TensorFlow2实战-系列教程11:RNN文本分类3
🧡💛💚TensorFlow2实战-系列教程 总目录
有任何问题欢迎在下面留言
本篇文章的代码运行界面均在Jupyter Notebook中进行
本篇文章配套的代码资源已经上传
6、构建训练数据
- 所有的输入样本必须都是相同shape(文本长度,词向量维度等)
- tf.data.Dataset.from_tensor_slices(tensor):将tensor沿其第一个维度切片,返回一个含有N个样本的数据集,这样做的问题就是需要将整个数据集整体传入,然后切片建立数据集类对象,比较占内存。
- tf.data.Dataset.from_generator(data_generator,output_data_type,output_data_shape):从一个生成器中不断读取样本
def data_generator(f_path, params):with open(f_path,encoding='utf-8') as f:print('Reading', f_path)for line in f:line = line.rstrip()label, text = line.split('\t')text = text.split(' ')x = [params['word2idx'].get(w, len(word2idx)) for w in text]#得到当前词所对应的IDif len(x) >= params['max_len']:#截断操作x = x[:params['max_len']]else:x += [0] * (params['max_len'] - len(x))#补齐操作y = int(label)yield x, y
- 定义一个生成器函数,传进来读数据的路径、和一些有限制的参数,params 在是一个字典,它包含了最大序列长度(max_len)、词到索引的映射(word2idx)等关键信息
- 打开文件
- 打印文件路径
- 遍历每行数据
- 获取标签和文本
- 文本按照空格分离出单词
- 获取当前句子的所有词对应的索引,for w in text取出这个句子的每一个单词,[params[‘word2idx’]取出params中对应的word2idx字典,.get(w, len(word2idx))从word2idx字典中取出该单词对应的索引,如果有这个索引则返回这个索引,如果没有则返回len(word2idx)作为索引,这个索引表示unknow
- 如果当前句子大于预设的最大句子长度
- 进行截断操作
- 如果小于
- 补充0
- 标签从str转换为int类型
- yield 关键字:用于从一个函数返回一个生成器(generator)。与 return 不同,yield 不会退出函数,而是将函数暂时挂起,保存当前的状态,当生成器再次被调用时,函数会从上次 yield 的地方继续执行,使用 yield 的函数可以在处理大数据集时节省内存,因为它允许逐个生成和处理数据,而不是一次性加载整个数据集到内存中
也就是说yield 会从上一次取得地方再接着去取数据,而return却不会
def dataset(is_training, params):_shapes = ([params['max_len']], ())_types = (tf.int32, tf.int32)if is_training:ds = tf.data.Dataset.from_generator(lambda: data_generator(params['train_path'], params),output_shapes = _shapes,output_types = _types,)ds = ds.shuffle(params['num_samples'])ds = ds.batch(params['batch_size'])ds = ds.prefetch(tf.data.experimental.AUTOTUNE)else:ds = tf.data.Dataset.from_generator(lambda: data_generator(params['test_path'], params),output_shapes = _shapes,output_types = _types,)ds = ds.batch(params['batch_size'])ds = ds.prefetch(tf.data.experimental.AUTOTUNE)return ds
- 定义一个制作数据集的函数,is_training表示是否是训练,这个函数在验证和测试也会使用,训练的时候设置为True,验证和测试为False
- 当前shape值
- 1
- 是否在训练,如果是:
- 构建一个Dataset
- 传进我们刚刚定义的生成器函数,并且传进实际的路径和配置参数
- 输出的shape值
- 输出的类型
- 指定shuffle
- 指定 batch_size
- 设置缓存序列,根据可用的CPU动态设置并行调用的数量,说白了就是加速
- 如果不是在训练,则:
- 验证和测试不同的就是路径不同,以及没有shuffle操作,其他都一样
- 最后把做好的Datasets返回回去
7、自定义网络模型
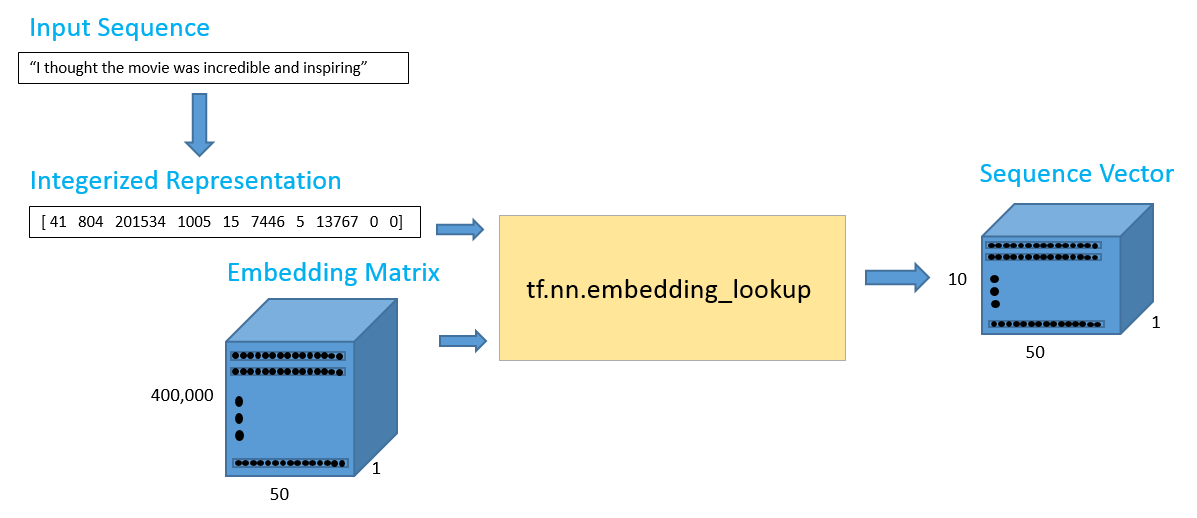
一条文本变成一组向量/矩阵的基本流程:
- 拿到一个英文句子
- 通过查语料表将句子变成一组索引
- 通过词嵌入表结合索引将每个单词都变成一组向量,一条句子就变成了一个矩阵,这就是特征了


BiLSTM即双向LSTM,就是在原本的LSTM增加了一个从后往前走的模块,这样前向和反向两个方向都各自生成了一组特征,把两个特征拼接起来得到一组新的特征,得到翻倍的特征。其他前面和后续的处理操作都是一样的。
class Model(tf.keras.Model):def __init__(self, params):super().__init__()self.embedding = tf.Variable(np.load('./vocab/word.npy'), dtype=tf.float32, name='pretrained_embedding', trainable=False,)self.drop1 = tf.keras.layers.Dropout(params['dropout_rate'])self.drop2 = tf.keras.layers.Dropout(params['dropout_rate'])self.drop3 = tf.keras.layers.Dropout(params['dropout_rate'])self.rnn1 = tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(params['rnn_units'], return_sequences=True))self.rnn2 = tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(params['rnn_units'], return_sequences=True))self.rnn3 = tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(params['rnn_units'], return_sequences=False))self.drop_fc = tf.keras.layers.Dropout(params['dropout_rate'])self.fc = tf.keras.layers.Dense(2*params['rnn_units'], tf.nn.elu)self.out_linear = tf.keras.layers.Dense(2) def call(self, inputs, training=False):if inputs.dtype != tf.int32:inputs = tf.cast(inputs, tf.int32)batch_sz = tf.shape(inputs)[0]rnn_units = 2*params['rnn_units']x = tf.nn.embedding_lookup(self.embedding, inputs) x = self.drop1(x, training=training)x = self.rnn1(x)x = self.drop2(x, training=training)x = self.rnn2(x)x = self.drop3(x, training=training)x = self.rnn3(x)x = self.drop_fc(x, training=training)x = self.fc(x)x = self.out_linear(x)return x
- 自定义一个模型,继承tf.keras.Model模块
- 初始化函数
- 初始化
- 词嵌入,把之前保存好的词嵌入文件向量读进来
- 定义一层dropout1
- 定义一层dropout2
- 定义一层dropout3
- 定义一个rnn1,rnn_units表示得到多少维的特征,return_sequences表示是返回一个序列还是最后一个输出
- 定义一个rnn2,最后一层的rnn肯定只需要最后一个输出,前后两个rnn的堆叠肯定需要返回一个序列
- 定义一个rnn3 ,tf.keras.layers.LSTM()直接就可以定义一个LSTM,在外面再封装一层API:tf.keras.layers.Bidirectional就实现了双向LSTM
- 定义全连接层的dropout
- 定义一个全连接层,因为是双向的,这里就需要把参数乘以2
- 定义最后输出的全连接层,只需要得到是正例还是负例,所以是2
- 定义前向传播函数,传进来一个batch的数据和是否是在训练
- 如果输入数据不是tf.int32类型
- 转换成tf.int32类型
- 取出batch_size
- 设置LSTM神经元个数,双向乘以2
- 使用 TensorFlow 的 embedding_lookup 函数将输入的整数索引转换为词向量
- 数据通过第1个 Dropout 层
- 数据通过第1个rnn
- 数据通过第2个 Dropout 层
- 数据通过第2个rnn
- 数据通过第3个 Dropout 层
- 数据通过第3个rnn
- 经过全连接层对应的Dropout
- 数据通过一个全连接层
- 最后,数据通过一个输出层
- 返回最终的模型输出
相关文章:
TensorFlow2实战-系列教程11:RNN文本分类3
🧡💛💚TensorFlow2实战-系列教程 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在Jupyter Notebook中进行 本篇文章配套的代码资源已经上传 6、构建训练数据 所有的输入样本必须都是相同shape(文本长度,…...

故障诊断 | 一文解决,RF随机森林的故障诊断(Matlab)
效果一览 文章概述 故障诊断 | 一文解决,RF随机森林的故障诊断(Matlab) 模型描述 随机森林(Random Forest)是一种集成学习(Ensemble Learning)方法,常用于解决分类和回归问题。它由多个决策树组成,每个决策树都独立地对数据进行训练,并且最终的预测结果是由所有决策…...

DAO设计模式
概念:DAO(Data Access Object) 数据库访问对象,**面向数据库SQL操作**的封装。 (一)场景 问题分析 在实际开发中,针对一张表的复杂业务功能通常需要和表交互多次(比如转账)。如果每次针对表的…...

【Midjourney】新手指南:参数设置
1.--aspect 或 --ar 用于设置图片长宽比,例如 --ar 16:9就是设置图片宽为16,高为9 2.--chaos 用于设置躁点,噪点值越高随机性越大,取值为0到100,例如 --chaos 50 3.--turbo 覆盖seetings的设置并启用极速模式生成…...

阿里云a10GPU,centos7,cuda11.2环境配置
Anaconda3-2022.05-Linux-x86_64.sh gcc升级 centos7升级gcc至8.2_centos7 yum gcc8.2.0-CSDN博客 paddlepaddle python -m pip install paddlepaddle-gpu2.5.1.post112 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html 报错 ImportError: libssl.so…...
RTSP/Onvif协议视频平台EasyNVR激活码授权异常该如何解决
TSINGSEE青犀视频安防监控平台EasyNVR可支持设备通过RTSP/Onvif协议接入,并能对接入的视频流进行处理与多端分发,包括RTSP、RTMP、HTTP-FLV、WS-FLV、HLS、WebRTC等多种格式。在智慧安防等视频监控场景中,EasyNVR可提供视频实时监控直播、云端…...

React16源码: React中event事件对象的创建过程源码实现
event 对象 1 ) 概述 在生产事件对象的过程当中,要去调用每一个 possiblePlugin.extractEvents 方法现在单独看下这里面的细节过程,即如何去生产这个事件对象的过程 2 )源码 定位到 packages/events/EventPluginHub.js#L172 f…...
深度学习(12)--Mnist分类任务
一.Mnist分类任务流程详解 1.1.引入数据集 Mnist数据集是官方的数据集,比较特殊,可以直接通过%matplotlib inline自动下载,博主此处已经完成下载,从本地文件中引入数据集。 设置数据路径 from pathlib import Path# 设置数据路…...

AI工具【OCR 01】Java可使用的OCR工具Tess4J使用举例(身份证信息识别核心代码及信息提取方法分享)
Java可使用的OCR工具Tess4J使用举例 1.简介1.1 简单介绍1.2 官方说明 2.使用举例2.1 依赖及语言数据包2.2 核心代码2.3 识别身份证信息2.3.1 核心代码2.3.2 截取指定字符2.3.3 去掉字符串里的非中文字符2.3.4 提取出生日期(待优化)2.3.5 实测 3.总结 1.简…...

【MySQL复制】半同步复制
介绍 除了内置的异步复制之外,MySQL 5.7 还支持通过插件实现的半同步复制接口。本节讨论半同步复制的概念及其工作原理。接下来的部分将涵盖与半同步复制相关的管理界面,以及如何安装、配置和监控它。 异步复制 MySQL 复制默认是异步的。源服务器将事…...

PHP面试知识点--echo、print、print_r、var_dump区别
echo、print、print_r、var_dump 区别 echo 输出单个或多个字符,多个使用逗号分隔无返回值 echo "String 1", "String 2";print 只可以输出单个字符返回1,因此可用于表达式 print "Hello"; if ($expr && pri…...
centos 7 部署若依前后端分离项目
目录 一、新建数据库 二、修改需求配置 1.修改数据库连接 2.修改Redis连接信息 3.文件路径 4.日志存储路径调整 三、编译后端项目 四、编译前端项目 1.上传项目 2.安装依赖 3.构建生产环境 五、项目部署 1.创建目录 2.后端文件上传 3. 前端文件上传 六、服务启…...

RFID手持终端_智能pda手持终端设备定制方案
手持终端是一款多功能、适用范围广泛的安卓产品,具有高性能、大容量存储、高端扫描头和全网通数据连接能力。它能够快速平稳地运行,并提供稳定的连接表现和快速的响应时,适用于医院、物流运输、零售配送、资产盘点等苛刻的环境。通过快速采集…...

51单片机学习——矩阵按键
目录 gitee链接 小程吃饭饭 (xiaocheng-has-a-meal) - Gitee.comhttps://gitee.com/xiaocheng-has-a-meal 1.图~突突突突突 矩阵键盘原理图 矩阵键盘的实物图 2.矩阵键盘 引入~啦啦啦啦啦 原理~沥沥沥沥沥 代码~嗷嗷嗷嗷嗷 【1】延时函数 【2】 LCD1602 【3】检测按…...

重写Sylar基于协程的服务器(1、日志模块的架构)
重写Sylar基于协程的服务器(1、日志模块的架构) 重写Sylar基于协程的服务器系列: 重写Sylar基于协程的服务器(0、搭建开发环境以及项目框架 || 下载编译简化版Sylar) 重写Sylar基于协程的服务器(1、日志模…...

ElementUI Form:Radio 单选框
ElementUI安装与使用指南 Radio 单选框 点击下载learnelementuispringboot项目源码 效果图 el-radio.vue (Radio 单选框)页面效果图 项目里el-radio.vue代码 <script> export default {name: el_radio,data() {return {radio: 1,radio2: 2,ra…...

react-activation实现缓存,且部分页面刷新缓存,清除缓存
1.安装依赖 npm i -S react-activation2.使用AliveScope 包裹根组件 import { AliveScope } from "react-activation" <AliveScope><Router><Switch><Route exact path"/" render{() > <Redirect to"/login" push …...
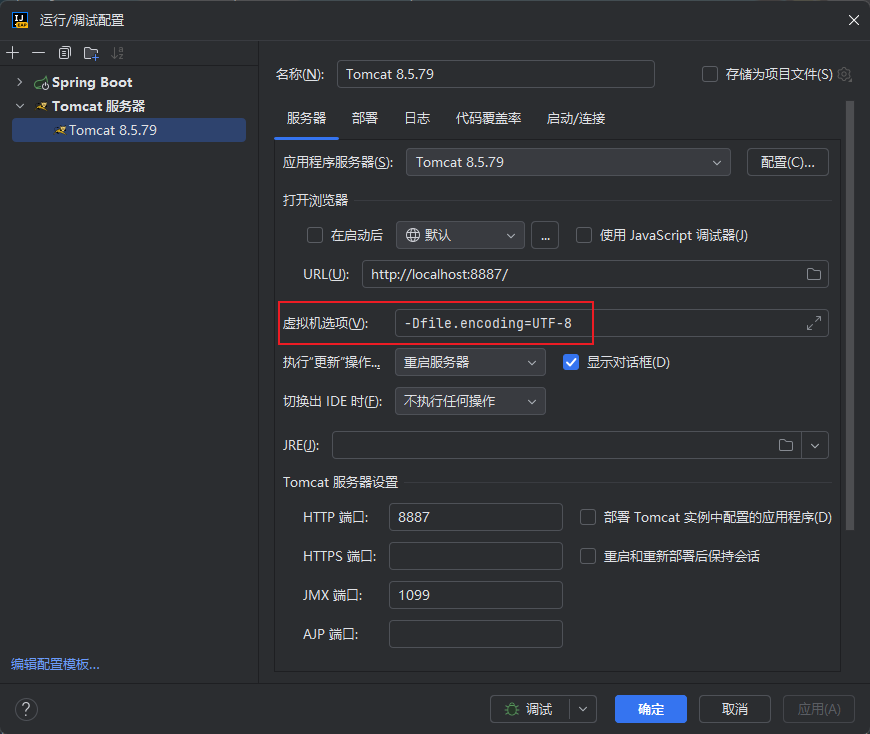
idea 中 tomcat 乱码问题修复
之前是修改 Tomcat 目录下 conf/logging.properties 的配置,将 UTF-8 修改为 GBK,现在发现不用这样修改了。只需要修改 IDEA 中 Tomcat 的配置就可以了。 修改IDEA中Tomcat的配置:添加-Dfile.encodingUTF-8 本文结束...

Modbus协议学习第七篇之libmodbus库API介绍(modbus_write_bits等)
写在前面 在第六篇中我们介绍了基于libmodbus库的演示代码,那本篇博客就详细介绍一下第六篇的代码中使用的基于该库的API函数。另各位读者,Modbus相关知识受众较少,如果觉得我的专栏文章有帮助,请一定点个赞,在此跪谢&…...

第九节HarmonyOS 常用基础组件13-TimePicker
1、描述 时间选择组件,根据指定参数创建选择器,支持选择小时以及分钟。默认以24小时的时间区间创建滑动选择器。 2、接口 TimePicker(options?: {selected?: Date}) 3、参数 selected - Date - 设置选中项的时间。默认是系统当前的时间。 4、属性…...

告别复杂配置!用SGLang+Docker轻松部署bge-large-zh-v1.5
告别复杂配置!用SGLangDocker轻松部署bge-large-zh-v1.5 1. 为什么选择bge-large-zh-v1.5 bge-large-zh-v1.5是目前中文语义理解领域表现最优秀的嵌入模型之一。它能将任意长度的中文文本转换为1024维的高质量向量表示,这些向量能够精准捕捉文本的深层…...

抖音风控参数‘bd-ticket-guard-client-data’深度解析:从X.509证书到请求签名的完整链路
抖音风控参数‘bd-ticket-guard-client-data’的技术内幕:从证书链到请求签名的安全架构 在移动互联网时代,平台风控系统如同数字世界的免疫系统,而bd-ticket-guard-client-data这类参数就是其识别"自我"与"非我"的关键标…...

快速入门:5步掌握OCR文字识别镜像,轻松提取图片文字
快速入门:5步掌握OCR文字识别镜像,轻松提取图片文字 1. 为什么选择这个OCR镜像 在日常工作和生活中,我们经常遇到需要从图片中提取文字的场景:扫描的文档、手机拍摄的发票、路牌标识等。传统手动输入不仅效率低下,还…...

Qwen3-TTS-Tokenizer-12Hz生产环境应用:高并发音频编解码服务架构
Qwen3-TTS-Tokenizer-12Hz生产环境应用:高并发音频编解码服务架构 1. 引言:音频编解码的技术挑战与解决方案 在现代语音应用中,音频数据的处理和传输一直是个头疼的问题。你想啊,一段普通的语音文件,动辄就是几MB甚至…...

OFA图像描述新手入门:无需代码基础,快速搭建图像描述AI
OFA图像描述新手入门:无需代码基础,快速搭建图像描述AI 1. 什么是OFA图像描述系统? 想象一下,你拍了一张照片,系统能自动为你写出照片里有什么、发生了什么——这就是OFA图像描述系统能做的事情。这个AI工具特别适合…...

HappyHorse-1.0空降榜首碾压Seedance 2.0:60分断层领先,开源可商用,音视频联合生成新王诞生!
文章目录引言第1章:榜单屠榜,数据说话1.1 Artificial Analysis 榜单成绩1.2 为什么60分的差距如此恐怖?1.3 唯一短板:音频赛道第2章:技术亮点详解2.1 核心参数:150亿参数的庞然大物2.2 音视频联合生成&…...

JS中彻底删除JSON对象组成的数组中的元素
在 JS 中,对于某个由 JSON 对象组成的数组,例如:var test [{ "a": "1", "b": "2" }, { "a": "3", "b": "4" }, { "a": "5", "b…...

HelloWord-Keyboard固件编程完全指南:从零掌握机械键盘定制开发
HelloWord-Keyboard固件编程完全指南:从零掌握机械键盘定制开发 【免费下载链接】HelloWord-Keyboard 项目地址: https://gitcode.com/gh_mirrors/he/HelloWord-Keyboard 想要打造属于自己的智能机械键盘吗?HelloWord-Keyboard项目为你提供了一个…...

从零到一:在CentOS 8上构建LNMP环境并部署WordPress实战
1. 环境准备与基础配置 在开始搭建LNMP环境之前,我们需要确保CentOS 8系统处于最佳状态。我建议使用全新的系统环境,这样可以避免各种依赖冲突问题。首先通过SSH连接到服务器,使用dnf update命令更新所有系统软件包。这个步骤很重要ÿ…...

软考机考绘图技巧与实战指南
1. 软考机考绘图工具基础操作 第一次参加软考机考的朋友们,最头疼的莫过于绘图题了。我当年第一次考试时,看到屏幕上密密麻麻的绘图工具,手指在键盘上悬了半天都不知道该点哪个按钮。后来经过多次实战,总结出一套快速上手的方法。…...