SparkSql---用户自定义函数UDFUDAF
文章目录
- 1.UDF
- 2.UDAF
- 2.1 UDF函数实现原理
- 2.2需求:计算用户平均年龄
- 2.2.1 使用RDD实现
- 2.2.2 使用UDAF弱类型实现
- 2.2.3 使用UDAF强类型实现
1.UDF
用户可以通过 spark.udf 功能添加自定义函数,实现自定义功能。
如:实现需求在用户name前加上"Name:"字符串,并打印在控制台
def main(args: Array[String]): Unit = {//创建上下文环境配置对象val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQLDemo03")//创建 SparkSession 对象val sc: SparkSession = SparkSession.builder().config(conf).getOrCreate()import sc.implicits._//创建DataFrameval dataRDD: RDD[(String,Int)] = sc.sparkContext.makeRDD(List(("zhangsan",21),("lisi",24)))val dataframe = dataRDD.toDF("name","age")//注册udf函数sc.udf.register("addName",(x:String)=>"Name:"+x)//创建临时视图dataframe.createOrReplaceTempView("people")//对临时视图使用udf函数sc.sql("select addName(name) from people").show()sc.stop()}

2.UDAF
强类型的 Dataset 和弱类型的 DataFrame 都提供了相关的聚合函数, 如 count(),countDistinct(),avg(),max(),min()。除此之外,用户可以设定自己的自定义聚合函数。**通过继承 UserDefinedAggregateFunction 来实现用户自定义弱类型聚合函数。**从 Spark3.0 版本后,UserDefinedAggregateFunction 已经不推荐使用了。可以统一采用强类型聚合函数Aggregator。
2.1 UDF函数实现原理
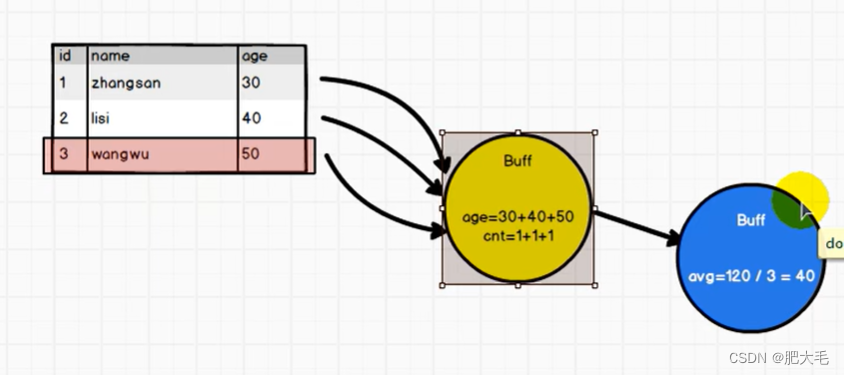
在Spark中,UDF(用户自定义函数)在对表中的数据进行处理时,通常会将数据放入缓冲区中以便进行计算。这种缓冲策略可以提高数据处理的效率,特别是对于大数据集。
2.2需求:计算用户平均年龄
2.2.1 使用RDD实现
val dataRDD: RDD[(String,Int)] = sc.sparkContext.makeRDD(List(("zhangsan",21),("lisi",24),("wangwu",26)))val reduceResult: (Int, Int) = dataRDD.map({case (name, age) => {(age, 1)}}).reduce((t1, t2) => {(t1._1 + t2._1, t1._2 + t2._2)})println(reduceResult._1/reduceResult._2)

2.2.2 使用UDAF弱类型实现
需要用户自定义类实现UserDefinedAggregateFunction,并重写其中的方法,当前已不推荐使用。
package bigdata.wordcount.udfimport org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, DoubleType, IntegerType, LongType, StructField, StructType}
import org.apache.spark.util.AccumulatorV2/*** 用户自定义函数*/
object UDF_Demo02 {def main(args: Array[String]): Unit = {//创建上下文环境配置对象val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQLDemo03")//创建 SparkSession 对象val sc: SparkSession = SparkSession.builder().config(conf).getOrCreate()import sc.implicits._val dataRDD: RDD[(String, Int)] = sc.sparkContext.makeRDD(List(("zhangsan", 19), ("lisi", 21), ("wangwu", 22)))val dataFrame: DataFrame = dataRDD.toDF("name","age")dataFrame.createOrReplaceTempView("user")//创建聚合函数var myAvg=new MyAverageUDAF()//在Spark中注册自定义的聚合函数sc.udf.register("avgMy",myAvg)sc.sql("select avgMy(age) from user").show()sc.stop()}case class User(var name:String,var age:Int)}class MyAverageUDAF extends UserDefinedAggregateFunction{//输入的要进行聚合的参数的类型override def inputSchema: StructType = StructType(Array(StructField("age",IntegerType)))//聚合函数缓冲区中的值的数据类型override def bufferSchema: StructType = StructType(Array(StructField("sum",LongType),StructField("count",LongType)))//函数返回的值的数据类型override def dataType: DataType = DoubleType//判断函数的稳定性//对于相同类型的输入是否有相同类型的输出override def deterministic: Boolean = true//聚合函数缓冲区中值的初始化//因为数据是弱类型的,函数缓冲区中是根据索引来找到对应的变量override def initialize(buffer: MutableAggregationBuffer): Unit = {//年龄的总和buffer(0)=0L//年龄的个数buffer(1)=0L}//更新缓冲区中的数据(执行操作步骤)override def update(buffer: MutableAggregationBuffer, input: Row): Unit ={//第0个索引值是否为空if(!input.isNullAt(0)) {//更新年龄sum的值buffer(0)=buffer.getLong(0)+input.getInt(0)//更新年龄个数buffer(1)=buffer.getLong(1)+1;}}//合并缓冲区override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {buffer1(0)=buffer1.getLong(0)+buffer2.getLong(0)buffer1(1)=buffer1.getLong(1)+buffer2.getLong(1)}//计算最终结果override def evaluate(buffer: Row): Double = {buffer.getLong(0).toDouble / buffer.getLong(1)}
}

2.2.3 使用UDAF强类型实现
Spark3.0 版本可以采用强类型的 Aggregator 方式代替 UserDefinedAggregateFunction
package bigdata.wordcount.udfimport org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Encoder, Encoders, Row, SparkSession, TypedColumn}
import org.apache.spark.sql.expressions.{Aggregator, MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, DoubleType, IntegerType, LongType, StructField, StructType}
import org.apache.spark.util.AccumulatorV2/*** 用户自定义函数*/
object UDF_Demo03 {def main(args: Array[String]): Unit = {//创建上下文环境配置对象val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQLDemo03")//创建 SparkSession 对象val sc: SparkSession = SparkSession.builder().config(conf).getOrCreate()import sc.implicits._val dataRDD: RDD[(String, Int)] = sc.sparkContext.makeRDD(List(("zhangsan", 19), ("lisi", 21), ("wangwu", 22)))val dataFrame: DataFrame = dataRDD.toDF("name","age")val dataset: Dataset[User01] = dataFrame.as[User01]//创建聚合函数var myAvg=new MyAverageUDAF01()//将聚合函数转换为查询的列val col: TypedColumn[User01, Double] = myAvg.toColumn//执行查询操作dataset.select(col).show()sc.stop()}case class User(var name:String,var age:Int)}//输入数据类型
case class User01(var name:String,var age:Int)
//缓存中的数据类型
case class AgeBuffer(var sum:Long,var count:Long)class MyAverageUDAF01 extends Aggregator[User01,AgeBuffer,Double]{//设置初始值override def zero: AgeBuffer = {AgeBuffer(0L,0L)}//缓冲区实现聚合override def reduce(b: AgeBuffer, a: User01): AgeBuffer = {b.sum = b.sum + a.ageb.count = b.count + 1b}//合并缓冲区override def merge(b1: AgeBuffer, b2: AgeBuffer): AgeBuffer = {b1.sum+=b2.sumb1.count+=b2.countb1}//计算最终结果override def finish(buff: AgeBuffer): Double = {buff.sum.toDouble/buff.count}//设置编码器和解码器//自定义类型就是 product 自带类型根据类型选择override def bufferEncoder: Encoder[AgeBuffer] = {Encoders.product}override def outputEncoder: Encoder[Double] = {Encoders.scalaDouble}
}
相关文章:
SparkSql---用户自定义函数UDFUDAF
文章目录 1.UDF2.UDAF2.1 UDF函数实现原理2.2需求:计算用户平均年龄2.2.1 使用RDD实现2.2.2 使用UDAF弱类型实现2.2.3 使用UDAF强类型实现 1.UDF 用户可以通过 spark.udf 功能添加自定义函数,实现自定义功能。 如:实现需求在用户name前加上"Name:…...

系统架构15 - 软件工程(3)
软件过程模型 瀑布模型特点缺点 原型化模型特点两个阶段不同类型注意 螺旋模型V 模型特点 增量模型特点 喷泉模型基于构件的开发模型(CBSD)形式化方法模型敏捷模型特点“适应性” (adaptive) 而非“预设性” (predictive)“面向人的” (People-oriented) 而非“面向过程的” (P…...

两个近期的计算机领域国际学术会议(软件工程、计算机安全):欢迎投稿
近期,受邀担任两个国际学术会议的Special session共同主席及程序委员会成员(TPC member),欢迎广大学界同行踊跃投稿,分享最新研究成果。期待这个夏天能够在夏威夷檀香山或者加利福尼亚圣荷西与各位学者深入交流。 SERA…...
(二十一)Flask之上下文管理第二篇(细细扣一遍源码)
每篇前言: 🏆🏆作者介绍:【孤寒者】—CSDN全栈领域优质创作者、HDZ核心组成员、华为云享专家Python全栈领域博主、CSDN原力计划作者 🔥🔥本文已收录于Flask框架从入门到实战专栏:《Flask框架从入…...
Java项目:基于SSM框架实现的企业员工岗前培训管理系统(ssm+B/S架构+源码+数据库+毕业论文)
一、项目简介 本项目是一套ssm821基于ssm框架实现的企业员工岗前培训管理系统,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的Java学习者。 包含:项目源码、数据库脚本等,该项目附带全部源码可作为毕设使用。 项目都经过严格…...
深入了解Redis:选择适用于你的场景的持久化方案
自然语言处理的发展 文章目录 自然语言处理的发展强烈推荐前言:Redis提供了几种主要的持久化方案:RDB快照持久化:工作原理: AOF日志文件持久化:混合持久化: 总结强烈推荐专栏集锦写在最后 强烈推荐 前些天…...
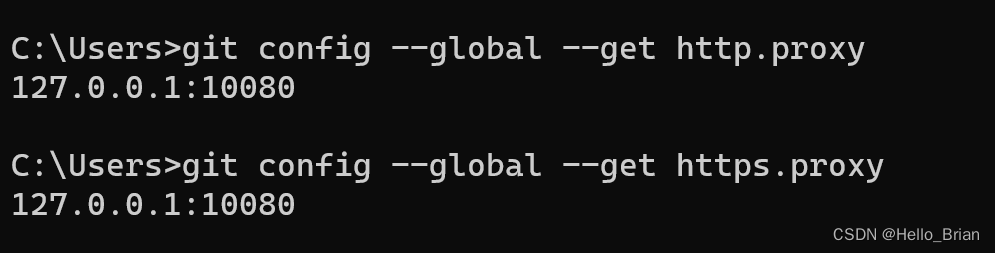
【Git配置代理】Failed to connect to github.com port 443 问题解决方法
前言: 在学习代码审计时,有时会需要使用git去拉取代码,然后就出现了如下错误 看过网上很多解决方法,觉得问题的关键还是因为命令行在拉取/推送代码时并没有使用VPN进行代理。 解决办法 : 配置http代理:…...

python提取word文档内容的示例
一、微软Word历史、背景: Word 的特异功能就是把那些应该写成简单的 TXT 或 PDF 格式的文件,变成了既大又慢且难以打开的怪兽,它们经常在系统切换和版本切换中出现格式不兼容,而且因为某些原因在文件内容已经定稿后仍处于可编辑的…...
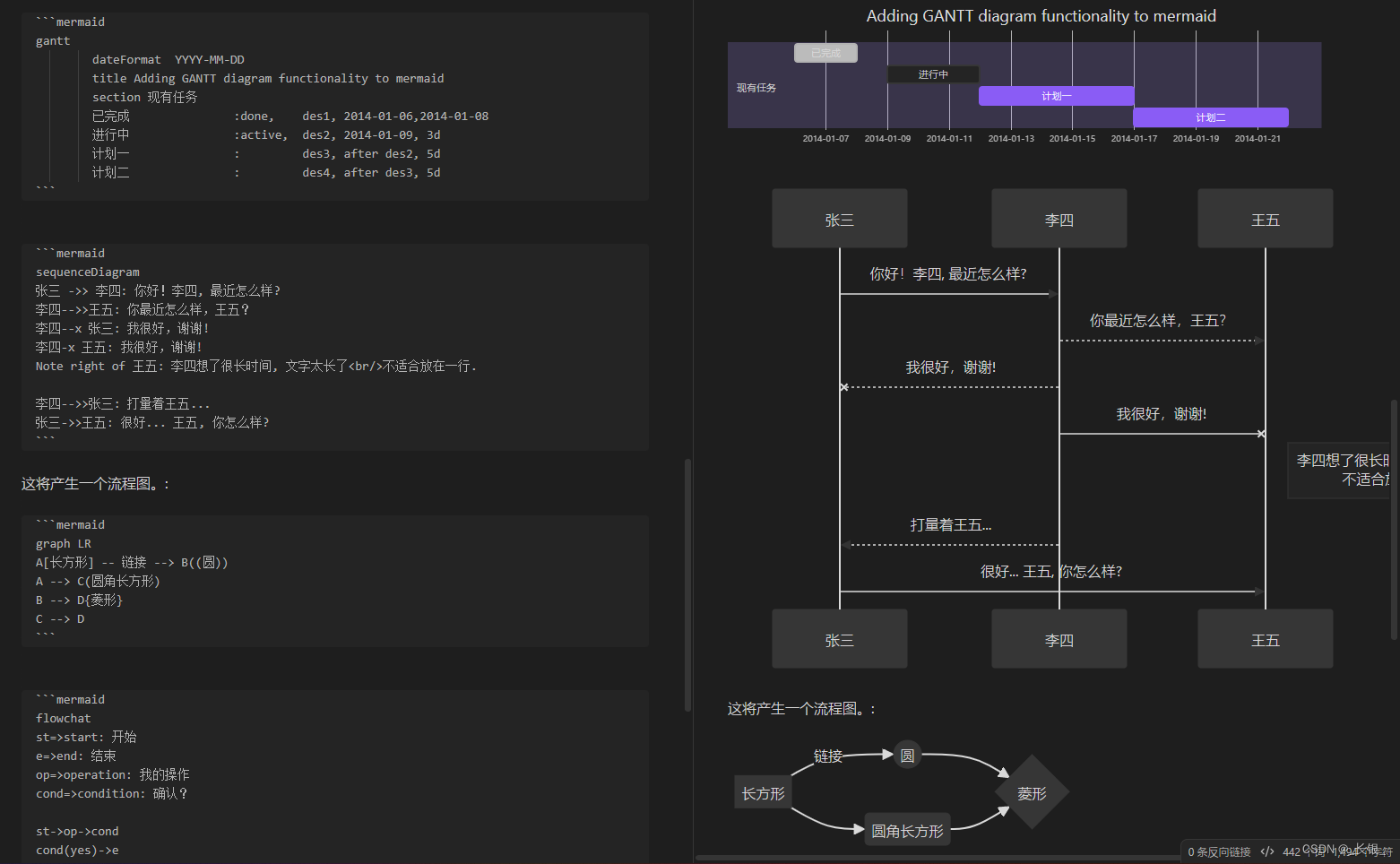
MarkDown快速入门-以Obsidian编辑器为例
直接上图,左右对应。 首先是基础语法。 # 标题,几个就代表几级标题;* 单个是序号,两个在一起就是斜体;- [ ] 代表任务,注意其中的空格; 然后是表格按钮代码 | 使用中竖线代表表格,…...
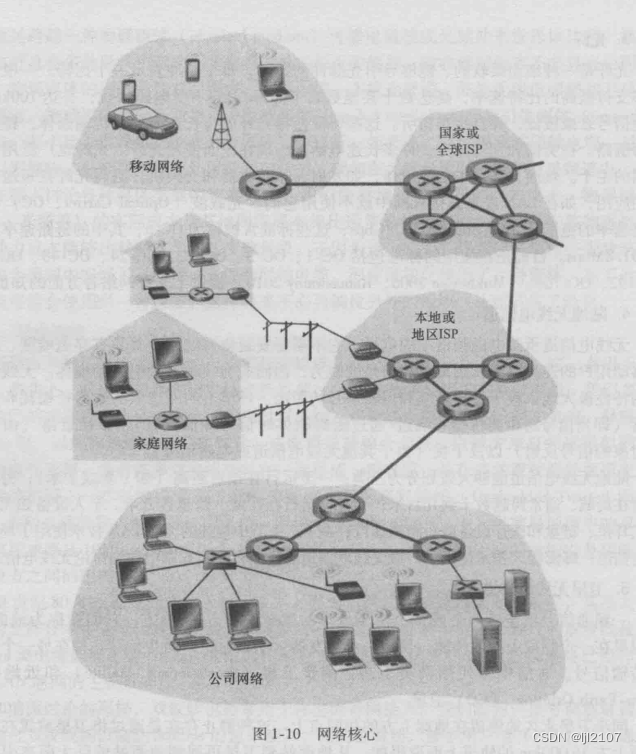
【计算机网络】协议,电路交换,分组交换
定义了在两个或多个通信实体之间交换的报文格式和次序,以及报文发送和/或接收一个报文或其他事件所采取的动作.网络边缘: 端系统 (因为处在因特网的边缘) 主机 端系统 客户 client服务器 server今天大部分服务器都属于大型数据中心(data center)接入网(access network) 指将端…...

加速应用开发:低代码云SaaS和源码交付模式如何选
随着数字化转型的加速,企业对于快速开发和交付高质量应用的需求也越来越迫切。为了满足这一需求,开发者们开始探索采用低代码平台进行软件开发工作,以加速应用开发过程。 目前,市场上的低代码产品众多,但基本可分为简单…...
ATT汇编
指令后缀 AT&T格式的汇编指令有不同的后缀 其中 b表示byte,字节 w表示word,字/两字节 l表示long,32位系统下的long是4字节 q表示quad,意味四重,表示4个字/8字节 寄存器用途 参见 AT&T的汇编世界 - Gemfield…...

java split 拆分字符串
今天突然把java里split 跟,kotlin中的split 弄混了 kotlin中split 的用法跟python 中的split 用法是一样的,java中由于返回值是String[] 的数组,所以 在使用的时候需要注意下返回值如果要获取里面的内容,还是需要遍历下里面的内…...

【InternLM 大模型实战】作业与笔记汇总
笔记1:https://blog.csdn.net/weixin_42567071/article/details/135375937 笔记2:https://blog.csdn.net/weixin_42567071/article/details/135423120 作业2:https://github.com/xiaomile/InternLM-homework/tree/main/%E4%BD%9C%E4%B8%9A1 笔…...
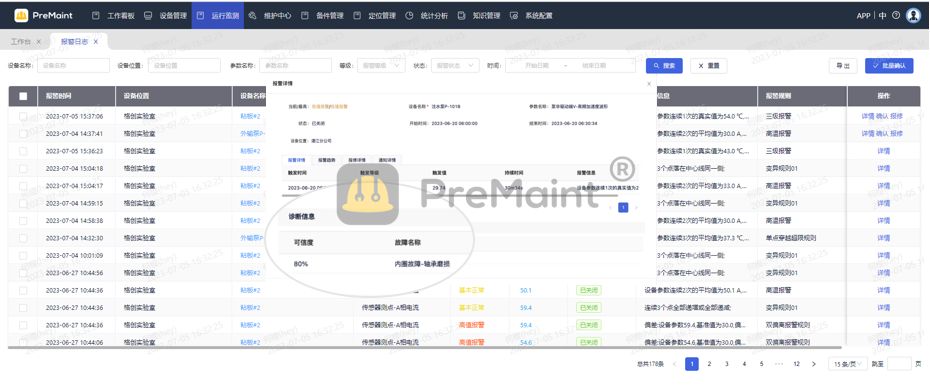
解析PreMaint在石油化工设备预测性维护领域的卓越表现
石油化工行业一直在寻找能够确保设备高效运行的先进维护解决方案。在这个领域,PreMaint以其卓越的性能和创新的技术引起了广泛关注。 一、为何选择预测性维护? 传统的维护方法,基于固定的时间表,无法灵活应对设备的真实运行状况。…...

C++面试宝典第25题:阶乘末尾零的个数
题目 给定一个整数n,返回n!(n的阶乘)结果尾数中零的个数。 示例 1: 输入:3 输出:0 解释:3! = 6,尾数中没有零。 示例 2: 输入:5 输出:1 解释:5! = 120,尾数中有1个零。 解析 这道题主要考察应聘者对于数学问题的分析和理解能力,以及在多个解决方案中,寻求最优…...
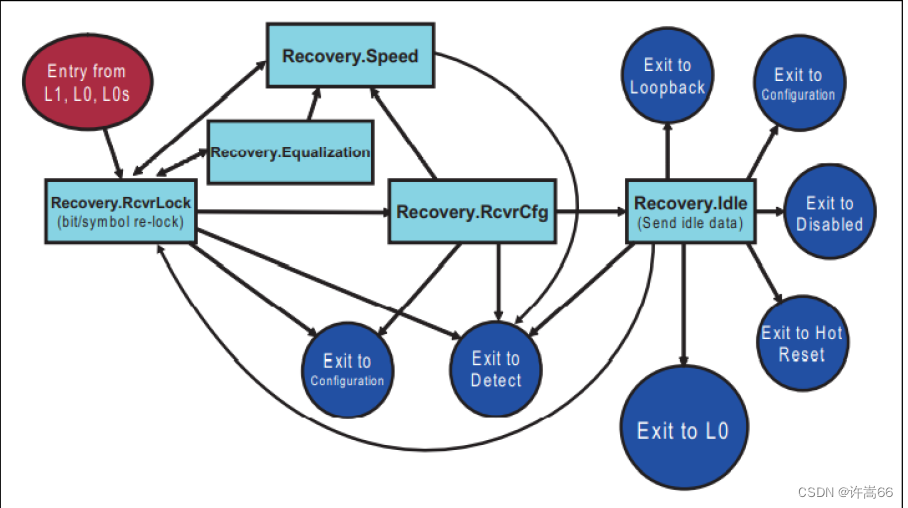
PCIE 4.0 Equalizaiton(LTSSM 均衡流程)
1. 均衡 在Tx端有FFE(Feed Forward Equalizer,前馈均衡器);在Rx端有:CTLE(Continuous Time Linear Equalizer,连续时间线性均衡器)和DFE(Decision Feedback Equalizer&a…...

[libwebsockets]lighttpd+libwebsockets支持ws和wss配置方法说明
libwebsockets介绍 libwebsockets是一款轻量级用来开发服务器和客户端的C库。它不仅支持ws,wss还同时支持http与https,可以轻轻松松结合openssl等库来实现ssl加密。 官方参考链接: https://libwebsockets.org/ lighttpd版本 lighttpd/1.4.59 (ssl) - a light and fast w…...
常用软件安装
服务器版本为Centos7.8 x86_64 1.yum下载提速 1.wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo 2. yum clean all 3.yum makecache2.jdk yum install java-1.8.0-openjdk* -y # yum update 时自动更新jdk版本 1.yum -y install …...

翻译: GPT-4 Vision静态图表转换为动态数据可视化 升级Streamlit 三
GPT-4 Vision 系列: 翻译: GPT-4 with Vision 升级 Streamlit 应用程序的 7 种方式一翻译: GPT-4 with Vision 升级 Streamlit 应用程序的 7 种方式二 1. 将任何静态图表转换为动态数据可视化 ChatGPT Vision 不仅可以将涂鸦变成功能齐全的 Streamlit 应用程序,还…...

Topit:macOS窗口置顶神器,让多任务处理效率翻倍
Topit:macOS窗口置顶神器,让多任务处理效率翻倍 【免费下载链接】Topit Pin any window to the top of your screen / 在Mac上将你的任何窗口强制置顶 项目地址: https://gitcode.com/gh_mirrors/to/Topit 你是否经常在macOS上同时处理多个任务时…...

Unity安卓构建72小时实战指南:从零到真机运行
1. 这不是“又一本Unity教程”,而是我带三个新人从零上线第一款安卓游戏的真实路径你点开这个标题,大概率正站在两个路口之间:一边是满屏“30天速成Unity”“零基础做爆款”的短视频封面,一边是你刚下载完Unity Hub、卡在Android …...
)
蓝牙抓包不求人:从HCI日志里‘挖’出Link Key的两种实用方法(附安卓路径)
蓝牙安全逆向实战:从HCI日志中提取Link Key的深度解析在蓝牙协议安全研究领域,Link Key作为设备配对认证的核心凭证,其获取方式一直是逆向工程师关注的焦点。许多安全审计场景下,我们往往只能获得加密后的HCI通信日志,…...

告别沉浸式白屏!UniApp中iOS/Android底部安全区与顶部状态栏颜色自定义全攻略
告别沉浸式白屏!UniApp中iOS/Android底部安全区与顶部状态栏颜色自定义全攻略当开发者尝试在UniApp中实现沉浸式设计时,往往会遇到一个令人头疼的问题——默认的白色安全区和状态栏导致界面元素(如电池图标、信号强度)几乎不可见。…...
:揭秘那个让虚拟世界“有重量感“的阴影魔法)
环境光遮蔽(Ambient Occlusion):揭秘那个让虚拟世界“有重量感“的阴影魔法
一、一个让我"开窍"的老木匠故事 我有个朋友是传统家具的修复师,他给我讲过一个让我至今难忘的故事。他说他刚入行时跟着一位 70 多岁的老木匠师父学习——师父让他做的第一件事不是雕花、不是榫卯——而是"看阴影"——这个看似奇怪的训练改变了…...

Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能
Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能 【免费下载链接】try.redis A demonstration of the Redis database. 项目地址: https://gitcode.com/gh_mirrors/tr/try.redis 当你第一次听说Redis时,是否被那些晦涩的技术术语吓退࿱…...

【UniApp小程序开发】解决无法使用Vue自定义指令的完美替代方案:权限组件封装
在 UniApp 开发中,你是否遇到过这样的困惑:明明在 Vue Web 项目中用得顺手的 v-permission 自定义指令,一到小程序端就完全失效?本文将深入剖析其原因,并提供一套可直接复用的组件化解决方案,让你在小程序中…...

Burp Suite拦截与替换机制深度解析:从协议层到规则链
1. 这不是“点开就能用”的功能,而是你和目标系统之间的一道可编程闸门很多人第一次在Burp Suite里点开Proxy → Intercept,看到HTTP请求被拦下来,兴奋地改个User-Agent、删个Cookie就点Forward,以为自己已经掌握了“拦截与替换”…...
)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)在游戏开发中,我们经常会遇到这样的场景:玩家拾取金币后,需要更新UI、播放音效、解锁成就、保存数据……如果把这些逻辑全部写在金币拾取的代…...

对比自行维护多个 API 源,使用 Taotoken 聚合服务在运维复杂度上的降低
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比自行维护多个 API 源,使用 Taotoken 聚合服务在运维复杂度上的降低 在构建依赖多个大语言模型的应用时,…...