#RAG|NLP|Jieba|PDF2WORD# pdf转word-换行问题
文档在生成PDF时,文宁都发生了什么。本文讲解了配置对象、resources对象和content对象的作用,以及字体、宇号、坐标、文本摆放等过程。同时,还解释了为什么PDF转word或转文字都是一行一行的以及为什么页眉页脚的问题会加大识别难度。最后提到了文本的编码和PDF中缺少文档结构标记的问题。PDF转word更像是一种逆向工程。
第三方库pdf转word的痛点-格式不保留
本文着力解决换行问题:
- 源文本正常输入,pdf解析第三方库识别出来多余换行符
如
原文:“你好”
识别:“你\n好” - 源文本出现多个换行符,pdf解析第三方库识别出一个换行符
如
原文:“你好\n\n\n\n\n\n我是向日葵花子”
识别:“你好\n我是向日葵花子”
word 转 pdf 经历了什么
文本转换为PDF时,记录的信息
包括:
- 位置和大小信息:记录每个文本在页面上的位置和大小。
- 字体信息:记录文本所使用的字体名称、大小和样式。
- 颜色信息:记录文本的颜色。
- 行间距和段落间距:记录文本之间的行间距和段落之间的间距。
- 文本属性:记录文本的对齐方式、装饰等其他属性。
- 超链接和书签:记录文本中的超链接和书签信息,以实现交互功能。
这些信息的记录旨在确保在PDF中正确呈现文本内容,并保持文档的原始格式和布局。
pdf文本信息
pdf文本是由文本空间组成的,其中包含:
文本矩阵,定义下一个字形的当前转换。它由文本定位和显示运算符的文本改变。
文本行矩阵,它是当前行开头的文本矩阵的状态。因此,通过使用操作员移动到下一行,可以垂直对齐文本行,而无需手动跟踪行的开始位置。
这些矩阵不会从文本部分持续到文本部分,而是在每个文本部分的开头重置为单位矩阵。 结合字体大小,水平缩放和文本上升,这两个矩阵定义了从文本空间到用户空间的转换。
如何获得pdf信息
大段处理
可以在调用第三方库的过程中加一些小算法,我这里给一点点提示
- 读取pdf基本信息
- 逐行获取pdf信息
- 根据每行的行宽来判断是不是多输出了换行符
- 每行即使没有文字只有换行符也要加入到获取的信息中
这一步可以完成百分之八十的换行格式还原。
获取每行信息的代码:
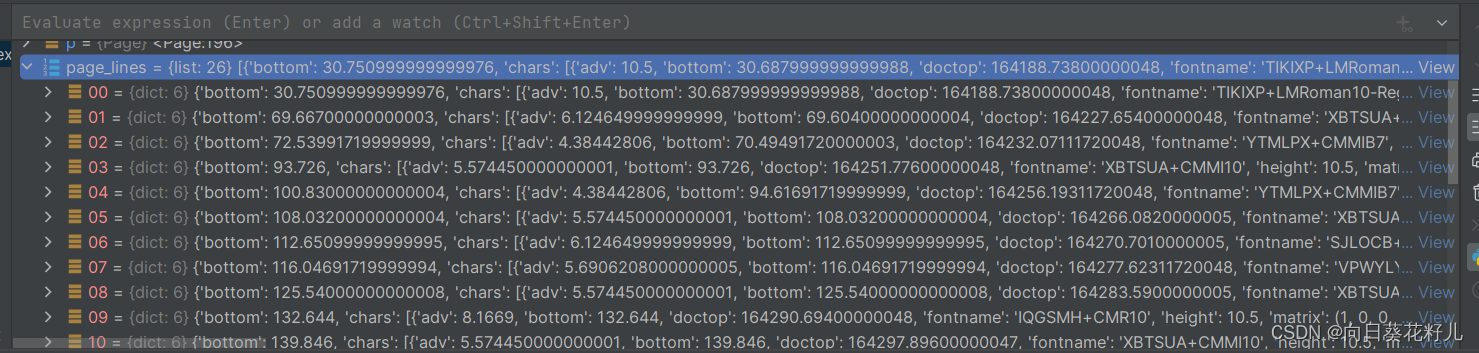
with pdfplumber.open(file_path) as pdf:for p in pdf.pages:# print(p.bbox)page_lines = p.extract_text_lines()
接下来就要去分析文档每行的信息,然后利用坐标去处理了,大家可以自己思考下代码怎么写。
页眉页脚、大小标题
识别处理思路和大段处理一致
小段处理

通过坐标处理不了两行的小段,特别是开头没有缩进的unstructured文本,这里我们需要加上其他算法。
我使用的是nlp的文本分析进行兜底。
处理流程:
- 分析上下文关系优化结构算法: 在获取到文本内容后,可以编写一个分析句子上下文关系的算法来处理文本,对于出现问题的地方进行修正。
主要用到:
词性标注(Part-of-Speech Tagging): 词性标注是将句子中的每个词汇标记为其对应的词性(如名词、动词、形容词等)的过程。通过词性标注可以识别句子中各个词汇的语法角色,从而帮助理解句子的结构和含义。
句法分析(Syntax Parsing): 句法分析是分析句子中各个词汇之间的语法关系,如主谓关系、动宾关系等。通过句法分析可以构建句子的语法树,从而帮助理解句子的结构和语义。 - 合并文本: 根据分析结果,将需要合并的部分合并到一起。
- 输出结果:输出处理后的文本。
这一步可以完成到90%的换行格式还原,通过不断优化句法分析的规则,可以逐渐接近100%。
清洗文本
nlp句法分析是分析句子中各个词汇之间的语法关系,因此,像emoji或者其他特殊、对于计算机语义处理无意义的符号保留下来必定对结果产生很大影响,最终合并的效果大打折扣,所以我们需要先对文本进行一个清洗,去掉无意义的符号。
由于我的文档只涉及到emoji这种特殊符号,所以我只进行了emoji的清洗
def remove_emoji(text):emoji_pattern = re.compile("["u"\U0001F600-\U0001F64F" # emoticonsu"\U0001F300-\U0001F5FF" # symbols & pictographsu"\U0001F680-\U0001F6FF" # transport & map symbolsu"\U0001F1E0-\U0001F1FF" # flags (iOS)u"\U00002600-\U000027BF" # miscellaneous symbolsu"\U0001F300-\U0001FAD6" # additional emoticons"]+", flags=re.UNICODE)return emoji_pattern.sub(r'', text)
句子拆分
按照逗号拆分就可以,然后找到带有换行符号的句子进行进一步的词性标注
注意只取带有换行符的小句,这样可以提高工作效率减少无意义的算法调用
使用split函数即可
词性标注
为了分析句子语法关系、上下文关系,我们必须先进行词性标注,构建语法树,然后再进行句子分析
这里我直接用的中文nlp库jieba,其他好用的库可以直接替换使用,如果是英文词性标注可以使用ntlk,ntlk也有中文词性标注,但是我中文标注我更喜欢用jieba
jieba的jieba词性标注表我也给大家整理好了
词性标注的代码:
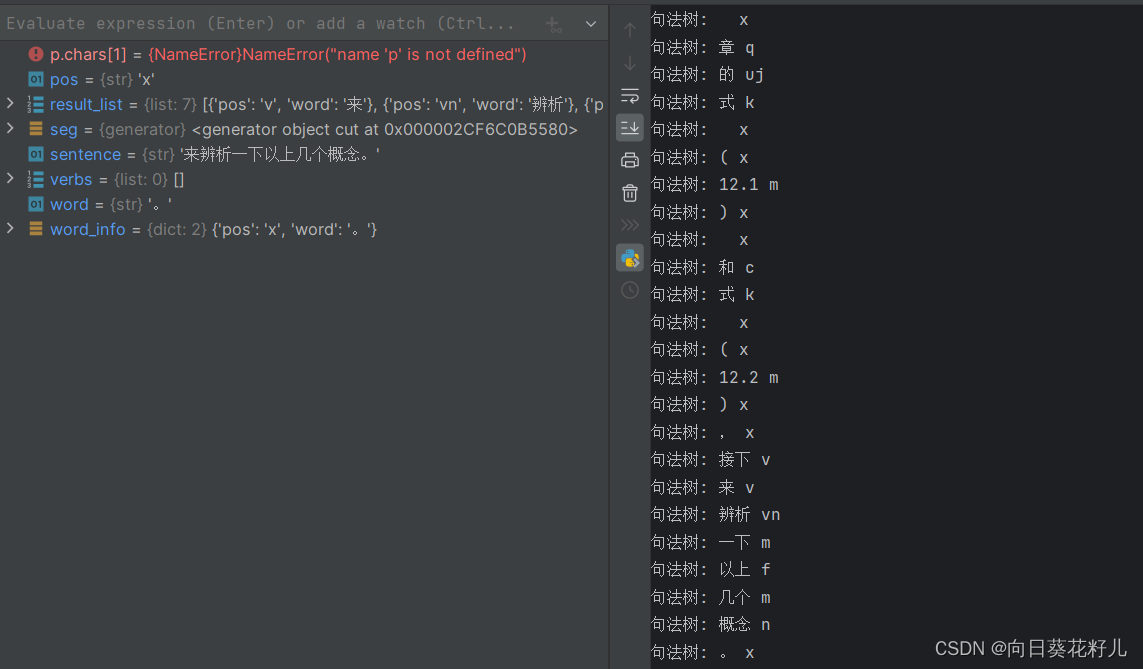
import jieba.posseg as psg
# 分词和词性标注
seg = psg.cut(sentence)
# 定义语法规则
result_list = []
verbs = []
for word, pos in seg:# 对句法树进行处理,这里只是简单打印出来,你可以根据需要处理print("句法树:", word, pos)word_info = {'word': word, 'pos': pos}# 将字典添加到列表中result_list.append(word_info)if pos == 'v':verbs.append(word_info)
verbs = [word for word, pos in seg if pos == 'v']
分析上下文关系
词性标注结束后,我们就可以根据语法树分析上下文关系了
merged_sentences = []
for i, sentence in enumerate(sentences):if i > 0:# 分析上下文关系verbs_prev, seg_prev = analyze_context(sentences[i - 1])verbs_curr, seg_curr = analyze_context(sentence)x = list(seg_prev)# 如果前一个句子或当前句子至少有一个含有动词,则进行合并if (len(verbs_prev) == 1 and len(verbs_curr) == 0) or (len(verbs_prev) == 0 and len(verbs_curr) == 1):merged_sentences[-1] += sentence# 如果上一句的最后一个词和下一句的第一个词都是动词,则进行合并elif seg_prev[-1] and seg_curr[0] and seg_prev[-1]["pos"] in ['r', 'v'] and seg_curr[0]["pos"] == 'v':merged_sentences[-1] += sentence# 代词和指示词:如果后一个句子以代词或指示词开头,这可能表明它是对前一个句子的补充。elif seg_curr[0]["pos"] in ['r', 'z', 'c'] or seg_curr[0]["word"] in ['这', '那', '其', ...]:merged_sentences[-1] += sentence# 时间+nelif seg_curr[0]["pos"] in ['n'] or seg_prev[0]["pos"] in ['t', 'm', ...]:merged_sentences[-1] += sentence# 句号和分号:虽然句号和分号通常表示句子的结束,但如果它们后面紧跟的是小写字母或标点符号,可能意味着这是同一句话的一部分。elif seg_prev[-1]["word"] in ['。', ';'] and not seg_curr[0]["word"].istitle():merged_sentences[-1] += sentence# 如果后一个句子的第一个词是“的”并且前一个句子的最后一个词是动词,则进行合并elif seg_curr[0] and seg_curr[0]["pos"] == 'm' and seg_prev[-1] and seg_prev[-1]["pos"] == 'v':merged_sentences[-1] += sentences[i]# 如果后一个句子的第一个词是“的”并且前一个句子的最后一个词是动词,则进行合并elif seg_curr[0] and seg_curr[0]["pos"] == 'p' and seg_prev[-1] and seg_prev[-1]["pos"] == 'd':merged_sentences[-1] += sentences[i]# 3. 如果上一句的最后一个词是标点符号,且下一句的第一个词不是句首发语词,则进行合并elif seg_prev[-1]["pos"] == 'x' and seg_curr[0]["pos"] not in ['c', 'r', 'u', 'p', 'm', 'e']:merged_sentences[-1] += sentence# 4. 如果上一句的最后一个词是名词或动词,且下一句以时间状语或条件状语开头,则进行合并elif (seg_prev[-1]["pos"] in {'n', 'vg', 'v'}) and (seg_curr[0]["pos"] in {'f', 'c'}):merged_sentences[-1] += sentenceelse:merged_sentences.append(sentence)else:merged_sentences.append(sentence)
我在判断规则的同时,进行了是否合并的判断,这样 我们就得到了合并后的文本merged_sentences
参考文献
https://www.bilibili.com/video/BV1Vi4y1C71M/?spm_id_from=333.788&vd_source=8c9777cd5733f7f447f766cd5105041b
相关文章:
#RAG|NLP|Jieba|PDF2WORD# pdf转word-换行问题
文档在生成PDF时,文宁都发生了什么。本文讲解了配置对象、resources对象和content对象的作用,以及字体、宇号、坐标、文本摆放等过程。同时,还解释了为什么PDF转word或转文字都是一行一行的以及为什么页眉页脚的问题会加大识别难度。最后提到了文本的编码和PDF中缺少文档结构标…...
solr的原理是什么
1 Java程序里如果有无限for循环的代码导致CPU负载超高,如何排查? 排查Java程序中由于无限循环导致的CPU负载过高的问题,可以按照以下步骤进行: 资源监控: 使用系统命令行工具(如Linux上的top或htop…...

【安装指南】nodejs下载、安装与配置详细教程
目录 🌼一、概述 🍀二、下载node.js 🌷三、安装node.js 🍁四、配置node.js 🌼一、概述 Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行时,用于构建可扩展的网络应用程序。Node.js 使用事件驱动、…...

Mobileye CES 2024 自动驾驶新技术新方向
Mobileye亮相2024年国际消费类电子产品展览会推出什么自动驾驶新技术? Mobileye再次亮相CES,展示了我们的最新技术,并推出了Mobileye DXP--我们全新的驾驶体验平台。 与往年一样,Mobileye是拉斯维加斯展会现场的一大亮点,让参观者有机会见证我们对自主未来的愿景。 在…...

【Linux】网络基本配置及网络测试、测试工具
一、网络基本配置 查看网络信息: ifconfigc / ip addr停止网卡eth0: ifconfig eth0 down在本地启动网卡eth0: ifconfig eth0 up改变网卡ip: ifconfig eth0 192.168. .修改子网掩码: ifconfig eth0 (I…...
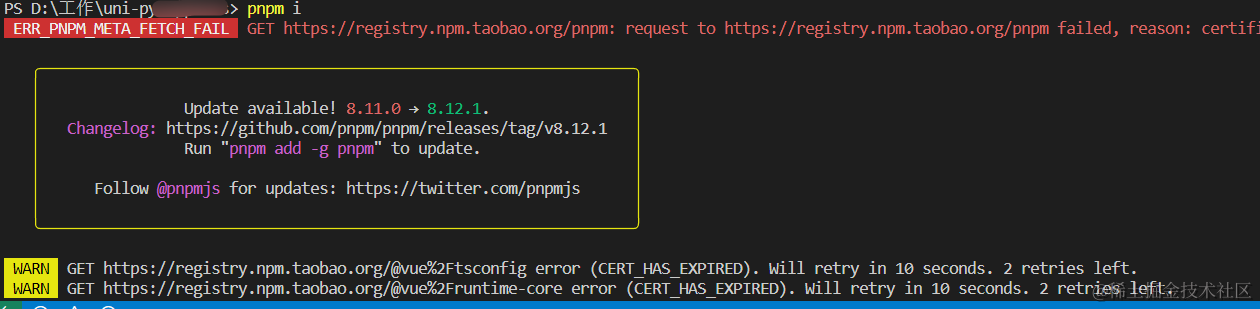
pnpm : 无法加载文件 D:\tool\nvm\nvm\node_global\pnpm.ps1,因为在此系统上禁止运行脚本
你们好,我是金金金。 场景 新创建的项目,在vscode编辑器终端输入 pnpm i,显示报错如上 解决 在终端输入get-ExecutionPolicy(查看执行策略/权限) 输出Restricted(受限的) 终端再次输入Set-ExecutionPolicy -Scope CurrentUser命令给用户赋予…...

Python 类与实例
在面向对象编程中,类(Class)是一种抽象的概念,它描述了对象的属性和行为。类可以看作是创建对象的蓝图或模板,它定义了一组属性和方法,并提供了创建对象的规范。 类包含了对象的属性和方法的定义ÿ…...

2的N次方
题目描述 输入n行,每行一个整数x,输出2的x次方的个位是多少?2的3次方表示3个2相乘,结果是8 输入 输入n行,每行一个整数x 输出 输出n行,每行一个整数,2的x次方的个位。 样例输入 Copy 5 4…...

cobra - 更容易地构建命令行应用
cobra 是什么 cobra 的主要功能是创建强大的现代 cli 应用程序。目前市面上许多的著名的 Go 语言开源项目都是使用 Cobra 来构建的,例如:K8s、Hugo、etcd、Docker 等,是非常可靠的一个开源项目。 没有 cobra 之前用什么 如果不用 cobra&am…...

windows10设置多个jar后台开机自启
1、window10启动多个jar包的脚本 新建一个txt文档,将以下内容复制到文档中: echo off taskkill /f /im javaw.exe //停用之前启动过的所有后台javaw程序 d: //jar包所在盘符 cd saas //jar包所在文件夹 start cmd /c "title 程序…...

数据库||数据库相关知识练习题目与答案
目录 1.只能读取本系学生的信息? 2.要查询选修“Computer”课的男生姓名,将涉及到关系( ) 3.实体完整性规则规定( ) 4.下列有关范式的叙述中正确的是( ) 5.从课程表course&…...

YOLOv8改进 | 损失函数篇 | 更加聚焦的边界框损失Focaler-IoU、InnerFocalerIoU(二次创新)
一、本文介绍 本文给大家带来的改进机制是更加聚焦的边界框损失Focaler-IoU已经我进行二次创新的InnerFocalerIoU同时本文的内容支持现阶段的百分之九十以上的IoU,比如Focaler-IoU、Focaler-ShapeIoU、Inner-Focaler-ShapeIoU包含非常全的损失函数,边界框的损失函数只看这一…...
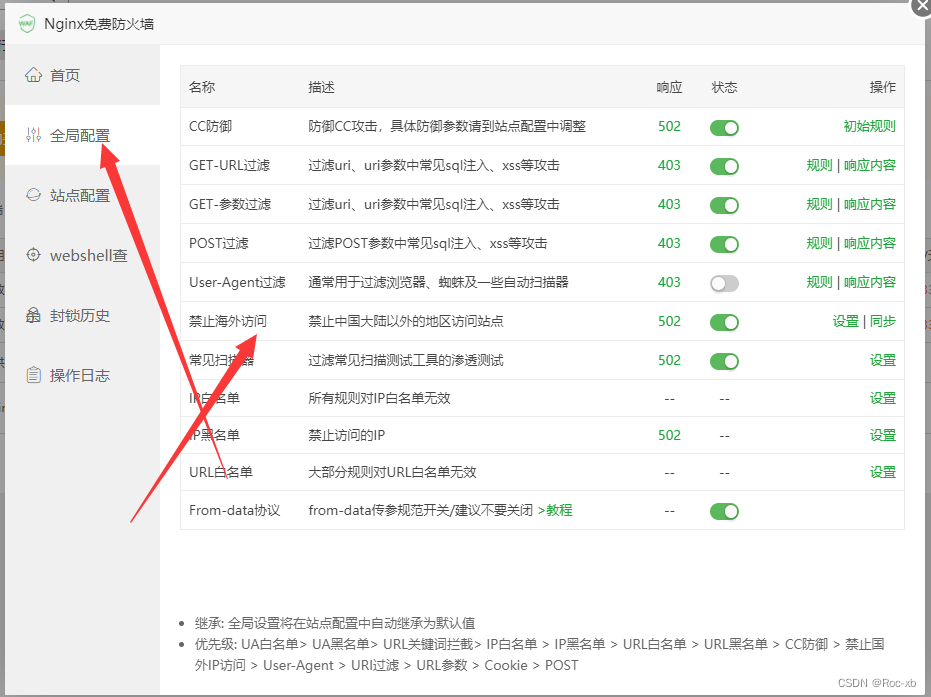
利用nginx宝塔免费防火墙实现禁止国外IP访问网站
本章教程,主要介绍,如何利用nginx宝塔面板中的插件免费防火墙,实现一键禁止国外IP访问网站。 目录 一、安装宝塔插件 二、 开启防火墙 一、安装宝塔插件 在宝塔面板中的软件商店,搜索防火墙关键词,找到Nginx免费防火…...
对比:RabbitMQ、Kafka、ActiveMQ 和 RocketMQ)
消息中间件(MQ)对比:RabbitMQ、Kafka、ActiveMQ 和 RocketMQ
前言 在构建分布式系统时,选择适合的消息中间件是至关重要的决策。RabbitMQ、Kafka、ActiveMQ 和 RocketMQ 是当前流行的消息中间件之一,它们各自具有独特的特点和适用场景。本文将对这四种消息中间件进行综合比较,帮助您在项目中作出明智的…...
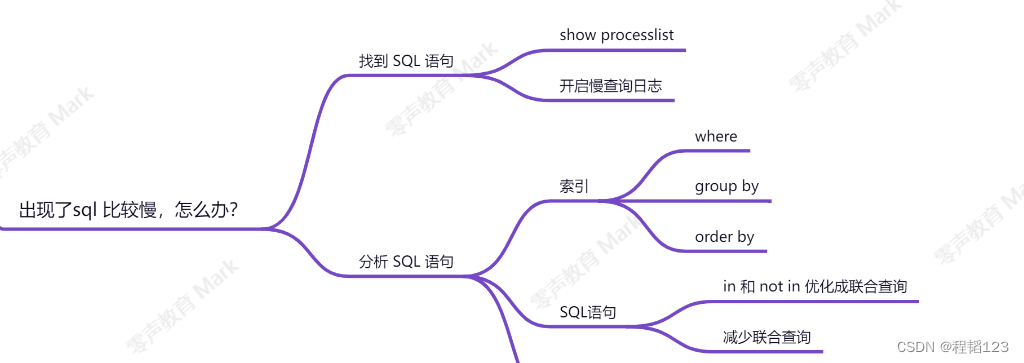
MySQL索引原理以及SQL优化
案例 struct index_failure_t{int id;string name;int cid;int score;string phonenumber;}Map<int,index_failure>; 熟悉C的同学知道,上述案例中,我们map底层是一颗红黑树,一个节点存储了一对kv(键值对)&…...
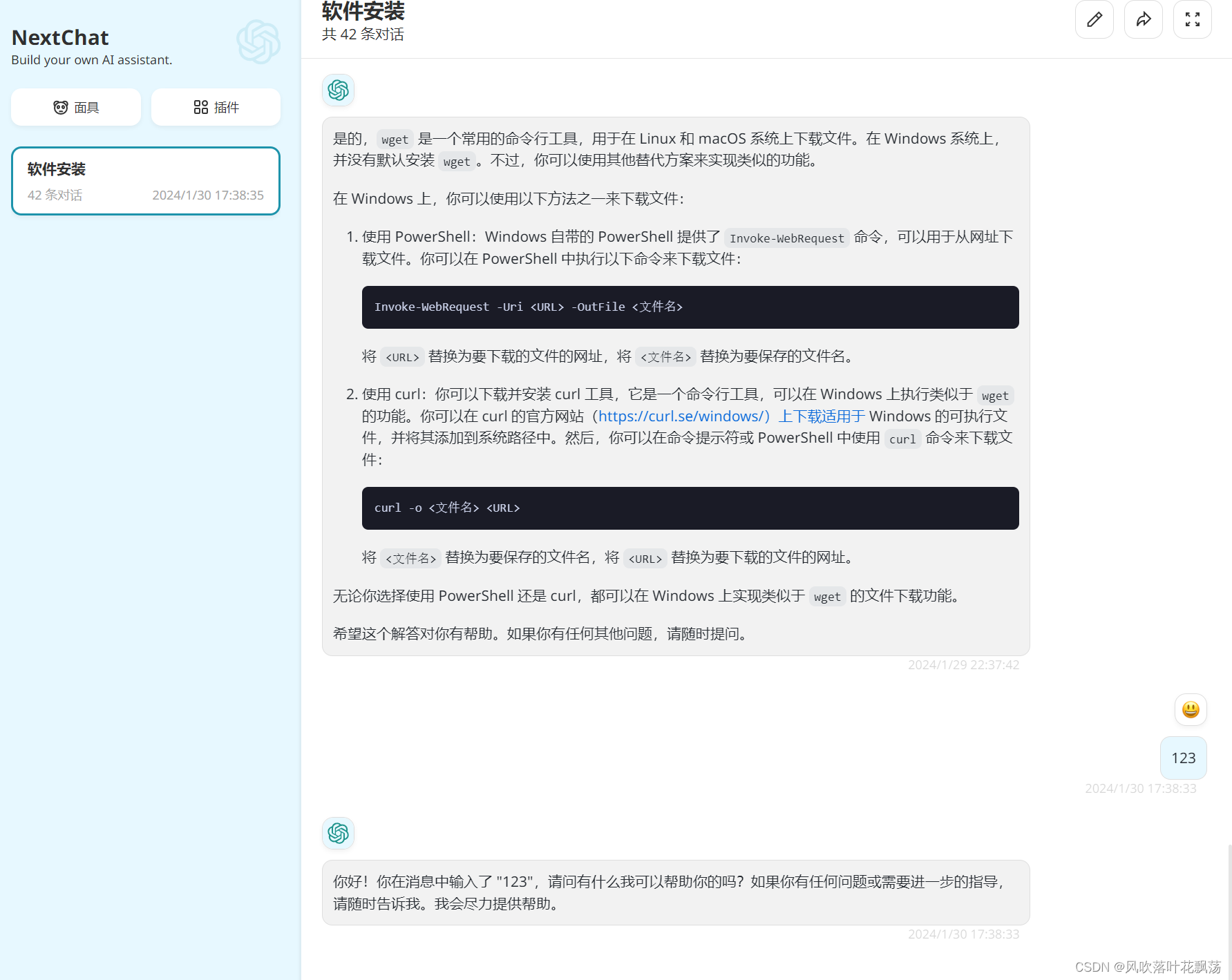
[Bug] [OpenAI] [TypeError: fetch failed] { cause: [Error: AggregateError] }
[Bug] [OpenAI] [TypeError: fetch failed] { cause: [Error: AggregateError] } ubuntu20 win10 edge浏览器访问 服务器部署 页面打开后想使用chatgpt报错了 rootcoal-pasi1cmp:/www/wwwroot/ChatGPT-Next-Web# PORT3000 yarn start yarn run v1.22.19 warning package.json:…...
|Day31(贪心算法))
@ 代码随想录算法训练营第5周(C语言)|Day31(贪心算法)
代码随想录算法训练营第5周(C语言)|Day31(贪心算法) Day31、贪心算法(包含题目 455.分发饼干 376. 摆动序列 53. 最大子序和 ) 455.分发饼干 题目描述 假设你是一位很棒的家长,想要给你的孩…...

面试手写第二期 Promsie相关
文章目录 一. 手写实现PromiseA规范二. Promise.all实现三. Promise.race实现四. Promise.allsettled实现六. Promise.any实现六. 如何实现 Promise.map,限制 Promise 并发数七. 实现函数 promisify,把回调函数改成 promise 形式八. 并发请求控制 一. 手…...

Windows冷知识:最小化远程桌面与ffmpeg
Windows冷知识:最小化远程桌面与ffmpeg – WhiteNights Site 标签:ffmpeg, Windows, 冷知识 最小化远程桌面会中断ffmpeg的录制 我觉得这个应该算冷知识吧。 前情提要 远程桌面连接至虚拟机,并通过ffmpeg录屏 这里可能不太好理解。 我在用…...
12nm工艺,2.5GHz频率,低功耗Cortex-A72处理器培训
“ 12nm工艺,2.5GHz频率,低功耗Cortex-A72处理器培训” 本项目是真实项目实战培训,低功耗UPF设计,后端参数如下: 工艺:12nm 频率:2.5GHz 资源:2000_0000 instances 为了满足更多…...

昇腾CANN ATB KV Cache 与 PagedAttention:显存碎片消除的完整方案
LLM 推理的最大瓶颈不是计算——是显存。长上下文下,KV Cache 的显存占用是二次增长的:seq_len128K → KV Cache 128K 每层 KV 大小 128K (2 hidden head_num) 128K 2 8192 32 32GB。加上模型参数(70B 2bytes 140GB)…...

boss app sig/sp/响应体 unidbg分析
声明 本文章中所有内容仅供学习交流使用,不用于其他任何目的,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关! 侵权通过头像私信或名字简介叫我删除博…...

大气层Atmosphere系统深度解析:解锁Switch潜能的终极技术指南
大气层Atmosphere系统深度解析:解锁Switch潜能的终极技术指南 【免费下载链接】Atmosphere-stable 大气层整合包系统稳定版 项目地址: https://gitcode.com/gh_mirrors/at/Atmosphere-stable Atmosphere大气层系统作为Nintendo Switch最稳定、功能最丰富的定…...

嵌入式C语言开发中的三大致命陷阱
很多人刚开始学习C语言时,会觉得: 会指针 会结构体 会寄存器操作 能驱动外设 似乎就已经掌握了嵌入式开发。 但真正进入项目后才会发现: 嵌入式开发最难的,从来不是语法,而是“代码与硬件现实世界之间的耦合”。 同样一句代码: 在PC上可能只是运行错误; 在单片机里却可…...

498元!某国产12代i7云终端小钢炮,仅1.7L迷你主机,可上i7-12700处理器,最大支持双M2+SATA三盘位,可惜还是准系统传家宝!
要说小主机品牌种类规格方面,最为丰富的不是个人家用消费级市场,而是云终端,痩客户机类型产品。奈何如今大环境不景气,再叠加如今处理器性能进步明显,以英特尔12代平台为例,如今依旧还是主流,所…...

AI绘画中的诡异谷:从技术缺陷到可控美学的跃迁
1. 项目概述:当AI画笔开始颤抖——我们为什么该认真对待“诡异谷”里的美你有没有盯着一张AI生成的肖像画,越看越不对劲?眼睛太亮、皮肤太滑、手指多了一节,或者笑容弧度精准得像用圆规画出来的——那种说不上来哪里怪,…...

JMeter HTTP接口压测实战:定位性能瓶颈的工程方法论
1. 这不是点几下就能出报告的“压测”,而是对系统真实承压能力的外科手术式探查很多人第一次打开JMeter,以为只要填个URL、设个线程数、点“启动”,跑完看个聚合报告就叫“压测完了”。我见过太多团队在上线前用JMeter跑出“99.9%成功率、平均…...

企业级RAG落地需要考虑的七个优化指标
在企业级RAG应用中,单纯跑通流程只是起点。要让系统真正稳定、准确、高效、安全地服务于业务,需要从以下七个维度进行系统性优化。这些建议基于生产环境的最佳实践总结。 一、检索质量优化(核心中的核心) 1.1 分块策略精细化文档类…...

如何在Mac上免费快速导出微信聊天记录:WeChatExporter终极指南
如何在Mac上免费快速导出微信聊天记录:WeChatExporter终极指南 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾因误删重要微信聊天记录而焦虑&#x…...

在Taotoken模型广场根据任务需求挑选合适模型的实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Taotoken模型广场根据任务需求挑选合适模型的实践 1. 模型广场:你的模型选型起点 当你开始一个新项目,或…...