14.java集合
文章目录
- `概念`
- `Collection 接口`
- 概念
- 示例
- `Iterator 迭代器`
- 基本操作:
- 并发修改异常
- 增强循环
- 遍历数组:
- 遍历集合:
- 遍历字符串:
- 限制
- `list接口`
- `ListIterator`
- `ArrayList`
- 创建 ArrayList:
- 添加元素:
- 获取元素:
- 修改元素:
- 删除元素:
- 获取列表大小:
- 遍历元素:
- 注意事项:
- 源码扩容
- `LinkedList`
- 创建 LinkedList:
- 添加元素:
- 在指定位置插入元素:
- 获取元素:
- 删除元素:
- 删除指定位置的元素:
- 遍历元素:
- 实现队列和栈:
- 注意事项:
- 源码链表
- `set接口`
- 概况
- `HashSet`
- 概况
- `LinkedHashSet`
- 概况
- `TreeSet`
- 概况
- `Collections 工具类`
- 概况
- `Map接口`
- 概况
- `HashMap`
- 概况
- 源码扩容
- `LinkedHashMap`
- 概况
- `Hashtable`
- 概况
- `TreeMap`
- 概况
- `Properties`
- 概况
概念
在Java中,集合是一种用于存储和处理多个对象的框架。Java集合框架提供了一组接口和类,用于表示和操作不同类型的集合数据结构。以下是Java集合框架的主要概念:
-
接口(Interfaces):
- Collection接口: 定义了一组通用的方法,适用于所有集合类。它是所有集合框架的根接口。
- Set接口: 继承自Collection接口,表示不包含重复元素的集合。
- List接口: 继承自Collection接口,表示有序且可重复的集合。
- Map接口: 不继承自Collection接口,表示键值对的集合。
-
类(Classes):
- ArrayList: 基于数组实现的动态数组,实现了List接口。
- LinkedList: 基于链表实现的双向链表,也实现了List接口。
- HashSet: 使用哈希表实现的Set接口,不保证元素的顺序。
- TreeSet: 基于红黑树实现的Set接口,以有序方式存储元素。
- HashMap: 使用哈希表实现的Map接口,存储键值对。
- TreeMap: 基于红黑树实现的Map接口,以键的自然顺序或自定义顺序存储键值对。
-
迭代器(Iterator): 用于遍历集合中的元素,是集合框架中通用的迭代方式。
-
泛型(Generics): 集合框架使用泛型来提供类型安全性,允许在编译时检测类型错误。
-
自动装箱和拆箱: 集合框架支持自动装箱(将基本数据类型转换为对应的包装类)和拆箱(将包装类转换为基本数据类型)。
-
并发集合: Java还提供了一些在多线程环境下安全使用的并发集合,如ConcurrentHashMap。
使用Java集合框架,可以轻松地处理各种数据结构,选择适当的集合类可以提高程序的效率和可读性。
Collection 接口
概念
Java 中的 Collection 接口是 Java 集合框架的根接口,它定义了一组通用的方法,可以用于操作和处理各种集合。Collection 接口派生出许多子接口和实现类,包括 Set、List 和 Queue。
以下是 Collection 接口的主要方法:
-
基本操作:
int size(): 返回集合中的元素个数。boolean isEmpty(): 判断集合是否为空。boolean contains(Object element): 判断集合是否包含指定的元素。boolean add(E element): 向集合中添加一个元素。boolean remove(Object element): 从集合中移除指定的元素。boolean containsAll(Collection<?> c): 判断集合是否包含给定集合的所有元素。boolean addAll(Collection<? extends E> c): 将给定集合的所有元素添加到集合中。boolean removeAll(Collection<?> c): 移除集合中与给定集合相同的所有元素。void clear(): 清空集合中的所有元素。
-
集合查找和迭代:
Iterator<E> iterator(): 返回一个用于迭代集合的迭代器。Object[] toArray(): 将集合转换为数组。<T> T[] toArray(T[] a): 将集合转换为指定类型的数组。
-
集合操作:
boolean retainAll(Collection<?> c): 仅保留集合中与给定集合相同的元素,移除其他元素。
-
比较和相等:
boolean equals(Object o): 判断集合是否与另一个对象相等。int hashCode(): 返回集合的哈希码值。
Collection 接口的实现类包括 ArrayList、LinkedList、HashSet 等,它们提供了不同的数据结构和行为,以满足不同的需求。此外,Collection 接口的子接口 Set、List 和 Queue 分别定义了集合的不同特性。
示例
当涉及到 Collection 接口和其实现类时,代码示例的具体内容会取决于你希望使用的集合类型和操作。以下是一些基本的代码示例,涵盖了一些常见的集合操作。
- 使用
ArrayList实现Collection接口:
import java.util.ArrayList;
import java.util.Collection;public class CollectionExample {public static void main(String[] args) {// 创建 ArrayList 实例Collection<String> myCollection = new ArrayList<>();// 添加元素myCollection.add("Apple");myCollection.add("Banana");myCollection.add("Orange");// 判断集合是否为空boolean isEmpty = myCollection.isEmpty();System.out.println("Is Collection empty? " + isEmpty);// 获取集合大小int size = myCollection.size();System.out.println("Collection size: " + size);// 判断集合是否包含特定元素boolean containsBanana = myCollection.contains("Banana");System.out.println("Collection contains Banana? " + containsBanana);// 移除元素myCollection.remove("Orange");// 遍历集合System.out.println("Collection elements:");for (String element : myCollection) {System.out.println(element);}// 清空集合myCollection.clear();System.out.println("Is Collection empty after clearing? " + myCollection.isEmpty());}
}
- 使用
HashSet实现Set接口:
import java.util.HashSet;
import java.util.Set;public class SetExample {public static void main(String[] args) {// 创建两个集合Set<String> set1 = new HashSet<>(Arrays.asList("Apple", "Banana", "Orange"));Set<String> set2 = new HashSet<>(Arrays.asList("Banana", "Orange", "Grapes"));// 计算两个集合的交集Set<String> intersection = new HashSet<>(set1);intersection.retainAll(set2);// 打印交集System.out.println("Intersection of set1 and set2: " + intersection);// 将集合转换为数组String[] arrayFromSet1 = set1.toArray(new String[0]);String[] arrayFromSet2 = set2.toArray(new String[0]);// 打印转换后的数组System.out.println("Array from set1: " + Arrays.toString(arrayFromSet1));System.out.println("Array from set2: " + Arrays.toString(arrayFromSet2));// 创建 HashSet 实例Set<String> mySet = new HashSet<>();// 添加元素mySet.add("Red");mySet.add("Green");mySet.add("Blue");// 判断集合是否包含特定元素boolean containsGreen = mySet.contains("Green");System.out.println("Set contains Green? " + containsGreen);// 遍历集合System.out.println("Set elements:");for (String element : mySet) {System.out.println(element);}}
}
这只是一个简单的示例,你可以根据需要进行更复杂的集合操作和使用其他实现类。希望这些例子能帮助你入门 Java 集合框架。
Iterator 迭代器
Iterator 接口是 Java 集合框架中用于遍历集合元素的迭代器接口。它定义了一组用于在集合中迭代元素的方法。迭代器提供了一种统一的方式,允许你遍历集合中的元素,而不必关心集合的底层实现。
以下是 Iterator 接口的主要方法:
基本操作:
boolean hasNext(): 判断是否还有下一个元素。E next(): 返回迭代器的下一个元素。void remove(): 从集合中移除迭代器最后返回的元素(可选操作)。
使用 Iterator 的示例代码如下:
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;public class IteratorExample {public static void main(String[] args) {// 创建一个 ArrayListList<String> myList = new ArrayList<>();myList.add("Apple");myList.add("Banana");myList.add("Orange");// 获取迭代器Iterator<String> iterator = myList.iterator();// 使用迭代器遍历集合System.out.println("Elements in the list:");while (iterator.hasNext()) {String element = iterator.next();System.out.println(element);// 可选操作:在遍历过程中移除元素if (element.equals("Banana")) {iterator.remove();}}// 打印修改后的集合System.out.println("List after removing 'Banana': " + myList);}
}
在这个例子中,我们使用 ArrayList 创建了一个列表,然后通过 iterator() 方法获取了该列表的迭代器。接着,使用 while 循环和迭代器的 hasNext() 和 next() 方法遍历集合中的元素。如果需要,在遍历的同时,可以使用迭代器的 remove() 方法从集合中移除元素(这是可选操作)。
输出应该类似于以下内容:
Elements in the list:
Apple
Banana
Orange
List after removing 'Banana': [Apple, Orange]
这个例子演示了如何使用 Iterator 遍历集合元素,并且在遍历的过程中进行一些操作。
并发修改异常
在 Java 中,如果在使用迭代器遍历集合的过程中,同时对集合进行了结构性修改(添加、删除等),就可能触发并发修改异常(ConcurrentModificationException)。
这种异常是一种检测到多个线程并发访问集合的机制,主要是为了避免由于一个线程修改集合的结构而导致另一个线程遍历集合时出现不一致的情况。
以下是一个示例,演示了在使用迭代器遍历集合时触发并发修改异常的情况:
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;public class ConcurrentModificationExample {public static void main(String[] args) {List<String> myList = new ArrayList<>();myList.add("Apple");myList.add("Banana");myList.add("Orange");Iterator<String> iterator = myList.iterator();// 使用迭代器遍历集合while (iterator.hasNext()) {String element = iterator.next();System.out.println(element);// 在遍历过程中尝试添加元素,会触发并发修改异常if (element.equals("Banana")) {myList.remove("Banana");}}}
}
在上述示例中,当迭代器遍历到 “Banana” 时,尝试在集合中添加 “Grapes”,这会导致并发修改异常。在多线程环境中,这种并发修改可能会导致不确定的行为。
为了避免并发修改异常,可以采取以下措施:
-
使用专门的并发集合: Java 提供了一些专门设计用于多线程并发访问的集合类,如
ConcurrentHashMap、CopyOnWriteArrayList等。 -
使用同步块: 在进行迭代时,可以使用同步块来确保在遍历期间不会有其他线程修改集合。
-
使用迭代器的安全删除方法: 迭代器的
remove()方法是安全的,可以用于在迭代期间移除元素。
示例中的异常触发是因为在遍历时进行了添加操作,这打破了迭代器的一致性。为了避免这种情况,最好在迭代过程中只使用迭代器的 remove() 方法来进行修改。
增强循环
Java 中的增强 for 循环,也称为 foreach 循环,是一种简化数组和集合遍历的语法糖。它提供了一种更简洁、可读性更好的方式来遍历数组、集合和其他 Iterable 对象。
语法格式如下:
for (element_type element : iterable) {// 循环体
}
其中:
element_type是集合中元素的类型。element是循环变量,表示每次迭代中的当前元素。iterable是要遍历的数组、集合或其他 Iterable 对象。
下面是一些使用增强 for 循环的示例:
遍历数组:
int[] numbers = {1, 2, 3, 4, 5};for (int number : numbers) {System.out.println(number);
}
遍历集合:
import java.util.ArrayList;
import java.util.List;List<String> fruits = new ArrayList<>();
fruits.add("Apple");
fruits.add("Banana");
fruits.add("Orange");for (String fruit : fruits) {System.out.println(fruit);
}
遍历字符串:
String message = "Hello";for (char ch : message.toCharArray()) {System.out.println(ch);
}
增强 for 循环适用于任何实现了 Iterable 接口的类,包括数组、集合等。需要注意的是,在使用增强 for 循环遍历集合时,不能在循环中修改集合的结构,否则会抛出 ConcurrentModificationException 异常。如果需要进行修改,建议使用迭代器或普通 for 循环。
限制
当使用增强 for 循环遍历集合时,Java 语言设计使得在循环内部隐藏了迭代器的具体细节。增强 for 循环是一种简洁的语法糖,让我们可以更方便地遍历数组或集合。然而,这种简洁性带来了一些限制。
在增强 for 循环中,我们不能直接访问迭代器的一些方法,比如 remove。因此,如果在增强 for 循环中尝试使用迭代器的 remove 方法,就会抛出异常。
相比之下,普通的 for 循环和显式使用迭代器的方式更为灵活。在普通的 for 循环中,我们可以显式地获取迭代器,并直接调用迭代器的 remove 方法,这是因为我们有更多的控制权。
下面是一个对比的例子:
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;public class Example {public static void main(String[] args) {List<String> fruits = new ArrayList<>();fruits.add("Apple");fruits.add("Banana");fruits.add("Orange");// 使用增强 for 循环,尝试使用迭代器的 remove 方法,会抛出异常for (String fruit : fruits) {// 尝试使用迭代器的 remove 方法,会抛出异常// fruits.remove(fruit); // 这行代码会抛出异常}// 使用普通的 for 循环和迭代器,不会抛出异常for (Iterator<String> iterator = fruits.iterator(); iterator.hasNext();) {String fruit = iterator.next();iterator.remove(); // 可以正常使用迭代器的 remove 方法}System.out.println("List after removing elements: " + fruits);}
}
总体来说,如果你需要在遍历集合的同时进行修改,最好选择普通的 for 循环和显式使用迭代器的方式。增强 for 循环则更适用于简单的遍历操作。
list接口
List 接口是 Java 集合框架中定义的一个接口,它继承自 Collection 接口,表示一个有序、可重复的集合。List 支持按索引访问元素,允许插入、更新和删除元素。Java 中常见的实现 List 接口的类包括 ArrayList、LinkedList 和 Vector。
以下是 List 接口的主要特点和方法:
-
有序性:
List中的元素是有序的,即它们按照插入的顺序排列。 -
可重复性:
List允许包含重复的元素,相同的元素可以出现多次。 -
索引访问:
List支持按索引访问元素。通过索引,可以获取、设置、插入和删除元素。 -
动态大小:
List集合的大小可以根据需要动态变化。
以下是 List 接口的一些常用方法:
boolean add(E element): 将指定的元素追加到列表的末尾。void add(int index, E element): 将指定的元素插入列表中的指定位置。boolean remove(Object o): 从列表中删除指定元素的第一个匹配项。E remove(int index): 删除列表中指定位置的元素。E get(int index): 返回列表中指定位置的元素。int indexOf(Object o): 返回列表中第一次出现的指定元素的索引。int size(): 返回列表中的元素数。
示例使用 ArrayList 实现 List 接口:
import java.util.ArrayList;
import java.util.List;public class ListExample {public static void main(String[] args) {// 创建一个 ArrayListList<String> fruits = new ArrayList<>();// 添加元素fruits.add("Apple");fruits.add("Banana");fruits.add("Orange");// 遍历元素for (String fruit : fruits) {System.out.println(fruit);}// 获取元素String firstFruit = fruits.get(0);System.out.println("First Fruit: " + firstFruit);// 插入元素fruits.add(1, "Grapes");// 删除元素fruits.remove("Banana");// 输出修改后的列表System.out.println("Modified List: " + fruits);}
}
上述示例演示了如何使用 ArrayList 实现的 List 接口进行元素的添加、访问、插入和删除操作。List 接口提供了丰富的方法,使得对有序集合的操作变得灵活和方便。
ListIterator
ListIterator 接口是 Iterator 接口的子接口,专门为实现 List 接口的集合提供了一种强化的迭代器。与普通的迭代器相比,ListIterator 提供了双向遍历的能力,并支持在迭代过程中修改列表的结构。
以下是 ListIterator 接口的主要方法:
-
双向遍历:
boolean hasPrevious(): 如果列表在迭代器当前位置的前面有元素,则返回 true。E previous(): 返回列表中的前一个元素,并将迭代器的位置向前移动。
-
索引位置:
int nextIndex(): 返回迭代器当前位置之后的元素的索引。int previousIndex(): 返回迭代器当前位置之前的元素的索引。
-
修改列表结构:
void add(E e): 将指定的元素插入列表。void set(E e): 用指定的元素替换由 next 或 previous 返回的最后一个元素(可选操作)。void remove(): 从列表中移除由 next 或 previous 返回的最后一个元素(可选操作)。
使用 ListIterator 进行双向遍历和修改列表的示例:
import java.util.ArrayList;
import java.util.List;
import java.util.ListIterator;public class ListIteratorExample {public static void main(String[] args) {List<String> fruits = new ArrayList<>();fruits.add("Apple");fruits.add("Banana");fruits.add("Orange");// 获取 ListIteratorListIterator<String> listIterator = fruits.listIterator();// 向前遍历while (listIterator.hasNext()) {String fruit = listIterator.next();System.out.println(fruit);}// 向后遍历并修改列表while (listIterator.hasPrevious()) {int index = listIterator.previousIndex();String fruit = listIterator.previous();System.out.println("Previous Fruit at index " + index + ": " + fruit);// 在迭代过程中修改列表if (fruit.equals("Banana")) {listIterator.remove();}}// 输出修改后的列表System.out.println("Modified List: " + fruits);}
}
在上述示例中,通过 listIterator() 方法获取了一个 ListIterator,然后使用 hasNext()、next() 进行向前遍历,使用 hasPrevious()、previous() 进行向后遍历,并通过 remove() 方法在迭代过程中移除元素。ListIterator 提供了比普通迭代器更多的功能,特别适用于需要在迭代过程中修改列表的情况。
ArrayList
- ArrayList 具备了List接口的特性(有序、重复、索引)。
- ArrayList 集合底层的实现原理是数组,大小可变。
- ArrayList 的特点:查询速度快、增删慢。
- ArrayList 在 JDK8 前后的实现区别:
- JDK7 :ArrayList 像饿汉式,直接创建了一个初始容量为 10 的数组,每次扩容是原来长度的 1.5 倍。
- JDK8 :ArrayList 像懒汉式,一开始创建一个长度为 0 的数组,当添加第一个元素的时候再创建一个容器为 10 的数组,每次扩容是原来长度的 1.5 倍。
- ArrayList 是线程不安全的集合,运行速度快。
创建 ArrayList:
import java.util.ArrayList;
import java.util.List;// 创建一个 ArrayList
List<String> arrayList = new ArrayList<>();
添加元素:
arrayList.add("Apple");
arrayList.add("Banana");
arrayList.add("Orange");
获取元素:
String firstFruit = arrayList.get(0);
System.out.println("First Fruit: " + firstFruit);
修改元素:
arrayList.set(1, "Grapes");
System.out.println("Modified List: " + arrayList);
删除元素:
arrayList.remove("Orange");
System.out.println("List after removing 'Orange': " + arrayList);
获取列表大小:
int size = arrayList.size();
System.out.println("List Size: " + size);
遍历元素:
System.out.println("List Elements:");
for (String fruit : arrayList) {System.out.println(fruit);
}
注意事项:
ArrayList支持存储任意类型的元素,包括null。- 在默认情况下,
ArrayList的初始容量为 10。当元素数量超过当前容量时,ArrayList会自动进行扩容。 - 在删除元素时,
ArrayList会自动调整大小,但可能会导致内存浪费。可以使用trimToSize()方法来减小容量以节省空间。 ArrayList不是线程安全的,如果在多个线程中同时修改,需要采取额外的同步措施。
总体而言,ArrayList 是一个灵活且常用的集合类,适用于需要动态管理元素集合的情况。
源码扩容
ArrayList 的扩容机制涉及到动态数组的容量调整。当元素数量超过当前数组容量时,会触发扩容。以下是 ArrayList 的扩容机制的主要步骤:
-
计算新容量: 新容量通常是当前容量的 1.5 倍(即
oldCapacity * 1.5),这是为了在扩容后减小不必要的空间浪费。如果新容量小于某个阈值(MIN_CAPACITY_INCREMENT),则使用该阈值作为新容量。 -
创建新数组: 使用新的容量创建一个新的数组。
-
复制元素: 将当前数组中的所有元素复制到新数组中。这是通过
System.arraycopy来实现的,效率相对较高。 -
更新引用: 将
ArrayList内部的引用指向新的数组,使后续的操作都基于新数组进行。
以下是 ArrayList 源码中的部分扩容相关的代码:
private void grow(int minCapacity) {// 当前数组容量int oldCapacity = elementData.length;// 计算新容量,1.5倍增长int newCapacity = oldCapacity + (oldCapacity >> 1);// 如果新容量小于所需容量,则使用所需容量if (newCapacity - minCapacity < 0)newCapacity = minCapacity;// 如果新容量大于数组最大容量,则使用最大容量if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);// 创建新数组并复制元素elementData = Arrays.copyOf(elementData, newCapacity);
}private static int hugeCapacity(int minCapacity) {if (minCapacity < 0) // overflowthrow new OutOfMemoryError();return (minCapacity > MAX_ARRAY_SIZE) ?Integer.MAX_VALUE :MAX_ARRAY_SIZE;
}
上述代码是 ArrayList 中的 grow 方法和 hugeCapacity 方法的部分实现。grow 方法负责实际的扩容操作,而 hugeCapacity 方法用于计算新容量时的一些边界检查。
需要注意的是,ArrayList 的扩容机制是在 add 操作中触发的。当元素数量达到数组容量时,会调用 grow 方法进行扩容。源码中还包含了一些其他细节,如对最大容量的限制等。这是 ArrayList 实现动态数组扩容的基本原理。
LinkedList
LinkedList 是 Java 集合框架中的一个类,实现了 List 接口。它使用双向链表(Doubly Linked List)实现,每个节点包含一个元素和对前后节点的引用。以下是关于 LinkedList 的一些重要概念和用法:
创建 LinkedList:
import java.util.LinkedList;// 创建一个 LinkedList
LinkedList<String> linkedList = new LinkedList<>();
添加元素:
linkedList.add("Apple");
linkedList.add("Banana");
linkedList.add("Orange");
在指定位置插入元素:
linkedList.add(1, "Grapes");
获取元素:
String firstElement = linkedList.getFirst();
String lastElement = linkedList.getLast();
删除元素:
linkedList.remove("Banana");
删除指定位置的元素:
linkedList.remove(1);
遍历元素:
for (String fruit : linkedList) {System.out.println(fruit);
}
实现队列和栈:
// 作为队列使用
linkedList.offer("Mango");
String removedFromQueue = linkedList.poll();// 作为栈使用
linkedList.push("Cherry");
String poppedFromStack = linkedList.pop();
注意事项:
LinkedList支持快速的插入和删除操作,但在随机访问时性能较差。- 链表结构使得在头部和尾部进行插入和删除元素非常高效。
LinkedList既实现了List接口,也实现了Queue和Deque接口,可以用作队列或栈的实现。LinkedList不是线程安全的,如果在多个线程中同时修改,需要采取额外的同步措施。
LinkedList 在某些场景下比较适用,例如需要频繁插入和删除元素的情况。它提供了一些额外的操作,如在头部和尾部插入和删除元素,以及作为队列或栈使用的功能。
源码链表
LinkedList 的底层机制是基于双向链表实现的。每个节点包含了一个元素(实际数据)以及对前一个节点和后一个节点的引用。以下是 LinkedList 的底层机制的主要特点:
-
节点结构:
LinkedList的节点是一个包含元素和两个引用的结构。每个节点有一个指向前一个节点的引用(prev)和一个指向后一个节点的引用(next)。 -
首尾引用:
LinkedList维护了两个特殊的节点,即头节点(first)和尾节点(last)。头节点的prev引用为null,尾节点的next引用为null。 -
元素添加: 在
LinkedList中,元素的添加涉及到创建一个新的节点,并调整节点的引用,将新节点插入到链表的合适位置。 -
元素删除: 删除元素时,找到对应节点,调整前一个节点和后一个节点的引用,然后释放对应节点的内存。
-
随机访问:
LinkedList并不支持通过索引直接访问元素。如果需要按索引访问元素,需要遍历链表找到对应位置的节点。
以下是 LinkedList 部分相关的源码片段,展示了节点结构和添加元素的过程:
private static class Node<E> {E item;Node<E> prev;Node<E> next;Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.prev = prev;this.next = next;}
}public boolean add(E e) {linkLast(e);return true;
}private void linkLast(E e) {final Node<E> l = last;final Node<E> newNode = new Node<>(l, e, null);last = newNode;if (l == null)first = newNode;elsel.next = newNode;size++;modCount++;
}
上述代码片段展示了 LinkedList 中的节点结构和添加元素的过程。Node 类表示链表中的节点,linkLast 方法用于在链表末尾添加新元素。在添加元素时,首先创建一个新的节点,然后调整链表中的引用,最后更新链表的大小和修改计数器。这个过程是基于链表结构的插入操作。
set接口
概况
在 Java 中,Set 接口是集合框架中定义的一种集合类型,它继承自 Collection 接口。Set 表示不包含重复元素的集合,它不保证集合中元素的顺序。Set 接口的主要实现类有 HashSet、LinkedHashSet 和 TreeSet。
以下是 Set 接口的主要特点和方法:
-
不允许重复元素:
Set不允许集合中存在相同的元素,即集合中的元素是唯一的。 -
无序性:
Set不保证元素的顺序。具体实现类的迭代顺序可能会根据具体的实现方式不同而有所区别。 -
基本方法:
Set继承自Collection接口,因此包含了add、remove、contains、size等基本方法。 -
实现类: 常见的
Set接口的实现类包括:HashSet: 基于哈希表实现,无序。LinkedHashSet: 继承自HashSet,具有按插入顺序排序的特性。TreeSet: 基于红黑树实现,元素按照自然顺序或指定比较器排序。
-
示例代码:
import java.util.HashSet;
import java.util.Set;public class SetExample {public static void main(String[] args) {// 创建 HashSet 实例Set<String> hashSet = new HashSet<>();// 添加元素hashSet.add("Apple");hashSet.add("Banana");hashSet.add("Orange");// 元素不允许重复,重复元素不会被添加hashSet.add("Apple");// 输出集合元素System.out.println("HashSet: " + hashSet);// 检查元素是否存在boolean containsBanana = hashSet.contains("Banana");System.out.println("Contains Banana: " + containsBanana);// 移除元素hashSet.remove("Orange");// 输出修改后的集合System.out.println("Modified HashSet: " + hashSet);}
}
上述代码演示了如何使用 HashSet 实现 Set 接口,包括添加元素、检查元素是否存在、移除元素等基本操作。
总体而言,Set 接口提供了一种不包含重复元素的集合,它的实现类提供了不同的性能和行为特点,可以根据具体需求选择合适的实现。
HashSet
概况
HashSet 是 Java 集合框架中实现了 Set 接口的类,它基于哈希表(hash table)实现。以下是关于 HashSet 的一些重要特点和用法:
-
不允许重复元素:
HashSet不允许集合中存在相同的元素,即集合中的元素是唯一的。如果尝试向HashSet中添加已存在的元素,该操作将被忽略。 -
无序性:
HashSet不保证元素的顺序。具体迭代的顺序可能会受到哈希表实现的影响。 -
基于哈希表:
HashSet的底层实现是一个哈希表,它使用哈希码(hash code)来存储和检索元素。这使得查找、插入和删除元素的操作具有较快的平均时间复杂度。 -
允许空元素:
HashSet允许存储空元素(null)。 -
实现了
Set接口:HashSet是Set接口的实现类,因此它继承了Set接口中定义的方法,如add、remove、contains等。 -
示例代码:
import java.util.HashSet;
import java.util.Set;public class HashSetExample {public static void main(String[] args) {// 创建 HashSet 实例Set<String> hashSet = new HashSet<>();// 添加元素hashSet.add("Apple");hashSet.add("Banana");hashSet.add("Orange");// 元素不允许重复,重复元素不会被添加hashSet.add("Apple");// 输出集合元素System.out.println("HashSet: " + hashSet);// 检查元素是否存在boolean containsBanana = hashSet.contains("Banana");System.out.println("Contains Banana: " + containsBanana);// 移除元素hashSet.remove("Orange");// 输出修改后的集合System.out.println("Modified HashSet: " + hashSet);}
}
上述代码演示了如何使用 HashSet,包括创建实例、添加元素、检查元素是否存在、移除元素等基本操作。需要注意的是,由于 HashSet 的无序性,输出的集合元素可能不按照添加的顺序排列。
LinkedHashSet
概况
LinkedHashSet 是 Java 集合框架中的一个实现了 Set 接口的类,它是 HashSet 的子类。LinkedHashSet 继承了 HashSet,并且在内部使用链表维护元素的插入顺序。以下是关于 LinkedHashSet 的一些重要特点和用法:
-
有序性: 与
HashSet不同,LinkedHashSet保留了元素的插入顺序。遍历集合时,元素的顺序与它们被添加到集合中的顺序一致。 -
不允许重复元素:
LinkedHashSet不允许集合中存在相同的元素,即集合中的元素是唯一的。如果尝试向LinkedHashSet中添加已存在的元素,该操作将被忽略。 -
基于哈希表和链表:
LinkedHashSet的底层实现既包括了哈希表,又包括了链表。哈希表用于快速查找元素,链表用于维护插入顺序。 -
允许空元素:
LinkedHashSet允许存储空元素(null)。 -
实现了
Set接口:LinkedHashSet是Set接口的实现类,因此它继承了Set接口中定义的方法,如add、remove、contains等。 -
示例代码:
import java.util.LinkedHashSet;
import java.util.Set;public class LinkedHashSetExample {public static void main(String[] args) {// 创建 LinkedHashSet 实例Set<String> linkedHashSet = new LinkedHashSet<>();// 添加元素linkedHashSet.add("Apple");linkedHashSet.add("Banana");linkedHashSet.add("Orange");// 元素不允许重复,重复元素不会被添加linkedHashSet.add("Apple");// 输出集合元素System.out.println("LinkedHashSet: " + linkedHashSet);// 检查元素是否存在boolean containsBanana = linkedHashSet.contains("Banana");System.out.println("Contains Banana: " + containsBanana);// 移除元素linkedHashSet.remove("Orange");// 输出修改后的集合System.out.println("Modified LinkedHashSet: " + linkedHashSet);}
}
上述代码演示了如何使用 LinkedHashSet,包括创建实例、添加元素、检查元素是否存在、移除元素等基本操作。由于 LinkedHashSet 的有序性,输出的集合元素会按照插入顺序排列。
TreeSet
概况
TreeSet 是 Java 集合框架中的一个实现了 SortedSet 接口的类,它继承了 AbstractSet 类。与 HashSet 和 LinkedHashSet 不同,TreeSet 是基于红黑树(Red-Black Tree)实现的。以下是关于 TreeSet 的一些重要特点和用法:
-
有序性:
TreeSet是有序的集合,它根据元素的自然顺序或者通过提供的比较器进行排序。因此,遍历TreeSet得到的元素是按照升序或降序排列的。 -
不允许重复元素:
TreeSet不允许集合中存在相同的元素,即集合中的元素是唯一的。如果尝试向TreeSet中添加已存在的元素,该操作将被忽略。 -
基于红黑树:
TreeSet的底层实现是一个红黑树,这是一种自平衡的二叉搜索树。红黑树的特性确保了插入、删除和查找等操作的较快平均时间复杂度。 -
允许空元素:
TreeSet允许存储空元素(null)。 -
实现了
SortedSet接口: 由于TreeSet实现了SortedSet接口,它提供了一些按顺序操作的方法,如first()、last()、headSet()、tailSet()等。 -
示例代码:
import java.util.TreeSet;
import java.util.Set;public class TreeSetExample {public static void main(String[] args) {// 创建 TreeSet 实例Set<String> treeSet = new TreeSet<>();// 添加元素treeSet.add("Apple");treeSet.add("Banana");treeSet.add("Orange");// 元素不允许重复,重复元素不会被添加treeSet.add("Apple");// 输出集合元素(有序)System.out.println("TreeSet: " + treeSet);// 检查元素是否存在boolean containsBanana = treeSet.contains("Banana");System.out.println("Contains Banana: " + containsBanana);// 移除元素treeSet.remove("Orange");// 输出修改后的集合System.out.println("Modified TreeSet: " + treeSet);}
}
上述代码演示了如何使用 TreeSet,包括创建实例、添加元素、检查元素是否存在、移除元素等基本操作。由于 TreeSet 的有序性,输出的集合元素会按照自然顺序(或比较器指定的顺序)排列。
Collections 工具类
概况
Collections 是 Java 集合框架中的一个工具类,提供了一系列静态方法,用于对集合进行操作和处理。这个工具类包含了各种实用的方法,涵盖了对列表、集合、映射等不同类型的集合进行排序、查找、替换、同步等操作。以下是一些常用的 Collections 类的方法:
-
排序:
sort(List<T> list): 对列表进行自然顺序排序。sort(List<T> list, Comparator<? super T> c): 使用指定的比较器对列表进行排序。reverse(List<?> list): 反转列表中元素的顺序。
-
查找和替换:
binarySearch(List<? extends Comparable<? super T>> list, T key): 使用二分查找算法在有序列表中查找指定元素。binarySearch(List<? extends T> list, T key, Comparator<? super T> c): 使用指定的比较器在有序列表中查找指定元素。replaceAll(List<T> list, T oldVal, T newVal): 替换列表中的所有旧元素为新元素。
-
同步:
synchronizedList(List<T> list): 返回由指定列表支持的同步(线程安全)列表。synchronizedSet(Set<T> s): 返回由指定集合支持的同步(线程安全)集合。synchronizedMap(Map<K,V> m): 返回由指定映射支持的同步(线程安全)映射。
-
不可修改:
unmodifiableList(List<? extends T> list): 返回指定列表的不可修改视图。unmodifiableSet(Set<? extends T> s): 返回指定集合的不可修改视图。unmodifiableMap(Map<? extends K,? extends V> m): 返回指定映射的不可修改视图。
-
其他操作:
shuffle(List<?> list): 随机置换列表中的元素。frequency(Collection<?> c, Object o): 返回指定集合中指定元素的出现次数。reverseOrder(): 返回一个比较器,强制逆序比较。
示例代码:
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;public class CollectionsExample {public static void main(String[] args) {// 创建一个列表List<String> myList = new ArrayList<>();myList.add("Apple");myList.add("Banana");myList.add("Orange");// 排序Collections.sort(myList);System.out.println("Sorted List: " + myList);// 反转Collections.reverse(myList);System.out.println("Reversed List: " + myList);// 随机置换Collections.shuffle(myList);System.out.println("Shuffled List: " + myList);// 查找元素int index = Collections.binarySearch(myList, "Banana");System.out.println("Index of Banana: " + index);// 创建不可修改的视图List<String> unmodifiableList = Collections.unmodifiableList(myList);// 尝试修改不可修改视图将抛出 UnsupportedOperationException// unmodifiableList.add("Grapes");}
}
上述代码演示了使用 Collections 类的一些方法,包括排序、反转、随机置换、查找等。需要注意的是,通过 unmodifiableList 方法创建的不可修改视图,尝试在这个视图上进行修改会抛出 UnsupportedOperationException 异常。
Map接口
概况
Map 接口是 Java 集合框架中表示键值对的一种集合类型。它表示一组键值对的映射关系,其中每个键(key)对应一个值(value)。Map 接口的主要实现类有 HashMap、LinkedHashMap、TreeMap 等。以下是关于 Map 接口的一些重要特点和用法:
-
键值对映射:
Map存储的是键值对,每个键对应一个值。键和值都可以是任意类型的对象,但键必须是唯一的。 -
不允许重复键: 在一个
Map中,不允许存在重复的键。如果尝试使用已存在的键添加新值,新值将覆盖旧值。 -
有序性:
Map接口不保证键值对的顺序,具体实现类有不同的有序性特点。HashMap: 无序,键值对的顺序不受控制。LinkedHashMap: 有序,键值对按照插入顺序或访问顺序排序。TreeMap: 有序,键值对按照键的自然顺序或比较器排序。
-
允许空键和空值:
Map接口允许键和值都为null。 -
基本方法:
Map提供了一系列基本方法,如put(添加键值对)、get(获取值)、remove(移除键值对)、containsKey(检查键是否存在)、containsValue(检查值是否存在)等。 -
实现类: 常见的
Map接口的实现类包括:HashMap: 基于哈希表实现,无序。LinkedHashMap: 继承自HashMap,有序。TreeMap: 基于红黑树实现,有序。
-
示例代码:
import java.util.HashMap;
import java.util.Map;public class MapExample {public static void main(String[] args) {// 创建 HashMap 实例Map<String, Integer> hashMap = new HashMap<>();// 添加键值对hashMap.put("Apple", 10);hashMap.put("Banana", 5);hashMap.put("Orange", 8);// 获取值int appleCount = hashMap.get("Apple");System.out.println("Number of Apples: " + appleCount);// 检查键是否存在boolean containsKey = hashMap.containsKey("Grapes");System.out.println("Contains Grapes: " + containsKey);// 移除键值对hashMap.remove("Banana");// 输出修改后的 MapSystem.out.println("Modified Map: " + hashMap);}
}
上述代码演示了如何使用 HashMap 实现 Map 接口,包括添加键值对、获取值、检查键是否存在、移除键值对等基本操作。
HashMap
概况
HashMap 是 Java 集合框架中的一个实现了 Map 接口的类,它基于哈希表实现键值对的存储。以下是关于 HashMap 的一些重要特点和用法:
-
键值对映射:
HashMap存储的是键值对,每个键对应一个值。键和值都可以是任意类型的对象,但键必须是唯一的。 -
无序性:
HashMap不保证键值对的顺序,即插入顺序不会影响遍历顺序。具体遍历的顺序可能随时间而变化。 -
允许空键和空值:
HashMap允许键和值都为null。 -
基于哈希表:
HashMap的底层实现是一个哈希表,它使用键的哈希码来存储和检索值。这使得查找、插入和删除键值对的操作具有较快的平均时间复杂度。 -
动态扩容:
HashMap具有动态扩容的特性,当元素数量达到一定阈值时,自动进行扩容以保持较低的负载因子,提高性能。 -
负载因子: 负载因子是
HashMap中用于判断是否需要扩容的一个重要参数,默认为 0.75。当元素数量达到负载因子与容量的乘积时,触发扩容。 -
常见方法:
HashMap提供了一系列常见的方法,如put(添加键值对)、get(获取值)、remove(移除键值对)、containsKey(检查键是否存在)、containsValue(检查值是否存在)等。 -
示例代码:
import java.util.HashMap;
import java.util.Map;public class HashMapExample {public static void main(String[] args) {// 创建 HashMap 实例Map<String, Integer> hashMap = new HashMap<>();// 添加键值对hashMap.put("Apple", 10);hashMap.put("Banana", 5);hashMap.put("Orange", 8);// 获取值int appleCount = hashMap.get("Apple");System.out.println("Number of Apples: " + appleCount);// 检查键是否存在boolean containsKey = hashMap.containsKey("Grapes");System.out.println("Contains Grapes: " + containsKey);// 移除键值对hashMap.remove("Banana");// 输出修改后的 HashMapSystem.out.println("Modified HashMap: " + hashMap);}
}
上述代码演示了如何使用 HashMap,包括添加键值对、获取值、检查键是否存在、移除键值对等基本操作。需要注意的是,由于 HashMap 的无序性,输出的键值对顺序可能与插入的顺序不一致。
源码扩容
HashMap是一种常见的数据结构,它通过哈希函数将键映射到存储桶中的位置。在Java中,HashMap的底层实现是基于数组和链表(或红黑树)的组合。以下是HashMap的底层扩容机制和数据结构:
底层数据结构:
-
数组: HashMap内部维护一个数组,这个数组的每个元素都是一个存储桶。存储桶是HashMap中实际存储数据的地方。
-
链表(或红黑树): 每个数组元素(存储桶)可能是一个链表或一棵红黑树。这是为了解决哈希冲突的问题。当不同的键经过哈希函数映射到同一个存储桶时,它们会被存储在这个存储桶对应的链表(或红黑树)中。
扩容机制:
-
负载因子: HashMap维护一个负载因子,默认为0.75。负载因子是指HashMap中存储的元素数量与存储桶数量的比率。当负载因子超过设定的阈值时,HashMap触发扩容操作。
-
扩容操作: 当HashMap中的元素数量达到负载因子乘以当前容量时,HashMap会进行扩容。扩容涉及到创建一个新的数组,通常是当前容量的两倍,然后将所有元素重新分配到新的存储桶中。
-
重新哈希: 在扩容时,所有的元素需要重新计算哈希并放入新的存储桶中。这个过程叫做重新哈希。
-
链表转红黑树: 如果链表的长度超过一定阈值(8),链表会被转换成红黑树,以提高查找效率。
总的来说,HashMap通过数组和链表(或红黑树)的组合来实现键值对的存储,并通过负载因子和扩容机制来动态调整容量,保持高效的性能。
LinkedHashMap
概况
LinkedHashMap 是 Java 集合框架中的一种具体实现类,它继承自 HashMap 类,除了具有 HashMap 的特性外,还保留了插入顺序或访问顺序(最近最少使用)的特性。具体来说,LinkedHashMap 维护了一个双向链表,用于保持键值对的插入顺序或访问顺序。
以下是 LinkedHashMap 的一些主要特点:
-
插入顺序: 默认情况下,
LinkedHashMap会按照键值对的插入顺序维护它们的顺序。新插入的键值对会被放到链表的尾部。 -
访问顺序: 通过构造函数参数设置,
LinkedHashMap可以按照键值对的访问顺序维护它们的顺序。每次访问一个键值对(包括 get、put、containsKey 等操作),都会将该键值对移到链表的尾部。 -
性能:
LinkedHashMap的性能和HashMap相近。由于维护了额外的链表,相对于HashMap,LinkedHashMap在插入和删除操作上可能稍微慢一些,但在迭代遍历时更具有优势。 -
构造函数:
LinkedHashMap提供了多个构造函数,允许选择是否按照插入顺序或访问顺序,以及设置初始容量和负载因子等参数。
以下是一个简单的 LinkedHashMap 示例:
import java.util.LinkedHashMap;
import java.util.Map;public class LinkedHashMapExample {public static void main(String[] args) {// 创建一个按插入顺序的LinkedHashMapMap<String, Integer> linkedHashMap = new LinkedHashMap<>();// 添加键值对linkedHashMap.put("One", 1);linkedHashMap.put("Two", 2);linkedHashMap.put("Three", 3);// 输出顺序是插入顺序System.out.println("Insertion Order: " + linkedHashMap);// 访问某个键,该键值对移到链表尾部linkedHashMap.get("Two");// 输出顺序是访问顺序,"Two" 移到了最后System.out.println("Access Order: " + linkedHashMap);}
}
在上述示例中,LinkedHashMap 在默认情况下按照插入顺序维护键值对的顺序。在访问了键值对 “Two” 后,该键值对被移到了链表的尾部,所以在输出时按照访问顺序输出。
Hashtable
概况
Hashtable 是 Java 集合框架中的一个古老的类,它实现了 Map 接口,提供了键值对的存储和检索功能。Hashtable 是线程安全的,这意味着多个线程可以同时访问 Hashtable 的方法而不会导致数据不一致。然而,由于其线程安全性,性能相对较低,通常不推荐在新代码中使用,而更常见的替代方案是 HashMap。
以下是 Hashtable 的一些主要特点和使用方法:
-
线程安全:
Hashtable是同步的,多个线程可以安全地同时访问Hashtable的方法。这是通过在每个公共方法上添加synchronized关键字实现的。 -
键和值:
Hashtable存储键值对,其中键和值都是对象。键不能为 null,值也不能为 null。 -
初始化容量和负载因子:
Hashtable可以通过构造函数指定初始容量和负载因子。初始容量是哈希表在创建时的容量,负载因子是在哈希表重新调整大小之前,它可以保存的键值对数与数组容量的比率。 -
哈希冲突解决:
Hashtable使用链表解决哈希冲突。当多个键映射到相同的哈希码时,它们会存储在同一个桶中的链表中。 -
方法:
Hashtable提供了许多方法,包括put、get、remove等用于操作键值对的方法。
以下是一个简单的 Hashtable 示例:
import java.util.Hashtable;
import java.util.Map;public class HashtableExample {public static void main(String[] args) {// 创建一个HashtableHashtable<String, Integer> hashtable = new Hashtable<>();// 添加键值对hashtable.put("One", 1);hashtable.put("Two", 2);hashtable.put("Three", 3);// 获取值int value = hashtable.get("Two");System.out.println("Value for key 'Two': " + value);// 移除键值对hashtable.remove("Three");// 遍历键值对for (Map.Entry<String, Integer> entry : hashtable.entrySet()) {System.out.println("Key: " + entry.getKey() + ", Value: " + entry.getValue());}}
}
在上述示例中,Hashtable 被创建并用于存储键值对。通过 put 方法添加键值对,通过 get 方法获取值,通过 remove 方法移除键值对。最后,通过 entrySet 方法遍历键值对。需要注意的是,由于 Hashtable 是线程安全的,它的性能相对较低,因此在单线程环境下,通常更推荐使用 HashMap。
TreeMap
概况
TreeMap 是 Java 集合框架中的一种实现 SortedMap 接口的有序映射。它基于红黑树(Red-Black Tree)实现,具有以下主要特点:
-
有序性:
TreeMap中的键值对是按照键的自然顺序或者通过构造函数提供的Comparator进行排序的。这使得TreeMap中的键值对是有序的。 -
红黑树: 内部使用红黑树来实现映射,这确保了对于常规操作(插入、删除、查找)的较高性能。
-
键和值:
TreeMap存储键值对,键和值都可以是任意对象。键不能为 null,但值可以为 null。 -
时间复杂度: 对于红黑树的常规操作(插入、删除、查找),时间复杂度是 O(log n),其中 n 是键值对的数量。
-
子映射:
TreeMap提供了一系列方法,如subMap、headMap、tailMap,用于获取子映射,以支持范围查找。
以下是一个简单的 TreeMap 示例:
import java.util.*;public class TreeMapExample {public static void main(String[] args) {// 创建一个TreeMapTreeMap<String, Integer> treeMap = new TreeMap<>();// 添加键值对treeMap.put("Three", 3);treeMap.put("One", 1);treeMap.put("Four", 4);treeMap.put("Two", 2);// 遍历键值对,按照键的自然顺序输出for (Map.Entry<String, Integer> entry : treeMap.entrySet()) {System.out.println("Key: " + entry.getKey() + ", Value: " + entry.getValue());}// 获取第一个和最后一个键值对System.out.println("First Entry: " + treeMap.firstEntry());System.out.println("Last Entry: " + treeMap.lastEntry());// 获取子映射,包含 "One" 到 "Three"SortedMap<String, Integer> subMap = treeMap.subMap("One", "Three");System.out.println("SubMap: " + subMap);}
}
在上述示例中,TreeMap 被创建并用于存储键值对。通过 put 方法添加键值对,通过 entrySet 方法遍历键值对。TreeMap 的输出顺序是按照键的自然顺序(字符串的字典顺序)输出。firstEntry 和 lastEntry 方法分别获取第一个和最后一个键值对。subMap 方法获取包含范围在 “One” 到 “Three” 之间的子映射。
Properties
概况
Properties 类是 Java 集合框架中的一种特殊实现,用于处理属性文件。它继承自 Hashtable 类,其中键和值都是字符串类型。通常,Properties 被用来处理配置文件,存储和读取应用程序的配置信息。
以下是 Properties 类的主要特点和用法:
-
键值对存储:
Properties使用键值对的方式存储配置信息。键和值都必须是字符串。 -
加载和保存:
Properties可以从输入流中加载属性文件,并将属性文件保存到输出流中。常见的方法有load和store。 -
默认值:
Properties可以指定默认属性,当在属性文件中找不到某个键对应的值时,会返回默认值。 -
获取属性: 通过键获取属性值的方法为
getProperty,也可以使用getProperty(String key, String defaultValue)指定默认值。
以下是一个简单的示例,展示了如何使用 Properties 类读取和写入属性文件:
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Properties;public class PropertiesExample {public static void main(String[] args) {// 读取属性文件Properties properties = new Properties();try (FileInputStream input = new FileInputStream("config.properties")) {properties.load(input);} catch (IOException e) {e.printStackTrace();}// 获取属性值String username = properties.getProperty("username");String password = properties.getProperty("password", "defaultPassword");System.out.println("Username: " + username);System.out.println("Password: " + password);// 写入属性文件try (FileOutputStream output = new FileOutputStream("config.properties")) {properties.setProperty("newProperty", "newValue");properties.store(output, "Updated properties");} catch (IOException e) {e.printStackTrace();}}
}
在上述示例中,Properties 类首先被用于读取属性文件 config.properties 中的配置信息。然后,通过 getProperty 方法获取属性值,并输出到控制台。接着,修改了属性值并存储到文件中,以更新配置信息。
`
相关文章:
14.java集合
文章目录 概念Collection 接口概念示例 Iterator 迭代器基本操作:并发修改异常增强循环遍历数组:遍历集合:遍历字符串:限制 list接口ListIteratorArrayList创建 ArrayList:添加元素:获取元素:修…...
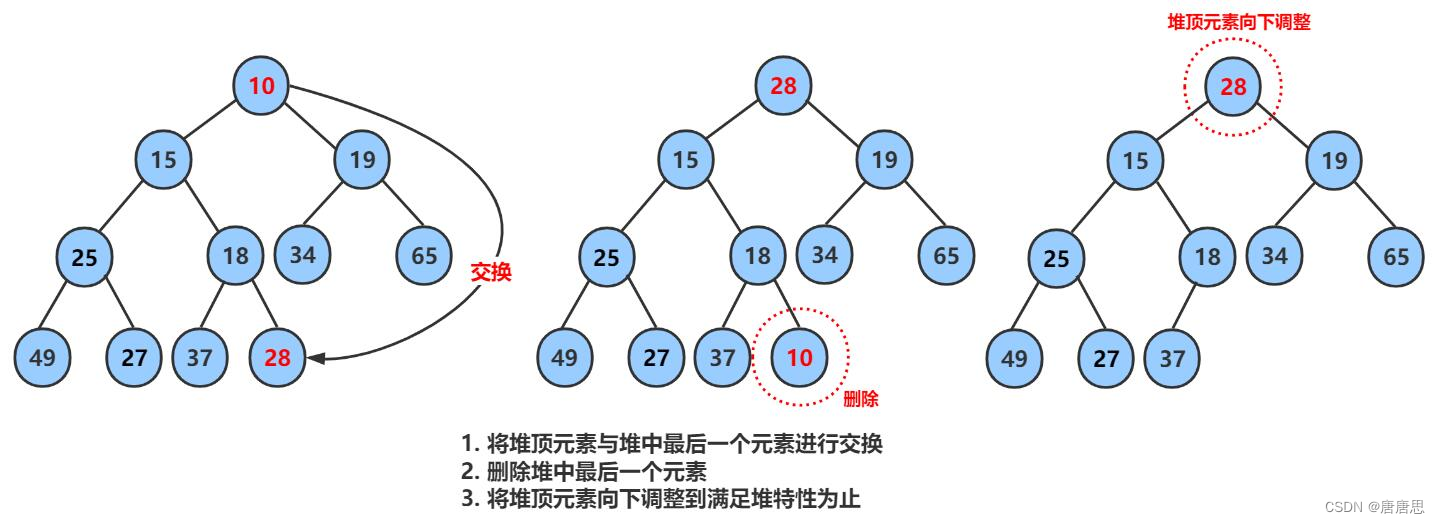
二叉树顺序结构堆实现
目录 Test.c测试代码 test1 test2 test3 🎇Test.c总代码 Heap.h头文件&函数声明 头文件 函数声明 🎇Heap.h总代码 Heap.c函数实现 ☁HeapInit初始化 ☁HeapDestroy销毁 ☁HeapPush插入数据 【1】插入数据 【2】向上调整Adjustup❗ …...

正则表达式 与文本三剑客(sed grep awk)
一,正则表达式 (一)正则表达式相关定义 1,正则表达式含义 REGEXP: Regular Expressions,由一类特殊字符及文本字符所编写的模式,其中有些字符(元字符)不表示字符字面意…...
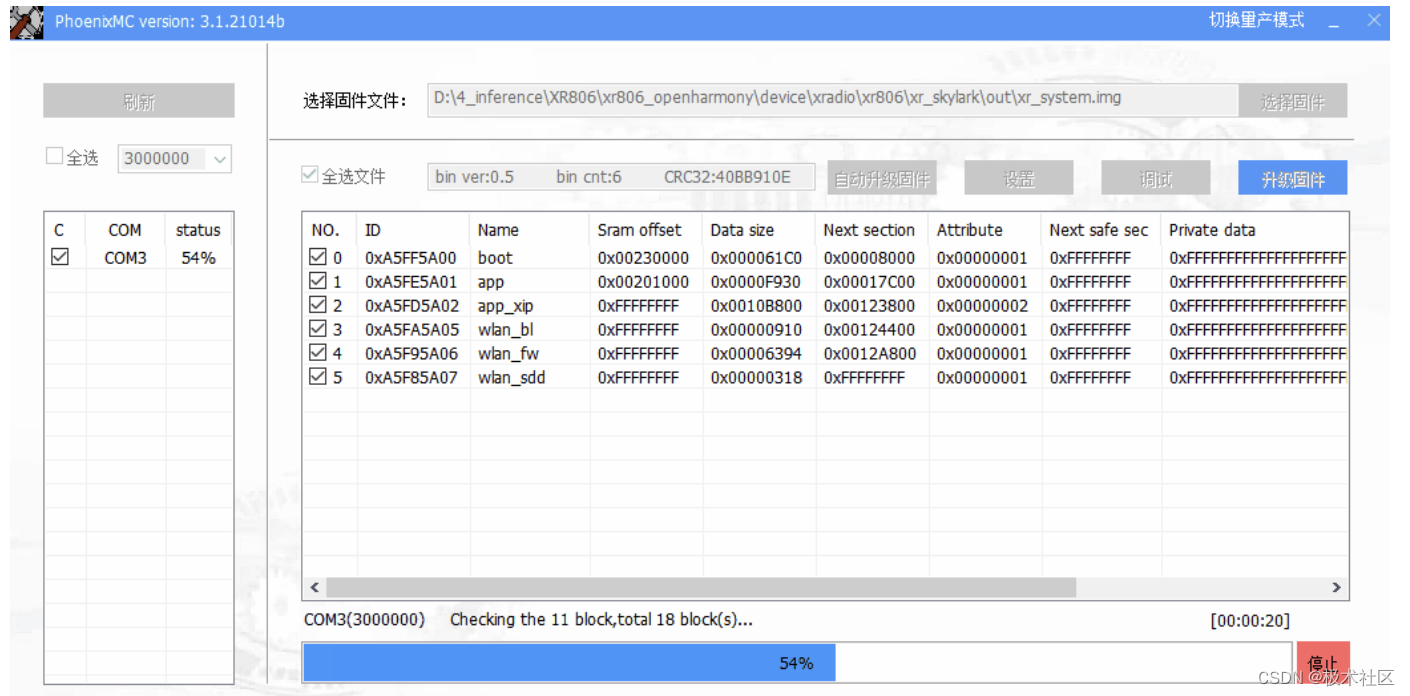
【XR806开发板试用】全志 XR806 OpenHarmony 鸿蒙系统固件烧录
大家好,我是极智视界,本教程详细记录了全志 XR806 OpenHarmony 鸿蒙系统固件烧录的方法。 在上一篇文章《【嵌入式AI】全志 XR806 OpenHarmony 鸿蒙系统固件编译》中咱们已经编译生成了系统镜像,这里把这个编译出来的镜像烧录到 XR806 板子里…...
linux环境安装git、maven、jenkins等
重启 jenkins的命令: systemctl start jenkins 如果没有vim 命令 可以使用 yum install vim 安装 vim git 下载包地址 https://www.kernel.org/pub/software/scm/git/git-2.28.0.tar.gz 1.安装依赖环境: yum install -y curl-devel expat-devel ge…...

RabbitMQ快速上手
首先他的需求实在什么地方。我美哟明显的感受到。 它给我的最大感受就是脱裤子放屁——多此一举,的感觉。 他将信息发送给服务端中间件。在由MQ服务器发送消息。 服务器会监听消息。 但是它不仅仅局限于削峰填谷和稳定发送信息的功能,它还有其他重要…...

SpringBoot activemq收发消息、配置及原理
SpringBoot集成消息处理框架 Spring framework提供了对JMS和AMQP消息框架的无缝集成,为Spring项目使用消息处理框架提供了极大的便利。 与Spring framework相比,Spring Boot更近了一步,通过auto-configuration机制实现了对jms及amqp主流框架…...

视频智能识别安全帽佩戴系统-工地安全帽佩戴识别算法---豌豆云
视频智能识别安全帽佩戴系统能够从繁杂的工地、煤矿、车间等场景下同时对多个目标是否戴安全帽穿反光衣进行实时识别。 当视频智能识别安全帽佩戴系统发现作业人员没有戴安全帽、穿反光衣或者戴安全带,系统会及时报警提醒,并抓拍存档。 视频智能识别安…...
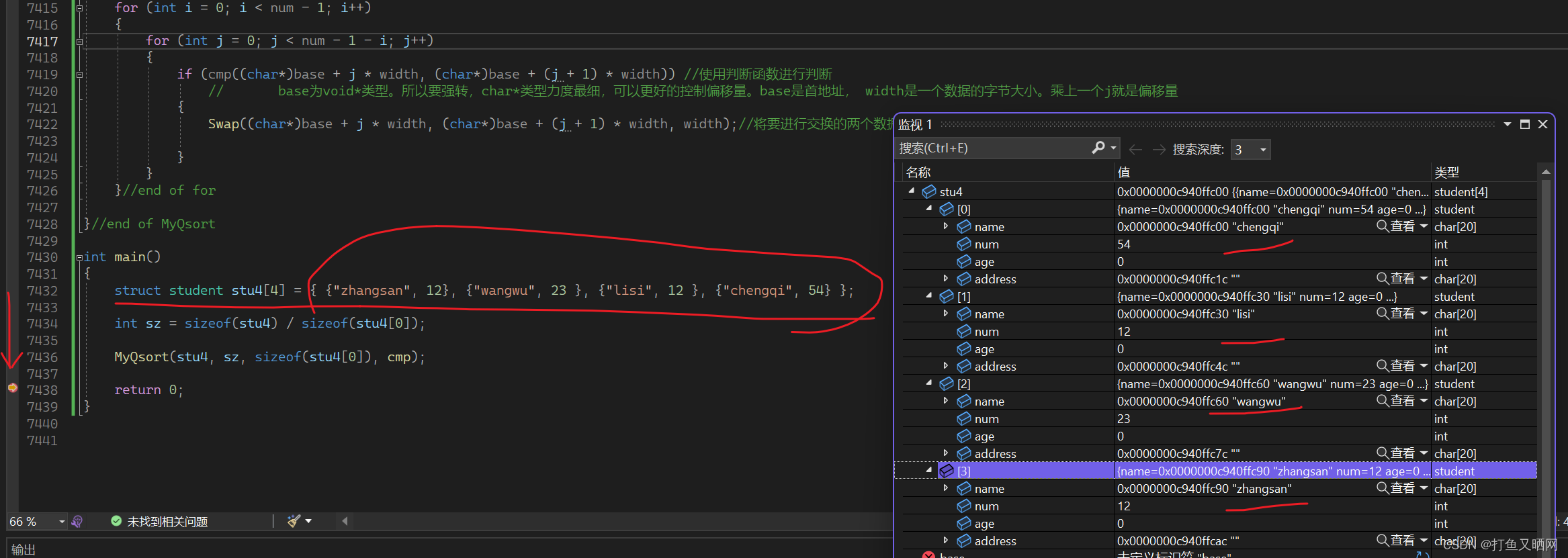
指针的深入理解(三)
这一节主要使用复习回调函数, 利用冒泡模拟实现qsort函数。 qsort 排序使用冒泡排序,主要难点在于运用元素个数和字节数以及基地址控制元素的比较: if里面使用了一个判断函数,qsort可以排序任意的数据,原因就是因为可…...

【Linux C | 网络编程】详细介绍 “三次握手(建立连接)、四次挥手(终止连接)、TCP状态”
😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀 🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C、数据结构、音视频🍭 🤣本文内容🤣&a…...
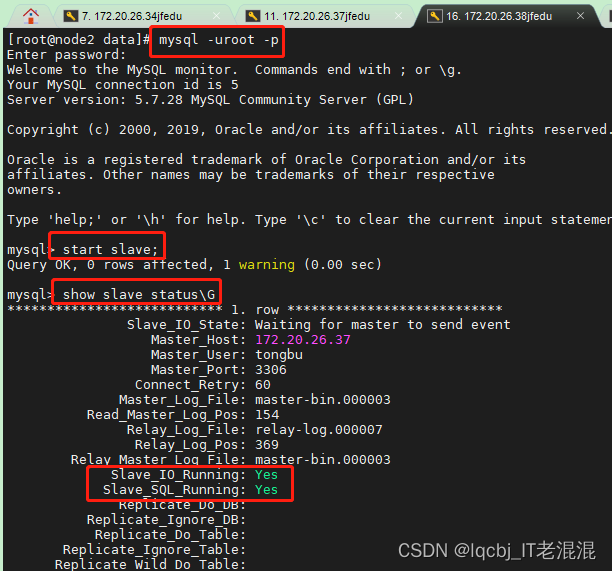
主从数据库MySQL服务重启步骤与注意事项
主从数据库MySQL服务重启步骤与注意事项 实验环境: 172.20.26.34 (主应用服务器) 172.20.26.26 (备应用服务器) 172.20.26.37 (主库服务器) 172.20.26.38 (从库服务器&…...

netlink学习
netlink是什么 netlink是Linux内核中的一种进程间通信(IPC)机制。它允许内核空间与用户空间之间,以及用户空间进程之间进行双向通信。 内核里的很多子系统使用netlink通信,包括网络管理(Routing,Netfilt…...

地理空间分析10——空间数据分析中的地理编码与Python
目录 写在开头1. 地理编码基础1.1 地理编码的基本原理1.1.1 坐标系统1.1.2 地名解析1.1.3 编码算法1.2 Python中使用地理编码的基础知识1.2.1 百度地图API1.2.2 高德地图API1.2.3 腾讯地图API1.3 Python中实现代码2. 逆地理编码2.1 利用Python进行逆地理编码2.1.1 获取高德地图…...

使用“快速开始”将数据传输到新的 iPhone 或 iPad
使用“快速开始”将数据传输到新的 iPhone 或 iPad 使用 iPhone 或 iPad 自动设置你的新 iOS 设备。 使用“快速开始”的过程会同时占用两台设备,因此请务必选择在几分钟内都不需要使用当前设备的时候进行设置。 确保你当前的设备已连接到无线局域网,并…...
复习提纲13)
计算机网络(第六版)复习提纲13
前同步码,七位1010交替出现,帧开始码:10101011 为什么没有帧结束?曼彻斯特码传播完成后,维持高电平,不再跳变,因此不必要设置帧结束。 3.无效的MAC帧 i.数据字段的长度与长度字段的值不一致&…...
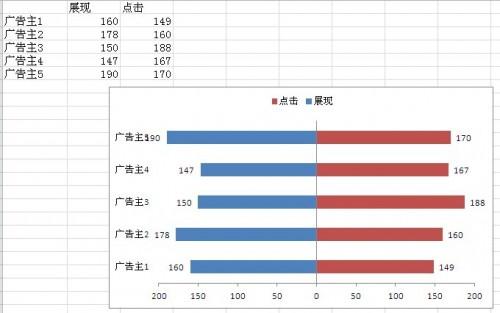
[office] excel2010双向条形图制作 #经验分享#微信
excel2010双向条形图制作 本教程为大家介绍一下excel2010中excel2010双向条形图制作方法。 1.选中工作区域 2.点击插入-->图表,选择条形图 3.为美观可将中间竖线可去掉 4.方法是选中竖线,右击-->删除 5.接下来将图例靠上,选中图例,右击-->设置图例格式-->图例选项…...

优雅管理多线程异步任务 - 永动异步任务
引言 在现代应用程序中,经常需要处理长时间运行的异步任务,如消息推送、定时任务等。为了确保这些异步任务能够安全可靠地执行,我们需要一种优雅的管理方式。本文将介绍一种基于线程池的多线程异步任务管理方案,并详细讨论任务的优雅关闭。 1. 多线程异步任务管理的需求 …...

软考笔记--分布式数据库
分布式数据库系统是数据库技术与网络技术相结合的产物,其基本思想是将传统的集中式数据库中的数据分布于网络上的多台计算机中。分布式数据库系统通常使用较小的计算机系统,每台计算机可单独放在一个地方,每台计算机中都有DBMS的一份完整的复…...

vue项目中路由懒加载的三种方式
1 . vue异步组件技术 异步加载 vue-router配置路由 , 使用vue的异步组件技术 , 可以实现按需加载 . 但是,这种情况下一个组件生成一个js文件 /* vue异步组件技术 */ { path: /home, name: home, component: resolve > require([/components/home],resolve) }, { path…...

【制作100个unity游戏之23】实现类似七日杀、森林一样的生存游戏6(附项目源码)
本节最终效果演示 文章目录 本节最终效果演示系列目录前言生命 食物 水简单绘制UI玩家状态脚本生命值控制饱食度控制水分控制 源码完结 系列目录 前言 欢迎来到【制作100个Unity游戏】系列!本系列将引导您一步步学习如何使用Unity开发各种类型的游戏。在这第23篇中…...
专栏近期有大量优惠 还请多多点一下关注 加油 谢谢 你的鼓励是我前行的动力 谢谢支持 加油 谢谢)
项目介绍 基于Python的大学生竞赛组队系统设计与实现(含模型描述及部分示例代码)专栏近期有大量优惠 还请多多点一下关注 加油 谢谢 你的鼓励是我前行的动力 谢谢支持 加油 谢谢
基于Python的大学生竞赛组队系统设计与实现的详细项目实例 请注意此篇内容只是一个项目介绍 更多详细内容可直接联系博主本人 或者访问对应标题的完整博客或者文档下载页面(含完整的程序,GUI设计和代码详解) 大学生竞赛已成为高校人才培养…...

HTML 零基础入门:从概念到常用标签详解,前端入门超详细版
一、HTML介绍HTML 全称超文本标记语言(HyperText Markup Language),是搭建网页的基础骨架语言,也是前端开发最入门、最核心的语言。它不属于编程语言,没有逻辑运算、没有变量,只是一套标记标签,…...

Python自动化登录:破解验证码与Cookie会话维持实战
1. 这不是“绕过验证”,而是理解会话机制的起点很多人看到“跳过验证码登陆”第一反应是:这合规吗?会不会被封?其实这个问题本身就暴露了一个关键误区——我们不是在“绕过”什么,而是在还原真实用户登录时浏览器自动完…...

工业视觉光源颜色选型全攻略|白/红/蓝/绿光适用场景、原理与避坑细则
摘要:在工业AI视觉缺陷检测项目落地中,绝大多数工程师过度聚焦相机参数、镜头焦距、模型调参优化,却忽略了光源颜色选型这一核心前置条件。工业检测有一条公认铁律:成像决定上限,模型只负责兜底。相同工件、相同光源结…...
)
AI Agent重构餐饮服务链:从排队超15分钟到响应<1.2秒的9大技术跃迁(行业首份效能白皮书)
更多请点击: https://kaifayun.com 第一章:AI Agent重构餐饮服务链:从排队超15分钟到响应<1.2秒的9大技术跃迁(行业首份效能白皮书) 传统餐饮服务链中,用户进店、点餐、支付、出餐、反馈等环节高度依赖…...

为小型创业团队搭建经济可控的大模型应用开发平台
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为小型创业团队搭建经济可控的大模型应用开发平台 对于资源有限的创业团队而言,在拥抱大模型技术的同时,必…...

告别手动打字:87种语言视频字幕5分钟本地提取全攻略
告别手动打字:87种语言视频字幕5分钟本地提取全攻略 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含字幕区域检测、字幕内容提…...

AI Agent开发效率提升300%的7个核心框架选择逻辑:从LangChain到AutoGen,2024企业级选型权威对比
更多请点击: https://codechina.net 第一章:AI Agent开发效率提升300%的7个核心框架选择逻辑:从LangChain到AutoGen,2024企业级选型权威对比 企业在构建生产级AI Agent时,框架选型直接决定迭代速度、可观测性与多模态…...

农业Agent不是“加个模型”,而是重写作业流程:3张架构图讲透农机调度、病虫害预警、供应链匹配的Agent协同范式
更多请点击: https://intelliparadigm.com 第一章:农业Agent不是“加个模型”,而是重写作业流程:3张架构图讲透农机调度、病虫害预警、供应链匹配的Agent协同范式 农业智能化的真正瓶颈,从来不在单点AI能力的强弱&…...
)
胶片颗粒≠噪点!20年胶片扫描工程师首曝Midjourney底层噪声映射逻辑(RGB通道衰减比=1.03:0.97:1.12)
更多请点击: https://codechina.net 第一章:胶片颗粒≠噪点!20年胶片扫描工程师首曝Midjourney底层噪声映射逻辑(RGB通道衰减比1.03:0.97:1.12) 胶片颗粒是银盐晶体在显影过程中形成的物理性随机簇状结构,…...