Redis核心技术与实战【学习笔记】 - 19.Pika:基于SSD实现大容量“Redis”
前言
随着业务数据的增加(比如电商业务中,随着用户规模和商品数量的增加),就需要 Redis 能保存更多的数据。你可能会想到使用 Redis 切片集群,把数据分散保存到不同的实例上。但是这样做的话,如果要保存的数据总量很大,但是每个实例保存的数据量较小的话,就会导致集群的实例规模增加,这会让集群的运维管理变的复杂,增加开销。
可能你又想到,可以增加 Redis 单实例的内存容量,形成大内存实例,每个实例就可以保存更多的数据,这样一来,在保存相同的数据总量时,所需要的大内存实例的个数就会减少,就可以节省开支。但是,基于大内存的大容量实例在实例恢复、主从同步过程中会引起一系列潜在问题,例如回复时间增长、主从切换开销大、缓冲区易溢出。
那该怎么办呢? 可以使用固态硬盘。他的成本很低(每 GB 的成本约是内存的十分之一),而且容量大,读写速度快,我们可以基于 SSD 来实现大容量的 “Redis” 实例。360 公司的 Pika,正好实现了这一需求。
Pika 的设计目标:
- 单实例可以保存大容量数据,同时避免了实例恢复和主从同步时的潜在问题;
- 和 Redis 数据类型保持兼容,可以支持 Redis 应用平滑地迁移到 Pika 上。
所以,如果你一直在使用 Redis,并且想使用 SSD 来扩展单实例容量,Pika 是一个不错的选择。
Pika 官网安装教程。
1.大内存 Redis 实例的潜在问题
Redis 使用内存保存数据,内容容量增加后,就会带来两方面的潜在问题,分别是内存快照 RB 生成和恢复效率低,以及主从节点全量同步时长增加、缓冲区溢出。
实例内存和内存快照 RDB 的关系是非常直接的:实例内存容量大,RDB 文件也会相应增加,那么,RDB 文件生成时的 fork 市场就会增加,这会导致 Redis 实例阻塞。而且,RDB 文件增大后,使用 RDB 进行恢复的时长也会增加,会导致 Redis 较长时间无法对外提供服务。
主从节点的同步的第一步就是要做全量同步。全量同步是主节点生成 RDB 文件,并传给从节点,从节点再加载。想一下,如果 RDB 文件很大,肯定会导致同步时长增加,效率不高,而且还可能会导致复制缓冲区溢出。一旦缓冲区溢出了,主从节点间就会又开始全量同步,影响业务的正常使用。如果我们增加复制缓冲区的容量,又会消耗宝贵的内存资源。
此外,如果主库发生了故障,进行主从切换后,其他从库都需要和新主库进行一次全量同步。如果 RDB 文件很大,会导致主从切换过程的耗时增加,同样会影响业务的可用性。
2.Pika 的整体架构
Pika 键值数据库的整体架构中包括了五部分,分别是 网络框架、Pika 线程模块、Nemo 存储模块、RocksDB 和 binlog 机制,如下图所示:
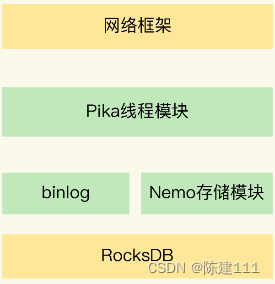
首先,网络框架主要负责底层网络请求的接收和发送。Pika 的网络框架是对操作系统底层的网络函数进行了封装。Pika 在进行网络通信时,可以直接调用网络封装好的函数。
其次,Pika 线程模块采用了多线程模型来具体处理客户端请求,包括一个请求分发线程(DispatchThread)、一组工作线程(WorkerThread)以及一个线程池(ThreadPool)。
- 请求分发线程专门监听网络端口,一旦接收到用户的连接请求后,就和客户端建立连接,并把连接交给工作线程处理。
- 工作线程负责接收客户端连接上发送的具体命令请求,并把命令请求封装成 Task,再交给线程池中的线程。
- 由这些线程进行实际的数据存取处理。
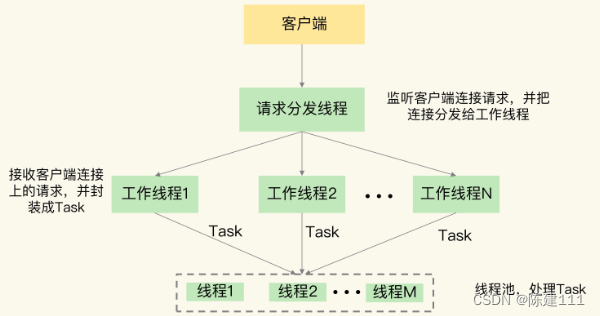
在实际应用 Pika 的时候,我们可以通过增加工作线程数和线程池的线程数,来提升 Pika 的请求处理吞吐率,进而满足业务层对数据处理性能的需求。
Nemo 模块很容易理解,它实现了 Pika 和 Redis 的数据类型兼容。这样一来,当我们把 Redis 服务迁移到 Pika 时,不用修改业务应用中的 Redis 的代码,而且还可以继续应用运行 Redis 的经验,这使得 Pika 的学习成本很低。Nemo 模块对数据类型的具体转换机制,下面会进行介绍。
最后,RocksDB 提供基于 SSD 保存数据的功能。它使得 Pika 可以不用大容量的内存,就能保存更多数据,还避免了使用内存快照。而且,Pika 使用 binlog 机制记录写命令,用于主从节点的命令同步,避免了刚刚所说的大内存实例在主从同步过程中的潜在问题。
3.Pika 如何基于 SSD 保存更多数据?
为了把数据保存到 SSD,Pika 使用了持久化数据库 RocksDB。RocksDB 本身的实现机制较为复杂,你只要记住 RocksDB 的基本数据读写机制,对于学习了解 Pika 来说就已经足够了。下面解释下这个基本读写机制。
Rocks 写数据流程
用一张图片来介绍下 RocksDB 写入数据的基本流程。
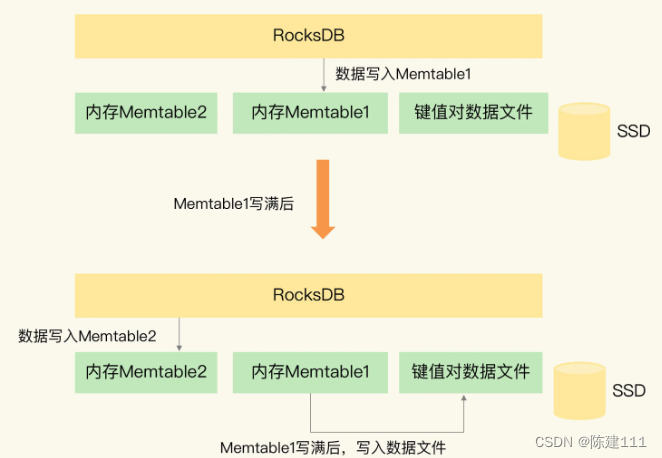
当 RocksDB 需要保存数据的时候,RocksDB 会使用两小块内存空间(Memtable1 和 Memtable2)来交替缓存写入数据。Memtable 的大小可设置,一个 Memtable 的大小一般为几 MB 或几十 MB。
- 当有数据需要写入 RocksDB 时,RocksDB 会先把数据写入到 Memtable1。
- 等到 Memtable1 写满后,RocksDB 再把数据以文件的形式,快速写入底层的 SSD。
- 同时,RocksDB 会使用 Memtable2 来代替 Memtable1,缓存新写入的数据。
- 等到 Memtable1 的数据都写入 SSD 了,RocksDB 会在 Memtable2 写满后,再用 Memtable1 缓存新写入的数据。
这么一分析我们就知道了,RocksDB 会先用 Memtable 缓存数据,再将数据快速写入 SSD,及时数据量再大,所有数据也都能保存到 SSD 中。而且 Memtable 本身容量不大,即使 RocksDB 使用了两个 Memtable,也不会占用过多的内存,这样一来,Pika 在保存大容量数据的同时,也不用占据太大的内存空间。
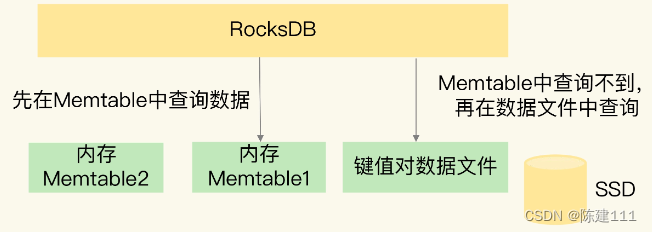
RocksDB 读数据流程
当 RocksDB 需要读数据时,RocksDB 会现在 Memtable 中查询是否有要读取的数据。因为,最新的数据都是先写入到 MemTable 中的。如果 Memtable 中没有要读取的数据,RocksDB 会再查询保存在 SSD 上的数据文件。
Redis 面临的 RDB 生成和恢复的效率问题,以及主从同步的效率和缓冲区溢出问题,在 Pika 中会有类似的问题吗?
其实,Pika 中是没有这些问题的。
- 一方面,Pika 基于 RocksDB 保存了数据文件,直接读取数据文件就能恢复,不需要在通过内存快照的方式进行恢复了。而且,Pika 从库在进行权利同步时,可以直接从主库拷贝数据文件,不需要使用内存快照,这样一来 Pika 就避免了大内存快照的生成效率低问题。
- 另一方面,Pika 使用 binlog 机制实现增量命令同步,即节省了内存,还避免了缓冲区溢出的问题。binlog 是保存在 SSD 上的文件,Pika 收到命令后,在数据写入 MemTable 时,也会把命令写入 binlog 文件中。和 Redis 类似,当全量同步结束后,从库会从 binlog 中把尚未同步的命令读取过来,这样就可以和主库的数据保持一致。当进行增量同步时,从库也是把自己以及复制的便宜量发给主库,主库把尚未同步的命令发给从库,来保持主从库的数据一致。
- 另外,和 Redis 使用缓存区相比,使用 binlog 的好处非常明显:binlog 是保存在 SSD 上的文件,文件大小不像缓冲区,会受到内存容量的较多限制。而且,当 binlog 文件增大后,还可以通过轮替操作,生成新的 binlog 文件,再把旧的 binlog 文件独立保存。这样一来,即使 Pika 实例保存了大量的数据,在同步过程中也不会出现缓冲区溢出的问题了。
小结
简单小结下:Pika 使用 RocksDB 把大量数据保存到了 SSD,同时避免了内存快照的生成和恢复问题。而且,Pika 使用 binlog 机制进行主从同步,避免了大内存时的影响,Pika 的第一个设计目标就实现了。
4.Pika 如何实现 Redis 数据类型兼容?
Pika 的底层使用了 RocksDB 来保存数据,但是 RocksDB 只提供了 单值的键值对类型,而 Redis 键值对中的值还可以是集合类型。Pika 的第二个设计目标(如何和 Redis 兼容)是如何实现的呢?
Pika 中的 Nemo 模块就负责把 Redis 的集合类型转换成单值的键值对。简单来说,我们可以把 Redis 的集合类型分成两类:
- 一类是 LIst 和 Set 类型,它们的集合中也只有单值。
- 另一类是 Hash 和 Sorted Set 类型,它们的集合中的元素是成对的,其中 Hash 集合元素是 Field-value 类型,而 Sorted Set 集合元素是 member-score 类型。
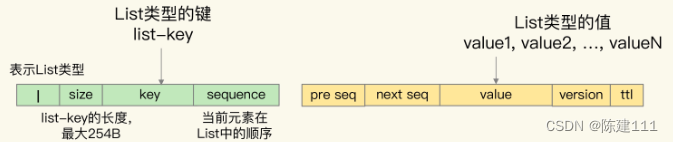
List 集合
- 在 Pika 中,List 集合的 key 被嵌入到单值键值对的键当中,用 key 字段表示;
- 而 List 集合中的元素值,则被嵌入到单键值对的值当中,用 value 字段表示。
- 因为 List 集合中的元素是有序的,所以,Nemo 模块还在单键值对的 key 后面增加了 sequence 字段,表示当前元素在 List 中顺序,同时,还在 value 的前面增加了 previous sequence 和 next sequence 者两个字段,分别表示当前元素的前一个元素和后一个元素。
- 此外,在单值键值对的 key 前面,Nemo 模块还增加了一个值 “l”,表示当前数据是 List 类型,以及增加了一个 1 字节的 size 字段,表示 List 集合 key 的大小。
- 在单键值对的 value 后面,Name 模块 还增加了 version 和 ttl 字段,分别表示当前数据的版本号和剩余存活时间(用来支持 key 过期功能)。
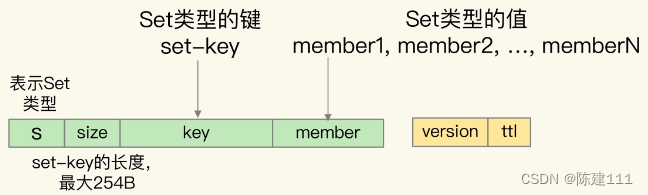
Set 集合
- Set 结合中的 key 和元素 member 值,都被嵌入到 Pika 单键值对的键当中,分别用 key 和 member 表示。
- 同时,单键值对的 key 前面有 “s”,表示数据类型是 Set 类型,同时还有 size 字段,用来表示 key 的大小。
- Pika 单键值对的值只保存了数据的版本信息和剩余存活时间。
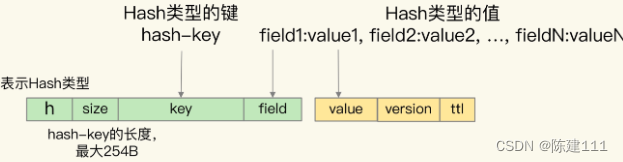
Hash 集合
- Hash 集合中 key 被嵌入到单键值对的键当中,用 key 字段表示。
- 而 Hash 元素的 field 也被嵌入到键值对的键当中,紧接着 key 字段,用 field 字段表示。
- Hash 集合元素的 value 字段,则是嵌入到单键值对的值当中,并且也带有版本号和剩余存活时间。
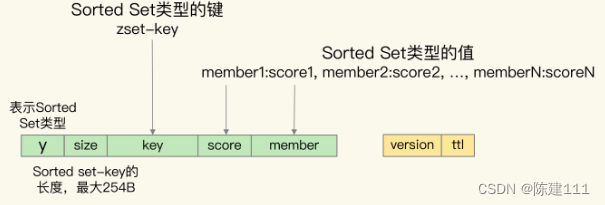
Sorted Set 集合
对于 Sorted Set 来说,该类型是需要能够按照元素的 socre 值排序的,而 RocksDB 只支持按照单键值对的键来排序。所以,Nemo 在转换数据时,就把 Sorted Set 集合 key、元素的 score 和 member 值都嵌入到了 单键值对的键当中。
Pika 单键值对的值只保存了数据的版本信息和剩余存活时间。
5.Pika 的其他优势与不足
和 Redis 相比,Pika 最大的特点就是使用 SSD 来保持数据,这个特点能带来的最直接好处就是,Pika 单实例能保存更多的数据了,实现了实例数据扩容。
此外,Pika 使用 SSD 来保持数据,还有额外两个优势。
- 首先,实例重启快。Pika 的数据在写入数据库时,会保存到 SSD 上。当 Pika 实例重启时,可以直接从 SSD 上的数据文件中读取数据,不需要向 Redis 一样,从 RDB 文件全部加载数据或是从 AOF 文件中全部回放操作,这极大的提高了 Pika 实例的重启速度,可以快速处理业务应用请求。
- 其次,主从库执行全量同步的风险低。Pika 通过 binlog 机制实现写命令的增量同步,不再受内存缓存区大小的限制,所以,即使在数据量很大,导致主从库同步耗时很长的情况下,Pika 也不用担心缓冲区溢出而触发的主从库重新全量同步。
但是,Pika 也有自身的一些不足。
虽然它保持了 Redis 操作接口,也能实现数据扩容,但是,当把数据保存到 SSD 上后,会降低数据的访问性能。这是因为,数据库操作毕竟在内存中直接执行了,而是要在底层的 SSD 中进行存取,这肯定会影响性能。而且,我们还需要把 binlog 机制记录的写命令同步到 SSD 上,者会降低 Pika 的写性能。
不过,Pika 的多线程模型,可以同时使用多个线程进行数据读写,这在一定程度上弥补了从 SSD 存取数据造成的性能损失。当然,你也可以使用高配的 SSD 来提升访问性能,进而减少读写 SSD 对 Pika 的性能影响。
为了更加了解 Pika 的性能情况,我从 Pika 官网 上扒出来的一种测试数据表。
| 操作性能 (OPS) | 写binlog | 不写binlog |
|---|---|---|
| SET | 124K | 211K |
| GET | 284K | 292K |
| HSET | 122K | 214K |
| HGET | 284K | 290K |
从上表的结果中,可以看出,在不写 binlog 时,Pika 的 SET/GET、HSET/HGET 的性能都能达到 200K OPS 以上,而一旦增加了 binlog 操作,SET/GET、HSET/HGET 的性能大约下降了 41%,只有约 120K OPS。
所以,在使用 Pika 时,需要在单实例扩容的必要性和可能的性能损失间做个权衡。如果保存大容量数据使我们的首要要求,那么 Pika 是一个不错的解决方案。
6.小结
我们学习了基于 SSD 给 Redis 单实例进行扩容的技术方案 Pika。跟 Redis 相比,Pika 的好处非常明显:既支持 Redis 操作接口,又能保持大容量的数据。如果你原来就在应用 Redis,现在想进行扩容,那么 Pika 是一个很好的选择,无论是代码迁移还是运维管理,Pika 基本上不需要额外的工作量。
不过,Pika 比较是将数据保存到 SSD 上,数据访问要读写 SSD ,所以读写性能要弱于 Redis。针对这一点,有两个小建议:
- 利用 Pika 的多线程模型,增加线程数量,提升 Pika 的并发请求处理能力;
- 为 Pika 配置高配的 SSD,提高 SSD 自身的访问性能。
最后,Pika 本身提供了很多工具,可以帮我我们把 Redis 数据迁移到 Pika,或者把 Redis 请求转发给 Pika。比如,aof_to_pika 命令,并且制定 Redis 的 AOF 文件以及 Pika 的连接信息,就可以把 Redis 数据迁移到 Pika 中了,如下所示:
aof_to_pika -i [Redis AOF文件] -h [Pika IP] -p [Pika 端口] -a [认证信息]
可以直接在 Pika 的官网上找到哦啊。并且,Pika 本身也还在迭代开发,你可以多去 GitHub 看看,进一步了解它,这样你可以获得 Pika 的最新进制,以便能更好地把它应用到你的业务实践中。
相关文章:
Redis核心技术与实战【学习笔记】 - 19.Pika:基于SSD实现大容量“Redis”
前言 随着业务数据的增加(比如电商业务中,随着用户规模和商品数量的增加),就需要 Redis 能保存更多的数据。你可能会想到使用 Redis 切片集群,把数据分散保存到不同的实例上。但是这样做的话,如果要保存的…...
qt-C++笔记之contains()和isEmpty()函数、以及部分其他函数列举
qt-C笔记之contains()和isEmpty()函数、以及部分其他函数列举 code review! 文章目录 qt-C笔记之contains()和isEmpty()函数、以及部分其他函数列举contains()isEmpty() 类似的其他函数列举通用容器类函数字符串特有函数 在Qt C开发中, contains() 和 isEmpty()…...
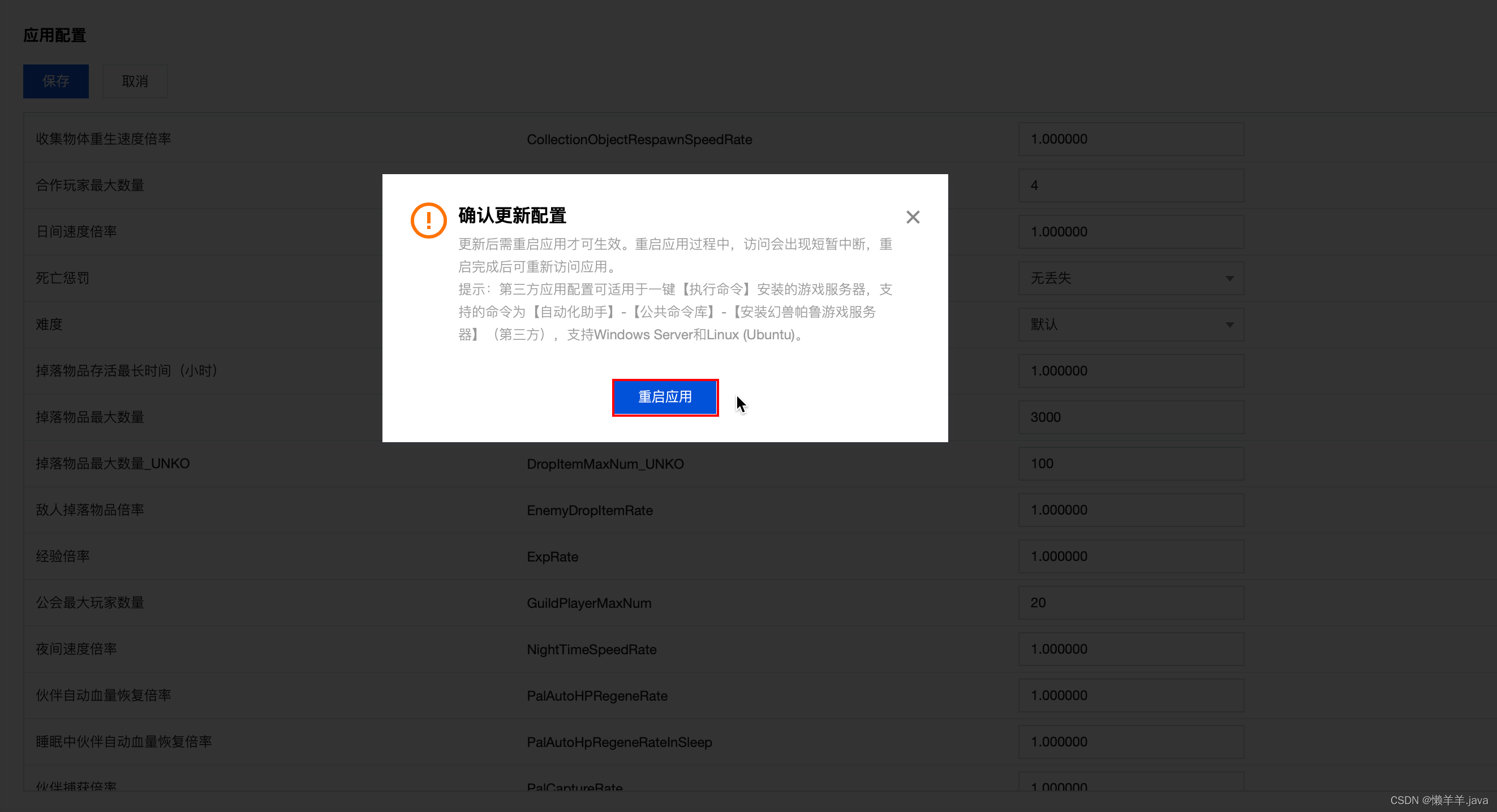
极速搭建幻兽帕鲁私服,叫上好友春节假期一起联机畅玩帕鲁
文章目录 前言幻兽帕鲁私服详细部署教程查看服务器开始游戏自定义游戏参数配置 前言 行业资讯 《幻兽帕鲁》的火爆对开发商 Pocketpair 来说,代价是巨大的。该游戏的成功让首席执行官沟部拓郎最近在推特上表示,他可能因服务器运营费用而面临破产。据他透…...

MagicVideo-V2:多阶段高保真视频生成框架
本项工作介绍了MagicVideo-V2,将文本到图像模型、视频运动生成器、参考图像embedding模块和帧内插模块集成到端到端的视频生成流程中。由于这些架构设计的好处,MagicVideo-V2能够生成具有极高保真度和流畅度的美观高分辨率视频。通过大规模用户评估&…...
【三】【C++】类与对象(二)
类的六个默认成员函数 在C中,有六个默认成员函数,它们是编译器在需要的情况下自动生成的成员函数,如果你不显式地定义它们,编译器会自动提供默认实现。这些默认成员函数包括: 默认构造函数 (Default Constructor)&…...

ffmpeg 输入文件,输入出udp-ts 指定pid
要使用FFmpeg将输入文件转换为UDP传输流(TS)并指定特定的PID,您可以使用以下命令: ffmpeg -i input_file -c:v libx264 -preset ultrafast -tune zerolatency -f mpegts -map 0:v:0 -map 0:a:0 -pid 0x12345678 udp://output_addr…...
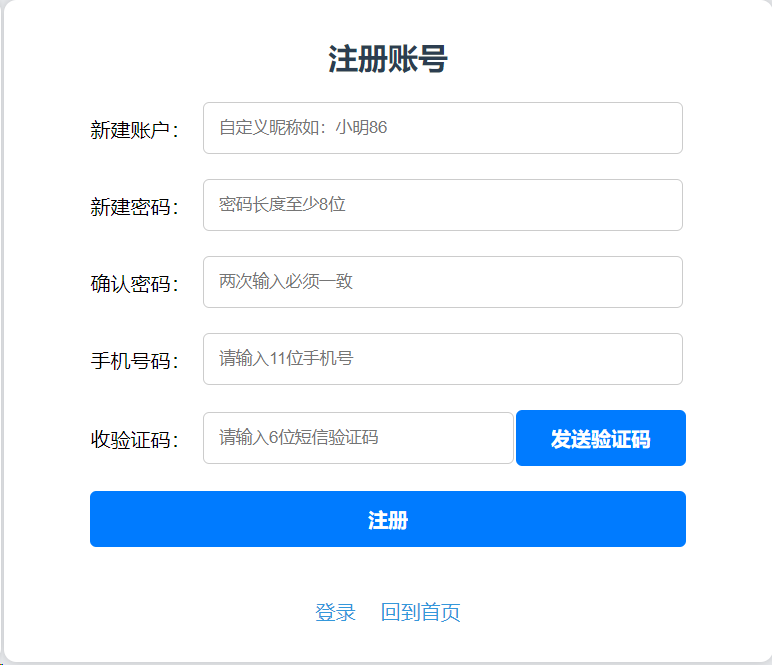
自研人工智能小工具-小蜜蜂(国外ChatGpt的平替)
国内有非常多好用的人工智能工具,但均无法完全替代国外ChatGpt。 ChatGPT相较于其他国内工具的优势在于以下几点: 创新的语言生成能力:ChatGPT是由OpenAI开发的先进的自然语言生成模型,它采用了大规模的预训练和精细调整方法。因此…...

Stable Diffusion 模型下载:ReV Animated
模型介绍 该模型能够创建 2.5D 类图像生成。此模型是检查点合并,这意味着它是其他模型的产物,以创建从原始模型派生的产品。 条目内容类型大模型基础模型SD 1.5来源CIVITAI作者s6yx文件名称revAnimated_v122EOL.safetensors文件大小5.13GB 生成案例 …...
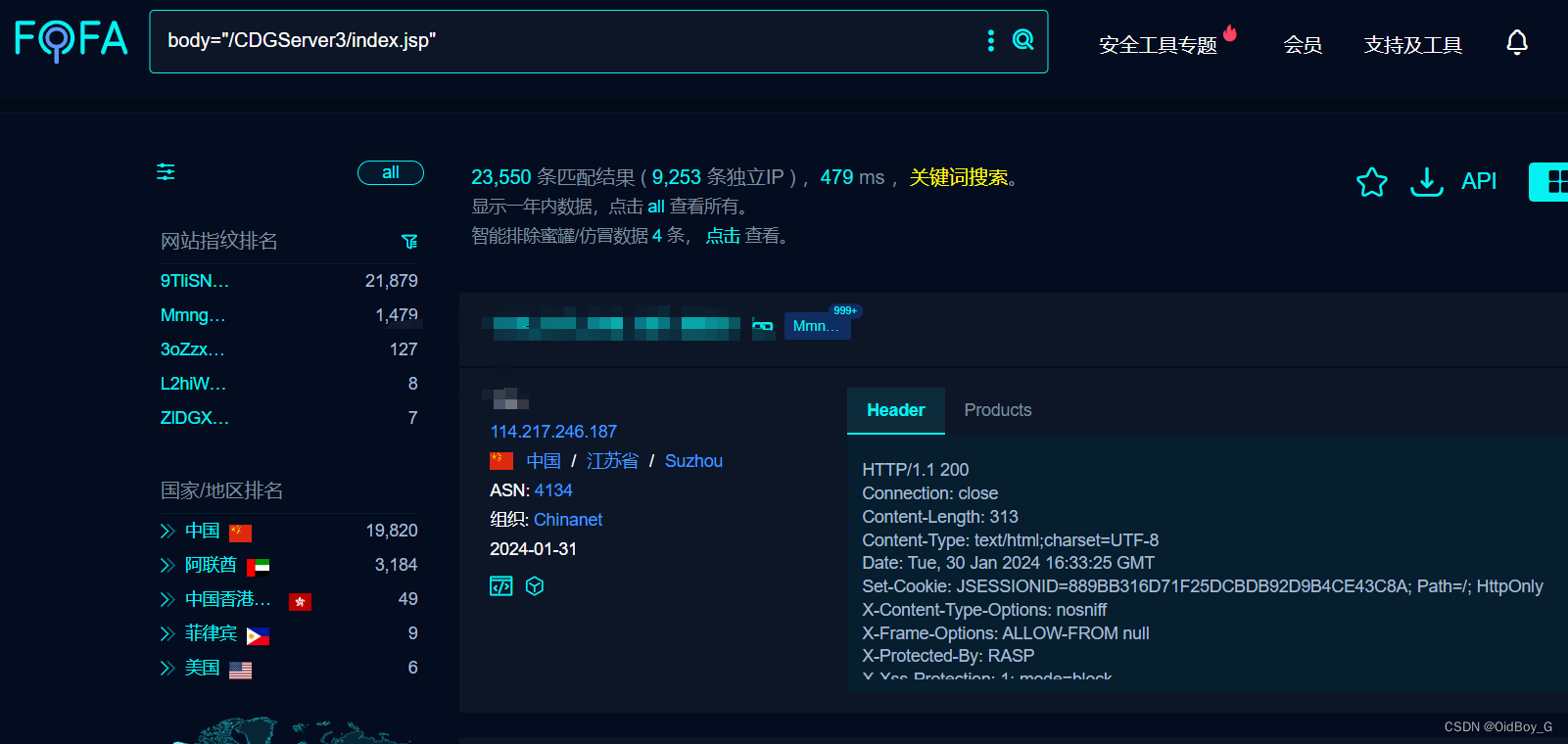
某赛通电子文档安全管理系统 PolicyAjax SQL注入漏洞复现
0x01 产品简介 某赛通电子文档安全管理系统(简称:CDG)是一款电子文档安全加密软件,该系统利用驱动层透明加密技术,通过对电子文档的加密保护,防止内部员工泄密和外部人员非法窃取企业核心重要数据资产,对电子文档进行全生命周期防护,系统具有透明加密、主动加密、智能…...

Prometheus 采集Oracle监控数据
前言 oracledb_exporter是一个开源的Prometheus Exporter,用于从Oracle数据库中收集关键指标并将其暴露给Prometheus进行监控和告警。它可以将Oracle数据库的性能指标转换为Prometheus所需的格式,并提供一些默认的查询和指标。 download Oracle Oracle Windows Install …...

【ARM Trace32(劳特巴赫) 使用介绍 3.1 -- 不 attach core 直接访问 memory】
文章目录 背景介绍背景介绍 在使用 trace32 时在有些场景需要不 attach core 然后去读写 memory,比如在某些情况下 core 已经挂死连接不上了,这个时候需要dump内存,这个时候需要怎做呢? print "test for memory access directly";SYStem.OPTION WAITRESET OF…...
MySQL事务和SQL优化
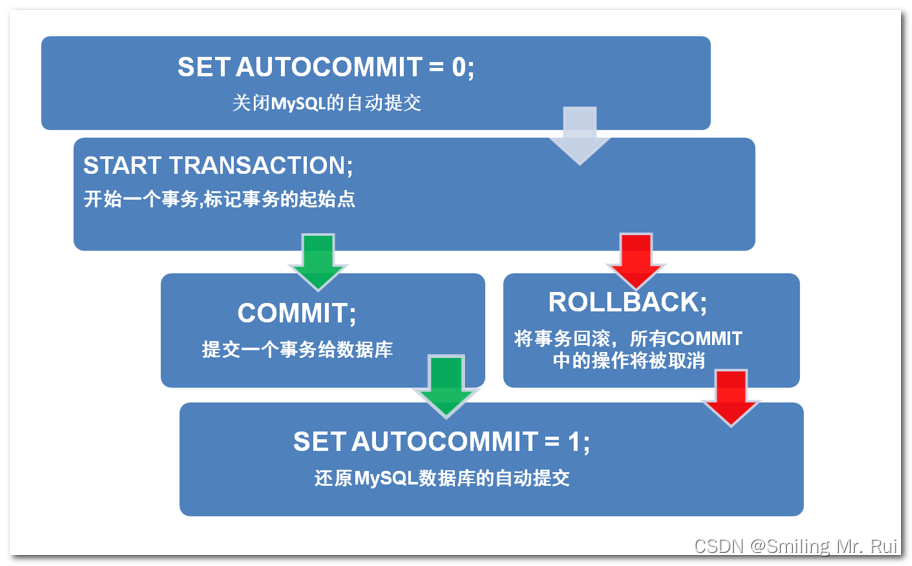
目录 一、什么是事务 二、事务的特征 三、MySQL使用事务 3.1 实现流程: 实现截图: 3.2 实例演示: 四、事务的隔离级别 幻读: 如何解决: 脏读: 不可重复读: 幻读和不可重复读两者区别…...

[C语言]结构体初识
结构体定义 结构体是一些值的集合,被成为成员变量,结构的每个成员可以是不同类型的变量 声明: 定义了一个结构体比如以张蓝图,不占据内存,当你创建了一个结构体变量时,才占空间. #include<stdio.h>//struct 为结构体关键字, student 自定义结构体名称 struct student …...
跨平台开发:浅析uni-app及其他主流APP开发方式
随着智能手机的普及,移动应用程序(APP)的需求不断增长。开发一款优秀的APP,不仅需要考虑功能和用户体验,还需要选择一种适合的开发方式。随着技术的发展,目前有多种主流的APP开发方式可供选择,其…...
MyBatis常见面试题汇总
说一下MyBatis执行流程? MyBatis是一款优秀的基于Java的持久层框架,它内部封装了JDBC,使开发者只需要关注SQL语句本身,而不需要花费精力去处理加载驱动、创建连接等的过程,MyBatis的执行流程如下: 加载配…...
)
juc并发线程学习笔记(一)
本系列会更新我在学习juc时的笔记和自己的一些思想记录。如有问题欢迎联系。 并发编程 进程与线程 1.进程和线程的概念 程序是静态的,进程是动态的 进程 程序由指令和数据组成,但这些指令要运行,数据要读写,就必须将指令加载…...
力扣热门100题刷题笔记 - 3.无重复字符的最长子串
力扣热门100题 - 3.无重复字符的最长子串 题目链接:3. 无重复字符的最长子串 题目描述: 给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。示例: 输入: s "abcabcbb" 输出: 3 解释: 因为无重复字…...

达梦数据库死锁排查与解决
在达梦数据库系统中,死锁是指两个或多个事务相互等待对方释放资源,从而造成循环等待的现象,严重影响数据库的正常运行。以下是使用达梦数据库进行死锁排查和解决的具体步骤: 死锁查看 查询当前死锁信息 SELECT lc.lmode, lc.ta…...

鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之TextClock组件
鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之TextClock组件 一、操作环境 操作系统: Windows 10 专业版、IDE:DevEco Studio 3.1、SDK:HarmonyOS 3.1 二、TextClock组件 TextClock组件通过文本将当前系统时间显示在设备上。支持不同…...

CICD注册和使用gitlab-runner常见问题
1、现象 fatal: unable to access https://github.com/homebrew/brew/: 2、解决 git config --global --unset http.proxy git config --global --unset https.proxy 查看gitlab-runner是否成功: userusers-MacBook-Pro ~ % gitlab-runner -h 查看gitlab-run…...

避开Arduino PID编程的3个常见坑:为什么你的控制总是不稳?
Arduino PID控制实战:避开3个致命陷阱实现精准调节 当你在深夜盯着反复震荡的电机转速曲线,或是加热棒温度始终无法稳定的数据时,是否怀疑过自己复制的PID代码有问题?这不是你的错觉——大多数Arduino PID控制问题都源于三个容易被…...

资源监控方案:OpenClaw+Phi-3-mini-128k-instruct实时预警服务器异常
资源监控方案:OpenClawPhi-3-mini-128k-instruct实时预警服务器异常 1. 为什么选择OpenClaw做轻量级监控 去年我的个人服务器因为内存泄漏连续宕机三次后,我开始寻找一个能兼顾灵活性和低成本的监控方案。传统方案如PrometheusGrafana对个人项目显得过…...

WTF, forms? CSS原理大揭秘:如何用纯CSS打造自定义表单控件
WTF, forms? CSS原理大揭秘:如何用纯CSS打造自定义表单控件 【免费下载链接】wtf-forms Friendlier HTML form controls with a little CSS magic. 项目地址: https://gitcode.com/gh_mirrors/wt/wtf-forms WTF, forms? 是一个通过纯CSS魔法打造友好HTML表…...

题目1514:蓝桥杯算法提高VIP-夺宝奇兵
#include<iostream> using namespace std; int dp[110][110]; int main(){ int n; cin>>n; for(int i1;i<n;i){ for(int j1;j<i;j){ cin>>dp[i][j]; } } //从倒数第二行向上推 for(int in-1;i&g…...

从CH341A编程器、SPI Flash到Linux+STM32理解
前言最近在折腾路由器刷机时入手了一款CH341A编程器,本以为它只能刷刷BIOS芯片,深入研究后发现这简直是“宝藏工具”。更有意思的是,在弄明白了存储芯片的底层操作后,我对嵌入式系统中Linux和STM32的协作关系有了全新的理解。本文…...

健身与猝死的关系
## 延迟性肌肉酸痛(DOMS)定义:延迟性肌肉酸痛(DOMS)是一种在进行了非常规或强度较大的体育锻炼后,特别是力量训练后出现的肌肉酸痛现象。这种痛感通常在锻炼后24到48小时内出现,最严重时可持续数…...
: 定制对话——Prompt模板引入)
Spring with AI (3): 定制对话——Prompt模板引入
1 创建模板先在pom.xml引入验证Starter:<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-validation</artifactId> </dependency>我们定义一个关于“世界各国地理历史知识”的AI&…...

嵌入式JPEG解码库JPEGDecoder深度解析
1. JPEGDecoder 库深度技术解析:面向嵌入式显示系统的轻量级 JPEG 解码实践1.1 库定位与工程价值JPEGDecoder 是一个专为资源受限嵌入式平台设计的轻量级 JPEG 解码库,其核心目标并非替代 PC 级全功能解码器,而是在 MCU 级别实现“够用、可控…...

基于MATLAB与SVM实现河道水面漂浮物的自动检测与识别
摘要:河道水面漂浮物不仅影响水环境质量,还威胁水利设施安全和水生态健康。传统人工巡检方式效率低、成本高,难以满足大范围、实时化的 监测需求。针对上述问题,本文基于 MATLAB 平台,结合支持向量机(SVM&a…...

**基于Python与BCI接口的脑机交互编程实践:从信号采集到实时控制的全流程实
基于Python与BCI接口的脑机交互编程实践:从信号采集到实时控制的全流程实现 在人工智能与神经科学融合加速发展的今天,脑机接口(Brain-Computer Interface, BCI) 正逐渐从实验室走向实用化场景。本文将带你深入一个完整的 Python驱…...