混淆矩阵、准确率、查准率、查全率、DSC、IoU、敏感度的计算
1.背景介绍
在训练的模型的时候,需要评价模型的好坏,就涉及到混淆矩阵、准确率、查准率、查全率、DSC、IoU、敏感度的计算。
2、混淆矩阵的概念
所谓的混淆矩阵如下表所示:
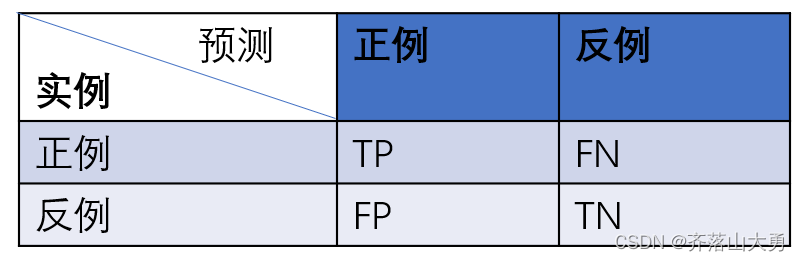
TP:真正类,真的正例被预测为正例
FN:假负类,样本为正例,被预测为负类
FP:假正类 ,原本实际为负,但是被预测为正例
TN:真负类,真的负样本被预测为负类。
从混淆矩阵当中,可以得到更高级的分类指标:Accuracy(准确率),Precision(查准率),Recall(查全率),Specificity(特异性),Sensitivity(灵敏度)。
3. 常用的分类指标
3.1 Accuracy(准确率)
不管是哪个类别,只要预测正确,其数量都放在分子上,而分母是全部数据量。常用于表示模型的精度,当数据类别不平衡时,不能用于模型的评价。
3.2 Precision(查准率)
即所有预测为正的样本中,预测正确的样本的所占的比重。
3.3 Recall(查全率)
真实的为正的样本,被正确检测出来的比重。
3.4 Specificity(特异性)
特异性指标,也称 负正类率(False Positive Rate, FPR),计算的是模型错识别为正类的负类样本占所有负类样本的比例,一般越低越好。
3.5 DSC(Dice coefficient)
Dice系数,是一种相似性度量,度量二进制图像分割的准确性。
如图所示红色的框的区域时Groudtruth,而蓝色的框为预测值Prediction。
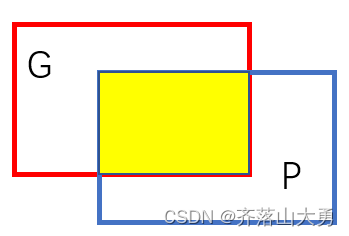
3.6 IoU(交并比)
3.7 Sensitivity(灵敏度)
反应的时预测正确的区域在Groundtruth中所占的比重。
4. 计算程序
ConfusionMatrix 这个类可以直接计算出混淆矩阵
from collections import defaultdict, deque
import datetime
import time
import torch
import torch.nn.functional as F
import torch.distributed as dist
import errno
import osclass SmoothedValue(object):"""Track a series of values and provide access to smoothed values over awindow or the global series average."""def __init__(self, window_size=20, fmt=None):if fmt is None:fmt = "{value:.4f} ({global_avg:.4f})"self.deque = deque(maxlen=window_size)self.total = 0.0self.count = 0self.fmt = fmtdef update(self, value, n=1):self.deque.append(value)self.count += nself.total += value * ndef synchronize_between_processes(self):"""Warning: does not synchronize the deque!"""if not is_dist_avail_and_initialized():returnt = torch.tensor([self.count, self.total], dtype=torch.float64, device='cuda')dist.barrier()dist.all_reduce(t)t = t.tolist()self.count = int(t[0])self.total = t[1]@propertydef median(self):d = torch.tensor(list(self.deque))return d.median().item()@propertydef avg(self):d = torch.tensor(list(self.deque), dtype=torch.float32)return d.mean().item()@propertydef global_avg(self):return self.total / self.count@propertydef max(self):return max(self.deque)@propertydef value(self):return self.deque[-1]def __str__(self):return self.fmt.format(median=self.median,avg=self.avg,global_avg=self.global_avg,max=self.max,value=self.value)class ConfusionMatrix(object):def __init__(self, num_classes):self.num_classes = num_classesself.mat = Nonedef update(self, a, b):n = self.num_classesif self.mat is None:# 创建混淆矩阵self.mat = torch.zeros((n, n), dtype=torch.int64, device=a.device)with torch.no_grad():# 寻找GT中为目标的像素索引k = (a >= 0) & (a < n)# 统计像素真实类别a[k]被预测成类别b[k]的个数(这里的做法很巧妙)inds = n * a[k].to(torch.int64) + b[k]self.mat += torch.bincount(inds, minlength=n**2).reshape(n, n)def reset(self):if self.mat is not None:self.mat.zero_()def compute(self):h = self.mat.float()# 计算全局预测准确率(混淆矩阵的对角线为预测正确的个数)acc_global = torch.diag(h).sum() / h.sum()# 计算每个类别的准确率acc = torch.diag(h) / h.sum(1)# 计算每个类别预测与真实目标的iouiu = torch.diag(h) / (h.sum(1) + h.sum(0) - torch.diag(h))return acc_global, acc, iudef reduce_from_all_processes(self):if not torch.distributed.is_available():returnif not torch.distributed.is_initialized():returntorch.distributed.barrier()torch.distributed.all_reduce(self.mat)def __str__(self):acc_global, acc, iu = self.compute()return ('global correct: {:.1f}\n''average row correct: {}\n''IoU: {}\n''mean IoU: {:.1f}').format(acc_global.item() * 100,['{:.1f}'.format(i) for i in (acc * 100).tolist()],['{:.1f}'.format(i) for i in (iu * 100).tolist()],iu.mean().item() * 100)class DiceCoefficient(object):def __init__(self, num_classes: int = 2, ignore_index: int = -100):self.cumulative_dice = Noneself.num_classes = num_classesself.ignore_index = ignore_indexself.count = Nonedef update(self, pred, target):if self.cumulative_dice is None:self.cumulative_dice = torch.zeros(1, dtype=pred.dtype, device=pred.device)if self.count is None:self.count = torch.zeros(1, dtype=pred.dtype, device=pred.device)# compute the Dice score, ignoring backgroundpred = F.one_hot(pred.argmax(dim=1), self.num_classes).permute(0, 3, 1, 2).float()dice_target = build_target(target, self.num_classes, self.ignore_index)self.cumulative_dice += multiclass_dice_coeff(pred[:, 1:], dice_target[:, 1:], ignore_index=self.ignore_index)self.count += 1@propertydef value(self):if self.count == 0:return 0else:return self.cumulative_dice / self.countdef reset(self):if self.cumulative_dice is not None:self.cumulative_dice.zero_()if self.count is not None:self.count.zeros_()def reduce_from_all_processes(self):if not torch.distributed.is_available():returnif not torch.distributed.is_initialized():returntorch.distributed.barrier()torch.distributed.all_reduce(self.cumulative_dice)torch.distributed.all_reduce(self.count)
分类指标的计算
import torch# SR : Segmentation Result
# GT : Ground Truthdef get_accuracy(SR,GT,threshold=0.5):SR = SR > thresholdGT = GT == torch.max(GT)corr = torch.sum(SR==GT)tensor_size = SR.size(0)*SR.size(1)*SR.size(2)*SR.size(3)acc = float(corr)/float(tensor_size)return accdef get_sensitivity(SR,GT,threshold=0.5):# Sensitivity == RecallSR = SR > thresholdGT = GT == torch.max(GT)# TP : True Positive# FN : False NegativeTP = ((SR==1)+(GT==1))==2FN = ((SR==0)+(GT==1))==2SE = float(torch.sum(TP))/(float(torch.sum(TP+FN)) + 1e-6) return SEdef get_specificity(SR,GT,threshold=0.5):SR = SR > thresholdGT = GT == torch.max(GT)# TN : True Negative# FP : False PositiveTN = ((SR==0)+(GT==0))==2FP = ((SR==1)+(GT==0))==2SP = float(torch.sum(TN))/(float(torch.sum(TN+FP)) + 1e-6)return SPdef get_precision(SR,GT,threshold=0.5):SR = SR > thresholdGT = GT == torch.max(GT)# TP : True Positive# FP : False PositiveTP = ((SR==1)+(GT==1))==2FP = ((SR==1)+(GT==0))==2PC = float(torch.sum(TP))/(float(torch.sum(TP+FP)) + 1e-6)return PCdef get_F1(SR,GT,threshold=0.5):# Sensitivity == RecallSE = get_sensitivity(SR,GT,threshold=threshold)PC = get_precision(SR,GT,threshold=threshold)F1 = 2*SE*PC/(SE+PC + 1e-6)return F1def get_JS(SR,GT,threshold=0.5):# JS : Jaccard similaritySR = SR > thresholdGT = GT == torch.max(GT)Inter = torch.sum((SR+GT)==2)Union = torch.sum((SR+GT)>=1)JS = float(Inter)/(float(Union) + 1e-6)return JSdef get_DC(SR,GT,threshold=0.5):# DC : Dice CoefficientSR = SR > thresholdGT = GT == torch.max(GT)Inter = torch.sum((SR+GT)==2)DC = float(2*Inter)/(float(torch.sum(SR)+torch.sum(GT)) + 1e-6)return DC
参考文献:
混淆矩阵的概念-CSDN博客
相关文章:
混淆矩阵、准确率、查准率、查全率、DSC、IoU、敏感度的计算
1.背景介绍 在训练的模型的时候,需要评价模型的好坏,就涉及到混淆矩阵、准确率、查准率、查全率、DSC、IoU、敏感度的计算。 2、混淆矩阵的概念 所谓的混淆矩阵如下表所示: TP:真正类,真的正例被预测为正例 FN:假负类…...

ChatGPT目前的AI一哥
ChatGPT和文心一言是两个不同的AI助手,各自有其独特的特点和应用场景。以下是对它们在智能回复、语言准确性和知识库丰富度等方面的简要比较: 智能回复:ChatGPT是由OpenAI开发的语言模型,具有强大的自然语言处理和生成能力&#x…...

认识思维之熵
经常有读者问我,说: 为什么向您请教一个问题,您总能很快指出在哪篇文章里面提到过,是因为您的记忆力特别好吗? 其实不是的。更重要的原因是:如果你经过系统训练,有意识地去获取知识的话&#x…...

蓝桥杯备战——1.点亮LED灯
1.解析原理图 由上图可以看到8个共阳LED灯接到了573输出口,而573输入接到单片机P0口上。当573 LE脚输入高电平时,输出随输入变化,当LE为低电平时,输出锁存。 由上图可以看到Y4C接到了或非门74HC02的输出端,而输入端为…...

【网络协议测试】畸形数据包——圣诞树攻击(DOS攻击)
简介 TCP所有标志位被设置为1的数据包被称为圣诞树数据包(XMas Tree packet),之所以叫这个名是因为这些标志位就像圣诞树上灯一样全部被点亮。 标志位介绍 TCP报文格式: 控制标志(Control Bits)共6个bi…...

Java基础面试题-5day
泛型 什么是泛型?有什么用? 泛型是jdk5引入的新特性,通过泛型可以提高代码的可读性和稳定性;当我们使用泛型时,传入的对象类型必须是指定的泛型类型,否则就会报错 泛型的使用方式有哪些? 一…...

软通智慧启动鲲鹏原生应用开发合作
1月25日,软通智慧科技有限公司启动鲲鹏原生应用开发合作,将基于鲲鹏硬件底座、openEuler、开发套件Kunpeng DevKit和应用使能套件Kunpeng BoostKit开展面向智慧园区、政务、水利水务等行业场景的软硬件原生应用开发,并持续发布性能更优的鲲鹏…...
【STM32】STM32F4中USB的CDC虚拟串口(VCP)使用方法
文章目录 一、前言二、STM32CubeMX生成代码2.1 选择芯片2.2 配置相关模式2.3 设置时钟频率2.4 生成代码2.5 编译并下载代码2.6 结果2.7 问题 三、回环测试3.1 打开工程3.2 添加回环代码3.3 编译烧录并测试 四、出现问题和解决方法4.1 烧录总是要自己插拔USB4.2 自己生成的工程没…...
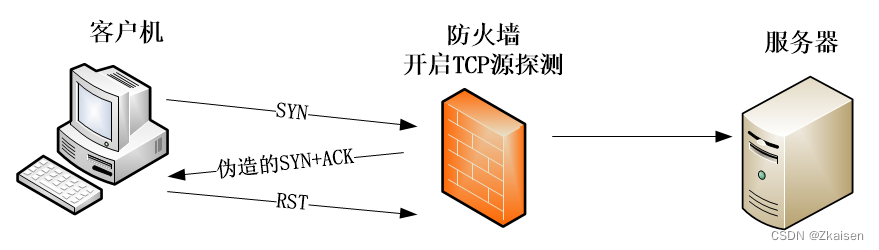
网络协议与攻击模拟_06攻击模拟SYN Flood
一、SYN Flood原理 在TCP三次握手过程中, 客户端发送一个SYN包给服务器服务端接收到SYN包后,会回复SYNACK包给客户端,然后等待客户端回复ACK包。但此时客户端并不会回复ACK包,所以服务端就只能一直等待直到超时。服务端超时后会…...

CPU,内存和硬盘之间的关系
计算机三大件:CPU,内存,硬盘。从运算速度来看,CPU>内存>固态硬盘>机械硬盘。 电脑卡顿怎么解决? 1、清理垃圾; 2、释放C盘空间,因为系统需要C盘空间当作虚拟内存; 3、增…...
Java面试题之基础篇
文章目录 一:谈谈你对面向对象的理解二:JDK、JRE、JVM三者区别和联系三:和equals比较四:hashCode与equals五:final六:String、StringBuffer、StringBuilder七:重载与重写的区别?八&a…...
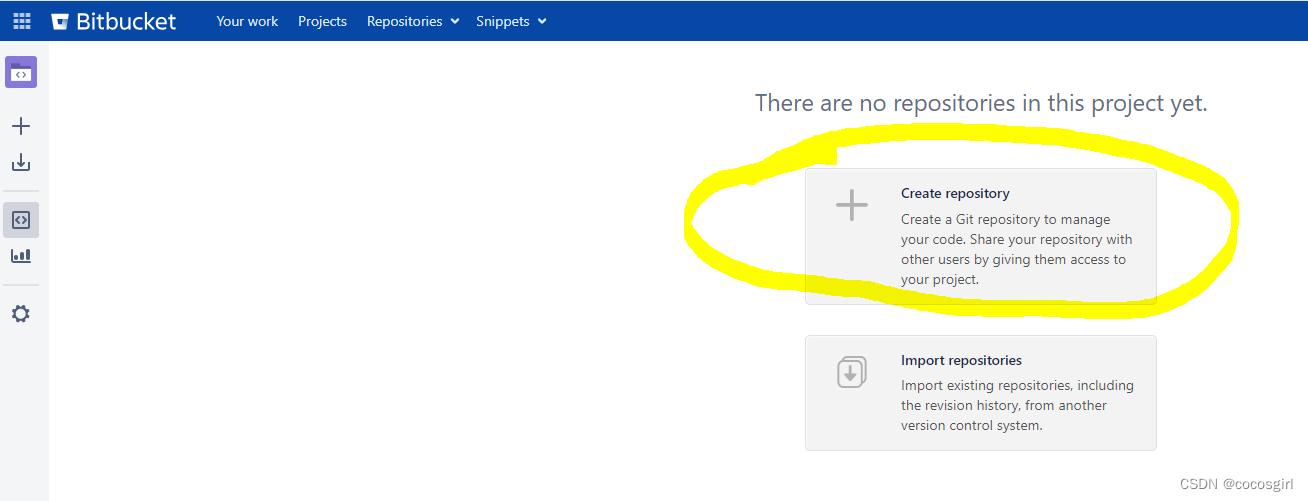
Bitbucket第一次代码仓库创建/提交/创建新分支/合并分支/忽略ignore
1. 首先要在bitbucket上创建一个项目,这个我没有权限创建,是找的管理员创建的。 管理员创建之后,这个项目给了我权限,我就可以创建我的代码仓库了。 2. 点击这个Projects下的具体项目名字,就会进入这样一个页面&#…...

c#反射用法
在 C# 中,反射是一种能够在运行时检查类型信息、访问属性和调用方法的机制。通过反射,你可以动态地操作类型、对象和程序集,而无需在编译时知道这些类型的具体信息。 反射提供了一组 API,可以让你在运行时获取和操作类型的信息。…...

WPF行为
背景:实现按钮鼠标移动到上方有点交互效果或变一下有阴影。这样使用触发器就行了,但是如果是每个控件都有效果的话使用行为更加合适 1、下载NuGet包:Microsoft.xaml.behavior.wpf 2、创建行为类EffectBehavior,对Behavior进行重写…...
N-141基于springboot,vue网上拍卖平台
开发工具:IDEA 服务器:Tomcat9.0, jdk1.8 项目构建:maven 数据库:mysql5.7 系统分前后台,项目采用前后端分离 前端技术:vueelementUI 服务端技术:springbootmybatis-plusredi…...

Unity之Cinemachine教程
前言 Cinemachine是Unity引擎的一个高级相机系统,旨在简化和改善游戏中的相机管理。Cinemachine提供了一组强大而灵活的工具,可用于创建令人印象深刻的视觉效果,使开发人员能够更轻松地掌控游戏中的摄像机行为。 主要功能和特性包括&#x…...
)
java面面试面经(面试过程)
一、校招一面面经 1.1 自我介绍(2min) 1.2 要求介绍项目一项目亮点以及做的具体工作 根据介绍项目进行细挖,其中包括方案设计、场景设计等等等 由于项目一种涉及数据库源的转换问题和限流方案,所以面试官拷打的是这两块,其中包括场景题&…...

大语言模型-大模型基础文献
大模型基础 1、Attention Is All You Need https://arxiv.org/abs/1706.03762 attention is all you need 2、Sequence to Sequence Learning with Neural Networks https://arxiv.org/abs/1409.3215 基于深度神经网络(DNN)的序列到序列学习方法 3、…...

【RH850U2A芯片】Reset Vector和Interrupt Vector介绍
目录 前言 正文 1. 什么是Reset Vector 1.1 S32K144芯片的Reset Vector 1.2 RH850芯片的Reset Vector 2. 什么是Interrupt Vector 2.1 S32K144芯片的Interrupt Vector 2.2 RH850芯片的Interrupt Vector 3. Reset Vector等价于Interrupt Vector吗 4. 总结 前言 最近在…...

Zabbix交换分区使用率过高排查
Zabbix High swap space usage 问题现象 Zabbix 出现Highswap space usage(less than 50% free)告警,提示交换分区空间使用率超过50% 处理过程 1. 确定swap分区是否已占满 free -h登录Zabbix服务器检查内存情况,检查发现Linux服务器空闲的内存还有不少…...

打造便携式Kali Linux安全评估工具:OpenClaw USB定制全攻略
1. 项目概述:一个便携式安全评估工具的诞生 在安全研究、渗透测试或者应急响应的现场,你经常会遇到一个经典困境:目标环境可能是一台物理隔离的机器,或者是一台你无法安装任何软件的“干净”主机。你需要一个功能强大、即插即用的…...

终极免费Switch模拟器yuzu:解决电脑玩任天堂游戏的5大痛点
终极免费Switch模拟器yuzu:解决电脑玩任天堂游戏的5大痛点 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在电脑上畅玩Switch游戏却总是遇到各种问题?yuzu模拟器作为全球最受欢迎的开源任…...

NVIDIA Profile Inspector深度解析:解锁显卡隐藏性能的实战指南
NVIDIA Profile Inspector深度解析:解锁显卡隐藏性能的实战指南 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 你是否曾为游戏卡顿而烦恼?是否觉得显卡性能总差那么一点&#x…...

UEFITool终极指南:轻松解析和编辑UEFI固件的开源利器
UEFITool终极指南:轻松解析和编辑UEFI固件的开源利器 【免费下载链接】UEFITool UEFI firmware image viewer and editor 项目地址: https://gitcode.com/gh_mirrors/ue/UEFITool 你是否曾好奇计算机启动时底层发生了什么?想要深入了解UEFI固件的…...

【ElevenLabs情绪模拟技术白皮书】:基于2,147小时情感语音标注数据集的11类基础情绪迁移模型验证报告
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs情绪模拟技术白皮书概述 ElevenLabs的情绪模拟技术并非简单调节音高或语速,而是基于多模态情感表征学习(Multimodal Affective Representation Learning, MARL&#x…...

MCP服务器开发指南:为AI助手构建安全可控的外部工具扩展
1. 项目概述:一个为AI助手赋能的MCP服务器最近在折腾AI应用开发的朋友,可能都绕不开一个词:MCP。全称是Model Context Protocol,你可以把它理解成一套标准化的“插件协议”。它让像Claude、Cursor这类AI助手,能够安全、…...

Windows Terminal 预览版:从安装到深度配置,打造现代化命令行工作流
1. 项目概述:为什么我们需要一个现代化的Windows终端?如果你和我一样,在Windows上敲了十几年命令行,从古老的cmd.exe到后来的PowerShell,一个绕不开的痛点就是:这终端工具,用起来总感觉差点意思…...

n8n-claw:在自动化工作流中实现零代码网页抓取
1. 项目概述与核心价值最近在折腾自动化工作流,发现了一个挺有意思的项目,叫freddy-schuetz/n8n-claw。乍一看名字,你可能会有点懵,“n8n”我知道,是那个开源的自动化工具,但这个“claw”是啥?爪…...

MedAgentBench:大模型临床决策能力评估基准详解与应用
1. 项目概述:当大模型成为医疗决策的“实习生” 最近在医疗AI的圈子里,一个名为“MedAgentBench”的开源项目引起了不小的讨论。这个由斯坦福机器学习组(Stanford ML Group)发布的项目,其核心目标非常明确:…...

AI编码工具选型指南:从原理到实践的全方位解析
1. 项目概述:为什么我们需要一份AI编码工具的“藏宝图”如果你是一名开发者,过去一年里,你的工作流可能已经被AI工具彻底重塑了。从最初用ChatGPT写几行注释,到后来用GitHub Copilot自动补全整段代码,再到如今各种能直…...