Python调用pyspark报错整理
前言
Pycharm配置了SSH服务器和Anaconda的python解释器,如果没有配置可参考 大数据单机学习环境搭建(8)Linux单节点Anaconda安装和Pycharm连接
Pycharm执行的脚本
执行如下 pyspark_model.py 的python脚本,构建SparkSession来执行sparksql
"""脚本名称:Pycharm使用pyspark测试功能:Pycharm远程执行sparksql
"""
from pyspark.sql import SparkSession
import osos.environ['SPARK_HOME'] = '/opt/spark'
os.environ['JAVA_HOME'] = '/opt/jdk1.8'spark = SparkSession.builder \.appName('pyspark_conda') \.master("yarn") \.config("spark.sql.warehouse.dir", "hdfs://bigdata01:8020/user/hive/warehouse") \.config("hive.metastore.uris", "thrift://bigdata01:9083") \.enableHiveSupport() \.getOrCreate()spark.sql('select * from hostnames limit 10;').show()spark.stop()
报错一:pyspark版本不匹配
例如我当前集群环境Spark3.0.0,python的pyspark3.5.0,没有指定版本默认下载了最新的
报错信息 [JAVA_GATEWAY_EXITED] Java gateway process exited before sending its port number., 具体如下:
ssh://slash@bigdata01:22/opt/python3/bin/python3 -u /home/slash/etl/dwtool/pyspark/pyspark_script/pyspark_model.py
JAVA_HOME is not set
Traceback (most recent call last):File "/home/slash/etl/dwtool/pyspark/pyspark_script/pyspark_model.py", line 7, in <module>spark = SparkSession.builder \File "/opt/python3/lib/python3.8/site-packages/pyspark/sql/session.py", line 497, in getOrCreatesc = SparkContext.getOrCreate(sparkConf)File "/opt/python3/lib/python3.8/site-packages/pyspark/context.py", line 515, in getOrCreateSparkContext(conf=conf or SparkConf())File "/opt/python3/lib/python3.8/site-packages/pyspark/context.py", line 201, in __init__SparkContext._ensure_initialized(self, gateway=gateway, conf=conf)File "/opt/python3/lib/python3.8/site-packages/pyspark/context.py", line 436, in _ensure_initializedSparkContext._gateway = gateway or launch_gateway(conf)File "/opt/python3/lib/python3.8/site-packages/pyspark/java_gateway.py", line 107, in launch_gatewayraise PySparkRuntimeError(
pyspark.errors.exceptions.base.PySparkRuntimeError: [JAVA_GATEWAY_EXITED] Java gateway process exited before sending its port number.
如果坚持不更换python的pyspark版本,即使像报错2已经指定了JAVA_HOME 依然会有其他报错。例如下方报错 Py4JError ,所以最彻底的方法是替换pyspark版本与spark版本一致
Traceback (most recent call last):File "/home/slash/etl/dwtool/pyspark/pyspark_script/pyspark_model.py", line 7, in <module>spark = SparkSession.builder \File "/opt/python3/lib/python3.8/site-packages/pyspark/sql/session.py", line 497, in getOrCreatesc = SparkContext.getOrCreate(sparkConf)File "/opt/python3/lib/python3.8/site-packages/pyspark/context.py", line 515, in getOrCreateSparkContext(conf=conf or SparkConf())File "/opt/python3/lib/python3.8/site-packages/pyspark/context.py", line 203, in __init__self._do_init(File "/opt/python3/lib/python3.8/site-packages/pyspark/context.py", line 316, in _do_initself._jvm.PythonUtils.getPythonAuthSocketTimeout(self._jsc)File "/opt/python3/lib/python3.8/site-packages/py4j/java_gateway.py", line 1549, in __getattr__raise Py4JError(
py4j.protocol.Py4JError: org.apache.spark.api.python.PythonUtils.getPythonAuthSocketTimeout does not exist in the JVM
报错二:JAVA_HOME指定不成功
python的pyspark已经重装3.0.0版本(下载时指定版本 pip install pyspark==3.0.0),报错信息 Java gateway process exited before sending its port number., JAVA_HOME is not set 具体如下:
ssh://slash@bigdata01:22/opt/python3/bin/python3 -u /home/slash/etl/dwtool/pyspark/pyspark_script/pyspark_model.py
JAVA_HOME is not set
Traceback (most recent call last):File "/home/slash/etl/dwtool/pyspark/pyspark_script/pyspark_model.py", line 7, in <module>spark = SparkSession.builder \File "/opt/python3/lib/python3.8/site-packages/pyspark/sql/session.py", line 186, in getOrCreatesc = SparkContext.getOrCreate(sparkConf)File "/opt/python3/lib/python3.8/site-packages/pyspark/context.py", line 371, in getOrCreateSparkContext(conf=conf or SparkConf())File "/opt/python3/lib/python3.8/site-packages/pyspark/context.py", line 128, in __init__SparkContext._ensure_initialized(self, gateway=gateway, conf=conf)File "/opt/python3/lib/python3.8/site-packages/pyspark/context.py", line 320, in _ensure_initializedSparkContext._gateway = gateway or launch_gateway(conf)File "/opt/python3/lib/python3.8/site-packages/pyspark/java_gateway.py", line 105, in launch_gatewayraise Exception("Java gateway process exited before sending its port number")
Exception: Java gateway process exited before sending its port number
指定内容如下:
# pyspark3.5.0指定了 SPARK_HOME JAVA_HOME还是会报错
# pyspark3.0.0指定后成功运行
os.environ['SPARK_HOME'] = '/opt/spark'
os.environ['JAVA_HOME'] = '/opt/jdk1.8'
报错三:python版本问题
最开始安装的最新版的anaconda环境,其中python3.11,安装pyspark3.0.0也会报错 TypeError: code() argument 13 must be str, not int,具体内容如下:
ssh://slash@bigdata01:22/opt/anaconda3/bin/python3.11 -u /home/slash/etl/dwtool/pyspark/pyspark_script/pyspark_model.py
Traceback (most recent call last):File "/home/slash/etl/dwtool/pyspark/pyspark_script/pyspark_model.py", line 1, in <module>from pyspark.sql import SparkSessionFile "/opt/anaconda3/lib/python3.11/site-packages/pyspark/__init__.py", line 51, in <module>from pyspark.context import SparkContextFile "/opt/anaconda3/lib/python3.11/site-packages/pyspark/context.py", line 30, in <module>from pyspark import accumulatorsFile "/opt/anaconda3/lib/python3.11/site-packages/pyspark/accumulators.py", line 97, in <module>from pyspark.serializers import read_int, PickleSerializerFile "/opt/anaconda3/lib/python3.11/site-packages/pyspark/serializers.py", line 71, in <module>from pyspark import cloudpickleFile "/opt/anaconda3/lib/python3.11/site-packages/pyspark/cloudpickle.py", line 209, in <module>_cell_set_template_code = _make_cell_set_template_code()^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^File "/opt/anaconda3/lib/python3.11/site-packages/pyspark/cloudpickle.py", line 172, in _make_cell_set_template_codereturn types.CodeType(^^^^^^^^^^^^^^^
TypeError: code() argument 13 must be str, not int
删除 /opt/anaconda3的文件夹后,重新安装了 Anaconda3-2021.05-Linux-x86_64.sh 版本的anaconda,其中python3.8,利用pyspark3.0.0第三方库操作spark3.0.0的计算引擎构建SparkSession,执行sparksql成功。
声明:本文所载信息不保证准确性和完整性。文中所述内容和意见仅供参考,不构成实际商业建议,如有雷同纯属巧合。
相关文章:

Python调用pyspark报错整理
前言 Pycharm配置了SSH服务器和Anaconda的python解释器,如果没有配置可参考 大数据单机学习环境搭建(8)Linux单节点Anaconda安装和Pycharm连接 Pycharm执行的脚本 执行如下 pyspark_model.py 的python脚本,构建SparkSession来执行sparksql "&qu…...

快递员的烦恼 - 华为OD统一考试
OD统一考试(C卷) 分值: 200分 题解: Java / Python / C 题目描述 快递公司每日早晨,给每位快递员推送需要淡到客户手中的快递以及路线信息,快递员自己又查找了一些客户与客户之间的路线距离信息࿰…...
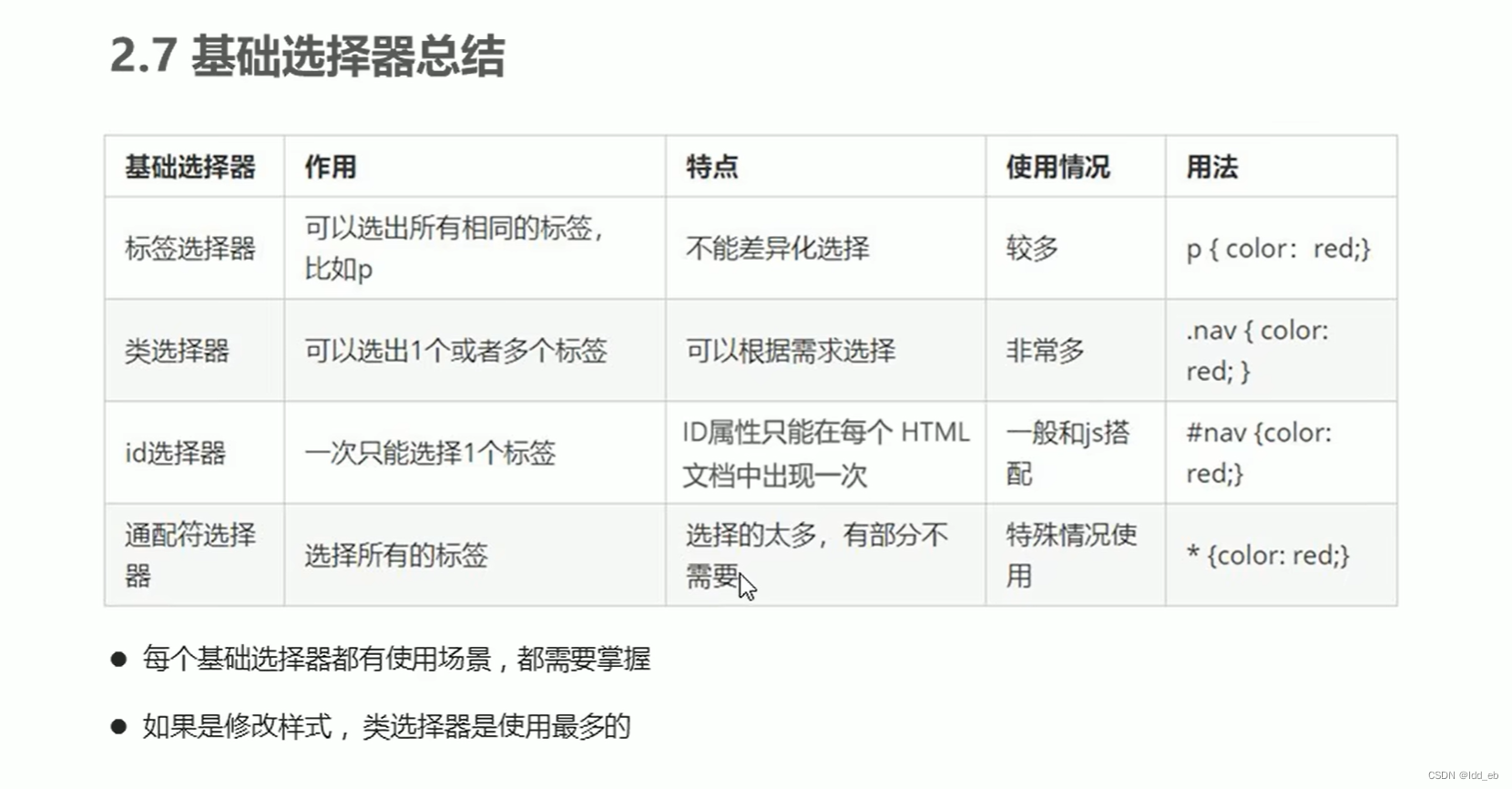
css1基础选择器
大纲 一.标签选择器 比较简单,前面直接写目标标签 二.类选择器 应用 例子 三.多类名选择器(调用时中间用空格隔开) 四.id选择器 应用 五.通配符选择器 应用 六.总结...

【C语言】内联函数总结
内联函数定义 inline关键字是C99标准的型关键字,其作用是将函数展开,把函数的代码复制到每一个调用处。这样调用函数的过程就可以直接执行函数代码,而不发生跳转、压栈等一般性函数操作。可以节省时间,也会提高程序的执行速度。 …...

鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之MenuItemGroup组件
鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之MenuItemGroup组件 一、操作环境 操作系统: Windows 10 专业版、IDE:DevEco Studio 3.1、SDK:HarmonyOS 3.1 二、MenuItemGroup组件 该组件用来展示菜单MenuItem的分组。 子组件 无 接…...

【Linux多线程编程】互斥锁及其使用
1、互斥锁 用于解决竞争问题的一种机制。 什么是竞争,竞争就是多个实体同时获取一个资源,例如多个线程写一个全局变量。 2、Linux如何使用互斥锁 以pthread为例,锁的创建和使用如下: /* 创建锁 */ pthread_mutex_t lock PTHR…...

RabbitMQ_00000
MQ的相关概念 RabbitMQ官网地址:https://www.rabbitmq.com RabbitMQ API地址:https://rabbitmq.github.io/rabbitmq-java-client/api/current/ 什么是MQ? MQ(message queue)本质是个队列,FIFO先入先出,只不过队列中…...

【linux】docker下homeassistant和nodered安装及配置
1、homeassistant安装 从 Docker Hub 上拉取 Home Assistant 的镜像文件 docker pull homeassistant/home-assistant 是运行 Home Assistant 容器 docker run -id --name"homeassistant" --privileged --restart always -p 8123:8123 -e TZAisa/Shanghai --nethost…...

Qt扩展-muParser数学公式解析
muParser数学公式解析 一、概述1. 针对速度进行了优化2. 支持的运算符3. 支持的函数4. 用户定义的常量5. 用户定义的变量6. 自定义值识别回调7. 其他功能 二、内置函数三、内置二元运算符四、三元运算符五、内置常量六、源码引入1. 源码文件2. 编译器开关1. MUP_BASETYPE2.MUP_…...

【Matplotlib】figure方法之图形的保存
🎈个人主页:甜美的江 🎉欢迎 👍点赞✍评论⭐收藏 🤗收录专栏:matplotlib 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进…...
)
数据库管理-第142期 DBA?DBA!(20240131)
数据库管理142期 2024-01-31 数据库管理-第142期 DBA?DBA!(20240131)正文总结 数据库管理-第142期 DBA?DBA!(20240131) 作者:胖头鱼的鱼缸(尹海文)…...
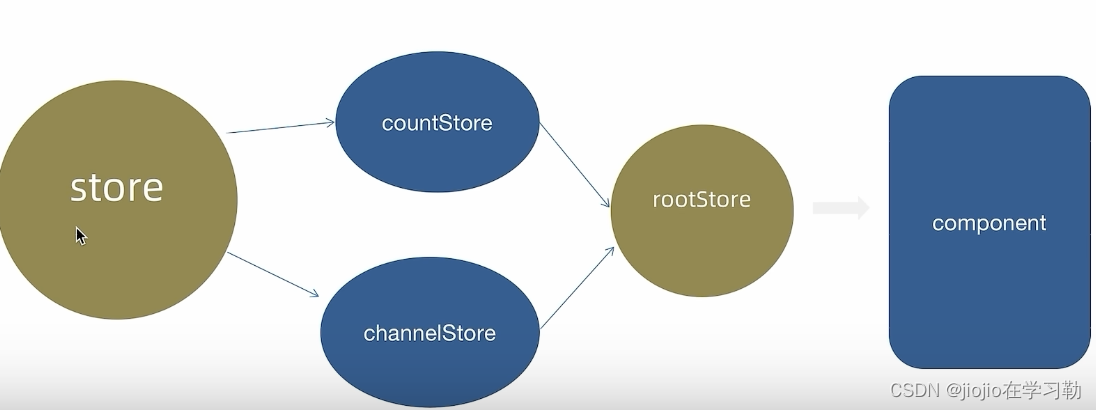
react 之 zustand
zustand可以说是redux的平替 官网地址:https://zustand-demo.pmnd.rs/ 1.安装 npm i zustand2.基础使用 // zustand import { create } from zustand// 1. 创建store // 语法容易出错 // 1. 函数参数必须返回一个对象 对象内部编写状态数据和方法 // 2. set是用来…...

leetcode-回文链表
234. 回文链表 在此对比的值,不是节点 # Definition for singly-linked list. # class ListNode: # def __init__(self, val0, nextNone): # self.val val # self.next next class Solution:def isPalindrome(self, head: Optional[ListNod…...

Pinia:一个Vue的状态管理库
Pinia的使用方法包括以下步骤: 安装Pinia:通过yarn或npm进行安装: yarn命令: yarn add pinianpm命令: npm install pinia创建根存储:在main.ts中引入Pinia插件,并创建一个根存储。这可以通过创建…...
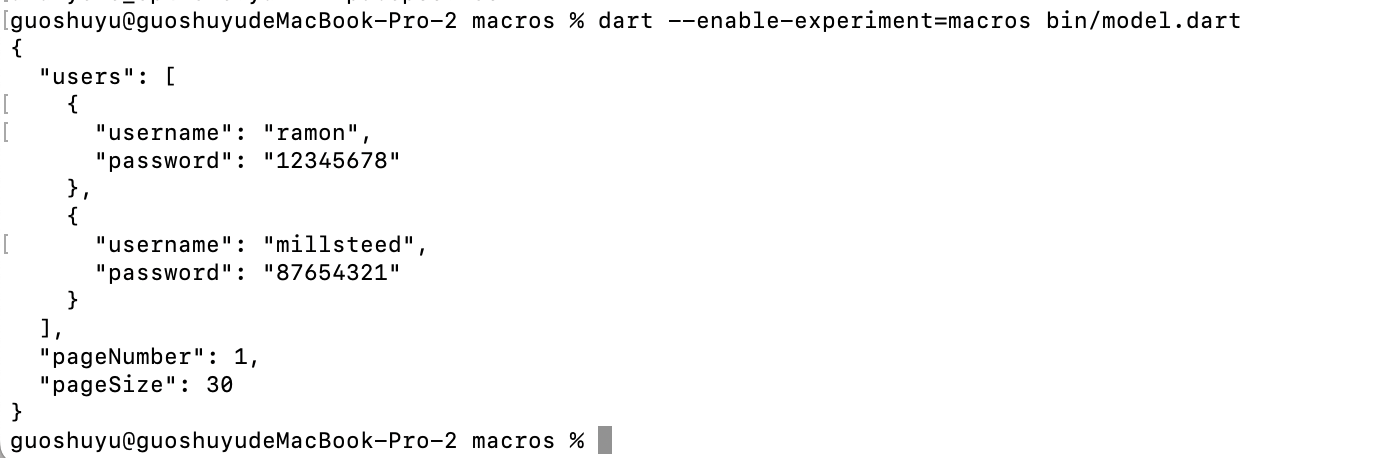
2024 Flutter 重大更新,Dart 宏(Macros)编程开始支持,JSON 序列化有救
说起宏编程可能大家并不陌生,但是这对于 Flutter 和 Dart 开发者来说它一直是一个「遗憾」,这个「遗憾」体现在编辑过程的代码修改支持上,其中最典型的莫过于 Dart 的 JSON 序列化。 举个例子,目前 Dart 语言的 JSON 序列化高度依…...

云计算概述(云计算类型、技术驱动力、关键技术、特征、特点、通用点、架构层次)(二)
云计算概述(二) (云计算类型、技术驱动力、关键技术、特征、特点、通用点、架构层次) 目录 零、00时光宝盒 一、云计算类型(以服务的内容或形态来分) 二、云计算的12种技术驱动力 三、云计算的关键技术 四、云计…...
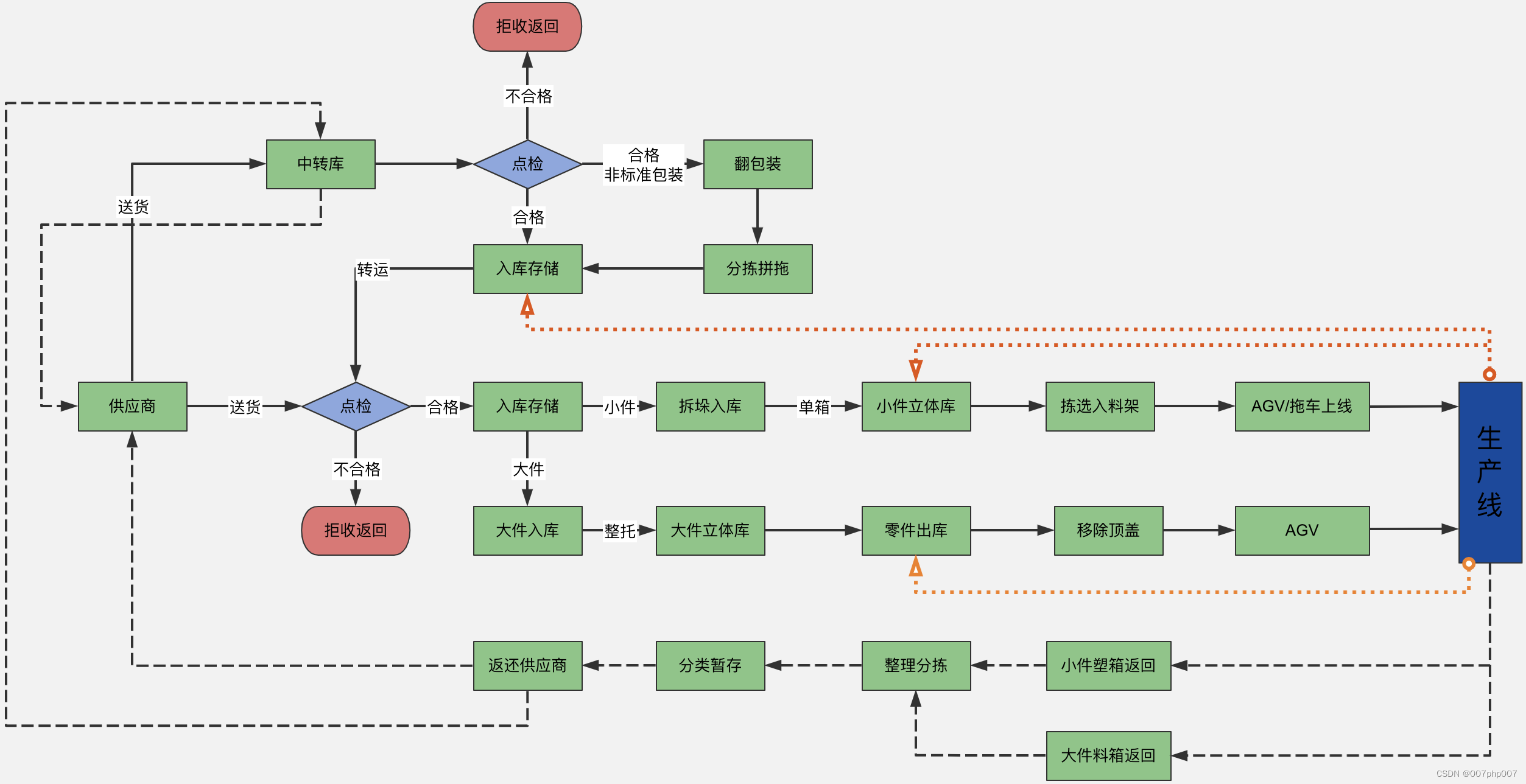
物流平台架构设计与实践
随着电商行业的迅猛发展,物流行业也得到了极大的发展。从最初的传统物流到现在的智慧物流,物流技术和模式也在不断的更新与升级。物流平台作为连接电商和物流的重要媒介,其架构设计和实践显得尤为重要。 一、物流平台架构设计 1. 前端架构设…...
RedHat8.4安装邮件服务器
一、配置发件服务器 1.1 根据现场IP,配置主机名 vim /etc/hosts 192.168.8.120 mail.test.com 将主机名更改为邮件服务器域名mail.test.com 1.2 关闭防火墙,禁止开机启动 systemctl stop firewalld systemctl disable firewalld 1.3 关闭selinux v…...

Linux Shell系列--dirname 去除基本文件名
一、目的 上一篇中我们介绍了basename命令的使用,本篇我们介绍dirname命令,dirname 命令与 basename 互补,它负责删除路径中的基本文件名部分(包括扩展名),只保留目录部分。 二、介绍 dirname首先去除字符…...
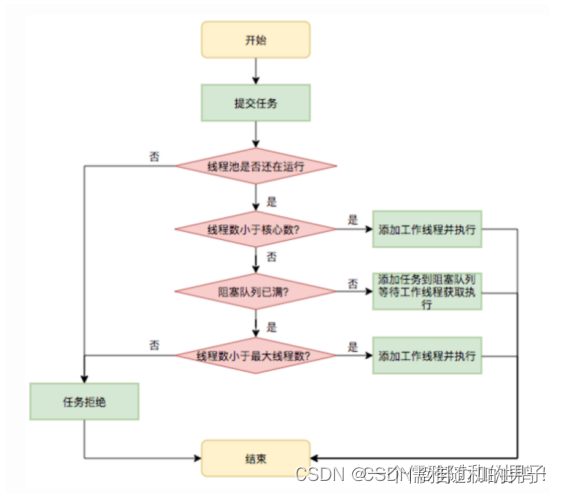
池化技术的总结
文章目录 1.什么是池化技术2.池化技术的应用一、连接池二、线程池三、内存池 3.池化技术的总结 1.什么是池化技术 池化技术指的是提前准备一些资源,在需要时可以重复使用这些预先准备的资源。 在系统开发过程中,我们经常会用到池化技术。通俗的讲&am…...

JAVA打车小程序实现原理及开源uniapp代码片段
JAVA打车小程序实现原理打车小程序的核心功能包括用户端、司机端和后台管理系统。用户端实现叫车、订单管理、支付等功能;司机端实现接单、导航、收益管理等功能;后台管理系统负责订单监控、用户管理、数据统计等。用户端功能模块包括地图定位、路线规划…...

从仿真到焊板:手把手教你用741运放和Multisim搞定一个1kHz文氏电桥振荡器
从仿真到焊板:用741运放构建1kHz文氏电桥振荡器的工程实践指南 当你第一次尝试将课本上的振荡电路理论转化为实际可工作的电路时,往往会发现仿真完美的设计在实际搭建时问题百出。文氏电桥振荡器作为经典的RC正弦波发生器,是理解振荡原理和掌…...

【花雕动手做】ESP32-S3 + MimiClaw 实战:通过飞书自然语言指令控制板载 WS2812 彩灯
【花雕动手做】嵌入式 AI Agent 实战:MimiClaw ESP32-S3 接入飞书,远程控制板载 RGB 全彩灯效 ——从源码修改到飞书指令,手把手打造一个能“听懂颜色话”的嵌入式 AI 智能体 一、引言:当“养龙虾”热潮遇到嵌入式 AI 2026 年开春…...

如何快速解锁WeMod Pro功能:Wand-Enhancer完整免费指南
如何快速解锁WeMod Pro功能:Wand-Enhancer完整免费指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer Wand-Enhancer是一款强大的开源工具&…...

掌握微信小程序逆向分析的3个关键:wxappUnpacker深度解析与实战指南
掌握微信小程序逆向分析的3个关键:wxappUnpacker深度解析与实战指南 【免费下载链接】wxappUnpacker 项目地址: https://gitcode.com/gh_mirrors/wxappu/wxappUnpacker 在微信小程序开发与学习过程中,开发者常常需要深入理解优秀小程序的实现原理…...

AI辅助开发:构思并实现智能交互式谷歌账号注册学习助手
AI辅助开发:构思并实现智能交互式谷歌账号注册学习助手 最近在做一个谷歌账号注册教程项目时,发现传统的图文教程存在几个痛点:用户容易迷失在步骤中、遇到错误时不知道如何解决、非英语用户理解困难。正好接触到InsCode(快马)平台的AI辅助开…...

突破系统壁垒:APK Installer实现Windows运行安卓应用的技术方案
突破系统壁垒:APK Installer实现Windows运行安卓应用的技术方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 随着跨平台应用需求的增长,Wind…...
—Linkage Mapper与Circuitscape环境部署详解)
生态廊道构建实战指南(1)—Linkage Mapper与Circuitscape环境部署详解
1. 生态廊道构建工具入门指南 第一次接触生态廊道分析的朋友可能会被各种专业术语吓到,其实没那么复杂。简单来说,Linkage Mapper和Circuitscape就是帮我们在数字地图上找出动物迁徙"高速公路"的神器。想象一下,你是一位城市规划师…...

VMware macOS虚拟机解锁方案:开源工具Unlocker完整实践指南
VMware macOS虚拟机解锁方案:开源工具Unlocker完整实践指南 【免费下载链接】unlocker VMware Workstation macOS 项目地址: https://gitcode.com/gh_mirrors/unloc/unlocker 你是否想在Windows或Linux系统上运行macOS虚拟机,却苦于VMware不支持…...

Maya Arnold前台渲染无响应问题排查与解决
1. Maya Arnold前台渲染无响应问题排查指南 最近在Maya中使用Arnold渲染时,不少朋友都遇到了前台渲染无响应的问题。点击渲染按钮后,Render View窗口毫无反应,就像什么都没发生过一样。这种情况在动画场景整合阶段尤其常见,我自己…...