【使用 Python 进行 NLP】 第 2 部分 NLTK
一、说明
Python 有一些非常强大的 NLP 库,NLTK — 自然语言工具包 — NLTK 是一个强大的开源库,用于 NLP 的研究和开发。它内置了 50 多个文本语料库和词汇资源。它支持文本标记化、词性标记、词干提取、词形还原、命名实体提取、分割、分类、语义推理。
SpaCY — SpaCy 也是一个开源 Python 库,用于构建现实世界项目的生产级别。它内置了对 BERT 等多重训练 Transformer 的支持,以及针对超过 17 种语言的预训练 NLP 管道。它速度非常快,并提供以下功能 - 超过 49 种语言的标记化、词性标记、分段、词形还原、命名实体识别、文本分类。
TextBlob — TextBlob 是一个构建在 NLTK 之上的开源库。它提供了一个简单的界面,并支持诸如情感分析、短语提取、解析、词性标记、N-gram、拼写纠正、标记分类、名词短语提取等任务。
Gensim — GenSim 支持分层狄利克雷过程 (HDP)、随机投影、潜在狄利克雷分配 (LDA)、潜在语义分析或 word2vec 深度学习等算法。它非常快并且优化了内存使用。
PolyGlot — PolyGlot 支持多种语言,并基于 SpaCy 和 NumPy 库构建。它支持165种语言的标记化、196种语言的语言检测、命名实体识别、POS标记、情感分析、137种语言的词嵌入、形态分析、69种语言的音译。
sklearn — Python 中的标准机器学习库
自然语言工具包(NLTK)
NLTK 是一个免费的开源 Python 库,用于在 Windows、Mac OS X 和 Linux 中构建 NLP 程序。它拥有 50 个内置语料库、WordNet 等词汇资源以及许多用于 NLP 任务(如分类、标记化、词干提取、标记、解析、语义推理)的库。
NLTK 提供了编程基础知识、计算语言学概念和优秀文档的实践指南,这使得 NLTK 非常适合语言学家、工程师、学生、教育工作者、研究人员和行业用户等使用。NLTK 有一本姊妹书——由 NLTK 的创建者编写的《Python 自然语言处理》。
下载并安装NLTK
# using pip:
pip install nltk
# using conda:
conda install nltk二、NLTK数据下载
数据下载地址:这里
NLTK附带了许多语料库、玩具语法、训练模型等。安装NLTK后,我们应该使用NLTK的数据下载器安装数据:
import nltk
nltk.download()应打开一个新窗口,显示 NLTK 下载程序。您可以选择要下载的语料库。您也可以下载全部。
NLTK 包括一组不同的语料库,可以使用 nltk.corpus 包读取。每个语料库都通过 nltk.corpus 中的“语料库阅读器”对象进行访问:
# Builtin corpora in NLTK (https://www.nltk.org/howto/corpus.html)
import nltk.corpus
from nltk.corpus import brown
brown.fileids()每个语料库阅读器都提供多种从语料库读取数据的方法,具体取决于语料库的格式。例如,纯文本语料库支持将语料库读取为原始文本、单词列表、句子列表或段落列表的方法。
from nltk.corpus import inaugural
inaugural.raw('1789-Washington.txt')三、单词列表和词典
NLTK 数据包还包括许多词典和单词列表。这些的访问就像文本语料库一样。以下示例说明了词表语料库的使用:
from nltk.corpus import words
words.fileids()停用词:对文本含义添加很少或没有添加的单词。
from nltk.corpus import stopwords
stopwords.fileids()四、语料库与词典
语料库是特定语言的文本数据(书面或口头)的大量集合。语料库可能包含有关单词的附加信息,例如它们的 POS 标签或句子的解析树等。
词典是语言的词位(词汇)的整个集合。许多词典包含一个核心标记(lexeme)、其名词形式、形容词形式、相关动词、相关副词等、其同义词、反义词等。
NLTK提供了一个opinion_lexicon,其中包含英语正面和负面意见词的列表
from nltk.corpus import opinion_lexicon
opinion_lexicon.negative()[:5]五、NLTK 中的简单 NLP 任务:
# Tokenization
from nltk import word_tokenize, sent_tokenize
sent = "I will walk 500 miles and I would walk 500 more, just to be the man who walks a thousand miles to fall down at your door!"
print(word_tokenize(sent))
print(sent_tokenize(sent))#Stopwords removal
from nltk.corpus import stopwords # the corpus module is an extremely useful one.
sent = "I will pick you up at 5.00 pm. We will go for a walk"
stop_words = stopwords.words('english') # this is the full list of all stop-words stored in nltk
token = nltk.word_tokenize(sent)
cleaned_token = []
for word in token:if word not in stop_words:cleaned_token.append(word)
print("This is the unclean version:", token)
print("This is the cleaned version:", cleaned_token)# Stemming
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
print(stemmer.stem("feet"))# Lemmatization
import nltk
from nltk.stem.wordnet import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize("feet"))# POS tagging
from nltk import pos_tag
from nltk.corpus import stopwords stop_words = stopwords.words('english')sentence = "The pos_tag() method takes in a list of tokenized words, and tags each of them with a corresponding Parts of Speech"
tokens = nltk.word_tokenize(sentence)cleaned_token = []
for word in tokens:if word not in stop_words:cleaned_token.append(word)
tagged = pos_tag(cleaned_token)
print(tagged)六、命名实体识别
NER 是 NLP 任务,用于定位命名实体并将其分类为预定义的类别,例如人名、组织、位置、时间表达、数量、货币价值、百分比等。它有助于回答如下问题:
- 报告中提到了哪些公司?
- 该推文是否谈到了特定的人?
- 新闻文章中提到了哪些地方、哪些公司?
- 正在谈论哪种产品?
entities = nltk.chunk.ne_chunk(tagged)
entities七、WordNet 语料库阅读器
WordNet 是 WordNet 的 NLTK 接口。WordNet 是英语词汇数据库。WordNet 使用 Synsets 来存储单词。同义词集是一组具有共同含义的同义词。使用同义词集,它有助于找到单词之间的概念关系。
八、使用 NLTK 朴素贝叶斯分类器构建电影评论分类器
import nltk
import string
#from nltk.tokenize import sent_tokenize, word_tokenize
from nltk.corpus import stopwords
from nltk.corpus import movie_reviewsneg_files = movie_reviews.fileids('neg')
pos_files = movie_reviews.fileids('pos')def feature_extraction(words):stopwordsandpunct = nltk.corpus.stopwords.words("english") + list(string.punctuation)return { word:'present' for word in words if not word in stopwordsandpunct}neg_words = [(feature_extraction(movie_reviews.words(fileids=[f])), 'neg') for f in neg_files]
pos_words = [(feature_extraction(movie_reviews.words(fileids=[f])), 'pos') for f in pos_files]from nltk.classify import NaiveBayesClassifier #load the buildin classifier
clf = NaiveBayesClassifier.train(pos_words[:500]+neg_words[:500])
#train it on 50% of records in positive and negative reviews
nltk.classify.util.accuracy(clf, pos_words[500:]+neg_words[500:])*100 #test it on remaining 50% recordsclf.show_most_informative_features()相关文章:

【使用 Python 进行 NLP】 第 2 部分 NLTK
一、说明 Python 有一些非常强大的 NLP 库,NLTK — 自然语言工具包 — NLTK 是一个强大的开源库,用于 NLP 的研究和开发。它内置了 50 多个文本语料库和词汇资源。它支持文本标记化、词性标记、词干提取、词形还原、命名实体提取、分割、分类、语义推理。…...
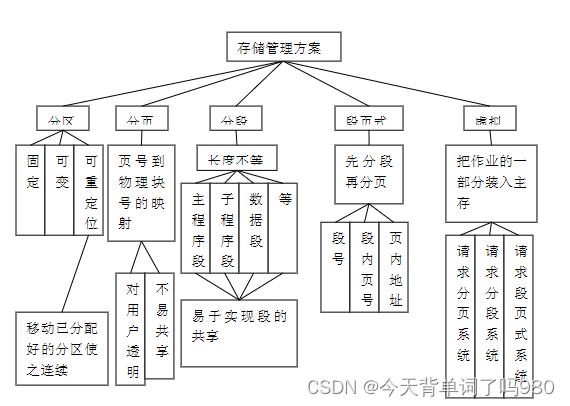
【软件设计师笔记】深入探究操作系统
【软件设计师笔记】计算机系统基础知识考点(传送门) 💖 【软件设计师笔记】程序语言设计考点(传送门) 💖 🐓 操作系统的作用 1.通过资源管理提高计算机系统的效率 2.改善人机界面向用户提供友好的工作环境 🐓 操作系统的特征 …...

python常用pandas函数nlargest / nsmallest及其手动实现
目录 pandas库 Series和DataFrame nlargest和nsmallest 用法示例 代替方法 手动实现 模拟代码 pandas库 是Python中一个非常强大的数据处理库,提供了高效的数据分析方法和数据结构。它特别适用于处理具有关系型数据或带标签数据的情况,同时在时间序列分析方面也有着出…...
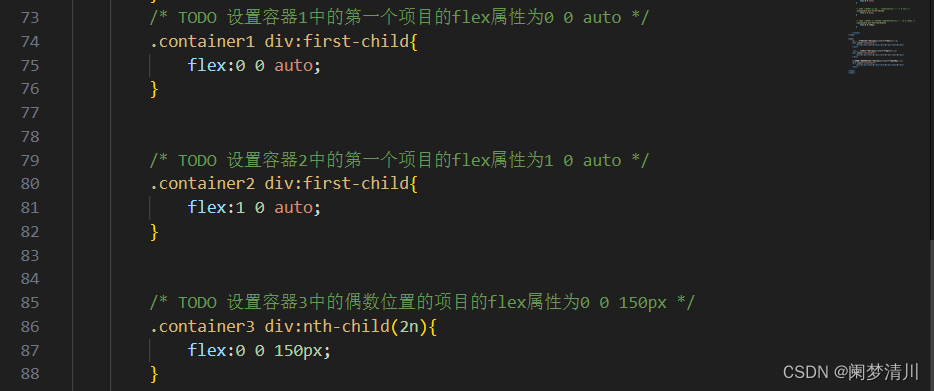
web前端-------弹性盒子(2)
上一讲我们谈的是盒子的容器实行,今天我们来聊一聊弹性盒子的项目属性; *******************(1)顺序属性 order属性,用于定义容器中项目的出现顺序。 顺序属性值,为整数,可以为负数ÿ…...
图论练习4
内容:染色划分,带权并查集,扩展并查集 Arpa’s overnight party and Mehrdad’s silent entering 题目链接 题目大意 个点围成一圈,分为对,对内两点不同染色同时,相邻3个点之间必须有两个点不同染色问构…...
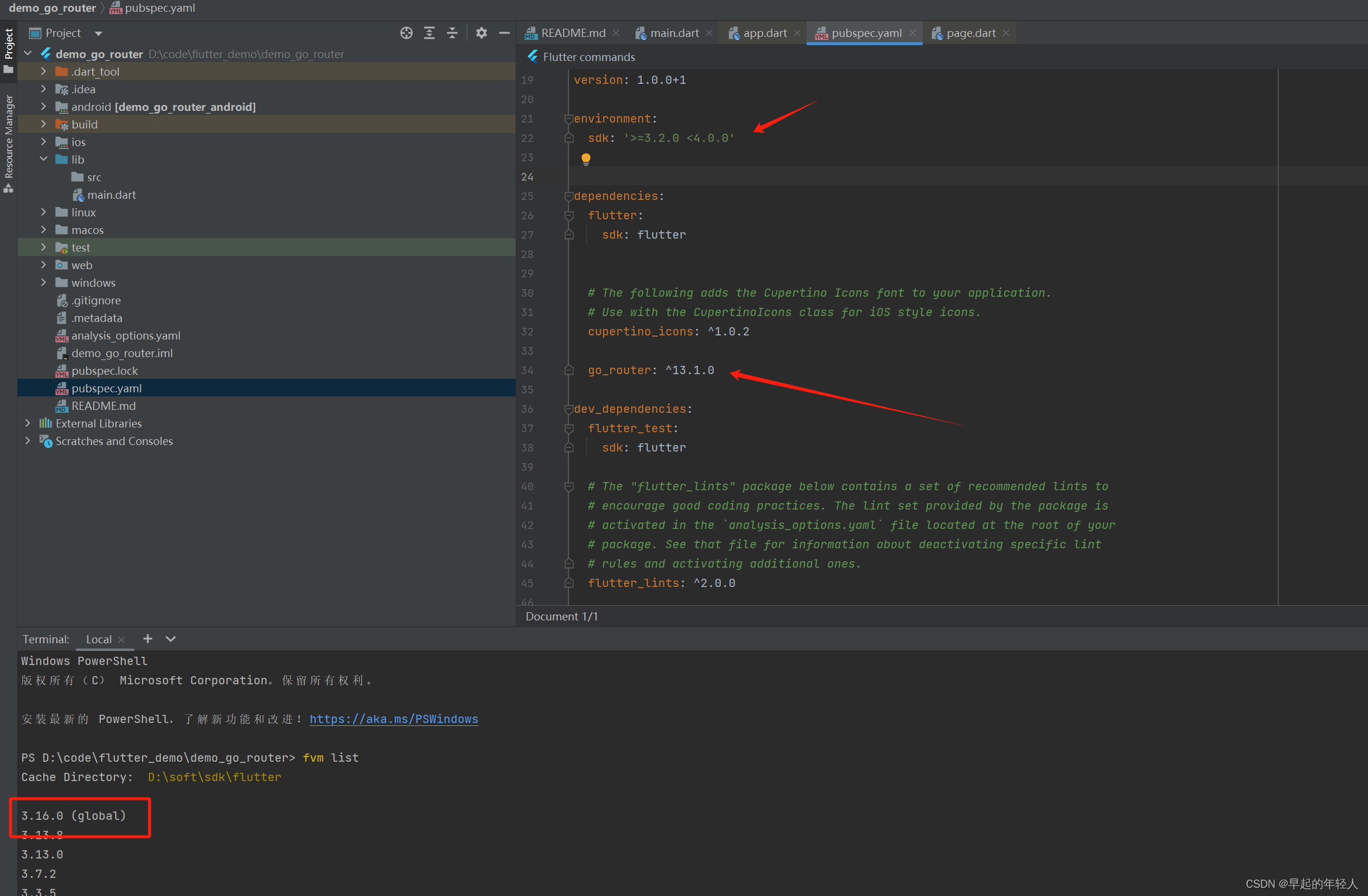
flutter go_router 官方路由(一)基本使用
1 项目中添加最新的依赖 go_router: ^13.1.0如下图所示,我当前使用的flutter版本为3.16.0 然后修改应用的入口函数如下: import package:flutter/material.dart; import package:go_router/go_router.dart;void main() {runApp(const MyApp()); }cla…...
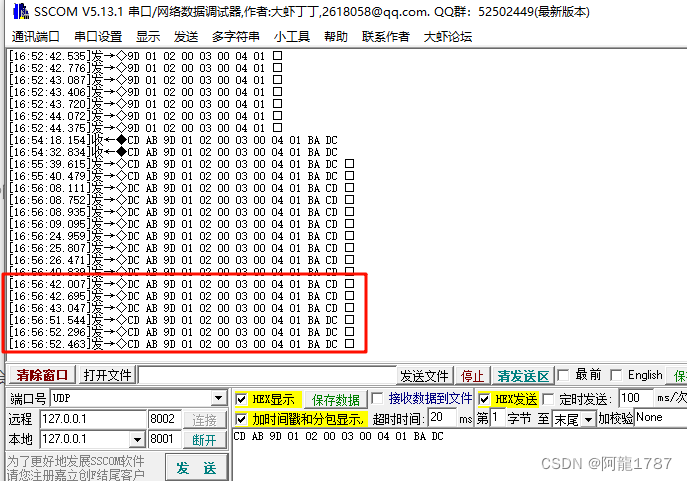
QT中,对于大小端UDP网络发送的demo,帧头帧尾
简单demo: 发送端: #include <QUdpSocket> #include <QtEndian>#pragma pack(1) struct Test {unsigned char t1:1;unsigned char t2:2;unsigned char t3:3;unsigned char t4:2;quint8 a 1;quint16 b 2;quint16 c 3;//double b …...

ip网络的三类地址及其相互关系
随着互联网的普及和发展,IP网络已成为全球范围内最重要的信息交换平台。在IP网络中,IP地址是每个设备在网络中的唯一标识,是实现网络通信的关键。虎观代理小二二将详细介绍IP网络中的三类地址,即A类、B类和C类地址,以及…...

开源计算机视觉库OpenCV详细介绍
开源计算机视觉库OpenCV详细介绍 1. OpenCV简介 OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉和机器学习软件库。它最初由Intel开发,现在由一个庞大的社区维护和更新。OpenCV旨在提供一个通用、跨平台的计算机…...
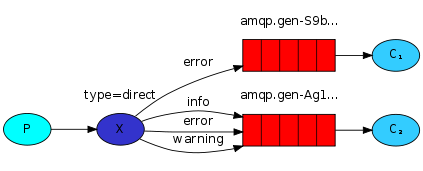
go消息队列RabbitMQ - 订阅模式-direct
1.发布订阅 在Fanout模式中,一条消息,会被所有订阅的队列都消费。但是,在某些场景下,我们希望不同的消息被不同的队列消费。这时就要用到Direct类型的Exchange。 在Direct模型下: 队列与交换机的绑定,不能…...

PyTorch 2.2 中文官方教程(十八)
开始使用完全分片数据并行(FSDP) 原文:pytorch.org/tutorials/intermediate/FSDP_tutorial.html 译者:飞龙 协议:CC BY-NC-SA 4.0 作者:Hamid Shojanazeri,Yanli Zhao,Shen Li 注意…...
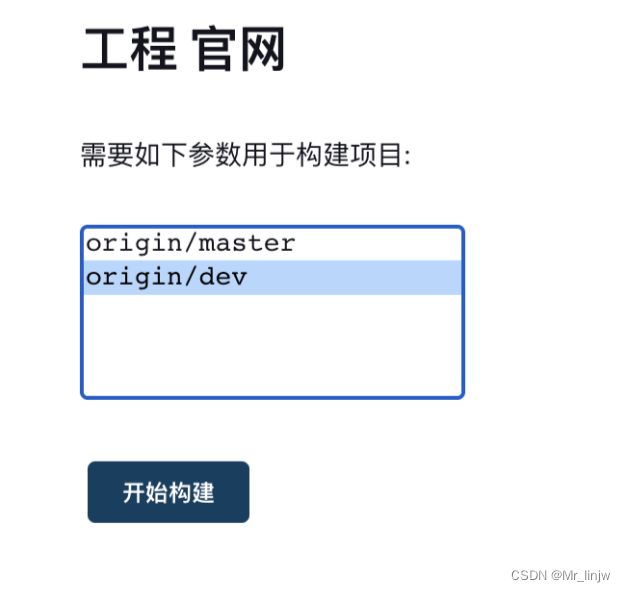
jenkins部署vue项目
首次加载比较慢、需要等待很长时间 到这个页面算是初始化完成了 输入密码路径为 之前设置的路径 可以在文件中找或者 docker logs jenkins 直接安装推荐插件 正在安装中!! 安装成功后创建管理员账号(一定要记住这个也是登录账号密码) 这里实例配置直接…...
引用)
十一、C++核心编程(2)引用
一、引用的基本使用 作用: 给变量起别名语法: 数据类型 &别名 原名 #include<iostream> #include<string.h> using namespace std;int main() {//引用基本语法//数据类型 &别名 原名int a 10;//创建引用int &b a;cout << "a "…...

numpy学习总结二
单词发音: squeeze 发音:死贵子 concatenation [kɒnˌktəˈneɪʃən] 拼接;串联 threshold [θreʃhəʊld] 死re后的 quantile 拷n太哦 分位数 因果不能改 智慧不能赐 正法不可说 无缘不能度 天雨虽宽不润无根之草;佛法虽广不度无缘之人 …...
3 编辑器(Vim)
1.完成 vimtutor。备注:它在一个 80x24(80 列,24 行) 终端窗口看起来效果最好。 2.下载我们提供的 vimrc,然后把它保存到 ~/.vimrc。 通读这个注释详细的文件 (用 Vim!), 然后观察 …...

C/C++ (stdio.h)标准库详解
cstdio,在C语言中称为stdio.h。该库使用所谓的流与物理设备(如键盘、打印机、终端)或系统支持的任何其他类型的文件一起操作。 在本文将会通过介绍函数参数,举出实际的简单例子来帮助大家快速上手使用函数。 目录 一、流 二、库函数 1、F…...

深度学习介绍
对于具备完善业务逻辑的任务,大多数情况下,正常的人都可以给出一个符合业务逻辑的应用程序。但是对于一些包含超过人类所能考虑到的逻辑的任务,例如面对如下任务: 编写一个应用程序,接受地理信息、卫星图像和一些历史…...
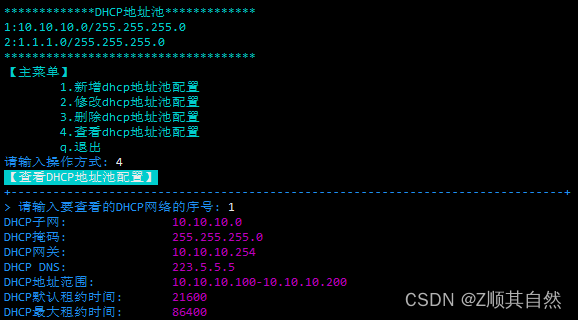
ywtool dhcp命令
一.dhcp功能介绍 就是通过脚本实现dhcp地址池的增、删、改、查这几个功能日志文件路径: /var/log/ywtools/ywtool-dhcp.log/usr/local/ywtools/config/config.ini中account参数(ywtool dhcp这个命令用的,但是这个命令只能配置1个地址池,所以这里面的参数没什么意义) 二.配置…...
)
ChatGPT高效提问—基础知识(LM、PLM以及LLM)
ChatGPT高效提问—基础知识(LM、PLM以及LLM) 了解语言模型(language model, LM)、预训练语言模型(pre-trained language model, PLM)和大型语言模型(large language model, LLM)…...
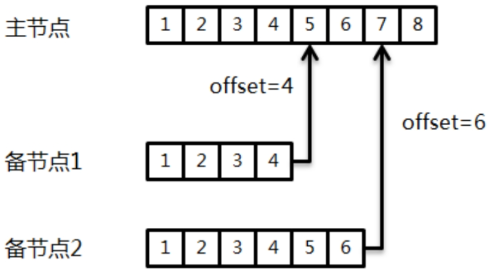
MongoDB复制集实战及原理分析
文章目录 MongoDB复制集复制集架构三节点复制集模式PSS模式(官方推荐模式)PSA模式 典型三节点复制集环境搭建复制集注意事项环境准备配置复制集复制集状态查询使用mtools创建复制集安全认证复制集连接方式 复制集成员角色属性一:Priority 0属…...

基于 N-gram 全新模型:嵌入扩展新范式,实现轻量化 MoE 高效进化
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...

零基础入门飞书机器人开发:快马平台带你写好第一个openclaw程序
零基础入门飞书机器人开发:快马平台带你写好第一个openclaw程序 最近想给团队做个飞书机器人小助手,但作为编程新手完全不知道从哪开始。摸索后发现用openclaw框架配合InsCode(快马)平台特别适合零基础入门,这里记录下我的学习过程。 1. 理…...

猫抓插件终极指南:5分钟快速掌握浏览器资源嗅探与高效下载
猫抓插件终极指南:5分钟快速掌握浏览器资源嗅探与高效下载 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾经在浏览网页时&…...
)
端侧AI 模型部署实战二(云端、PC 本地、手机端侧主流大模型及部署工具 )
AI的大模型部署主要有云端、PC 本地、手机端侧 三大场景。* 云端大模型(在线 API / 网页,最强能力)* PC 本地大模型(Windows/macOS,GGUF 优先)* 消费电子(手机端侧大模型Android/iOS,…...

3个专业技巧:BilibiliDown跨平台B站视频下载器的完整应用指南
3个专业技巧:BilibiliDown跨平台B站视频下载器的完整应用指南 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mi…...

新手友好!FUTURE POLICE语音解构模型快速入门:搭建智能音频处理流水线
新手友好!FUTURE POLICE语音解构模型快速入门:搭建智能音频处理流水线 1. 认识FUTURE POLICE语音解构模型 1.1 什么是语音解构技术 想象一下,你有一段会议录音,想要快速找到某个关键词出现的确切时间点。传统语音识别只能告诉你…...

SiameseUIE模型Git使用进阶:团队协作开发指南
SiameseUIE模型Git使用进阶:团队协作开发指南 1. 开篇:为什么团队开发需要Git规范 咱们做AI项目开发时,经常遇到这样的场景:几个人同时修改代码,结果合并时冲突不断;或者某位同事的代码把整个项目搞崩了&…...

终极多店铺管理指南:如何在Fecshop中轻松运营多个独立商城
终极多店铺管理指南:如何在Fecshop中轻松运营多个独立商城 【免费下载链接】yii2_fecshop Yii2_fecshop是一个基于Yii2框架的电商系统,适合用于搭建在线商城、B2C网站等。特点:功能丰富、易于扩展、支持多种支付方式。 项目地址: https://g…...

抖音批量下载工具终极指南:免费无水印下载视频、图文、合集和直播
抖音批量下载工具终极指南:免费无水印下载视频、图文、合集和直播 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fal…...

Z-Image-Turbo实战指南:用Gradio搭建交互式绘画站
Z-Image-Turbo实战指南:用Gradio搭建交互式绘画站 1. 为什么选择Z-Image-Turbo 在AI绘画领域,速度和质量的平衡一直是开发者面临的挑战。Z-Image-Turbo作为阿里巴巴通义实验室开源的高效文生图模型,以其独特的优势脱颖而出: 惊…...