k8s Sidecar filebeat 收集容器中的trace日志和app日志
目录
一、背景
二、设计
三、具体实现
Filebeat配置
K8S SideCar yaml
Logstash配置
一、背景
将容器中服务的trace日志和应用日志收集到KAFKA,需要注意的是 trace 日志和app 日志需要存放在同一个KAFKA两个不同的topic中。分别为APP_TOPIC和TRACE_TOPIC
二、设计
流程图如下:
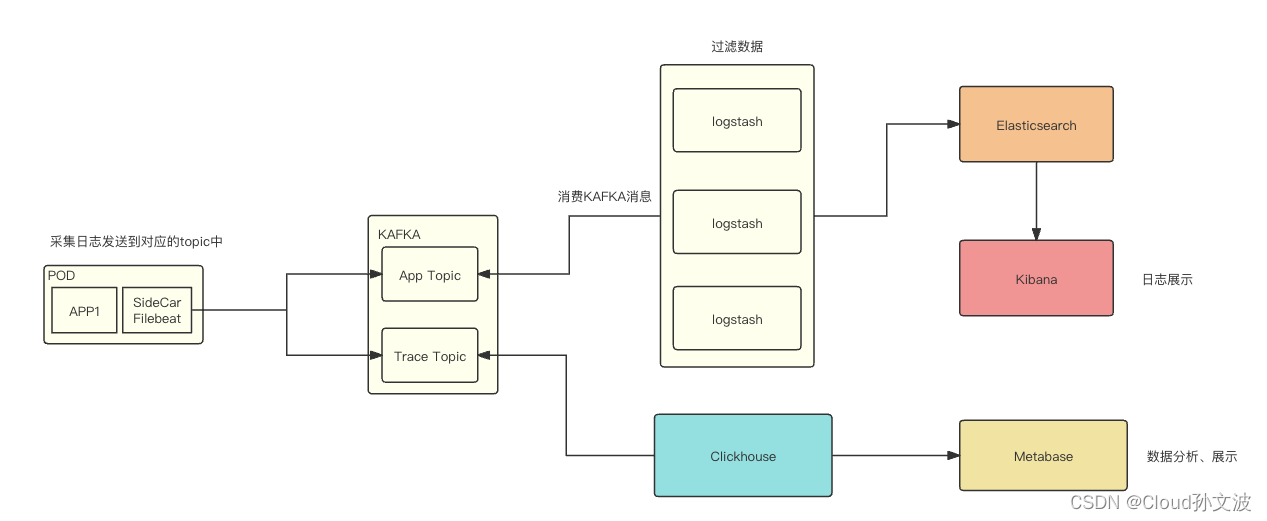
说明:
APP_TOPIC:主要存放服务的应用日志
TRACE_TOPIC:存放程序输出的trace日志,用于排查某一个请求的链路
文字说明:
filebeat 采集容器中的日志(这里需要定义一些规范,我们定义的容器日志路径如下),filebeat会采集两个不同目录下的日志,然后输出到对应的topic中,之后对kafka 的topic进行消费、存储。最终展示出来
/home/service/
└── logs├── app│ └── pass│ ├── 10.246.84.58-paas-biz-784c68f79f-cxczf.log│ ├── 1.log│ ├── 2.log│ ├── 3.log│ ├── 4.log│ └── 5.log└── trace├── 1.log├── 2.log├── 3.log├── 4.log├── 5.log└── trace.log4 directories, 13 files三、具体实现
上干货~
Filebeat配置
配置说明:
其中我将filebeat的一些配置设置成了变量,在接下来的k8s yaml文件中需要定义变量和设置变量的value。
需要特别说明的是我这里是使用了 tags: ["trace-log"]结合when.contains来匹配,实现将对应intput中的日志输出到对应kafka的topic中
filebeat.inputs:
- type: logenabled: truepaths:- /home/service/logs/trace/*.logfields_under_root: truefields:topic: "${TRACE_TOPIC}"json.keys_under_root: truejson.add_error_key: truejson.message_key: messagescan_frequency: 10smax_bytes: 10485760harvester_buffer_size: 1638400ignore_older: 24hclose_inactive: 1htags: ["trace-log"]processors:- decode_json_fields:fields: ["message"]process_array: falsemax_depth: 1target: ""overwrite_keys: true- type: logenabled: truepaths:- /home/service/logs/app/*/*.logfields:topic: "${APP_TOPIC}"scan_frequency: 10smax_bytes: 10485760harvester_buffer_size: 1638400close_inactive: 1htags: ["app-log"]output.kafka:enabled: truecodec.json:pretty: true # 是否格式化json数据,默认falsecompression: gziphosts: "${KAFKA_HOST}"topics:- topic: "${TRACE_TOPIC}"bulk_max_duration: 2sbulk_max_size: 2048required_acks: 1max_message_bytes: 10485760when.contains:tags: "trace-log"- topic: "${APP_TOPIC}"bulk_flush_frequency: 0bulk_max_size: 2048compression: gzipcompression_level: 4group_id: "k8s_filebeat"grouping_enabled: truemax_message_bytes: 10485760partition.round_robin:reachable_only: truerequired_acks: 1workers: 2when.contains:tags: "app-log"K8S SideCar yaml
配置说明:
该yaml中定一个两个容器,容器1为nginx(示例)容器2为filebeat容器。定义了一个名称为logs的emptryDir类型的卷,将logs卷同时挂载在了容器1和容器2的/home/service/logs目录
接下来又在filebeat容器中自定义了三个环境变量,这样我们就可以通过修改yaml的方式很灵活的来配置filebeat
TRACE_TOPIC: Trace日志的topic
APP_TOPIC:App日志的topic
KAFKA_HOST:KAFKA地址
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: nginxname: nginxnamespace: default
spec:replicas: 2selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:imagePullSecrets:- name: uhub-registrycontainers:- image: uhub.service.ucloud.cn/sre-paas/nginx:v1imagePullPolicy: IfNotPresentname: nginxports:- name: nginxcontainerPort: 80- mountPath: /home/service/logsname: logsterminationMessagePath: /dev/termination-logterminationMessagePolicy: FilevolumeMounts:- mountPath: /home/service/logsname: logs- env:- name: TRACE_TOPICvalue: pro_platform_monitor_log- name: APP_TOPICvalue: platform_logs- name: KAFKA_HOSTvalue: '["xxx.xxx.xxx.xxx:9092","xx.xxx.xxx.xxx:9092","xx.xxx.xxx.xxx:9092"]'- name: MY_POD_NAMEvalueFrom:fieldRef:apiVersion: v1fieldPath: metadata.nameimage: xxx.xxx.xxx.cn/sre-paas/filebeat-v2:8.11.2imagePullPolicy: Alwaysname: filebeatresources:limits:cpu: 150mmemory: 200Mirequests:cpu: 50mmemory: 100MisecurityContext:privileged: truerunAsUser: 0terminationMessagePath: /dev/termination-logterminationMessagePolicy: FilevolumeMounts:- mountPath: /home/service/logsname: logsdnsPolicy: ClusterFirstimagePullSecrets:- name: xxx-registryrestartPolicy: AlwaysschedulerName: default-schedulersecurityContext: {}terminationGracePeriodSeconds: 30volumes:- emptyDir: {}name: logs Logstash配置
input {kafka {type => "platform_logs"bootstrap_servers => "xxx.xxx.xxx.xxx:9092,xxx.xxx.xxx.xxx:9092,xxx.xxx.xxx.xxx:9092"topics => ["platform_logs"]group_id => 'platform_logs'client_id => 'open-platform-logstash-logs'}kafka {type => "platform_pre_log"bootstrap_servers => "xxx.xxx.xxx.xxx:9092,xxx.xxx.xxx.xxx:9092,xxx.xxx.xxx.xxx:9092"topics => ["pre_platform_logs"]group_id => 'pre_platform_logs'client_id => 'open-platform-logstash-pre'}kafka {type => "platform_nginx_log"bootstrap_servers => "xxx.xxx.xxx.xxx:9092,xxx.xxx.xxx.xxx:9092,xxx.xxx.xxx.xxx:9092"topics => ["platform_nginx_log"]group_id => 'platform_nginx_log'client_id => 'open-platform-logstash-nginx'}
}
filter {if [type] == "platform_pre_log" {grok {match => { "message" => "\[%{IP}-(?<service>[a-zA-Z-]+)-%{DATA}\]" }}}if [type] == "platform_logs" {grok {match => { "message" => "\[%{IP}-(?<service>[a-zA-Z-]+)-%{DATA}\]" }}}
}
output {if [type] == "platform_logs" {elasticsearch {id => "platform_logs"hosts => ["http://xxx.xxx.xxx.xxx:9200","http://xxx.xxx.xxx.xxx:9200","http://xxx.xxx.xxx.xxx:9200"]index => "log-xxx-prod-%{service}-%{+yyyy.MM.dd}"user => "logstash_transformer"password => "xxxxxxx"template_name => "log-xxx-prod"manage_template => "true"template_overwrite => "true"}}if [type] == "platform_pre_log" {elasticsearch {id => "platform_pre_logs"hosts => ["http://xxx.xxx.xxx.xxx:9200","http://xxx.xxx.xxx.xxx:9200","http://xxx.xxx.xxx.xxx:9200"]index => "log-xxx-pre-%{service}-%{+yyyy.MM.dd}"user => "logstash_transformer"password => "xxxxxxx"template_name => "log-xxx-pre"manage_template => "true"template_overwrite => "true"}}if [type] == "platform_nginx_log" {elasticsearch {id => "platform_nginx_log"hosts => ["http://xxx.xxx.xxx.xxx:9200","http://xxx.xxx.xxx.xxx:9200","http://xxx.xxx.xxx.xxx:9200"]index => "log-platform-nginx-%{+yyyy.MM.dd}"user => "logstash_transformer"password => "xxxxxxx"template_name => "log-platform-nginx"manage_template => "true"template_overwrite => "true"}}
}如果有帮助到你麻烦给个赞或者收藏一下~,有问题可以随时私聊我或者在评论区评论,我看到会第一时间回复
相关文章:
k8s Sidecar filebeat 收集容器中的trace日志和app日志
目录 一、背景 二、设计 三、具体实现 Filebeat配置 K8S SideCar yaml Logstash配置 一、背景 将容器中服务的trace日志和应用日志收集到KAFKA,需要注意的是 trace 日志和app 日志需要存放在同一个KAFKA两个不同的topic中。分别为APP_TOPIC和TRACE_TOPIC 二、…...
三维模型设计新纪元:3D开发工具HOOPS在机械加工行业的应用与优势
在当今快速发展的科技时代,机械加工行业正经历着巨大的变革,而HOOPS技术正是其中一项重要的创新。HOOPS技术不仅仅是一种用于处理和可视化计算机辅助设计(CAD)数据的工具,更是机械加工领域中提升效率、优化设计的利器。…...

Python爬虫子页面并写入text代码
这是工具类 class UrlManager():"""url管理器"""def __init__(self):self.new_urls set()self.old_urls set()def add_new_url(self,url):if url is None or len(url) 0:returnif url in self.new_urls or url in self.old_urls:returnself.…...

《PyTorch基础教程》01 搭建环境 基于Docker搭建ubuntu22+Python3.10+Pytorch2+cuda11+jupyter的开发环境
01 环境搭建 《PyTorch基础教程》01 搭建环境 基于Docker搭建ubuntu22+Python3.10+Pytorch2+cuda11+jupyter的开发环境 Docker部署PyTorch 拉取cnstark/pytorch镜像 拉取镜像: docker pull cnstark/pytorch:2.0.1-py3.10.11-cuda11.8.0-ubuntu22.04导出镜像: docker sa…...

MySQL进阶之触发器
触发器 触发器是与表有关的数据库对象,指在insert/update/delete之前(BEFORE)或之后(AFTER),触 发并执行触发器中定义的SQL语句集合。触发器的这种特性可以协助应用在数据库端确保数据的完整性 , 日志记录 , 数据校验等操作 。 使用别名OLD和NEW来引用…...
循环神经网络RNN专题(01/6)
一、说明 RNN用于处理序列数据。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能无力。例如,你要预测句子的下一个单词是什么&a…...

C# 怎么判断屏幕是第几屏幕?屏幕是垂直还是水平?屏幕的分辨率?
一、怎么判断屏幕是第几屏幕? 可以使用System.Windows.Forms.Screen.AllScreens属性来获取所有已连接的屏幕,并根据鼠标位置或窗口的位置来判断它所在的屏幕索引。 using System; using System.Windows.Forms;// 获取鼠标当前位置所在的屏幕 Point cur…...

在 SQL Server 中使用 SQL 语句查询不同时间范围的数据
在 SQL Server 中,我们经常需要从数据库中检索特定时间范围内的数据。通过合理运用 SQL 语句,我们可以轻松地查询今天、昨天、近7天、近30天、一个月内、上一月、本年和去年的数据。下面是一些示例 SQL 查询,让我们逐一了解。 查询今天的数据…...

学习使用Flask模拟接口进行测试
前言 学习使用一个新工具,首先找一段代码学习一下,基本掌握用法,然后再考虑每一部分是做什么的 Flask的初始化 app Flask(__name__):初始化,创建一个该类的实例,第一个参数是应用模块或者包的名称 app…...

深度学习快速入门--7天做项目
深度学习快速入门--7天做项目 0. 引言1. 本文内容2. 深度学习是什么3. 项目是一个很好的切入点4. 7天做项目4.1 第一天:数据整理4.2 第二天:数据处理4.3 第三天:简单神经网络设计4.4 第四天:分析效果与原因4.5 第五天:…...
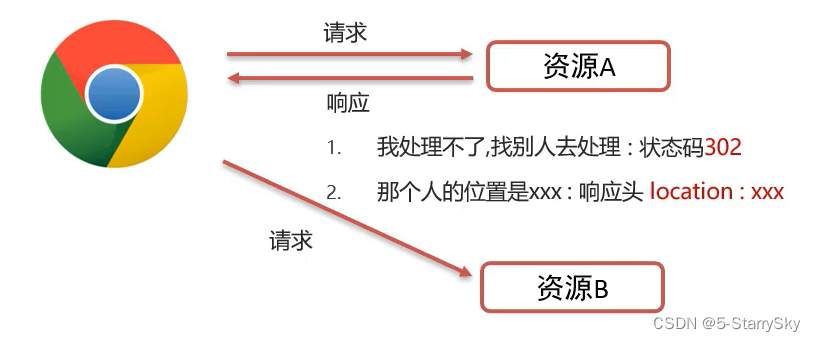
Request Response 基础篇
Request & Response 在之前的博客中,初最初见到Request和Response对象,是在Servlet的Service方法的参数中,之前隐性地介绍过Request的作用是获取请求数据。通过获取的数据来进行进一步的逻辑处理,然后通过对Response来进行数…...

数据爬虫是什么
数据爬虫是一种自动化程序,用于从互联网上收集数据。它通过模拟人类浏览器的行为,访问网页并提取所需的数据。数据爬虫通常使用网络爬虫框架或库来实现。 数据爬虫的工作流程通常包括以下几个步骤: 发起请求:爬虫发送HTTP请求到…...

Java注解与策略模式的奇妙结合:Autowired探秘
大家好,欢迎收听今天的播客节目!我是你们的主持人,也是一位对软件开发充满热情的开发者。在今天的节目中,我们将探讨如何巧妙地结合注解与策略模式,创建一个灵活而强大的策略规则工厂。让我们带着好奇的心情一同深入研…...
Datax3.0+DataX-Web部署分布式可视化ETL系统
一、DataX 简介 DataX 是阿里云 DataWorks 数据集成的开源版本,主要就是用于实现数据间的离线同步。DataX 致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源(即不同的数据库&#x…...
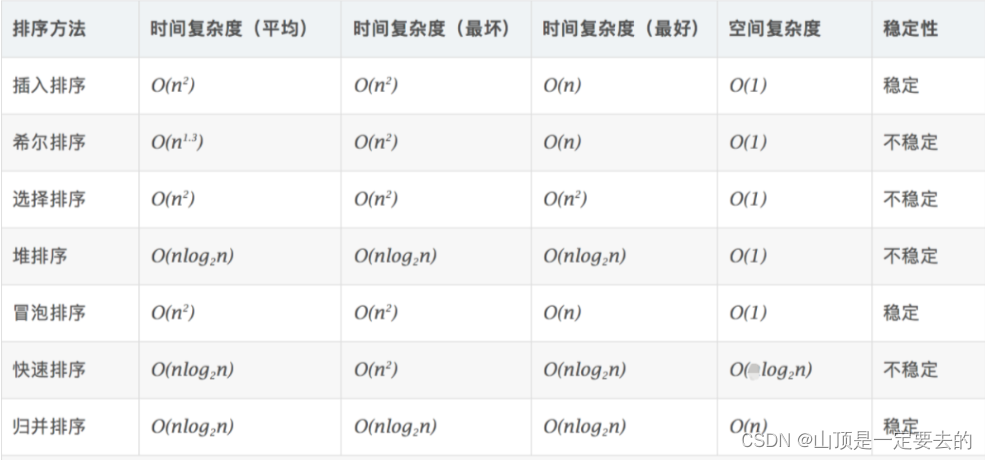
【Java 数据结构】排序
排序算法 1. 排序的概念及引用1.1 排序的概念1.2 常见的排序算法 2. 常见排序算法的实现2.1 插入排序2.1.1 直接插入排序2.1.2 希尔排序( 缩小增量排序 ) 2.2 选择排序2.2.1 直接选择排序2.2.2 堆排序 2.3 交换排序2.3.1冒泡排序2.3.2 快速排序2.3.3 快速排序非递归 2.4 归并排…...
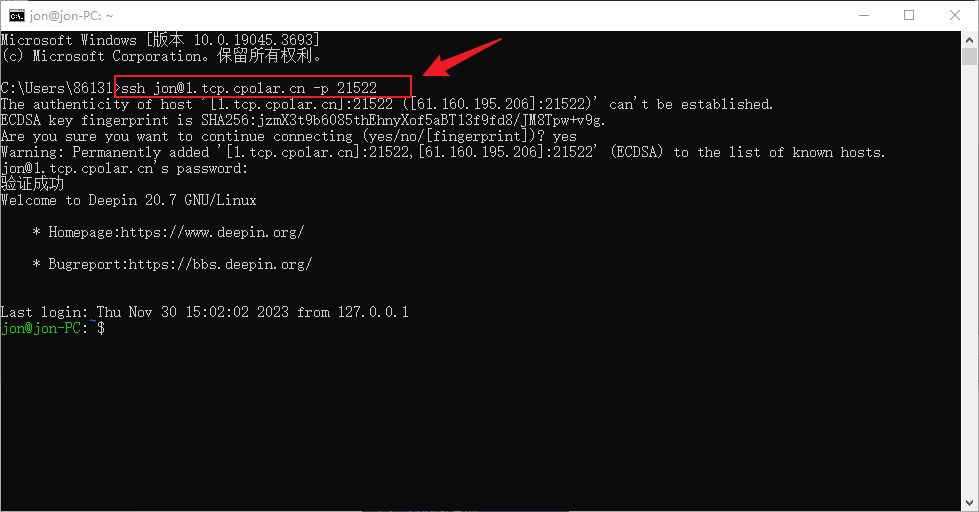
Deepin如何开启与配置SSH实现无公网ip远程连接
文章目录 前言1. 开启SSH服务2. Deppin安装Cpolar3. 配置ssh公网地址4. 公网远程SSH连接5. 固定连接SSH公网地址6. SSH固定地址连接测试 前言 Deepin操作系统是一个基于Debian的Linux操作系统,专注于使用者对日常办公、学习、生活和娱乐的操作体验的极致࿰…...
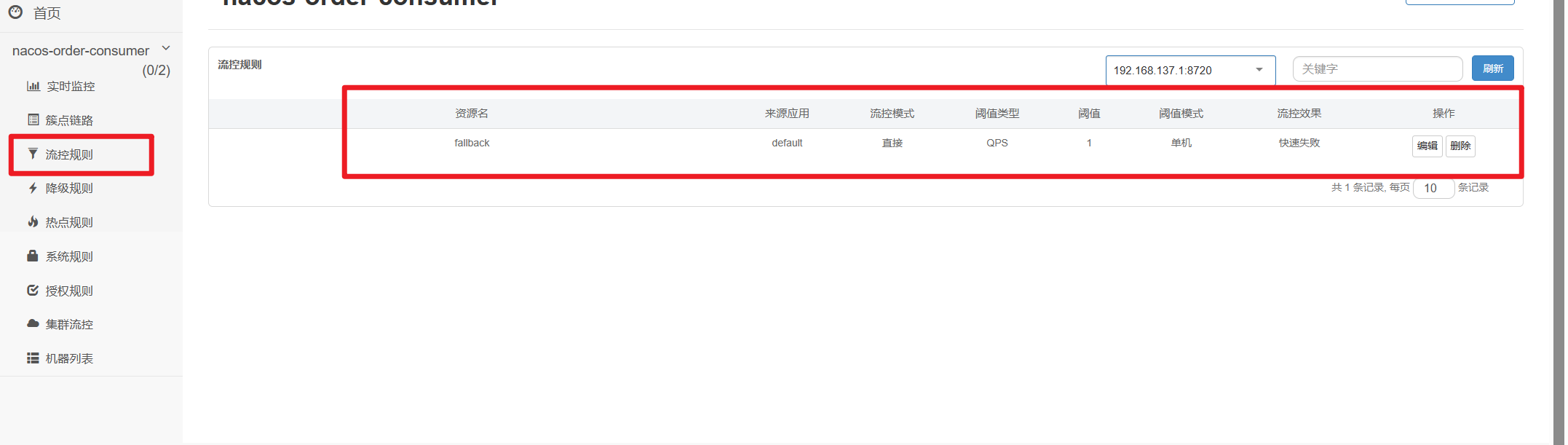
【Springcloud篇】学习笔记十(十七章):Sentinel实现熔断与限流——Hystrix升级
第十七章_Sentinel实现熔断与限流 1.Sentinel介绍 1.1是什么 随着微服务的流行,服务和服务之间的稳定性变得越来越重要。 Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。 用来代替Hystrix Sentinel 具有…...
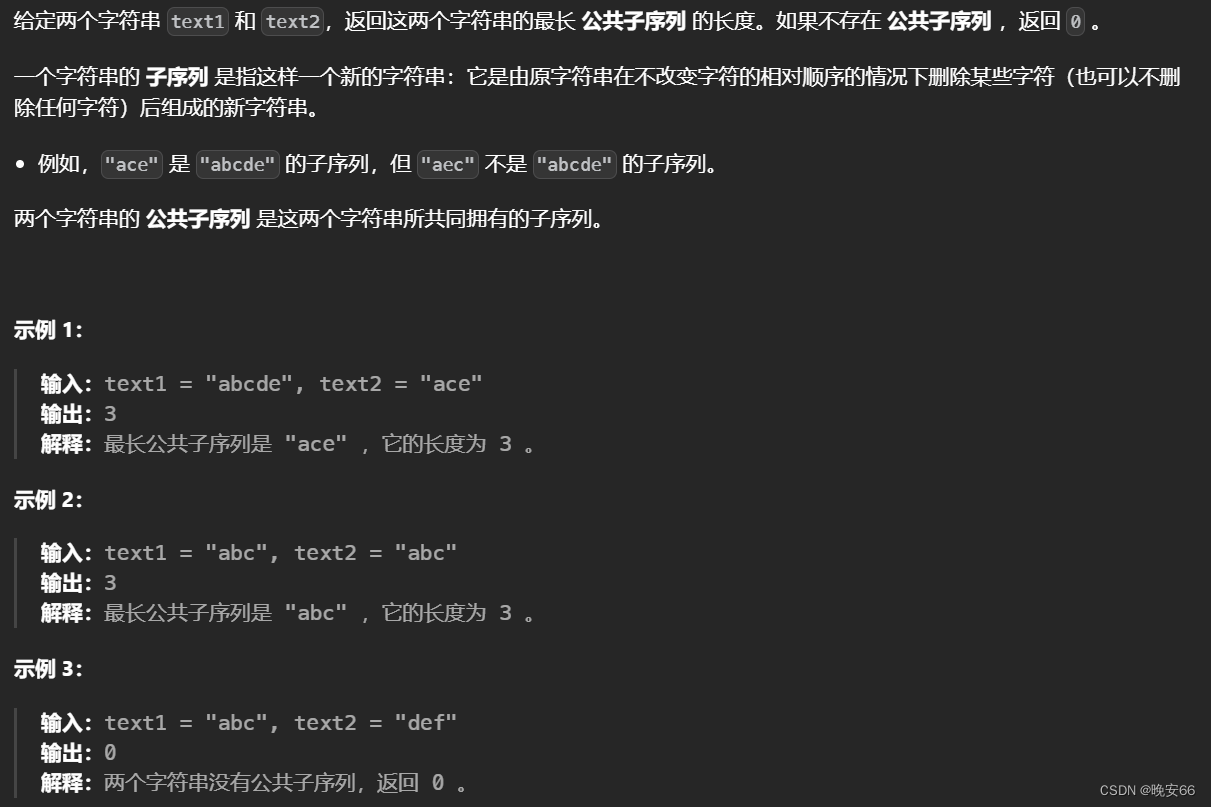
【算法与数据结构】718、1143、LeetCode最长重复子数组 最长公共子序列
文章目录 一、718、最长重复子数组二、1143、最长公共子序列三、完整代码 所有的LeetCode题解索引,可以看这篇文章——【算法和数据结构】LeetCode题解。 一、718、最长重复子数组 思路分析: 第一步,动态数组的含义。 d p [ i ] [ j ] dp[i]…...
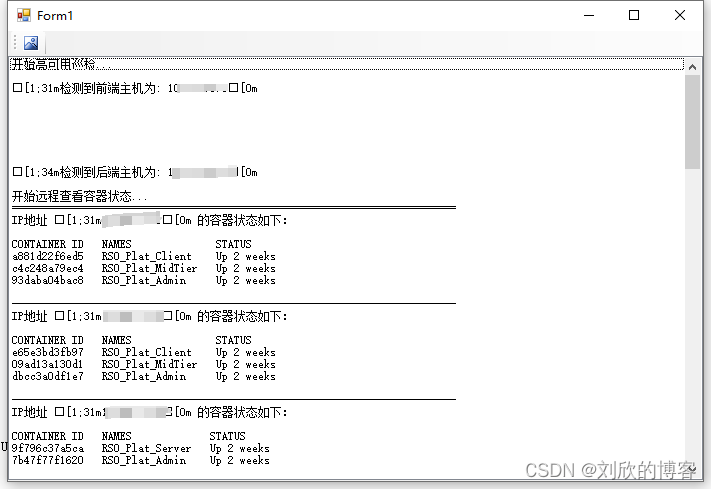
C# SSH.NET 长命令及时返回
在SSH中执行长时间的命令,SSH.NET及时在文本框中返回连续显示结果。 c# - Execute long time command in SSH.NET and display the results continuously in TextBox - Stack Overflow 博主管理了一个服务器集群,准备上自动巡检工具,测试在…...

Rust学习之Features
Rust学习之Features 一 什么是 Features二 默认 feature三 简单的features应用示例四 可选(optional)的依赖五 依赖的特性5.1 在依赖表中指定5.2 在features表中指定 六 命令行中特性控制七 特性统一路径八 其它8.1 相互排斥特性8.2 观察启用特性8.3 Feature resolver version …...

C9,再获5亿捐赠!
点击下方卡片,关注“CVer”公众号AI/CV重磅干货,第一时间送达点击进入—>【顶会/顶刊】投稿交流群添加微信号:CVer2233,小助手拉你进群!扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶…...

如何通过可视化学习快速掌握RISC-V?专业仿真平台全解析
如何通过可视化学习快速掌握RISC-V?专业仿真平台全解析 【免费下载链接】Ripes A graphical processor simulator and assembly editor for the RISC-V ISA 项目地址: https://gitcode.com/gh_mirrors/ri/Ripes RISC-V学习工具的选择直接影响掌握效率&#x…...

Outlook邮箱爆满无法接收邮件怎么办?一篇文章教你用“归档”快速释放空间
🔥个人主页:杨利杰YJlio❄️个人专栏:《Sysinternals实战教程》《Windows PowerShell 实战》《WINDOWS教程》《IOS教程》《微信助手》《锤子助手》 《Python》 《Kali Linux》《那些年未解决的Windows疑难杂症》🌟 让复杂的事情更…...

[特殊字符] 第30课:排序链表
想系统提升编程能力、查看更完整的学习路线,欢迎访问 AI Compass:https://github.com/tingaicompass/AI-Compass 仓库持续更新刷题题解、Python 基础和 AI 实战内容,适合想高效进阶的你。📖 第30课:排序链表模块&#…...
)
基于YOLOv11深度学习的蘑菇毒性检测系统(YOLOv11+YOLO数据集+UI界面+登录注册界面+Python项目源码+模型)
一、项目介绍 本项目基于 YOLOv11(You Only Look Once v11)轻量化深度学习目标检测算法,构建了一套端到端的蘑菇毒性检测系统,旨在解决传统蘑菇毒性鉴别依赖专业知识、效率低且易出错的问题。系统面向普通用户、食品安全监管人员…...

Go语言命名规则实战:从变量到包名的完整避坑指南
Go语言命名规则实战:从变量到包名的完整避坑指南 当你第一次接触Go语言时,可能会被它简洁的语法所吸引,但很快就会发现这门语言对命名有着近乎苛刻的要求。我至今还记得刚学Go时,因为一个包名的大小写问题调试了整个下午的经历。本…...

别再只用Chat模式了!Cursor的Rule和Docs功能,才是提升Java开发效率的隐藏王牌
解锁Cursor的Rule与Docs功能:Java开发者的效率革命 在Java开发领域,我们常常陷入重复性工作的泥潭——手动检查代码规范、翻阅过时的API文档、反复调试基础配置。Cursor编辑器远不止是一个智能补全工具,它的Rule和Docs功能正在悄然改变Java开…...

告别手动排版:Illustrator智能填充工具提升设计效率指南
告别手动排版:Illustrator智能填充工具提升设计效率指南 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 问题:设计师为何困在重复劳动中? 为什么…...
的深度技术解析与选型指南)
赋能软件测试:三大主流数据标注平台(Label Studio, Prodigy, Scale)的深度技术解析与选型指南
当软件测试遇见AI数据工程在人工智能驱动的软件测试新时代,数据已不仅仅是应用运行的输入,更是构建智能测试模型、实现自动化测试演进的核心“燃料”。数据标注,作为将原始数据转化为机器可理解、可学习结构化信息的关键工序,其质…...

Multisim电路仿真与Qwen3.5-2B结合:自动化生成电路分析报告
Multisim电路仿真与Qwen3.5-2B结合:自动化生成电路分析报告 1. 电子工程师的设计痛点 每个电子工程师都经历过这样的场景:在Multisim中反复调整电路参数,盯着示波器波形来回对比,手动记录各项性能指标,最后还要花大量…...