linux -- 内存管理 -- 页面分配器
linux内存管理
为什么要了解linux内存管理
分配并使用内存,是内核程序与驱动程序中非常重要的一环。内存分配函数都依赖于内核中一个非常复杂而重要的组件 - 内存管理。 linux驱动程序不可避免要与内核中的内存管理模块打交道。
linux内存管理可以总体上分为两大块:一是对物理内存的管理,二是对虚拟内存的管理。
物理内存管理
对物理内存的定义,引入了三个概念:内存节点node,内存区域zone,内存页page
对于物理内存的管理,总体上可以分为两层:
- 最底层的页面级内存管理
- 页面级管理之上,有slab内存管理
内存节点 node
为了将UMA系统和NUMA系统,结合起来,所以引入了内存节点这样一个概念。
在计算机体系结构上,有两种物理内存管理模型,被广泛使用:
- UMA(一致内存访问, Uniform Memory Access)模型,该模型的内存空间在物理上,也许是不连续的(比如有空洞的存在),但是所有内存空间对系统中的处理器而言,具有相同的访问特性
- NUMA(非一致内存访问,Non-Uniform Memory Access)模型,该模型总是用在多核处理器系统,系统中每个处理器都有本地内存,处理器与处理器之间通过总线连接起来,以支持其他处理器对比其本地的访问。与UMA模型不同的是,处理器在访问本地内存时速度更加快。
两种模型的区别:
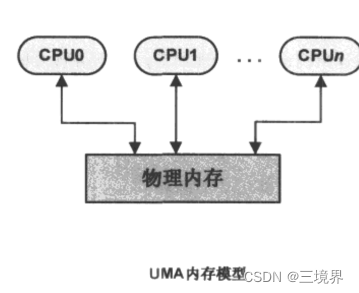
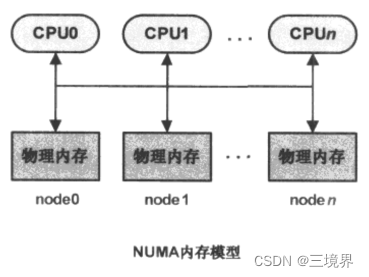
linux源码中,以struct pglist_data数据结构,来表示单个内存节点,NUMA系统,有多个内存节点,所以会有多个pglist_data结构存在。而UMA结构中,只会有一个pglist_data结构。
内存区域zone
内存区域的概念,其范围要小于内存节点的概念。系统中各个模块,对物理内存的属性有不同的要求,因此linux又将每个内存节点所管理的物理内存,划分为不同的内存区域。
linux源码中,以strcut zone数据结构表示一个内存区域,内存区域的类型用枚举类型 zone_type表示:
ZONE_DMA:
当有些设备不能使用所有的ZONE_NORMAL区域中的内存作为内存空间的DMA访问时,就可以使用ZONE_DMA所表示的内存区域,于是我们把这部分空间划分出来专门用与DMA访问的内存空间。这部分区域的空间访问是处理器体系结构相关的(比如32位的x86体系结构下DMA只能访问16MB以下的物理内存空间)
ZONE_NORMAL:
常规内存访问区域,如果DMA可以使用这个区域作为内存访问,也可以使用这个区域。
ZONE_HIGHMEM:
高端内存区域,这个区域无法从内核虚拟地址空间直接作线性映射,所以为访问该区域,必须经内核作特殊的页映射。
i386体系上,内核空间1GB,除去其他开销,能对物理地址进行线性映射的空间大约只有896MB,高于896MB以上的物理地址空间就叫ZONE_HIGHMEM区域。
enum zone_type {/** ZONE_DMA and ZONE_DMA32 are used when there are peripherals not able* to DMA to all of the addressable memory (ZONE_NORMAL).* On architectures where this area covers the whole 32 bit address* space ZONE_DMA32 is used. ZONE_DMA is left for the ones with smaller* DMA addressing constraints. This distinction is important as a 32bit* DMA mask is assumed when ZONE_DMA32 is defined. Some 64-bit* platforms may need both zones as they support peripherals with* different DMA addressing limitations.*/
#ifdef CONFIG_ZONE_DMAZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32ZONE_DMA32,
#endif/** Normal addressable memory is in ZONE_NORMAL. DMA operations can be* performed on pages in ZONE_NORMAL if the DMA devices support* transfers to all addressable memory.*/ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM/** A memory area that is only addressable by the kernel through* mapping portions into its own address space. This is for example* used by i386 to allow the kernel to address the memory beyond* 900MB. The kernel will set up special mappings (page* table entries on i386) for each page that the kernel needs to* access.*/ZONE_HIGHMEM,
#endif/** ZONE_MOVABLE is similar to ZONE_NORMAL, except that it contains* movable pages with few exceptional cases described below. Main use* cases for ZONE_MOVABLE are to make memory offlining/unplug more* likely to succeed, and to locally limit unmovable allocations - e.g.,* to increase the number of THP/huge pages. Notable special cases are:** 1. Pinned pages: (long-term) pinning of movable pages might* essentially turn such pages unmovable. Therefore, we do not allow* pinning long-term pages in ZONE_MOVABLE. When pages are pinned and* faulted, they come from the right zone right away. However, it is* still possible that address space already has pages in* ZONE_MOVABLE at the time when pages are pinned (i.e. user has* touches that memory before pinning). In such case we migrate them* to a different zone. When migration fails - pinning fails.* 2. memblock allocations: kernelcore/movablecore setups might create* situations where ZONE_MOVABLE contains unmovable allocations* after boot. Memory offlining and allocations fail early.* 3. Memory holes: kernelcore/movablecore setups might create very rare* situations where ZONE_MOVABLE contains memory holes after boot,* for example, if we have sections that are only partially* populated. Memory offlining and allocations fail early.* 4. PG_hwpoison pages: while poisoned pages can be skipped during* memory offlining, such pages cannot be allocated.* 5. Unmovable PG_offline pages: in paravirtualized environments,* hotplugged memory blocks might only partially be managed by the* buddy (e.g., via XEN-balloon, Hyper-V balloon, virtio-mem). The* parts not manged by the buddy are unmovable PG_offline pages. In* some cases (virtio-mem), such pages can be skipped during* memory offlining, however, cannot be moved/allocated. These* techniques might use alloc_contig_range() to hide previously* exposed pages from the buddy again (e.g., to implement some sort* of memory unplug in virtio-mem).* 6. ZERO_PAGE(0), kernelcore/movablecore setups might create* situations where ZERO_PAGE(0) which is allocated differently* on different platforms may end up in a movable zone. ZERO_PAGE(0)* cannot be migrated.* 7. Memory-hotplug: when using memmap_on_memory and onlining the* memory to the MOVABLE zone, the vmemmap pages are also placed in* such zone. Such pages cannot be really moved around as they are* self-stored in the range, but they are treated as movable when* the range they describe is about to be offlined.** In general, no unmovable allocations that degrade memory offlining* should end up in ZONE_MOVABLE. Allocators (like alloc_contig_range())* have to expect that migrating pages in ZONE_MOVABLE can fail (even* if has_unmovable_pages() states that there are no unmovable pages,* there can be false negatives).*/ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICEZONE_DEVICE,
#endif__MAX_NR_ZONES};
内存页
page,是内存管理中的最小粒度,优势也叫做页帧(page frame,页帧号pfn)。linux会为系统物理内存的每个页都创建一个struct page对象,系统同一用struct page* mem_map存放所有物理页page 对象的指针。
一个内存页的大小,取决于MMU,ARMv8MMU可以支持4KB,16KB,64KB这三种页面粒度。一般来说4KB用的最多。
/** Each physical page in the system has a struct page associated with* it to keep track of whatever it is we are using the page for at the* moment. Note that we have no way to track which tasks are using* a page, though if it is a pagecache page, rmap structures can tell us* who is mapping it.*/
struct page {unsigned long flags; /* Atomic flags, some possibly* updated asynchronously */atomic_t _count; /* Usage count, see below. */union {atomic_t _mapcount; /* Count of ptes mapped in mms,* to show when page is mapped* & limit reverse map searches.*/struct { /* SLUB */u16 inuse;u16 objects;};};union {struct {unsigned long private; /* Mapping-private opaque data:* usually used for buffer_heads* if PagePrivate set; used for* swp_entry_t if PageSwapCache;* indicates order in the buddy* system if PG_buddy is set.*/struct address_space *mapping; /* If low bit clear, points to* inode address_space, or NULL.* If page mapped as anonymous* memory, low bit is set, and* it points to anon_vma object:* see PAGE_MAPPING_ANON below.*/};
#if USE_SPLIT_PTLOCKSspinlock_t ptl;
#endifstruct kmem_cache *slab; /* SLUB: Pointer to slab */struct page *first_page; /* Compound tail pages */};union {pgoff_t index; /* Our offset within mapping. */void *freelist; /* SLUB: freelist req. slab lock */};struct list_head lru; /* Pageout list, eg. active_list* protected by zone->lru_lock !*//** On machines where all RAM is mapped into kernel address space,* we can simply calculate the virtual address. On machines with* highmem some memory is mapped into kernel virtual memory* dynamically, so we need a place to store that address.* Note that this field could be 16 bits on x86 ... ;)** Architectures with slow multiplication can define* WANT_PAGE_VIRTUAL in asm/page.h*/
#if defined(WANT_PAGE_VIRTUAL)void *virtual; /* Kernel virtual address (NULL ifnot kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
#ifdef CONFIG_WANT_PAGE_DEBUG_FLAGSunsigned long debug_flags; /* Use atomic bitops on this */
#endif#ifdef CONFIG_KMEMCHECK/** kmemcheck wants to track the status of each byte in a page; this* is a pointer to such a status block. NULL if not tracked.*/void *shadow;
#endif
};
页面分配器(page allocator)
物理内存分配。linux系统的物理内存分配是建立在伙伴系统的基础之上的。系统初始化期间,伙伴系统负责对物理内存进行整理,跟踪哪些物理内存页面已经被占用,哪些是空闲的。
其他组件,通过访问伙伴系统,可以获取单独的,或者连续的多个物理页面。 驱动程序如果需要使用比较大的地址空间,可以利用这一层面的页面分配器提供的接口函数。这些函数,或者是宏,只能分配2的整数次幂个连续的物理页
下面给出mem_map – 物理内存页面 – 系统虚拟地址空间 之间的关系
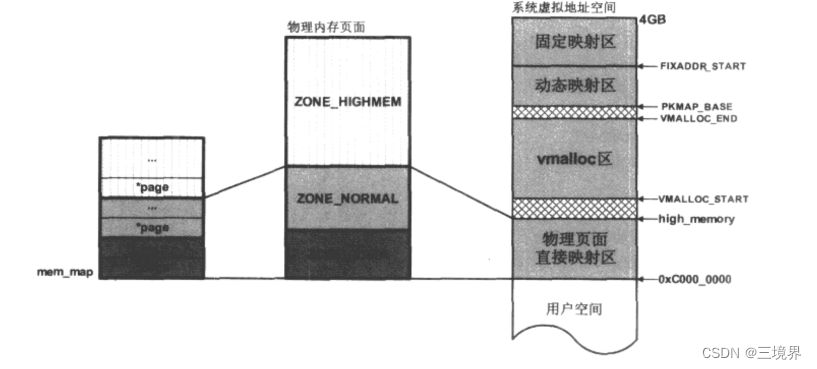
物理内存页面,被分为三个区域:ZONE_HIGHMEM, ZONE_NORMAL, ZONE_DMA。mem_map集合中,每个struct page
对象都与物理页面之间一一对应,所以mem_map也会被分为三个区域。(图中颜色相同的,对应同一个区)
在linux内核的初始化阶段,虚拟地址空间中 物理页面直接映射区域 会被映射到 ZONE_NORMAL和ZONE_DMA中。进内核后,可以直接通过页面分配器分配 物理页面直接映射这块区域的内存,因为这块区域对应的页表项已经建立好了。他们的内核虚拟地址和物理地址之间只是有个一差值(PAGE_OFFSET,也就是图中的0xC000_0000)。
如果页面分配器分配到的页面,落在ZONE_HIGHMEM中,此时内核是暂时没有对该页面进行映射的,因此,页面分配器的使用者,需要作一些前置操作:在内核虚拟地址空间的动态映射区,或者固定映射区,分配一个虚拟地址,然后建立映射,到这块区域的物理页面上。(内核已经提供了实现这些步骤的接口函数)
页面分配器所提供的接口函数,对于UMA和NUMA系统都是一样的。
核心成员:
- alloc_pages
- __get_free_pages
这两个函数最后都是会调用到alloc_pages_node,二者背后实现原理都是一样的
区别是__get_free_pages无法在高端内存区分配页面。
这两个函数有一些变体,这些变体只是调整了一些参数,然后换了个马甲。
gfp_mask
gfp_mask是这些页面分配函数的一个重要参数,决定了他们的分配行为,可以告诉内核应该到哪一个zone中分配物理内存页面。
/** In case of changes, please don't forget to update* include/trace/events/mmflags.h and tools/perf/builtin-kmem.c*//* Plain integer GFP bitmasks. Do not use this directly. */
#define ___GFP_DMA 0x01u
#define ___GFP_HIGHMEM 0x02u
#define ___GFP_DMA32 0x04u
#define ___GFP_MOVABLE 0x08u
#define ___GFP_RECLAIMABLE 0x10u
#define ___GFP_HIGH 0x20u
#define ___GFP_IO 0x40u
#define ___GFP_FS 0x80u
#define ___GFP_ZERO 0x100u
/* 0x200u unused */
#define ___GFP_DIRECT_RECLAIM 0x400u
#define ___GFP_KSWAPD_RECLAIM 0x800u
#define ___GFP_WRITE 0x1000u
#define ___GFP_NOWARN 0x2000u
#define ___GFP_RETRY_MAYFAIL 0x4000u
#define ___GFP_NOFAIL 0x8000u
#define ___GFP_NORETRY 0x10000u
#define ___GFP_MEMALLOC 0x20000u
#define ___GFP_COMP 0x40000u
#define ___GFP_NOMEMALLOC 0x80000u
#define ___GFP_HARDWALL 0x100000u
#define ___GFP_THISNODE 0x200000u
#define ___GFP_ACCOUNT 0x400000u
#define ___GFP_ZEROTAGS 0x800000u
#ifdef CONFIG_KASAN_HW_TAGS
#define ___GFP_SKIP_ZERO 0x1000000u
#define ___GFP_SKIP_KASAN 0x2000000u
#else
#define ___GFP_SKIP_ZERO 0
#define ___GFP_SKIP_KASAN 0
#endif
#ifdef CONFIG_LOCKDEP
#define ___GFP_NOLOCKDEP 0x4000000u
#else
#define ___GFP_NOLOCKDEP 0
#endif
/* If the above are modified, __GFP_BITS_SHIFT may need updating */
带有__下划线的宏留给内存管理部件内部使用,内核也利用这些内部宏定义了一些给其他模块使用的宏:
#define GFP_ATOMIC (__GFP_HIGH|__GFP_KSWAPD_RECLAIM)
#define GFP_KERNEL (__GFP_RECLAIM | __GFP_IO | __GFP_FS)
#define GFP_KERNEL_ACCOUNT (GFP_KERNEL | __GFP_ACCOUNT)
#define GFP_NOWAIT (__GFP_KSWAPD_RECLAIM)
#define GFP_NOIO (__GFP_RECLAIM)
#define GFP_NOFS (__GFP_RECLAIM | __GFP_IO)
#define GFP_USER (__GFP_RECLAIM | __GFP_IO | __GFP_FS | __GFP_HARDWALL)
#define GFP_DMA __GFP_DMA
#define GFP_DMA32 __GFP_DMA32
#define GFP_HIGHUSER (GFP_USER | __GFP_HIGHMEM)
#define GFP_HIGHUSER_MOVABLE (GFP_HIGHUSER | __GFP_MOVABLE | __GFP_SKIP_KASAN)
#define GFP_TRANSHUGE_LIGHT ((GFP_HIGHUSER_MOVABLE | __GFP_COMP | \__GFP_NOMEMALLOC | __GFP_NOWARN) & ~__GFP_RECLAIM)
#define GFP_TRANSHUGE (GFP_TRANSHUGE_LIGHT | __GFP_DIRECT_RECLAIM)
最常用的是GFP_KERNEL与GFP_ATOMIC,如果不指定__GFP_HIGHMEM或者__GFP_DMA,默认就是__GFP_NORMAL,优先在ZONE_KERNEL里分配,其次是ZONE_DMA域。
GFP_DMA限制了页面分配器只能在ZONE_DMA中分配空闲的物理页面,用于分配DMA缓冲区的内存。
alloc_pages
/** Allocate pages, preferring the node given as nid. When nid == NUMA_NO_NODE,* prefer the current CPU's closest node. Otherwise node must be valid and* online.*/
static inline struct page *alloc_pages_node(int nid, gfp_t gfp_mask,unsigned int order)
{if (nid == NUMA_NO_NODE)nid = numa_mem_id();return __alloc_pages_node(nid, gfp_mask, order);
}static inline struct page *alloc_pages(gfp_t gfp_mask, unsigned int order)
{return alloc_pages_node(numa_node_id(), gfp_mask, order);
}
负责分配2的order次方个连续的物理页面并返回其实页的struct page实例。传入gfp_mask如果没有指明__GFP_HIGHMEM,那么分配的物理页必然来自ZONE_NORMAL或者ZONE_DMA,这两个区域在内核初始化阶段就建立了映射关系。
内核模块可以使用page_address来获得对应页面的内核虚拟地址KVA。
ZONE_NORMAL和ZONE_DMA的PA和KVA之间是简单的线性映射关系,有一个PAGE_OFFSET差值:
page_address宏的实现原理:
unsigned long pfn = (unsigned long)(page - mem_map); //页帧
unsigned long pg_pa = pfn << PAGE_SHIFT; //获得页面所在的物理地址
return (void* )__va(pg_pa); //KVA = PAGE_OFFSET + pg_pa
如果gfp_mask = __GFP_HIGHMEM,那么页分配器将有限在ZONE_HIGHMEM域中分配物理页,但也不排除因为ZONE_HIGHMEM没有足够的空闲页导致页面来自ZONE_NORMAL和ZONE_DMA。
新分配的来自高端物理区域的页面,由于内核还没在页表建立映射,所以需要:
- 在内核的动态映射区域分配一个KVA
- 操作页表,KVA 映射到该物理页面
步骤2,内核已经实现了这种函数:kmap
kmap/unkmap系统调用是用来映射高端物理内存页到内核地址空间的api函数
arch/arm/mm/highmem.c
void *kmap(struct page *page)
{might_sleep();if (!PageHighMem(page)){//如果是低端内存,则直接返内存页对应的直接映射虚拟地址//printk("low mem page\n");return page_address(page);//所有的低端内存,在内核初始化时就已经映射好了,并且是不变得,且物理到虚拟相差0xc0000000}else{//printk("high mem page\n");}return kmap_high(page);//高端内存页
}/*** kmap_high - map a highmem page into memory* @page: &struct page to map** Returns the page's virtual memory address.** We cannot call this from interrupts, as it may block.*/
void *kmap_high(struct page *page)
{unsigned long vaddr;/** For highmem pages, we can't trust "virtual" until* after we have the lock.*/lock_kmap();vaddr = (unsigned long)page_address(page);if (!vaddr)vaddr = map_new_virtual(page); //建立MMU的页表项pkmap_count[PKMAP_NR(vaddr)]++;BUG_ON(pkmap_count[PKMAP_NR(vaddr)] < 2);unlock_kmap();return (void *) vaddr;
}
EXPORT_SYMBOL(kmap_high);
kmap在执行过程中可能会睡眠,不能用于中断上下文中。
涉及页表建立,开销比较大
kunmap函数拆除页表项中对page的映射,同时来自动态映射区的KVA被释放出去,使得KVA可以被用于映射其他的物理页面。
如果不想让kmap睡眠,可以使用kmap_atomic,原子执行,且比kmap快。
alloc_page 是 alloc_pages 在order=0时的简化形式,分配单个页面。
__get_free_pages
/** Common helper functions. Never use with __GFP_HIGHMEM because the returned* address cannot represent highmem pages. Use alloc_pages and then kmap if* you need to access high mem.*/
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
{struct page *page;page = alloc_pages(gfp_mask & ~__GFP_HIGHMEM, order);if (!page)return 0;return (unsigned long) page_address(page);
}
EXPORT_SYMBOL(__get_free_pages);
函数注释里说的很清楚了,绝不要使用__GFP_HIGHMEM,因为返回的地址不会存在与高端内存页面。如果你要访问高端内存,那你就通过alloc_pages然后kmap这种路子吧
即使传入__GFP_HIGHMEM,也会将它mask掉 gfp_mask & ~__GFP_HIGHMEM
返回的是KVA
get_zero_page
分配物理页面,并以0填充。返回的是内核线性地址
__get_dma_pages
从ZONE_DMA区域分配物理页面,返回页面所在的内核线性地址
SLAB分配器
页面分配器分配出的内存粒度比较大,如果需要更细的粒度,比如几十,几百字节的,还得是SLAB分配器。slab是内核最早推出的小内存分配方案,slob和slub分配器则是内核在2.6版本新增的替代品,针对大型系统和嵌入式系统。
查看下节
相关文章:
linux -- 内存管理 -- 页面分配器
linux内存管理 为什么要了解linux内存管理 分配并使用内存,是内核程序与驱动程序中非常重要的一环。内存分配函数都依赖于内核中一个非常复杂而重要的组件 - 内存管理。 linux驱动程序不可避免要与内核中的内存管理模块打交道。 linux内存管理可以总体上分为两大…...
StarRocks-3.1.0 单节点部署
1. 相关环境准备 FE: /opt/starrocks BE: /opt/starrocks 安装包下载 wget https://releases.starrocks.io/starrocks/StarRocks-3.1.0.tar.gz解压缩 tar -zxvf StarRocks-3.1.0.tar.gz 安装jdk (v2.5 及以上版本建议安装 JDK 11,我们使用…...
2023美赛A题之Lotka-Volterra【完整思路+代码】
这是2023年的成功,考虑到曾经付费用户的负责,2024年可以发出来了。去年我辅导队伍数量:15,获奖M为主,个别F,H,零S。言归正传,这里我开始分享去年的方案。由于时间久远,我…...
关于如何将Win幻兽帕鲁服务端存档转化为单人本地存档的一种方法(无损转移)
本文转自博主的个人博客:https://blog.zhumengmeng.work,欢迎大家前往查看。 原文链接:点我访问 **起因:**最近大火的开放世界缝合体游戏幻兽帕鲁的大火也是引起了博主的注意,然后博主和周边小伙伴纷纷入手,博主也是利…...
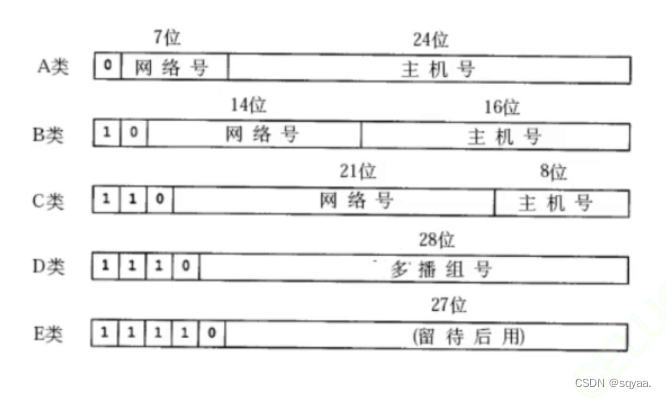
计算机网络——IP协议
前言 网络层的主要负责地址分配和路由选择,ip负责在网络中进行数据包的路由和传输。 IPv4报文组成(了解) IPv4首部:IPv4首部包含了用于路由和传输数据的控制信息,其长度为20个字节(固定长度)。 版本&#…...
)
Linux命令-ar命令(建立或修改备存文件,或是从备存文件中抽取文件)
补充说明 ar命令 是一个建立或修改备存文件,或是从备存文件中抽取文件的工具,ar可让您集合许多文件,成 为单一的备存文件。在备存文件中,所有成员文件皆保有原来的属性与权限. 语法 ar [-]{dmpqrtx}[abcfilNoPsSuvV] [memberna…...
flask基于python的个人理财备忘录记账提醒系统vue
在当今高度发达的信息中,信息管理改革已成为一种更加广泛和全面的趋势。 “备忘记账系统”是基于Mysql数据库,在python程序设计的基础上实现的。为确保中国经济的持续发展,信息时代日益更新,蓬勃发展。同时,随着信息社…...
【leetcode题解C++】257.二叉树的所有路径 and 404.左叶子之和 and 112.路径总和
257. 二叉树的所有路径 给你一个二叉树的根节点 root ,按 任意顺序 ,返回所有从根节点到叶子节点的路径。 叶子节点 是指没有子节点的节点。 示例 1: 输入:root [1,2,3,null,5] 输出:["1->2->5",&…...
Linux——文本编辑器Vim
Linux中的所有内容以文件形式管理,在命令行下更改文件内容,常常会用到文本编辑器。我们首选的文本编辑器是Vim,它是一个基于文本界面的编辑工具,使用简单且功能强大,更重要的是,Vim是所有Linux发行版本的默…...
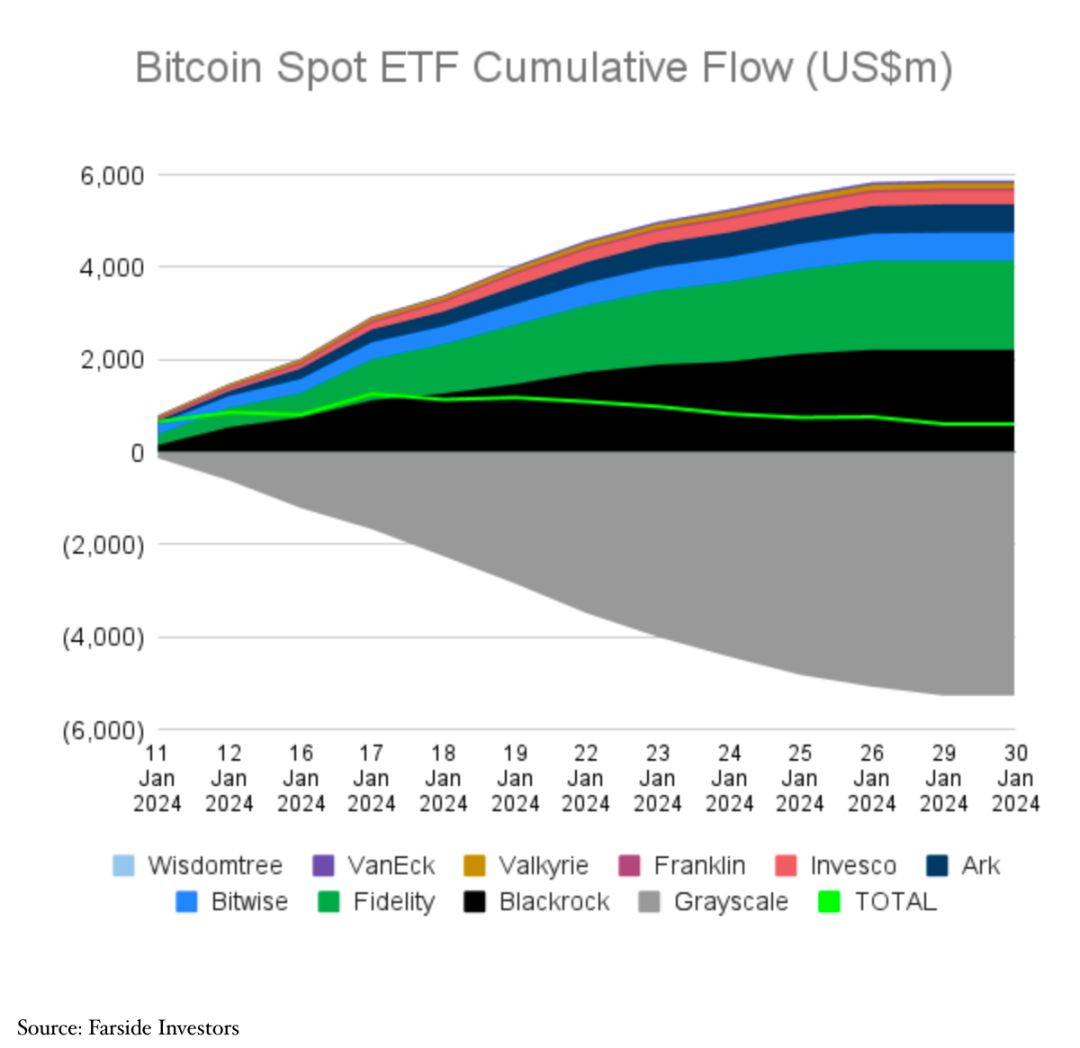
以“美”为鉴,探寻香港比特币现货ETF的未来发展
出品|欧科云链研究院 作者|Hedy Bi 根据The Block于1月29日的报道,嘉实国际成为了首家向香港证监会提交比特币现货ETF申请的机构。早在去年12月22日,香港证监会发布了《有关证监会认可基金投资虚拟资产的通函》,明确…...
)
Unity项目打包的方法(之一)
在 Unity 中,将项目打包成 .unitypackage 文件和直接压缩 Assets、Packages 和 ProjectSettings 目录有几个关键区别,主要体现在打包方式、使用目的和包含的内容上。 打包成 UnityPackage .unitypackage 是 Unity 的一种打包格式,它允许你将项…...

如何安装MySQL
如何安装MySQL 前提条件下载MySQL在 Windows 上安装 MySQL验证 MySQL 安装 MySQL是当今工业界广泛使用的最流行的关系数据库管理软件之一。它通过各种存储引擎提供多用户访问支持。它得到了甲骨文公司的支持。在本节中,我们将学习如何为初学者下载和安装 MySQL。 前…...

如何编写.gitignore文件
文章目录 前端架构师教你如何编写.gitignore文件.gitignore文件简介.gitignore文件的语法规则.gitignore文件的最佳实践常见问题与解决 前端架构师教你如何编写.gitignore文件 .gitignore文件简介 .gitignore文件是Git版本控制系统中一个非常有用的工具。它可以指定一组文件或…...
U-Boot学习(7):内核启动之bootz启动zImage源码分析
在上一节中,我们分析了U-BOOT初始化的流程,最后就是进入U-Boot的命令行中执行了,如果用户没有任何操作,则经过固定延时后将执行默认的bootcmd环境变量里的指令,那这里面肯定就是启动内核了。在U-BOOT简介及命令行指令详…...

[GN] DP学习笔记板子
文章目录 Bitset滚动数组多重背包区间DP树形dp状压dp模拟退火 Bitset 使用bitset需要引用<bitset>头文件。 其声明方法为: std::bitset<N>s; (N为s长度)常用函数: b.any() 判断b中是否存在值为1的二进制位 b.none() 判断b中是否不存在值为1的二…...
GLog开源库使用
Glog地址:https://github.com/google/glog 官方文档:http://google-glog.googlecode.com/svn/trunk/doc/glog.html 1.利用CMake进行编译,生成VS解决方案 (1)在glog-master文件夹内新建一个build文件夹,用…...
微信小程序如何实现点击上传图片功能
如下所示,实际需求中常常存在需要点击上传图片的功能,上传前显示边框表面图片显示大小,上传后将图形缩放到边框大小。 实现如下: .wxml <view class="{{img_src==?blank-area:}}" style="width:100%;height:40%;display:flex;align-items: center;jus…...
Windows Qt C++ VTK 绘制三维曲线
Qt 自带数据可视化从文档上看,只能实现三维曲面。 QwtPlot3D在Qt6.6.0上没编译通过。 QCustomPlot 只能搞二维。 VTK~搞起。抄官网demo。 后续需求: 1、对数轴 2、Y轴逆序 3、Z轴值给色带,类似等高线图的色带 期待各位大佬多多指导。…...

Android T 远程动画显示流程(更新中)
序 本地动画和远程动画区别是什么? 本地动画:自给自足。对自身SurfaceControl矢量动画进行控制。 远程动画:拿来吧你!一个app A对另一个app B通过binder跨进程通信,控制app B的SurfaceControl矢量动画。 无论是本地动画还是远程…...

【计算机网络】【练习题及解答】【新加坡南洋理工大学】【Computer Control Network】
说明: 仅供学习使用。 一、题目描述 题目共4问,描述网络通信中的 帧传输时延(Frame Delay)、传播时延(Propagation Delay),以及 链接利用率(Link Utilization) 的相关…...

C语言--day19
第十章 内存管理当./a.out 运行起来后,系统会给a.out分配一段内存区域1、code ,存放编写好的c语言代码。 只读特性,在运行期间不能修改2、data 数据段。 存储全局变量,和被static 修改的变量细分:data 数据段ÿ…...

猫抓浏览器扩展技术深度解析:构建高效流媒体资源捕获工作流
猫抓浏览器扩展技术深度解析:构建高效流媒体资源捕获工作流 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓浏览器扩展是一个基于C…...

终极指南:如何在Windows上直接访问Linux RAID阵列数据
终极指南:如何在Windows上直接访问Linux RAID阵列数据 【免费下载链接】winmd WinMD 项目地址: https://gitcode.com/gh_mirrors/wi/winmd 你是否曾面临这样的困境:企业Linux服务器上存储着重要的业务数据,使用mdadm创建的RAID阵列运行…...

剖析爆炸事故失联成因,UWB穿戴模式隐患重重,无感定位筑牢矿山透明化空间管理根基
剖析爆炸事故失联成因,UWB穿戴模式隐患重重,无感定位筑牢矿山透明化空间管理根基一、爆炸事故深度溯源:井下人员大面积失联核心诱因矿山瓦斯爆炸突发灾害,瞬间伴随剧烈冲击、粉尘弥漫、巷道形变、线路损毁与人员紧急避险疏散&…...
详解 + 实例代码)
IDE 重构(Refactoring)详解 + 实例代码
IDE 重构(Refactoring)详解 实例代码 重构是指在不改变代码外部行为的前提下,对代码内部结构进行调整、优化,使代码更易读、易维护、易扩展的过程。IDE(集成开发环境)是重构的最强助手,它能自动…...

Android 13 HTTPS抓包失效原因与Proxyman实战解决方案
1. 为什么Android 13上抓HTTPS包突然变难了?从Fiddler/Charles失效说起 你是不是也遇到过:上周还能用Fiddler在Android 12真机上稳稳抓到某电商App的登录接口,升级到Android 13后,所有HTTPS请求全变成“Connection refused”或直接…...

3分钟掌握猫抓扩展:浏览器资源嗅探的完整实用指南
3分钟掌握猫抓扩展:浏览器资源嗅探的完整实用指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 还在为网页上的视频无法保存而烦恼吗…...

iOS砸壳与反编译实战:从FairPlay解密到Swift逆向分析
1. 砸壳不是“破解”,而是理解iOS应用分发机制的第一道门很多人第一次听说“砸壳”,脑子里立刻浮现出“绕过App Store审核”“盗取商业逻辑”“窃取用户数据”这类词。这其实是个根深蒂固的误解。在我过去八年做iOS底层工具链开发、参与多个企业级MDM方案…...

BepInEx 6.0技术揭秘:如何构建跨平台Unity插件框架的5大核心机制
BepInEx 6.0技术揭秘:如何构建跨平台Unity插件框架的5大核心机制 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx 在Unity游戏开发领域,插件框架的技术实现一…...

Charles断点调试:HTTP/HTTPS流量精准控制与实战避坑
1. 这不是“抓包”,是精准外科手术式调试 很多人第一次听说 Charles,第一反应是“哦,又一个抓包工具”。但如果你真这么用,大概率会在某次接口联调中卡住两小时,反复刷新页面却始终看不到后端返回的错误码,…...