哈希->模拟实现+位图应用
致前行路上的人:
要努力,但不要着急,繁花锦簇,硕果累累都需要过程!

目录
1. unordered系列关联式容器
1.1 unordered_map
1.1.1概念介绍:
1.1.2 unordered_map的接口说明
1.2unordered_set
1.3常见面试题oj
2.底层结构
2.1 哈希概念
2.2 哈希冲突
2.3哈希函数
2.4哈希冲突解决
2.4.1闭散列
2.4.2开散列
3.模拟实现
3.1哈希表的改造:
3.2unordered_map模拟实现
3.3unordered_set模拟实现
4.哈希的应用
4.1位图
4.1.1 位图概念
4.1.2 位图的实现
4.1.3 位图的应用
4.2哈希切割
4.3布隆过滤器
4.3.1布隆过滤器的提出
4.3.2布隆过滤的概念
4.3.3布隆过滤器的插入
4.2.4 布隆过滤器的查找
4.2.5 布隆过滤器删除
4.2.6如何选择哈希函数个数和布隆过滤器长度
4.2.6布隆过滤器优点
4.2.7 布隆过滤器缺陷
4.2.8布隆过滤器的应用场景
4.2.9布隆过滤器代码实现
4.2.10布隆过滤器的面试题
1. unordered系列关联式容器
在C++98中,STL提供了底层为红黑树结构的一系列关联式容器,在查询时效率可达到logN,即最差情况下需要比较红黑树的高度次,当树中的节点非常多时,查询效率也不理想。最好的查询是,进行很少的比较次数就能够将元素找到,因此在C++11中,STL又提供了4个unordered系列的关联式容器,这四个容器与红黑树结构的关联式容器使用方式基本类似,只是其底层结构不同,本文中对unordered_map和unordered_set进行介绍,unordered_multimap和unordered_multiset使用方式类型类似,后面两个相较于前两个,不同的是允许数据重复。
1.1 unordered_map
1.1.1概念介绍:
1. unordered_map是存储<key, value>键值对的关联式容器,其允许通过keys快速的索引到与其对应的value。
2. 在unordered_map中,键值通常用于唯一地标识元素,而映射值是一个对象,其内容与此键关联。键和映射值的类型可能不同。
3. 在内部,unordered_map没有对<kye, value>按照任何特定的顺序排序, 为了能在常数范围内找到key所对应的value,unordered_map将相同哈希值的键值对放在相同的桶中。
4. unordered_map容器通过key访问单个元素要比map快,但它通常在遍历元素子集的范围迭代方面效率较低。
5. unordered_map实现了直接访问操作符(operator[]),它允许使用key作为参数直接访问value。
6. 它的迭代器至少是前向迭代器。
1.1.2 unordered_map的接口说明
1. unordered_map的构造
unordered_map 构造不同格式的unordered_map对象
2. unordered_map的容量
| bool empty() const | 检测unordered_map是否为空 |
| size_t size() const | 获取unordered_map的有效元素个数 |
3. unordered_map的迭代器
| begin | 返回unordered_map第一个元素的迭代器 |
| end | 返回unordered_map最后一个元素下一个位置的迭代器 |
| cbegin | 返回unordered_map第一个元素的const迭代器 |
| cend | 返回unordered_map最后一个元素下一个位置的const迭代器 |
4. unordered_map的元素访问
| operator[] | 返回与key对应的value,没有一个默认值 |
注意:该函数中实际调用哈希桶的插入操作,用参数key与V()构造一个默认值往底层哈希桶
中插入,如果key不在哈希桶中,插入成功,返回V(),插入失败,说明key已经在哈希桶中,
将key对应的value返回。
#include <iostream>
#include <string>
#include <unordered_map>int main()
{std::unordered_map<std::string, std::string> mymap;mymap["Bakery"] = "Barbara"; // new element insertedmymap["Seafood"] = "Lisa"; // new element insertedmymap["Produce"] = "John"; // new element insertedstd::string name = mymap["Bakery"]; // existing element accessed (read)mymap["Seafood"] = name; // existing element accessed (written)mymap["Bakery"] = mymap["Produce"]; // existing elements accessed (read/written)name = mymap["Deli"]; // non-existing element: new element "Deli" inserted!mymap["Produce"] = mymap["Gifts"]; // new element "Gifts" inserted, "Produce" writtenfor (auto& x : mymap) {std::cout << x.first << ": " << x.second << std::endl;}return 0;
}运行结果:

5. unordered_map的查询
| iterator find(const K& key) | 返回key在哈希桶中的位置 |
| size_t count(const K& key) | 返回哈希桶中关键码为key的键值对的个数 |
6. unordered_map的修改操作
| insert | 向容器中插入键值对 |
| erase | 删除容器中的键值对 |
| clear | 清空容器中有效元素个数 |
| void swap(unordered_map&) | 交换两个容器中的元素 |
7. unordered_map的桶操作
| size_t bucket_count()const | 返回哈希桶中桶的总个数 |
| size_t bucket_size(size_t n)const | 返回n号桶中有效元素的总个数 |
| size_t bucket(const K& key) | 返回元素key所在的桶号 |
1.2unordered_set
unordered_set文档说明
1.3常见面试题oj
在长度 2N 的数组中找出重复 N 次的元素
class Solution {
public:int repeatedNTimes(vector<int>& nums) {size_t N = nums.size() / 2;unordered_map<int,int>m;//统计每个元素出现的次数for(auto& e : nums){m[e]++;}//找到出现N次的元素:for(auto& e : m){if(e.second == N)return e.first;}return -1;}
};349. 两个数组的交集
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {unordered_set<int>s1(nums1.begin(),nums1.end());unordered_set<int>s2(nums2.begin(),nums2.end());vector<int> result;for(auto& e : s1){if(s2.find(e) != s2.end())result.push_back(e);}return result;}
};
2.底层结构
unordered系列的关联式容器之所以效率比较高,是因为其底层使用了哈希结构。
2.1 哈希概念
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素
时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N),平衡树中为树的高度,即
O(log N),搜索的效率取决于搜索过程中元素的比较次数。
理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。
如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立
一 一映射的关系,那么在查找时通过该函数可以很快找到该元素。
当向该结构中:
插入元素
根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放
搜索元素
对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置
取元素比较,若关键码相等,则搜索成功
该方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称
为哈希表(Hash Table)(或者称散列表
例如:数据集合{1,7,6,4,5,9};
哈希函数设置为:hash(key) = key % capacity; capacity为存储元素底层空间总的大小。
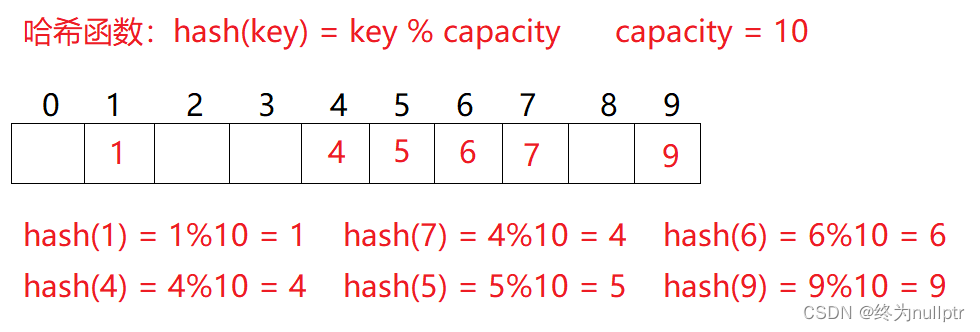
用该方法进行搜索不必进行多次关键码的比较,因此搜索的速度比较快
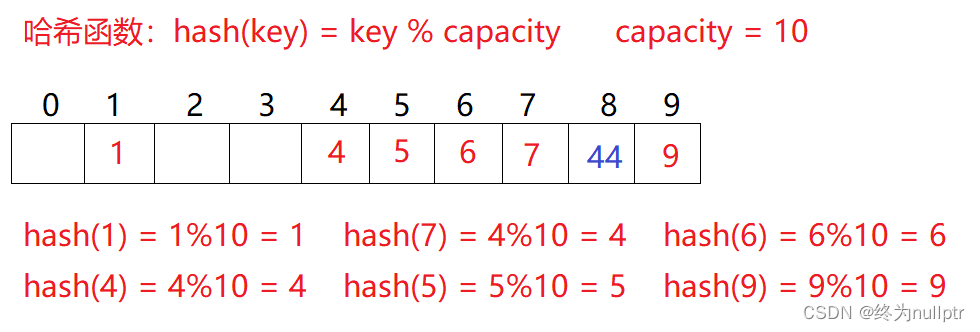
问题:按照上述哈希方式,向集合中插入元素44,会出现什么问题
2.2 哈希冲突
不同关键字通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。
发生哈希冲突该如何处理呢?
2.3哈希函数
引起哈希冲突的一个原因可能是:哈希函数设计不够合理。
哈希函数设计原则:
~哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有m个地址时,其值
域必须在0到m-1之间
~哈希函数计算出来的地址能均匀分布在整个空间中
~哈希函数应该比较简单
常见哈希函数
1. 直接定址法--(常用)
取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B
优点:简单、均匀
缺点:需要事先知道关键字的分布情况
使用场景:适合查找比较小且连续的情况
2. 除留余数法--(常用)
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,
按照哈希函数:Hash(key) = key% p(p<=m),将关键码转换成哈希地址、
2.4哈希冲突解决
解决哈希冲突的两种方法:闭散列和开散列
2.4.1闭散列
闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有
空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。那如何寻找下一个空位置
呢?
1. 线性探测
现在需要插入元素44,先通过哈希函数计算哈希地址,hashAddr为4,因此44理论上应该插在该位置,但是该位置已经放了值为4的元素,即发生哈希冲突。
线性探测:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
插入
1.通过哈希函数获取待插入元素在哈希表中的位置
2.如果该位置中没有元素则直接插入新元素,如果该位置中有元素发生哈希冲突,
使用线性探测找到下一个空位置,插入新元素
扩容:
散列表中有一个载荷因子(负载因子)= 散列表元素的个数 / 散列表的长度,载荷因子越大,产生冲突的可能性就越大,载荷因子越小,产生冲突的可能性就越小,但是可能会造成空间浪费,因此,一般建议将载荷因子控制在0.7~0.8之间
删除
采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素
会影响其他元素的搜索。比如删除元素4,如果直接删除掉,44查找起来可能会受影
响。因此线性探测采用标记的伪删除法来删除一个元素。
// 哈希表每个空间给个标记
// EMPTY此位置空, EXIST此位置已经有元素, DELETE元素已经删除
enum State{EMPTY, EXIST, DELETE};线性探测的实现
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};
template<>
struct HashFunc<string>
{size_t operator()(const string& key){size_t hash = 0;for (auto& e : key){hash = hash * 131 + e;}return hash;}
};enum State
{EMPTY,EXIST,DELETE
};
template<class K,class V>
struct HashData
{pair<K, V> _kv;State _state = EMPTY;
};
template<class K, class V, class Hash = HashFunc<K>>
class HashTable
{typedef HashData<K, V> data;
public:HashTable():_n(0){_tables.resize(10);}bool Insert(const pair<K, V>& kv){if (Find(kv.first))return false;if (_n * 10 / _tables.size() >= 7){HashTable<K, V,Hash> newHT;newHT._tables.resize(_tables.size() * 2);for (auto& e : _tables){if (e._state == EXIST){newHT.Insert(e._kv);}}_tables.swap(newHT._tables);}Hash ha;size_t hashi = ha(kv.first) % _tables.size();while (_tables[hashi]._state == EXIST){//线性探测:++hashi;hashi %= _tables.size();}_tables[hashi]._kv = kv;_tables[hashi]._state = EXIST;++_n;return true;}data* Find(const K& key){Hash ha;size_t hashi = ha(key) % _tables.size();size_t starti = hashi;while (_tables[hashi]._state != EMPTY){if (_tables[hashi]._state == EXIST && _tables[hashi]._kv.first == key){return &_tables[hashi];}++hashi;hashi %= _tables.size();//极端场景下,不是存在就是删除,可能会造成死循环的问题if(hashi == starti){break;}}return nullptr;}bool Erase(const K& key){data* ret = Find(key);if (ret){ret->_state = DELETE;--_n;return true;}return false;}
private:vector<data> _tables;size_t _n = 0;
};
线性探测优点:实现非常简单,
线性探测缺点:一旦发生哈希冲突,所有的冲突连在一起,容易产生数据“堆积”,即:不同
关键码占据了可利用的空位置,使得寻找某关键码的位置需要许多次比较,导致搜索效率降
低。
2.4.2开散列
1. 开散列概念
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地
址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链
接起来,各链表的头结点存储在哈希表中。
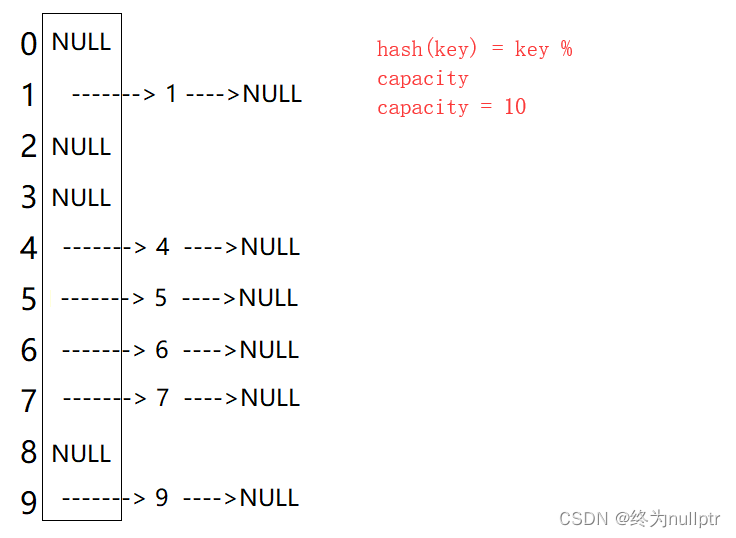
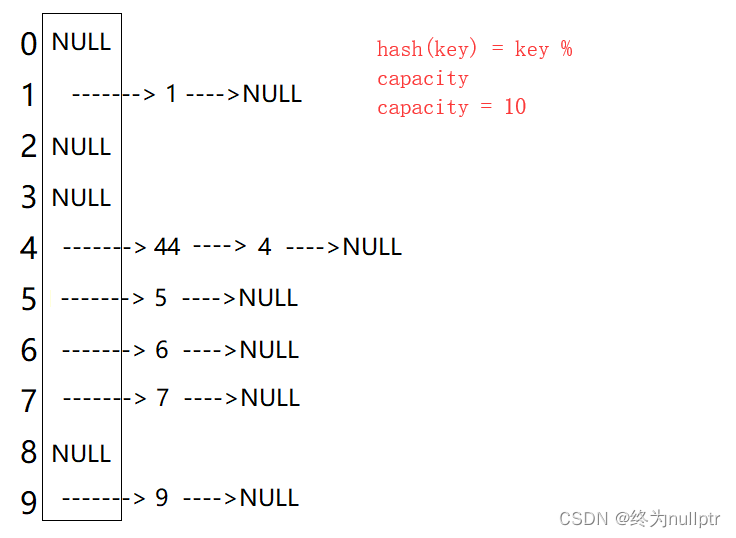
从上图可以看出,开散列中每个桶中放的都是发生哈希冲突的元素。
2. 开散列实现
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};
template<>
struct HashFunc<string>
{size_t operator()(const string& key){size_t hash = 0;for (auto& e : key){hash = hash * 131 + e;}return hash;}
};
template<class K,class V>
struct HashNode
{pair<K, V> _kv;HashNode* next;HashNode(const pair<K,V>&kv):_kv(kv),next(nullptr){}
};
template<class K,class V,class Hash=HashFunc<K>>
class HashTable
{typedef HashNode<K, V> node;
public:HashTable():_n(0){_tables.resize(10);}~HashTable(){for (size_t i = 0; i < _tables.size(); i++){node* cur = _tables[i];while (cur){node* next = cur->next;delete cur;cur = next;}_tables[i] = nullptr;}}bool Insert(const pair<K, V>& kv){//负载因子控制在1,超过就扩容if (_n == _tables.size()){/*HashTable<K, V, Hash> newHT;newHT._tables.resize(_tables.size() * 2);for (auto cur : _tables){while (cur){newHT.Insert(cur->_kv);cur = cur->next;}}_tables.swap(newHT._tables);*/vector<node*> newTable;newTable.resize(2 * _tables.size(), nullptr);for (size_t i = 0; i < _tables.size(); i++){node* cur = _tables[i];while (cur){node* next = cur->next;size_t hashi = Hash()(cur->_kv.first) % newTable.size();//头插到新表cur->next = newTable[hashi];newTable[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newTable);}size_t hashi = Hash()(kv.first) % _tables.size();node* newNode = new node(kv);newNode->next = _tables[hashi];_tables[hashi] = newNode;++_n;return true;}node* Find(const K& key){size_t hashi = Hash()(key) % _tables.size();node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){return cur;}else{cur = cur->next;}}return nullptr;}bool Erase(const K& key){size_t hashi = Hash()(key) % _tables.size();node* prev = nullptr;node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){if (cur == _tables[hashi]){_tables[hashi] = cur->next;delete cur;}else{prev->next = cur->next;delete cur;}--_n;return true;}else{prev = cur;cur = cur->next;}}return false;}
private:vector<node*> _tables;size_t _n = 0;
};3.模拟实现
3.1哈希表的改造:
1. 模板参数列表的改造:
K:关键码类型
T: 不同容器V的类型不同,如果是unordered_map,T代表一个键值对,如果是
unordered_set,T为 K
KeyOfT: 因为V的类型不同,通过value取key的方式就不同
Hash:哈希函数仿函数对象类型,哈希函数使用除留余数法,需要将Key转换为整形数字才能
取模
2.代码实现:
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};
template<>
struct HashFunc<string>
{size_t operator()(const string& key){size_t hash = 0;for (auto& e : key){hash = hash * 131 + e;}return hash;}
};
template<class T>
struct HashNode
{T _data;HashNode<T>* next;HashNode(const T& data):_data(data),next(nullptr){}
};
template<class K,class T,class Hash,class KeyOfT>
class HashTable;
template<class K,class T,class Hash,class KeyOfT>
struct __HTiterator
{typedef HashNode<T> node;typedef __HTiterator<K, T, Hash, KeyOfT> Self;typedef HashTable<K, T, Hash, KeyOfT> HT;node* _node;HT* ht;__HTiterator(node* node, HT* ht):_node(node), ht(ht) {}T& operator*(){return _node->_data;}T* operator->(){return &_node->_data;}bool operator !=(const Self& s){return _node != s._node;}Self& operator++(){if (_node->next){_node = _node->next;}else{//当前桶走完了,走桶的下一个:KeyOfT kot;size_t hashi = Hash()(kot(_node->_data)) % ht->_tables.size();++hashi;while (hashi < ht->_tables.size()){if (ht->_tables[hashi]){_node = ht->_tables[hashi];break;}else{++hashi;}}if (hashi == ht->_tables.size())_node = nullptr;}return *this;}
};
template<class K,class T,class Hash,class KeyOfT>
class HashTable
{typedef HashNode<T> node;template<class K, class T, class Hash, class KeyOfT>friend struct __HTiterator;
public:typedef __HTiterator<K, T, Hash, KeyOfT> iterator;iterator begin(){for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]){return iterator(_tables[i], this);}}return iterator(nullptr, this);}iterator end(){return iterator(nullptr, this);}HashTable():_n(0){_tables.resize(10);}~HashTable(){for (size_t i = 0; i < _tables.size(); i++){node* cur = _tables[i];while (cur){node* next = cur->next;delete cur;cur = next;}_tables[i] = nullptr;}}pair<iterator,bool> Insert(const T& data){KeyOfT kot;iterator it = Find(kot(data));if (it != end())return make_pair(it, false);//负载因子控制在1,超过就扩容if (_n == _tables.size()){/*HashTable<K, V, Hash> newHT;newHT._tables.resize(_tables.size() * 2);for (auto cur : _tables){while (cur){newHT.Insert(cur->_kv);cur = cur->next;}}_tables.swap(newHT._tables);*/vector<node*> newTable;newTable.resize(2 * _tables.size(), nullptr);for (size_t i = 0; i < _tables.size(); i++){node* cur = _tables[i];while (cur){node* next = cur->next;size_t hashi = Hash()(kot(cur->_data)) % newTable.size();//头插到新表cur->next = newTable[hashi];newTable[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newTable);}size_t hashi = Hash()(kot(data)) % _tables.size();node* newNode = new node(data);newNode->next = _tables[hashi];_tables[hashi] = newNode;++_n;return make_pair(iterator(newNode, this), true);}iterator Find(const K& key){KeyOfT kot;size_t hashi = Hash()(key) % _tables.size();node* cur = _tables[hashi];while (cur){if (kot(cur->_data) == key){return iterator(cur, this);}else{cur = cur->next;}}return end();}bool Erase(const K& key){KeyOfT kot;size_t hashi = Hash()(key) % _tables.size();node* prev = nullptr;node* cur = _tables[hashi];while (cur){if (kot(cur->_data) == key){if (cur == _tables[hashi]){_tables[hashi] = cur->next;delete cur;}else{prev->next = cur->next;delete cur;}--_n;return true;}else{prev = cur;cur = cur->next;}}return false;}
private:vector<node*> _tables;size_t _n = 0;
};3.2unordered_map模拟实现
namespace ns
{template<class K, class V,class Hash = HashFunc<K>>class unordered_map{struct MapKeyOfT{const K& operator()(const pair<K, V>& kv){return kv.first;}};public:typedef typename HashTable<K, pair<const K, V>, Hash, MapKeyOfT>::iterator iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}pair<iterator,bool> Insert(const pair<const K, V>& kv){return _ht.Insert(kv);}V& operator[](const K& key){pair<iterator, bool> ret = _ht.Insert(make_pair(key, V()));return ret.first->second;}iterator Find(const K& key){return _ht.Find(key);}iterator Erase(const K& key){return _ht.Erase(key);}private:HashTable<K, pair<const K,V>, Hash, MapKeyOfT>_ht;};3.3unordered_set模拟实现
namespace ns
{template<class K,class Hash = HashFunc<K>>class unordered_set{struct SetKeyOfT{const K& operator()(const K& key){return key;}};public:typedef typename HashTable<K, K, Hash, SetKeyOfT>::iterator iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}pair<iterator,bool> Insert(const K& key){return _ht.Insert(key);}iterator Find(const K& key){return _ht.Find(key);}iterator Erase(const K& key){return _ht.Erase(key);}private:HashTable<K, K, Hash, SetKeyOfT>_ht;};4.哈希的应用
4.1位图
4.1.1 位图概念
关于位图的概念,下面通过一道面试题来进行介绍:
1. 面试题
给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在
这40亿个数中。【腾讯】
这道题直观的思路是使用排序+二分的方法,或者是使用红黑树,或者是使用哈希表,但是这三种方法对于40亿个整数,不合适,因为40个整数大概占16GB的空间,而普通计算机提供不了16GB的空间,所以这三种方式都被否决了!
下面介绍一种新的思路,使用位图的方式进行判断。
数据是否在给定的整形数据中,结果是在或者不在,刚好是两种状态,那么可以使用一
个二进制比特位来代表数据是否存在的信息,如果二进制比特位为1,代表存在,为0
代表不存在。比如:
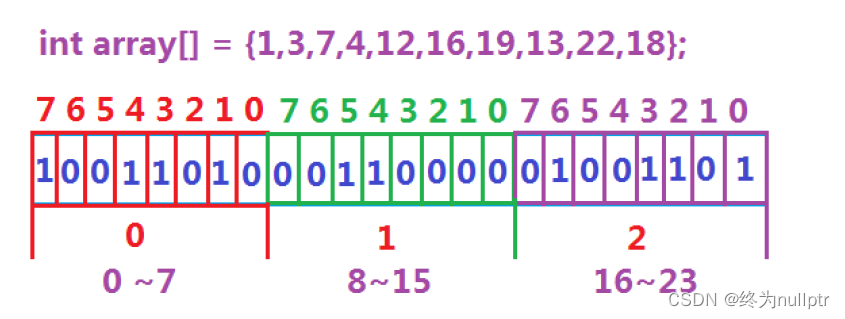
4.1.2 位图的实现
namespace ns
{template<size_t N>class bit_set{public:bit_set(){_bits.resize(N / 8 + 1, 0);}void set(size_t x){size_t i = x / 8; //表示在第几个char上size_t j = x % 8; //表示在几个char的bit位上_bits[i] |= (1 << j);}void reset(size_t x){size_t i = x / 8;size_t j = x % 8;_bits[i] &= (~(1 << j));}bool test(size_t x){size_t i = x / 8;size_t j = x % 8;return _bits[i] & (1 << j);}private:vector<char> _bits;};void test_bit_set(){bit_set<-1> bs1;bs1.set(10);bs1.set(30);bs1.set(40);bs1.set(20);bs1.set(1000);bs1.set(1090);bs1.set(4);cout << bs1.test(10) << endl;cout << bs1.test(1) << endl;cout << bs1.test(40) << endl;bs1.reset(40);cout << bs1.test(40) << endl;}
}4.1.3 位图的应用
1. 给定100亿个整数,设计算法找到只出现一次的整数?
实现思路:定义两个bit_set的对象,00表示一次都没有出现,01表示出现一次,10表示出现一次以上
template<size_t N>class two_bit_set{public:void set(size_t x){if (!_bs1.test(x) && !_bs2.test(x)) // 00{_bs2.set(x);}else if (!_bs1.test(x) && _bs2.test(x)) //01{_bs1.set(x);_bs2.reset(x);}//10}void PrintOnce(){for (size_t i = 0; i < N; i++){if (!_bs1.test(i) && _bs2.test(i)){cout << i << " ";}}cout << endl;}private:bit_set<N> _bs1;bit_set<N> _bs2;};void test_two_bit_set(){two_bit_set<100> tbs;int a[] = { 3, 5, 6, 7, 8, 9, 33, 55, 67, 3, 3, 3, 5, 9, 33 };for (auto e : a){tbs.set(e);}tbs.PrintOnce();}
2. 给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
实现思路:定义两个bit_set的对象,将100一个整数分别设置到两个对象中,然后遍历找,如果同时在两个对象中则说明就是交集
3. 位图应用变形:1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整
数
实现思路:定义两个bit_set的对象,将100一个整数分别设置到两个对象中,00表示一次都没有出现,01表示出现一次,10表示出现2次,11表示出现3次及以上,然后遍历查找出现次数不超过两次的所有整数
4.2哈希切割
给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址?
实现思路:可以将100G大小的文件,按照哈希切分的方式,分别切到大小为1G的小文件,然后通过map来一个一个统计次数,统计完一个,clear掉map,再统计下一个,当Ai小文件超过1个G的时候,分两种情况,第一种是这个小文件冲突的ip很多,都是不同的ip,大多数都是不重复的,map统计不下,可以换一个字符串哈希函数,递归再切分,进行统计,第二种情况是这个小文件冲突的ip很多,大多数都是重复的map可以统计
如图所示:

直接用map统计,如果是第二种情况,可以统计出来,不会报错,如果是第一种情况,map insert插入失败,相当于new结点失败,可以捕获异常
4.3布隆过滤器
4.3.1布隆过滤器的提出
我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉
那些已经看过的内容。问题来了,新闻客户端推荐系统如何实现推送去重的? 用服务器记录了用
户看过的所有历史记录,当推荐系统推荐新闻时会从每个用户的历史记录里进行筛选,过滤掉那
些已经存在的记录。 如何快速查找呢?
1. 用哈希表存储用户记录,缺点:浪费空间
2. 用位图存储用户记录,缺点:位图一般只能处理整形,如果内容编号是字符串,就无法处理了。
3. 将哈希与位图结合,即布隆过滤器
4.3.2布隆过滤的概念
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构的多个位置中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。
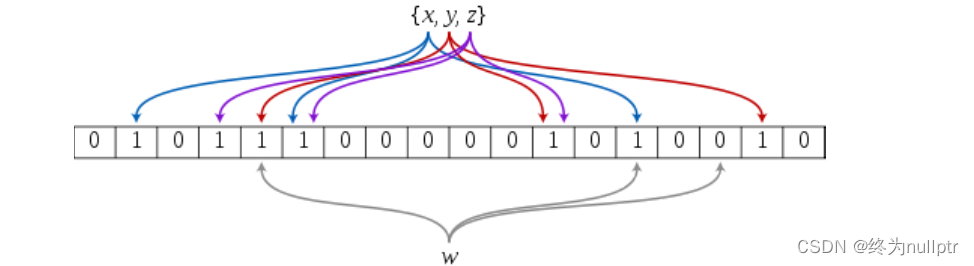
存在是不准确的,因为可能不存在,但是这个位置可能和别人冲突,出现误判
不存在是准确的
4.3.3布隆过滤器的插入
布隆过滤器是一个bit数组,如图所示:
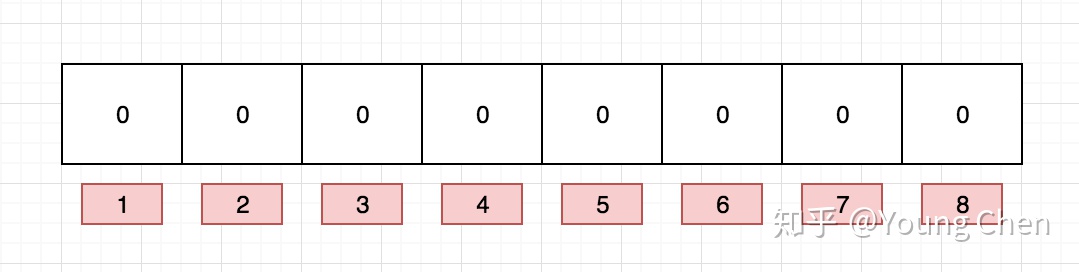
如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置 1,例如针对值 “baidu” 和三个不同的哈希函数分别生成了哈希值 1、4、7,则上图转变为:
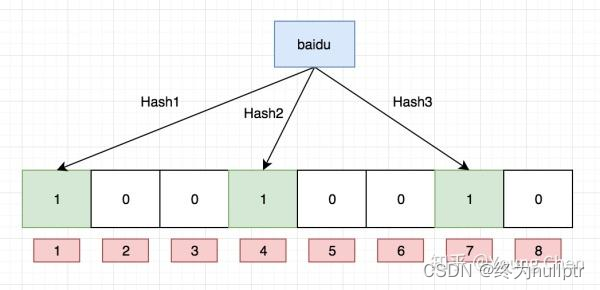
Ok,我们现在再存一个值 “tencent”,如果哈希函数返回 3、4、8 的话,图继续变为:
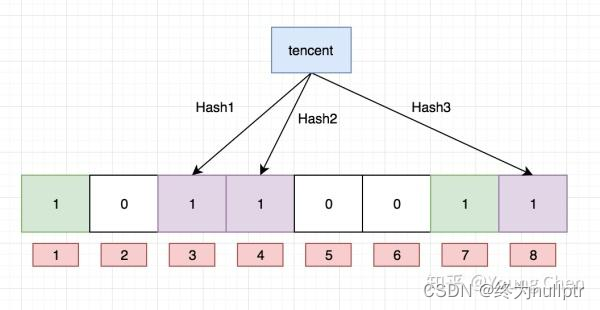
值得注意的是,4 这个 bit 位由于两个值的哈希函数都返回了这个 bit 位,因此它被覆盖了。现在我们如果想查询 “dianping” 这个值是否存在,哈希函数返回了 1、5、8三个值,结果我们发现 5 这个 bit 位上的值为 0,说明没有任何一个值映射到这个 bit 位上,因此我们可以很确定地说 “dianping” 这个值不存在。而当我们需要查询 “baidu” 这个值是否存在的话,那么哈希函数必然会返回 1、4、7,然后我们检查发现这三个 bit 位上的值均为 1,那么我们可以说 “baidu” 存在了么?答案是不可以,只能是 “baidu” 这个值可能存在。
这是为什么呢?答案跟简单,因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值 “taobao” 即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断 “taobao” 这个值存在。
4.2.4 布隆过滤器的查找
布隆过滤器的思想是将一个元素用多个哈希函数映射到一个位图中,因此被映射到的位置的比特
位一定为1。所以可以按照以下方式进行查找:分别计算每个哈希值对应的比特位置存储的是否为
零,只要有一个为零,代表该元素一定不在哈希表中,否则可能在哈希表中。
注意:布隆过滤器如果说某个元素不存在时,该元素一定不存在,如果该元素存在时,该元素可
能存在,因为有些哈希函数存在一定的误判。
比如:在布隆过滤器中查找"alibaba"时,假设3个哈希函数计算的哈希值为:1、3、7,刚好和其
他元素的比特位重叠,此时布隆过滤器告诉该元素存在,但实该元素是不存在的。
4.2.5 布隆过滤器删除
布隆过滤器不能直接支持删除工作,因为在删除一个元素时,可能会影响其他元素。
比如:删除上图中"tencent"元素,如果直接将该元素所对应的二进制比特位置0,“baidu”元素也
被删除了,因为这两个元素在多个哈希函数计算出的比特位上刚好有重叠。
一种支持删除的方法:将布隆过滤器中的每个比特位扩展成一个小的计数器,插入元素时给k个计
数器(k个哈希函数计算出的哈希地址)加一,删除元素时,给k个计数器减一,通过多占用几倍存储
空间的代价来增加删除操作。
注:上面的方法也不能确保一定就能够删除,因为要删除的元素,无法确保是否真正存在在布隆过滤器中
4.2.6如何选择哈希函数个数和布隆过滤器长度
很显然,过小的布隆过滤器很快所有的 bit 位均为 1,那么查询任何值都会返回“可能存在”,起不到过滤的目的了。布隆过滤器的长度会直接影响误报率,布隆过滤器越长其误报率越小。
另外,哈希函数的个数也需要权衡,个数越多则布隆过滤器 bit 位置位 1 的速度越快,且布隆过滤器的效率越低;但是如果太少的话,那我们的误报率会变高。
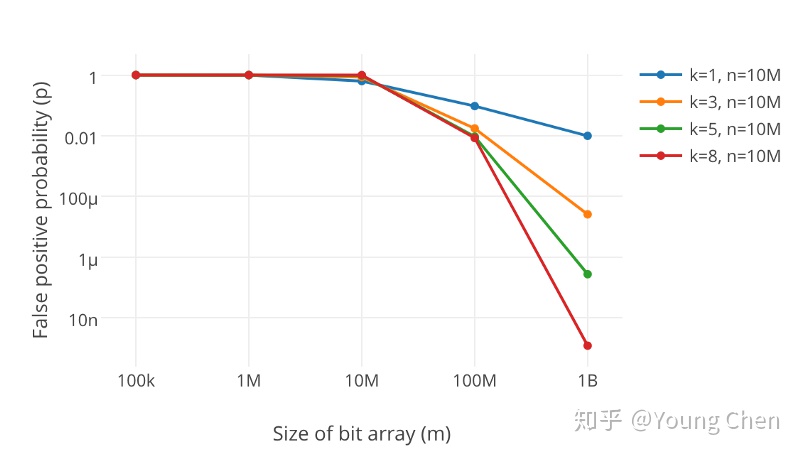
k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数,p 为误报率
如何选择适合业务的 k 和 m 值呢,这里直接贴一个公式:
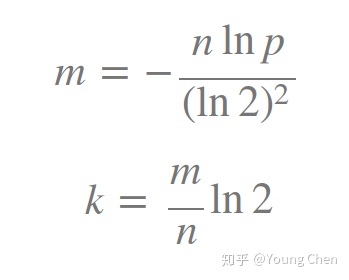
4.2.6布隆过滤器优点
1. 增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无
关
2. 哈希函数相互之间没有关系,方便硬件并行运算
3. 布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
4. 在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势
5. 数据量很大时,布隆过滤器可以表示全集,其他数据结构不能
6. 使用同一组散列函数的布隆过滤器可以进行交、并、差运算
4.2.7 布隆过滤器缺陷
1. 有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:再
建立一个白名单,存储可能会误判的数据)
2. 不能获取元素本身
3. 一般情况下不能从布隆过滤器中删除元素
4. 如果采用计数方式删除,可能会存在计数回绕问题
4.2.8布隆过滤器的应用场景
1.不需要一定准确的场景
2.可以在注册昵称的时候判重
如图所示:
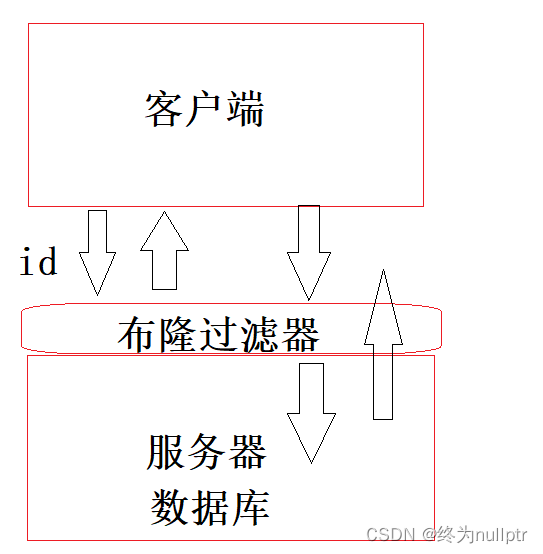
当客户端要查询某个id是否存在的时候,首先在布隆过滤器中查找,查找结果为不在就可以直接返回了,如果查找的结果在,就到数据库外设中查找,这种方式就大大提高了查询效率
4.2.9布隆过滤器代码实现
#include<iostream>
#include<string>
#include<vector>
#include<bitset>
#include<stdlib.h>
using namespace std;
namespace ns
{struct BKDRHash{size_t operator()(const string& s){// BKDRsize_t value = 0;for (auto ch : s){value *= 31;value += ch;}return value;}};struct APHash{size_t operator()(const string& s){size_t hash = 0;for (long i = 0; i < s.size(); i++){if ((i & 1) == 0){hash ^= ((hash << 7) ^ s[i] ^ (hash >> 3));}else{hash ^= (~((hash << 11) ^ s[i] ^ (hash >> 5)));}}return hash;}};struct DJBHash{size_t operator()(const string& s){size_t hash = 5381;for (auto ch : s){hash += (hash << 5) + ch;}return hash;}};//N是最多存储的元素个数,X:平均存储一个值,开辟X个位template<size_t N,size_t X,class K = string,class HashFunc1 = BKDRHash,class HashFunc2 = APHash,class HashFunc3 = DJBHash>class BloomFilter{public:void set(const K& key){size_t hashi1 = HashFunc1()(key) % (N * X);size_t hashi2 = HashFunc2()(key) % (N * X);size_t hashi3 = HashFunc3()(key) % (N * X);_bs.set(hashi1);_bs.set(hashi2);_bs.set(hashi3);}bool test(const K& key){size_t hashi1 = HashFunc1()(key) % (N * X);if (!_bs.test(hashi1))return false;size_t hashi2 = HashFunc1()(key) % (N * X);if (!_bs.test(hashi2))return false;size_t hashi3 = HashFunc1()(key) % (N * X);if (!_bs.test(hashi3))return false;//前面不存在判读都是准确的,不存在误判return true; //可能会存在误判,映射的几个位置冲突}private:bitset<N* X> _bs;};void test_bloomfilter1(){string str[] = { "猪八戒", "孙悟空", "沙悟净", "唐三藏", \"白龙马1","1白龙马","白1龙马","白11龙马","1白龙马1" };BloomFilter<10,5> bf;for (auto& str : str){bf.set(str);}for (auto& s : str){cout << bf.test(s) << endl;}cout << endl;srand(time(0));for (const auto& s : str){cout << bf.test(s + to_string(rand())) << endl;}}void test_bloomfilter2(){srand(time(0));const size_t N = 100000;BloomFilter<N,6> bf;std::vector<std::string> v1;std::string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";for (size_t i = 0; i < N; ++i){v1.push_back(url + std::to_string(i));}for (auto& str : v1){bf.set(str);}// v2跟v1是相似字符串集,但是不一样std::vector<std::string> v2;for (size_t i = 0; i < N; ++i){std::string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";url += std::to_string(999999 + i);v2.push_back(url);}size_t n2 = 0;for (auto& str : v2){if (bf.test(str)){++n2;}}cout << "相似字符串误判率:" << (double)n2 / (double)N << endl;// 不相似字符串集std::vector<std::string> v3;for (size_t i = 0; i < N; ++i){string url = "zhihu.com";url += std::to_string(i + rand());v3.push_back(url);}size_t n3 = 0;for (auto& str : v3){if (bf.test(str)){++n3;}}cout << "不相似字符串误判率:" << (double)n3 / (double)N << endl;}
}4.2.10布隆过滤器的面试题
1. 给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出
精确算法和近似算法
近似算法:
可以使用布隆过滤器,将一个文件的内容都set到布隆过滤器当中,然后遍历另一个文件依次查找,如果存在就说明是交集。
精确算法:
将两个文件的内容,分别通过哈希切分的方式,切分成一个一个的小文件,然后将小文件放到map中,进行找交集。
切分的时候存在的两个问题:
1.切分完之后的文件大小超过1G,大多数都是不重复的,可以换一个哈希切分函数,递归在切分
2.切分完之后的文件大小超过1G
相关文章:
哈希->模拟实现+位图应用
致前行路上的人: 要努力,但不要着急,繁花锦簇,硕果累累都需要过程! 目录 1. unordered系列关联式容器 1.1 unordered_map 1.1.1概念介绍: 1.1.2 unordered_map的接口说明 1.2unordered_set 1.3常见面试题oj…...
苹果手机想要传输数据到电脑怎么传输呢?
苹果手机想要传输数据到电脑怎么传输呢?尤其是传输数据到Windows系统,可能需要使用一些传输软件,那么常用的传输软件有哪些呢?下文将为大家推荐几款常用的苹果手机数据传输常用工具。近期苹果发布了iPhone14系列手机,如…...

Linux 练习四 (目录操作 + 文件操作)
文章目录1 基于文件指针的文件操作1.1 文件的创建,打开和关闭1.2 文件读写操作2 基于文件描述符的文件操作2.1 打开、创建和关闭文件2.2 文件读写2.3 改变文件大小2.4 文件映射2.5 文件定位2.6 获取文件信息2.7 复制文件描述符2.8 文件描述符和文件指针2.9 标准输入…...
自学大数据第四天~hadoop集群的搭建
Hadoop集群安装配置 当hadoop采用分布式模式部署和运行时,存储采用分布式文件系统HDFS,此时HDFS名称节点和数据节点位于不同的机器上; 数据就可以分布到多个节点,不同的数据节点上的数据计算可以并行执行了,这时候MR才能发挥其本该有的作用; 没那么多机器怎么办~~~~多几个虚拟…...

ULID和UUID
ULID:Universally Unique Lexicographically Sortable Identifier(通用唯一词典分类标识符)UUID:Universally Unique Identifier(通用唯一标识符)为什么不选择UUIDUUID 目前有 5 个版本:版本1&a…...

java基础面试10题
1.JVM、JRE 和 JDK 的关系 Jvm:java虚拟机,类似于一个小型的计算机,它能够将java程序编译后的.class 文件解释给相应平台的本地系统执行,从而实现跨平台。 jre:是运行java程序所需要的环境的集合,它包含了…...

Golang闭包问题及并发闭包问题
目录Golang闭包问题及并发闭包问题匿名函数闭包闭包可以不传入外部参数,仍然可以访问外部变量闭包提供数据隔离并发闭包为什么解决方法Golang闭包问题及并发闭包问题 参考原文链接:https://blog.csdn.net/qq_35976351/article/details/81986496 htt…...

基频的后处理
基频归一化 基频为什么要归一化?为了消除人际随机差异,提取恒定参数,在语际变异中找到共性。 引言 声调的主要载体就是基频。但是对声调的感知会因人而异,例如某个听感上的高升调,不同的调查人员可能会分别描写成 […...

vue3 toRefs详解
简介 toRefs函数的作用是将响应式对象中的所有属性转换为单独的响应式数据,对象成为普通对象,并且值是关联的。在这个过程中toRefs会做以下两件事: 把一个响应式对象转换成普通对象对该普通对象的每个属性都做一次ref操作,这样每…...
Spring——AOP是什么?如何使用?
一、什么是AOP?在不修改源代码的情况下 增加功能二、底层是什么?动态代理aop是IOC的一个扩展功能,现有IOC,再有AOP,只是在IOC的整个流程中新增的一个扩展点而已:BeanPostProcessorbean的创建过程中有一个步…...
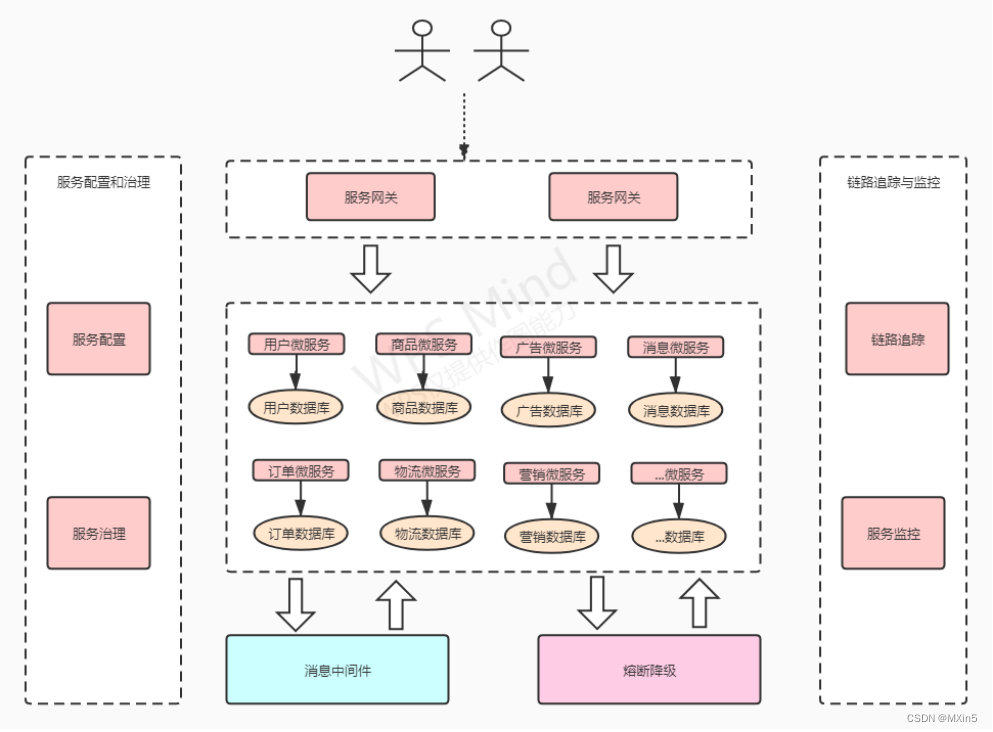
【微服务】认识微服务
目录 1.1 单体、分布式、集群 单体 分布式 集群 1.2 系统架构演变 1.2.1 单体应⽤架构 1.2.2 垂直应⽤架构 1.2.3 分布式架构 1.2.4 SOA架构 1.2.5 微服务架构 1.3 微服务架构介绍 微服务架构的常⻅问题 1.4 SpringCloud介绍 1.4.1 SpringBoot和SpringCloud有啥关…...

【独家】华为OD机试 C 语言解题 - 最长连续子串
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧文章目录 最近更新的博客使用说明本期…...
【Linux】CentOS7操作系统安装nginx实战(多种方法,超详细)
文章目录前言一. 实验环境二. 使用yum安装nginx2.1 添加yum源2.1.1 使用官网提供的源地址(方法一)2.1.2 使用epel的方式进行安装(方法二)2.2 开始安装nginx2.3 启动并进行测试2.4 其他的一些用法:三. 编译方式安装ngin…...

【FMCW 01】中频IF信号
FMCW信号 调频连续波(frequency modulated continuous wave,FMCW)顾名思义,就是对信号的频率进行线性调制的信号。 从时域上看,对频率的调制,就像一把连续的锯齿波。其中每一个锯齿叫做一个chirp,其持续的时间叫做ch…...

【蓝桥杯试题】暴力枚举题型
💃🏼 本人简介:男 👶🏼 年龄:18 🤞 作者:那就叫我亮亮叭 📕 专栏:蓝桥杯试题 文章目录1. 统计方形(数据加强版)1. 1 题目描述1.2 思路…...

I.MX6ULL_Linux_系统篇(22) kernel移植
原厂 Linux 内核编译 NXP 提供的 Linux 源码肯定是可以在自己的 I.MX6ULL EVK 开发板上运行下去的,所以我们肯定是以 I.MX6ULL EVK 开发板为参考,然后将 Linux 内核移植到 I.MX6U-ALPHA 开发板上的。 配置编译 Linux 内核 和uboot一样,在编…...

UE实现相机聚焦物体功能
文章目录 1.实现目标2.实现过程2.1 实现原理2.2 源码浅析2.3 具体代码2.3.1 蓝图实现2.3.2 C++实现3.参考资料1.实现目标 实现根据输入的Actor,自动计算出其缩放显示到当前屏幕上相机的最终位置,然后相机飞行过去,实现相机对物体的聚集效果,避免每次输入FlyTo坐标参数,GI…...
算法系列之数值积分的目的
PLC算法里的数字积分器详细介绍请参看下面的文章链接: PLC算法系列之数值积分器(Integrator)_RXXW_Dor的博客-CSDN博客数值积分和微分在工程上的重要意义不用多说,闭环控制的PID控制器就是积分和微分信号的应用。流量累加也会用到。有关积分运算在流量累加上的应用,请参看下…...

【2.4 golang中循环语句for】
1. 循环语句for 1.1.1. Golang for支持三种循环方式,包括类似 while 的语法。 for循环是一个循环控制结构,可以执行指定次数的循环。 语法 Go语言的For循环有3中形式,只有其中的一种使用分号。 for init; condition; post { }for conditi…...

代码随想录 动态规划||343 96
Day35343. 整数拆分力扣题目链接给定一个正整数 n,将其拆分为至少两个正整数的和,并使这些整数的乘积最大化。 返回你可以获得的最大乘积。思路动规逻辑确定dp数组(dp table)以及下标的含义dp[i]指的是拆分数字i能得到的最大成绩d…...

LangChain串联DeepSeek时,如何用自定义OutputParser解决‘思考污染’问题?
LangChain串联DeepSeek时如何用自定义OutputParser解决"思考污染"问题 当我们在LangChain框架中串联使用具备"思考过程"输出的推理模型(如DeepSeek)时,经常会遇到一个棘手的问题:前序节点的思考标签会污染后续…...

MORNSUN金升阳 E0505S-1WR3 SIP 隔离电源模块
特性隔离电压:3000VDC空载功耗低:0.025W(Typ.)效率:高达90%工作环境温度:-40C~85CMTBF 2350万小时(3500000Hrs)输出短路保护:可持续短路保护,自动恢复小型SIP封装,塑料外壳国际标准引脚方式纹波…...

NASM高级特性详解:条件汇编、上下文栈和宏重载
NASM高级特性详解:条件汇编、上下文栈和宏重载 【免费下载链接】nasm A cross-platform x86 assembler with an Intel-like syntax 项目地址: https://gitcode.com/gh_mirrors/na/nasm NASM(Netwide Assembler)是一款跨平台的x86汇编器…...

Qwen2.5-7B-Instruct效果展示:复杂代码生成与深度知识解答真实案例
Qwen2.5-7B-Instruct效果展示:复杂代码生成与深度知识解答真实案例 1. 项目简介 Qwen2.5-7B-Instruct是阿里通义千问系列的旗舰级大模型,相比1.5B和3B的轻量版本,这个7B参数的模型在能力上实现了质的飞跃。它专门针对复杂的文本交互场景设计…...

开发者的软实力:沟通、协作与影响力的修炼手册
在软件开发的精密世界里,代码是骨骼,架构是经脉,而沟通、协作与影响力,则是驱动整个系统顺畅运行的血液与神经。对于软件测试从业者而言,这种认知尤为深刻。我们早已超越了“找Bug”的单一角色,成为质量文化…...

企业级离线OCR深度解析:5大策略实现高性能文字识别
企业级离线OCR深度解析:5大策略实现高性能文字识别 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库…...

寒冬降临:当资本撤出AI测试赛道
2026年初,全球资本市场对AI技术的狂热投资骤然降温。随着VC基金转向更保守的资产配置,依赖融资的AI测试工具开发商面临生存危机:初创公司批量裁员,开源项目停止维护,企业采购的智能测试平台因无法续约沦为“断线木偶”…...

AI报告文档审核助力本地化升级:IACheck如何支撑食品加工行业数据安全与质量协同发展
在食品加工行业不断强化质量控制与数据安全要求的背景之下,“本地部署”正逐渐成为企业数字化转型中的关键路径之一,尤其是在涉及检测数据与质量报告的场景中,数据不仅需要具备高度准确性,还必须满足合规与安全要求,因…...
iPhone上跑Transformer太慢?试试EfficientFormer-L1,实测延迟比MobileViT快一倍
iPhone端Transformer模型加速实战:EfficientFormer-L1性能优化解析 移动端AI开发者常面临一个核心矛盾:如何在有限的计算资源下,既保持模型精度又实现实时推理?传统方案往往需要在MobileNet等轻量卷积网络和视觉Transformer&#…...

根据以上内容,可拟定的标题为:“MATLAB仿真复现光纤激光器中耗散孤子共振DSR的演化过程:...
MATLAB仿真复现耗散孤子共振DSR 根据谱方法求解复立方五次方金兹堡朗道方程 获得光纤激光器中耗散孤子的演化过程耗散孤子共振光纤激光器仿真平台:从 Ginzburg-Landau 方程到多维度脉冲演化分析—— 一套可扩展、可配置、可动画的 MATLAB 谱方法框架一、背景与需求高…...