python爬虫-多线程-数据库——WB用户
数据库database的包:
Python操作Mysql数据库-CSDN博客
效果:
控制台输出:
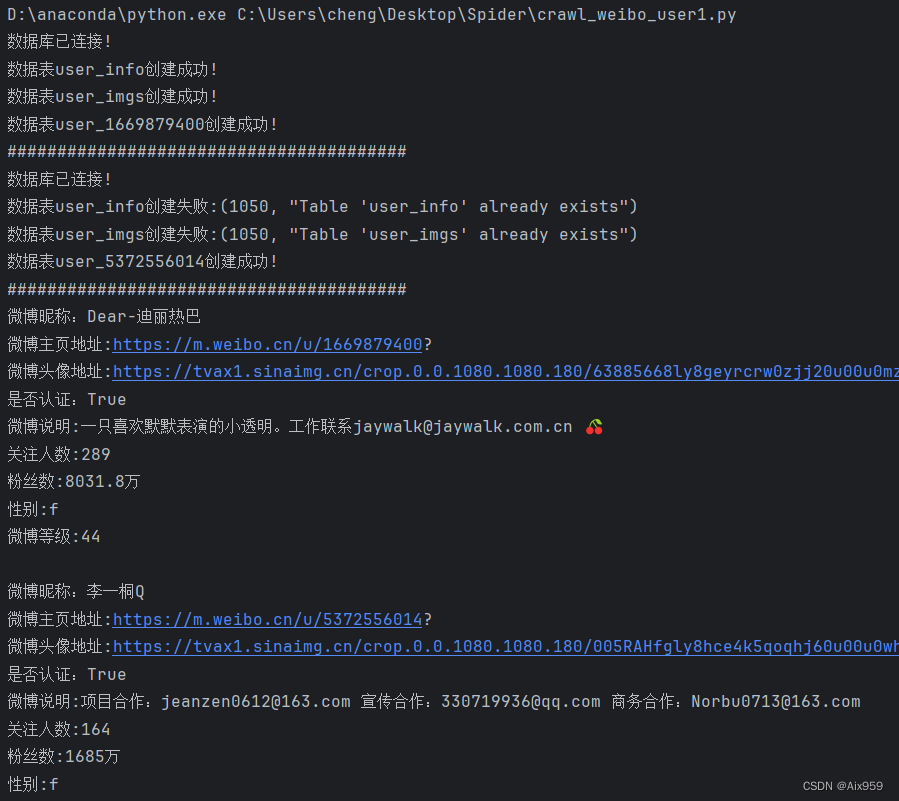
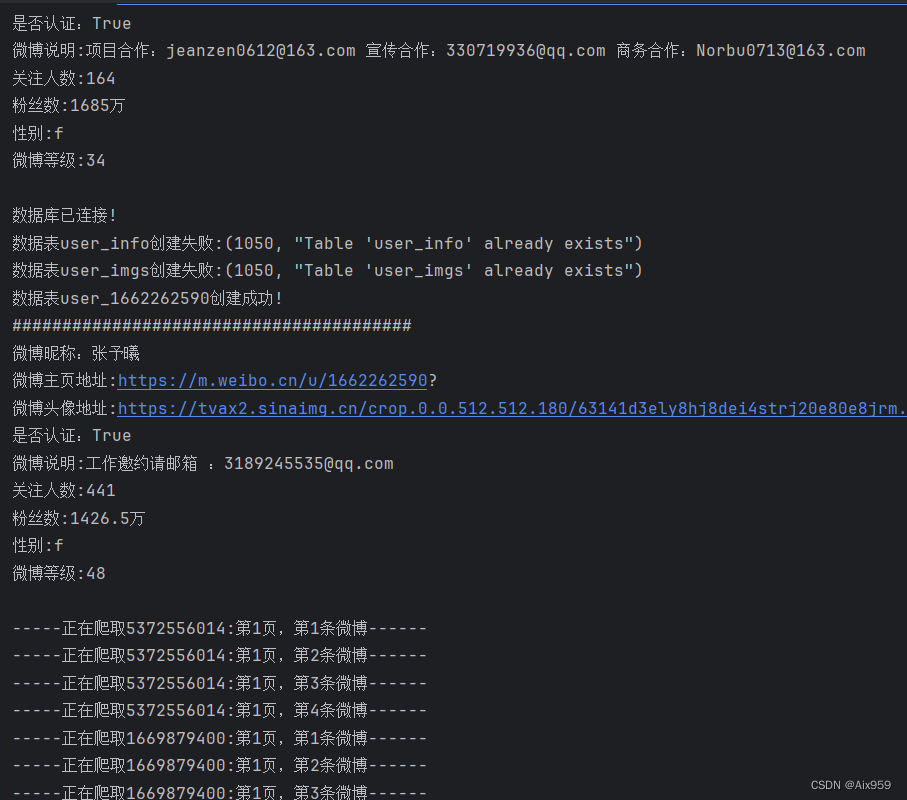

数据库记录:

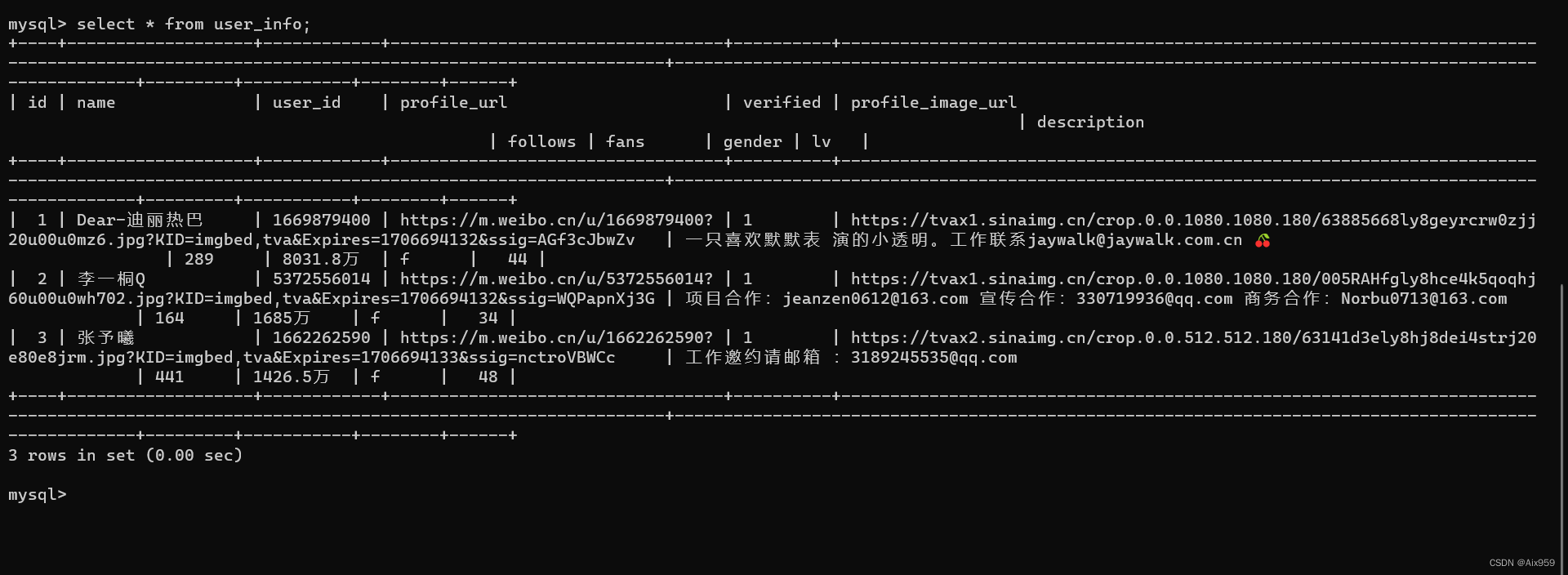
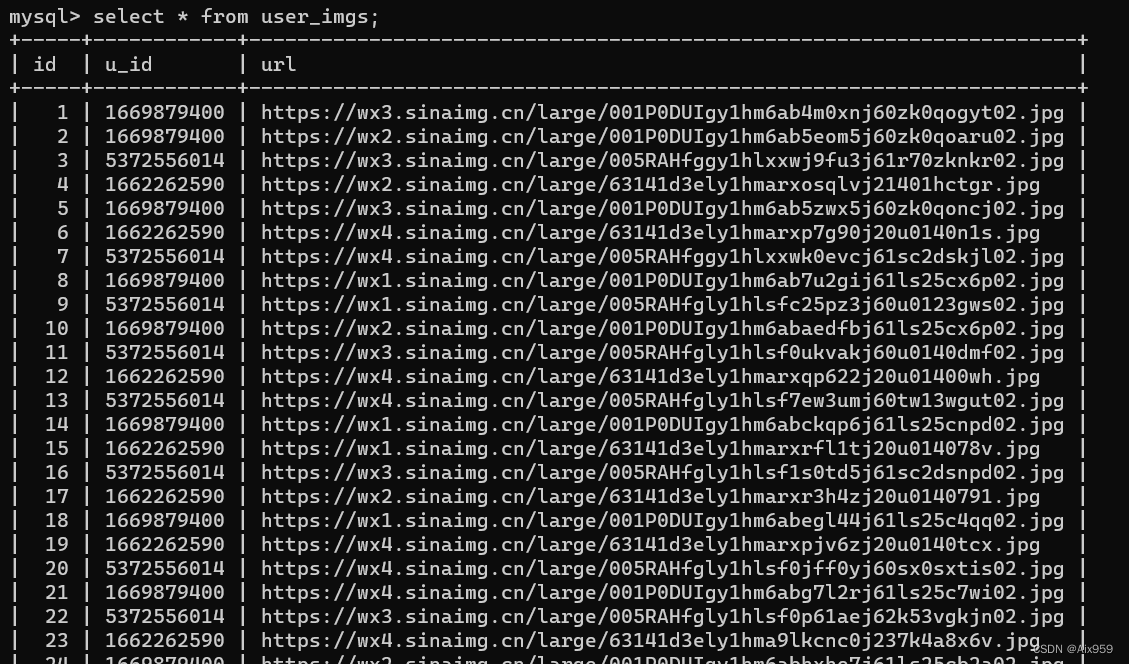
全部代码:
import json
import os
import threading
import tracebackimport requests
import urllib.request
from utils import make_headers, base64_encode_img, url_img_cv2img
from database import MyDataBaseclass WeiboUserCrawler(threading.Thread):def __init__(self, user_id: str, path: str = "weibo", proxy_addr: str = "122.241.72.191:808"):super(WeiboUserCrawler, self).__init__(target=self.run)self.user_id = user_idself.path = pathself.proxy_addr = proxy_addrself.url = 'https://m.weibo.cn/api/container/getIndex?type=uid&value=' + self.user_idself.container_id = self.get_container_id(self.url)self.page = 1 # 微博页数self.pic_num = 0 # 图片编号self.flag = Trueself.wb_db = MyDataBase("localhost", "123456", charset="utf8mb4")self.users_sheet = "user_info" # 所有用户信息表self.user_sheet = "user_" + self.user_id # 单个用户内容表self.imgs_sheet = "user_imgs" # 所有用户图片表self.create_file()self.create_db_tables()print("####" * 10)# 创建文件夹def create_file(self):if not os.path.exists(self.path):os.makedirs(self.path)if not os.path.exists(self.path + "/" + self.user_id):os.makedirs(self.path + "/" + self.user_id)# 创建三张表def create_db_tables(self):self.wb_db.connect()kwargs = {"id": "int primary key auto_increment","name": "varchar(128)","user_id": "varchar(20)","profile_url": "varchar(200)","verified": "varchar(50)","profile_image_url": "varchar(200)","description": "text","follows": "varchar(50)","fans": "varchar(50)","gender": "varchar(8)","lv": "tinyint"}self.wb_db.create_table(self.users_sheet, kwargs)kwargs = {"id": "int primary key auto_increment","u_id": "varchar(20)","url": "varchar(200)",}self.wb_db.create_table(self.imgs_sheet, kwargs)kwargs = {"id": "int primary key auto_increment","page": "int","locate": "varchar(128)","created_time": "varchar(128)","content": "text","praise": "varchar(50)","comments": "text","reposts": "varchar(50)",}self.wb_db.create_table(self.user_sheet, kwargs)def use_proxy(self, url):req = urllib.request.Request(url)req.add_header("User-Agent", make_headers()["User-Agent"])proxy = urllib.request.ProxyHandler({'http': self.proxy_addr})opener = urllib.request.build_opener(proxy, urllib.request.HTTPHandler)urllib.request.install_opener(opener)data = urllib.request.urlopen(req).read().decode('utf-8', 'ignore')return data # 返回的是字符串def get_container_id(self, url):data = self.use_proxy(url)# 通过json从获取的网页数据中,找到datacontent = json.loads(data).get('data')# 从data中找到container_idfor data in content.get('tabsInfo').get('tabs'):if data.get('tab_type') == 'weibo':container_id = data.get('containerid')return container_iddef get_user_info(self):data = self.use_proxy(self.url)# 通过json从获取的网页数据中,找到datacontent = json.loads(data).get('data')# 从data数据中获取下列信息profile_image_url = content.get('userInfo').get('profile_image_url')description = content.get('userInfo').get('description')profile_url = content.get('userInfo').get('profile_url')verified = content.get('userInfo').get('verified')follows = content.get('userInfo').get('follow_count')name = content.get('userInfo').get('screen_name')fans = content.get('userInfo').get('followers_count')gender = content.get('userInfo').get('gender')lv = content.get('userInfo').get('urank')data = f"微博昵称:{name}\n微博主页地址:{profile_url}\n微博头像地址:{profile_image_url}\n" \f"是否认证:{verified}\n微博说明:{description}\n关注人数:{follows}\n" \f"粉丝数:{fans}\n性别:{gender}\n微博等级:{lv}\n"print(data)path = f"{self.path}/{self.user_id}/{self.user_id}.txt"with open(path, 'a', encoding='utf-8') as f:f.write(data)# 数据库存用户users_sheet_field = ("name", "user_id", "profile_url", "verified", "profile_image_url", "description", "follows","fans", "gender", "lv")data = [name, self.user_id, profile_url, verified, profile_image_url, description, follows, fans, gender,lv]res = self.wb_db.select_table_record(self.users_sheet, f"where user_id={self.user_id}")for i in res:if self.user_id in i:print("该用户已在数据库!")returnself.wb_db.insert_data(self.users_sheet, users_sheet_field, data)# 存图下载图def save_img(self, mblog):try:if mblog.get('pics'):pic_archive = mblog.get('pics')for _ in range(len(pic_archive)):self.pic_num += 1img_url = pic_archive[_]['large']['url']img_data = requests.get(img_url)path = f"{self.path}/{self.user_id}/{self.user_id}_{self.pic_num}{img_url[-4:]}"with open(path, "wb") as f:f.write(img_data.content)# 数据库存图imgs_sheet_field = ("u_id", "url")data = [self.user_id, img_url]self.wb_db.insert_data(self.imgs_sheet, imgs_sheet_field, data)except Exception as err:traceback.print_exc()def save_data(self, j, mblog, cards):path = f"{self.path}/{self.user_id}/{self.user_id}.txt"attitudes_count = mblog.get('attitudes_count')comments_count = mblog.get('comments_count')created_at = mblog.get('created_at')reposts_count = mblog.get('reposts_count')scheme = cards[j].get('scheme')text = mblog.get('text')with open(path, 'a', encoding='utf-8') as f:f.write(f"----第{self.page}页,第{j}条微博----" + "\n")f.write(f"微博地址:{str(scheme)}\n发布时间:{str(created_at)}\n微博内容:{text}\n"f"点赞数:{attitudes_count}\n评论数:{comments_count}\n转发数:{reposts_count}\n")# 数据库存微博内容user_sheet_field = ("page", "locate", "created_time", "content", "praise", "comments", "reposts")data = [self.page, scheme, created_at, text, attitudes_count, comments_count, reposts_count]self.wb_db.insert_data(self.user_sheet, user_sheet_field, data)def process_data(self, data):content = json.loads(data).get('data')cards = content.get('cards')if len(cards) > 0:for j in range(len(cards)):print(f"-----正在爬取{self.user_id}:第{self.page}页,第{j + 1}条微博------")card_type = cards[j].get('card_type')if card_type == 9:mblog = cards[j].get('mblog')self.save_img(mblog)self.save_data(j, mblog, cards)self.page += 1else:self.flag = Falsedef run(self):try:self.get_user_info()while True:weibo_url = f"{self.url}&containerid={self.container_id}&page={self.page}"try:data = self.use_proxy(weibo_url)self.process_data(data)if not self.flag:print(f">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>已完成{self.user_id}")self.wb_db.close()breakexcept Exception as err:print(err)except Exception as err:print('>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>异常退出!')self.wb_db.close()if __name__ == '__main__':# 1669879400 # 热巴# 5372556014 # 李一桐# 1662262590 # 张予曦# uid = "1669879400"# wb = WeiboUserCrawler(uid)# wb.start()uids = ["1669879400", "5372556014", "1662262590"]for uid in uids:t = WeiboUserCrawler(uid)t.start()
相关文章:
python爬虫-多线程-数据库——WB用户
数据库database的包: Python操作Mysql数据库-CSDN博客 效果: 控制台输出: 数据库记录: 全部代码: import json import os import threading import tracebackimport requests import urllib.request from utils im…...

有向图查询所有环,非递归
图: 有向图查询所有环,非递归: import java.util.*;public class CycleTest {private final int V; // 顶点数private final List<List<Integer>> adjList; // 邻接表public CycleTest(int vertices) {this.V vertices;this.…...
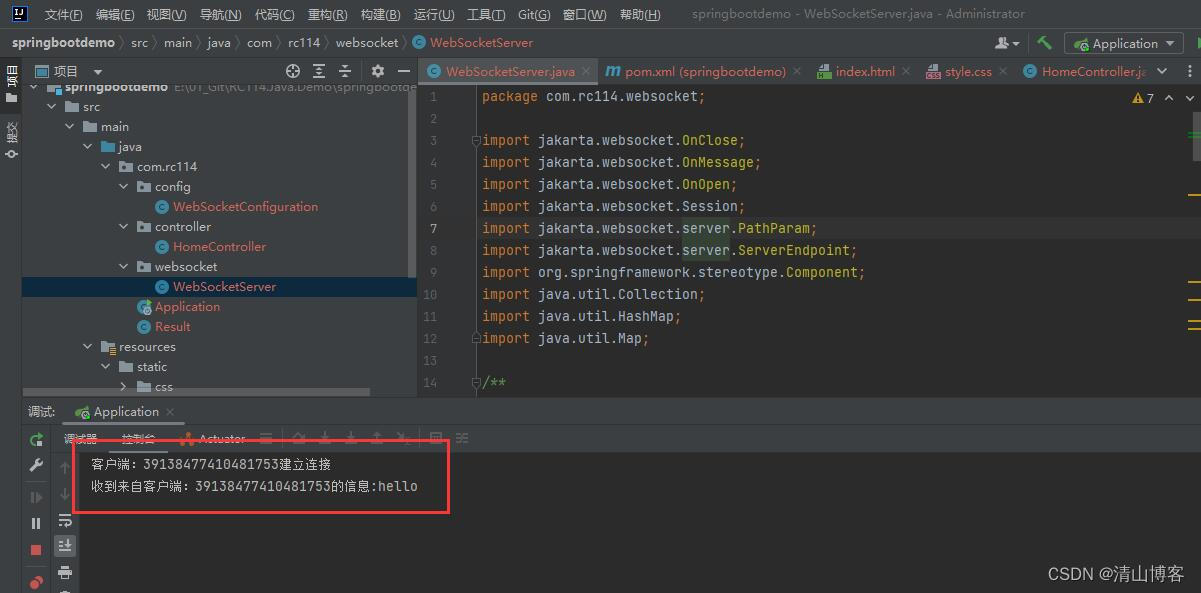
SpringBoot 使用WebSocket功能
实现步骤: 1.导入WebSocket坐标。 在pom.xml中增加依赖项: <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId> </dependency>2.编写WebSocket配…...
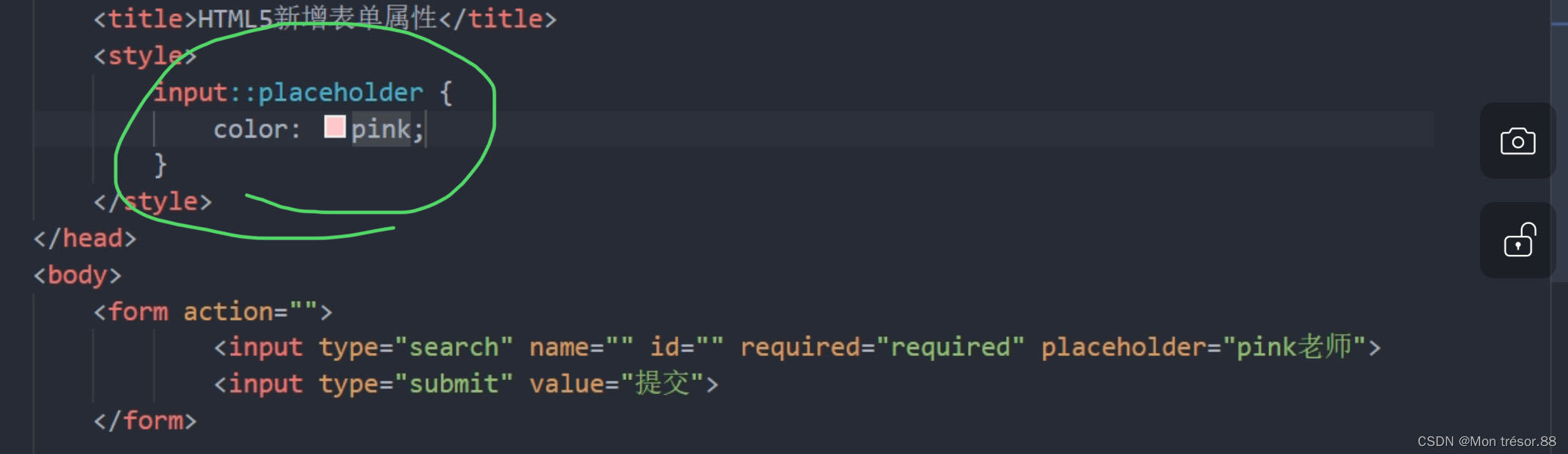
HTML5的新特性
目录 一,新增语义化标签 二,新增的多媒体标签 三,新增input表单 四,新增的表单属性 一,新增语义化标签 二,新增的多媒体标签 1,音频:<audio>.。。用MP3 <audio src…...

Filter过滤器学习使用
验证token 对外API过滤器 public class APIFilter implements Filter {private static Logger logger LogManager.getLogger(APIFilter.class);private ICachedTokenService tokenService;public APIFilter(ICachedTokenService tokenService) {super();this.tokenService …...

关于修改数据库服务器时间导致达梦数据库集群裂开
故障原因: 因为每天数据库服务器时间都不一致,想要给数据库服务器配置个NTP服务器。结果导致达梦数据库裂库。后面查看了达梦系统管理员手册了解了达梦集群的机制,知道数据库服务器时间需要先关闭数据库服务之后才可以修改数据库服务器时间。…...

自定义包的设计与实现
这是一个 CPacket 类,用于解析包含固定格式的数据。该类的成员变量包括固定包头 sHead、包长度 nLength、控制命令 sCmd、包数据 strData 和和校验 sSum。 构造函数: CPacket():默认构造函数,初始化成员变量。 CPacket(const B…...

时机成熟了
时机成熟了。 有一个老乡群,一到年底就各种人找车、车找人的消息。这些消息如果能直接爬取到一个小的网页里面去,则可以极大地便利大家做检索。如何把非结构化的内容转成结构化的 json,在以前是一个难题,但是有了 ChatGPT&#x…...

Linux 驱动开发基础知识——总线设备驱动模型(八)
个人名片: 🦁作者简介:学生 🐯个人主页:妄北y 🐧个人QQ:2061314755 🐻个人邮箱:2061314755qq.com 🦉个人WeChat:Vir2021GKBS 🐼本文由…...
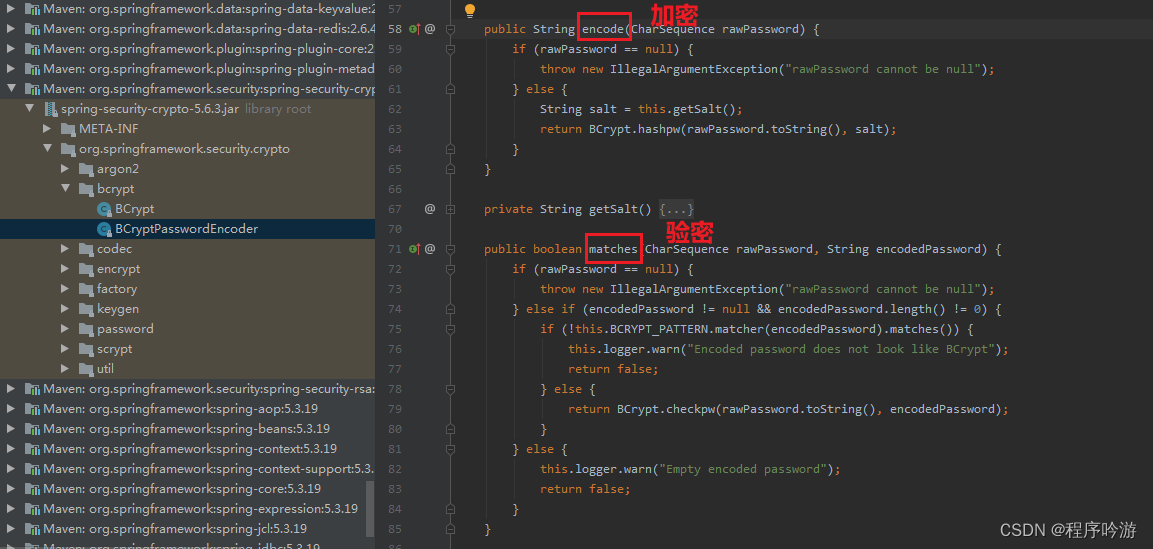
SpringBoot+BCrypt算法加密
BCrypt是一种密码哈希函数,BCrypt算法使用“盐”来加密密码,这是一种随机生成的字符串,可以在密码加密过程中使用,以确保每次加密结果都不同。盐的使用增强了安全性,因为攻击者需要花费更多的时间来破解密码。 下图为…...
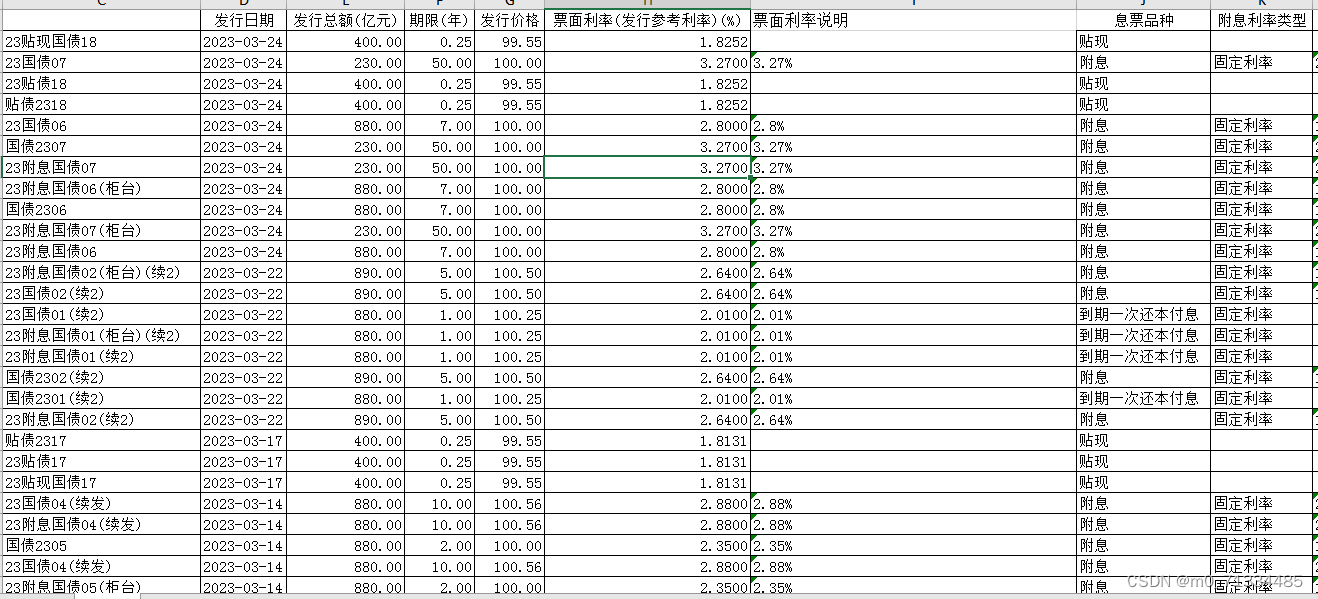
更新至2023年,2002-2023年3月中国国债发行数据
更新至2023年,2002-2023年3月中国国债发行数据 1、时间:2002-2023年3月 2、指标:序号、代码、发行日期、发行总额(亿元)、期限(年)、发行价格、票面利率(发行参考利率)(%)、票面利率说明、息票品种、附息利率类型、付息频率、起息日期、付息…...
2024最新版TypeScript安装使用指南
2024最新版TypeScript安装使用指南 Installation and Development Guide to the Latest TypeScript in 2024 By JacksonML 1. 什么是TypeScript? TypeScript is JavaScript with syntax for types. – typescriptlang.org TypeScript 是 JavaScript 的一个超集,…...

国外知名的农业机器人公司
从高科技温室到云播种,农业机器人如何帮助农民填补劳动力短缺以及超市货架的短缺。 概要 “高科技农业”并不矛盾。当代农业经营更像是硅谷,而不是美国哥特式,拥有控制灌溉的应用程序、驾驶拖拉机的 GPS 系统和监控牲畜的带有 RFID 芯片的耳…...

【EI会议征稿中|ACM出版】#先投稿,先送审#第三届网络安全、人工智能与数字经济国际学术会议(CSAIDE 2024)
#先投稿,先送审#ACM出版#第三届网络安全、人工智能与数字经济国际学术会议(CSAIDE 2024) 2024 3rd International Conference on Cyber Security, Artificial Intelligence and Digital Economy 2024年3月8日-10日 | 中国济南 会议官网&…...
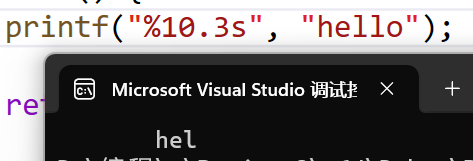
【笔试常见易错选择题01】else、表达式、二维数组、%m.ns、%m.nf、常量指针和指针常量、宏定义、传参、数组越界、位段
1. 下列main()函数执行后的结果为() int func(){ int i, j, k 0; for(i 0, j -1;j 0;i, j){ k; } return k; } int main(){cout << (func());return 0; }A. -1 B. 0 C. 1 D. 2 判断为赋值语句,j等于0 0为假不进循环 选B. 2. 下面程…...

Unity中常见的单词
前言 unity中常见的单词学习积累 一.常用的基础词。 new:新建; as:像。。一样; null:对象空值; void:函数返回空值; switch:开关; abstract:抽象的; event:事件; return:返回; class:类; …...
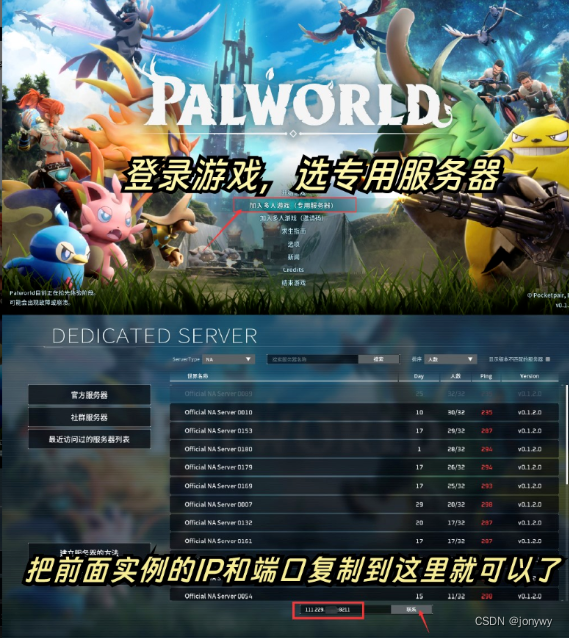
【仅需一步,1分钟极速开服】幻兽帕鲁保姆级教程
本教程分为两部分。一、开服教程。二、如何登录游戏(第一次接触游戏,如何玩) 一、开服教程。 1、通过 游戏服务器专属优惠页,选择以下应用模板并点击立即购买。 - 【服务器套餐配置推荐】* 1、入门配置(2~…...

Zoho Mail 2023:回顾过去,展望未来:不断进化的企业级邮箱解决方案
当我们告别又一个非凡的一年时,我们想回顾一下Zoho Mail如何融合传统与创新。我们迎来了成立15周年,这是一个由客户、合作伙伴和我们的敬业团队共同庆祝的里程碑。与我们一起回顾这段旅程,探索定义Zoho Mail历史篇章的敏捷性、精确性和创新性…...
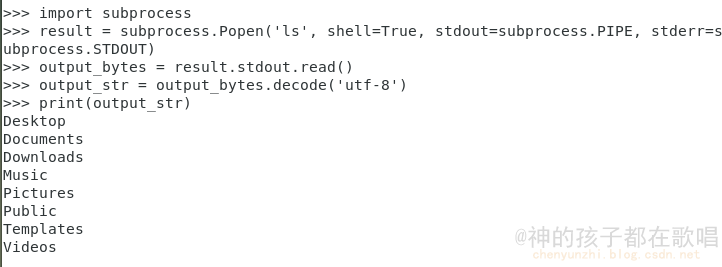
python执行linux系统命令的三种方式
前言 这是我在这个网站整理的笔记,有错误的地方请指出,关注我,接下来还会持续更新。 作者:神的孩子都在歌唱 1. 使用os.system 无法获取命令执行后的返回信息 import osos.system(ls)2. 使用os.popen 能够获取命令执行后的返回信息 impor…...
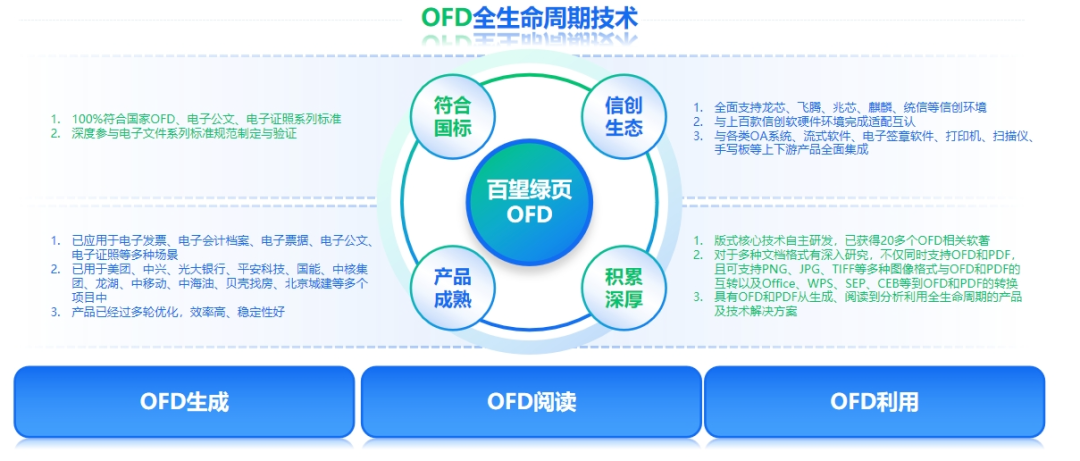
协会认证!百望云荣获信创工委会年度“卓越贡献成员单位”称号
当前,新一轮科技革命和产业变革正加速重塑全球经济结构,强化企业科技创新的主体地位,推动创新链、产业链、人才链深度融合,加快科技成果产业化进程至关重要。 近日,中国电子工业标准化技术协会信息技术应用创新工作委员…...

如何快速完成AI智能图像分层:layerdivider完整使用指南
如何快速完成AI智能图像分层:layerdivider完整使用指南 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 你是否曾经面对复杂的插画设计&#x…...

Navicat16/17 Mac版试用期终极重置指南:三种自动化方案实现无限免费使用
Navicat16/17 Mac版试用期终极重置指南:三种自动化方案实现无限免费使用 【免费下载链接】navicat_reset_mac navicat mac版无限重置试用期脚本 Navicat Mac Version Unlimited Trial Reset Script 项目地址: https://gitcode.com/gh_mirrors/na/navicat_reset_ma…...

边缘视觉模型实战指南:ViT优化、多模态对齐与事件相机融合
1. 项目概述:这不是一份“论文清单”,而是一份实战派视觉工程师的周度技术雷达上周(2023年8月28日至9月3日)我像往常一样,在晨会前半小时打开arXiv、CVPR官网和几所顶尖实验室的GitHub更新页,准备快速扫一遍…...
SPF-10G-T :10G 电口模块,重塑短距网络升级性价比)
安科士(AndXe)SPF-10G-T :10G 电口模块,重塑短距网络升级性价比
数字化转型浪潮下,企业园区、数据中心对10Gbps 高速互联的需求呈爆发式增长。但传统 10G 升级方案深陷困境:光纤布线成本高昂、施工周期长且需专业运维技能,而多数企业机架内、相邻机架间及办公楼层内的链路距离普遍低于 30 米,光…...

前端html字体包体积压缩,网站工程下字体压缩裁剪工具
整个网站项目如果字体包体积太大就会影响其加载速度,字体加载完会让页面字体突然变换。做一个工具他会自动检索网站上所有展现给用户的字符,然后原地裁剪字体。来解决这个问题。实现效果如下: 执行py文件以后,在网站字体文件所在目…...

深入GD32 CAN FD驱动:从寄存器配置到ISO 15765数据发送的代码逐行解析
GD32 CAN FD驱动开发实战:从寄存器配置到ISO 15765协议栈实现 在汽车电子和工业控制领域,CAN FD协议正逐步取代传统CAN总线成为高速通信的主流方案。GD32系列MCU凭借其出色的性价比和完整的外设支持,成为许多嵌入式开发者的首选。本文将深入剖…...

避坑指南:Ubuntu 20.04上VINS-Fusion环境搭建,从源码修改到手机数据实测的完整流程
Ubuntu 20.04下VINS-Fusion环境搭建全流程避坑手册 当你在Ubuntu 20.04上尝试搭建VINS-Fusion环境时,可能会遇到各种令人头疼的问题。从依赖项安装到源码修改,再到手机摄像头数据的适配,每一步都可能隐藏着意想不到的"坑"。本文将带…...

Gemini 访问要不要额外网络工具?国内直连体验怎么看
最近不少开发者开始把 Gemini 放进日常工作流里:查资料、写代码注释、整理技术方案、做内容大纲。但实际使用前,大家最关心的往往不是模型参数,而是“能不能顺畅访问”。如果只是想先体验模型能力,可以通过 库拉 这类 AI模型聚合平…...

初创团队如何利用 Taotoken Token Plan 有效控制 AI 实验成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何利用 Taotoken Token Plan 有效控制 AI 实验成本 对于资源有限的初创团队而言,在产品原型和概念验证阶段&…...

大中小型企业数据配置年度成本估算分析
引言 在数字化转型浪潮下,数据已成为企业的核心资产。无论是初创公司、中型企业还是大型集团,合理规划数据存储、处理与分析的成本,对于优化IT预算、提升投资回报率至关重要。本文旨在为不同规模的企业提供一个清晰、可操作的年度数据配置成本…...