跳表--C++实现
目录
作者有话说
为何要学习跳表?为了快,为了更快,为了折磨自己.....
跳表作用场景
1.不少公司自己会设计哈希表,如果解决哈希冲突是不可避免的事情。通常情况下会使用链址,很好理解,当有冲突产生时,我们在附加的链表中添加一位(如果使用的循环双链表没直接在后面加,效率很高O(1)。如果是单链表也可以使用头插法直接在头部添加,效率很高O(1),如果使用跳表需要O(logN))。
2.看到这里不少朋友会觉得,那需要什么跳表呀,还变慢了。不要着急,我们继续往下看,首先使用简单的头差法,得到的序列可以认为是乱序(不考虑依次插入是有序的),那么查找起来会变得比较费劲,需要O(N)。但是使用跳表查找的平均效率是O(logN),插入O(logN),删除O(logN)。
【注意这里写的是平均情况,如果跳表设计不好,很容易导致跳表退化成链表】
3.跳表有时候可以代替红黑树和AVL树,甚至说跳表的插入和删除的维护比AVL树代价低与红黑树差不多。
跳表的主要思想
二分!二分!还是二分!
接触了这么久的编程,会发现很多比较优秀的算法都是基于二分思想演变而来的。
至于算法如何选择,需要结合具体的业务情况,一个算法的最好时间复杂度、平均时间复杂度、最坏时间复杂度都是需要考虑的。两个相同功能的算法在不同应用场景下会有很大是差距,即使平时我们都认为他们的时间复杂度都是O(logN).
与时间复杂度具有类似概念的就是空间复杂度了,空间复杂度也是需要考虑的问题。一个占据CPU、一个占据内存....
空间复杂度总是与时间复杂度此消彼长,他们向一对冤家。但是通常情况下,我们普遍接受在允许的内存消耗内,选择最快的算法。天下武功为快不破....
跳表的特点
1.单向链表(这个不是绝对的,如果想居于范围查找,使用双向链表会更快 ==> 未测试过)
2.有序保存(二分的前提条件)
3.支持添加、删除和查找
4.查找效率 O(logN)
跳表与普通链表的区别
普通单链表
对于普通的单链表,越靠前的节点,查找快。对于越靠后的节点查找效率越低。其平均效率 = (1+ 2 + 3 + ... + n) / n = (1/2 * n(a1+an))/n = (1 + n) / 2 ==> O(N)
简单的跳表
跳表的结构是通过建立高纬度的索引来减少低纬度从而达到任何元素的检索接近线性时间的目的O(logN)。其实跳表的思想并不复杂,为了提高查找效率将中间节点提高维度,在查找过程中逐步的对半减小查找过程。


跳表的建立
我们知道了跳表的基本思想后,我们来手动模拟建立一个跳表。现在我们依次顺序插入1 5 8 3 2 7 9 这七个元素。===> 【我们采用间隔一个的方式提取高纬度的节点】
1.初始化 ==> 准备一个头部节点,我们知道链表有两种方式(一种是有头节点的、一种是没有头节点的,为了方便对第一个节点的操作,我们统一使用有头节点的)。
注意:指针域这里没有画出来
2.插入 1 ==> 像单链表一样直接将节点插入到右边就可以了。
注意: 空白部分代表指针指向NULL,防止野指针
3.插入 5 ==> 这里考虑将向上提取元素(也可以不提取),先查找需要查找的位置,5 > 1所以插入到1的后面就可以了。
==> 为了保证隔一个的一致性和写代码时少考虑一种情况,我们还是向上提取 5
注意: 空白部分代表指针指向NULL,防止野指针
4. 插入 8 ==> 还是同样的道理,我们需要提取查找8所需要查找的位置。8 > 5因为提前做了5的提升,我们不需要比较1,然后再比较5,我们直接拿到5就可以知道8应该插入到5的后面,跳表的优势就表现出来了。
【这个过程插入过程分成了两个步骤,先在1维链表中插入8】
注意:空白部分代表指针指向NULL,防止野指针
注意: 空白部分代表指针指向NULL,防止野指针
5.插入 3 ==> 我们先比较 5 > 3,那么整个范围变成了 【1-5】,然后 1 < 3 < 5 。那么需要将3插入到1和5之间
【将3插入,按两个提取的原则,需要将3提升,然后 3、5在同一层,需要将5提升】
注意:空白部分代表指针指向NULL,防止野指针
6.插入 2 ==> 过程同上面一样。不做过多的解释了....
【画图不易,点个关注吧....只输出优质文章:大家有什么想算法,可以下方留言】
注意:空白部分代表指针指向NULL,防止野指针
7.插入 7 ==> 过程同上面一样。不做过多的解释了....
注意:空白部分代表指针指向NULL,防止野指针
8.插入 9 ==> 过程同上面一样。不做过多的解释了....
注意:空白部分代表指针指向NULL,防止野指针
【以上就是跳表建立的全部过程,如果不明白可以加入微信C++技术交流群:C++技术交流群-陈达叔】
【bilibili 搜索 陈达叔视频后续会更新,感谢大家关注....创作不易,点个关注吧...】
跳表的查找
跳表的查找很简单,就是二分查找的逻辑,为了更好的了解查找的过程,我们来看下示例...
示例1: 查找 3
先比较 5 ==> 3 < 5 ==> 查找范围变成 1-5之间
然后 header向下移动一位,比较 3 == 3 ==> 找到 3 返回 true
示例2:查找 9
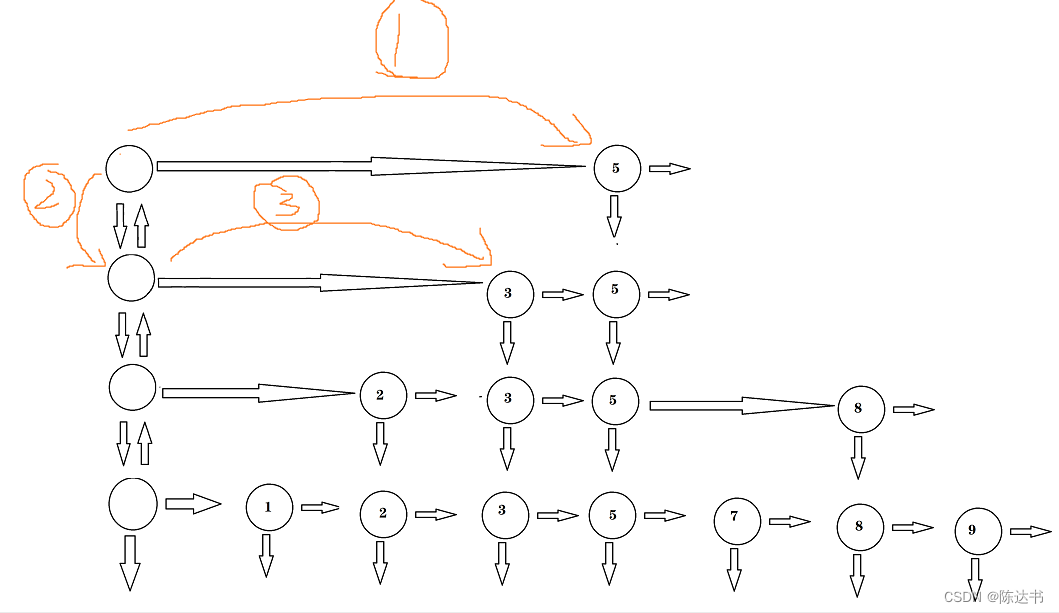
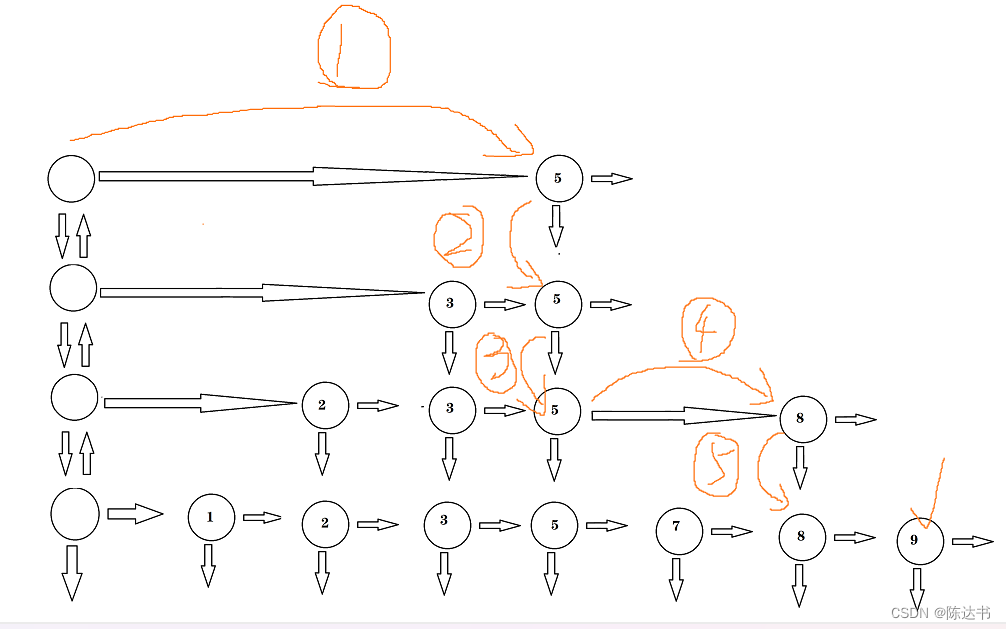
跳表的删除
跳表的查找很简单,就是二分查找的逻辑,为了更好的了解查找的过程,我们来看下示例...
示例1:删除 2
为了防止不断是增加,层数过高,我们可以做个调整
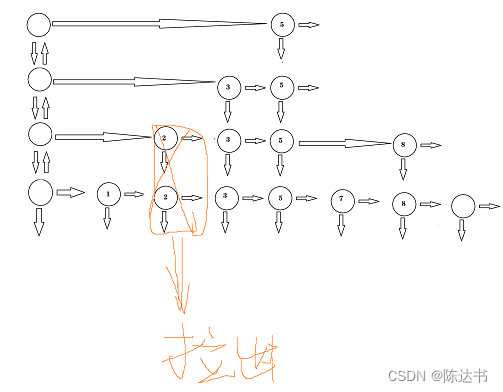
跳表的提取维度说明
不难发现,跳表的实现就是对数据做了向上的冗余操作,以时间换空间的的典型。
当我们设置的冗余颗粒越小,那么需要的空间越大。所以选择好的冗余颗粒度很重要,这个需要根据具体情况而定。
再跳表存在一个随机函数,其存在的意义是决定什么时候需要向上做冗余。实际的建造过程不会像我们示例一样的建造,这样代价会比较高。为了防止跳表插入节点增加而导致退化成链表的情况,我们通常通过一个随机函数来决定向上做提升的时刻。
跳表的代码
#pragma once #ifndef SKIPLIST_ENTRY_H_ #define SKIPLIST_ENTRY_H_ /* 一个更具备代表性的泛型版本 */ #include <ctime> #include <cstdlib>template<typename T> class Entry { private:int key; // 排序值T value; // 保存对象Entry* pNext;Entry* pDown; public:Entry(int k, T v) :value(v), key(k), pNext(nullptr), pDown(nullptr) {}Entry(const Entry& e) :value(e.value), key(e.key), pNext(nullptr), pDown(nullptr) {}public:/* 重载运算符 */bool operator<(const Entry& right) {return key < right.key;}bool operator>(const Entry& right) {return key > right.key;}bool operator<=(const Entry& right) {return key <= right.key;}bool operator>=(const Entry& right) {return key >= right.key;}bool operator==(const Entry& right) {return key == right.key;}Entry*& next() {return pNext;}Entry*& down() {return pDown;} };template<typename T> class SkipList_Entry { private:struct Endpoint {Endpoint* up;Endpoint* down;Entry<T>* right;};struct Endpoint* header;int lvl_num; // level_number 已存在的层数unsigned int seed;bool random() {srand(seed);int ret = rand() % 2;seed = rand();return ret == 0;} public:SkipList_Entry() :lvl_num(1), seed(time(0)) {header = new Endpoint();}/* 插入新元素 */void insert(Entry<T>* entry) { // 插入是一系列自底向上的操作struct Endpoint* cur_header = header;// 首先使用链表header到达L1while (cur_header->down != nullptr) {cur_header = cur_header->down;}/* 这里的一个简单想法是L1必定需要插入元素,而在上面的各跳跃层是否插入则根据random确定因此这是一个典型的do-while循环模式 */int cur_lvl = 0; // current_level 当前层数Entry<T>* temp_entry = nullptr; // 用来临时保存一个已经完成插入的节点指针do {Entry<T>* cur_cp_entry = new Entry<T>(*entry); // 拷贝新对象// 首先需要判断当前层是否已经存在,如果不存在增新增cur_lvl++;if (lvl_num < cur_lvl) {lvl_num++;Endpoint *new_header = new Endpoint();new_header->down = header;header->up = new_header;header = new_header;}// 使用cur_lvl作为判断标准,!=1表示cur_header需要上移并连接“同位素”指针if (cur_lvl != 1) {cur_header = cur_header->up;cur_cp_entry->down() = temp_entry;}temp_entry = cur_cp_entry;// 再需要判断的情况是当前所在链表是否已经有元素节点存在,如果是空链表则直接对右侧指针赋值并跳出循环if (cur_header->right == nullptr) {cur_header->right = cur_cp_entry;break;}else {Entry<T>* cursor = cur_header->right; // 创建一个游标指针while (true) { // 于当前链表循环向右寻找可插入点,并在找到后跳出当前循环if (*cur_cp_entry < *cursor) { // 元素小于当前链表所有元素,插入链表头cur_header->right = cur_cp_entry;cur_cp_entry->next() = cursor;break;}else if (cursor->next() == nullptr) { // 元素大于当前链表所有元素,插入链表尾cursor->next() = cur_cp_entry;break;}else if (*cur_cp_entry < *cursor->next()) { // 插入链表中间cur_cp_entry->next() = cursor->next();cursor->next() = cur_cp_entry;break;}cursor = cursor->next(); // 右移动游标}}} while(random());}/* 查询元素 */bool search(Entry<T>* entry) const {if (header->right == nullptr) { // 判断链表头右侧空指针return false;}Endpoint* cur_header = header;// 在lvl_num层中首先找到可以接入的点for (int i = 0; i < lvl_num; i++) {if (*entry < *cur_header->right) {cur_header = cur_header->down;}else {Entry<T>* cursor = cur_header->right;while (cursor->down() != nullptr) {while (cursor->next() != nullptr) {if (*entry <= *cursor->next()) {break;}cursor = cursor->next();}cursor = cursor->down();}while (cursor->next() != nullptr) {if (*entry > *cursor->next()) {cursor = cursor->next();}else if (*entry == *cursor->next()) {return true;}else {return false;}}return false; // 节点大于L1最后一个元素节点,返回false}}return false; // 找不到接入点,则直接返回false;}/* 删除元素 */void remove(Entry<T>* entry) {if (header->right == nullptr) {return;}Endpoint* cur_header = header;Entry<T>* cursor = cur_header->right;int lvl_counter = lvl_num; // 因为在删除的过程中,跳跃表的层数会中途发生变化,因此应该在进入循环之前要获取它的值。for (int i = 0; i < lvl_num; i++) {if (*entry == *cur_header->right) {Entry<T>* delptr = cur_header->right;cur_header->right = cur_header->right->next();delete delptr;}else {Entry<T> *cursor = cur_header->right;while (cursor->next() != nullptr) {if (*entry == *cursor->next()) { // 找到节点->删除->跳出循环Entry<T>* delptr = cursor->next();cursor->next() = cursor->next()->next();delete delptr;break;}cursor = cursor->next();}}// 向下移动链表头指针的时候需要先判断当前链表中是否还存在Entry节点if (cur_header->right == nullptr) {Endpoint* delheader = cur_header;cur_header = cur_header->down;header = cur_header;delete delheader;lvl_num--;}else {cur_header = cur_header->down;}}} }; #endif // !SKIPLIST_ENTRY_H_
对于C++的学习,存在一个的最大问题就是很少可以交流的人,甚至而言网上的资料又比较少。
如果对c++有疑惑或者想要交流的朋友记得加入V: Errrr113
坚持初心,勇敢果断....至每一个热爱技术的朋友!!!
相关文章:
跳表--C++实现
目录 作者有话说 为何要学习跳表?为了快,为了更快,为了折磨自己..... 跳表作用场景 1.不少公司自己会设计哈希表,如果解决哈希冲突是不可避免的事情。通常情况下会使用链址,很好理解,当有冲突产生时&#…...

c#:System.Text.Json 的使用一
环境: .net 6.0vs2022 参考: 从 Newtonsoft.Json 迁移到 System.Text.Json System.Text.Json 常规用法 一、写入时的控制 1.1 非ascii码转换 直接看代码: var str System.Text.Json.JsonSerializer.Serialize(new Model { Id 1, Name …...
kaggle数据集下载当中所遇到的问题
kaggle数据集下载当中所遇到的问题报错分析pip install kagglethe SSL module is not available解决方法pip的版本升级解决办法下载kaggle包kaggle数据集下载问题解决参考内容报错分析 今天在尝试使用pip install kaggle的方法去下载我需要的数据集的时候遇到了一些报错的问题…...

TEX:高阶用法
文章目录定制LATEX记数器创建记数器改变记数器的值显示记数器的值长度橡皮长度用户定义命令用户定义的环境标题定制正文中标题设置使用titlesec宏包设置标题格式目录中标题设置LATEX 2ε\varepsilonε程序设计语言命令的层次文件识别上载其他类和宏包输入文件检测文件选项的处理…...
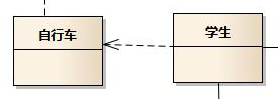
UML 类图
车的类图结构为<>,表示车是一个抽象类; 它有两个继承类:小汽车和自行车;它们之间的关系为实现关系,使用带空心箭头的虚线表示; 小汽车为与SUV之间也是继承关系,它们之间的关系为泛化关系…...

项目实战典型案例1——redis只管存不管删除 让失效时间删除的问题
redis只管存不管删除 让失效时间删除的问题一:背景介绍二:思路&方案三:代码模拟1.错误示范通过班级id查询课程名称执行结果通过班级id修改课程名称(并没有删除对应缓存)执行结果2.正确示范在错误示范的更新接口上添…...
@RequestParam和@PathVariable的用法与区别
PathVariable PathVariable 映射 URL 绑定的占位符带占位符的 URL 是 Spring3.0 新增的功能,该功能在SpringMVC 向 REST 目标挺进发展过程中具有里程碑的意义通过 PathVariable 可以将 URL 中占位符参数绑定到控制器处理方法的入参中:URL 中的 {xxx} 占…...

【大数据 AI 人工智能】数据科学家必学的 9 个核心机器学习算法
如今,机器学习正改变着我们的世界。借助机器学习(ML),谷歌在为我们推荐搜索结果,奈飞在为我们推荐观看影片,脸书在为我们推荐可能认识的朋友。 机器学习从未像在今天这样重要。但与此同时,机器学习这一领域也充斥着各种术语,晦涩难懂,各种机器学习的算法每年层出不穷…...
IronPDF for .NET 2023.2.4 Crack
适用于 .NET 2023.2.4 的 IronPDF 添加对增量 PDF 保存的支持。 2023 年 3 月 2 日 - 10:23新版本 特征 添加了对 IronPdfEngine Docker 的支持。 添加了对增量 PDF 保存的支持。 重新设计了 PDF 签名和签名。 删除了 iTextSharp 依赖项。 在文本页眉/页脚中添加了 DrawDivider…...

3.4-前端的10个问题
01、null和undefined undefined是全局对象的一个属性,当一个变量没有赋值或者访问一个对象不存在的属性,这时候都是undefined。 null:表示是一个空对象。在需要释放一个对象的时候,直接赋值为null即可。 02、箭头函数 箭头函数…...

开发手册——一、编程规约_9.其他
这篇文章主要梳理了在java的实际开发过程中的编程规范问题。本篇文章主要借鉴于《阿里巴巴java开发手册终极版》 下面我们一起来看一下吧。 1. 【强制】在使用正则表达式时,利用好其预编译功能,可以有效加快正则匹配速度。 说明:不要在方法…...
23.3.4打卡 AtCoder Beginner Contest 291(Sponsored by TOYOTA SYSTEMS)A~E
F题题面都看不懂嘞!开摆! 没找到合适的markdown, 截图网页翻译了我真是天才 比赛链接: https://atcoder.jp/contests/abc291 A题 题意 给出一个字符串, 找到第一个大写字母的下标 简单题就不多说了, 直接放代码 代码 void solve() {cin>>str;nstr.size();str"…...
Gem5模拟器,一些运行的小tips(十一)
一些基础知识,下面提到的东西与前面的文章有一定的关系,感兴趣的小伙伴可以看一下: (21条消息) Gem5模拟器,全流程运行Chiplet-Gem5-SharedMemory-main(十)_好啊啊啊啊的博客-CSDN博客 Gem5模拟器…...

【JAVA】List接口
🏆今日学习目标:List接口 😃创作者:颜颜yan_ ✨个人主页:颜颜yan_的个人主页 ⏰本期期数:第四期 🎉专栏系列:JAVA List接口一、ArrayList二、LinkedList总结一、ArrayList ArrayLis…...
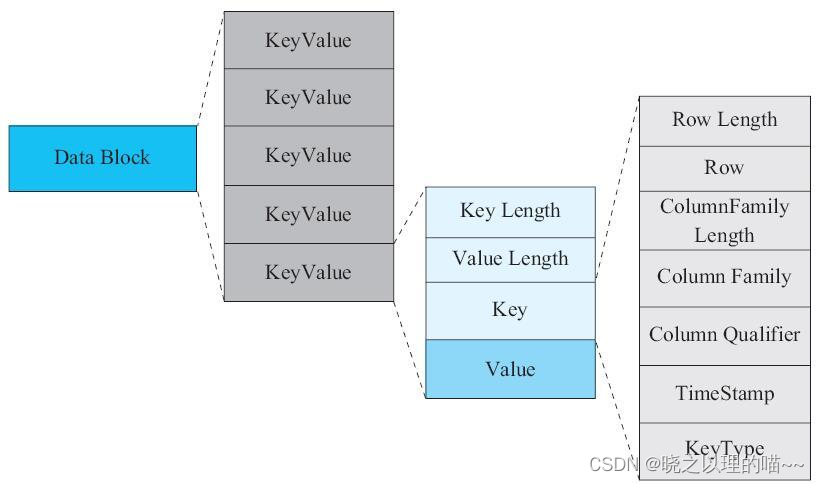
Hbase RegionServer的核心模块
RegionServer是HBase系统中最核心的组件,主要负责用户数据写入、读取等基础操作。RegionServer组件实际上是一个综合体系,包含多个各司其职的核心模块:HLog、MemStore、HFile以及BlockCache。 一、RegionServer内部结构 RegionServer是HBas…...

【Java开发】JUC进阶 01:Lock锁详解
1 Lock锁介绍已经在【JUC基础】04简单介绍过了,本文做进一步的拓展,比如公平锁和非公平锁、📌 明白锁的核心四个对象:线程,共享资源,锁,锁操作包括线程如何操作资源,使用锁锁哪个资源…...
--项目开发那点事(自问自答版本))
关于登录校验的解决方案以及原理(回顾知识点)--项目开发那点事(自问自答版本)
开始前奏: 嘻嘻😄 通常一个完整的系统,需要安全性的保证。如登录校验,登录成功后,才可以访问服务资源。在服务端渲染项目中,我们通常使用 session来进行登录校验。在前后端分离的场景中,很多时…...
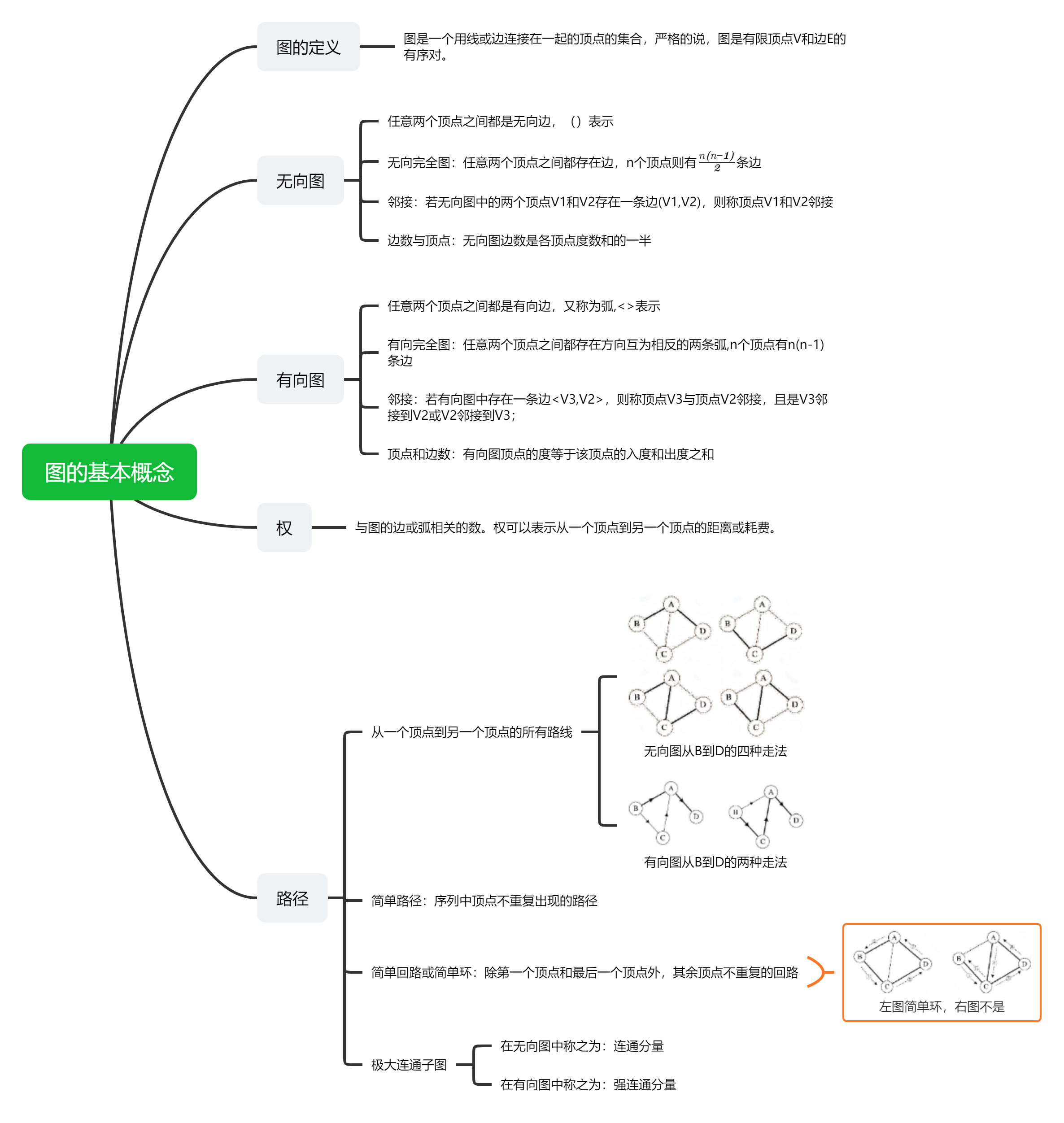
【数据结构】邻接矩阵和邻接图的遍历
写在前面 本篇文章开始学习数据结构的图的相关知识,涉及的基本概念还是很多的。本文的行文思路:学习图的基本概念学习图的存储结构——本文主要介绍邻接矩阵和邻接表对每种结构进行深度优先遍历和广度优先遍历先识概念话不多说,狠活献上学习思想等等&…...
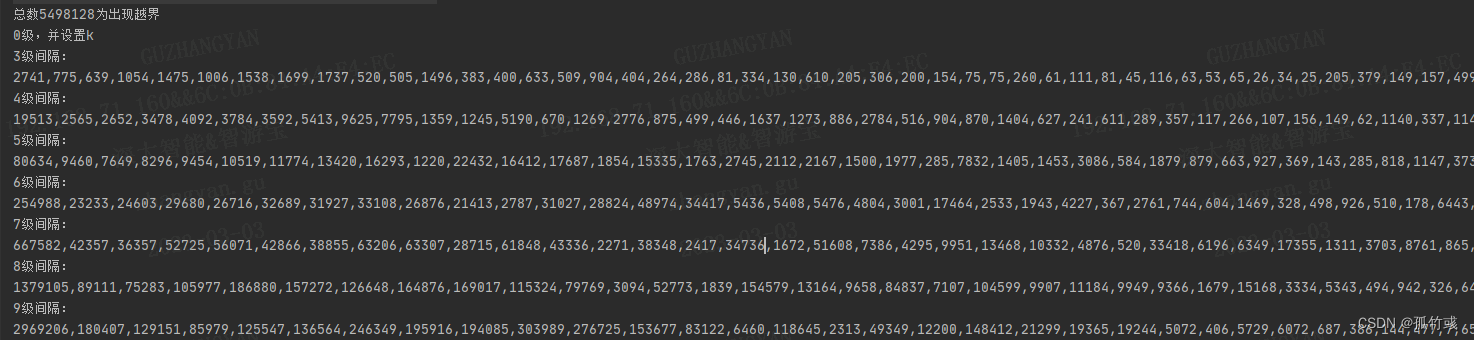
设计跳表(动态设置节点高度)
最近学习redis的zset时候,又看到跳表的思想,突然对跳表的设置有了新的思考 这是19年设计的跳表,在leetcode的执行时间是200ms 现在我对跳表有了新的想法 1、跳表的设计,类似二分查找,但是不是二分查找,比较…...

基于神经辐射场(Neural Radiance Fileds, NeRF)的三维重建- 简介(1)
Nerf简介 Nerf(neural Radiance Fileds) 为2020年ICCV上提出的一个基于隐式表达的三维重建方法,使用2D的 Posed Imageds 来生成(表达)复杂的三维场景。现在越来越多的研究人员开始关注这个潜力巨大的领域,也…...

用Python+Neo4j构建A股知识图谱:从同花顺网页到Cypher查询的完整实战
用PythonNeo4j构建A股知识图谱:从数据采集到智能分析的完整技术方案 金融数据分析领域正在经历一场由知识图谱技术驱动的变革。本文将分享一个完整的A股知识图谱构建方案,涵盖从同花顺网页数据采集到Neo4j图数据库应用的完整技术链路。不同于简单的工具使…...

AI辅助开发新思路:让快马平台生成风车动漫智能推荐与摘要代码
用AI辅助开发提升动漫网站体验 最近在做一个动漫网站项目,需要实现智能推荐和内容摘要功能。传统开发方式需要自己写复杂的算法,但借助InsCode(快马)平台的AI辅助功能,可以快速生成代码框架,大大提升开发效率。下面分享我的实现思…...

FPGA调试:除了SignalTap,你更应该试试Quartus自带的这个免费“信号发生器+逻辑分析仪”
FPGA调试实战:Quartus自带的轻量级调试利器In-System Sources and Probes Editor 在FPGA开发中,调试环节往往占据项目周期的半壁江山。当SignalTap II这类逻辑分析仪因资源占用过高而显得"杀鸡用牛刀"时,许多工程师会陷入两难——既…...

SecGPT-14B提示工程:提升OpenClaw安全报告可读性的秘诀
SecGPT-14B提示工程:提升OpenClaw安全报告可读性的秘诀 1. 当安全报告遇上OpenClaw:我的真实痛点 上周五凌晨2点,我被OpenClaw的告警邮件惊醒——它发现我的个人服务器存在一个高危漏洞。但当我打开那份自动生成的安全报告时,眼…...

从零到一:基于51单片机与DS1302的智能万年历系统设计与实现
1. 项目背景与核心功能 每次看到桌面上那些动辄几百块的智能时钟,我都会想:这东西真的需要这么贵吗?作为一个玩了多年51单片机的老鸟,我决定用最基础的STC89C52芯片搭配DS1302时钟模块,打造一个功能不输商业产品的智能…...

ROS小车导航总是一顿一顿的?试试用yocs_smoother_velocity给速度上个‘柔顺剂’
ROS导航卡顿难题:用yocs_smoother_velocity实现丝滑运动控制 当你看着辛苦搭建的ROS导航机器人像醉汉一样踉踉跄跄地移动,急停急转让人心惊肉跳时,是否怀疑过人生?这背后往往不是路径规划算法的问题,而是速度指令的&qu…...

批量为视频文件添加内嵌封面:两种模式的适用场景与配置
记录一下使用【批量添加MP4封面工具】的实践经验,重点讲两种封面模式的选择和配置。背景视频文件(MP4、MKV等)支持在文件内部嵌入封面图片(attached_pic)。嵌入后,在文件管理器的缩略图视图中会显示指定的封…...

OpenClaw技能开发入门:千问3.5-9B定制天气查询
OpenClaw技能开发入门:千问3.5-9B定制天气查询 1. 为什么需要自定义技能? 去年冬天,我经常需要同时查看多个城市的天气情况来安排出差行程。每次手动打开天气网站、输入城市名、截图保存的操作让我不胜其烦。直到发现OpenClaw支持自定义技能…...

从BGA封装到Xtacking架构:图解NAND堆叠技术如何影响SSD性能
从BGA封装到Xtacking架构:NAND堆叠技术如何重塑SSD性能格局 当一块企业级SSD的读写速度突破7GB/s时,工程师们发现传统的NAND封装技术正在成为性能提升的瓶颈。在PCIe 5.0时代,信号传输速率需要达到2400MT/s才能充分发挥带宽潜力,而…...

3步掌握PinWin效率工具:让窗口置顶操作效率提升10倍
3步掌握PinWin效率工具:让窗口置顶操作效率提升10倍 【免费下载链接】PinWin Pin any window to be always on top of the screen 项目地址: https://gitcode.com/gh_mirrors/pin/PinWin 你是否曾在视频会议时手忙脚乱地寻找被覆盖的会议窗口?在多…...