sql优化的方法
目录
一、准备数据
1.1、创建表结构
1.2、创建存储过程
二、索引介绍
2.1、类型介绍
2.2、建立索引
2.3、建立复合索引
2.4、查看所有建立的索引
2.5、删除索引
三、EXPLAIN分析参数说明
四、SQL优化案例
4.1、避免使用SELECT *
4.2、慎用UNION关键字
4.4、避免使用or条件(有争议)
4.5、LIKE语句优化
4.6、字符串字段优化
4.7、最左匹配原则(重要)
4.8、COUNT查询数据是否存在优化
4.9、LIMIT关键字优化
4.10、提升GROUP BY的效率
4.11、避免使用!=或<>
4.12、避免NULL值判断
4.13、避免函数运算
4.14、JOIN的表中使用索引字段
4.15、用EXISTS代替IN
一、准备数据
提前准备一张学生表数据和一张特殊学生表数据,用于后面的测试用。
1.1、创建表结构
创建一个学生表:
CREATE TABLE student (id int(11) unsigned NOT NULL AUTO_INCREMENT,name varchar(50) DEFAULT NULL,age tinyint(4) DEFAULT NULL,id_card varchar(20) DEFAULT NULL,sex tinyint(1) DEFAULT '0', address varchar(100) DEFAULT NULL,phone varchar(20) DEFAULT NULL, create_time timestamp NULL DEFAULT CURRENT_TIMESTAMP,remark varchar(200) DEFAULT NULL,PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;再创建一个特殊学生表:
CREATE TABLE special_student (id int(11) unsigned NOT NULL AUTO_INCREMENT,stu_id int(11) DEFAULT NULL,PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;1.2、创建存储过程
在学生表中插入100w条数据,手动开启和提交事务,每插入1w条记录后,手动COMMIT一次事务,最后再COMMIT一次以提交剩下的记录,这样可以让插入速度更快,因为不需要为每条记录都 COMMIT,从而降低 IO 次数。
CREATE PROCEDURE insert_student_data()
BEGINDECLARE i INT DEFAULT 0; DECLARE done INT DEFAULT 0; DECLARE continue HANDLER FOR NOT FOUND SET done = 1;START TRANSACTION; WHILE i < 1000000 DOINSERT INTO student(name,age,id_card,sex,address,phone,remark)VALUES(CONCAT('姓名_',i), FLOOR(RAND()*100),FLOOR(RAND()*10000000000),FLOOR(RAND()*2),CONCAT('地址_',i), CONCAT('12937742',i),CONCAT('备注_',i));SET i = i + 1; IF MOD(i,10000) = 0 THEN COMMIT;START TRANSACTION;END IF; END WHILE; COMMIT;
END执行特殊学生表的存储过程:
CALL insert_special_student();二、索引介绍
2.1、类型介绍
普通索引 最基本的索引,没有任何限制
唯一索引 与普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值
主索引 即主键索引,关键字PRIMARY
复合索引 为了更多的提高MySQL效率可建立组合索引,遵循“最左前缀”原则
全文索引 可用于MyISAM表,MySQL5.6之后也可用于innodb表,用于在一篇文章中,检索文本信息的, 针对较大的数据,生成全文索引很耗时和空间
2.2、建立索引
CREATE INDEX id_card_index ON student(id_card);2.3、建立复合索引
CREATE INDEX name_address_phone_index ON student(name,address,phone);2.4、查看所有建立的索引
SHOW INDEX FROM student;
2.5、删除索引
ALTER TABLE 表名 DROP INDEX 索引名称;三、EXPLAIN分析参数说明
1、id:SELECT语句的编号。可以通过id来区别多条SELECT语句。
2、select_type:SELECT类型,主要有SIMPLE、PRIMARY、DERIVED等类型。
SIMPLE:简单的SELECT(不含子查询及UNION)。
PRIMARY:查询中最外层的SELECT。
DERIVED:包含的子查询中的SELECT。
3、table:显示这一行的数据是关于哪张表的。
4、partitions:匹配的分区信息。
5、type:显示连接使用了何种类型。
最好到最差的连接类型为 system > const > eq_reg > ref > range > index > ALL.
| system | 表只有一行记录(等于系统表) |
| const | 使用常量进行索引查询 |
| eq_ref | 唯一索引扫描,通常使用主键约束 |
| ref | 非唯一性索引扫描 |
| range | 索引范围扫描 |
| index | 全索引扫描 |
| ALL | 全表扫描 |
6、possible_keys:显示可能应用在这张表中的索引。
7、key:实际使用的索引。
8、key_len:使用的索引的长度。
9、ref:显示索引的哪一列被使用。
10、rows:根据表统计信息及索引条件估算,查询返回的且接近的行数
11、filtered:显示了通过条件过滤出的行数的百分比估计值。
12、Extra:包含不适合在其他列展示但是需要展示的信息。
四、SQL优化案例
4.1、避免使用SELECT *
有的时候,我们为了图方便,会直接使用SELECT * 一次性查出表中所有的数据:
SELECT * FROM student执行结果如图所示:
可以看到,执行时间花了2s左右,耗时很长!
在实际开发中,我们给页面展示的数据可能就只要2-3个字段,如果直接全部查出来了,岂不是白白浪费了字段,同时也损耗了性能,这是因为SELECT * 不会走覆盖索引,会出现大量的回表操作,从而导致SQL性能大幅度降低。
我们上面建立了联合索引,我们就可以只查询索引列,这样会大幅度提升查询效率,优化的SQL如下:
SELECT name,address,phone FROM student执行结果如图所示:

这样执行的速度大大提高!
分析SQL:
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT name,address,phone FROM student执行结果如图所示:

确实走了我们建立的复合索引。
4.2、慎用UNION关键字
例如我们根据性别去查询所有学生的信息,虽然这种操作多此一举,直接SELECT *就好了,为了演示这2个关键字的详细区别,使用UNION关键字执行的SQL如下:
SELECT * FROM student WHERE sex = 0
UNION
SELECT * FROM student WHERE sex = 1执行结果如图所示:
我滴妈,查了100w条足足整整等了32s左右,这个速度要是放到系统上,查个数据等到娃娃菜都凉了!
这是因为在使用UNION执行完SQL后,会帮我们获取所有数据并去掉重复的数据,性能的损耗就在这里,而UNION ALL和UNION相反,帮我们获取所有数据但会保留重复的数据。
我们改用UNION ALL关键字,优化的SQL如下:
SELECT * FROM student WHERE sex = 0
UNION ALL
SELECT * FROM student WHERE sex = 1执行结果如图所示:
同样查询100w条数据,这边执行速度大大提高了,只用到了3s左右!
4.3、小表驱动大表
言简意赅,意思就是让小表查出来的数据去再查询大表当中的数据。比如我们想查询学生表当中特殊学生的信息,我们就可以使用以special_student这个小表去驱动student这个大表,SQL如下:
SELECT * FROM student WHERE id
IN (SELECT stu_id FROM special_student)执行结果如图所示:
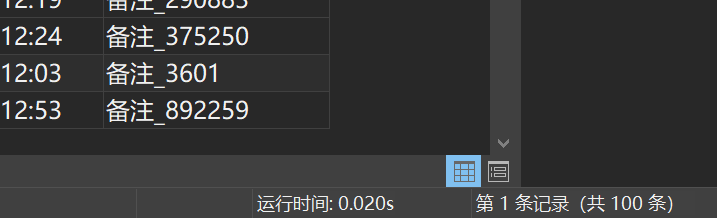
只用了0.02s,速度很可观!因为IN关键字中的子查询语句,子查询语句的数据量很少,所以查询速度会很快!
4.4、避免使用or条件(有争议)
如果我们要查询指定的性别或者指定的身份证号码的学生,执行SQL如下:
SELECT * FROM student WHERE sex = 0 OR id_card = '7121877527789'
执行结果如图所示:
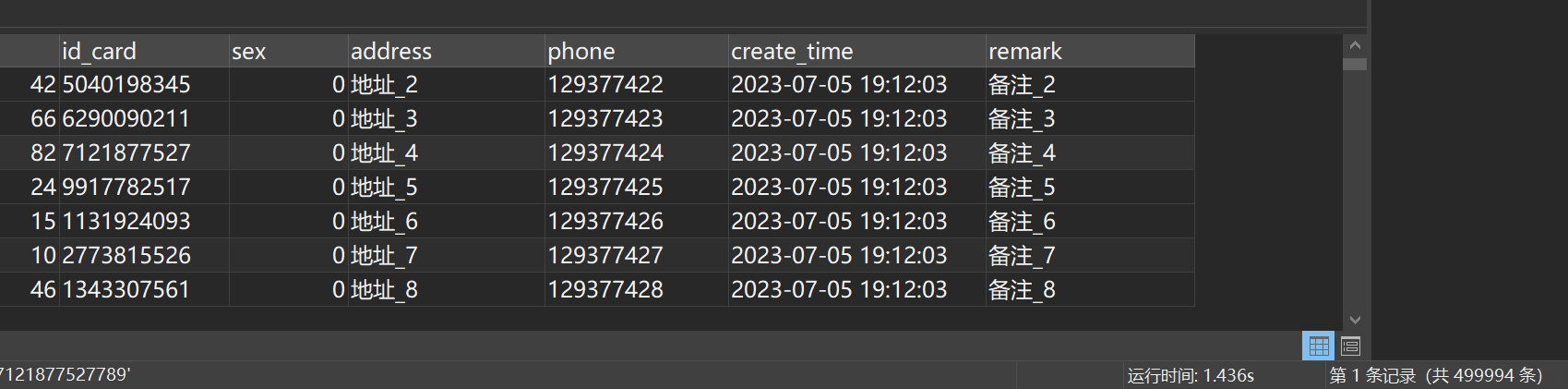
总共查询了近50w条数据,耗时1.4s左右,我们改用UNION ALL关键字查询:
SELECT * FROM student WHERE sex = 0
UNION ALL
SELECT * FROM student WHERE id_card = '7121877527789'执行结果如图所示:

和上面查询的数据量一样,好事在1.7s左右,怎么会没什么区别呢?
分析SQL:
使用EXPLAIN关键字分析一下使用OR关键字的这段SQL:
EXPLAIN SELECT * FROM student WHERE SEX = 0 OR id_card = '7121877527789'执行结果如图所示:
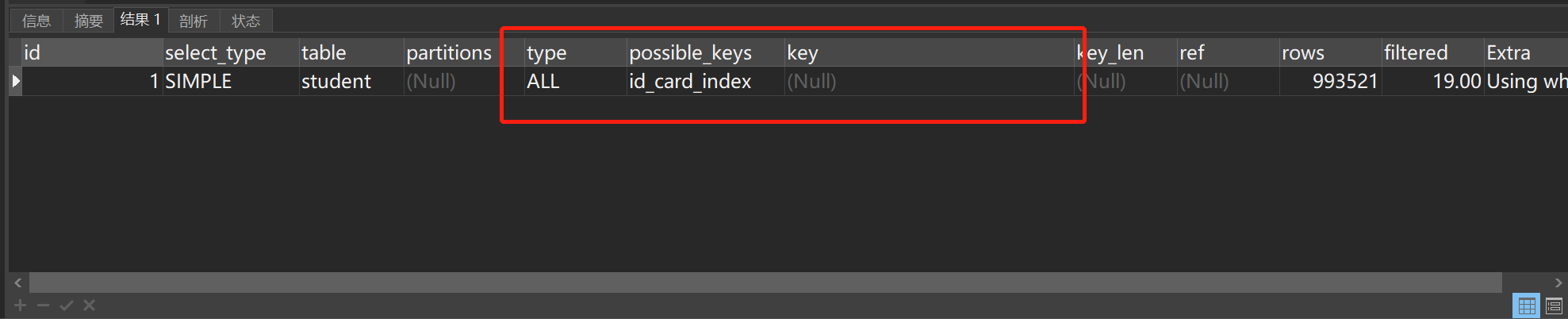
很明显,虽然可能会用到建立id_card的索引,正因为sex这个字段没有建立索引,还是走了一次全表扫描。
使用EXPLAIN关键字执行这段SQL:
EXPLAIN
SELECT * FROM student WHERE sex = 0
UNION ALL
SELECT * FROM student WHERE id_card = '7121877527789'执行结果如图所示:

很明显条件是sex的走了全表,但是id_card走了索引,所以依旧还是走了一次全表扫描,所以网上说的关于UNION ALL代替OR的,我这边实测感觉还是存在争议的!
4.5、LIKE语句优化
平时我们日常开发用到的LIKE关键字进行模糊匹配会非常多,但是有的情况会使索引失效,导致查询效率变慢,例如:
只要身份证字段包含50就查出来,执行SQL如下:
SELECT * FROM student WHERE id_card like '%50%'执行结果如图所示:

用了0.8s左右。
只要身份证号码以50结尾就查出来,执行SQL如下:
SELECT * FROM student WHERE id_card like '%50'执行结果如图所示:
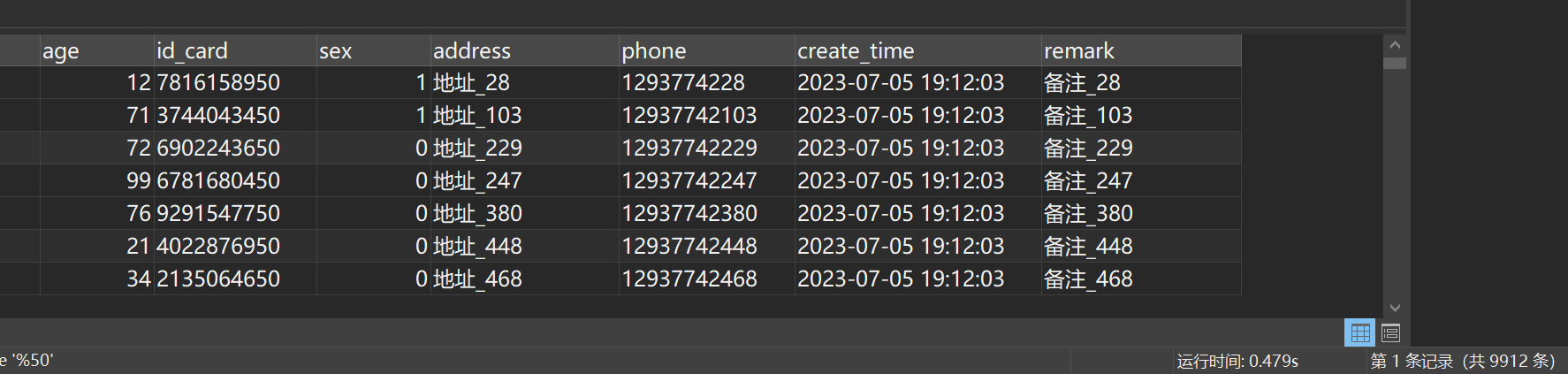
用了0.4s左右。
只要身份证号码以50开头的就查出来,执行SQL如下:
SELECT * FROM student WHERE id_card like '50%'执行结果如图所示:
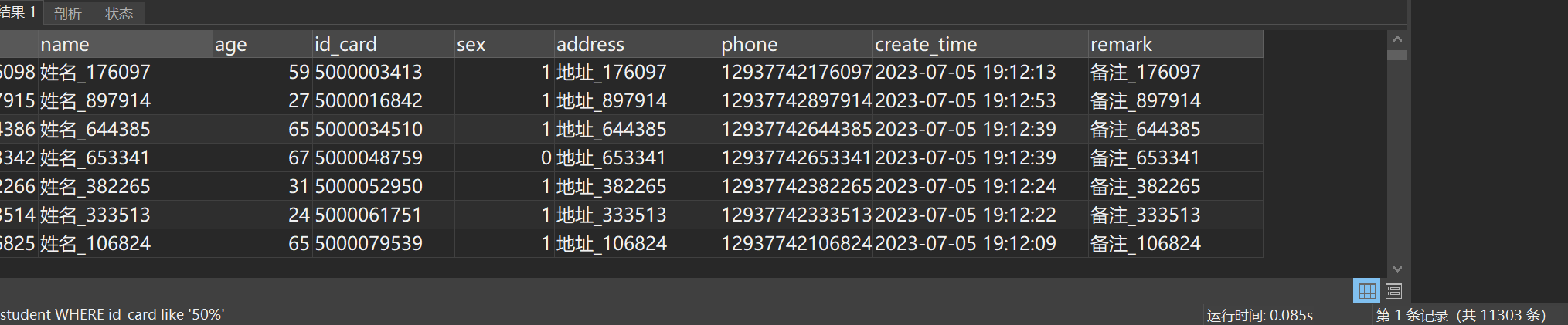
这次执行非常快,0.08s左右。
分析SQL:
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT * FROM student WHERE id_card like '%50%'执行结果如图所示:

很明显走了全表扫描!
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT * FROM student WHERE id_card like '%50'执行结果如图所示:

这次便走了索引!
4.6、字符串字段优化
查询指定的身份证号码的学生,如果我们平时疏忽了给身份证号码加上单引号,执行SQL如下:
SELECT * FROM student WHERE id_card = 5040198345执行结果如图所示:
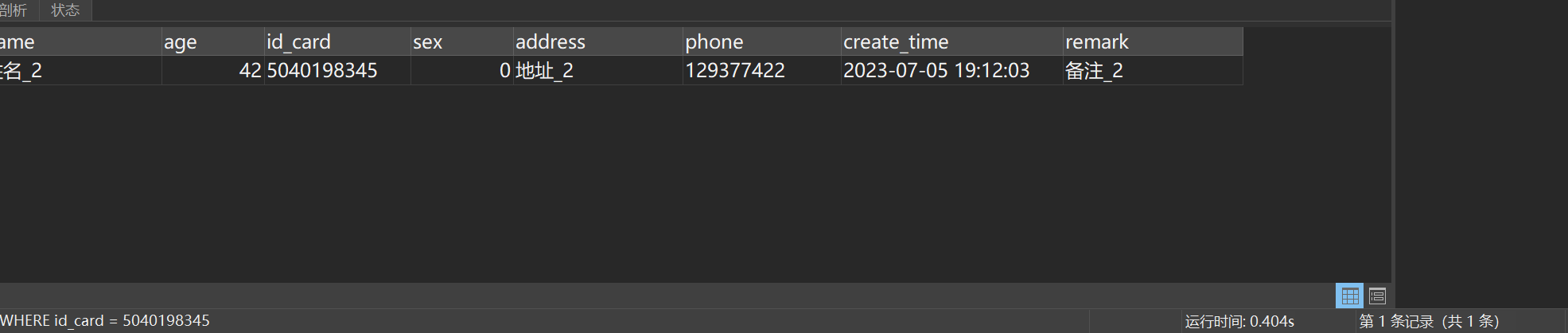
耗时0.4s左右。
给身份证号码加上单引号,优化的SQL如下:
SELECT * FROM student WHERE id_card = '5040198345'执行结果如图所示:
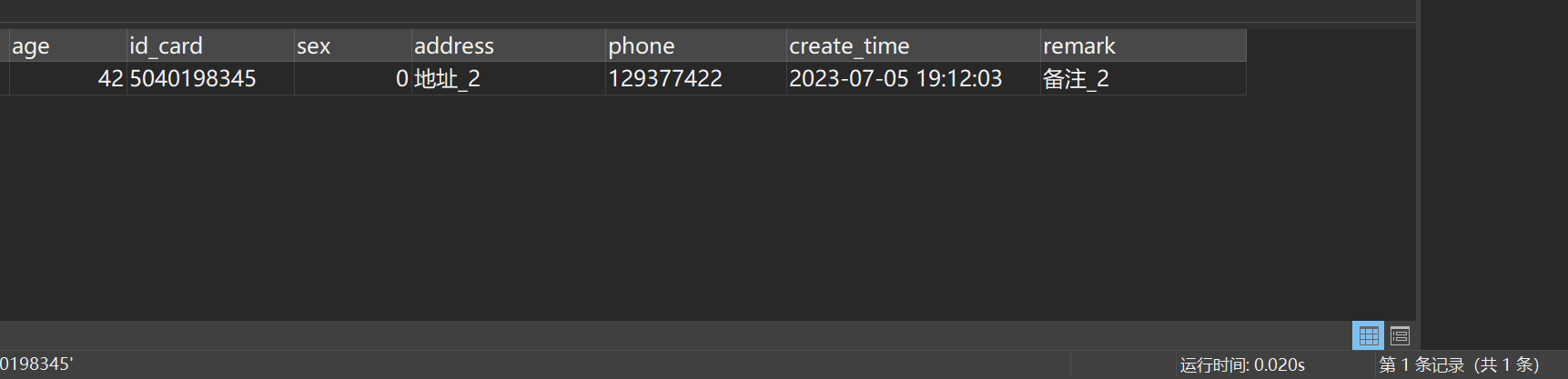
耗时0.02s左右,这次明显快多了!
分析SQL:
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT * FROM student WHERE id_card = 5040198345执行结果如图所示:
可能用到了id_card的索引,但是还是走了全表扫描!
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT * FROM student WHERE id_card = '5040198345'
执行结果如图所示:
这边走了索引。
这边走了索引。
4.7、最左匹配原则(重要)
上面我们按照name,address和phone这个顺序建立了复合索引,相当于建立了(name),(name、address)和(name、address、phone)三个索引,如果我们查询的where条件违背了建立的顺序,则复合索引就失效了,下面直接进行SQL分析:
分析SQL:
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT * FROM student WHERE name = '姓名_4' and phone = '7121877527' and address = '地址_4'执行结果如图:
为什么明明违背了最左匹配原则,依旧还是走了复合索引呢?可能是如下原因:

1、通过索引过滤性能足够好,所以还是选择利用索引。
2、联合索引中前几个字段过滤效果较好,所以仍然选择利用索引。
可能的执行计划大概是:
1、优先通过phone字段过滤,将要扫描的记录减少一部分。
2、然后通过address字段继续过滤,再减少一部分记录。
3、最后通过name字段过滤,已经剩下很少的记录需要扫描。
4、尽管违反了最左匹配,解释器可能认为仍然利用索引效率比较高。
所以总的来说,就是解释器会根据实际情况进行权衡,即使是违反最左匹配原则,也可能会选择利用索引。但这并不是一个良好的查询优化,最好还是严格遵守最左匹配原则。
以下是严格遵守最左匹配原则的SQL:
SELECT * FROM student WHERE name = '姓名_4'
SELECT * FROM student WHERE name = '姓名_4' and address = '地址_4'
SELECT * FROM student WHERE name = '姓名_4' and address = '地址_4' and phone = '7121877527' 4.8、COUNT查询数据是否存在优化
比如我想判断年龄为18岁的学生是否存在,我们往往会执行如下SQL:
SELECT COUNT(*) FROM student WHERE age = 18执行结果如图所示:
耗时0.4s左右,虽然知道学生年龄18岁存在,但是没必要查询出这么多数量出来,我们只要知道是否存在即可!
不再使用COUNT,而是改用LIMIT 1,让数据库查询时遇到一条就返回,这样就不要再继续查找还有多少条了,优化的SQL如下:
SELECT 1 FROM student WHERE age = 18 LIMIT 1执行结果如图所示:
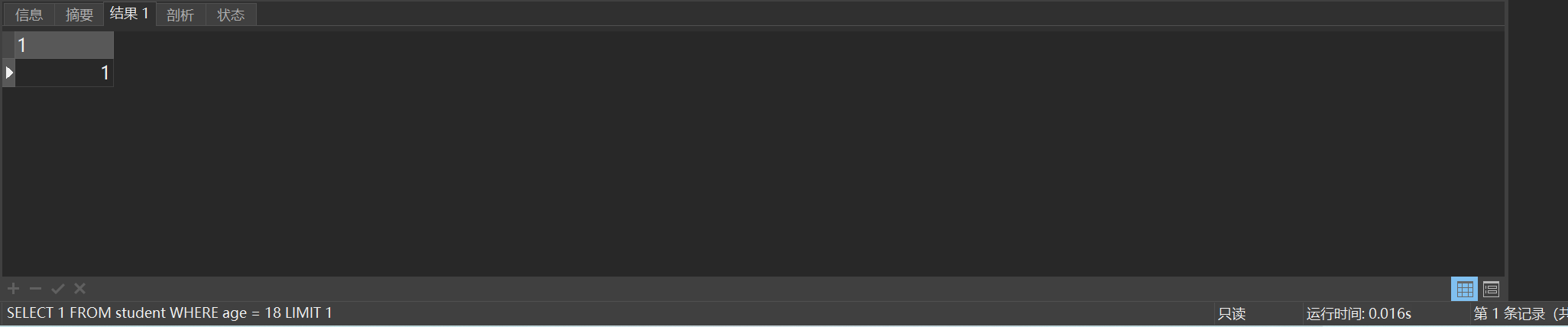
耗时0.01s左右,很快就知道了。
4.9、LIMIT关键字优化
平日开发工作中,我们对于分页的处理一般是这样的:
SELECT * FROM student LIMIT 999910,10执行结果如图所示:
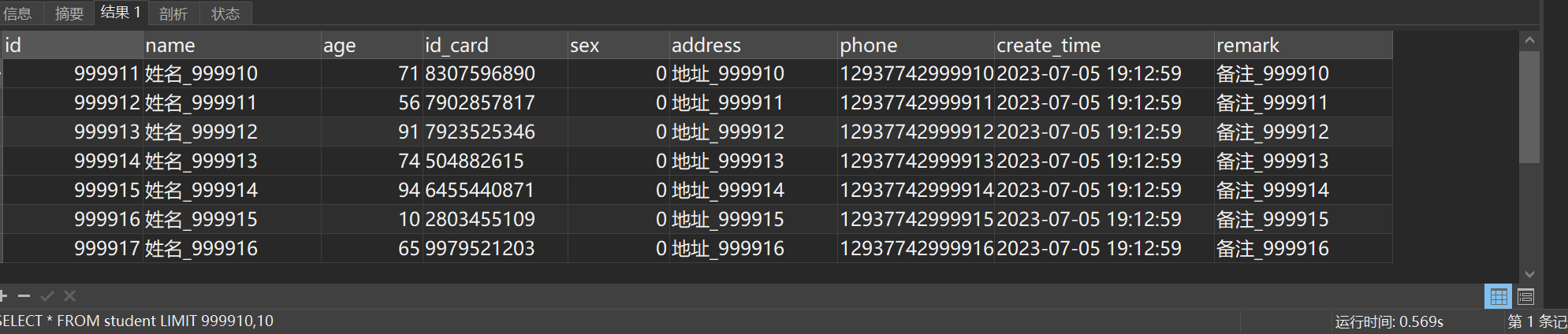
耗时0.56s,但是因为我们的ID属于自增长,所以我们可以在此基础上进行一定的优化,优化的SQL如下:
SELECT * FROM student WHERE ID >= 999910 LIMIT 10执行结果如图所示:

仅仅用时0.02s,非常快!
4.10、提升GROUP BY的效率
我们平日写SQL需要多多少少会使用GROUP BY关键字,它主要的功能是去重和分组。 通常它会跟HAVING一起配合使用,表示分组后再根据一定的条件过滤数据,常规执行的SQL如下:
SELECT age,COUNT(1) FROM student GROUP BY age HAVING age > 18执行结果如图所示:
耗时总计0.53s左右,不过还可以进行优化,我们可以在分组之前缩小筛选的范围,然后再进行分组,优化的SQL如下:
SELECT age,COUNT(1) FROM student where age > 18 GROUP BY age
执行结果如图所示:
耗时0.51s左右,虽然不明显,也是一种不错的思路。
4.11、避免使用!=或<>
尽量避免使用!=或<>操作符,下面直接分析SQL:
SQL分析:
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT * FROM student WHERE id_card != '5031520645'执行结果如图所示:

虽然我们给了id_card字段建立了索引,但还是走了全表扫描
4.12、避免NULL值判断
为了确保没有NULL值,我们可以设定一个默认值,下面直接分析SQL:
SQL分析:
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT * FROM student WHERE id_card IS NOT NULL执行结果如图所示:
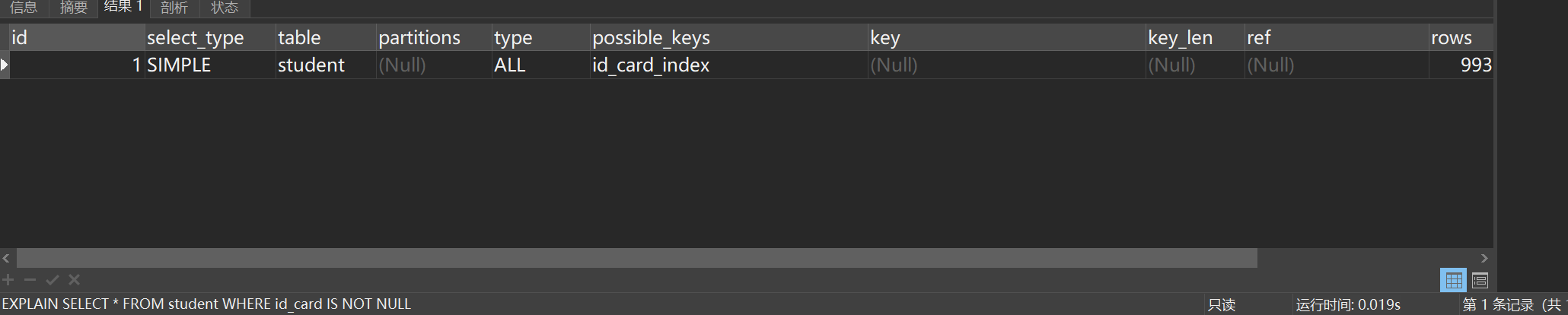
依旧还是走了全表扫描。
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT * FROM student WHERE id_card IS NULL执行结果如图所示:
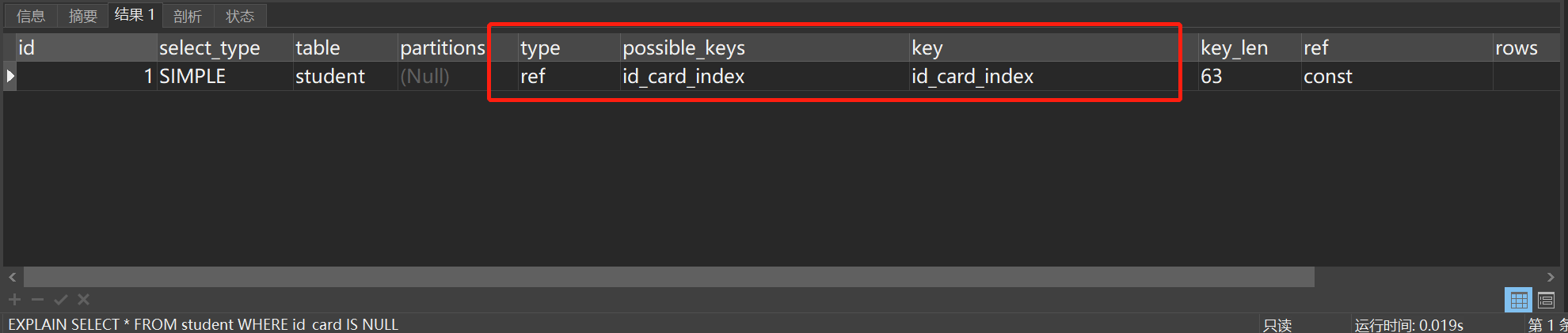
这样是走索引的!
4.13、避免函数运算
在日常SQL撰写中,在WHERE条件上多多少少会用到一些函数,例如截取字符串,执行SQL如下:
分析SQL:
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT * FROM student WHERE SUBSTR(id_card,0,9)执行结果如图所示:

索引失效,走了全表扫描。
4.14、JOIN的表中使用索引字段
如果日常开发中,使用JOIN关键字链接表后,使用的ON关键字进行条件链接时,如果条件没有索引,则会进行全表扫描,执行SQL如下:
EXPLAIN SELECT * FROM student a,special_student b WHERE a.id = b.stu_id执行结果如图所示:

正因为special_student表的stu_id没有建立索引,则导致了全表扫描!
为stu_id建立索引后,执行SQL如下:
CREATE INDEX stu_id_index ON special_student(stu_id);EXPLAIN SELECT * FROM student a,special_student b WHERE a.id = b.stu_id执行结果如图所示:
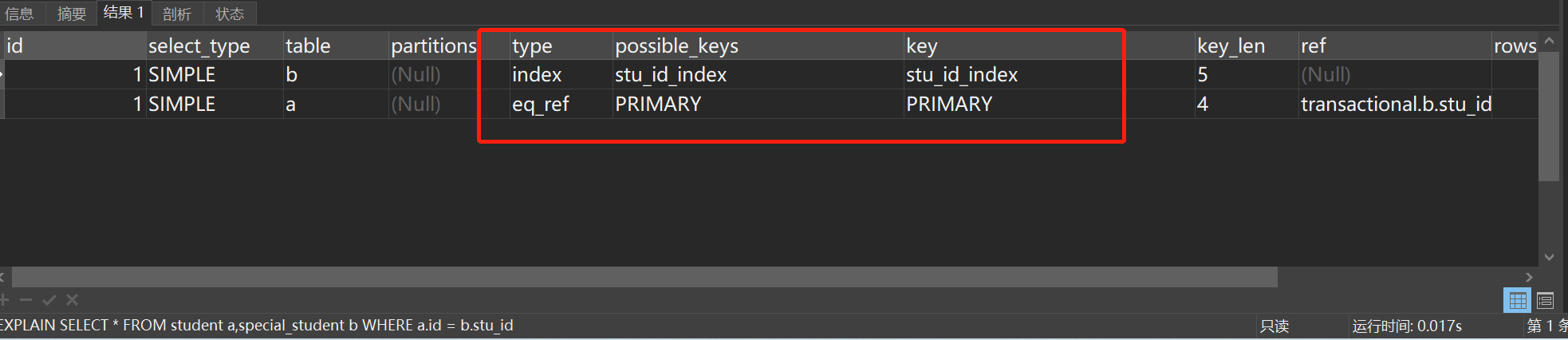
两张表都走了索引。
4.15、用EXISTS代替IN
IN关键字适合于外表大而内表小的情况,EXISTS适合于外表小而内表大的情
SELECT * FROM special_student
WHERE EXISTS
( SELECT 1 FROM student WHERE special_student.stu_id = student.id)况,执行SQL如下:
运行结果如图所示:
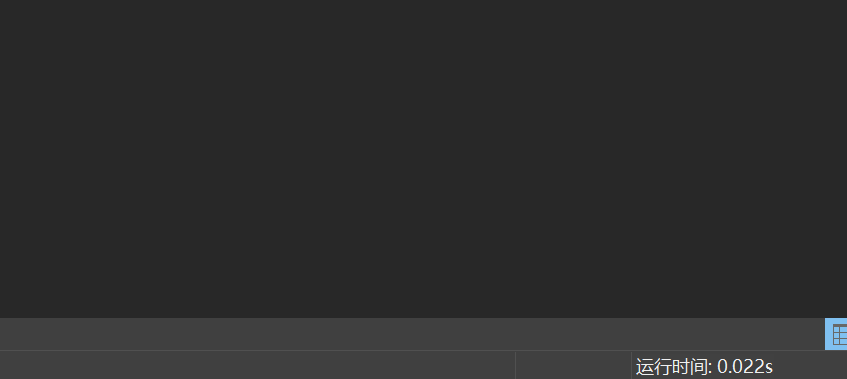
执行效率在0.02s左右,这里special_student是小表,student是大表,速度非常快!
相关文章:
sql优化的方法
目录 一、准备数据 1.1、创建表结构 1.2、创建存储过程 二、索引介绍 2.1、类型介绍 2.2、建立索引 2.3、建立复合索引 2.4、查看所有建立的索引 2.5、删除索引 三、EXPLAIN分析参数说明 四、SQL优化案例 4.1、避免使用SELECT * 4.2、慎用UNION关键字 4.4、避免使…...
C++ Qt开发:运用QJSON模块解析数据
Qt 是一个跨平台C图形界面开发库,利用Qt可以快速开发跨平台窗体应用程序,在Qt中我们可以通过拖拽的方式将不同组件放到指定的位置,实现图形化开发极大的方便了开发效率,本章将重点介绍如何运用QJson组件的实现对JSON文本的灵活解析…...
MySQL数据库基础合集
MySQL数据库基础合集 目录 MySQL数据库基础合集SQL关键字DDL关键字DML关键字DQL关键字DCL关键字约束关键字 SQL基础数据类型整数类型字符类型浮点类型时间类型 数据定义语言DDL1.查看数据库2.创建库3.删除库4.切换库5.创建表6.删除表7.查看表8.查看表属性9.插入列10.修改列11.设…...
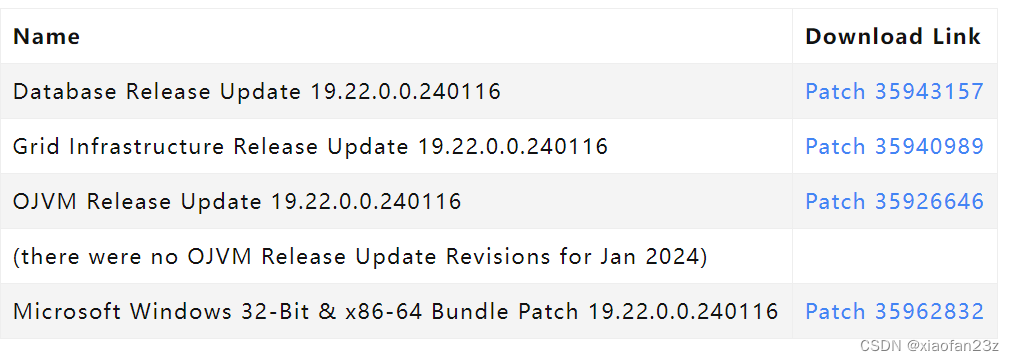
oracle19.22的patch已发布
2024年01月16日,oracle发布了19.22的patch 具体patch如下 Reserved for Database - Do not edit or delete (Doc ID 19202401.9) 文档ID规则如下 19(版本)年份(202x)(季度首月01,04,07,10).9 往期patch no信息和下…...

HTML+CSS:3D轮播卡片
效果演示 实现了一个3D翻转的卡片动画,其中每个卡片都有不同的图片和不同的旋转角度。整个动画循环播放,无限次。整个页面的背景是一个占据整个屏幕的背景图片,并且页面内容被隐藏在背景图片之下。 Code <div class"container"…...
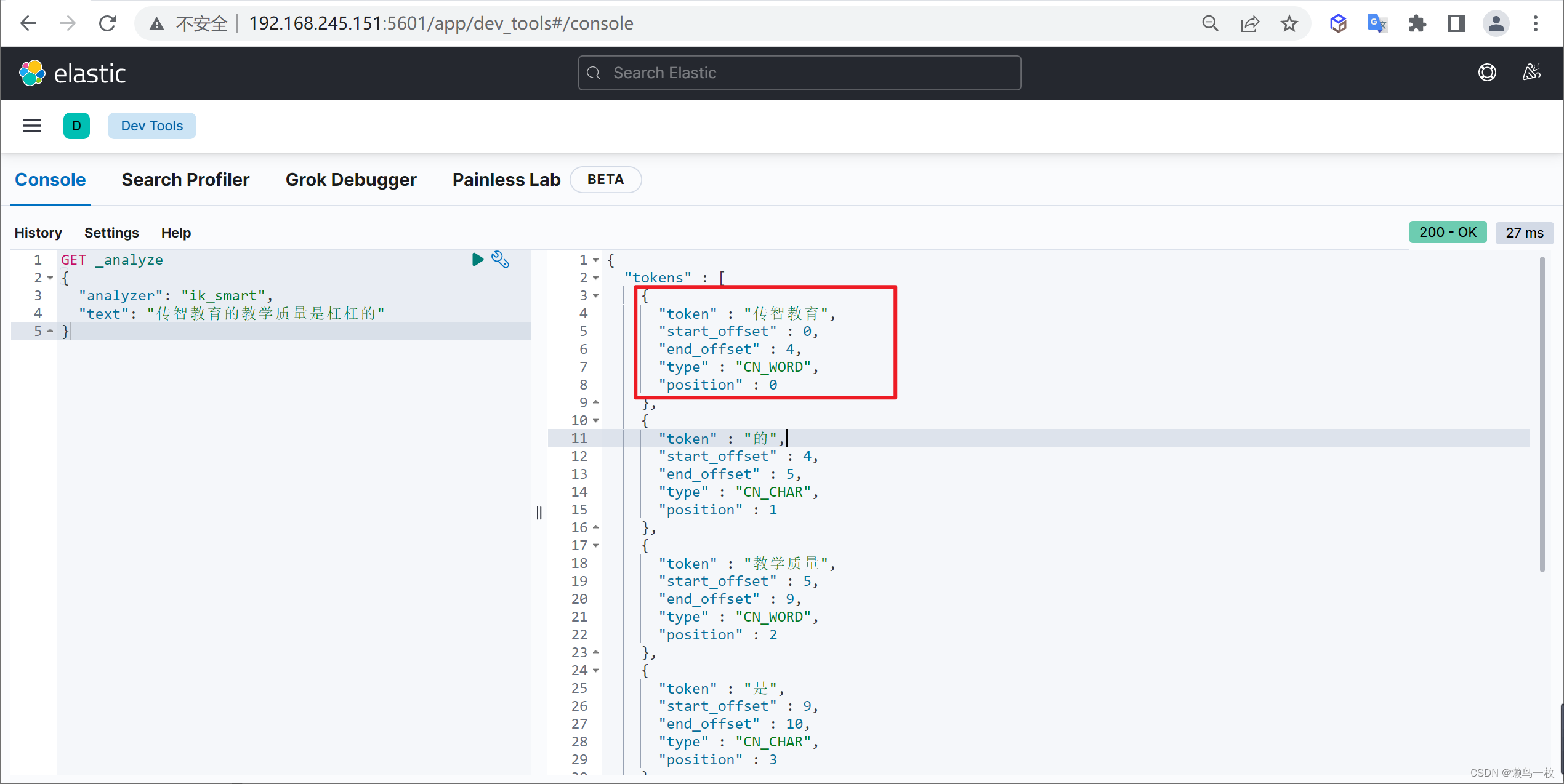
ES 分词器
概述 分词器的主要作用将用户输入的一段文本,按照一定逻辑,分析成多个词语的一种工具 什么是分词器 顾名思义,文本分析就是把全文本转换成一系列单词(term/token)的过程,也叫分词。在 ES 中,Ana…...
从0开始搭建若依微服务项目 RuoYi-Cloud(保姆式教程完结)
文章接上一章: 从0开始搭建若依微服务项目 RuoYi-Cloud(保姆式教程 一)-CSDN博客 四. 项目配置与启动 当上面环境全部准备好之后,接下来就是项目配置。需要将项目相关配置修改成当前相关环境。 数据库配置 新建数据库ÿ…...
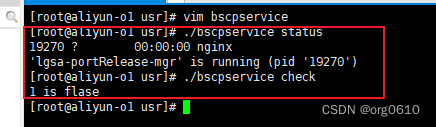
Linux true/false区分
bash的数值代表和其它代表相反:0表示true;非0代表false。 #!/bin/sh PIDFILE"pid"# truenginx进程运行 falsenginx进程未运行 checkRunning(){# -f true表示普通文件if [ -f "$PIDFILE" ]; then# -z 字符串长度为0trueif [ -z &qu…...

一些著名的软件都用什么语言编写?
1、操作系统 Microsoft Windows :汇编 -> C -> C 备注:曾经在智能手机的操作系统(Windows Mobile)考虑掺点C#写的程序,比如软键盘,结果因为写出来的程序太慢,实在无法和别的模块合并&…...

外卖跑腿系统开发:构建高效、安全的服务平台
在当今快节奏的生活中,外卖跑腿系统的开发已成为技术领域的一个重要课题。本文将介绍如何使用一些常见的编程语言和技术框架,构建一个高效、安全的外卖跑腿系统。 1. 技术选择 在开始开发之前,我们需要选择适合的技术栈。常用的技术包括&a…...

【MQ02】基础简单消息队列应用
基础简单消息队列应用 在上一课中,我们已经学习到了什么是消息队列,有哪些消息队列,以及我们会用到哪个消息队列。今天,就直接进入主题,学习第一种,最简单,但也是最常用,最好用的消息…...
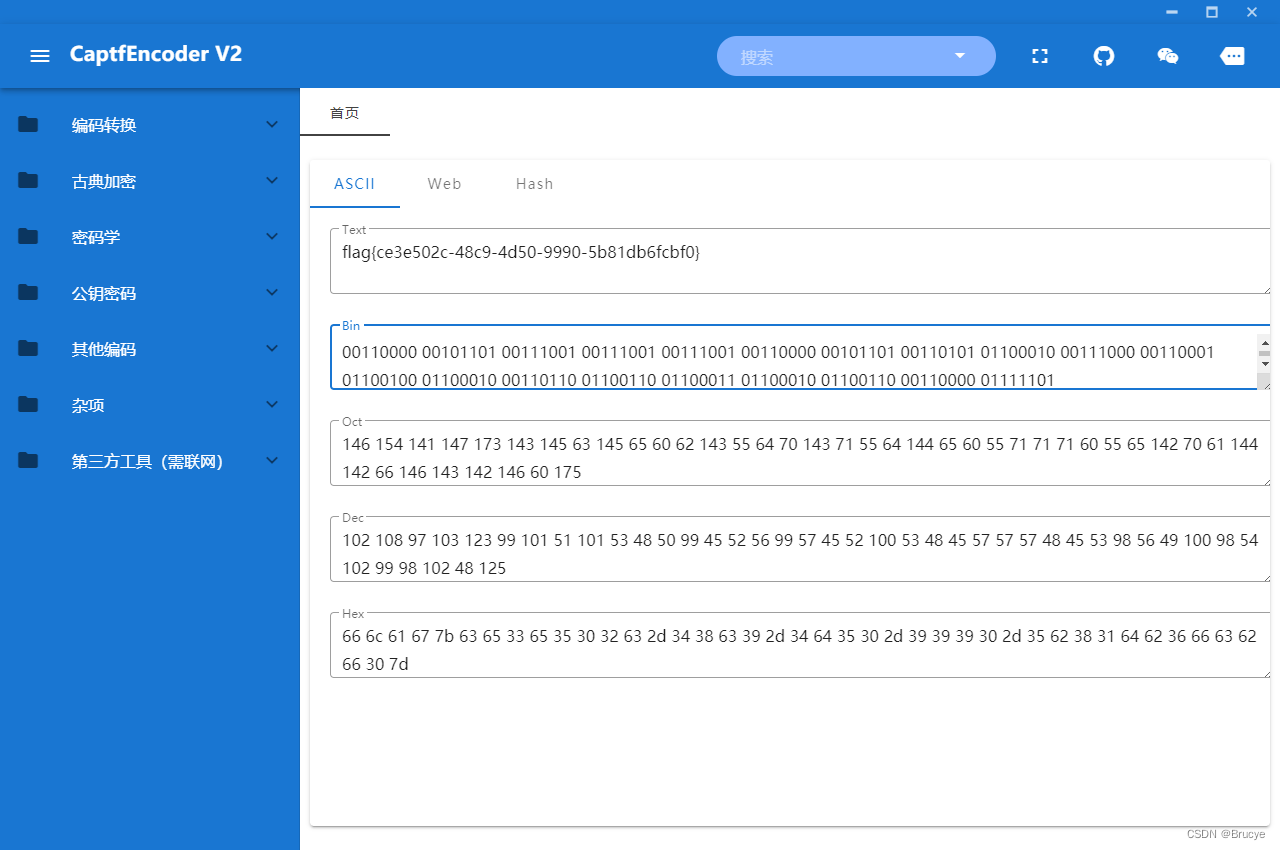
CTF CRYPTO 密码学-7
题目名称:敲击 题目描述: 让我们回到最开始的地方 0110011001101100011000010110011101111011011000110110010100110011011001010011010100110000001100100110001100101101001101000011100001100011001110010010110100110100011001000011010100110000…...

随机森林和决策树区别
随机森林(Random Forest)和决策树(Decision Tree)是两种不同的机器学习算法,其中随机森林是基于决策树构建的一种集成学习方法。以下是它们之间的主要区别: 决策树: 单一模型: 决策树是一种单一模型&#…...

新建VM虚拟机-安装centOS7-连接finalshell调试
原文 这里有问题 首先进入/etc/sysconfig/network-scripts/目录 cd /etc/sysconfig/network-scripts/ 然后编辑文件 ifcfg-ens33 vi ifcfg-ens33...

936. 戳印序列
Problem: 936. 戳印序列 文章目录 思路解题方法复杂度Code 思路 这道题目要求我们通过使用印章来印刷目标字符串,使得目标字符串最终变成全为’?‘的字符串。我们可以使用贪心的思想来解决这个问题。 首先,我们需要找到所有可以匹配印章的位置ÿ…...
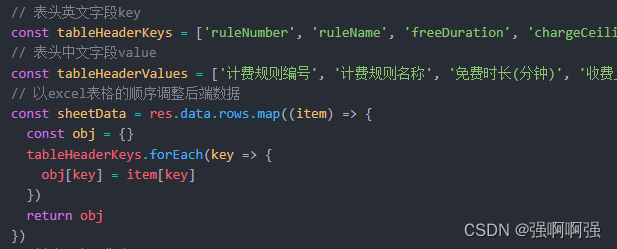
20240129收获
今天终于发现《八部金刚功》第五部我一直做的是错的,嗨。这里这个写法非常聪明,创立的数组,以及用obj[key] item[key]这样的写法,这个写法充分展示了js常规写法中只有等号右边会去参与运算,等号左边就是普通的键的写法…...

【虚拟机数据恢复】异常断电导致虚拟机无法启动的数据恢复案例
虚拟机数据恢复环境: 某品牌R710服务器MD3200存储,上层是ESXI虚拟机和虚拟机文件,虚拟机中存放有SQL Server数据库。 虚拟机故障: 机房非正常断电导致虚拟机无法启动。服务器管理员检查后发现虚拟机配置文件丢失,所幸…...

vue3 + antd 封装动态表单组件(三)
传送带: vue3 antd 封装动态表单组件(一) vue3 antd 封装动态表单组件(二) 前置条件: vue版本 v3.3.11 ant-design-vue版本 v4.1.1 我们发现ant-design-vue Input组件和FormItem组件某些属性支持slot插…...
【算法专题】贪心算法
贪心算法 贪心算法介绍1. 柠檬水找零2. 将数组和减半的最少操作次数3. 最大数4. 摆动序列(贪心思路)5. 最长递增子序列(贪心算法)6. 递增的三元子序列7. 最长连续递增序列8. 买卖股票的最佳时机9. 买卖股票的最佳时机Ⅱ(贪心算法)10. K 次取反后最大化的数组和11. 按身高排序12…...

x-cmd pkg | sqlite3 - 轻量级的嵌入式关系型数据库
目录 简介首次用户 技术特点竞品和相关产品sqlite 与 x-cmd进一步阅读 简介 sqlite3 是一个轻量级的文件数据库,体积非常小,提供简单优雅而功能强大的 sql 化的数据查询。 通常情况下,sqlite 指的是 SQLite 2.x 版本,而 sqlite3 …...

用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑
用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑 当你第一次面对"换硬币"这类组合问题时,那种既兴奋又困惑的感觉我至今记忆犹新。作为C语言初学者,理解多重循环的运作机制就像在迷宫中寻找出口——每次你以为找到了…...

AI赋能5G核心网故障诊断:从PCAP解析到智能根因分析的工程实践
1. 项目概述:当AI遇见5G核心网故障诊断在5G核心网的运维与测试一线干了这么多年,最头疼的莫过于面对海量的PCAP抓包文件。一个复杂的信令流程下来,动辄几千甚至上万个数据包,工程师需要像侦探一样,逐帧审视协议交互&am…...

如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优
如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcode.co…...

PentestGPT实战部署指南:AI驱动的渗透测试工作流落地
1. 这不是另一个“AI安全”的概念玩具,而是一套能真正跑起来的渗透测试辅助工作流“PentestGPT”这个名字刚在GitHub上出现时,我第一反应是点开又关掉——过去三年里,我见过太多打着“AI渗透”旗号的项目:有的只是把ChatGPT API封…...

Owl-Alpha 新手快速上手指南
在处理大规模数据或构建高性能应用时,我们常常会遇到一个棘手的问题:如何在不阻塞主线程的情况下,高效地执行耗时任务?无论是处理图像、解析大型文件,还是进行复杂的数学运算,传统的单线程模式往往会让界面…...

1901-2022年中国气温变化分析实战:用这份1km栅格数据我们能发现什么?
1901-2022年中国气温变化分析实战:如何从1km栅格数据中挖掘气候演变规律当一份覆盖122年、分辨率精确到1公里的气温栅格数据摆在面前时,我们看到的不仅是数字矩阵,更是一部写在经纬度坐标里的气候变迁史诗。这份由逐月数据聚合生成的逐年气温…...

股票买卖最佳时机:LeetCode121题解
题目LeetCode121给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。返回你可以从这笔交易中获取…...

如何快速掌握MoveIt2:面向ROS 2开发者的工业机器人运动规划完整指南
如何快速掌握MoveIt2:面向ROS 2开发者的工业机器人运动规划完整指南 【免费下载链接】moveit2 :robot: MoveIt for ROS 2 项目地址: https://gitcode.com/gh_mirrors/mo/moveit2 想要为你的机器人实现智能运动规划吗?MoveIt2作为ROS 2生态中最强大…...

Hindsight测试策略:单元测试、集成测试和端到端测试
Hindsight测试策略:单元测试、集成测试和端到端测试 【免费下载链接】hindsight Hindsight: Agent Memory That Learns 项目地址: https://gitcode.com/GitHub_Trending/hindsight2/hindsight Hindsight作为一款专注于Agent Memory的开源项目,其可…...

不止于绘图:用GMT 6.4的`grdtrack`和`project`命令玩转地形剖面分析与可视化
不止于绘图:用GMT 6.4的grdtrack和project命令玩转地形剖面分析与可视化 当我们谈论地理空间分析时,很多人首先想到的是绘制精美的地图。但GMT(Generic Mapping Tools)的真正魅力在于它强大的地理计算能力。本文将带你超越基础绘图…...