网络原理-TCP/IP(1)
应用层
我们之前编写完了基本的java socket, 要知道,我们之前所写的所有代码都在应用层中,都是为了完成某项业务,如翻译等.关于应用层,后面会有专门的讲解,在此处先讲一下基础知识.
应用层对应着应用程序,是程序员打交道最多的一层,调用系统提供的网络api写出的代码都是应用层的.
应用层这里虽然有很多协议,但程序员应该按照场景,自定义协议.(网络传输的数据要怎么用,也要考虑数据是什么格式,里面包含哪些内容).
自定义协议约定:1.服务器,客户端要交互哪些信息
2.数据具体格式(网络上是字符串/二进制比特流).
客户端按照上述约定发送请求,服务器按照上述约定解析请求.
服务器按照上述约定构造响应,客户端也按照上述约定解析响应.
举个例子:点餐软件
打开点餐软件,显示出主页.主页里就要显示出商家列表,而且这些商家都是附近的(打开软件的时候,就需要把你的位置告诉服务器).显示的商家列表中,也会包含一些信息:如商家名称,图片,商家的评分,商家的简介等.(交互过程中需要传输哪些信息,并不是程序员规定的,而是产品经理规定)
而这里的数据格式组织,就有了固定的套路,属于程序员的事情.
客户端和服务器之间往往要交互的是"结构化数据"(一个结构体/类:包含很多属性).
网络传输的数据其实是"字符串","二进制比特流".
约定协议的过程,就是把结构化数据转成字符串/二进制比特流的过程.
把结构化的数据,转成字符串/二进制比特流这个操作,称为"序列化".
把字符串/二进制比特流还原成结构化数据,这个操作,称为"反序列化".
序列化/反序列化具体要组织成什么样的格式,这里包含哪些信息.
约定这两件事的过程就是自定义协议的过程.
为了让程序员简单约定这里的协议格式,这里有几个供参考的方案.
xml, json, protobuffer
这里就简单一下json,其它的如果有兴趣的话可以自行了解.
json是当今非常主流,非常常用的数据组织格式了,举个例子如下:
请求:
{
userId: 1000,
position: [经纬度]
}
响应:
[
{
id: 1001,
name: "老八秘制小汉堡"
},
{
id: 1002,
name: "初饮味来"
}
]
解释:主要用到的是键值对格式. 键和值之间用 : 分割. 键值对之间用 , 分割
把若干个键值对使用{ }括起来,此时就形成了一个json对象.
还可以把多个json对象放到一起,使用 , 分割开, 并且使用[ ]整体括起来.
特性:可读性很好,扩展性也很好,通过key来对数据起到解释说明的作用.
对于xml来说解释说明是通过标签,需要有开始和结束两个标签,比较占用空间.相比之下json只使用一个key就能描述,占用的空间就比xml更少,更节省带宽了.
虽然json比xml是节省了带宽但是很明显,当前这里的带宽仍是有浪费的部分.
尤其是这种数组格式的json,这种情况下往往传输的数据字段都是相同的.使刚才这里的key名字被重复传输了.
传输层
负责数据能够从发送端到接收端.
这一层是系统内核实现好了的,提供socket的api供程序员使用.
再谈端口号
端口号(port)标识了一个主机上进行通信的不同的应用程序;

在TCP/IP协议中,用"源IP","源端口号","目的IP","目的端口号","协议号"这样一个五元组来表识一个通信.
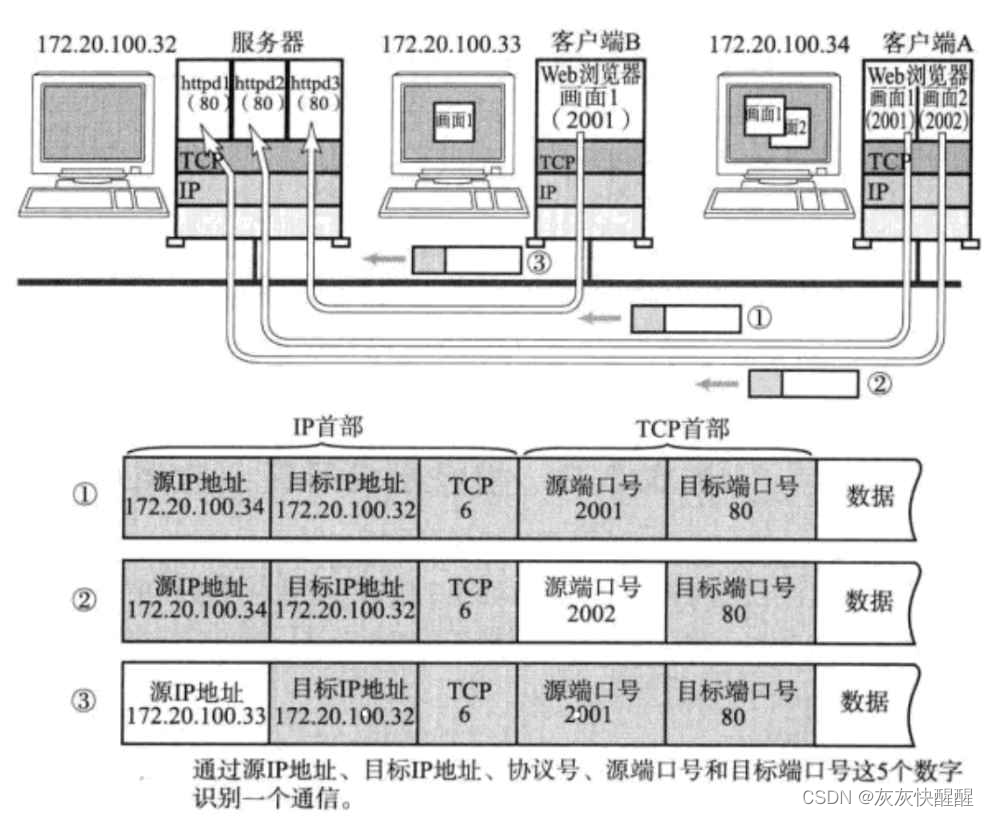
端口号范围划分
0-1023:知名端口号:HTTP,FTP,SSH等这些广为使用的应用层协议,他们的端口号都是固定的.
1024-65535:操作系统动态分配的端口号.客户端程序的端口号,就是由操作系统从这个范围中分配的.
认识知名的端口号
有些服务器是非常常用的,为了使用方便,人们约定一些常用的服务器,都是用以下固定的端口号:
ssh服务器,使用22端口
ftp服务器,使用21端口
telnet服务器,使用23端口
http服务器,使用80端口
https服务器,使用443
我们自己写一个程序使用端口号时,要避开这些知名端口号.
UDP协议
UDP协议端格式
我们知道,研究一个协议,主要就是研究报文格式,基于报文格式,了解这个协议其它各个属性.
UDP = 报头(重点) + 载荷(应用层数据包).
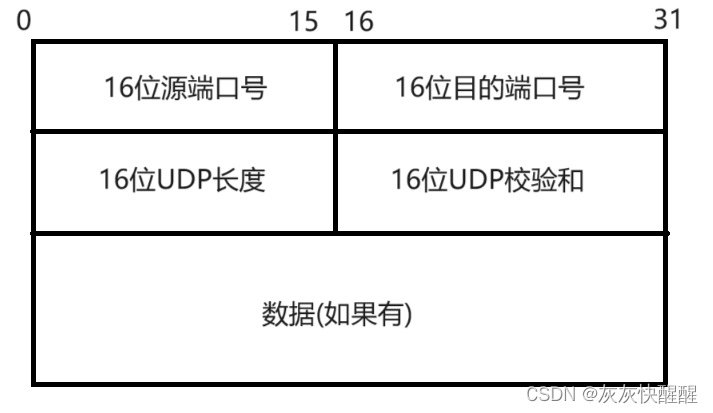
UDP报头中一共有4个字段,每个字段两个字节(一共八个字节),由于协议报头中使用两个字节表示端口号,端口号范围是: 0 ~ 65535. (这里的最大值是64kb),一旦数据超过64kb就会被截断.
16位UDP长度, 表示整个数据报(UDP首部 + UDP数据)的最大长度;
如果校验和出错,直接丢弃.
下面来讲解一下校验和:
校验和起到的效果,就是去尝试检查当前的数据是否存在问题.是否出现了比特翻转(网络中的校验和并非是简单的按照长度/数量作为校验标准的,一定是能让数据加入进去),就可以把错误的数据包丢掉.
简单讲一下校验的方法:
1.CRC算法完成校验(循环冗余校验):
比如要产生一个两个字节的校验和.
short checksum = 0;
for(循环遍历取出数据报中每个字节的数据) {
checksum += 当前字节的数据;
}
加的过程,也有可能会溢出,这里也不用管.
UDP数据报发送方,在发送之前,先计算一遍CRC,把算好的CRC值放到UDP数据报中.(设这个CRC值为value1). 接下来这个数据包通过网络传输到接收端.接收端收到这个数据之后,也会按照同样的算法,再算一遍CRC的值,得到的结果是value2.比较自己计算的value2和收到的value1是否一致.如果是一致的,就说明数据ok,如果不一致,传输过程中就发生了比特翻转了.
上述CRC算法中,如果只有一个bit位发生翻转,能够100%发现问题,但如果有两个/多个bit位发生翻转,有可能恰好校验和和之前一样.
虽然这种概率比较低,可以忽略不计,但是要想有更高的精确度,就需要其它算法了.
除了CRC,还有精度更高的md5/sha1算法.
其中md5就涉及到一系列更加复杂的数学公式了.
介绍一下MD5算法的特点:
1.定长:无论数据有多长,算出来的md5最终值为固定长度.
2.分散:计算md5时,原始数据变化一点点,计算的md5差异就会很大,(这种特性,决定md5可作为字符串的hash算法).
3.不可逆:给一个源字符串,计算md5值很简单,但要想将md5值还原为字符串,几乎无法实现.
UDP特点
UDP传输过程类似于寄信.
1.无连接:知道对端的IP和端口号就可以直接传输,不需要建立连接.
2.不可靠:没有确认机制,没有重传机制;如果因为网络故障无法发送到对方,UDP协议层也不会给应用层返回任何错误信息;
3.面向数据报:不能够灵活的控制读写数据的次数和数量.
面向数据报
应用层交给UDP多长的报文,UDP原样发送,既不会拆分,也不会合并;
用UDP传输100个字节的数据.
如果发送端调用一次sendto,发送100字节,那么接收端也必须调用对应的一次recvfrom,接收100个字节;而不能循环调用10次recvfrom,每次接收10个字节.
基于UDP的应用层协议
NFS:网络文件系统,
TFTP:简单文件传输协议
DHCP:动态主机配置协议
BOOTP:启动协议(用于无盘设备启动)
DNS:域名解析协议.
当然,也包括你写的UDP程序时自定义的应用层协议.
相关文章:
网络原理-TCP/IP(1)
应用层 我们之前编写完了基本的java socket, 要知道,我们之前所写的所有代码都在应用层中,都是为了完成某项业务,如翻译等.关于应用层,后面会有专门的讲解,在此处先讲一下基础知识. 应用层对应着应用程序,是程序员打交道最多的一层,调用系统提供的网络api写出的代码都是应用层…...
C# Socket 允许控制台应用通过防火墙
需求: 在代码中将exe添加到防火墙规则中,允许Socket通过 添加库引用 效果: 一键三联 若可用记得点赞评论收藏哦,你的支持就是写作的动力。 源地址: https://gist.github.com/cstrahan/513804 调用代码: private static void …...

Centos安装mysql/mariadb
1,yum install mysql-apt-config_0.8.12-1_all.deb 似乎后面会有冲突,不建议安装mysql了,直接mariadb吧 2, No such command: uninstall. Please use /usr/bin/yum --help It could be a YUM plugin command, try: "yum install dnf-command(uninstall)" It…...
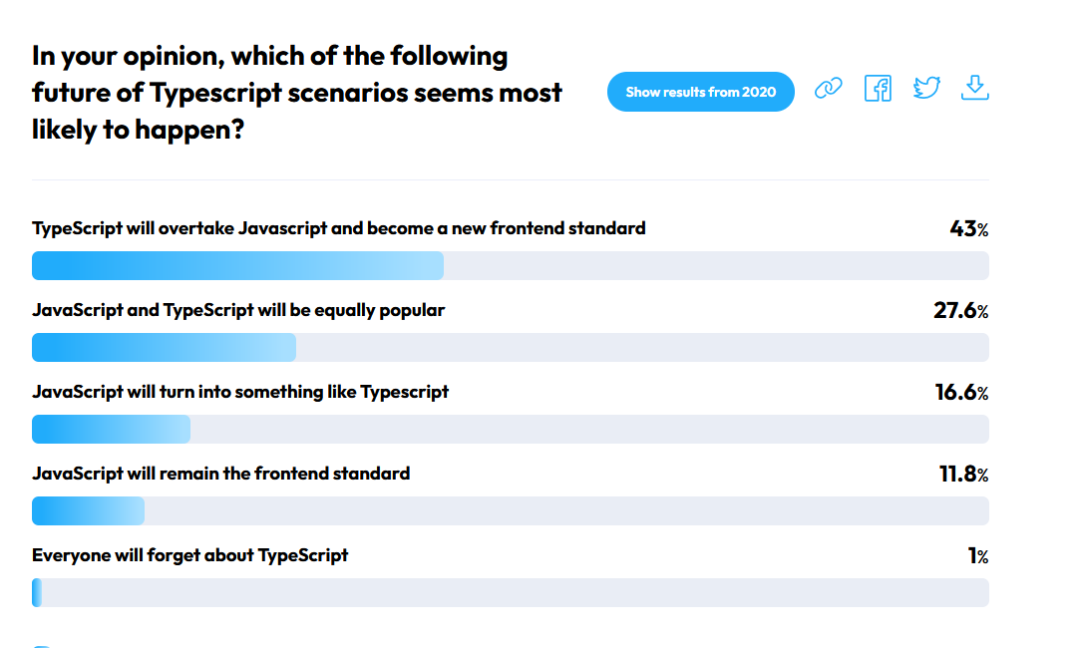
2024 年, Web 前端开发趋势
希腊哲学家赫拉克利特认为,变化是生命中唯一不变的东西。这句话适用于我们的个人生活、行业和职业领域。 尤其是前端开发领域,新技术、开发趋势、库和框架不断涌现,变化并不陌生。最近发生的一些事件正在改变开发人员构建网站和 Web 应用的方…...

Mysql 插入数据
1 为表的所有字段插入数据 使用基本的INSERT语句插入数据要求指定表名称和插入到新记录中的值。基本语法格式为: INSERT INTO table_name (column_list) VALUES (value_list); 使用INSERT插入数据时,允许列名称列表column_list为空,此时&…...

【每日一题】YACS 473:栈的判断
这是上海计算机学会竞赛 P 473 P473 P473:栈的判断( 2021 2021 2021年 8 8 8月月赛 丙组 T 4 T4 T4)标签:栈题意:给定 n n n个数字,已知这些数字的入栈顺序为 1 , 2 , 3... , n 1,2,3...,n 1,2,3...,n&…...

Python - 整理 MySQL 慢查询日志
在实际的数据库管理和性能优化工作中,MySQL 慢查询日志(slow query log)是一个重要的工具。当系统中的 SQL 查询花费的时间超过阈值时,MySQL 会将这些查询记录在慢查询日志中,方便进行性能分析和调优。 本文将介绍如何…...

Python算法题集_无重复字符的最长子串
本文为Python算法题集之一的代码示例 题目3:无重复字符的最长子串 说明:给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。 示例 1: 输入: s "abcabcbb" 输出: 3 解释: 因为无重复字符的最长子串是 "a…...

12.Elasticsearch应用(十二)
Elasticsearch应用(十二) 1.单机ES面临的问题 海量数据存储问题单点故障问题 2.ES集群如何解决上面的问题 海量数据存储解决问题: 将索引库从逻辑上拆分为N个分片(Shard),存储到多个节点单点故障问题&a…...

linux -- 内存管理 -- SLAB分配器
SLAB分配器(slab allocator) SLAB分配器用于小内存空间管理,基本思想是:先利用页面分配器分配出单个或多个连续的物理页面,然后再此基础上将整块页面分割为多个相等的小内存单元,来满足小内存空间分配的需…...

【MySQL】学习如何通过DQL进行数据库数据的条件查询
🌈个人主页: Aileen_0v0 🔥热门专栏: 华为鸿蒙系统学习|计算机网络|数据结构与算法 💫个人格言:“没有罗马,那就自己创造罗马~” #mermaid-svg-63IIm2s5sIhQfsfy {font-family:"trebuchet ms",verdana,arial,sans-serif;font-siz…...

TS:子类型关系
子类型关系 1、概念1.1 里氏替换原则1.2 自反性1.3 传递性 2、顶端类型 和 尾端类型3、字面量类型4、undefined 和 null5、枚举类型6、函数类型6.1 变型6.1.1 协变6.1.2 逆变6.1.3 双变 6.2 函数类型间的子类型关系6.2.1 函数参数数量6.2.2 函数参数类型A、非严格函数类型检查B…...
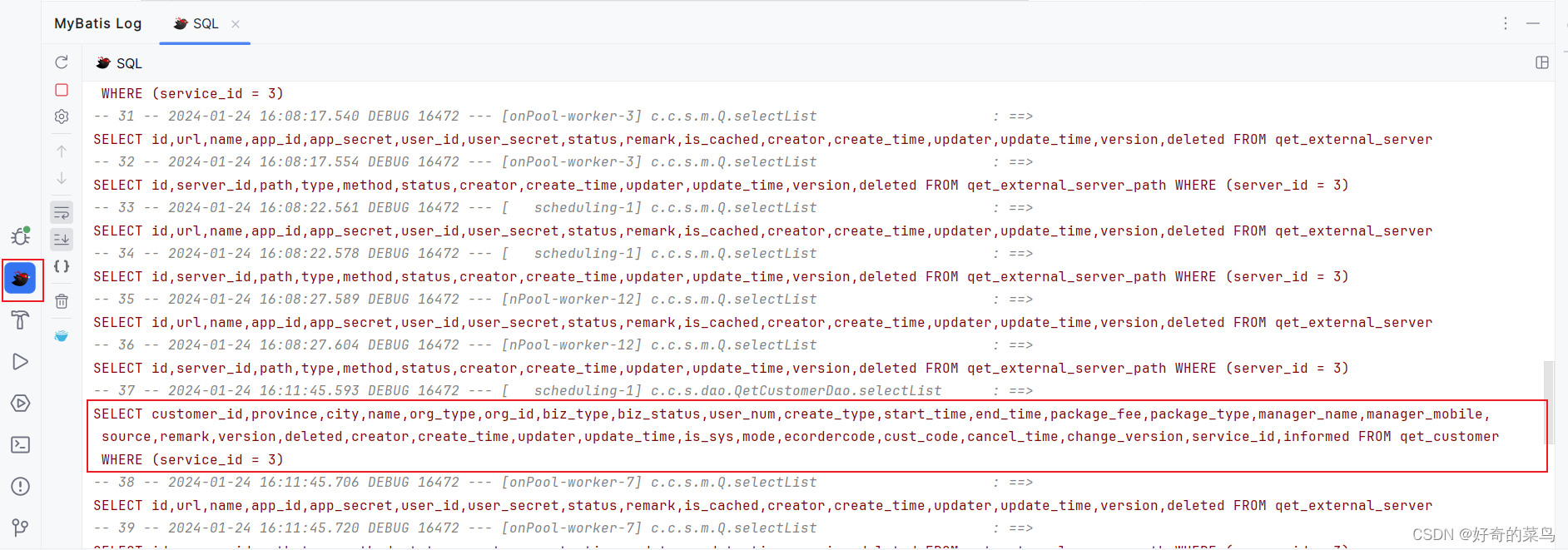
IDEA插件(MyBatis Log Free)
引言 在Java开发中,MyBatis 是一款广泛使用的持久层框架,它简化了SQL映射并提供了强大的数据访问能力。为了更好地调试和优化MyBatis应用中的SQL语句执行,一款名为 MyBatis Log Free 的 IntelliJ IDEA 插件应运而生。这款插件旨在帮助开发者…...
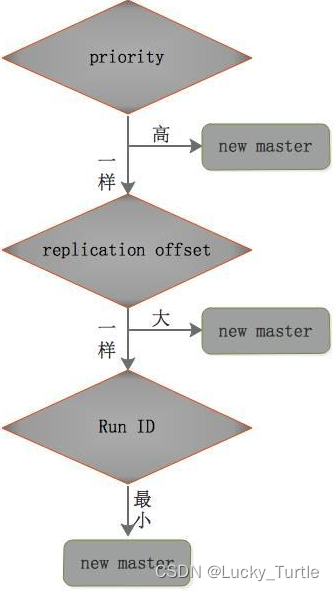
Redis(八)哨兵机制(sentinel)
文章目录 哨兵机制案例认识异常 哨兵运行流程及选举原理主观下线(Subjectively Down)ODown客观下线(Objectively Down)选举出领导者哨兵选出新master过程 哨兵使用建议 哨兵机制 吹哨人巡查监控后台master主机是否故障,如果故障了根据投票数自动将某一个从库转换为新…...
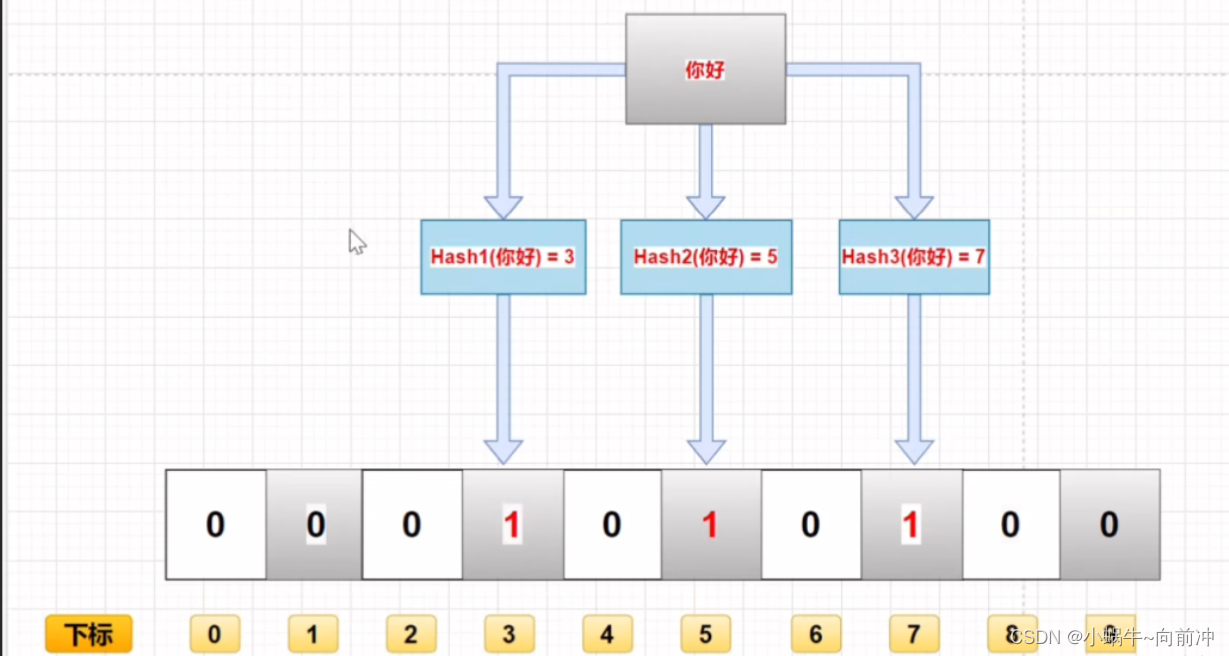
[数据结构]-哈希
前言 作者:小蜗牛向前冲 名言:我可以接受失败,但我不能接受放弃 如果觉的博主的文章还不错的话,还请点赞,收藏,关注👀支持博主。如果发现有问题的地方欢迎❀大家在评论区指正 本期学习目标&…...
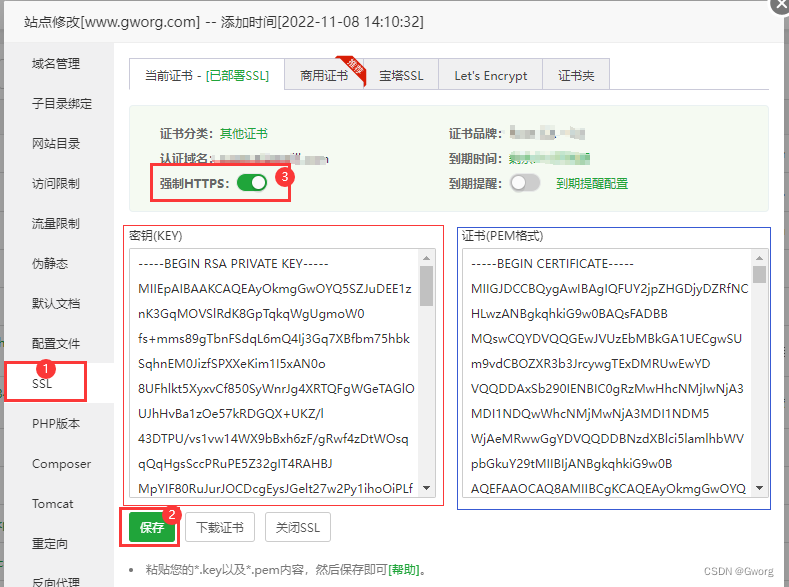
宝塔控制面板配置SSL证书实现网站HTTPS
宝塔安装SSL证书提前申请好SSL证书,如果还没有,先去Gworg里面申请,一般几分钟就可以下来,申请地址:首页-Gworg官方店-淘宝网 一、登录邮箱下载:Gworg证书文件目录 ,都会有以下五个文件夹。宝塔…...

elasticsearch优化总结
参考: https://docs.docker.com/manuals/ Manuals | Docker Docs Run Elasticsearch locally | Elasticsearch Guide [8.12] | Elastic 让你的ES查询性能起飞:Elasticsearch 查询优化攻略“一网打尽” - 知乎...

图论第三天|127. 单词接龙 841.钥匙和房间 463. 岛屿的周长 1971. 寻找图中是否存在路径 684.冗余连接 685.冗余连接II
目录 Leetcode127. 单词接龙Leetcode841.钥匙和房间Leetcode463. 岛屿的周长Leetcode1971. 寻找图中是否存在路径Leetcode684.冗余连接Leetcode685.冗余连接II Leetcode127. 单词接龙 文章链接:代码随想录 题目链接:127. 单词接龙 思路:广搜搜…...

react的高阶函数HOC:
React 的高阶组件(Higher-Order Component,HOC)是一种用于复用组件逻辑的模式。它是一个函数,接收一个组件作为参数,并返回一个新的增强过的组件。 HOC 可以用于实现以下功能: 代码复用:通过将…...

STM32——中断系统和外部中断EXTI
一、中断 1.1中断系统 中断系统是管理和执行中断的逻辑结构; 1.2中断 系统在执行主程序过程中,出现了特定的触发条件(触发源),系统停止执行当前程序,转而去执行中断程序,执行完毕后…...

BurpSuite 2025插件开发JDK版本兼容性实战指南
1. 为什么BurpSuite插件开发环境总在JDK版本上翻车?你是不是也经历过:下载好BurpSuite最新版2025.4,兴冲冲打开插件开发文档,照着官方示例写完第一个HelloWorld插件,一编译——java.lang.UnsupportedClassVersionError…...

为什么软件开发偏爱 Linux?深度剖析 Linux 相较于 Windows 的核心优势
引言 在软件开发的世界里,一个有趣的现象是:无论是大型互联网公司的服务器集群,还是资深程序员的个人开发机,Linux 操作系统的身影无处不在。与之形成鲜明对比的是,尽管 Windows 在个人消费市场占据绝对主导地位&…...

FT231XQ USB串口桥接板设计解析与实战应用指南
1. 项目概述:从FT232R到FT231XQ的USB串口桥接板演进在嵌入式开发和硬件调试的日常工作中,一个可靠、小巧且功能清晰的USB转串口(UART)桥接板(Breakout Board, 简称BoB)几乎是工程师手边的标配工…...

腾讯 Marvis 初级使用教程——从安装到上手
腾讯最新系统级AI助手Marvis(2026年5月20日发布),官网 https://marvis.qq.com,主打“一句话操作电脑”、跨端协同、GUI Agent执行。虽然是个【小龙虾】,但上手其实不难。这篇就简单写写 Marvis 的安装和基础使用&#…...
)
Mysql:事务管理(中)
在前面的章节中,我们提到了 MVCC(多版本并发控制),它巧妙地通过“版本快照”解决了“读-写”冲突,实现了非阻塞读。但如果两个事务同时执行 UPDATE 操作修改同一行数据,即 写-写(Write-Write&am…...

Burp Suite拦截与替换机制深度解析:从协议层到规则链
1. 这不是“点开就能用”的功能,而是你和目标系统之间的一道可编程闸门很多人第一次在Burp Suite里点开Proxy → Intercept,看到HTTP请求被拦下来,兴奋地改个User-Agent、删个Cookie就点Forward,以为自己已经掌握了“拦截与替换”…...
适合全体毕业生)
口碑最好的AI论文写作工具推荐(从文献整理到论文成稿全流程)适合全体毕业生
还在为选题方向纠结、文献资料翻找耗时、开题报告无从下手、论文框架反复修改、查重率居高不下、降重过程痛苦不堪,甚至答辩PPT还要临时抱佛脚?作为学术新手、应届生或本科硕士毕业生,面对论文写作的重重关卡,流程复杂、操作门槛高…...

Taotoken的审计日志功能为企业API安全与合规管理提供支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的审计日志功能为企业API安全与合规管理提供支持 当企业决定将大模型能力集成到内部业务流程中时,IT管理员和安…...

Elden Ring帧率解锁终极指南:从60帧到144+的完整教程
Elden Ring帧率解锁终极指南:从60帧到144的完整教程 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/Elden…...

3分钟快速解决Windows热键冲突检测难题:Hotkey Detective终极指南
3分钟快速解决Windows热键冲突检测难题:Hotkey Detective终极指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective …...