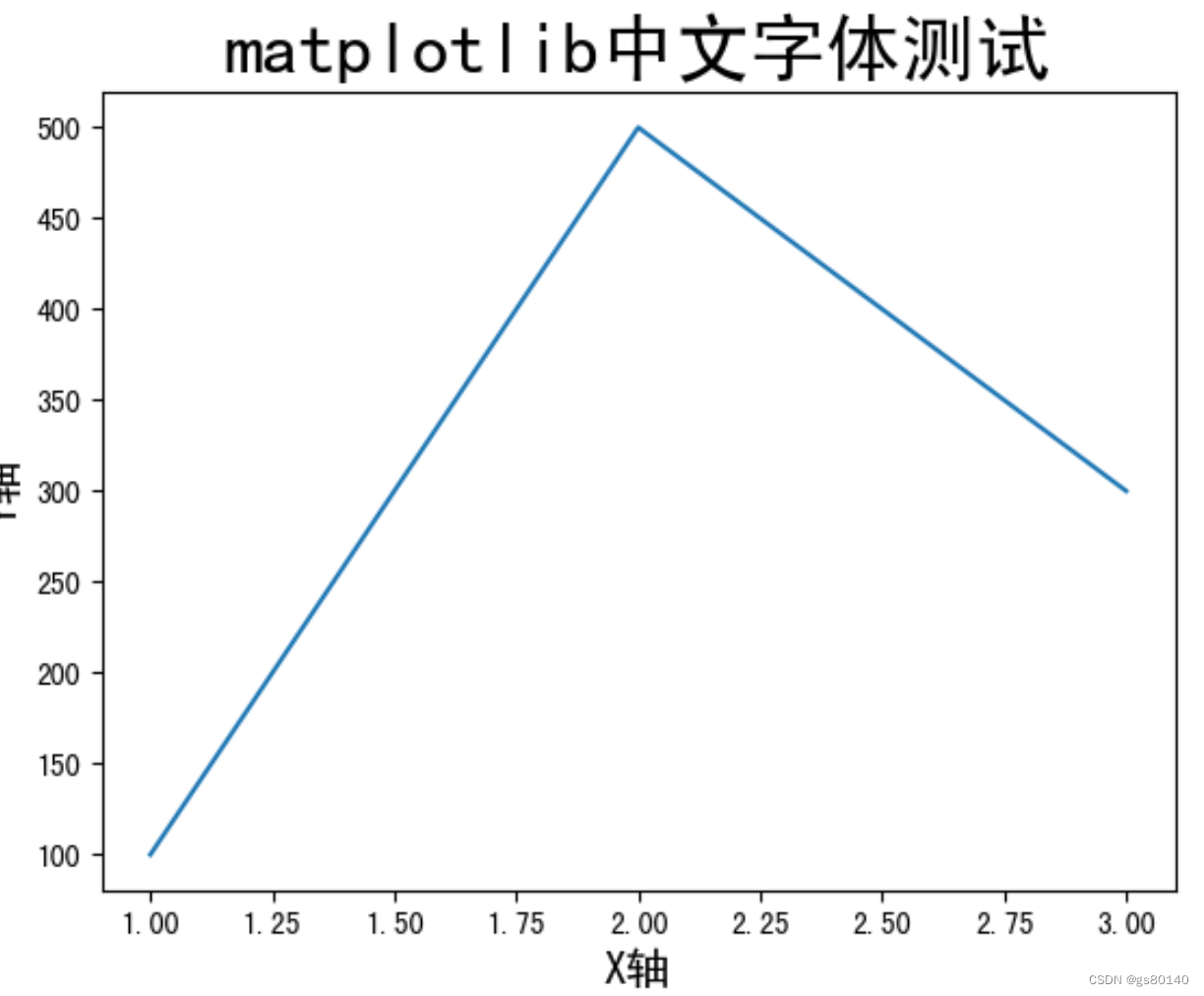
Ubuntu findfont: Font family ‘SimHei‘ not found.
matplotlib中文乱码显示 当我们遇到这样奇怪的问题时, 结果往往很搞笑 尝试1不行 Stopping Jupyter Installing font-manager: sudo apt install font-manager Cleaning the matplotlib cache directory: rm ~/.cache/matplotlib -fr Restarting Jupyter. 尝试2 This work fo…...

mysql小知识
什么是sql语句的子查询 SQL语句的子查询是指在一个SQL语句中嵌套另一个SQL语句。子查询可以嵌套在主查询的FROM子句、WHERE子句、HAVING子句、SELECT子句或INSERT语句中。 子查询可以返回一个结果集,这个结果集可以被主查询使用。子查询通常用于获取需要在主查询中使…...
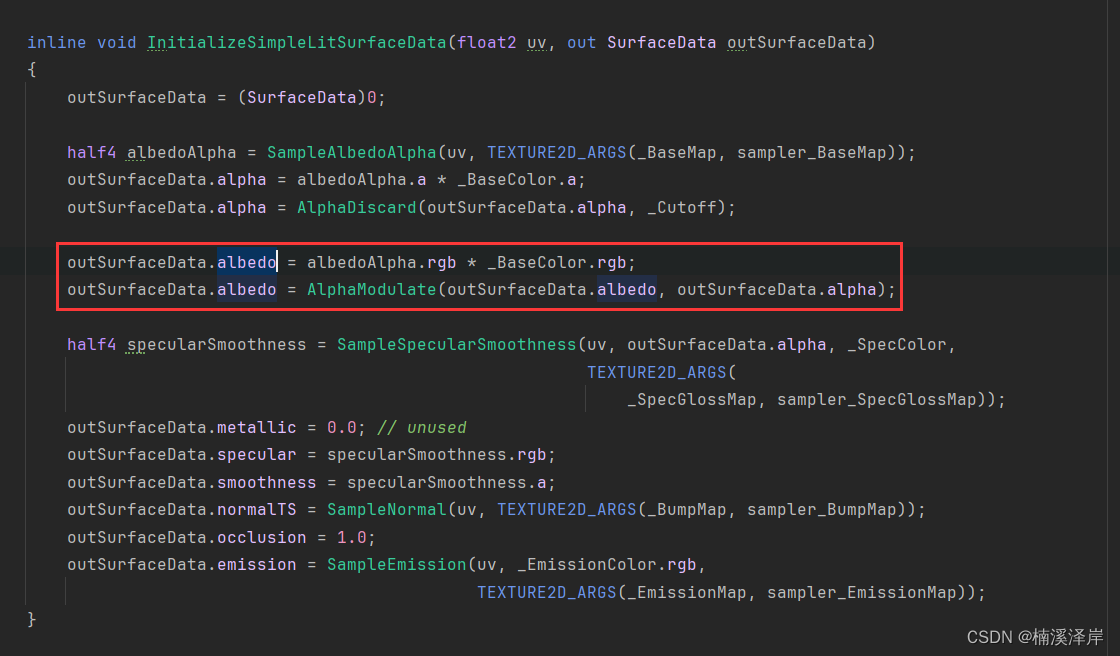
Unity中URP下逐顶点光照
文章目录 前言一、之前额外灯逐像素光照的数据准备好后,还有最后的处理二、额外灯的逐顶点光照1、逐顶点额外灯的光照颜色2、inputData.vertexLighting3、surfaceData.albedo 前言 在上篇文章中,我们分析了Unity中URP下额外灯,逐像素光照中聚…...

使用mcp-maker快速构建AI工具调用服务器:从协议原理到工程实践
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想给大语言模型(LLM)装上更强大的“手脚”,让它能直接操作我电脑上的各种软件和工具。这听起来很酷,对吧?但实际操作起来,你会发现一个核心痛…...

阴阳师自动化脚本OAS终极指南:轻松解放双手的完整教程
阴阳师自动化脚本OAS终极指南:轻松解放双手的完整教程 【免费下载链接】OnmyojiAutoScript Onmyoji Auto Script | 阴阳师脚本 项目地址: https://gitcode.com/gh_mirrors/on/OnmyojiAutoScript 阴阳师自动化脚本OAS是一款专门为《阴阳师》游戏设计的智能自动…...

【C语言】printf格式化输出:你真的理解“四舍五入”的陷阱吗?
1. 从printf的"四舍五入"陷阱说起 那天我在调试一个财务计算程序时,发现金额显示总差那么几分钱。比如3.145元应该显示为3.15,但程序输出却是3.14。这让我想起刚学C语言时踩过的坑——printf的格式化输出并不像数学课教的四舍五入那样简单。 先…...

Kubernetes配置管理实战:基于Kustomize的结构化部署与多环境管理
1. 项目概述:一个被低估的Kubernetes配置管理利器如果你和我一样,长期在Kubernetes生态里摸爬滚打,那你一定经历过这样的场景:为了部署一个稍微复杂点的应用,需要维护一堆YAML文件——Deployment、Service、ConfigMap、…...

Python自动化股票分析工具:从数据采集到可视化报告全流程实战
1. 项目概述:一个面向个人投资者的自动化股票分析工具如果你和我一样,是个对A股市场有点兴趣,但又没时间天天盯盘的上班族,那你肯定也经历过这种纠结:早上开盘前想看看心仪的几只股票有没有什么异动,结果一…...

结构化数字工作空间:提升创意工作效率的目录设计与自动化实践
1. 项目概述:一个为创意工作者量身定制的数字工作空间 如果你是一名设计师、开发者、内容创作者,或者任何需要处理大量数字资产、管理复杂项目流程的创意工作者,那么“Workspace-di-Yivo”这个名字可能会让你眼前一亮。这不仅仅是一个简单的文…...
)
用STM32+LoRa+阿里云IoT Studio,我DIY了一个低成本畜牧电子围栏(附完整代码)
基于STM32与LoRa的智能畜牧围栏系统开发实战 在广袤的牧区,牲畜走失一直是困扰牧民的核心问题。传统物理围栏不仅成本高昂,在草原这类开放地形中实施难度也很大。本文将详细介绍如何利用STM32微控制器、LoRa远距离通信模块和阿里云IoT Studio平台&#x…...

Claude模型思维链评估框架claweval:原理、实战与高级定制指南
1. 项目概述:一个专为Claude模型设计的“思维链”评估框架最近在AI应用开发圈里,一个名为claweval的项目开始被频繁提及。如果你正在使用Anthropic的Claude系列模型(无论是Claude 3 Opus、Sonnet还是Haiku)来构建需要复杂推理能力…...

ANSYS APDL函数方程加载:从GUI操作到命令流集成的完整指南
1. 项目概述:为什么我们需要函数方程加载?在ANSYS的仿真世界里,我们经常遇到一个头疼的问题:载荷不是一成不变的。比如,一个大型储罐的侧壁,水压会随着深度线性增加;一个高速旋转的叶片…...

DashClaw:模块化命令行工具的设计哲学与实战应用
1. 项目概述:一个为开发者打造的“瑞士军刀”式命令行工具最近在折腾一个自动化部署脚本时,遇到了一个老生常谈的问题:我需要从一堆杂乱的日志文件里,快速提取出特定时间段的错误信息,同时还要把这些信息按照严重程度分…...