Hadoop与Spark横向比较【大数据扫盲】
大数据场景下的数据库有很多种,每种数据库根据其数据模型、查询语言、一致性模型和分布式架构等特性,都有其特定的使用场景。以下是一些常见的大数据数据库:
-
NoSQL 数据库:这类数据库通常用于处理大规模、非结构化的数据。它们通常提供简单的查询语言,并强调水平扩展和高可用性。例如:
- 键值存储:如 Redis,Amazon DynamoDB
- 列式存储:如 Apache Cassandra,HBase
- 文档数据库:如 MongoDB,CouchDB
- 图数据库:如 Neo4j,Amazon Neptune
-
搜索引擎:这类数据库通常用于全文搜索和日志数据分析。例如 Elasticsearch。
-
时间序列数据库:这类数据库通常用于存储和查询时间序列数据,例如物联网设备的数据。例如 InfluxDB,TimescaleDB。
-
分布式 SQL 数据库:这类数据库试图将 SQL 数据库的丰富功能与 NoSQL 数据库的水平扩展能力相结合。例如 Google Spanner,CockroachDB。
-
大数据计算引擎:虽然它们不是数据库,但这些系统通常用于在大规模数据上执行复杂的分析查询。例如 Apache Hadoop,Apache Spark。
-
内存数据库:这类数据库将所有数据都存储在内存中,以提供极高的读写速度。例如 MemSQL,SAP HANA。
请注意,这里列出的只是一些常见的大数据数据库和大数据处理系统,实际上还有很多其他类型的数据库,它们各有优势,适合不同的使用场景。
Hadoop和Spark有什么区别?
Apache Hadoop 和 Apache Spark 都是大数据处理框架,但它们在设计理念、处理速度、易用性、数据处理方式等方面有一些重要的区别:
-
设计理念:
- Hadoop 是一个分布式数据存储和计算框架,主要由 Hadoop Distributed File System (HDFS) 和 MapReduce 两部分组成。HDFS 提供分布式数据存储,MapReduce 提供分布式数据处理。
- Spark 是一个分布式数据处理框架,设计目标是提供一个快速、通用和易用的大数据计算平台。Spark 不包含自己的文件系统,通常与 HDFS 或其他存储系统(如 Amazon S3)一起使用。
-
处理速度:
- Hadoop 的 MapReduce 在处理大数据时,每个阶段的输出都需要写入磁盘,这会增加 I/O 开销,降低处理速度。
- Spark 利用内存计算,可以将中间处理数据缓存在内存中,避免频繁的磁盘 I/O,因此通常比 Hadoop 快很多。
-
易用性:
- Hadoop 的 MapReduce 需要用户自己编写 Map 和 Reduce 函数,对于复杂的数据处理任务,编程难度较大。
- Spark 提供了丰富的高级 API(如 DataFrame 和 Dataset),并支持 Scala、Java、Python 和 R 语言,使得数据处理任务的编程更加简单。
-
数据处理方式:
- Hadoop 的 MapReduce 只支持批处理,适合大规模、非实时的数据处理任务。
- Spark 不仅支持批处理,还支持流处理(Spark Streaming)、交互式查询(Spark SQL)、机器学习(MLlib)和图计算(GraphX),更加灵活和通用。
-
容错性:
- Hadoop 和 Spark 都支持数据和计算的分布式,具有良好的容错性。但由于 Spark 的内存计算特性,如果节点失败,可能需要从头开始重新计算,而 Hadoop 的 MapReduce 由于每个阶段的结果都保存在磁盘中,因此可能更能容忍节点失败。
总的来说,Hadoop 和 Spark 各有优势,适合不同的使用场景。在选择时,需要根据你的具体需求和环境来决定。
如果只从性能上来说,Hadoop比Spark要快很多吗?
实际上,从性能角度看,Apache Spark 通常比 Apache Hadoop MapReduce 要快很多。这主要是因为 Spark 的设计允许它在内存中执行计算,而 Hadoop MapReduce 在每个阶段都需要将数据写入磁盘,这会导致大量的 I/O 开销。
Spark 的 “Resilient Distributed Datasets” (RDD) 抽象允许它在集群的节点间透明地缓存数据,这对于需要多次迭代的数据分析算法(例如机器学习算法)特别有用,因为这些算法可以在内存中多次读取同一数据,而无需每次都从磁盘加载。
然而,这并不是说 Spark 在所有情况下都比 Hadoop 快。例如,对于非常大的数据集,如果超过了 Spark 可以缓存的内存大小,Spark 可能需要频繁地将数据换出到磁盘,这会降低其性能。在这种情况下,Hadoop MapReduce 的性能可能会更好,因为它的设计更适合处理大规模的磁盘数据。
总的来说,Spark 和 Hadoop 的性能会根据具体的工作负载和数据集大小有所不同,但在大多数情况下,Spark 由于其内存计算的优势,通常会提供更高的性能。
那么hadoop完全没有使用的场景了吗?在同样的场景下spark能够完成的更好,不是么?
虽然 Apache Spark 在许多情况下可能提供更高的性能和更大的灵活性,但这并不意味着 Apache Hadoop 没有存在的价值或者在所有场景下 Spark 都能做得更好。以下是一些 Hadoop 仍然具有优势的情况:
-
大规模数据处理:当处理的数据集非常大,超过了可用内存的大小时,Hadoop MapReduce 的磁盘 I/O 模型可能会比 Spark 提供更好的性能。这是因为 Spark 需要将数据集加载到内存中以实现高速处理,如果数据集太大,Spark 就需要频繁地将数据换出到磁盘,这会降低其性能。
-
成本:Hadoop 通常在廉价的硬件上运行得很好,而 Spark 由于其对内存的高需求,可能需要更高配置(因此更昂贵)的硬件。
-
成熟的生态系统:Hadoop 已经存在了很长时间,拥有成熟的生态系统。许多工具(如 Hive、Pig 等)都是基于 Hadoop 构建的。这些工具已经在许多生产环境中得到了广泛的测试和使用,因此在某些情况下可能比 Spark 更稳定和可靠。
-
数据存储:Hadoop 的分布式文件系统(HDFS)是一个优秀的大规模数据存储解决方案。虽然 Spark 可以与 HDFS 配合使用,但 Spark 本身并不包含文件系统。
因此,虽然 Spark 在许多场景下可能是更好的选择,但在某些情况下,Hadoop 可能仍然是更好的选择。在决定使用哪种工具时,需要考虑你的具体需求,例如数据集的大小、处理速度的需求、可用硬件的配置、预算等因素。
相关文章:

Hadoop与Spark横向比较【大数据扫盲】
大数据场景下的数据库有很多种,每种数据库根据其数据模型、查询语言、一致性模型和分布式架构等特性,都有其特定的使用场景。以下是一些常见的大数据数据库: NoSQL 数据库:这类数据库通常用于处理大规模、非结构化的数据。它们通常…...

软件工程知识梳理5-实现和测试
编码和测试统称为实现。 编码:把软件设计结果翻译成某种程序设计语言书写的程序。是对设计的进一步具体化,是软件工程过程的一个阶段。 测试:单元测试和集成测试,软件测试往往占软件开发总工作量的40%以上。 编码:选…...

WebRTC系列-自定义媒体数据加密
文章目录 1. 对外加密接口2. 对外加密实现前面的文章都有提过WebRTC使用的加密方式是SRTP这个库提供的,这个三方库这里就不做介绍,主要是对rtp包进行加密;自然的其调用也是WebRTC的rtp相关模块;同时在WebRTC里也提供一个自定义加密的接口,本文将围绕这个接口做介绍及分析;…...

golang的sqlite驱动不使用cgo实现 更换gorm默认的SQLite驱动
golang的sqlite驱动不使用cgo实现 更换gorm默认的SQLite驱动 最近在开发一个边缘物联网程序时使用Golang开发,用到GORM来操作SQLite数据库,GORM默认使用gorm.io/driver/sqlite这个库作为SQLite驱动,该库用CGO实现,在使用过程中遇…...

Linux 系统 ubuntu22.04 发行版本 固定 USB 设备端口号
前言: 项目中为了解决 usb 设备屏幕上电顺序导致屏幕偏移、触屏出现偏移等问题。 一、方法1:使用设备 ID 号 步骤: 查看 USB 设备的供应商ID和产品ID Bus 001 Device 003: ID 090c:1000 Silicon Motion, Inc. - Taiwan (formerly Feiya Te…...

Vue - 面试题持续更新
1.Vue路由模式 总共有Hash和History两种模式 Hash模式:在浏览器里面的符号 “#”,以及"#"后面的字符称之为Hash,用window.location.hash读取。 Hash模式的特点:hash是和浏览器对话的,和服务器没有关系&…...
Django的web框架Django Rest_Framework精讲(二)
文章目录 1.自定义校验功能(1)validators(2)局部钩子:单字段校验(3)全局钩子:多字段校验 2.raise_exception 参数3.context参数4.反序列化校验后保存,新增和更新数据&…...

VR视频编辑解决方案,全新视频内容创作方式
随着科技的飞速发展,虚拟现实(VR)技术正逐渐成为各个领域的创新力量。而美摄科技,作为VR技术的引领者,特别推出了一套全新的VR视频编辑方案,为企业提供了一个全新的视频内容创作方式。 美摄科技的VR视频编…...

有趣的CSS - 输入框选中交互动效
页面效果 此效果主要使用 css 伪选择器配合 html5 required 属性来实现一个简单的输入框的交互效果。 此效果可适用于登录页入口、小表单提交等页面,增强用户实时交互体验。 核心代码部分,简要说明了写法思路;完整代码在最后,可直…...

Unknown custom element:<xxx>-did you register the component correctly解决方案
如图所示控制台发现了爆红(大哭): 报错解释: 当我们看到报错时,我们需要看到一些关键词,比如显眼的“component”和“name”这两个单词, 因此我们就从此处切入,大概与组件有关系。…...
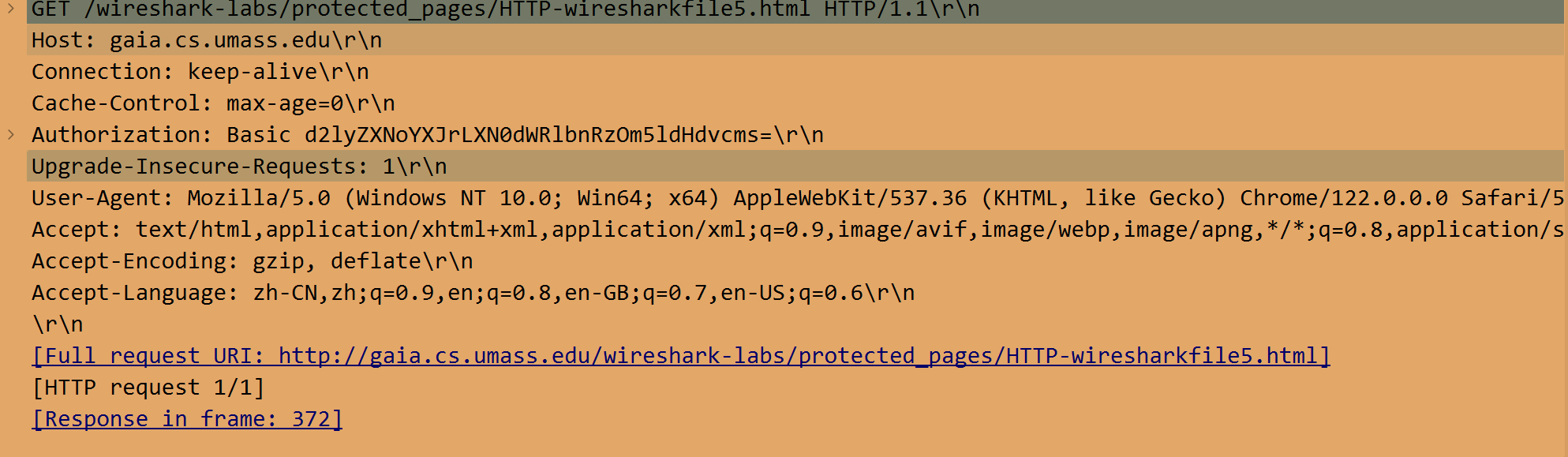
计算机网络自顶向下Wireshark labs-HTTP
我直接翻译并在题目下面直接下我的答案了。 1.基本HTTP GET/response交互 我们开始探索HTTP,方法是下载一个非常简单的HTML文件 非常短,并且不包含嵌入的对象。执行以下操作: 启动您的浏览器。启动Wireshark数据包嗅探器,如Wir…...

解决pandas写入excel时的ValueError: All strings must be XML compatible报错
报错内容: ValueError: All strings must be XML compatible: Unicode or ASCII, no NULL bytes or control characters 报错背景 用pands批量写入excel文件,发生编码报错。检索了很多方案,都不能解决。 导致报错的原因是存在违法字符&…...

华为手表应用APP开发:watch系列 GT系列 1.配置调试设备
表开发:GT3(1)配置调试设备 初环境与设备获取手表UUID登录 AppGallery Connect 点击用户与访问初 希望能写一些简单的教程和案例分享给需要的人 鸿蒙可穿戴开发 支持外包开发:xkk9866@yeah.net 环境与设备 系统:window 设备:HUAWEI WATCH 3 Pro 开发工具:DevEco St…...
Vue(十九):ElementUI 扩展实现树形结构表格组件的勾父选子、半勾选、过滤出半勾选节点功能
效果 原理分析 从后端获取数据后,判断当前节点是否勾选,从而判断是否勾选子节点勾选当前节点时,子节点均勾选全勾选与半勾选与不勾选的样式处理全勾选和全取消勾选的逻辑筛选出半勾选的节点定义变量 import {computed, nextTick, reactive, ref} from vue; import {tree} f…...
SpringBoot RestTemplate 设置挡板
项目结构 代码 BaffleConfig /*** Description 记录配置信息* Author wjx* Date 2024/2/1 14:47**/ public interface BaffleConfig {// 是否开启挡板的开关public static boolean SWITCH true;// 文件根目录public static String ROOT_PATH "D:\\TIS\\mock";// …...
arcgis javascript api4.x加载非公开或者私有的arcgis地图服务
需求: 加载arcgis没有公开或者私有的地图服务,同时还想实现加载时不弹出登录窗口 提示: 下述是针对独立的arcgis server,没有portal的应用场景; 如果有portal可以参考链接:https://mp.weixin.qq.com/s/W…...
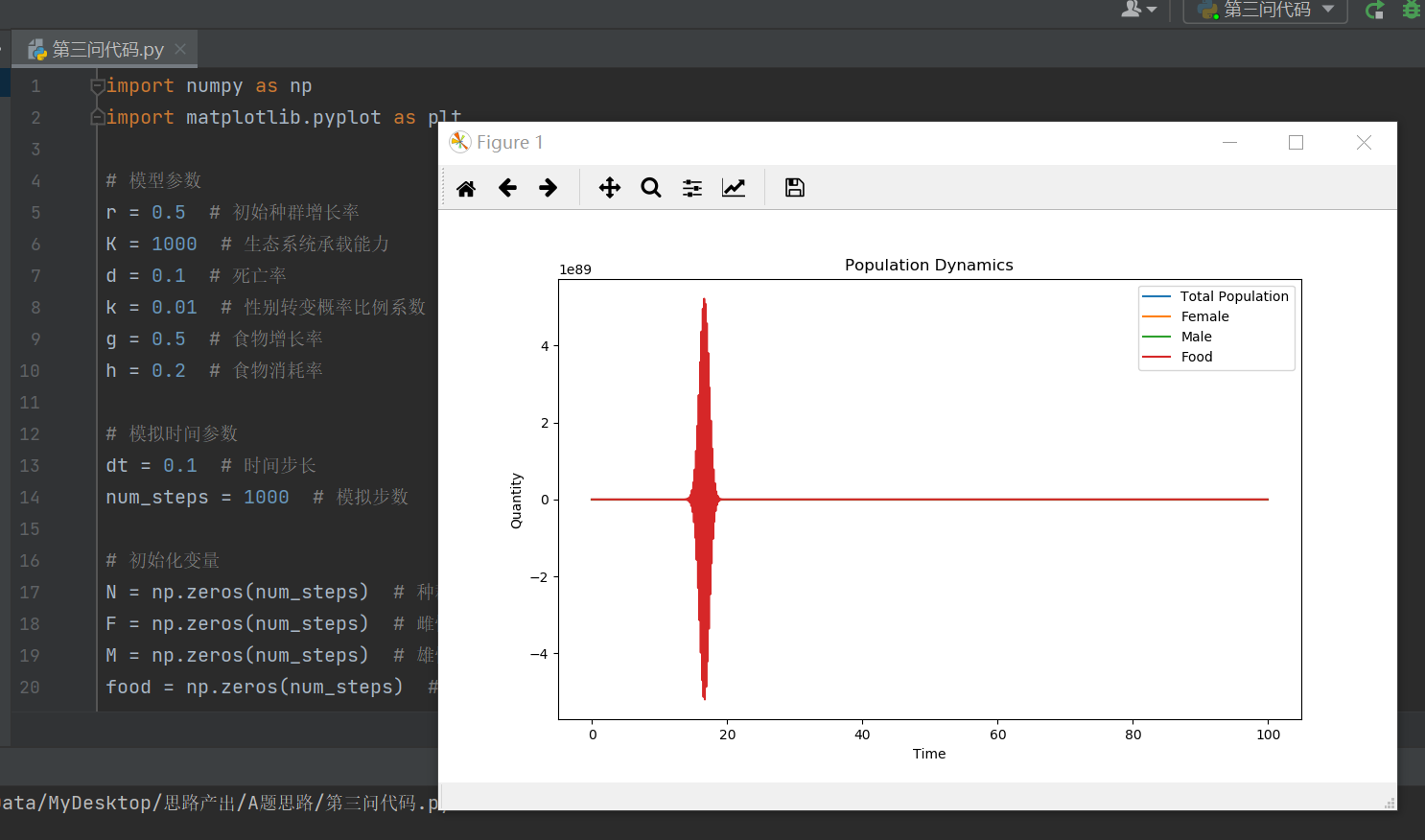
2024年美赛数学建模A题思路分析 - 资源可用性和性别比例
# 1 赛题 问题A:资源可用性和性别比例 虽然一些动物物种存在于通常的雄性或雌性性别之外,但大多数物种实质上是雄性或雌性。虽然许多物种在出生时的性别比例为1:1,但其他物种的性别比例并不均匀。这被称为适应性性别比例的变化。…...

UDP和TCP的区别和联系
传输层:定义传输数据的协议端口号,以及流控和差错校验。 协议有:TCP、UDP等 UDP和TCP的主要区别包括以下几个方面: 1、连接性与无连接性:TCP是面向连接的传输控制协议,而UDP提供无连接的数据报服务。这意…...
delete、truncate和drop区别
一、从执行速度上来说 drop > truncate >> DELETE 二、从原理上讲 1、DELETE DELETE from TABLE_NAME where xxx1.1、DELETE属于数据库DML操作语言,只删除数据不删除表的结构,会走事务,执行时会触发trigger( 触发器…...

946. 验证栈序列
946. 验证栈序列 描述 : 给定 pushed 和 popped 两个序列,每个序列中的 值都不重复,只有当它们可能是在最初空栈上进行的推入 push 和弹出 pop 操作序列的结果时,返回 true;否则,返回 false 。 题目 : LeetCode 94…...

从“看见光点”到“看懂世界”:视觉重建让这个世界变得更近一些
三十多年前,“让盲人重新看见”更像一句带有未来感的科学想象。而今天,这件事已经进入临床试验和真实的人体研究。视觉重建之所以被视为脑机接口里最具挑战性的方向之一,不只是因为它要解决“能不能刺激大脑”的问题,更因为它要回…...

避坑指南:Windows系统下WampServer2.2e与MySQL5.5.24的完美兼容配置
避坑指南:Windows系统下WampServer2.2e与MySQL5.5.24的完美兼容配置 在本地开发环境中,WampServer因其便捷的一键式部署深受开发者喜爱。但当系统已存在其他MySQL服务时,端口冲突问题往往让新手束手无策。本文将深入解决WampServer2.2e与既有…...

FRCRN处理长音频文件实战:切片、批处理与结果合并
FRCRN处理长音频文件实战:切片、批处理与结果合并 你是不是遇到过这样的问题?手头有一段长达数小时的会议录音、访谈素材或者播客音频,背景噪音让人头疼,想用FRCRN这样的降噪模型处理一下,结果发现模型一次只能处理几…...

FastAPI日志配置终极指南:10个简单步骤实现生产级日志管理
FastAPI日志配置终极指南:10个简单步骤实现生产级日志管理 【免费下载链接】fastapi FastAPI framework, high performance, easy to learn, fast to code, ready for production 项目地址: https://gitcode.com/GitHub_Trending/fa/fastapi FastAPI作为现代…...

嵌入式系统中的累加和校验算法原理与实现
1. 累加和校验算法概述在嵌入式系统开发中,数据通信的可靠性至关重要。想象一下,当你通过无线模块控制一台工业机器人时,如果传输的运动指令数据出现错误,可能导致机械臂做出完全不可预测的动作,轻则损坏产品ÿ…...

从Java到AI Agent:传统后端工程师的下一站,不是学AI,是成为系统工程师!
文章探讨了在AI技术发展的背景下,传统后端工程师的转型方向。作者认为,未来的竞争焦点不再是单纯的技术能力,而是如何将AI技术融入现有系统,构建自动化系统。文章提出了AI Agent工程师的概念,强调系统工程能力的重要性…...

新手零障碍入门:在免激活的快马平台完成你的第一个Python小游戏
作为一个刚接触编程的新手,我最近在InsCode(快马)平台上完成了人生第一个Python小游戏——猜数字。整个过程比想象中简单得多,特别适合像我这样零基础的小白入门。下面分享我的学习笔记,希望能帮到同样想尝试编程的朋友。 为什么选择猜数字游…...

3步搞定B站4K视频下载:开源工具bilibili-downloader终极指南
3步搞定B站4K视频下载:开源工具bilibili-downloader终极指南 【免费下载链接】bilibili-downloader B站视频下载,支持下载大会员清晰度4K,持续更新中 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-downloader 想要免费下载…...

英雄联盟ChampR助手:5分钟快速上手,轻松获取专业出装符文
英雄联盟ChampR助手:5分钟快速上手,轻松获取专业出装符文 【免费下载链接】champ-r 🐶 Yet another League of Legends helper 项目地址: https://gitcode.com/gh_mirrors/ch/champ-r 还在为每次游戏都要手动查找英雄出装和符文而烦恼…...

分组网络频率同步互通测试
概述随着3G/4G网络大规模的部署和应用,网络和业务的全IP化发展,分组传送技术将替代SDH/MSTP网络而成为主流的传送承载网络。这时,一方面新的传送网络技术会对网络的同步性能提出相应的要求,另一方面在通信网络由电路交换型向分组交…...