将 Amazon Bedrock 与 Elasticsearch 和 Langchain 结合使用

Amazon Bedrock 是一项完全托管的服务,通过单一 API 提供来自 AI21 Labs、Anthropic、Cohere、Meta、Stability AI 和 Amazon 等领先 AI 公司的高性能基础模型 (FMs) 选择,以及广泛的 构建生成式 AI 应用程序所需的功能,简化开发,同时维护隐私和安全。 由于 Amazon Bedrock 是无服务器的,因此你无需管理任何基础设施,并且可以使用你已经熟悉的 AWS 服务将生成式 AI 功能安全地集成和部署到你的应用程序中。
在此示例中,我们将文档拆分为段落,在 Elasticsearch 中索引该文档,使用 ELSER 执行语义搜索来检索相关段落。 通过相关段落,我们构建了上下文并使用 Amazon Bedrock 来回答问题。
1. 安装包并导入模块
首先我们需要安装模块。 确保 python 安装的最低版本为 3.8.1。
!python3 -m pip install -qU langchain elasticsearch boto3然后我们需要导入模块
from getpass import getpass
from urllib.request import urlopen
from langchain.vectorstores import ElasticsearchStore
from langchain.text_splitter import CharacterTextSplitter
from langchain.llms import Bedrock
from langchain.chains import RetrievalQA
import boto3
import json注意:boto3 是适用于 Python 的 AWS 开发工具包的一部分,并且需要使用 Bedrock LLM
2. 初始化基岩客户端
要在 AWS 服务中授权,我们可以使用 ~/.aws/config 文件和配置凭证或将 AWS_ACCESS_KEY、AWS_SECRET_KEY、AWS_REGION 传递给 boto3 模块
我们的示例使用第二种方法。
default_region = "us-east-1"
AWS_ACCESS_KEY = getpass("AWS Acces key: ")
AWS_SECRET_KEY = getpass("AWS Secret key: ")
AWS_REGION = input(f"AWS Region [default: {default_region}]: ") or default_regionbedrock_client = boto3.client(service_name="bedrock-runtime",region_name=AWS_REGION,aws_access_key_id=AWS_ACCESS_KEY,aws_secret_access_key=AWS_SECRET_KEY
)3. 连接到 Elasticsearch
ℹ️ 我们为此 notebook 使用 Elasticsearch 的 Elastic Cloud 部署。 如果你没有 Elastic Cloud 部署,请在此处注册免费试用。
我们将使用 Cloud ID 来标识我们的部署,因为我们使用的是 Elastic Cloud 部署。 要查找你的部署的 Cloud ID,请转至 https://cloud.elastic.co/deployments 并选择你的部署。
我们将使用 ElasticsearchStore 连接到我们的 Elastic 云部署。 这将有助于轻松创建和索引数据。 在 ElasticsearchStore 实例中,将嵌入设置为 BedrockEmbeddings 以嵌入本示例中将使用的文本和 elasticsearch 索引名称。 在本例中,我们将 strategy 设置为 ElasticsearchStore.SparseVectorRetrievalStrategy(),因为我们使用此策略来拆分文档。
当我们使用 ELSER 时,我们使用 SparseVectorRetrievalStrategy 策略。 该策略使用 Elasticsearch 的稀疏向量检索来检索 top-k 结果。 Langchain 中还有更多其他 strategies 可以根据你的需要使用。
CLOUD_ID = getpass("Elastic deployment Cloud ID: ")
CLOUD_USERNAME = "elastic"
CLOUD_PASSWORD = getpass("Elastic deployment Password: ")vector_store = ElasticsearchStore(es_cloud_id=CLOUD_ID,es_user=CLOUD_USERNAME,es_password=CLOUD_PASSWORD,index_name= "workplace_index",strategy=ElasticsearchStore.SparseVectorRetrievalStrategy()
)4. 下载数据集
让我们下载示例数据集并反序列化文档。
url = "https://raw.githubusercontent.com/elastic/elasticsearch-labs/main/example-apps/chatbot-rag-app/data/data.json"response = urlopen(url)workplace_docs = json.loads(response.read())5. 将文档分割成段落
我们将把文档分成段落,以提高检索的特异性,并确保我们可以在最终问答提示的上下文窗口中提供多个段落。
在这里,我们将文档分块为 800 个标记段落,其中有 400 个标记重叠。
这里我们使用一个简单的拆分器,但 Langchain 提供了更高级的拆分器来减少上下文丢失的机会。
metadata = []
content = []for doc in workplace_docs:content.append(doc["content"])metadata.append({"name": doc["name"],"summary": doc["summary"],"rolePermissions":doc["rolePermissions"]})text_splitter = CharacterTextSplitter(chunk_size=800, chunk_overlap=400)
docs = text_splitter.create_documents(content, metadatas=metadata)6. 将数据索引到 Elasticsearch 中
接下来,我们将使用 ElasticsearchStore.from_documents 将数据索引到 elasticsearch。 我们将使用在创建云部署步骤中设置的云 ID、密码和索引名称值。
在实例中,我们将策略设置为 SparseVectorRetrievalStrategy()
注意:在开始索引之前,请确保你已在部署中下载并部署了 ELSER 模型,并且正在 ml 节点中运行。
documents = vector_store.from_documents(docs,es_cloud_id=CLOUD_ID,es_user=CLOUD_USERNAME,es_password=CLOUD_PASSWORD,index_name="workplace_index",strategy=ElasticsearchStore.SparseVectorRetrievalStrategy()
)7. 初始 Bedrock 硕士
接下来,我们将初始化 Bedrock LLM。 在 Bedrock 实例中,将传递 bedrock_client 和特定 model_id:amazon.titan-text-express-v1、ai21.j2-ultra-v1、anthropic.claude-v2、cohere.command-text-v14 等。你可以看到列表 Amazon Bedrock 用户指南上的可用基本模型
default_model_id = "amazon.titan-text-express-v1"
AWS_MODEL_ID = input(f"AWS model [default: {default_model_id}]: ") or default_model_id
llm = Bedrock(client=bedrock_client,model_id=AWS_MODEL_ID
)8. 提出问题
现在我们已经将段落存储在 Elasticsearch 中并且 LLM 已初始化,我们现在可以提出问题来获取相关段落。
retriever = vector_store.as_retriever()qa = RetrievalQA.from_llm(llm=llm,retriever=retriever,return_source_documents=True
)questions = ['What is the nasa sales team?','What is our work from home policy?','Does the company own my personal project?','What job openings do we have?','How does compensation work?'
]
question = questions[1]
print(f"Question: {question}\n")ans = qa({"query": question})print("\033[92m ---- Answer ---- \033[0m")
print(ans["result"] + "\n")
print("\033[94m ---- Sources ---- \033[0m")
for doc in ans["source_documents"]:print("Name: " + doc.metadata["name"])print("Content: "+ doc.page_content)print("-------\n")尝试一下
Amazon Bedrock LLM 是一个功能强大的工具,可以通过多种方式使用。 你可以尝试使用不同的基本模型和不同的问题。 你还可以使用不同的数据集进行尝试,看看它的表现如何。 要了解有关 Amazon Bedrock 的更多信息,请查看文档。
你可以尝试在 Google Colab 中运行此示例。
相关文章:
将 Amazon Bedrock 与 Elasticsearch 和 Langchain 结合使用
Amazon Bedrock 是一项完全托管的服务,通过单一 API 提供来自 AI21 Labs、Anthropic、Cohere、Meta、Stability AI 和 Amazon 等领先 AI 公司的高性能基础模型 (FMs) 选择,以及广泛的 构建生成式 AI 应用程序所需的功能,简化开发,…...

###C语言程序设计-----C语言学习(6)#
前言:感谢老铁的浏览,希望老铁可以一键三连加个关注,您的支持和鼓励是我前进的动力,后续会分享更多学习编程的内容。 一. 主干知识的学习 1. while语句 除了for语句以外,while语句也用于实现循环,而且它…...
Hadoop3.x源码解析
文章目录 一、RPC通信原理解析1、概要2、代码demo 二、NameNode启动源码解析1、概述2、启动9870端口服务3、加载镜像文件和编辑日志4、初始化NN的RPC服务端5、NN启动资源检查6、NN对心跳超时判断7、安全模式 三、DataNode启动源码解析1、概述2、初始化DataXceiverServer3、初始…...
基于vue实现待办清单案例
一、需求 新增内容; 删除内容; 统计操作; 清空数据。 示例图: 二、代码演示 1、基础准备 index.css代码 html, body {margin: 0;padding: 0; } body {background: #fff ; } button {margin: 0;padding: 0;border: 0;backgr…...
应急响应-流量分析
在应急响应中,有时需要用到流量分析工具,。当需要看到内部流量的具体情况时,就需要我们对网络通信进行抓包,并对数据包进行过滤分析,最常用的工具是Wireshark。 Wireshark是一个网络封包分析软件。网络封包分析软件的…...
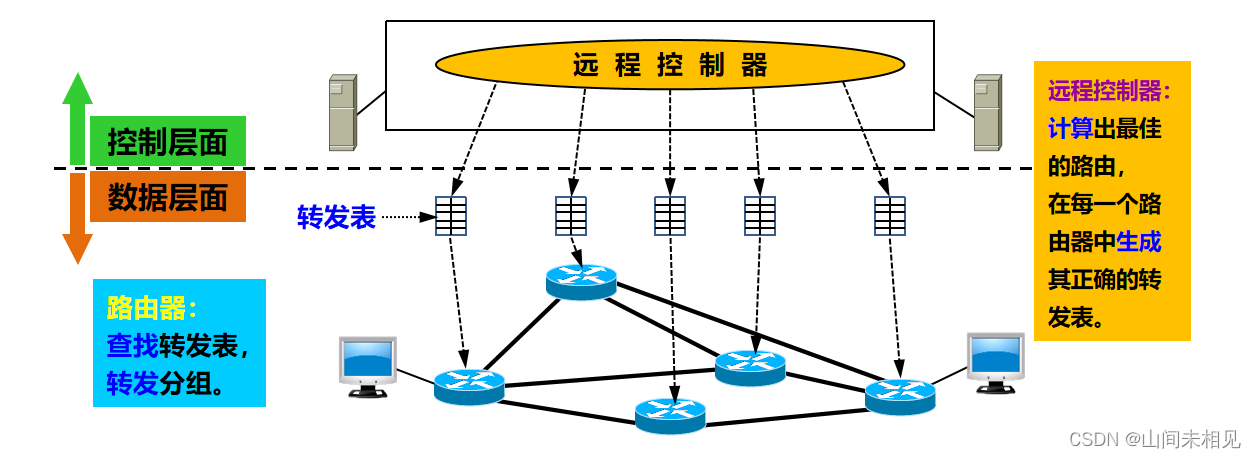
计算机网络·网络层
网络层 网络层提供的两种服务 争论: 网络层应该向运输层提供怎样的服务?面向连接还是无连接? 在计算机通信中,可靠交付应当由谁来负责?是网络还是端系统? 2 种观点: 面向连接的可靠交付。 无连…...
2024/1/28周报
文章目录 摘要Abstract文献阅读题目引言方法The ARIMA modelTime delay neural network (TDNN) modelLSTM and DLSTM model 评估准则实验数据描述实验结果 深度学习AttentionAttention思想公式步骤 Attention代码实现注意力机制seq2seq解码器Model验证 总结 摘要 本周阅读了一…...

Vue3中的ref和shallowRef、reactive和shallowReactive
一:ref、reactive简介 ref和reactive是Vue3中定义响应式数据的一种方式。ref通常用来定义基础类型数据。reactive通常用来定义复杂类型数据。 二、shallowRef、shallowReactive简介 shallowRef和shallowReactive是Vue3中定义浅层次响应式数据的方式 三、Api使用对比…...
go包与依赖管理
包(package) 包介绍 Go语言中支持模块化的开发理念,在Go语言中使用包(package)来支持代码模块化和代码复用。一个包是由一个或多个Go源码文件(.go结尾的文件)组成,是一种高级的代码…...

C++文件操作基础 读写文本、二进制文件 输入输出流 文件位置指针以及随机存取 文件缓冲区以及流状态
一、写入文本文件 文本文件一般以行的形式组织数据。 包含头文件:#include <fstream> 类:ofstream(output file stream) ofstream 打开文件的模式(方式):类内open()成员函数参数2.参数1是…...
nginx部署前端(vue)项目及配置修改
目录 一、前端应用打包 二、部署前端应用 1、上传前端文件夹 2、修改nginx配置文件 3、重启nginx 三、查看效果 nginx安装参考:linux安装nginx-CSDN博客 一、前端应用打包 打包命令 npm run build 打包成功如下,会在项目路径下生成dist文件夹 二…...

FreeRTOS
1.新建一个无FreeRTOS的工程,取名为Motor,根据风扇模块PDF原理图和操作文档让风扇转动 2.新建一个包含FreeRTOS的工程,取名为Semaphore 具体步骤:创建两个任务和一个共享资源,在两个任务中使用信号量来同时访问共享资源…...

windows 10/11 home左键点击开始菜单无反应
用户电脑点开始没反应,用户配置文件出错。 用户电脑是home版 windows hello指纹设置不了,其实是不能使用默认帐号administrator。 使用windowspe启用administrator用户,重启使用administrator删除出错用户。 直接使用administrator用户windows hello…...
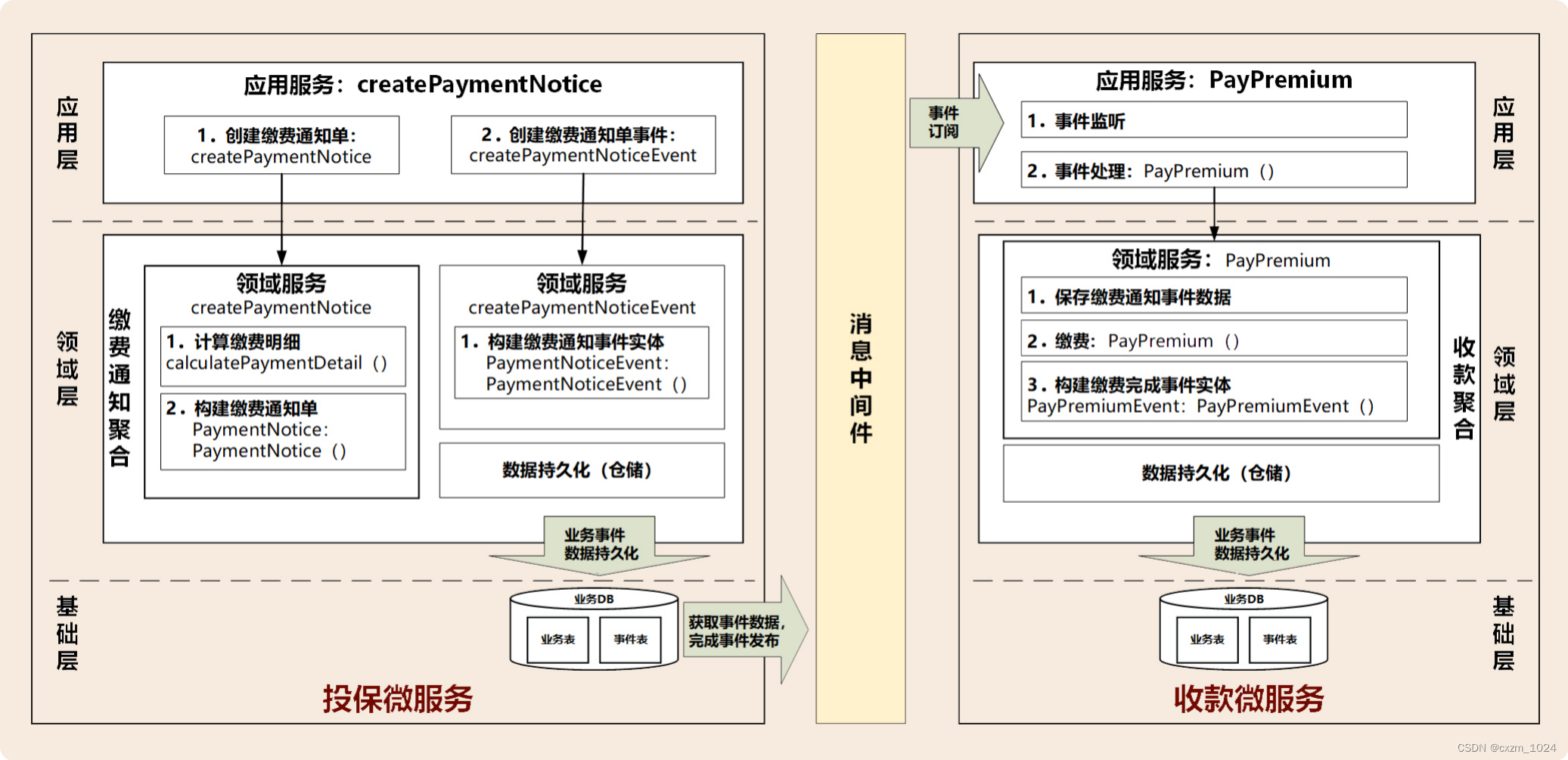
05.领域驱动设计:认识领域事件,解耦微服务的关键
目录 1、概述 2、领域事件 2.1 如何识别领域事件 1.微服务内的领域事件 2.微服务之间的领域事件 3、领域事件总体架构 3.1 事件构建和发布 3.2 事件数据持久化 3.3 事件总线 (EventBus) 3.4 消息中间件 3.5 事件接收和处理 4、案例 5、总结 1、概述 在事件风暴&a…...

「仙逆」王麻子结丹救下老婆,极识斩杀金丹修士,元婴期下第一人
Hello,小伙伴们,我是拾荒君。 国漫《仙逆》第21期超前爆料,据透露王麻子因急需天离丹来突破至金丹期,购买了被斗邪派预定的百兽灵炉,却遭其宗派追杀。虽然王麻子已触及结丹边缘,但面对五名邪派长老,他毫无…...

GoogleNet Inception v2 和 Inception v3详解
1 GoogleNet Inception v2 v1具体结构: v2具体结构: 1 引入Batch Normalization(BN): Inception v2在每个卷积层之后引入了BN。这有助于解决深层网络中的梯度消失问题,同时加快训练过程并提高模型的收敛速度。BN通过…...
在虚拟机上安装ubuntu
记得看目录哦! 软件自取1. 新建虚拟机2. Ubuntu的汉化 软件自取 链接:百度网盘自取哦!!! 提取码:8888 1. 新建虚拟机 文件–新建虚拟机 完成完会自动启动,等待一段时间,我等了一个…...
nav02 学习03 机器人传感器
机器人传感器 移动机器人配备了大量传感器,使它们能够看到和感知周围的环境。这些传感器获取的信息可用于构建和维护环境地图、在地图上定位机器人以及查看环境中的障碍物。这些任务对于能够安全有效地在动态环境中导航机器人至关重要。 机器人的传感器类似人的感官…...
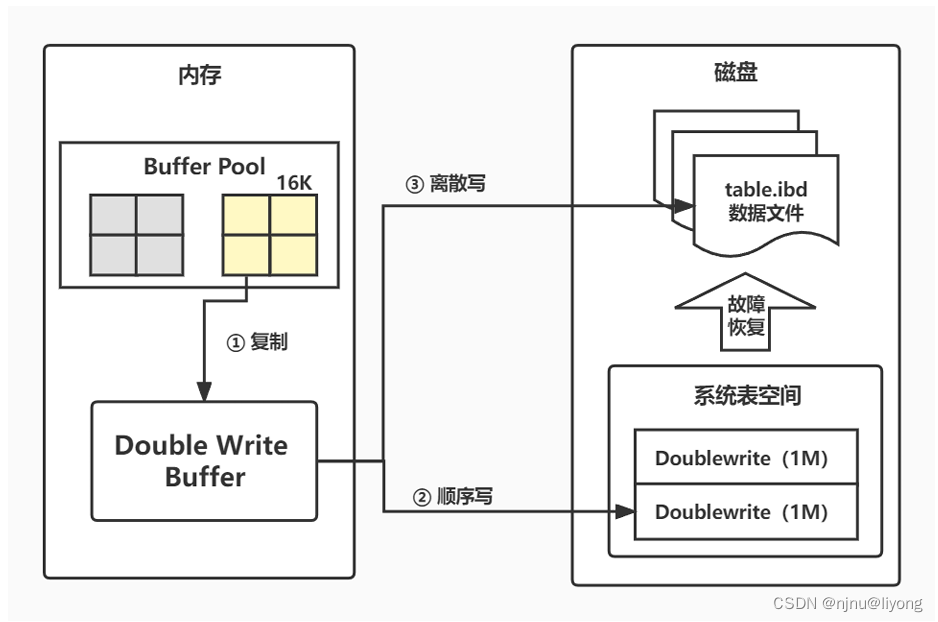
Mysql-InnoDB-数据落盘
概念 1 什么是脏页? 对于数据库中页的修改操作,则首先修改在缓冲区中的页,缓冲区中的页与磁盘中的页数据不一致,所以称缓冲区中的页为脏页。 2 脏页什么时候写入磁盘? 脏页以一定的频率将脏页刷新到磁盘上。页从缓冲区…...

<el-date-picker>时间戳单位
神级操作,搞了半天,秒是大X,毫秒是小x,yue了。 // 秒 <el-date-pickerv-model"timestamp"value-format"X" ></el-date-picker>// 毫秒 <el-date-pickerv-model"timestamp"value-fo…...
)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)在当今微服务架构盛行的时代,Go语言因其高性能和并发优势成为后端开发的热门选择。而Goframe作为一款企业级的Go应用开发框架,提供了从数据库操作到API…...

【DeepSeek-R1代码相似度引擎解密】:3层语义比对机制、Token归一化偏差修正与Jaccard阈值黄金分割点
更多请点击: https://kaifayun.com 第一章:DeepSeek代码重复检测 DeepSeek-R1 模型在训练过程中引入了严格的代码去重机制,其核心目标是消除训练语料中语义等价或高度相似的代码片段,从而提升模型对真实编程模式的学习能力与泛化…...

户外实用|艾迪欧 R6000 测评 —— 户外 / 自驾 / 露营的通讯好搭档
户外出行,通讯工具的核心是稳定、清晰、耐用、续航久、功能全。艾迪欧 R6000 作为一款兼顾专业与户外的 DMR 对讲机,全频段覆盖、双模通讯、自定义功能、长续航,完美适配自驾、露营、登山、越野等户外场景,是户外爱好者的靠谱通讯…...

转行网络安全运维:从0到1的可落地指南
转行网络安全运维:从0到1的可落地指南 一、 「3个核心技能:从零起步也能会」 网上学习资料多到爆炸,不用纠结“哪个最好”,记住一句话:**能学会、能上手的就是好的**!不管是免费视频还是付费课,…...

HDI 高密度互连板阶数的深度理解
一、概述高密度互连板(High Density Interconnector, HDI)是通过激光微孔技术和逐层积层工艺实现高密度布线的印制电路板。其阶数划分是行业内统一的技术标准,核心依据为独立积层压合次数与配套激光盲孔制程次数,而非单面层数或钻…...

翻译 GDB 官方文档
翻译 GDB 官方文档项目地址官方文档地址下载源码包编译html运行翻译程序项目地址 https://github.com/shootercheng/gdb-translate.git 项目结构 $ tree -L 1 . ├── cmd ├── go.mod ├── input ├── internal ├── LICENSE ├── output ├── README.md ├─…...

简单学习 --> SSE
我们使用AI时,AI对我们说的话不会一次性把全部内容弹出来,而是会像流水一样,一点点吐出来,那么这种丝滑的交互体验,背后的核心就是 SSE (Server-Sent Events)。 什么是 SSE? SSE(Server-Sent …...
,锁定雾浓度≤0.38的7个关键阈值参数)
【云雾效果商业级交付标准】:基于Adobe Sensei图像雾度分析报告(N=1,247张MJ生成图),锁定雾浓度≤0.38的7个关键阈值参数
更多请点击: https://intelliparadigm.com 第一章:云雾效果商业级交付标准的定义与行业意义 云雾效果在现代数字体验中已超越视觉装饰范畴,成为空间感知建模、沉浸式交互与品牌情绪传达的核心媒介。商业级交付标准并非仅关注“是否可见雾气”…...

GEO优化可以覆盖哪些搜索平台
这是一个非常现实的问题。企业投放资源做GEO,当然希望覆盖面越广越好。那么GEO优化到底能覆盖哪些平台?覆盖到什么程度?不同平台的GEO逻辑有什么差异?GEO平台覆盖的三个层级第一层级:通用大模型AI平台(核心…...

告别手动复制!用这个自定义编辑器脚本一键备份/克隆Unity Terrain Data
告别手动复制!用这个自定义编辑器脚本一键备份/克隆Unity Terrain Data在Unity关卡设计和技术美术的工作流中,地形数据的灵活复用往往意味着反复的手动操作——导出高度图、备份材质参数、复制植被分布,每个环节都可能成为效率瓶颈。想象这样…...