深度学习手写字符识别:训练模型
说明
本篇博客主要是跟着B站中国计量大学杨老师的视频实战深度学习手写字符识别。
第一个深度学习实例手写字符识别
深度学习环境配置
可以参考下篇博客,网上也有很多教程,很容易搭建好深度学习的环境。
Windows11搭建GPU版本PyTorch环境详细过程
数据集
手写字符识别用到的数据集是MNIST数据集(Mixed National Institute of Standards and Technology database);MNIST是一个用来训练各种图像处理系统二进制图像数据集,广泛应用到机器学习中的训练和测试。
作为一个入门级的计算机视觉数据集,发布20多年来,它已经被无数机器学习入门者应用无数遍,是最受欢迎的深度学习数据集之一。
| 序号 | 说明 |
|---|---|
| 发布方 | National Institute of Standards and Technology(美国国家标准技术研究所,简称NIST) |
| 发布时间 | 1998 |
| 背景 | 该数据集的论文想要证明在模式识别问题上,基于CNN的方法可以取代之前的基于手工特征的方法,所以作者创建了一个手写数字的数据集,以手写数字识别作为例子证明CNN在模式识别问题上的优越性。 |
| 简介 | MNIST数据集是从NIST的两个手写数字数据集:Special Database 3 和Special Database 1中分别取出部分图像,并经过一些图像处理后得到的。MNIST数据集共有70000张图像,其中训练集60000张,测试集10000张。所有图像都是28×28的灰度图像,每张图像包含一个手写数字。 |
跟着视频跑源码
- 下载源码:mivlab/AI_course (github.com)
- 下载数据集:https://opendatalab.com/MNIST;网上下载的地址比较多,也可以直接下载B站中国计量大学杨老师的百度网盘位置里的MNIST。
运行源码
- 在Pycharm中打开
AI_course项目,运行classify_pytorch文件目录里train_mnist.py的Python文件。
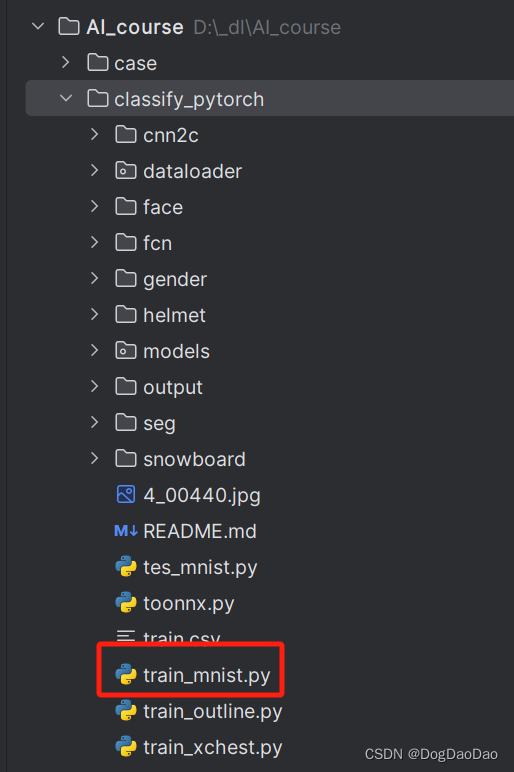
train_mnist.py具体的源码如下:
import torch
import math
import torch.nn as nn
from torch.autograd import Variable
from torchvision import transforms, models
import argparse
import os
from torch.utils.data import DataLoaderfrom dataloader import mnist_loader as ml
from models.cnn import Net
from toonnx import to_onnxparser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--datapath', required=True, help='data path')
parser.add_argument('--batch_size', type=int, default=256, help='training batch size')
parser.add_argument('--epochs', type=int, default=300, help='number of epochs to train')
parser.add_argument('--use_cuda', default=False, help='using CUDA for training')args = parser.parse_args()
args.cuda = args.use_cuda and torch.cuda.is_available()
if args.cuda:torch.backends.cudnn.benchmark = Truedef train():os.makedirs('./output', exist_ok=True)if True: #not os.path.exists('output/total.txt'):ml.image_list(args.datapath, 'output/total.txt')ml.shuffle_split('output/total.txt', 'output/train.txt', 'output/val.txt')train_data = ml.MyDataset(txt='output/train.txt', transform=transforms.ToTensor())val_data = ml.MyDataset(txt='output/val.txt', transform=transforms.ToTensor())train_loader = DataLoader(dataset=train_data, batch_size=args.batch_size, shuffle=True)val_loader = DataLoader(dataset=val_data, batch_size=args.batch_size)model = Net(10)#model = models.vgg16(num_classes=10)#model = models.resnet18(num_classes=10) # 调用内置模型#model.load_state_dict(torch.load('./output/params_10.pth'))#from torchsummary import summary#summary(model, (3, 28, 28))if args.cuda:print('training with cuda')model.cuda()optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=1e-3)scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, [20, 30], 0.1)loss_func = nn.CrossEntropyLoss()for epoch in range(args.epochs):# training-----------------------------------model.train()train_loss = 0train_acc = 0for batch, (batch_x, batch_y) in enumerate(train_loader):if args.cuda:batch_x, batch_y = Variable(batch_x.cuda()), Variable(batch_y.cuda())else:batch_x, batch_y = Variable(batch_x), Variable(batch_y)out = model(batch_x) # 256x3x28x28 out 256x10loss = loss_func(out, batch_y)train_loss += loss.item()pred = torch.max(out, 1)[1]train_correct = (pred == batch_y).sum()train_acc += train_correct.item()print('epoch: %2d/%d batch %3d/%d Train Loss: %.3f, Acc: %.3f'% (epoch + 1, args.epochs, batch, math.ceil(len(train_data) / args.batch_size),loss.item(), train_correct.item() / len(batch_x)))optimizer.zero_grad()loss.backward()optimizer.step()scheduler.step() # 更新learning rateprint('Train Loss: %.6f, Acc: %.3f' % (train_loss / (math.ceil(len(train_data)/args.batch_size)),train_acc / (len(train_data))))# evaluation--------------------------------model.eval()eval_loss = 0eval_acc = 0for batch_x, batch_y in val_loader:if args.cuda:batch_x, batch_y = Variable(batch_x.cuda()), Variable(batch_y.cuda())else:batch_x, batch_y = Variable(batch_x), Variable(batch_y)out = model(batch_x)loss = loss_func(out, batch_y)eval_loss += loss.item()pred = torch.max(out, 1)[1]num_correct = (pred == batch_y).sum()eval_acc += num_correct.item()print('Val Loss: %.6f, Acc: %.3f' % (eval_loss / (math.ceil(len(val_data)/args.batch_size)),eval_acc / (len(val_data))))# 保存模型。每隔多少帧存模型,此处可修改------------if (epoch + 1) % 1 == 0:# torch.save(model, 'output/model_' + str(epoch+1) + '.pth')torch.save(model.state_dict(), 'output/params_' + str(epoch + 1) + '.pth')#to_onnx(model, 3, 28, 28, 'params.onnx')if __name__ == '__main__':train()- 报错:没有
cv2,即没有安装OpenCV库。
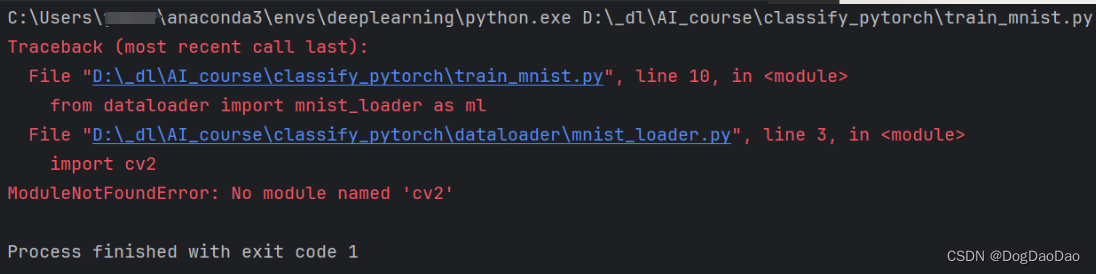
- 安装OpenCV库,可以命令行安装,也可以Pycharm中安装。
- 命令行激活虚拟环境:
conda activate deeplearning - 命令行安装:
pip install opencv-python(也可以Pycharm中下载,可能上梯子安装更快)

- 再次运行,出现如下图提示,表明需要将下载好的数据集配置到
configure中。

- 加载下载好的数据集,即
--datapath=数据集的路径。
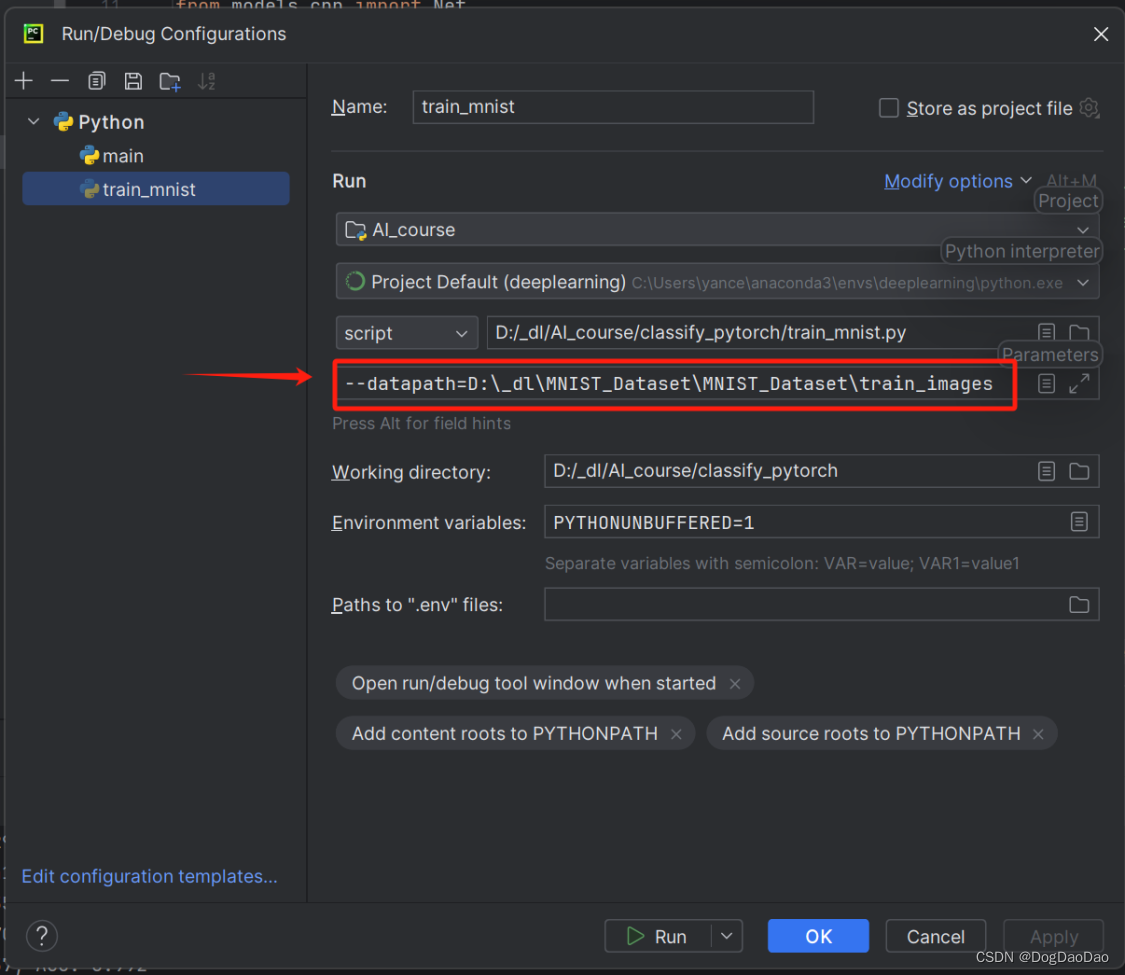
- 点击“
Run”,开始训练,损失和准确率在一直更新,持续训练,直到模型完成,未改动源码的情况下,训练时间可能需要较长。
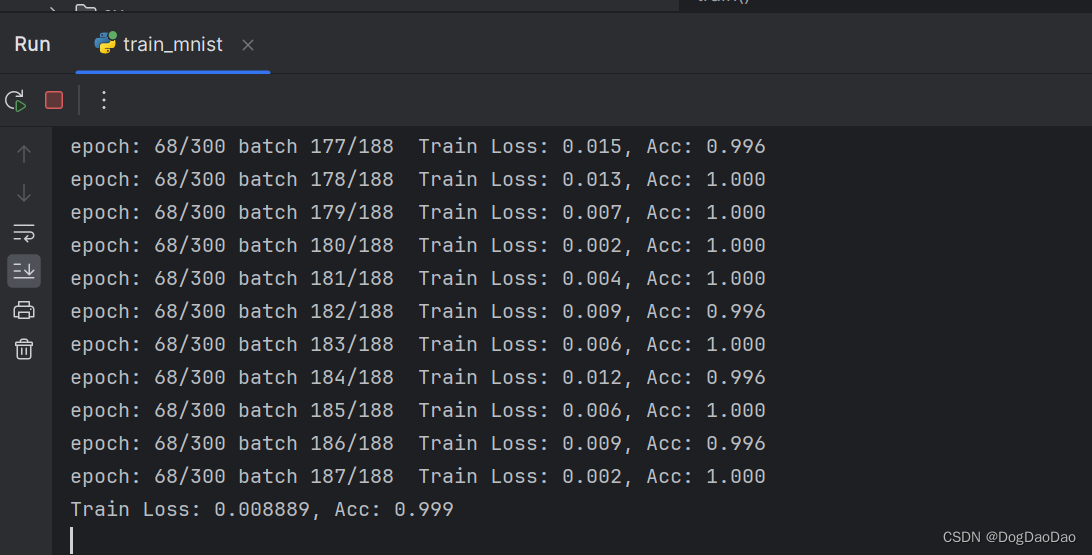
- 在小编的拯救者笔记本电脑上持续训练了10小时才完成最终的模型训练,可以看到训练损失已经很低了,准确度很高水平。
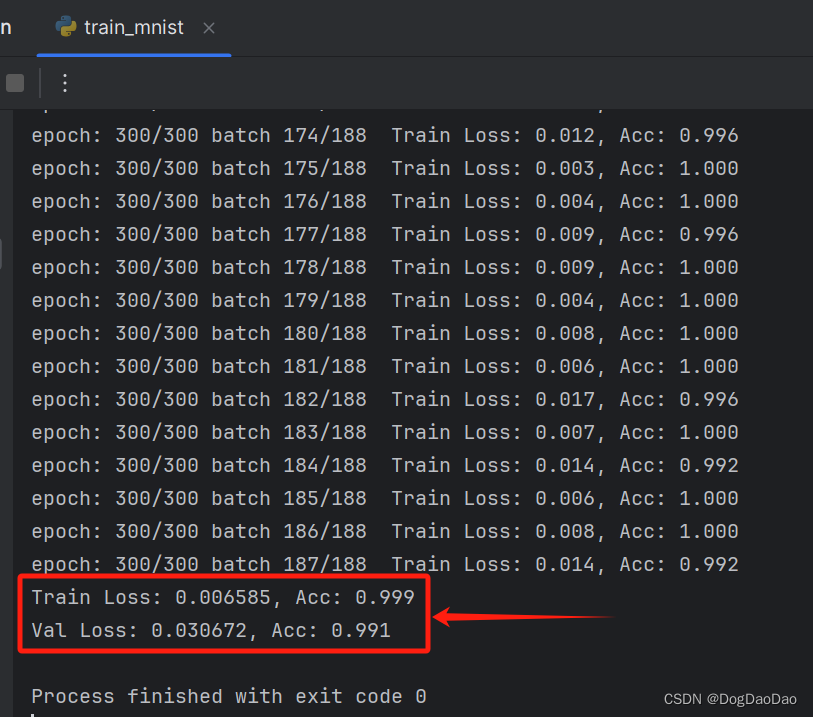
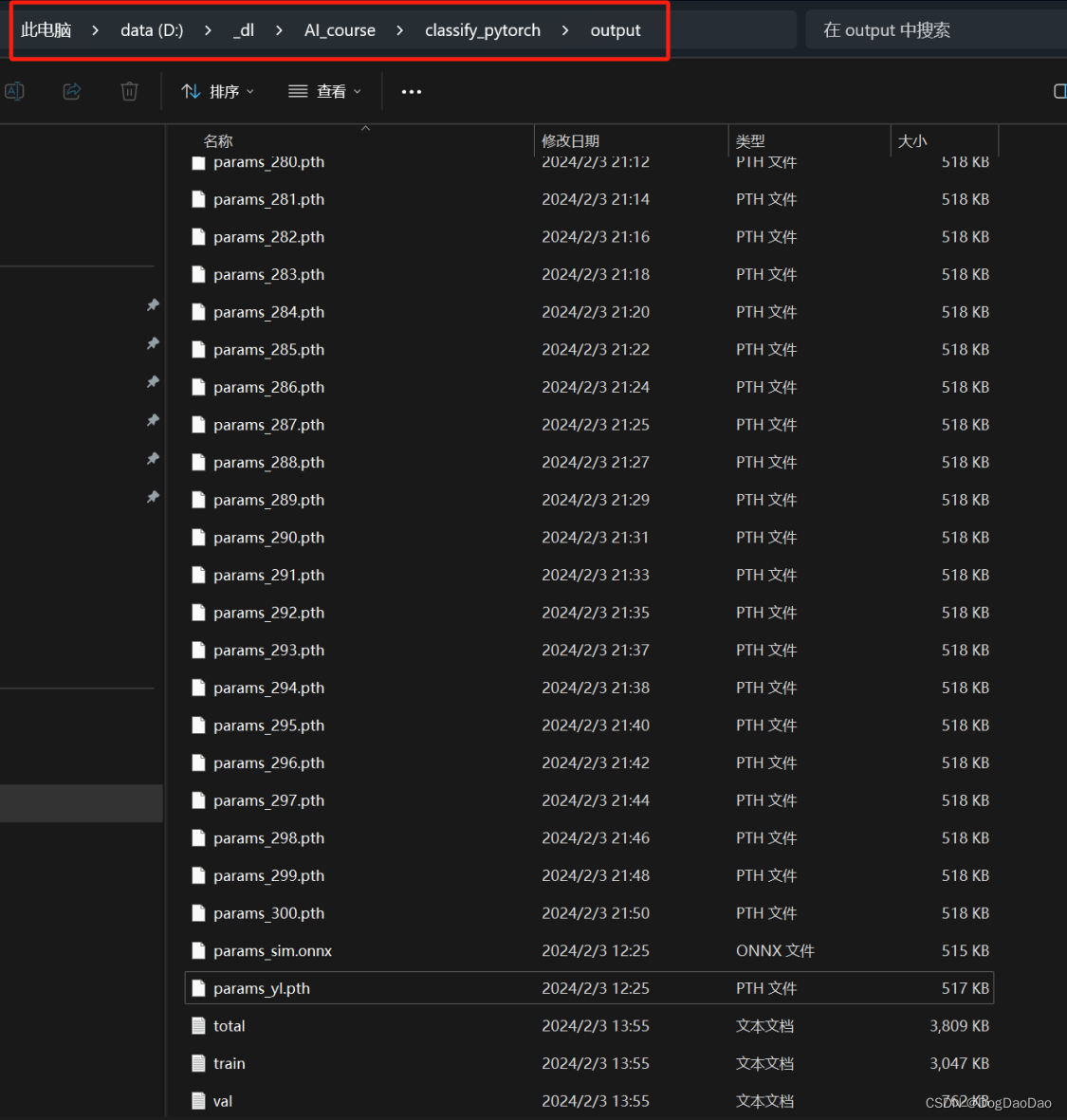
- 在项目中
output文件夹中可以看到已经训练好了很多模型;后面可以利用模型进行推理了。
参考
https://zhuanlan.zhihu.com/p/681236488
相关文章:
深度学习手写字符识别:训练模型
说明 本篇博客主要是跟着B站中国计量大学杨老师的视频实战深度学习手写字符识别。 第一个深度学习实例手写字符识别 深度学习环境配置 可以参考下篇博客,网上也有很多教程,很容易搭建好深度学习的环境。 Windows11搭建GPU版本PyTorch环境详细过程 数…...
Day 1. 学习linux高级编程之Shell命令和IO
1.C语言基础 现阶段学习安排 2.IO编程 多任务编程(进程、线程) 网络编程 数据库编程 3.数据结构 linux软件编程 1.linux: 操作系统:linux其实是操作系统的内核 系统调用:linux内核的函数接口 操作流程ÿ…...
STM32--SPI通信协议(1)SPI基础知识总结
前言 I2C (Inter-Integrated Circuit)和SPI (Serial Peripheral Interface)是两种常见的串行通信协议,用于连接集成电路芯片之间的通信,选择I2C或SPI取决于具体的应用需求。如果需要较高的传输速度和简单的接口,可以选择SPI。如果需要连接多…...

Debezium系列之:MariaDB10.5以上版本赋予数据库账号读取binlog权限的变化
Debezium系列之:MariaDB10.5以上版本赋予数据库账号读取binlog权限的变化 一、背景二、BINLOG MONITOR权限三、BINLOG MONITOR和REPLICA MONITOR的区别四、MariaDB版本升级的影响五、总结一、背景 数据接入会检测账号是否具有REPLICATION SLAVE、REPLICATION CLIENT的权限Mari…...

迅为STM32MP157开发板底板板载4G接口(选配)、千兆以太网、WIFI蓝牙模块
底板扩展接口丰富 底板板载4G接口(选配)、千兆以太网、WIFI蓝牙模块HDMI、CAN、RS485、LVDS接口、温湿度传感器(选配)光环境传感器、六轴传感器、2路USB OTG、3路串口CAMERA接口、ADC电位器、SPDIF、SDIO接口等。 支持多种显示屏 迅为在MP157开发板支持了多种屏幕࿰…...
「实用分享」用界面组件Telerik UI for Blazor增强你的财务图表!
Telerik UI for Blazor拥有110个原生的、易于定制的Blazor UI组件和高性能网格组件,能节约一半的时间开发全新的Blazor应用程序并使传统web项目现代化,其中囊括了设计和生成工具等。Telerik UI for Blazor控件提供的控件,可轻松满足应用程序对…...

使用org.openscada.utgard java opcda库做opc客户端时长期运行存在的若干问题
牛11月09日反馈东区存在以下问题,由于在现场未来得及处理。11月10日反馈西区亦存在此问题。经排查此问题已存在相当长一段时间(最长为9月底即存在)。 1、读报错Value: [[org.jinterop.dcom.core.VariantBody$EMPTY212c0aff]], Timestamp: Mo…...

杰克与魔法树的冒险
从前有一个小村庄,里面住着一个善良勇敢的小男孩叫杰克。杰克非常喜欢冒险和探索未知的事物。 一天,杰克听说村庄附近的森林里有一个神奇的魔法树,树上结满了金色的苹果。他决定去寻找这棵魔法树,并带回一些金苹果给村庄的居民们。…...
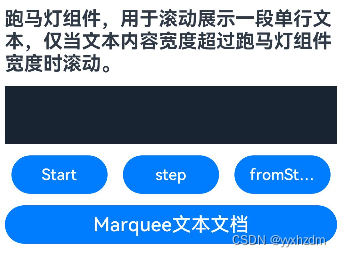
第九节HarmonyOS 常用基础组件22-Marquee
1、描述 跑马灯组件,用于滚动展示一段单行文本,仅当文本内容宽度超过跑马灯组件宽度时滚动。 2、接口 Marquee(value:{start:boolean, step?:number, loop?:number, fromStart?: boolean ,src:string}) 3、参数 参数名 参数类型 必填 描述 st…...

烽火传递
看似很简单的单调队列优化DP 但是如果状态是表示前\(i\)个烽火台被处理完的最小代价(即不知道最后一个烽火台在哪里)就无法降低复杂度 因为假设你在区间\([i-m1,i]\)中枚举最后一个烽火台(设为\(k\)),你前面的状态并不是\(f[k-1]\),因为此时\(k\)已经可以…...

《深入浅出Go语言》大纲
目录 为什么选择《深入浅出Go语言》? 基础核心模块 为什么选择《深入浅出Go语言》? 🚀 全面的基础知识体系 从环境搭建开始,对Go语言核心知识点进行深入探讨,深度挖掘每个基础知识的本质,为后续深入学习…...

flv视频格式批量截取封面图(不占内存版)--其他视频格式也通用
flv视频格式批量截取封面图(不占内存版)--其他视频格式也通用 需求(实现的效果)功能实现htmlcssjs 需求(实现的效果) 批量显示视频,后端若返回有imgUrl,则直接显示图1, 若无…...
【鸿蒙】大模型对话应用(三):跨Ability跳转页面
Demo介绍 本demo对接阿里云和百度的大模型API,实现一个简单的对话应用。 DecEco Studio版本:DevEco Studio 3.1.1 Release HarmonyOS SDK版本:API9 关键点:ArkTS、ArkUI、UIAbility、网络http请求、列表布局、层叠布局 页面跳…...

明道云入选亿欧智库《AIGC入局与低代码产品市场的发展研究》
2023年12月27日,亿欧智库正式发布**《AIGC入局与低代码产品市场的发展研究》**。该报告剖析了低代码/零代码市场的现状和发展趋势,深入探讨了大模型技术对此领域的影响和发展洞察。其中,亿欧智库将明道云作为标杆产品进行了研究和分析。 明…...

【深度学习】SDXL TensorRT Dockerfile Docker容器
文章目录 过程SDXL TensorRT构建SDXL TensorRT LCM 调度器过程 docker push kevinchina/deeplearning:cuda12.1torch2.1.1 FROM nvidia/cuda:12.1.1-cudnn8-devel-ubuntu22.04 ENV DEBIAN_FRONTEND=noninteractive# 安装基本软件包 RUN apt-get update && \apt-get u…...

深入了解 Ansible:全面掌握自动化 IT 环境的利器
本文以详尽的篇幅介绍了 Ansible 的方方面面,旨在帮助读者从入门到精通。无论您是初学者还是有一定经验的 Ansible 用户,都可以在本文中找到对应的内容,加深对 Ansible 的理解和应用。愿本文能成为您在 Ansible 自动化旅程中的良师益友&#…...
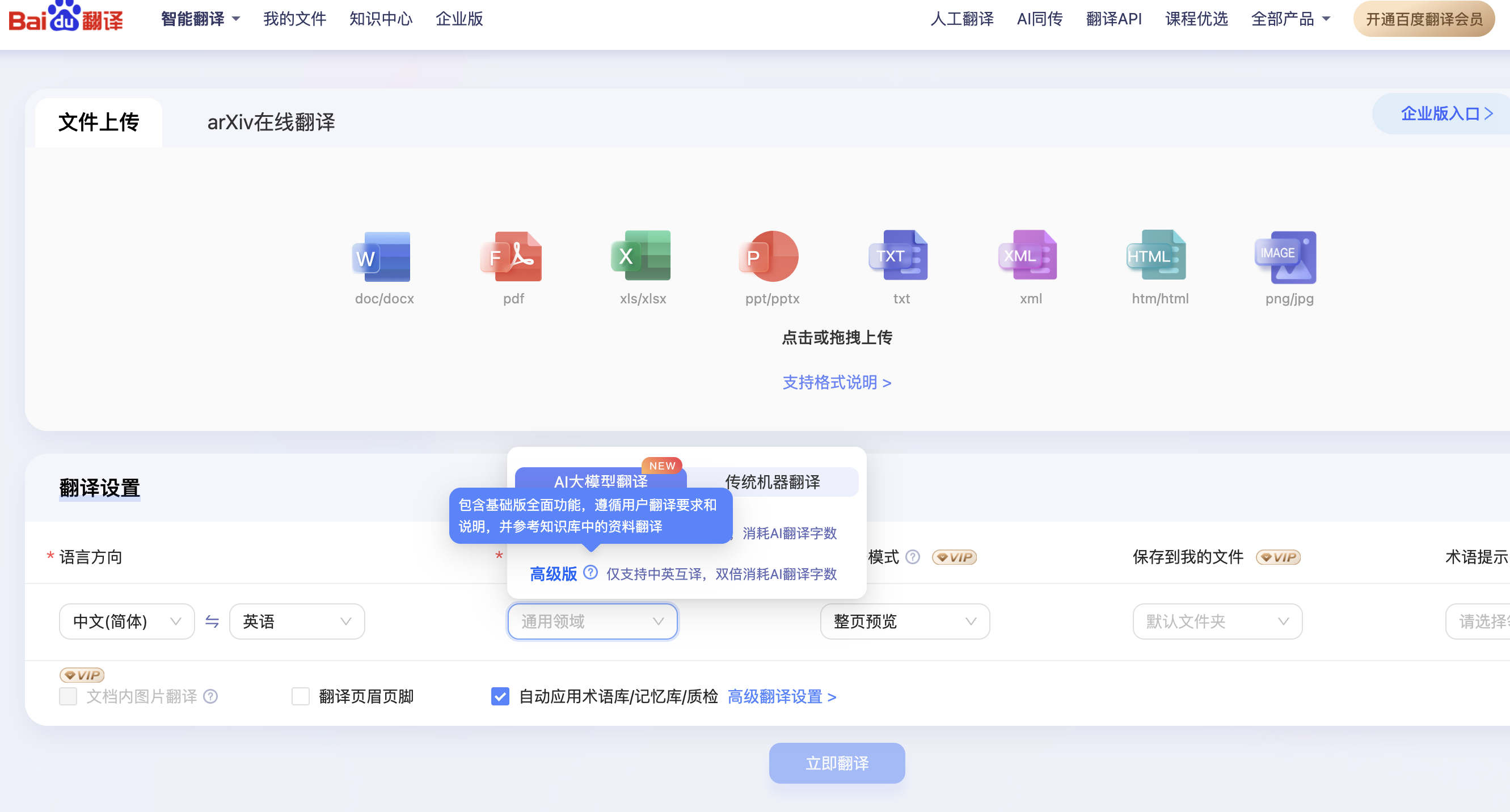
PPT、PDF全文档翻译相关产品调研笔记
主要找一下是否有比较给力的全文档翻译 文章目录 1 百度翻译2 小牛翻译3 腾讯交互翻译4 DeepL5 languagex6 云译科技7 快翻:qtrans8 simplifyai9 officetranslator10 火山引擎翻译-无文档翻译1 百度翻译 地址: https://fanyi.baidu.com/ 配套的比较完善,对于不同行业也有区…...

JavaScript 垃圾回收的常用策略和内存管理
垃圾回收 JavaScript 是使用垃圾回收的语言,也就是说执行环境负责在代码执行时管理内存。在 C 和 C等语言中,跟踪内存使用对开发者来说是个很大的负担,也是很多问题的来源。JavaScript 为开发者卸下了这个负担,通过自动内存管…...
如何结合ChatGPT生成个人魔法咒语词库
3.6.1 ChatGPT辅助力AI绘画 3.6.1.1 给定主题让ChatGPT直接描述 上面给了一个简易主题演示一下,这是完全我没有细化的提问,然后把直接把这些关键词组合在一起。 关键词: 黄山的美景,生机勃勃,湛蓝天空,青…...

瑞_23种设计模式_抽象工厂模式
文章目录 1 抽象工厂模式(Abstract Factory Pattern)1.1 概念1.2 介绍1.3 小结1.4 结构 2 案例一2.1 案例需求2.2 代码实现 3 案例二3.1 需求3.2 实现 4 总结4.1 抽象工厂模式优缺点4.2 抽象工厂模式使用场景4.3 抽象工厂模式VS工厂方法模式4.4 抽象工厂…...

SEO_如何通过内容SEO有效获取精准流量?
如何通过内容SEO有效获取精准流量? 在互联网时代,获取精准流量是每个网站和博客主人的首要目标之一。通过内容SEO,我们可以有效地提高网站在搜索引擎上的排名,吸引更多的访客。如何通过内容SEO有效获取精准流量呢?本文…...

手把手教你用Proteus给Arduino项目做“硬件体检”:以舵机控制为例
用Proteus为Arduino舵机项目做虚拟压力测试的5个实战技巧 当你花了两天时间焊接好电路板,满怀期待地给舵机通电时,突然闻到一股焦糊味——这种硬件翻车现场每个创客都经历过。仿真工具的价值就在于,它能让你在烧毁第一个元器件之前࿰…...

CSS如何制作透明度渐变的蒙版_使用linear-gradient从黑色过渡到透明
linear-gradient做透明蒙版时背景没变暗,是因为未使用带alpha通道的颜色(如rgba或带透明度的十六进制),而默认颜色如black或#000无透明度,导致渐变失效;必须用rgba(0,0,0,0.8)到rgba(0,0,0,0)等显式透明色&…...

3大核心优势!Calibre中文路径保护插件:从乱码困扰到高效管理的完整解决方案
3大核心优势!Calibre中文路径保护插件:从乱码困扰到高效管理的完整解决方案 【免费下载链接】calibre-do-not-translate-my-path Switch my calibre library from ascii path to plain Unicode path. 将我的书库从拼音目录切换至非纯英文(中文…...

Linux内核中的虚拟化技术
Linux内核中的虚拟化技术 引言 虚拟化技术是一种将物理资源抽象为虚拟资源的技术,它允许多个操作系统或应用程序在同一物理硬件上运行。Linux内核提供了丰富的虚拟化支持,包括KVM、容器、虚拟内存等。本文将深入探讨Linux内核中的虚拟化技术,…...

1949-2023年各地级市、县新注册农民专业合作社数量数据
数据介绍 农民专业合作社可以推动农业规模化与产业化经营资源整合,合作社通过集中土地、劳动力、资金等生产要素,实现规模化种植或养殖,降低单位生产成本。通过统一采购农资、技术培训、品牌销售,提升市场竞争力。 产业链延伸&a…...

Spring Security 2026 最佳实践:构建安全的 Java 应用
Spring Security 2026 最佳实践:构建安全的 Java 应用别叫我大神,叫我 Alex 就好。一、引言 大家好,我是 Alex。Spring Security 作为 Java 生态中最流行的安全框架,一直以其强大的功能和灵活的配置而受到开发者的喜爱。随着 Spri…...

中国AI Agent发展现状与生态分析
中国AI Agent发展现状与生态分析 1. 标题 (Title) [从“工具助手”到“决策伙伴”:全景拆解中国AI Agent的爆发逻辑、玩家图谱与下一个十年机遇][万字深度:202X中国AI Agent发展白皮书——技术攻坚、商业落地与生态全景解析][抢滩AGI入口之战:…...

MATLAB连续潮流程序:IEEE节点标准PV曲线绘制工具,支持14节点与33节点系统,具备分...
matlab连续潮流程序绘制PV曲线 静态电压稳定 该程序为连续潮流IEEE14节点和33节点的程序 运行出来有分岔点和鼻点 可移植性强,注释详细 这段程序主要是用来计算电力系统中的潮流分布,并绘制PV曲线。下面我将对程序进行详细的分析。首先,程序开…...

Go接口interface与鸭子类型
Go语言中的接口与鸭子类型编程 在编程世界中,Go语言的接口(interface)和鸭子类型(Duck Typing)是两种灵活而强大的设计模式。它们通过解耦类型与行为,让代码更具扩展性和可维护性。Go的接口不同于其他语言…...