构建知识图谱:从技术到实战的完整指南
目录
- 一、概述
- 二、知识图谱的基础理论
- 定义与分类
- 核心组成
- 历史与发展
- 三、知识获取与预处理
- 数据源选择
- 数据清洗
- 实体识别
- 四、知识表示方法
- 知识表示模型
- RDF
- OWL
- 属性图模型
- 本体构建
- 关系提取与表示
- 五、知识图谱构建技术
- 图数据库选择
- Neo4j
- ArangoDB
- 构建流程
- 数据预处理
- 实体关系识别
- 图数据库存储
- 优化和索引
- 深度学习在构建中的应用
本文深入探讨了知识图谱的构建全流程,涵盖了基础理论、数据获取与预处理、知识表示方法、知识图谱构建技术等关键环节。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人
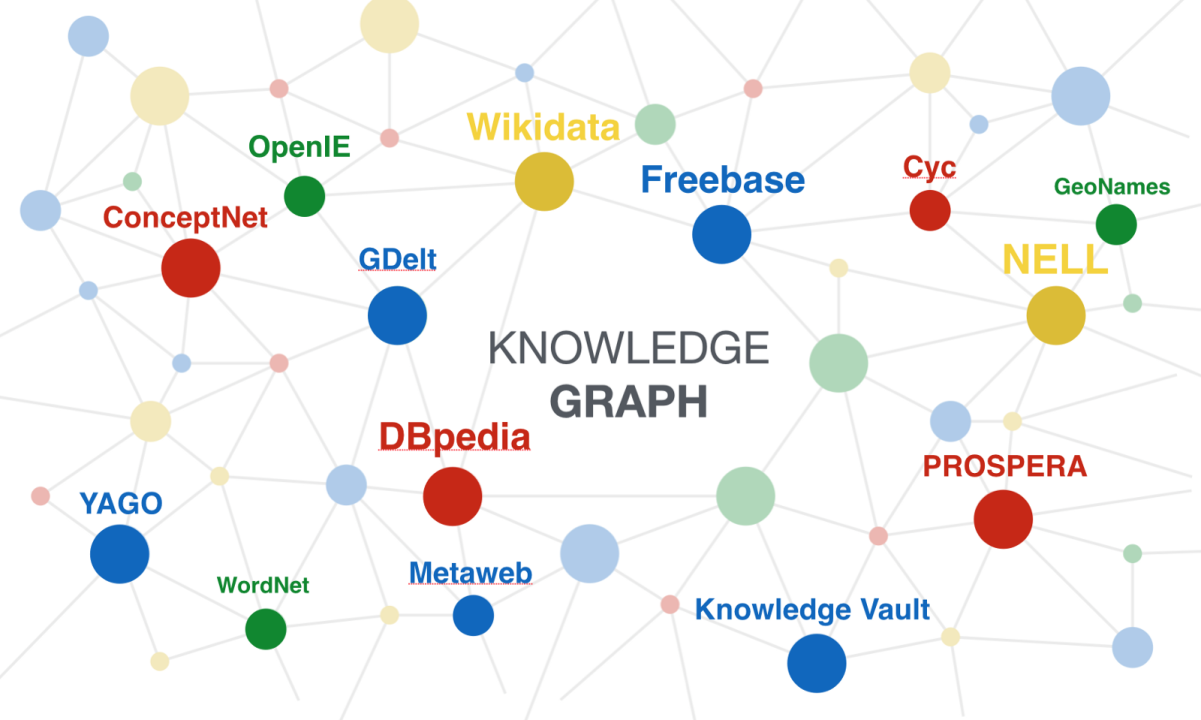
一、概述
知识图谱,作为人工智能和语义网技术的重要组成部分,其核心在于将现实世界的对象和概念以及它们之间的多种关系以图形的方式组织起来。它不仅仅是一种数据结构,更是一种知识的表达和存储方式,能够为机器学习提供丰富、结构化的背景知识,从而提升算法的理解和推理能力。
在人工智能领域,知识图谱的重要性不言而喻。它提供了一种机器可读的知识表达方式,使计算机能够更好地理解和处理复杂的人类语言和现实世界的关系。通过构建知识图谱,人工智能系统可以更有效地进行知识的整合、推理和查询,从而在众多应用领域发挥重要作用。
具体到应用场景,知识图谱被广泛应用于搜索引擎优化、智能问答系统、推荐系统、自然语言处理等领域。例如,在搜索引擎中,通过知识图谱可以更精确地理解用户的查询意图和上下文,提供更相关和丰富的搜索结果。在智能问答系统中,知识图谱使得机器能够理解和回答更复杂的问题,实现更准确的信息检索和知识发现。
此外,知识图谱还在医疗健康、金融分析、风险管理等领域展现出巨大潜力。在医疗领域,利用知识图谱可以整合和分析大量的医疗数据,为疾病诊断和药物研发提供支持。在金融领域,则可以通过知识图谱对市场趋势、风险因素进行更深入的分析和预测。
总的来说,知识图谱作为连接数据、知识和智能的桥梁,其在人工智能的各个领域都扮演着至关重要的角色。随着技术的不断进步和应用领域的拓展,知识图谱将在智能化社会中发挥越来越重要的作用。
二、知识图谱的基础理论
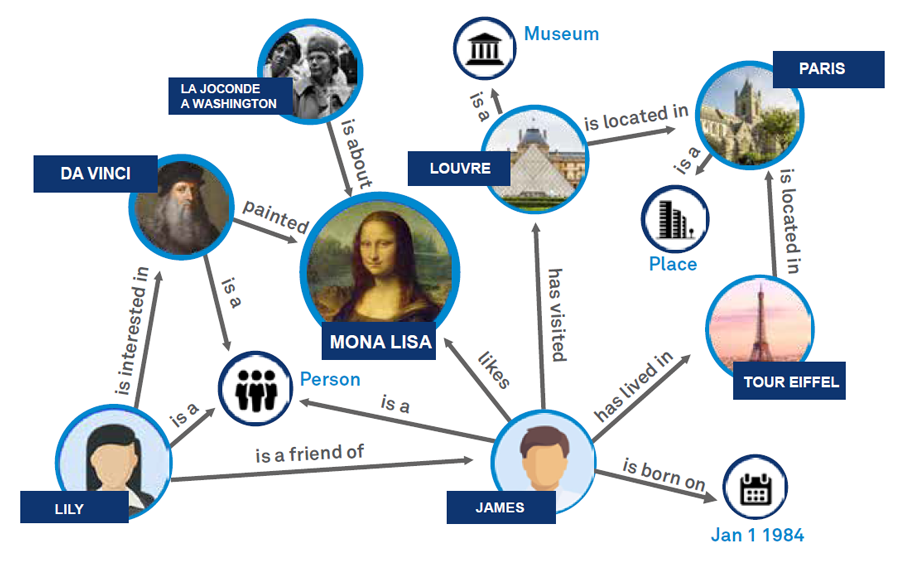
定义与分类
知识图谱是一种通过图形结构表达知识的方法,它通过节点(实体)和边(关系)来表示和存储现实世界中的各种对象及其相互联系。这些实体和关系构成了一个复杂的网络,使得知识的存储不再是孤立的,而是相互关联和支持的。
知识图谱根据其内容和应用领域可以分为多种类型。例如,通用知识图谱旨在覆盖广泛的领域知识,如Google的Knowledge Graph;而领域知识图谱则专注于特定领域,如医疗、金融等。此外,根据构建方法的不同,知识图谱还可以分为基于规则的、基于统计的和混合型知识图谱。
核心组成
知识图谱的核心组成元素包括实体、关系和属性。实体是知识图谱中的基本单位,代表现实世界中的对象,如人、地点、组织等。关系则描述了实体之间的各种联系,例如“属于”、“位于”等。属性是对实体的具体描述,如年龄、位置等。这些元素共同构成了知识图谱的骨架,使得知识的组织和检索变得更加高效和精确。
历史与发展
知识图谱的概念最早可以追溯到语义网和链接数据的概念。早期的语义网关注于如何使网络上的数据更加机器可读,而链接数据则强调了数据之间的关联。知识图谱的出现是对这些理念的进一步发展和实践应用,它通过更加高效的数据结构和技术,使得知识的表示、存储和检索更加高效和智能。
随着人工智能和大数据技术的发展,知识图谱在自然语言处理、机器学习等领域得到了广泛应用。例如,知识图谱在提升搜索引擎的智能化、优化推荐系统的准确性等方面发挥了重要作用。此外,随着技术的不断进步,知识图谱的构建和应用也在不断地演变和优化,包括利用深度学习技术进行知识提取和图谱构建,以及在更多领域的应用拓展。
三、知识获取与预处理
数据源选择
知识图谱构建的首要步骤是确定和获取数据源。数据源的选择直接影响知识图谱的质量和应用范围。通常,数据源可以分为两大类:公开数据集和私有数据。公开数据集,如Wikipedia、Freebase、DBpedia等,提供了丰富的通用知识,适用于构建通用知识图谱。而私有数据,如企业内部数据库、专业期刊等,则更适用于构建特定领域的知识图谱。
选择数据源时,应考虑数据的可靠性、相关性、完整性和更新频率。可靠性保证了数据的准确性,相关性和完整性直接影响知识图谱的应用价值,而更新频率则关系到知识图谱的时效性。在实践中,通常需要结合多个数据源,以获取更全面和深入的知识覆盖。
数据清洗
获取数据后,下一步是数据清洗。这一过程涉及从原始数据中移除错误、重复或不完整的信息。数据清洗的方法包括去噪声、数据规范化、缺失值处理等。去噪声是移除数据集中的错误和无关数据,例如,去除格式错误的记录或非相关领域的信息。数据规范化涉及将数据转换为一致的格式,如统一日期格式、货币单位等。对于缺失值,可以采用插值、预测或删除不完整记录的方法处理。
数据清洗不仅提高了数据的质量,还能增强后续处理的效率和准确性。因此,这一步骤在知识图谱构建中至关重要。
实体识别
实体识别是指从文本中识别出知识图谱中的实体,这是构建知识图谱的核心步骤之一。实体识别通常依赖于自然语言处理(NLP)技术,特别是命名实体识别(NER)。NER技术能够从非结构化的文本中识别出具有特定意义的片段,如人名、地名、机构名等。
实体识别的方法多种多样,包括基于规则的方法、统计模型以及近年来兴起的基于深度学习的方法。基于规则的方法依赖于预定义的规则来识别实体,适用于结构化程度较高的领域。统计模型,如隐马尔可夫模型(HMM)、条件随机场(CRF)等,通过学习样本数据中的统计特征来识别实体。而基于深度学习的方法,如使用长短时记忆网络(LSTM)或BERT等预训练模型,能够更有效地处理语言的复杂性和多样性,提高识别的准确率和鲁棒性。
实体识别不仅需要高准确性,还要考虑到速度和可扩展性,特别是在处理大规模数据集时。因此,选择合适的实体识别技术和优化算法是至关重要的。
四、知识表示方法
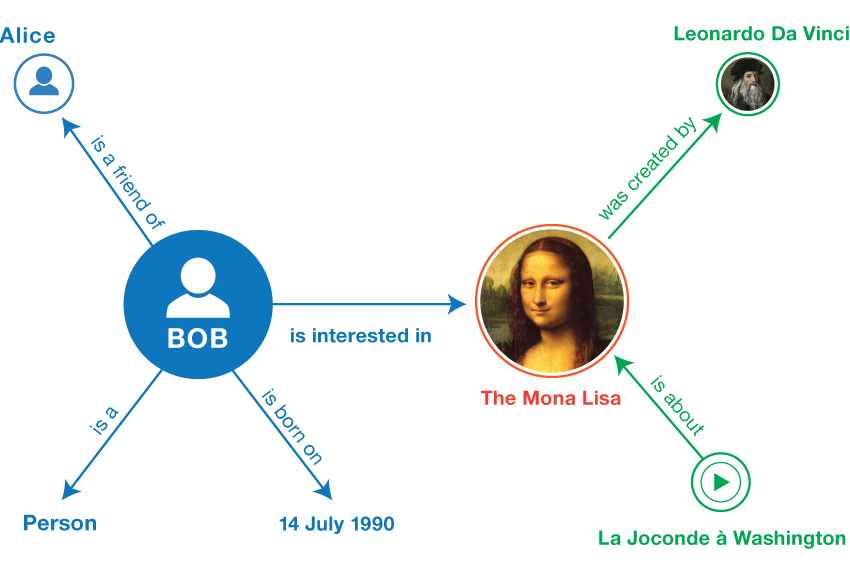
知识表示是知识图谱构建中的核心环节,它涉及将现实世界的复杂信息和关系转化为计算机可理解和处理的格式。有效的知识表示不仅有助于提高知识图谱的查询效率,还能加强知识的推理能力,是实现知识图谱功能的关键。
知识表示模型
知识表示的首要任务是选择合适的模型。当前主流的知识表示模型包括资源描述框架(RDF)、Web本体语言(OWL)和属性图模型。
RDF
RDF是一种将信息表示为“主体-谓词-宾语”三元组的模型,它使得知识的表示形式既灵活又标准化。在RDF中,每个实体和关系都被赋予一个唯一的URI(统一资源标识符),以确保其全球唯一性和可互操作性。RDF的优势在于其简单性和扩展性,但它在表达复杂关系和属性方面存在局限。
OWL
OWL是基于RDF的一种更为复杂和强大的知识表示语言。它支持更丰富的数据类型和关系,包括类、属性、个体等,并能表达复杂的逻辑关系,如等价类、属性限制等。OWL的优势在于其表达能力和逻辑推理能力,适用于构建复杂的领域知识图谱。
属性图模型
属性图模型通过图结构来表示知识,其中节点代表实体,边代表关系,节点和边都可以附带属性。这种模型直观且易于实现,适用于大规模的图数据处理。它在图数据库中得到了广泛应用,如Neo4j、ArangoDB等。
本体构建
本体是知识图谱中用来描述特定领域知识和概念的一组术语和定义。本体的构建是知识图谱构建的重要部分,它定义了知识图谱中的实体类别、属性和关系类型。
本体构建的关键在于准确地把握和表达领域知识。这通常需要领域专家的参与,以确保本体的准确性和全面性。在实际操作中,可以使用本体编辑工具如Protégé来创建和管理本体,同时结合NLP技术自动化提取和维护本体结构。
关系提取与表示
关系提取是指从原始数据中识别出实体之间的关系,并将其加入到知识图谱中。这一步骤通常依赖于文本分析和数据挖掘技术。关系提取的方法包括基于规则的方法、机器学习方法和深度学习方法。
关系的表示要考虑到其多样性和复杂性。在简单的情况下,关系可以被直接表示为实体之间的连接。但在复杂情况下,关系可能涉及多个实体和属性,甚至是关系的层次和类型。在这种情况下,需要更复杂的数据结构和算法来准确表示关系。
五、知识图谱构建技术
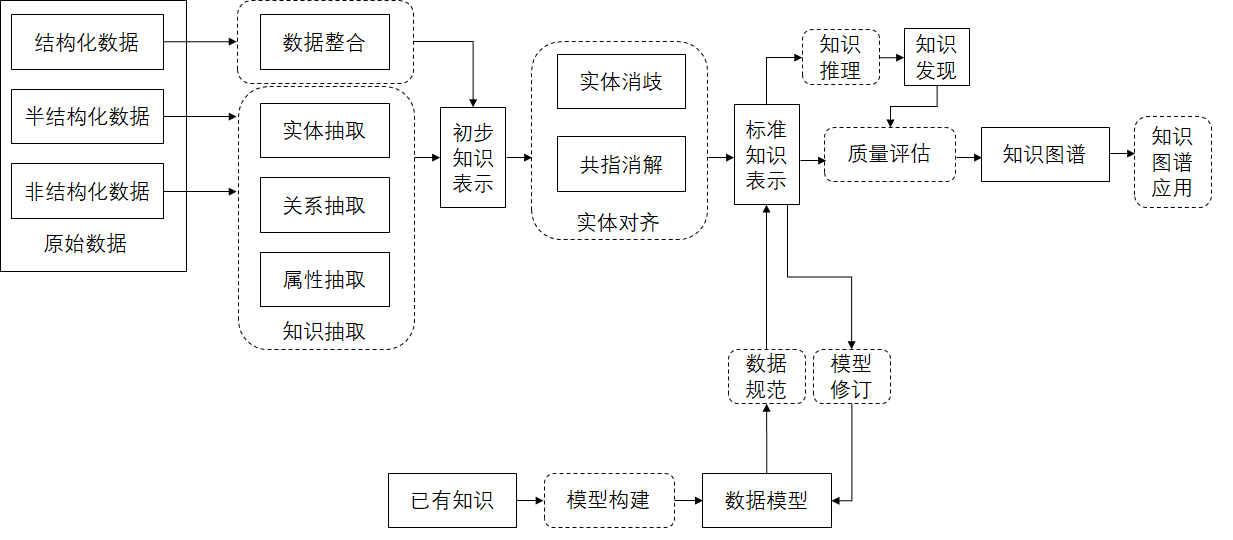
构建知识图谱是一个复杂的过程,涉及数据处理、知识提取、存储管理等多个阶段。本节将详细探讨知识图谱构建的关键技术,并提供具体的代码示例。
图数据库选择
选择合适的图数据库是构建知识图谱的首要步骤。图数据库专为处理图形数据而设计,提供高效的节点、边查询和存储能力。常见的图数据库有Neo4j、ArangoDB等。
Neo4j
Neo4j是一个高性能的NoSQL图形数据库,支持Cypher查询语言,适合于处理复杂的关系数据。它的优势在于强大的关系处理能力和良好的社区支持。
ArangoDB
ArangoDB是一个多模型数据库,支持文档、键值及图形数据。它在灵活性和扩展性方面表现出色,适用于多种类型的数据存储需求。
构建流程
构建知识图谱的过程大致可分为数据预处理、实体关系识别、图数据库存储和优化几个阶段。
数据预处理
数据预处理包括数据清洗、实体识别等步骤,目的是将原始数据转换为适合构建知识图谱的格式。
import pandas as pd# 示例:清洗和准备数据
def clean_data(data):# 数据清洗逻辑cleaned_data = data.dropna() # 去除空值return cleaned_data# 假设我们有一个原始数据集
raw_data = pd.read_csv('example_dataset.csv')
cleaned_data = clean_data(raw_data)
实体关系识别
实体关系识别是从清洗后的数据中提取实体和关系。这里以Python和PyTorch实现一个简单的命名实体识别模型为例。
import torch
import torch.nn as nn
import torch.optim as optim# 示例:定义一个简单的命名实体识别模型
class NERModel(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim):super(NERModel, self).__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim)self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)self.fc = nn.Linear(hidden_dim, vocab_size)def forward(self, x):embedded = self.embedding(x)lstm_out, _ = self.lstm(embedded)out = self.fc(lstm_out)return out# 初始化模型、损失函数和优化器
model = NERModel(vocab_size=1000, embedding_dim=64, hidden_dim=128)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
图数据库存储
将提取的实体和关系存储到图数据库中。以Neo4j为例,展示如何使用Cypher语言存储数据。
// 示例:使用Cypher语言在Neo4j中创建节点和关系
CREATE (p1:Person {name: 'Alice'})
CREATE (p2:Person {name: 'Bob'})
CREATE (p1)-[:KNOWS]->(p2)
优化和索引
为提高查询效率,可以在图数据库中创建索引。
// 示例:在Neo4j中为Person节点的name属性创建索引
CREATE INDEX ON :Person(name)
深度学习在构建中的应用
深度学习技术在知识图谱构建中主要用于实体识别、关系提取和知识融合。以下展示一个使用深度学习进行关系提取的示例。
# 示例:使用深度学习进行关系提取
class RelationExtractionModel(nn.Module):def __init__(self, input_dim, hidden_dim):super(RelationExtractionModel, self).__init__()self.lstm = nn.LSTM(input_dim, hidden_dim, batch_first=True)self.fc = nn.Linear(hidden_dim, 2) # 假设有两种关系类型def forward(self, x):lstm_out, _ = self.lstm(x)out = self.fc(lstm_out[:, -1, :])return out# 初始化模型、损失函数和优化器
relation_model = RelationExtractionModel(input_dim=300, hidden_dim=128)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(relation_model.parameters(), lr=0.001)
在这个模型中,我们使用LSTM网络从文本数据中提取特征,并通过全连接层预测实体间的关系类型。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人
相关文章:
构建知识图谱:从技术到实战的完整指南
目录 一、概述二、知识图谱的基础理论定义与分类核心组成历史与发展 三、知识获取与预处理数据源选择数据清洗实体识别 四、知识表示方法知识表示模型RDFOWL属性图模型 本体构建关系提取与表示 五、知识图谱构建技术图数据库选择Neo4jArangoDB 构建流程数据预处理实体关系识别图…...

STM32的分类和选型
F系列(主要用于普通应用) STM32F0xx:低成本、低功耗,适用于成本敏感和低功耗的应用。STM32F1xx:中低端微控制器,具有丰富的外设和良好的性能。STM32F2xx:高性能微控制器,适用于要求…...

python使用read_sql与to_sql读写数据库
文章目录 详细说明示例程序 详细说明 使用pandas读写数据库的方法(以Mysql为例)如下: 首先是打包一个工具函数: import pandas as pd import numpy as np from sqlalchemy import create_engine, textdef get_sql_engine():# 数据…...

【ArcGIS微课1000例】0096:dem三维块状表达(层次地形模型)
文章目录 一、DEM表达方式二、层次模型表达三、注意事项一、DEM表达方式 DEM数字高程模型的表达方式通常有以下4种: 1. 规则格网 2. 不规则三角网 3. 等高线 4. 层次地形模型 作为栅格地理数据,DEM 数据具有2.5维的特征,能够以三维表面的形式进行三维空间表达。但受其数…...

OJ_糖果分享游戏
题干 c实现 #define _CRT_SECURE_NO_WARNINGS #include<stdio.h> #include<vector> using namespace std;void ShareCandy(vector<int>& student) {int size student.size();vector<int> share(size); //保存每个同学交换前,糖果数量…...
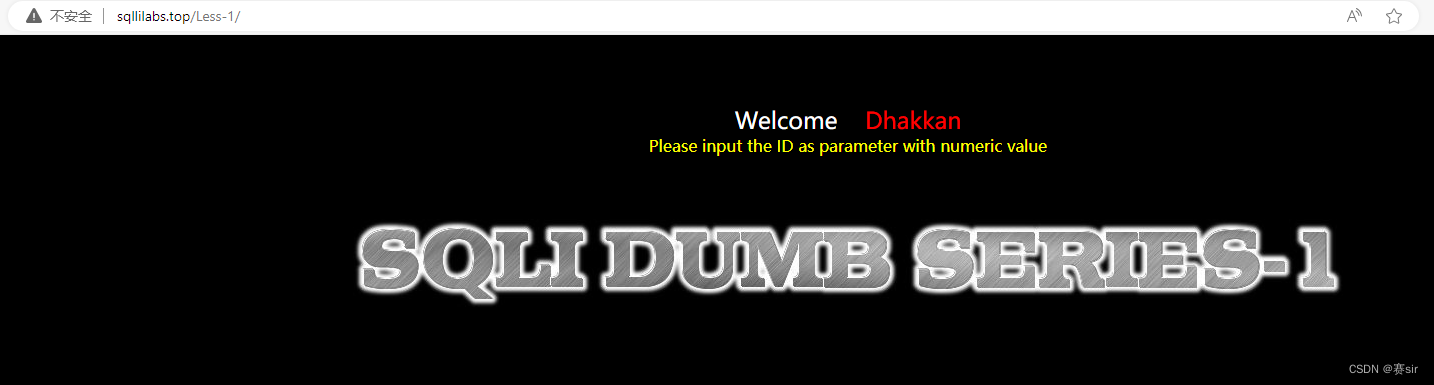
sqli-lbs靶场搭建
目录 环境小皮源码下载 1.源码解压: 2.搭建网站 2.1点击创建网站 2.2修改sql-connections\db-creds.inc 2.3重新启动 3.访问你设置的域名 3.1点击启动数据库配置 3.2返回第一个页面(开启题目) sqlilbs靶场搭建 环境小皮源码下载 下载地址&am…...
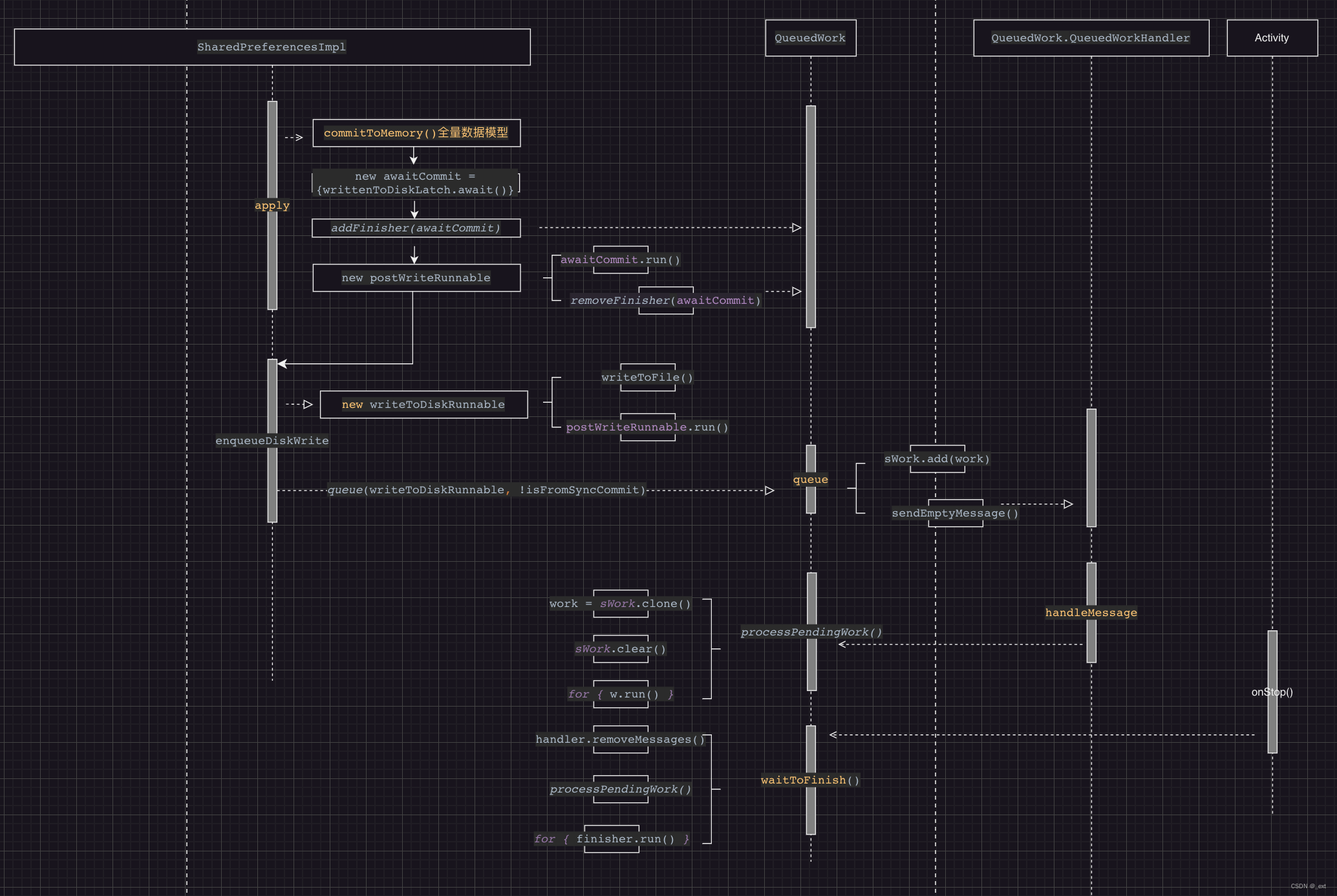
SharedPreferences卡顿分析
SP的使用及存在的问题 SharedPreferences(以下简称SP)是Android本地存储的一种方式,是以key-value的形式存储在/data/data/项目包名/shared_prefs/sp_name.xml里,SP的使用示例及源码解析参见:Android本地存储之SharedPreferences源码解析。以…...
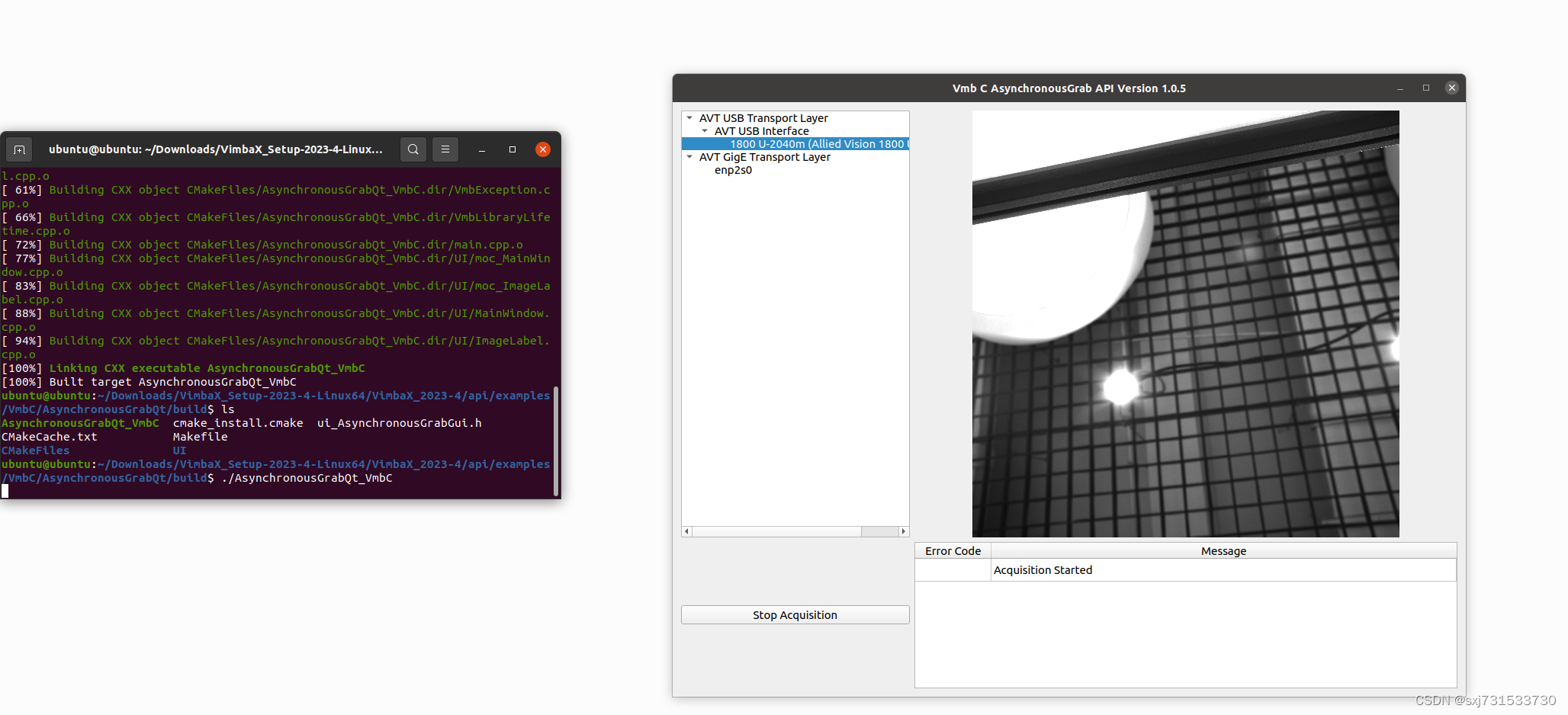
64、ubuntu使用c++/python调用alliedvisio工业相机
基本思想:需要使用linux系统调用alliedvisio工业相机完成业务,这里只做驱动相机调用,具体不涉及业务开发 Alvium 相机选型 - Allied Vision 一、先用软件调用一下用于机器视觉和嵌入式视觉的Vimba X 软件开发包 - Allied Vision VimbaX_Set…...

网络端口与 IP 地址有什么区别?
网络端口和IP地址是计算机网络中两个非常重要的概念,它们在实现网络通信和数据传输中扮演着不同的角色。 IP地址 IP地址(Internet Protocol Address)是用于标识网络上设备的唯一地址。它是一个由数字组成的标识符,用于在网络中准…...

C语言标准的输入输出
目录 1. 格式化输入输出 2. 控制字符串长度 3. 混合格式化输出 4. 格式化浮点数 5. 格式化日期和时间 在C语言编程中,输入输出格式非常重要,它决定了程序如何向用户展示数据以及如何从用户接收数据。本篇博客将介绍C语言输入输出格式的一些基本概念…...

C++ 类与对象(上)
目录 本节目标 1.面向过程和面向对象初步认识 2.类的引入 3.类的定义 4.类的访问限定符及封装 4.1 访问限定符 4.2 封装 5. 类的作用域 6. 类的实例化 7.类对象模型 7.1 如何计算类对象的大小 7.2 类对象的存储方式猜测 7.3 结构体内存对齐规则 8.this指针 8.1 thi…...
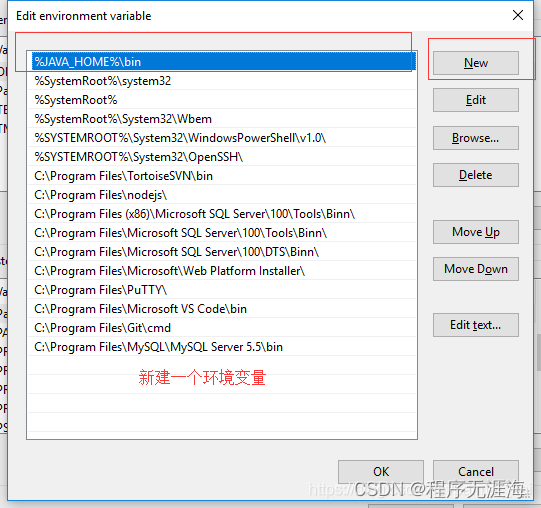
如何配置MacLinuxWindows环境变量
这里写目录标题 什么是环境变量什么是PATH为什么要配置环境变量 如何配置环境变量环境变量有哪些环境变量加载顺序环境变量加载详解 配置参考方法一: export PATHLinux环境变量配置方法二:vim ~/.bashrcLinux环境变量配置方法三:vim ~/.bash_…...
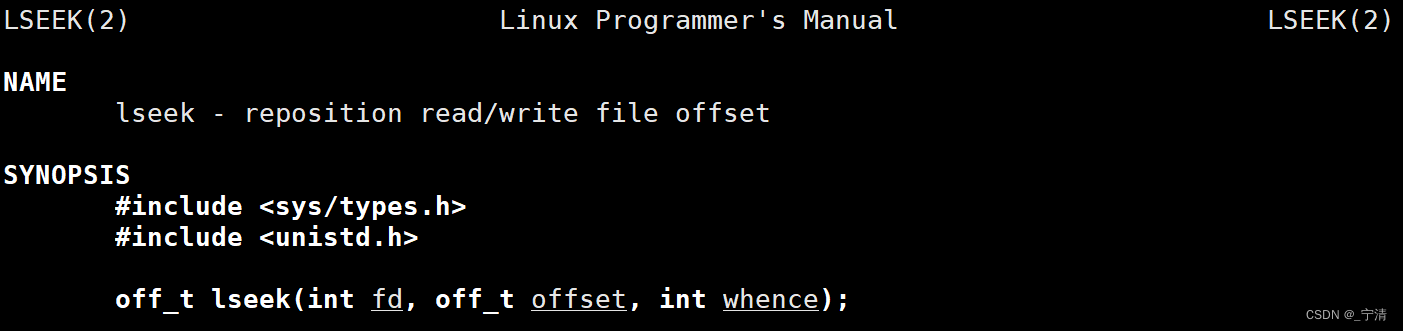
【Linux】从C语言文件操作 到Linux文件IO | 文件系统调用
文章目录 前言一、C语言文件I/O复习文件操作:打开和关闭文件操作:顺序读写文件操作:随机读写stdin、stdout、stderr 二、承上启下三、Linux系统的文件I/O系统调用接口介绍open()close()read()write()lseek() Linux文件相关重点 复习C文件IO相…...

mask transformer相关论文阅读
前面讲了mask-transformer对医学图像分割任务是非常适用的。本文就是总结一些近期看过的mask-transformer方面的论文。 因为不知道mask transformer是什么就看了一些论文。后来得出结论,应该就是生成mask的transformer就是mask transformer。 相关论文: …...
springboot+vue3支付宝接口案例-第二节-准备后端数据接口
springbootvue3支付宝接口案例-第二节-准备后端数据接口!今天经过2个小时的折腾。准备好了我们这次测试支付宝线上支付接口的后端业务数据接口。下面为大家分享一下,期间发生遇到了一些弯路。 首先,我们本次后端接口使用的持久层框架是JPA。这…...
)
贪吃蛇游戏设计文档(基于C语言)
1. 引言 本设计文档旨在详细阐述一款2D贪吃蛇游戏的设计思路、功能模块划分以及具体实现要点。通过严谨的需求分析与清晰的架构设计,确保游戏开发过程有序进行,并最终打造出一款用户友好、稳定流畅的经典贪吃蛇游戏。 2. 需求分析 2.1 核心元素 - 蛇&…...
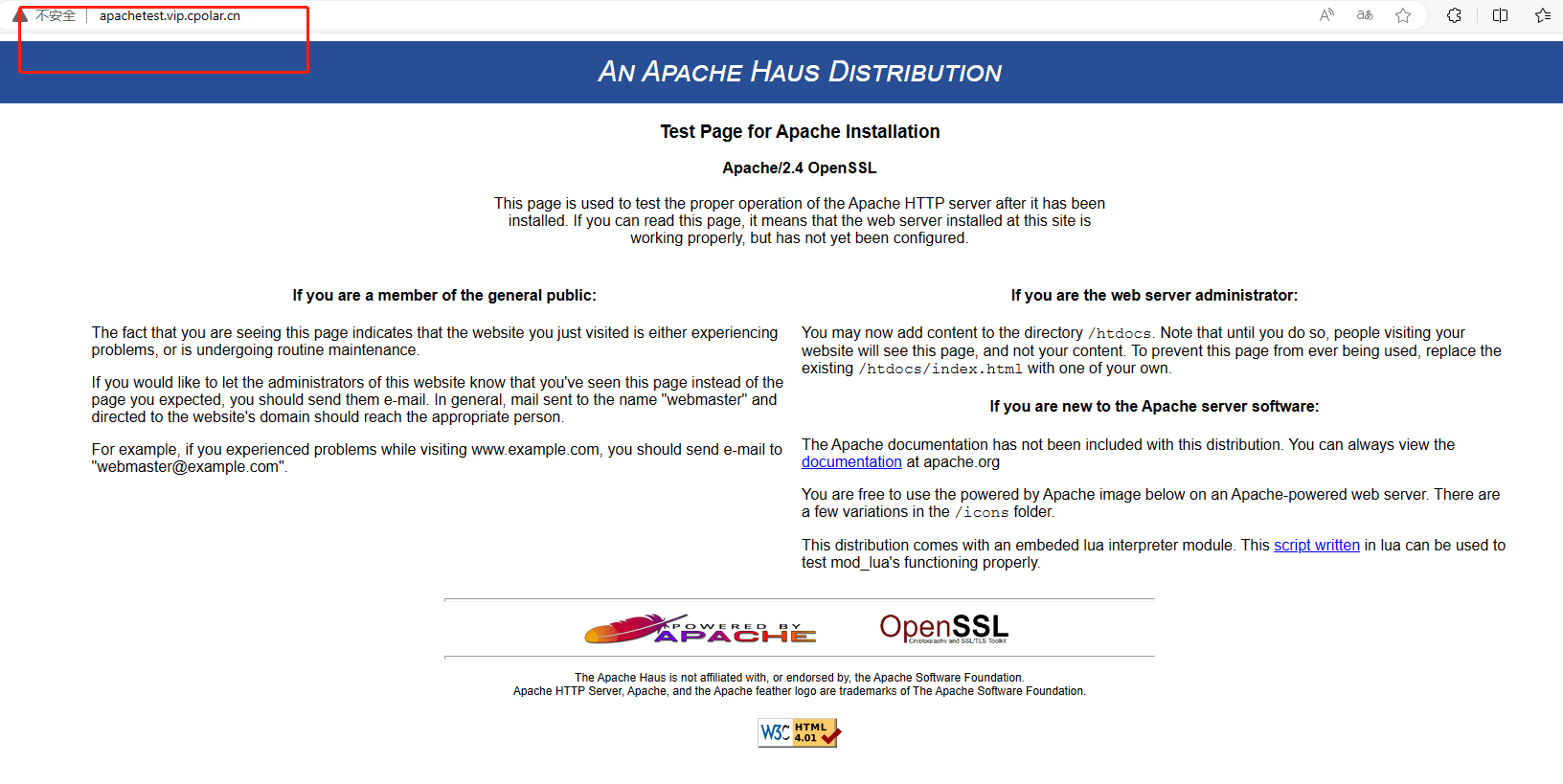
在Windows上安装与配置Apache服务并结合内网穿透工具实现公网远程访问本地内网服务
文章目录 前言1.Apache服务安装配置1.1 进入官网下载安装包1.2 Apache服务配置 2.安装cpolar内网穿透2.1 注册cpolar账号2.2 下载cpolar客户端 3. 获取远程桌面公网地址3.1 登录cpolar web ui管理界面3.2 创建公网地址 4. 固定公网地址 前言 Apache作为全球使用较高的Web服务器…...

幻兽帕鲁服务器出租,腾讯云PK阿里云怎么收费?
幻兽帕鲁服务器价格多少钱?4核16G服务器Palworld官方推荐配置,阿里云4核16G服务器32元1个月、96元3个月,腾讯云换手帕服务器服务器4核16G14M带宽66元一个月、277元3个月,8核32G22M配置115元1个月、345元3个月,16核64G3…...

day05休息,day06 有效的字母异位词、两个数组的交集、快乐数、两数之和
题目链接:有效的字母异位词、两个数组的交集、快乐数、两数之和 有效的字母异位词 时间复杂度: O(n) 空间复杂度: O(S), S为字符集大小,这里为26 Go func isAnagram(s string, t string) bool {// s和t的长度一定是相等的if len(s) ! len(t) {return…...

star原则
"STAR" 原则通常用于回答面试或描述工作经验等场景中,以清晰、有条理地传达信息。"STAR" 是 Situation(情境)、Task(任务)、Action(行动)、Result(结果…...

深度学习从心电信号中解码呼吸频率:原理、实现与临床价值
1. 项目概述:从心电信号中“听”到呼吸声呼吸频率,这个我们每分钟都在进行却很少被精确量化的生命体征,在临床医学中扮演着至关重要的角色。它不仅是评估呼吸系统功能的直接指标,更是反映全身代谢、循环乃至神经系统状态的“窗口”…...

从‘文件夹’到对象列表:手把手教你用MinIO Java Client实现灵活的文件查询与过滤
从‘文件夹’到对象列表:手把手教你用MinIO Java Client实现灵活的文件查询与过滤在当今数据驱动的时代,对象存储已成为现代应用架构中不可或缺的一部分。MinIO作为高性能、兼容S3协议的开源对象存储解决方案,凭借其轻量级和易用性赢得了众多…...

告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略
告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略当GIS初学者第一次安装ArcGIS 10.6时,往往会被其庞大的安装体积所震惊。许多用户习惯性地点击"下一步",结果发现C盘空间被迅速吞噬,系统运行变得迟缓。本文将深…...

FT231XQ USB串口桥接板设计解析与实战应用指南
1. 项目概述:从FT232R到FT231XQ的USB串口桥接板演进在嵌入式开发和硬件调试的日常工作中,一个可靠、小巧且功能清晰的USB转串口(UART)桥接板(Breakout Board, 简称BoB)几乎是工程师手边的标配工…...

从“DOC/PDF”到“WPS”:细看GJB438C-2021文档格式要求背后的国产化信号与落地指南
从“DOC/PDF”到“WPS”:GJB438C-2021文档格式变革的深度解读与实施策略 当一份国家军用标准在文档格式描述中刻意删除"DOC/PDF"字样,转而明确标注"(WPS)文档处理器"时,这绝非简单的技术参数调整。…...

3分钟告别英文恐惧:Android Studio中文界面轻松切换指南
3分钟告别英文恐惧:Android Studio中文界面轻松切换指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 你是否曾经因…...

输电线路在线监测系统|架空线路安全运行的“第一道防线“!
输电线路微气象监测站是专为高压输电线路、电网廊道、杆塔运维量身打造的专利级一体化微气象智能监测设备。依托双专利超声波探测技术、六要素集成传感架构、无启动风速高精测量、智能抗干扰稳控系统,实现输电线路沿线气象24小时全自动捕捉、动态实时监测、大风风险…...

终极解决方案:Windows Cleaner免费开源工具,3步彻底解决C盘爆红问题
终极解决方案:Windows Cleaner免费开源工具,3步彻底解决C盘爆红问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否也经历过这样的…...

开源三角洲机器人Delta-Robot One:从入门到精通的创客实践指南
1. 项目概述:一个为学习而生的开源三角洲机器人如果你对机器人感兴趣,但又觉得它高深莫测、无从下手,那么Delta-Robot One(我们亲切地称它为“One”)可能就是为你量身打造的入门项目。这不是一个遥不可及的工业设备&am…...

三步破解百度网盘限速:免费获取真实下载链接的终极指南
三步破解百度网盘限速:免费获取真实下载链接的终极指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘几十KB的龟速下载而苦恼吗?想要彻…...