【项目设计】高并发内存池(五)[释放内存流程及调通]
🎇C++学习历程:入门
- 博客主页:一起去看日落吗
- 持续分享博主的C++学习历程
博主的能力有限,出现错误希望大家不吝赐教- 分享给大家一句我很喜欢的话: 也许你现在做的事情,暂时看不到成果,但不要忘记,树🌿成长之前也要扎根,也要在漫长的时光🌞中沉淀养分。静下来想一想,哪有这么多的天赋异禀,那些让你羡慕的优秀的人也都曾默默地翻山越岭🐾。
🍁 🍃 🍂 🌿
目录
- 🌿1. threadcache 回收内存
- 🌿2. centralcache 回收内存
- 🌿3. pagecache 回收内存
- 🌿4. 释放内存过程联调
🌿1. threadcache 回收内存
当某个线程申请的对象不用了,可以将其释放给thread cache,然后thread cache将该对象插入到对应哈希桶的自由链表当中即可。
但是随着线程不断的释放,对应自由链表的长度也会越来越长,这些内存堆积在一个thread cache中就是一种浪费,我们应该将这些内存还给central cache,这样一来,这些内存对其他线程来说也是可申请的,因此当thread cache某个桶当中的自由链表太长时我们可以进行一些处理。
如果thread cache某个桶当中自由链表的长度超过它一次批量向central cache申请的对象个数,那么此时我们就要把该自由链表当中的这些对象还给central cache。
//释放内存对象
void ThreadCache::Deallocate(void* ptr, size_t size)
{assert(ptr);assert(size <= MAX_BYTES);//找出对应的自由链表桶将对象插入size_t index = SizeClass::Index(size);_freeLists[index].Push(ptr);//当自由链表长度大于一次批量申请的对象个数时就开始还一段list给central cacheif (_freeLists[index].Size() >= _freeLists[index].MaxSize()){ListTooLong(_freeLists[index], size);}
}
当自由链表的长度大于一次批量申请的对象时,我们具体的做法就是,从该自由链表中取出一次批量个数的对象,然后将取出的这些对象还给central cache中对应的span即可。
//释放对象导致链表过长,回收内存到中心缓存
void ThreadCache::ListTooLong(FreeList& list, size_t size)
{void* start = nullptr;void* end = nullptr;//从list中取出一次批量个数的对象list.PopRange(start, end, list.MaxSize());//将取出的对象还给central cache中对应的spanCentralCache::GetInstance()->ReleaseListToSpans(start, size);
}
从上述代码可以看出,FreeList类需要支持用Size函数获取自由链表中对象的个数,还需要支持用PopRange函数从自由链表中取出指定个数的对象。因此我们需要给FreeList类增加一个对应的PopRange函数,然后再增加一个_size成员变量,该成员变量用于记录当前自由链表中对象的个数,当我们向自由链表插入或删除对象时,都应该更新_size的值。
//管理切分好的小对象的自由链表
class FreeList
{
public://将释放的对象头插到自由链表void Push(void* obj){assert(obj);//头插NextObj(obj) = _freeList;_freeList = obj;_size++;}//从自由链表头部获取一个对象void* Pop(){assert(_freeList);//头删void* obj = _freeList;_freeList = NextObj(_freeList);_size--;return obj;}//插入一段范围的对象到自由链表void PushRange(void* start, void* end, size_t n){assert(start);assert(end);//头插NextObj(end) = _freeList;_freeList = start;_size += n;}//从自由链表获取一段范围的对象void PopRange(void*& start, void*& end, size_t n){assert(n <= _size);//头删start = _freeList;end = start;for (size_t i = 0; i < n - 1;i++){end = NextObj(end);}_freeList = NextObj(end); //自由链表指向end的下一个对象NextObj(end) = nullptr; //取出的一段链表的表尾置空_size -= n;}bool Empty(){return _freeList == nullptr;}size_t& MaxSize(){return _maxSize;}size_t Size(){return _size;}
private:void* _freeList = nullptr; //自由链表size_t _maxSize = 1;size_t _size = 0;
};
而对于FreeList类当中的PushRange成员函数,我们最好也像PopRange一样给它增加一个参数,表示插入对象的个数,不然我们这时还需要通过遍历统计插入对象的个数。
因此之前在调用PushRange的地方就需要修改一下,而我们实际就在一个地方调用过PushRange函数,并且此时插入对象的个数也是很容易知道的。当时thread cache从central cache获取了actualNum个对象,将其中的一个返回给了申请对象的线程,剩下的actualNum-1个挂到了thread cache对应的桶当中,所以这里插入对象的个数就是actualNum-1。
_freeLists[index].PushRange(NextObj(start), end, actualNum - 1);
说明一下:
当thread cache的某个自由链表过长时,我们实际就是把这个自由链表当中全部的对象都还给central cache了,但这里在设计PopRange接口时还是设计的是取出指定个数的对象,因为在某些情况下当自由链表过长时,我们可能并不一定想把链表中全部的对象都取出来还给central cache,这样设计就是为了增加代码的可修改性。
其次,当我们判断thread cache是否应该还对象给central cache时,还可以综合考虑每个thread cache整体的大小。比如当某个thread cache的总占用大小超过一定阈值时,我们就将该thread cache当中的对象还一些给central cache,这样就尽量避免了某个线程的thread cache占用太多的内存。对于这一点,在tcmalloc当中就是考虑到了的。
🌿2. centralcache 回收内存
当thread cache中某个自由链表太长时,会将自由链表当中的这些对象还给central cache中的span。
但是需要注意的是,还给central cache的这些对象不一定都是属于同一个span的。central cache中的每个哈希桶当中可能都不止一个span,因此当我们计算出还回来的对象应该还给central cache的哪一个桶后,还需要知道这些对象到底应该还给这个桶当中的哪一个span。
- 如何根据对象的地址得到对象所在的页号?
首先我们必须理解的是,某个页当中的所有地址除以页的大小都等该页的页号。比如我们这里假设一页的大小是100,那么地址099都属于第0页,它们除以100都等于0,而地址100199都属于第1页,它们除以100都等于1。
- 如何找到一个对象对应的span?
虽然我们现在可以通过对象的地址得到其所在的页号,但是我们还是不能知道这个对象到底属于哪一个span。因为一个span管理的可能是多个页。
为了解决这个问题,我们可以建立页号和span之间的映射。由于这个映射关系在page cache进行span的合并时也需要用到,因此我们直接将其存放到page cache里面。这时我们就需要在PageCache类当中添加一个映射关系了,这里可以用C++当中的unordered_map进行实现,并且添加一个函数接口,用于让central cache获取这里的映射关系。
//单例模式
class PageCache
{
public://获取从对象到span的映射Span* MapObjectToSpan(void* obj);
private:std::unordered_map<PAGE_ID, Span*> _idSpanMap;
};
每当page cache分配span给central cache时,都需要记录一下页号和span之间的映射关系。此后当thread cache还对象给central cache时,才知道应该具体还给哪一个span。
因此当central cache在调用NewSpan接口向page cache申请k页的span时,page cache在返回这个k页的span给central cache之前,应该建立这k个页号与该span之间的映射关系。
//获取一个k页的span
Span* PageCache::NewSpan(size_t k)
{assert(k > 0 && k < NPAGES);//先检查第k个桶里面有没有spanif (!_spanLists[k].Empty()){Span* kSpan = _spanLists[k].PopFront();return kSpan;}//检查一下后面的桶里面有没有span,如果有可以将其进行切分for (size_t i = k + 1; i < NPAGES; i++){if (!_spanLists[i].Empty()){Span* nSpan = _spanLists[i].PopFront();Span* kSpan = new Span;//在nSpan的头部切k页下来kSpan->_pageId = nSpan->_pageId;kSpan->_n = k;nSpan->_pageId += k;nSpan->_n -= k;//将剩下的挂到对应映射的位置_spanLists[nSpan->_n].PushFront(nSpan);//建立页号与span的映射,方便central cache回收小块内存时查找对应的spanfor (PAGE_ID i = 0; i < kSpan->_n; i++){_idSpanMap[kSpan->_pageId + i] = kSpan;}return kSpan;}}//走到这里说明后面没有大页的span了,这时就向堆申请一个128页的spanSpan* bigSpan = new Span;void* ptr = SystemAlloc(NPAGES - 1);bigSpan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;bigSpan->_n = NPAGES - 1;_spanLists[bigSpan->_n].PushFront(bigSpan);//尽量避免代码重复,递归调用自己return NewSpan(k);
}
此时我们就可以通过对象的地址找到该对象对应的span了,直接将该对象的地址除以页的大小得到页号,然后在unordered_map当中找到其对应的span即可。
//获取从对象到span的映射
Span* PageCache::MapObjectToSpan(void* obj)
{PAGE_ID id = (PAGE_ID)obj >> PAGE_SHIFT; //页号auto ret = _idSpanMap.find(id);if (ret != _idSpanMap.end()){return ret->second;}else{assert(false);return nullptr;}
}
当我们要通过某个页号查找其对应的span时,该页号与其span之间的映射一定是建立过的,如果此时我们没有在unordered_map当中找到,则说明我们之前的代码逻辑有问题,因此当没有找到对应的span时可以直接用断言结束程序,以表明程序逻辑出错。
- central cache回收内存
这时当thread cache还对象给central cache时,就可以依次遍历这些对象,将这些对象插入到其对应span的自由链表当中,并且及时更新该span的_usseCount计数即可。
在thread cache还对象给central cache的过程中,如果central cache中某个span的_useCount减到0时,说明这个span分配出去的对象全部都还回来了,那么此时就可以将这个span再进一步还给page cache。
//将一定数量的对象还给对应的span
void CentralCache::ReleaseListToSpans(void* start, size_t size)
{size_t index = SizeClass::Index(size);_spanLists[index]._mtx.lock(); //加锁while (start){void* next = NextObj(start); //记录下一个Span* span = PageCache::GetInstance()->MapObjectToSpan(start);//将对象头插到span的自由链表NextObj(start) = span->_freeList;span->_freeList = start;span->_useCount--; //更新被分配给thread cache的计数if (span->_useCount == 0) //说明这个span分配出去的对象全部都回来了{//此时这个span就可以再回收给page cache,page cache可以再尝试去做前后页的合并_spanLists[index].Erase(span);span->_freeList = nullptr; //自由链表置空span->_next = nullptr;span->_prev = nullptr;//释放span给page cache时,使用page cache的锁就可以了,这时把桶锁解掉_spanLists[index]._mtx.unlock(); //解桶锁PageCache::GetInstance()->_pageMtx.lock(); //加大锁PageCache::GetInstance()->ReleaseSpanToPageCache(span);PageCache::GetInstance()->_pageMtx.unlock(); //解大锁_spanLists[index]._mtx.lock(); //加桶锁}start = next;}_spanLists[index]._mtx.unlock(); //解锁
}
需要注意,如果要把某个span还给page cache,我们需要先将这个span从central cache对应的双链表中移除,然后再将该span的自由链表置空,因为page cache中的span是不需要切分成一个个的小对象的,以及该span的前后指针也都应该置空,因为之后要将其插入到page cache对应的双链表中。但span当中记录的起始页号以及它管理的页数是不能清除的,否则对应内存块就找不到了。
并且在central cache还span给page cache时也存在锁的问题,此时需要先将central cache中对应的桶锁解掉,然后再加上page cache的大锁之后才能进入page cache进行相关操作,当处理完毕回到central cache时,除了将page cache的大锁解掉,还需要立刻获得central cache对应的桶锁,然后将还未还完对象继续还给central cache中对应的span。
🌿3. pagecache 回收内存
如果central cache中有某个span的_useCount减到0了,那么central cache就需要将这个span还给page cache了。
这个过程看似是非常简单的,page cache只需将还回来的span挂到对应的哈希桶上就行了。但实际为了缓解内存碎片的问题,page cache还需要尝试将还回来的span与其他空闲的span进行合并。
- page cache进行前后页的合并
合并的过程可以分为向前合并和向后合并。如果还回来的span的起始页号是num,该span所管理的页数是n。那么在向前合并时,就需要判断第num-1页对应span是否空闲,如果空闲则可以将其进行合并,并且合并后还需要继续向前尝试进行合并,直到不能进行合并为止。而在向后合并时,就需要判断第num+n页对应的span是否空闲,如果空闲则可以将其进行合并,并且合并后还需要继续向后尝试进行合并,直到不能进行合并为止。
因此page cache在合并span时,是需要通过页号获取到对应的span的,这就是我们要把页号与span之间的映射关系存储到page cache的原因。
但需要注意的是,当我们通过页号找到其对应的span时,这个span此时可能挂在page cache,也可能挂在central cache。而在合并时我们只能合并挂在page cache的span,因为挂在central cache的span当中的对象正在被其他线程使用。
可是我们不能通过span结构当中的_useCount成员,来判断某个span到底是在central cache还是在page cache。因为当central cache刚向page cache申请到一个span时,这个span的_useCount就是等于0的,这时可能当我们正在对该span进行切分的时候,page cache就把这个span拿去进行合并了,这显然是不合理的。
鉴于此,我们可以在span结构中再增加一个_isUse成员,用于标记这个span是否正在被使用,而当一个span结构被创建时我们默认该span是没有被使用的。
//管理以页为单位的大块内存
struct Span
{PAGE_ID _pageId = 0; //大块内存起始页的页号size_t _n = 0; //页的数量Span* _next = nullptr; //双链表结构Span* _prev = nullptr;size_t _useCount = 0; //切好的小块内存,被分配给thread cache的计数void* _freeList = nullptr; //切好的小块内存的自由链表bool _isUse = false; //是否在被使用
};
由于在合并page cache当中的span时,需要通过页号找到其对应的span,而一个span是在被分配给central cache时,才建立的各个页号与span之间的映射关系,因此page cache当中的span也需要建立页号与span之间的映射关系。
与central cache中的span不同的是,在page cache中,只需建立一个span的首尾页号与该span之间的映射关系。因为当一个span在尝试进行合并时,如果是往前合并,那么只需要通过一个span的尾页找到这个span,如果是向后合并,那么只需要通过一个span的首页找到这个span。也就是说,在进行合并时我们只需要用到span与其首尾页之间的映射关系就够了。
因此当我们申请k页的span时,如果是将n页的span切成了一个k页的span和一个n-k页的span,我们除了需要建立k页span中每个页与该span之间的映射关系之外,还需要建立剩下的n-k页的span与其首尾页之间的映射关系。
//获取一个k页的span
Span* PageCache::NewSpan(size_t k)
{assert(k > 0 && k < NPAGES);//先检查第k个桶里面有没有spanif (!_spanLists[k].Empty()){Span* kSpan = _spanLists[k].PopFront();return kSpan;}//检查一下后面的桶里面有没有span,如果有可以将其进行切分for (size_t i = k + 1; i < NPAGES; i++){if (!_spanLists[i].Empty()){Span* nSpan = _spanLists[i].PopFront();Span* kSpan = new Span;//在nSpan的头部切k页下来kSpan->_pageId = nSpan->_pageId;kSpan->_n = k;nSpan->_pageId += k;nSpan->_n -= k;//将剩下的挂到对应映射的位置_spanLists[nSpan->_n].PushFront(nSpan);//存储nSpan的首尾页号与nSpan之间的映射,方便page cache合并span时进行前后页的查找_idSpanMap[nSpan->_pageId] = nSpan;_idSpanMap[nSpan->_pageId + nSpan->_n - 1] = nSpan;//建立页号与span的映射,方便central cache回收小块内存时查找对应的spanfor (PAGE_ID i = 0; i < kSpan->_n; i++){_idSpanMap[kSpan->_pageId + i] = kSpan;}return kSpan;}}//走到这里说明后面没有大页的span了,这时就向堆申请一个128页的spanSpan* bigSpan = new Span;void* ptr = SystemAlloc(NPAGES - 1);bigSpan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;bigSpan->_n = NPAGES - 1;_spanLists[bigSpan->_n].PushFront(bigSpan);//尽量避免代码重复,递归调用自己return NewSpan(k);
}
此时page cache当中的span就都与其首尾页之间建立了映射关系,现在我们就可以进行span的合并了
//释放空闲的span回到PageCache,并合并相邻的span
void PageCache::ReleaseSpanToPageCache(Span* span)
{//对span的前后页,尝试进行合并,缓解内存碎片问题//1、向前合并while (1){PAGE_ID prevId = span->_pageId - 1;auto ret = _idSpanMap.find(prevId);//前面的页号没有(还未向系统申请),停止向前合并if (ret == _idSpanMap.end()){break;}//前面的页号对应的span正在被使用,停止向前合并Span* prevSpan = ret->second;if (prevSpan->_isUse == true){break;}//合并出超过128页的span无法进行管理,停止向前合并if (prevSpan->_n + span->_n > NPAGES - 1){break;}//进行向前合并span->_pageId = prevSpan->_pageId;span->_n += prevSpan->_n;//将prevSpan从对应的双链表中移除_spanLists[prevSpan->_n].Erase(prevSpan);delete prevSpan;}//2、向后合并while (1){PAGE_ID nextId = span->_pageId + span->_n;auto ret = _idSpanMap.find(nextId);//后面的页号没有(还未向系统申请),停止向后合并if (ret == _idSpanMap.end()){break;}//后面的页号对应的span正在被使用,停止向后合并Span* nextSpan = ret->second;if (nextSpan->_isUse == true){break;}//合并出超过128页的span无法进行管理,停止向后合并if (nextSpan->_n + span->_n > NPAGES - 1){break;}//进行向后合并span->_n += nextSpan->_n;//将nextSpan从对应的双链表中移除_spanLists[nextSpan->_n].Erase(nextSpan);delete nextSpan;}//将合并后的span挂到对应的双链表当中_spanLists[span->_n].PushFront(span);//建立该span与其首尾页的映射_idSpanMap[span->_pageId] = span;_idSpanMap[span->_pageId + span->_n - 1] = span;//将该span设置为未被使用的状态span->_isUse = false;
}
需要注意的是,在向前或向后进行合并的过程中:
- 如果没有通过页号获取到其对应的span,说明对应到该页的内存块还未申请,此时需要停止合并。
- 如果通过页号获取到了其对应的span,但该span处于被使用的状态,那我们也必须停止合并。
- 如果合并后大于128页则不能进行本次合并,因为page cache无法对大于128页的span进行管理。
在合并span时,由于这个span是在page cache的某个哈希桶的双链表当中的,因此在合并后需要将其从对应的双链表中移除,然后再将这个被合并了的span结构进行delete。
除此之外,在合并结束后,除了将合并后的span挂到page cache对应哈希桶的双链表当中,还需要建立该span与其首位页之间的映射关系,便于此后合并出更大的span。
🌿4. 释放内存过程联调
- ConcurrentFree函数
至此我们将thread cache、central cache以及page cache的释放流程也都写完了,此时我们就可以向外提供一个ConcurrentFree函数,用于释放内存块,释放内存块时每个线程通过自己的thread cache对象,调用thread cache中释放内存对象的接口即可。
static void ConcurrentFree(void* ptr, size_t size/*暂时*/)
{assert(pTLSThreadCache);pTLSThreadCache->Deallocate(ptr, size);
}
相关文章:

【项目设计】高并发内存池(五)[释放内存流程及调通]
🎇C学习历程:入门 博客主页:一起去看日落吗持续分享博主的C学习历程博主的能力有限,出现错误希望大家不吝赐教分享给大家一句我很喜欢的话: 也许你现在做的事情,暂时看不到成果,但不要忘记&…...
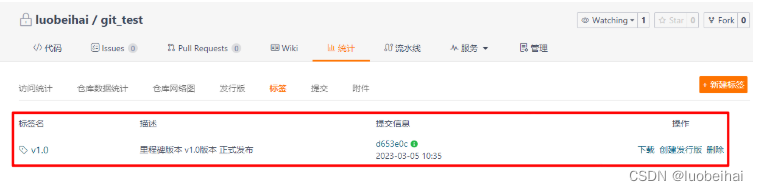
Git标签与版本发布
1. 什么是git标签 标签,就类似我们阅读时的书签,可以很轻易找到自己阅读到了哪里。 对于git来说,在使用git对项目进行版本管理的时候,当我们的项目开发到一定的阶段,需要发布一个版本。这时,我们就可以对…...

Python面向对象编程
文章目录1 作用域1.1 局部作用域2 类成员权限3 是否继承新式类4 多重继承5 虚拟子类6 内省【在运行时确定对象类型的能力】7 函数参数8 生成器1 作用域 1.1 局部作用域 1,当局部变量遮盖全局变量,使用globals()[变量名]来使用全局变量;2&am…...

【什么情况会导致 MySQL 索引失效?】
MySQL索引失效可能有多种原因,下面列举一些常见的情况: 数据库表数据量太小: 如果表的数据量非常小,则MySQL可能不会使用索引,因为它认为全表扫描的代价更小。 索引列上进行了函数操作: 如果在索引列上…...
--自问自答系列版本)
Java核心知识点整理之小碎片--每天一点点(坚持呀)--自问自答系列版本
1.int和Integer Integer是int的包装类;int是基本数据类型。 Integer变量必须实例化后才能使用;int变量不需要。 Integer实际是对象的引用,当new一个Integer时,实际上是生成一个指针指向此对象;而int则是直接存储数据值…...
的使用方法)
js中new Map()的使用方法
1.map的方法及属性Map对象存有键值对,其中的键可以是任何数据类型。Map对象记得键的原始插入顺序。Map对象具有表示映射大小的属性。1.1 基本的Map() 方法MethodDescriptionnew Map()创建新的 Map 对象。set()为 Map 对象中的键设置值。get()获取 Map 对象中键的值。…...

synchronized从入门到踹门
synchronized是什么synchronized是Java关键字,为了维护高并发是出现的原子性问题。技术是把双刃剑,多线程并发给我带来了前所未有的速率,然而在享受快速编程的过程,也给我们带来了原子性问题。如下:public class Main …...

ubuntu-8-安装nfs服务共享目录
Ubuntu最新版本(Ubuntu22.04LTS)安装nfs服务器及使用教程 ubuntu16.04挂载_如何在Ubuntu 20.04上设置NFS挂载 Ubuntu 20.04 设置时区、配置NTP同步 timesyncd 代替 ntpd 服务器 10.0.2.11 客户端 10.0.2.121 NFS简介 (1)什么是NFS NFS就是Network File System的缩写…...
设计算法的常用思想)
算法练习(特辑)设计算法的常用思想
1、递推法 递推的思想是把一个复杂的庞大的计算过程转换为简单过程的多次重复,每一次推导的结果作为下一次推导的开始。 2、递归法 递归算法实际上是把问题转化成规模更小的同类子问题,先解决子问题,再通过相同的求解过程逐步解决更高层次…...
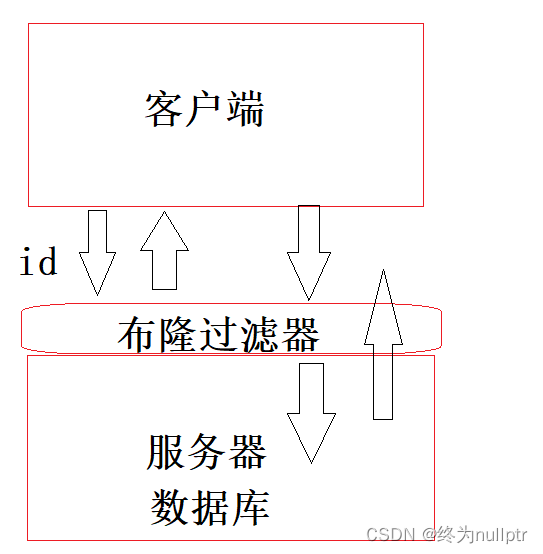
哈希->模拟实现+位图应用
致前行路上的人: 要努力,但不要着急,繁花锦簇,硕果累累都需要过程! 目录 1. unordered系列关联式容器 1.1 unordered_map 1.1.1概念介绍: 1.1.2 unordered_map的接口说明 1.2unordered_set 1.3常见面试题oj…...
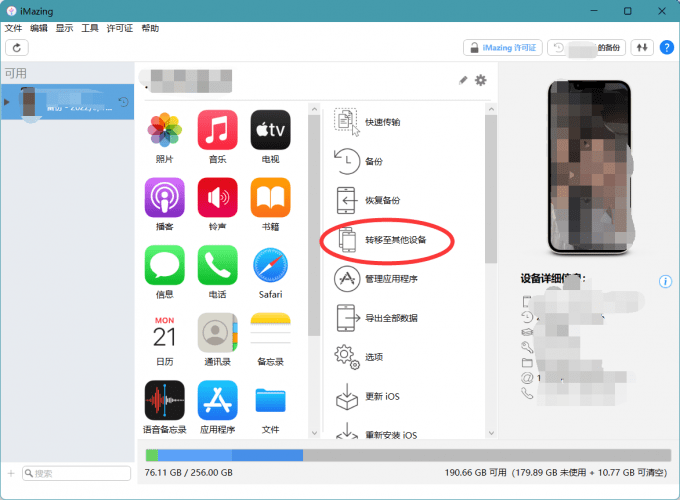
苹果手机想要传输数据到电脑怎么传输呢?
苹果手机想要传输数据到电脑怎么传输呢?尤其是传输数据到Windows系统,可能需要使用一些传输软件,那么常用的传输软件有哪些呢?下文将为大家推荐几款常用的苹果手机数据传输常用工具。近期苹果发布了iPhone14系列手机,如…...

Linux 练习四 (目录操作 + 文件操作)
文章目录1 基于文件指针的文件操作1.1 文件的创建,打开和关闭1.2 文件读写操作2 基于文件描述符的文件操作2.1 打开、创建和关闭文件2.2 文件读写2.3 改变文件大小2.4 文件映射2.5 文件定位2.6 获取文件信息2.7 复制文件描述符2.8 文件描述符和文件指针2.9 标准输入…...
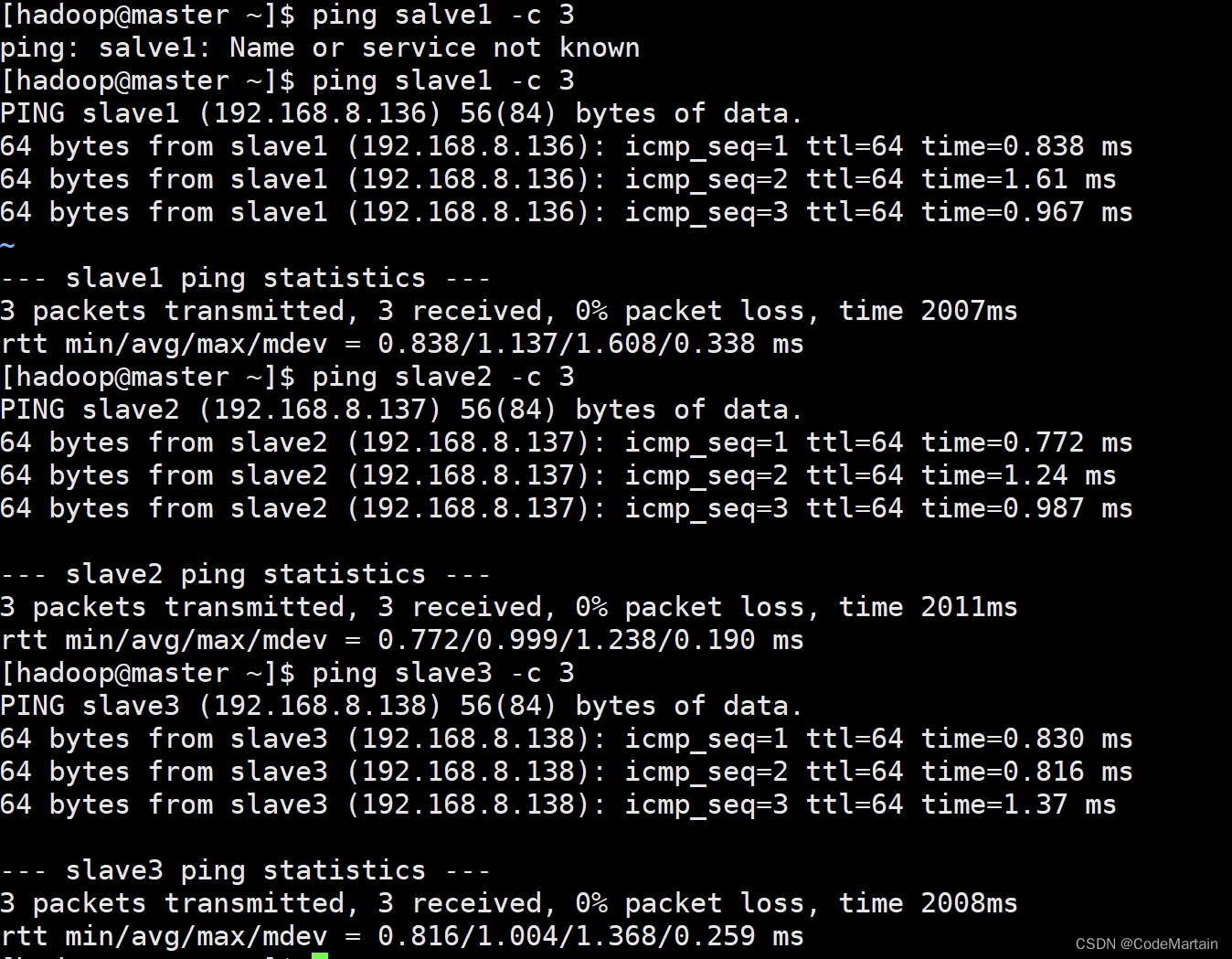
自学大数据第四天~hadoop集群的搭建
Hadoop集群安装配置 当hadoop采用分布式模式部署和运行时,存储采用分布式文件系统HDFS,此时HDFS名称节点和数据节点位于不同的机器上; 数据就可以分布到多个节点,不同的数据节点上的数据计算可以并行执行了,这时候MR才能发挥其本该有的作用; 没那么多机器怎么办~~~~多几个虚拟…...

ULID和UUID
ULID:Universally Unique Lexicographically Sortable Identifier(通用唯一词典分类标识符)UUID:Universally Unique Identifier(通用唯一标识符)为什么不选择UUIDUUID 目前有 5 个版本:版本1&a…...

java基础面试10题
1.JVM、JRE 和 JDK 的关系 Jvm:java虚拟机,类似于一个小型的计算机,它能够将java程序编译后的.class 文件解释给相应平台的本地系统执行,从而实现跨平台。 jre:是运行java程序所需要的环境的集合,它包含了…...

Golang闭包问题及并发闭包问题
目录Golang闭包问题及并发闭包问题匿名函数闭包闭包可以不传入外部参数,仍然可以访问外部变量闭包提供数据隔离并发闭包为什么解决方法Golang闭包问题及并发闭包问题 参考原文链接:https://blog.csdn.net/qq_35976351/article/details/81986496 htt…...

基频的后处理
基频归一化 基频为什么要归一化?为了消除人际随机差异,提取恒定参数,在语际变异中找到共性。 引言 声调的主要载体就是基频。但是对声调的感知会因人而异,例如某个听感上的高升调,不同的调查人员可能会分别描写成 […...

vue3 toRefs详解
简介 toRefs函数的作用是将响应式对象中的所有属性转换为单独的响应式数据,对象成为普通对象,并且值是关联的。在这个过程中toRefs会做以下两件事: 把一个响应式对象转换成普通对象对该普通对象的每个属性都做一次ref操作,这样每…...
Spring——AOP是什么?如何使用?
一、什么是AOP?在不修改源代码的情况下 增加功能二、底层是什么?动态代理aop是IOC的一个扩展功能,现有IOC,再有AOP,只是在IOC的整个流程中新增的一个扩展点而已:BeanPostProcessorbean的创建过程中有一个步…...
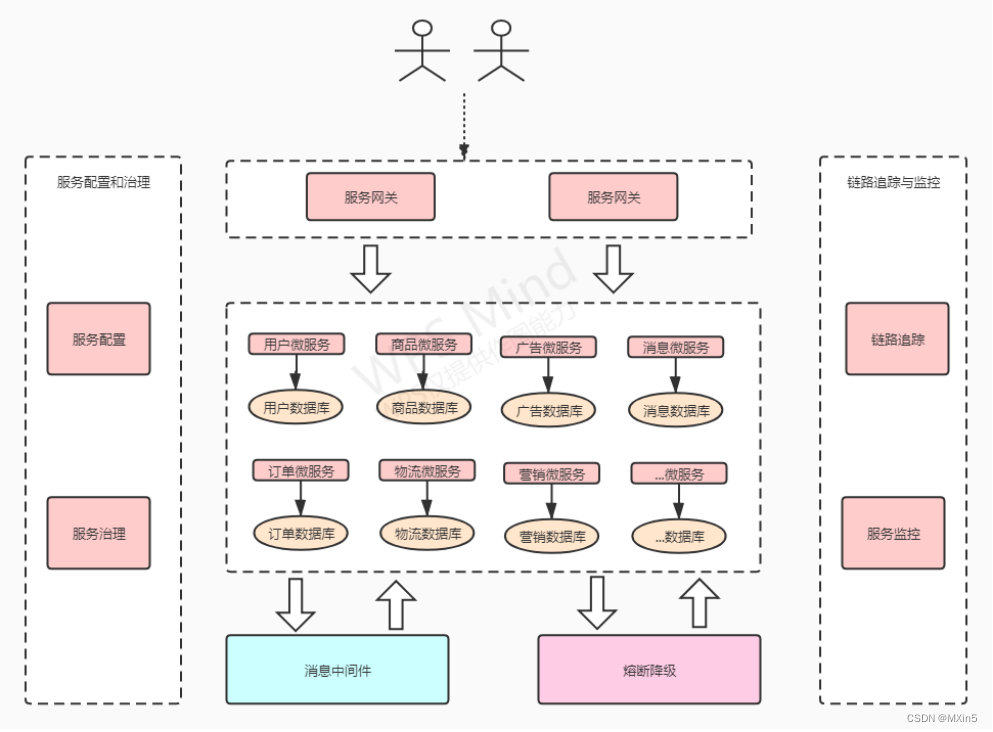
【微服务】认识微服务
目录 1.1 单体、分布式、集群 单体 分布式 集群 1.2 系统架构演变 1.2.1 单体应⽤架构 1.2.2 垂直应⽤架构 1.2.3 分布式架构 1.2.4 SOA架构 1.2.5 微服务架构 1.3 微服务架构介绍 微服务架构的常⻅问题 1.4 SpringCloud介绍 1.4.1 SpringBoot和SpringCloud有啥关…...

保姆级教学:用星图AI云平台快速搭建Clawdbot,让Qwen3-VL:30B接入飞书
保姆级教学:用星图AI云平台快速搭建Clawdbot,让Qwen3-VL:30B接入飞书 1. 为什么选择本地部署多模态办公助手? 在日常办公中,我们经常遇到需要处理图片和文字的场景: 同事发来的产品截图需要快速分析内容会议白板照片…...

nli-distilroberta-base实际项目:新闻摘要与原文蕴含关系自动评估
nli-distilroberta-base实际项目:新闻摘要与原文蕴含关系自动评估 1. 项目概述 在新闻媒体和内容创作领域,如何快速评估一篇摘要是否准确反映了原文内容一直是个挑战。传统的人工审核方式效率低下且成本高昂。nli-distilroberta-base项目正是为解决这一…...
支持自动排版与LaTeX智能匹配)
AI论文生成工具推荐:7款高效平台(含爱毕业aibiye)支持自动排版与LaTeX智能匹配
工具快速对比排名(前7推荐) 工具名称 核心功能亮点 处理时间 适配平台 aibiye 学生/编辑双模式降AIGC 1分钟 知网、万方等 aicheck AI痕迹精准弱化查重一体 ~20分钟 知网、格子达、维普 askpaper AIGC率个位数优化 ~20分钟 高校检测规则通…...

高效大麦抢票自动化工具实战指南:开源项目的专业配置教程
高效大麦抢票自动化工具实战指南:开源项目的专业配置教程 【免费下载链接】ticket-purchase 大麦自动抢票,支持人员、城市、日期场次、价格选择 项目地址: https://gitcode.com/GitHub_Trending/ti/ticket-purchase 大麦网作为国内领先的演出票务…...

硅橡胶资源平台对接的靠谱对接企业哪家强
在深圳这座创新与制造之都,硅橡胶产业上下游企业林立,从原材料、模具设计到制品生产,形成了一个庞大而复杂的产业链。对于许多企业而言,“深圳硅橡胶资源平台对接” 的需求日益迫切——无论是寻找稳定供应商、开拓新客户ÿ…...

OpenClaw多模型切换指南:Qwen3.5-9B与Llama3混合调度实战
OpenClaw多模型切换指南:Qwen3.5-9B与Llama3混合调度实战 1. 为什么需要多模型切换? 去年我在搭建个人AI工作流时,发现单一模型很难满足所有需求。用Qwen处理文档时效果惊艳,但遇到代码生成任务就显得力不从心;换成专…...

OpenClaw未来展望:Qwen3-14B与本地自动化的5个进化方向
OpenClaw未来展望:Qwen3-14B与本地自动化的5个进化方向 1. 从工具到伙伴:OpenClaw的现状与定位 去年冬天,当我第一次在本地MacBook上部署OpenClaw时,它还是个需要手动配置JSON文件才能调用本地模型的"半成品"。如今看…...

Krita 5.3.0 与 6.0.0 发布:功能升级与技术革新
文本与工具革新,Krita 功能升级Krita 5.3.0 和 6.0.0 正式推出,带来了一系列显著的功能改进。文本工具被完全重写,支持在画布上进行所见即所得编辑,还能支持 OpenType 的所有特性以及文本置入形状,这大大提升了文字处理…...

4步攻克Fiji在macOS系统的启动难题:从诊断到长效维护的全方位解决方案
4步攻克Fiji在macOS系统的启动难题:从诊断到长效维护的全方位解决方案 【免费下载链接】fiji A "batteries-included" distribution of ImageJ :battery: 项目地址: https://gitcode.com/gh_mirrors/fi/fiji 问题定位:精准识别Fiji启动…...

3张表搞定财务BP工作!财务BP必须会的3张表
做了这么多年财务数据分析,我发现国内很多公司的财务BP,还停留在自己造表的阶段。每人一套表,格式五花八门,数据口径对不上。结果就是BP花大量时间在拉表、对数的琐事上,真正花在业务分析和决策支持上的时间少之又少。…...