pytorch-模型构建,参数访问,模型存取API接口,对比学习
- 多层感知机的简洁实现pytorch-多层感知机,最简单的深度学习模型,将非线性激活函数引入到模型中。_羞儿的博客-CSDN博客中含单隐藏层的多层感知机的实现方法。首先构造
Sequential实例,然后依次添加两个全连接层。其中第一层的输出大小为256,即隐藏层单元个数是256;第二层的输出大小为10,即输出层单元个数是10。我们在上一章的其他节中也使用了Sequential类构造模型。这里我们介绍另外一种基于Module类的模型构造方法:它让模型构造更加灵活。
继承Module类来构造模型
-
Module类是nn模块里提供的一个模型构造类,是所有神经网络模块的基类,可以继承它来定义我们想要的模型。下面继承Module类构造本节开头提到的多层感知机。这里定义的MLP类重载了Module类的__init__函数和forward函数。它们分别用于创建模型参数和定义前向计算。前向计算也即正向传播。MLP类中无须定义反向传播函数。系统将通过自动求梯度而自动生成反向传播所需的backward函数。 -
import torch from torch import nn class MLP(nn.Module):# 声明带有模型参数的层,这里声明了两个全连接层def __init__(self, **kwargs):# 调用MLP父类Module的构造函数来进行必要的初始化。这样在构造实例时还可以指定其他函数# 参数,如“模型参数的访问、初始化和共享”一节将介绍的模型参数paramssuper(MLP, self).__init__(**kwargs)self.hidden = nn.Linear(784, 256) # 隐藏层self.act = nn.ReLU()self.output = nn.Linear(256, 10) # 输出层# 定义模型的前向计算,即如何根据输入x计算返回所需要的模型输出def forward(self, x):a = self.act(self.hidden(x))return self.output(a) -
可以实例化
MLP类得到模型变量net。下面的代码初始化net并传入输入数据X做一次前向计算。其中,net(X)会调用MLP继承自Module类的__call__函数,这个函数将调用MLP类定义的forward函数来完成前向计算。 -
x = torch.rand(2, 784) net = MLP() print(net) net(X)ag-0-1gqj7fqh9ag-1-1gqj7fqh9 -
MLP((hidden): Linear(in_features=784, out_features=256, bias=True)(act): ReLU()(output): Linear(in_features=256, out_features=10, bias=True) ) tensor([[ 0.0569, 0.0350, -0.0277, -0.0978, 0.0526, -0.1721, 0.1613, 0.0384,0.0745, -0.1180],[ 0.1452, 0.0046, 0.0880, -0.0355, -0.0086, -0.0448, 0.2466, 0.0487,0.0475, -0.0972]], grad_fn=<AddmmBackward0>) -
注意,这里并没有将
Module类命名为Layer(层)或者Model(模型)之类的名字,这是因为该类是一个可供自由组建的部件。它的子类既可以是一个层(如PyTorch提供的Linear类),又可以是一个模型(如这里定义的MLP类),或者是模型的一个部分。
Module的子类
-
Module
类是一个通用的部件。事实上,PyTorch还实现了继承自Module的可以方便构建模型的类: 如Sequential、ModuleList和ModuleDict`等等。 -
Sequential类-
当模型的前向计算为简单串联各个层的计算时,
Sequential类可以通过更加简单的方式定义模型。这正是Sequential类的目的:它可以接收一个子模块的有序字典(OrderedDict)或者一系列子模块作为参数来逐一添加Module的实例,而模型的前向计算就是将这些实例按添加的顺序逐一计算。 -
实现一个与
Sequential类有相同功能的MySequential类。这或许可以帮助读者更加清晰地理解Sequential类的工作机制。用MySequential类来实现前面描述的MLP类,并使用随机初始化的模型做一次前向计算。 -
MySequential((0): Linear(in_features=784, out_features=256, bias=True)(1): ReLU()(2): Linear(in_features=256, out_features=10, bias=True) ) tensor([[ 0.0266, 0.0073, 0.1667, -0.0249, -0.0646, 0.0612, 0.0847, 0.0460,0.3148, 0.0031],[ 0.0881, 0.0829, 0.1487, 0.0068, -0.1228, -0.1077, 0.0487, -0.0836,0.1567, -0.1193]], grad_fn=<AddmmBackward0>)
-
-
ModuleList类-
ModuleList接收一个子模块的列表作为输入,然后也可以类似List那样进行append和extend操作: -
net = nn.ModuleList([nn.Linear(784, 256), nn.ReLU()]) net.append(nn.Linear(256, 10)) # # 类似List的append操作 print(net[-1]) # 类似List的索引访问 print(net) net(torch.zeros(1, 784)) # 会报NotImplementedError -
Linear(in_features=256, out_features=10, bias=True) ModuleList((0): Linear(in_features=784, out_features=256, bias=True)(1): ReLU()(2): Linear(in_features=256, out_features=10, bias=True) ) NotImplementedError: Module [ModuleList] is missing the required "forward" function -
既然
Sequential和ModuleList都可以进行列表化构造网络,那二者区别是什么呢。ModuleList仅仅是一个储存各种模块的列表,这些模块之间没有联系也没有顺序(所以不用保证相邻层的输入输出维度匹配),而且没有实现forward功能需要自己实现,所以上面执行net(torch.zeros(1, 784))会报NotImplementedError;而Sequential内的模块需要按照顺序排列,要保证相邻层的输入输出大小相匹配,内部forward功能已经实现。 -
ModuleList的出现只是让网络定义前向传播时更加灵活,见下面官网的例子。 -
class MyModule(nn.Module):def __init__(self):super(MyModule, self).__init__()self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(10)])def forward(self, x):# ModuleList can act as an iterable, or be indexed using intsfor i, l in enumerate(self.linears):x = self.linears[i // 2](x) + l(x)return x -
另外,
ModuleList不同于一般的Python的list,加入到ModuleList里面的所有模块的参数会被自动添加到整个网络中,下面看一个例子对比一下。 -
class Module_ModuleList(nn.Module):def __init__(self):super(Module_ModuleList, self).__init__()self.linears = nn.ModuleList([nn.Linear(10, 10)])class Module_List(nn.Module):def __init__(self):super(Module_List, self).__init__()self.linears = [nn.Linear(10, 10)] net1 = Module_ModuleList() net2 = Module_List() print("net1:") for p in net1.parameters():print(p.size()) print("net2:") for p in net2.parameters():print(p) -
net1: torch.Size([10, 10]) torch.Size([10]) net2:
-
-
ModuleDict类-
ModuleDict接收一个子模块的字典作为输入, 然后也可以类似字典那样进行添加访问操作: -
net = nn.ModuleDict({'linear': nn.Linear(784, 256),'act': nn.ReLU(), }) net['output'] = nn.Linear(256, 10) # 添加 print(net['linear']) # 访问 print(net.output) print(net) # net(torch.zeros(1, 784)) # 会报NotImplementedError -
Linear(in_features=784, out_features=256, bias=True) Linear(in_features=256, out_features=10, bias=True) ModuleDict((linear): Linear(in_features=784, out_features=256, bias=True)(act): ReLU()(output): Linear(in_features=256, out_features=10, bias=True) ) -
和
ModuleList一样,ModuleDict实例仅仅是存放了一些模块的字典,并没有定义forward函数需要自己定义。同样,ModuleDict也与Python的Dict有所不同,ModuleDict里的所有模块的参数会被自动添加到整个网络中。
-
构造复杂的模型
-
虽然上面介绍的这些类可以使模型构造更加简单,且不需要定义
forward函数,但直接继承Module类可以极大地拓展模型构造的灵活性。下面我们构造一个稍微复杂点的网络FancyMLP。在这个网络中,我们通过get_constant函数创建训练中不被迭代的参数,即常数参数。在前向计算中,除了使用创建的常数参数外,我们还使用Tensor的函数和Python的控制流,并多次调用相同的层。在这个FancyMLP模型中,我们使用了常数权重rand_weight(注意它不是可训练模型参数)、做了矩阵乘法操作(torch.mm)并重复使用了相同的Linear层。下面我们来测试该模型的前向计算。 -
class FancyMLP(nn.Module):def __init__(self, **kwargs):super(FancyMLP, self).__init__(**kwargs)self.rand_weight = torch.rand((20, 20), requires_grad=False) # 不可训练参数(常数参数)self.linear = nn.Linear(20, 20)def forward(self, x):x = self.linear(x)# 使用创建的常数参数,以及nn.functional中的relu函数和mm函数x = nn.functional.relu(torch.mm(x, self.rand_weight.data) + 1)# 复用全连接层。等价于两个全连接层共享参数x = self.linear(x)# 控制流,这里我们需要调用item函数来返回标量进行比较while x.norm().item() > 1:x /= 2if x.norm().item() < 0.8:x *= 10return x.sum() X = torch.rand(2, 20) net = FancyMLP() print(net) net(X) -
FancyMLP((linear): Linear(in_features=20, out_features=20, bias=True) ) tensor(-13.7453, grad_fn=<SumBackward0>) -
因为
FancyMLP和Sequential类都是Module类的子类,所以我们可以嵌套调用它们。 -
class NestMLP(nn.Module):def __init__(self, **kwargs):super(NestMLP, self).__init__(**kwargs)self.net = nn.Sequential(nn.Linear(40, 30), nn.ReLU()) def forward(self, x):return self.net(x) net = nn.Sequential(NestMLP(), nn.Linear(30, 20), FancyMLP()) X = torch.rand(2, 40) print(net) net(X) -
Sequential((0): NestMLP((net): Sequential((0): Linear(in_features=40, out_features=30, bias=True)(1): ReLU()))(1): Linear(in_features=30, out_features=20, bias=True)(2): FancyMLP((linear): Linear(in_features=20, out_features=20, bias=True)) ) tensor(-8.4966, grad_fn=<SumBackward0>) -
可以通过继承
Module类来构造模型。Sequential、ModuleList、ModuleDict类都继承自Module类。与Sequential不同,ModuleList和ModuleDict并没有定义一个完整的网络,它们只是将不同的模块存放在一起,需要自己定义forward函数。虽然Sequential等类可以使模型构造更加简单,但直接继承Module类可以极大地拓展模型构造的灵活性。
模型参数的访问、初始化和共享
-
通过
init模块来初始化模型的参数。我们也介绍了访问模型参数的简单方法。本节将深入讲解如何访问和初始化模型参数,以及如何在多个层之间共享同一份模型参数。我们先定义一个与上一节中相同的含单隐藏层的多层感知机。我们依然使用默认方式初始化它的参数,并做一次前向计算。与之前不同的是,在这里我们从nn中导入了init模块,它包含了多种模型初始化方法。 -
import torch from torch import nn from torch.nn import init net = nn.Sequential(nn.Linear(4, 3), nn.ReLU(), nn.Linear(3, 1)) # pytorch已进行默认初始化 print(net) X = torch.rand(2, 4) Y = net(X).sum() -
Sequential((0): Linear(in_features=4, out_features=3, bias=True)(1): ReLU()(2): Linear(in_features=3, out_features=1, bias=True) ) -
访问模型参数
-
上一节中提到的
Sequential类与Module类的继承关系。对于Sequential实例中含模型参数的层,我们可以通过Module类的parameters()或者named_parameters方法来访问所有参数(以迭代器的形式返回),后者除了返回参数Tensor外还会返回其名字。下面,访问多层感知机net的所有参数: -
print(type(net.named_parameters())) for name, param in net.named_parameters():print(name, param.size()) -
<class 'generator'> 0.weight torch.Size([3, 4]) 0.bias torch.Size([3]) 2.weight torch.Size([1, 3]) 2.bias torch.Size([1])
-
-
可见返回的名字自动加上了层数的索引作为前缀。我们再来访问
net中单层的参数。对于使用Sequential类构造的神经网络,我们可以通过方括号[]来访问网络的任一层。索引0表示隐藏层为Sequential实例最先添加的层。-
import torch from torch import nn from torch.nn import init net = nn.Sequential(nn.Linear(4, 3), nn.ReLU(), nn.Linear(3, 1)) # pytorch已进行默认初始化 print(net) X = torch.rand(2, 4) Y = net(X).sum() print(X,Y) print(type(net.named_parameters())) for name, param in net.named_parameters():print(name, param.size()) for name, param in net[0].named_parameters():print(name, param.size(), type(param)) -
Sequential((0): Linear(in_features=4, out_features=3, bias=True)(1): ReLU()(2): Linear(in_features=3, out_features=1, bias=True) ) tensor([[0.3863, 0.5931, 0.4958, 0.5612],[0.6388, 0.5556, 0.0613, 0.0673]]) tensor(0.0355, grad_fn=<SumBackward0>) <class 'generator'> 0.weight torch.Size([3, 4]) 0.bias torch.Size([3]) 2.weight torch.Size([1, 3]) 2.bias torch.Size([1]) weight torch.Size([3, 4]) <class 'torch.nn.parameter.Parameter'> bias torch.Size([3]) <class 'torch.nn.parameter.Parameter'>
-
-
因为这里是单层的所以没有了层数索引的前缀。另外返回的
param的类型为torch.nn.parameter.Parameter,其实这是Tensor的子类,和Tensor不同的是如果一个Tensor是Parameter,那么它会自动被添加到模型的参数列表里,来看下面这个例子。-
class MyModel(nn.Module):def __init__(self, **kwargs):super(MyModel, self).__init__(**kwargs)self.weight1 = nn.Parameter(torch.rand(20, 20))self.weight2 = torch.rand(20, 20)def forward(self, x):pass n = MyModel() for name, param in n.named_parameters():print(name) -
weight1 -
上面的代码中
weight1在参数列表中但是weight2却没在参数列表中。因为Parameter是Tensor,即Tensor拥有的属性它都有,比如可以根据data来访问参数数值,用grad来访问参数梯度。 -
weight_0 = list(net[0].parameters())[0] print(weight_0.data) print(weight_0.grad) # 反向传播前梯度为None Y.backward() print(weight_0.grad) -
tensor([[ 0.1633, 0.4935, -0.2096, 0.3643],[-0.3411, -0.4858, -0.0935, -0.4009],[ 0.0155, 0.2264, 0.2721, 0.3809]]) None tensor([[-0.5175, -0.5799, -0.2812, -0.3173],[ 0.0000, 0.0000, 0.0000, 0.0000],[-0.2534, -0.2840, -0.1377, -0.1554]])
-
初始化模型参数
-
PyTorch中
nn.Module的模块参数都采取了较为合理的初始化策略(不同类型的layer具体采样的哪一种初始化方法的可参考源代码)。但我们经常需要使用其他方法来初始化权重。PyTorch的init模块里提供了多种预设的初始化方法。在下面的例子中,我们将权重参数初始化成均值为0、标准差为0.01的正态分布随机数,并依然将偏差参数清零。-
for name, param in net.named_parameters():if 'weight' in name:init.normal_(param, mean=0, std=0.01)print(name, param.data) -
0.weight tensor([[ 0.0024, 0.0115, 0.0088, 0.0098],[-0.0160, -0.0014, 0.0021, 0.0019],[ 0.0031, 0.0009, 0.0060, -0.0080]]) 2.weight tensor([[ 0.0137, -0.0166, -0.0243]])
-
自定义初始化方法
-
有时候我们需要的初始化方法并没有在
init模块中提供。这时,可以实现一个初始化方法,从而能够像使用其他初始化方法那样使用它。在这之前我们先来看看PyTorch是怎么实现这些初始化方法的,例如torch.nn.init.normal_:可以看到这就是一个inplace改变Tensor值的函数,而且这个过程是不记录梯度的。类似的我们来实现一个自定义的初始化方法。在下面的例子里,我们令权重有一半概率初始化为0,有另一半概率初始化为[-10,-5]和[5,10]两个区间里均匀分布的随机数。 -
def normal_(tensor, mean=0, std=1):with torch.no_grad():return tensor.normal_(mean, std) def init_weight_(tensor):with torch.no_grad():tensor.uniform_(-10, 10)tensor *= (tensor.abs() >= 5).float() for name, param in net.named_parameters():if 'weight' in name:init_weight_(param)print(name, param.data) -
0.weight tensor([[-0.0000, -9.1898, 6.7726, -0.0000],[ 0.0000, -0.0000, -7.7626, 0.0000],[ 6.0222, 9.4339, -8.2883, -0.0000]]) 2.weight tensor([[0., 0., -0.]]) -
还可以通过改变这些参数的
data来改写模型参数值同时不会影响梯度: -
for name, param in net.named_parameters():if 'bias' in name:param.data += 1print(name, param.data) -
0.bias tensor([0.7341, 1.0775, 1.1191]) 2.bias tensor([1.2091])
共享模型参数
-
在有些情况下,我们希望在多个层之间共享模型参数。如何共享模型参数:
Module类的forward函数里多次调用同一个层。此外,如果我们传入Sequential的模块是同一个Module实例的话参数也是共享的,下面来看一个例子:在内存中,这两个线性层其实一个对象,因为模型参数里包含了梯度,所以在反向传播计算时,这些共享的参数的梯度是累加的: -
linear = nn.Linear(1, 1, bias=False) net = nn.Sequential(linear, linear) print(net) for name, param in net.named_parameters():init.constant_(param, val=3)print(name, param.data) print(id(net[0]) == id(net[1])) print(id(net[0].weight) == id(net[1].weight)) x = torch.ones(1, 1) y = net(x).sum() print(y) y.backward() print(net[0].weight.grad) # 单次梯度是3,两次所以就是6 -
Sequential((0): Linear(in_features=1, out_features=1, bias=False)(1): Linear(in_features=1, out_features=1, bias=False) ) 0.weight tensor([[3.]]) True True tensor(9., grad_fn=<SumBackward0>) tensor([[6.]])
自定义层
-
深度学习的一个魅力在于神经网络中各式各样的层,例如全连接层和后面章节中将要介绍的卷积层、池化层与循环层。虽然PyTorch提供了大量常用的层,但有时候我们依然希望自定义层。本节将介绍如何使用
Module来自定义层,从而可以被重复调用。 -
不含模型参数的自定义层
- 先介绍如何定义一个不含模型参数的自定义层。模型构造中介绍的使用
Module类构造模型类似。下面的CenteredLayer类通过继承Module类自定义了一个将输入减掉均值后输出的层,并将层的计算定义在了forward函数里。这个层里不含模型参数。可以实例化这个层,然后做前向计算。 -
import torch from torch import nn class CenteredLayer(nn.Module):def __init__(self, **kwargs):super(CenteredLayer, self).__init__(**kwargs)def forward(self, x):return x - x.mean() layer = CenteredLayer() layer(torch.tensor([1, 2, 3, 4, 5], dtype=torch.float)) -
tensor([-2., -1., 0., 1., 2.]) - 也可以用它来构造更复杂的模型。下面打印自定义层各个输出的均值。因为均值是浮点数,所以它的值是一个很接近0的数。
-
y = net(torch.rand(4, 8)) y.mean().item() -
-3.259629011154175e-09
-
- 先介绍如何定义一个不含模型参数的自定义层。模型构造中介绍的使用
-
含模型参数的自定义层
-
还可以自定义含模型参数的自定义层。其中的模型参数可以通过训练学出。模型参数的访问、初始化和共享中介绍了
Parameter类其实是Tensor的子类,如果一个Tensor是Parameter,那么它会自动被添加到模型的参数列表里。所以在自定义含模型参数的层时,应该将参数定义成Parameter,那样直接定义成Parameter类外,还可以使用ParameterList和ParameterDict分别定义参数的列表和字典。 -
ParameterList接收一个Parameter实例的列表作为输入然后得到一个参数列表,使用的时候可以用索引来访问某个参数,另外也可以使用append和extend在列表后面新增参数。 -
class MyDense(nn.Module):def __init__(self):super(MyDense, self).__init__()self.params = nn.ParameterList([nn.Parameter(torch.randn(4, 4)) for i in range(3)])self.params.append(nn.Parameter(torch.randn(4, 1)))def forward(self, x):for i in range(len(self.params)):x = torch.mm(x, self.params[i])return x net = MyDense() print(net) -
MyDense((params): ParameterList((0): Parameter containing: [torch.float32 of size 4x4](1): Parameter containing: [torch.float32 of size 4x4](2): Parameter containing: [torch.float32 of size 4x4](3): Parameter containing: [torch.float32 of size 4x1]) ) -
而
ParameterDict接收一个Parameter实例的字典作为输入然后得到一个参数字典,然后可以按照字典的规则使用了。例如使用update()新增参数,使用keys()返回所有键值,使用items()返回所有键值对等等,可参考官方文档。 -
class MyDictDense(nn.Module):def __init__(self):super(MyDictDense, self).__init__()self.params = nn.ParameterDict({'linear1': nn.Parameter(torch.randn(4, 4)),'linear2': nn.Parameter(torch.randn(4, 1))})self.params.update({'linear3': nn.Parameter(torch.randn(4, 2))}) # 新增def forward(self, x, choice='linear1'):return torch.mm(x, self.params[choice]) net = MyDictDense() print(net) x = torch.ones(1, 4) # 这样就可以根据传入的键值来进行不同的前向传播: print(net(x, 'linear1')) print(net(x, 'linear2')) print(net(x, 'linear3')) -
MyDictDense((params): ParameterDict((linear1): Parameter containing: [torch.FloatTensor of size 4x4](linear2): Parameter containing: [torch.FloatTensor of size 4x1](linear3): Parameter containing: [torch.FloatTensor of size 4x2]) ) tensor([[ 0.0328, 2.9246, 1.9687, -0.0347]], grad_fn=<MmBackward0>) tensor([[-1.4231]], grad_fn=<MmBackward0>) tensor([[ 2.0699, -0.0636]], grad_fn=<MmBackward0>)
-
-
也可以使用自定义层构造模型。它和PyTorch的其他层在使用上很类似。
-
net = nn.Sequential(MyDictDense(),CenteredLayer(), ) print(net) print(net(x)) -
Sequential((0): MyDictDense((params): ParameterDict((linear1): Parameter containing: [torch.FloatTensor of size 4x4](linear2): Parameter containing: [torch.FloatTensor of size 4x1](linear3): Parameter containing: [torch.FloatTensor of size 4x2]))(1): CenteredLayer() ) tensor([[-0.9821, 2.2057, 1.5066, -2.7302]], grad_fn=<SubBackward0>)
-
-
可以通过
Module类自定义神经网络中的层,从而可以被重复调用。
读取和存储
-
到目前为止,介绍了如何处理数据以及如何构建、训练和测试深度学习模型。然而在实际中,有时需要把训练好的模型部署到很多不同的设备。在这种情况下,可以把内存中训练好的模型参数存储在硬盘上供后续读取使用。
-
读写
Tensor- 可以直接使用
save函数和load函数分别存储和读取Tensor。save使用Python的pickle实用程序将对象进行序列化,然后将序列化的对象保存到disk,使用save可以保存各种对象,包括模型、张量和字典等。而load使用pickle unpickle工具将pickle的对象文件反序列化为内存。 - 下面的例子创建了
Tensor变量x,并将其存在文件名同为x.pt的文件里。 -
import torch from torch import nn x = torch.ones(3) torch.save(x, 'x.pt') x2 = torch.load('x.pt') print(x2) # 还可以存储一个`Tensor`列表并读回内存。 y = torch.zeros(4) torch.save([x, y], 'xy.pt') xy_list = torch.load('xy.pt') print(xy_list) # 存储并读取一个从字符串映射到`Tensor`的字典。 torch.save({'x': x, 'y': y}, 'xy_dict.pt') xy = torch.load('xy_dict.pt') print(xy) -
tensor([1., 1., 1.]) [tensor([1., 1., 1.]), tensor([0., 0., 0., 0.])] {'x': tensor([1., 1., 1.]), 'y': tensor([0., 0., 0., 0.])} - [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SKoP2sZg-1677897286625)(C:\Users\23105\AppData\Roaming\marktext\images\2023-03-04-10-20-35-image.png)]
- 可以直接使用
读写模型
-
在PyTorch中,
Module的可学习参数(即权重和偏差),模块模型包含在参数中(通过model.parameters()访问)。state_dict是一个从参数名称隐射到参数Tesnor的字典对象。-
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.hidden = nn.Linear(3, 2)self.act = nn.ReLU()self.output = nn.Linear(2, 1)def forward(self, x):a = self.act(self.hidden(x))return self.output(a) net = MLP() net.state_dict() -
OrderedDict([('hidden.weight',tensor([[-0.3441, 0.5054, 0.5027],[ 0.4022, -0.0523, 0.2171]])),('hidden.bias', tensor([0.0867, 0.5426])),('output.weight', tensor([[ 0.5839, -0.6612]])),('output.bias', tensor([0.2582]))])
-
-
注意,只有具有可学习参数的层(卷积层、线性层等)才有
state_dict中的条目。优化器(optim)也有一个state_dict,其中包含关于优化器状态以及所使用的超参数的信息。-
optimizer = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.9) optimizer.state_dict() -
{'state': {},'param_groups': [{'lr': 0.001,'momentum': 0.9,'dampening': 0,'weight_decay': 0,'nesterov': False,'maximize': False,'foreach': None,'differentiable': False,'params': [0, 1, 2, 3]}]}
-
保存和加载模型加载预训练模型,模型微调,在自己的数据集上快速出效果_羞儿的博客-CSDN博客
-
PyTorch中保存和加载训练模型有两种常见的方法:
-
仅保存和加载模型参数(
state_dict); -
保存和加载整个模型。
-
-
保存和加载
state_dict(推荐方式)-
# 保存 torch.save(model.state_dict(), PATH) # 推荐的文件后缀名是pt或pth # 加载 model = TheModelClass(*args, **kwargs) model.load_state_dict(torch.load(PATH))
-
-
保存和加载整个模型
-
torch.save(model, PATH) # 保存 model = torch.load(PATH) # 加载
-
-
采用推荐的方法一来实验一下:
-
X = torch.randn(2, 3) Y = net(X) PATH = "./net.pt" torch.save(net.state_dict(), PATH) net2 = MLP() net2.load_state_dict(torch.load(PATH)) Y2 = net2(X) Y2 == Y -
tensor([[True],[True]])
-
-
因为这
net和net2都有同样的模型参数,那么对同一个输入X的计算结果将会是一样的。上面的输出也验证了这一点。此外,还有一些其他使用场景,例如GPU与CPU之间的模型保存与读取、使用多块GPU的模型的存储等等,使用的时候可以参考官方文档。 -
通过
save函数和load函数可以很方便地读写Tensor。通过save函数和load_state_dict函数可以很方便地读写模型的参数。
torch.save(model, PATH) # 保存
model = torch.load(PATH) # 加载 -
采用推荐的方法一来实验一下:
-
X = torch.randn(2, 3) Y = net(X) PATH = "./net.pt" torch.save(net.state_dict(), PATH) net2 = MLP() net2.load_state_dict(torch.load(PATH)) Y2 = net2(X) Y2 == Y -
tensor([[True],[True]])
-
-
因为这
net和net2都有同样的模型参数,那么对同一个输入X的计算结果将会是一样的。上面的输出也验证了这一点。此外,还有一些其他使用场景,例如GPU与CPU之间的模型保存与读取、使用多块GPU的模型的存储等等,使用的时候可以参考官方文档。 -
通过
save函数和load函数可以很方便地读写Tensor。通过save函数和load_state_dict函数可以很方便地读写模型的参数。
相关文章:

pytorch-模型构建,参数访问,模型存取API接口,对比学习
多层感知机的简洁实现pytorch-多层感知机,最简单的深度学习模型,将非线性激活函数引入到模型中。_羞儿的博客-CSDN博客中含单隐藏层的多层感知机的实现方法。首先构造Sequential实例,然后依次添加两个全连接层。其中第一层的输出大小为256&am…...

javaEE 初阶 — 数据链路层中的以太网数据帧
文章目录以太网帧格式1. MAC 地址2. MAC 地址是如何与 IP 地址相互配合的3. 以太网帧格式中的类型MTU(了解)以太网帧格式 数据链路层主要考虑的是相邻的两个结点之间的传输。 这里最知名的协议就是 以太网。 一个以太网数据帧有三个部分组成。帧头载荷…...
泼辣修图Polarr5.11.4 版,让你的创意无限延伸
泼辣修图是一款非常实用的图片处理软件,它不仅拥有丰富的图片处理功能,而且还能够轻松地实现自定义操作。泼辣修图的操作界面非常简洁,功能也非常丰富,使用起来非常方便快捷。 泼辣修图拥有非常丰富的图片处理功能,包括…...
leetcode打卡-深度优先遍历和广度优先遍历
200.岛屿数量 leetcode题目链接:https://leetcode.cn/problems/number-of-islands leetcode AC记录: 思路:深度优先遍历,从0,0开始遍历数组,使用boolean类型数组used记录是否被访问过,进行一…...

【0177】Linux中POSIX信号量实现机制
文章目录 1. 信号量概念1.1 信号量类比1.2 重要的观察1.3 信号量分类2. POSIX与System V信号量3. 信号量API4. 代码演示5. 信号量内核实现1. 信号量概念 在计算机科学中,信号量(semaphores )是一种变量或抽象数据类型,用于控制多个进程对公共资源的访问,并避免并发系统(如…...
跳表--C++实现
目录 作者有话说 为何要学习跳表?为了快,为了更快,为了折磨自己..... 跳表作用场景 1.不少公司自己会设计哈希表,如果解决哈希冲突是不可避免的事情。通常情况下会使用链址,很好理解,当有冲突产生时&#…...

c#:System.Text.Json 的使用一
环境: .net 6.0vs2022 参考: 从 Newtonsoft.Json 迁移到 System.Text.Json System.Text.Json 常规用法 一、写入时的控制 1.1 非ascii码转换 直接看代码: var str System.Text.Json.JsonSerializer.Serialize(new Model { Id 1, Name …...
kaggle数据集下载当中所遇到的问题
kaggle数据集下载当中所遇到的问题报错分析pip install kagglethe SSL module is not available解决方法pip的版本升级解决办法下载kaggle包kaggle数据集下载问题解决参考内容报错分析 今天在尝试使用pip install kaggle的方法去下载我需要的数据集的时候遇到了一些报错的问题…...

TEX:高阶用法
文章目录定制LATEX记数器创建记数器改变记数器的值显示记数器的值长度橡皮长度用户定义命令用户定义的环境标题定制正文中标题设置使用titlesec宏包设置标题格式目录中标题设置LATEX 2ε\varepsilonε程序设计语言命令的层次文件识别上载其他类和宏包输入文件检测文件选项的处理…...
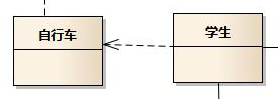
UML 类图
车的类图结构为<>,表示车是一个抽象类; 它有两个继承类:小汽车和自行车;它们之间的关系为实现关系,使用带空心箭头的虚线表示; 小汽车为与SUV之间也是继承关系,它们之间的关系为泛化关系…...

项目实战典型案例1——redis只管存不管删除 让失效时间删除的问题
redis只管存不管删除 让失效时间删除的问题一:背景介绍二:思路&方案三:代码模拟1.错误示范通过班级id查询课程名称执行结果通过班级id修改课程名称(并没有删除对应缓存)执行结果2.正确示范在错误示范的更新接口上添…...
@RequestParam和@PathVariable的用法与区别
PathVariable PathVariable 映射 URL 绑定的占位符带占位符的 URL 是 Spring3.0 新增的功能,该功能在SpringMVC 向 REST 目标挺进发展过程中具有里程碑的意义通过 PathVariable 可以将 URL 中占位符参数绑定到控制器处理方法的入参中:URL 中的 {xxx} 占…...

【大数据 AI 人工智能】数据科学家必学的 9 个核心机器学习算法
如今,机器学习正改变着我们的世界。借助机器学习(ML),谷歌在为我们推荐搜索结果,奈飞在为我们推荐观看影片,脸书在为我们推荐可能认识的朋友。 机器学习从未像在今天这样重要。但与此同时,机器学习这一领域也充斥着各种术语,晦涩难懂,各种机器学习的算法每年层出不穷…...
IronPDF for .NET 2023.2.4 Crack
适用于 .NET 2023.2.4 的 IronPDF 添加对增量 PDF 保存的支持。 2023 年 3 月 2 日 - 10:23新版本 特征 添加了对 IronPdfEngine Docker 的支持。 添加了对增量 PDF 保存的支持。 重新设计了 PDF 签名和签名。 删除了 iTextSharp 依赖项。 在文本页眉/页脚中添加了 DrawDivider…...

3.4-前端的10个问题
01、null和undefined undefined是全局对象的一个属性,当一个变量没有赋值或者访问一个对象不存在的属性,这时候都是undefined。 null:表示是一个空对象。在需要释放一个对象的时候,直接赋值为null即可。 02、箭头函数 箭头函数…...

开发手册——一、编程规约_9.其他
这篇文章主要梳理了在java的实际开发过程中的编程规范问题。本篇文章主要借鉴于《阿里巴巴java开发手册终极版》 下面我们一起来看一下吧。 1. 【强制】在使用正则表达式时,利用好其预编译功能,可以有效加快正则匹配速度。 说明:不要在方法…...
23.3.4打卡 AtCoder Beginner Contest 291(Sponsored by TOYOTA SYSTEMS)A~E
F题题面都看不懂嘞!开摆! 没找到合适的markdown, 截图网页翻译了我真是天才 比赛链接: https://atcoder.jp/contests/abc291 A题 题意 给出一个字符串, 找到第一个大写字母的下标 简单题就不多说了, 直接放代码 代码 void solve() {cin>>str;nstr.size();str"…...
Gem5模拟器,一些运行的小tips(十一)
一些基础知识,下面提到的东西与前面的文章有一定的关系,感兴趣的小伙伴可以看一下: (21条消息) Gem5模拟器,全流程运行Chiplet-Gem5-SharedMemory-main(十)_好啊啊啊啊的博客-CSDN博客 Gem5模拟器…...

【JAVA】List接口
🏆今日学习目标:List接口 😃创作者:颜颜yan_ ✨个人主页:颜颜yan_的个人主页 ⏰本期期数:第四期 🎉专栏系列:JAVA List接口一、ArrayList二、LinkedList总结一、ArrayList ArrayLis…...
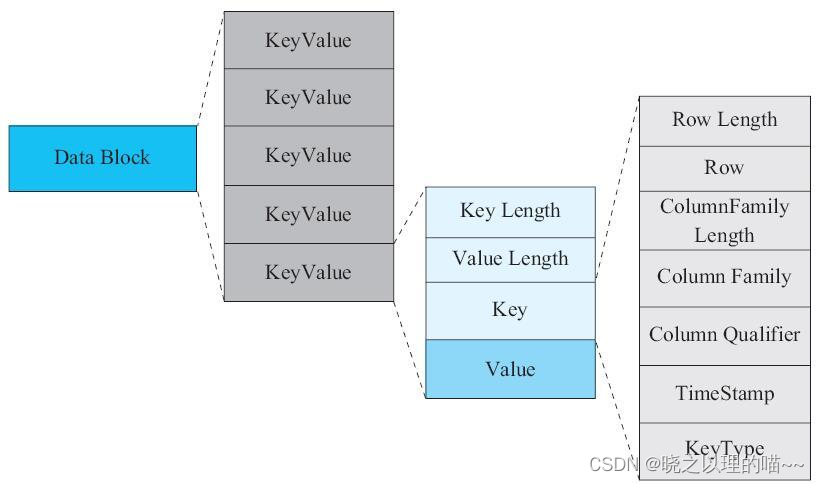
Hbase RegionServer的核心模块
RegionServer是HBase系统中最核心的组件,主要负责用户数据写入、读取等基础操作。RegionServer组件实际上是一个综合体系,包含多个各司其职的核心模块:HLog、MemStore、HFile以及BlockCache。 一、RegionServer内部结构 RegionServer是HBas…...

Kubernetes与GitOps最佳实践
Kubernetes与GitOps最佳实践 1. GitOps概述 GitOps是一种基于Git的持续部署方法,它将基础设施和应用配置存储在Git仓库中,并通过自动化工具来实现部署。GitOps的核心原则是: Git作为单一事实来源:所有配置变更都通过Git进行版本控…...

【MobaXterm进阶】SSH连接稳定性优化:Keepalive与超时设置详解
1. 为什么SSH连接会频繁断开? 很多朋友在用MobaXterm远程连接服务器时都遇到过这样的困扰:明明连接得好好的,过一会儿就莫名其妙断开了。特别是当你正在执行一个耗时较长的任务时,突然中断简直让人抓狂。这种情况在家庭版用户中尤…...

重构时间选择体验:flatpickr的现代前端实践指南
重构时间选择体验:flatpickr的现代前端实践指南 【免费下载链接】flatpickr lightweight, powerful javascript datetimepicker with no dependencies 项目地址: https://gitcode.com/gh_mirrors/fl/flatpickr 问题引入:你的时间选择器是否还在制…...

OpenClaw技能开发案例:为千问3.5-9B添加日历管理功能
OpenClaw技能开发案例:为千问3.5-9B添加日历管理功能 1. 为什么需要自定义日历管理技能 去年我接手了一个私人项目,需要定期跟踪十几个线上活动的排期。最初尝试用Python脚本Google Calendar API管理,但每次修改都要手动调整代码参数。后来…...

NSC_BUILDER:全能Switch文件处理工具的深度应用指南
NSC_BUILDER:全能Switch文件处理工具的深度应用指南 【免费下载链接】NSC_BUILDER Nintendo Switch Cleaner and Builder. A batchfile, python and html script based in hacbuild and Nuts python libraries. Designed initially to erase titlerights encryption…...

技术深度解析:logitech-pubg项目实现PUBG后坐力控制的Lua脚本架构设计
技术深度解析:logitech-pubg项目实现PUBG后坐力控制的Lua脚本架构设计 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 在竞技射击游戏…...

告别手动逐个校验,用快马快速构建vmware密钥批量验证工具提升效率
告别手动逐个校验,用快马快速构建vmware密钥批量验证工具提升效率 最近在帮朋友处理一批VMware16的密钥验证工作,发现手动逐个检查不仅耗时耗力,还容易出错。特别是当需要验证几十甚至上百个密钥时,这种重复劳动简直让人崩溃。于…...

3步构建企业级实时日志分析系统:从数据采集到智能告警
3步构建企业级实时日志分析系统:从数据采集到智能告警 【免费下载链接】DouyinLiveWebFetcher 抖音直播间网页版的弹幕数据抓取(2025最新版本) 项目地址: https://gitcode.com/gh_mirrors/do/DouyinLiveWebFetcher 在现代企业IT架构中…...
)
基于YOLOv8深度学习的蘑菇毒性检测系统(YOLOv8+YOLO数据集+UI界面+Python项目源码+模型)
一、项目介绍 摘要 随着人们对于野生菌菇膳食兴趣的增加以及户外采摘活动的普及,误食有毒蘑菇的事件频发,对公众健康构成了严重威胁。传统的蘑菇种类鉴别高度依赖专家的形态学经验,普通爱好者难以准确掌握,且现有识别应用在应对…...

Qwen3.5-9B多模态能力解析:图文输入联合建模+VL变体兼容性说明
Qwen3.5-9B多模态能力解析:图文输入联合建模VL变体兼容性说明 1. 模型概述与核心能力 Qwen3.5-9B是一款拥有90亿参数的开源大语言模型,在多模态理解和长上下文处理方面展现出卓越性能。作为当前开源社区的重要贡献,该模型特别强化了图文联合…...