【操作系统】HeapByteBuffer和DirectByteBuffer的区别
DirectByteBuffer和HeapByteBuffer是Java NIO中ByteBuffer的两种实现方式。
HeapByteBuffer是在Java堆上分配的字节缓冲区,它使用数组来存储数据。HeapByteBuffer的优点是它具有良好的兼容性和可移植性,且在大多数情况下性能表现良好。它适用于大部分的应用场景,并且在内存管理方面具有更好的可控性和可调优性。
DirectByteBuffer是在直接内存中分配的字节缓冲区,它不是使用Java堆上的数组来存储数据,而是使用JNI(Java Native Interface)来直接操作本地内存。DirectByteBuffer的优点是它可以提供更高的IO性能,因为数据可以直接从内核缓冲区复制到DirectByteBuffer中,避免了数据的复制。它适用于处理大量的数据、网络数据传输、以及需要与本地库进行高效交互的场景。
堆内内存与堆外内存
堆内内存(Heap Memory)和堆外内存(Off-Heap Memory)是指在JAVA中两种不同的内存分配方式,其中的堆指的是JVM中的堆。
堆内内存:
-
堆内内存是指在Java堆中分配的内存。在Java中,对象的创建和销毁都是在堆内存中进行的。堆内内存由Java虚拟机(JVM)的垃圾回收机制进行管理,即通过垃圾回收器自动进行内存回收。
-
堆内内存具有自动内存管理的特性,程序员不需要手动释放内存。Java的堆内内存使用的是Java堆中的对象引用,通过引用计数和可达性分析等机制进行垃圾回收。
堆外内存:
-
堆外内存是指在Java堆之外分配的内存,也称为直接内存(Direct Memory)。
-
堆外内存通常由本地操作系统管理,不受JVM垃圾回收的控制。程序员需要手动释放这部分内存,一般通过Java NIO中的ByteBuffer的
cleaner()方法或显式调用free()方法来释放。 -
堆外内存的分配和释放并不会受到Java堆内存的限制,可以提供更大的内存空间。
-
堆外内存适用于需要更高的IO性能、处理大量数据或需要与本地库进行高效交互的场景。在网络编程、数据库操作、图形处理等领域常常使用堆外内存。
需要注意的是,堆外内存的分配和释放需要谨慎操作,因为它不受Java堆内存的自动管理,容易导致内存泄漏和内存溢出等问题。因此,在使用堆外内存时,需要合理地管理内存的生命周期。
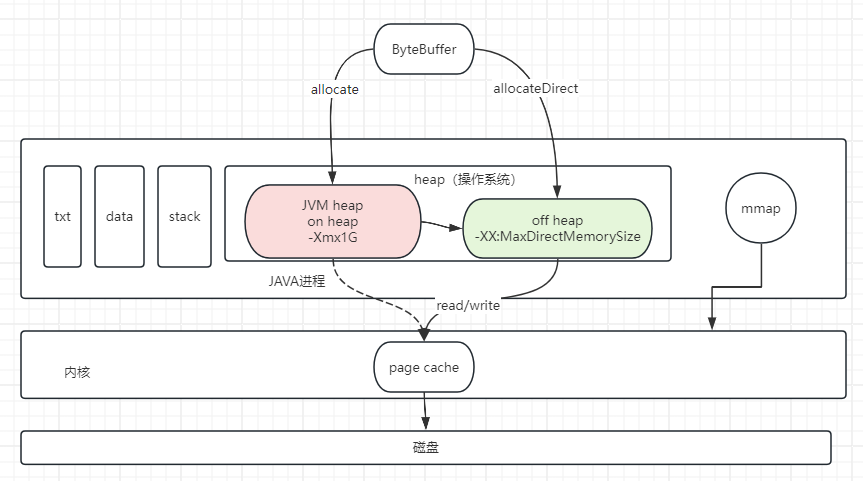
HeapByteBuffer
HeapByteBuffer主要用于在JVM堆内存中分配和操作字节。
HeapByteBuffer的使用如下:
package com.morris.io;import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
import java.nio.charset.StandardCharsets;/*** HeapByteBuffer的使用*/
public class HeapByteBufferDemo {public static void main(String[] args) throws IOException {ByteBuffer byteBuffer = ByteBuffer.allocate(1024);byteBuffer.put("hello".getBytes(StandardCharsets.UTF_8));byteBuffer.flip();FileOutputStream fos = new FileOutputStream("HeapByteBufferDemo.txt");FileChannel channel = fos.getChannel();channel.write(byteBuffer);channel.close();fos.close();}
}
产生的系统调用如下:
openat(AT_FDCWD, "HeapByteBufferDemo.txt", O_WRONLY|O_CREAT|O_TRUNC, 0666) = 4
fstat(4, {st_mode=S_IFREG|0777, st_size=0, ...}) = 0
write(4, "hello", 5) = 5
close(4)
HeapByteBuffer的内部实现通过使用数组来存储数据,可以在HeapByteBuffer的构造方法中看到数组的创建:
HeapByteBuffer(int cap, int lim) { // package-private// 创建了一个字节数组super(-1, 0, lim, cap, new byte[cap], 0);
}
DirectByteBuffer
DirectByteBuffer主要用于在操作系统的内存中分配和操作字节。与HeapByteBuffer不同,DirectByteBuffer直接在操作系统的内存中分配数据。
DirectByteBuffer的使用如下:
package com.morris.io;import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
import java.nio.charset.StandardCharsets;/*** DirectByteBuffer的使用*/
public class DirectByteBufferDemo {public static void main(String[] args) throws IOException {System.in.read();ByteBuffer byteBuffer = ByteBuffer.allocateDirect(1024*128);byteBuffer.put("hello".getBytes(StandardCharsets.UTF_8));byteBuffer.flip();System.in.read();FileOutputStream fos = new FileOutputStream("DirectByteBufferDemo.txt");FileChannel channel = fos.getChannel();channel.write(byteBuffer);channel.close();fos.close();}
}
产生的系统调用如下:
mmap(NULL, 135168, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7fdb8c000000
openat(AT_FDCWD, "DirectByteBufferDemo.txt", O_WRONLY|O_CREAT|O_TRUNC, 0666) = 4
fstat(4, {st_mode=S_IFREG|0777, st_size=0, ...}) = 0
write(4, "hello", 5) = 5
close(4)
我们在应用程序中申请了128KB(128*1024=131072B)的内存,底层会使用mmap系统调用在进程的堆内分配一块132KB的内存,这块内存是在进程的堆内,JVM的堆外
在上面的例子中,我们申请了128KB的内存,实际上分配一块132KB的内存,为什么会多分配4KB呢?我也没明白?
DirectByteBuffer的构造方法如下:
DirectByteBuffer(int cap) { // package-privatesuper(-1, 0, cap, cap);boolean pa = VM.isDirectMemoryPageAligned();int ps = Bits.pageSize();long size = Math.max(1L, (long)cap + (pa ? ps : 0));Bits.reserveMemory(size, cap);long base = 0;try {base = unsafe.allocateMemory(size);} catch (OutOfMemoryError x) {Bits.unreserveMemory(size, cap);throw x;}unsafe.setMemory(base, size, (byte) 0);if (pa && (base % ps != 0)) {// Round up to page boundaryaddress = base + ps - (base & (ps - 1));} else {address = base;}cleaner = Cleaner.create(this, new Deallocator(base, size, cap));att = null;
}
我们可以看到DirectByteBuffer底层是使用unsafe.allocateMemory来申请堆外内存,这是一个本地方法。
实际上我们自己也可以借助unsafe来申请堆外内存:
package com.morris.io;import sun.misc.Unsafe;import java.io.IOException;
import java.lang.reflect.Field;/*** 使用unsafe来申请内存*/
public class UnsafeAllocateMemoryDemo {public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException, IOException {Unsafe unsafe = getUnsafe();long address = unsafe.allocateMemory(128 * 1024);unsafe.freeMemory(address);}public static Unsafe getUnsafe() throws NoSuchFieldException, IllegalAccessException {Field field = Unsafe.class.getDeclaredField("theUnsafe");field.setAccessible(true);return (Unsafe) field.get(null);}
}
产生的系统调用如下:
mmap(NULL, 135168, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7fe07801c000
munmap(0x7fe07801c000, 135168) = 0
当使用mmap系统调用申请到堆外内存空间后,可以使用munmap系统调用来释放这块内存。
为什么要使用DirectByteBuffer?
从上面的例子可以看到DirectByteBuffer在使用的过程中会比HeapByteBuffer多一次系统调用,性能不如HeapByteBuffer,为什么性能差却还使用DirectByteBuffer呢?
看源码,这里以FileChannel实现类FileChannelImpl.read中为例:
sun.nio.ch.FileChannelImpl#write(java.nio.ByteBuffer)
public int write(ByteBuffer var1) throws IOException {this.ensureOpen();if (!this.writable) {throw new NonWritableChannelException();} else {synchronized(this.positionLock) {int var3 = 0;int var4 = -1;byte var5;try {this.begin();var4 = this.threads.add();if (this.isOpen()) {do {var3 = IOUtil.write(this.fd, var1, -1L, this.nd);} while(var3 == -3 && this.isOpen());int var12 = IOStatus.normalize(var3);return var12;}var5 = 0;} finally {this.threads.remove(var4);this.end(var3 > 0);assert IOStatus.check(var3);}return var5;}}
}
然后会调用IOUtil.write():
static int write(FileDescriptor var0, ByteBuffer var1, long var2, NativeDispatcher var4) throws IOException {if (var1 instanceof DirectBuffer) {return writeFromNativeBuffer(var0, var1, var2, var4);} else {int var5 = var1.position();int var6 = var1.limit();assert var5 <= var6;int var7 = var5 <= var6 ? var6 - var5 : 0;ByteBuffer var8 = Util.getTemporaryDirectBuffer(var7);int var10;try {var8.put(var1);var8.flip();var1.position(var5);int var9 = writeFromNativeBuffer(var0, var8, var2, var4);if (var9 > 0) {var1.position(var5 + var9);}var10 = var9;} finally {Util.offerFirstTemporaryDirectBuffer(var8);}return var10;}
}
当向FileChannel中写数据,数据来源是DirectByteBuffer时,可以直接将DirectByteBuffer中的数据写入到文件中。
当向FileChannel中写数据,数据来源是HeapByteBuffer时,需要先将数据从HeapByteBuffer写入到一个临时的DirectByteBuffer中,再将临时DirectByteBuffer中的数据写入到文件中。
所以,当java程序数据需要频繁与本地io(本地磁盘、socket传输数据时),使用HeapByteBuffer读取时要多复制一次数据(即从DirectByteBuffer再复制到heapByteBuffer)。再加上写数据到本地时,又要再从HeapByteBuffer复制到另一个DirectByteBuffer,多了两次复制。
HeapByteBuffer底层其实是java的字节数组,而java字节数组是一个java对象,对象的内存是由jvm的堆进行管理的,那么不可避免的是GC时年轻代的eden、suvivor到老年代的各种复制以及回收。当字节数组比较小的时候还好说,如果是大对象,那么对于jvm的GC来说是一个很大的负担。而使用DirectByteBuffer,则是把字节数组交给操作系统管理(堆外内存),就可以极大的减少jvm的负担了。
DirectByteBuffer和HeapByteBuffer的使用场景
什么情况下使用DirectByteBuffer?
-
频繁的native IO,即java程序与本地磁盘、socket传输数据。
-
不需要经常创建和销毁DirectByteBuffer对象,有系统调用代价大,可以使用池复用DirectByteBuffer
-
DirectByteBuffer不会占用堆内存。也就是不会受到堆大小限制,只在DirectByteBuffer对象被回收后才会释放该缓冲区。
-
大文件造成大对象,对GC负担比较重的情况
什么情况下使用HeapByteBuffer?其实除了上述的DirectByteBuffer使用场景之外的,基本可以用HeapByteBuffer。
-
数据仅在java程序中流转传输,不与本地进行IO,例如Netty的责任链中传递对象可以使用HeapByteBuffer
-
容量低,对GC负担低。快速回收
相关文章:
【操作系统】HeapByteBuffer和DirectByteBuffer的区别
DirectByteBuffer和HeapByteBuffer是Java NIO中ByteBuffer的两种实现方式。 HeapByteBuffer是在Java堆上分配的字节缓冲区,它使用数组来存储数据。HeapByteBuffer的优点是它具有良好的兼容性和可移植性,且在大多数情况下性能表现良好。它适用于大部分的…...

C++并发编程 -2.线程间共享数据
本章就以在C中进行安全的数据共享为主题。避免上述及其他潜在问题的发生的同时,将共享数据的优势发挥到最大。 一. 锁分类和使用 按照用途分为互斥、递归、读写、自旋、条件变量。本章节着重介绍前四种,条件变量后续章节单独介绍。 由于锁无法进行拷贝…...
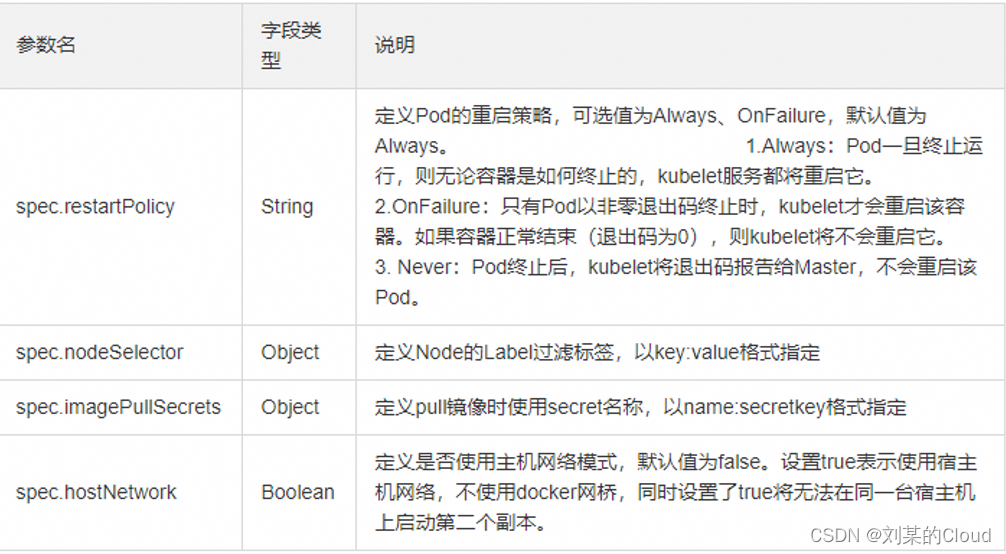
Kubernetes-资源清单
一、k8s中的资源 什么是资源清单 我们跟kubernetes集群进行交互的时候,我们需要给K8S集群传输数据,传输信息,K8S才能按照我们的要求来运行,这个传输的文件,基本上都会通过资源清单进行传递。资源清单是我们跟集群进行…...

ABAP 笔记--内表结构不一致,无法更新数据库MODIFY和UPDATE
目录 ABAP 笔记内表结构不一致,无法更新数据库MODIFY和UPDATE ABAP 笔记 内表结构不一致,无法更新数据库 MODIFY和UPDATE 如果是使用MODIFY或者UPDATE...
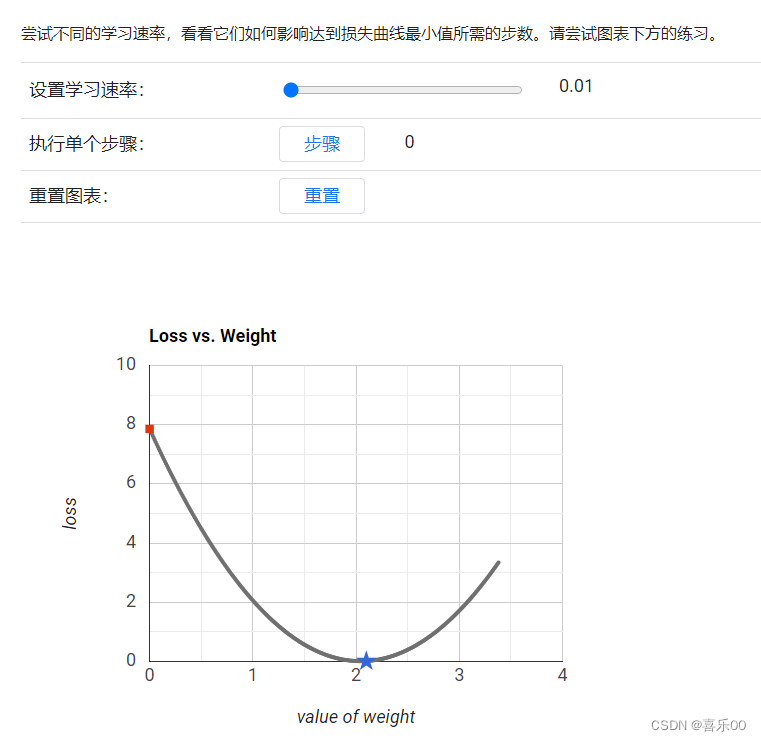
机器学习-3降低损失(Reducing Loss)
机器学习-3降低损失(Reducing Loss) 学习内容来自:谷歌ai学习 https://developers.google.cn/machine-learning/crash-course/framing/check-your-understanding?hlzh-cn 本文作为学习记录1.降低损失:迭代方法 迭代学习 下图展示了机器学习算法用于训…...
-高精度-减-高精度)
蓝桥杯备战(AcWing算法基础课)-高精度-减-高精度
目录 前言 1 题目描述 2 分析 2.1 第一步 2.2 第二步 3 代码 前言 详细的代码里面有自己的理解注释 1 题目描述 给定两个正整数(不含前导 00),计算它们的差,计算结果可能为负数。 输入格式 共两行,每行包含一…...
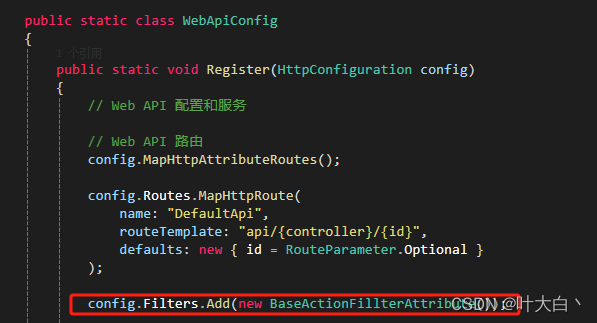
AspNet web api 和mvc 过滤器差异
最近在维护老项目。定义个拦截器记录接口日志。但是发现不生效 最后发现因为继承的 ApiController不是Controller 只能用 System.Web.Http下的拦截器生效。所以现在总结归纳一下 Web Api: System.Web.Http.Filters.ActionFilterAttribute 继承该类 Mvc: System.Web.Mvc.Ac…...
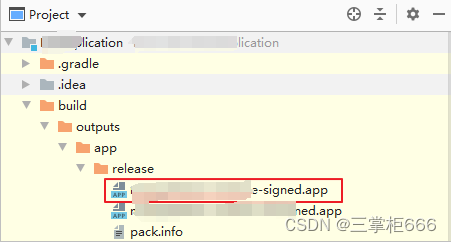
HarmonyOS应用/服务发布:打造多设备生态的关键一步
目前 前言HarmonyOS 应用/服务发布的重要性使用HarmonyOS 构建跨设备的应用生态前期准备工作简述发布流程生成签名文件配置签名信息编译构建.app文件上架.app文件到AGC结束语 前言 随着智能设备的快速普及和多样化,以及编程语言的迅猛发展,构建一个无缝…...
【数据结构】双向带头循环链表实现及总结
简单不先于复杂,而是在复杂之后。 文章目录 1. 双向带头循环链表的实现2. 顺序表和链表的区别 1. 双向带头循环链表的实现 List.h #pragma once #include <stdio.h> #include <assert.h> #include <stdlib.h> #include <stdbool.h>typede…...
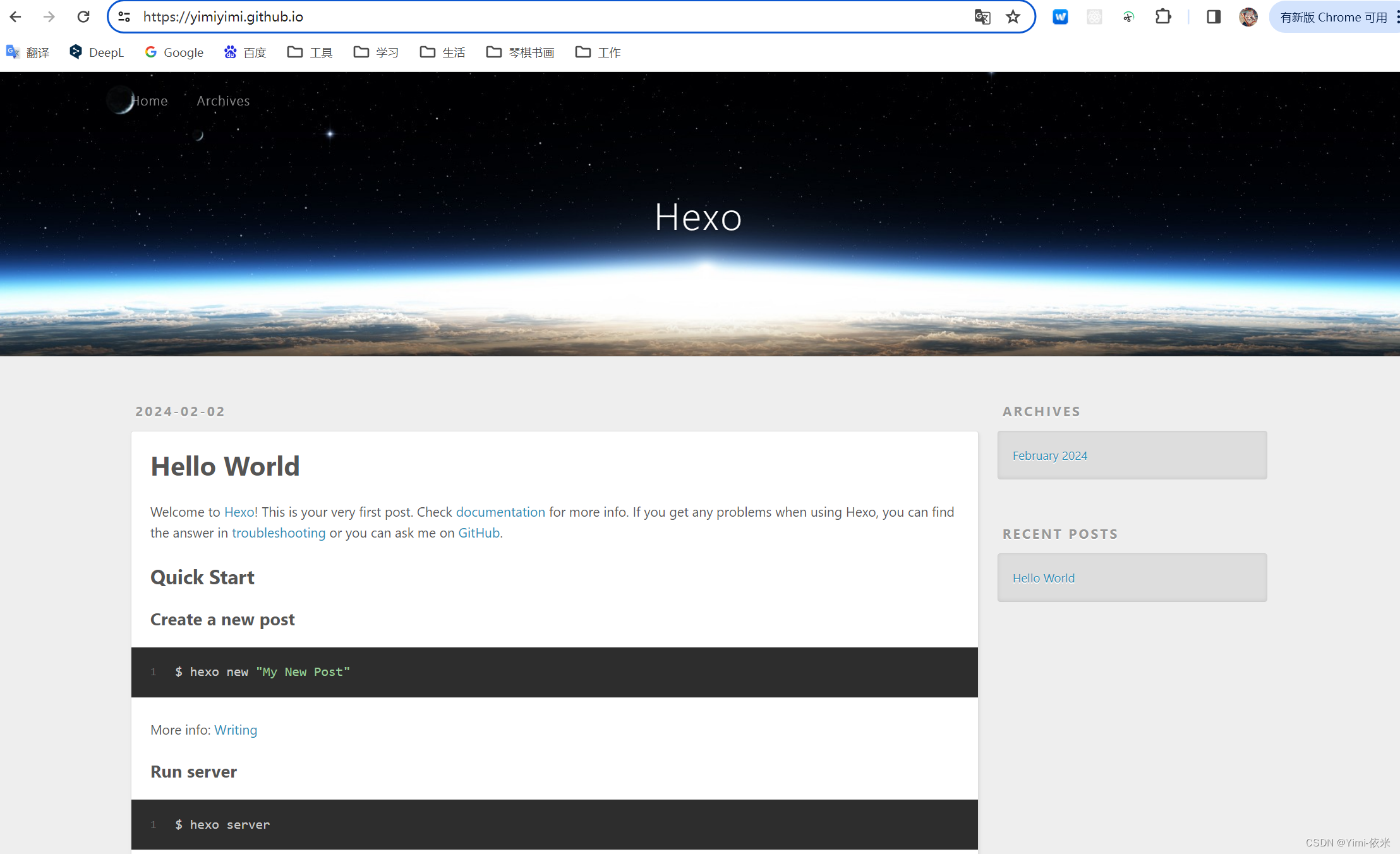
创建自己的Hexo博客
目录 一、Github新建仓库二、支持环境安装Git安装Node.js安装Hexo安装 三、博客本地运行本地hexo文件初始化本地启动Hexo服务 四、博客与Github绑定建立SSH密钥,并将公钥配置到github配置Hexo与Github的联系检查github链接访问hexo生成的博客 一、Github新建仓库 登…...
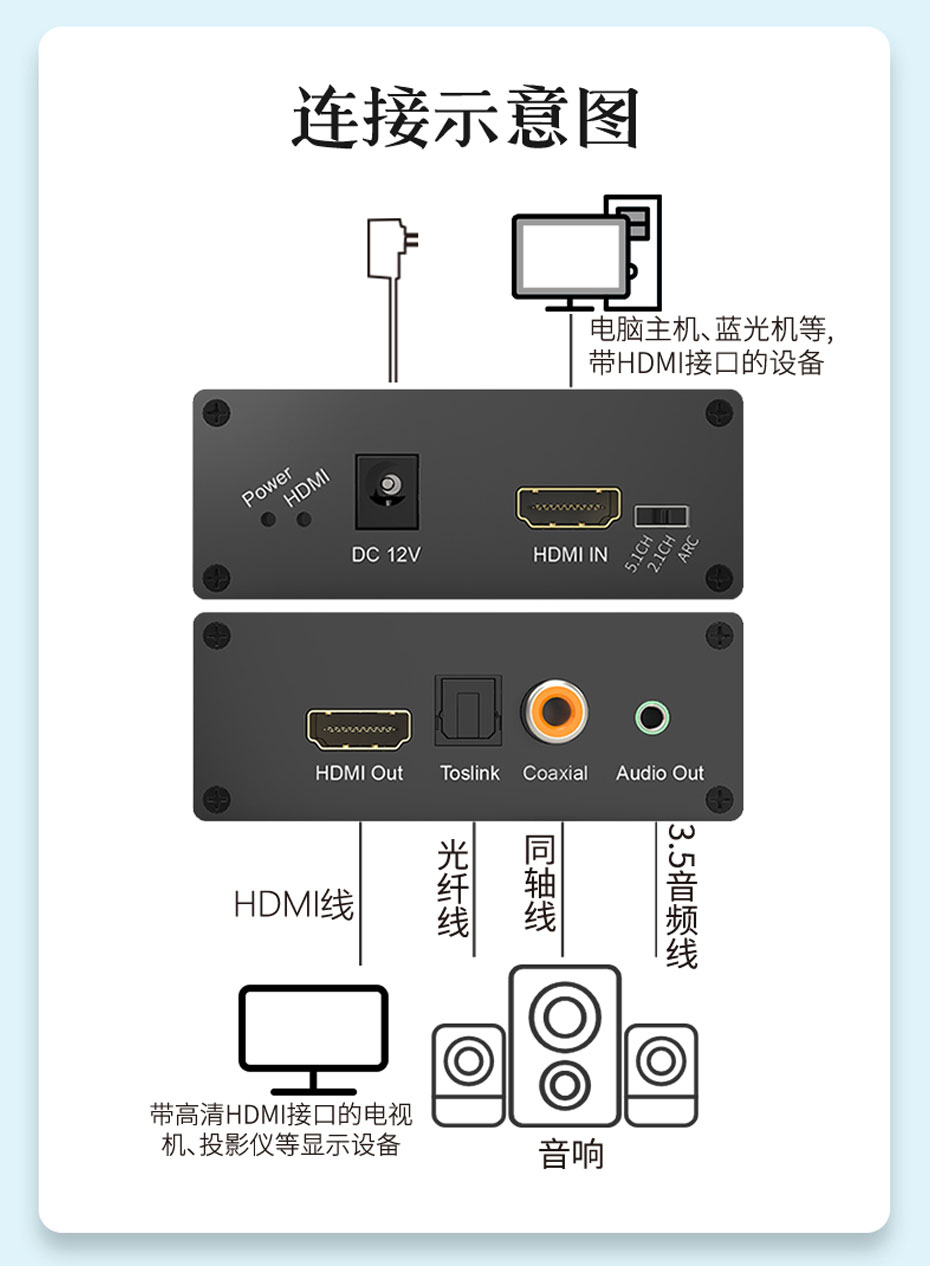
音箱、功放播放HDMI音频解决方案之HDMI音频分离器HHA
HDMI音频分离器HHA简介 HDMI音频分离器HHA具有一路HDMI信号输入,转换成一路HDMI信号、一路5.1光纤音频信号、一路5.1 SPDIF/同轴音频信号和一路模拟左右声道立体声信号输出,同时还支持EDID存储及兼容HDCP功能;分辨率最高支持1920*1080p&#…...
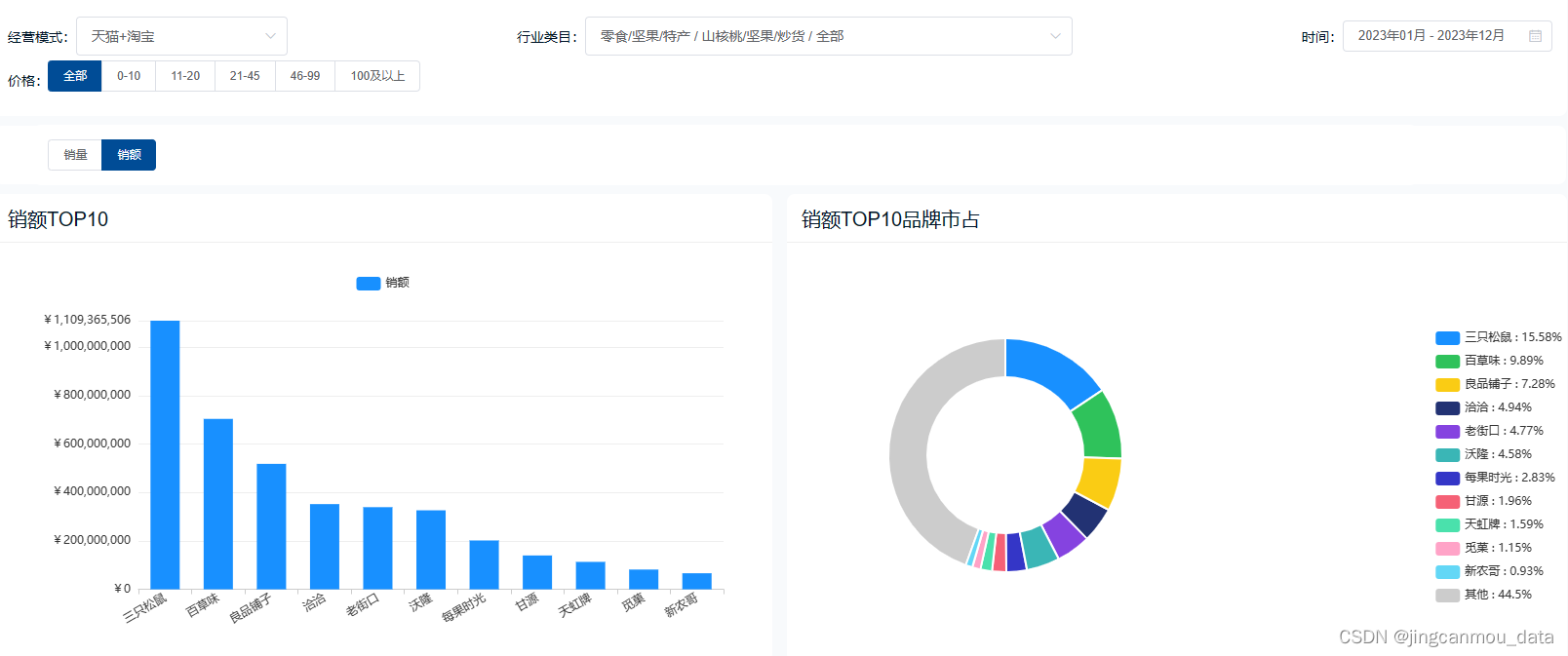
天猫数据分析:2023年坚果炒货市场年销额超71亿,混合坚果成多数消费者首选
近年来,随着人们生活水平和健康意识的提升,在休闲零食市场中,消费者们也越来越关注食品的营养价值,消费者这一消费偏好的转变也为坚果炒货食品行业带来了发展契机。 整体来看,坚果炒货市场的体量较大。根据鲸参谋电商…...
YouTrack 用户登录提示 JIRA 错误
就算输入正确的用户名和密码,我们也得到了下面的错误信息: youtrack Cannot retrieve JIRA user profile details. 解决办法 出现这个问题是因为 YouTrack 在当前的系统重有 JIRA 的导入关联。 需要把这个导入关联取消掉。 找到后台配置的导入关联&a…...

题目 1163: 排队买票
题目描述: 有M个小孩到公园玩,门票是1元。其中N个小孩带的钱为1元,K个小孩带的钱为2元。售票员没有零钱,问这些小孩共有多少种排队方法,使得售票员总能找得开零钱。注意:两个拿一元零钱的小孩,他们的位置互…...
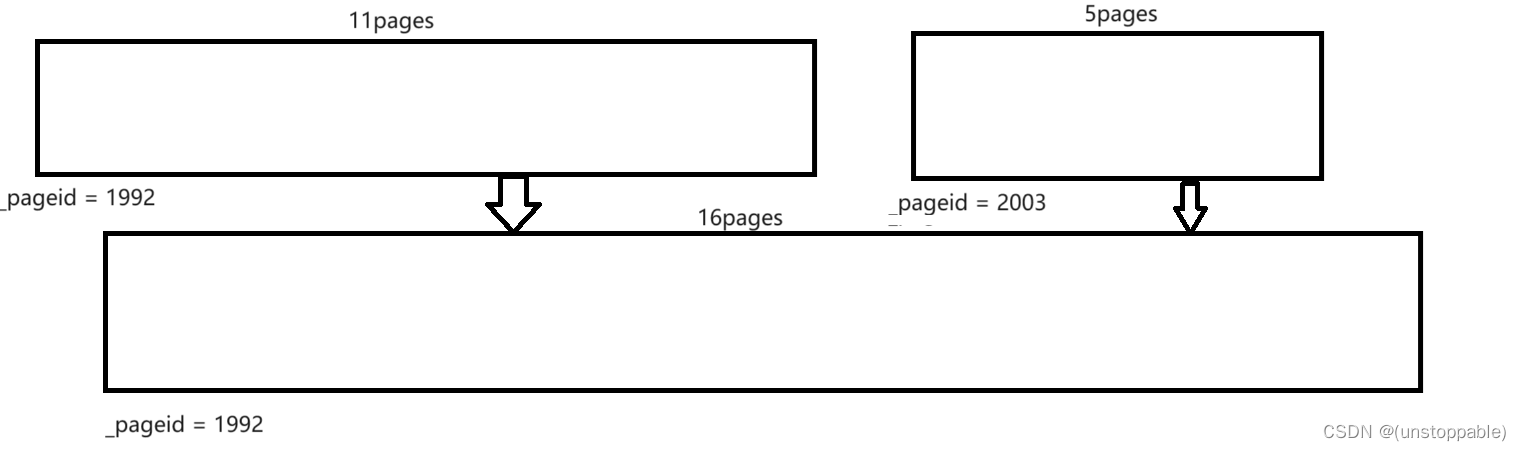
【lesson9】高并发内存池Page Cache层释放内存的实现
文章目录 Page Cache层释放内存的流程Page Cache层释放内存的实现 Page Cache层释放内存的流程 如果central cache释放回一个span,则依次寻找span的前后page id的没有在使用的空闲span,看是否可以合并,如果合并继续向前寻找。这样就可以将切…...

Java基础面试题-6day
I/O流基础知识总结 (1) io即输入输出流, 如何区分输入还是输入流 以内存为中介,当我们是将数据存储到内存即为输入,反之存储到外部存储器,即为输出 在Java中分输入输出流,根据数据处理又可以分…...
--RAC工作原理和相关组件)
【Oracle 集群】RAC知识图文详细教程(三)--RAC工作原理和相关组件
RAC 工作原理和相关组件 OracleRAC 是多个单实例在配置意义上的扩展,实现由两个或者多个节点(实例)使用一个共同的共享数据库(例如,一个数据库同时安装多个实例并打开)。在这种情况下,每一个单独…...

二级C语言笔试2
(总分100,考试时间90分钟) 一、选择题 下列各题A)、B)、C)、D)四个选项中,只有一个选项是正确的。 1. 下列叙述中正确的是( )。 A) 算法的效率只与问题的规模有关,而与数据的存储结构无关 B) 算法的时间复杂度是指执行算法所需要的计算工作量 …...
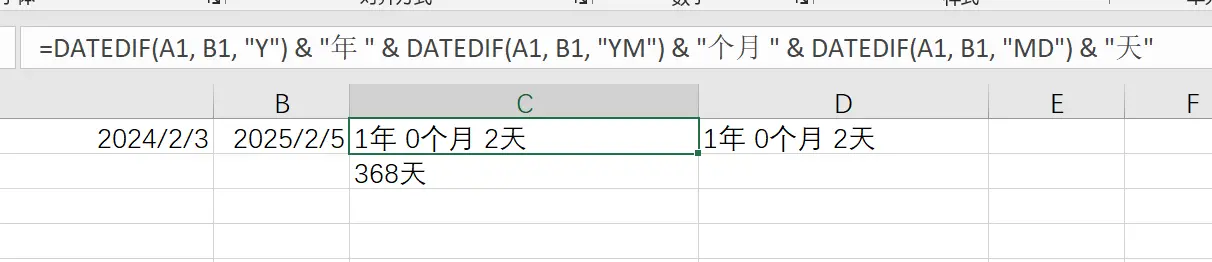
如何计算两个指定日期相差几年几月几日
一、题目要求 假定给出两个日期,让你计算两个日期之间相差多少年,多少月,多少天,应该如何操作呢? 本文提供网页、ChatGPT法、VBA法和Python法等四种不同的解法。 二、解决办法 1. 网页计算法 这种方法是利用网站给…...

再识C语言 DAY13 【递归函数(超详细)】
文章目录 前言一、函数递归什么是递归递归的两个重要条件练习一练习二 递归与迭代练习三练习四在练习三、四中出现的问题 如果您发现文章有错误请与我留言,感谢 前言 本文总结于此文章 一、函数递归 什么是递归 函数调用自身的编程技巧称为递归 (函数自…...

革新性植物大战僵尸辅助工具:PVZ Toolkit全方位功能解析
革新性植物大战僵尸辅助工具:PVZ Toolkit全方位功能解析 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit PVZ Toolkit是一款专为《植物大战僵尸》PC版设计的革新性辅助工具,集…...

高级编程 第一节:Python中的时间处理
一、时间标准库:time 1、time库介绍 time库是Python中处理时间的标准库,提供获取系统时间并格式化输出功能,但是功能上,没有datatime库强大。 time库中相关概念: 时间戳:格林威治时间1970年01月01日00分00秒(北京时间1970年01月01日08时00分00秒)起至现在的总秒数,…...

seo发布网站和传统推广方式相比有什么优势
SEO发布网站与传统推广方式相比有哪些优势 在当今数字化时代,网络已经成为人们获取信息和消费产品的重要途径。如何在众多的网站中脱颖而出,吸引更多的目标用户,是每一个企业和品牌都面临的问题。在这种背景下,SEO发布网站和传统…...

vscode-react-native终极入门指南:5分钟搭建React Native开发环境
vscode-react-native终极入门指南:5分钟搭建React Native开发环境 【免费下载链接】vscode-react-native VSCode extension for React Native - supports debugging and editor integration 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-react-native …...

如何快速掌握Unity Mod Manager:新手的完整入门指南
如何快速掌握Unity Mod Manager:新手的完整入门指南 【免费下载链接】unity-mod-manager UnityModManager 项目地址: https://gitcode.com/gh_mirrors/un/unity-mod-manager 还在为Unity游戏模组管理而烦恼吗?Unity Mod Manager正是你需要的终极解…...

PCB圆弧拐角和45度拐角走线实操
目录 0 前言 1 PCB圆弧拐角实操 1.2参数设置,如上图所示 1.3筛选导线,如上图所示 1.4选中所有走线,如上图所示(按shift键框选) 1.5 45拐角变为圆弧拐角,如上图所示 1.6 优化前后对比图,如上图所示 2 PCB 45度拐角走线实操 2.1 进入设置,如上图所示 2.2 参数设…...

如何用百元电视盒子打造你的第一台Linux服务器?这个开源项目让你轻松上手!
如何用百元电视盒子打造你的第一台Linux服务器?这个开源项目让你轻松上手! 【免费下载链接】amlogic-s9xxx-armbian Supports running Armbian on Amlogic, Allwinner, and Rockchip devices. Support a311d, s922x, s905x3, s905x2, s912, s905d, s905x…...
)
告别PWM!用STM32串口轻松驱动幻尔16路舵机控制板(附完整代码)
STM32串口驱动幻尔16路舵机控制板的实战指南 从PWM到串口:舵机控制的技术演进 记得我第一次尝试用STM32控制机械臂时,光是配置PWM定时器就花了两天时间。每个舵机需要独立的PWM通道,复杂的定时器分频计算,还有那令人头疼的占空比换…...

Arcgis实战:坐标系与投影的精准转换技巧
1. 坐标系与投影的基础概念 第一次用ArcGIS做项目时,我犯了个低级错误——把地理坐标系的经纬度数据直接当成了平面距离计算。结果客户问我"这条道路有多长"时,我报出的0.0023这个数字让他一脸茫然。这就是没搞懂坐标系和投影区别的典型教训。…...

2026届学术党必备的五大AI学术神器实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek DeepSeek身为智能写作工具,可在论文写作之整个流程里起到辅助功效,于…...