C++引用、内联函数、auto关键字介绍以及C++中无法使用NULL的原因
文章目录
- 一、引用
- 1.1 引用概念
- 1.2 引用特性
- 1.3 常引用
- 1.4 使用场景
- 1.4.1 做参数
- 1.4.2做返回值
- 1.5 引用和指针的区别
- 1.6 小结一下
- 二、内联函数
- 2.1 内联的概念
- 2.2 内联的特性
- 2.3 【面试题】
- 三、auto关键字(C++11)
- 3.1 类型别名思考
- 3.2 auto简介
- 四、auto的使用细则
- 4.1 基于范围的for循环(C++11)
- 4.2 范围for的使用条件
- 五、指针空值nullptr(C++11)
一、引用
1.1 引用概念
C++是C语言的继承,它可进行过程化程序设计,又可以进行以抽象数据类型为特点的基于对象的程序设计,还可以进行以继承和多态为特点的面向对象的程序设计。引用(reference)就是C++对C语言的重要扩充。引用就是某一变量(目标)的一个别名,对引用的操作与对变量直接操作完全一样。引用的声明方法:类型标识符 &引用名=目标变量名; -->百度百科
- 这个引用就相当于是别名
void TestRef()
{int a = 10;int& ra = a;//<====定义引用类型printf("%p\n", &a);printf("%p\n", &ra);
}
- 类型& 引用变量名(对象名) = 引用实体;
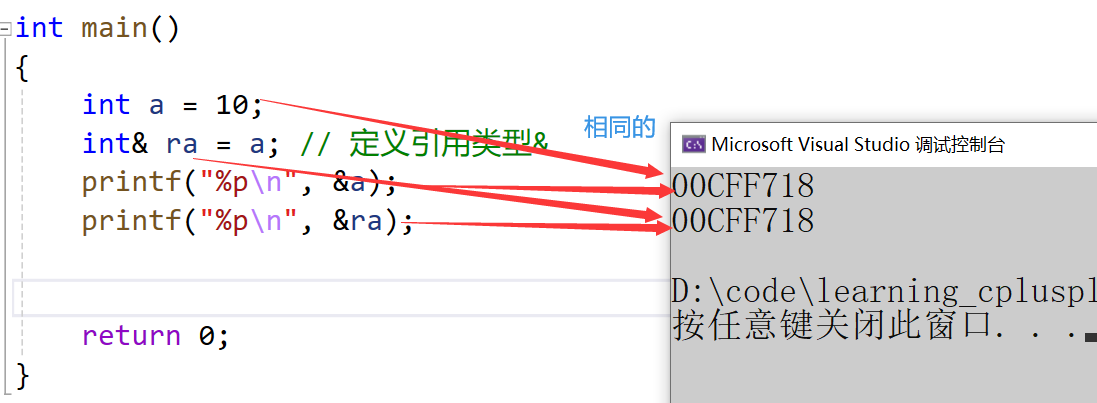
- 我们通过调试来看一下:
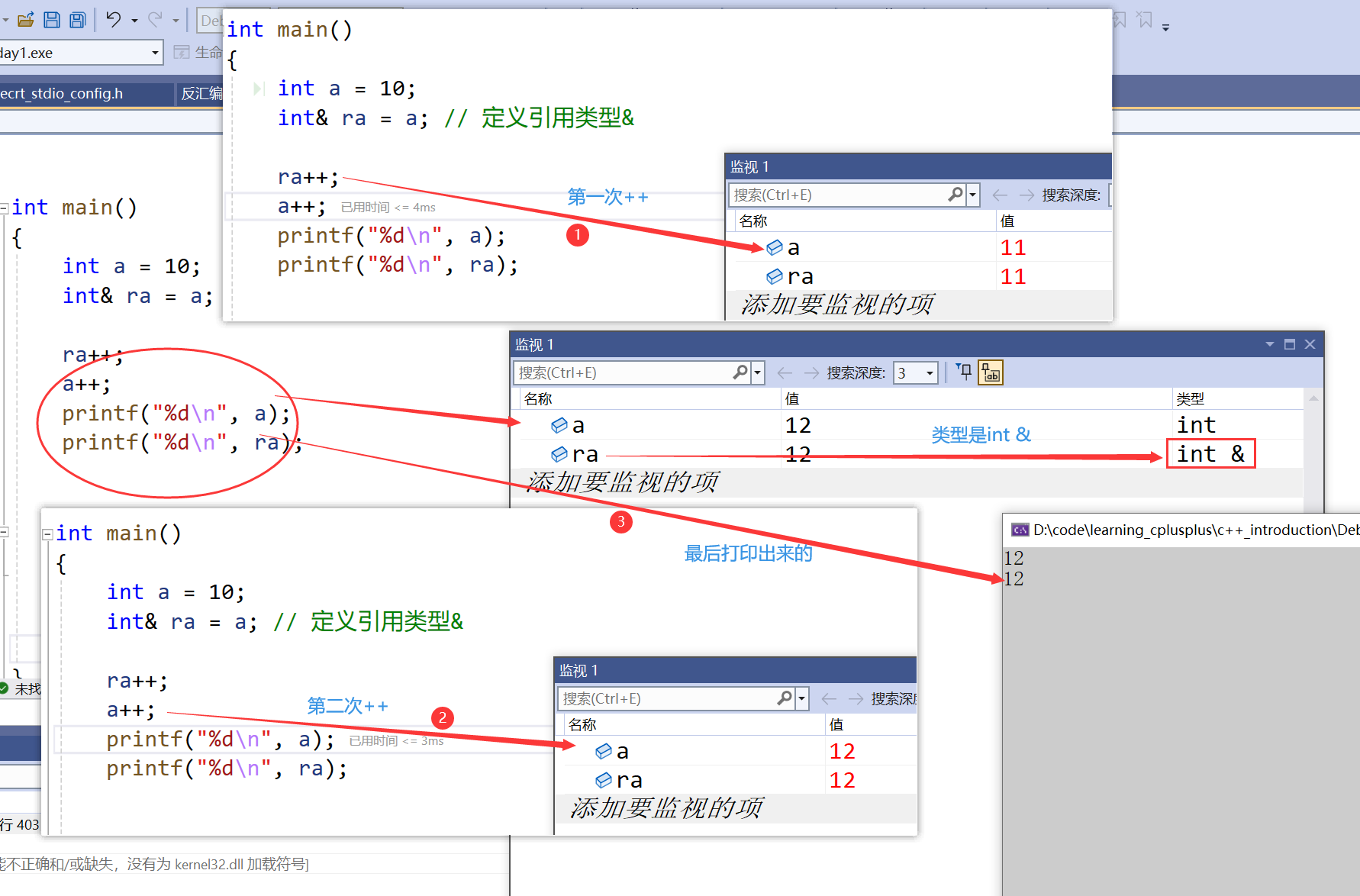
1.2 引用特性
- 引用在定义时必须初始化
- 一个变量可以有多个引用
- 引用一旦引用一个实体,再不能引用其他实体
void main()
{int a = 10;// int& ra; // 该条语句编译时会出错,必须要初始化int& ra = a;int& rra = a;printf("%p %p %p\n", &a, &ra, &rra);
}
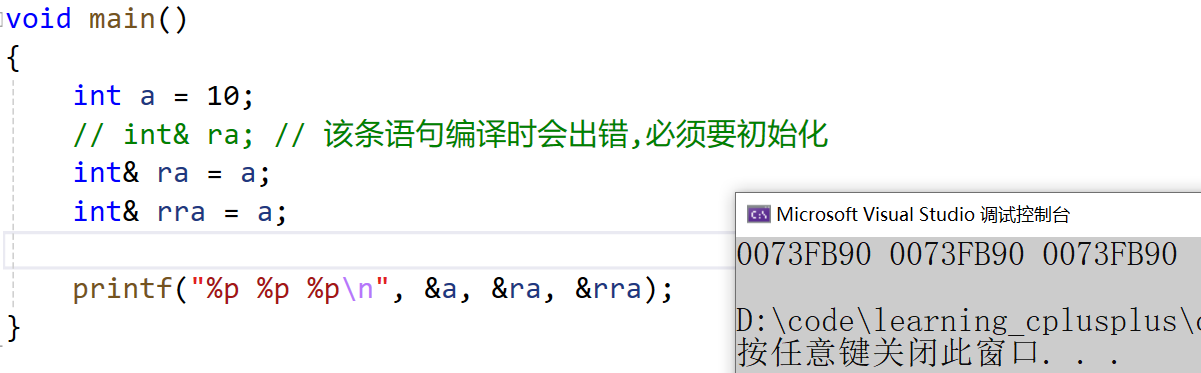
1.3 常引用
- 取别名不能放大权限
int main()
{int a = 0;// 权限的缩小const int& c = a;const int x = 10;// 权限的放大int& y = x;return 0;
}
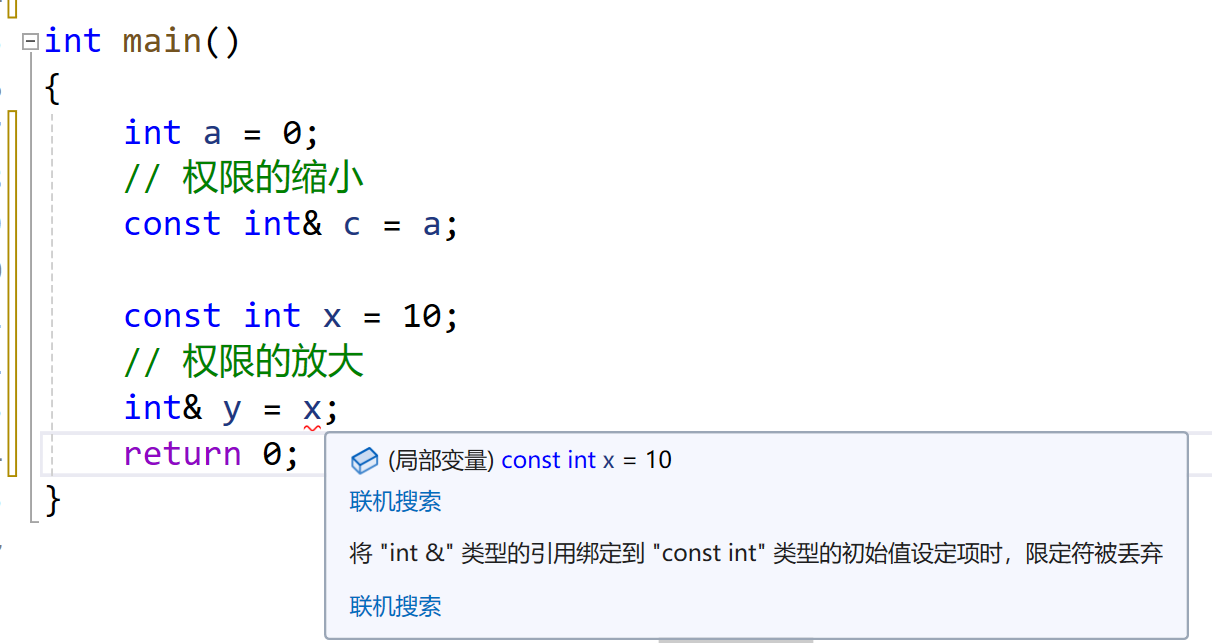
- 可以这样写,相等的就可以
const int x = 10;
const int y = x;
a+x的结果是一个临时变量,临时变量具有常性,const引用就可以int& n = a + x;的返回值是临时变量,临时对象具有常性,是一个权限放大
int a = 0;
const int x = 10;
const int& z = 10;
const int& m = a + x; //这样写也可以
int& n = a + x; // 这样写不可以
- 这里const加上就可以将不同类型取别名
- 类型转换的时候会出现一个临时变量**,临时变量具有常性,所以就可以~**
double d = 1.1;
int i = d; // 强制类型转换
int& ri = d; // 无法赋予,类型不同
const int& ri = d; // 加上const就可以了
- 被引用的实体不能是常量
- 引用的类型必须相同
1.4 使用场景
引用有两个场景分别是做参数和做返回值
1.4.1 做参数
- 做参数【在我们C语言阶段的时候使用函数交换两个变量的值就需要传地址过去,否则的话,形参只是实参的一份临时拷贝】
void Swap(int* a, int* b)
{int tmp = *a;*a = *b;*b = tmp;
}
int main()
{int x = 0, y = 1;Swap(&x, &y);return 0;
}
- 而我们学了引用,这个时候就可以把指针替换下去了,使用引用作为参数
void Swap(int& a, int& b)
{int tmp = a;a = b;b = tmp;
}int main()
{int x = 0, y = 1;Swap(x, y);return 0;
}
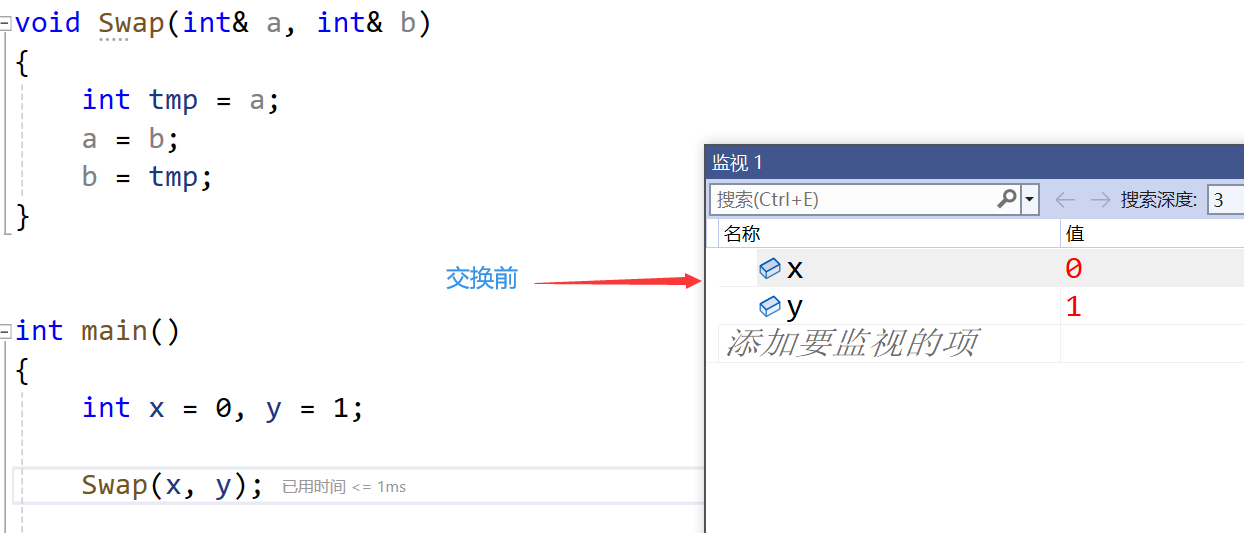
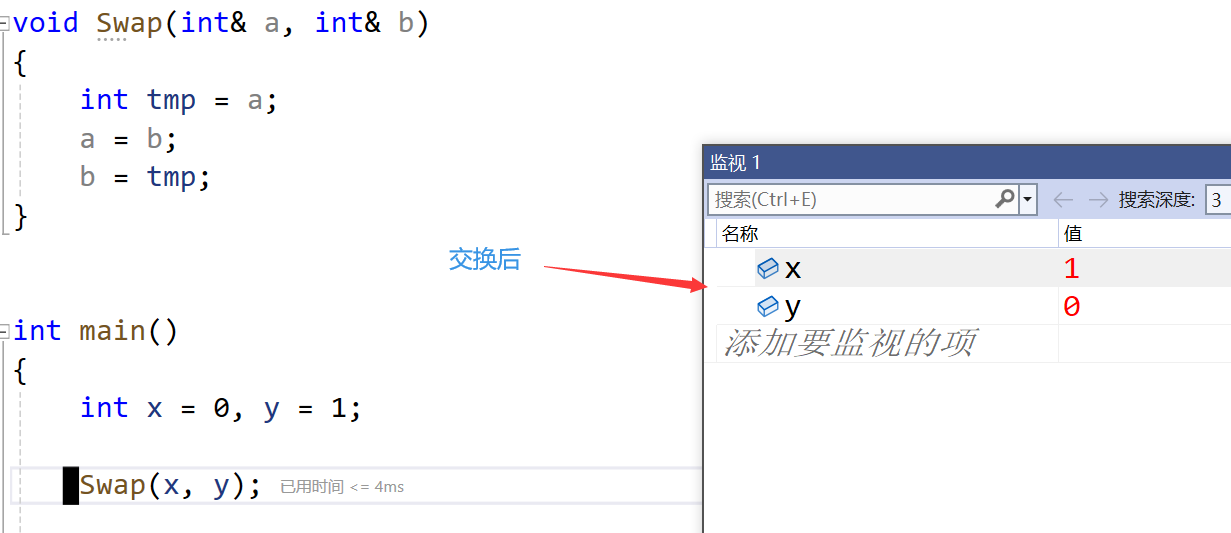
- 那么引用可以代替指针吗?【不可以!】
指针和引用的功能是类似的,有重叠的
C++的引用,对指针使用比较复杂的场景进行一些替换,让代码更简单易懂,但是不能完全替代指
- 针引用不能完全替代指针原因:引用定义后,不能改变指向
就比如说在数据结构中学的链表,指针需要改变指向,引用不能改变指向,这就是引用不能代替指针的原因
- 那java和pythone等其他语言有没有指针?–>没有
- 那他们的链表是怎么实现的呢?–>引用
- 本质上就是引用可以改变指向
- 我们再来看一个案例,在我们学数据结构的时候单链表学习阶段
- 有这这么一段代码,这里的pphead必须要传二级指针,有点不好理解呀
void PushBack(struct Node** pphead, int x)
{*pphead = newnode;
}
int main()
{struct Node* plist = NULL;return 0;
}
- 而我们学了引用就可以这样写了,加上一个引用,也就是phead是plist的一份临时拷贝
void PushBack(struct Node*& phead, int x)
{phead = newnode;
}int main()
{struct Node* plist = NULL;return 0;
}
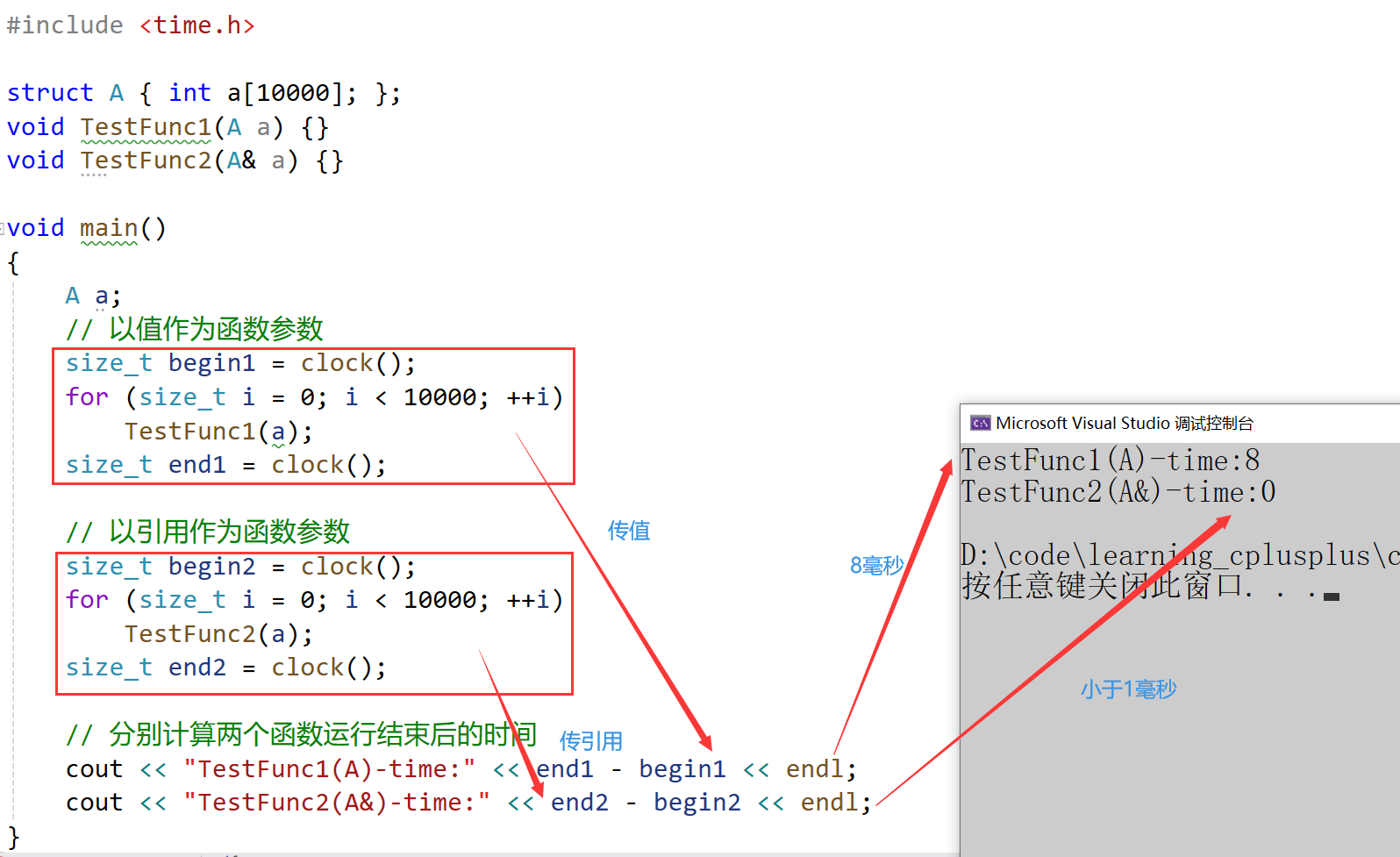
传值、传引用效率比较
- 我们这里可以测试一下性能,对比一下传值、传引用
#include <time.h>struct A { int a[10000]; };
void TestFunc1(A a) {}
void TestFunc2(A& a) {}void main()
{A a;// 以值作为函数参数size_t begin1 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc1(a);size_t end1 = clock();// 以引用作为函数参数size_t begin2 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc2(a);size_t end2 = clock();// 分别计算两个函数运行结束后的时间cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;
}- 可以看到传值需要8毫秒,而传引用小于0毫秒,小于0毫秒这里显示不出来,所以显示的0
- 那我再次测试一下以引用作为函数的返回值类型和以值作为函数的返回值类型的性能
#include <time.h>
struct A { int a[10000]; };
A a;
// 值返回
A TestFunc1() { return a; }
// 引用返回
A& TestFunc2() { return a; }
void main()
{// 以值作为函数的返回值类型size_t begin1 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc1();size_t end1 = clock();// 以引用作为函数的返回值类型size_t begin2 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc2();size_t end2 = clock();// 计算两个函数运算完成之后的时间cout << "TestFunc1 time:" << end1 - begin1 << endl;cout << "TestFunc2 time:" << end2 - begin2 << endl;
}
- 这就不用我说了吧~~
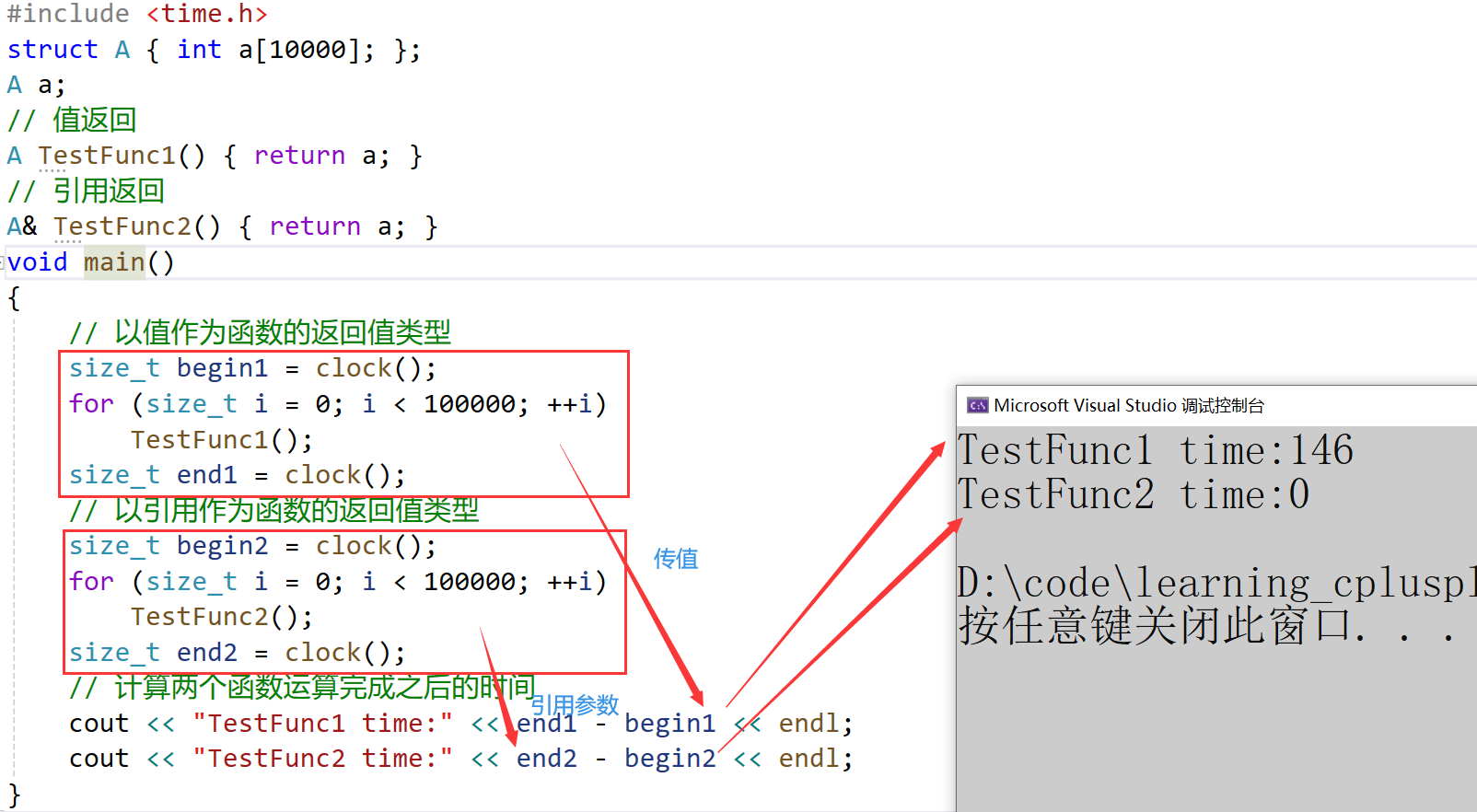
- 以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低
1.4.2做返回值
- 首先来看这段代码,这段代码是将a的值返回,然后ret接收,没有什么问题
int func()
{int a = 0;return a;
}int main()
{int ret = func();cout << ret << endl;return 0;
}
- 学了引用后,我们是不是可以这样
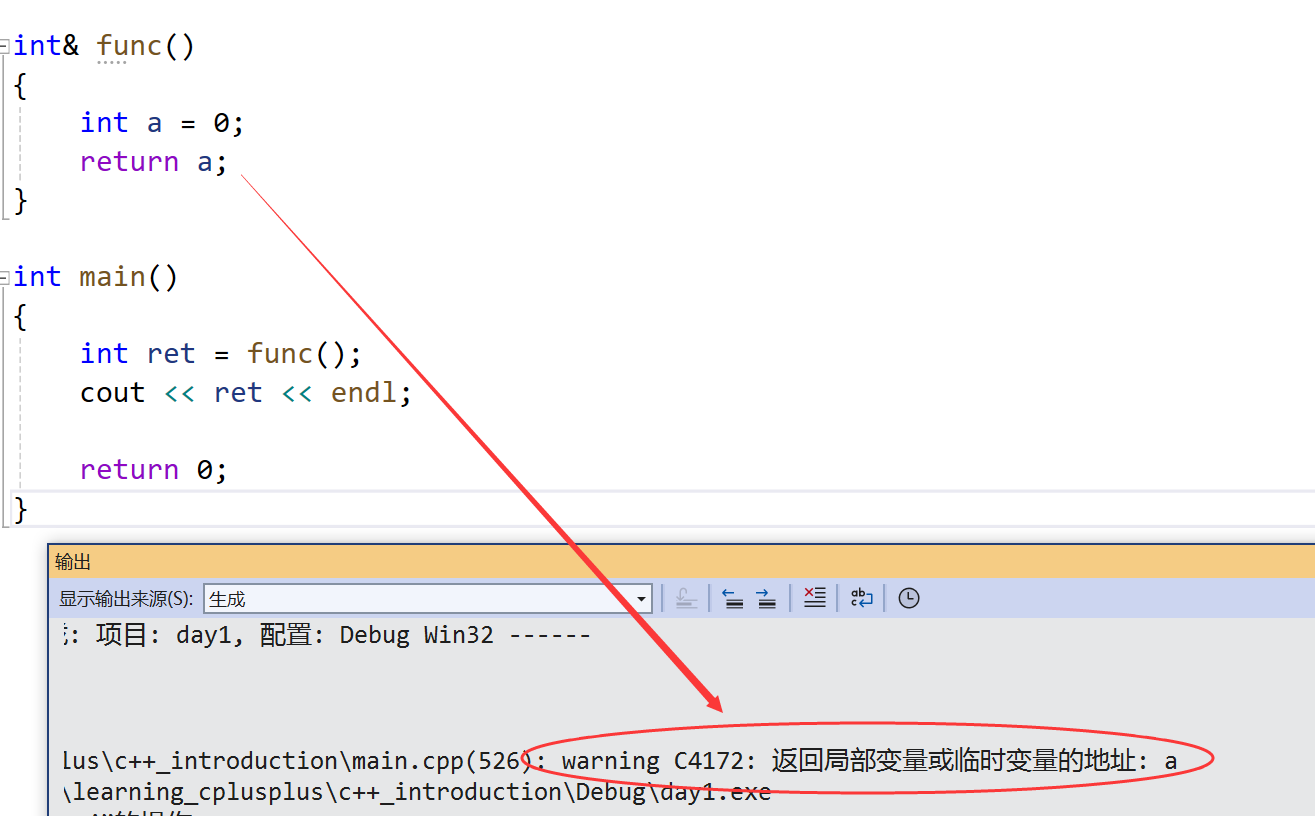
int& func()
{int a = 0;return a;
}int main()
{int ret = func();cout << ret << endl;return 0;
}
- 这里是报了一个警告,返回局部变量或临时变量的地址,那么这个程序的结果是什么?
-
我们以前说指针有野指针,那么引用也有野引用
-
上面的代码在func函数里是将a的别名返回了,函数调用完会销毁,这里与函数的栈帧的创建与销毁有关
-
在调用完函数后,那块空间会被销毁,然后再访问被销毁的地址,会造成野引用
-
栈帧销毁的时候可能被清理,结果可能是随机值,但是在vs上是不清理的
-
我们可以证明一下
int& func()
{int a = 0;return a;
}int& fx()
{int b = 1;return b;
}int main()
{int& ret = func();cout << ret << endl;fx();cout << ret << endl;return 0;
}
- 在调用完一次后再次调用,栈帧大小是一样的,会复用前面的空间
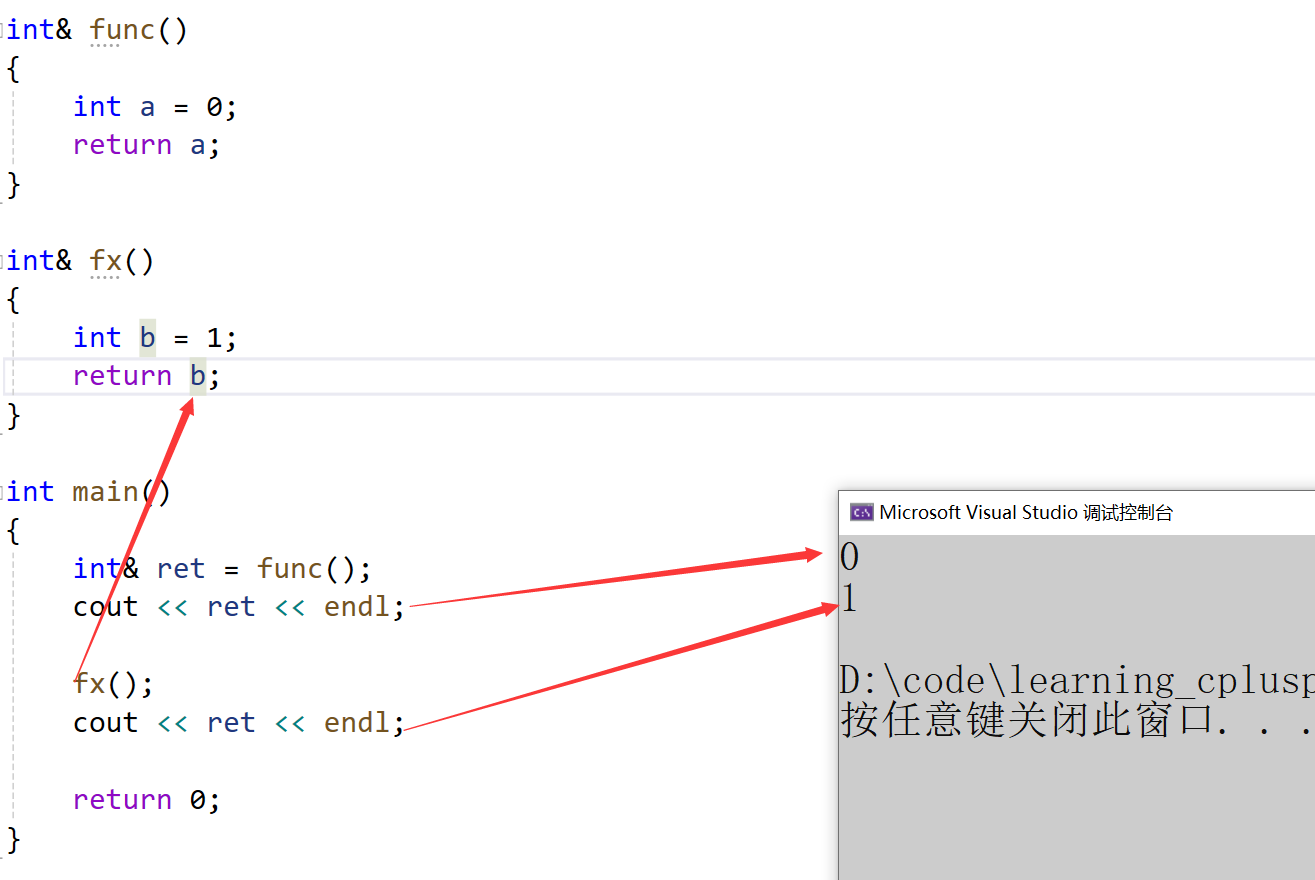
结论:返回变量出了函数作用域生命周期就销毁了,不能用引用返回
- 那什么情况下可以用引用返回呢?
全局变量/静态变量/堆上的变量等就可以用引用返回
那么我这里举例用一个现实中的场景:
- 首先来看一下
- 这里已经c和c++混着写了
#include<assert.h>
// 升级成类了,直接就可以使用名字,不用typedef了
struct SeqList
{int* a;int size;int capacity;
};void SLInit(SeqList& sl)
{sl.a = (int*)malloc(sizeof(int) * 4);// ..sl.size = 0;sl.capacity = 4;
}void SLPushBack(SeqList& sl, int x)
{//...扩容sl.a[sl.size++] = x;
}// 修改
void SLModity(SeqList& sl, int pos, int x)
{assert(pos >= 0);assert(pos < sl.size);sl.a[pos] = x;
}int SLGet(SeqList& sl, int pos)
{assert(pos >= 0);assert(pos < sl.size);return sl.a[pos];
}int main()
{SeqList s;SLInit(s);// 这里接收的是引用,所以我们就不需要取地址了SLPushBack(s, 1);SLPushBack(s, 2);SLPushBack(s, 3);SLPushBack(s, 4);for (int i = 0; i < s.size; i++){cout << SLGet(s, i) << " ";}cout << endl;// 获取每偶数进行*2for (int i = 0; i < s.size; i++){int val = SLGet(s, i);if (val % 2 == 0){SLModity(s, i, val * 2);}}cout << endl;for (int i = 0; i < s.size; i++){cout << SLGet(s, i) << " ";}cout << endl;return 0;
}
- 首先这里C++写有变化
struct SeqList
{// 成员变量int* a;int size;int capacity;// 成员函数void Init(){a = (int*)malloc(sizeof(int) * 4);// ...size = 0;capacity = 4;}void PushBack(int x){// ... 扩容a[size++] = x;}// 读写返回变量// 临时变量具有常性// 所以必须返回引用,引用中间没有产生临时变量,是一个别名int& Get(int pos){assert(pos >= 0);assert(pos < size);return a[pos];}
};int main()
{SeqList s;s.Init();s.PushBack(1);s.PushBack(2);s.PushBack(3);s.PushBack(4);for (int i = 0; i < s.size; i++){cout << s.Get(i)<< " ";}cout << endl;for (int i = 0; i < s.size; i++){if (s.Get(i) % 2 == 0){s.Get(i) *= 2;}}cout << endl;for (int i = 0; i < s.size; i++){cout << s.Get(i) << " ";}cout << endl;return 0;
}
- 上面的代码C++首先将C语言的结构体升级成了类了,然后函数可以定义到类里面了,在使用的时候获取值就要注意一个点:必须返回引用,之前不是说不能用引用返回码,这里就不一样了,这个malloc出来的空间,是在堆上的,所以可以返回,返回别名后,修改,修改别名也就是修改原来的地址…end
1.5 引用和指针的区别
- 对比区别的话,要从两个维度来对比,一个是语法,一个是底层,这两个不要混在一起了
语法层面理解:
- 来看下面的这段代码:
int main()
{int a = 10;int& ra = a; // 语法不开空间,ra = 20;int* pa = &a; // 语法上开空间*pa = 20;return 0;
}
- 引用是别名,不开空间,指针是地址,需要开空间
- 这里我们上面都已经知道了~
底层理解:
- 我们来看一下汇编代码

- 看到在底层是开空间的,引用底层是指针实现的
- 语法含义和底层实现是背离的
1.6 小结一下
语法层面上:
- 引用是别名,不开空间,指针是地址,需要开空间
- 引用必须初始化,指针可以初始化也可以不初始化
- 引用不能改变指向,指针可以
- 引用相对更安全,没有空引用,但是有空指针,容易出现野指针,但是不容易出现野引用
- sizeof 、++、解用访问等方面的区别
底层层面上:【汇编】
汇编层面上,没有引用,都是指针,引用编译后也转换成指针了
引用…End
二、内联函数
2.1 内联的概念
以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数调用建立栈帧的开销,内联函数提升程序运行的效率。
- 假设我要频繁调用100w次,建立100w个栈帧
int Add(int a, int b)
{return a + b;
}
- c语言如何解决这个问题的?宏函数
#define ADD(a, b) ((a)+(b))
- 核心点:宏是预处理阶段进行替换
宏的缺点:
1、语法复杂,坑很多,不容易控制
2、不能调试
3、没有类型安全的检查
- 这个时候C++就引入了一个概念inline,就是把函数的运算逻辑放到里面来,不进行建立栈帧
inline int Add(int a, int b)
{return a + b;
}int main()
{int ret1 = Add(1, 2) * 3;int x = 1, y = 2;int ret2 = Add(x | y, x & y);return 0;
}
- 如果在上述函数前增加inline关键字将其改成内联函数,在编译期间编译器会用函数体替换函数的调用
查看方式:
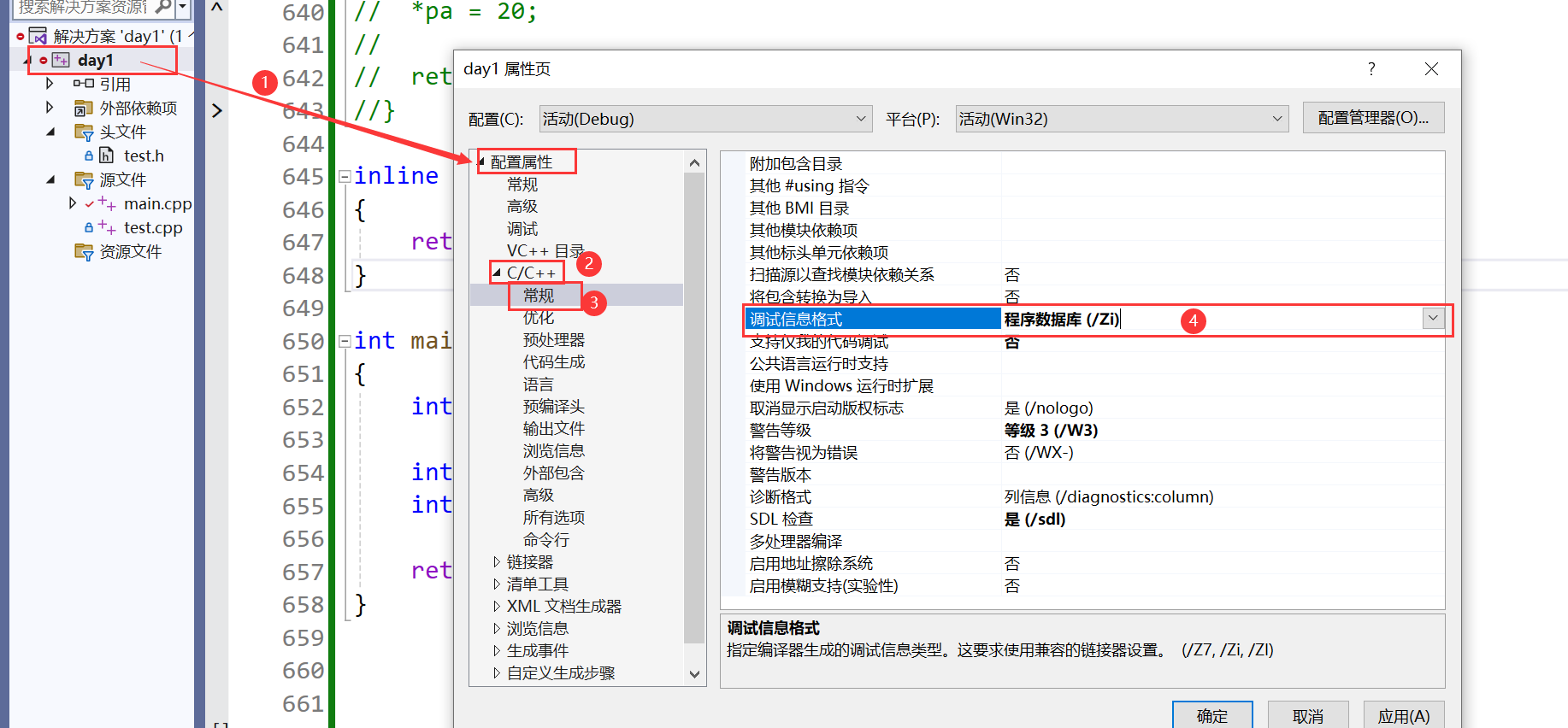
- 在release模式下,查看编译器生成的汇编代码中是否存在call Add
- 在debug模式下,需要对编译器进行设置,否则不会展开(因为debug模式下,编译器默认不会对代码进行优化,下面是vs2022的设置)

- 在不加内联的情况下
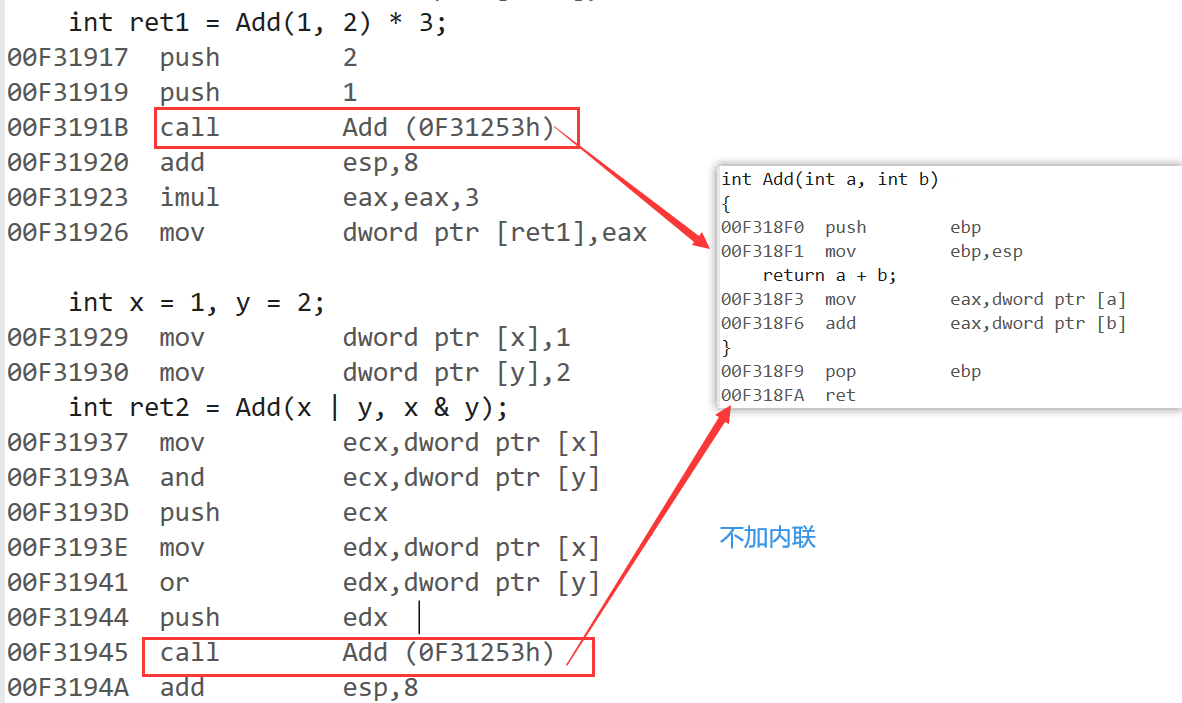
- 添加了内联后,可以看到有很大的特别

- 我们再来看一个场景
- 就是分文件定义的时候,我就想在.h文件中定义一个函数
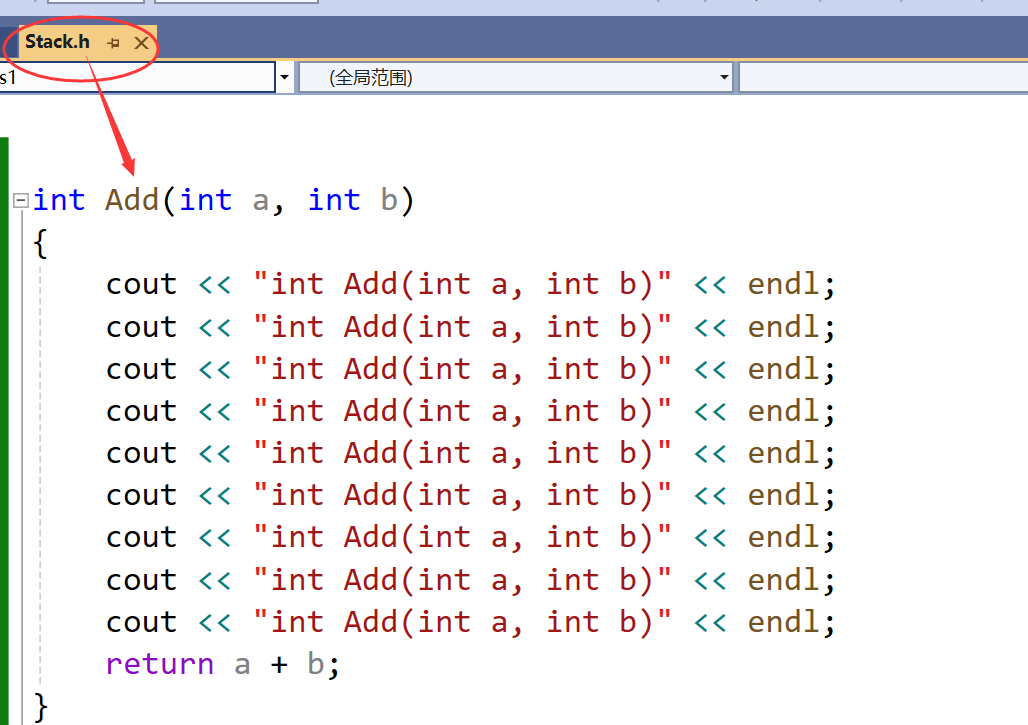
- 然而我在使用的时候两个文件都包含了这个头文件,在编译阶段链接的时候就会报链接错误,冲突的原因就是两个文件都会生成符号表,进行链接,有同名,会冲突因为是同一个函数,这咋办啊~
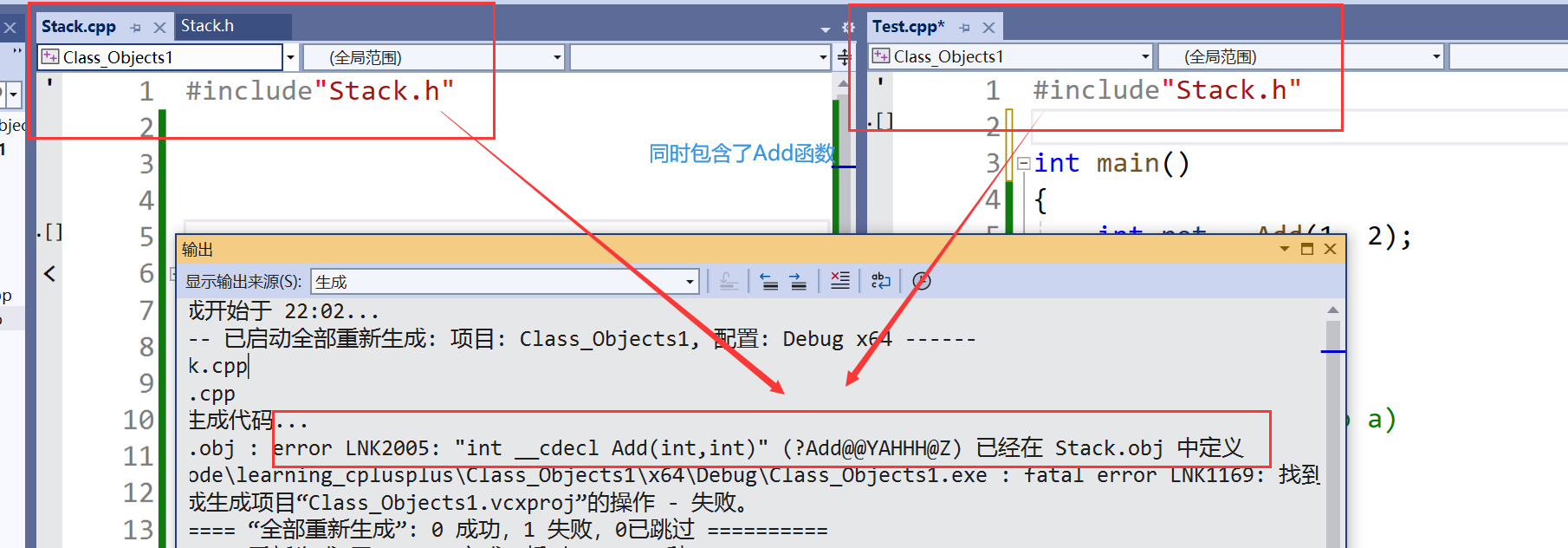
我们有三种解决方案:
第一种就是声明和定义分离
- 这个不多说,基本都会,之前我们用的都是这样的方法
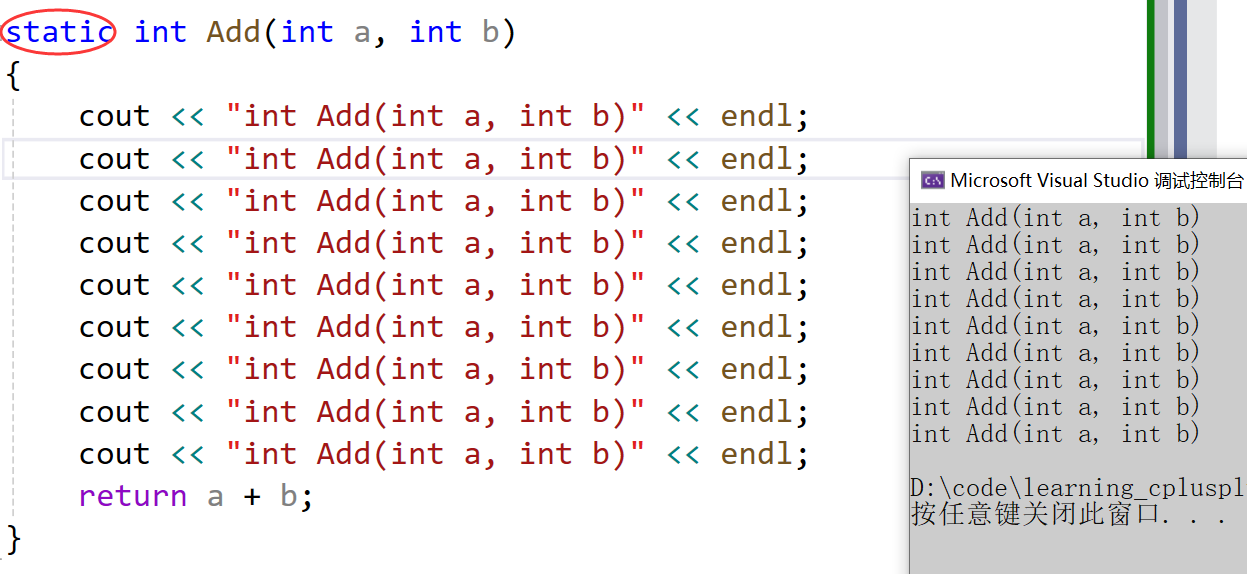
第二种方式就是static修饰函数,链接属性,只在当前文件可见
- 在C语言阶段详细大家知道滴~~
第三种方式就是加入内联函数
- 这里的内联函数相当于也就是static
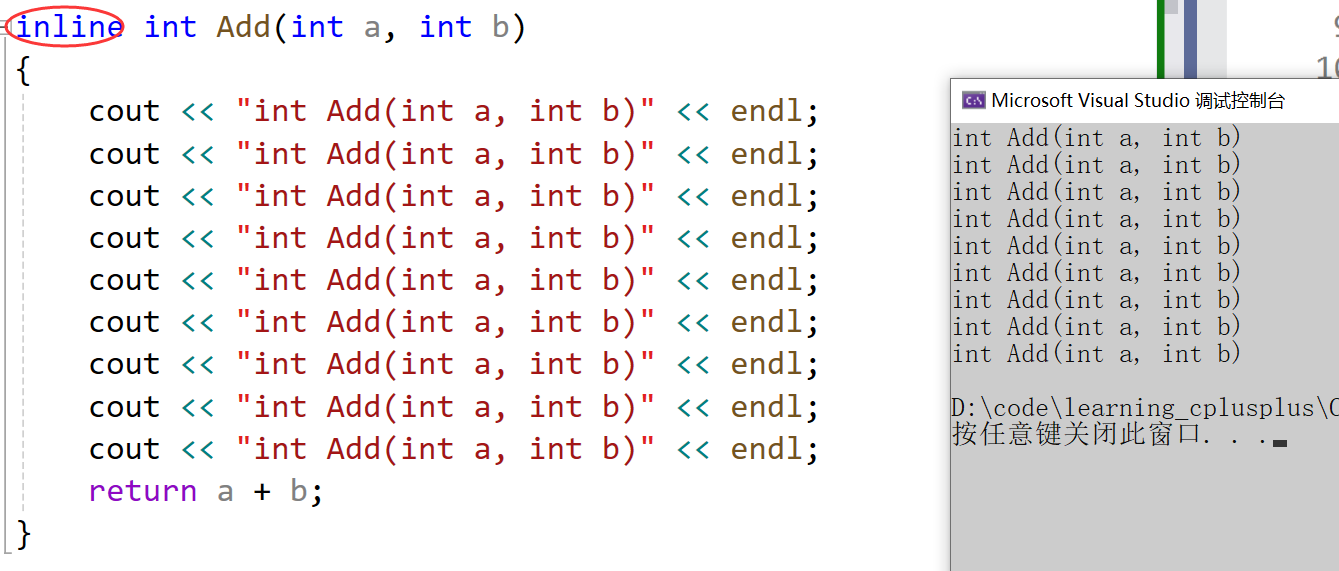
- 这里要注意,内联修饰的函数比较大,他是不会展开的,小函数就会展开,所以小函数使用内联,大函数使用静态
2.2 内联的特性
- inline是一种以空间换时间的做法,如果编译器将函数当成内联函数处理,在编译阶段,会用函数体替换函数调用,缺陷:可能会使目标文件变大,优势:少了调用开销,提高程序运行效率。
- inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性。下图为《C++prime》第五版关于inline的建议:

- inline 不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址了,链接就会找不到。
2.3 【面试题】
宏的优缺点?
优点:
- 增强代码的复用性。
- 提高性能。
缺点:
- 不方便调试宏。(因为预编译阶段进行了替换)
- 导致代码可读性差,可维护性差,容易误用。
- 没有类型安全的检查 。
C++有哪些技术替代宏?
- 常量定义 换用const enum
- 短小函数定义 换用内联函数
三、auto关键字(C++11)
3.1 类型别名思考
- 随着程序越来越复杂,程序中用到的类型也越来越复杂,经常体现在:
- 类型难于拼写
- 含义不明确导致容易出错
int main()
{std::map<std::string, std::string> m{ { "apple", "苹果" }, { "orange","橙子" },{"pear","梨"} };std::map<std::string, std::string>::iterator it = m.begin();while (it != m.end()){//....}return 0;
}
- 大家来上面的一个代码,有可能看不懂,但是我们只需要知道
std::map<std::string, std::string>::iterator是一个类型但是该类型太长了,特别容易写错。聪明的同学可能已经想到:可以通过typedef给类型取别名,比如:
typedef std::map<std::string, std::string> Map;
使用typedef给类型取别名确实可以简化代码,但是typedef有会遇到新的难题:
typedef char* pstring;int main()
{const pstring p1; const pstring* p2; return 0;
}
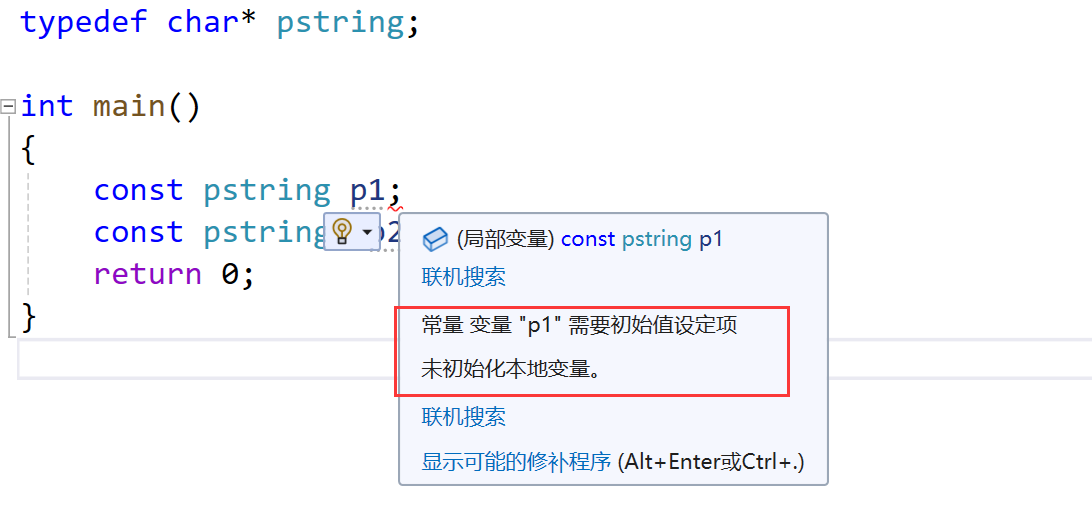
在编程时,常常需要把表达式的值赋值给变量,这就要求在声明变量的时候清楚地知道表达式的
类型。然而有时候要做到这点并非那么容易,因此C++11给auto赋予了新的含义。
- 这个时候auto就有作用了
3.2 auto简介
-
在早期C/C++中auto的含义是:使用auto修饰的变量,是具有自动存储器的局部变量,但遗憾的是一直没有人去使用它,大家可思考下为什么?
-
C++11中,标准委员会赋予了auto全新的含义即:auto不再是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。
如下所示:
int TestAuto()
{return 10;
}
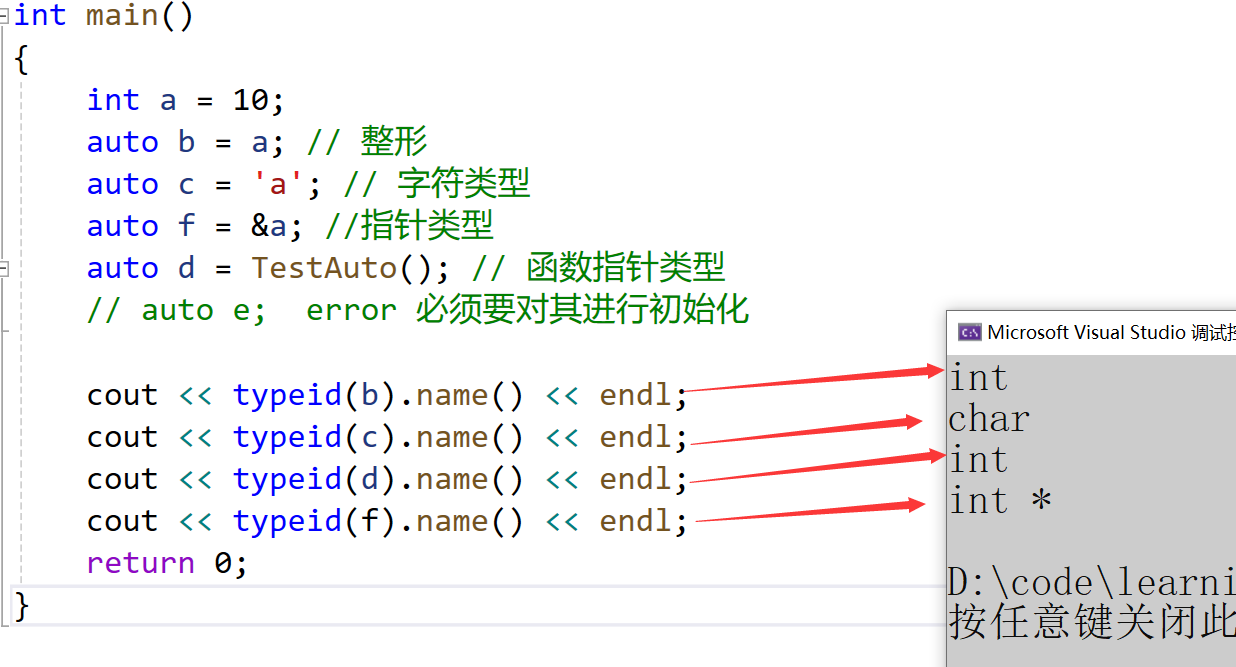
int main()
{int a = 10;auto b = a; // 整形auto c = 'a'; // 字符类型auto f = &a; //指针类型auto d = TestAuto(); // 函数指针类型// auto e; error 必须要对其进行初始化cout << typeid(b).name() << endl;cout << typeid(c).name() << endl;cout << typeid(d).name() << endl;cout << typeid(f).name() << endl;return 0;
}
- 这里的typeid(函数名).name(),就是打印类型
- 就刚刚上面的代码就可以这样写了
#include <string>
#include <map>
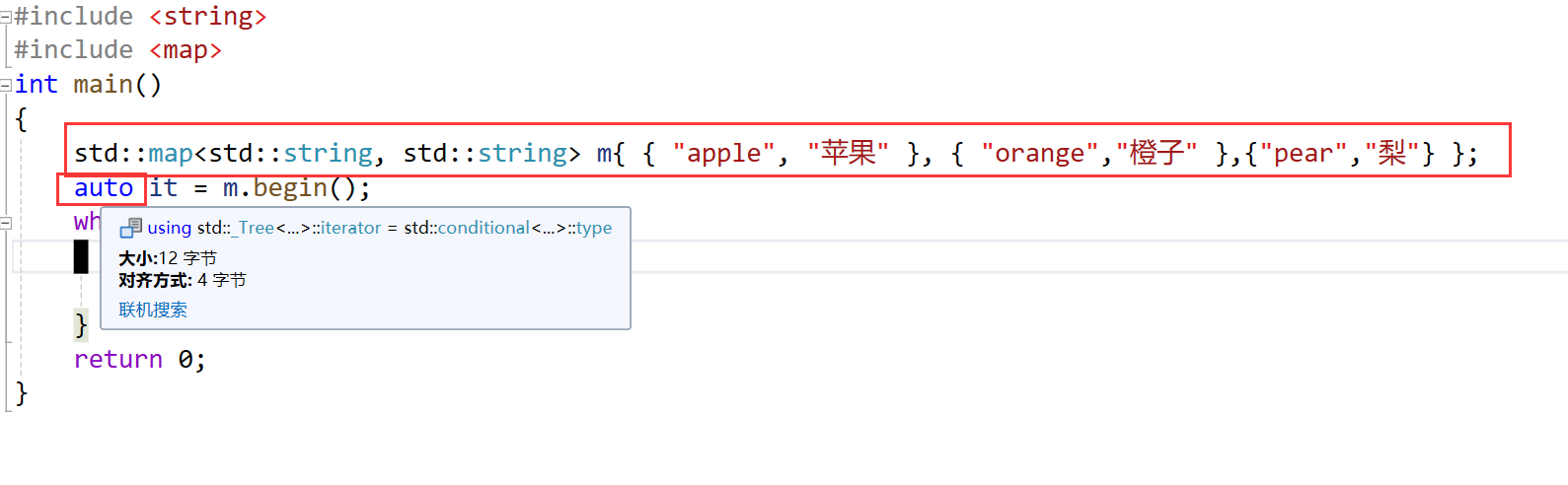
int main()
{std::map<std::string, std::string> m{ { "apple", "苹果" }, { "orange","橙子" },{"pear","梨"} };auto it = m.begin();while (it != m.end()){//....}return 0;
}
- 类型就可以写成auto自动识别了~~
【注意】
使用auto定义变量时必须对其进行初始化,在编译阶段编译器需要根据初始化表达式来推导auto的实际类型。因此auto并非是一种“类型”的声明,而是一个类型声明时的“占位符”,编译器在编译期会将auto替换为变量实际的类型。
四、auto的使用细则
- auto与指针和引用结合起来使用
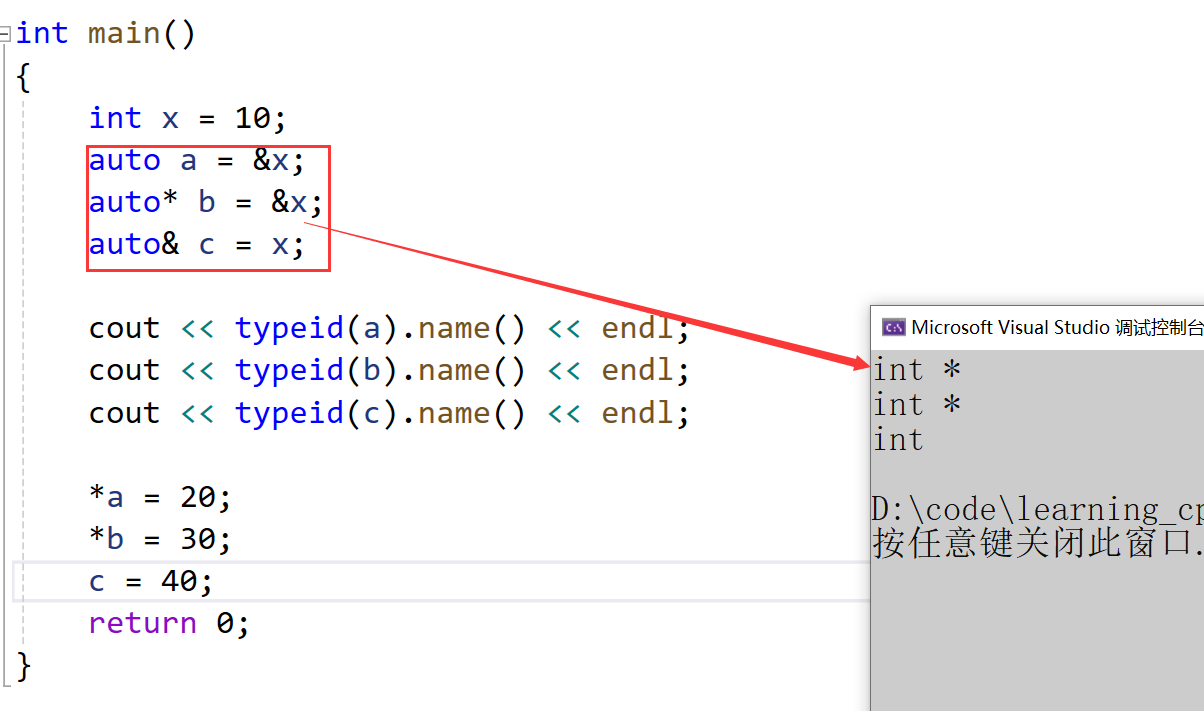
用auto声明指针类型时,用auto和auto*没有任何区别,但用 auto 声明引用类型时则必须加 &
int main()
{int x = 10;auto a = &x;auto* b = &x;auto& c = x;cout << typeid(a).name() << endl;cout << typeid(b).name() << endl;cout << typeid(c).name() << endl;*a = 20;*b = 30;c = 40;return 0;
}
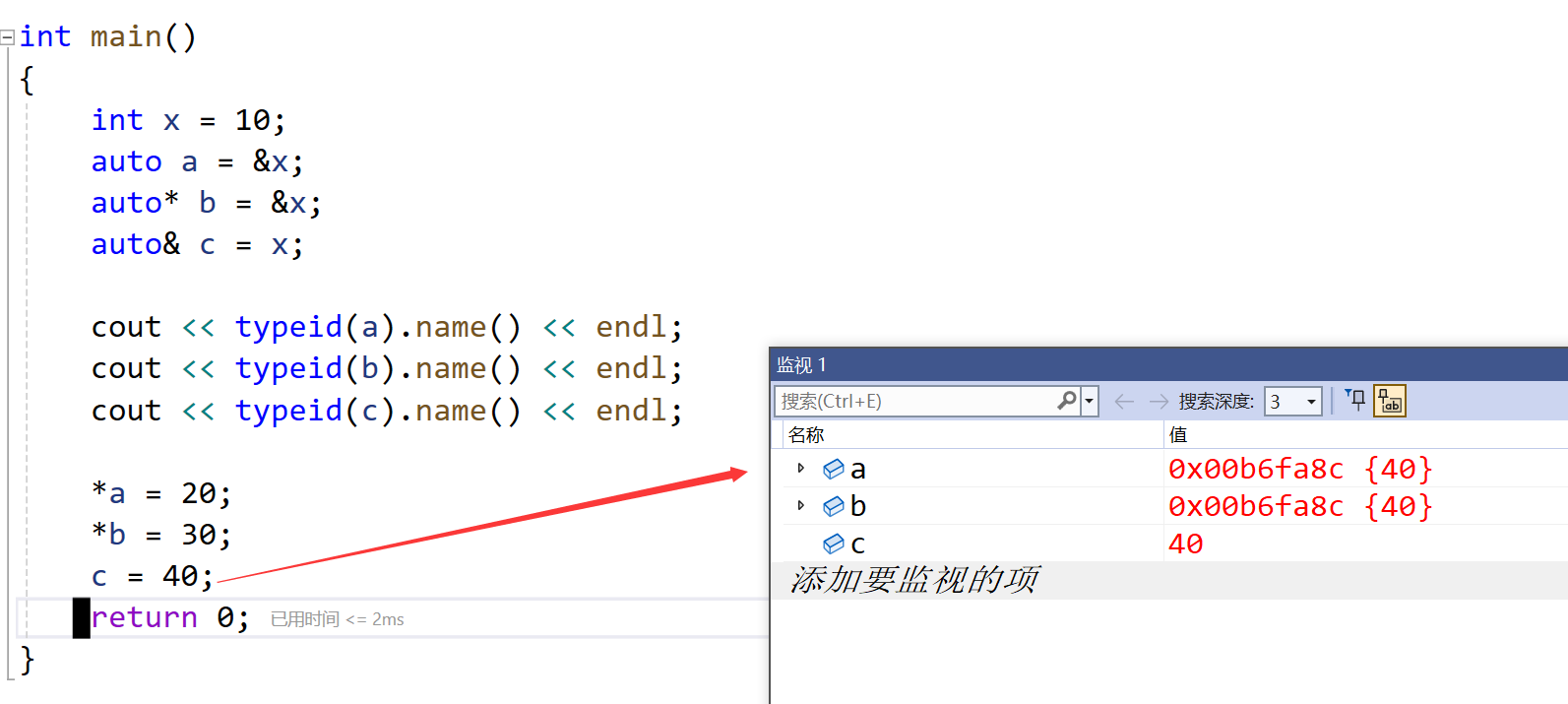
- 在同一行定义多个变量
当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译器实际只对第一个类型进行推导,然后用推导出来的类型定义其他变量。
void TestAuto()
{auto a = 1, b = 2;auto c = 3, d = 4.0;
}

- auto不能推导的场景
- auto不能作为函数的参数
// 此处代码编译失败,auto不能作为形参类型,因为编译器无法对a的实际类型进行推导
void TestAuto(auto a)
{}
- auto不能直接用来声明数组
void TestAuto()
{int a[] = {1,2,3};auto b[] = {4,5,6};
}
- 为了避免与C++98中的auto发生混淆,C++11只保留了auto作为类型指示符的用法
- auto在实际中最常见的优势用法就是跟以后会讲到的C++11提供的新式for循环,还有
lambda表达式等进行配合使用。
4.1 基于范围的for循环(C++11)
范围for的语法
- 在C++98中如果要遍历一个数组,可以按照以下方式进行:
void TestFor()
{int array[] = { 1, 2, 3, 4, 5 };for (int i = 0; i < sizeof(array) / sizeof(array[0]); ++i)array[i] *= 2;for (int* p = array; p < array + sizeof(array)/ sizeof(array[0]); ++p)cout << *p << endl;
}
- 对于一个有范围的集合而言,由程序员来说明循环的范围是多余的,有时候还会容易犯错误。因此C++11中引入了基于范围的for循环。for循环后的括号由冒号“ :”分为两部分:第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围。
void TestFor()
{int array[] = { 1, 2, 3, 4, 5 };for (auto& e : array)e *= 2;for (auto e : array)cout << e << " ";
}
- 注意:与普通循环类似,可以用continue来结束本次循环,也可以用break来跳出整个循环。9.2 范围for的使用条件
4.2 范围for的使用条件
-
for循环迭代的范围必须是确定的
-
对于数组而言,就是数组中第一个元素和最后一个元素的范围;对于类而言,应该提供begin和end的方法,begin和end就是for循环迭代的范围。
注意:以下代码就有问题,因为for的范围不确定
void TestFor(int array[])
{for(auto& e : array)cout<< e <<endl;
}
- 迭代的对象要实现++和==的操作。(关于迭代器这个问题,以后会讲,现在提一下,没办法讲清楚,现在大家了解一下就可以了)
五、指针空值nullptr(C++11)
- 在良好的C/C++编程习惯中,声明一个变量时最好给该变量一个合适的初始值,否则可能会出现不可预料的错误,比如未初始化的指针。如果一个指针没有合法的指向,我们基本都是按照如下方式对其进行初始化:
void TestPtr()
{int* p1 = NULL;int* p2 = 0;// ……
}
- NULL实际是一个宏,在传统的C头文件(stddef.h)中,可以看到如下代码:
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
- 或者我们右键转到定义就可以看到
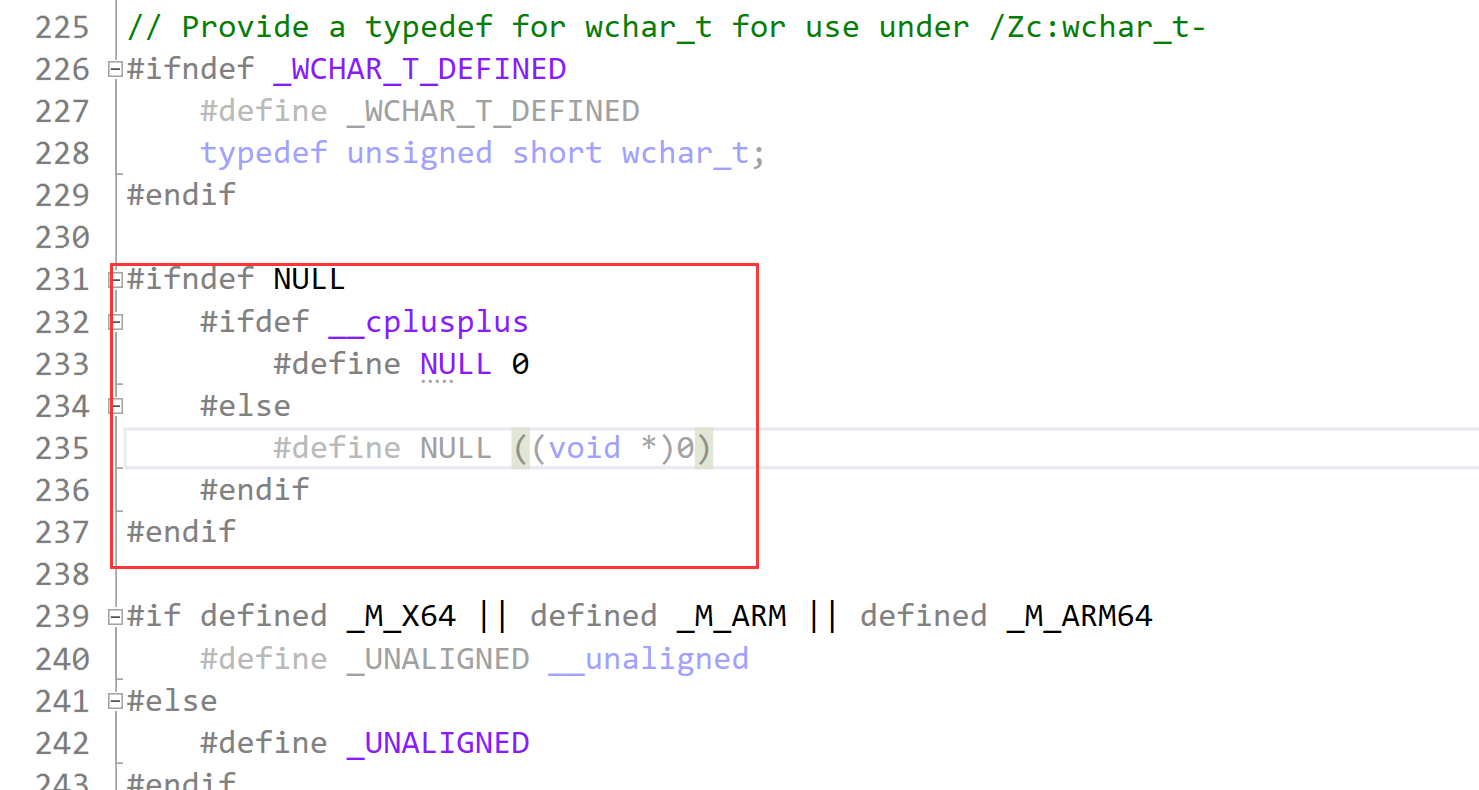
- 可以看到,NULL可能被定义为字面常量0,或者被定义为无类型指针(void*)的常量。不论采取何种定义,在使用空值的指针时,都不可避免的会遇到一些麻烦,比如:
void f(int)
{cout << "f(int)" << endl;
}
void f(int*)
{cout << "f(int*)" << endl;
}
int main()
{f(0);f(NULL);f((int*)NULL);return 0;
}
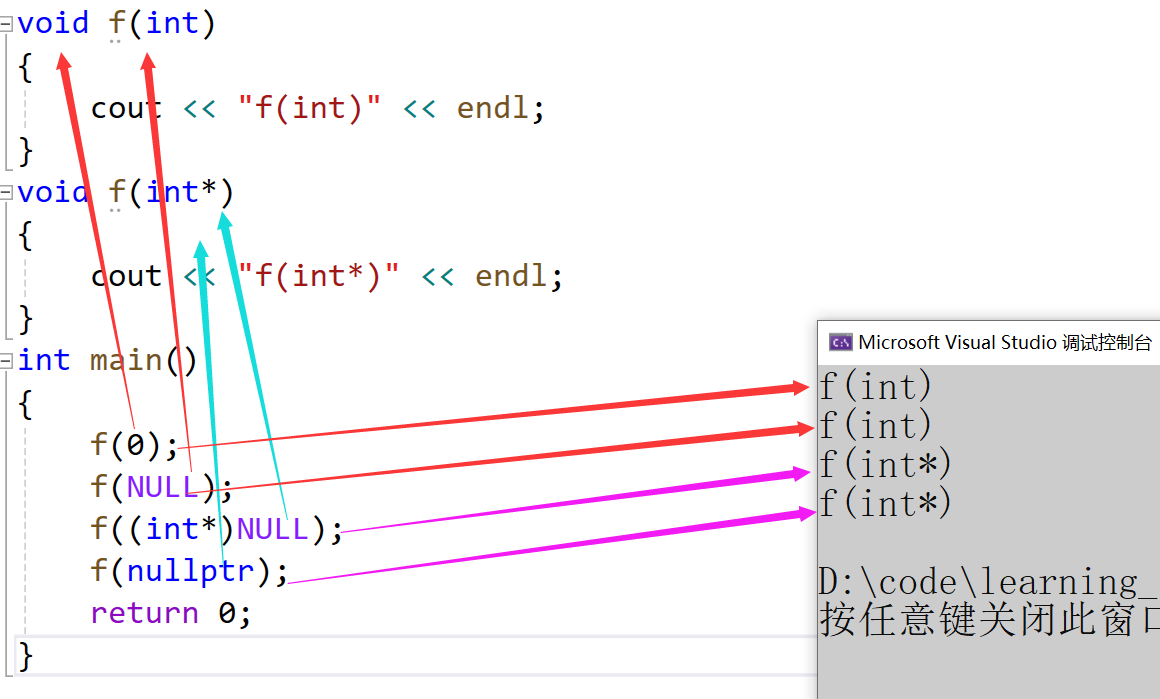
-
程序本意是想通过f(NULL)调用指针版本的f(int*)函数,但是由于NULL被定义成0,因此与程序的初衷相悖。
-
在C++98中,字面常量0既可以是一个整形数字,也可以是无类型的指针(void*)常量,但是编译器默认情况下将其看成是一个整形常量,如果要将其按照指针方式来使用,必须对其进行强转(void*)0。
注意:
- 在使用nullptr表示指针空值时,不需要包含头文件,因为nullptr是C++11作为新关键字引入的。
- 在C++11中,sizeof(nullptr) 与 sizeof((void*)0)所占的字节数相同。
- 为了提高代码的健壮性,在后续表示指针空值时建议最好使用nullptr。
本文章重点介绍了引用,内联函数的注意事项以及使用,提了一下auto关键字和空指针问题,能看完的烙铁相信已经学会了,最后请多多指教,如有疑问请在评论区或私信交流~~
相关文章:
C++引用、内联函数、auto关键字介绍以及C++中无法使用NULL的原因
文章目录 一、引用1.1 引用概念1.2 引用特性1.3 常引用1.4 使用场景1.4.1 做参数1.4.2做返回值 1.5 引用和指针的区别1.6 小结一下 二、内联函数2.1 内联的概念2.2 内联的特性2.3 【面试题】 三、auto关键字(C11)3.1 类型别名思考3.2 auto简介 四、auto的使用细则4.1 基于范围的…...
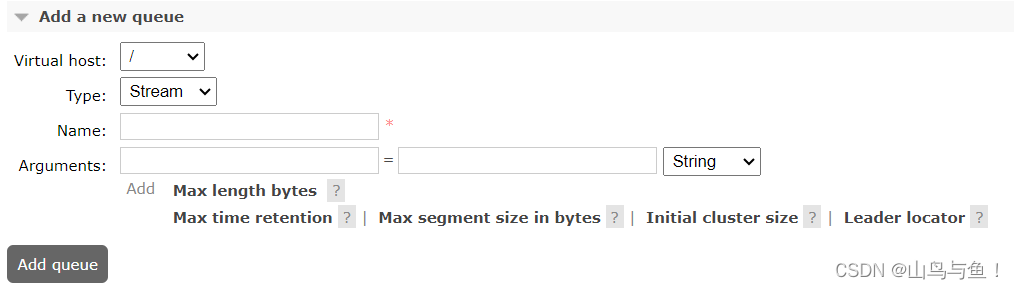
RabbitMQ之三种队列之间的区别及如何选型
目录 不同队列之间的区别 Classic经典队列 Quorum仲裁队列 Stream流式队列 如何使用不同类型的队列 Quorum队列 Stream队列 不同队列之间的区别 Classic经典队列 这是RabbitMQ最为经典的队列类型。在单机环境中,拥有比较高的消息可靠性。 经典队列可以选…...

【ArcGIS微课1000例】0099:土地利用变化分析
本实验讲述在ArcGIS软件中基于两期土地利用数据,做土地利用变化分析。 文章目录 一、实验描述二、实验过程三、注意事项一、实验描述 对城市土地利用情况进行分析时,需要考虑不同时期土地利用图层在空间上的差异性,如农用地转建筑用地的空间变化。而该变化过程表现为各时期…...
学习鸿蒙基础(2)
arkts是声名式UI DevEcoStudio的右侧预览器可以预览。有个TT的图标可以看布局的大小。和html的布局浏览很像。 上图布局对应的代码: Entry //入口 Component struct Index {State message: string Hello Harmonyos //State 数据改变了也刷新的标签build() {Row()…...

2024年美国大学生数学建模竞赛思路与源代码【2024美赛C题】
B站账号,提前关注,会有直播:有为社的个人空间-有为社个人主页-哔哩哔哩视频 (bilibili.com) 题目 待定 问题一 思路 待定 模型 待定 程序 待定 问题二 待定 思路 待定 模型 待定 程序 待定...
Windows11搭建GPU版本PyTorch环境详细过程
Anaconda安装 https://www.anaconda.com/ Anaconda: 中文大蟒蛇,是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。从官网下载Setup:点击安装,之后勾选上可以方便在普通命令行cmd和PowerShell中使用…...

Springboot项目基础配置:小白也能快速上手!
推荐文章 给软件行业带来了春天——揭秘Spring究竟是何方神圣(一) 给软件行业带来了春天——揭秘Spring究竟是何方神圣(二) 给软件行业带来了春天——揭秘Spring究竟是何方神圣(三) 给软件行业带来了春天—…...
20240127在ubuntu20.04.6下配置whisper
20240131在ubuntu20.04.6下配置whisper 2024/1/31 15:48 首先你要有一张NVIDIA的显卡,比如我用的PDD拼多多的二手GTX1080显卡。【并且极其可能是矿卡!】800¥ 2、请正确安装好NVIDIA最新的驱动程序和CUDA。可选安装! 3、配置whispe…...

C# 递归执行顺序
为了方便进一步理解递归,写了一个数字输出 class Program {static void Main(string[] args){int number 5;RecursiveDecrease(number);}static void RecursiveDecrease(int n){if (n > 0){Console.WriteLine("Before recursive call do : " n);Rec…...
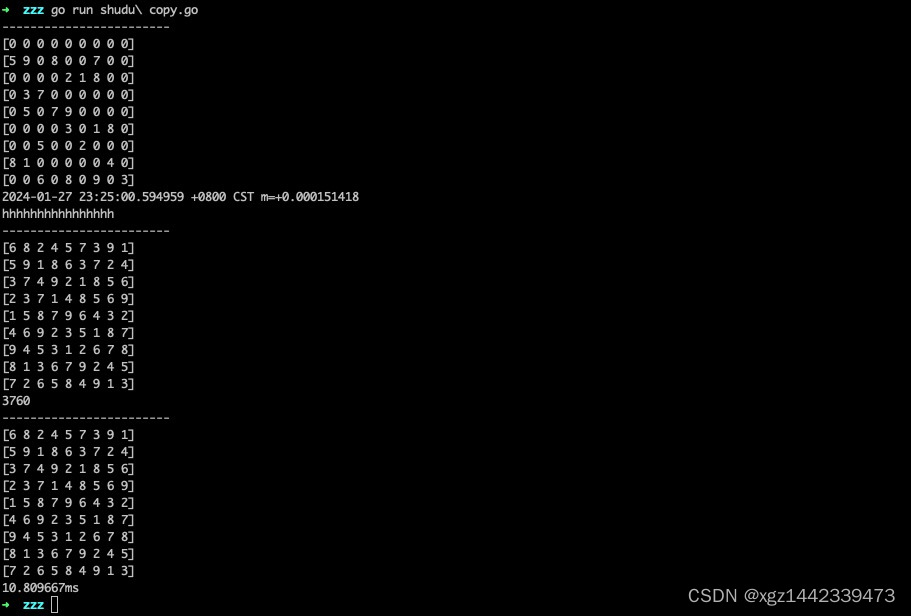
go 实现暴力破解数独
一切罪恶的来源是昨晚睡前玩了一把数独,找虐的选了个最难的模式,做了一个多小时才做完,然后就睡不着了..........程序员不能受这委屈,今天咋样也得把这玩意儿破解了 破解思路(暴力破解加深度遍历) 把数独…...

go语言-字符串处理常用函数
本文介绍go语言处理字符串类型的常见函数。 ## 多行字符串 在 Go 中创建多行字符串非常容易。只需要在你声明或赋值时使用 () 。 str : This is a multiline string. ## 字符串的拼接 go // fmt.Sprintf方式拼接字符串 str1 : "abc" str2 : "def" …...
DevOps落地笔记-05|非功能需求:如何有效关注非功能需求
上一讲主要介绍了看板方法以及如何使用看板方法来解决软件研发过程中出现的团队过载、工作不均、任务延期等问题。通过学习前面几个课时介绍的知识,你的团队开始源源不断地交付用户价值。用户对交付的功能非常满意,但等到系统上线后经常出现服务不可用的…...
vs 撤销本地 commit 并保留更改
没想到特别好的办法,我想的是用 vs 打开 git 命令行工具 然后通过 git 命令来撤销提交,尝试之前建议先建个分支实验,以免丢失代码, git 操作见 git 合并多个 commit / 修改上一次 commit...

深度解读NVMe计算存储协议-1
随着云计算、企业级应用以及物联网领域的飞速发展,当前的数据处理需求正以前所未有的规模增长,以满足存储行业不断变化的需求。这种增长导致网络带宽压力增大,并对主机计算资源(如内存和CPU)造成极大负担,进…...
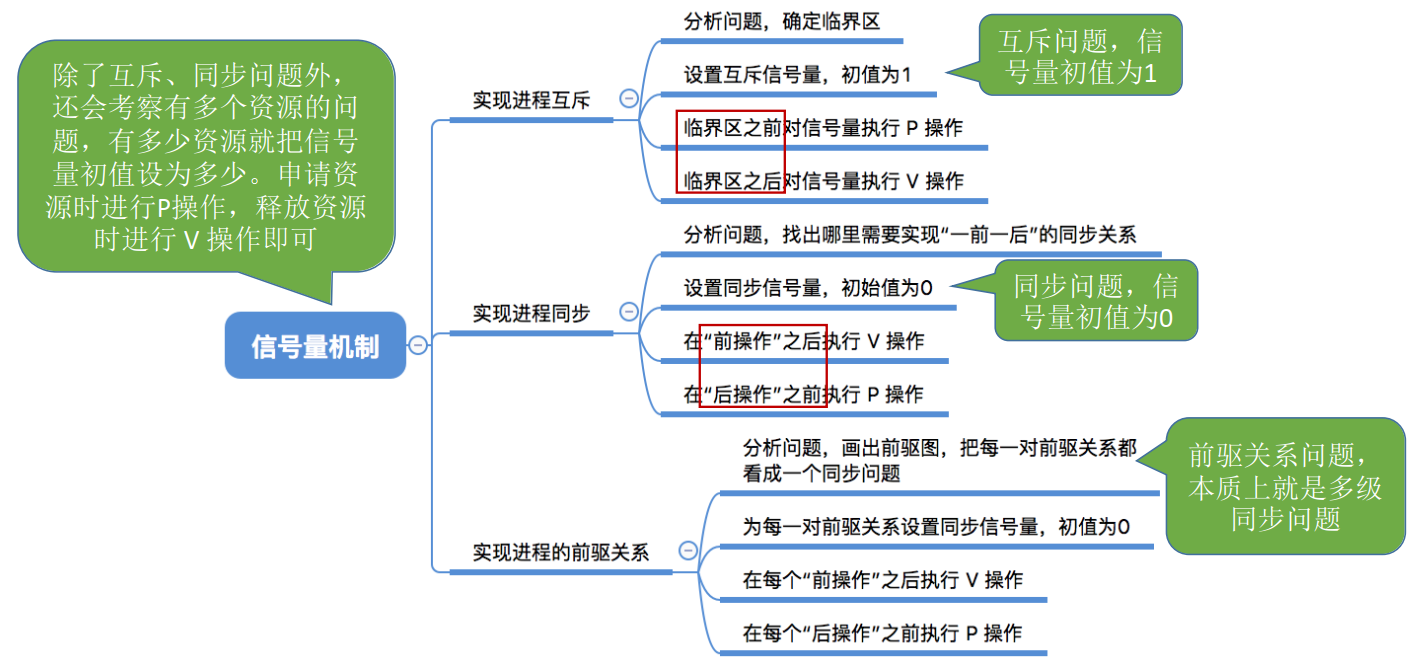
CHS_06.2.3.4_2+用信号量实现进程互斥、同步、前驱关系
CHS_06.2.3.4_2用信号量实现进程互斥、同步、前驱关系 知识总览信号量机制实现进程互斥信号量机制实现进程同步信号量机制实现前驱关系 知识回顾 各位同学 大家好 在这个小节中 我们要学习怎么用信号量机制来实现进程的同步互制关系 知识总览 那么 我们之前学习了互斥的几种软…...
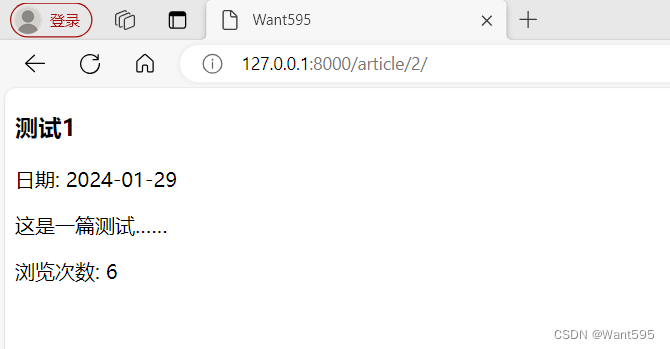
Web实战丨基于Django的简单网页计数器
文章目录 写在前面Django简介主要程序运行结果系列文章写在后面 写在前面 本期内容 基于django的简单网页计数器 所需环境 pythonpycharm或vscodedjango 下载地址 https://download.csdn.net/download/m0_68111267/88795604 Django简介 Django 是一个用 Python 编写的高…...

mysql8安装基础操作(一)
一、下载mysql8.0 1.查看系统glibc版本 这里可以看到glibc版本为2.17,所以下载mysql8.0的版本时候尽量和glibc版本对应 [rootnode2 ~]# rpm -qa |grep -w glibc glibc-2.17-222.el7.x86_64 glibc-devel-2.17-222.el7.x86_64 glibc-common-2.17-222.el7.x86_64 gl…...
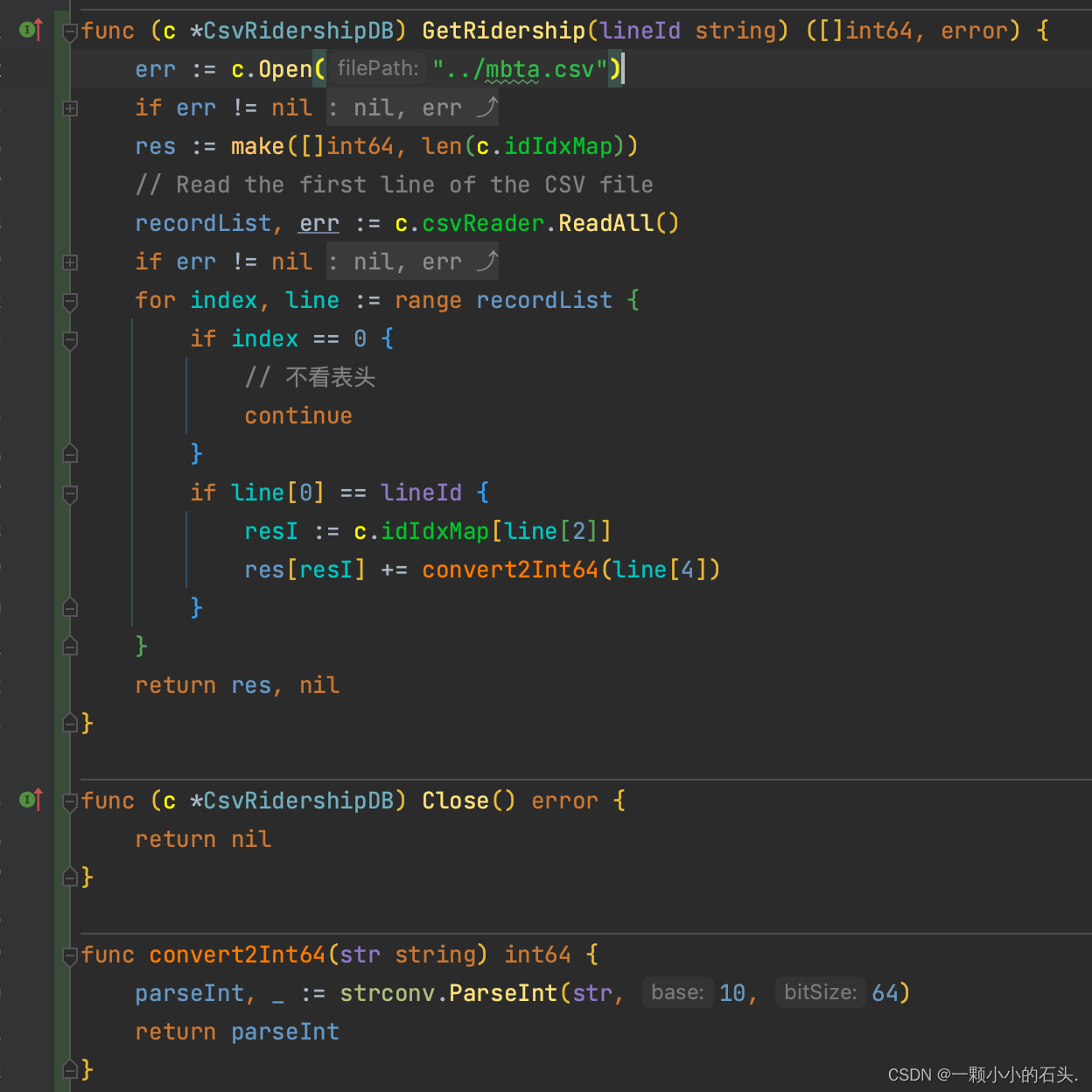
MIT6.5830 实验0
前置 本次实验使用 Golang 语言实现,在之前的年份中,都是像 cs186 那样使用 Java 实现。原因: Golang 语言作为现代化语言,简单易上手但功能强大。 使参加实验的同学有同一起跑线,而不是像Java那样,有些同…...
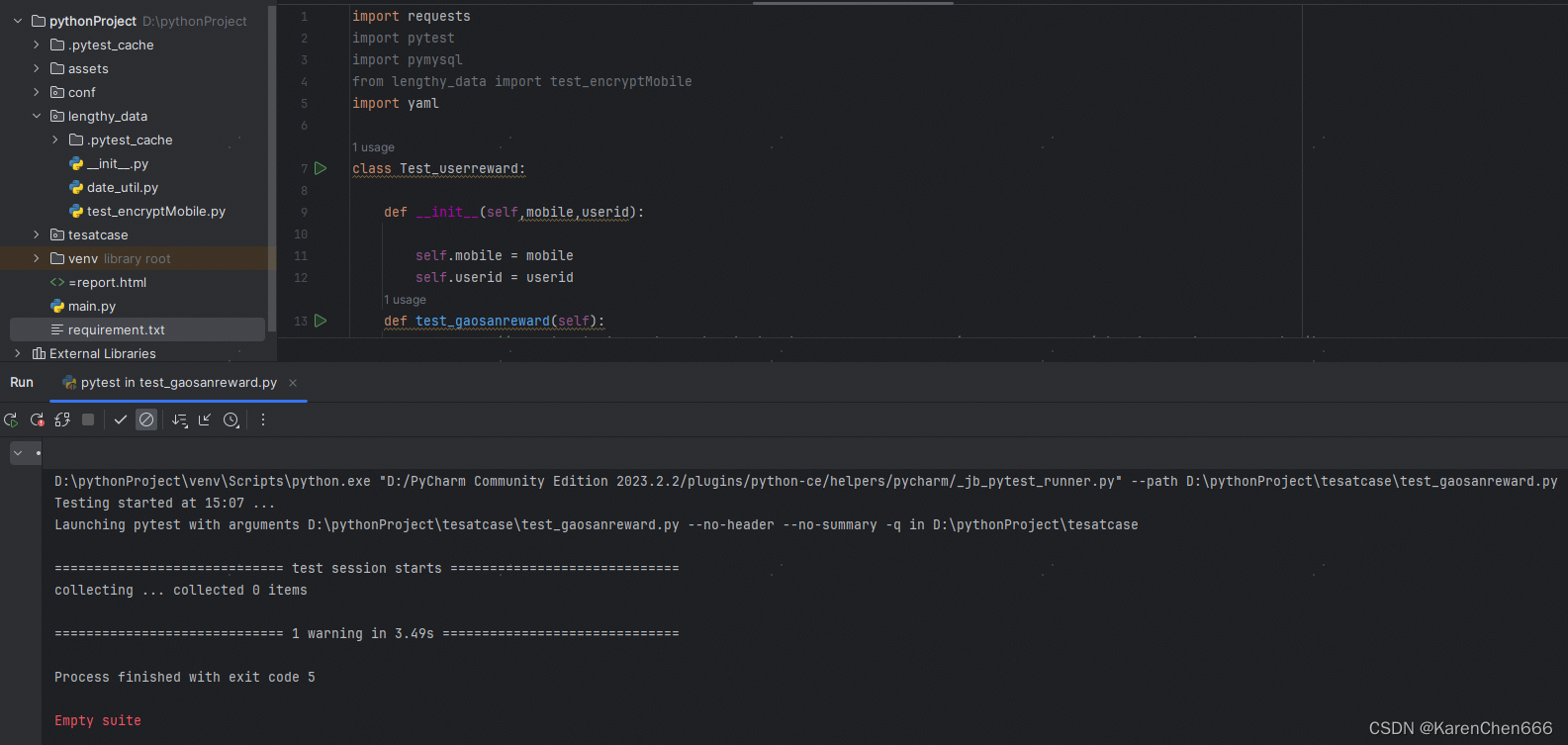
【简便方法和积累】pytest 单元测试框架中便捷安装插件和执行问题
又来进步一点点~~~ 背景:之前写了两篇关于pytest单元测试框架的文章,本篇内容对之前的做一个补充 一、pytest插件: pytest 有非常多的插件,很方便,以下为插件举例: pytest,pytest-html&#x…...
Zabbix数据库分离与邮件报警
基础环境:要有zabbix服务端与被监控端实验目标:源数据库与服务端存放在一台服务器上,分离后源数据库单独在一台服务器上,zabbix服务端上不再有数据库。环境拓扑图: 实验步骤: 1.在8.7服务器上安装相同版本…...

掌握微信聊天记录永久备份:从数据主权到智能记忆管理
掌握微信聊天记录永久备份:从数据主权到智能记忆管理 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeChat…...
)
GoLang实战:5分钟搞定Langchaingo调用DeepSeek-R1大模型(附完整代码)
GoLang实战:5分钟搞定Langchaingo调用DeepSeek-R1大模型(附完整代码) 如果你是一位Go开发者,正需要在项目中快速集成大语言模型能力,却苦于时间有限、文档繁杂,那么这篇文章就是为你量身定制的。我们将用最…...
)
R语言实战:从Raw Counts到TPM/FPKM的完整转换指南(含代码调试技巧)
R语言实战:从Raw Counts到TPM/FPKM的完整转换指南(含代码调试技巧) 在生物信息学分析中,RNA-seq数据的标准化处理是确保后续差异表达分析可靠性的关键步骤。对于刚接触转录组数据分析的研究生和初级分析师来说,如何在R…...

有关数组的学习
数组的概念简介数组是编程中最基础也最常用的数据结构之一,理解它能帮你高效管理一组同类型的数据。1. 什么是数组?核心概念同类型:数组里的所有元素必须是相同的数据类型(如全是 int 或全是 float)。连续内存…...

vLLM-v0.17.1助力Java微服务:高并发下的模型推理集成方案
vLLM-v0.17.1助力Java微服务:高并发下的模型推理集成方案 1. 引言:当Java微服务遇见大模型推理 最近两年,大模型技术在企业应用中的落地速度远超预期。作为Java开发者,我们可能已经习惯了SpringBoot生态的舒适区,但当…...

如何高效使用AI音频分离神器:Ultimate Vocal Remover GUI完全指南
如何高效使用AI音频分离神器:Ultimate Vocal Remover GUI完全指南 【免费下载链接】ultimatevocalremovergui 使用深度神经网络的声音消除器的图形用户界面。 项目地址: https://gitcode.com/GitHub_Trending/ul/ultimatevocalremovergui Ultimate Vocal Rem…...

开源工具管理效率提升使用指南
开源工具管理效率提升使用指南 【免费下载链接】xcom2-launcher The Alternative Mod Launcher (AML) is a replacement for the default game launchers from XCOM 2 and XCOM Chimera Squad. 项目地址: https://gitcode.com/gh_mirrors/xc/xcom2-launcher 开源工具管理…...

终极指南:3步在3DS上原生运行GBA游戏,告别模拟器延迟!
终极指南:3步在3DS上原生运行GBA游戏,告别模拟器延迟! 【免费下载链接】open_agb_firm open_agb_firm is a bare metal app for running GBA homebrew/games using the 3DS builtin GBA hardware. 项目地址: https://gitcode.com/gh_mirror…...
)
JIT编译延迟高达2.3秒?紧急修复Python 3.14.0b3中`--jit-threshold=0`参数失效Bug的3种绕行方案(含补丁级patch)
第一章:JIT编译延迟高达2.3秒?紧急修复Python 3.14.0b3中--jit-threshold0参数失效Bug的3种绕行方案(含补丁级patch) Python 3.14.0b3 引入的自适应JIT编译器在启用 --jit-threshold0 时未能立即触发热路径编译,导致首…...

5步解决Windows Defender被移除后的系统防护重建难题
5步解决Windows Defender被移除后的系统防护重建难题 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcode.com/gh_mirrors/wi/windows-defe…...