【时间序列篇】基于LSTM的序列分类-Pytorch实现 part2 自有数据集构建
系列文章目录
【时间序列篇】基于LSTM的序列分类-Pytorch实现 part1 案例复现
【时间序列篇】基于LSTM的序列分类-Pytorch实现 part2 自有数据集构建
【时间序列篇】基于LSTM的序列分类-Pytorch实现 part3 化为己用
在一个人体姿态估计的任务中,需要用深度学习模型来进行序列分类。
时间花费最多的是在数据集的处理上。
这一节主要内容就是对数据集的处理。
文章目录
- 系列文章目录
- 前言
- 一、任务问题和数据采集
- 1 任务问题
- 2 原始数据采集
- 二、数据处理和生成样本
- 1 data_merge2single.py
- 2 data_plot.py
- 3 data_split.py
- 三、制作标签文件和数据集划分文件
- 1 target 文件
- 2 DatasetGroup 文件
- 四、总结
- 1 数据集示例
- 2 数据集下载路径
前言
类似于part1的工作,这部分对数据集进行了分析处理
一、任务问题和数据采集
1 任务问题
人体姿态估计:
在人体左右腿放置加速度传感器,分别采集横滚角和俯仰角。传感器生成高频数据,对不同状态下采集的数据进行分类,可以识别人体姿态。
2 原始数据采集
采集6类动作姿态,每种动作记录10次过程量。
蹲姿到站立(右蹲) ------ 1
蹲姿到站立(左蹲)----- 2
行进 ----------------------- 3
原地踏步 ----------------- 4
站立到蹲姿(右蹲) ------ 5
站立到蹲姿(左蹲) ------ 6
data_merge 文件夹下存放采集到的原始数据。
data_merge_1.xlsx
data_merge_2.xlsx
data_merge_3.xlsx
data_merge_4.xlsx
data_merge_5.xlsx
data_merge_6.xlsx
每一个 xlsx 文件对应一类动作姿态,保存有10组实验数据。
以 data_merge_1.xlsx 文件内容为例:
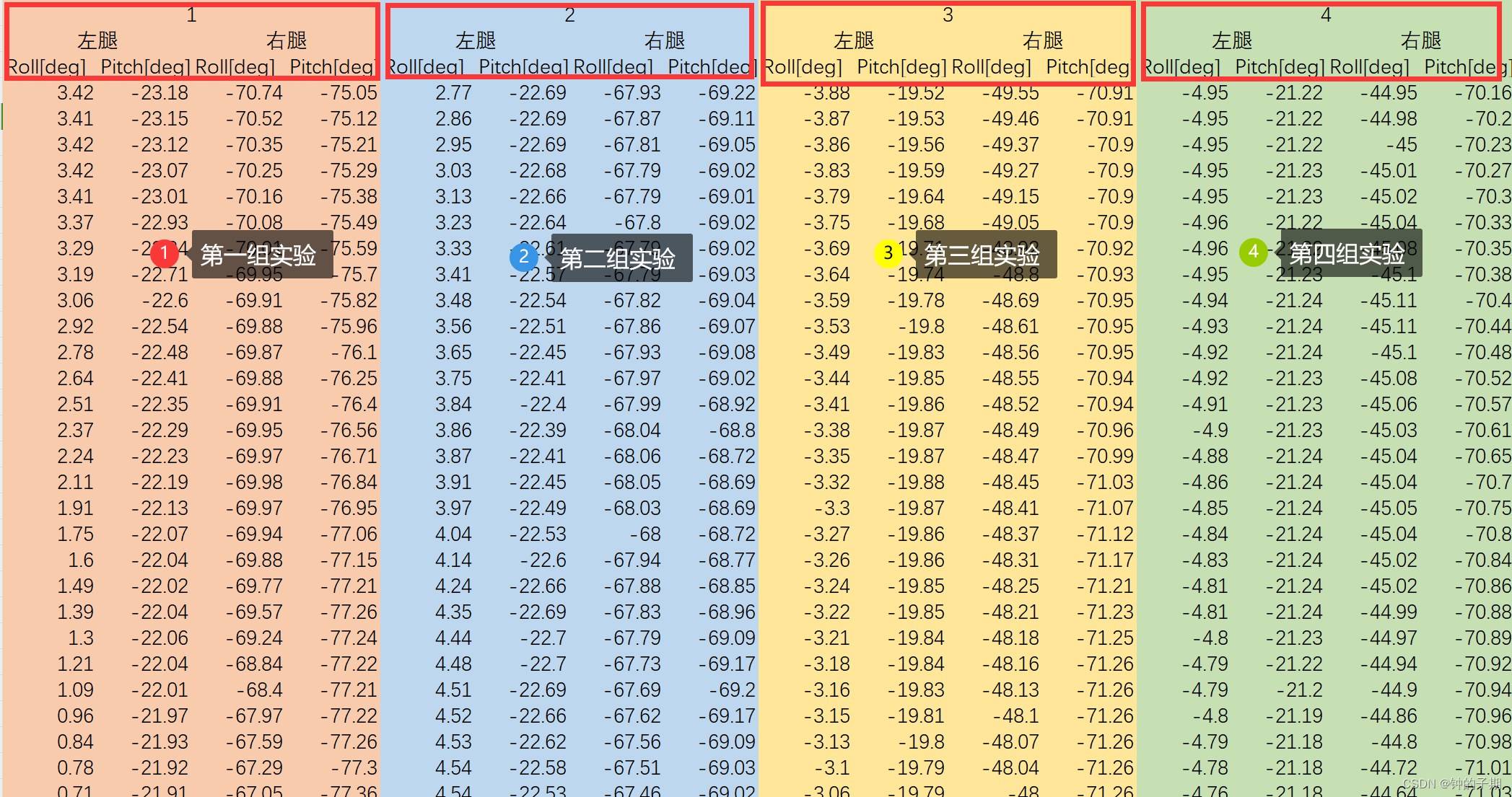
二、数据处理和生成样本
1 data_merge2single.py
将每类动作姿态的data_merge_x.xlsx文件分解,每一组实验单独保存在一个文件中。
"""
@file name:data_merge2single.py
@desc: 得到每次实验的单独数据
"""
import os
import pandas as pd'''
/****************************************************/路径指定
/****************************************************/
'''
# ----------------------------------------------------#
# 数据路径
# ----------------------------------------------------#
ROOT_path = "DATA/RT_Position_dataset"
merge_path = os.path.join(ROOT_path, "data_merge")
path_list = os.listdir(merge_path)
# print(path_list)
# ['data_merge_1.xlsx', 'data_merge_2.xlsx', 'data_merge_3.xlsx', 'data_merge_4.xlsx', 'data_merge_5.xlsx', 'data_merge_6.xlsx', '~$data_merge_1.xlsx']single_path = os.path.join(ROOT_path, "data_single_test")
if not os.path.exists(single_path):os.mkdir(single_path)# ----------------------------------------------------#
# 对每个文件进行读取
# ----------------------------------------------------#
for i in range(0, len(path_list)): # 遍历 data_merge_x.xlsx 文件file_path = os.path.join(merge_path, path_list[i])save_path = os.path.join(single_path, str(i + 1))if not os.path.exists(save_path):os.makedirs(save_path)print("----------------------------------------------------")print(file_path)# 使用pandas读取Excel文件df = pd.read_excel(file_path)# 计算总列数total_columns = df.shape[1]index = 0# 每四列分割并保存(在实验中,分别采集左右腿的俯仰角和横滚角,特征数目为4)for start_col in range(0, total_columns, 4):index += 1# 确定每个文件的列范围end_col = min(start_col + 4, total_columns)# 提取四列数据sub_df = df.iloc[:, start_col:end_col]# 保存到新的xlsx文件sub_df.to_csv(f'{save_path}/{str(i + 1)}_{index}.csv', index=False)data_singe_test 文件夹下存放每组实验的单独数据。
2 data_plot.py
分析每个类别下的每一组实验,不是所有数据都有用,得到有效数据区间
"""
@file name:data_plot.py
@desc: 绘制每组实验的数据图,分析有效数据区间
"""
import pandas as pd
import matplotlib.pyplot as plt# ----------------------------------------------------#
# 数据路径
# ----------------------------------------------------#
file_path = "DATA/RT_Position_dataset/data_single_test/2/2_5.csv"df = pd.read_csv(file_path, header=2) # 使用pandas读取Excel文件
# 跳过前两行数据
# df = df.iloc[2:]# 绘制波形图
plt.figure(figsize=(12, 8))for i, column in enumerate(df.columns):plt.subplot(len(df.columns), 1, i+1)plt.plot(df[column])plt.title(f'Column: {column}')plt.tight_layout()
plt.show()
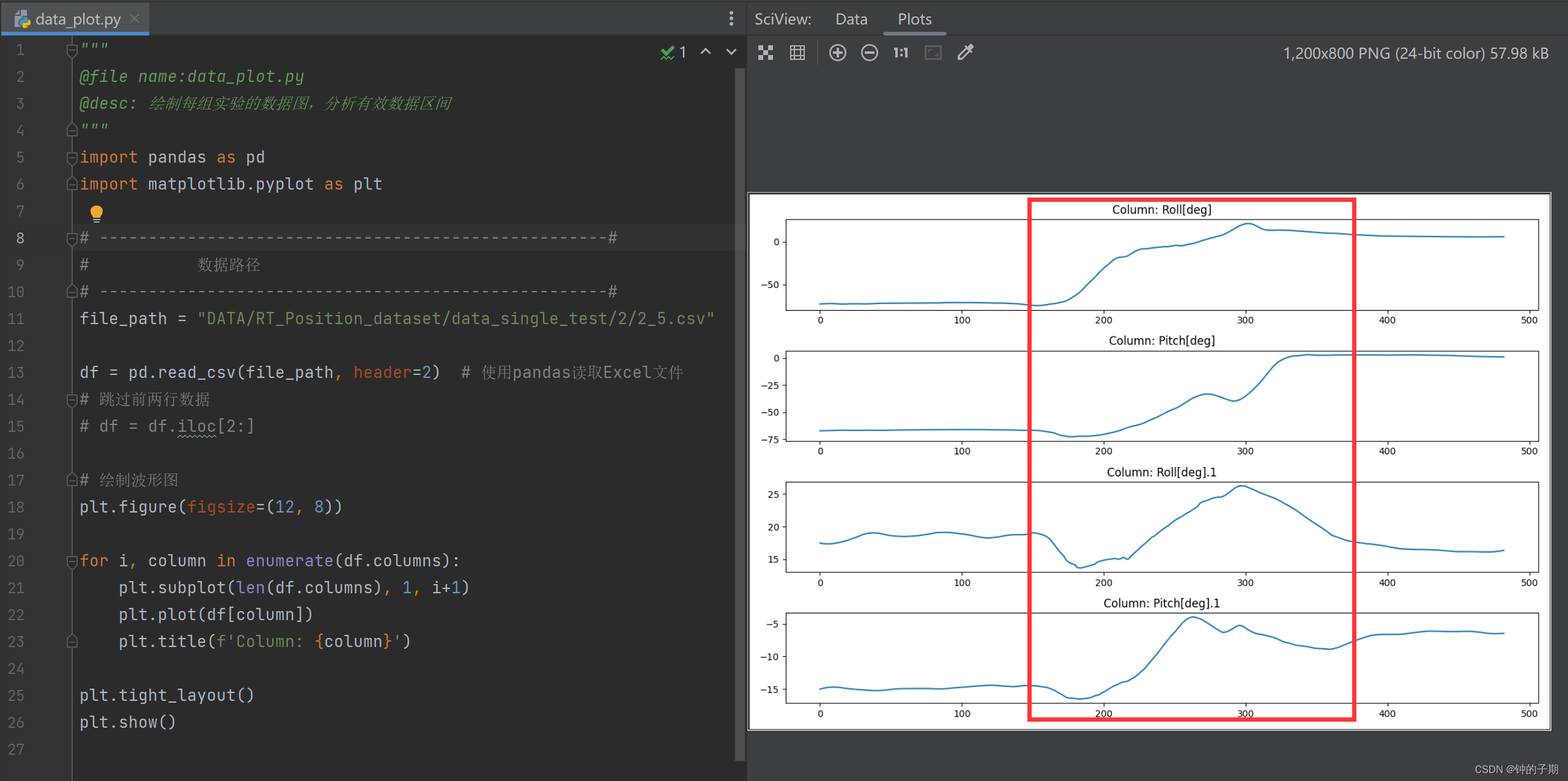
后续的工作就是从每组实验的有效数据区间中生成样本。
log = {'1': [[130, 300], [100, 250], [160, 310], [130, 300], [120, 280],[200, 370], [120, 270], [100, 270], [100, 290], [160, 320]],'2': [[100, 250], [290, 400], [200, 360], [180, 320], [180, 310],[150, 290], [160, 300], [140, 270], [120, 270], [100, 260]],'3': [[100, 400], [100, 370], [100, 450], [100, 450], [100, 450],[150, 450], [130, 450], [100, 400], [150, 420], [150, 400]],'4': [[100, 420], [100, 420], [200, 420], [200, 420], [200, 420],[200, 420], [200, 420], [150, 400], [100, 400], [200, 400]],'5': [[100, 300], [170, 300], [100, 300], [100, 250], [250, 400],[100, 270], [150, 300], [100, 280], [120, 270], [130, 270]],'6': [[120, 300], [150, 250], [100, 300], [50, 300], [100, 240],[170, 310], [50, 250], [80, 280], [80, 280], [100, 300]],} # 记录每组实验的有效数据区间
3 data_split.py
针对每一组实验的有效区间,提取并生成样本
"""
@file name:data_split.py
@desc: 分割并生成样本
"""
import os
import pandas as pdlog = {'1': [[130, 300], [100, 250], [160, 310], [130, 300], [120, 280],[200, 370], [120, 270], [100, 270], [100, 290], [160, 320]],'2': [[100, 250], [290, 400], [200, 360], [180, 320], [180, 310],[150, 290], [160, 300], [140, 270], [120, 270], [100, 260]],'3': [[100, 400], [100, 370], [100, 450], [100, 450], [100, 450],[150, 450], [130, 450], [100, 400], [150, 420], [150, 400]],'4': [[100, 420], [100, 420], [200, 420], [200, 420], [200, 420],[200, 420], [200, 420], [150, 400], [100, 400], [200, 400]],'5': [[100, 300], [170, 300], [100, 300], [100, 250], [250, 400],[100, 270], [150, 300], [100, 280], [120, 270], [130, 270]],'6': [[120, 300], [150, 250], [100, 300], [50, 300], [100, 240],[170, 310], [50, 250], [80, 280], [80, 280], [100, 300]],}
'''
/****************************************************/路径指定
/****************************************************/
'''
ROOT_path = "DATA/RT_Position_dataset"
# ----------------------------------------------------#
# 单次实验数据路径
# ----------------------------------------------------#
single_test_path = os.path.join(ROOT_path, "data_single_test")
# 样本保存路径
save_path = os.path.join(ROOT_path, "dataset")
if not os.path.exists(save_path):os.mkdir(save_path)
# ----------------------------------------------------#
# 设置数据样本长度len_seq(设置每个文件的行数)
# ----------------------------------------------------#
rows_per_file = 16'''
/****************************************************/导出数据样本
/****************************************************/
'''
index = 0
# 使用os.listdir()列出文件夹中的所有内容(包括子文件夹和文件)
contents = os.listdir(single_test_path) # ['1', '2', '3', '4', '5', '6']
# 使用列表推导式过滤出所有子文件夹
folders = [content for content in contents if os.path.isdir(os.path.join(single_test_path, content))]
# 遍历文件夹中的所有子文件夹
for folder in folders: # ['1', '2', '3', '4', '5', '6']folder_path = os.path.join(single_test_path, folder)# print(folder_path)# 遍历子文件夹中的所有文件for csv_file in os.listdir(folder_path):part = csv_file.split('_')[1].split('.')[0] # part = 1,2,3,4,5,6,7,8,9,10file_path = os.path.join(folder_path, csv_file)# ----------------------------------------------------------------# 使用pandas读取Excel文件df = pd.read_csv(file_path, header=2)# 读取每次实验有效数据序列索引[start, end] = log[folder][int(part) - 1]# 选择每次实验中的有效数据df_selected = df.iloc[start:end]# 有效数据的总行数total_rows = len(df_selected)# ----------------------------------------------------## 核心的参数调整# ----------------------------------------------------#number_of_files = 200 # 每次实验的有效数据中,可以生成样本数的上限window_size = rows_per_file # 滑动窗口的大小step_size = 3 # 滑动窗口的步长for file_number in range(number_of_files):# 计算滑动窗口的起始和结束索引start_index = file_number * step_sizeend_index = start_index + window_size# 防止结束索引超出数据范围if end_index > total_rows:break# 提取数据df_subset = df_selected.iloc[start_index:end_index]index += 1# 保存到新的csv文件df_subset.to_csv(f'{save_path}/Movement4_{index}.csv', index=False)print(f"{folder}输出的文件索引截止到{index}")
从所有实验数据中,生成样本并保存到 dataset 文件夹下。
这里的超参数设置:
- rows_per_file = 16 样本数据的长度是16,size是[16,4]
- number_of_files = 200 每次实验的有效数据中,可以生成样本数的上限
- step_size = 3 滑动窗口的步长,步长过长数据无法充分利用,过小容易过拟合
1~500索引文件对应类别1,以此类推。共生成3730个样本。

三、制作标签文件和数据集划分文件
上述步骤已生成样本,仿照 part1 文章中提及的数据集,制作 target 文件和 DatasetGroup 文件
本节手动制作两个csv文件。
1 target 文件
新建一个Movement4_target.csv文件,两列分别记录索引和对应类别。索引为1 ~ 3730,类别为1 ~ 6。
2 DatasetGroup 文件
新建一个Movement4_DatasetGroup.csv文件,两列分别记录索引和对应数据集。索引为1 ~ 3730,数据集组别为1 ~ 3。

将制作的 target 文件和 DatasetGroup 文件 保存到 groups 文件夹下。
四、总结
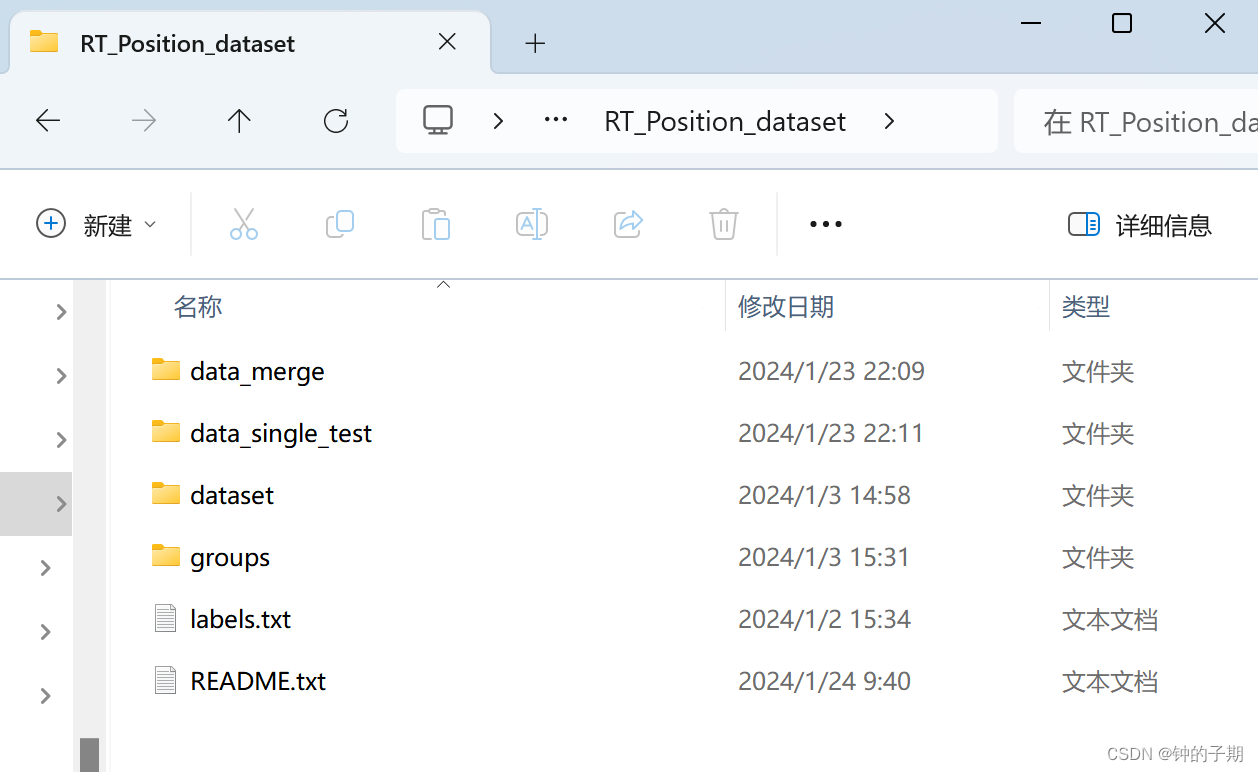
1 数据集示例
最终得到的数据集文件如下所示。
核心是 dataset 和 groups 文件夹。
2 数据集下载路径
相关文章:
【时间序列篇】基于LSTM的序列分类-Pytorch实现 part2 自有数据集构建
系列文章目录 【时间序列篇】基于LSTM的序列分类-Pytorch实现 part1 案例复现 【时间序列篇】基于LSTM的序列分类-Pytorch实现 part2 自有数据集构建 【时间序列篇】基于LSTM的序列分类-Pytorch实现 part3 化为己用 在一个人体姿态估计的任务中,需要用深度学习模型…...

《设计模式的艺术》笔记 - 策略模式
介绍 策略模式定义一系列算法类,将每一个算法封装起来,并让它们可以相互替换。策略模式让算法独立于使用它的客户而变化,也称为政策模式。策略模式是一种对象行为模式。 实现 myclass.h // // Created by yuwp on 2024/1/12. //#ifndef DES…...

【Elasticsearch篇】详解使用RestClient操作索引库的相关操作
文章目录 🍔什么是Elasticsearch🌺什么是RestClient🎆代码操作⭐初始化RestClient⭐使用RestClient操作索引库⭐使用RestClient删除索引库⭐使用RestClient判断索引库是否存在 🍔什么是Elasticsearch Elasticsearch是一个开源的分…...

ES数据处理方法
由于日志数据存在ES项目里,需要从ES中获取日志进行分析,使用SQL数据进行处理,如下: select traceid-- STRING COMMENT 流程id, ,appnum -- BIGINT COMMENT 迭代号, ,appversion --STRING COMMENT APP版本, ,appc…...

STM32实现软件IIC协议操作OLED显示屏(2)
时间记录:2024/1/27 一、OLED相关介绍 (1)显示分辨率128*64点阵 (2)IIC作为从机的地址0x78 (3)操作步骤:主机先发送IIC起始信号S,然后发送OLED的地址0x78,然…...

【linux】远程桌面连接到Debian
远程桌面连接到Debian系统,可以使用以下几种工具: 1. VNC (Virtual Network Computing) VNC(Virtual Network Computing)是一种流行的远程桌面解决方案,它使用RFB(Remote Framebuffer Protocol࿰…...
python222网站实战(SpringBoot+SpringSecurity+MybatisPlus+thymeleaf+layui)-菜单管理实现
锋哥原创的SpringbootLayui python222网站实战: python222网站实战课程视频教程(SpringBootPython爬虫实战) ( 火爆连载更新中... )_哔哩哔哩_bilibilipython222网站实战课程视频教程(SpringBootPython爬虫实战) ( 火…...
JS之隐式转换与布尔判定
大家思考一下 [ ] [ ] ? 答案是空字符串 为什么呢? 当做加法运算的时候,发现左右两端存在非原始类型,也就是引用类型对象,就会对对象做隐式类型转换 如何执行的?或者说怎么查找的? 第一步&…...
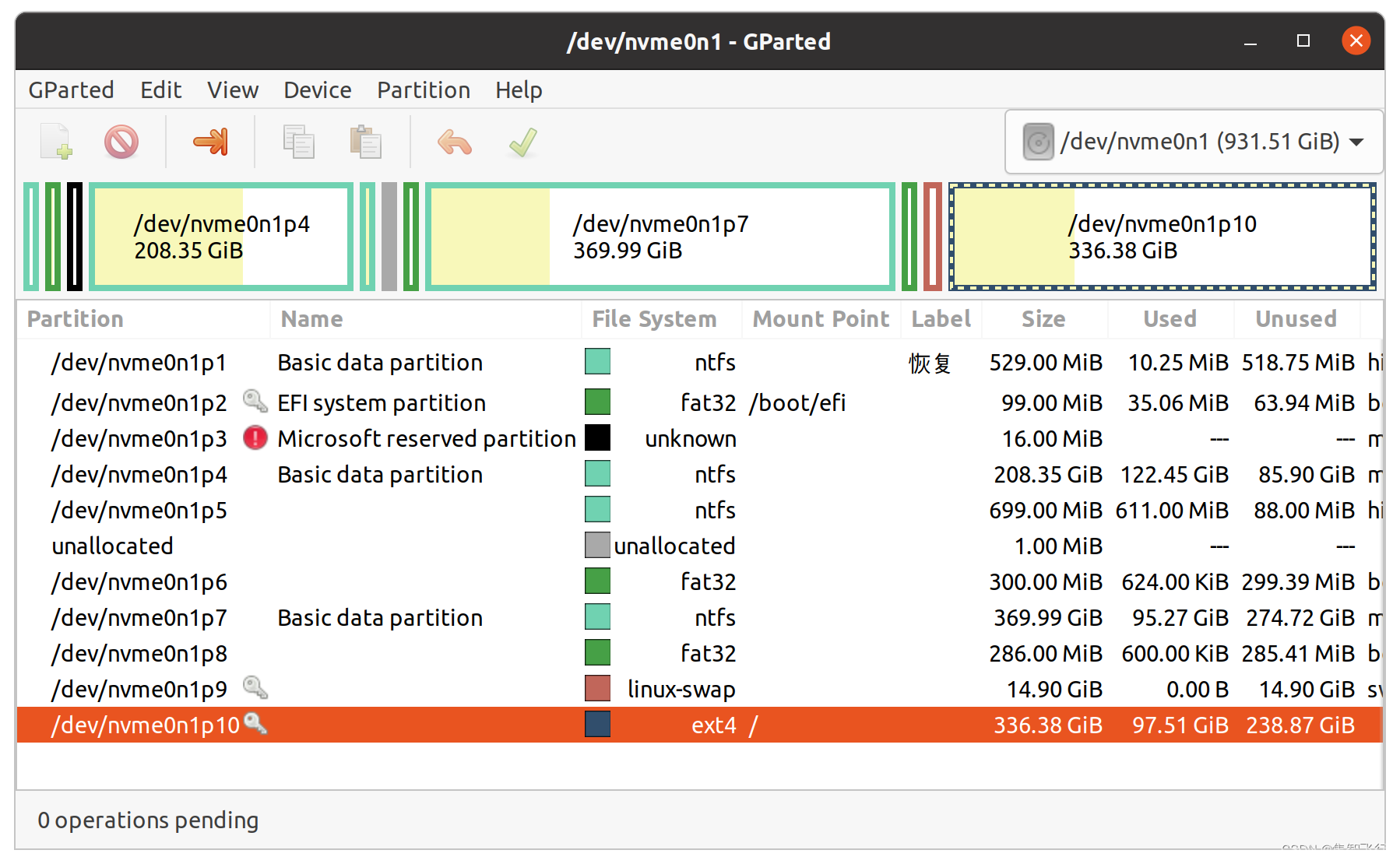
ubuntu20根目录扩容
ubuntu根目录/ 或者 /home文件夹有时出现空间满了的情况,可以用gparted工具进行空间的重新分配。 首先,如果你是双系统,需要从windows系统下磁盘压缩分配一部分未使用的空间给ubuntu,注意压缩的空间要邻接ubuntu所在盘的位置。 …...
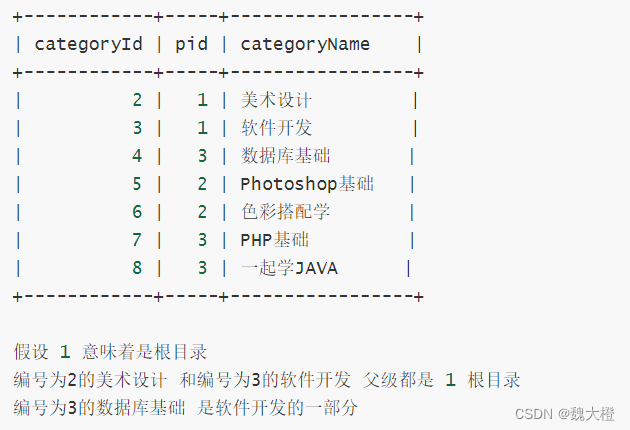
(四)DQL数据查询语言
基础语法 SELECT {*,列名,函数} FROM 表名 [WHERE 条件]; 说明: -SELECT检索关键字 *匹配所有列 , 匹配指定列 -FROM 所提供的数据源(表,视图,另一个查询机制反馈的结果) -WHERE 条件(控制查询的区…...
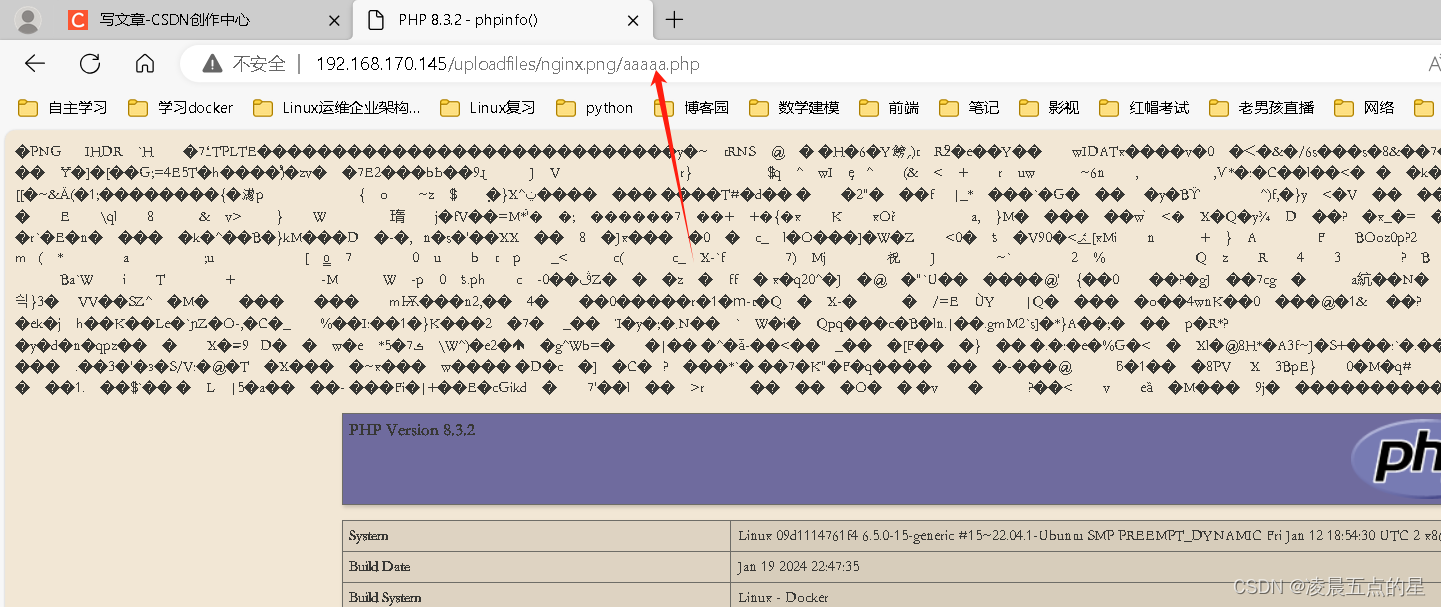
网络安全03---Nginx 解析漏洞复现
目录 一、准备环境 二、实验开始 2.1上传压缩包并解压 2.2进入目录,开始制作镜像 2.3可能会受之前环境影响,删除即可 编辑 2.4制作成功结果 2.5我们的环境一个nginx一个php 2.6访问漏洞 2.7漏洞触发结果 2.8上传代码不存在漏洞 2.9补充&#…...

第十四届蓝桥杯C组题目 三国游戏
4965. 三国游戏 - AcWing题库 小蓝正在玩一款游戏。 游戏中魏蜀吴三个国家各自拥有一定数量的士兵 X,Y,Z(一开始可以认为都为 00)。 游戏有 n 个可能会发生的事件,每个事件之间相互独立且最多只会发生一次,当第 i个事件发生时会分…...
)
【LeetCode-435】无重叠区间(贪心)
题目链接 题目简介 给定一个区间的集合,找到需要移除区间的最小数量,使剩余区间互不重叠。 注意: 可以认为区间的终点总是大于它的起点。 区间 [1,2] 和 [2,3] 的边界相互“接触”,但没有相互重叠。 示例 1: 输入: [ [1,2], [2,3], [3,4…...

写读后感的时候,可以适当地引用书中的内容吗?
写读后感时,适当地引用书中的内容是可以的,这样可以更好地支持你的观点和感受,增强文章的可信度和说服力。 引用书中的内容可以帮助读者更好地理解你所讨论的主题和人物,同时也可以展示你对原著的深入理解和阅读能力。但是&#…...
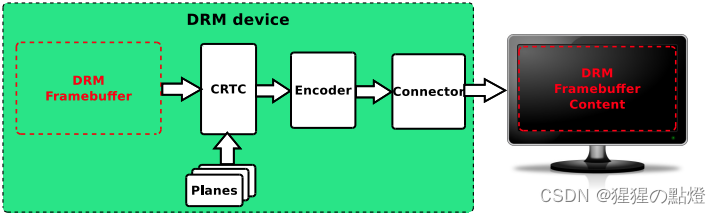
RockChip DRM Display Driver
资料来源: 《Rockchip_DRM_Display_Driver_Development_Guide_V1.0.pdf》 《Rockchip_Developer_Guide_DRM_Display_Driver_CN.pdf》 一:DRM概述 DRM(Direct Rendering Manager)直接渲染管理,buffer分配,帧缓冲。对应userspace库位libdrm,libdrm库提供了一系列友好的…...

【数据库】GaussDB数据类型和简单DDL概述
GaussDB是一款华为公司开发的关系型数据库管理系统(RDBMS),提供了多种数据类型用于存储和处理不同类型的数据。以下是GaussDB常见的数据类型: 1、GaussDB常见的数据类型 1.1、数值型(Numeric Types)&…...

malloc/free和new/delete相关问题:
面试题: 1、两种方式的区别: (1)malloc需要强制类型转换,new不需要 (2)malloc需要计算空间大小,new不需要 例如:创建5个int类型的空间 int*p(int *)malloc(sizeof(i…...

设计一套扑克牌
约束和假设 这是一幅用于类似扑克和二十一点等游戏的通用扑克牌吗? 我们可以假设这副牌有52张(2-10,杰克,女王,国王,埃斯)和4种花色吗? 我们可以假设输入是有效的,还是需…...

ubuntu20.04 外接hdmi没有声音
pulseaudio -k 请尝试执行该命令...

Mybatis 拦截器注册方式
在MyBatis中注册拦截器可以通过以下三种方式: 1. XML配置文件方式 在Mybatis的核心配置文件(mybatis-config.xml)中的标签下定义拦截器,并指定实现类。 <configuration><!-- ...其他配置... --><plugins><…...

别再手动改路径了!用LabVIEW + MATLAB Script做自动化测试,这份环境配置指南让你效率翻倍
LabVIEW与MATLAB深度整合:构建自动化测试系统的工程实践指南在工业自动化与测试测量领域,LabVIEW和MATLAB的组合堪称黄金搭档。LabVIEW擅长硬件接口和实时控制,而MATLAB在算法开发和数据分析方面具有无可比拟的优势。本文将深入探讨如何将两者…...

户外实用|艾迪欧 R6000 测评 —— 户外 / 自驾 / 露营的通讯好搭档
户外出行,通讯工具的核心是稳定、清晰、耐用、续航久、功能全。艾迪欧 R6000 作为一款兼顾专业与户外的 DMR 对讲机,全频段覆盖、双模通讯、自定义功能、长续航,完美适配自驾、露营、登山、越野等户外场景,是户外爱好者的靠谱通讯…...
)
保姆级教程:Windows系统下Arcgis 10.2从下载、安装到汉化一次搞定(附常见License启动失败解决方案)
Windows系统下Arcgis 10.2完整安装与汉化实战指南第一次接触Arcgis的新手往往会被复杂的安装流程和神秘的License Manager搞得晕头转向。作为一款功能强大的地理信息系统软件,Arcgis在科研、城市规划、环境监测等领域有着广泛应用,但它的安装过程确实会让…...

关于psthon问题
我想问问各位 我python可以查到 但是我的bit文件查不到python怎么回事...

AI圈神秘领袖Ilya一幅画引爆全网,OpenAI三件大事暗示AGI时代将至?
AI圈神秘精神领袖Ilya在Instagram上传一幅画引发疯狂解读,与此同时,OpenAI连续公布数学成果、升级Codex、筹备IPO,释放AGI到来的强烈信号。Ilya画作引猜测Ilya上传的画中,罗丹的「思考者」踩在芯片Die Shot上,右下角签…...

Codex使用API Key授权无法使用插件?
小伙伴们,大家好,我是小溪,见字如面。对于没有ChatGPT账号的小伙伴来说,虽然可以通过API Key授权的方式使用Codex桌面端,但是会有一些限制。比如无法使用插件功能,无法使用Codex移动端进行远程控制等。为了…...

如何用HsMod解锁炉石传说60+项隐藏功能:终极优化指南
如何用HsMod解锁炉石传说60项隐藏功能:终极优化指南 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是一款基于BepInEx开发的炉石传说功能增强插件,为玩家提供…...

输电线路在线监测系统|架空线路安全运行的“第一道防线“!
输电线路微气象监测站是专为高压输电线路、电网廊道、杆塔运维量身打造的专利级一体化微气象智能监测设备。依托双专利超声波探测技术、六要素集成传感架构、无启动风速高精测量、智能抗干扰稳控系统,实现输电线路沿线气象24小时全自动捕捉、动态实时监测、大风风险…...

告别手动预约:i茅台自动预约系统5分钟部署指南
告别手动预约:i茅台自动预约系统5分钟部署指南 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://gitcode…...

天文时序数据分析:机器学习评估、半监督学习与无监督方法实战
1. 项目概述:当机器学习遇见星空 处理海量的天文时序数据,比如来自Kepler、TESS这些“巡天巨眼”的光变曲线,早已不是靠人眼一张张图去翻的时代了。数据量太大,噪声复杂,信号微弱,传统方法常常力不从心。这…...