基于Python flask MySQL 猫眼电影可视化系统设计与实现
1 绪论
1.1 设计背景及目的
猫眼电影作为国内知名的电影信息网站,拥有海量的电影信息、票房数据和用户评价数据。这些数据对于电影市场的研究和分析具有重要意义。然而,由于数据的复杂性和数据来源的多样性,如何有效地采集、存储和展示这些数据成为了一个挑战。因此,本文介绍了一种基于Python Flask框架的猫眼电影数据采集分析与可视化系统,旨在帮助用户更好地理解和分析猫眼电影网站的数据。
该系统的主要功能包括:电影信息的爬取、存储和展示、电影票房数据的采集和展示、电影评分数据的采集和展示、电影评价词云图的展示等。这些功能能够满足用户对于电影市场数据的需求,帮助用户更好地了解电影市场的变化和趋势。
该系统后端采用了Flask和MySQL,前端使用了Layui框架,可视化效果使用了Echart。爬虫使用了Python的requests库实现。Flask框架是一种轻量级的Web应用框架,易于使用和扩展,MySQL是一种常用的关系型数据库,Layui是一种易于使用的前端UI框架,Echart是一种常用的可视化库,requests库是Python中常用的网络请求库。这些技术的选择使得我们能够快速地开发出一个功能完备、易于使用的数据采集分析与可视化系统。
在设计该系统时,首先确定系统的需求和目标。本系统的目标是开发一个方便用户使用、易于扩展的系统,能够满足用户对于电影市场数据的需求。为了实现这一目标,本系统采用了一系列技术和方法,包括Flask框架、MySQL数据库、Layui前端框架、Echart可视化库和requests爬虫库等。
在具体实现方面,系统首先使用爬虫技术采集猫眼电影网站的电影信息、票房数据和评分数据,经过处理和存储后,将这些数据通过Flask框架和MySQL数据库展示在前端页面上。同时,系统使用Echart可视化库将数据以直观的方式展示出来,帮助用户更好地理解和分析数据。此外,系统还使用Layui框架设计了一个美观、易于操作的用户界面,方便用户使用系统。
总之,这个基于Python Flask的猫眼电影数据采集分析与可视化系统旨在帮助用户更好地了解电影市场数据,提供一个方便、直观的数据分析和可视化工具。通过使用Flask框架、MySQL数据库、Layui前端框架、Echart可视化库和requests爬虫库等技术,我们能够实现一个功能完备、易于使用、数据实时更新的系统,满足用户对于电影市场数据的需求。
1.2 国内外研究现状
1.2.1 国外研究现状
在国外,电影市场的数据分析和可视化工具已经得到广泛的应用。例如,美国的Box Office Mojo就是一个专门用于票房数据收集、分析和可视化展示的网站,为电影行业提供了非常准确、实时的票房数据。此外,还有IMDb(Internet Movie Database)这样的电影信息数据库和评价平台,为用户提供了电影相关的各种信息和评论。
近年来,随着大数据和人工智能技术的不断发展,电影市场数据分析和可视化工具也得到了极大的提升。例如,美国的Movio公司就利用大数据和机器学习技术,针对电影观众的个性化喜好和消费偏好进行深度分析,为电影营销提供更加精准的决策支持。
因此,在国外,猫眼电影数据采集、分析和可视化已经成为电影市场分析的重要手段。通过高效准确地获取、处理和呈现电影市场数据,为电影从业者提供更加科学合理的市场营销策略和推广方案,为广大电影爱好者提供更为全面、直观和便捷的电影资讯和服务,进而促进电影市场的发展和壮大。
1.2.2 国内研究现状
国内的电影市场也在不断发展和壮大,对于电影市场的数据采集、分析和可视化呈现等方面的需求日益增长。目前,国内已经出现了一些猫眼电影数据采集、分析和可视化系统的研究。
例如,清华大学的饭否电影团队就针对猫眼电影网站上的电影评论和评分数据进行了分析,探索了影片口碑和票房之间的关系。此外,还有一些商业化的电影数据分析平台,例如艺恩数据、追光娱乐等,提供了丰富的电影市场数据,并利用大数据和人工智能技术对数据进行处理和分析,为电影从业者提供更加准确、实用的市场分析结果。
然而,当前国内的电影数据采集、分析和可视化系统仍存在着一些问题,例如数据获取难度较大、数据质量不稳定、统计方法不完善等。因此,基于Python Flask框架、MySQL数据库和Layui前端框架的猫眼电影数据采集分析与可视化系统的研究具有重要意义。该系统通过爬虫技术获取数据,使用Python开源数据分析库对数据进行处理和分析,并利用Echart可视化工具呈现统计图表,以实现对电影市场情况和趋势的深入了解和探索,为电影从业者提供更加科学、全面、实用的市场分析结果。
1.3 主要研究内容
基于Python Flask框架、MySQL数据库和Layui前端框架的猫眼电影数据采集分析与可视化系统的主要研究内容包括以下几个方面:
猫眼电影数据的采集:通过Request库从猫眼电影网站上爬取电影相关数据,包括票房、评分、演员、导演等信息,并进行数据清洗和处理。
数据存储和管理:使用MySQL数据库进行数据存储和管理,实现数据的持久化和查询。本系统采用数据库来存储采集到的电影数据,便于后续的数据处理和统计分析。
数据分析和统计:利用Python开源数据分析库对数据进行处理和分析,包括数据预处理、数据分组、数据聚合、统计分析等。同时,使用Echart可视化工具呈现统计图表,展示猫眼电影各项指标的变化趋势,如票房排行榜、电影类型占比等。
用户交互和体验:通过Layui前端框架实现用户界面,包括电影列表、搜索、排序、分页等功能,提供一种简单易用的交互方式。采用先进的前端技术,使得用户可以直接从前端页面获取到所需的电影信息。
2 系统技术介绍
2.1 Python技术介绍
基于Python Flask框架的猫眼电影数据采集、分析和可视化系统,主要依托于Python编程语言及其相关技术栈。Python是一种高级的、面向对象的解释型脚本语言,具有简洁、易读、易学的特点,被广泛应用于各个领域。
Python Flask是一款轻量级Web框架,基于Werkzeug和Jinja2构建而成,提供了路由、模板、请求、响应等核心功能,可以快速搭建Web应用程序。本系统采用Python Flask框架来实现用户与后端之间的通信,提供RESTful风格的API接口,实现数据的获取和传输。
在数据处理和分析方面,本系统使用了Python的众多开源数据科学库,如NumPy、Pandas等。这些库提供了丰富的数据结构、算法和统计分析方法,可以对大量的电影数据进行高效准确的分析和处理。
此外,为了实现数据的可视化展示,本系统还使用了Echart可视化工具,它是一个基于JavaScript的数据可视化库,可以生成丰富多彩的图表,包括折线图、柱状图、饼图、散点图等,可以有效地呈现分析结果,flask框架图如图2-1所示。

图2-1 flask框架图
2.2 Layui前端框架介绍
Layui是一个轻量级的模块化Web前端框架,提供了丰富的UI组件和JS模块,可以快速搭建Web应用程序,并使得前端开发更加高效、简洁、美观。
本系统使用Layui框架实现了一系列用户交互界面和功能,包括电影列表、搜索、排序、分页等。具体来说,Layui提供了以下几个重要特点:
-
模块化:Layui采用模块化设计,将各种功能组织成不同的模块,每个模块都有明确的作用和接口,可以方便地组合和调用,提高代码的复用性和可维护性。
-
简约易用:Layui提供了简洁、易用、美观的UI组件,尤其适合中小型Web应用程序的开发,可以快速构建出符合用户需求的界面。
-
响应式布局:Layui采用响应式布局,可以自适应各种设备和屏幕大小,保证在PC端和移动端都有良好的显示效果。
-
多版本支持:Layui支持多种版本和打包方式,可以根据需求进行选择和定制。
通过Layui前端框架的使用,本系统实现了良好的用户交互和体验,使得用户可以方便地浏览、搜索和筛选电影信息。与Python Flask框架、MySQL数据库和开源数据科学库相结合,本系统为电影从业者提供了更加全面、可靠、精准的市场分析结果,促进电影市场的发展和壮大。
2.3 Mysql数据库介绍
MySQL是一种常用的关系型数据库管理系统,具有开源、高效、稳定等特点,被广泛应用于各类Web应用程序中。
本系统使用MySQL数据库来存储采集到的电影数据,包括电影名称、上映时间、票房、评分、演职人员等信息。其主要优点如下:
可靠性高:MySQL具有较高的数据安全性和完整性,可以对多用户访问进行控制和管理,避免数据丢失和损坏情况的发生。
高效性强:MySQL支持多线程、索引优化、缓存机制等技术手段,能够快速处理大量数据,保证了对数据的高效率管理和查询。
易扩展性好:MySQL支持水平和垂直两个方向的扩展,能够满足不同规模和需求的应用程序。
易维护性高:MySQL提供了丰富的管理工具和接口,可进行数据备份、恢复、维护等操作,使得数据库的运维更加便捷和高效。
在本系统中,MySQL数据库作为后端数据存储和管理的核心组件,为数据分析和可视化展示提供了强有力的支撑。同时通过Python Flask框架的ORM映射机制,可以将MySQL数据库中的数据与Python对象进行关联,从而实现更加便捷和高效的数据操作。
3 系统需求分析
3.1 系统任务目标
其主要任务目标包括以下几个方面:
电影数据采集:通过爬虫技术从猫眼电影网站上获取电影相关数据,包括票房、评分、演员、导演等信息,并进行数据清洗和处理。该过程需要保证数据的准确性和完整性,以便后续的分析和展示。
数据存储和管理:采用MySQL数据库进行数据存储和管理,实现数据的持久化和查询。该过程需要建立合适的数据模型和表结构,以便于后续的数据处理和统计分析。
数据分析和统计:利用Python开源数据分析库对数据进行处理和分析,包括数据预处理、数据分组、数据聚合、统计分析等。同时,使用Echart可视化工具呈现统计图表,展示猫眼电影各项指标的变化趋势,如票房排行榜、电影类型占比等。
用户交互和体验:通过Layui前端框架实现用户界面,包括电影列表、搜索、排序、分页等功能,提供一种简单易用的交互方式。该过程需要保证用户界面的美观、易用性和响应速度,以提高用户体验。
系统整合和优化:通过Python Flask框架实现各个模块之间的整合和调用,优化系统的性能和可靠性。该过程需要保证系统的稳定性和安全性,以便于后续的部署和维护。
3.2 系统功能需求分析
基于Python Flask的猫眼电影数据采集、分析和可视化系统,具有多种功能需求,本系统功能总用例图如图3-1所示。其主要包括以下几个方面:

图3-1系统用例图
数据采集功能:该系统从猫眼电影网站获取相关的电影信息数据,如票房数据、评分数据、演员、导演等信息。为了保证数据的实时性和准确性,应当周期性地更新数据,以便后续的处理和分析。
数据清洗和分析功能:猫眼电影网站上的数据可能存在一些杂乱无章的信息,需要通过数据清洗功能对数据进行处理和过滤。同时使用Python开源数据分析库(如pandas)进行数据统计和分析,包括对电影票房的分析、演员的分析、电影类型分析等。
数据可视化功能:在进行数据分析之后,将结果进行数据可视化处理,使得数据更加直观、易懂。可以使用Echart等可视化工具进行图表展示,如折线图、柱状图、饼图、玫瑰图、词云图等,以便于用户快速了解猫眼电影各项指标的变化趋势。
数据存储功能:猫眼电影网站上的数据保存到MySQL数据库中,并建立合适的数据模型和表结构,以方便后续的数据处理和查询。在数据存储过程中,应当保证数据的完整性和可靠性,以免出现数据丢失或损坏的情况。
3.3 系统非功能需求分析
除了功能需求之外,基于Python Flask的猫眼电影数据采集、分析和可视化系统还需要满足一些非功能需求,包括以下几个方面:
可操作性:系统必须具有易用、易操作的特点,以便于用户使用。系统应当提供友好的用户界面和交互方式,使得用户可以方便地浏览、搜索和筛选电影信息等数据,同时系统应当保证响应速度快,以避免用户体验不佳的情况。
美观度:系统的用户界面应当具有美观、简洁、清晰等特点,以提高用户的视觉体验。系统设计应当注意图标大小、颜色搭配、排版等因素,力求使得系统界面风格统一、美观大方,提升用户的使用感受。
可移植性:系统应当具备良好的可移植性,以便在不同平台上运行。系统开发过程中应当尽量避免使用与平台相关的代码,保持它的通用性和兼容性。此外,在部署时也要考虑到不同环境下的差异性,确保系统在各种环境下都能正确运行。
安全性:系统应当具备较高的安全性,以确保数据的机密性和完整性。系统开发过程中应当采用各种技术手段对敏感信息进行加密和保护,防止恶意攻击和非法访问。
可扩展性:系统应当具有良好的可扩展性,以便在未来进行功能升级和扩展。此外,在进行系统开发时应当注意代码的规范性、模块化和分层架构,以方便后续的维护和改进。
4 系统功能设计
4.1 系统功能结构
针对前面对本系统需求分析,基于Python Flask的猫眼电影数据采集分析可视化系统的功能模块图,如图4-1所示。
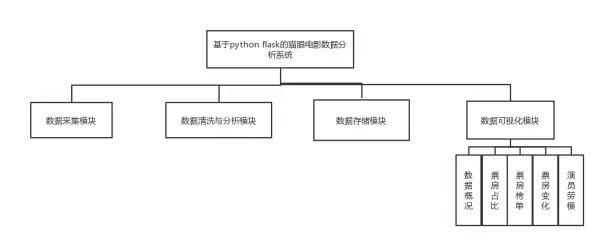
图4-1系统功能模块图
4.2 数据采集功能设计
4.2.1 设计思想
数据采集功能是基于Python的BeautifulSoup库实现的。BeautifulSoup是一个HTML/XML解析器,能够方便地从HTML文档中提取数据。在本系统中,使用BeautifulSoup向猫眼电影网站发送HTTP请求,并通过解析响应内容,获取猫眼电影的相关数据。
为了实现数据采集功能,首先需要确定要采集的数据类型和数据来源。在本系统中,选择采集猫眼电影网站上正在上映的电影信息,包括电影名称、导演、主演、上映时间、评分等信息。这些数据来自猫眼电影网站上的页面,需要通过发送HTTP请求获取页面的HTML内容,并通过BeautifulSoup解析HTML内容,提取出需要的电影信息,页面信息如下图4-2所示。
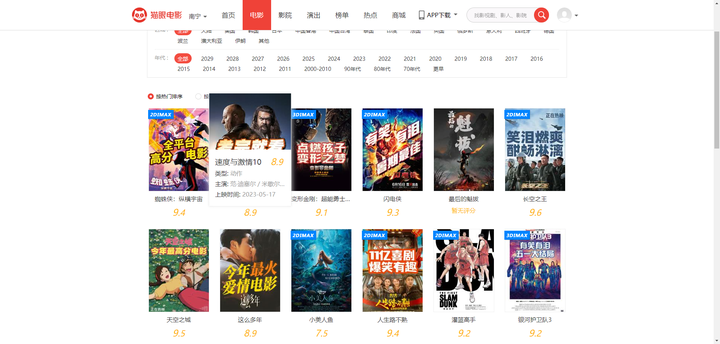
图4-2数据采集页面信息
4.2.2 业务逻辑设计
数据采集功能的业务逻辑设计主要包括数据源选择、数据采集、数据清洗和数据存储四个环节。
首先,在数据源选择过程中,确定采集的数据类型和数据来源。在本系统中,我们选择采集猫眼电影网站上正在上映的电影信息。
其次,在数据采集环节中,需要向猫眼电影网站发送HTTP请求来获取页面HTML内容。通过BeautifulSoup解析HTML内容,提取出需要的电影信息,并对采集到的数据进行去重处理,避免重复采集同一条数据。
接下来,在数据清洗环节中,对采集到的数据进行清洗处理,去除无用信息、纠正错误信息以及格式化数据。例如,将评分从字符串类型转换为浮点数类型,并将时间转换为标准日期格式。
最后,在数据存储环节中,将采集到的数据存储到数据库中。选择使用MySQL等关系型数据库进行存储,数据采集流程图如图4-3所示。

图4-3数据采集流程图
4.3 数据清洗与分析功能设计
4.3.1 设计思想
使用pandas库的数据清洗和数据分析方法,对采集到的数据进行清洗处理,去除无用信息、纠正错误信息以及格式化数据,再将清洗好的电影数据进行排序、筛选和统计等操作,以了解不同电影类型的票房情况和评分情况。
4.3.2 业务逻辑设计
数据清洗和分析功能的业务逻辑设计主要包括数据清洗、数据预处理和数据分析三个环节。
首先,在数据清洗环节中,需要对采集到的数据进行去重、缺失值处理和异常值处理等操作,保证数据质量。例如,对于评分信息,如果某些电影没有评分,则需要将这些数据删除或填充默认值。同时,还需要对数据进行格式化处理,例如将时间转换为标准日期格式,以方便后续的数据分析和可视化。
其次,在数据预处理环节中,对数据进行特征工程、变量转换和特征选择等操作,以减少数据维度、降低数据噪声和提高模型性能。例如,对于电影类型信息,将每一部电影的类型拆分出来。
最后,在数据分析环节中,使用Python的pandas、numpy等库对数据进行分析,通过数据分析,能够了解数据之间的关系和趋势,找出数据中的模式和规律,例如,在本系统中,使用pandas库对采集到的电影数据进行排序、筛选和统计等操作,以了解不同电影类型的票房情况和评分情况。同时,方便后期对数据进行可视化,例如生成饼图、柱状图和散点图等,直观地展示数据分布和趋势。数据清洗与分析流程图如图4-4所示。

图4-4数据清洗与分析流程图
4.4 数据可视化功能设计
4.4.1 设计思想
此功能模块用于从MySQL数据库中查询出猫眼电影的分析数据,并展示到前端页面。使用pymysql库连接MySQL数据库,获取前端传入的参数实现按需查询。最后将数据用JSON格式封装返回到页面使用echart可视化技术进行渲染展示。
猫眼电影数据分析系统下应包含不同可视化功能,例如柱状图、折线图、饼状图、词云图等。在展示页面上应包含选择想查看的TopN的下拉列表、提供查询功能的按钮、辅助用户理解的图形表格等。
4.4.2 业务逻辑设计
该功能通过Ajax请求进行实现。具体而言,当用户在展示页面中发起查询请求时,页面会发送一个Ajax请求到后端服务器,并附带上相应的查询参数。服务器端接收到请求后,通过Flask路由绑定将请求映射到相应的处理方法上。
对于查询请求,服务器端的处理方法首先需要通过调用数据库服务进行查询操作,并将查询结果封装成JSON格式返回给前端。返回的JSON数据包含了符合查询条件的所有电影信息。在返回结果之前,服务器端还需要对数据进行必要的处理和转换,例如对时间格式进行处理、去掉无用字段等。这样可以保证返回的数据符合前端的要求,便于前端进行处理和可视化展示。
前端页面在接收到服务器端返回的JSON数据后,利用CSS、JQuery和Echarts等技术将数据进行可视化展示。根据不同的查询需求,前端页面可以绘制出各种不同的表格和图形,以直观地呈现数据的分布和趋势。例如,在查询某一类型电影的票房排名时,前端页面可以使用柱状图或饼图进行展示,让用户更加直观地了解该类型电影的市场占比和受欢迎程度。
总的来说,可视化功能上采用了Ajax请求和Flask路由绑定等技术,通过前后端协作完成对数据的处理、转换和可视化展示。这样可以让用户更加方便地进行电影数据的查询和分析,数据可视化流程图如图4-5所示。

图4-5数据可视化流程图
4.5 数据存储功能设计
4.5.1 数据库概念E-R图设计
对需求中的各个模块进行了分析,并对涉及到的实体、属性和实体的关系进行了设计,涉及到两个实体:用户实体和电影实体,用户实体图和电影实体图如图4-6和图4-7所示。

图4-6用户实体图

图4-7电影实体图
4.5.2 数据库物理结构设计
根据上诉的E-R图设计,下面给出物理模型的设计,如下表4-1电影表和表4-2用户表所示。
电影表
| 字段名称 | 字段描述 | 字段类型 | 可空 |
|---|---|---|---|
| id | 电影ID | int | NOT NULL |
| name | 电影名称 | varchar | NOT NULL |
| type | 电影类型 | varchar | NOT NULL |
| actor | 主演 | varchar | NOT NULL |
| director | 导演 | varchar | NOT NULL |
| release_time | 上映时间 | varchar | NOT NULL |
| country | 国家/地区 | varchar | NOT NULL |
| score | 评分 | float | NOT NULL |
| box_office | 票房 | varchar | NULL |
用户表
| 字段名称 | 字段描述 | 字段类型 | 可空 |
|---|---|---|---|
| id | 用户ID | int | NOT NULL |
| username | 用户名 | varchar | NOT NULL |
| password | 密码 | varchar | NOT NULL |
5 系统功能实现
5.1 数据采集功能实现
首先,数据采集包括两方面一是电影列表页采集和电影详情页采集。电影列表页采集在主函数中通过循环进行多页的数据采集,每次请求页面时,程序会构造完整的URL地址,并设置请求头部,以模拟浏览器访问。然后使用requests库发送GET请求获取页面内容。接着,使用BeautifulSoup库解析页面内容,提取出所需的电影信息,包括电影名、详情页链接、评分、主演、导演等,并将其存储到list0列表中。
在获取完一页的电影信息后,程序会将list0列表中的所有数据写入CSV文件中,以便后续进行数据清洗、处理和分析。其中,使用csv库实现了对CSV文件的读写操作。在每次写入数据前,还会检查CSV文件是否存在,如果不存在则创建新的CSV文件,并写入表头信息。
电影详情页采集是经过列表页采集后读取之前爬取到的猫眼电影列表页的CSV数据,并遍历所有电影的URL地址。对于每个电影URL,程序会从中提取出电影ID,并使用该ID构造获取电影详情页数据的AJAX请求URL。在发送AJAX请求时,程序会设置合适的请求头部信息,并使用params参数传递必要的参数信息(如时间戳、索引号、签名key、渠道ID、版本号和webdriver模式等)。
接着,程序解析AJAX响应内容,提取出所需的电影信息(包括电影名、国家时长和票房等),并将其存储到list0列表中。在获取完一个电影的详细信息后,程序会将list0列表中的所有数据写入CSV文件中,以便后续进行数据清洗、处理和分析。
需要注意的是,由于网络原因和网站反爬机制的存在,程序在发送请求时需要设置适当的超时时间和请求头部信息,并使用随机间隔时间来避免被封IP。另外,在解析页面时还进行异常处理,以确保程序的稳定性,爬虫主要代码和采集结果如下图5-1和图5-2所示。
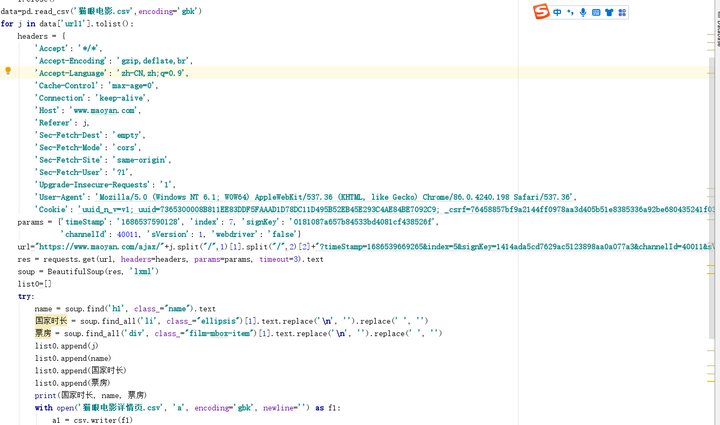
图5-1爬虫主要代码
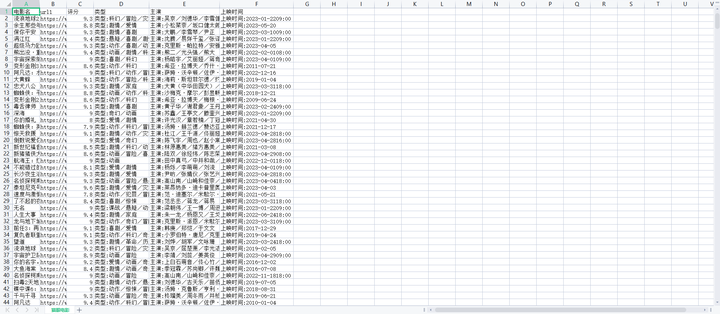
图5-2爬虫采集结果
5.2 数据清洗与分析功能实现
使用pandas等库实现了对猫眼电影数据的清洗和分析功能。
首先读取之前爬取到的两个CSV文件(即猫眼电影列表页和详情页),并进行一系列数据清洗的操作。具体来说,程序先使用str.replace()函数将数据中多余的字符(如“类型:”、“主演:”和“上映时间:”等)进行替换,以得到更加规范和易于处理的数据格式。然后,程序使用str.split()函数将某些字段(如票房、类型、主演、上映时间和国家时长等)进行分割,并使用pd.concat()函数将分割后的数据按列合并。在合并过程中,还需要使用rename()函数对列名进行重新命名,以保证数据的准确性和可读性。清洗和分析功能主要代码如图5-3。

图5-3数据清洗和数据存储功能主要代码
5.3 数据清洗与存储功能实现
使用pandas、pymysql和sqlalchemy等库实现了对猫眼电影数据的存储功能。
程序使用pd.concat()函数将清洗后的数据按行合并,并将结果存储到MySQL数据库中。在存储过程中,程序使用create_engine()函数建立与MySQL数据库的连接,使用to_sql()函数将数据写入指定的表中,并设置if_exists参数为replace,以实现数据覆盖更新的功能。
需要注意的是,由于MySQL数据库的配置和版本不同,程序可能需要根据实际情况进行相应的修改和调整。另外,在进行数据清洗和存储时,程序还需要考虑数据的缺失、异常和重复等情况,并进行相应的处理和判断,以得到更加准确和完整的数据,存储结果图5-4所示。

图5-4数据存储结果
5.4 数据分析和可视化功能实现
5.4.1 数据概况功能实现
该功能实现了猫眼电影数据的分页展示功能,主要使用了pymysql库和JSON格式。
首先定义了一个名为data的路由,当用户访问该路由时,程序从MySQL数据库中查询所有电影信息,并按照分页的形式(即每页限制数量以及当前页码)返回给前端页面。具体来说,程序使用MySQL的SELECT语句查询所有电影信息,并使用count()函数统计总共有多少条数据。然后,根据用户提交的参数(即每页限制数量和当前页码),从查询结果中截取相应的数据,并将结果按照JSON格式打包并返回给前端。
在数据查询和处理过程中,功能使用了pymysql库建立与MySQL数据库的连接,并使用execute()函数执行SQL语句。通过fetchall()函数获取查询结果,并使用for循环将结果转换为字典对象,以便后续处理和封装。程序最终返回的JSON数据包含了分页信息、电影数据以及数据总数等字段,以方便前端进行分页展示和数据处理,数据概况效果图如图5-5所示。
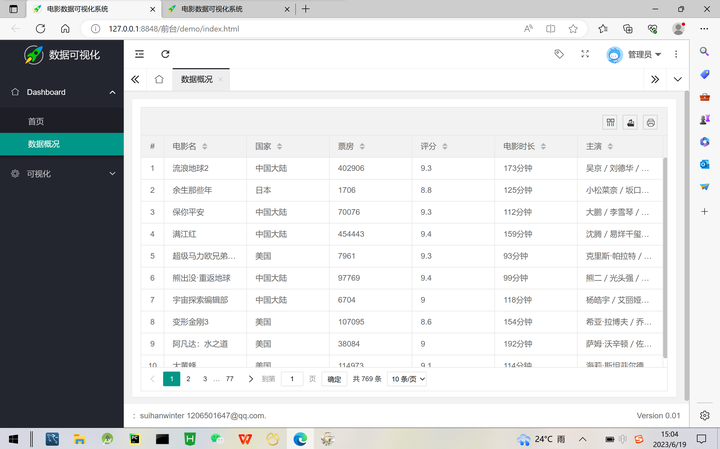
添加图片注释,不超过 140 字(可选)
图5-5数据概况效果图
5.4.2 票房占比功能实现
该功能实现实现了猫眼电影数据票房占比功能。该功能主要使用了Echarts图表库和pymysql等库。
首先定义了一个名为page1的路由,当用户访问该路由时,程序根据用户提交的参数(即年份和月份),从MySQL数据库中查询相应的数据,并使用Echarts图表库将数据展示在前端页面上。具体来说,程序使用MySQL的SELECT语句查询各种电影类型在指定时间段内的票房总额,然后将结果按照JSON格式打包并返回给前端。
在数据查询和处理过程中,该功能使用了pymysql库建立与MySQL数据库的连接,并使用execute()函数执行SQL语句。通过fetchall()函数获取查询结果,并使用for循环和字典对象将结果转换为可读性较高的JSON格式。程序最终返回的JSON数据包含了各个电影类型的名称、票房总额以及数据对应的X轴标签(即月份),票房占比效果图如图5-6所示。

图5-6票房占比效果图
5.4.3 榜单变化功能实现
该功能实现实现了猫眼电影数据榜单变化功能。该功能主要使用了Echarts图表库词云图和pymysql等库。
首先定义了一个名为page2的路由,当用户访问该路由时,程序根据用户提交的参数(即年份和排名数量),从MySQL数据库中查询相应的数据,并使用Echarts图表库将数据展示在前端页面上。具体来说,程序使用MySQL的SELECT语句查询指定年份内票房排名前N的电影信息,然后将结果按照JSON格式打包并返回给前端。
在数据查询和处理过程中,程序使用了pymysql库建立与MySQL数据库的连接,并使用execute()函数执行SQL语句。通过fetchall()函数获取查询结果,并使用for循环和字典对象将结果转换为可读性较高的JSON格式。程序最终返回的JSON数据包含了电影名称、票房总额,最后通过echart渲染生成词云图,榜单变化效果图如图5-7所示。
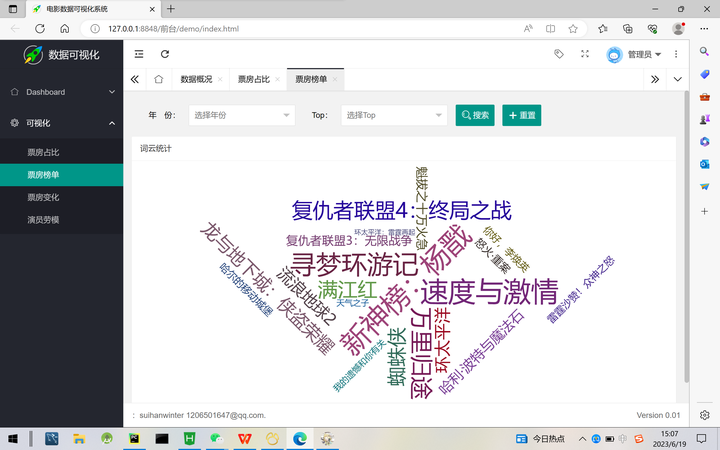
图5-7榜单变化效果图
5.4.4 票房变化功能实现
该功能实现实现了猫眼电影数据票房变化功能。该功能主要使用了Echarts图表库折线图和pymysql等库。
首先定义了一个名为page2的路由,当用户访问该路由时,程序根据用户提交的参数(即年份和排名数量),从MySQL数据库中查询相应的数据,并使用Echarts图表库将数据展示在前端页面上。具体来说,程序使用MySQL的SELECT语句查询指定年份内票房排名前N的电影信息,然后将结果按照JSON格式打包并返回给前端。
在数据查询和处理过程中,程序使用了pymysql库建立与MySQL数据库的连接,并使用execute()函数执行SQL语句。通过fetchall()函数获取查询结果,并使用for循环和字典对象将结果转换为可读性较高的JSON格式。程序最终返回的JSON数据包含了电影名称、票房总额以及数据对应的X轴标签(即年份),最后通过echart渲染生成折线图,票房变化效果图如图5-8所示。
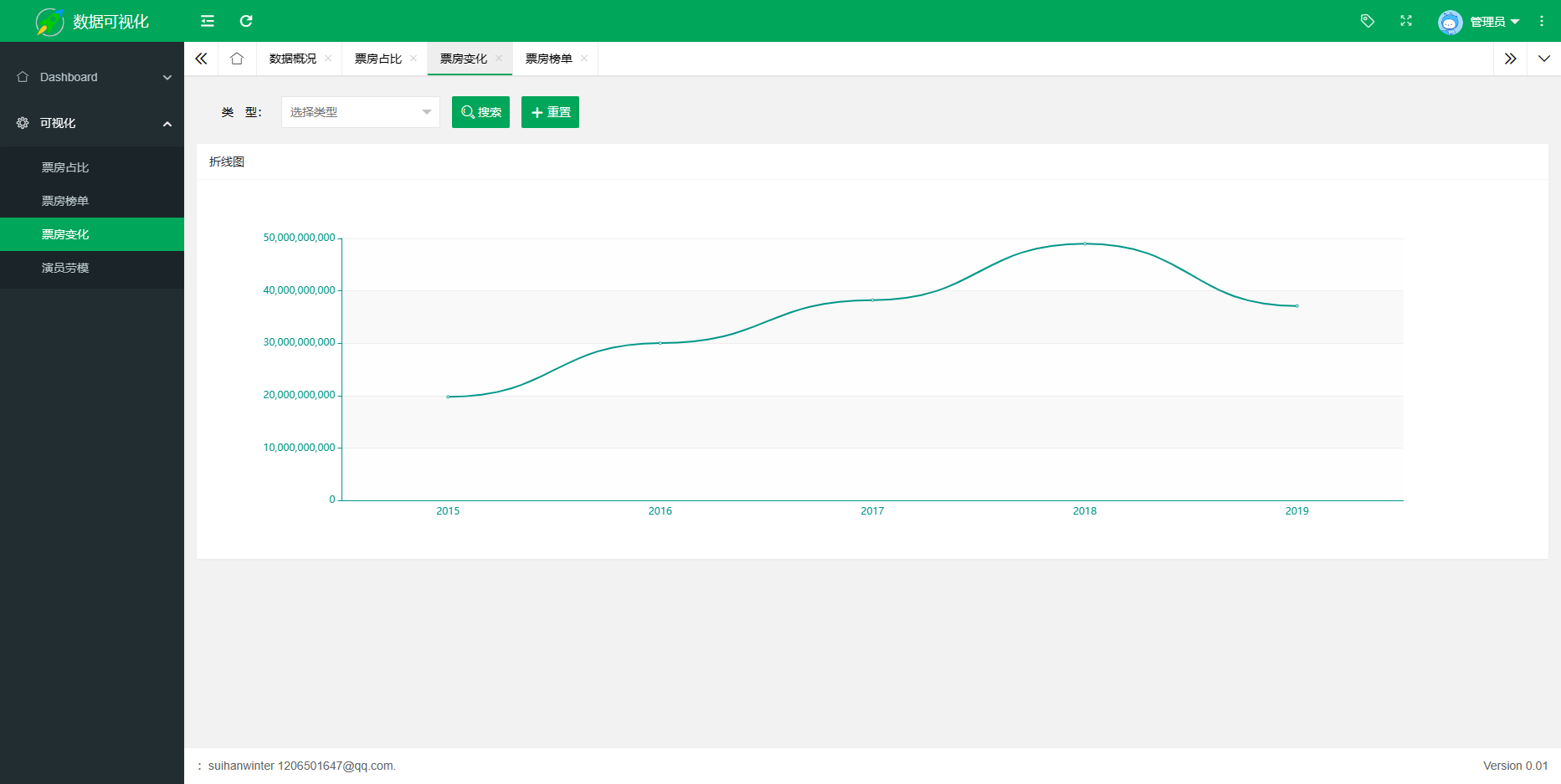
图5-8票房变化效果图
5.4.5 演员劳模功能实现
该功能实现实现了猫眼电影演员出演作品数排名前N的数据可视化功能。该功能主要使用了Echarts图表库柱形图和词云图组合而成。
首先定义了一个名为page4的路由,当用户访问该路由时,程序根据用户提交的参数(即年份和排名数量),从MySQL数据库中查询所有电影信息,并使用pandas库进行数据清洗和统计。具体来说,程序使用MySQL的SELECT语句查询所有电影信息,然后使用read_sql()函数将结果转换为pandas数据框,并进行按照演员姓名进行统计排序。最终,程序将统计结果按照JSON格式打包并返回给前端。
在数据查询和处理过程中,程序使用了pymysql和pandas库建立与MySQL数据库的连接,并使用read_sql()函数将查询结果转换为pandas数据框。通过使用dropna()函数去除空值,再使用most_common()函数进行数据统计和排序等操作,以得到演员出演作品数排名前N的统计结果。程序最终返回的JSON数据包含了演员姓名以及对应出演作品数等字段,以方便前端进行数据展示和处理。最后通过echart渲染生成词云图和柱形图,演员劳模效果图如图5-9所示。
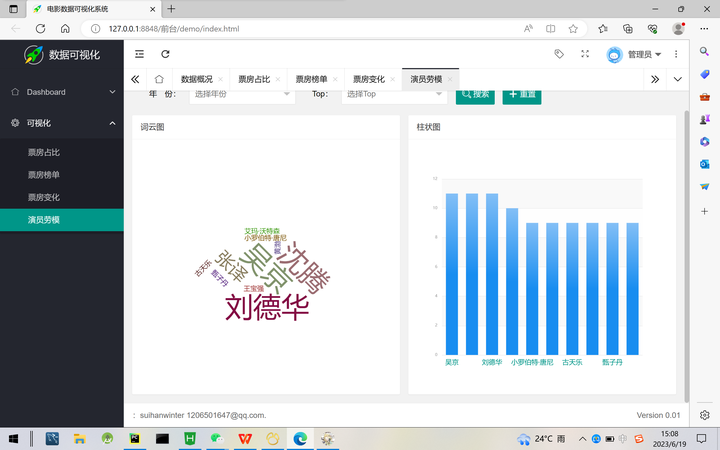
图5-9演员劳模效果图
6 系统测试
6.1 系统测试概况
系统测试的重要目的之一是发现潜在的错误或问题,以提供良好的用户体验和安全服务,同时也可以增强软件竞争力。软件测试主要采用黑盒测试和白盒测试两种方法,本课题选择以功能为主要测试方向的黑盒测试方法。测试执行需要遵循一定的规则,通常由测试用例规定。测试用例综合考虑需求和说明书等因素来制定。尽管硬件出厂前测试十分关键,但本课题基于时间和资源限制,将实现的功能作为测试重点进行测试。
6.2 系统测试内容
针对本系统的开发模式以及所采用的开发框架和根据,测试将按照以下进行:
(1)界面美观性测试
在界面美观性测试中,主要针对颜色搭配是否美观、页面布局是否显示正常、整体布局规划是否符合用户习惯等。
(2)功能测试
在功能测试中,主要是对系统功能是否能正常工作进行测试。
(3)兼容性测试
在兼容性测试方面,主要是对系统在不同的浏览器上的运行情况、页面的显示、功能是否正常等进行了检测。
6.2.1 页面和兼容性测试
页面和兼容性测试,以确认该页面符合使用者的要求,并能在多种浏览器中正常的显示。如表6-1所示:
表6-1 界面及兼容性测试用例
| 序号 | 输入 | 预期结果 | 实际结果 | 测试结果 |
|---|---|---|---|---|
| 1 | 使用Chrome登陆系统 | 各功能界面正常显示 | 各功能界面正常显示 | 通过 |
| 2 | 使用Edge登陆系统 | 各功能界面正常显示 | 各功能界面正常显示 | 通过 |
6.2.2 数据采集功能测试
数据采集测试。数据采集的数据是否正常采集成功,是否能存储到表中。如表6-2所示:
表6-2 数据采集功能测试用例
| 序号 | 输入 | 预期结果 | 实际结果 | 测试结果 |
|---|---|---|---|---|
| 1 | 运行数据采集程序 | 采集成功,并存入表中 | 采集成功 | 通过 |
6.2.3 数据清洗和存储功能测试
数据清洗和存储测试。数据清洗的数据是否正常清洗成功,是否能存储到表中。如表6-3所示:
表6-3 数据清洗与存储功能测试用例
| 序号 | 输入 | 预期结果 | 实际结果 | 测试结果 |
|---|---|---|---|---|
| 1 | 运行数据清洗和存储程序 | 清洗成功,并存入数据库表中 | 清洗成功 | 通过 |
6.2.4 数据可视化功能测试
数据可视化测试。数据可视化是否正常显示数据和图表。如表6-4所示:
表6-4 数据可视化功能测试用例
| 序号 | 输入 | 预期结果 | 实际结果 | 测试结果 |
|---|---|---|---|---|
| 1 | 票房占比功能测试:输入页面参数,点击搜索 | 生成柱形图和玫瑰图 | 可视化成功 | 通过 |
| 2 | 票房榜单功能测试:输入页面参数,点击搜索 | 生成词云图 | 可视化成功 | 通过 |
| 3 | 票房变化功能测试:输入页面参数,点击搜索 | 生成折线图 | 可视化成功 | 通过 |
| 4 | 演员劳模功能测试:输入页面参数,点击搜索 | 生成词云图和柱形图 | 可视化成功 | 通过 |
7 总结
基于Python Flask的猫眼电影数据采集分析与可视化系统通过爬虫技术实现了对猫眼电影网站上的电影数据采集,并将采集到的数据进行了清洗、分析和可视化处理。该系统具有良好的用户体验和数据价值,为研究电影市场、观众喜好等方面提供了有力的支持。
在该系统的开发过程中,充分利用了Python Flask框架的优势,构建了一个功能完备、易于扩展、稳定可靠的Web应用程序。同时,系统也采用了多种库和技术,如pymysql、pandas和Echarts等,以提高数据的处理效率和展示效果。这些都为顺利完成项目任务和达成预期目标提供了坚实的技术保障。
然而,该系统仍存在不足之处。首先,由于猫眼电影网站的反爬机制较为严格,因此系统仍需要进一步探索更加高效和稳定的数据采集方法。其次,在数据处理和分析阶段,可以进一步深入挖掘数据背后的规律和模式,并结合其他领域的数据进行交叉分析,以提高数据的质量和价值。最后,在系统的可视化设计和交互体验方面,系统可以探索更加多样化和创新性的展示方式,并进一步优化用户界面和操作流程,以提高用户体验和易用性。
未来,系统将继续改进和完善该系统,不断提高数据采集、处理和分析的能力,同时也将重点关注数据安全和隐私保护等问题。在不断迭代优化的过程中,该系统将为更多人群提供更加便捷、准确和有价值的电影数据服务,同时也将推动数据挖掘和可视化技术的发展和应用。
参考文献
[1]裴丽丽.基于Python对豆瓣电影数据爬虫的设计与实现[J].电子技术与软件工程,2019,0(13):176-177.
[2]李玉香,王孟玉,涂宇晰.基于python的网络爬虫技术研究[J].信息技术与信息化,2019,0(12):143-145.
[3]魏冬梅,何忠秀,唐建梅.基于Python的Web信息获取方法研究[J].软件导刊,2018,17(1):41-43.
[4]杨艳,姜婧怡,赵银,郑传行,敖进.基于Python 的房屋租赁数据分析应用[J].信息技术与标准化,2021(9):75-78.
[5]王迷莉.基于Python的大学生职业推荐平台设计[J].信息技术与信息化,2021(8):149-152.
[6]李相霏,韩珂.基于Flask框架的疫情数据可视化分析[J].计算机时代,2021(12):60-63.
[7]彭顺生.基于ECharts的肺炎疫情数据处理与可视化[J].计算机时代,2020(7):47-49.
[8]韩洪勇,冉春晴,陈硕.基于Echarts和Flask的数据可视化系统[J].中国新通信,2020,22(12):59-59.
[9]冷四军.基于Python Flask的运维信息管理系统设计与实现[J].电脑编程技巧与维护,2021(5):87-88.
[10]范路桥,高洁,段班祥,陈红玲.基于Python+ECharts的手机销售数据可视化系统[J].电脑编程技巧与维护,2022(6):78-81.
相关文章:
基于Python flask MySQL 猫眼电影可视化系统设计与实现
1 绪论 1.1 设计背景及目的 猫眼电影作为国内知名的电影信息网站,拥有海量的电影信息、票房数据和用户评价数据。这些数据对于电影市场的研究和分析具有重要意义。然而,由于数据的复杂性和数据来源的多样性,如何有效地采集、存储和展示这些数…...
【新课上架】安装部署系列Ⅲ—Oracle 19c Data Guard部署之两节点RAC部署实战
01 课程介绍 Oracle Real Application Clusters (RAC) 是一种跨多个节点分布数据库的企业级解决方案。它使组织能够通过实现容错和负载平衡来提高可用性和可扩展性,同时提高性能。本课程基于当前主流版本Oracle 19cOEL7.9解析如何搭建2节点RAC对1节点单机的DATA GU…...

gdb调试std::list和std::vector等容器的方法
GDB中print方法并不能直接打印STL容器中保存的变量,其实只要http://www.yolinux.com/TUTORIALS/src/dbinit_stl_views-1.03.txt这个文件保存为~/.gdbinit 就可以使用它提供的方法方便调试容器 指定启动文件:~/.gdbinit,下面的方法任选其一。…...

python stomp 转发activemq topic消息
import pysimplestomp 连接到ActiveMQ的Topic: # 连接ActiveMQ服务器 server "tcp://localhost:61613" topic "/topic/your_topic"# 连接到ActiveMQ的Topic destination f"destination://{topic}" connection pysimplestomp.con…...

Spring Boot使用AOP
一、为什么需要面向切面编程? 面向对象编程(OOP)的好处是显而易见的,缺点也同样明显。当需要为多个不具有继承关系的对象添加一个公共的方法的时候,例如日志记录、性能监控等,如果采用面向对象编程的方法&…...

C语言通过IXMLHttpRequest以get或post方式发送http请求获取服务器文本或xml数据
做过网页设计的人应该都知道ajax。 Ajax即Asynchronous Javascript And XML(异步的JavaScript和XML)。使用Ajax的最大优点,就是能在不更新整个页面的前提下维护数据。这使得Web应用程序更为迅捷地回应用户动作,并避免了在网络上发…...
QtRVSim(二)一个 RISC-V 程序的解码流程
继上一篇文章简单代码分析后,本文主要调研如何实现对指令的解析运行。 调试配置 使用 gdb 工具跟踪调试运行。 c_cpp_properties.json 项目配置: {"name": "QtRvSim","includePath": ["${workspaceFolder}/**&quo…...

x-cmd pkg | httpx - 为 Python 设计的下一代 HTTP 客户端库
目录 简介首次用户功能特点进一步探索 简介 HTTPX 是一个为 Python 设计的下一代 HTTP 客户端库,由 Tom Christie 创建。它提供了同步和异步的 API,并支持 HTTP/1.1 和 HTTP/2 协议。与 Requests 库类似,但增加了对异步请求的支持和 HTTP/2 …...
|62. 不同路径)
代码随想录算法训练营第四十二天(动态规划篇)|62. 不同路径
62. 不同路径 题目链接:62. 不同路径 - 力扣(LeetCode) 思路 dp[i][j]: 从0到位置[i, j]共有dp[i][j]条路径。 dp[i][j] dp[i-1][j] dp[i][j-1] 到位置[i,j],可以从它的上面或者左边来,所以路径和为这两个方向的路…...
YOLO 全面回顾:从最初的YOLOv1到最新的YOLOv8、YOLO-NAS,以及整合了 Transformers 的 YOLO
YOLO 全面回顾 综述评估指标YOLO v1YOLO v2YOLO v3YOLO v4YOLOv5 与 Scaled-YOLOv4 YOLORYOLOXYOLOv6YOLOv7DAMO-YOLOYOLOv8PP-YOLO, PP-YOLOv2, and PP-YOLOEYOLO-NASYOLO with Transformers 综述 论文:https://arxiv.org/pdf/2304.00501.pdf 代码:gi…...
Android双指缩放ScaleGestureDetector检测放大因子大图移动到双指中心点ImageView区域中心,Kotlin(2)
Android双指缩放ScaleGestureDetector检测放大因子大图移动到双指中心点ImageView区域中心,Kotlin(2) 在 Android ScaleGestureDetector检测双指缩放Bitmap基于Matrix动画移动到双指捏合中心点ImageView区域中心,Kotlin-CSDN博客 …...

同为科技(TOWE)自动控制循环定时插座
随着科技的发展,智能化家居已成为我们生活的重要组成部分。作为国内领先的智能家居品牌,同为科技(TOWE)推出的自动控制循环定时插座,无疑将科技与生活完美地结合在一起。 1.外观设计 同为科技(TOWE&#x…...
游戏设计模式
单列模式 概念 单例模式是一种创建型设计模式,可以保证一个类只有一个实例,并提供一个访问该实例的全局节点。 优点 可以派生:在单例类的实例构造函数中可以设置以允许子类派生。受控访问:因为单例类封装他的唯一实例…...

CUBEMX与FreeRTOS在Arm Compiler 6下的配置方法
在嵌入式开发中,STM32是一种广泛使用的微控制器。为了提高开发效率,我们通常会利用ST公司提供的STM32CubeMX工具来配置硬件,并结合FreeRTOS这一实时操作系统来进行多任务处理。本文将深入探讨如何在这一框架下,使用Arm Compiler 6…...
Android Studio 提示Use app:drawableStartCompat instead of android:drawableStart
每次提交代码时,AS这个老妈子总爱唠叨一堆warning,这些Warning都在讲什么? 1.Use app:drawableStartCompat instead of android:drawableStart 在Android开发中,android:drawableStart和app:drawableStartCompat是两个用于设置…...

C# wpf 实现任意控件(包括窗口)更多调整大小功能
WPF拖动改变大小系列 第一节 Grid内控件拖动调整大小 第二节 Canvas内控件拖动调整大小 第三节 窗口拖动调整大小 第四节 附加属性实现拖动调整大小 第五章 拓展更多调整大小功能(本章) 文章目录 WPF拖动改变大小系列前言一、添加的功能1、任意控件Drag…...

Vue+OpenLayers7入门到实战:快速搭建Vue+OpenLayers7地图脚手架项目。从零开始构建Vue项目并整合OpenLayers7.5.2
返回《Vue+OpenLayers7》专栏目录:Vue+OpenLayers7 前言 本章针对Vue初学者,对Vue不熟悉,甚至还不会Vue的入门学生读者。 本章会详细讲解从NodeJS环境到npm环境的各个步骤,再到使用vue-cli脚手架快速生成项目,以及添加OpenLayers7地图库依赖,编写简单的xyz高德地图显示…...

mysql-线上常用运维sql
1.表备份 INSERT INTO table1 SELECT * FROM table2; 2.用一个表中的字段更新另一张表中的字段 UPDATE table2 JOIN table1 ON table2.id table1.id SET table2.column2 table1.column1; 3.在MySQL中,查询一个表的列字段值是否包含另一个表的字段,…...
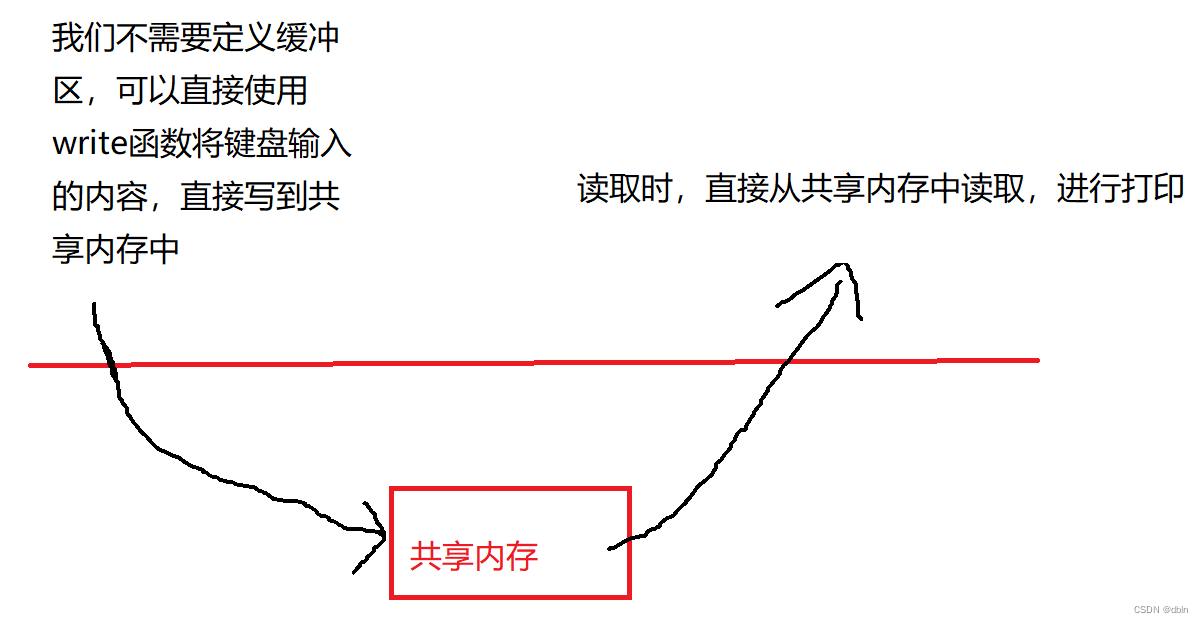
Linux之进程间通信(system V 共享内存)
目录 一、共享内存 1、基本原理 2、共享内存的创建 3、共享内存的释放 4、共享内存的关联 5、共享内存的去关联 6、查看IPC资源 二、完整通信代码 三、共享内存的特点 四、信号量 1、相关概念 2、信号量概念 进程间通信的本质就是让不同的进程看到同一个资源。而前…...

数据库 sql select *from account where name=‘张三‘ 执行过程
select *from account where name张三分析上面语句的执行过程 用到了索引 由于是根据 1.name字段进行查询,所以先根据name张三’到name字段的二级索引中进行匹配查 找。但是在二级索引中只能查找到 Arm 对应的主键值 10。 2.由于查询返回的数据是*,…...

Hirschmann RS20-0800M4M4SDAE工业以太网交换机
Hirschmann RS20-0800M4M4SDAE 工业以太网交换机产品特点:端口配置:共8个端口,含6个RJ45电口和2个ST光纤接口。端口速率:所有端口均为100Mbps快速以太网。光纤类型:2个光纤端口为多模、ST接头。管理类型:二…...

内网环境下Win7系统批量离线补丁部署实战指南
1. 内网Win7补丁部署的挑战与解决方案老旧Win7系统在内网环境中的安全隐患就像漏雨的屋顶,看似不影响日常使用,但随时可能引发严重后果。我经手过几十家单位的系统加固项目,发现这些场景存在三个典型痛点:首先是补丁来源问题&…...
)
别再只用鼠标了!用Leap Motion手势控制Unity游戏,保姆级配置避坑指南(2024版)
2024年Unity手势交互开发实战:Leap Motion从配置到游戏逻辑全解析在游戏开发领域,交互方式的创新往往能带来全新的体验。想象一下,玩家不再需要键盘鼠标,仅凭自然的手部动作就能操控游戏角色——这正是Leap Motion手势识别技术为U…...

MeloTTS实战指南:解决多语言TTS部署中的核心挑战
MeloTTS实战指南:解决多语言TTS部署中的核心挑战 【免费下载链接】MeloTTS High-quality multi-lingual text-to-speech library by MyShell.ai. Support English, Spanish, French, Chinese, Japanese and Korean. 项目地址: https://gitcode.com/GitHub_Trendin…...

终极STL到STEP转换指南:如何实现3D打印模型到CAD设计的无缝衔接
终极STL到STEP转换指南:如何实现3D打印模型到CAD设计的无缝衔接 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 在数字化制造和工程设计领域,STL到STEP转换已成为连接3D…...

5分钟掌握AutoClicker:Windows鼠标点击自动化的终极指南
5分钟掌握AutoClicker:Windows鼠标点击自动化的终极指南 【免费下载链接】AutoClicker AutoClicker is a useful simple tool for automating mouse clicks. 项目地址: https://gitcode.com/gh_mirrors/au/AutoClicker AutoClicker是一款专为Windows设计的鼠…...

3步免费解锁Cursor Pro:告别设备限制,永久享受AI编程助手高级功能
3步免费解锁Cursor Pro:告别设备限制,永久享受AI编程助手高级功能 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: …...

Windows安卓应用安装终极指南:APK Installer让你的电脑变身安卓平台
Windows安卓应用安装终极指南:APK Installer让你的电脑变身安卓平台 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为无法在Windows电脑上直接安装安卓…...

中兴光猫深度管理:用zteOnu工具解锁隐藏的管理权限
中兴光猫深度管理:用zteOnu工具解锁隐藏的管理权限 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 想象一下,你正在管理一个企业网络,面对几十台中兴…...

全方位防护矿山开采三维透明化智能安全防控整体方案
依托黎阳之光核心技术矿山开采三维透明化智能安全防控整体方案一、方案前言1.建设背景矿山开采井下巷道错综复杂、采掘工作面地质隐蔽,顶板、透水、瓦斯、边坡失稳、三违作业、设备故障为高发安全风险。传统二维监控、分散监测系统存在场景碎片化、地质不可视、风险…...