mask transformer相关论文阅读
前面讲了mask-transformer对医学图像分割任务是非常适用的。本文就是总结一些近期看过的mask-transformer方面的论文。
因为不知道mask transformer是什么就看了一些论文。后来得出结论,应该就是生成mask的transformer就是mask transformer。
相关论文:
1.DETR(eccv2020):https://link.springer.com/chapter/10.1007/978-3-030-58452-8_13
2.MaX-Deeplab(CVPR 2021):https://openaccess.thecvf.com/content/CVPR2021/html/Wang_MaX-DeepLab_End-to-End_Panoptic_Segmentation_With_Mask_Transformers_CVPR_2021_paper.html
3.MaskForm(NeurIPS 2021):https://papers.nips.cc/paper/2021/file/950a4152c2b4aa3ad78bdd6b366cc179-Paper.pdf
4.Mask2Form(CVPR2022):https://ieeexplore.ieee.org/document/9878483
5.kMaX-DeepLab(ECCV2022):https://link.springer.com/chapter/10.1007/978-3-031-19818-2_17
DETR
很多这些论文都是受到DETR的启发得到的。DETR为数不多的目标检测里端到端的模型,它把目标检测看作集合预测问题,不需要人为一些先验和调参,没有了NMS,让模型训练和部署变得容易。

简单描述一下它训练过程就是图片经过CNN得到的特征和位置编码(给定的)相加放入到Transformer进行编码。学习全局的特征,encoder中有6个transformer block进行编码,编码得到的特征进入到decoder中。object queries是可学习的变量。object queries与得到的特征进行cross attention(特征作为key,value,object queries作为queries),object queries也会进行self attention(以保证object queries之间相互通信,知道其他object得到的框是什么,避免冗余框)得到新的object queries。新的object queries进入FFN预测类别和box相关的参数。使用匈牙利算法选择合适的框输出。测试的时候设定置信度阈值。
DETR中使用了深监督(深监督)
DETR:对小目标检测不友好,后面分割也是改进让他有多尺度特征,能够有更好的性能。
MaX-DeepLab
问题:目前严重依赖于代理子任务和手工设计组件的全景分割流水线,例如框检测,非极大值抑制,事物-内容合并等。虽然这些子任务都是由领域专家来完成的,但是它们并不能全面地解决目标任务。
目的:全景分割可以使用端到端模型,不需要实例分割和语义分割相结合。
我不了解全景分割,全景分割好像之前也是很难是端到端的,MaX-DeepLab是一个端到端的模型,它简化了当前严重依赖代理子任务和手工设计组件的流水线,如盒子检测、非最大值抑制、东西合并等。下面这幅图就显示了之前全景分割方法和本文提出的方法,之前的方法依赖于代理子任务树。通过融合语义和实例分割结果,得到泛全景分割掩模。实例分割进一步分解为盒检测和基于盒的分割,而盒检测则通过锚回归和锚分类来实现。

我们的方法正确的分割出了狗和椅子。而基于锚点的方法因为狗和椅子的中心太相近所以导致分不出椅子和狗。基于边界框的方法由于椅子边缘有太低的置信度所以分割不出椅子。

全景分割的任务就是通过一幅图片获得很多类别标记的标签,我们的模型就是把图片分割成一组固定数量集合的类别标记的标签,预测的标签mask是软互斥的。mask的类别包含thing classes, stuff classes, 空集类别(没有物体)三种。把thing和stuff类别分割统一起来,去掉了合并操作。
类似于DETR,有没有觉得这个memory bank和object query很相似。就是它们都能够端到端,不需要NMS和合并操作原因是它们都实现给定了一个数,就出100个框,就分割100个类或者物体,这个数量大于图片中含有最大物体数,所以有一些是没有类别的,所以对损失函数入手,从训练策略入手。DETR是使用了匈牙利算法匹配预测框,这个也是使用匈牙利算法匹配的分割图分类。它提出来了PQ来衡量这个匈牙利算法中每个选择的损失,PQ就是分类得到的概率乘以分割得到的Dice值。它的损失就是动态加权的CE Loss和Dice Loss,这个是匹配的损失。

不匹配的损失就是空集,预测空集这个类别的CE损失。

总损失就是匹配的损失加上不匹配的损失。两者加权和。

Transformer块实现了2D像素路径CNN和1D存储器路径之间的所有四种可能类型的通信:(1)传统的存储器到像素(M2P)注意力,(2)存储器到存储器(M2M)自我注意力,(3)允许像素从存储器中读取的像素到存储器(P2M)反馈注意力,以及(4)像素到像素(P2P)自我注意,实现为轴向注意力。
还有一个很大的堆叠了很多块的decoder,为了聚合多尺度特征。
最后输出是memory经过FC后得到的类别和解码器得到的经过上采样的mask预测和memory的进行点乘获得的mask。简单来说是这样。其中为了学习不同类别之间和类别背景之间的区别,引入了对比学习的损失。感兴趣的可以看原文。

MaskFormer
目的:掩码分类足够通用,可以使用完全相同的模型、损失和训练程序以统一的方式解决语义和实例级的分割任务。
这篇就简单列一下。就是把语义分割和实例分割统一用掩码分类来解决。

逐像素分类的语义分割对每个位置应用相同的分类损失。掩码分类预测一组二分割掩码,并为每个掩码分配一个类。
Architecture: pixel-level module, transformer module, segmentation module
为了训练掩码分类模型,预测集和真实标签集之间的匹配是需要的。由于预测集和真实标签集的大小通常不同,我们假设N≥Ngt,并用“无对象”标记填充真实标签集,以允许一对一匹配。对于语义分割,如果预测的数量N与类别标签的数量K匹配,则固定匹配是可能的。在这种情况下,第i个预测与具有类别标签i和。如果具有类标签i的区域不存在于真实标签中。在实验中,发现基于二部分匹配的分配比固定匹配显示出更好的结果。与使用边界框来计算匹配问题的预测和真实标签之间的分配成本的DETR不同,我们直接使用类和掩码预测,Lmask-cls即-第j个类的类别概率+第j个类别掩码的dice损失。除了Lmask-cls之外,大多数现有的掩码分类模型还使用辅助损失(例如,边界框损失或实例判别损失,前面MaX deeplab就是用的个体判别损失就是对比学习损失一种)。

分为三个部分:
Pixel-level module:编码器解码器架构,获得特征图和初始的分割预测。
Transformer module:类似于DETR object query那个decoder,query不断与特征进行交互获得全局信息,一部分用来分类,一部分作为mask embedding对初始的分割预测进行加权。
Segmentation module:queries经过分类头得到分类结果,queries与初始预测的mask进行点积得到最后的分割预测。
trick:概率掩码对的索引i有助于区分同一类的不同实例。最后,为了降低全景分割中的假阳性率,我们遵循之前的推理策略[4,24]。具体来说,我们在推理之前过滤掉低置信度预测,并去除其二进制掩码(mi>0:5)的大部分被其他预测遮挡的预测片段。
Mask2Former
目的:为了统一分割任务,就不要有什么语义分割、实例分割、全景分割了,给你统一起来,只用一个框架。
Architecture: a backbone feature extractor, a pixel decoder. a Transformer decoder
改进:
- 在Transformer解码器中使用掩蔽注意力(就是前一层预测得到的mask用作当前层掩码),它将注意力限制在以预测片段为中心的局部特征上,这些片段可以是对象,也可以是区域,这取决于分组的特定语义。与关注图像中所有位置的标准Transformer解码器中使用的交叉注意力相比,我们的掩蔽注意力导致更快的收敛和改进的性能。
- 使用多尺度高分辨率特征来帮助模型分割小对象/区域。
- 我们提出了优化改进,如切换自注意和交叉注意的顺序,使查询特征可学习,并消除遗漏;所有这些都在无需额外计算的情况下提高了性能
- 我们通过计算几个随机采样点上的掩码损失,在不影响性能的情况下节省了3倍的训练内存。
这些改进不仅提高了模型性能,而且大大简化了训练,使计算量有限的用户更容易访问通用体系结构。

其中还用了深监督的方法,DETR中也用了深监督。
缺点:这表明,即使Mask2Former可以推广到不同的任务,它仍然需要针对这些特定任务进行训练。未来,我们希望开发一种模型,该模型可以针对多个任务甚至多个数据集只训练一次。
kMaX-DeepLab: k-Means Mask Transformer
解决的问题:用于视觉的transformer忽视了语言与图像的重要区别。这阻碍了像素特征和对象查询之间的交叉注意力学习。
目的:让transformer更加适合视觉任务。
重新思考了像素和对象查询之间的关系,并提出将交叉注意力学习重新表述为一个聚类过程。
Architecture:pixel encoder, enhanced pixel decoder, and kMaX decoder
与原始Mask Transformer的交叉注意力在大空间维度(图像高度乘以宽度)上执行softmax不同,我们的kMaX - DeepLab在聚类中心维度上执行argmax,类似于k - means像素-聚类分配步骤(伴随着一项艰巨的任务)。然后,我们通过基于像素-簇分配(通过它们的特征亲和度计算)的像素特征聚合来更新聚类中心,类似于k - means中心更新步骤。

整个模型分为两条路径:像素路径和聚类路径,分别负责提取像素特征和聚类中心。


以ResNet - 50和MaX - S为骨架的kMaX - DeepLab示例。FFN的隐藏维数为256。通过简单地更新像素编码器(用深蓝色标记),kMaX - Deep Lab的设计对不同的主干通用。增强型像素解码器和kMaX解码器分别用浅蓝色和黄色进行着色。
通过提出的单头k - means聚类代替多头交叉注意力来简化掩码变压器模型。通过建立传统k - means聚类算法和交叉注意力之间的联系,为分割任务定制了基于Transformer的模型。
相关文章:
mask transformer相关论文阅读
前面讲了mask-transformer对医学图像分割任务是非常适用的。本文就是总结一些近期看过的mask-transformer方面的论文。 因为不知道mask transformer是什么就看了一些论文。后来得出结论,应该就是生成mask的transformer就是mask transformer。 相关论文: …...
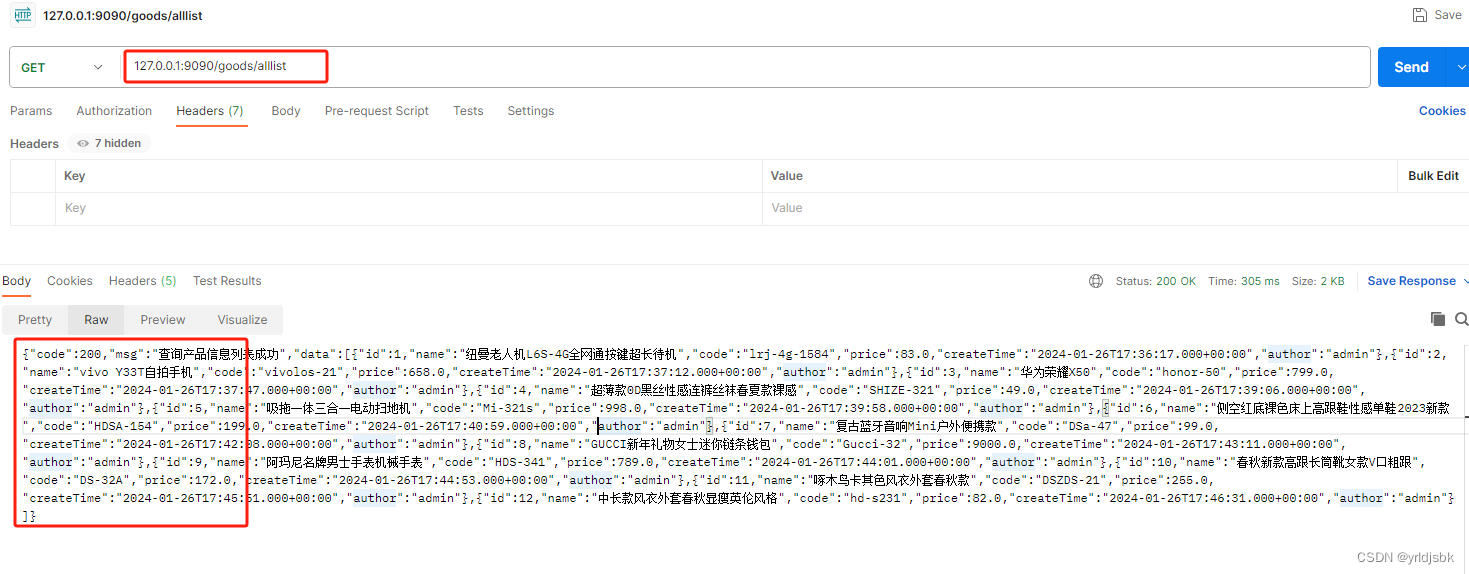
springboot+vue3支付宝接口案例-第二节-准备后端数据接口
springbootvue3支付宝接口案例-第二节-准备后端数据接口!今天经过2个小时的折腾。准备好了我们这次测试支付宝线上支付接口的后端业务数据接口。下面为大家分享一下,期间发生遇到了一些弯路。 首先,我们本次后端接口使用的持久层框架是JPA。这…...
)
贪吃蛇游戏设计文档(基于C语言)
1. 引言 本设计文档旨在详细阐述一款2D贪吃蛇游戏的设计思路、功能模块划分以及具体实现要点。通过严谨的需求分析与清晰的架构设计,确保游戏开发过程有序进行,并最终打造出一款用户友好、稳定流畅的经典贪吃蛇游戏。 2. 需求分析 2.1 核心元素 - 蛇&…...
在Windows上安装与配置Apache服务并结合内网穿透工具实现公网远程访问本地内网服务
文章目录 前言1.Apache服务安装配置1.1 进入官网下载安装包1.2 Apache服务配置 2.安装cpolar内网穿透2.1 注册cpolar账号2.2 下载cpolar客户端 3. 获取远程桌面公网地址3.1 登录cpolar web ui管理界面3.2 创建公网地址 4. 固定公网地址 前言 Apache作为全球使用较高的Web服务器…...

幻兽帕鲁服务器出租,腾讯云PK阿里云怎么收费?
幻兽帕鲁服务器价格多少钱?4核16G服务器Palworld官方推荐配置,阿里云4核16G服务器32元1个月、96元3个月,腾讯云换手帕服务器服务器4核16G14M带宽66元一个月、277元3个月,8核32G22M配置115元1个月、345元3个月,16核64G3…...

day05休息,day06 有效的字母异位词、两个数组的交集、快乐数、两数之和
题目链接:有效的字母异位词、两个数组的交集、快乐数、两数之和 有效的字母异位词 时间复杂度: O(n) 空间复杂度: O(S), S为字符集大小,这里为26 Go func isAnagram(s string, t string) bool {// s和t的长度一定是相等的if len(s) ! len(t) {return…...

star原则
"STAR" 原则通常用于回答面试或描述工作经验等场景中,以清晰、有条理地传达信息。"STAR" 是 Situation(情境)、Task(任务)、Action(行动)、Result(结果…...
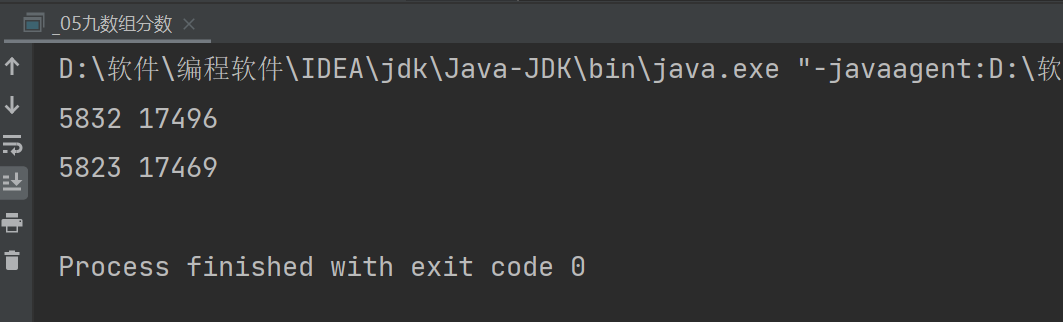
蓝桥杯---九数组分数
1,2,3 ... 9 这九个数字组成一个分数,其值恰好为1/3,如何组法? 下面的程序实现了该功能,请填写划线部分缺失的代码。 注意,只能填写缺少的部分,不要重复抄写已有代码。不要填写任何多余的文字。 代码 public class _05九数组分数 {public static void test(int[] x){int a …...

将 Amazon Bedrock 与 Elasticsearch 和 Langchain 结合使用
Amazon Bedrock 是一项完全托管的服务,通过单一 API 提供来自 AI21 Labs、Anthropic、Cohere、Meta、Stability AI 和 Amazon 等领先 AI 公司的高性能基础模型 (FMs) 选择,以及广泛的 构建生成式 AI 应用程序所需的功能,简化开发,…...

###C语言程序设计-----C语言学习(6)#
前言:感谢老铁的浏览,希望老铁可以一键三连加个关注,您的支持和鼓励是我前进的动力,后续会分享更多学习编程的内容。 一. 主干知识的学习 1. while语句 除了for语句以外,while语句也用于实现循环,而且它…...
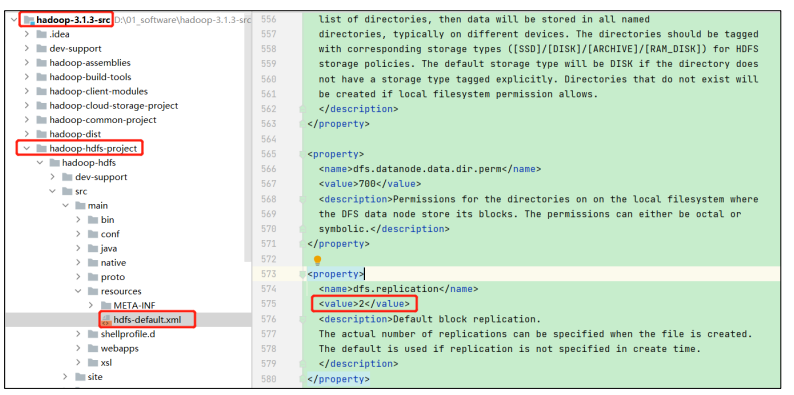
Hadoop3.x源码解析
文章目录 一、RPC通信原理解析1、概要2、代码demo 二、NameNode启动源码解析1、概述2、启动9870端口服务3、加载镜像文件和编辑日志4、初始化NN的RPC服务端5、NN启动资源检查6、NN对心跳超时判断7、安全模式 三、DataNode启动源码解析1、概述2、初始化DataXceiverServer3、初始…...
基于vue实现待办清单案例
一、需求 新增内容; 删除内容; 统计操作; 清空数据。 示例图: 二、代码演示 1、基础准备 index.css代码 html, body {margin: 0;padding: 0; } body {background: #fff ; } button {margin: 0;padding: 0;border: 0;backgr…...
应急响应-流量分析
在应急响应中,有时需要用到流量分析工具,。当需要看到内部流量的具体情况时,就需要我们对网络通信进行抓包,并对数据包进行过滤分析,最常用的工具是Wireshark。 Wireshark是一个网络封包分析软件。网络封包分析软件的…...
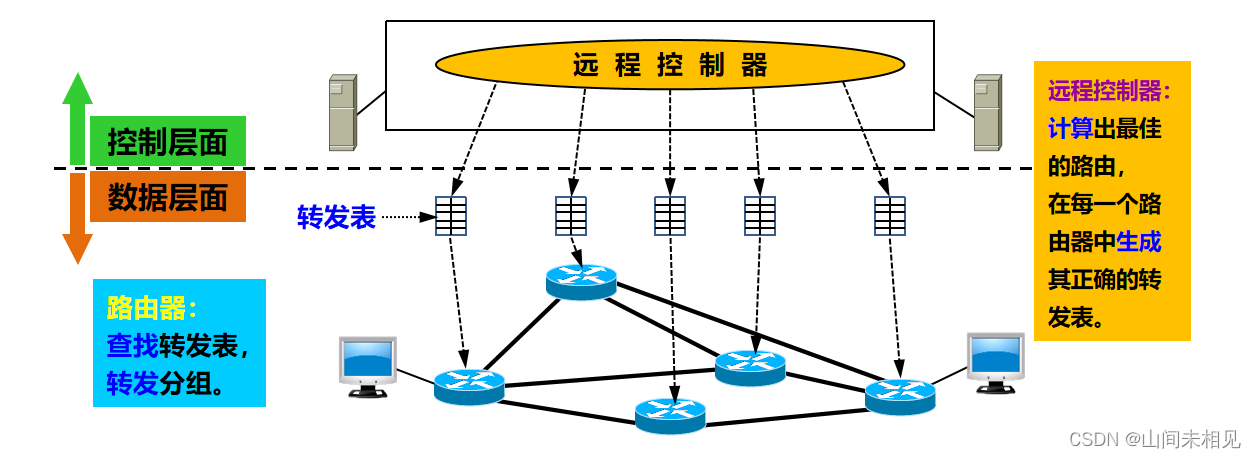
计算机网络·网络层
网络层 网络层提供的两种服务 争论: 网络层应该向运输层提供怎样的服务?面向连接还是无连接? 在计算机通信中,可靠交付应当由谁来负责?是网络还是端系统? 2 种观点: 面向连接的可靠交付。 无连…...
2024/1/28周报
文章目录 摘要Abstract文献阅读题目引言方法The ARIMA modelTime delay neural network (TDNN) modelLSTM and DLSTM model 评估准则实验数据描述实验结果 深度学习AttentionAttention思想公式步骤 Attention代码实现注意力机制seq2seq解码器Model验证 总结 摘要 本周阅读了一…...

Vue3中的ref和shallowRef、reactive和shallowReactive
一:ref、reactive简介 ref和reactive是Vue3中定义响应式数据的一种方式。ref通常用来定义基础类型数据。reactive通常用来定义复杂类型数据。 二、shallowRef、shallowReactive简介 shallowRef和shallowReactive是Vue3中定义浅层次响应式数据的方式 三、Api使用对比…...
go包与依赖管理
包(package) 包介绍 Go语言中支持模块化的开发理念,在Go语言中使用包(package)来支持代码模块化和代码复用。一个包是由一个或多个Go源码文件(.go结尾的文件)组成,是一种高级的代码…...

C++文件操作基础 读写文本、二进制文件 输入输出流 文件位置指针以及随机存取 文件缓冲区以及流状态
一、写入文本文件 文本文件一般以行的形式组织数据。 包含头文件:#include <fstream> 类:ofstream(output file stream) ofstream 打开文件的模式(方式):类内open()成员函数参数2.参数1是…...
nginx部署前端(vue)项目及配置修改
目录 一、前端应用打包 二、部署前端应用 1、上传前端文件夹 2、修改nginx配置文件 3、重启nginx 三、查看效果 nginx安装参考:linux安装nginx-CSDN博客 一、前端应用打包 打包命令 npm run build 打包成功如下,会在项目路径下生成dist文件夹 二…...

FreeRTOS
1.新建一个无FreeRTOS的工程,取名为Motor,根据风扇模块PDF原理图和操作文档让风扇转动 2.新建一个包含FreeRTOS的工程,取名为Semaphore 具体步骤:创建两个任务和一个共享资源,在两个任务中使用信号量来同时访问共享资源…...

HFSS仿真结果怎么看?以T型波导为例,读懂S参数与电场动态图
HFSS仿真结果深度解析:从S参数到电场动态图的实战指南当你第一次在HFSS中完成T型波导仿真后,面对满屏的曲线和彩色云图,是否感到既兴奋又困惑?那些起伏的S参数曲线究竟告诉你什么信息?电场图中跳跃的颜色又代表怎样的物…...

HFSS仿真结果怎么看?一文读懂S参数与电场图,让你的T型波导分析不再迷茫
HFSS仿真结果深度解析:从S参数到电场图的工程实践指南面对HFSS仿真生成的复杂数据图表,许多工程师常陷入"看得见数据却读不懂含义"的困境。本文将带您穿透数据表象,掌握T型波导性能分析的核心方法论。1. S参数:波导性能…...

我靠这个测试设计方法,把漏测率降低了80%
当“直觉测试”撞上南墙很长一段时间里,我和许多测试同行一样,测试用例的设计主要依靠两样东西:需求文档和“测试直觉”。这种模式在业务逻辑相对简单、迭代速度平缓时还能勉强应付。一旦面对复杂的企业级应用、高频的敏捷迭代,或…...

钱钟书《围城》第1-5章阅读笔记:一场关于人生困境的提前预演
前言 钱钟书先生的《围城》被誉为"新儒林外史",是中国现代文学史上风格独特的讽刺经典。这部创作于20世纪40年代的长篇小说,以抗战初期为背景,通过主人公方鸿渐的人生轨迹,深刻揭示了知识分子群体的精神困境与人性弱点。…...

上线前最后一道防线,DeepSeek代码审查如何帮你拦截87%的CVE类缺陷?
更多请点击: https://intelliparadigm.com 第一章:上线前最后一道防线,DeepSeek代码审查如何帮你拦截87%的CVE类缺陷? 在软件交付生命周期末期,传统人工代码审计与通用SAST工具常因误报率高、上下文理解弱而漏检高危漏…...

对比按量计费与Token Plan套餐的实际成本差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比按量计费与Token Plan套餐的实际成本差异 在构建和运营基于大模型的应用时,成本控制是一个核心的工程考量。Taotok…...

Redis 客户端连接详解
Redis 客户端连接详解 引言 Redis 是一款高性能的内存数据结构存储系统,常用于缓存、会话管理、实时排行榜等功能。客户端连接是 Redis 生态系统中的重要组成部分,本文将详细介绍 Redis 客户端连接的相关知识,包括连接方式、连接配置、连接管理等方面。 Redis 客户端连接…...

别再盲调temperature=0.2!DeepSeek补全效果突变的4个隐藏参数,资深架构师压箱底调参清单
更多请点击: https://intelliparadigm.com 第一章:别再盲调temperature0.2!DeepSeek补全效果突变的4个隐藏参数,资深架构师压箱底调参清单 DeepSeek-R1/VL 等开源大模型在实际部署中,仅靠调节 temperature 往往收效甚…...

对比直接调用厂商API使用Taotoken聚合调用的延迟体感差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接调用厂商API使用Taotoken聚合调用的延迟体感差异 在将应用从直接调用单一厂商的模型API迁移到Taotoken平台后,…...

UE5 GPU崩溃终极解决方案:Windows TDR注册表调优指南
1. 这不是玄学,是显卡驱动与UE引擎的底层握手失败 你刚点下Play,编辑器还没完全加载完场景,屏幕突然黑一下,然后弹出“GPU has stopped responding and has recovered”——或者更糟,直接蓝屏、黑屏死机、编辑器无响应…...