橘子学Mybatis08之Mybatis关于一级缓存的使用和适配器设计模式
前面我们说了mybatis的缓存设计体系,这里我们来正式看一下这玩意到底是咋个用法。
首先我们是知道的,Mybatis中存在两级缓存。分别是一级缓存(会话级),和二级缓存(全局级)。
下面我们就来看看这两级缓存。
一、准备工作
1、准备数据库
在此之前我们先来准备一个数据库,并且设计一个表user用户表,加几条数据进去。
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;-- ----------------------------
-- Table structure for user
-- ----------------------------
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (`id` int(32) NOT NULL COMMENT '主键id',`name` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '名字',PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '用户表' ROW_FORMAT = Dynamic;-- ----------------------------
-- Records of user
-- ----------------------------
INSERT INTO `user` VALUES (1, '张飞');
INSERT INTO `user` VALUES (2, '关羽');
INSERT INTO `user` VALUES (3, '孙权');SET FOREIGN_KEY_CHECKS = 1;
2、然后我们创建一个mybatis中的DAO接口。
public interface IUserDao {// 查询所有用户List<User> findAll();
}
3、创建UserMapper.xml文件
<mapper namespace="com.yx.dao.IUserDao"><select id="findAll" resultType="com.yx.domain.User" statementType="CALLABLE">SELECT * FROM `user`</select
</mapper>
4、创建Mybatis核心配置文件
<configuration><!--加载外部properties文件,位置必须在第一个--><properties resource="jdbc.properties"/><settings><!-- 控制台输出sql语句 --><setting name="logImpl" value="STDOUT_LOGGING" /></settings><typeAliases><!--给单独的实体类取别名--><!--<typeAlias type="com.lwq.domain.User" alias="user"/>--><!--批量给实体类取别名:指定包下面所有的类的别名默认为其类名,不区分大小写--><package name="com.yx.domain"/></typeAliases><environments default="development"><!--开发环境,可以配置多套环境,default指定用哪个--><environment id="development"><!--當前事務交給jdbc處理--><transactionManager type="JDBC"/><dataSource type="POOLED"><property name="driver" value="${jdbc.driver}"/><property name="url" value="${jdbc.url}"/><property name="username" value="${jdbc.username}"/><property name="password" value="${jdbc.password}"/></dataSource></environment></environments><mappers><mapper resource="UserMapper.xml"/></mappers>
</configuration>
5、创建jdbc.properties
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql:///mybatis22
jdbc.username=root
jdbc.password=root
好了,我们现在可以使用mybatis来操作数据库了。
二、一级缓存
1、验证
一级缓存在mybatis中是默认开启的,我们先来测试一下,他到底存在不存在,并且是不是能用,是不是默认开启的。我们来做一个测试代码。
@Test
public void test1() throws IOException {// 读取配置文件转化为流InputStream inputStream = Resources.getResourceAsStream("sqlMapConfig.xml");SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(inputStream);SqlSession sqlSession = factory.openSession();//这⾥不调⽤SqlSession的api,⽽是获得了接⼝对象,调⽤接⼝中的⽅法。使用JDK动态代理产生代理IUserDao userDao = sqlSession.getMapper(IUserDao.class);// 第一次执行查询List<User> userList = userDao.findAll();userList.forEach(user -> {System.out.println(user.toString());});System.out.println("*************************************************");// 第二次执行相同的查询List<User> userList2 = userDao.findAll();userList2.forEach(user -> {System.out.println(user.toString());});
}这里我们做了两次查询,第一次和第二次的查询是一模一样的,如果存在缓存,那它一定第二次就不会去查数据库
了,下面我们来验证一下。
输出如下:
Opening JDBC Connection
Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary.
Created connection 1011044643.
Setting autocommit to false on JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@3c435123]
==> Preparing: SELECT * FROM `user`
==> Parameters:
<== Columns: id, name
<== Row: 1, 张飞
<== Row: 2, 关羽
<== Row: 3, 孙权
<== Total: 3
User{id=1, username='张飞'}
User{id=2, username='关羽'}
User{id=3, username='孙权'}
*************************************************
User{id=1, username='张飞'}
User{id=2, username='关羽'}
User{id=3, username='孙权'}
我们看到第一次调用进行了创建connection连接,下面执行了sql,然后输出,但是第二次再执行,他就不会再去查库了,而是直接输出了缓存,这就说明了这个缓存是存在并且开启的。
2、注意
2.1、注意点1
一级缓存只在当前sqlsession中生效,也就是他是会话级别的,每一次连接内的多次相同查询可以共享这次缓存,如果你换了sqlsession,新的sqlsession和其他的sqlsession的查询是不能共享缓存使用的。下面我们来验证一下。
@Test
public void test2() throws IOException {// 读取配置文件转化为流InputStream inputStream = Resources.getResourceAsStream("sqlMapConfig.xml");SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(inputStream);SqlSession sqlSession = factory.openSession();SqlSession sqlSession2 = factory.openSession();//这⾥不调⽤SqlSession的api,⽽是获得了接⼝对象,调⽤接⼝中的⽅法。使用JDK动态代理产生代理对象IUserDao userDao = sqlSession.getMapper(IUserDao.class);IUserDao userDao2 = sqlSession2.getMapper(IUserDao.class);// 第一次执行查询List<User> userList = userDao.findAll();userList.forEach(user -> {System.out.println(user.toString());});System.out.println("*************************************************");// 第二次执行相同的查询List<User> userList2 = userDao2.findAll();userList2.forEach(user -> {System.out.println(user.toString());});
}
我们开启创建了两个不同的sqlSession分别是sqlSession和sqlSession2,然后执行相同的查询。
输出如下:
Opening JDBC Connection
Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary.
Created connection 1011044643.
Setting autocommit to false on JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@3c435123]
==> Preparing: SELECT * FROM `user`
==> Parameters:
<== Columns: id, name
<== Row: 1, 张飞
<== Row: 2, 关羽
<== Row: 3, 孙权
<== Total: 3
User{id=1, username='张飞'}
User{id=2, username='关羽'}
User{id=3, username='孙权'}
*************************************************
Opening JDBC Connection
Created connection 156199931.
Setting autocommit to false on JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@94f6bfb]
==> Preparing: SELECT * FROM `user`
==> Parameters:
<== Columns: id, name
<== Row: 1, 张飞
<== Row: 2, 关羽
<== Row: 3, 孙权
<== Total: 3
User{id=1, username='张飞'}
User{id=2, username='关羽'}
User{id=3, username='孙权'}
此时我们就看到,第二次查询并没有利用到缓存,而是又开始了一次新的查询。所以这种跨sqlsession是不能使用缓存的。不是不存在,而是使用不到。
2.2、注意点2
我们既然知道了在sqlseeion不同的时候,缓存是不能利用的,那么问题来了,你的以后的日常开发中这个sqlsession他会经常变吗,如果变了,那岂不是走不了缓存了。
实际上就是经常变的,比如你页面上有一个按钮就是搜索,每次都会查询数据库,实际上你每次点击都会建立新的sqlsession,因为这玩意是伴随着连接的。你每次请求都会创建新的连接,那你的缓存就没用,除非你在你的service里面连着调用了两次一样的查询,这个,,,你没事吧。
所以你的一级缓存大部分情况下,没卵用。
那你为啥说每次请求都是单独的sqlSession或者单独的jdbc connection呢,因为这里牵扯到要控制事务,不同请求必须是独立隔离的连接,这样才能独立控制事务,如果共享事务,可能会造成混乱。比如请求1,请求2开启一个连接,那请求1还没完呢,你请求2就提交了事务,这不就寄了。
2.3、注意点3
那么查询是不是不需要事务呢,查询是不是就可以共享连接了,不对,查询也需要,select后面可以加锁。需要事务。
后面的二级缓存,这里也是需要的。后面我们再说,而且设计的时候肯定是统一处理的,不会说为了你一个加锁或者二级缓存就去区分开代码处理。
所以基于一级缓存的苛刻条件,我们知道这个一级缓存其实在使用者层面,他用处不大,实际上他也是在内部他自己的使用的。
既然我们说了他没啥用,那他设计出来干嘛呢,必然是有用处,下面我们来看下源码来分析一下他的用处。但是在进入源码之前,我们先来看一个设计模式,就是适配器设计模式。
3、适配器设计模式
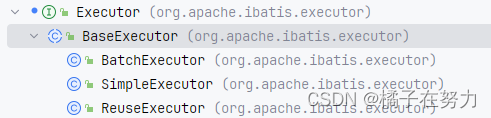
我们在前面看到了mybatis的设计结构,大致如下。

我们看到首先他是一个Executor的接口,然后下面一个BaseExecutor来实现了这个接口,下面又是三个子类继承了BaseExecutor这个类,这其实就是一个适配器模式。我们看下他的类结构。
1、什么是适配器。
这个玩意一般资料都会拿出一个电压的例子,比如中国的常规电压是220伏特,人能承受的大概是36伏特,那我们要是碰到220伏特就寄了,于是我们可以使用一个变压器,放在中间。

这个变压器的作用就是适配器,这个例子你是不是在无数地方都看吐了,我们还是直接在代码说吧。
比如此时有一个Servlet的接口,里面有五个接口(我简化了一下)。
public interface Servlet {void init();void service();void destory();String getServletInfo();void getServletConfig();
}
此时我想实现一个自己的Servlet就叫做MyServlet,其中我只想实现 String getServletInfo();这个方法,但是java的语法就是我只要实现这个接口,就得实现他所有的方法,这个压力太大,等于直接把220V的电压给我了,我不想这么整,所以此时需要一个变压器。也就是适配器登场。
此时我们在创建一个类,去实现这个接口,如下:
public abstract class MyServletAdapter implements Servlet{@Overridepublic void init() {}@Overridepublic void service() {}@Overridepublic void destory() {}@Overridepublic String getServletInfo() {return null;}public abstract void getServletConfig();
}
你看到我们此时实现了这个接口,并且实现了其中四个方法,最后一个我们做成了抽象方法,其他四个你想不想实现看你。最后一个我们做成抽象的,给我们自己的那个servlet去实现。
于是就变为这样、
public class MyServlet extends MyServletAdapter{@Overridepublic void getServletConfig() {System.out.println("我自己的servlet实现单独的一个方法");}
}
此时我们的这个类就完成了变压器到达终端,此时就只需要实现一个即可,而因为这个在变压器里面是抽象方法,所以这里是存在必须实现的约束的。还是有接口的作用。这就是适配器模式。
2、mybatis中的适配器
这样我们知道了适配器模式,那么其实上面那张图中的BaseExecutor就是适配器了。

BaseExecutor把接口中的一部分方法实现了,没实现的最后交个那三个子类各自实现各自定制化的东西,而公共的则由适配器里面去实现了。子类里面的还能用这些公共的,节省了代码量。这和模板设计模式很像。但虽然像,只是他们实现过程中表现出来的抽象,因为设计模式都是为了复用,抽象,扩展这些特点的,而适配器模式实际上出发点他是为了"变压"。
4、一级缓存的静态源码分析
我们说其实不管你哪个Excutor子类都是有这个缓存的,所以我么能猜出来,这个缓存功能其实是放在适配器里面的公共部分让子类使用的,我们看下这个适配器BaseExecutor。
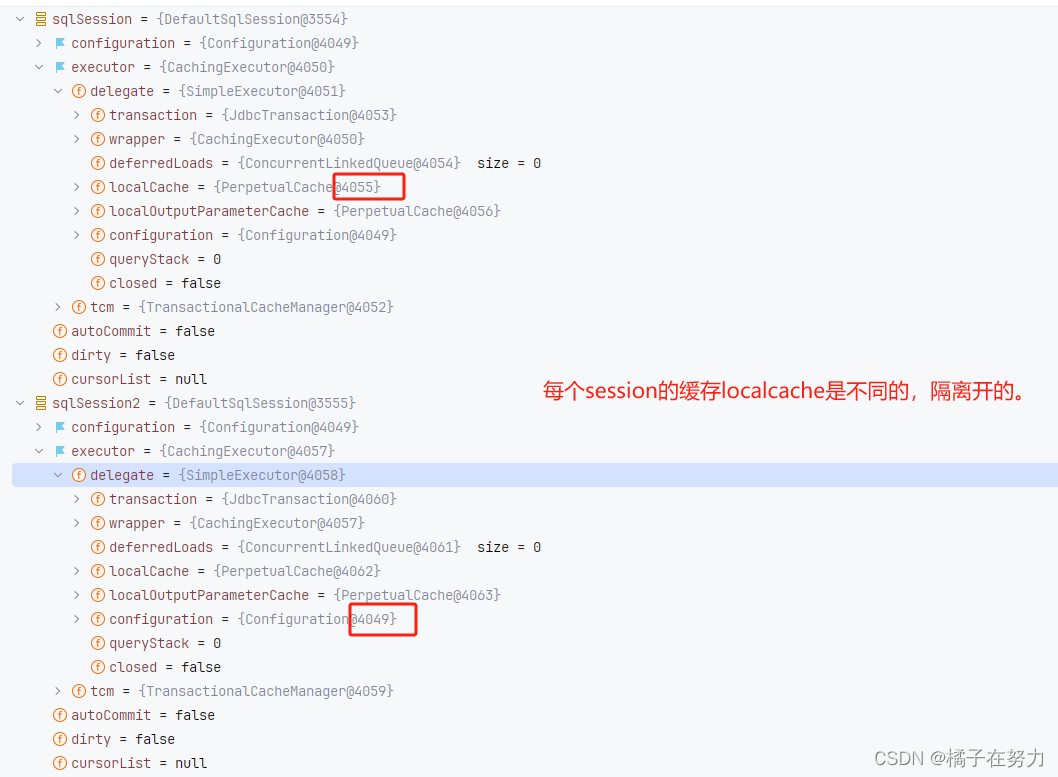
public abstract class BaseExecutor implements Executor {......protected PerpetualCache localCache;// 一级缓存protected PerpetualCache localOutputParameterCache;// 存储过程的,一般不用@Overridepublic <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {// 根据你传进来的参数,动态生成sql,返回的boundSql就有这个sqlBoundSql boundSql = ms.getBoundSql(parameter);// 为本次查询创建缓存的keyCacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);//重载方法,实现查询return query(ms, parameter, rowBounds, resultHandler, key, boundSql);}// 在这里重载@SuppressWarnings("unchecked")@Overridepublic <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());// 判断执行器是不是被关闭,关闭直接抛出异常if (closed) {throw new ExecutorException("Executor was closed.");}// 清空本地缓存,如果queryStack为0,就要清空本地缓存if (queryStack == 0 && ms.isFlushCacheRequired()) {clearLocalCache();}List<E> list;try {queryStack++;// localCache.getObject(key)取出一级缓存里面的查询结果list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;if (list != null) {// 如果缓存中有,就直接返回缓存的handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);} else {//如果缓存中没有本次查找的值,那么queryFromDatabase方法从数据库中查询list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);}} finally {queryStack--;}if (queryStack == 0) {// 执行延迟加载for (DeferredLoad deferredLoad : deferredLoads) {deferredLoad.load();}// issue #601deferredLoads.clear();if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {// issue #482clearLocalCache();}}return list;}}private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {List<E> list;// 在缓存中添加占位对象,此处的占位符和延迟加载有关,见DeferredLoad#canLoad()localCache.putObject(key, EXECUTION_PLACEHOLDER);try {//doQuery是真正的最后的去执行读操作list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);} finally {// 从缓存中溢出占位对象localCache.removeObject(key);}// 查询完把结果添加到缓存中localCache.putObject(key, list);// 暂时忽略,存储过程相关if (ms.getStatementType() == StatementType.CALLABLE) {localOutputParameterCache.putObject(key, parameter);}return list;}所以这里大致你能看到这个过程,就是他会读取缓存,没有缓存就去读取数据库,并且设置缓存,这是我们基于代码看到的效果,实际上的过程我们需要debug来看一下,就能看到如何读取,并且跨sqlSession是如何不生效的,这个可以直接在debug看到,每个sqlsession下面有不同的localCache,实现了缓存隔离。这个我们下面再来debug追踪源码。这里先简单贴个图。
相关文章:
橘子学Mybatis08之Mybatis关于一级缓存的使用和适配器设计模式
前面我们说了mybatis的缓存设计体系,这里我们来正式看一下这玩意到底是咋个用法。 首先我们是知道的,Mybatis中存在两级缓存。分别是一级缓存(会话级),和二级缓存(全局级)。 下面我们就来看看这两级缓存。 一、准备工作 1、准备数据库 在此之…...
看图说话:Git图谱解读
很多新加入公司的同学在使用Git各类客户端管理代码的过程中对于Git图谱解读不太理解,我们常用的Git客户端是SourceTree,配合P4Merge进行冲突解决基本可以满足日常工作大部分需要。不同的Git客户端工具对图谱展示会有些许差异,以下是SourceTre…...

linux新增用户,指定home目录和bash脚本且加入到sudoer列表
前言 近3年一直用自动化脚本,搞得连useradd命令都不会用了。哈哈。 今天还碰到一个问题,有个系统没有‘useradd’和‘passwd’命令,直接蒙了。当然直接用apt install就能安装,不然还得自己编译折腾一会。新建用户 useradd -d /h…...

经典目标检测YOLO系列(三)YOLOV3的复现(1)总体网络架构及前向处理过程
经典目标检测YOLO系列(三)YOLOV3的复现(1)总体网络架构及前向处理过程 和之前实现的YOLOv2一样,根据《YOLO目标检测》(ISBN:9787115627094)一书,在不脱离YOLOv3的大部分核心理念的前提下,重构一款较新的YOLOv3检测器,来对YOLOv3有…...
OpenGL/C++_学习笔记(四)空间概念与摄像头
汇总页 上一篇: OpenGL/C_学习笔记(三) 绘制第一个图形 OpenGL/C_学习笔记(四)空间概念与摄像头 空间概念与摄像头前置科技树: 线性代数空间概念流程简述各空间相关概念详述 空间概念与摄像头 前置科技树: 线性代数 矩阵/向量定…...

C语言2024-1-27练习记录
#define _CRT_SECURE_NO_WARNINGS 1#include<stdio.h>//int main() //{ // char c[15] { I, ,a,n,d, ,you,. }; // int i; // for(i 0; i < 15; i) //这个地方有几个地方需要注意一下,首先变量指定之后必须要加上英文状态下的分号 // printf("%c&q…...

深入解析HTTPS:安全机制全方位剖析
随着互联网的深入发展,网络传输中的数据安全性受到了前所未有的关注。HTTPS,作为HTTP的安全版本,为数据在客户端和服务器之间的传输提供了加密和身份验证,从而确保了数据的机密性、完整性和身份真实性。本文将详细探讨HTTPS背后的…...

【197】JAVA8调用阿里云对象存储API,保存图片并获取图片URL地址。
实际工作中,需要用阿里云对象存储保存图片,并且在上传图片到阿里云对象存储服务器后,获取图片在阿里云对象存储服务器的URL地址,以便给 WEB 前端显示。 阿里云对象存储上传图片的工具类 package zhangchao;import com.aliyun.os…...

2024.1.24 C++QT 作业
思维导图 练习题 1.提示并输入一个字符串,统计该字符中大写、小写字母个数、数字个数、空格个数以及其他字符个数 #include <iostream> #include <string.h> #include <array> using namespace std;int main() {string str;cout << "…...

jenkins部署过程记录
一、jenkins部署git链接找不到 原因分析: 机器的git环境不是个人git的权限,所以clone不了。Jenkins的master节点部署机器已经部署较多其他的job在跑,如果直接修改机器的git配置,很可能影响到其他的job clone 不了代码,…...

JS-策略设计模式
设计模式:针对特定问题提出的简洁优化的解决方案 一个问题有多种处理方案,而且处理方案随时可能增加或减少比如:商场满减活动 满50元减5元满100元减15元满200元减35元满500元减100元 // 满减金额计算函数 function count(money, type) {if …...

漏洞复现-EduSoho任意文件读取漏洞(附漏洞检测脚本)
免责声明 文章中涉及的漏洞均已修复,敏感信息均已做打码处理,文章仅做经验分享用途,切勿当真,未授权的攻击属于非法行为!文章中敏感信息均已做多层打马处理。传播、利用本文章所提供的信息而造成的任何直接或者间接的…...

「QT」QString类的详细说明
✨博客主页何曾参静谧的博客📌文章专栏「QT」QT5程序设计📚全部专栏「VS」Visual Studio「C/C++」C/C++程序设计「UG/NX」BlockUI集合「Win」Windows程序设计「...
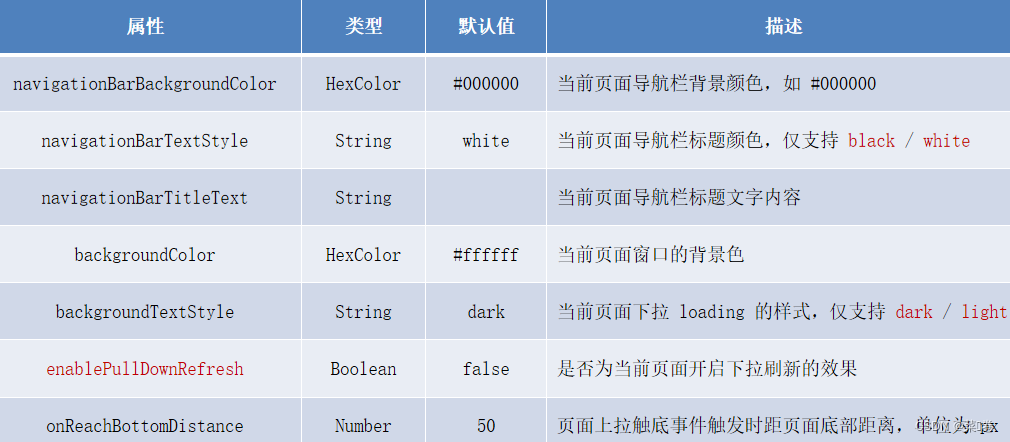
微信小程序-04
rpx(responsive pixel)是微信小程序独有的,用来解决屏适配的尺寸单位。 import 后跟需要导入的外联样式表的相对路径,用 ; 表示语句结束。 定义在 app.wxss 中的样式为全局样式,作用于每一个页面。 在页面的 .wxss 文…...
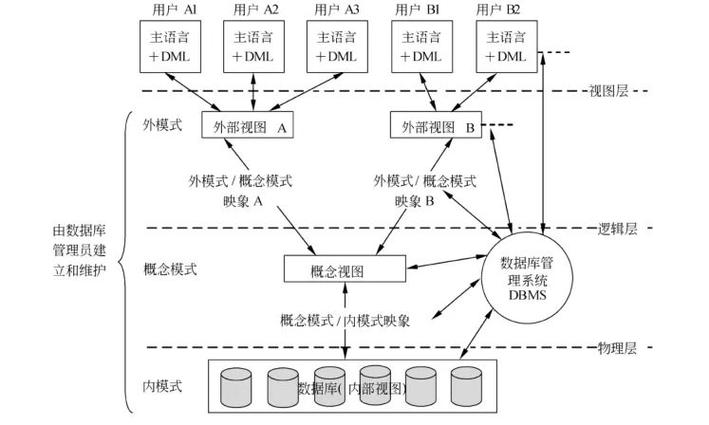
什么是数据库的三级模式两级映象?
三级模式两级映象结构图 概念 三级模式 内模式:也称为存储模式,是数据物理结构和存储方式的描述,是数据在数据库内部的表示方式。定义所有的内部记录类型、索引和文件组织方式,以及数据控制方面的细节。模式:又称概念…...

初识人工智能,一文读懂机器学习之逻辑回归知识文集(6)
🏆作者简介,普修罗双战士,一直追求不断学习和成长,在技术的道路上持续探索和实践。 🏆多年互联网行业从业经验,历任核心研发工程师,项目技术负责人。 🎉欢迎 👍点赞✍评论…...

2024 CKA 题库 | 15、备份还原 etcd
不等更新题库 文章目录 15、备份还原 etcd题目:考点:参考链接:解答:备份快照恢复快照 检查 15、备份还原 etcd 题目: 设置配置环境 此项目无需更改配置环境。但是,在执行此项目之前,请确保您已返回初始节点。 [candidatemaster01] $ exit #…...
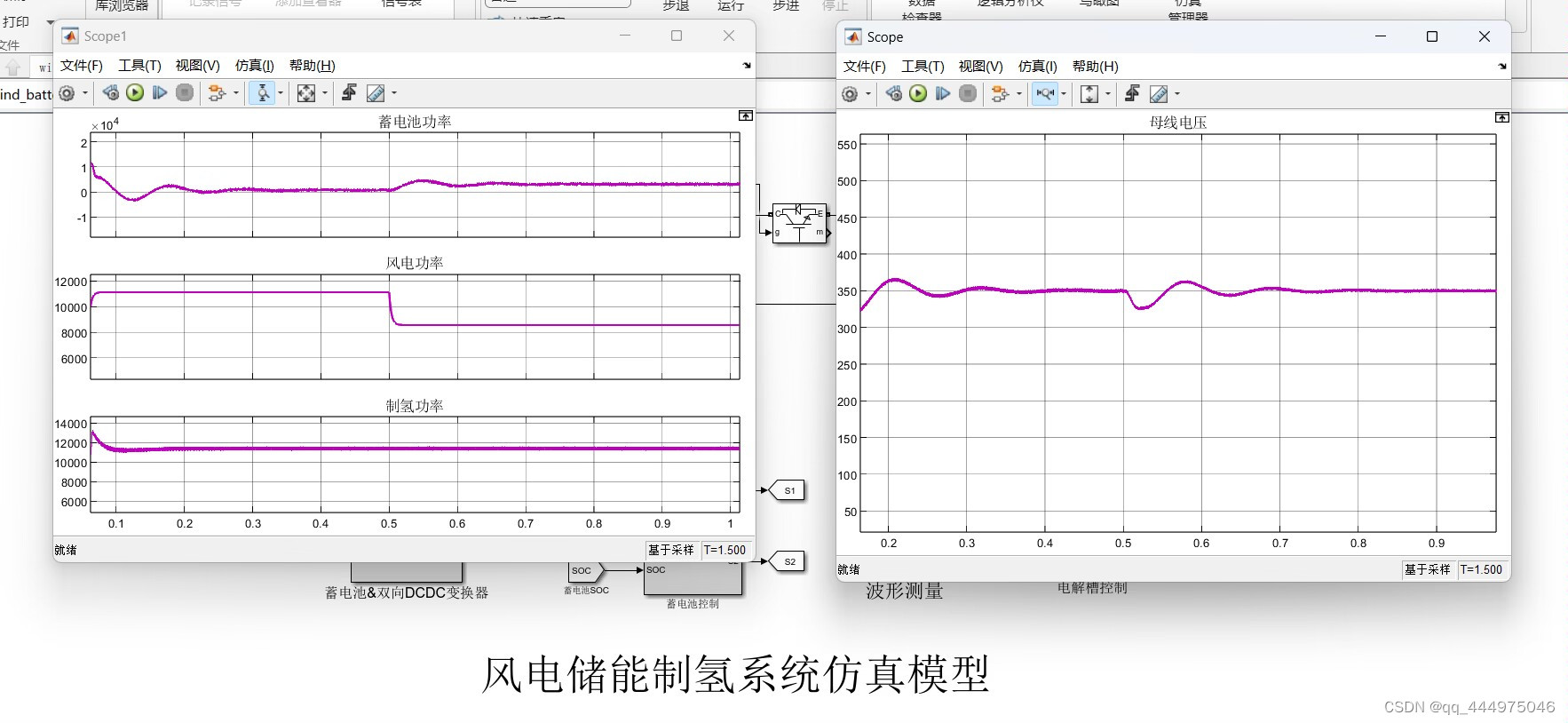
基于Matlab/Simulink直驱式风电储能制氢仿真模型
接着还是以直驱式风电为DG中的研究对象,上篇博客考虑的风电并网惯性的问题,这边博客主要讨论功率消纳的问题。 考虑到风速是随机变化的,导致风电输出功率的波动性和间歇性问题突出;随着其应用规模的不断扩大以及风电在电网中渗透率…...
复习提纲16)
计算机网络(第六版)复习提纲16
三 IP地址与MAC地址 1 IP层只能看到IP数据报 2 路由器只根据目的IP地址进行转发 3 局域网的链路层只能看到MAC帧 4 IP层抽象的互联网屏蔽了下层的复杂细节,在网络层讨论问题能够使用统一的、抽象的IP地址来研究主机和主机或路由间的通信 问题: 1 主机或路…...
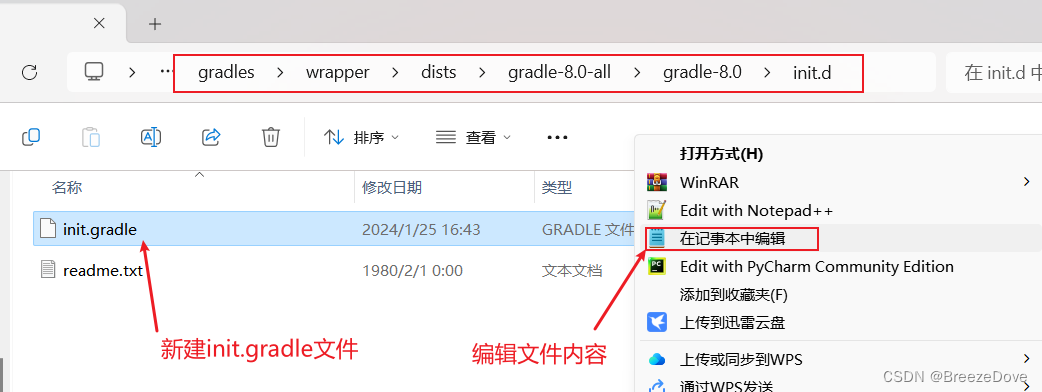
【AndroidStudio】2022.3Giraffe连接超时,更换下载源,使用本地gradle,版本对应问题
记录了使用AndroidStudio2022.3 Giraffe版本在搭建环境时遇到的问题,包括连接超时,gradle无法读取等。 如果只看如何正确的配置,直接跳转第3节 配置汇总 1 连接超时 项目一开始会自动下载gardle文件来加载项目 1.1 Connect timed out 基…...

LLM API安全攻防实战:从提示词注入到自动化测试方案
1. 项目概述:被忽视的LLM API安全前线最近在帮几个团队做上线前的安全审计,发现一个挺有意思的现象:大家对于传统API的鉴权、限流、SQL注入这些常规检查已经形成了肌肉记忆,但一旦涉及到LLM(大语言模型)的A…...

小说下载器终极指南:一站式解决100+网站小说保存难题
小说下载器终极指南:一站式解决100网站小说保存难题 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader 在数字阅读时代,你是否曾因小说突然下架、网站404或网络中…...
)
告别网盘客户端!用Alist+RaiDrive把百度云盘变成电脑本地文件夹(保姆级图文教程)
用AlistRaiDrive实现网盘本地化管理的终极方案 你是否厌倦了电脑上安装多个网盘客户端,不仅占用系统资源,操作还繁琐割裂?每次上传下载文件都要在不同客户端间切换,效率低下。现在,通过Alist和RaiDrive的组合…...

Windows文件夹共享
目标:同一局域网实现在一台计算机上共享文件夹,在另一台电脑访问一、电脑A 1.点击要共享的文件夹 -> 属性 -> 共享2.添加Everyone用户组3.控制面板中网络共享关闭密码保存,在访问时不用输入账号密码。二、电脑B 1.在文件资源管理器路径…...

浏览器指纹识别机制深度剖析与反识别技术实现
一、浏览器指纹技术基础认知1.1 浏览器指纹的核心定义在数字化时代,每一台接入互联网的设备都会留下独特的数字标识,浏览器指纹便是其中最关键的识别凭证之一。浏览器指纹是网站通过 JavaScript 脚本、HTTP 请求头、硬件接口调用等多种技术手段ÿ…...

【DeepSeek集成测试黄金标准】:20年专家亲授5大避坑指南与自动化落地框架
更多请点击: https://intelliparadigm.com 第一章:DeepSeek集成测试黄金标准的演进与核心价值 集成测试在大语言模型工程化落地过程中已从“验证功能可用”跃迁为“保障推理一致性、上下文鲁棒性与安全边界的三位一体质量门禁”。DeepSeek系列模型&…...

基于窗口比较器与晶体管逻辑的可编程非线性电压指示器设计
1. 项目概述:打造一个可编程的“移动光点”电压指示器在电子制作和仪器仪表领域,我们经常需要一个直观的电压指示器。经典的LM3914点/条图显示驱动芯片大家都很熟悉,它能把一个模拟电压信号转换成10个LED的点亮状态,形成移动的光点…...

语音AI落地最后一公里卡点,PlayAI质量波动真相:采样率适配缺陷、韵律断层、情感衰减三大隐性陷阱
更多请点击: https://intelliparadigm.com 第一章:PlayAI语音质量评测报告总览 PlayAI语音质量评测体系基于客观指标与主观听感双维度构建,覆盖清晰度、自然度、时延、抗噪性及情感一致性五大核心能力。本报告汇总了在标准测试集(…...

You-Get下载视频音画不同步?可能是FFmpeg路径没配对!附Mac/Linux/Windows三平台配置指南
You-Get跨平台音视频同步解决方案:FFmpeg环境配置全指南 当你在Mac上流畅使用you-get下载合并好的视频,切换到Windows却遭遇音画分离的尴尬时,问题往往出在FFmpeg的环境配置上。本文将带你深入理解多平台下FFmpeg的配置差异,并提…...

终极跨平台空洞骑士模组管理器:Lumafly如何让模组管理变得简单高效
终极跨平台空洞骑士模组管理器:Lumafly如何让模组管理变得简单高效 【免费下载链接】Lumafly A cross platform mod manager for Hollow Knight written in Avalonia. 项目地址: https://gitcode.com/gh_mirrors/lu/Lumafly 你是否曾经因为空洞骑士模组安装…...