Python爬虫---Scrapy框架---CrawlSpider
CrawlSpider
1. CrawlSpider继承自scrapy.Spider
2. CrawlSpider可以定义规则,再解析html内容的时候,可以根据链接规则提取出指定的链接,然后再向这些链接发送请求,所以,如果有需要跟进链接的需求,意思就是爬取了网页之后,需要提取链接再次爬取,使用Crawlspider是非常合适的
使用scrapy shell提取:
1. 在命令提示符中输入: scrapy shell https://www.dushu.com/lianzai/1115.html
![]()
2. 导入链接提取器:from scrapy.linkextractors import LinkExtractor
![]()
3. allow = () :正则表达式 ,提取符合正则的链接
![]()

5. 查看连接提取器提取的内容

6. restrict_xpaths = () :xpath语法,提取符合xpath规则的链接

查看提取的内容:

7. restrict_css = () :提取符合选择器规则的链接
小案例:
1. 创建项目:scrapy startproject 项目名
2. 跳转到spider目录下: cd .\项目名\项目名\spiders\
3. 创建爬虫类:scrapy genspider -t crawl 爬虫文件名 要爬取的网页 (这里与之前的不一样)
4. 运行:scrapy crawl 爬虫文件名
指定日志等级:(settings.py文件中)
LOG_LEVEL = "DEBUG"
将日志保存在文件中: .log(settings.py文件中)
LOG_FILE = "logdemo.log"
callback只能写函数字符串
follow=true 是否跟进 就是按照提取连接规则进行提取
爬虫文件:
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy_readbook_20240120.items import ScrapyReadbook20240120Itemclass RbookSpider(CrawlSpider):name = "rbook"allowed_domains = ["www.dushu.com"]start_urls = ["https://www.dushu.com/lianzai/1115_1.html"]rules = (Rule(LinkExtractor(allow=r"/lianzai/1115_\d+.html"),callback="parse_item",follow=False),)def parse_item(self, response):print("++++++++++++++++++++")img_list = response.xpath("//div[@class='bookslist']//img")for img in img_list:src = img.xpath("./@data-original").extract_first()name = img.xpath("./@alt").extract_first()book = ScrapyReadbook20240120Item(name=name, src=src)yield bookpipelines.py文件
class ScrapyReadbook20240120Pipeline:def open_spider(self, spider):self.fp = open("book.json", "w", encoding="utf-8")def process_item(self, item, spider):self.fp.write(str(item))return itemdef close_spider(self, spider):self.fp.close()items.py文件
import scrapyclass ScrapyReadbook20240120Item(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()name = scrapy.Field()src = scrapy.Field()
settings.py文件
# 开启管道
ITEM_PIPELINES = {"scrapy_readbook_20240120.pipelines.ScrapyReadbook20240120Pipeline": 300,
}保存在数据库中:
1. 创建数据库
create database 数据库名字 charset utf8;
2. 使用数据库
use 数据库名字;
3. 创建表格 :例子
create table 表名(
id int primary key auto_increment,
name varchar(128),
src varchar(128)
);
4. 在settings.py 文件中添加 ip地址、端口号、数据库密码、数据库名字、字符集
DB_HOST = "localhost" # ip地址
DB_PORT = 3306 # 端口号,必须是整数
DB_USER = "root" # 数据库用户名
DB_PASSWORD = "123456" # 数据库密码
DB_NAME = "rbook" # 数据库名字
DB_CHARSET = "utf8" # 字符集,不允许写 -
5. 在pipelines管道文件中增加
# 加载settings文件
from scrapy.utils.project import get_project_settings
import pymysqlclass MysqlPipeline:def open_spider(self, spider):settings = get_project_settings()self.host = settings["DB_HOST"] # ip地址self.port = settings["DB_PORT"] # 端口号self.user = settings["DB_USER"] # 数据库用户名self.password = settings["DB_PASSWORD"] # 数据库密码self.name = settings["DB_NAME"] # 数据库名字self.charset = settings["DB_CHARSET"] # 字符集self.connect()def connect(self):self.conn = pymysql.connect(host=self.host,port=self.port,user=self.user,password=self.password,db=self.name,charset=self.charset)self.cursor = self.conn.cursor()def process_item(self, item, spider):sql = "insert into rbook(name,src) values('{}','{}')".format(item["name"], item["src"])# 执行sql语句self.cursor.execute(sql)# 提交sql语句self.conn.commit()return itemdef close_spider(self, spider):# 关闭数据库链接self.cursor.close()self.conn.close()6. settings文件:添加新的管道
ITEM_PIPELINES = {"scrapy_readbook_20240120.pipelines.ScrapyReadbook20240120Pipeline": 300,"scrapy_readbook_20240120.pipelines.MysqlPipeline": 301,
}7. 若要一直下载,把所有数据都下载,则需要把爬虫文件里的 follow 的值设为 True
数据库的数据:
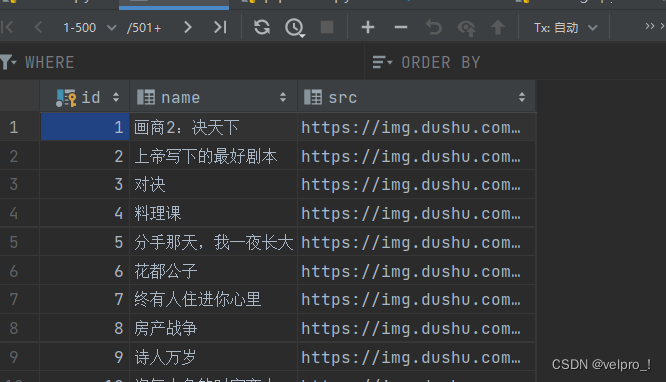
相关文章:
Python爬虫---Scrapy框架---CrawlSpider
CrawlSpider 1. CrawlSpider继承自scrapy.Spider 2. CrawlSpider可以定义规则,再解析html内容的时候,可以根据链接规则提取出指定的链接,然后再向这些链接发送请求,所以,如果有需要跟进链接的需求,意思就是…...

关机恶搞小程序
1. system("shutdown")的介绍 当system函数的参数是"shutdown"时,它将会执行系统的关机命令。 具体来说,system("shutdown")的功能是向操作系统发送一个关机信号,请求关闭计算机。这将触发操作系统执行一系列…...

《HTML 简易速速上手小册》第9章:HTML5 新特性(2024 最新版)
文章目录 9.1 HTML5 新增标签和属性9.1.1 基础知识9.1.2 案例 1:创建一个结构化的博客页面9.1.3 案例 2:使用新的表单元素创建事件注册表单9.1.4 案例 3:创建一个具有高级搜索功能的搜索表单 9.2 HTML5 表单增强9.2.1 基础知识9.2.2 案例 1&a…...

计算机网络之NAT
NAT(网络地址转换,Network Address Translation)是一种网络技术,用于在一个网络与另一个网络之间重新映射IP地址。NAT最常见的应用是在家庭和小型办公室的路由器中,用于将私有(内部)IP地址转换为…...

SQL - 数据操作语句
SQL - 数据操作语句 文章目录 SQL - 数据操作语句数据操作语言-DML1 新增2 修改3 删除4 清空 数据类型1 数值类型2 字符串类型3 日期时间类型 数据操作语言-DML 概念: DML(Data Manipulation Language), 数据操作语言。对数据表数据的增、删…...
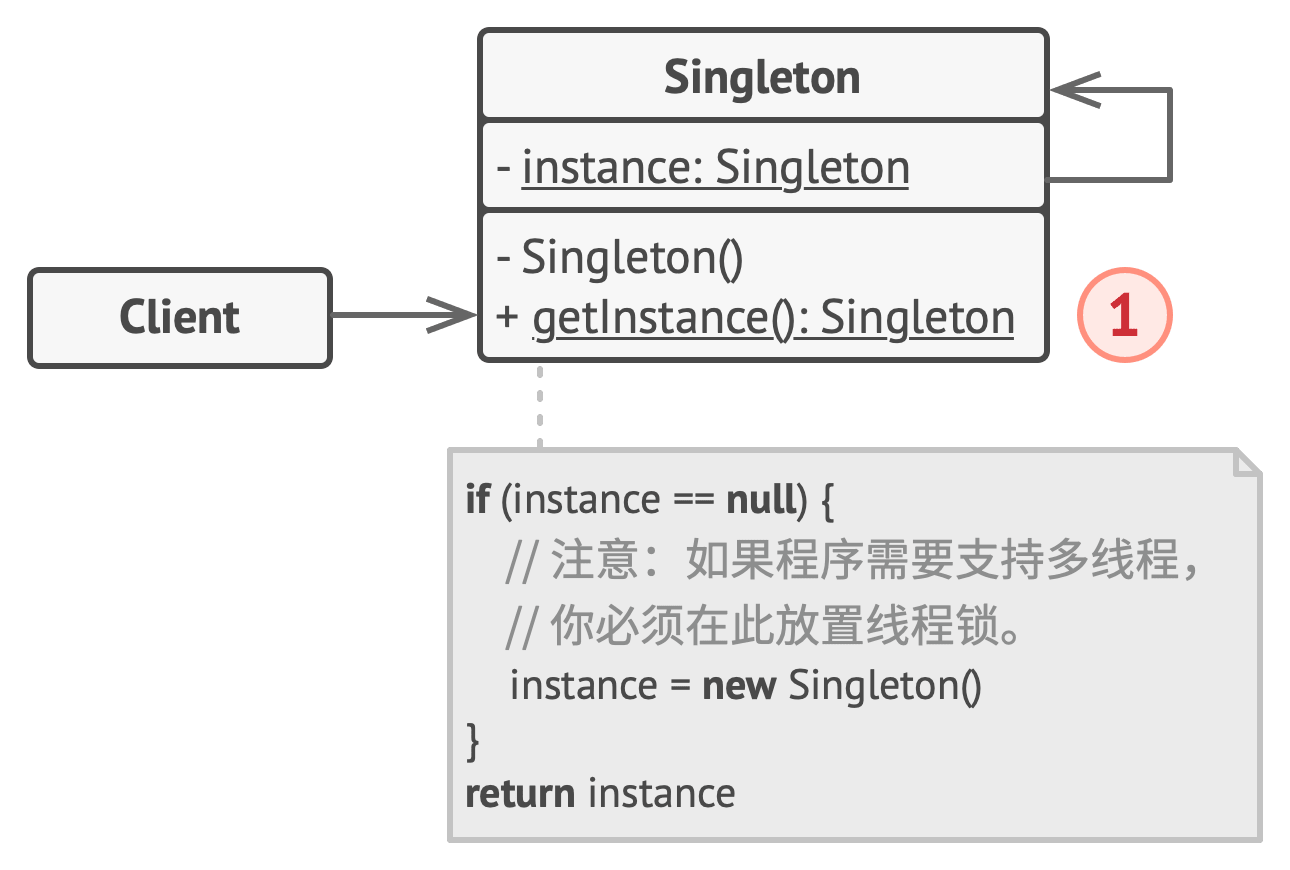
【Python笔记-设计模式】单例模式
一、说明 单例是一种创建型设计模式,能够保证一个类只有一个实例, 并提供一个访问该实例的全局节点。 (一) 解决问题 维护共享资源(数据库或文件)的访问权限,避免多个实例覆盖同一变量,引发程序崩溃。 …...

Java使用io流生成pdf文件
首先生成pdf和正常请求接口一样,直接写~ Controller层: 第一个注解:最顶层增加 Controller 注解(控制器)不多讲了 直接加上。 第二个注解:最顶层增加 CrossOrigin 注解此注解是为了浏览器请求的时候防…...
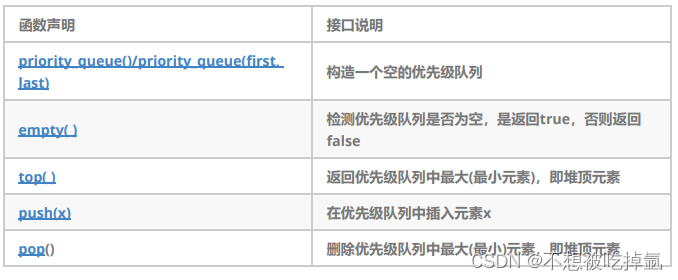
STL-priority_queue
文档 目录 1.关于priority_queued1的定义 2.priority_queue的使用 1.关于priority_queued1的定义 1. 优先队列是一种容器适配器,根据严格的弱排序标准,它的第一个元素总是它所包含的元素中最大的。 2. 此上下文类似于堆,在堆中可以随时插入元…...

SpringBoot基于注解形式配置多数据源@DS
TOC() 1.引入依赖 <!-- dynamic-datasource 多数据源--><dependency><groupId>com.baomidou</groupId><artifactId>dynamic-datasource-spring-boot-starter</artifactId><version>3.5.2</version></dependency>2.配置…...

华清远见作业第三十四天——C++(第三天)
思维导图: 题目: 设计一个Per类,类中包含私有成员:姓名、年龄、指针成员身高、体重,再设计一个Stu类,类中包含私有成员:成绩、Per类对象p1,设计这两个类的构造函数、析构函数和拷贝构造函数。 代码&#…...

Shell中正则表达式
1.正则表达式介绍 1、正则表达式---通常用于判断语句中,用来检查某一字符串是否满足某一格式 2、正则表达式是由普通字符与元字符组成 3、普通字符包括大小写字母、数字、标点符号及一些其他符号 4、元字符是指在正则表达式中具有特殊意义的专用字符,…...

Flutter Canvas 属性详解与实际运用
在Flutter中,Canvas是一个强大的绘图工具,允许我们以各种方式绘制图形、文字和图像。了解Canvas的属性是开发高度定制化UI的关键。在本篇博客中,我们将深入探讨Flutter中Canvas的一些重要属性,并展示它们在实际应用中的使用。 1.…...

Django配置websocket时的错误解决
基于移动群智感知的网络图谱构建系统需要手机app不断上传数据到服务器并把数据推到前端标记在百度地图上,由于众多手机向同一服务器发送数据,如果使用长轮询,则实时性差、延迟高且服务器的负载过大,而使用websocket则有更好的性能…...
(免费分享)springboot,vue在线考试系统
springboot 在线考试系统 前后端分离 一、项目简介 基于SpringBoot的在线考试系统 二、技术实现 后台框架:SpringBoot,mybatis-plus UI界面:Vue、ElementUI、Axios、Node.js(前后端分离) 数据库:MySQ…...
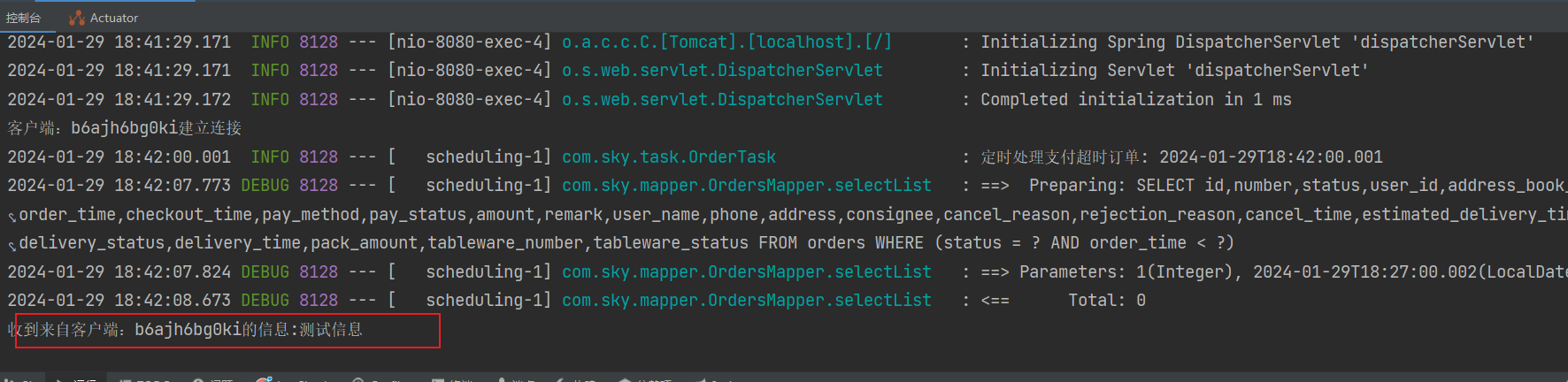
WebSocket 整合 记录用法
WebSocket 介绍 WebSocket 是基于tcp的一种新的网络协议,可以让浏览器 和 服务器进行通信,然后区别于http需要三次握手,websocket只用一次握手,就可以创建持久性的连接,并进行双向数据传输 Http和WebSocket的区别 Http是短连接,WebSocket’是长连接Http通信是单向的,基于请求…...

推荐5个我常用的软件,简单高效
今天给大家推荐5个我自己也常用的软件,可以解决很多问题,给你的学习和办公带来巨大帮助。 1.快速启动——Keypirinha Keypirinha是一款快速启动软件,可以让用户通过输入关键词来快速打开程序、文件、网页、搜索引擎等。Keypirinha支持…...

代码随想录训练营第三十一天|122.买卖股票的最佳时机II55.跳跃游戏45.跳跃游戏II
122.买卖股票的最佳时机II class Solution { public:int maxProfit(vector<int>& prices) {int earn0;for(int i 0; i < prices.size()-1;i){int x prices[i 1] - prices[i];if(x>0){earnx;}}return earn;} }; 55.跳跃游戏 本题关键在于看覆盖的范围 利…...

python17-Python的字符串格式化
Python提供了“%”对各种类型的数据进行格式化输出,例如如下代码。 # !/usr/bin/env python# -*- coding: utf-8 -*-# @Time : 2024/01# @Author : Laopiweight = 180print(老师傅的体重是 %s % weight) 上面程序就是格式化输出的关键代码,这行代码中的 print 函数包含三个部…...

HTTPS 之fiddler抓包--jmeter请求
一、浅谈HTTPS 我们都知道HTTP并非是安全传输,在HTTPS基础上使用SSL协议进行加密构成的HTTPS协议是相对安全的。目前越来越多的企业选择使用HTTPS协议与用户进行通信,如百度、谷歌等。HTTPS在传输数据之前需要客户端(浏览器)与服…...
Kotlin快速入门系列6
Kotlin的接口与扩展 接口 与Java类似,Kotlin使用interface关键字定义接口,同时允许方法有默认实现: interface KtInterfaceTest {fun method()fun methodGo(){println("上面方法未实现,此方法已实现")} } 接口实现 …...

Claude in Excel:原生集成的AI表格协作者
1. 项目概述:这不是插件,是Excel里长出来的AI同事“Claude in Excel”这个标题刚看到时,我下意识点开几个技术社区翻了一圈,发现多数人第一反应是:“又一个AI插件?”——其实完全不是。它根本没走传统Offic…...

Python基础语法:访问器@property和修改器@xxx.setter
一、简介 访问器和修改器也是装饰器的一种。 property: 访问器,getter xxx.setter: 修改器,setter 访问器和修改器的根本目的是想将属性私有化,提供getter&setter去访问。 访问器和修改器能够做到访问属性其实在调用getter方法࿰…...

除了ulimit -c unlimited:深入理解Linux core dump机制与高级配置指南
深入Linux核心转储:从基础配置到生产环境实战指南当服务器上的关键应用突然崩溃时,系统管理员最需要的就是一份完整的"事故现场记录"。Linux的core dump机制正是为此而生,它能保存程序崩溃时的内存状态、寄存器值和调用堆栈&#x…...

用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑
用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑 当你第一次面对"换硬币"这类组合问题时,那种既兴奋又困惑的感觉我至今记忆犹新。作为C语言初学者,理解多重循环的运作机制就像在迷宫中寻找出口——每次你以为找到了…...

Rydberg原子量子门实现原理与优化技术
1. Rydberg原子平台中的量子门实现基础1.1 Rydberg原子特性与量子计算优势Rydberg原子是指外层电子被激发到高主量子数能级的原子态,这类原子具有三个关键特性使其成为量子计算的理想平台:强偶极-偶极相互作用:当两个原子同时处于Rydberg态时…...

别再手动改路径了!用LabVIEW + MATLAB Script做自动化测试,这份环境配置指南让你效率翻倍
LabVIEW与MATLAB深度整合:构建自动化测试系统的工程实践指南在工业自动化与测试测量领域,LabVIEW和MATLAB的组合堪称黄金搭档。LabVIEW擅长硬件接口和实时控制,而MATLAB在算法开发和数据分析方面具有无可比拟的优势。本文将深入探讨如何将两者…...

【深度解析】AI Coding 模型竞速:从 Claude Mythos 安全编码到 GPT-5.6 传闻,如何落地代码审查智能体
摘要 AI 编码模型正在从“代码补全”进入“复杂代码库理解、漏洞发现与自动修复”阶段。本文结合 Claude Mythos、Claude Opus 4.8 与 GPT-5.6 相关信息,解析新一代 Coding Agent 的技术趋势,并给出基于大模型 API 的代码安全审查实战方案。背景介绍&…...

如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型
如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型 【免费下载链接】DeepPurpose A Deep Learning Toolkit for DTI, Drug Property, PPI, DDI, Protein Function Prediction (Bioinformatics) 项目地址: https://gitcode.com/gh_mirrors/de…...

如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析
如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析 【免费下载链接】Magpie-LuckyDraw 🏅A fancy lucky-draw tool supporting multiple platforms💻(Mac/Linux/Windows/Web/Docker) 项目地址: https…...

Noto字体终极指南:告别“豆腐块“,让全球文字清晰显示
Noto字体终极指南:告别"豆腐块",让全球文字清晰显示 【免费下载链接】noto-fonts Noto fonts, except for CJK and emoji 项目地址: https://gitcode.com/gh_mirrors/no/noto-fonts 在数字世界中,你是否经常看到那些令人困…...