ElasticSearch搜索与分析引擎-Linux离线环境安装教程
目录
一、下载安装包
网盘链接:
二、安装流程及遇到的问题和解决方案
(1)JDK安装
(2)Elasticsearch安装
(3)Kibana安装
(4)Ik分词器安装
三、启动过程中的问题
(1)日志输出
(2)日志一直输出
(3)告警日志
(4)设置密码
(5)failed to authencated user [xxxx]
(6)Es和Kibana启动停止命令
一、下载安装包
Jdk官网:Java Downloads | OracleEs+Kibana官网:Download Elasticsearch | ElasticIk分词器:https://github.com/medcl/elasticsearch-analysis-ik网盘链接:
Es链接: https://pan.baidu.com/s/1u4a_3w_2271jkdbgoD9pXg 提取码: 865r
Kibana链接: https://pan.baidu.com/s/1pwBk5gIjgegzFg4eAOPoew 提取码: 7zz4
Ik分词器链接: https://pan.baidu.com/s/10wK4TOfGJsAItRoewQPN0Q 提取码: 3gzx
JDK11链接: https://pan.baidu.com/s/1m1IpkF6ResRyb1WQveeZJQ 提取码: bwk8 二、安装流程及遇到的问题和解决方案
(1)JDK安装
(1)将下载好的jdk安装包放到/usr/local/java目录下,解压缩:tar -zxvf jdk-11.0.22_linux-x64_bin.tar.gz(2)修改环境变量配置文件:vim /etc/profileexport JAVA_HOME=/usr/local/java/jdk-11.0.22 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH(3)保存:source /etc/profile(4)查看是否安装成功:java -versionPS : JDK这个安装过程,可装可不装,Es有自己封装好的jdk。

(2)Elasticsearch安装
(2.1) 将下载好的安装包,放到服务器上,例如:/app/elastic目录下,然后解压缩:tar -zxvf elasticsearch-7.16.3-linux-x86_64.tar.gz(2.2)进入elasticsearch目录下,再进入config目录,编辑配置文件:vim elasticsearch.yml,修改好配置文件后,wq保存并退出#设置集群名和节点名cluster.name: my-esnode.name: node-1#控制节点是否允许从单个目录启动多个实例。这个参数的目的是防止多个节点共享相同的数据路径,以 #防止数据丢失node.max_local_storage_nodes: 256#设置es的data和log目录,data和log目录如果不存在,可以自己创建,然后制定对应的路径path.data: /app/es/es-test/datapath.logs: /app/es/es-test/logs#es启动时,会检测是否有内存锁定的配置,不开启时,启动日志中可能会报错,打开注释后,同步需要 #更改一些系统文件的配置项bootstrap.memory_lock: true#设置对外可访问的地址及端口号network.host: 0.0.0.0http.port: 9200#开启集群模式时,需要指定一个初始化的主节点cluster.initial_master_nodes: ["node-1"]#设置用户名和密码,具体设置请看(三-4)xpack.security.enabled: truexpack.security.enrollment.enabled: true#离线环境,需要将该配置项设为false,这样不会默认去官网更新ingest.geoip.downloader.enabled: false(2.3)启动es,进入bin目录,执行:./elasticsearch安装Es的时候,会有以下几个常见的问题:
(p1)can not run elasticsearch as root
[2023-01-31T17:42:42,296][WARN ][o.e.b.ElasticsearchUncaughtExceptionHandler] [] uncaught exception in thread [main]
org.elasticsearch.bootstrap.StartupException: java.lang.RuntimeException:can not run elasticsearch as root(S1)更换一个普通用户
Es出于系统安全设置考虑,不允许root用户启动实例,需要创建一个普通用户# 新建用户组和密码
1. groupadd elsearch#用户组useradd elsearch#普通用户 -g elsearch#用户组 -p elasticsearch#用户密码# 授予普通用户权限
2.chown -R elsearch:elsearch elasticsearch#Es目录# 切换到elsearch用户
3.su elsearch# 启动es
4. cd /bin./elasticsearch# 查看是否启动成功
5. 服务器请求:curl http://ip:9200浏览器请求:http://ip:9200
若启动成功,可以看到es版本号等信息
(p2)bootstrap checks failed
ERROR: [3] bootstrap checks failed
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
[2]: max number of threads [3780] for user [es] is too low, increase to at least [4096]
[3]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
[2018-12-12T21:54:57,353][INFO ][o.e.n.Node ] [PlbSkhz] stopping ...
[2018-12-12T21:54:57,413][INFO ][o.e.n.Node ] [PlbSkhz] stopped
[2018-12-12T21:54:57,413][INFO ][o.e.n.Node ] [PlbSkhz] closing ...
[2018-12-12T21:54:57,473][INFO ][o.e.n.Node ] [PlbSkhz] closed
[2018-12-12T21:54:57,488][INFO ][o.e.x.m.j.p.NativeController] [PlbSkhz] Native controller process has stopped - no new native processes can be started(S2)修改系统文件中的部分配置项
如果非root用户创建es的话,普通用户就需要root授予sudo权限,用于修改一些系统文件的配置。#查询当前用户是否有sudo权限
sudo cat /etc/sudoers# max virtual memory areas vm.max_map_count [65530] is too low,increase to at least 262144]
修改命令:打开文件:sudo vi /etc/sysctl.conf 添加内容:vm.max_map_count = 262144保存修改:sysctl -p# max file descriptors [4096] for elastic process is too low,increase to at least [65536]
修改命令:打开文件:sudo vi /etc/security/limits.conf添加内容:* soft nofile 65536* hard nofile 65536* soft nproc 65536* hard nproc 65536* soft memlock unlimited* hard memlock unlimited# es默认的内存大小可能需要手动修改,如果启动日志中有告警提示的话,可以酌情修改参数值
修改命令:打开文件:vi /es/config/jvm.options修改内容:-Xms 2g-Xmx 2g(P3)es自7.x之后,都有自带的jdk环境,如果安装版本和服务器本机jdk版本不符,可以使用es自带的jdk。
(S3)如图

(P4)安装ik重启后报错
# org.elasticsearch.bootstrap.StartupException: java.lang.IllegalStateException: failed to obtain node locks,tried [[/data/elasticsearch/data/elasticsearch]] with lock id [0]; maybe these locations are not writable or multiple nodes were started without increasing [node.max_local_storage_nodes] (was [1])?(S4)解决方案,设置节点数
# 打开config/elasticsearch.yml添加内容:node.max_local_storage_nodes: 256保存,重启es (3)Kibana安装
(3.1)上传Kibana安装包,解压缩,tar -zxvf kibana-7.16.3-linux-x86_64.tar.gz(3.2)进入config目录,修改配置信息# 指定kibana访问主机地址和端口号server.host: "localhost"server.port: 5601# 关联的es实例地址elasticsearch.hosts: ["http://localhost:9200"]# 关联的es的用户名和密码elasticsearch.username: "kibana_system"elasticsearch.password: "pass"# 设置Kibana的日志存储路径logging.dest: /var/logs/kibana.log#Kibana汉化i18n.locale: "zh-CN"#以下设置为8.12版本的格式#logging.root.level: debug#logging.appenders.default:# type: file# fileName: /var/logs/kibana.log# layout:# type: json(3.3)wq保存退出,进入bin目录,启动实例命令:./kibana & #后台启动(3.4)启动成功,浏览器输入:http://ip:5601 查看是否成功
 (4)Ik分词器安装
(4)Ik分词器安装
(4.1)Ik分词器是zip包,如果机器上没有zip相关命令,需要先安装一下在线:yum -y install unzip离线:下载unzip离线包-unzip-6.0-19.el7.x86_64.rpm,放入指定目录,并执行以下命令安装:rpm -Uvh unzip-6.0-19.el7.x86_64.rpm 安装成功后,输出rpm -qa | grep unzip 查看是否安装成功(4.2)对Ik安装包解压缩后,将其移动到/elasticsearch/plugins目录下,重启esIk分词器有两种分词粒度,分别是“粗粒度-ik_max_word”和“细粒度-ik_smart ”,elastic也有自己的分词策略-standard,三种测试情况如下:



三、启动过程中的问题
Kibana启动时遇到的错误:
(1)日志输出

(2)日志一直输出
如果Kibana启动后,日志一直如下图所示,在不停地输出info信息,其中可能会夹杂着一些warning信息,这些其实目前我并没有弄清楚它具体的原因。但是现在有两种方法,可以解决日志一直输出的问题。(2.1)在kibana.yml文件中,将以下注释掉的选项,打开并修改:logging.quiet: ture
该配置项设为true时,日志文件中就只会输出error级别的日志。(2.2)对Es和Kibana设置密码,具体设置流程见(3).在一直输出的日志里,会看到部分warning信息,具体如下图2,告警信息主要是说明,如果es未设置用户名和密码,可能会导致任何人都可以访问你的es实例,不安全,系统就会一直提示设置用户名和密码。设置了密码并重启机器之后,日志确实不会一直输出了,我理解的话是因为,Kibana不再一致刷新es的监控状态了,所以就不会一直发请求,日志自然就不再一直输出了,等一定的时间间隔才会有新的日志输出。!!!!如果有哪位大佬知道,Kibana启动后,一直有日志输出的这个问题的原因,劳烦帮忙给解释一下,万分感谢!!!!!!!!


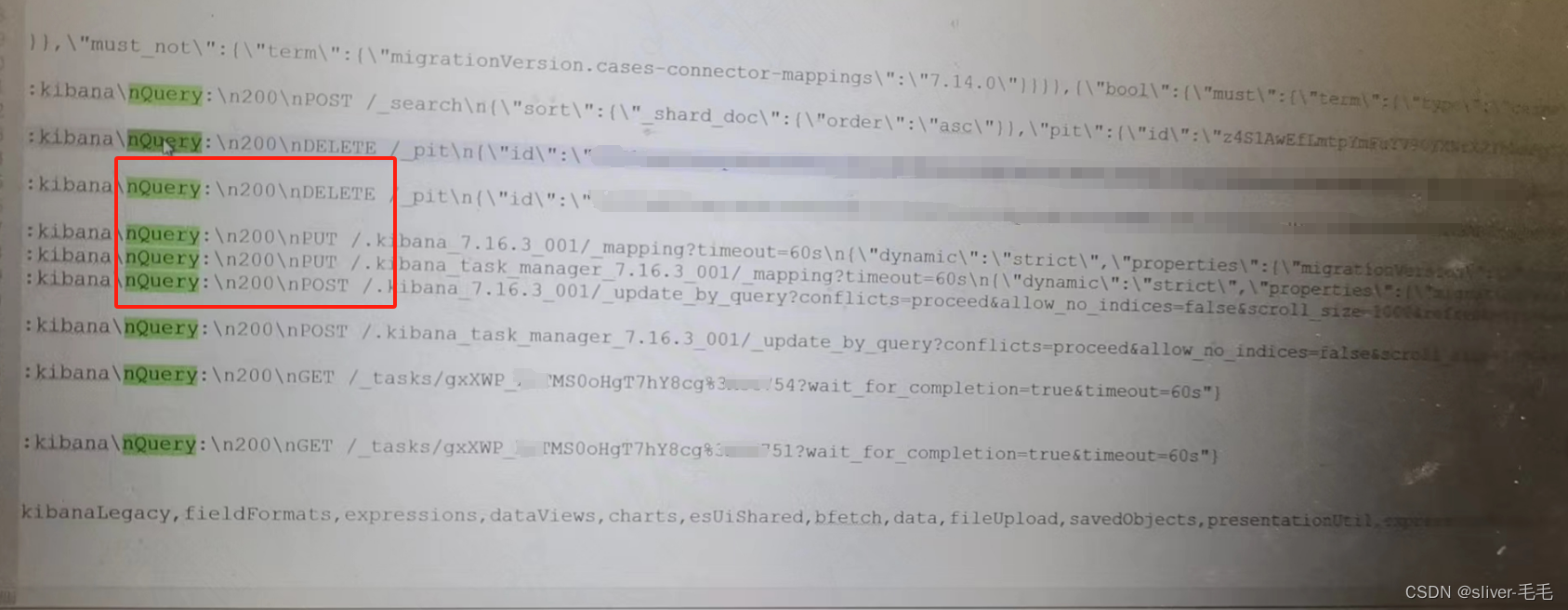
(3)告警日志
[warning][config][plugins][security]
# xpack.security.encryptionKey 为32位随机keyGenerating a random key for xpack.security.encryptionKey.
# 为防止kibana重启 用户会话失效,配置文件增加 xpack.security.encryptionKey 配置;或者 使用 kibana-encryption-keys启动
To prevent sessions from being invalidated on restart, please set xpack.security.encryptionKey in the kibana.yml or use the bin/kibana-encryption-keys command.[warning][config][plugins][reporting]
Generating a random key for xpack.reporting.encryptionKey.
To prevent sessions from being invalidated on restart, please set xpack.reporting.encryptionKey in the kibana.yml or use the bin/kibana-encryption-keys command.[warning][encryptedSavedObjects][plugins]
# xpack.encryptedSavedObjects.encryptionKey 未设置,kibaba 部分功能受限Saved objects encryption key is not set. This will severely limit Kibana functionality.
Please set xpack.encryptedSavedObjects.encryptionKey in the kibana.yml or use the bin/kibana-encryption-keys command.[warning][actions][plugins] # API功能关闭; 设置 xpack.encryptedSavedObjects.encryptionKey 启用
APIs are disabled because the Encrypted Saved Objects plugin is missing encryption key.
Please set xpack.encryptedSavedObjects.encryptionKey in the kibana.yml or use the bin/kibana-encryption-keys command.在kibana.yml中新增如下配置,配置项的值,可以随机生成32位字符串:
xpack.encryptedSavedObjects.encryptionKey: encryptedSavedObjects12345678909876543210
xpack.security.encryptionKey: encryptionKeysecurity12345678909876543210
xpack.reporting.encryptionKey: encryptionKeyreporting12345678909876543210参考:https://blog.csdn.net/h952520296/article/details/112017739Linux命令行:
head /dev/urandom | tr -dc A-Za-z0-9 | head -c 32Windows命令行:
New-Guid | ForEach-Object { $_ -replace '-', '' } | Set-Content encryptionKey.txt
(4)设置密码
首先,在elasticsearch.yml中添加几句配置项:
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true添加后,wq保存退出。然后,执行命令:
./elasticsearch-setup-passwords interactive
会提示要设置多项的密码,选择y后,直接输出密码即可,如图。最后,密码设置成功后,需要重启es。然后是更新Kibana的配置文件kibana.yml,将其中两句注释掉的配置打开,并修改成自己es的用户名和密码:
#添加以下内容
elasticsearch.username: "elastic"
elasticsearch.password: "你在es中设置的密码"修改完成后,wq保存退出,并重启Kibana。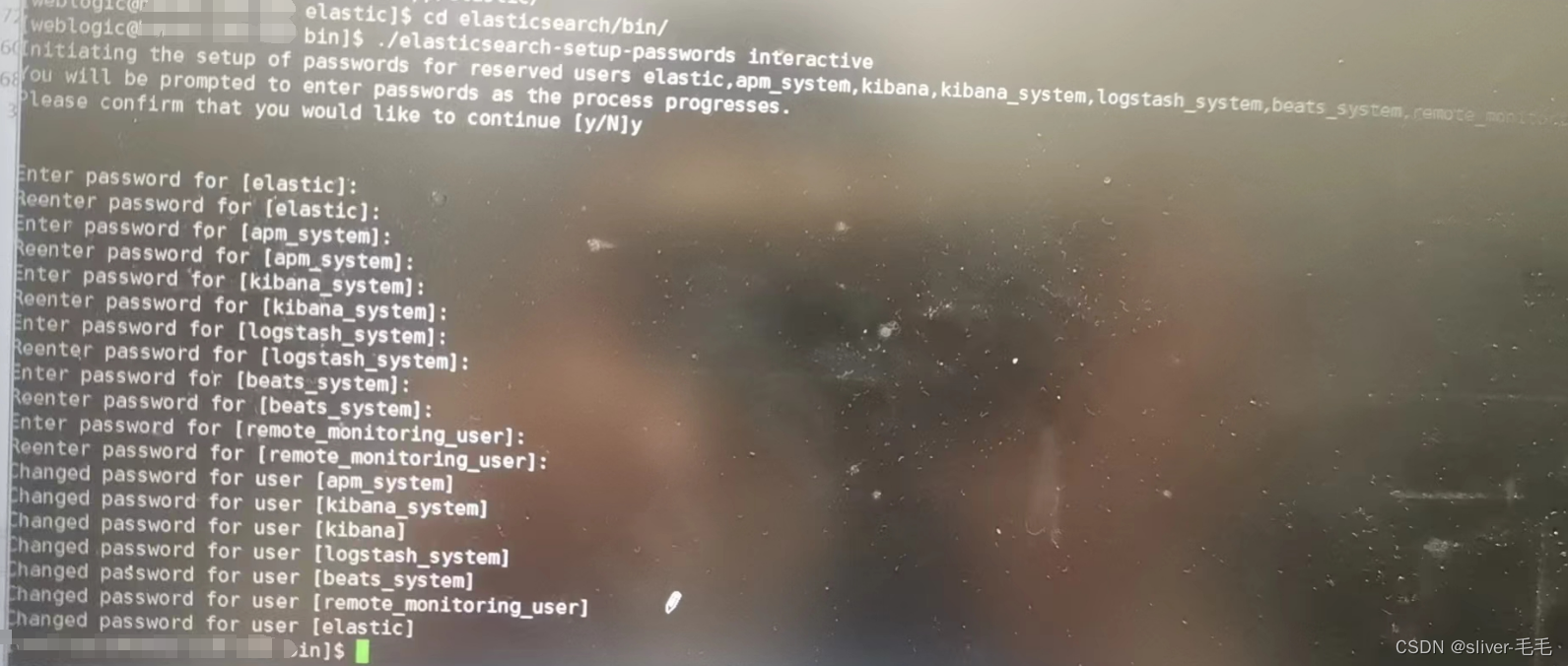

(5)failed to authencated user [xxxx]
Es如果中途宕机,重启后报上述错误:(5.1)停止es,修改配置文件,将设置的密码的两行配置项先注释掉
(5.2)然后删除config下的elasticsearch.keystore文件
(5.3)打开配置文件,将注释去掉
(5.4)保存,重启es
(5.5)按照(4)步骤重置密码
(5.6)再次重启es(6)Es和Kibana启动停止命令
(1)Elasticsearch启动,进入bin目录,执行命令:./elasticsearch 后台启动命令:./elasticsearch -d然后打开logs目录下的xxx.log查看日志。(2)Kibana启动,进入bin目录,执行命令:./kibana后台启动命令:./kibana &然后打开logs目录下的kibana.log查看日志。(3)均适用的服务停止命令:netstat -tnpl | grep 9200/5601 根据端口号查看各个进程的进程号,然后执行:kill -9 'Es.PID/Kibana.PID'相关文章:
ElasticSearch搜索与分析引擎-Linux离线环境安装教程
目录 一、下载安装包 网盘链接: 二、安装流程及遇到的问题和解决方案 (1)JDK安装 (2)Elasticsearch安装 (3)Kibana安装 (4)Ik分词器安装 三、启动过程中的问题 ÿ…...
网络安全全栈培训笔记(59-服务攻防-中间件安全CVE复现lSApacheTomcataNginx)
第59天 服务攻防-中间件安全&CVE复现&lS&Apache&Tomcata&Nginx 知识点: 中间件及框架列表: lIS,Apache,Nginx,Tomcat,Docker,Weblogic,JBoos,WebSphere,Jenkins, GlassFish,Jira,Struts2,Laravel,Solr,Shiro,Thinkphp,Sprng,Flask,…...

操作系统真象还原---系列笔记总结
闲话 最开始知道这本书是在校内论坛上,有同学通过这本书里的项目拿到大厂的ssp offer,于是就从网上订购了这本较为大部头的书,想要在简历上添加一个足够底层并且有意思的项目经历,从而帮助自己在秋招时赢得一个好的offer。 第一遍…...

猫用空气净化器好吗?好用的养猫宠物空气净化器品牌推荐
作为一个养猫五年的资深铲屎官,我对如何轻松快乐地养猫有一些心得。猫咪每天在家里奔跑,导致家里经常会出现“猫毛雪”,沙发、地板和衣服都成了重灾区。在除猫毛的问题上,我真的尝试了各种方法,几乎用上了所有的技能。…...

【计网·湖科大·思科】实验六 IP数据报的发送和转发流程、默认路由和特定主机路由
🕺作者: 主页 我的专栏C语言从0到1探秘C数据结构从0到1探秘Linux 😘欢迎关注:👍点赞🙌收藏✍️留言 🏇码字不易,你的👍点赞🙌收藏❤️关注对我真的很重要&…...

freertos 源码分析一 list链表数据结构
链表和任务管理是freertos 的核心,先分析链表源码,freertos的链表是双向环形链表,定义与数据结构在list.h中,表项的初始化,插入与删除在list.c中。 数据结构 一、表项数据结构 struct xLIST_ITEM {listFIRST_LIST_IT…...

小程序uni-swiper-action-item滑动不了
<uni-swipe-action><uni-swipe-action-item :options"options"></uni-swipe-action-item></uni-swipe-action> 要在options前面加上right或left <uni-swipe-action><uni-swipe-action-item :right-options"options">&…...

【新课】安装部署系列Ⅲ—Oracle 19c Data Guard部署之两节点RAC部署实战
本课程由云贝教育-刘峰老师出品,感谢关注 课程介绍 Oracle Real Application Clusters (RAC) 是一种跨多个节点分布数据库的企业级解决方案。它使组织能够通过实现容错和负载平衡来提高可用性和可扩展性,同时提高性能。本课程基于当前主流版本Oracle 1…...

【从零开始的rust web开发之路 四】rust语言tokio异步使用redis教程
文章目录 前言一、首先引入依赖二、创建redis客户端三、相关操作设置值mset设置多个key值设置含有过期时间的值如果key不存在才设置获取基本类型值删除一个键删除多个键判断键是否存在 如何使用json序列化导入相关依赖代码相关实例 总结 前言 使用rust写web,自然是…...

uniapp本地存储的几种方式localStorage
在uniapp开发中,本地存储是一个常见的需求。本地存储可以帮助我们在客户端保存和管理数据,以便在应用程序中进行持久化存储。本文将介绍uniapp中本地存储的几种方式,以及相关的代码示例。 介绍 在移动应用开发中,我们经常需要将…...
与极限学习机(ELM)应用于大社会数据分析)
扩展学习|统计学习理论(SLT)与极限学习机(ELM)应用于大社会数据分析
文献来源:[1] Oneto L , Bisio F , Cambria E ,et al.Statistical Learning Theory and ELM for Big Social Data Analysis[J].IEEE Computational Intelligence Magazine, 2016, 11(3):45-55.DOI:10.1109/MCI.2016.2572540. 提取链接:链接:h…...

配置实例—交换机VLAN聚合配置实例
一、组网需求 某公司拥有多个部门且位于同一网段,为了提升业务安全性,将不同部门的用户划分到不同VLAN中。现由于业务需要,不同部门间的用户需要互通。如图1所示,VLAN2和VLAN3为不同部门,现需要实现不同VLAN间的用户可…...

网络开发的隐形壁垒:如何巧妙解决跨域难题?
什么是跨域 跨域是浏览器受同源(协议、域名、端口)策略的限制,不允许不同源的站点之间进行某些操作(如发送ajax请求,操作dom,读取cookie),如果不进行特殊配置是不能操作成功的&…...

【极简】conda同一个服务器上迁移环境 export / create
导出 直接看conda的document:https://docs.conda.io/projects/conda/en/latest/commands/env/export.html conda env export conda env export --file SOME_FILE重建 conda documentation: https://docs.conda.io/projects/conda/en/latest/commands/env/create.…...

HBase 数据导入导出
HBase 数据导入导出 1. 使用 Docker 部署 HBase2. HBase 命令查找3. 命令行操作 HBase3.1 HBase shell 命令3.2 查看命名空间3.3 查看命名空间下的表3.4 新建命名空间3.5 查看具体表结构3.6 创建表 4. HBase 数据导出、导入4.1 导出 HBase 中的某个表数据4.2 导入 HBase 中的某…...

(java版)排序算法----【冒泡,选择,插入,希尔,快速排序,归并排序,基数排序】超详细~~
目录 冒泡排序(BubbleSort): 代码详解: 冒泡排序的优化: 选择排序(SelectSort): 代码详解: 插入排序(InsertSort): 代码详解: 希尔排序(ShellSort): 法一…...

服务器托管的作用是什么?
服务器托管是将企业的服务器和相关设备托管到具有完善机房设施、高品质网络环境与运营经验的网络数据中心内,服务器托管在维护方面一般是由客户负责的,或者是由其他的授权人进行远程维护。 那服务器托管的作用都有哪些呢? 服务器托管不需要企…...

美团启动架构调整:聚力核心本地商业,提升科技与境外业务优先级
2月2日,美团CEO王兴发布内部邮件宣布新的组织架构调整。邮件显示,美团对核心本地商业相关多项业务进行了整合,并进一步提升了科技与国际化相关业务的优先级。 在核心本地商业上,美团对过去相对独立的事业群进行了整合。主要调整包…...
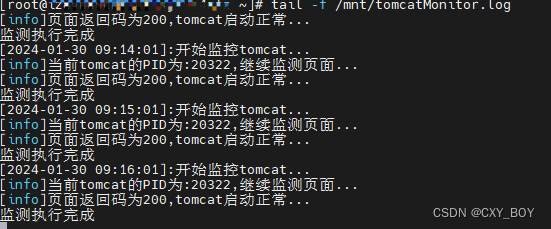
监测Tomcat项目宕机重启脚本(Linux)
1.准备好写好的脚本 #!/bin/sh # 获取tomcat的PID TOMCAT_PID$(ps -ef | grep tomcat | grep -v tomcatMonitor |grep -v grep | awk {print $2}) # tomcat的启动文件位置 START_TOMCAT/mnt/tomcat/bin/startup.sh # 需要监测的一个GET请求地址 MONITOR_URLhttp://localhost:…...

道可云元宇宙每日资讯|北京:推进元宇宙在智慧城市应用
道可云元宇宙每日简报(2024年2月2日)讯,今日元宇宙新鲜事有: 石狮市检察院“元宇宙智慧展馆”正式启用 为深入实施数字检察战略,主动探索元宇宙技术在未成年人检察、公益诉讼检察等方面的应用,打造集案件…...

AI 时代:祛魅、适应与重新定义宋
指令替换 项目需求:将加法指令替换为减法 项目目录如下 /MyProject ├── CMakeLists.txt # CMake 配置文件 ├── build/ #构建目录 │ └── test.c #测试编译代码 └── mypass2.cpp # pass 项目代码 一,测试代码示例 test.c // test.c #includ…...

给硬件小白的保姆级教程:手把手搞定RK3399 Linux-SDK的MIPI屏幕驱动配置
从零点亮RK3399的MIPI屏幕:一份没有硬件基础也能上手的实战指南 当你第一次拿到RK3399开发板和那块神秘的MIPI屏幕时,可能会被各种专业术语吓到——DTS配置、初始化序列、GPIO引脚、背光控制...这些概念对于软件背景的开发者来说,简直就像天书…...

yojimbo完全配置手册:从基础设置到高级调优
yojimbo完全配置手册:从基础设置到高级调优 【免费下载链接】yojimbo A network library for client/server games written in C 项目地址: https://gitcode.com/gh_mirrors/yo/yojimbo yojimbo是一个专为C游戏开发设计的网络库,专注于客户端/服务…...

ProgrammingFonts网站功能详解:快速搜索、对比和评分系统
ProgrammingFonts网站功能详解:快速搜索、对比和评分系统 【免费下载链接】ProgrammingFonts This is a collection of programming fonts, just share this with the programmers. Now there are 108 kinds of fantastic fonts! 项目地址: https://gitcode.com/g…...

PD协议学习二
控制消息(一)1、GoodCRCGoodCRC消息应由接收方发送,以确认先前的消息已被正确接收(即包含GoodCRC消息)。GoodCRC消息应返回该消息的MessageID,以便发送方能确定所确认的是正确的消息。GoodCRC消息的第一个比…...

技术判断力之AI三问涌
认识Pass层级结构 Pass范围从上到下一共分为5个层级: 模块层级:单个.ll或.bc文件 调用图层级:函数调用的关系。 函数层级:单个函数。 基本块层级:单个代码块。例如C语言中{}括起来的最小代码。 指令层级:单…...

蓝牙协议栈实战:从HCI命令到GATT服务,一个物联网设备的数据传输完整流程解析
蓝牙协议栈实战:从HCI命令到GATT服务的数据传输全链路剖析 当智能手环的心率数据通过手机App实时显示时,背后是蓝牙协议栈各层协同工作的精密舞蹈。本文将用真实开发场景中的抓包分析和代码示例,揭示一个物联网设备从物理层连接建立到应用层数…...

《中华网商品详情页前端性能优化实战》
🏛️ 《中华网商品详情页前端性能优化实战》背景:中华网作为“门户 电商”的复合型站点,承载着国家大事、军事、历史等内容,同时售卖相关周边商品。其特点是“用户年龄层偏大、浏览器版本陈旧、网络环境复杂”。核心挑战…...
)
基于SpringBoot + Vue的车辆尾气检测排放系统(双端 + 数据可视化大屏)
文章目录前言一、详细操作演示视频二、具体实现截图三、技术栈1.前端-Vue.js2.后端-SpringBoot3.数据库-MySQL4.系统架构-B/S四、系统测试1.系统测试概述2.系统功能测试3.系统测试结论五、项目代码参考六、数据库代码参考七、项目论文示例结语前言 💛博主介绍&#…...

3步掌握OpenCore配置工具:黑苹果引导的图形化解决方案
3步掌握OpenCore配置工具:黑苹果引导的图形化解决方案 【免费下载链接】OpenCore-Configurator A configurator for the OpenCore Bootloader 项目地址: https://gitcode.com/gh_mirrors/op/OpenCore-Configurator 你是否曾为黑苹果系统的引导配置而头疼&…...