linux -- 内存管理 -- SLAB分配器
SLAB分配器(slab allocator)
SLAB分配器用于小内存空间管理,基本思想是:先利用页面分配器分配出单个或多个连续的物理页面,然后再此基础上将整块页面分割为多个相等的小内存单元,来满足小内存空间分配的需要。有效地管理这些小的内存单元并保证极高的内存使用速度和效率是非常难的。
关键数据结构
关键成员的含义在注释中解释
kmem_cache
/** Definitions unique to the original Linux SLAB allocator.*/struct kmem_cache {struct array_cache __percpu *cpu_cache;/* 1) Cache tunables. Protected by slab_mutex */unsigned int batchcount;unsigned int limit;unsigned int shared;unsigned int size;struct reciprocal_value reciprocal_buffer_size;
/* 2) touched by every alloc & free from the backend */slab_flags_t flags; /* constant flags */unsigned int num; /* # of objs per slab *//* 3) cache_grow/shrink *//* order of pgs per slab (2^n) *///该kmem_cache中每个slab占用的页面数量,2^gfporder个unsigned int gfporder;/* force GFP flags, e.g. GFP_DMA *///影响通过伙伴系统寻找空闲页时的行为,GFP Flagsgfp_t allocflags;size_t colour; /* cache colouring range */unsigned int colour_off; /* colour offset */struct kmem_cache *freelist_cache;unsigned int freelist_size;/* constructor func *///构造函数,当在kmem_cache中分配一个新的slab时,用来初始化slab中的所有内存对象void (*ctor)(void *obj);/* 4) cache creation/removal *///该kmem_cache的名字,导出到/proc/slabinfo中const char *name;//将该kmem_cache加入到cache_chain链表中struct list_head list;int refcount;int object_size;int align;/* 5) statistics */
#ifdef CONFIG_DEBUG_SLABunsigned long num_active;unsigned long num_allocations;unsigned long high_mark;unsigned long grown;unsigned long reaped;unsigned long errors;unsigned long max_freeable;unsigned long node_allocs;unsigned long node_frees;unsigned long node_overflow;atomic_t allochit;atomic_t allocmiss;atomic_t freehit;atomic_t freemiss;
#ifdef CONFIG_DEBUG_SLAB_LEAKatomic_t store_user_clean;
#endif/** If debugging is enabled, then the allocator can add additional* fields and/or padding to every object. 'size' contains the total* object size including these internal fields, while 'obj_offset'* and 'object_size' contain the offset to the user object and its* size.*/int obj_offset;
#endif /* CONFIG_DEBUG_SLAB */#ifdef CONFIG_MEMCGstruct memcg_cache_params memcg_params;
#endif
#ifdef CONFIG_KASANstruct kasan_cache kasan_info;
#endif#ifdef CONFIG_SLAB_FREELIST_RANDOMunsigned int *random_seq;
#endifunsigned int useroffset; /* Usercopy region offset */unsigned int usersize; /* Usercopy region size */struct kmem_cache_node *node[MAX_NUMNODES];
};
kmem_cache_node
/** The slab lists for all objects.*/
struct kmem_cache_node {spinlock_t list_lock;#ifdef CONFIG_SLAB//将kmem_cache中所有半空闲的slab加入到该链表中struct list_head slabs_partial; /* partial list first, better asm code *///将kmem_cache中所有已经满员的slab加到该链表中struct list_head slabs_full;//将kmem_cache中所有完全空闲的slab加入到该链表中struct list_head slabs_free;unsigned long total_slabs; /* length of all slab lists */unsigned long free_slabs; /* length of free slab list only */unsigned long free_objects;unsigned int free_limit;unsigned int colour_next; /* Per-node cache coloring */struct array_cache *shared; /* shared per node */struct alien_cache **alien; /* on other nodes */unsigned long next_reap; /* updated without locking */int free_touched; /* updated without locking */
#endif#ifdef CONFIG_SLUBunsigned long nr_partial;struct list_head partial;
#ifdef CONFIG_SLUB_DEBUGatomic_long_t nr_slabs;atomic_long_t total_objects;struct list_head full;
#endif
#endif};
slab
/* Reuses the bits in struct page */
struct slab {unsigned long __page_flags;struct kmem_cache *slab_cache;union {struct {union {struct list_head slab_list;
#ifdef CONFIG_SLUB_CPU_PARTIALstruct {struct slab *next;int slabs; /* Nr of slabs left */};
#endif};/* Double-word boundary */union {struct {void *freelist; /* first free object */union {unsigned long counters;struct {unsigned inuse:16;unsigned objects:15;unsigned frozen:1;};};};
#ifdef system_has_freelist_abafreelist_aba_t freelist_counter;
#endif};};struct rcu_head rcu_head;};unsigned int __unused;atomic_t __page_refcount;
#ifdef CONFIG_MEMCGunsigned long memcg_data;
#endif
};
如何组合使用这些数据结构?
struct kmem_cache和struct slab在一个slab分配器中形成分级管理。
kmem_cache管理者旗下所有的struct slab,它通过三个链表成员
struct list_head slabs_full,表示链表中每一个slab所在的物理内存页面都已经分配完
struct list_head slabs_partial, 表示链表中每一个slab所在的物理内存页面都部分空闲
struct list_head slabs_free, 表示链表中每一个slab所在的物理内存页面都是完全空闲的
将旗下的所有slab实例都加入链表。
各数据结构之间的关系:

struct slab结构用于管理一块连续的物理页面中内存对象的分配。实际存放slab的位置有两种做法:
- 像上图这样,放在起始的物理页面的首部。
- 放在物理页面的外部
宏CFLGS_OFF_SLAB用于表示slab对象存放于外部
kmem_cache之间通过list成员链接起来
cache_cache
每一个slab分配器,都需要一个struct kmem_cache实例,那么,在slab系统尚未完全建立起来时,kmem_cache实例所在的空间从哪里分配?
系统在初始化期间提供了一个特殊的slab分配器kmem_cache_boot,专门用来分配struct kmem_cache空间。
因为kmem_cache_boot在slab系统还未完备时就被创造了出来,所以这个struct kmem_cache结构采用了静态的内存分配方式:
mm/slab.c
/* internal cache of cache description objs */
static struct kmem_cache kmem_cache_boot = {.batchcount = 1,.limit = BOOT_CPUCACHE_ENTRIES,.shared = 1,.size = sizeof(struct kmem_cache),.name = "kmem_cache",
};
.name为kmem_cache,他所领衔的slab分配器,专门用来分配struct kmem_cache这样的内存对象。
.buffer_size = sizeof(struct kmem_cache)其buffersize是kmem_cache结构的大小。
系统在初始化kmem_cache_boot时buddy组件已经完备,所以可以把slab放在页面内部,这个slab分配器就可以工作了(不需要其他分配组件给这个slab寻找内存)。
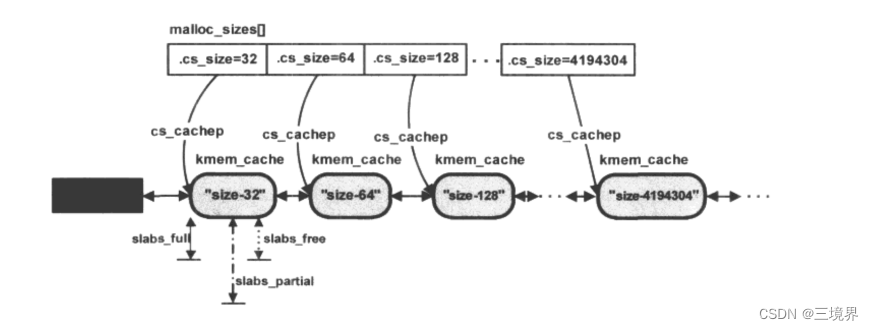
cache_sizes
cache_sizes是实现kmalloc函数的基础
/include/linux/slab_def.h
/* Size description struct for general caches. */
struct cache_sizes {size_t cs_size;struct kmem_cache *cs_cachep;
#ifdef CONFIG_ZONE_DMAstruct kmem_cache *cs_dmacachep;
#endif
};
extern struct cache_sizes malloc_sizes[];
/mm/slab.c
/** These are the default caches for kmalloc. Custom caches can have other sizes.*/
struct cache_sizes malloc_sizes[] = {
#define CACHE(x) { .cs_size = (x) },
#include <linux/kmalloc_sizes.h>CACHE(ULONG_MAX)
#undef CACHE
};
EXPORT_SYMBOL(malloc_sizes);
<linux/kmalloc_sizes.h>文件里包含了所有可支持的slab大小。
在系统初始化期间,内核委托kmem_cache_init函数遍历数组,对应每个元素,都调用kmem_cache_create函数在kmem_cache_boot中分配一个kmem_cache实例
/** Initialisation. Called after the page allocator have been initialised and* before smp_init().*/
void __init kmem_cache_init(void)
{size_t left_over;struct cache_sizes *sizes;struct cache_names *names;int i;int order;int node;if (num_possible_nodes() == 1)use_alien_caches = 0;for (i = 0; i < NUM_INIT_LISTS; i++) {kmem_list3_init(&initkmem_list3[i]);if (i < MAX_NUMNODES)cache_cache.nodelists[i] = NULL;}set_up_list3s(&cache_cache, CACHE_CACHE);/** Fragmentation resistance on low memory - only use bigger* page orders on machines with more than 32MB of memory.*/if (totalram_pages > (32 << 20) >> PAGE_SHIFT)slab_break_gfp_order = BREAK_GFP_ORDER_HI;/* Bootstrap is tricky, because several objects are allocated* from caches that do not exist yet:* 1) initialize the cache_cache cache: it contains the struct* kmem_cache structures of all caches, except cache_cache itself:* cache_cache is statically allocated.* Initially an __init data area is used for the head array and the* kmem_list3 structures, it's replaced with a kmalloc allocated* array at the end of the bootstrap.* 2) Create the first kmalloc cache.* The struct kmem_cache for the new cache is allocated normally.* An __init data area is used for the head array.* 3) Create the remaining kmalloc caches, with minimally sized* head arrays.* 4) Replace the __init data head arrays for cache_cache and the first* kmalloc cache with kmalloc allocated arrays.* 5) Replace the __init data for kmem_list3 for cache_cache and* the other cache's with kmalloc allocated memory.* 6) Resize the head arrays of the kmalloc caches to their final sizes.*/node = numa_mem_id();/* 1) create the cache_cache */INIT_LIST_HEAD(&cache_chain);list_add(&cache_cache.next, &cache_chain);cache_cache.colour_off = cache_line_size();cache_cache.array[smp_processor_id()] = &initarray_cache.cache;cache_cache.nodelists[node] = &initkmem_list3[CACHE_CACHE + node];/** struct kmem_cache size depends on nr_node_ids, which* can be less than MAX_NUMNODES.*/cache_cache.buffer_size = offsetof(struct kmem_cache, nodelists) +nr_node_ids * sizeof(struct kmem_list3 *);
#if DEBUGcache_cache.obj_size = cache_cache.buffer_size;
#endifcache_cache.buffer_size = ALIGN(cache_cache.buffer_size,cache_line_size());cache_cache.reciprocal_buffer_size =reciprocal_value(cache_cache.buffer_size);for (order = 0; order < MAX_ORDER; order++) {cache_estimate(order, cache_cache.buffer_size,cache_line_size(), 0, &left_over, &cache_cache.num);if (cache_cache.num)break;}BUG_ON(!cache_cache.num);cache_cache.gfporder = order;cache_cache.colour = left_over / cache_cache.colour_off;cache_cache.slab_size = ALIGN(cache_cache.num * sizeof(kmem_bufctl_t) +sizeof(struct slab), cache_line_size());/* 2+3) create the kmalloc caches */sizes = malloc_sizes;names = cache_names;/** Initialize the caches that provide memory for the array cache and the* kmem_list3 structures first. Without this, further allocations will* bug.*/sizes[INDEX_AC].cs_cachep = kmem_cache_create(names[INDEX_AC].name,sizes[INDEX_AC].cs_size,ARCH_KMALLOC_MINALIGN,ARCH_KMALLOC_FLAGS|SLAB_PANIC,NULL);if (INDEX_AC != INDEX_L3) {sizes[INDEX_L3].cs_cachep =kmem_cache_create(names[INDEX_L3].name,sizes[INDEX_L3].cs_size,ARCH_KMALLOC_MINALIGN,ARCH_KMALLOC_FLAGS|SLAB_PANIC,NULL);}slab_early_init = 0;//!!! 初始化malloc_sizeswhile (sizes->cs_size != ULONG_MAX) {/** For performance, all the general caches are L1 aligned.* This should be particularly beneficial on SMP boxes, as it* eliminates "false sharing".* Note for systems short on memory removing the alignment will* allow tighter packing of the smaller caches.*/if (!sizes->cs_cachep) {sizes->cs_cachep = kmem_cache_create(names->name,sizes->cs_size,ARCH_KMALLOC_MINALIGN,ARCH_KMALLOC_FLAGS|SLAB_PANIC,NULL);}
#ifdef CONFIG_ZONE_DMAsizes->cs_dmacachep = kmem_cache_create(names->name_dma,sizes->cs_size,ARCH_KMALLOC_MINALIGN,ARCH_KMALLOC_FLAGS|SLAB_CACHE_DMA|SLAB_PANIC,NULL);
#endifsizes++;names++;}/* 4) Replace the bootstrap head arrays */{struct array_cache *ptr;ptr = kmalloc(sizeof(struct arraycache_init), GFP_NOWAIT);BUG_ON(cpu_cache_get(&cache_cache) != &initarray_cache.cache);memcpy(ptr, cpu_cache_get(&cache_cache),sizeof(struct arraycache_init));/** Do not assume that spinlocks can be initialized via memcpy:*/spin_lock_init(&ptr->lock);cache_cache.array[smp_processor_id()] = ptr;ptr = kmalloc(sizeof(struct arraycache_init), GFP_NOWAIT);BUG_ON(cpu_cache_get(malloc_sizes[INDEX_AC].cs_cachep)!= &initarray_generic.cache);memcpy(ptr, cpu_cache_get(malloc_sizes[INDEX_AC].cs_cachep),sizeof(struct arraycache_init));/** Do not assume that spinlocks can be initialized via memcpy:*/spin_lock_init(&ptr->lock);malloc_sizes[INDEX_AC].cs_cachep->array[smp_processor_id()] =ptr;}/* 5) Replace the bootstrap kmem_list3's */{int nid;for_each_online_node(nid) {init_list(&cache_cache, &initkmem_list3[CACHE_CACHE + nid], nid);init_list(malloc_sizes[INDEX_AC].cs_cachep,&initkmem_list3[SIZE_AC + nid], nid);if (INDEX_AC != INDEX_L3) {init_list(malloc_sizes[INDEX_L3].cs_cachep,&initkmem_list3[SIZE_L3 + nid], nid);}}}g_cpucache_up = EARLY;
}
在whille循环里初始化malloc_sizes数组中的每个cache_sizes结构实例,cs_cachep指针指向动态kmem_cache_create函数生成的kmem_cache实例,每个kmem_cache的实例的kmem_cache_node成员里的三条链表,都还没有初始化,即还没有任何slab对象挂上去。直到有内核其他组件调用了kmalloc函数。
kmalloc和kzalloc
kmalloc函数时驱动程序中使用最多的一个内存分配函数,其分配出的内存空间在物理上是连续的。
void *kmalloc(size_t size, gfp_t flags)
这个函数建立在slab分配器基础之上,其实现主要围绕cache_sizes展开。
kmalloc的简洁版本:

根据上层传入的size,在malloc_sizes数组中找一个比size大的最小cs_size,找到一个合适的cache_size后,也就找到了合适的kmem_cache对象cachep,它在上面说的kmem_cache_init中已经初始化过了。
最后调用kmem_cache_alloc来在cachep领衔的slab分配其中执行内存分配。此时会遇到两种情况:
- slab分配器中有空闲的内存对象 --> 返回
- slab分配器中没有空闲的内存对象 --> 利用下层的页面分配器来分配一段新的物理页面,调用链:
a. __cache_alloc()
b. __do_cache_alloc()
c. cache_alloc_refill()
d. cache_grow()
e. kmem_getpages()
f. alloc_pages_exact_node()
g. __alloc_pages()
最终还是调到了页面管理器核心的分配函数__alloc_pages去分配2^orders个连续的物理页面
cache_grow
cache_grpw中,主要是设置对传入的flags再次处理,随后调用kmem_getpages获取物理页面

flags的处理很有意思:
BUG_ON里判断了flags是否带有GFP_SLAB_BUG_MASK,这个宏的定义
/* Do not use these with a slab allocator */
#define GFP_SLAB_BUG_MASK (__GFP_DMA32|__GFP_HIGHMEM|~__GFP_BITS_MASK)
看注释可知,slab分配器不欢迎这种组合的flgs,也即,不能来自高端内存区域和DMA32区域。如果上层传入了他俩的组合,会触发BUG_ON,这个函数差不多是个空操作。
#define BUG_ON(condition) do { if (unlikely(condition)) BUG(); } while (0)
这不是一个严格的惩罚,但是也体现了一个原则,底层的页面分配来自低端物理内存区域。
local_flags也严格践行了这一原则,GFP_CONSTRAINT_MASK和GFP_RECLAIM_MASK这两个宏会清除掉__GFP_DMA32|__GFP_HIGHMEM。以此来调用分配内存,函数最终会返回低端物理物理内存页面说对应的线性内核虚拟地址,而不是vmalloc区或者其他动态映射区的虚拟地址。
最后,仔细检查kmalloc的返回值,如果是NULL则代表没有可用的内存而分配失败了。
应用到内核对象的缓存
相关文章:
linux -- 内存管理 -- SLAB分配器
SLAB分配器(slab allocator) SLAB分配器用于小内存空间管理,基本思想是:先利用页面分配器分配出单个或多个连续的物理页面,然后再此基础上将整块页面分割为多个相等的小内存单元,来满足小内存空间分配的需…...

【MySQL】学习如何通过DQL进行数据库数据的条件查询
🌈个人主页: Aileen_0v0 🔥热门专栏: 华为鸿蒙系统学习|计算机网络|数据结构与算法 💫个人格言:“没有罗马,那就自己创造罗马~” #mermaid-svg-63IIm2s5sIhQfsfy {font-family:"trebuchet ms",verdana,arial,sans-serif;font-siz…...

TS:子类型关系
子类型关系 1、概念1.1 里氏替换原则1.2 自反性1.3 传递性 2、顶端类型 和 尾端类型3、字面量类型4、undefined 和 null5、枚举类型6、函数类型6.1 变型6.1.1 协变6.1.2 逆变6.1.3 双变 6.2 函数类型间的子类型关系6.2.1 函数参数数量6.2.2 函数参数类型A、非严格函数类型检查B…...
IDEA插件(MyBatis Log Free)
引言 在Java开发中,MyBatis 是一款广泛使用的持久层框架,它简化了SQL映射并提供了强大的数据访问能力。为了更好地调试和优化MyBatis应用中的SQL语句执行,一款名为 MyBatis Log Free 的 IntelliJ IDEA 插件应运而生。这款插件旨在帮助开发者…...
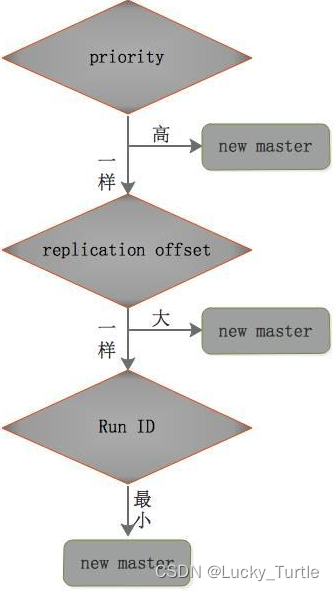
Redis(八)哨兵机制(sentinel)
文章目录 哨兵机制案例认识异常 哨兵运行流程及选举原理主观下线(Subjectively Down)ODown客观下线(Objectively Down)选举出领导者哨兵选出新master过程 哨兵使用建议 哨兵机制 吹哨人巡查监控后台master主机是否故障,如果故障了根据投票数自动将某一个从库转换为新…...
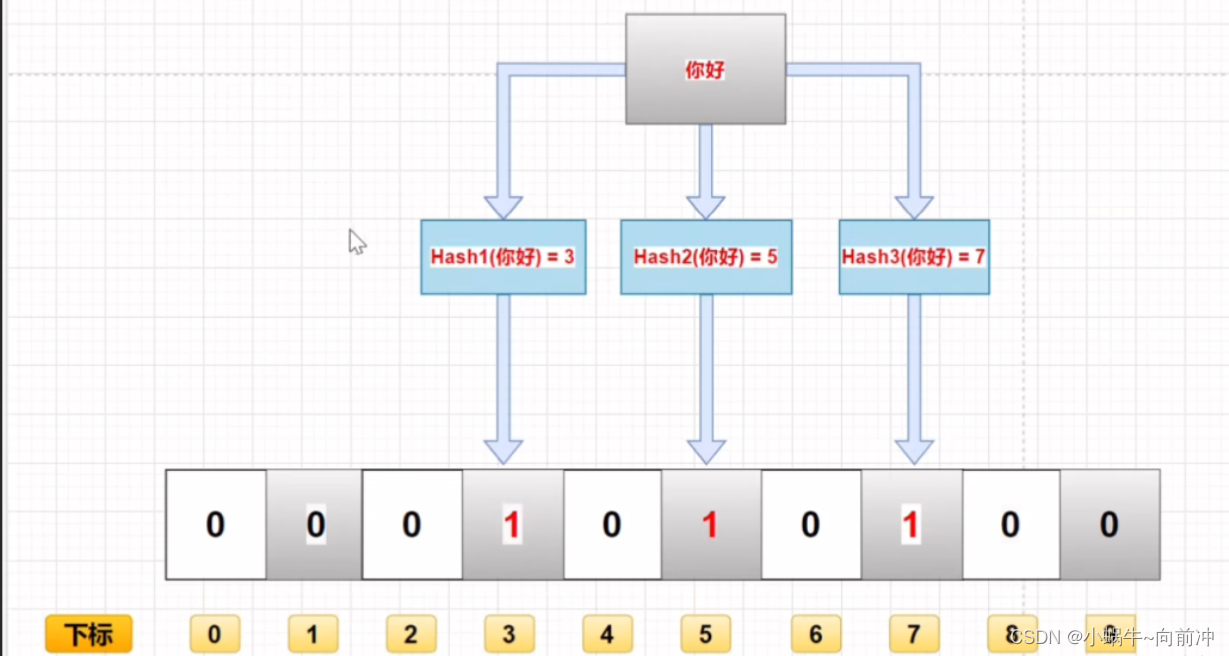
[数据结构]-哈希
前言 作者:小蜗牛向前冲 名言:我可以接受失败,但我不能接受放弃 如果觉的博主的文章还不错的话,还请点赞,收藏,关注👀支持博主。如果发现有问题的地方欢迎❀大家在评论区指正 本期学习目标&…...
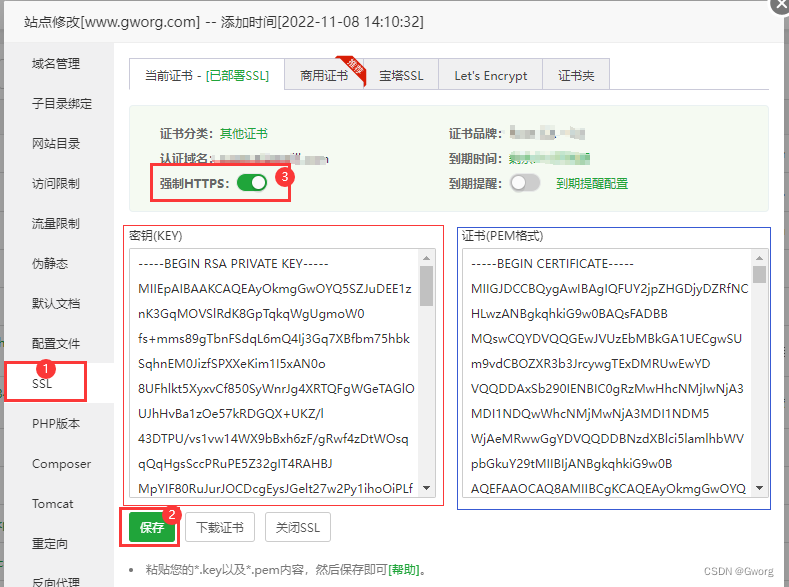
宝塔控制面板配置SSL证书实现网站HTTPS
宝塔安装SSL证书提前申请好SSL证书,如果还没有,先去Gworg里面申请,一般几分钟就可以下来,申请地址:首页-Gworg官方店-淘宝网 一、登录邮箱下载:Gworg证书文件目录 ,都会有以下五个文件夹。宝塔…...

elasticsearch优化总结
参考: https://docs.docker.com/manuals/ Manuals | Docker Docs Run Elasticsearch locally | Elasticsearch Guide [8.12] | Elastic 让你的ES查询性能起飞:Elasticsearch 查询优化攻略“一网打尽” - 知乎...

图论第三天|127. 单词接龙 841.钥匙和房间 463. 岛屿的周长 1971. 寻找图中是否存在路径 684.冗余连接 685.冗余连接II
目录 Leetcode127. 单词接龙Leetcode841.钥匙和房间Leetcode463. 岛屿的周长Leetcode1971. 寻找图中是否存在路径Leetcode684.冗余连接Leetcode685.冗余连接II Leetcode127. 单词接龙 文章链接:代码随想录 题目链接:127. 单词接龙 思路:广搜搜…...

react的高阶函数HOC:
React 的高阶组件(Higher-Order Component,HOC)是一种用于复用组件逻辑的模式。它是一个函数,接收一个组件作为参数,并返回一个新的增强过的组件。 HOC 可以用于实现以下功能: 代码复用:通过将…...

STM32——中断系统和外部中断EXTI
一、中断 1.1中断系统 中断系统是管理和执行中断的逻辑结构; 1.2中断 系统在执行主程序过程中,出现了特定的触发条件(触发源),系统停止执行当前程序,转而去执行中断程序,执行完毕后…...

使用uniApp+vue3+Vite4+pinia+sass技术栈构建微信小程序
使用uniApp的cli模式安装,可以使用vscode开发。不用再单独去下载HBuilderX. 1.基础安装 vue3tsuniapp 方法一: npx degit dcloudio/uni-preset-vue#vite-ts my-vue3-project方法二:可以去uni-preset-vue的vite分支下选择vite-ts直接下载zi…...
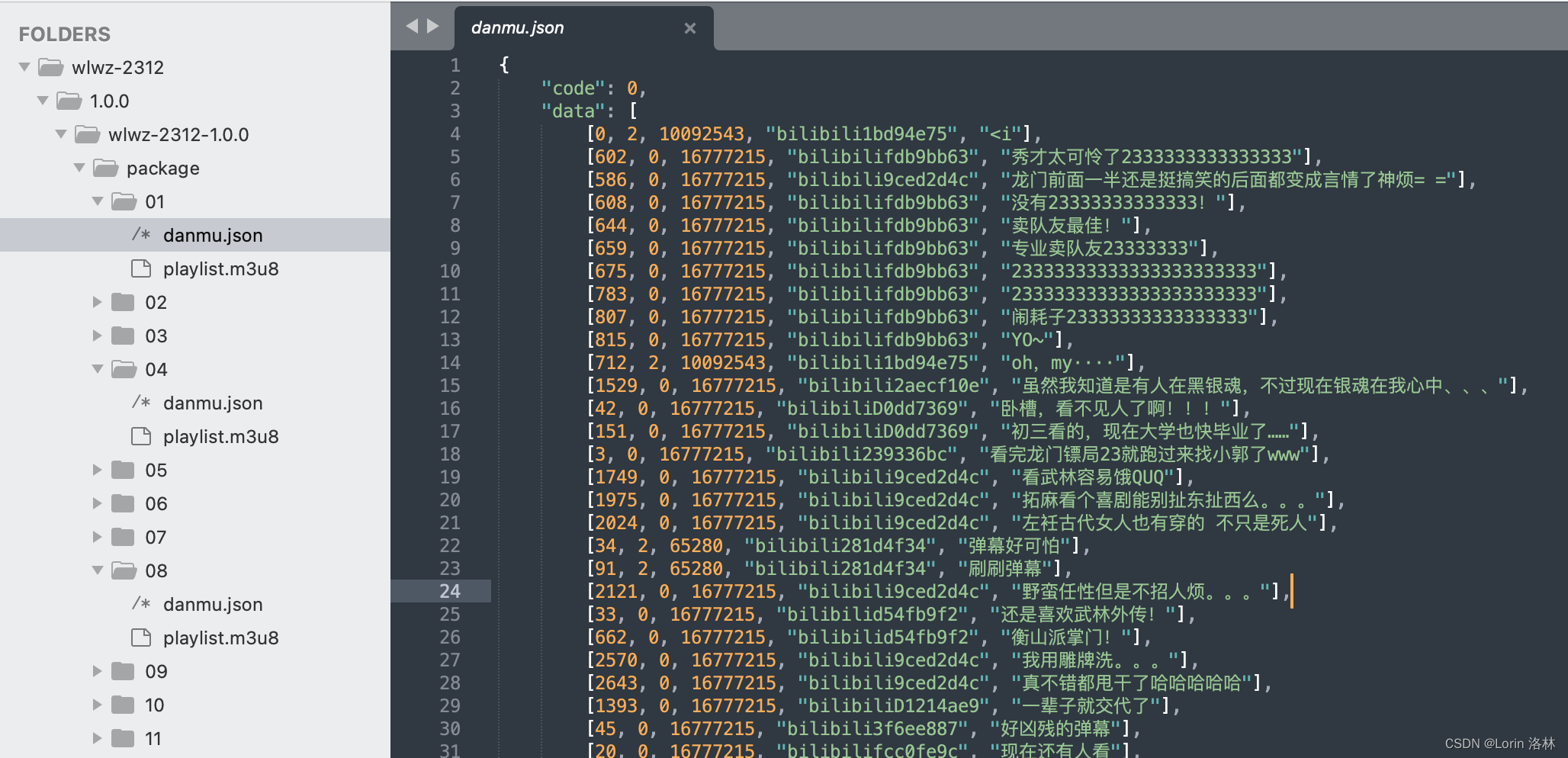
npm 被滥用 -- 有人上传了 700 多个武林外传切片视频
Sonatype 安全研究团队最近曝光了一起滥用 npm 的案例 —— 他们发现在 npm 上托管的 748 个软件包实际上是视频文件。 据介绍,这些软件包每个大小约为 54.5MB,包名以 “wlwz” 为前缀,并附带了代表日期的数字。根据时间戳显示,这…...

代码随想录算法训练营29期|day34 任务以及具体任务
第八章 贪心算法 part03 1005.K次取反后最大化的数组和 class Solution {public int largestSumAfterKNegations(int[] nums, int K) {// 将数组按照绝对值大小从大到小排序,注意要按照绝对值的大小nums IntStream.of(nums).boxed().sorted((o1, o2) -> Math.ab…...

LeetCode 每日一题 2024/1/22-2024/1/28
记录了初步解题思路 以及本地实现代码;并不一定为最优 也希望大家能一起探讨 一起进步 目录 1/22 670. 最大交换1/23 2765. 最长交替子数组1/24 2865. 美丽塔 I1/25 2859. 计算 K 置位下标对应元素的和1/26 2846. 边权重均等查询1/27 2861. 最大合金数1/28 365. 水壶…...

好用的学习与开发工具
1. 首推 UTools 官网地址 uTools官网 - 新一代效率工具平台 介绍 uTools 是一个极简、插件化的现代桌面软件,通过自由选配丰富的插件,打造得心应手的工具集合。 通过快捷键(默认 alt space )就可以快速呼出这个搜索框。你可…...

(自用)learnOpenGL学习总结-高级OpenGL-立方体贴图
ok终于来到了立方体贴图了,在这里面我们可以加入好看的天空包围盒,这样的画我们的背景就不再是黑色的了! 首先,立方体贴图和前面的sampler2D贴图一样,不过是6个2D组成的立方体而已。 那么为什么要把6个组合在一起呢&…...

【计算机网络】——TCP协议
📑前言 本文主要是【计算机网络】——传输层TCP协议的文章,如果有什么需要改进的地方还请大佬指出⛺️ 🎬作者简介:大家好,我是青衿🥇 ☁️博客首页:CSDN主页放风讲故事 🌄每日一句…...
sql优化的方法
目录 一、准备数据 1.1、创建表结构 1.2、创建存储过程 二、索引介绍 2.1、类型介绍 2.2、建立索引 2.3、建立复合索引 2.4、查看所有建立的索引 2.5、删除索引 三、EXPLAIN分析参数说明 四、SQL优化案例 4.1、避免使用SELECT * 4.2、慎用UNION关键字 4.4、避免使…...
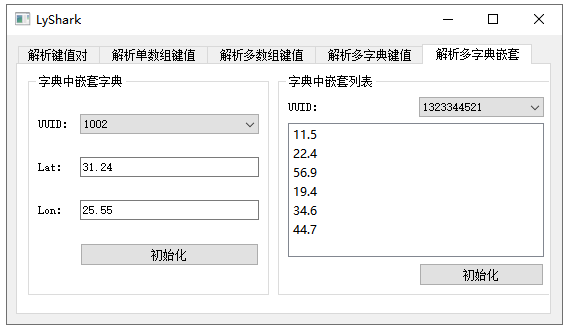
C++ Qt开发:运用QJSON模块解析数据
Qt 是一个跨平台C图形界面开发库,利用Qt可以快速开发跨平台窗体应用程序,在Qt中我们可以通过拖拽的方式将不同组件放到指定的位置,实现图形化开发极大的方便了开发效率,本章将重点介绍如何运用QJson组件的实现对JSON文本的灵活解析…...

AMLP框架实战:基于MACE构建高精度机器学习势函数
1. 项目概述:当机器学习势函数遇上自动化管道在计算化学和材料科学领域,我们长久以来面临着一个核心矛盾:精度与效率的权衡。密度泛函理论(DFT)能提供接近实验的精度,但计算成本高昂,通常只能处…...

用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程
用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程当你第一次接触脑电信号处理时,面对原始数据文件可能会感到无从下手。BCI Competition IV 2a数据集作为脑机接口领域的经典基准数据,包含了9名受试者四种运动想…...
)
Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析)
更多请点击: https://intelliparadigm.com 第一章:Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析) 自2024年V6.2版本起,大量用户反馈 --stylize 与 --sharp 参数组合下图像边缘锐化效果显著弱化&am…...

通过curl命令快速测试Taotoken大模型API的连通性与返回格式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken大模型API的连通性与返回格式 在集成大模型能力到应用时,开发者通常需要一种快速、轻量的…...

航空发动机叶片三维扫描-诺斯顿
航空发动机叶片作为发动机的核心动力部件,其精度与性能直接决定发动机的推力、燃油效率及运行安全性,三维扫描技术作为航空制造领域的核心数字化手段,已广泛应用于叶片全生命周期的多个关键环节。其应用涵盖叶片研发设计阶段的逆向工程&#…...

别再死记公式了!用Python手写一个卷积层,彻底搞懂CNN里的‘卷’是怎么算的
用Python手写卷积层:从零理解CNN的"卷"运算 当你第一次看到卷积神经网络(CNN)的数学公式时,那些复杂的符号和下标是否让你望而却步?作为计算机视觉领域的基石,CNN的核心在于理解卷积运算的本质。本文将带你用NumPy从零实…...

在Node.js服务中集成Taotoken实现稳定的大模型能力调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js服务中集成Taotoken实现稳定的大模型能力调用 对于需要在后端服务中集成AI功能的Node.js开发者而言,直接对接…...

用PyTorch复现FactorVAE:一个能同时预测收益和风险的量化模型实战教程
用PyTorch实战FactorVAE:构建收益与风险双预测的量化模型 在量化投资领域,传统线性因子模型正逐渐被非线性机器学习方法所取代。然而金融数据特有的低信噪比特性,使得直接从市场数据中提取有效因子成为一项艰巨挑战。本文将深入探讨如何利用P…...

解决claude code频繁封号与token不足的taotoken接入方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code频繁封号与Token不足的Taotoken接入方案 1. 问题背景:Claude Code用户面临的挑战 对于依赖Claude Cod…...

Claude Code + LM Studio + CC-Switch 本地自动化编程部署指南
Claude Code LM Studio CC-Switch 本地自动化编程部署指南 本指南汇总了在 Windows 本地环境下,使用 Claude Code 配合 LM Studio 本地模型、CC-Switch 代理进行自动化编程开发的完整配置方案。 目录 硬件与模型选型LM Studio 本地模型部署CC-Switch 代理配置Cla…...