【ACL 2023】Enhancing Document-level EAE with Contextual Clues and Role Relevance
【ACL 2023】Enhancing Document-level Event Argument Extraction with Contextual Clues and Role Relevance

论文:https://aclanthology.org/2023.findings-acl.817/
代码:https://github.com/LWL-cpu/SCPRG-master
Abstract
与句子级推理相比,文档级事件论元抽取在长输入和跨句推理方面提出了新的挑战。然而,大多数先前的工作都集中在捕捉每个事件中候选论元和事件触发词之间的关系,忽略了两个关键点:a)非论元上下文线索信息;b) 论元角色之间的相关性。在本文中,我们提出了一个SCPRG(基于跨度触发词的上下文池化和潜在角色引导)模型,该模型包含两个新颖有效的模块来解决上述问题。基于跨度触发的上下文池化(STCP)基于预训练模型中特定论元-触发词对的上下文注意力权重,自适应地选择和聚合非论元线索词的信息。基于角色的潜在信息引导(RLIG)模块构建潜在角色表示,使其通过角色交互编码进行交互,以获取语义相关性,并将其合并为候选论点。与基本模型相比,STCP和RLIG都引入了不超过1%的新参数,并且可以很容易地应用于其他事件抽取模型,这些模型紧凑且可移植。在两个公共数据集上的实验表明,我们的SCPRG优于以前最先进的方法,在RAMS和WikiEvents上分别改进了1.13 F1和2.64 F1。进一步的分析说明了我们模型的可解释性。
Introduction

然而,先前所有SOTA的作品都忽略了两个关键点:(a)非论元的线索信息;(b) 论点角色之间的相关性。
非论元线索是除目标论元外的上下文文本,可以为预测许多复杂的论元角色提供重要的指导信息。例如,在图1中,对于Conflict and Attack事件,非论元线索被detonated, claim responsibility 和 terrorist attack可以为识别论元explosive belts和Islamic State提供重要的线索信息。然而,以前的许多工作只使用了经过预训练的Transformer编码器隐式获取全局上下文信息,忽略了对于事件中出现的不同论元,他们应该关注与实体和目标事件高度相关的上下文信息。因此,在本文中,我们设计了一个基于跨度触发词的上下文池化(STCP)模块,该模块基于预训练模型中的上下文注意力乘积,将每个论元-触发词对的非论元线索的信息合并,用额外的相关上下文信息增强候选论元的表示。
一些论元角色具有密切的语义相关性,这有利于论元抽取。例如,在图1中,角色injurer和victim之间存在密切的语义相关性,这可以为目标事件Conflict and Attack中这两个角色的论点抽取提供重要的信息指导。此外,许多角色共同发生在多个事件中,这可能具有密切的语义相关性。具体而言,我们统计并可视化了图2中RAMS数据集中15个最频繁角色之间的共现频率。例如,attacker, target 和 instrument的角色经常同时出现,这表明它们在语义上比其他角色更相关。在本文中,我们提出了一个基于角色的潜在信息引导(RLIG)模块,该模块由角色交互编码和角色信息融合组成。具体来说,我们设计了一个角色交互编码器,将角色添加到输入序列中,其中角色嵌入不仅可以学习角色的潜在语义信息,还可以捕捉角色之间的语义相关性。然后,通过池化和串联操作将潜在的角色嵌入合并到候选论元中,为文档级EAE提供信息指导。

针对上述两个问题,本文分别提出了一个有效的文档级EAE模型SCPRG(Span-trigger-based Contextual Pooling and Role-based Potential information Guidance),该模型包含STCP模块和RLIG模块。值得注意的是,这两个模块利用了来自预训练的语言模型的学习良好的注意力权重,引入了不超过1%的新参数,并且很容易应用于其他紧凑且可移植的事件抽取模型。此外,我们试图通过排除有争议的不可能跨度来消除噪声信息。我们的贡献总结如下:
- 我们提出了一个基于跨度触发词的上下文池化模块,该模块自适应地选择和聚合非论元线索的信息,用相关的上下文信息增强候选论元的表示。
- 我们提出了一个基于角色的潜在信息指导模块,该模块提供包含角色之间语义相关性的潜在角色信息指导。
- 大量实验表明,SCPRG的性能优于之前的最新模型,在公共RAMS和WikiEvents数据集上分别提高了1.13 F1和2.64 F1。我们进一步分析了注意力权重和潜在角色表征,这表明了我们模型的可解释性。
Method
文档级时间论元抽取可以作为一个多分类问题。给出一个文档 D D D包含 N N N个单词, D = { w 1 , w 2 , … , w N } D=\{ w_1,w_2,\dots,w_N \} D={w1,w2,…,wN},预定义的事件类型集合 E \mathcal{E} E,对应的论元角色集合 R e \mathcal{R}_e Re,触发词 t ∈ D t \in D t∈D,每一个事件 e ∈ E e \in \mathcal{E} e∈E。该任务的目的是预测出文档 D D D中的所有事件对 ( r , s ) (r,s) (r,s)。其中 r ∈ R e r \in \mathcal{R}_e r∈Re是事件 e ∈ E e \in \mathcal{E} e∈E的论元角色, s ⊆ D s \subseteq D s⊆D。
Role-interactive Encoder

Role Type Representation:为了捕捉角色之间的语义相关性,我们将角色类型信息添加到输入序列中,并通过多头注意力在上下文和角色之间进行交互,从而在共享的知识空间中获得上下文和角色的表示。具体来说,我们在预训练的模型中构建具有不同特殊标记的角色的潜在嵌入,其中每个角色类型都有特定的潜在表示。考虑到角色名称也包含有价值的语义信息,我们用特殊的角色类型标记包裹角色名称,并将起始特殊标记的嵌入作为角色嵌入。以角色Place为例,我们最终将其表示为[R0] Place [R0],其中[R0]是 Place 的特殊角色类型表征。
Role-interactive Encoding:对于输入文档 D = { w 1 , w 2 , … , w N } D=\{ w_1,w_2,\dots,w_N\} D={w1,w2,…,wN},目标事件 e e e和其对应的论元角色集合 R e = { r 1 , r 2 , r 3 , … } \mathcal{R}_e =\{ r_1,r_2,r_3,\dots\} Re={r1,r2,r3,…},我们将其连接成一个序列:
S = [ C L S ] [ E e ] e [ E e ] [ S E P ] w 1 … w N [ S E P ] [ R 1 ] r 1 [ R 2 ] r 2 … [ S E P ] S =[CLS]\ [E_e]\ e\ [E_e]\ [SEP] \ w_1 \dots\ w_N \ [SEP]\ [R1] \ r_1 \ [R2]\ r_2 \dots [SEP] S=[CLS] [Ee] e [Ee] [SEP] w1… wN [SEP] [R1] r1 [R2] r2…[SEP]
[ E e ] [E_e] [Ee]是事件 e e e的特殊事件token, [ R 1 ] , [ R 2 ] [R1],[R2] [R1],[R2]是角色类型 r 1 , r 2 r_1,r_2 r1,r2的特殊token。最后的 [ S E P ] [SEP] [SEP]来表示无类别。接下来,我们利用预训练的语言模型作为编码器来获得每个token的嵌入,如下所示:
H s = E n c o d e r ( S ) H^s=Encoder(S) Hs=Encoder(S)
然后我们获取 [ E e ] [E_e] [Ee]的事件嵌入 H e ∈ R 1 × d H^e \in \mathbb{R}^{1 \times d} He∈R1×d,上下文表示 H w ∈ R l w × d H^w \in \mathbb{R}^{l_w \times d} Hw∈Rlw×d,角色表示 H r ∈ R l r × d H^r \in \mathbb{R}^{l_r \times d} Hr∈Rlr×d,其中 l w l_w lw是分词列表的长度, l r l_r lr是角色列表的长度。对于长度超过512的输入序列,我们利用动态窗口对整个序列进行编码,并对不同窗口的重叠token嵌入进行平均,以获得最终表示。
值得注意的是,通过角色交互编码,角色嵌入可以捕捉语义相关性并适应目标事件和上下文,从而更好地指导论元抽取。
Span-Trigger-based Contextual Pooling
Argument-impossible Spans Exclusion:为了消除无用跨度的噪声信息,我们通过排除一些有争议的不可能跨度来减少候选跨度的数量,例如在中间的跨度。有了这样的改进,我们平均减少了四分之一的候选跨度并使我们的模型关注具有有用信息的候选跨度。
Span-Trigger-based Contextual Pooling: 对于从 w i w_i wi到 w j w_j wj的候选跨度,大多数以前的基于跨度的方法通过该跨度内token的隐藏状态的平均池化来表示: 1 j − i + 1 ∑ k = i j h k w \frac{1}{j-i+1} \sum_{k=i}^j h_k^w j−i+11∑k=ijhkw,其中 h k w h_k^w hkw是从 H w H^w Hw嵌入的第 k k k个token。
然而,平均池化表示忽略了其他非论元词的重要线索信息。尽管预训练编码器的自注意机制可以对token级交互进行建模,但这种全局交互是特定于事件和候选论元的。因此,我们建议选择并融合与由候选跨度和事件触发词组成的每个元组高度相关的有用上下文信息,即 ( s i : j , t ) (s_{i:j},t) (si:j,t)。我们直接利用预训练的基于Transformer的编码器的注意力头进行基于跨度触发词的上下文池化,这将从预训练的语言模型中转移学习良好的依赖关系,而无需从头开始学习新的注意力层。
具体来说,我们在预训练的语言模型中使用来自最后一个Transformer的上下文的token级注意力头 A w ∈ R H × l w × l w A^w∈\mathbb{R}^{H \times l_w \times l_w} Aw∈RH×lw×lw。然后,我们可以通过平均池化获得从 w i w_i wi到 w j w_j wj的每个候选跨度的上下文注意力 A i : j C ∈ R l w A^C_{i:j}∈\mathbb{R}^{l_w} Ai:jC∈Rlw:
A i : j C = 1 H ( j − i + 1 ) ∑ h = 1 H ∑ m = i j A h , m w A_{i:j}^C=\frac{1}{H(j-i+1)} \sum_{h=1}^H \sum_{m=i}^j A_{h,m}^w Ai:jC=H(j−i+1)1h=1∑Hm=i∑jAh,mw
然后,对于跨度触发词对 ( s i : j , t ) (s_{i:j},t) (si:j,t),我们通过乘以注意力和归一化来获得对候选跨度重要的上下文线索信息 c s i : j ∈ R d c^{s_{i:j}}∈\mathbb{R}^d csi:j∈Rd:
p i : j c = s o f t m a x ( A i : j C ⋅ A t C ) , c s i : j = H w p i : j c p_{i:j}^c=softmax(A_{i:j}^C \cdot A_t^C),\\ c^{s_{i:j}}=H^w p_{i:j}^c pi:jc=softmax(Ai:jC⋅AtC),csi:j=Hwpi:jc
A t c ∈ R l w A_t^c \in \mathbb{R}^{l_w} Atc∈Rlw是触发词 t t t的上下文注意力, p i : j c ∈ R l w p_{i:j}^c \in \mathbb{R}^{l_w} pi:jc∈Rlw是上下文的计算注意力权重向量。
Role-based Latent Information Guidance
RLIG模块通过角色交互编码构建潜在角色嵌入,并通过池化操作进行角色信息融合,为潜在角色信息提供有价值的指导。
Role Information Fusion:为了使每个候选论点都能得到有用的角色信息指导,我们修改了基于跨度触发的上下文池方法,以自适应地选择角色信息。通过上下文池化得到 s i : j s_{i:j} si:j的潜在角色信息 r s i : j ∈ R d r^{s_{i:j}}\in \mathbb{R}^d rsi:j∈Rd,
A i : j R = 1 H ( j − i + 1 ) ∑ h = 1 H ∑ m = i j A h , m r , p i : j r = s o f t m a x ( A i : j R ⋅ A t R ) , r s i : j = H r p i : j r A_{i:j}^R=\frac{1}{H(j-i+1)} \sum_{h=1}^H \sum_{m=i}^j A_{h,m}^r,\\ p_{i:j}^r=softmax(A_{i:j}^R \cdot A_t^R),\\ r^{s_{i:j}}=H^r p_{i:j}^r Ai:jR=H(j−i+1)1h=1∑Hm=i∑jAh,mr,pi:jr=softmax(Ai:jR⋅AtR),rsi:j=Hrpi:jr
A r ∈ R H × l w × l r A^r \in \mathbb{R}^{H \times l_w \times l_r} Ar∈RH×lw×lr是来自预训练语言模型中最后一个transformer层的角色的注意力。 A i : j R ∈ R l r A^R_{i:j} \in \mathbb{R}^{l_r} Ai:jR∈Rlr是每个候选跨度的角色注意力, A t R ∈ R l r A^R_t \in \mathbb{R}^{l_r} AtR∈Rlr是触发词 t t t的角色注意力。 p i : j r ∈ R l r p^r_{i:j} \in \mathbb{R}^{l_r} pi:jr∈Rlr为角色的计算注意力权重向量。
对于候选跨度 s i : j s_{i:j} si:j,我们如下融合平均池化表示、上下文线索信息 c s i : j c^{s_{i:j}} csi:j和潜在角色信息 r s i : j r^{s_{i:j}} rsi:j:
s i : j = tanh ( W 1 [ 1 j − i + 1 ∑ k = i j h k w ; c s i : j ; r s i : j ] ) s_{i:j}=\tanh (W_1 [\frac{1}{j-i+1} \sum_{k=i}^{j} h_k^w;c^{s_{i:j}};r^{s_{i:j}}]) si:j=tanh(W1[j−i+11k=i∑jhkw;csi:j;rsi:j])
W 1 ∈ R 3 d × d W_1 \in \mathbb{R}^{3d \times d} W1∈R3d×d是可学习参数。
Classification Module
Boundary Loss:由于我们抽取跨度级别的论元,其边界可能是模糊的,因此我们使用全连接神经网络构建开始和结束表示,以增强候选跨度的表示: H s t a r t = W s t a r t H s H^{start}=W^{start}H^{s} Hstart=WstartHs, H e n d = W e n d H s H^{end}=W^{end}H^s Hend=WendHs,其中 H s H^s Hs是输入序列 S S S的隐藏表示。在此基础上,我们通过将上下文和角色信息与基于跨度触发词的上下文池化集成来增强开始和结束表示,如下所示:
z i : j s t a r t = H s t a r t p i : j , z i : j e n d = H e n d p i : j , h i : j s t a r t = tanh ( W 2 [ h i s t a r t ; z i : j s t a r t ] ) , h i : j e n d = tanh ( W 3 [ h j e n d ; z i : j e n d ] ) z_{i:j}^{start}=H^{start}p_{i:j},\\ z_{i:j}^{end}=H^{end}p_{i:j},\\ h_{i:j}^{start}=\tanh(W_2[h_i^{start};z_{i:j}^{start}]),\\ h_{i:j}^end=\tanh(W_3[h_j^{end};z_{i:j}^{end}]) zi:jstart=Hstartpi:j,zi:jend=Hendpi:j,hi:jstart=tanh(W2[histart;zi:jstart]),hi:jend=tanh(W3[hjend;zi:jend])
h i s t a r t , h j e n d h_i^{start},h_j^{end} histart,hjend是 H s t a r t , H e n d H^{start},H^{end} Hstart,Hend的第 i , j i,j i,j个向量。 W 2 , W 3 ∈ R 2 d × d W_2,W_3 \in \mathbb{R}^{2d \times d} W2,W3∈R2d×d是可学习参数,我们获得最终的候选片段表征 s ~ i : j \tilde{s}_{i:j} s~i:j: s ~ i : j = W s [ h i : j s t a r t ; s i : j ; h i : j e n d ] \tilde{s}_{i:j} = W^s[h_{i:j}^{start};s_{i:j};h_{i:j}^{end}] s~i:j=Ws[hi:jstart;si:j;hi:jend], W s ∈ R 3 d × d W^s \in \mathbb{R}^{3d \times d} Ws∈R3d×d是可学习参数。
最终的边界损失被定义去检测开始和结束位置:
L b = ∑ i = 1 ∣ D ∣ [ y i s log P i s + ( 1 − y i s ) log ( 1 − P i s ) + y i e log P i e + ( 1 − y i e ) log ( 1 − P i e ) ] \mathcal{L}_b=\sum_{i=1}^{|\mathcal{D}|}[y_i^s \log P_i^s + (1-y_i^s) \log (1-P_i^s)+y_i^e \log P_i^e + (1-y_i^e) \log (1-P_i^e)] Lb=i=1∑∣D∣[yislogPis+(1−yis)log(1−Pis)+yielogPie+(1−yie)log(1−Pie)]
其中 y i s y^s_i yis和 y i e y^e_i yie表示标准标注,并且 P i s = s i g m o i d ( W 4 h i s t a r t ) P^s_i=sigmoid(W_4h^{start}_i) Pis=sigmoid(W4histart)和 P i s = s i g m o i d ( W 5 h i e n d ) P^s_i=sigmoid(W_5h^{end}_i) Pis=sigmoid(W5hiend)是单词 w i w_i wi被预测为正确论元跨度的第一个或最后一个单词的概率。
Classification Loss:对于事件 e e e中的候选跨度 s i : j s_{i:j} si:j,我们将跨度表示 s ~ i : j \tilde{s}_{i:j} s~i:j、触发词表示 h t h_t ht、它们的绝对差 ∣ h t − s ~ i : j ∣ |h_t−\tilde{s}_{i:j}| ∣ht−s~i:j∣、逐元素乘法 h t ⊙ s ~ i : j h_t \odot \tilde{s}_{i:j} ht⊙s~i:j,事件类型嵌入 H e H^e He和跨度长度嵌入 E l e n E_{len} Elen连接起来,并通过前馈网络获得候选跨度 s i : j s_{i:j} si:j的预测 P ( r i : j ) P(r_{i:j}) P(ri:j):
I i : j = [ s ~ i : j ; h t ; ∣ h t − s ~ i : j ∣ ; h t ⊙ s ~ i : j ; H e ; E l e n ] , P ( r i : j ) = F F N ( I i : j ) I_{i:j}=[\tilde{s}_{i:j};h_t;|h_t - \tilde{s}_{i:j}|;h_t \odot \tilde{s}_{i:j};H^e;E_{len}],\\ P(r_{i:j})=FFN(I_{i:j}) Ii:j=[s~i:j;ht;∣ht−s~i:j∣;ht⊙s~i:j;He;Elen],P(ri:j)=FFN(Ii:j)
考虑到大多数候选论点都是负样本和不平衡的角色分布,我们采用focal loss来使训练过程更多地关注有用的正样本,其中 α α α和 γ γ γ是超参数。
L c = − ∑ i = 1 ∣ D ∣ ∑ j = 1 ∣ D ∣ α [ 1 − P ( r i : j = y i : j ) ] γ ⋅ log P ( r i : j = y i : j ) \mathcal{L}_c=-\sum_{i=1}^{|\mathcal{D}|} \sum_{j=1}^{|\mathcal{D}|} \alpha [1-P(r_{i:j}=y_{i:j})]^{\gamma} \cdot \log P(r_{i:j}=y_{i:j}) Lc=−i=1∑∣D∣j=1∑∣D∣α[1−P(ri:j=yi:j)]γ⋅logP(ri:j=yi:j)
最后,训练损失被定义如下:
L = L c + λ L b \mathcal{L}=\mathcal{L}_c + \lambda \mathcal{L}_b L=Lc+λLb
Experiments







Conclusion
在本文中,我们提出了一种新的用于文档级EAE的SCPRG框架,该框架主要由两个紧凑、有效且可移植的模块组成。具体来说,我们的STCP自适应地聚合了非论元线索词的信息,RLIG提供了包含角色之间语义相关性的潜在角色信息指导。实验结果表明,SCPRG的性能优于现有最先进的EAE模型和进一步的分析表明,我们的方法既有效又可解释。对于未来的工作,我们希望将SCPRG应用于更多的信息抽取任务,如关系抽取和多语言抽取,其中上下文信息发挥着重要作用。
相关文章:
【ACL 2023】Enhancing Document-level EAE with Contextual Clues and Role Relevance
【ACL 2023】Enhancing Document-level Event Argument Extraction with Contextual Clues and Role Relevance 论文:https://aclanthology.org/2023.findings-acl.817/ 代码:https://github.com/LWL-cpu/SCPRG-master Abstract 与句子级推理相比&…...
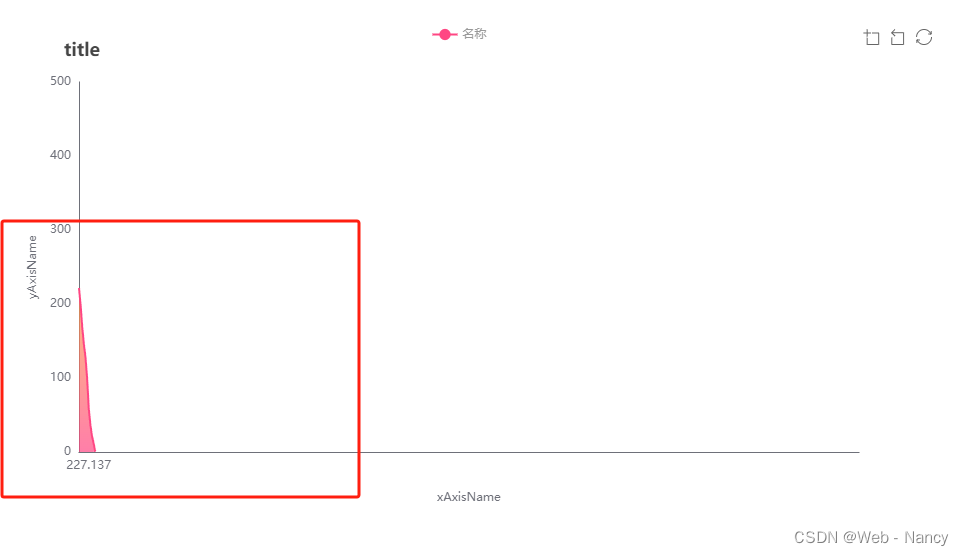
Vue ECharts X轴 type为value的数据格式 + X轴固定间隔并向上取整十位数 - 附完整示例
ECharts:一个基于 JavaScript 的开源可视化图表库。 目录 效果 一、介绍 1、官方文档:Apache ECharts 2、官方示例 二、准备工作 1、安装依赖包 2、示例版本 三、使用步骤 1、在单页面引入 echarts 2、指定容器并设置容器宽高 3、数据处理&am…...
)
统计成绩(c++题解)
题目描述 半期考试结束了,几多欢喜几多愁!作为竞赛的选手,迟早是要经历大风大浪的,这点小小的涟漪无须太在意。但是对于成绩,还是要好好的分析一下的。 有N个学生,每个学生的数据包括学号、姓名、3门课的…...

【Qt】—— Hello World程序的实现
目录 (一)使⽤"按钮"实现 1.1 纯代码方式实现 1.2 可视化操作实现 (二)使⽤"标签"实现 2.1 纯代码方式实现 2.2 可视化操作实现 (一)使⽤"按钮"实现 1.1 纯代码方式实…...

谷歌浏览器网站打不开,显示叹号
问题: 您与此网站之间建立的连接不安全请勿在此网站上输入任何敏感信息(例如密码或信用卡信息),因为攻击者可能会盗取这些信息。 了解详情 解决方式: 网上有很多原因,亲测为DNS问题,设置&…...

怎么去除图片中不需要的部分?这三种高效方法快来试一下
在数字图像处理的浩瀚世界中,去除图片中不必要部分的任务,宛如一幅细致的画卷,需精心描绘。这些不必要部分,可能是背景、水印、无关紧要物体或错误部分,它们如同图片中的瑕疵,需要被巧妙地修饰或去除。这不…...

yolov5导出onnx模型问题
为了适配C工程代码,我在导出onnx模型时,会把models/yolo.py里面的forward函数改成下面这样, #转模型def forward(self, x):z [] # inference outputfor i in range(self.nl):x[i] self.m[i](x[i]) # convbs, _, ny, nx x[i].shape # x(…...
JS第一课简单看看这是啥东西
1.什么是JavaScript JS是一门编程语言,是一种运行在客户端(浏览器)的编程语言,主要是让前端的画面动起来,注意HTML和CSS不是编程语言,他俩是一种标记语言。JS只要有浏览器就能运行不用跟Python或者Java一样上来装一个jdk或者Pyth…...

2023年常用网络安全政策标准整合
文章目录 前言一、政策篇(一)等级保护(二)关键信息基础设施保护(三)数据安全(四)数据出境安全评估(五)网络信息安全(六)应急响应(七)网络安全专用产品检测认证制度(八)个人信息保护(九)商用密码二、标准篇前言 2023年,国家网络安全政策和标准密集发布,逐渐…...
Redis -- 背景知识
“知识就是力量” -- 弗朗西斯培根 目录 特性 为啥Redis快? 应用场景 Redis不能做什么? Redis是在内存中存储数据的一个中间件,用作为数据库,也可以用作为缓存,在分布式中有很高的威望。 特性 In-memory data structures&…...
如何在Shopee平台上进行手机类目选品?
在Shopee平台上进行手机类目的选品是一个关键而复杂的任务。卖家需要经过一系列的策略和步骤,以确保选品的成功和销售业绩的提升。下面将介绍一些有效的策略,帮助卖家在Shopee平台上进行手机类目选品。 先给大家推荐一款shopee知虾数据运营工具知虾免费…...

班级管理神器,教师在线发布系统
现如今,班级管理也需要与时俱进。传统的管理方式不仅效率低下,而且容易出错。为了更好地管理班级,教师需要一个强大的工具来帮助他们发布信息和管理学生。 发布系统是一款专门为教师设计的数字化管理工具。通过系统,老师们就可以…...

【Spring Boot 3】异步线程任务
【Spring Boot 3】异步线程任务 背景介绍开发环境开发步骤及源码工程目录结构总结背景 软件开发是一门实践性科学,对大多数人来说,学习一种新技术不是一开始就去深究其原理,而是先从做出一个可工作的DEMO入手。但在我个人学习和工作经历中,每次学习新技术总是要花费或多或…...

JAVA斗地主逻辑-控制台版
未排序版: 准备牌->洗牌 -> 发牌 -> 看牌: App程序入口: package doudihzu01;public class App {public static void main(String[] args) {/*作为斗地主程序入口这里不写代码逻辑*///无参创建对象,作为程序启动new PokerGame();…...
Harmony的自定义组件和Page的数据同步
在开发过程中会经常使用自定义组件,就会遇到一个问题,在页面中引入组件后,如何把改变的值传递到自定义组件中呢,这就用到了装饰器,在这是单向传递的,用的装饰器是@State和@Prop @State在page页面中监听数据的变化 @Prop在自定义组件中监听page页面传递过来的变化值,并赋…...

【Vue3+Vite】路由机制router 快速学习 第四期
文章目录 路由简介路由是什么路由的作用 一、路由入门案例1. 创建项目 导入路由依赖2. 准备页面和组件3. 准备路由配置4. main.js引入router配置 二、路由重定向三、编程式路由(useRouter)四、路由传参(useRoute)五、路由守卫总结 路由简介 路由是什么 路由就是根据不同的 URL…...

python脚本实现浏览器驱动chromedriver的版本自动升级
chromedriver的版本号与chrome浏览器版本不匹配时在运行程序时就会报错 用下面的脚本可以自动安装chromedriver的最新版本到指定路径 from webdriver_manager.utils import get_browser_version_from_os from webdriver_manager.chrome import ChromeDriverManager import re…...

npm使用国内淘宝镜像
一、命令配置 1、设置淘宝镜像源 npm config set registry https://registry.npmmirror.com2、查看镜像使用状态 npm config get registry如果返回https://registry.npmmirror.com/,说明配置的是淘宝镜像。 如果返回https://registry.npmjs.org/,说明配置的是官网镜像。 二…...
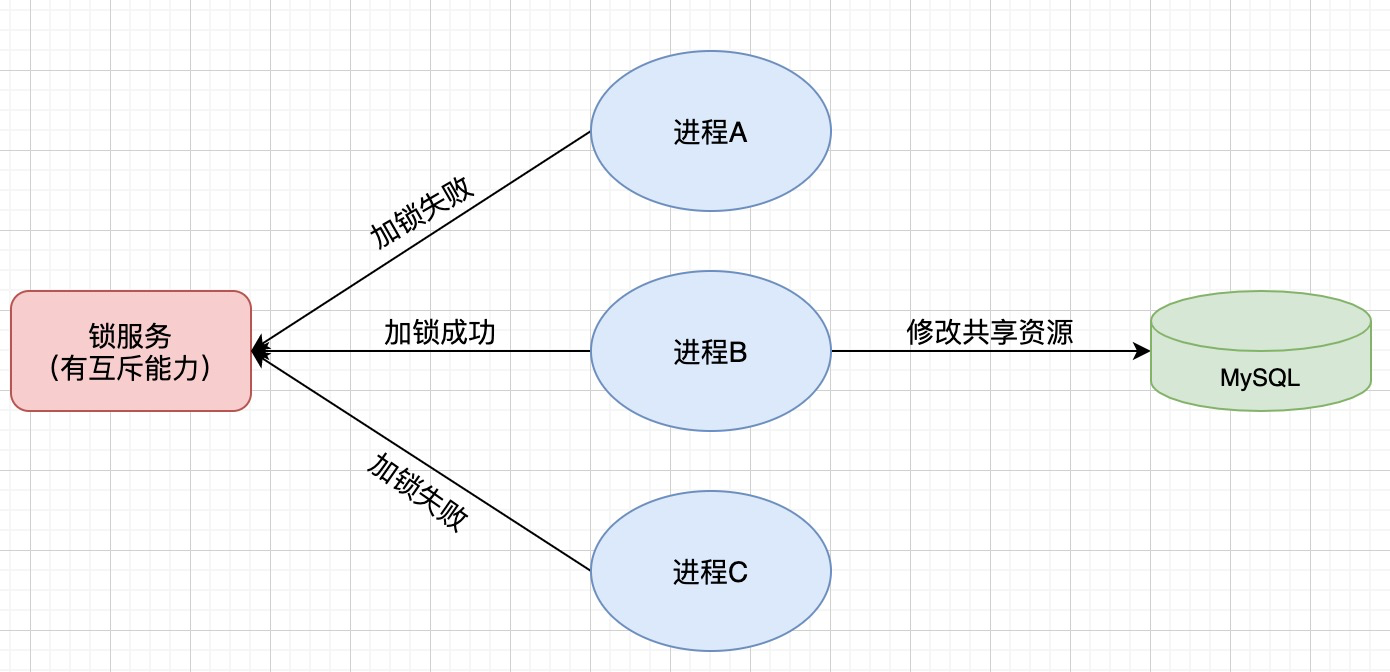
# Redis 分布式锁如何自动续期
Redis 分布式锁如何自动续期 何为分布式 分布式,从狭义上理解,也与集群差不多,但是它的组织比较松散,不像集群,有一定组织性,一台服务器宕了,其他的服务器可以顶上来。分布式的每一个节点&…...

数据结构 归并排序详解
1.基本思想 归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide andConquer)的一个非常典型的应用。 将已有序的子序列合并,得到完全有序的序列,即先使每个子序列有序…...

即插即用AI记忆协议:跨模型兼容的记忆中间件
1. 项目概述:不是“插件”,而是一套可即插即用的AI记忆增强协议你有没有遇到过这样的情况:刚让大模型帮你梳理完一份30页产品需求文档的逻辑漏洞,转头问它“第三章提到的用户分层标准是否和第五章的测试样本筛选条件冲突”&#x…...

2026年,专业打造湖南美缝施工极致体验的宝藏公司你知道吗?
在湖南,装修市场日益繁荣,美缝作为装修中至关重要的一环,其品质直接影响着家居的整体美观与舒适度。今天,就带大家了解一家专业打造湖南美缝施工极致体验的宝藏公司——长沙匠心徐师傅美缝团队。一、高端服务体系贴合业主核心诉求…...

深度解析:光引擎、光模块、光器件之间的关系和区别?
随着AI大模型加速迭代,算力集群正从“千卡”向“万卡”“十万卡”规模迈进,光通信作为连接算力的“血管”,其内部层级关系变得愈发关键。然而,光器件、光模块、光引擎这三者并非同一概念,而是产业链中层层递进的“铁三…...
)
为什么你的ElevenLabs四川话输出总像“普通话+口音”?3步声学特征解耦法让韵律自然度提升2.8倍(附Python声谱可视化代码)
更多请点击: https://intelliparadigm.com 第一章:为什么你的ElevenLabs四川话输出总像“普通话口音”? ElevenLabs 当前并未提供原生四川话(西南官话成渝片)语音模型,其所谓“方言支持”实为在标准普通话…...

ChatGPT-Web-Midjourney-Proxy 终极备份策略:数据安全与灾难恢复完全指南
ChatGPT-Web-Midjourney-Proxy 终极备份策略:数据安全与灾难恢复完全指南 ChatGPT-Web-Midjourney-Proxy 是一款集成 ChatGPT、Midjourney 和 GPTs 功能的一站式 UI 工具,为用户提供便捷的 AI 交互体验。在日常使用中,数据安全与灾难恢复至关…...

上海AI实验室发布WildClawBench:AI智能体究竟能走多远?
这项由上海人工智能实验室联合香港中文大学、复旦大学、中国科学技术大学、上海交通大学、清华大学、浙江大学及南洋理工大学等多所顶尖机构共同完成的研究,于2026年5月11日以预印本形式发布,论文编号为arXiv:2605.10912v1。感兴趣的读者可通过该编号在a…...
)
别再只会画矩形了!用Leaflet+L.geoJSON搞定复杂行政区遮罩(含飞地处理)
突破Leaflet遮罩技术瓶颈:复杂行政区与飞地处理的终极方案 当我们面对真实世界中的行政区划数据时,理想化的矩形遮罩显得力不从心。中国行政区划的复杂性——飞地、嵌套洞、不规则边界——要求开发者掌握更高级的地图遮罩技术。本文将带您深入Leaflet的L…...

苏姿丰来华,AMD能否借中国市场突破英伟达生态封锁?
苏姿丰访华与AMD战略布局黄仁勋走后第四天,苏姿丰来到上海。上周,黄仁勋在最后一刻挤进特朗普访华队伍,想把英伟达重新带回中国。但他离开北京后,随行企业家很多拿到大单,H200在中国落地仍无明确说法。紧接着ÿ…...

Nodejs开发者三步接入Taotoken,实现异步聊天补全
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Nodejs开发者三步接入Taotoken,实现异步聊天补全 对于使用Node.js进行开发的工程师来说,无论是构建前端应用…...

Windhawk终极指南:5分钟掌握Windows系统个性化定制
Windhawk终极指南:5分钟掌握Windows系统个性化定制 【免费下载链接】windhawk The customization marketplace for Windows programs: https://windhawk.net/ 项目地址: https://gitcode.com/gh_mirrors/wi/windhawk Windows系统定制一直是许多用户的痛点&am…...