深入解剖指针篇(2)
目录
指针的使用
strlen的模拟实现
传值调用和传址调用
数组名的理解
使用指针访问数组
一维数组传参的本质
冒泡排序
个人主页(找往期文章):我要学编程(ಥ_ಥ)-CSDN博客
指针的使用
strlen的模拟实现
库函数strlen的功能是求字符串长度,统计的是字符串中 \0 之前的字符的个数。
函数原型:

知道了上面这些,我们就直接开是写代码 。
#include <stdio.h>
int my_strlen(const char* p)
{int count = 0;while (*p != '\0'){count++;p++;}return count;
}
int main()
{char arr[] = "abcdef";int len = my_strlen(arr);printf("%d\n", len);return 0;
}如果要真正相同的话,这个函数的返回类型也应该改一改。
#include <stdio.h>
size_t my_strlen(const char* p)
{size_t count = 0;while (*p != '\0'){count++;p++;}return count;
}
int main()
{char arr[] = "abcdef";size_t len = my_strlen(arr);printf("%zd\n", len);return 0;
}
因为函数返回类型改了,那么那个返回的值(count)的类型也应该变,接收的,打印的都要变。
传值调用和传址调用
学习指针的目的是使用指针解决问题,那什么问题,非指针不可呢?
例如:写一个函数,交换两个整型变量的值
#include <stdio.h>
void swap(int a, int b)
{int tmp = 0;tmp = a;a = b;b = tmp;
}
int main()
{int a = 0;int b = 0;scanf("%d%d", &a, &b);printf("交换前:a=%d,b=%d\n", a, b);swap(a, b);printf("交换后:a=%d,b=%d\n", a, b);return 0;
}我们去运行这个代码会发现,交换前后a与b的值根本就没有发生变化。
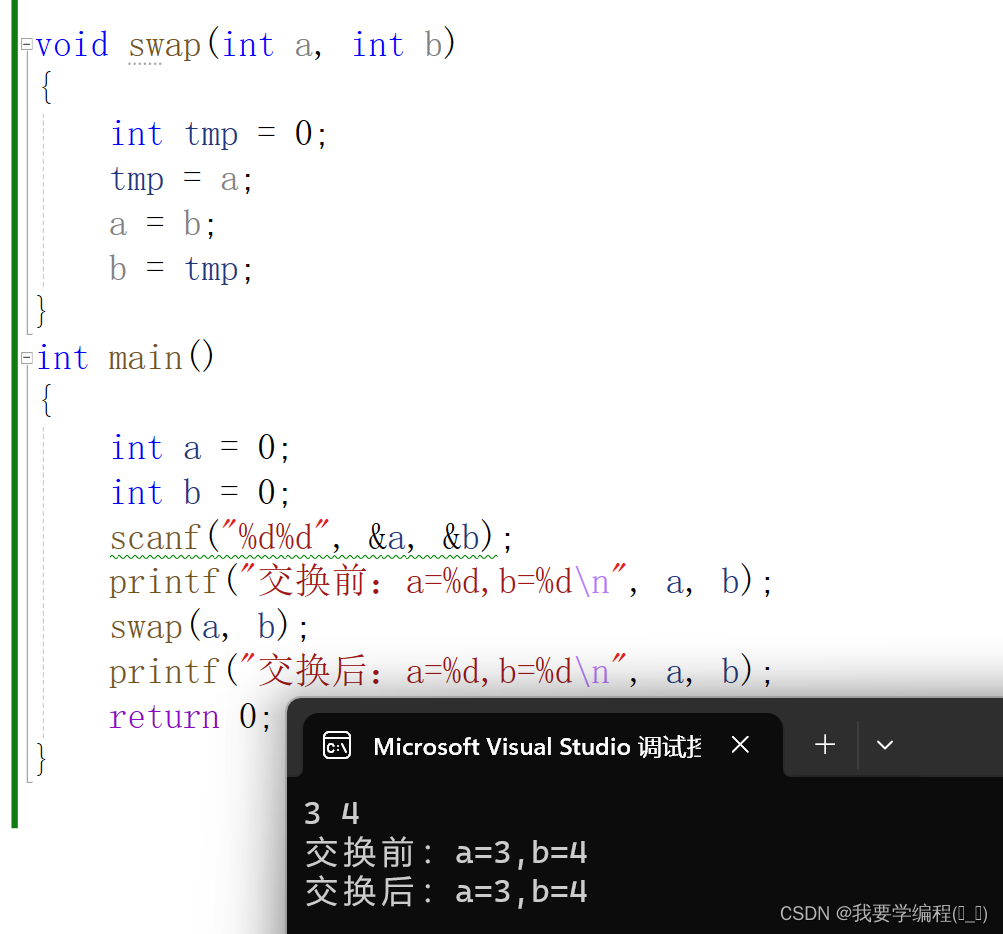
这到底是什么原因导致的呢?我们可以尝试调试一下(因为这里我形参和实参都是设置a和b,不好观察,我就把形参改成x和y了):
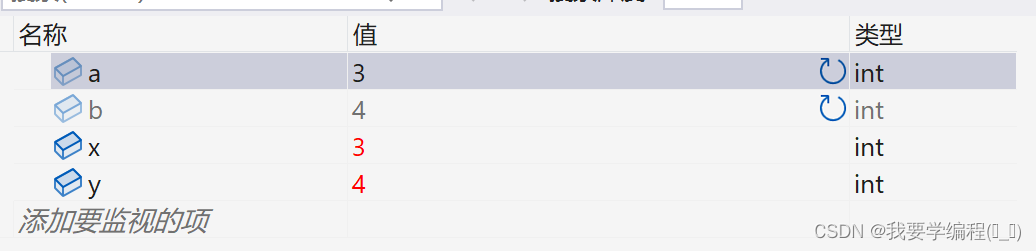

通过上面两幅图,我们可以看到x与y的值,虽然交换了,但是却没有影响到a与b。我们在通过指针来深入观察:
我们可以看到a,b与x,y的地址不是一样的,相当于x和y是独立的空间,那么在swap函数内部交换x和y的值, 自然不会影响a和b,当swap函数调用结束后回到main函数,a和b的没法交换。swap函数在使用的时候,是把变量本身直接传递给了函数,这种调用函数的方式我们之前在函数的时候就知道了,这种叫传值调用。
结论:实参传递给形参的时候,形参会单独创建一份临时空间来接收实参,对形参的修改不影响实 参。 所以swap函数是无效的。
通过前面指针的学习,我们知道可以通过指针来寻找到它所指向的对象,并且可以修改这个对象的值。在main函数中将a和b的地址传递给swap函数,swap 函数里边通过地址间接的操作main函数中的a和b,并达到交换的效果就好了。
#include <stdio.h>
void swap(int* x, int* y)
{int tmp = 0;tmp = *x;*x = *y;*y = tmp;
}
int main()
{int a = 0;int b = 0;scanf("%d%d", &a, &b);printf("交换前:a=%d,b=%d\n", a, b);swap(&a, &b);printf("交换后:a=%d,b=%d\n", a, b);return 0;
}
上面代码是将a与b的地址传给了函数swap,这种叫做传址调用。
传址调用,可以让函数和主调函数之间建立真正的联系,在函数内部可以修改主调函数中的变量;所以未来函数中只是需要主调函数中的变量值来实现计算,就可以采用传值调用。如果函数内部要修改主调函数中的变量的值,就需要传址调用。
数组名的理解
在使用指针访问数组的内容时,有这样的代码:

上面两种写法都是对的,用代码验证一下。
&arr[0]的写法:
#include <stdiio.h>
void Print(int* p, int sz)
{int i = 0;for (i = 0; i < sz; i++){printf("%d ", *(p + i));}
}
int main()
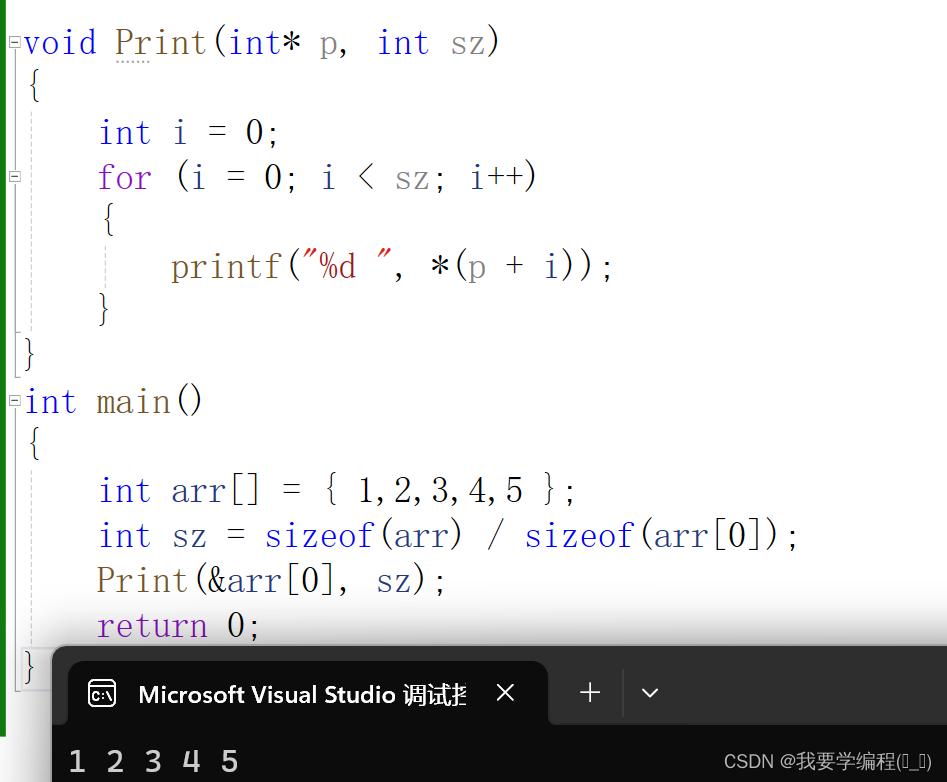
{int arr[] = { 1,2,3,4,5 };int sz = sizeof(arr) / sizeof(arr[0]);Print(&arr[0], sz);return 0;
}
arr的写法:
#inlcude <stdio.h>
void Print(int* p, int sz)
{int i = 0;for (i = 0; i < sz; i++){printf("%d ", *(p + i));}
}
int main()
{int arr[] = { 1,2,3,4,5 };int sz = sizeof(arr) / sizeof(arr[0]);Print(arr, sz);return 0;
}
我们可以看到这两个代码的结果是一模一样的。就说明&arr[0]与arr是一样的。换句话说,数组名就是数组首元素的地址。但是有两种情况是例外:
• sizeof(数组名),sizeof中单独放数组名,这里的数组名表示整个数组,计算的是整个数组的大小, 单位是字节
• &数组名,这里的数组名表示整个数组,取出的是整个数组的地址(整个数组的地址和数组首元素的地址是有区别的) 除此之外,任何地方使用数组名,数组名都表示首元素的地址。

我们可以通过打印的结果知道: sizeof中单独放数组名,这里的数组名表示整个数组,计算的是整个数组的大小。
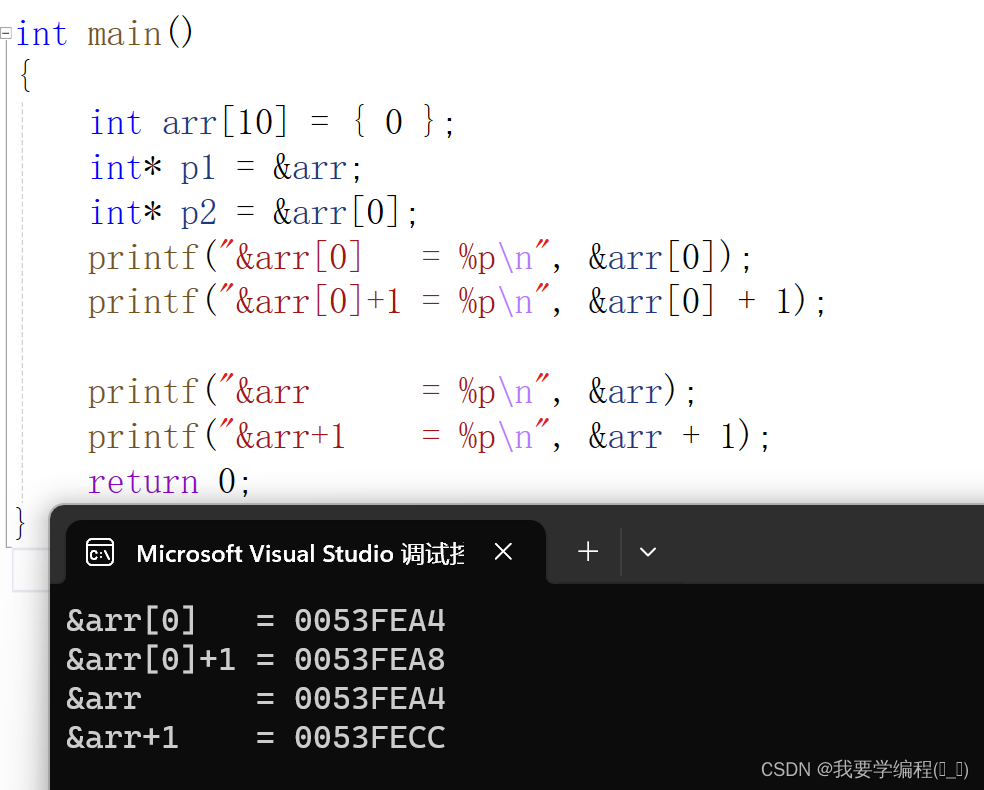
这些是十六进制,通过计算可以得知:&arr[0]和&arr[0]+1相差4个字节,是因为&arr[0] 都是首元素的地址,+1就是跳过一个元素。但是&arr 和 &arr+1相差40个字节,这就是因为&arr是数组的地址,+1 操作是跳过整个数组的。
但是在用代码证明时,有的小伙伴,可能会写成下面的代码,从而无法证明。

之所以会这样,是因为这个&arr,是指整个数组,而这个p1是一个指针变量,只能存放一个地址,不能将整个地址给存放。如果强行这样做,就导致整个p1,只是存了第一个元素的地址。达不到我们的预期。
使用指针访问数组
有了前面知识的支持,再结合数组的特点,我们就可以很方便的使用指针访问数组了。
练习:用指针实现数组的输入和输出。
#include <stdio.h>
int main()
{int arr[10] = { 0 };int sz = sizeof(arr) / sizeof(arr[0]);int* p = arr;int i = 0;for (i = 0; i < sz; i++){scanf("%d", p + i);}for (i = 0; i < sz; i++){printf("%d ", *(p + i));}
}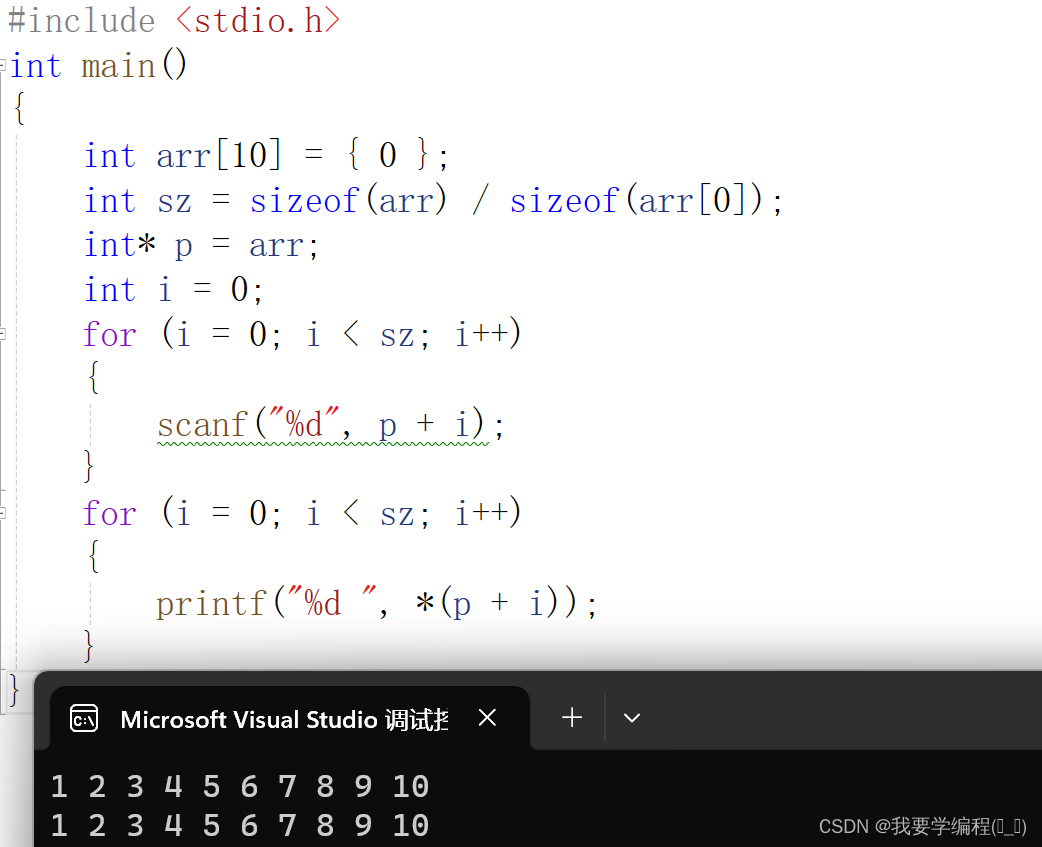
我们再分析一下,数组名arr是数组首元素的地址,可以赋值给p,其实数组名arr和p在这里是等价的。那我们可以使用arr[i]可以访问数组的元素,那p[i]是否也可以访问数组呢?
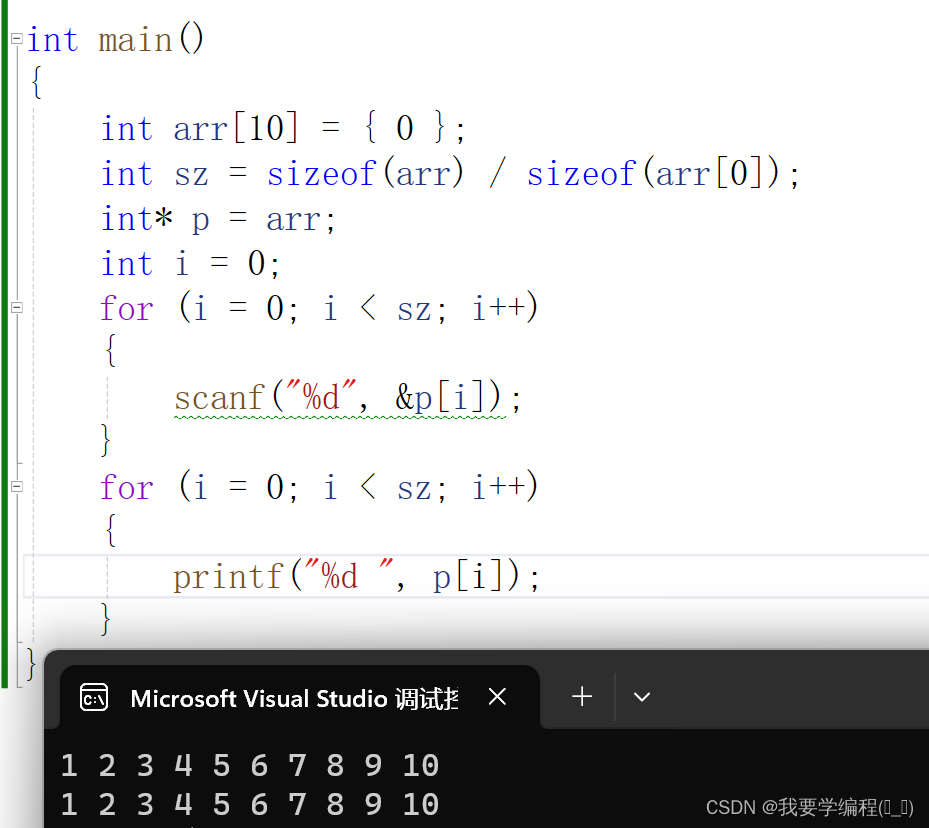
所以本质上p[i] 是等价于 *(p+i)。我们可以理解为[ ] == * 。
一维数组传参的本质
数组是可以传递给函数的,我们讨论一下数组传参的本质。 首先从一个问题开始,我们之前都是在函数外部计算数组的元素个数,那我们可以把数组传给一个函数后,函数内部求数组的元素个数吗?
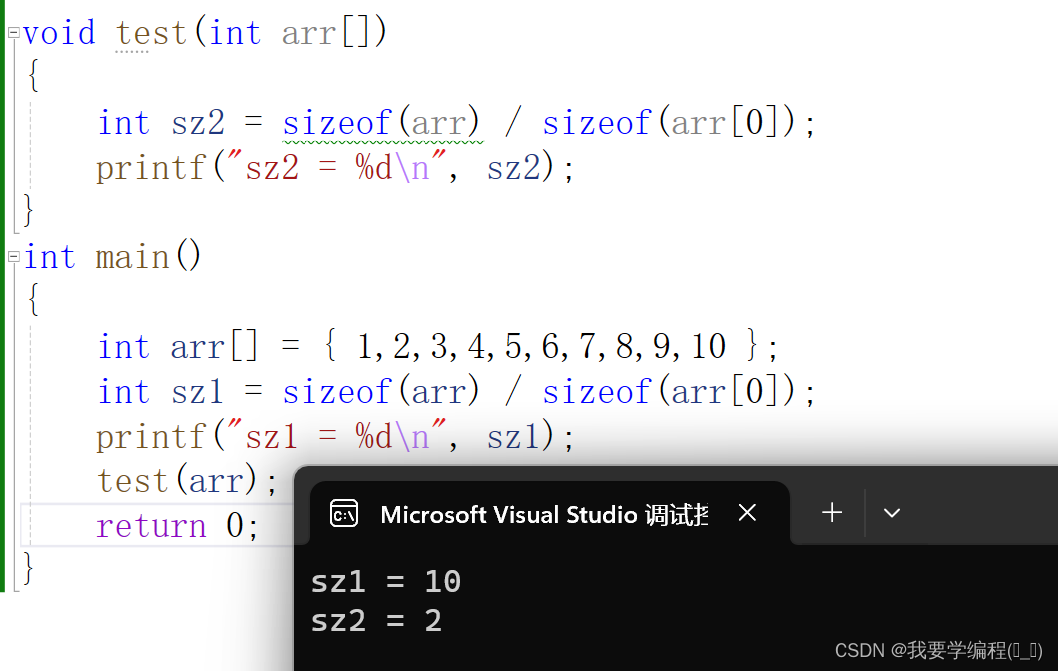
我们发现在函数内部是没有正确获得数组的元素个数。 这就要学习数组传参的本质了,上面验证了:数组名是数组首元素的地址;那么在数组传参的时候,传递的是数组名,也就是说本质上数组传参本质上传递的是数组首元素的地址。 所以函数形参的部分理论上应该使用指针变量来接收首元素的地址。那么在函数内部我们写 sizeof(arr) 计算的是一个指针的大小(单位字节)而不是数组的大小(单位字节)。正是因为函数的参数部分是本质是指针,所以在函数内部是没办法求的数组元素个数的。 而这个sz2的值是和32位平台还是64位有关。因为指针变量的大小在32位平台下是4个字节,64位是8个字节。
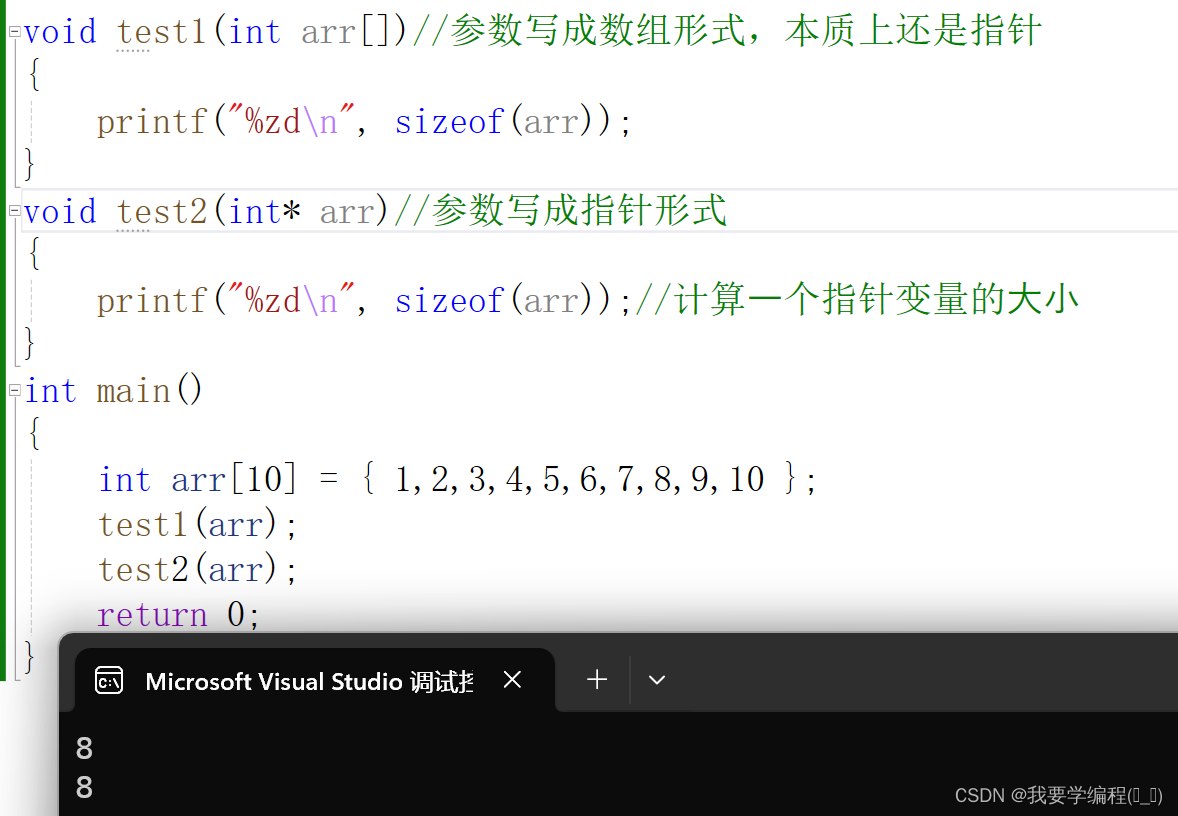
总结:一维数组传参,形参的部分可以写成数组的形式,也可以写成指针的形式。
冒泡排序
冒泡排序的核心思想就是:两两相邻的元素进行比较。
冒泡排序是一种算法,用来解决数组内部元素有序的问题。比如:有一个数组,内部元素杂乱无章,但是我们要的是一个降序的数组。这时就可以采用冒泡排序的方法。具体怎么实现呢?我就用画图的方式给大家展现出来。

到这里这个代码也就可以写出来了。
#include <stdio.h>
void bubble_sort(int* p, int sz)
{int i = 0;for (i = 0; i < sz - 1; i++)//趟数{int j = 0;for (j = 0; j < sz - 1; j++)//每一趟{if (*(p + j) < *(p + j + 1)){int tmp = *(p + j);*(p + j) = *(p + j + 1);*(p + j + 1) = tmp;}}}
}
void Print(int* p, int sz)
{int i = 0;for (i = 0; i < sz; i++){printf("%d ", *(p + i));}
}
int main()
{int arr[10] = { 0 };int sz = sizeof(arr) / sizeof(arr[0]);Init(arr, sz);bubble_sort(arr, sz);//改成降序Print(arr, sz);return 0;
}但是如果我们再仔细分析的话,就会发现在每一趟的元素比较中,需要比较的元素个数是随着趟数的增加,变得越来越少。举例:第一趟要比较10个数,得出一个数是最小的之后,第二趟来比较时,就不需要和那个第一趟比较出的数再来比较了。因为第一趟比较出的数之所以最小,是因为它在这是个元素中是最小的,那么第二趟比较出的那个最小数,一定比那个第一趟比较出的那个数要大才行。以此类推,第二趟比较9个数就是j到7就可以了(j+1等于8,第九个数的下标是8),第三趟比较8个数就是j到6就可以了。那么最终的规律就是j<sz-1-i。
改进的代码:
#include <stdio.h>
void bubble_sort(int* p, int sz)
{int i = 0;for (i = 0; i < sz - 1; i++)//趟数{int j = 0;for (j = 0; j < sz - 1 - i; j++)//每一趟{if (*(p + j) < *(p + j + 1)){int tmp = *(p + j);*(p + j) = *(p + j + 1);*(p + j + 1) = tmp;}}}
}
void Print(int* p, int sz)
{int i = 0;for (i = 0; i < sz; i++){printf("%d ", *(p + i));}
}
int main()
{int arr[10] = { 0 };int sz = sizeof(arr) / sizeof(arr[0]);Init(arr, sz);bubble_sort(arr, sz);//改成降序Print(arr, sz);return 0;
}其实到这里了,这个代码还能够优化一点:如果我们的数组里,就只有一个元素不是有序的,其余的都是有顺序的,因此我们只需要比较一次就可以了。
如果这个数组是9 8 7 6 5 4 3 2 1 10,这个想要变成降序,就需要走9趟了。因为第一趟就只能把1和10换位置。还剩下其它的数要换,就只能走9趟
那么怎么判断这个数组比较过后是有序还是无序呢?
法一:可以定义一个flag变量,初始化为1。如果这个有序了,啥也不干,那么就令它为0;否则就是1。每走完一趟之后就可以根据flag的值,判断是否有序。如果是0,就说明这个数组有序,跳出循环。
#include <stdio.h>
//void init(int* p, int sz)
//{
// int i = 0;
// for (i = 0; i < sz; i++)
// {
// scanf("%d", (p + i));
// }
//}
void bubble_sort(int* p, int sz)
{int i = 0;for (i = 0; i < sz - 1; i++)//趟数{int flag = 1;//注意这个定义的位置。int j = 0;for (j = 0; j < sz - 1 - i; j++)//每一趟{if (*(p + j) < *(p + j + 1)){int tmp = *(p + j);*(p + j) = *(p + j + 1);*(p + j + 1) = tmp;flag = 0;//一旦进入就变为0。} }if (flag == 1)//等于1,代表if一次也没有执行。{break;}}
}
void print(int* p, int sz)
{int i = 0;for (i = 0; i < sz; i++){printf("%d ", *(p + i));}
}
int main()
{int arr[10] = { 9,10,8,7,6,5,4,3,2,1 };int sz = sizeof(arr) / sizeof(arr[0]);//init(arr, sz);bubble_sort(arr, sz);//改成降序print(arr, sz);return 0;
}法二:可以定义一个变量count,如果这个一趟里面每没有执行一次,count就++。一趟走完之后,如果count==sz-1-i,那么说明这个数组已经有序,就跳出循环。
#include <stdio.h>
//void Init(int* p, int sz)
//{
// int i = 0;
// for (i = 0; i < sz; i++)
// {
// scanf("%d", (p + i));
// }
//}
void bubble_sort(int* p, int sz)
{int i = 0;for (i = 0; i < sz - 1; i++)//趟数{int j = 0;int count = 0;//注意这个定义的位置,如果定义在趟数的外面,这个count就会累加for (j = 0; j < sz - 1 - i; j++)//每一趟{if (*(p + j) < *(p + j + 1)){int tmp = *(p + j);*(p + j) = *(p + j + 1);*(p + j + 1) = tmp;}else{count++;}}if (count == sz - 1 - i)如果count等于这个,就说明if一次也没有执行{break;}}
}
void Print(int* p, int sz)
{int i = 0;for (i = 0; i < sz; i++){printf("%d ", *(p + i));}
}
int main()
{int arr[10] = { 9,10,8,7,6,5,4,3,2,1 };int sz = sizeof(arr) / sizeof(arr[0]);//Init(arr, sz);bubble_sort(arr, sz);//改成降序Print(arr, sz);return 0;
}上面有些代码被注释,是为了更好的调试观察。当然大家可以把那些注释去掉。
上面两种优化可以通过调试来观察是否优化成功(VS的调试方法在我往期的文章里,可以去主页里找) 。
感觉四篇文章可能写不完指针的所有内容。
相关文章:
深入解剖指针篇(2)
目录 指针的使用 strlen的模拟实现 传值调用和传址调用 数组名的理解 使用指针访问数组 一维数组传参的本质 冒泡排序 个人主页(找往期文章):我要学编程(ಥ_ಥ)-CSDN博客 指针的使用 strlen的模拟实现 库函数strlen的功能是求字符串…...

【知识点】Java常用
文章目录 基础基础数据类型内部类Java IOIO多路复用重要概念 Channel **通道**重要概念 Buffer **数据缓存区**重要概念 Selector **选择器** 关键字final 元注解常用接口异常处理ErrorException JVM与虚拟机JVM内存模型本地方法栈虚拟机栈 Stack堆 Heap方法区 Method Area (JD…...
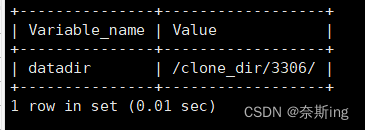
MySQL篇—迁移数据目录到新的本地路径
☘️博主介绍☘️: ✨又是一天没白过,我是奈斯,DBA一名✨ ✌✌️擅长Oracle、MySQL、SQLserver、Linux,也在积极的扩展IT方向的其他知识面✌✌️ ❣️❣️❣️大佬们都喜欢静静的看文章,并且也会默默的点赞收藏加关注❣…...

【FPGA】高云FPGA之IP核的使用->PLL锁相环
FPGA开发流程 1、设计定义2、设计输入3、分析和综合4、功能仿真5、布局布线6、时序仿真7、IO分配以及配置文件(bit流文件)的生成8、配置(烧录)FPGA9、在线调试 1、设计定义 使用高云内置IP核实现多路不同时钟输出 输入时钟50M由晶…...

程控设备和电脑通信的总线和协议选择
文章目录 程控设备都通过什么协议和总线和电脑通信?工控设备都使用什么通信协议与电脑通信?各种工控设备通信协议的优缺点如何选择适合工控设备的通信协议?各种工控设备通信总线的优缺点如何判断一种总线是否适合特定的应用场景?程控设备都通过什么协议和总线和电脑通信? …...
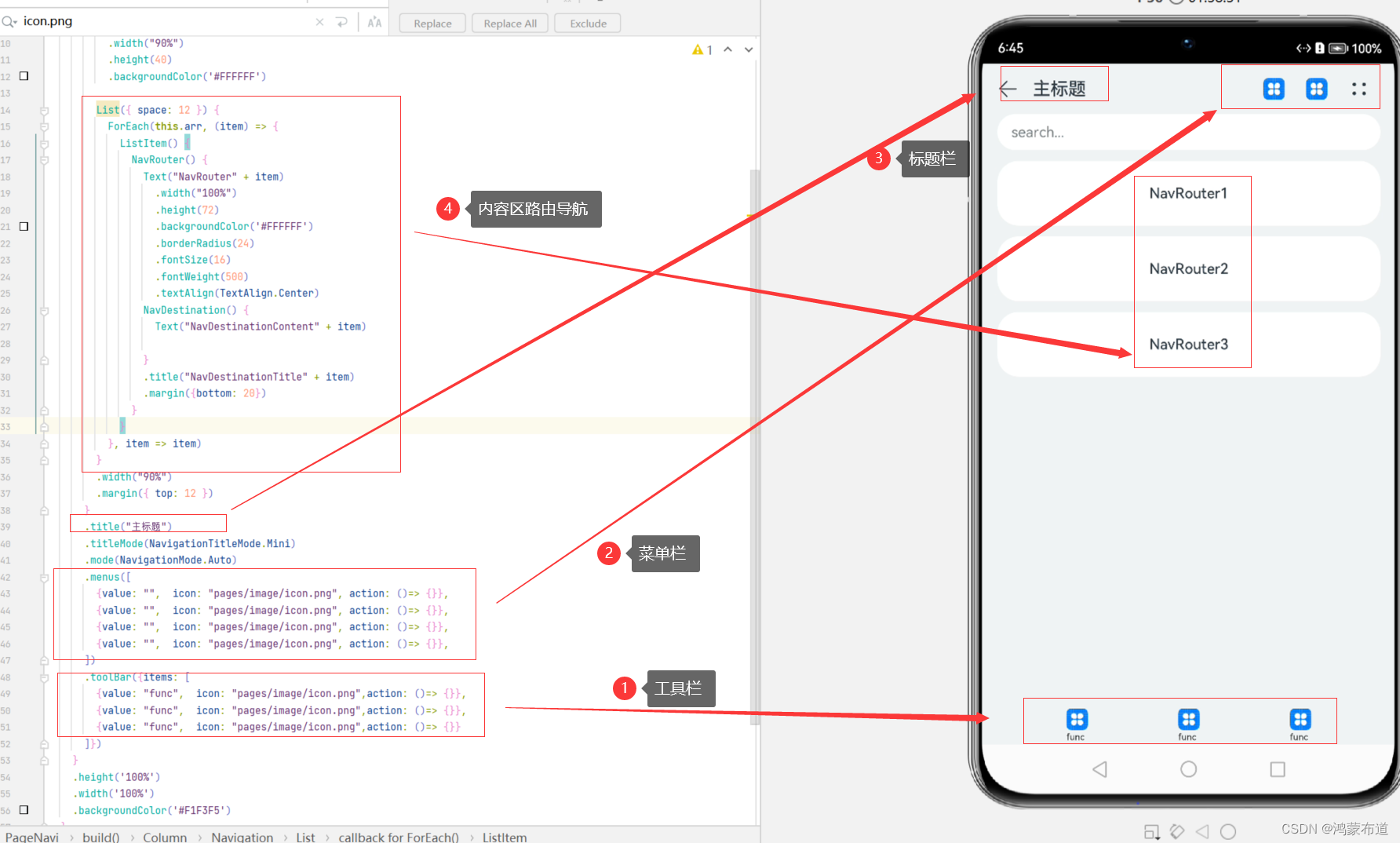
鸿蒙开发-UI-组件导航-Navigation
鸿蒙开发-UI-组件 鸿蒙开发-UI-组件2 鸿蒙开发-UI-组件3 鸿蒙开发-UI-气泡/菜单 鸿蒙开发-UI-页面路由 文章目录 目录 一、基本概念 二、页面显示模式 1.自适应模式 2.单页面模式 3.分栏模式 三、标题栏模式 1.Mini模式 2.Full模式 四、菜单栏 五、工具栏 六、案例 …...
(A~D)补题)
Codeforces Round 922 (Div. 2)(A~D)补题
A题考虑贪心,要使使用的砖头越多,每块转的k应尽可能小,最小取2,最后可能多出来,多出来的就是最后一块k3,我们一行内用到的砖头就是 m 2 \frac{m}{2} 2m下取整,然后乘以行数就是答案。 #inclu…...
Seata下载与配置、启动
目录 Seata下载Seata配置启动Seata Seata下载 首先,我们需要知道我们要使用哪个版本的seata,这就要查看spring-cloud-alibaba版本说明,找到我们对应的seata。 spring-cloud-alibaba版本说明: 地址链接 下面是部分版本说明: s…...
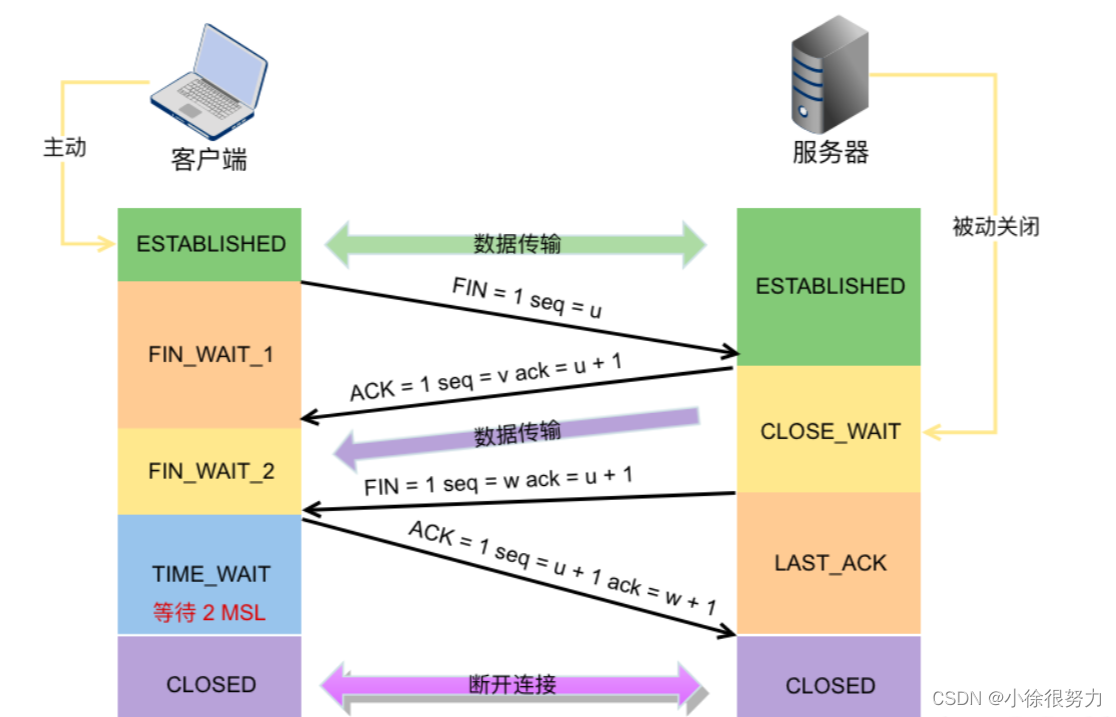
什么是TCP三次握手、四次挥手?
1、三次握手 你(客户端)给一个朋友(服务器)打电话,告诉他你想开始对话。这就像是发送一个SYN(同步序列编号)信号,表示你想开始建立连接。(client向server发送syn,seqx,此时client验证client发送能力正常。client置为SYN SENT状态)…...

C++程序在开机自启和定时器执行时遇到的问题和解决方法
遇到的错误如下: Camera is created.load vfvlog.[dll/so] failed for dll[/vfvlog.so] unexistedLoadDbgConfig, LoadFile fail, err:-3, errno: No such file or directoryqt.qpa.xcb: could not connect to displayqt.qpa.plugin: Could not load the Qt platfo…...

R17 extended DRX(eDRX)
根据工业无线传感器的要求,电池至少可持续使用数年。 在NB-IoT和LTE eMTC中,也有类似的要求。 为了满足极长电池寿命的要求,NB-IoT和LTE eMTC在Release 13中为RRC IDLE UE引入了扩展DRX,在Release 16中为RRC INACTIVE UE引入了eDRX,上面是LTE 引入eDRX的背景。 一 概述 到…...

Debezium发布历史102
原文地址: https://debezium.io/blog/2021/02/24/debezium-1-5-beta1-released/ 欢迎关注留言,我是收集整理小能手,工具翻译,仅供参考,笔芯笔芯. Debezium 1.5.0.Beta1 发布 2021 年 2 月 24 日 作者: Gu…...

探索自然语言处理在改善搜索引擎、语音助手和机器翻译中的应用
文章目录 每日一句正能量前言文本分析语音识别机器翻译语义分析自然语言生成情感分析后记 每日一句正能量 努力学习,勤奋工作,让青春更加光彩。 前言 自然语言处理(NLP)是人工智能领域中与人类语言相关的重要研究方向,…...

echarts:获取省、市、区/县、镇的地图数据
目录 第一章 前言 第二章 获取地图的数据(GeoJSON格式) 2.1 获取省、市、区/县地图数据 2.2 获取乡/镇/街道地图数据 第一章 前言 需求:接到要做大屏的需求,其中需要用echarts绘画一个地图,但是需要的地图是区/县…...

Java_简单模拟实现ArrayList_学习ArrayList
文章目录 一、 了解线性表和顺序表区别1.线性表2.顺序表 二、模拟实现1.定义接口2.定义MyArrayList3.成员变量以及构造方法4.实现打印数组5.实现add方法6.实现查找某个数是否存在contains或者某个数的下标indexOf7.获取或更改pos位置的值 get和set8.获取数组大小 size9.删除某个…...
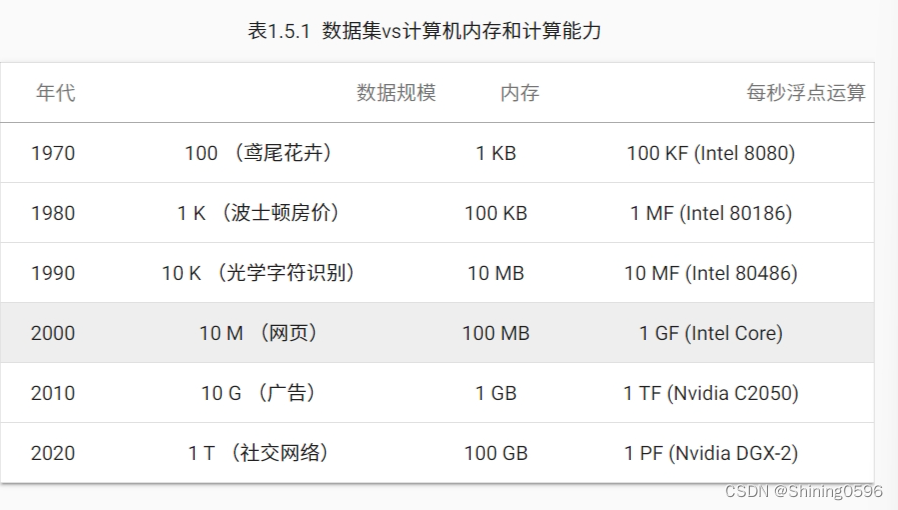
动手学深度学习(一)深度学习介绍2
目录 二、起源 三、深度学习的成功案例: 四、特点: 五、小结: 二、起源 为了解决各种各样的机器学习问题,深度学习提供了强大的工具。 虽然许多深度学习方法都是最近才有重大突破,但使用数据和神经网络编程的核心思…...
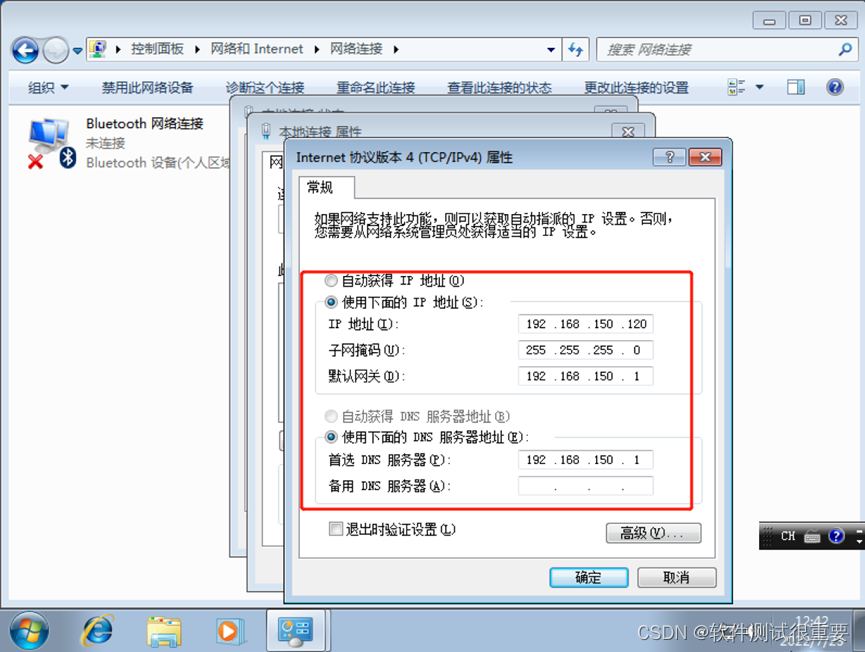
vmware网络配置,VMware的三种网络模式详解与配置
vmware为我们提供了三种网络工作模式 vmware为我们提供了三种网络工作模式, 它们分别是: Bridged(桥接模式)、NAT(网络地址转换模式)、Host-Only(仅主机模式)。 VMware虚拟机的三种网络类型的适用场景如下…...

【Ubuntu】安装hbase
前提 需要安装java 安装 HBase 下载并解压 HBase 安装包: wget https://dlcdn.apache.org/hbase/2.5.7/hbase-2.5.7-bin.tar.gz tar -zxvf hbase-2.5.7-bin.tar.gz配置 HBase 环境变量: export HBASE_HOME/path/to/hbase-2.5.7 export PATH$PATH:$H…...

ubuntu16.04环境轻松安装和应用opencv4.9.0(基于源码编译)
目录 一、环境准备 1、安装cmake 2、安装依赖 3、从github上下载opencv4.9.0.zip 二、安装opencv4.9.0 1、解压4.9.0.zip 2、进入build目录编译 3、安装编译好的相关库 4、修改opencv配置文件并使其生效 5、添加PKG_CONFIG路径,并使其生效 三、opencv环境…...
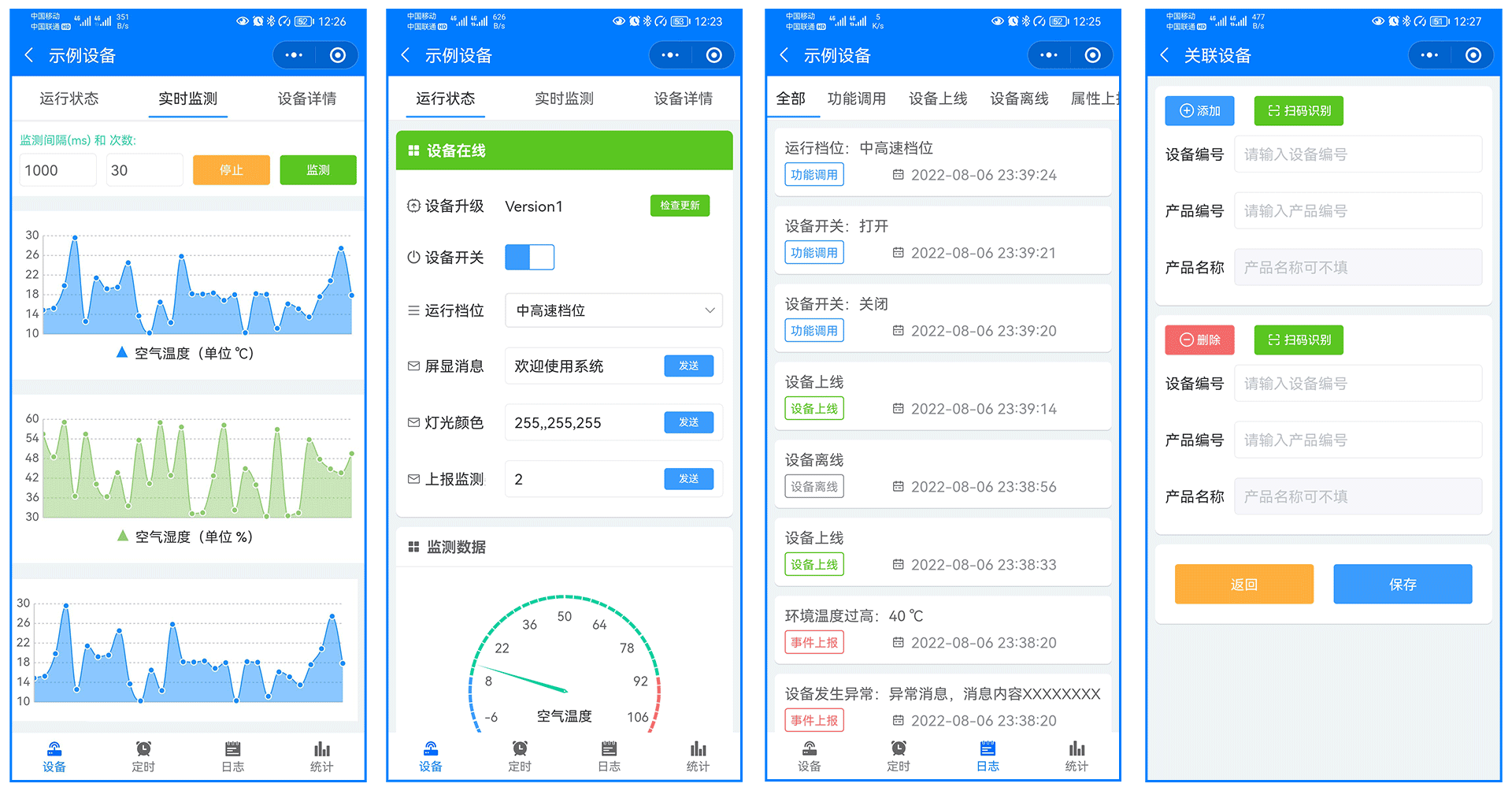
FastBee开源物联网平台2.0开源版发布啦!!!
一、项目介绍 物美智能(wumei-smart)更名为蜂信物联(FastBee)。 FastBee开源物联网平台,简单易用,更适合中小企业和个人学习使用。适用于智能家居、智慧办公、智慧社区、农业监测、水利监测、工业控制等。 系统后端采用Spring boot;前端采用…...
部署步骤 小白避坑手册)
2026 最新 OpenClaw(小龙虾)部署步骤 小白避坑手册
OpenClaw(小龙虾)Windows 一键部署保姆级教程 | 10 分钟养出你的数字员工(2026 最新版) ✨ 前言 2026 年爆火的开源 AI 智能体 OpenClaw(昵称小龙虾),GitHub 星标超 28 万,凭 “本…...

formality
get_app_var verification_set_undriven_signalsset_app_var verification_set_undriven_signals binary 0ref的port是undriven,会说original undriven,并且给出0的cut_net激励,得到的值为0。这里的值给的是0而不是x,所以会特意说…...

抖音批量下载完整指南:3步实现无水印视频高效获取
抖音批量下载完整指南:3步实现无水印视频高效获取 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. …...

破解Windows安装程序本地化难题:Inno Setup简体中文翻译的技术实现与架构设计
破解Windows安装程序本地化难题:Inno Setup简体中文翻译的技术实现与架构设计 【免费下载链接】Inno-Setup-Chinese-Simplified-Translation :earth_asia: Inno Setup Chinese Simplified Translation 项目地址: https://gitcode.com/gh_mirrors/in/Inno-Setup-Ch…...

Windows键盘终极改造指南:用SharpKeys解锁键盘隐藏潜力
Windows键盘终极改造指南:用SharpKeys解锁键盘隐藏潜力 【免费下载链接】sharpkeys SharpKeys is a utility that manages a Registry key that allows Windows to remap one key to any other key. 项目地址: https://gitcode.com/gh_mirrors/sh/sharpkeys …...

拒绝复杂配置!OpenClaw Win11 版,双击安装,AI 自动干活
OpenClaw 一键安装包|全程图文教程 open claw一键部署包点击下载https://xiake.yun/api/download/package/16?promoCodeIVD643FDE29A 适配系统:Windows 10 64位(新手专享版) 产品亮点: 零门槛安装:无需…...

PTFE材料在多领域的创新应用与发展分析
PTFE材料在生活领域的独特贡献不粘锅技术的演变与PTFE应用不粘锅的问世大大推动了厨房烹饪的便利性,而PTFE材料在其中扮演了关键角色。随着科技的发展,我们见证了PTFE涂层技术的不断创新,早期的传统不粘锅被更为耐磨、不易脱落的新型PTFE涂层…...

宇树go2机械狗远程操控联网问题
用手机“Unitree Go”app的wifi模式,让狗和电脑连接同一个wifi,使其处于同一个局域网下。要求wifi名和密码无中文。然后在本地电脑powershell输入ipconfig查询本机局域网网段,确认机械狗同一网段 IP 地址。终端执行命令:ssh unitr…...
》读书笔记:异常检测方法梳理与实践理解)
《数据挖掘(主编:吕欣 王梦宁)》读书笔记:异常检测方法梳理与实践理解
《数据挖掘(主编:吕欣 王梦宁)》读书笔记:异常检测方法梳理与实践理解本文是学习《数据挖掘(主编:吕欣 王梦宁)》中“异常检测”相关内容后的整理笔记。文章不追求逐条复述教材,而是…...

【与我学 ClaudeCode】规划与协调篇 之 Skills:按需加载的领域知识框架
作者:逆境不可逃 技术永无止境 希望我的内容可以帮助到你!!!!! 大家吼 ! 我是 逆境不可逃 今天给大家带来文章《【与我学 ClaudeCode】规划与协调篇 之 Skills:按需加载的领域知识框架》. Lea…...